مقدمه
همانطور که در بخش قبل بحث شد، یک انبار داده، دادههای تاریخی و جاری را به شیوهای موضوعگرا و غیرفرار ادغام میکند. مدلهای دادهای که در انبارهای داده استفاده میشوند، دادهها را بر اساس موضوعات سازماندهی میکنند. در اینجا، یک موضوع، مانند مشتریان، توسط ابعادی مانند جنسیت، گروه سنی و شغل و سنجههایی مانند کل خرید و میانگین مبلغ تراکنش ثبت میشود. طبیعتاً، انبارهای داده و ابزارهای OLAP مبتنی بر مدلهای داده چندبعدی هستند که دادهها را در قالب یک مکعب داده مشاهده میکنند. در این بخش، خواهید آموخت که چگونه مکعبهای داده، دادههای n بعدی را مدلسازی میکنند (بخش ۳.۲.۱). در بخش ۳.۲.۲، مدلهای چندبعدی مختلفی توضیح داده شدهاند: طرحواره ستارهای، طرحواره دانه برفی و صورت فلکی واقعیت. دادهها در یک انبار داده ممکن است در دانهبندیهای مختلفی که توسط سلسله مراتب مفهومی تعریف میشوند، تجزیه و تحلیل شوند. شما سلسله مراتب مفهومی را در بخش ۳.۲.۳ خواهید آموخت. همچنین در مورد دستههای مختلف سنجهها و نحوه محاسبه کارآمد آنها خواهید آموخت (بخش ۳.۲.۴).
مکعب داده: یک مدل داده چندبعدی
«مکعب داده چیست؟» در هسته تحلیل دادههای چندبعدی، محاسبه کارآمد تجمیعها در مجموعههای زیادی از ابعاد قرار دارد. یک مکعب داده امکان مدلسازی و مشاهده دادهها را در ابعاد مختلف فراهم میکند. این مکعب توسط ابعاد و حقایق تعریف میشود.
یک مدل داده چندبعدی معمولاً حول یک موضوع اصلی، که به عنوان یک موضوع نیز شناخته میشود، مانند فروش، سازماندهی میشود. اطلاعات مربوط به یک موضوع را میتوان در تحلیل به دو بخش تقسیم کرد. بخش اول، دیدگاههایی است که موضوع باید مورد تجزیه و تحلیل قرار گیرد. به عنوان مثال، برای فروش موضوعی در یک شرکت، دیدگاههای ممکن ممکن است شامل زمان، کالا، شعبه و مکان باشد. این دیدگاهها به صورت ابعاد مدلسازی میشوند. در سادهترین مدل داده چندبعدی، میتوان برای هر بعد یک جدول ابعاد ساخت. به عنوان مثال، یک جدول ابعاد برای کالا ممکن است شامل ویژگیهای item_name، brand و type باشد.
بخش دوم، اندازهگیریهای مربوط به یک موضوع است. این اندازهگیریها، حقایق نامیده میشوند. برای مثال، برای فروش موضوعی در یک شرکت، حقایق ممکن است به صورت دلار_فروش (مبلغ فروش به دلار)، واحد_فروش (تعداد واحدهای فروخته شده) و مبلغ_بودجهبندی شده باشند. حقایق معمولاً عددی هستند، اما ممکن است انواع داده دیگری مانند دادههای دستهبندی یا متن را نیز در بر بگیرند.
در یک انبار داده، یک جدول حقایق، نام حقایق یا سنجهها و همچنین کلیدهای (خارجی) ارجاع دهنده به هر یک از جداول ابعاد مرتبط را ذخیره میکند.
به طور کلی، یک مکعب داده میتواند به اندازه نیاز کسب و کار ابعاد داشته باشد و بنابراین n بعدی است. برای توضیح مکعبهای داده و مدل داده چندبعدی، اجازه دهید با نگاهی به یک مکعب داده ساده دوبعدی شروع کنیم که در واقع یک جدول یا صفحه گسترده برای دادههای فروش برای یک شرکت است. به طور خاص، ما به دادههای فروش اقلام فروخته شده در هر فصل در یک شهر، مثلاً ونکوور، نگاه خواهیم کرد. دادهها در جدول 3.1 نشان داده شدهاند. در این نمایش دوبعدی، فروش ونکوور با توجه به بُعد زمان (به صورت فصلی) و بُعد کالا (بر اساس انواع اقلام فروخته شده) نشان داده شده است. واقعیت یا سنجه نمایش داده شده، دلار_فروش (به هزار دلار) است.
حال، فرض کنید میخواهیم دادههای فروش را با بُعد سوم مشاهده کنیم. برای مثال، فرض کنید میخواهیم دادهها را بر اساس زمان و کالا و همچنین مکان، برای شهرهای شیکاگو، نیویورک، تورنتو و ونکوور مشاهده کنیم. این دادههای سهبعدی در جدول 3.2 نشان داده شدهاند. دادههای سهبعدی در جدول به صورت مجموعهای از جداول دوبعدی نمایش داده میشوند. از نظر مفهومی، میتوانیم همان دادهها را به شکل یک مکعب داده سهبعدی نیز نمایش دهیم، همانطور که در شکل 3.4 نشان داده شده است.
|
جدول ۳.۱ نمای دوبعدی از دادههای فروش بر اساس زمان و کالا. |
|||
|
مکان = ونکوور |
|||
|
زمان (ربع) |
مورد (نوع) |
|
|
|
|
سرگرمی خانگی کامپیوتر |
تلفن |
امنیت |
|
Q1 |
605 825 |
14 |
400 |
|
Q2 |
680 952 |
31 |
512 |
|
Q3 |
812 1023 |
30 |
501 |
|
Q4 |
927 1038 |
38 |
580 |
|
توجه: فروشها از شعب واقع در شهر ونکوور است. واحد اندازهگیری نمایش داده شده، دلار_فروش (به هزار دلار) است. |
|||
|
جدول ۳.۲ نمای سهبعدی از دادههای فروش بر اساس زمان، کالا و مکان. |
||||||||||||||||
|
|
مکان = شیکاگو |
|
|
مکان = نیویورک |
مکان = تورنتو |
|
مکان = ونکوور |
|||||||||
|
زمان |
مورد |
|
مورد |
مورد |
|
مورد |
||||||||||
|
|
home ent. |
comp. |
phone |
sec. |
home ent. |
comp. |
phone |
sec. |
home ent. |
comp. |
phone |
sec. |
home ent. |
comp. |
phone |
sec. |
|
Q1 |
854 |
882 |
89 |
623 |
1087 |
968 |
38 |
872 |
818 |
746 |
43 |
591 |
605 |
825 |
14 |
400 |
|
Q2 |
943 |
890 |
64 |
698 |
1130 |
1024 |
41 |
925 |
894 |
769 |
52 |
682 |
680 |
952 |
31 |
512 |
|
Q3 |
1032 |
924 |
59 |
789 |
1034 |
1048 |
45 |
1002 |
940 |
795 |
58 |
728 |
812 |
1023 |
30 |
501 |
|
Q4 |
1129 |
992 |
63 |
870 |
1142 |
1091 |
54 |
984 |
978 |
864 |
59 |
784 |
927 |
1038 |
38 |
580 |
|
توجه: سنجه نمایش داده شده، دلار_فروش (به هزار دلار) است. |
||||||||||||||||
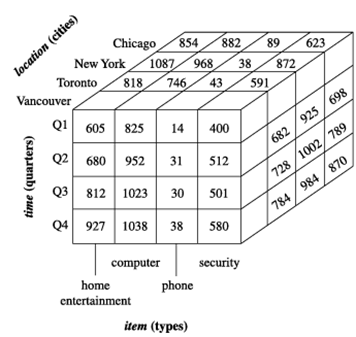
نمایش مکعب داده سهبعدی از دادههای جدول ۳.۲، بر اساس زمان، کالا و مکان. سنجه نمایش داده شده، دلار_فروش (به هزار) است.
به صورت مجموعهای از جداول دوبعدی نمایش داده میشوند. از نظر مفهومی، میتوانیم همین دادهها را به شکل یک مکعب داده سهبعدی نیز نمایش دهیم، همانطور که در شکل ۳.۴ نشان داده شده است.
فرض کنید اکنون میخواهیم دادههای فروش خود را با یک بعد چهارم اضافی، مثلاً تأمینکننده، مشاهده کنیم. تجسم چیزها در حالت چهاربعدی دشوار میشود. با این حال، میتوانیم یک مکعب چهاربعدی را به عنوان مجموعهای از مکعبهای سهبعدی در نظر بگیریم، همانطور که در شکل ۳.۵ نشان داده شده است. اگر به این روش ادامه دهیم، میتوانیم هر داده n بعدی را به عنوان مجموعهای از «مکعبهای» (n ۱) بعدی نمایش دهیم. مکعب داده استعارهای برای ذخیرهسازی دادههای چندبعدی است. ذخیرهسازی فیزیکی واقعی چنین دادههایی ممکن است با نمایش منطقی آن متفاوت باشد. نکته مهمی که باید به خاطر داشته باشید این است که مکعبهای داده n بعدی هستند و دادهها را به سهبعدی محدود نمیکنند.
جداول ۳.۱ و ۳.۲ دادهها را در درجات مختلف خلاصهسازی نشان میدهند. در ادبیات تحقیقاتی انبار داده، یک مکعب داده مانند آنچه در شکلهای ۳.۴ و ۳.۵ نشان داده شده است، اغلب به عنوان یک مکعب مستطیل شناخته میشود. در اصطلاحات SQL، این تجمیعها به عنوان گروهبندیها شناخته میشوند. هر گروهبندی را میتوان با یک مکعب مستطیل نشان داد.
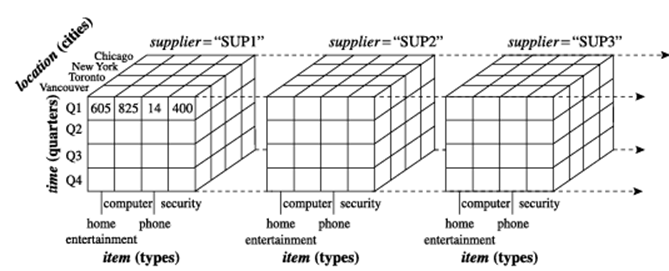
نمایش مکعب داده چهاربعدی از دادههای فروش، بر اساس زمان، کالا، مکان و تأمینکننده. سنجه نمایش داده شده، دلار_فروش (به هزار دلار) است. برای بهبود خوانایی، فقط برخی از مقادیر مکعب نشان داده شده است.
با داشتن مجموعهای از ابعاد، میتوانیم برای هر یک از زیرمجموعههای ممکن از ابعاد داده شده، از جمله مجموعه خالی، یک مکعب مستطیل ایجاد کنیم. نتیجه، شبکهای از مکعبهای مستطیل را تشکیل میدهد که هر کدام دادهها را در سطح متفاوتی از خلاصهسازی یا گروهبندی نشان میدهند. سپس به شبکه مکعبهای مستطیل، مکعب داده گفته میشود. شکل ۳.۶ شبکهای از مکعبهای مستطیل را نشان میدهد که یک مکعب داده را برای ابعاد زمان، کالا، مکان و تأمینکننده تشکیل میدهند. مکعب مستطیلی که پایینترین سطح خلاصهسازی را دارد، مکعب مستطیل پایه نامیده میشود. به عنوان مثال، مکعب مستطیل ۴ بعدی در شکل ۳.۵، مکعب مستطیل پایه برای ابعاد زمان، کالا، مکان و تأمینکننده داده شده است. شکل ۳.۴ یک مکعب مستطیل سهبعدی (غیرپایه) برای زمان، کالا و مکان است که برای همه تأمینکنندگان خلاصه شده است. مکعب مستطیل ۰ بعدی که بالاترین سطح خلاصهسازی را دارد، مکعب مستطیل رأسی نامیده میشود. در مثال ما، این کل فروش یا دلار فروخته شده است که در هر چهار بعد خلاصه شده است. مکعب رأس معمولاً با all نشان داده میشود.
طرحوارهها برای مدلهای داده چندبعدی: ستارهها، دانههای برف و صورتهای فلکی واقعیت
مدل داده موجودیت-رابطه معمولاً در طراحی پایگاههای داده رابطهای استفاده میشود، که در آن یک طرحواره پایگاه داده شامل مجموعهای از موجودیتها و روابط بین آنها است. نرمالسازی برای شکستن یک جدول عریض به جداول باریکتر انجام میشود تا بسیاری از عملیات تراکنشی فقط به تعداد بسیار کمی رکورد در یک یا تعداد کمی از جداول دسترسی داشته باشند و بنابراین همزمانی عملیات تراکنشی به حداکثر برسد. چنین مدل دادهای برای پردازش تراکنش آنلاین مناسب است. یک تحلیل داده آنلاین اغلب باید دادههای زیادی را اسکن کند. برای پشتیبانی از تحلیل داده آنلاین، یک انبار داده به یک طرحواره مختصر و موضوعگرا نیاز دارد که اسکن مقدار زیادی از دادهها را به طور موثر تسهیل کند.
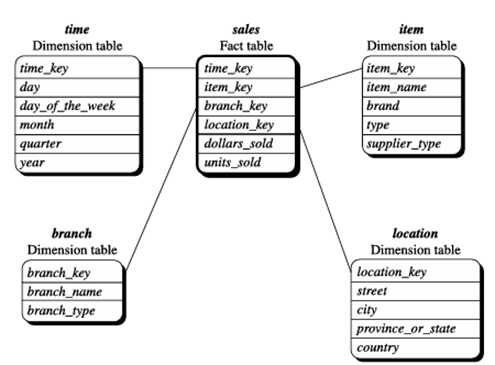
محبوبترین مدل داده برای یک انبار داده، یک مدل چندبعدی است. رایجترین الگوی مدل چندبعدی، طرحواره ستارهای است که در آن یک انبار داده شامل (1) یک جدول مرکزی بزرگ (جدول حقایق) است که شامل بخش عمدهای از دادهها، بدون افزونگی، و (2) مجموعهای از جداول کوچکتر وابسته (جداول بُعد)، یکی برای هر بُعد، میباشد. نمودار طرحواره شبیه یک ستارهافشان است که جداول بُعد در یک الگوی شعاعی در اطراف جدول حقایق مرکزی نمایش داده میشوند.
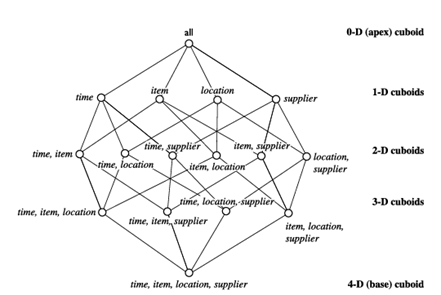
شبکهای از مکعبهای مستطیلی، که یک مکعب داده چهاربعدی برای زمان، کالا، مکان و تأمینکننده تشکیل میدهد. هر مکعب مستطیل نشاندهنده درجه متفاوتی از خلاصهسازی است.
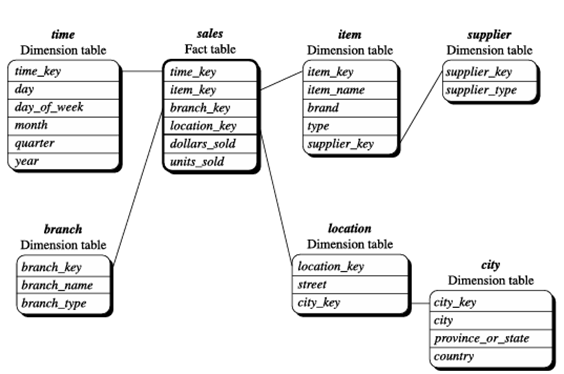
مثال ۳.۱. طرحواره ستارهای. یک طرحواره ستارهای برای فروش در شکل ۳.۷ نشان داده شده است. فروش در چهار بُعد زمان، کالا، شعبه و مکان در نظر گرفته میشود. این طرحواره شامل یک جدول واقعیت مرکزی برای فروش است که شامل کلیدهای هر یک از چهار بُعد به همراه دو سنجه است: دلار_فروش شده و واحد_فروش شده. برای به حداقل رساندن اندازه جدول واقعیت، شناسههای بُعد (مثلاً کلید_زمان و کلید_کالا) شناسههای تولید شده توسط سیستم هستند.
توجه داشته باشید که در طرحواره ستارهای، هر بُعد فقط با یک جدول نمایش داده میشود و هر جدول شامل مجموعهای از ویژگیها است. به عنوان مثال، جدول بُعد مکان شامل مجموعه ویژگیهای {کلید_مکان، خیابان، شهر، استان_یا_ایالت، کشور} است. این محدودیت ممکن است باعث ایجاد افزونگی شود. به عنوان مثال، “اوربانا” و “شیکاگو” هر دو شهرهایی در ایالت ایلینوی، ایالات متحده آمریکا هستند. ورودیهای مربوط به چنین شهرهایی در جدول بُعد مکان، افزونگی بین ویژگیهای province_or_state و country ایجاد میکنند، یعنی (…، Urbana، IL، USA) و (…، Chicago، IL، USA).
طرحواره دانه برفی نوعی از طرحواره ستارهای است که در آن برخی از جداول بُعد نرمالسازی میشوند و در نتیجه دادهها به جداول اضافی تقسیم میشوند. نمودار طرحواره حاصل، شکلی شبیه به دانه برف تشکیل میدهد.
تفاوت عمده بین مدلهای طرحواره دانه برفی و طرحواره ستارهای این است که جداول بُعد مدل دانه برفی را میتوان به صورت نرمالسازی شده نگه داشت تا افزونگیها کاهش یابد. نگهداری چنین جدولی آسان است و فضای ذخیرهسازی را صرفهجویی میکند. با این حال، این صرفهجویی در فضا در مقایسه با بزرگی معمول جدول واقعیت ناچیز است. علاوه بر این، ساختار دانه برفی ممکن است اثربخشی مرور را کاهش دهد، زیرا برای اجرای یک پرسوجو به اتصالهای بیشتری نیاز است. در نتیجه، عملکرد سیستم ممکن است به طور نامطلوبی تحت تأثیر قرار گیرد. از این رو، اگرچه طرحواره دانه برفی افزونگی را کاهش میدهد، اما به اندازه طرحواره ستارهای در طراحی انبار داده محبوب نیست.
طرح ستارهای انبار دادههای فروش.
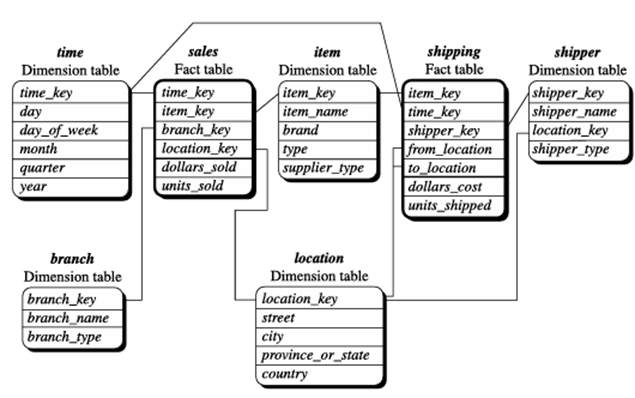
مثال ۳.۲. طرحواره دانه برف. یک طرحواره دانه برف برای فروش در شکل ۳.۸ ارائه شده است. در اینجا، جدول واقعیت فروش با جدول طرحواره ستاره در شکل ۳.۷ یکسان است. تفاوت اصلی بین این دو طرحواره در تعریف جداول بعد است. جدول تک بعدی برای کالا در طرحواره ستاره در طرحواره دانه برف نرمالسازی شده است که منجر به جداول جدید کالا و تأمینکننده میشود. به عنوان مثال، جدول بعد کالا اکنون شامل ویژگیهای item_key، item_name، brand، type و supplier_key است که supplier_key به جدول بعد تأمینکننده مرتبط است و حاوی اطلاعات supplier_key و supplier_type است. به طور مشابه، جدول تک بعدی برای مکان در طرحواره ستاره را میتوان در دو جدول جدید نرمالسازی کرد: مکان و شهر. city_key در جدول مکان جدید به بعد شهر پیوند میخورد. توجه داشته باشید که در صورت تمایل، میتوان نرمالسازی بیشتری را روی province_or_state و country در طرحواره دانه برف نشان داده شده در شکل ۳.۸ انجام داد.
برنامههای کاربردی پیچیده ممکن است برای اشتراکگذاری جداول بعد به چندین جدول واقعیت نیاز داشته باشند. این نوع طرحواره را میتوان به عنوان مجموعهای از ستارهها در نظر گرفت و از این رو طرحواره کهکشانی یا صورت فلکی واقعیت نامیده میشود.
مثال ۳.۳. صورت فلکی واقعیت. یک طرحواره صورت فلکی واقعیت در شکل ۳.۹ نشان داده شده است. این طرحواره دو جدول واقعیت، فروش و حمل و نقل را مشخص میکند. تعریف جدول فروش با تعریف طرحواره ستارهای (شکل ۳.۷) یکسان است. جدول حمل و نقل دارای پنج بُعد یا کلید – کلید_کالا، کلید_زمان، کلید_ارسال، کلید_از_موقعیت و کلید_به_موقعیت – و دو سنجه – هزینه_دلار و واحد_ارسال_شده – است. یک طرحواره صورت فلکی واقعیت اجازه میدهد تا جداول بعد بین جداول واقعیت به اشتراک گذاشته شوند. به عنوان مثال، جداول بعد برای زمان، کالا و مکان بین جداول واقعیت فروش و حمل و نقل به اشتراک گذاشته میشوند.
طرح دانه برفی از یک انبار داده فروش.
طرحواره صورت فلکی واقعیتها از یک انبار داده فروش و حمل و نقل.
سلسله مراتب مفاهیم
ابعاد، سلسله مراتب مفاهیم را تعریف میکنند. سلسله مراتب مفاهیم، توالی نگاشتها را از مجموعهای از مفاهیم سطح پایین به مفاهیم سطح بالاتر و عمومیتر تعریف میکند. یک سلسله مراتب مفهومی برای مکان بُعد در نظر بگیرید. مقادیر شهر برای مکان شامل ونکوور، تورنتو، نیویورک و شیکاگو است. با این حال، هر شهر میتواند به استان یا ایالتی که به آن تعلق دارد نگاشت شود. به عنوان مثال، ونکوور را میتوان به بریتیش کلمبیا و شیکاگو را به ایلینوی نگاشت کرد. استانها و ایالتها نیز میتوانند به نوبه خود به کشوری (مثلاً کانادا یا ایالات متحده) که به آن تعلق دارند نگاشت شوند. این نگاشتها یک سلسله مراتب مفهومی برای مکان بُعد تشکیل میدهند و مجموعهای از مفاهیم سطح پایین (یعنی شهرها) را به مفاهیم سطح بالاتر و عمومیتر (یعنی کشورها) نگاشت میکنند. این سلسله مراتب مفهومی در شکل ۳.۱۰ نشان داده شده است.
بسیاری از سلسله مراتب مفاهیم در طرحواره پایگاه داده ضمنی هستند. به عنوان مثال، فرض کنید مکان بُعد با ویژگیهای شماره، خیابان، شهر، استان یا ایالت، کد پستی و کشور توصیف میشود. این ویژگیها با یک ترتیب کلی به هم مرتبط هستند و یک سلسله مراتب مفهومی مانند «خیابان < شهر< استان یا ایالت < کشور» را تشکیل میدهند. این سلسله مراتب در شکل 3.11 (الف) نشان داده شده است. به طور جایگزین، ویژگیهای یک بُعد ممکن است به صورت ترتیب جزئی سازماندهی شوند و یک گراف جهتدار غیردوری تشکیل دهند. نمونهای از ترتیب جزئی برای بُعد زمان بر اساس ویژگیهای روز، هفته، ماه، ربع و سال به صورت «روز < {ماه < ربع؛ هفته} < سال» است. این ساختار ترتیب جزئی در شکل 3.11 (ب) نشان داده شده است.
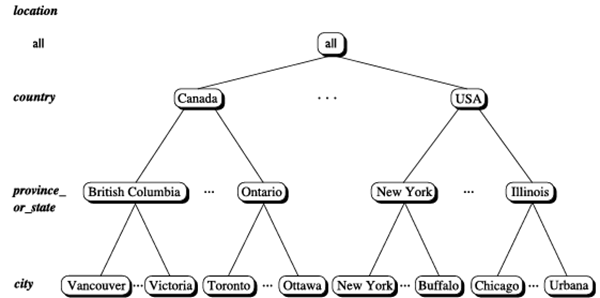
یک سلسله مراتب مفهومی برای مکان. به دلیل محدودیتهای فضا، همه گرههای سلسله مراتب نشان داده نشدهاند، که با بیضیهای بین گرهها نشان داده شدهاند.
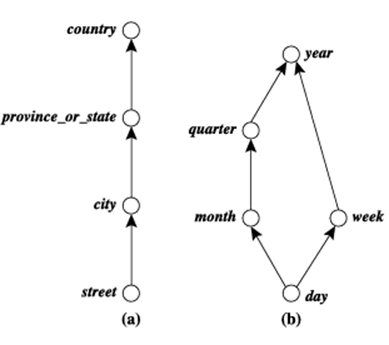
ساختارهای سلسله مراتبی و شبکهای ویژگیها در ابعاد انبار: (الف) سلسله مراتبی برای مکان و (ب) شبکهای برای زمان.
سلسله مراتب مفهومی که یک ترتیب کلی یا جزئی بین ویژگیها در یک طرحواره پایگاه داده است، سلسله مراتب طرحواره نامیده میشود. سلسله مراتب مفهومی که در بسیاری از کاربردها مشترک هستند (مثلاً برای زمان) ممکن است در سیستم دادهکاوی از پیش تعریف شده باشند. سیستمهای دادهکاوی باید انعطافپذیری لازم را برای کاربران فراهم کنند تا سلسله مراتب از پیش تعریف شده را مطابق با نیازهای خاص خود تنظیم کنند. به عنوان مثال، کاربران ممکن است بخواهند یک سال مالی را که از اول آوریل شروع میشود یا یک سال تحصیلی را که از اول سپتامبر شروع میشود، تعریف کنند.
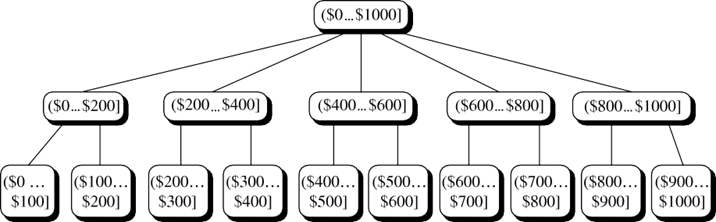
سلسله مراتب مفهومی همچنین میتواند با گسستهسازی یا گروهبندی مقادیر برای یک بُعد یا ویژگی مشخص تعریف شود که منجر به یک سلسله مراتب گروهبندی مجموعه میشود. یک ترتیب کلی یا جزئی را میتوان بین گروههای مقادیر تعریف کرد. نمونهای از یک سلسله مراتب گروهبندی مجموعه در شکل 3.12 برای قیمت بُعد نشان داده شده است، که در آن یک بازه ($X… $Y] نشاندهنده محدوده از $X (منحصراً) تا $Y (شامل) است.
ممکن است بر اساس دیدگاههای مختلف کاربران، بیش از یک سلسله مراتب مفهومی برای یک ویژگی یا بُعد مشخص وجود داشته باشد. به عنوان مثال، یک کاربر ممکن است ترجیح دهد قیمت را با تعریف محدودههایی برای ارزان، با قیمت متوسط و گران سازماندهی کند.
سلسله مراتب مفهومی ممکن است به صورت دستی توسط کاربران سیستم، متخصصان حوزه یا مهندسان دانش ارائه شود، یا ممکن است به طور خودکار بر اساس تجزیه و تحلیل آماری توزیع دادهها ایجاد شود. سلسله مراتب مفهومی اجازه میدهد دادهها در سطوح مختلف انتزاع مدیریت شوند، همانطور که در بخش 3.2.4 خواهیم دید.
سنجهها: طبقهبندی و محاسبه
“سنجهها چگونه محاسبه میشوند؟” برای پاسخ به این سوال، ابتدا بررسی میکنیم که چگونه سنجهها میتوانند طبقهبندی شوند. توجه داشته باشید که یک نقطه چندبعدی در فضای مکعب داده، که به عنوان یک سلول در مکعب داده نیز شناخته میشود، میتواند توسط مجموعهای از جفتهای بعد-مقدار تعریف شود. به عنوان مثال، زمان “Q1″، مکان “ونکوور”، آیتم “کامپیوتر”. یک سنجه در یک مکعب داده، یک تابع عددی است که میتواند در هر نقطه از فضای مکعب داده ارزیابی شود. یک مقدار سنجه برای یک نقطه معین با تجمیع دادههای مربوط به جفتهای بعد-مقدار مربوطه که نقطه معین را تعریف میکنند، محاسبه میشود. به عنوان مثال، مقدار کل فروش برای زمان سلول “Q1″، مکان “ونکوور”، آیتم “کامپیوتر” با جمع کردن تمام مقادیر رخ داده در Q1، در شعبه ونکوور و در مورد کامپیوترهای جدول حقایق محاسبه میشود.
سنجهها را میتوان بر اساس نوع توابع تجمیعی مورد استفاده، به سه دسته – توزیعی، جبری و کلنگر – طبقهبندی کرد.
توزیعی: یک تابع تجمیعی توزیعی است اگر بتوان آن را به صورت توزیعشده به شرح زیر محاسبه کرد. فرض کنید دادهها به طور دلخواه به n مجموعه تقسیم شدهاند. ما تابع تجمیعی را برای هر بخش اعمال میکنیم که منجر به n مقدار تجمیعی میشود. اگر نتیجه حاصل از اعمال تابع بر روی n مقدار تجمیعی مشابه نتیجه حاصل از اعمال تابع بر روی کل مجموعه دادهها باشد (یعنی بدون تقسیمبندی)، گفته میشود که تابع به صورت توزیعشده محاسبه شده است. برای مثال، تابع sum() را میتوان برای یک مکعب داده با تقسیم مکعب به مجموعهای از زیرمکعبها، محاسبه sum() برای هر زیرمکعب و سپس جمع کردن تعداد به دست آمده برای هر زیرمکعب محاسبه کرد. از این رو sum() یک تابع تجمیع توزیعی است. به همین دلیل، توابع count()، min() و max() نیز توابع تجمیع توزیعی هستند. با در نظر گرفتن مقدار شمارش هر سلول پایه غیرتهی به طور پیشفرض برابر با ۱، تابع count() هر سلول در یک مکعب را میتوان به عنوان مجموع مقادیر شمارش تمام سلولهای فرزند مربوطه در زیرمکعب آن در نظر گرفت. بنابراین count() توزیعی است. یک سنجه توزیعی است اگر با اعمال یک تابع تجمیع توزیعی به دست آید. سنجههای توزیعی را میتوان به دلیل نحوه تقسیم محاسبه، به طور کارآمد محاسبه کرد.
جبر: یک تابع تجمیع جبری است اگر بتوان آن را با یک تابع جبری با M آرگومان (که در آن M یک عدد صحیح مثبت ثابت است) محاسبه کرد که هر کدام از آنها با اعمال یک تابع تجمیع توزیعی به دست میآیند. برای مثال، avg() (میانگین) را میتوان با sum()/count() با دو آرگومان محاسبه کرد، که در آن هم sum() و هم count() توابع تجمعی توزیعی هستند. به طور مشابه، میتوان نشان داد که min_N() و max_N() (که به ترتیب N مقدار حداقل و N مقدار حداکثر را در یک مجموعه معین پیدا میکنند) و standard_deviation() توابع تجمعی جبری هستند. یک سنجه جبری است اگر با اعمال یک تابع تجمعی جبری به دست آید.
کلنگر: یک تابع تجمعی در صورتی کلنگر است که هیچ حد ثابتی برای اندازه ذخیرهسازی مورد نیاز برای توصیف یک زیرمجموعه وجود نداشته باشد. یعنی، یک تابع جبری با M آرگومان (که در آن M یک ثابت است) وجود ندارد که محاسبه را مشخص کند. برخی از نمونههای توابع جامع شامل median()، mode() و rank() هستند. یک سنجه در صورتی کلنگر است که با اعمال یک تابع تجمعی کلنگر به دست آید. اکثر کاربردهای مکعب دادههای بزرگ نیاز به محاسبات کارآمد و مقیاسپذیر دارند و بنابراین اغلب از سنجههای توزیعی و جبری استفاده میشود. تکنیکهای کارآمد زیادی برای محاسبه مکعبهای داده با استفاده از سنجههای توزیعی و جبری وجود دارد. ما بعداً در این فصل برخی از روشهای اصولی را معرفی خواهیم کرد. در مقابل، محاسبه کارآمد سنجههای جامع دشوار است. با این حال، تکنیکهای کارآمدی برای تقریب محاسبه برخی از سنجههای جامع وجود دارد. در بسیاری از موارد، چنین تکنیکهایی برای غلبه بر مشکلات محاسبه کارآمد سنجههای جامع کافی هستند.


