مقدمه
کاهش ابعاد فرآیند کاهش تعداد متغیرهای تصادفی یا ویژگیها یا ویژگیهای مورد بررسی است. روشهای کاهش ابعاد شامل تحلیل مؤلفههای اصلی (PCA) (بخش ۲.۶.۱) است که یک روش خطی است که دادههای اصلی را به فضای کوچکتری تبدیل یا تصویر میکند. انتخاب زیرمجموعه ویژگی روشی برای کاهش ابعاد است که در آن ویژگیها یا ابعاد نامربوط، با ارتباط ضعیف یا اضافی شناسایی و حذف میشوند (بخش ۲.۶.۲). روشهای غیرخطی زیادی برای کاهش ابعاد وجود دارد (بخش ۲.۶.۳) مانند PCA هسته و تعبیه همسایه تصادفی.
تحلیل مؤلفههای اصلی
در این زیربخش، مقدمهای شهودی بر تحلیل مؤلفههای اصلی به عنوان روشی برای کاهش ابعاد ارائه میدهیم. توضیح نظری دقیق فراتر از محدوده این کتاب است. برای منابع بیشتر، لطفاً به یادداشتهای کتابشناختی در انتهای این فصل مراجعه کنید. فرض کنید دادههایی که قرار است کاهش یابند شامل تاپلها یا بردارهای دادهای هستند که توسط d ویژگی یا بُعد توصیف میشوند.
تحلیل مؤلفههای اصلی (PCA؛ که روش کارهونن-لوو یا K-L نیز نامیده میشود) به دنبال k بردار متعامد d بعدی میگردد که میتوانند به بهترین شکل برای نمایش دادهها استفاده شوند، که در آن k d. بنابراین دادههای اصلی بر روی فضای بسیار کوچکتری تصویر میشوند و منجر به کاهش ابعاد میشوند. برخلاف انتخاب زیرمجموعه ویژگی (بخش 2.6.2)، که اندازه مجموعه ویژگیها را با حفظ زیرمجموعهای از مجموعه اولیه ویژگیها کاهش میدهد، PCA با ایجاد یک مجموعه جایگزین و کوچکتر از متغیرها، جوهره ویژگیها را “ترکیب” میکند. سپس دادههای اولیه را میتوان بر روی این مجموعه کوچکتر تصویر کرد. PCA اغلب روابطی را آشکار میکند که قبلاً مشکوک نبودند و در نتیجه امکان تفسیرهایی را فراهم میکند که معمولاً حاصل نمیشوند.
روش اساسی به شرح زیر است:
- دادههای ورودی نرمالسازی میشوند، به طوری که هر ویژگی در یک محدوده قرار میگیرد. این مرحله به اطمینان از این امر کمک میکند که ویژگیهایی با دامنههای بزرگ، بر ویژگیهایی با دامنههای کوچکتر غلبه نکنند.
- PCA، k بردار متعامد را محاسبه میکند که مبنایی برای دادههای ورودی نرمالسازی شده فراهم میکنند. این بردارها، بردارهای واحدی هستند که بر یکدیگر عمود هستند. این بردارها به عنوان مؤلفههای اصلی شناخته میشوند. دادههای ورودی ترکیبی خطی از مؤلفههای اصلی هستند.
- مؤلفههای اصلی به ترتیب کاهش «اهمیت» یا قدرت مرتب میشوند. مؤلفههای اصلی اساساً به عنوان مجموعهای جدید از محورها برای دادهها عمل میکنند و اطلاعات مهمی در مورد واریانس ارائه میدهند. یعنی محورهای مرتبشده به گونهای هستند که محور اول بیشترین واریانس را در بین دادهها نشان میدهد، محور دوم بالاترین واریانس بعدی را نشان میدهد و به همین ترتیب ادامه مییابد. به عنوان مثال، شکل ۲.۱۷ دو مؤلفه اصلی اول، Y1 و Y2، را برای مجموعه دادههای داده شده که در ابتدا به محورهای X1 و X2 نگاشت شدهاند، نشان میدهد. این اطلاعات به شناسایی گروهها یا الگوهای درون دادهها کمک میکند
- از آنجا که مؤلفهها به ترتیب نزولی «اهمیت» مرتب شدهاند، میتوان با حذف مؤلفههای ضعیفتر، یعنی مؤلفههایی که واریانس کمی دارند، اندازه دادهها را کاهش داد. با استفاده از قویترین مؤلفههای اصلی، میتوان تقریب خوبی از دادههای اصلی را بازسازی کرد. PCA را میتوان برای ویژگیهای مرتب و نامرتب اعمال کرد و میتواند دادههای پراکنده و دادههای چولگی را مدیریت کند. دادههای چندبعدی بیش از دو بُعد را میتوان با کاهش مسئله به دو بُعد مدیریت کرد. مؤلفههای اصلی ممکن است به عنوان ورودی برای رگرسیون چندگانه و تحلیل خوشهای استفاده شوند.
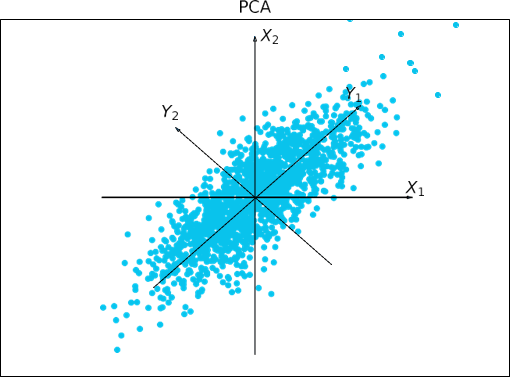
تحلیل مؤلفههای اصلی. Y1 و Y2 دو مؤلفه اصلی اول برای دادههای داده شده هستند.
انتخاب زیرمجموعه ویژگی
مجموعه دادهها برای تحلیل ممکن است شامل صدها ویژگی باشد که بسیاری از آنها ممکن است به وظیفه کاوش نامربوط یا اضافی باشند. به عنوان مثال، اگر وظیفه طبقهبندی مشتریان بر اساس این باشد که آیا آنها احتمالاً هنگام اطلاع از حراج، یک آلبوم موسیقی جدید محبوب را خریداری میکنند یا خیر، ویژگیهایی مانند شماره تلفن مشتری احتمالاً نامربوط هستند، برخلاف ویژگیهایی مانند سن یا سلیقه موسیقی. اگرچه ممکن است برای یک متخصص حوزه انتخاب برخی از ویژگیهای مفید امکانپذیر باشد، اما این میتواند یک کار دشوار و زمانبر باشد، به خصوص زمانی که رفتار دادهها به خوبی شناخته نشده باشد. (از این رو، دلیلی برای تحلیل آن وجود دارد!) کنار گذاشتن ویژگیهای مرتبط یا نگه داشتن ویژگیهای نامربوط ممکن است مضر باشد و باعث سردرگمی الگوریتم کاوش مورد استفاده شود. این میتواند منجر به کشف الگوهای بیکیفیت شود. علاوه بر این، حجم اضافه شده از ویژگیهای نامربوط یا اضافی میتواند روند کاوش را کند کند.
انتخاب زیرمجموعه ویژگیها با حذف ویژگیهای (یا ابعاد) نامرتبط یا اضافی، اندازه مجموعه دادهها را کاهش میدهد. این امر باعث میشود کاوش بر ابعاد مرتبط متمرکز شود. کاوش بر روی مجموعهای کاهشیافته از ویژگیها یک مزیت اضافی نیز دارد: تعداد ویژگیهای ظاهر شده در الگوهای کشفشده را کاهش میدهد و به درک آسانتر الگوها کمک میکند.
“چگونه میتوانیم یک زیرمجموعه “خوب” از ویژگیهای اصلی پیدا کنیم؟” برای d ویژگی، دو زیرمجموعه ممکن وجود دارد. جستجوی جامع برای زیرمجموعه بهینه ویژگیها میتواند بسیار پرهزینه باشد، بهویژه زمانی که d و تعداد کلاسهای داده افزایش مییابند. بنابراین، روشهای اکتشافی که یک فضای جستجوی کاهشیافته را کاوش میکنند، معمولاً برای انتخاب زیرمجموعه ویژگیها استفاده میشوند. این روشها معمولاً حریصانه هستند، زیرا هنگام جستجو در فضای ویژگی، همیشه چیزی را انتخاب میکنند که در آن زمان بهترین انتخاب به نظر میرسد. استراتژی آنها این است که یک انتخاب بهینه محلی انجام دهند به این امید که این منجر به یک راهحل خوب جهانی شود. چنین روشهای حریصانهای در عمل مؤثر هستند و ممکن است به تخمین یک راهحل بهینه نزدیک شوند. ویژگیهای «بهترین» (و «بدترین») معمولاً با استفاده از آزمونهای معناداری آماری تعیین میشوند که فرض میکنند ویژگیها مستقل از یکدیگر هستند. بسیاری از معیارهای ارزیابی ویژگی دیگر مانند معیار افزایش اطلاعات که در ساخت درختهای تصمیمگیری برای طبقهبندی استفاده میشود، میتوانند مورد استفاده قرار گیرند.3
روشهای اکتشافی اساسی انتخاب زیرمجموعه ویژگی شامل تکنیکهای زیر است که برخی از آنها در شکل 2.18 نشان داده شده است.
1. انتخاب گام به گام رو به جلو
این روش با یک مجموعه خالی از ویژگیها به عنوان مجموعه کاهش یافته شروع میشود. بهترین ویژگی اصلی تعیین شده و به مجموعه کاهش یافته اضافه میشود. در هر تکرار یا مرحله بعدی، بهترین ویژگی اصلی باقی مانده به مجموعه اضافه میشود.
2. حذف گام به گام رو به عقب
این روش با مجموعه کامل ویژگیها شروع میشود. در هر مرحله، بدترین ویژگی باقی مانده در مجموعه را حذف میکند.
3. ترکیب انتخاب رو به جلو و حذف رو به عقب
روشهای انتخاب گام به گام رو به جلو و حذف رو به عقب را میتوان به گونهای ترکیب کرد که در هر مرحله، روش بهترین ویژگی را انتخاب کرده و بدترین را از بین ویژگیهای باقی مانده حذف کند.
4. القای درخت تصمیم
الگوریتمهای درخت تصمیم (مثل ID3، C4.5 و CART) در ابتدا برای طبقهبندی در نظر گرفته شده بودند. القای درخت تصمیم، ساختاری شبیه به فلوچارت ایجاد میکند که در آن هر گره داخلی (غیربرگ) نشاندهنده یک آزمایش روی یک ویژگی، هر شاخه مربوط به یک نتیجه آزمایش و هر گره خارجی (برگ) نشاندهنده یک پیشبینی کلاس است. در هر گره، الگوریتم «بهترین» ویژگی را برای تقسیم دادهها به کلاسهای جداگانه انتخاب میکند.
هنگامی که از القای درخت تصمیم برای انتخاب زیرمجموعه ویژگی استفاده میشود، یک درخت از دادههای داده شده ساخته میشود. فرض میشود تمام ویژگیهایی که در درخت ظاهر نمیشوند، نامربوط هستند. مجموعه ویژگیهای ظاهر شده در درخت، زیرمجموعه کاهشیافته ویژگیها را تشکیل میدهند.
معیارهای توقف برای روشها ممکن است متفاوت باشد. این روش ممکن است از یک آستانه روی معیار مورد استفاده برای تعیین زمان توقف فرآیند انتخاب ویژگی استفاده کند.
در برخی موارد، ممکن است بخواهیم ویژگیهای جدیدی را بر اساس ویژگیهای دیگر ایجاد کنیم. چنین ساخت ویژگی۴ میتواند به بهبود دقت و درک ساختار در دادههای با ابعاد بالا کمک کند. برای مثال، ممکن است بخواهیم مساحت ویژگی را بر اساس ویژگیهای ارتفاع و عرض اضافه کنیم. با ترکیب ویژگیها، ساخت ویژگی میتواند اطلاعات از دست رفته در مورد روابط بین ویژگیهای داده را که میتوانند برای کشف دانش مفید باشند، کشف کند.
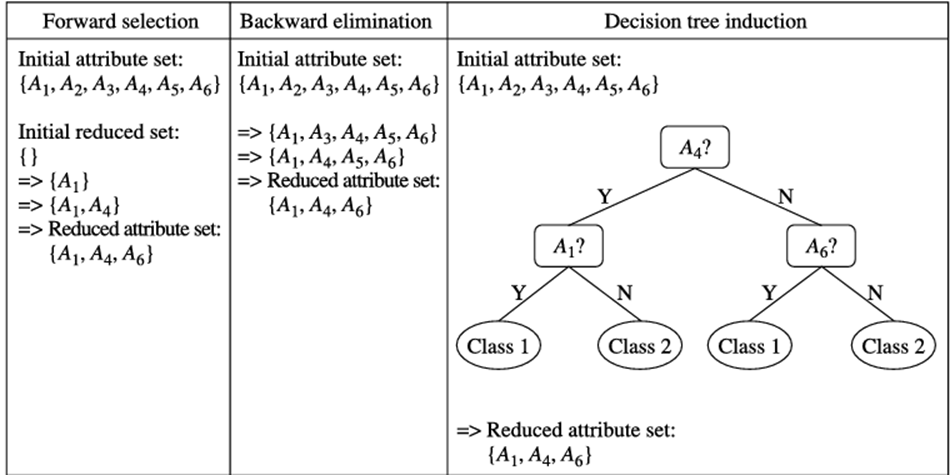
روشهای حریصانه (اکتشافی) برای انتخاب زیرمجموعه ویژگی.
روشهای کاهش ابعاد غیرخطی
PCA یک روش خطی برای کاهش ابعاد است به این صورت که هر مؤلفه اصلی ترکیبی خطی از ویژگیهای ورودی اصلی است. این روش در صورتی که دادههای ورودی تقریباً از توزیع گاوسی پیروی کنند یا چند خوشه خطی جداشدنی تشکیل دهند، به خوبی کار میکند. با این حال، هنگامی که دادههای ورودی به صورت خطی جدانشدنی باشند، PCA بیاثر میشود. خوشبختانه، روشهای غیرخطی زیادی وجود دارد که میتوانیم در این مورد به آنها متوسل شویم.
روش کلی
فرض کنید n تاپل داده xi، i = 1)، …، (n وجود دارد که هر کدام توسط یک بردار ویژگی d بعدی نمایش داده میشوند. چگونه میتوانیم ابعاد را به k کاهش دهیم که در آن k « d؟ به عبارت دیگر، میخواهیم هر یک از تاپلهای داده ورودی را با یک بردار ویژگی k بعدی xˆ i، (i = 1، …، n) نمایش دهیم. از آنجا که k « d است، بردار ویژگی k بعدی xˆ i، (i = 1، …، n) را به عنوان نمایشهای کمبعد از تاپلهای داده اصلی xi، (i 1، …، n) مینامیم.
برای بسیاری از روشهای کاهش ابعاد غیرخطی، آنها اغلب دو مرحله زیر را دنبال میکنند (برای توضیح به شکل 2.19 مراجعه کنید). در مرحله اول (ساخت ماتریس مجاورت)، یک ماتریس مجاورت n × n P میسازیم که ورودی آن P (i, j) (i, j = 1، …، n) نشاندهنده وابستگی یا ارتباط بین دو تاپل داده مربوطه xi و xj است. در مرحله دوم (حفظ مجاورت)، نمایشهای جدید کمبعد از تاپلهای داده ورودی را در فضای k بعدی xi (i 1، …، n) یاد میگیریم تا ماتریس مجاورت P که در مرحله اول ساخته شده است تا حدودی حفظ شود. بسته به نحوه ساخت ماتریس مجاورت (مرحله 1) و نحوه حفظ ماتریس مجاورت ساخته شده (مرحله 2)، تکنیکهای کاهش ابعاد غیرخطی متنوعی توسعه یافتهاند. در ادامه به دو تکنیک نمونه، شامل kernel PCA (KPCA) و stochastic hood embedding (SNE) نگاهی میاندازیم. مقایسه این دو روش در جدول 2.8 خلاصه شده است.
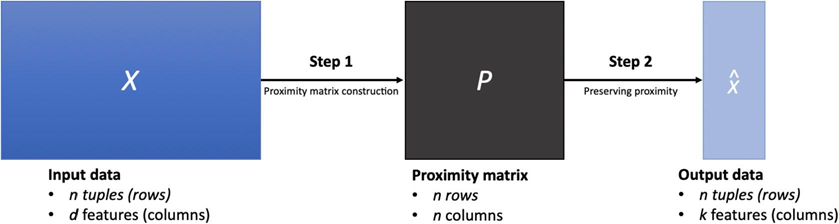
تصویری از کاهش ابعاد غیرخطی.

تحلیل مؤلفههای اصلی کرنل (Kernel PCA)
در تحلیل مؤلفههای اصلی کرنل (KPCA)، ما از یک تابع کرنل κ(·) برای ساختن ماتریس نزدیکی (proximity matrix) که ماتریس کرنل نامیده میشود، استفاده میکنیم (گام 1): P(i,j) = κ(x_i, x_j), (i,j = 1, …, n). جزئیات کامل تابع کرنل κ(·) را به فصلهای بعدی موکول میکنیم (برای مثال، فصل 7). به سادهترین شکل، یک تابع کرنل شباهت یک جفت از دادههای ورودی را در یک فضای با بعد بالا، اغلب غیرخطی، محاسبه میکند.
در همین حال، ما میتوانیم چنین نزدیکی (یعنی شباهت) را بر اساس نمایشهای کمبعدی یادگرفتهشده نیز تخمین بزنیم: P^(i,j) = x̂_i · x̂_j, (i,j = 1, …, n) که در آن x̂_i نمایش کمبعدی بردار ورودی x_i است. بهترین (یعنی بهینهترین) نمایشهای کمبعدی x̂_i , (i=1,…,n) آنهایی هستند که باعث شوند ماتریس نزدیکی تخمینی P^ تا حد ممکن به ماتریس کرنل P نزدیک باشد. این ما را به مسئله بهینهسازی زیر میرساند (گام 2)، که میگوید بهترین نمایشهای کمبعدی آنهایی هستند که مقدار زیر را کمینه کنند
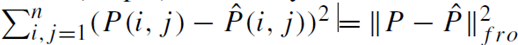
که fro‖·‖ در آن نرم فروبنیوس ماتریس است. ما وارد جزئیات ریاضی نحوه حل این مسئله بهینهسازی نمیشویم. برای خلاصه کردن داستان، نمایشهای کمبعدی بهینه x̂_i, (i=1,…,n) را میتوان از بردارهای ویژه و مقادیر ویژه برتر ماتریس کرنل P به دست آورد. برای مرور بردارها و مقادیر ویژه، به ضمیمه A مراجعه کنید.
انتخابهای متداول برای توابع کرنل شامل موارد زیر است
1. کرنل چندجملهای
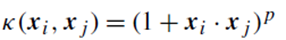
که در آن p پارامتر است.
2. تابع پایه شعاعی (RBF)
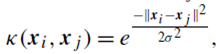
که در آن σ پارامتر است.
اگر یک کرنل خطی انتخاب
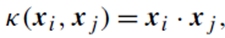
کنیم در این حالت KPCA به تحلیل مؤلفههای اصلی استاندارد (PCA) تقلیل مییابد.
جاسازی همسایگی تصادفی (Stochastic Neighbor Embedding – SNE)
در جاسازی همسایگی تصادفی (SNE)، ابتدا ماتریس مجاورت P را به شکل زیر میسازیم:
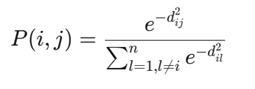
که
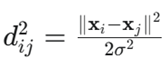
در آن و σ یک پارامتر است.
ما میتوانیم چندک P(i, j) چندک را به عنوان احتمال اینکه تاپل داده xj همسایه تاپل داده xi باشد در نظر بگیریم: هرچه دو تاپل داده به هم نزدیکتر باشند (یعنی dij کوچکتر باشد)، احتمال همسایه بودن xj برای xi بیشتر است.
فرض کنید نمایشهای کمبُعد ˆxi, (i = 1, …, n) را آموختهایم. میتوانیم ماتریس مجاورت تخمینی دیگری را به روش مشابهی به دست آوریم:
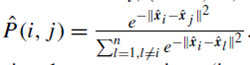
باز هم، ایده اصلی این است که اگر دو تاپل داده نمایشهای کمبُعد مشابهی داشته باشند (یعنی کوچک باشد)، مجاورت تخمینی بین آنها زیاد است (یعنی P(i,j)) بالا است.
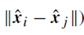
اکنون، برای یافتن بهترین نمایشهای کمبُعد ˆx i, (i = 1, …, n), برایP^ ، دوباره به دنبال مواردی میگردیم که ماتریس مجاورت تخمینی را تا حد ممکن به ماتریس مجاورت P نزدیک کند: P: P ≈ ˆ P.
برخلاف KPCA، در این مورد، هر سطر از هر دو ماتریس P و P^ برابر با ۱ جمع میشود و تمام ورودیها نامنفی هستند. به عبارت دیگر، هر سطر از ماتریسهای P و P^ یک توزیع احتمال است که احتمال همسایه بودن هر تاپل داده را برای یک تاپل داده مشخص بیان میکند.
به طور طبیعی میتوانیم از واگرایی کولبک-لایبلر (KL divergence) (به بخش ۲.۳.۸ مراجعه کنید) برای اندازهگیری تفاوت بین آنها استفاده کنیم و نمایشهای کمبُعد بهینه ˆxi, (i = 1, …, n), (برای ) آنهایی هستند که کمینه کننده واگراییهای KL کلی بین تمام سطرهای P و سطرهای متناظر P^ باشند:
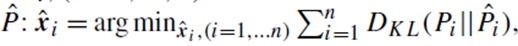
که در آن Pi و ^Pi سطرهای i -ام P و P^ هستند.
مجدداً، ما وارد جزئیات ریاضی بسیار ریز در مورد نحوه حل این مسئله بهینهسازی نخواهیم شد. بسیاری از بستههای نرمافزاری بهینهسازی آماده، مانند روش گرادیان کاهشی (gradient descent method)، میتوانند استفاده شوند.
یک گونه از SNE به نام t-SNE (t-distributed stochastic neighbor embedding) به طور گستردهای برای نمایش بصری نگاشت نمایش چندبُعدی تولید شده توسط مدلهای مختلف یادگیری عمیق (فصل ۱۰) به یک فضای دو یا سهبُعدی استفاده شده است.
توجه داشته باشید که در مقدمه بالا، برخی از جزئیات پیادهسازی KPCA و SNE را حذف کردهایم. به عنوان مثال، در KPCA باید اطمینان حاصل کنیم که تاپلهای داده متمرکز (centered) هستند؛ در SNE اغلب چندکP(i, i) = 0چندک را تنظیم میکنیم؛ و یک گونه از SNE یک ماتریس مجاورت متقارن چندکPچندک میسازد. خوانندگان علاقهمند میتوانند به مقالات مرتبط در نکات کتابشناختی مراجعه کنند.
حالا بیایید به یک مثال نگاه کنیم.
مثال ۲.۳۰. مجموعهای از تاپلهای داده در فضای دوبعدی (شکل ۲.۲۰ (الف)) در نظر گرفته شده است. دادههای ورودی به طور طبیعی دو خوشه تشکیل میدهند: یک هلال رو به بالا و یک هلال رو به پایین. این دو خوشه با یکدیگر در هم تنیدهاند و هیچ راهی وجود ندارد که بتوانیم یک زیرفضای خطی (در این مورد یک خط خطی) برای جدا کردن آنها از یکدیگر پیدا کنیم. این بدان معناست که مهم نیست چه نوع خطی را از فضای ورودی انتخاب کنیم، اگر تاپلهای دادههای اصلی را روی این خط تصویر کنیم، بخشهای تصویر شده (یعنی نمایش با ابعاد پایین) همیشه با یکدیگر مخلوط میشوند. این همان چیزی است که با PCA در شکل ۲.۲۰ (ب) اتفاق میافتد، جایی که تصویر دادههای ورودی را روی فضایی که توسط دو مؤلفه اصلی پوشانده شده است، رسم میکنیم. میتوانیم ببینیم که دو خوشه هنوز با یکدیگر مخلوط هستند و نمایشهای جدید توسط مؤلفههای اصلی اساساً یک چرخش خطی از دادههای ورودی هستند. در مقابل، با استفاده از تکنیک کاهش ابعاد غیرخطی KPCA (شکل 2.20(c)) یا t-SNE (شکل 2.20(d))، دو خوشه اکنون در این فضای جدید بهتر از یکدیگر جدا میشوند. شکل 2.21 نقشههای حرارتی ماتریسهای شباهت یا نزدیکی را به ترتیب در PCA (a)، KPCA (b) و t-SNE (c) نشان میدهد. دو بلوک مورب به ترتیب نزدیکی درون دو خوشه را نشان میدهند و دو بلوک غیر مورب نزدیکی بین دادههای دو خوشه را نشان میدهند.
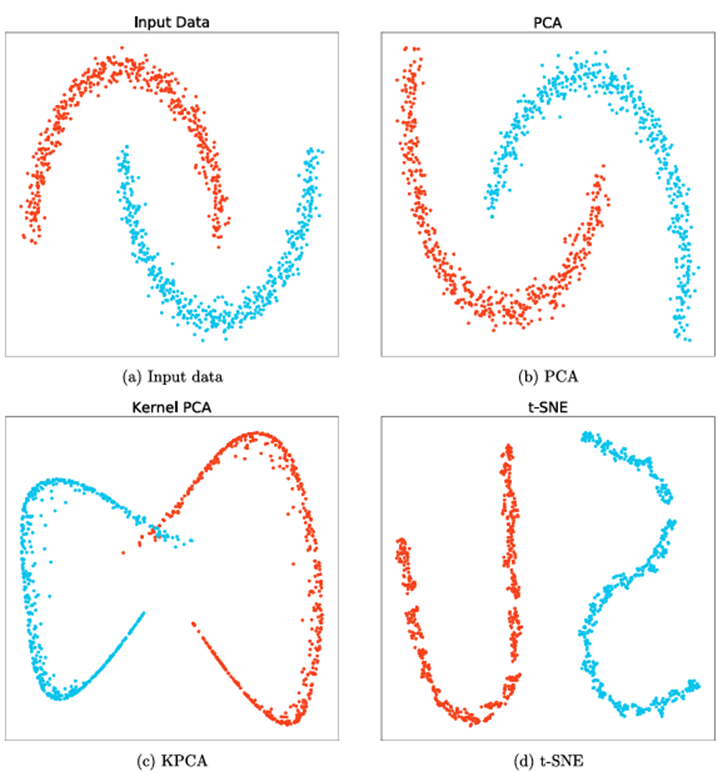
مثالی از روشهای کاهش ابعاد خطی در مقابل غیرخطی.
خوشهها. میتوانیم ببینیم که به طور کلی، با روشهای غیرخطی (KPCA و t-SNE)، نزدیکی بین تاپلهای داده از یک خوشه بسیار بیشتر از نزدیکی بین تاپلهای داده از خوشههای مختلف است. این به نوبه خود منجر به نتایج کاهش ابعاد بهتری نسبت به روشهای خطی (مثلاً PCA) میشود.
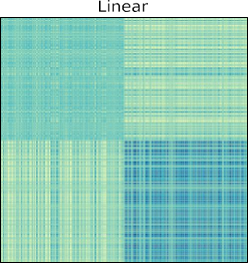

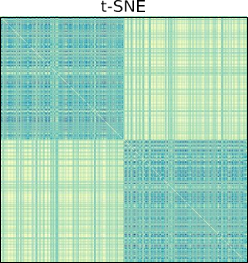
شکل ۲.۲۱
نقشههای حرارتی ماتریسهای شباهت یا نزدیکی در PCA (a)، KPCA (b) و t-SNE (c) به ترتیب. دو بلوک قطری مربوط به دو خوشه در شکل ۲.۲۰ هستند.
میتوان PCA را به صورت فرآیند زیر در نظر گرفت. ابتدا، مؤلفههای اصلی را پیدا میکنیم و تاپلهای دادههای اصلی را به زیرفضای پوشش داده شده توسط مؤلفههای اصلی تصویر میکنیم. سپس، از تاپلهای دادههای تصویر شده به همراه مؤلفههای اصلی برای بازسازی تاپلهای دادههای اصلی استفاده میکنیم. این یک فرآیند خطی است به این معنی که هم مرحله تصویر و هم مرحله بازسازی، عملیات خطی هستند. با استفاده از یک تکنیک یادگیری عمیق خاص به نام خودرمزگذار، که در فصل ۱۰ معرفی خواهد شد، میتوانیم هر دو مرحله تصویر و بازسازی را غیرخطی کنیم. بنابراین خروجی چنین مرحله تصویر غیرخطی، نمایشهای کمبعد از تاپلهای دادههای ورودی را تشکیل میدهد.
PCA، انتخاب زیرمجموعه ویژگی، KPCA و SNE میتوانند به عنوان یک مرحله پیشپردازش داده استفاده شوند. یعنی، ما ابتدا یکی از این تکنیکها را روی تاپلهای داده ورودی اعمال میکنیم تا نمایشهای کمبعد آنها را قبل از مشاهده وظیفه دادهکاوی خاص (مثلاً طبقهبندی، خوشهبندی و تشخیص دادههای پرت) تولید کنیم. ما همچنین میتوانیم کاهش ابعاد را همراه با یک وظیفه دادهکاوی خاص انجام دهیم. منطقی بودن این است که کاهش ابعاد و وظیفه دادهکاوی مربوطه احتمالاً مکمل یکدیگر هستند. به عنوان مثال، هنگام ترکیب انتخاب زیرمجموعه ویژگی با وظیفه طبقهبندی (که انتخاب ویژگی تعبیهشده نامیده میشود)، مدل طبقهبندی فرآیند انتخاب ویژگی را هدایت میکند و ویژگیهای انتخابشده به نوبه خود به ساخت یک مدل طبقهبندی بهتر کمک میکنند. هنگام ترکیب کاهش ابعاد با وظیفه خوشهبندی، ساختار خوشهبندی احتمالاً در فضای جدید کمبعد مشهودتر خواهد بود و در عین حال، چنین ساختار خوشهبندی به یافتن نمایشهای کمبعد بهتر کمک میکند. ما چنین تکنیکهای کاهش ابعادی را در فصل طبقهبندی معرفی خواهیم کرد.
کاهش ابعاد، که در این بخش معرفی کردیم، و روشهای فشردهسازی و نمونهبرداری دادهها که در بخش قبلی معرفی شدند، تکنیکهای رایج کاهش داده هستند. نوع دیگری از تکنیک کاهش داده، کاهش تعداد نام دارد که از مدلهای پارامتری یا ناپارامتری برای به دست آوردن نمایشهای کوچکتر از دادههای اصلی استفاده میکند. مدلهای پارامتری فقط پارامترهای مدل را به جای دادههای واقعی ذخیره میکنند. نمونههایی از این مدلها شامل رگرسیون و مدلهای لگاریتمی خطی هستند. روشهای ناپارامتری شامل هیستوگرامها، خوشهبندی، نمونهگیری و تجمیع مکعب دادهها هستند.
خلاصه
• مجموعه دادهها از اشیاء داده تشکیل شدهاند. یک شیء داده نشاندهنده یک موجودیت است. اشیاء داده توسط ویژگیها توصیف میشوند. ویژگیها میتوانند اسمی، دودویی، ترتیبی یا عددی باشند.
• مقادیر یک ویژگی اسمی (یا دستهبندی) نمادها یا نامهای چیزها هستند که در آن هر مقدار نشاندهنده نوعی دسته، کد یا حالت است.
• ویژگیهای دودویی، ویژگیهای اسمی با تنها دو حالت ممکن (مانند ۱ و ۰ یا درست و نادرست) هستند. اگر دو حالت به یک اندازه مهم باشند، ویژگی متقارن است؛ در غیر این صورت نامتقارن است.
• یک ویژگی ترتیبی، ویژگی با مقادیر ممکن است که ترتیب یا رتبهبندی معناداری بین آنها وجود دارد، اما بزرگی بین مقادیر متوالی مشخص نیست.
• یک ویژگی عددی، کمی است (یعنی یک کمیت قابل اندازهگیری است) که با مقادیر صحیح یا واقعی نشان داده میشود. انواع ویژگیهای عددی میتوانند مقیاس بازهای یا مقیاس نسبی باشند. مقادیر یک ویژگی مقیاس بازهای در واحدهای ثابت و مساوی اندازهگیری میشوند. ویژگیهای نسبی-مقیاس، ویژگیهای عددی با یک نقطه صفر ذاتی هستند. اندازهگیریها به این صورت نسبی-مقیاس هستند که میتوانیم از مقادیر به عنوان مرتبه بزرگی بزرگتر از واحد اندازهگیری صحبت کنیم.
• توصیفات آماری پایه، پایه تحلیلی برای پیشپردازش دادهها را فراهم میکنند. معیارهای آماری پایه برای خلاصهسازی دادهها شامل میانگین، میانگین وزنی، میانه و مد برای اندازهگیری گرایش مرکزی دادهها؛ و دامنه، چندکها، چارکها، دامنه بین چارکی، واریانس و انحراف معیار برای اندازهگیری پراکندگی دادهها هستند. نمایشهای گرافیکی (به عنوان مثال، نمودارهای جعبهای، نمودارهای چندک، نمودارهای چندک-چندک، هیستوگرامها و نمودارهای پراکندگی) بررسی بصری دادهها را تسهیل میکنند و بنابراین برای پیشپردازش و کاوش دادهها مفید هستند.
• معیارهای شباهت و عدم شباهت اشیاء در کاربردهای دادهکاوی مانند خوشهبندی، تحلیل دادههای پرت و طبقهبندی نزدیکترین همسایه استفاده میشوند. چنین معیارهای نزدیکی را میتوان برای هر نوع ویژگی مورد مطالعه در این فصل یا برای ترکیبی از چنین ویژگیهایی محاسبه کرد. نمونههایی از این معیارها شامل ضریب جاکارد برای ویژگیهای دودویی نامتقارن و فواصل اقلیدسی، منهتن، مینکوفسکی و سوپریمم برای ویژگیهای عددی است. برای کاربردهایی که شامل بردارهای داده عددی پراکنده، مانند بردارهای عبارت-فرکانس هستند، معیار کسینوس و ضریب تانیموتو اغلب در ارزیابی شباهت استفاده میشوند. برای اندازهگیری تفاوت بین دو توزیع احتمال روی متغیر یکسان x، واگرایی کولبک-لیبلر (یا واگرایی KL) به طور رایج مورد استفاده قرار گرفته است. DKL(p(x) q(x)) تعداد بیتهای اضافی مورد انتظار مورد نیاز برای کدگذاری نمونهها از p(x) را هنگام استفاده از کدی مبتنی بر q(x) به جای استفاده از کدی مبتنی بر p(x) اندازهگیری میکند. • کیفیت دادهها بر اساس دقت، کامل بودن، سازگاری، به موقع بودن، باورپذیری و تفسیرپذیری تعریف میشود. این ویژگیها بر اساس کاربرد مورد نظر دادهها ارزیابی میشوند.
• روالهای پاکسازی دادهها تلاش میکنند تا مقادیر گمشده را پر کنند، نویز را در حین شناسایی دادههای پرت صاف کنند و ناسازگاریهای موجود در دادهها را اصلاح کنند. پاکسازی دادهها معمولاً به عنوان یک فرآیند دو مرحلهای تکراری شامل تشخیص اختلاف و تبدیل دادهها انجام میشود.
• ادغام دادهها، دادهها را از منابع متعدد ترکیب میکند تا یک مخزن داده منسجم تشکیل دهد. حل ناهمگونی معنایی، فراداده، تحلیل همبستگی، تشخیص تکرار تاپل و تشخیص تضاد دادهها به یکپارچهسازی روان دادهها کمک میکند.
• روالهای تبدیل دادهها، دادهها را به اشکال مناسب برای کاوش تبدیل میکنند. به عنوان مثال، در نرمالسازی، مقادیر ویژگی مقیاسبندی میشوند؛ گسستهسازی دادهها با نگاشت مقادیر به برچسبهای بازه یا مفهوم، دادههای عددی را تبدیل میکند؛ و فشردهسازی دادهها و نمونهبرداری دادهها، به عنوان دو تکنیک معمول کاهش داده، دادههای ورودی را به یک نمایش کاهشیافته تبدیل میکنند.
• کاهش ابعاد، تعداد متغیرهای تصادفی یا ویژگیهای مورد بررسی را کاهش میدهد. روشها شامل تحلیل مؤلفههای اصلی، انتخاب زیرمجموعه ویژگی، تحلیل مؤلفه اصلی هسته و تعبیه همسایه تصادفی هستند.
تمرینها
۲.۱. سه معیار آماری رایج دیگر که قبلاً در این فصل برای توصیف پراکندگی دادهها نشان داده نشدهاند را بیان کنید و در مورد نحوه محاسبه کارآمد آنها در پایگاههای داده بزرگ بحث کنید.
۲.۲. فرض کنید دادههای مورد تجزیه و تحلیل شامل ویژگی سن هستند. مقادیر سن برای تاپلهای داده (به ترتیب صعودی) ۱۳، ۱۵، ۱۶، ۱۶، ۱۹، ۲۰، ۲۰، ۲۱، ۲۲، ۲۲، ۲۵، ۲۵، ۲۵، ۲۵، ۳۰، ۳۳، ۳۳، ۳۵، ۳۵، ۳۵، ۳۵، ۳۵، ۳۶، ۴۰، ۴۵، ۴۶، ۵۲، ۷۰ هستند.
الف. میانگین دادهها چیست؟ میانه چیست؟
ب. مد دادهها چیست؟ در مورد مد دادهها نظر دهید (یعنی دووجهی، سه وجهی و غیره). ج. میانگین دادهها چقدر است
د. آیا میتوانید (تقریباً) چارک اول (Q1) و چارک سوم (Q3) دادهها را پیدا کنید؟
ه. خلاصه پنج عددی دادهها را بیان کنید.
و. نمودار جعبهای دادهها را نشان دهید.
2.3. فرض کنید مقادیر یک مجموعه داده مشخص در فواصل گروهبندی شدهاند. فواصل و فراوانیهای مربوطه به شرح زیر است:
|
Age |
Frequency |
|
1–5 |
200 |
|
6–15 |
450 |
|
16–20 |
300 |
|
21–50 |
1500 |
|
51–80 |
700 |
|
81–110 |
44 |
یک مقدار میانه تقریبی برای دادهها محاسبه کنید.
۲.۴. نمودار کوانتایل-کوانتایل چه تفاوتی با نمودار کوانتایل دارد؟
۲.۵. در متن خود، بیان میکنیم که واریانس N مشاهده، x1، x2،…، xN (وقتی N بزرگ باشد)، برای یک ویژگی عددی X به صورت زیر تعریف میشود.
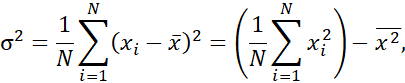
که در آن x مقدار میانگین مشاهدات است، همانطور که در معادله (2.1) تعریف شده است. این در واقع فرمولی برای محاسبه واریانس برای کل جمعیت با استفاده از تمام دادهها است (از این رو واریانس جمعیت نامیده میشود). اگر واریانس را فقط با استفاده از یک نمونه از دادهها محاسبه کنیم (از این رو واریانس نمونه نامیده میشود)، باید از فرمول زیر استفاده کنیم:
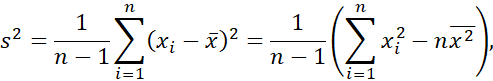
که در آن n اندازه نمونه است. با اندازه نمونه n، انحراف معیار نمونه را میتوان به طور مشابه تعریف کرد. توضیح دهید که چرا چنین تفاوت جزئی در تعریف واریانس نمونه و واریانس جمعیت وجود دارد.
۲.۶. دلیل اینکه واریانس و انحراف معیار را میتوان به طور موثر در مجموعه دادههای بسیار بزرگ محاسبه کرد.
۲.۷. فرض کنید یک بیمارستان دادههای سن و چربی بدن را برای ۱۸ بزرگسال که به طور تصادفی انتخاب شدهاند، آزمایش کرده و نتایج زیر را به دست آورده است:
|
age |
23 |
23 |
27 |
27 |
39 |
41 |
47 |
49 |
50 |
|
%fat |
9.5 |
26.5 |
7.8 |
17.8 |
31.4 |
25.9 |
27.4 |
27.2 |
31.2 |
|
age |
52 |
54 |
54 |
56 |
57 |
58 |
58 |
60 |
61 |
|
%fat |
34.6 |
42.5 |
28.8 |
33.4 |
30.2 |
34.1 |
32.9 |
41.2 |
35.7 |
الف. میانگین، میانه و انحراف معیار سن و درصد چربی را محاسبه کنید.
ب. نمودارهای جعبهای سن و درصد چربی را رسم کنید.
ج. یک نمودار پراکندگی و یک نمودار q-q بر اساس این دو متغیر رسم کنید.
2.8. به طور خلاصه نحوه محاسبه عدم تشابه بین اشیاء شرح داده شده با موارد زیر را شرح دهید:
الف. ویژگیهای اسمی
ب. ویژگیهای دودویی نامتقارن
ج. ویژگیهای عددی
د. بردارهای فراوانی-جمله
2.9. با توجه به دو شیء که با تاپلهای (22، 1، 42، 10) و (20، 0، 36، 8) نشان داده شدهاند:
الف. فاصله اقلیدسی بین دو شیء را محاسبه کنید. ب. فاصله منهتن بین دو شیء را محاسبه کنید. ج. فاصله مینکوفسکی بین دو شیء را با استفاده از h محاسبه کنید.
2.10. میانه یکی از مهمترین معیارها در تجزیه و تحلیل دادهها است. چندین روش برای تقریب میانه پیشنهاد دهید. پیچیدگی مربوط به آنها را تحت تنظیمات پارامترهای مختلف تجزیه و تحلیل کنید و تصمیم بگیرید که تا چه حد میتوان مقدار واقعی را تقریب زد. علاوه بر این، یک استراتژی اکتشافی برای ایجاد تعادل بین دقت و پیچیدگی پیشنهاد دهید و سپس آن را در تمام روشهایی که ارائه دادهاید اعمال کنید.
۲.۱۱. تعریف یا انتخاب معیارهای شباهت در تجزیه و تحلیل دادهها مهم است. با این حال، هیچ معیار شباهت ذهنی پذیرفته شدهای وجود ندارد. نتایج میتوانند بسته به معیارهای شباهت مورد استفاده متفاوت باشند. با این وجود، معیارهای شباهت به ظاهر متفاوت ممکن است پس از مقداری تبدیل، معادل باشند.
فرض کنید مجموعه دادههای دوبعدی زیر را داریم:
|
|
A1 |
A2 |
|
x1 |
1.5 |
1.7 |
|
x2 |
2 |
1.9 |
|
x3 |
1.6 |
1.8 |
|
x4 |
1.2 |
1.5 |
|
x5 |
1.5 |
1.0 |
الف. دادهها را به عنوان نقاط داده دوبعدی در نظر بگیرید. با توجه به یک نقطه داده جدید، x (1.4، 1.6) به عنوان یک پرسوجو، نقاط پایگاه داده را بر اساس شباهت با پرسوجو با استفاده از فاصله اقلیدسی، فاصله منهتن، فاصله سوپریمم و شباهت کسینوسی رتبهبندی کنید.
ب. مجموعه دادهها را نرمالسازی کنید تا هنجار هر نقطه داده برابر با ۱ شود. از فاصله اقلیدسی روی دادههای تبدیلشده برای رتبهبندی نقاط داده استفاده کنید.
2.12. کیفیت دادهها را میتوان از نظر چندین موضوع، از جمله دقت، کامل بودن و سازگاری، ارزیابی کرد. برای هر یک از سه موضوع فوق، با ذکر مثال، در مورد چگونگی وابستگی ارزیابی کیفیت دادهها به کاربرد مورد نظر از دادهها بحث کنید. دو بعد دیگر از کیفیت دادهها را پیشنهاد دهید.
2.13. در دادههای دنیای واقعی، تاپلهایی با مقادیر گمشده برای برخی از ویژگیها یک اتفاق رایج هستند. روشهای مختلفی را برای رسیدگی به این مشکل شرح دهید.
2.14. با توجه به دادههای زیر (به ترتیب صعودی) برای ویژگی سن: ۱۳، ۱۵، ۱۶، ۱۶، ۱۹، ۲۰، ۲۰،
۲۱، ۲۲، ۲۲، ۲۵، ۲۵، ۲۵، ۲۵، ۳۰، ۳۳، ۳۳، ۳۵، ۳۵، ۳۵، ۳۵، ۳۶، ۴۰، ۴۵، ۴۶، ۵۲، ۷۰.
الف. از هموارسازی به روش دستهای برای هموارسازی این دادهها، با استفاده از دستههای با فراوانی برابر با اندازه ۳، استفاده کنید. مراحل خود را شرح دهید. در مورد تأثیر این تکنیک برای دادههای داده شده نظر دهید.
ب. چگونه میتوانید دادههای پرت را در دادهها تعیین کنید؟
ج. چه روشهای دیگری برای هموارسازی دادهها وجود دارد؟
۲.۱۵. در مورد مسائلی که باید در طول ادغام دادهها در نظر گرفته شوند، بحث کنید.
۲.۱۶. محدوده مقادیر روشهای نرمالسازی زیر چیست؟
الف. نرمالسازی حداقل-حداکثر
ب. نرمالسازی امتیاز z
ج. نرمالسازی امتیاز z با استفاده از میانگین انحراف مطلق به جای انحراف معیار
د. نرمالسازی با مقیاس اعشاری
2.17. از این روشها برای نرمالسازی گروه دادههای زیر استفاده کنید:
200، 300، 400، 600، 1000
الف. نرمالسازی حداقل-حداکثر با تنظیم new_min 0 و new_max 1
ب. نرمالسازی امتیاز z
ج. نرمالسازی امتیاز z با استفاده از میانگین انحراف مطلق به جای انحراف معیار
د. نرمالسازی با مقیاس اعشاری
2.18. با استفاده از دادههای سن داده شده در تمرین 2.14، به موارد زیر پاسخ دهید:
الف. از نرمالسازی حداقل-حداکثر برای تبدیل مقدار 35 برای سن به محدوده 0.0، 1.0 استفاده کنید.
ب. از نرمالسازی امتیاز z برای تبدیل مقدار 35 برای سن استفاده کنید، که در آن انحراف معیار سن 12.70 سال است.
ج. از نرمالسازی با مقیاس اعشاری برای تبدیل مقدار ۳۵ برای سن استفاده کنید. د. در مورد روشی که ترجیح میدهید برای دادههای داده شده استفاده کنید، نظر دهید و دلایل خود را ذکر کنید.
۲.۱۹. با استفاده از دادههای سن و چربی بدن که در تمرین ۲.۷ داده شده است، به موارد زیر پاسخ دهید:
الف. دو ویژگی را بر اساس نرمالسازی نمره z نرمالسازی کنید.
ب. ضریب همبستگی (ضریب گشتاور حاصلضرب پیرسون) را محاسبه کنید. آیا این دو ویژگی همبستگی مثبت یا منفی دارند؟ کوواریانس آنها را محاسبه کنید.
۲.۲۰. فرض کنید گروهی از ۱۲ رکورد قیمت فروش به صورت زیر مرتب شدهاند:
۵، ۱۰، ۱۱، ۱۳، ۱۵، ۳۵، ۵۰، ۵۵، ۷۲، ۹۲، ۲۰۴، ۲۱۵.
آنها را با هر یک از روشهای زیر به سه دسته تقسیم کنید:
الف. پارتیشنبندی با فراوانی برابر (عمق برابر)
ب. پارتیشنبندی با عرض برابر
ج. خوشهبندی
۲.۲۱. با استفاده از یک فلوچارت، رویههای زیر را برای انتخاب زیرمجموعه ویژگی خلاصه کنید:
الف. انتخاب گام به گام رو به جلو
ب. حذف گام به گام رو به عقب
ج. ترکیبی از انتخاب گام به جلو و حذف گام به عقب
2.22. با استفاده از دادههای سن داده شده در تمرین 2.14،
الف. یک هیستوگرام با عرض مساوی با عرض 10 رسم کنید.
ب. مثالهایی از هر یک از تکنیکهای نمونهگیری زیر را رسم کنید: SRSWOR، SRSWR، نمونهگیری خوشهای و نمونهگیری طبقهبندی شده، با استفاده از نمونههایی با اندازه 5 و طبقات “جوانان”، “میانسالان” و “سالمندان”.
2.23. بارگذاری قوی دادهها در سیستمهای پایگاه داده چالشی ایجاد میکند زیرا دادههای ورودی اغلب کثیف هستند. در بسیاری از موارد، یک رکورد ورودی ممکن است چندین مقدار را از دست بدهد. برخی از رکوردها میتوانند آلوده باشند، برخی از مقادیر دادهها خارج از محدوده یا از نوع دادهای متفاوت از حد انتظار باشند. یک الگوریتم خودکار برای پاکسازی و بارگذاری دادهها ایجاد کنید تا دادههای اشتباه علامتگذاری شوند و دادههای آلوده به اشتباه در حین بارگذاری دادهها در پایگاه داده وارد نشوند.


