مقدمه
در کاربردهای دادهکاوی، مانند خوشهبندی، تحلیل دادههای پرت و طبقهبندی نزدیکترین همسایه، به روشهایی برای ارزیابی میزان شباهت یا عدم شباهت اشیاء در مقایسه با یکدیگر نیاز داریم. به عنوان مثال، یک فروشگاه ممکن است بخواهد خوشههایی از اشیاء مشتری را جستجو کند که منجر به گروههایی از مشتریان با ویژگیهای مشابه (مثلاً درآمد، منطقه سکونت و سن مشابه) میشود. چنین اطلاعاتی را میتوان برای بازاریابی استفاده کرد.
یک خوشه مجموعهای از اشیاء داده است به طوری که اشیاء درون یک خوشه مشابه یکدیگر و متفاوت از اشیاء در خوشههای دیگر هستند. تحلیل دادههای پرت همچنین از تکنیکهای مبتنی بر خوشهبندی برای شناسایی دادههای پرت بالقوه به عنوان اشیایی که بسیار با یکدیگر متفاوت هستند، استفاده میکند. دانش شباهتهای اشیا همچنین میتواند در طرحهای طبقهبندی نزدیکترین همسایه مورد استفاده قرار گیرد که در آن به یک شیء معین (مثلاً یک بیمار) بر اساس شباهت آن با سایر اشیاء در مدل، یک برچسب کلاس (مربوط به مثلاً یک تشخیص) اختصاص داده میشود.
این بخش معیارهای شباهت و عدم شباهت را ارائه میدهد که به عنوان معیارهای نزدیکی شناخته میشوند. شباهت و عدم شباهت به هم مرتبط هستند. یک معیار شباهت برای دو شیء، i و j، معمولاً اگر اشیاء کاملاً غیرمشابه باشند، مقدار 0 را برمیگرداند. هرچه مقدار شباهت بیشتر باشد، شباهت بین اشیاء بیشتر است. (معمولاً مقدار 1 نشان دهنده شباهت کامل است، یعنی اشیاء یکسان هستند.) یک معیار عدم شباهت برعکس عمل میکند. اگر اشیاء یکسان باشند (و بنابراین، به دور از تفاوت باشند) مقدار 0 را برمیگرداند. هرچه مقدار عدم شباهت بیشتر باشد، دو شیء متفاوتتر هستند. در بخش 2.3.1، دو ساختار دادهای را ارائه میدهیم که معمولاً در انواع کاربردهای فوق استفاده میشوند: ماتریس داده (که برای ذخیره اشیاء داده استفاده میشود) و ماتریس عدم تشابه (که برای ذخیره مقادیر عدم تشابه برای جفت اشیاء استفاده میشود).
همچنین، از آنجایی که اکنون با اشیاء توصیف شده توسط بیش از یک ویژگی سروکار داریم، به نمادگذاری متفاوتی برای اشیاء دادهای نسبت به آنچه قبلاً در این فصل استفاده شده است، روی میآوریم. سپس در مورد چگونگی محاسبه عدم تشابه اشیاء برای اشیاء توصیف شده توسط ویژگیهای اسمی (بخش 2.3.2)، ویژگیهای دودویی (بخش 2.3.3)، ویژگیهای عددی (بخش 2.3.4)، ویژگیهای ترتیبی (بخش 2.3.5) یا ترکیبی از این انواع ویژگی (بخش 2.3.6) بحث خواهیم کرد. بخش 2.3.7 معیارهای شباهت را برای بردارهای داده بسیار طولانی و پراکنده، مانند بردارهای عبارت-فراوانی که اسناد را در بازیابی اطلاعات نشان میدهند، ارائه میدهد.
در نهایت، بخش 2.3.8 به چگونگی اندازهگیری تفاوت بین دو توزیع احتمال روی متغیر یکسان x میپردازد و معیاری به نام واگرایی کولبک-لیبلر یا به طور خلاصه، واگرایی KL را معرفی میکند که به طور گسترده در ادبیات دادهکاوی مورد استفاده قرار گرفته است. دانستن نحوه محاسبه عدم تشابه در مطالعه ویژگیها مفید است و همچنین در مباحث بعدی در مورد خوشهبندی (فصلهای 8 و 9)، تحلیل دادههای پرت (فصل 11) و طبقهبندی نزدیکترین همسایه (فصل 6) به آن اشاره خواهد شد.
ماتریس دادهها در مقابل ماتریس عدم تشابه
در بخش ۲.۲، به روشهای مطالعه گرایش مرکزی، پراکندگی و پراکندگی مقادیر مشاهده شده برای برخی از ویژگیهای X پرداختیم. اشیاء ما در آنجا تکبعدی بودند، یعنی توسط یک ویژگی واحد توصیف میشدند. در این بخش، در مورد اشیاء توصیف شده توسط چندین ویژگی صحبت میکنیم. بنابراین به تغییر در نمادگذاری نیاز داریم.
فرض کنید n شیء (مثلاً افراد، اقلام یا دورهها) داریم که توسط p ویژگی (که به آنها اندازهگیری یا ویژگی نیز گفته میشود، مانند سن، قد، وزن یا جنسیت) توصیف شدهاند. اشیاء عبارتند از x1 = (x11, x12, . . . , x1p), x2 = (x21, x22, . . . , x2p), و غیره، که در آن xij مقدار شیء xi از ویژگی j ام است. برای اختصار، از این پس به شیء xi به عنوان شیء i اشاره میکنیم. اشیاء ممکن است در یک پایگاه داده رابطهای به صورت چندتایی باشند و همچنین به عنوان نمونههای داده یا بردارهای ویژگی شناخته میشوند. الگوریتمهای خوشهبندی مبتنی بر حافظه اصلی و نزدیکترین همسایه معمولاً بر روی یکی از دو ساختار داده زیر عمل میکنند:
• ماتریس داده (یا ساختار شیء بر اساس ویژگی): این ساختار n شیء داده را در قالب یک جدول رابطهای یا یک ماتریس n در p (n شیء × p ویژگی) ذخیره میکند.
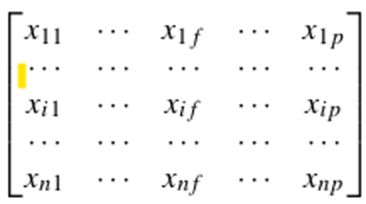
هر سطر مربوط به یک شیء است. به عنوان بخشی از نمادگذاری، میتوانیم از f برای فهرستبندی ویژگیها استفاده کنیم. • ماتریس عدم تشابه (یا ساختار شیء به شیء): این ساختار مجموعهای از نزدیکیهایی را ذخیره میکند که برای همه جفتهای n شیء موجود است. این اغلب توسط یک جدول n در n نمایش داده میشود:
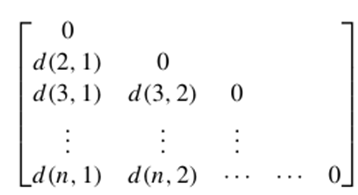
که در آن d(i, j) عدم تشابه یا «تفاوت» اندازهگیری شده بین اشیاء i و j است. به طور کلی، d(i, j) یک عدد غیرمنفی است که وقتی اشیاء i و j بسیار شبیه یا «نزدیک» به یکدیگر باشند، نزدیک به 0 است و هرچه بیشتر با هم تفاوت داشته باشند، بزرگتر میشود. توجه داشته باشید که d(i, i) برابر با 0 است؛ یعنی تفاوت بین یک شیء و خودش برابر با 0 است. علاوه بر این، d(i, j) d(j, i). (برای خوانایی، ورودیهای d(j, i) را نشان نمیدهیم زیرا ماتریس متقارن است.) معیارهای عدم تشابه در ادامه این فصل مورد بحث قرار میگیرند. معیارهای شباهت اغلب میتوانند به عنوان تابعی از معیارهای عدم تشابه بیان شوند. به عنوان مثال، برای دادههای اسمی
sim(i, j) = 1 − d(i, j),
که در آن sim(i, j) شباهت بین اشیاء i و j است. در ادامه این فصل، در مورد معیارهای شباهت نیز توضیح خواهیم داد.
یک ماتریس داده از دو موجودیت یا “چیز” تشکیل شده است، یعنی ردیفها (برای اشیاء) و ستونها (برای ویژگیها). بنابراین، ماتریس داده اغلب ماتریس دو حالته نامیده میشود. ماتریس عدم تشابه شامل یک نوع موجودیت (عدم تشابهها) است و بنابراین ماتریس یک حالته نامیده میشود. بسیاری از الگوریتمهای خوشهبندی و نزدیکترین همسایه بر روی یک ماتریس عدم تشابه عمل میکنند. دادهها به شکل ماتریس داده میتوانند قبل از اعمال چنین الگوریتمهایی به یک ماتریس عدم تشابه تبدیل شوند.
معیارهای نزدیکی برای ویژگیهای اسمی
یک ویژگی اسمی میتواند دو یا چند حالت را به خود بگیرد (بخش 2.1.1). به عنوان مثال، map_color یک ویژگی اسمی است که ممکن است مثلاً پنج حالت داشته باشد: قرمز، زرد، سبز، صورتی و آبی. فرض کنید تعداد حالتهای یک ویژگی اسمی M باشد. حالتها را میتوان با حروف، نمادها یا مجموعهای از اعداد صحیح مانند ۱، ۲،…،M نشان داد. توجه داشته باشید که چنین اعداد صحیحی فقط برای پردازش دادهها استفاده میشوند و هیچ ترتیب خاصی را نشان نمیدهند.
“چگونه عدم تشابه بین اشیاء توصیف شده توسط ویژگیهای اسمی محاسبه میشود؟” عدم تشابه بین دو شیء i و j را میتوان بر اساس نسبت عدم تطابقها محاسبه کرد:
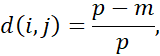
که در آن m تعداد تطابقها (یعنی تعداد ویژگیهایی که i و j در یک حالت هستند) و p تعداد کل ویژگیهایی است که اشیاء را توصیف میکنند. میتوان وزنهایی را برای افزایش اثر m یا اختصاص وزن بیشتر به تطابقها در ویژگیهایی که تعداد حالتهای بیشتری دارند، اختصاص داد.
مثال ۲.۱۸. عدم تشابه بین ویژگیهای اسمی. فرض کنید دادههای نمونه جدول ۲.۴ را داریم، با این تفاوت که فقط شناسه شیء و ویژگی test۱ در دسترس هستند، که در آن -test۱ اسمی است. (در مثالهای بعدی از -test۲ وtest -۳ استفاده خواهیم کرد.) بیایید ماتریس عدم تشابه معادله (۲.۱۴) را محاسبه کنیم، یعنی
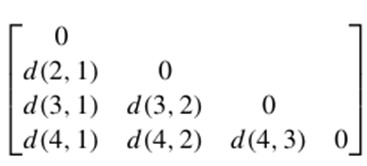
از آنجایی که در اینجا یک ویژگی اسمی، test-1، داریم، p را در معادله (2.16) طوری تنظیم میکنیم که d(i, j) در صورت تطابق اشیاء i و j برابر با 0 و در صورت تفاوت اشیاء برابر با 1 باشد. بنابراین، داریم:

از این رو، میبینیم که همه اشیاء به جز اشیاء ۱ و ۴ متفاوت هستند (یعنی d(4, 1) = 0). به طور جایگزین، شباهت را میتوان به صورت زیر محاسبه کرد:
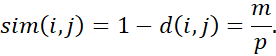
|
جدول ۲.۴ یک جدول داده نمونه شامل ویژگیهای انواع مختلط. |
|||
|
شناسه شیء |
تست-۱ (اسمی) |
تست -۲ (ترتیبی) |
تست-3 (عددی) |
|
1 |
code A |
عالی |
45 |
|
2 |
code B |
منصفانه |
22 |
|
3 |
code C |
خوب |
64 |
|
4 |
code A |
عالی |
28 |
نزدیکی بین اشیاء توصیف شده توسط ویژگیهای اسمی را میتوان با استفاده از یک طرح رمزگذاری جایگزین محاسبه کرد. ویژگیهای اسمی را میتوان با استفاده از ویژگیهای دودویی نامتقارن با ایجاد یک ویژگی دودویی جدید برای هر یک از M حالت، رمزگذاری کرد. برای یک شیء با مقدار حالت معین، ویژگی دودویی که نشان دهنده آن حالت است روی ۱ تنظیم میشود، در حالی که ویژگیهای دودویی باقی مانده روی ۰ تنظیم میشوند. به عنوان مثال، برای رمزگذاری ویژگی اسمی map_color، میتوان برای هر یک از پنج رنگی که قبلاً ذکر شده است، یک ویژگی دودویی ایجاد کرد. برای یک شیء با رنگ زرد، ویژگی زرد روی ۱ تنظیم میشود، در حالی که چهار ویژگی باقی مانده روی ۰ تنظیم میشوند. معیارهای نزدیکی برای این نوع رمزگذاری را میتوان با استفاده از روشهای مورد بحث در بخش بعدی محاسبه کرد.
معیارهای نزدیکی برای ویژگیهای دودویی
بیایید به معیارهای عدم تشابه و شباهت برای اشیاء توصیف شده توسط ویژگیهای دودویی متقارن یا نامتقارن نگاهی بیندازیم. به یاد داشته باشید که یک ویژگی دودویی فقط یکی از دو حالت ۰ و ۱ را دارد، که ۰ به معنی عدم وجود ویژگی و ۱ به معنی وجود آن است (بخش ۲.۱.۲). برای مثال، با توجه به ویژگی «سیگاری» که یک بیمار را توصیف میکند، ۱ نشان میدهد که بیمار سیگار میکشد، در حالی که ۰ نشان میدهد که بیمار سیگار نمیکشد. برخورد با ویژگیهای دودویی به گونهای که گویی ویژگیهای عددی دیگری هستند، میتواند گمراهکننده باشد. بنابراین، روشهای مختص دادههای دودویی برای محاسبه عدم تشابه ضروری هستند.
«بنابراین، چگونه میتوانیم عدم تشابه بین دو ویژگی دودویی را محاسبه کنیم؟» یک رویکرد شامل محاسبه یک ماتریس عدم تشابه از دادههای دودویی داده شده است. اگر همه ویژگیهای دودویی دارای وزن یکسان در نظر گرفته شوند، جدول احتمال ۲ ۲ جدول ۲.۵ را خواهیم داشت که در آن q تعداد ویژگیهایی است که برای هر دو شیء i و j برابر با ۱ است، r تعداد ویژگیهایی است که برای شیء i برابر با ۱ است اما برای شیء j برابر با ۰ است، s تعداد ویژگیهایی است که برای شیء i برابر با ۰ است اما برای شیء j برابر با ۱ است و t تعداد ویژگیهایی است که برای هر دو شیء i و j برابر با ۰ است. تعداد کل ویژگیها p است، که در آن p=q+r+s+t است.
به یاد داشته باشید که برای ویژگیهای دودویی متقارن، هر حالت به یک اندازه ارزشمند است. عدم تشابهی که مبتنی بر ویژگیهای دودویی متقارن است، عدم تشابه دودویی متقارن نامیده میشود. اگر اشیاء i و j توسط ویژگیهای دودویی متقارن توصیف شوند، عدم تشابه بین i و j برابر است با
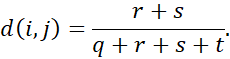
برای ویژگیهای دودویی نامتقارن، دو حالت به یک اندازه مهم نیستند، مانند نتایج مثبت (1) و منفی (0) یک آزمایش بیماری. با توجه به دو ویژگی دودویی نامتقارن، توافق دو 1 (یک تطابق مثبت) مهمتر از توافق دو 0 (یک تطابق منفی) در نظر گرفته میشود. بنابراین، چنین ویژگیهای دودویی اغلب “موناری” (دارای یک حالت) در نظر گرفته میشوند.
|
جدول ۲.۵ جدول احتمال برای ویژگیهای دودویی. |
||||
|
شیء j |
||||
|
Object i |
1 0 sum |
1 q s q + s |
0 r t r + t |
sum q + r s + t p |
عدم تشابه مبتنی بر این ویژگیها، عدم تشابه دودویی نامتقارن نامیده میشود، که در آن تعداد تطابقهای منفی، t، بیاهمیت در نظر گرفته میشود و بنابراین در محاسبه زیر نادیده گرفته میشود:
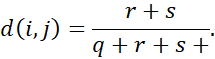
به طور مکمل، میتوانیم تفاوت بین دو ویژگی دودویی را بر اساس مفهوم شباهت به جای عدم شباهت اندازهگیری کنیم. به عنوان مثال، شباهت دودویی نامتقارن بین اشیاء i و j را میتوان به صورت زیر محاسبه کرد:
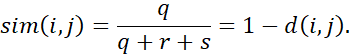
ضریب sim(i, j) از معادله (2.20) ضریب جاکارد نامیده میشود و در مقالات به طور گسترده به آن اشاره شده است.
هنگامی که هر دو ویژگی دودویی متقارن و نامتقارن در یک مجموعه داده رخ میدهند، میتوان از رویکرد ویژگیهای مختلط شرح داده شده در بخش 2.3.6 استفاده کرد.
مثال 2.19. عدم تشابه بین ویژگیهای دودویی. فرض کنید جدول ثبت بیمار (جدول 2.6) شامل ویژگیهای نام، جنسیت، تب، سرفه، تست-1، تست-2، تست-3 و تست-4 باشد، که در آن نام یک شناسه شیء، جنسیت یک ویژگی دودویی متقارن و سایر ویژگیها دودویی نامتقارن هستند.
برای مقادیر ویژگی دودویی نامتقارن، مقادیر Y (بله) و P (مثبت) را روی 1 و مقدار N (خیر یا منفی) را روی 0 تنظیم کنید. فرض کنید فاصله بین اشیاء (بیماران) فقط بر اساس ویژگیهای دودویی نامتقارن محاسبه میشود. طبق معادله (2.19)، فاصله بین هر جفت از سه بیمار – جک، مری و جیم – برابر است با
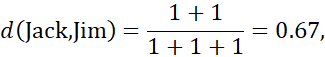
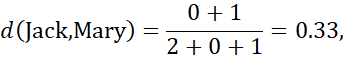
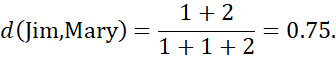
این اندازهگیریها نشان میدهد که بعید است جیم و مری بیماری مشابهی داشته باشند، زیرا آنها بالاترین مقدار عدم تشابه را در بین سه جفت دارند. از بین این سه بیمار، جک و مری بیشترین احتمال را برای داشتن بیماری مشابه دارند.
|
جدول ۲.۶ جدول رابطهای که در آن بیماران با ویژگیهای دودویی توصیف میشوند. |
|||||||
|
نام |
جنسیت |
تب |
سرفه |
تست-۱ |
تست-۲ |
تست-۳ |
تست-۴ |
|
Jack |
M |
Y |
N |
P |
N |
N |
N |
|
Jim |
M |
Y |
Y |
N |
N |
N |
N |
|
Mary |
F |
Y |
N |
P |
N |
P |
N |
|
. |
. |
. |
. |
. |
. |
. |
. |
عدم تشابه دادههای عددی: فاصله مینکوفسکی
در این بخش، معیارهای فاصلهای را شرح میدهیم که معمولاً برای محاسبه عدم تشابه اشیاء توصیف شده توسط ویژگیهای عددی استفاده میشوند. این معیارها شامل فواصل اقلیدسی، منهتن و مینکوفسکی هستند.
در برخی موارد، دادهها قبل از اعمال محاسبات فاصله، نرمالسازی میشوند. این شامل تبدیل دادهها به گونهای است که در یک محدوده کوچکتر یا رایج، مانند ۱.۰، ۱.۰ یا [۰.۰، ۱.۰] قرار گیرند. به عنوان مثال، یک ویژگی ارتفاع را در نظر بگیرید که میتواند بر حسب متر یا اینچ اندازهگیری شود. به طور کلی، بیان یک ویژگی در واحدهای کوچکتر منجر به محدوده بزرگتری برای آن ویژگی میشود و بنابراین به چنین ویژگیهایی اثر یا “وزن” بیشتری میدهد. نرمالسازی دادهها تلاش میکند تا به همه ویژگیها وزن یکسانی بدهد. این کار ممکن است در یک کاربرد خاص مفید باشد یا نباشد. روشهای نرمالسازی دادهها به طور مفصل در بخش ۲.۵ در مورد تبدیل دادهها مورد بحث قرار گرفته است.
رایجترین معیار فاصله، فاصله اقلیدسی است (یعنی خط مستقیم یا «مثل کلاغ که پرواز میکند»). فرض کنید i(xi1, xi2,…, xip) و j(xj1, xj2,…, xjp) دو شیء باشند که با p ویژگی عددی توصیف میشوند. فاصله اقلیدسی بین اشیاء i و j به صورت زیر تعریف میشود.
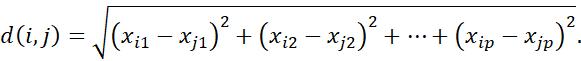
یکی دیگر از معیارهای شناختهشده، فاصله منهتن (یا بلوک شهری) است که به این دلیل به این نام خوانده میشود که فاصله بین هر دو نقطه در یک شهر (مانند ۲ بلوک پایینتر و ۳ بلوک بالاتر که در مجموع ۵ بلوک میشود) بر حسب بلوک است. این فاصله به صورت زیر تعریف میشود:
d(i, j) = |xi1 − xj1|+ |xi2 − xj2| + ··· + |xip − xjp|
هر دو فاصله اقلیدسی و منهتن، خواص ریاضی زیر را برآورده میکنند:
عدم منفی بودن: d(i, j) 0: فاصله یک عدد غیر منفی است.
هویت نامتمایزها: d(i, i) 0: فاصله یک شیء تا خودش 0 است.
تقارن: d(i, j) d(j, i): فاصله یک تابع متقارن است.
نامساوی مثلثی: d(i, j) d(i, k) d(k, j): رفتن مستقیم از شیء i به شیء j در فضا چیزی بیش از ایجاد یک مسیر انحرافی روی هر شیء k دیگر نیست.
معیاری که این شرایط را برآورده کند، به عنوان متریک شناخته میشود. لطفاً توجه داشته باشید که خاصیت عدم منفی بودن توسط سه خاصیت دیگر نیز بیان میشود.
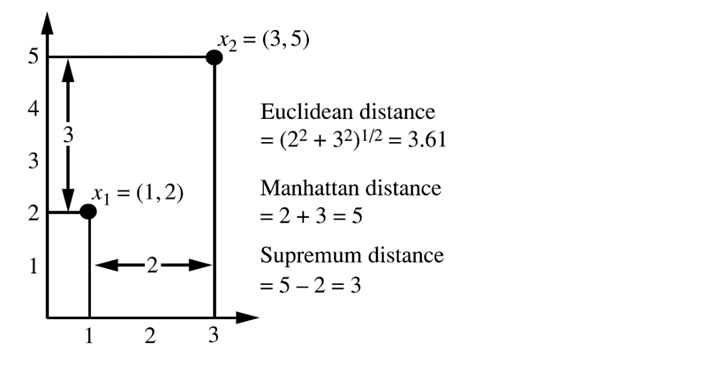
مثال 2.20. فاصله اقلیدسی و فاصله منهتن. فرض کنید x1 = (1, 2) و x2 = (3, 5) نمایانگر دو شیء مطابق شکل 2.10 باشند. فاصله اقلیدسی بین این دو
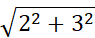
=3.61،
فاصله منهتن بین این دو است 2 + 3 = 5.
فاصله مینکوفسکی تعمیمی از فواصل اقلیدسی و منهتن است. به صورت زیر تعریف میشود.
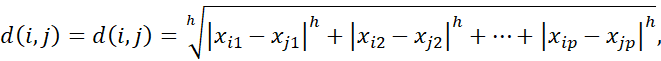
که در آن h یک عدد حقیقی است به طوری که h برابر با ۱ باشد. (چنین فاصلهای در برخی منابع، نرم Lp نیز نامیده میشود، که در آن نماد p به نمادگذاری ما از h اشاره دارد. ما p را به عنوان تعداد ویژگیها در نظر گرفتهایم تا با بقیه این فصل سازگار باشد.) این فاصله، فاصله منهتن را هنگامی که h = 1 است (یعنی نرم L1) و فاصله اقلیدسی را هنگامی که h = 2 است (یعنی نرم L2) نشان میدهد.
فواصل اقلیدسی، منهتن و سوپریمم بین دو جسم.
فاصله سوپریمم (که با نامهای Lmax، L∞ norm و فاصله چبیشف نیز شناخته میشود) تعمیمی از فاصله مینکوفسکی برای h است. برای محاسبه آن، ویژگی f را که حداکثر اختلاف مقادیر بین دو جسم را نشان میدهد، پیدا میکنیم. این اختلاف، فاصله سوپریمم است که به صورت رسمیتر به صورت زیر تعریف میشود:
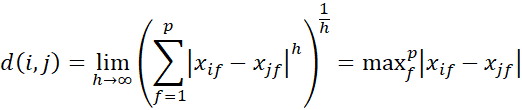
نرم L∞ همچنین به عنوان نرم یکنواخت شناخته میشود.
مثال ۲.۲۱. فاصلهی برتر. بیایید از همان دو شیء، x1 (1, 2) و x2 (3, 5)، مانند شکل ۲.۱۰ استفاده کنیم. ویژگی دوم بیشترین تفاوت بین مقادیر اشیاء را نشان میدهد. یعنی max{(|3 − 1|, |5 − 2|} = 3. این فاصلهی برتر بین دو شیء است.
اگر به هر ویژگی بر اساس اهمیت درک شدهاش وزنی اختصاص داده شود، فاصلهی اقلیدسی وزندار را میتوان به صورت زیر محاسبه کرد.
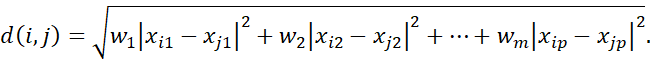
وزندهی را میتوان برای سایر معیارهای فاصله نیز اعمال کرد.
معیارهای نزدیکی برای ویژگیهای ترتیبی
مقادیر یک ویژگی ترتیبی دارای ترتیب یا رتبهبندی معناداری در مورد خود هستند، اما بزرگی بین مقادیر متوالی ناشناخته است (بخش ۲.۱.۳). یک مثال شامل توالی کوچک، متوسط، بزرگ برای یک ویژگی اندازه است. ویژگیهای ترتیبی را میتوان از گسستهسازی ویژگیهای عددی با تقسیم محدوده مقدار به تعداد محدودی از دستهها نیز بدست آورد. این دستهها به صورت رتبهای سازماندهی میشوند. یعنی، محدوده یک ویژگی عددی را میتوان به یک ویژگی ترتیبی f که دارای حالتهای Mf است، نگاشت کرد. به عنوان مثال، محدوده ویژگی دما با مقیاس فاصلهای (برحسب سانتیگراد) را میتوان به حالتهای زیر سازماندهی کرد: ۳۰ تا ۱۰، ۱۰ تا ۱۰ و ۱۰ تا ۳۰ که به ترتیب نشاندهنده دستههای دمای سرد، دمای متوسط و دمای گرم هستند. فرض کنید Mf نشاندهنده تعداد حالتهای ممکنی باشد که یک ویژگی ترتیبی میتواند داشته باشد. این حالتهای مرتب، رتبهبندی ۱،…، Mf را تعریف میکنند.
“ویژگیهای ترتیبی چگونه مدیریت میشوند؟” نحوه برخورد با ویژگیهای ترتیبی کاملاً مشابه با ویژگیهای عددی هنگام محاسبه عدم تشابه بین اشیاء است. فرض کنید f یک ویژگی از مجموعهای از ویژگیهای ترتیبی است که n شیء را توصیف میکند. محاسبه عدم تشابه نسبت به f شامل مراحل زیر است:
1. مقدار f برای شیء iام xif است و f دارای حالتهای مرتب Mf است که نشاندهنده رتبه ۱،…، Mf است. هر xif را با رتبه مربوطه آن، rif 1،…، Mf، جایگزین کنید.
2. از آنجایی که هر ویژگی ترتیبی میتواند تعداد متفاوتی از حالتها داشته باشد، اغلب لازم است که محدوده هر ویژگی را روی [0.0، 1.0] نگاشت کنیم تا هر ویژگی وزن برابری داشته باشد. ما این نرمالسازی دادهها را با جایگزینی رتبه rif شیء iام در ویژگی fام با
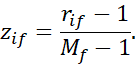
۳. سپس میتوان با استفاده از هر یک از معیارهای فاصلهای که در بخش ۲.۳.۴ برای ویژگیهای عددی شرح داده شده است، با استفاده از zif برای نمایش مقدار f برای شیء i ام، عدم تشابه را محاسبه کرد.
مثال ۲.۲۲. عدم تشابه بین ویژگیهای ترتیبی. فرض کنید دادههای نمونهای که قبلاً در جدول ۲.۴ نشان داده شده است را داریم، با این تفاوت که این بار فقط شناسه شیء و ویژگی ترتیبی پیوسته، -test۲، در دسترس هستند. سه حالت برای -test۲ وجود دارد: متوسط، خوب و عالی، یعنی Mf ۳. برای مرحله ۱، اگر هر مقدار را برای -test۲ با رتبه آن جایگزین کنیم، به چهار شیء به ترتیب رتبههای ۳، ۱، ۲ و ۳ اختصاص داده میشود. مرحله ۲ با نگاشت رتبه ۱ به ۰.۰، رتبه ۲ به ۰.۵ و رتبه ۳ به ۱.۰، رتبهبندی را نرمال میکند. برای مرحله ۳، میتوانیم مثلاً از فاصله اقلیدسی تعریف شده در معادله استفاده کنیم. (2.21)، که منجر به ماتریس عدم تشابه زیر میشود:

بنابراین اشیاء ۱ و ۲ بیشترین تفاوت را دارند، همانطور که اشیاء ۲ و ۴ (یعنی d(2, 1) 1.0 و d(4, 2) 1.0) نیز همینطور هستند. این امر به طور شهودی منطقی است زیرا اشیاء ۱ و ۴ هر دو عالی هستند. شیء ۲ متوسط است، که در انتهای مخالف محدوده مقادیر برای test-2 قرار دارد.
مقادیر شباهت برای ویژگیهای ترتیبی را میتوان از عدم شباهت به صورت -d(I,j) sim(i, j)= 1تفسیر کرد.
عدم شباهت برای ویژگیهای انواع مختلط
بخشهای ۲.۳.۲ تا ۲.۳.۵ نحوه محاسبه عدم شباهت بین اشیاء توصیف شده توسط ویژگیهایی از یک نوع را مورد بحث قرار دادند، که در آن این نوعها ممکن است اسمی، دودویی متقارن، دودویی نامتقارن، عددی یا ترتیبی باشند. با این حال، در بسیاری از پایگاههای داده واقعی، اشیاء توسط ترکیبی از انواع ویژگیها توصیف میشوند. به طور کلی، یک پایگاه داده میتواند شامل همه این انواع ویژگی باشد. «بنابراین، چگونه میتوانیم عدم تشابه بین اشیاء با انواع ویژگیهای مختلط را محاسبه کنیم؟» یک رویکرد این است که هر نوع ویژگی را با هم گروهبندی کنیم و برای هر نوع، تحلیل دادهکاوی جداگانهای (مثلاً خوشهبندی) انجام دهیم. این امر در صورتی امکانپذیر است که این تحلیلها نتایج سازگار با هم داشته باشند. با این حال، در کاربردهای واقعی، بعید است که یک تحلیل جداگانه برای هر نوع ویژگی، نتایج سازگار با هم ایجاد کند.
یک رویکرد ترجیحیتر، پردازش همه انواع ویژگی با هم و انجام یک تحلیل واحد است. یکی از این تکنیکها، ویژگیهای مختلف را در یک ماتریس عدم تشابه واحد ترکیب میکند و همه ویژگیهای معنادار را در یک مقیاس مشترک از بازه [0.0، 1.0] قرار میدهد.
فرض کنید مجموعه دادهها شامل p ویژگی از انواع مختلط است. عدم تشابه d(i, j) بین اشیاء i و j به صورت زیر تعریف میشود
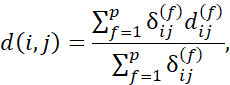
که در آن شاخص
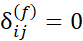
است اگر
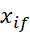
یا
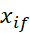
موجود نباشد (یعنی هیچ اندازهگیریای برای ویژگی f از شیء i یا شیء j وجود ندارد)، یا
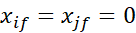
و ویژگی f نامتقارن دودویی باشد؛ در غیر این صورت،
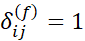
مقدار d_{ij}^{(f)} برای ویژگی f به نوع آن بستگی دارد و به صورت زیر محاسبه میشود:
اگر f عددی باشد،
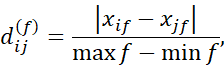
که در آن max_f و min_f به ترتیب بیشینه و کمینه مقدار ویژگی f هستند؛
اگر f اسمی یا دودویی باشد
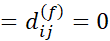
اگر
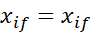
در غیر این صورت
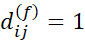
اگر f ترتیبی باشد: رتبههای rif و
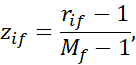
را محاسبه کرده و سپس zif را به عنوان عددی در نظر میگیریم.
این مراحل مشابه آن چیزی است که قبلاً برای هر یک از انواع ویژگیهای منفرد دیدهایم. تنها تفاوت برای ویژگیهای عددی این است که ما نرمالسازی را طوری انجام میدهیم که مقادیر در بازه [0, 1.0] قرار گیرند. بنابراین، ناهماهنگی بین اشیاء را میتوان حتی زمانی که ویژگیهای توصیفکننده اشیاء از انواع مختلف هستند، محاسبه کرد.
مثال ۲.۲۳. عدم تشابه بین ویژگیهای انواع مختلط. بیایید یک ماتریس عدم تشابه برای اشیاء جدول ۲.۴ محاسبه کنیم. اکنون تمام ویژگیها را که از انواع مختلفی هستند در نظر خواهیم گرفت. در مثالهای ۲.۱۸ و ۲.۲۲، ماتریسهای عدم تشابه را برای هر یک از ویژگیهای جداگانه محاسبه کردیم. رویههایی که برای test-1 (که اسمی است) و test-2 (که ترتیبی است) دنبال کردیم، همان رویههایی هستند که قبلاً برای پردازش ویژگیهای انواع مختلط شرح داده شده است. بنابراین میتوانیم از ماتریسهای عدم تشابه بهدستآمده برای test-1 و test-2 بعداً هنگام محاسبه معادله (۲.۲۷) استفاده کنیم.
با این حال، ابتدا باید ماتریس عدم تشابه را برای ویژگی سوم، test-3 (که عددی است) محاسبه کنیم. یعنی، باید d (3) را محاسبه کنیم. در ادامه برای ویژگیهای عددی، maxhxh = ۶۴ و minhxh = ۲۲ در نظر میگیریم. تفاوت بین این دو در معادله استفاده میشود. (2.27) برای نرمالسازی مقادیر ماتریس عدم تشابه. ماتریس عدم تشابه حاصل برای آزمون-3 به صورت زیر است:

اکنون میتوانیم از ماتریسهای عدم تشابه برای سه ویژگی در محاسبه معادله (2.27) استفاده کنیم. شاخص1= برای هر یک از سه ویژگی، f، است. برای مثال، 0.65
را بدست میآوریم. ماتریس عدم تشابه حاصل برای دادههای توصیف شده توسط سه ویژگی از انواع مختلط به صورت زیر است:
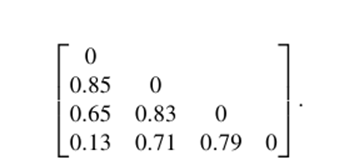
از جدول 2.4، میتوانیم به طور شهودی حدس بزنیم که اشیاء 1 و 4 بر اساس مقادیرشان برای آزمون-1 و آزمون-2 بیشترین شباهت را دارند. این موضوع توسط ماتریس عدم تشابه تأیید میشود، که در آن d(4, 1) کمترین مقدار برای هر جفت از اشیاء مختلف است. به طور مشابه، این ماتریس نشان میدهد که اشیاء 1 و 2 کمترین شباهت را دارند.
شباهت کسینوسی
شباهت کسینوسی، شباهت بین دو بردار از یک فضای ضرب داخلی را اندازهگیری میکند. این مقدار با کسینوس زاویه بین دو بردار اندازهگیری میشود و تعیین میکند که آیا دو بردار تقریباً در یک جهت قرار دارند یا خیر. اغلب برای اندازهگیری شباهت سند در تحلیل متن استفاده میشود.
یک سند را میتوان با هزاران ویژگی نشان داد که هر کدام فراوانی یک کلمه خاص (مانند یک کلمه کلیدی) یا عبارت را در سند ثبت میکنند. بنابراین هر سند یک شیء است که توسط چیزی که بردار فراوانی اصطلاح نامیده میشود، نشان داده میشود. به عنوان مثال، در جدول 2.7، میبینیم که سند 1 شامل پنج نمونه از کلمه team است، در حالی که هاکی سه بار تکرار شده است. کلمه مربی در کل سند وجود ندارد، همانطور که با مقدار شمارش ۰ نشان داده شده است. چنین دادههایی میتوانند بسیار نامتقارن باشند.
بردارهای فراوانی-اصطلاح معمولاً بسیار طولانی و پراکنده هستند (یعنی مقادیر ۰ زیادی دارند). کاربردهایی که از چنین ساختارهایی استفاده میکنند شامل بازیابی اطلاعات، خوشهبندی اسناد متنی و تجزیه و تحلیل دادههای بیولوژیکی است. معیارهای سنتی فاصله که در این فصل مطالعه کردهایم برای چنین دادههای عددی پراکندهای به خوبی کار نمیکنند.
به عنوان مثال، دو بردار فراوانی-اصطلاح ممکن است مقادیر ۰ مشترک زیادی داشته باشند، به این معنی که اسناد مربوطه کلمات زیادی را به اشتراک نمیگذارند، اما این باعث نمیشود که آنها مشابه باشند. ما به معیاری نیاز داریم که بر کلماتی که دو سند مشترک دارند و فراوانی وقوع چنین کلماتی تمرکز کند. به عبارت دیگر، ما به معیاری برای دادههای عددی نیاز داریم که تطابقهای صفر را نادیده میگیرد. شباهت کسینوسی معیاری از شباهت است که میتواند برای مقایسه اسناد یا مثلاً رتبهبندی اسناد نسبت به یک بردار مشخص از کلمات پرسوجو استفاده شود. فرض کنید x و y دو بردار برای مقایسه باشند. با استفاده از معیار کسینوس به عنوان تابع شباهت، داریم:
|
جدول ۲.۷ بردار سند یا بردار فراوانی عبارت.. |
||||||||||
|
سند |
تیم |
مربی |
هاکی |
بیسبال |
فوتبال |
پنالتی |
امتیاز |
برد |
ضرر |
فصل |
|
سند 1 |
5 |
0 |
3 |
0 |
2 |
0 |
0 |
2 |
0 |
0 |
|
سند 2 |
3 |
0 |
2 |
0 |
1 |
1 |
0 |
1 |
0 |
1 |
|
سند 3 |
0 |
7 |
0 |
2 |
1 |
0 |
0 |
3 |
0 |
0 |
|
سند 4 |
0 |
1 |
0 |
0 |
1 |
2 |
2 |
0 |
3 |
0 |
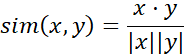
که در آن ||x|| نرم اقلیدسی بردار x = (x1, x2,…, xp) است که به صورت:
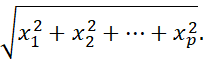
تعریف میشود. از نظر مفهومی، طول بردار است. به طور مشابه، y نرم اقلیدسی بردار y است. این معیار، کسینوس زاویه بین بردارهای x و y را محاسبه میکند. مقدار کسینوس 0 به این معنی است که دو بردار در زاویه 90 درجه نسبت به یکدیگر (متعامد) قرار دارند و هیچ تطابقی ندارند. هرچه مقدار کسینوس به 1 نزدیکتر باشد، زاویه کوچکتر و تطابق بین بردارها بیشتر است. توجه داشته باشید که از آنجا که معیار شباهت کسینوسی از تمام ویژگیهای بخش 2.3.4 که معیارهای متریک را تعریف میکند، پیروی نمیکند، به عنوان یک معیار غیرمتریک شناخته میشود.
مثال 2.24. شباهت کسینوسی بین دو بردار با فرکانس جمله. فرض کنید x و y دو بردار اول با فرکانس جمله در جدول 2.7 هستند. یعنی، x=(5, 0, 3, 0, 2, 0, 0, 2, 0, 0) وy=(3, 0, 2, 0, 1, 1, 0, 1, 0, 1)x و y چقدر به هم شبیه هستند؟ با استفاده از معادله (2.28) برای محاسبه شباهت کسینوسی بین دو بردار، به دست میآوریم:
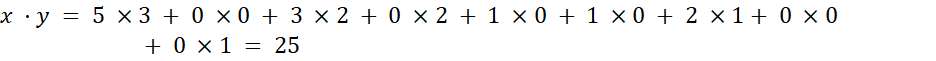
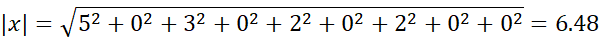
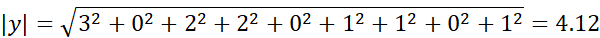
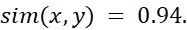
بنابراین اگر از معیار شباهت کسینوسی برای مقایسه این اسناد استفاده میکردیم، کاملاً مشابه در نظر گرفته میشدند. وقتی ویژگیها دودویی باشند، تابع شباهت کسینوسی را میتوان بر اساس ویژگیها یا صفات مشترک تفسیر کرد. فرض کنید یک شیء x دارای iامین ویژگی است اگر xi برابر با ۱ باشد. آنگاه xy تعداد ویژگیهایی است که x و y دارند (یعنی مشترک هستند) و x و y میانگین هندسی تعداد ویژگیهایی هستند که x و y به ترتیب دارند. بنابراین، sim(x, y) معیاری برای داشتن نسبی ویژگیهای مشترک است. یک تغییر ساده از شباهت کسینوسی برای سناریوی قبلی به صورت زیر است:
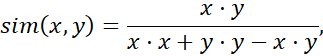
که نسبت تعداد ویژگیهای مشترک x و y به تعداد ویژگیهای دارای x یا y است. این تابع که به عنوان ضریب تانیموتو یا فاصله تانیموتو شناخته میشود، اغلب در بازیابی اطلاعات و طبقهبندی زیستشناسی استفاده میشود.
اندازهگیری توزیعهای مشابه: واگرایی کولبک-لیبلر
در نهایت، واگرایی کولبک-لیبلر یا به طور ساده، واگرایی KL را معرفی میکنیم، معیاری که به طور گسترده در ادبیات دادهکاوی برای اندازهگیری تفاوت بین دو توزیع احتمال بر روی متغیر x یکسان استفاده شده است. این مفهوم در نظریه احتمال و نظریه اطلاعات سرچشمه گرفته است.
واگرایی KL، که ارتباط نزدیکی با آنتروپی نسبی، واگرایی اطلاعات و اطلاعات برای تمایز دارد، معیاری نامتقارن از تفاوت بین دو توزیع احتمال p(x) و q(x) است. به طور خاص، واگرایی KL مربوط به q(x) از p(x)، که با DKL(p(x) q(x)) نشان داده میشود، معیاری برای از دست دادن اطلاعات است، زمانی که q(x) برای تقریب p(x) استفاده میشود. فرض کنید p(x) و) q(x دو توزیع احتمال از یک متغیر تصادفی گسسته x باشند. یعنی، مجموع p(x) و q(x) هر دو برابر با ۱ باشد، و p(x) > 0 و q(x) > 0 برای هر x در X باشد. DKL(p(x) q(x) در معادله (2.30) تعریف شده است.
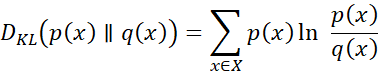
واگرایی KL تعداد بیتهای اضافی مورد انتظار مورد نیاز برای کدگذاری نمونهها از p(x) را هنگام استفاده از کدی مبتنی بر q(x) به جای استفاده از کدی مبتنی بر p(x) اندازهگیری میکند. معمولاً p(x) نشان دهنده توزیع “واقعی” دادهها، مشاهدات یا یک توزیع نظری دقیقاً محاسبه شده است. معیار q(x) معمولاً نشان دهنده یک نظریه، مدل، توصیف یا تقریبی از p(x) است.
نسخه پیوسته واگرایی KL به صورت زیر است:
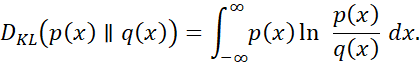
اگرچه واگرایی KL «فاصله» بین دو توزیع را اندازهگیری میکند، اما یک معیار فاصله نیست. دلیل این امر این است که واگرایی KL یک معیار متریک نیست. متقارن نیست: KL از p(x) تا q(x) عموماً با KL از q(x) تا p(x) یکسان نیست. علاوه بر این، نیازی به برآورده کردن نابرابری مثلثی ندارد. با این وجود، DKL(p(x)||q(x)) یک معیار غیرمنفی است.
DKL(p(x)||q(x)) ≥ 0 و DKL(p(x)||q(x)) = 0 اگر و تنها اگر p(x) = q(x). توجه داشته باشید که هنگام محاسبه واگرایی KL باید توجه شود. ما میدانیم که limp(x)→0 p(x) log p(x) 0 است. با این حال، وقتی p(x) 0 باشد اما q(x) 0 باشد، DKL(p(x) q(x)) به صورت زیر تعریف میشود. این بدان معناست که اگر یک رویداد e ممکن باشد (یعنی p(e) > 0) و دیگری پیشبینی کند که کاملاً غیرممکن است (یعنی q(e) 0)، آنگاه دو توزیع کاملاً متفاوت هستند. با این حال، در عمل، دو توزیع P و Q از مشاهدات و شمارش نمونه، یعنی از توزیعهای فراوانی، مشتق میشوند. پیشبینی اینکه در توزیع احتمال مشتقشده یک رویداد کاملاً غیرممکن است، غیرمنطقی است زیرا باید احتمال رویدادهای نادیده را در نظر بگیریم. میتوان از یک روش هموارسازی برای استخراج توزیع احتمال از یک توزیع فراوانی مشاهدهشده استفاده کرد، همانطور که در مثال زیر نشان داده شده است.
مثال ۲.۲۵. محاسبه واگرایی KL با هموارسازی. فرض کنید دو توزیع نمونه P و Q به شرح زیر وجود دارد: P (a 3/5,b 1/5,c 1/5) و Q (a 5/9,b 3/9,d 1/9). برای محاسبه واگرایی KL DKL(P Q)، یک ثابت کوچک E، مثلاً E 10−3، را معرفی میکنیم و یک نسخه هموار از P و Q، P t و Qt را به شرح زیر تعریف میکنیم.
مجموعه نمونه مشاهده شده در P، SP = {a, b, c}. به طور مشابه، SQ = {a, b, d}. مجموعه اتحاد SU = {a, b, c, d} است. با هموارسازی، نمادهای گمشده را میتوان به ترتیب و با احتمال کم E به هر توزیع اضافه کرد. بنابراین داریم Pt: (a: 3/5 − E/3,b: 1/5 − E/3,c: 1/5 − E/3,d: E) و Qt: (a: 5/9 − E/3,b: 3/9 − E/3,c: E, d: 1/9 − E/3). DKL(Pt, Qt) را میتوان به راحتی محاسبه کرد.
به دست آوردن معانی پنهان در معیارهای شباهت
معیار شباهت یک مفهوم اساسی در دادهکاوی است. ما معیارهای متعددی را برای محاسبه شباهت بین اشیاء شامل ویژگی عددی، ویژگی دودویی متقارن و نامتقارن، ویژگی ترتیبی و ویژگی اسمی معرفی کردهایم. همچنین نحوه محاسبه شباهت اسناد با استفاده از مدل فضای برداری و نحوه مقایسه دو توزیع با استفاده از مفهوم واگرایی KL را معرفی کردهایم. این مفاهیم و معیارهای مربوط به شباهت اشیاء به طور قابل توجهی در مطالعات بعدی ما در مورد روشهای کشف الگو، طبقهبندی، خوشهبندی و تحلیل دادههای پرت استفاده خواهند شد. در کاربردهای واقعی، ممکن است با مفهوم شباهت اشیاء فراتر از آنچه در این فصل مورد بحث قرار دادهایم، مواجه شویم. حتی برای اشیاء ساده، شباهتهای بین اشیاء اغلب ارتباط نزدیکی با معانی معنایی آنها دارند که نمیتوان آنها را بر اساس معیارهای شباهت تعریف شده فوق به دست آورد.
به عنوان مثال، مردم اغلب هندسه و جبر را مشابهتر از هندسه در مقابل موسیقی یا سیاست میدانند، حتی اگر همه آنها موضوعاتی باشند که در مدارس مورد مطالعه قرار میگیرند. علاوه بر این، اسنادی که از توزیعهای فراوانی مشابه کلمات (یا بستههای کلمات مشابه) تشکیل شدهاند، ممکن است معانی نسبتاً متفاوتی را بیان کنند (مثلاً، در نظر گرفتن «گربه موش را گاز میگیرد» در مقابل «موش گربه را گاز میگیرد»). این فراتر از آن چیزی است که یک مدل فضای برداری (یعنی بیان کلمات به عنوان مجموعهای از بردارها در یک فضای برداری با ابعاد بالا، همانطور که در بخش 2.3.7 نشان داده شده است) میتواند از عهده آن برآید. علاوه بر این، اشیاء میتوانند از ساختارها و اتصالات نسبتاً پیچیدهای تشکیل شوند. ممکن است لازم باشد معیارهای شباهت برای گرافها و شبکهها معرفی شوند، که فراتر از مفاهیم شباهت شیء معرفی شده در اینجا است.
در فصلهای آینده، در صورت مواجهه با مشکلات و روشهای مورد بحث، معیارهای شباهت بیشتری را معرفی خواهیم کرد. به طور خاص، در فصل 12، به طور خلاصه مفهوم بازنمایی توزیعی و یادگیری بازنمایی را معرفی خواهیم کرد، که در آن از جاسازی متن و یادگیری عمیق برای محاسبه چنین مفهوم پیشرفتهای از شباهتها استفاده خواهد شد.


