مقدمه
در تبدیل دادهها، دادهها به اشکال مناسب برای کاوش تبدیل یا تجمیع میشوند. از طریق تبدیل مناسب دادهها، فرآیند کاوش حاصل ممکن است کارآمدتر باشد و الگوهای یافتشده ممکن است آسانتر قابل درک باشند. استراتژیهای مختلفی برای تبدیل دادهها توسعه داده شده است. در این بخش، با معرفی نرمالسازی دادهها (بخش ۲.۵.۱) شروع میکنیم، که در آن دادههای ویژگی به گونهای مقیاسبندی میشوند که در محدوده کوچکتری مانند -۱.۰ تا ۱.۰ یا ۰.۰ تا ۱.۰ قرار گیرند. سپس، گسستهسازی دادهها (بخش ۲.۵.۲) را یاد خواهیم گرفت، که مقادیر خام یک ویژگی عددی (مثلاً سن) را با برچسبهای بازه (مثلاً ۰-۱۰، ۱۱-۲۰ و غیره) یا برچسبهای مفهومی (مثلاً جوان، بزرگسال، سالمند) جایگزین میکند. فشردهسازی دادهها (بخش ۲.۵.۳) و نمونهبرداری (بخش ۲.۵.۴) دو تکنیک کاهش داده هستند که دادههای ورودی را به یک نمایش کاهشیافته تبدیل میکنند که از نظر حجم بسیار کوچکتر است، اما یکپارچگی دادههای اصلی را به دقت حفظ میکند.
نرمالسازی دادهها
واحد اندازهگیری مورد استفاده میتواند بر تجزیه و تحلیل دادهها تأثیر بگذارد. به عنوان مثال، تغییر واحدهای اندازهگیری از متر به اینچ برای ارتفاع، یا از کیلوگرم به پوند برای وزن، ممکن است منجر به نتایج بسیار متفاوتی شود. به طور کلی، بیان یک ویژگی در واحدهای کوچکتر منجر به محدوده بزرگتری برای آن ویژگی میشود و بنابراین به چنین ویژگیای اثر یا “وزن” بیشتری میدهد. برای کمک به جلوگیری از وابستگی به انتخاب واحدهای اندازهگیری، دادهها باید نرمالسازی یا استانداردسازی شوند. این شامل تبدیل دادهها به گونهای است که در یک محدوده کوچکتر یا رایج مانند ۱.۰، ۱.۰ یا [۰.۰، ۱.۰] قرار گیرند. (اصطلاحات استانداردسازی و نرمالسازی در پیشپردازش دادهها به جای یکدیگر استفاده میشوند، اگرچه در آمار، اصطلاح دوم معانی دیگری نیز دارد.)
نرمالسازی دادهها تلاش میکند تا به همه ویژگیها وزن یکسانی بدهد. نرمالسازی به ویژه برای الگوریتمهای طبقهبندی شامل شبکههای عصبی یا اندازهگیریهای فاصله مانند طبقهبندی و خوشهبندی نزدیکترین همسایه مفید است. اگر از الگوریتم پسانتشار شبکه عصبی برای طبقهبندی استفاده شود (فصل 10)، نرمالسازی مقادیر ورودی برای هر ویژگی اندازهگیری شده در تاپلهای آموزشی به سرعت بخشیدن به مرحله یادگیری کمک میکند. برای روشهای مبتنی بر فاصله، نرمالسازی به جلوگیری از غلبه ویژگیهایی با محدودههای اولیه بزرگ (مثلاً درآمد) بر ویژگیهایی با محدودههای اولیه کوچکتر (مثلاً ویژگیهای دودویی) کمک میکند. همچنین زمانی که هیچ دانش قبلی از دادهها وجود ندارد، مفید است.
روشهای زیادی برای نرمالسازی دادهها وجود دارد. ما نرمالسازی حداقل-حداکثر، نرمالسازی امتیاز z و نرمالسازی با مقیاس اعشاری را مطالعه میکنیم. برای بحث ما، فرض کنید A یک ویژگی عددی با n مقدار مشاهده شده، v1، v2،…، vn باشد.
نرمالسازی حداقل-حداکثر یک تبدیل خطی روی دادههای اصلی انجام میدهد. فرض کنید minA و maxA مقادیر حداقل و حداکثر یک ویژگی A باشند. نرمالسازی Min-max با محاسبهی
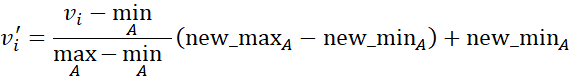
نرمالسازی حداقل-حداکثر، روابط بین مقادیر دادههای اصلی را حفظ میکند. اگر یک مورد ورودی آینده برای نرمالسازی خارج از محدوده دادههای اصلی برای A قرار گیرد، با خطای “خارج از محدوده” مواجه خواهد شد.
مثال ۲.۲۶. نرمالسازی حداقل-حداکثر. فرض کنید که حداقل و حداکثر مقادیر برای ویژگی درآمد به ترتیب ۱۲۰۰۰ دلار و ۹۸۰۰۰ دلار هستند. ما میخواهیم درآمد را به محدوده [۰.۰،۱.۰] نگاشت کنیم. با نرمالسازی حداقل-حداکثر، مقدار ۷۳۶۰۰ دلار برای درآمد به … تبدیل میشود.
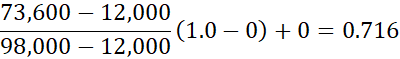
در نرمالسازی امتیاز z (یا نرمالسازی با میانگین صفر)، مقادیر یک ویژگی، A، بر اساس میانگین (یعنی میانگین) و انحراف معیار A نرمالسازی میشوند. یک مقدار، vi، از A با محاسبهی به vi نرمالسازی میشود.
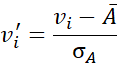
که در آن Ā و σA به ترتیب میانگین و انحراف معیار ویژگی A هستند. میانگین و انحراف معیار در بخش 2.2 مورد بحث قرار گرفت، که در آن
Ā = 1/n (v₁ + v₂ + ⋯ + vₙ) و σA به عنوان جذر واریانس A محاسبه میشود (به معادله (2.6) مراجعه کنید). این روش نرمالسازی زمانی مفید است که حداقل و حداکثر واقعی ویژگی A ناشناخته باشد یا زمانی که دادههای پرت وجود داشته باشند که بر نرمالسازی حداقل-حداکثر غلبه میکنند.
مثال ۲.۲۷. نرمالسازی امتیاز z. فرض کنید میانگین و انحراف معیار مقادیر برای ویژگی درآمد به ترتیب ۵۴۰۰۰ و ۱۶۰۰۰ دلار باشد. با نرمالسازی امتیاز z، مقدار ۷۳۶۰۰ دلار برای درآمد به (73600 − 54000) ÷ 16000 = 1.225تبدیل میشود.
تغییر این نرمالسازی نمره z، انحراف معیار معادله (2.33) را با میانگین انحراف مطلق A جایگزین میکند. میانگین انحراف مطلق A که با sA نشان داده میشود، برابر است با
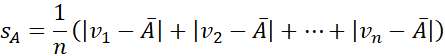
بنابراین نرمالسازی نمره z با استفاده از میانگین انحراف مطلق به صورت زیر است:
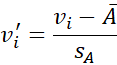
انحراف مطلق میانگین، sA، در مقایسه با انحراف معیار، σA، در برابر دادههای پرت مقاومتر است. هنگام محاسبه انحراف مطلق میانگین، انحرافات از میانگین (یعنی xi- x) به توان دو نمیرسند؛ از این رو، اثر دادههای پرت تا حدودی کاهش مییابد.
نرمالسازی با مقیاسبندی اعشاری، با جابجایی نقطه اعشار مقادیر ویژگی A، نرمالسازی میکند. تعداد نقاط اعشار جابجا شده به حداکثر مقدار مطلق A بستگی دارد. یک مقدار، vi، ازA با محاسبه به vi نرمالسازی میشود.
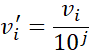
که در آن j کوچکترین عدد صحیح است به طوری که max(|vit |)< 1.
مثال ۲.۲۸. مقیاسبندی اعشاری. فرض کنید مقادیر ثبت شده A از ۹۸۶ تا ۹۱۷ متغیر باشد. حداکثر قدر مطلق A برابر با ۹۸۶ است. برای نرمالسازی با مقیاسبندی اعشاری، بنابراین هر مقدار را بر ۱۰۰۰ تقسیم میکنیم (یعنی3 j =) به طوری که ۹۸۶- به ۰.۹۸۶- و ۹۱۷ به ۰.۹۱۷ نرمالسازی شود.
توجه داشته باشید که نرمالسازی میتواند دادههای اصلی را تا حد زیادی تغییر دهد، به خصوص هنگام استفاده از نرمالسازی z-score یا مقیاسبندی اعشاری. همچنین لازم است پارامترهای نرمالسازی (مثلاً میانگین و انحراف معیار در صورت استفاده از نرمالسازی z-score) ذخیره شوند تا دادههای آینده بتوانند به طور یکنواخت نرمالسازی شوند.
گسستهسازی دادهها
گسستهسازی دادهها یک تکنیک رایج تبدیل دادهها است که در آن مقادیر خام یک ویژگی عددی (مثلاً سن) با برچسبهای بازه (مثلاً ۰-۱۰، ۱۱-۲۰ و غیره) یا برچسبهای مفهومی (مثلاً جوان، بزرگسال، سالمند) جایگزین میشوند. برچسبها، به نوبه خود، میتوانند به صورت بازگشتی در مفاهیم سطح بالاتر سازماندهی شوند که منجر به یک سلسله مراتب مفهومی برای ویژگی عددی میشود. شکل ۲.۱۳ یک سلسله مراتب مفهومی برای ویژگی قیمت را نشان میدهد. برای تطبیق با نیازهای کاربران مختلف، میتوان بیش از یک سلسله مراتب مفهومی برای یک ویژگی تعریف کرد.
تکنیکهای گسستهسازی را میتوان بر اساس نحوه انجام گسستهسازی، مانند اینکه آیا از اطلاعات کلاس استفاده میکند یا اینکه در کدام جهت پیش میرود (یعنی از بالا به پایین در مقابل از پایین به بالا)، طبقهبندی کرد. اگر فرآیند گسستهسازی از اطلاعات کلاس استفاده کند، میگوییم گسستهسازی نظارتشده است. در غیر این صورت، بدون نظارت است. اگر فرآیند با یافتن یک یا چند نقطه (به نام نقاط تقسیم یا نقاط برش) برای تقسیم کل محدوده ویژگی شروع شود و سپس این کار را به صورت بازگشتی روی فواصل حاصل تکرار کند، گسستهسازی یا تقسیم بالا به پایین نامیده میشود. این در تضاد با گسستهسازی یا ادغام پایین به بالا است که با در نظر گرفتن تمام مقادیر پیوسته به عنوان نقاط تقسیم بالقوه شروع میشود، برخی را با ادغام مقادیر همسایگی برای تشکیل فواصل حذف میکند و سپس به صورت بازگشتی این فرآیند را روی فواصل حاصل اعمال میکند.
ما دو تکنیک گسستهسازی اساسی، از جمله binning و تحلیل هیستوگرام را معرفی میکنیم. روشهای دیگر برای گسستهسازی شامل تحلیل خوشهای، تحلیل درخت تصمیمگیری و تحلیل همبستگی است. هر یک از این تکنیکها میتوانند برای تولید سلسله مراتب مفهومی برای ویژگیهای عددی مورد استفاده قرار گیرند.
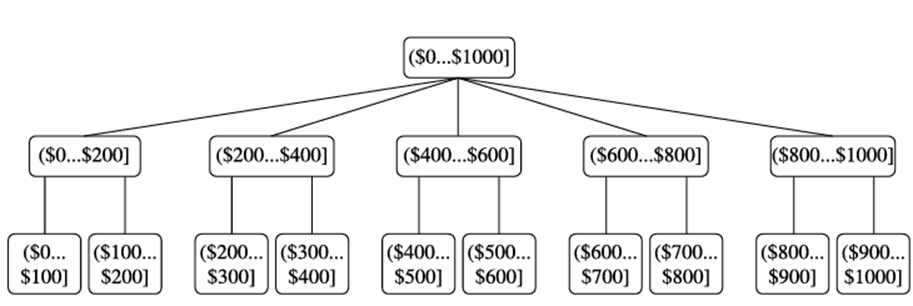
یک سلسله مراتب مفهومی برای قیمت ویژگی، که در آن یک بازه ($X … $Y] نشاندهنده محدوده از $X (منحصراً) تا $Y (شامل) است.
گسستهسازی با استفاده از binning
Binning یک تکنیک تقسیم از بالا به پایین بر اساس تعداد مشخصی از bin ها است. بخش 2.4.2 روشهای binning را برای هموارسازی دادهها مورد بحث قرار داد. این روشها همچنین به عنوان روشهای گسستهسازی برای کاهش دادهها و تولید سلسله مراتب مفهومی استفاده میشوند. به عنوان مثال، مقادیر ویژگی را میتوان با اعمال binning با عرض برابر یا فرکانس برابر و سپس جایگزینی هر مقدار bin با میانگین bin یا میانه، مانند هموارسازی با میانگین bin یا هموارسازی با میانه bin، گسستهسازی کرد. این تکنیکها را میتوان به صورت بازگشتی بر روی پارتیشنهای حاصل اعمال کرد تا سلسله مراتب مفهومی ایجاد شود.
Binning از اطلاعات کلاس استفاده نمیکند و بنابراین یک تکنیک گسستهسازی بدون نظارت است. این تکنیک به تعداد bin های مشخص شده توسط کاربر و همچنین وجود دادههای پرت حساس است.
گسستهسازی با تحلیل هیستوگرام
تحلیل هیستوگرام یک تکنیک گسستهسازی بدون نظارت است زیرا از اطلاعات کلاس استفاده نمیکند. هیستوگرامها در بخش 2.2.4 معرفی شدند. یک هیستوگرام، مقادیر یک ویژگی، A، را به محدودههای مجزایی به نام سطل یا دسته تقسیم میکند. اگر هر سطل فقط یک جفت ویژگی-مقدار/فراوانی را نشان دهد، سطلها، سطلهای تکگانه نامیده میشوند. سطلهای تکگانه برای ذخیره دادههای پرت با فراوانی بالا مفید هستند. اغلب، سطلها محدودههای پیوستهای را برای ویژگی داده شده نشان میدهند.
مثال ۲.۲۹. دادههای زیر لیستی از قیمت اقلام رایج فروخته شده در شرکت هستند (گرد شده به نزدیکترین دلار). اعداد مرتب شدهاند: ۱، ۱، ۵، ۵، ۵، ۵، ۸، ۸، ۱۰، ۱۰، ۱۰، ۱۰، ۱۲، ۱۴، ۱۴، ۱۴، ۱۵، ۱۵، ۱۵، ۱۵، ۱۵، ۱۵، ۱۸، ۱۸، ۱۸، ۱۸، ۱۸، ۱۸، ۱۸، ۱۸، ۱۸، ۱۸، ۱۸، ۲۰، ۲۰، ۲۰، ۲۰، ۲۱، ۲۱، ۲۱، ۲۵،۲۵، ۲۵، ۲۵، ۲۵، ۲۸، ۲۸، ۳۰، ۳۰.
شکل ۲.۱۴ یک هیستوگرام برای دادهها با استفاده از سطلهای تکقلو نشان میدهد. برای کاهش بیشتر دادهها، معمولاً هر سطل نشاندهنده یک محدوده مقدار پیوسته برای ویژگی داده شده است. در شکل 2.15، هر سطل نشاندهنده یک محدوده 10 دلاری متفاوت برای قیمت است.
“چگونه سطلها تعیین و مقادیر ویژگیها تقسیمبندی میشوند؟” چندین قانون تقسیمبندی وجود دارد، از جمله موارد زیر:
- عرض برابر: در یک هیستوگرام با عرض برابر، عرض هر محدوده سطل یکنواخت است (مثلاً عرض 10 دلار برای سطلها در شکل 2.15).
- فراوانی برابر (یا عمق برابر): در یک هیستوگرام با فراوانی برابر، سطلها به گونهای ایجاد میشوند که تقریباً فراوانی هر سطل ثابت باشد (یعنی هر سطل تقریباً شامل تعداد یکسانی از نمونههای داده پیوسته باشد).
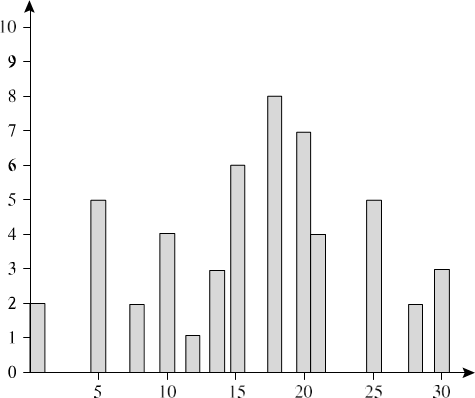
هیستوگرام قیمت با استفاده از سطلهای تکی – هر سطل نشان دهنده یک جفت قیمت-ارزش/فراوانی است.
هیستوگرامها در تقریب دادههای پراکنده و متراکم، و همچنین دادههای بسیار کج و یکنواخت، بسیار مؤثر هستند. هیستوگرامهایی که قبلاً برای ویژگیهای تکی توضیح داده شدند، میتوانند برای چندین ویژگی نیز گسترش یابند. هیستوگرامهای چندبعدی میتوانند وابستگیهای بین ویژگیها را ثبت کنند. این هیستوگرامها در تقریب دادههایی با حداکثر پنج ویژگی مؤثر بودهاند. مطالعات بیشتری در مورد اثربخشی هیستوگرامهای چندبعدی برای ابعاد بالا مورد نیاز است.
الگوریتم تحلیل هیستوگرام را میتوان به صورت بازگشتی برای هر پارتیشن اعمال کرد تا به طور خودکار یک سلسله مراتب مفهومی چندسطحی ایجاد شود، و این روش پس از رسیدن به تعداد از پیش تعیینشدهای از سطوح مفهومی خاتمه مییابد. همچنین میتوان از حداقل اندازه بازه در هر سطح برای کنترل روش بازگشتی استفاده کرد. این حداقل عرض یک پارتیشن یا حداقل تعداد مقادیر برای هر پارتیشن در هر سطح را مشخص میکند.
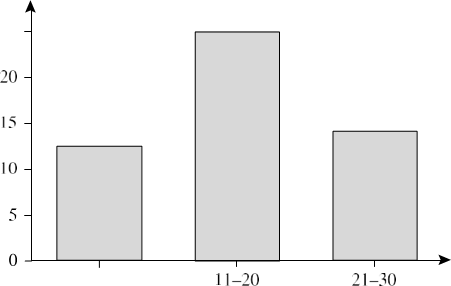
یک هیستوگرام با عرض مساوی برای قیمت، که در آن مقادیر به گونهای تجمیع شدهاند که هر سطل دارای عرض یکنواخت ۱۰ دلار باشد.
فشردهسازی دادهها
در فشردهسازی دادهها، تبدیلها به گونهای اعمال میشوند که یک نمایش کاهشیافته یا «فشردهشده» از دادههای اصلی به دست آید. اگر دادههای اصلی را بتوان از دادههای فشردهشده بدون هیچگونه از دست دادن اطلاعات بازسازی کرد، کاهش دادهها را بدون اتلاف مینامند. اگر در عوض، فقط بتوانیم تقریبی از دادههای اصلی را بازسازی کنیم، کاهش دادهها را با اتلاف مینامند. چندین الگوریتم بدون اتلاف برای فشردهسازی رشته وجود دارد؛ با این حال، آنها معمولاً فقط امکان دستکاری دادههای محدودی را فراهم میکنند. تکنیکهای کاهش ابعاد (بخش ۲.۶) نیز میتوانند به عنوان اشکالی از فشردهسازی دادهها در نظر گرفته شوند.
تبدیل موجک گسسته (DWT) یک تکنیک پردازش سیگنال خطی است که وقتی بر روی یک بردار داده x اعمال میشود، آن را به یک بردار عددی متفاوت، xt، از ضرایب موجک تبدیل میکند. دو بردار طول یکسانی دارند. هنگام اعمال این تکنیک بر روی کاهش دادهها، هر تاپل را به عنوان یک بردار داده n بعدی، یعنی x(x1, x2,…, xn) در نظر میگیریم که n اندازهگیری انجام شده بر روی تاپل از n ویژگی پایگاه داده را نشان میدهد.
«اگر دادههای تبدیلشده به موجک طولی برابر با دادههای اصلی داشته باشند، این تکنیک چگونه میتواند برای کاهش دادهها مفید باشد؟» فایدهی این تکنیک در این واقعیت نهفته است که دادههای تبدیلشده به موجک را میتوان کوتاه کرد. با ذخیرهی تنها بخش کوچکی از قویترین ضرایب موجک، میتوان تقریب فشردهای از دادهها را حفظ کرد. به عنوان مثال، تمام ضرایب موجک بزرگتر از یک آستانهی مشخصشده توسط کاربر را میتوان حفظ کرد. تمام ضرایب دیگر روی ۰ تنظیم میشوند. بنابراین، نمایش دادههای حاصل بسیار پراکنده است، به طوری که عملیاتی که میتوانند از پراکندگی دادهها بهره ببرند، اگر در فضای موجک انجام شوند، از نظر محاسباتی بسیار سریع هستند. این تکنیک همچنین برای حذف نویز بدون هموارسازی ویژگیهای اصلی دادهها عمل میکند و آن را برای تمیز کردن دادهها نیز مؤثر میسازد. با داشتن مجموعهای از ضرایب، میتوان با اعمال معکوس تبدیل موجک گسسته مورد استفاده، تقریبی از دادههای اصلی ایجاد کرد.
تبدیل موجک گسسته (DWT) ارتباط نزدیکی با تبدیل فوریه گسسته (DFT)، یک تکنیک پردازش سیگنال شامل سینوسها و کسینوسها، دارد. با این حال، به طور کلی، تبدیل موجک گسسته فشردهسازی با اتلاف بهتری را ارائه میدهد. به این معنی که اگر تعداد ضرایب یکسانی برای یک تبدیل موجک گسسته و یک تبدیل فوریه گسسته از یک بردار داده معین حفظ شود، نسخه DWT اغلب تقریب دقیقتری از دادههای اصلی ارائه میدهد. از این رو، برای یک تقریب معادل، تبدیل موجک گسسته به فضای کمتری نسبت به DFT نیاز دارد. برخلاف DFT، موجکها کاملاً در فضا محلی هستند و به حفظ جزئیات محلی کمک میکنند.
تنها یک DFT وجود دارد، اما چندین خانواده از DWTها وجود دارد. شکل 2.16 برخی از خانوادههای موجک را نشان میدهد. تبدیلهای موجک محبوب شامل Haar-2، Daubechies-4 و Daubechies-6 هستند. روش کلی برای اعمال تبدیل موجک گسسته از یک الگوریتم هرمی سلسله مراتبی استفاده میکند که دادهها را در هر تکرار به نصف کاهش میدهد و در نتیجه سرعت محاسباتی سریعی را به همراه دارد. این روش به شرح زیر است:
۱. طول، L، بردار داده ورودی باید توان صحیحی از باشد. این شرط را میتوان با پر کردن بردار داده با صفر در صورت لزوم (L > n) برآورده کرد.
۲. هر تبدیل شامل اعمال دو تابع است. تابع اول مقداری هموارسازی دادهها، مانند مجموع یا میانگین وزنی، اعمال میکند. تابع دوم یک تفاضل وزنی انجام میدهد که برای نمایش ویژگیهای دقیق دادهها عمل میکند.
۳. دو تابع بر روی جفت نقاط داده در X اعمال میشوند، یعنی بر روی همه جفتهای اندازهگیری (x2i، x2i 1). این منجر به دو مجموعه داده با طول L/2 میشود. به طور کلی، این دو مجموعه داده به ترتیب نشاندهنده یک نسخه هموار شده یا با فرکانس پایین از دادههای ورودی و محتوای با فرکانس بالای آن هستند.
۴. دو تابع به صورت بازگشتی بر روی مجموعه دادههای به دست آمده در تکرار قبلی اعمال میشوند، تا زمانی که مجموعه دادههای حاصل به طول ۲ برسند.
۵. مقادیر انتخاب شده از مجموعه دادههای به دست آمده در تکرارهای قبلی به عنوان ضرایب موجک دادههای تبدیل شده تعیین میشوند.
تبدیلهای موجک را میتوان برای دادههای چندبعدی مانند یک مکعب داده اعمال کرد. این کار با اعمال تبدیل ابتدا به بعد اول، سپس به بعد دوم و غیره انجام میشود. پیچیدگی محاسباتی مربوط به تعداد سلولهای مکعب خطی است. تبدیلهای موجک نتایج خوبی روی دادههای پراکنده یا چولهای و دادههایی با ویژگیهای مرتب ارائه میدهند. طبق گزارشها، فشردهسازی پراتلاف توسط موجکها بهتر از فشردهسازی JPEG، استاندارد تجاری فعلی، است. تبدیلهای موجک کاربردهای زیادی در دنیای واقعی دارند، از جمله فشردهسازی تصاویر اثر انگشت، بینایی کامپیوتر، تجزیه و تحلیل دادههای سری زمانی و پاکسازی دادهها.
به طور معادل، میتوان یک ضرب ماتریسی را برای دادههای ورودی اعمال کرد تا ضرایب موجک را به دست آورد، که در آن ماتریس مورد استفاده به تبدیل موجک گسسته داده شده بستگی دارد. ماتریس باید متعامد باشد، به این معنی که ستونها بردارهای واحد هستند و متعامد متقابل هستند، به طوری که معکوس ماتریس فقط ترانهاده آن است. اگرچه در اینجا جایی برای بحث در مورد آن نداریم، اما این ویژگی امکان بازسازی دادهها از مجموعه دادههای هموار و تفاضل هموار را فراهم میکند. با فاکتورگیری ماتریس مورد استفاده در حاصلضرب چند ماتریس پراکنده، الگوریتم “تبدیل موجک سریع” حاصل، برای یک بردار ورودی با طول n، پیچیدگی O(n) دارد.
تبدیلهای موجک را میتوان برای دادههای چندبعدی مانند یک مکعب داده اعمال کرد. این کار با اعمال تبدیل ابتدا به بعد اول، سپس به بعد دوم و غیره انجام میشود. پیچیدگی محاسباتی مربوط به تعداد سلولهای مکعب خطی است. تبدیلهای موجک نتایج خوبی روی دادههای پراکنده یا چولهای و دادههایی با ویژگیهای مرتب ارائه میدهند. طبق گزارشها، فشردهسازی پراتلاف توسط موجکها بهتر از فشردهسازی JPEG، استاندارد تجاری فعلی، است. تبدیلهای موجک کاربردهای زیادی در دنیای واقعی دارند، از جمله فشردهسازی تصاویر اثر انگشت، بینایی کامپیوتر، تجزیه و تحلیل دادههای سری زمانی و پاکسازی دادهها.
شکل ۲.۱۶
نمونههایی از خانوادههای موجک. عدد کنار نام موجک، تعداد گشتاورهای ناپدید شدن موجک است. این مجموعهای از روابط ریاضی است که ضرایب باید آنها را برآورده کنند و به تعداد ضرایب مربوط میشود.
نمونهگیری از دادهها
نمونهگیری میتواند به عنوان یک تکنیک کاهش داده مورد استفاده قرار گیرد زیرا اجازه میدهد یک مجموعه داده بزرگ توسط یک نمونه (یا زیرمجموعه) داده تصادفی بسیار کوچکتر نمایش داده شود. فرض کنید یک مجموعه داده بزرگ، D، شامل N تاپل است. بیایید به رایجترین روشهای نمونهگیری از D برای کاهش داده نگاهی بیندازیم.
- نمونه تصادفی ساده بدون جایگزینی (SRSWOR) با اندازه s: این با کشیدن s نمونه از D ایجاد میشود و هر بار که یک نمونه کشیده میشود، قرار نیست به مجموعه داده D برگردانده شود.
- نمونه تصادفی ساده با جایگزینی (SRSWR) با اندازه s: این شبیه به SRSWOR است، با این تفاوت که هر بار که یک تاپل از D کشیده میشود، ثبت و سپس جایگزین میشود. یعنی پس از کشیدن یک تاپل، دوباره در D قرار میگیرد تا بتوان دوباره آن را کشید.
- نمونه خوشهای: اگر تاپلهای D در M «خوشه»های متقابلاً جدا از هم گروهبندی شوند، میتوان نمونهای از s خوشه به دست آورد، که در آن s < M است. به عنوان مثال، تاپلهای یک پایگاه داده معمولاً به صورت صفحه به صفحه بازیابی میشوند، به طوری که هر صفحه را میتوان یک خوشه در نظر گرفت. میتوان با اعمال مثلاً SRSWOR بر روی صفحات، یک نمایش داده کاهش یافته به دست آورد که منجر به یک نمونه خوشهای از تاپلها میشود. سایر معیارهای خوشهبندی که معانی غنی را منتقل میکنند نیز قابل بررسی هستند. به عنوان مثال، در یک پایگاه داده مکانی، میتوانیم خوشهها را بر اساس میزان نزدیکی مناطق مختلف به یکدیگر، از نظر جغرافیایی تعریف کنیم.
- نمونه طبقهبندی شده: اگر D به بخشهای متقابلاً جدا از هم به نام لایهها تقسیم شود، با به دست آوردن یک نمونه در هر لایه، یک نمونه طبقهبندی شده از D ایجاد میشود. این امر به اطمینان از یک نمونه نماینده، به ویژه هنگامی که دادهها دارای انحراف هستند، کمک میکند. به عنوان مثال، یک نمونه طبقهبندی شده ممکن است از دادههای مشتری به دست آید، که در آن یک لایه برای هر گروه سنی مشتری ایجاد میشود. به این ترتیب، گروه سنی که کمترین تعداد مشتری را دارد، مطمئناً نمایش داده خواهد شد.
یکی از مزایای نمونهگیری برای کاهش دادهها این است که هزینه به دست آوردن یک نمونه متناسب با اندازه نمونه، s، است، برخلاف N، اندازه مجموعه دادهها. از این رو، پیچیدگی نمونهگیری به طور بالقوه نسبت به اندازه دادهها زیرخطی است. سایر تکنیکهای کاهش دادهها میتوانند حداقل به یک گذر کامل از D نیاز داشته باشند. برای یک اندازه نمونه ثابت، پیچیدگی نمونهگیری فقط به صورت خطی با افزایش تعداد ابعاد داده، n، افزایش مییابد، در حالی که تکنیکهایی که به عنوان مثال از هیستوگرام استفاده میکنند، میتوانند به صورت نمایی در n افزایش یابند.
هنگامی که برای کاهش دادهها اعمال میشود، نمونهگیری معمولاً برای تخمین پاسخ به یک پرسوجوی کلی استفاده میشود. میتوان (با استفاده از قضیه حد مرکزی) اندازه نمونه کافی را برای تخمین یک تابع معین در یک درجه خطای مشخص تعیین کرد. این اندازه نمونه، s، ممکن است در مقایسه با N بسیار کوچک باشد. نمونهگیری یک انتخاب طبیعی برای اصلاح تدریجی یک مجموعه داده کاهش یافته است. چنین مجموعهای را میتوان با افزایش ساده اندازه نمونه، بیشتر اصلاح کرد.


