مقدمه
به عنوان رشتهای که روشهای کارآمد و مؤثر برای کشف الگوها و دانش از انواع مختلف مجموعه دادههای عظیم برای بسیاری از کاربردها را مطالعه میکند، دادهکاوی به طور طبیعی تلاقی رشتههای مختلف از جمله یادگیری ماشین، آمار، تشخیص الگو، پردازش زبان طبیعی، فناوری پایگاه داده، تجسم و تعامل انسان و کامپیوتر (HCI)، الگوریتمها، محاسبات با کارایی بالا، علوم اجتماعی و بسیاری از حوزههای کاربردی را ارائه میدهد (شکل ۱.۴).
ماهیت بین رشتهای تحقیق و توسعه دادهکاوی به طور قابل توجهی در موفقیت دادهکاوی و کاربردهای گسترده آن نقش دارد. از سوی دیگر، دادهکاوی نه تنها از دانش و توسعه این رشتهها تغذیه میشود، بلکه تحقیقات، توسعه و کاربردهای اختصاصی دادهکاوی بر روی انواع مختلف کلان داده نیز ممکن است در سالهای اخیر تأثیر قابل توجهی بر توسعه این رشتهها داشته باشد. در این بخش، چندین رشته را مورد بحث قرار میدهیم که به شدت بر تحقیق، توسعه و کاربردهای دادهکاوی تأثیر میگذارند و به طور فعال با آن تعامل دارند.
آمار و دادهکاوی
آمار، جمعآوری، تجزیه و تحلیل، تفسیر یا توضیح و ارائه دادهها را مطالعه میکند. دادهکاوی ارتباط ذاتی با آمار دارد.
یک مدل آماری مجموعهای از توابع ریاضی است که رفتار اشیاء در یک کلاس هدف را بر حسب متغیرهای تصادفی و توزیع احتمال مرتبط با آنها توصیف میکند. مدلهای آماری به طور گسترده برای مدلسازی دادهها و کلاسهای داده استفاده میشوند. به عنوان مثال، در وظایف دادهکاوی مانند توصیف و طبقهبندی دادهها، میتوان مدلهای آماری کلاسهای هدف را ساخت. به عبارت دیگر، چنین مدلهای آماری میتوانند نتیجه یک وظیفه دادهکاوی باشند. از طرف دیگر، وظایف دادهکاوی را میتوان بر روی مدلهای آماری ساخت. به عنوان مثال، میتوانیم از آمار برای مدلسازی نویز و مقادیر دادههای گمشده استفاده کنیم. سپس، هنگام کاوش الگوها در یک مجموعه داده بزرگ، فرآیند دادهکاوی میتواند از مدل برای کمک به شناسایی و مدیریت مقادیر نویز یا گمشده در دادهها استفاده کند.
تحقیقات آماری ابزارهایی را برای پیشبینی و پیشگویی با استفاده از دادهها و مدلهای آماری توسعه میدهد. از روشهای آماری میتوان برای خلاصهسازی یا توصیف مجموعهای از دادهها استفاده کرد. توصیفات آماری اولیه دادهها در فصل 2 معرفی شدهاند. آمار برای استخراج الگوهای مختلف از دادهها و برای درک مکانیسمهای اساسی تولید و تأثیرگذاری بر الگوها مفید است. آمار استنباطی (یا آمار پیشبینیکننده) دادهها را به گونهای مدلسازی میکند که تصادفی بودن و عدم قطعیت در مشاهدات را در نظر میگیرد و برای استنتاج در مورد فرآیند یا جمعیت مورد بررسی استفاده میشود.
روشهای آماری همچنین میتوانند برای تأیید نتایج دادهکاوی استفاده شوند. به عنوان مثال، پس از استخراج یک مدل طبقهبندی یا پیشبینی، مدل باید با آزمون فرضیه آماری تأیید شود. آزمون فرضیه آماری (که گاهی اوقات تحلیل دادههای تأییدی نامیده میشود) با استفاده از دادههای تجربی، تصمیمات آماری میگیرد. اگر بعید باشد که نتیجه به طور تصادفی رخ داده باشد، از نظر آماری معنادار نامیده میشود. اگر مدل طبقهبندی یا پیشبینی برقرار باشد، آمار توصیفی مدل، صحت مدل را افزایش میدهد.
اعمال روشهای آماری در دادهکاوی به هیچ وجه ساده نیست. اغلب، یک چالش جدی این است که چگونه یک روش آماری را بر روی یک مجموعه داده بزرگ مقیاسبندی کنیم. بسیاری از روشهای آماری پیچیدگی بالایی در محاسبات دارند. هنگامی که چنین روشهایی بر روی مجموعه دادههای بزرگی که در چندین مکان منطقی یا فیزیکی نیز توزیع شدهاند، اعمال میشوند، الگوریتمها باید با دقت طراحی و تنظیم شوند تا هزینه محاسباتی کاهش یابد. این چالش برای برنامههای آنلاین، مانند پیشنهادهای جستجوی آنلاین در موتورهای جستجو، که در آنها دادهکاوی برای مدیریت مداوم جریانهای داده سریع و بلادرنگ مورد نیاز است، حتی سختتر میشود.
تحقیقات دادهکاوی، راهحلهای مقیاسپذیر و مؤثر بسیاری را برای تجزیه و تحلیل مجموعهها و جریانهای داده عظیم توسعه داده است. علاوه بر این، انواع مختلف مجموعه دادهها و برنامههای مختلف ممکن است به روشهای تجزیه و تحلیل نسبتاً متفاوتی نیاز داشته باشند. راهحلهای مؤثری پیشنهاد و آزمایش شدهاند که منجر به بسیاری از روشهای تجزیه و تحلیل آماری جدید و مقیاسپذیر مبتنی بر دادهکاوی شده است.

یادگیری ماشین و دادهکاوی
این مورد بررسی میکند که چگونه کامپیوترها میتوانند بر اساس دادهها یاد بگیرند (یا عملکرد خود را بهبود بخشند). یادگیری ماشین یک رشته علمی با رشد سریع است که در سالهای اخیر روشها و کاربردهای جدید زیادی از ماشینهای بردار پشتیبان گرفته تا مدلهای گرافیکی احتمالی و یادگیری عمیق توسعه یافته است که در این کتاب به آنها خواهیم پرداخت.
به طور کلی، یادگیری ماشین به دو مشکل کلاسیک میپردازد: یادگیری نظارتشده و یادگیری بدون نظارت.
• یادگیری نظارتشده: یک نمونه کلاسیک از یادگیری نظارتشده، طبقهبندی است. نظارت در یادگیری از نمونههای برچسبگذاریشده در مجموعه دادههای آموزشی ناشی میشود. به عنوان مثال، برای تشخیص خودکار کدهای پستی دستنویس روی نامهها، سیستم یادگیری مجموعهای از تصاویر کد پستی دستنویس و ترجمههای قابل خواندن توسط ماشین مربوط به آنها را به عنوان نمونههای آموزشی میگیرد و یک مدل طبقهبندی را یاد میگیرد (یعنی محاسبه میکند).
• یادگیری بدون نظارت: یک نمونه کلاسیک از یادگیری بدون نظارت، خوشهبندی است. فرآیند یادگیری بدون نظارت است زیرا نمونههای ورودی دارای برچسب کلاس نیستند. معمولاً، ما ممکن است از خوشهبندی
برای کشف گروهها در دادهها استفاده کنیم. به عنوان مثال، یک روش یادگیری بدون نظارت میتواند مجموعهای از تصاویر ارقام دستنویس را به عنوان ورودی دریافت کند. فرض کنید که 10 خوشه از دادهها را پیدا میکند. این خوشهها میتوانند به ترتیب با 10 رقم متمایز 0 تا 9 مطابقت داشته باشند. با این حال، از آنجایی که دادههای آموزشی برچسبگذاری نشدهاند، مدل یادگیری شده نمیتواند معنای معنایی خوشههای یافت شده را به ما بگوید.
در مورد این دو مسئله اساسی، دادهکاوی و یادگیری ماشین شباهتهای زیادی دارند. با این حال، دادهکاوی از چندین جنبه اصلی با یادگیری ماشین متفاوت است. اول، حتی در کارهای مشابه مانند طبقهبندی و خوشهبندی، دادهکاوی اغلب روی مجموعه دادههای بسیار بزرگ یا حتی روی جریانهای داده نامحدود کار میکند، مقیاسپذیری میتواند یک نگرانی مهم باشد و بسیاری از الگوریتمهای دادهکاوی کارآمد و بسیار مقیاسپذیر یا الگوریتمهای دادهکاوی جریانی باید برای انجام چنین کارهایی توسعه داده شوند.
دوم، در بسیاری از مسائل دادهکاوی، مجموعه دادهها معمولاً بزرگ هستند، اما دادههای آموزشی هنوز هم میتوانند نسبتاً کوچک باشند زیرا ارائه برچسبهای با کیفیت برای بسیاری از نمونهها برای متخصصان پرهزینه است. بنابراین، دادهکاوی باید تلاش زیادی برای توسعه روشهای نظارتشده ضعیف انجام دهد. این روشها شامل روشهایی مانند یادگیری نیمهنظارتی با مجموعه کوچکی از دادههای برچسبگذاریشده اما مجموعه بزرگی از دادههای بدون برچسب (با ایدهای که در شکل 1.5 ترسیم شده است)، ادغام یا مجموعهای از چندین مدل ضعیف بهدستآمده از افراد غیرمتخصص (مثلاً مدلهای بهدستآمده از طریق جمعسپاری)، نظارت از راه دور، مانند استفاده از پایگاههای دانش عمومی و در دسترس (اما ارتباط دوری با مسئله مورد نظر) (مثلاً ویکیپدیا، DBPedia)، یادگیری فعال با انتخاب دقیق مثالها برای پرسیدن از متخصصان انسانی، یا انتقال یادگیری با ادغام مدلهای آموختهشده از حوزههای مسئله مشابه است. دادهکاوی در حال گسترش چنین روشهای نظارتشده ضعیفی برای ساخت مدلهای طبقهبندی با کیفیت بر روی مجموعه دادههای بزرگ با مجموعه بسیار محدودی از دادههای آموزشی با کیفیت بالا بوده است.
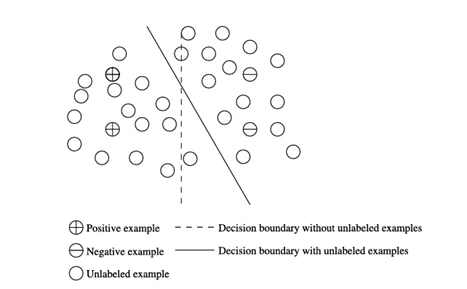
سوم، روشهای یادگیری ماشین ممکن است نتوانند بسیاری از انواع مسائل کشف دانش را در کلاندادهها مدیریت کنند. از سوی دیگر، دادهکاوی، با توسعه راهحلهای مؤثر برای مسائل کاربردی ملموس، به عمق حوزه مسئله میرود و بسیار فراتر از محدوده تحت پوشش یادگیری ماشین گسترش مییابد. به عنوان مثال، بسیاری از مسائل کاربردی، مانند تحلیل دادههای تراکنشهای تجاری، تحلیل توالی اجرای برنامههای نرمافزاری و تحلیل ساختاری شیمیایی و بیولوژیکی، به روشهای مؤثری برای کاوش الگوهای مکرر، الگوهای متوالی و الگوهای ساختاریافته نیاز دارند. تحقیقات دادهکاوی، روشهای کاوش مقیاسپذیر، مؤثر و متنوعی را برای چنین وظایفی ایجاد کرده است.
به عنوان مثال دیگر، تحلیل شبکههای اجتماعی و اطلاعاتی در مقیاس بزرگ، مسائل چالشبرانگیز بسیاری را مطرح میکند که ممکن است به دلیل تعامل اطلاعات در پیوندها و گرهها در چنین شبکههایی، با دامنه معمول بسیاری از روشهای یادگیری ماشین مطابقت نداشته باشند. دادهکاوی راهحلهای جالب زیادی را برای چنین مسائلی توسعه داده است. از این منظر، دادهکاوی و یادگیری ماشین دو رشته متفاوت اما نزدیک به هم هستند. دادهکاوی عمیقاً به حوزههای کاربردی ملموس و دادهمحور میپردازد، خود را به یک روششناسی حل مسئله واحد محدود نمیکند و راهحلهای ملموس (گاهی اوقات نسبتاً بدیع)، مؤثر و مقیاسپذیر را برای بسیاری از مشکلات کاربردی چالشبرانگیز توسعه میدهد. این یک رشته تحقیقاتی جوان، گسترده و امیدوارکننده برای بسیاری از محققان و متخصصان است تا روی آن مطالعه و کار کنند.
فناوری پایگاه داده و دادهکاوی
تحقیقات سیستم پایگاه داده بر ایجاد، نگهداری و استفاده از پایگاههای داده برای سازمانها و کاربران نهایی تمرکز دارد. به ویژه، محققان سیستم پایگاه داده اصول شناختهشدهای را در مدلهای داده، زبانهای پرسوجو، پردازش و بهینهسازی پرسوجو، ذخیرهسازی دادهها و روشهای نمایهسازی ایجاد کردهاند. فناوری پایگاه داده به دلیل مقیاسپذیریاش در پردازش مجموعه دادههای بسیار بزرگ و نسبتاً ساختاریافته شناخته شده است.
بسیاری از وظایف دادهکاوی نیاز به مدیریت مجموعه دادههای بزرگ یا حتی دادههای جریانی سریع و بلادرنگ دارند. دادهکاوی میتواند از فناوریهای پایگاه داده مقیاسپذیر برای دستیابی به کارایی و مقیاسپذیری بالا در مجموعه دادههای بزرگ به خوبی استفاده کند. علاوه بر این، وظایف دادهکاوی میتوانند برای گسترش قابلیت سیستمهای پایگاه داده موجود برای برآوردن نیازهای پیچیده تجزیه و تحلیل دادههای کاربران استفاده شوند.
سیستمهای پایگاه داده اخیر با استفاده از انبار داده و امکانات دادهکاوی، قابلیتهای تحلیل سیستماتیک دادهها را بر روی دادههای پایگاه داده ایجاد کردهاند. یک انبار داده، دادههای حاصل از منابع متعدد و بازههای زمانی مختلف را ادغام میکند. این انبار داده، دادهها را در فضای چندبعدی ادغام میکند تا مکعبهای دادهای که تا حدی مادی شدهاند را تشکیل دهد. مدل مکعب داده نه تنها پردازش تحلیلی آنلاین (OLAP) را در پایگاههای داده چندبعدی تسهیل میکند، بلکه دادهکاوی چندبعدی را نیز ارتقا میدهد که در فصلهای آینده بیشتر مورد بحث قرار خواهد گرفت.
دادهکاوی و علم داده
با وجود حجم عظیم دادهها در تقریباً هر رشته و انواع مختلف کاربردها، کلان داده و علم داده در سالهای اخیر به کلمات کلیدی تبدیل شدهاند. کلان داده عموماً به مقادیر عظیمی از دادههای ساختاریافته و بدون ساختار از اشکال مختلف اشاره دارد و علم داده یک حوزه میانرشتهای است که از روشها، فرآیندها، الگوریتمها و سیستمهای علمی برای استخراج دانش و بینش از دادههای عظیم از اشکال مختلف استفاده میکند. واضح است که دادهکاوی نقش اساسی در علم داده ایفا میکند.
برای اکثر مردم، علم داده مفهومی است که آمار، یادگیری ماشین، دادهکاوی و روشهای مرتبط با آنها را برای درک و تجزیه و تحلیل دادههای عظیم متحد میکند. این علم از تکنیکها و نظریههایی برگرفته از زمینههای مختلف در زمینه ریاضیات، آمار، علوم اطلاعات و علوم کامپیوتر استفاده میکند. برای بسیاری از افراد شاغل در صنعت، اصطلاح «علم داده» اغلب به تجزیه و تحلیل کسب و کار، هوش تجاری، مدلسازی پیشبینی یا هرگونه استفاده معنادار از دادهها اشاره دارد و به عنوان یک اصطلاح جذاب برای تغییر نام آمار، دادهکاوی، یادگیری ماشین یا هر نوع تجزیه و تحلیل داده در نظر گرفته میشود.
تاکنون، هیچ اجماعی در مورد تعریف یا محتوای برنامه درسی مناسب در برنامههای مدرک علوم داده بسیاری از دانشگاهها وجود ندارد. با این وجود، اکثر دانشگاهها دانش پایه تولید شده در آمار، یادگیری ماشین، دادهکاوی، پایگاه داده و تعامل انسان و کامپیوتر را به عنوان برنامه درسی اصلی در آموزش علوم داده در نظر میگیرند.
در دهه 1990، جیم گری، برنده فقید جایزه تورینگ، علم داده را به عنوان «الگوی چهارم» علم (یعنی از تجربی به نظری، محاسباتی و اکنون دادهمحور) پیشبینی کرد و ادعا کرد که «همه چیز در مورد علم به دلیل تأثیر فناوری اطلاعات» و ظهور دادههای عظیم در حال تغییر است. بنابراین جای تعجب نیست که علم داده، کلان داده و دادهکاوی ارتباط تنگاتنگی با هم دارند و نشاندهنده یک روند اجتنابناپذیر در پیشرفتهای علم و فناوری هستند.
دادهکاوی و سایر رشتهها
علاوه بر آمار، یادگیری ماشین و فناوری پایگاه داده، دادهکاوی روابط نزدیکی با بسیاری از رشتههای دیگر نیز دارد.
اکثر دادههای دنیای واقعی بدون ساختار هستند و به شکل متن زبان طبیعی، تصاویر یا دادههای صوتی-تصویری میباشند. بنابراین، پردازش زبان طبیعی، بینایی کامپیوتر، تشخیص الگو، پردازش سیگنال صوتی-تصویری و بازیابی اطلاعات، کمک شایانی در مدیریت چنین دادههایی ارائه میدهند. در واقع، مدیریت هر نوع داده خاص، به دانش زیادی در حوزه مورد نظر برای ادغام در طراحی الگوریتم دادهکاوی نیاز دارد. به عنوان مثال، دادهکاوی زیستپزشکی به ادغام دانش علوم زیستی، علوم پزشکی و بیوانفورماتیک نیاز دارد. دادهکاوی دادههای مکانی به دانش و تکنیکهای زیادی از جغرافیا و علوم دادههای مکانی نیاز دارد. باگهای نرمافزاری در برنامههای نرمافزاری بزرگ باید مهندسی نرمافزار را با دادهکاوی ادغام کنند. دادهکاوی رسانههای اجتماعی و شبکههای اجتماعی به دانش و مهارتهای علوم اجتماعی و علوم شبکه نیاز دارد.
چنین مثالهایی میتوانند ادامه داشته باشند، زیرا دادهکاوی تقریباً در هر حوزه کاربردی نفوذ خواهد کرد. یکی از چالشهای اصلی در دادهکاوی، کارایی و مقیاسپذیری است، زیرا ما اغلب باید با حجم عظیمی از دادهها با محدودیتهای زمانی و منابع بحرانی سروکار داشته باشیم. دادهکاوی به طور حیاتی با طراحی الگوریتم کارآمد مانند الگوریتمهای دادهکاوی با پیچیدگی کم، افزایشی و جریانی مرتبط است. اغلب نیاز به بررسی محاسبات با کارایی بالا، محاسبات موازی و محاسبات توزیعشده، با سختافزار پیشرفته و محیط محاسبات ابری یا خوشهای دارد.
دادهکاوی همچنین ارتباط نزدیکی با تعامل انسان و کامپیوتر دارد. کاربران باید به طور مؤثر با یک سیستم یا فرآیند دادهکاوی تعامل داشته باشند و به سیستم بگویند چه چیزی را استخراج کند، چگونه دانش پسزمینه را در آن بگنجاند، چگونه استخراج کند و چگونه نتایج استخراج را به روشی آسان برای درک (مثلاً با تفسیر و تجسم) و آسان برای تعامل (مثلاً با رابط کاربری گرافیکی دوستانه و دادهکاوی تعاملی) ارائه دهد.
در واقع، امروزه نه تنها سیستمهای دادهکاوی تعاملی زیادی وجود دارد، بلکه عملکردهای دادهکاوی بسیار بیشتری نیز در انواع مختلف برنامههای کاربردی پنهان شدهاند. انتظار اینکه همه افراد جامعه ما تکنیکهای دادهکاوی را درک و بر آنها تسلط داشته باشند، غیرواقعی است. همچنین برای صنایع ممنوع است که مجموعه دادههای بزرگ خود را در معرض نمایش بگذارند. بسیاری از سیستمها دارای توابع دادهکاوی داخلی هستند تا افراد بتوانند با کلیک ماوس، دادهکاوی انجام دهند یا از نتایج دادهکاوی استفاده کنند. به عنوان مثال، موتورهای جستجوی هوشمند و خردهفروشیهای آنلاین با جمعآوری دادهها و سابقه جستجو یا خرید کاربر، چنین دادهکاوی نامرئی را انجام میدهند و دادهکاوی را در اجزای خود گنجانیده تا عملکرد، کارایی و رضایت کاربر را بهبود بخشند. وقتی مادربزرگ شما به صورت آنلاین خرید میکند، ممکن است از دریافت برخی توصیههای هوشمند شگفتزده شود. این احتمالاً میتواند ناشی از چنین دادهکاوی نامرئی باشد.
دادهکاوی و کاربردها
هر جا که داده وجود داشته باشد، کاربردهای دادهکاوی نیز وجود دارد.
دادهکاوی به عنوان یک رشته بسیار کاربردی، موفقیتهای بزرگی را در بسیاری از کاربردها تجربه کرده است. برشمردن تمام کاربردهایی که دادهکاوی در آنها نقش حیاتی ایفا میکند، غیرممکن است. ارائه دادهکاوی در حوزههای کاربردی دانشمحور، مانند بیوانفورماتیک و مهندسی نرمافزار، نیاز به بررسی عمیقتری دارد و فراتر از محدوده این کتاب است. برای نشان دادن اهمیت کاربردهای دادهکاوی، به طور خلاصه چند نمونه کاربردی بسیار موفق و محبوب دادهکاوی را مورد بحث قرار میدهیم: هوش تجاری؛ موتورهای جستجو؛ رسانههای اجتماعی و شبکههای اجتماعی؛ و زیستشناسی، علوم پزشکی و مراقبتهای بهداشتی.
هوش تجاری
برای کسبوکارها بسیار مهم است که درک بهتری از زمینه تجاری سازمان خود، مانند مشتریان، بازار، عرضه و منابع و رقبا، به دست آورند. فناوریهای هوش تجاری (BI) دیدگاههای تاریخی، فعلی و پیشبینیکننده از عملیات تجاری ارائه میدهند. نمونههایی از جمله گزارشدهی، پردازش تحلیلی آنلاین، مدیریت عملکرد کسبوکار، هوش رقابتی، معیارسنجی و تجزیه و تحلیل پیشبینیکننده. «دادهکاوی در هوش تجاری چقدر مهم است؟» بدون دادهکاوی، بسیاری از کسبوکارها ممکن است قادر به انجام تحلیل مؤثر بازار، مقایسه بازخورد مشتری در مورد محصولات مشابه، کشف نقاط قوت و ضعف رقبای خود، حفظ مشتریان بسیار ارزشمند و تصمیمگیریهای هوشمندانه تجاری نباشند.
واضح است که دادهکاوی هسته اصلی هوش تجاری است. ابزارهای پردازش تحلیلی آنلاین در هوش تجاری به انبار دادهها و دادهکاوی چندبعدی متکی هستند. تکنیکهای طبقهبندی و پیشبینی، هسته اصلی تحلیلهای پیشبینیکننده در هوش تجاری هستند که کاربردهای زیادی در تحلیل بازارها، عرضهها و فروش دارند. علاوه بر این، خوشهبندی نقش محوری در مدیریت ارتباط با مشتری دارد که مشتریان را بر اساس شباهتهایشان گروهبندی میکند. با استفاده از تکنیکهای خلاصهسازی چندبعدی، میتوانیم ویژگیهای هر گروه مشتری را بهتر درک کنیم و برنامههای پاداش مشتری سفارشیشده را توسعه دهیم.
موتورهای جستجوی وب
یک موتور جستجوی وب یک سرور کامپیوتری تخصصی است که اطلاعات را در وب جستجو میکند. نتایج جستجوی یک پرسوجوی کاربر اغلب به صورت یک لیست (که گاهی اوقات به آن هیت میگویند) برگردانده میشود. هیتها ممکن است شامل صفحات وب، تصاویر و انواع دیگر فایلها باشند. برخی از موتورهای جستجو همچنین دادههای موجود در پایگاههای داده عمومی یا دایرکتوریهای باز را جستجو و برمیگردانند. موتورهای جستجو با دایرکتوریهای وب متفاوت هستند، زیرا دایرکتوریهای وب توسط ویراستاران انسانی نگهداری میشوند، در حالی که موتورهای جستجو به صورت الگوریتمی یا با ترکیبی از ورودیهای الگوریتمی و انسانی کار میکنند.
موتورهای جستجو چالشهای بزرگی را برای دادهکاوی ایجاد میکنند. اول، آنها باید حجم عظیمی از دادهها را که دائماً در حال افزایش است، مدیریت کنند. معمولاً چنین دادههایی را نمیتوان با استفاده از یک یا چند ماشین پردازش کرد. در عوض، موتورهای جستجو اغلب نیاز به استفاده از ابرهای رایانهای دارند که شامل هزاران یا حتی صدها هزار رایانه هستند که به طور مشترک حجم عظیمی از دادهها را کاوش میکنند. گسترش روشهای دادهکاوی بر روی ابرهای رایانهای و مجموعه دادههای توزیعشده بزرگ، حوزهای از تحقیق و توسعه فعال است.
دوم، موتورهای جستجوی وب اغلب باید با دادههای آنلاین سر و کار داشته باشند. یک موتور جستجو ممکن است بتواند از عهده ساخت یک مدل به صورت آفلاین بر روی مجموعه دادههای عظیم برآید. برای انجام این کار، ممکن است یک طبقهبندیکننده پرسوجو ایجاد کند که یک پرسوجو را به دستههای از پیش تعریفشده بر اساس موضوع پرسوجو اختصاص دهد (به عنوان مثال، آیا پرسوجوی “سیب” برای بازیابی اطلاعات در مورد یک میوه یا یک برند رایانه است). حتی اگر یک مدل به صورت آفلاین ساخته شود، تطبیق مدل آنلاین باید به اندازه کافی سریع باشد تا به سؤالات کاربر در زمان واقعی پاسخ دهد.
چالش دیگر، نگهداری و بهروزرسانی تدریجی یک مدل روی جریانهای دادهای با رشد سریع است. به عنوان مثال، یک طبقهبندیکننده پرسوجو ممکن است نیاز به نگهداری تدریجی مداوم داشته باشد، زیرا پرسوجوهای جدید مرتباً در حال ظهور و دستهبندیهای از پیش تعریفشده هستند و توزیع دادهها ممکن است تغییر کند. اکثر روشهای آموزش مدل موجود آفلاین و ایستا هستند و بنابراین نمیتوان در چنین سناریویی از آنها استفاده کرد.
سوم، موتورهای جستجوی وب اغلب باید با پرسوجوهایی که فقط تعداد بسیار کمی بار پرسیده میشوند، سر و کار داشته باشند. فرض کنید یک موتور جستجو میخواهد توصیههای پرسوجوی آگاه از متن ارائه دهد. یعنی وقتی کاربر پرسوجویی را مطرح میکند، موتور جستجو سعی میکند با استفاده از پروفایل کاربر و سابقه پرسوجوی او، زمینه پرسوجو را استنباط کند تا در کسری از ثانیه پاسخهای سفارشیتری را برگرداند. با این حال، اگرچه تعداد کل پرسوجوهای پرسیده شده میتواند بسیار زیاد باشد، بسیاری از پرسوجوها ممکن است فقط یک یا چند بار پرسیده شوند. چنین دادههای به شدت کجشدهای برای بسیاری از روشهای دادهکاوی و یادگیری ماشین چالشبرانگیز هستند.
رسانههای اجتماعی و شبکههای اجتماعی
شیوع رسانههای اجتماعی و شبکههای اجتماعی اساساً زندگی ما و نحوه تبادل اطلاعات و معاشرت امروزی را تغییر داده است. با وجود حجم عظیمی از دادههای رسانههای اجتماعی و شبکههای اجتماعی، تجزیه و تحلیل چنین دادههایی برای استخراج الگوها و روندهای قابل اجرا از دادههای رسانههای اجتماعی و شبکههای اجتماعی بسیار مهم است.
کاوش رسانههای اجتماعی به معنای بررسی حجم عظیمی از دادههای رسانههای اجتماعی (مثلاً در مورد استفاده از رسانههای اجتماعی، رفتارهای اجتماعی آنلاین، ارتباطات بین افراد، رفتار خرید آنلاین، تبادل محتوا و غیره) به منظور تشخیص الگوها و روندها است. این الگوها و روندها برای تشخیص رویدادهای اجتماعی، نظارت و پایش سلامت عمومی، تحلیل احساسات در رسانههای اجتماعی، توصیه در رسانههای اجتماعی، منشأ اطلاعات، تحلیل اعتمادپذیری رسانههای اجتماعی و تشخیص اسپمرهای اجتماعی استفاده شدهاند.
کاوش شبکههای اجتماعی به معنای بررسی ساختارهای شبکههای اجتماعی و اطلاعات مرتبط با چنین شبکههایی از طریق استفاده از شبکهها و نظریه گراف و روشهای دادهکاوی است. ساختارهای شبکههای اجتماعی بر اساس گرهها (بازیگران فردی، افراد یا اشیاء درون شبکه) و پیوندها، لبهها یا لینکها (روابط یا تعاملات) که آنها را به هم متصل میکنند، مشخص میشوند. نمونههایی از ساختارهای اجتماعی که معمولاً از طریق تحلیل شبکههای اجتماعی تجسم میشوند عبارتند از شبکههای رسانههای اجتماعی، گسترش میمها، شبکههای دوستی و آشنایی، نمودارهای همکاری، خویشاوندی، انتقال بیماری و روابط جنسی. این شبکهها اغلب از طریق نمودارهای اجتماعی تجسم میشوند که در آنها گرهها به صورت نقطه و پیوندها به صورت خط نمایش داده میشوند.
از کاوش شبکههای اجتماعی برای شناسایی جوامع پنهان، کشف تکامل و پویایی شبکههای اجتماعی، محاسبه معیارهای شبکه (مانند مرکزیت، انتقالپذیری، عمل متقابل، تعادل، وضعیت و شباهت)، تجزیه و تحلیل نحوه انتشار اطلاعات در سایتهای رسانههای اجتماعی، اندازهگیری و مدلسازی نفوذ و هموفیلی گره/زیرساخت، و انجام تحلیل شبکههای اجتماعی مبتنی بر مکان استفاده شده است.
کاوش رسانههای اجتماعی و کاوش شبکههای اجتماعی از کاربردهای مهم دادهکاوی هستند.
زیستشناسی، علوم پزشکی و مراقبتهای بهداشتی
زیستشناسی، علوم پزشکی و مراقبتهای بهداشتی نیز دادههای عظیمی را در مقیاس نمایی تولید کردهاند. دادههای زیستپزشکی اشکال مختلفی دارند، از «امیکس» گرفته تا تصویربرداری، سلامت موبایل و پروندههای الکترونیکی سلامت. با در دسترس بودن روشهای جمعآوری دیجیتال کارآمدتر، دانشمندان و پزشکان زیستپزشکی اکنون خود را با مجموعههای بزرگتری از دادهها روبرو میبینند و سعی میکنند راههای خلاقانهای برای بررسی این کوه دادهها و درک آنها ابداع کنند. در واقع، دادههایی که قبلاً بزرگ تلقی میشدند، اکنون کوچک به نظر میرسند، زیرا مقدار دادههایی که اکنون توسط یک محقق در یک روز جمعآوری میشود، میتواند از آنچه که ممکن است حتی یک دهه پیش در طول دوران حرفهای او تولید شده باشد، فراتر رود. این سیل اطلاعات زیستپزشکی نیاز به تفکر جدید در مورد چگونگی مدیریت و تجزیه و تحلیل دادهها برای درک علمی بیشتر و بهبود مراقبتهای بهداشتی دارد.
دادهکاوی زیستپزشکی شامل بسیاری از وظایف دادهکاوی چالشبرانگیز است، از جمله کاوش دادههای عظیم توالی ژنومی و پروتئومی، کاوش الگوهای زیرگراف مکرر برای طبقهبندی دادههای زیستی، کاوش شبکههای تنظیمی، توصیف و پیشبینی تعاملات پروتئین-پروتئین، طبقهبندی و تحلیل پیشبینیکننده تصاویر پزشکی، کاوش متن زیستی، ساخت شبکه اطلاعات زیستی از دادههای زیستپزشکی، کاوش پروندههای سلامت الکترونیکی و کاوش شبکههای زیستپزشکی.
دادهکاوی و جامعه
با نفوذ دادهکاوی در زندگی روزمره ما، مطالعه تأثیر دادهکاوی بر جامعه مهم است. چگونه میتوانیم از فناوری دادهکاوی برای منفعت جامعه استفاده کنیم؟ چگونه میتوانیم از سوءاستفاده از آن جلوگیری کنیم؟ افشای یا استفاده نادرست از دادهها و نقض احتمالی حریم خصوصی و حقوق حفاظت از دادهها، حوزههای نگرانی هستند که باید به آنها پرداخته شود.
دادهکاوی به کشف علمی، مدیریت کسبوکار، بهبود اقتصاد و حفاظت از امنیت (به عنوان مثال، کشف بلادرنگ مزاحمان و حملات سایبری) کمک خواهد کرد. با این حال، خطر افشای ناخواسته برخی از اطلاعات محرمانه تجاری یا دولتی و افشای اطلاعات شخصی فرد را نیز به همراه دارد. مطالعات در مورد امنیت دادهها در دادهکاوی و انتشار و دادهکاوی با حفظ حریم خصوصی، از موضوعات مهم و در حال انجام تحقیقات هستند. فلسفه این است که حساسیت دادهها رعایت شود و امنیت دادهها و حریم خصوصی افراد در حین انجام موفقیتآمیز دادهکاوی حفظ شود.
این مسائل و بسیاری از مسائل دیگر مربوط به تحقیق، توسعه و کاربرد دادهکاوی در سراسر کتاب مورد بحث قرار خواهد گرفت.
خلاصه
• ضرورت، مادر اختراع است. با رشد فزاینده دادهها در هر کاربردی، دادهکاوی نیاز قریبالوقوع به تجزیه و تحلیل دادههای مؤثر، مقیاسپذیر و انعطافپذیر در جامعه ما را برآورده میکند. دادهکاوی را میتوان به عنوان تکامل طبیعی فناوری اطلاعات و محل تلاقی چندین رشته و حوزه کاربردی مرتبط در نظر گرفت.
• دادهکاوی فرآیند کشف الگوها و دانش جالب از حجم انبوهی از دادهها است. به عنوان یک فرآیند کشف دانش، معمولاً شامل پاکسازی دادهها، ادغام دادهها، انتخاب دادهها، تبدیل دادهها، کشف الگو و مدل، ارزیابی الگو یا مدل و ارائه دانش است.
• یک الگو یا مدل در صورتی جالب است که روی دادههای آزمایشی با درجهای از قطعیت، جدید، بالقوه مفید (مثلاً بتوان بر اساس آن عمل کرد یا حدسی را که کاربر در مورد آن کنجکاو بوده است، تأیید کرد) و به راحتی توسط انسانها قابل درک باشد. الگوهای جالب، نشاندهنده دانش هستند. معیارهای جالب بودن الگو، چه عینی و چه ذهنی، میتوانند برای هدایت فرآیند کشف استفاده شوند.
• دادهکاوی را میتوان روی هر نوع دادهای انجام داد، مادامی که دادهها برای یک برنامه کاربردی هدف معنادار باشند، مانند دادههای ساختاریافته (مثلاً پایگاه داده رابطهای، دادههای تراکنشی) و دادههای بدون ساختار (مثلاً دادههای متنی و چندرسانهای) و همچنین دادههای مرتبط با برنامههای کاربردی مختلف. دادهها همچنین میتوانند به عنوان دادههای ذخیرهشده در مقابل دادههای جریانی طبقهبندی شوند، در حالی که مورد دوم ممکن است نیاز به بررسی الگوریتمهای ویژه دادهکاوی جریانی داشته باشد.
• از قابلیتهای دادهکاوی برای تعیین انواع الگوها یا دانشی که در وظایف دادهکاوی یافت میشوند، استفاده میشود. این قابلیتها شامل توصیف و تمایز؛ کاوش الگوهای مکرر، ارتباطات و همبستگیها؛ طبقهبندی و رگرسیون؛ یادگیری عمیق؛ تحلیل خوشهای؛ و تشخیص دادههای پرت است. با ظهور انواع جدید دادهها، کاربردهای جدید و تقاضاهای جدید برای تحلیل، شکی نیست که در آینده شاهد وظایف دادهکاوی جدیدتر و بیشتری خواهیم بود.
• دادهکاوی، تلاقی رشتههای متعدد است، اما تمرکز تحقیقاتی منحصر به فرد خود را دارد که به بسیاری از کاربردهای پیشرفته اختصاص دارد. ما روابط نزدیک دادهکاوی با آمار، یادگیری ماشین، فناوری پایگاه داده و بسیاری از رشتههای دیگر را مطالعه میکنیم.
• دادهکاوی کاربردهای موفق بسیاری دارد، مانند هوش تجاری، جستجوی وب، بیوانفورماتیک، انفورماتیک سلامت، امور مالی، کتابخانههای دیجیتال و دولتهای دیجیتال.
• دادهکاوی ممکن است در حال حاضر تأثیر قوی خود را بر جامعه داشته باشد و مطالعه چنین تأثیری، مانند چگونگی تضمین اثربخشی دادهکاوی و در عین حال تضمین حریم خصوصی و امنیت دادهها، به یک موضوع مهم در تحقیقات تبدیل شده است.
تمرین
1. دادهکاوی چیست؟ در پاسخ خود، به موارد زیر بپردازید:
الف. آیا این یک تحول ساده یا کاربرد فناوری توسعهیافته از پایگاههای داده، آمار، یادگیری ماشین و تشخیص الگو است؟
ب. کسی معتقد است که دادهکاوی نتیجه اجتنابناپذیر تکامل فناوری اطلاعات است. اگر شما یک محقق پایگاه داده هستید، نشان دهید که دادهکاوی ناشی از تکامل ماهیت فناوری پایگاه داده است. اگر شما یک محقق یادگیری ماشین یا یک آمارشناس هستید، چه؟
ج. مراحل مربوط به دادهکاوی را وقتی به عنوان یک فرآیند کشف دانش در نظر گرفته میشود، شرح دهید.
2. هر یک از قابلیتهای دادهکاوی زیر را تعریف کنید: تحلیل ارتباط و همبستگی، طبقهبندی، رگرسیون، خوشهبندی، یادگیری عمیق و تحلیل دادههای پرت. با استفاده از یک پایگاه داده واقعی که با آن آشنا هستید، نمونههایی از هر قابلیت دادهکاوی را ارائه دهید.
3. مثالی ارائه دهید که در آن دادهکاوی برای موفقیت یک کسبوکار حیاتی است. این کسبوکار به چه قابلیتهای دادهکاوی نیاز دارد (مثلاً به انواع الگوهایی که میتوانند استخراج شوند فکر کنید)؟ آیا چنین الگوهایی میتوانند به طور متناوب با پردازش پرسوجوی دادهها یا تحلیل آماری ساده تولید شوند؟
4. تفاوت و شباهت بین تحلیل همبستگی و طبقهبندی، بین طبقهبندی و خوشهبندی، و بین طبقهبندی و رگرسیون را توضیح دهید.
5. بر اساس مشاهدات خود، نوع دیگری از دانش ممکن را که باید توسط روشهای دادهکاوی کشف شود اما در این فصل فهرست نشده است، شرح دهید. آیا به یک روش دادهکاوی کاملاً متفاوت از روشهای ذکر شده در این فصل نیاز دارد؟
6. دادههای پرت اغلب به عنوان نویز کنار گذاشته میشوند. با این حال، زبالههای یک نفر میتواند گنج دیگری باشد.
به عنوان مثال، استثنائات در تراکنشهای کارت اعتباری میتواند به ما در تشخیص استفاده جعلی از کارتهای اعتباری کمک کند. با استفاده از تشخیص تقلب به عنوان مثال، دو روش را پیشنهاد دهید که میتوانند برای تشخیص دادههای پرت استفاده شوند و در مورد اینکه کدام یک قابل اعتمادتر است، بحث کنید.
7. چالشهای اصلی دادهکاوی حجم عظیمی از دادهها (مثلاً میلیاردها تاپل) در مقایسه با دادهکاوی حجم کمی از دادهها (مثلاً مجموعه دادههایی با چند صد تاپل) چیست؟
8. چالشهای اصلی تحقیقاتی دادهکاوی را در یک حوزه کاربردی خاص، مانند تحلیل دادههای جریان/حسگر، تحلیل دادههای مکانی-زمانی یا بیوانفورماتیک، شرح دهید.


