مقدمه
محاسبه مکعب داده یک کار ضروری در پیادهسازی انبار داده است. پیشمحاسبه تمام یا بخشی از یک مکعب داده میتواند زمان پاسخ را تا حد زیادی کاهش داده و عملکرد پردازش تحلیلی آنلاین را افزایش دهد. با این حال، چنین محاسباتی چالش برانگیز است زیرا ممکن است به زمان محاسباتی و فضای ذخیرهسازی قابل توجهی نیاز داشته باشد. این بخش روشهای کارآمد برای محاسبه مکعب داده را بررسی میکند. بخش ۳.۵.۱ روش تجمیع آرایه چندراهه (MultiWay) را برای محاسبه مکعبهای کامل شرح میدهد. بخش ۳.۵.۲ روش BUC را شرح میدهد که مکعبهای کوه یخ را از رأس مکعب به سمت پایین محاسبه میکند. بخش ۳.۵.۳ یک رویکرد مکعبسازی قطعه-پوسته را شرح میدهد که قطعات پوسته را برای OLAP با ابعاد بالا و کارآمد محاسبه میکند. در نهایت، بخش ۳.۵.۴ نحوه پاسخ به پرسوجوهای OLAP با استفاده از مکعبهای داده در مکعبهای داده را نشان میدهد.
برای سادهسازی بحث، مکعبهایی را که با بالا رفتن از هر سلسله مراتب موجود برای ابعاد ایجاد میشوند، حذف میکنیم. این نوع مکعبها را میتوان با بسطهای سادهای از روشهای مورد بحث محاسبه کرد. روشهای محاسبه کارآمد مکعبهای بسته به عنوان تمرین برای خوانندگان علاقهمند ارائه شده است.
تجمیع آرایه چندراهه برای محاسبه کامل مکعب
روش تجمیع آرایه چندراهه (یا به طور خلاصه MultiWay) یک مکعب داده کامل را با استفاده از یک آرایه چندبعدی به عنوان ساختار داده پایه خود محاسبه میکند. این یک رویکرد MOLAP معمولی است که از آدرسدهی مستقیم آرایه استفاده میکند، که در آن مقادیر ابعاد از طریق موقعیت یا اندیس مکانهای آرایه مربوطه قابل دسترسی هستند. MultiWay یک مکعب مبتنی بر آرایه را به شرح زیر میسازد.
۱. آرایه را به تکههایی تقسیم کنید. یک تکه، یک زیرمکعب است که به اندازه کافی کوچک است تا در حافظه موجود برای محاسبه مکعب جا شود. تکهبندی روشی برای تقسیم یک آرایه n بعدی به تکههای کوچک n بعدی است که در آن هر تکه به عنوان یک شیء روی دیسک ذخیره میشود. تکهها فشرده میشوند تا فضای هدر رفته ناشی از سلولهای آرایه خالی حذف شود. یک سلول اگر حاوی هیچ داده معتبری نباشد (یعنی تعداد سلولهای آن ۰ باشد) خالی است. به عنوان مثال، «جابجایی شناسه تکهای» میتواند به عنوان یک مکانیسم آدرسدهی سلول برای فشردهسازی ساختار آرایه پراکنده و هنگام جستجوی سلولهای درون یک تکه استفاده شود. چنین تکنیک فشردهسازی در مدیریت مکعبهای پراکنده، چه روی دیسک و چه در حافظه، قدرتمند است.
۲. محاسبه تجمیعها با مراجعه (یعنی دسترسی به مقادیر در) سلولهای مکعبی. ترتیب بازدید از سلولها را میتوان بهینه کرد تا تعداد دفعاتی که هر سلول باید دوباره بازدید شود، به حداقل برسد و در نتیجه هزینههای دسترسی به حافظه و ذخیرهسازی کاهش یابد. ایده این است که از این ترتیب استفاده شود تا بخشهایی از سلولهای تجمیع شده در چندین مکعب مستطیل به طور همزمان محاسبه شوند و از هرگونه بازدید مجدد غیرضروری سلولها جلوگیری شود.
این تکنیک قطعهبندی شامل «همپوشانی» برخی از محاسبات تجمیع است. بنابراین به آن تجمیع آرایه چندوجهی گفته میشود. این تکنیک تجمیع همزمان را انجام میدهد، یعنی تجمیعها را به طور همزمان در چندین بعد محاسبه میکند. ما این رویکرد برای ساخت مکعب مبتنی بر آرایه را با نگاهی به یک مثال ملموس توضیح میدهیم.
مثال ۳.۱۳. محاسبه مکعب آرایه چندوجهی. یک آرایه داده سهبعدی شامل سه بعد A، B و C را در نظر بگیرید. آرایه سهبعدی به قطعات کوچک مبتنی بر حافظه تقسیم میشود. در این مثال، آرایه به ۶۴ قطعه تقسیم میشود، همانطور که در شکل ۳.۲۰ نشان داده شده است. بعد A به چهار قطعه با اندازه مساوی سازماندهی شده است: a0، a1، a2 و a3. ابعاد B و C نیز به طور مشابه هر کدام به چهار قطعه سازماندهی شدهاند. قطعات ۱، ۲، …، ۶۴ به ترتیب مربوط به زیرمکعبهای a0b0c0، a1b0c0، …، a3b3c3 هستند. فرض کنید که کاردینالیتی ابعاد A، B و C به ترتیب ۴۰، ۴۰۰ و ۴۰۰۰ باشد. بنابراین اندازه آرایه برای هر بُعد، A، B و C، نیز به ترتیب ۴۰، ۴۰۰ و ۴۰۰۰ است. از آنجایی که تعداد پارتیشنهای هر بُعد ۴ است، بنابراین اندازه هر پارتیشن در A، B و C به ترتیب ۱۰، ۱۰۰ و ۱۰۰۰ است. تحقق کامل مکعب داده مربوطه شامل محاسبه تمام مکعبهای تعریفکننده این مکعب است. مکعب کامل حاصل شامل مکعبهای زیر است:
- مکعب پایه، که با ABC نشان داده میشود (که تمام مکعبهای دیگر به طور مستقیم یا غیرمستقیم از آن محاسبه میشوند). این مکعب از قبل محاسبه شده و با آرایه سهبعدی داده شده مطابقت دارد.
- مکعبهای دوبعدی، AB، AC و BC، که به ترتیب با AB، AC و BC گروهبندی شده مطابقت دارند. این مکعبها باید محاسبه شوند.
- مکعبهای یک بعدی، A، B و C، که به ترتیب مربوط به گروهبندی A، B و C هستند. این مکعبها باید محاسبه شوند.
- مکعب صفر بعدی (راس) که با all نشان داده میشود، مربوط به گروهبندی (group-by) است؛ یعنی در اینجا گروهبندی وجود ندارد. این مکعبها باید محاسبه شوند. این مکعبها فقط از یک مقدار تشکیل شدهاند. اگر، مثلاً، سنجه مکعب داده، count باشد، مقداری که باید محاسبه شود، صرفاً تعداد کل تاپلهای ABC است.
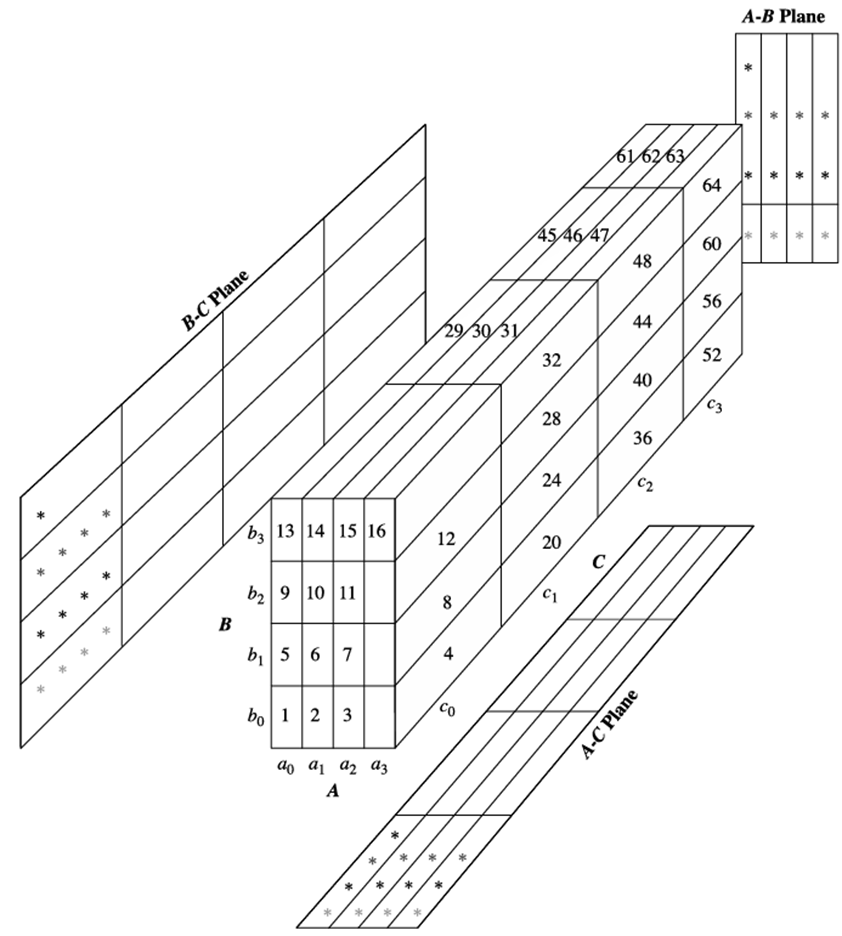
یک آرایه سهبعدی برای ابعاد A، B و C، که در ۶۴ قطعه سازماندهی شده است. هر قطعه به اندازه کافی کوچک است که در حافظه موجود برای محاسبه مکعب جا شود. *ها قطعاتی از ۱ تا ۱۳ را نشان میدهند که تاکنون در این فرآیند تجمیع شدهاند.
بیایید نگاهی به نحوه استفاده از تکنیک تجمیع آرایه چندوجهی در این محاسبه بیندازیم. ترتیبهای ممکن زیادی وجود دارد که میتوان قطعات را با آنها برای استفاده در محاسبه مکعب در حافظه خواند. ترتیب برچسبگذاری شده از ۱ تا ۶۴ را که در شکل ۳.۲۰ نشان داده شده است، در نظر بگیرید. فرض کنید میخواهیم قطعه b0c0 از مکعب BC را محاسبه کنیم. ما فضایی را برای این قطعه در حافظه قطعه اختصاص میدهیم. با اسکن قطعات ABC ۱ تا ۴، قطعه b0c0 محاسبه میشود. یعنی سلولهای b0c0 در a0 تا a3 تجمیع میشوند. سپس میتوان حافظهی این تکه را به تکهی بعدی، b1c0، اختصاص داد که پس از اسکن چهار تکهی بعدی ABC: 5 تا 8، تجمیع خود را تکمیل میکند. با ادامهی این روش، کل مکعب مستطیل BC قابل محاسبه خواهد بود. بنابراین، فقط یک تکهی BC باید در یک زمان در حافظه باشد تا تمام تکههای BC محاسبه شوند.
در محاسبهی مکعب مستطیل BC، ما هر 64 تکه را اسکن کردهایم. “آیا راهی وجود دارد که از اسکن مجدد تمام این تکهها برای محاسبهی مکعبهای دیگر، مانند AC و AB، اجتناب کنیم؟” پاسخ، قطعاً، بله است. اینجاست که ایده «محاسبه چندوجهی» یا «تجمیع همزمان» مطرح میشود. برای مثال، وقتی بخش ۱ (یعنی a0b0c0) در حال اسکن شدن است (مثلاً برای محاسبه بخش دوبعدی b0c0 از BC، همانطور که قبلاً توضیح داده شد)، تمام بخشهای دوبعدی دیگر مربوط به a0b0c0 میتوانند همزمان محاسبه شوند. یعنی وقتی a0b0c0 در حال اسکن شدن است، هر یک از سه بخش (b0c0، a0c0 و a0b0) در سه صفحه تجمیع دوبعدی (BC، AC و AB) نیز باید همزمان محاسبه شوند. به عبارت دیگر، محاسبه چندوجهی به طور همزمان در هر یک از صفحات دوبعدی تجمیع میشود در حالی که یک بخش سه بعدی در حافظه است. حال بیایید بررسی کنیم که چگونه ترتیبهای مختلف اسکن بخشها و محاسبه مکعب مستطیل میتواند بر کارایی کلی محاسبه مکعب داده تأثیر بگذارد. به یاد داشته باشید که اندازه ابعاد A، B و C به ترتیب ۴۰، ۴۰۰ و ۴۰۰۰ است. بنابراین بزرگترین صفحه دوبعدی BC (با اندازه ۴۰۰ × ۴۰۰۰ = ۱,۶۰۰,۰۰۰) است.
دومین صفحه دوبعدی بزرگ AC (با اندازه ۴۰ × ۴۰۰۰ = ۱۶۰,۰۰۰) است. AB کوچکترین صفحه دوبعدی (با اندازه ۴۰ × ۴۰۰ = ۱۶,۰۰۰) است.
فرض کنید که قطعات به ترتیب نشان داده شده، از قطعات ۱ تا ۶۴، اسکن میشوند. همانطور که قبلاً ذکر شد، b0c0 پس از اسکن ردیف حاوی قطعات ۱ تا ۴ به طور کامل تجمیع میشود؛ b1c0 پس از اسکن قطعات ۵ تا ۸ به طور کامل تجمیع میشود و به همین ترتیب ادامه مییابد. بنابراین برای محاسبه کامل یک قطعه از مکعب BC (که BC بزرگترین صفحه دوبعدی است)، باید چهار قطعه از آرایه سهبعدی را اسکن کنیم. به عبارت دیگر، با اسکن کردن به این ترتیب، برای هر ردیف اسکن شده، یک قطعه BC به طور کامل محاسبه میشود. در مقایسه، محاسبه کامل یک قطعه از دومین صفحه دو بعدی بزرگ، AC، نیاز به اسکن ۱۳ قطعه دارد، با توجه به ترتیب ۱ تا ۶۴. یعنی، a0c0 تنها پس از اسکن قطعات ۱، ۵، ۹ و ۱۳ به طور کامل تجمیع میشود.
در نهایت، محاسبه کامل یک قطعه از کوچکترین صفحه دو بعدی، AB، نیاز به اسکن ۴۹ قطعه دارد. به عنوان مثال، a0b0 پس از اسکن قطعات ۱، ۱۷، ۳۳ و ۴۹ به طور کامل تجمیع میشود. از این رو، AB برای تکمیل محاسبات خود به طولانیترین اسکن قطعات نیاز دارد. برای جلوگیری از وارد کردن بیش از یک بار یک قطعه داده سهبعدی به حافظه، حداقل حافظه مورد نیاز برای نگهداری تمام صفحات دوبعدی مربوطه در حافظه قطعه داده، طبق ترتیب قطعه داده از ۱ تا ۶۴، به شرح زیر است: ۴۰×۴۰۰ (برای کل صفحه AB) + ۴۰×۱۰۰۰ (برای یک ستون از صفحه AC) + ۱۰۰×۱۰۰۰ (برای یک قطعه داده از صفحه BC) = ۱۶۰۰۰ + ۴۰۰۰۰ + ۱۰۰۰۰۰ = ۱۵۶۰۰۰ واحد حافظه. در عوض، فرض کنید که قطعات داده به ترتیب ۱، ۱۷، ۳۳، ۴۹، ۵، ۲۱، ۳۷، ۵۳ و غیره اسکن شوند. یعنی فرض کنید اسکن به ترتیب ابتدا به سمت صفحه AB و سپس به سمت صفحه AC و در نهایت به سمت صفحه BC جمع شود. حداقل حافظه مورد نیاز برای نگهداری صفحات دوبعدی در حافظه به صورت زیر خواهد بود: ۴۰۰×۴۰۰۰ (برای کل صفحه BC) + ۱۰×۴۰۰۰ (برای یک ردیف صفحه AC) + ۱۰×۱۰۰ (برای یک قطعه صفحه AB) = ۱,۶۰۰,۰۰۰ + ۴۰,۰۰۰ + ۱۰۰۰ = ۱,۶۴۱,۰۰۰ واحد حافظه. توجه داشته باشید که این بیش از ۱۰ برابر حافظه مورد نیاز برای مرتبسازی اسکن ۱ تا ۶۴ است. به طور مشابه، میتوانیم حداقل حافظه مورد نیاز برای محاسبه چندوجهی … را محاسبه کنیم.
به طور مشابه، میتوانیم حداقل حافظه مورد نیاز برای محاسبه چندوجهی مکعبهای یک بعدی و صفر بعدی را محاسبه کنیم. شکل ۳.۲۱ کارآمدترین روش برای محاسبه مکعبهای یک بعدی را نشان میدهد. قطعات مکعبهای یک بعدی A و B در طول محاسبه کوچکترین مکعب دو بعدی، AB، محاسبه میشوند. کوچکترین مکعب یک بعدی، A، تمام قطعات خود را در حافظه اختصاص میدهد، در حالی که مکعب یک بعدی بزرگتر، B، فقط یک قطعه در حافظه در هر زمان اختصاص میدهد. به طور مشابه، قطعه C در طول محاسبه دومین مکعب دو بعدی کوچک، AC، محاسبه میشود و فقط به یک قطعه در حافظه در هر زمان نیاز دارد. بر اساس این تحلیل، میبینیم که کارآمدترین ترتیب در محاسبه این مکعب آرایهای، ترتیب قطعات ۱ تا ۶۴ با استراتژی تخصیص حافظه ذکر شده است.
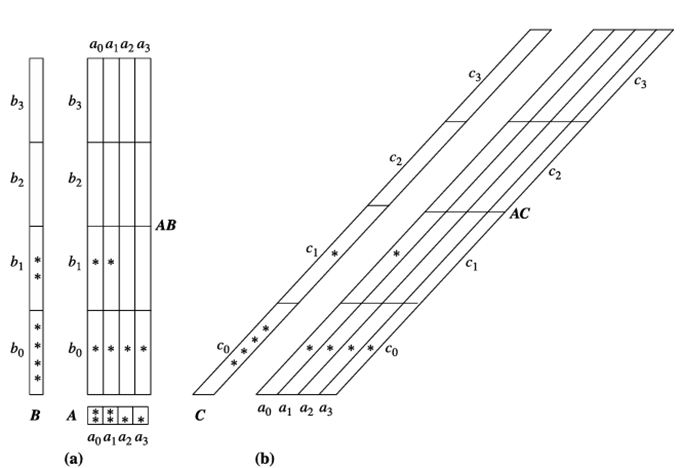
تخصیص حافظه و ترتیب محاسبه برای محاسبه مکعبهای یک بعدی مثال ۵.۴. (الف) مکعبهای یک بعدی، A و B، در طول محاسبه کوچکترین مکعب دو بعدی، AB، جمع میشوند. (ب) مکعب یک بعدی، C، در طول محاسبه دومین مکعب دو بعدی کوچک، AC، جمع میشود. *ها نشان دهنده تکههایی هستند که تاکنون جمع شدهاند..
مثال ۳.۱۳ فرض میکند که فضای حافظه کافی برای محاسبه مکعب تکگذری وجود دارد (یعنی برای محاسبه همه مکعبها از یک اسکن همه تکهها). اگر فضای حافظه کافی نباشد، محاسبه به بیش از یک بار عبور از آرایه سهبعدی نیاز خواهد داشت. با این حال، در چنین مواردی، اصل اساسی محاسبه تکههای مرتب ثابت میماند. MultiWay زمانی بیشترین تأثیر را دارد که حاصلضرب کاردینالیتیهای ابعاد متوسط باشد و دادهها خیلی پراکنده نباشند. وقتی ابعاد زیاد باشد یا دادهها خیلی پراکنده باشند، آرایههای درون حافظه برای جا شدن در حافظه خیلی بزرگ میشوند و این روش غیرعملی میشود. با استفاده از تکنیکهای فشردهسازی آرایه پراکنده مناسب و مرتبسازی دقیق محاسبه مکعبها، آزمایشها نشان دادهاند که محاسبه مکعب آرایه MultiWay به طور قابل توجهی سریعتر از محاسبه سنتی ROLAP (مبتنی بر رکورد رابطهای) است. برخلاف ROLAP، ساختار آرایه MultiWay نیازی به صرفهجویی در فضا برای ذخیره کلیدهای جستجو ندارد. علاوه بر این، MultiWay از آدرسدهی مستقیم آرایه استفاده میکند که سریعتر از استراتژی جستجوی آدرسدهی مبتنی بر کلید ROLAP است. برای محاسبه مکعب ROLAP، به جای مکعببندی مستقیم یک جدول، میتوان جدول را به یک آرایه تبدیل کرد، آرایه را مکعببندی کرد و سپس نتیجه را دوباره به یک جدول تبدیل کرد. با این حال، این مشاهده فقط برای مکعبهایی با تعداد ابعاد نسبتاً کم کار میکند، زیرا تعداد مکعبهای محاسبهشده نسبت به تعداد ابعاد نمایی است.
“اگر سعی کنیم از MultiWay برای محاسبه مکعبهای کوه یخ استفاده کنیم چه اتفاقی میافتد؟” به یاد داشته باشید که خاصیت ضدیکنواختی رو به پایین بیان میکند که اگر یک سلول معین خاصیت کوه یخ را برآورده نکند، هیچ یک از فرزندان آن نیز چنین نخواهند کرد. متأسفانه، محاسبه MultiWay از مکعب پایه شروع میشود و به سمت مکعبهای جد تعمیمیافتهتر پیش میرود. نمیتواند از هرس احتمالی با استفاده از خاصیت ضدیکنواختی بهره ببرد، که مستلزم محاسبه گره والد قبل از گرههای فرزندش (یعنی خاصتر) است. به عنوان مثال، اگر تعداد سلول c در، مثلاً AB، حداقل پشتیبانی مشخص شده در شرط کوه یخ را برآورده نکند، نمیتوانیم سلول c را هرس کنیم، زیرا تعداد اجداد c در مکعبهای A یا B ممکن است بیشتر از حداقل پشتیبانی باشد و محاسبه آنها نیاز به تجمیع شامل تعداد c خواهد داشت.
BUC: محاسبه مکعبهای کوه یخ از رأس مکعب به سمت پایین
BUC الگوریتمی برای محاسبه مکعبهای پراکنده و کوه یخ است. برخلاف MultiWay، BUC مکعب را از رأس مکعب به سمت قاعده مکعب میسازد. این امر به BUC اجازه میدهد تا هزینههای پارتیشنبندی دادهها را به اشتراک بگذارد. این ترتیب پردازش همچنین به BUC اجازه میدهد تا در طول ساخت، با استفاده از خاصیت ضدیکنواختی رو به پایین، هرس کند.
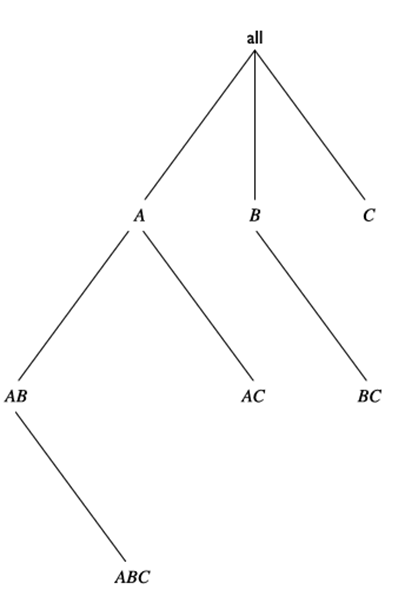
شکل ۳.۲۲ شبکهای از مکعبها را نشان میدهد که یک مکعب داده سهبعدی با ابعاد A، B و C را تشکیل میدهند.
مکعب رأس (۰-D) که نمایانگر مفهوم همه (یعنی (*،*،*)) است، در بالای شبکه قرار دارد. این سطح، متراکمترین یا تعمیمیافتهترین سطح است. مکعب پایه سهبعدی، ABC، در پایین شبکه قرار دارد. این سطح، کمترین تجمیع (جزئیترین یا تخصصیترین) سطح را دارد. این نمایش شبکهای از مکعبها، با رأس در بالا و قاعده در پایین، معمولاً در انبار دادهها پذیرفته شده است. این مفهوم، مفاهیم حفاری به پایین (جایی که میتوانیم از یک سلول بسیار تجمیعشده به سلولهای پایینتر و جزئیتر حرکت کنیم) و جمع کردن (جایی که میتوانیم از سلولهای دقیق و سطح پایین به سلولهای سطح بالاتر و تجمیعشدهتر حرکت کنیم) را ادغام میکند.
BUC مخفف “ساخت پایین به بالا” است. با این حال، طبق قرارداد شبکهای که قبلاً توضیح داده شده و در سراسر این کتاب استفاده شده است، ترتیب پردازش BUC در واقع از بالا به پایین است! نویسندگان BUC، شبکهای از مکعبها را به ترتیب معکوس مشاهده میکنند، که مکعب رأس در پایین و مکعب قاعده در بالا قرار دارد. در این دیدگاه، BUC ساخت پایین به بالا را انجام میدهد. با این حال، از آنجا که ما جهانبینی کاربردی را اتخاذ میکنیم که در آن حفاری از رأس مکعب مستطیل به سمت قاعده آن اشاره دارد، فرآیند کاوش BUC از بالا به پایین در نظر گرفته میشود. کاوش BUC برای محاسبه یک مکعب داده سهبعدی در شکل 3.22 نشان داده شده است.
الگوریتم BUC در شکل 3.23 نشان داده شده است. ابتدا توضیحی در مورد الگوریتم ارائه میدهیم و سپس با یک مثال ادامه میدهیم. در ابتدا، الگوریتم با رابطه ورودی (مجموعهای از تاپلها) فراخوانی میشود. BUC کل ورودی (خط 1) را جمع میکند و مجموع حاصل را مینویسد (خط 3). (خط 2 یک ویژگی بهینهسازی است که بعداً در مثال ما مورد بحث قرار میگیرد.) برای هر بعد d (خط 4)، ورودی روی d (خط 6) پارتیشنبندی میشود. در بازگشت از Partition()، dataCount شامل تعداد کل تاپلها برای هر مقدار متمایز از بعد d است. هر مقدار متمایز از d پارتیشن خاص خود را تشکیل میدهد. خط 8 از طریق هر پارتیشن تکرار میشود. خط 10 پارتیشن را برای حداقل پشتیبانی آزمایش میکند. یعنی، اگر تعداد تاپلها در پارتیشن حداقل پشتیبانی را برآورده کند (یعنی ≥ باشد)، آنگاه پارتیشن به رابطه ورودی برای یک فراخوانی بازگشتی به BUC تبدیل میشود، که مکعب کوه یخ را روی پارتیشنها برای ابعاد d +1 تا numDims محاسبه میکند (خط 12).
کاوش BUC برای محاسبه مکعب داده سهبعدی. توجه داشته باشید که محاسبه از رأس مکعب مستطیل شروع میشود.
توجه داشته باشید که برای یک مکعب کامل (یعنی جایی که حداقل پشتیبانی در بند having برابر با ۱ است)، شرط حداقل پشتیبانی همیشه برقرار است. بنابراین فراخوانی بازگشتی یک سطح پایینتر در شبکه قرار میگیرد.
در بازگشت از فراخوانی بازگشتی، با پارتیشن بعدی برای d ادامه میدهیم. پس از پردازش تمام پارتیشنها، کل فرآیند برای هر یک از ابعاد باقی مانده تکرار میشود.
مثال ۳.۱۴. ساخت BUC یک مکعب کوه یخ. مکعب کوه یخ را که در SQL به صورت زیر بیان شده است، در نظر بگیرید:
compute cube iceberg_cube as
select A, B, C, D, count(*)
from R
cube by A, B, C, D
having count(*) >= 3
بیایید ببینیم BUC چگونه مکعب کوه یخ را برای ابعاد A، B، C و D میسازد، که در آن 3 حداقل تعداد پشتیبانی است. فرض کنید بُعد A دارای چهار مقدار متمایز a1، a2، a3، a4 است؛ B دارای چهار مقدار متمایز b1، b2، b3، b4 است؛ C دارای دو مقدار متمایز c1، c2 است؛ و D دارای دو مقدار متمایز d1، d2 است. اگرهر group-by را یک پارتیشن در نظر بگیریم، باید هر ترکیبی از ویژگیهای گروهبندی را که حداقل پشتیبانی را برآورده میکنند (یعنی سه تاپل دارند) محاسبه کنیم. شکل ۳.۲۴ نشان میدهد که چگونه ورودی ابتدا بر اساس مقادیر مختلف ویژگی بُعد A و سپس B، C و D تقسیمبندی میشود. برای انجام این کار، BUC ورودی را اسکن میکند و تاپلها را تجمیع میکند تا تعداد همه آنها را که مربوط به سلول (*،*،*،*) است، به دست آورد. بُعد A برای تقسیم ورودی به چهار پارتیشن استفاده میشود، یکی برای هر مقدار متمایز A. تعداد تاپلها (تعدادها) برای هر مقدار متمایز A در dataCount ثبت میشود.

الگوریتم BUC برای محاسبه مکعب پراکنده یا کوه یخ. منبع: Beyer و Ramakrishnan [BR99]
BUC از ویژگی ضدیکنواختی رو به پایین برای صرفهجویی در زمان هنگام جستجوی تاپلهایی که شرط کوه یخ را برآورده میکنند، استفاده میکند. با شروع از مقدار بعد A، پارتیشن a1,thea1 تجمیع میشود و یک تاپل برای گروه A، مربوط به سلول (a1,∗,∗,∗) ایجاد میکند. فرض کنید (a1,∗,∗,∗) حداقل پشتیبانی را برآورده کند، در این صورت یک فراخوانی بازگشتی روی پارتیشن مربوط به a1 انجام میشود. BUC، a1 را روی بعد B پارتیشنبندی میکند. تعداد (a1,b1,∗,∗) را بررسی میکند تا ببیند آیا حداقل پشتیبانی را برآورده میکند یا خیر. اگر این کار را انجام دهد، تاپل تجمیعشده را به گروه AB ارسال میکند و روی (a1,b1,∗,∗) برای پارتیشنبندی روی C، با شروع از c1، بازگشت میکند. فرض کنید تعداد سلول برای (a1,b1,c1,∗) برابر با 2 باشد که حداقل پشتیبانی را برآورده نمیکند. طبق ویژگی ضدیکنواختی رو به پایین، اگر سلولی حداقل پشتیبانی را برآورده نکند، هیچ یک از فرزندان آن نیز نمیتوانند. بنابراین، BUC هرگونه کاوش بیشتر روی (a1,b1,c1,∗) را هرس میکند. یعنی از پارتیشنبندی این سلول روی بعد D اجتناب میکند. به پارتیشن a1,b1 برمیگردد و روی (a1,b1,c2,∗) و غیره بازگشت میکند. با بررسی وضعیت کوه یخ هر بار قبل از انجام یک فراخوانی بازگشتی، BUC هر زمان که تعداد سلول حداقل پشتیبانی را برآورده نکند، زمان پردازش زیادی را صرفهجویی میکند.
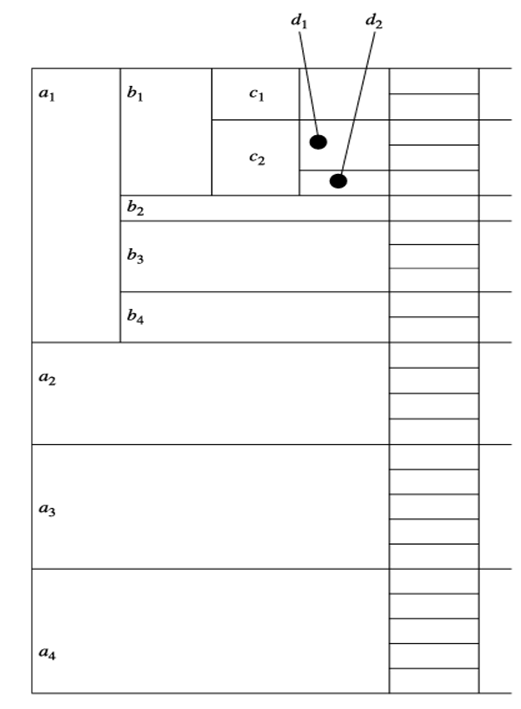
تصویر لحظهای پارتیشنبندی BUC با توجه به یک مجموعه داده ۴ بعدی به عنوان مثال فرآیند پارتیشنبندی توسط یک روش مرتبسازی خطی، CountingSort، تسهیل میشود. CountingSort سریع است زیرا هیچ مقایسه کلیدی برای یافتن مرزهای پارتیشن انجام نمیدهد. به عنوان مثال، برای مرتبسازی۱۰۰۰۰ تاپل بر اساس ویژگی A که مقدار آن یک عدد صحیح در محدوده بین ۱ تا ۱۰۰ است، میتوانیم۱۰۰ شمارنده تنظیم کنیم و یک بار دادهها را اسکن کنیم تا تعداد ۱ها، ۲ها، …،۱۰۰ها را روی ویژگی A بشماریم. فرض کنید i۱ تاپل با ۱ روی A، i۲ تاپل با ۲ روی A و غیره وجود دارد. سپس، در اسکن بعدی، میتوانیم تمام تاپلهایی که مقدار ۱ روی ویژگی A دارند را به اولین اسلاتهای i۱ منتقل کنیم، تاپلهایی که مقدار ۲ روی ویژگی A دارند را به اسلاتهای i۱ +۱،…،i۱ +i۲ و غیره منتقل کنیم. پس از این دو اسکن، تاپلها بر اساس A مرتب میشوند. علاوه بر این، تعداد محاسبهشده در طول مرتبسازی میتواند برای محاسبهی گروهبندیها در BUC مورد استفاده مجدد قرار گیرد.
خط 2 بهینهسازی برای پارتیشنهایی با تعداد 1 مانند (a1,b2,∗,∗) در مثال ما است. برای صرفهجویی در هزینههای پارتیشنبندی، تعداد در هر یک از گروهبندیهای فرزند تاپل نوشته میشود. این امر به ویژه مفید است زیرا در عمل، بسیاری از پارتیشنها ممکن است یک تاپل واحد داشته باشند.عملکرد BUC به ترتیب ابعاد و انحراف در دادهها حساس است. در حالت ایدهآل،ابعادی که بیشترین تمایز را دارند باید ابتدا پردازش شوند. ابعاد باید به ترتیب کاهش کاردینالیتی پردازش شوند. هرچه کاردینالیتی بالاتر باشد، پارتیشنها کوچکتر میشوند و بنابراین پارتیشنهای بیشتری وجود خواهد داشت، در نتیجه BUC فرصت بیشتری برای هرس کردن خواهد داشت. به طور مشابه، هرچه یک بُعد یکنواختتر باشد (یعنی انحراف کمتری داشته باشد)، برای هرس کردن بهتر است.
سهم اصلی BUC ایده اشتراکگذاری هزینههای پارتیشنبندی است. با این حال، برخلاف MultiWay، محاسبه مجموعها بین گروههای والد و فرزند را به اشتراک نمیگذارد. به عنوان مثال،محاسبه مکعب AB به محاسبه ABC کمکی نمیکند. مورد دوم اساساً باید از ابتدا محاسبه شود.
پیشمحاسبه قطعات پوسته برای OLAP سریع با ابعاد بالا
مادیسازی مکعبهای داده، عملیات OLAP انعطافپذیر و سریع را تسهیل میکند. با این حال، محاسبه مکعب داده کامل با ابعاد بالا به فضای ذخیرهسازی عظیم و زمان محاسبه غیرواقعی نیاز دارد. اگرچه پیشنهادهایی برای محاسبه مکعبهای کوه یخ و مکعبهای بسته وجود دارد، اما آنها هنوز به دادههای با ابعاد پایین (مثلاً کمتر از ۱۲ بعد) محدود هستند و نمیتوانند چالشهای ابعاد بالا را برطرف کنند. یک جایگزین ممکن، محاسبه یک پوسته مکعب نازک است، مانند محاسبه همه مکعبهای با سه بعد یا کمتر در یک مکعب داده ۶۰ بعدی، که منجر به یک پوسته مکعب با اندازه ۳ میشود. با این حال، چنین پوسته مکعبی نمیتواند از OLAP یا پرسوجو شامل چهار بعد یا بیشتر پشتیبانی کند.
در اینجا ما یک رویکرد قطعه پوسته برای OLAP با ابعاد بالا را بر اساس مشاهده زیر معرفی میکنیم: اگرچه یک مکعب داده ممکن است شامل ابعاد زیادی باشد، اما اکثر عملیات OLAP فقط روی تعداد کمی از ابعاد مربوط به برخی از شرایط انتخاب شده توسط پرسوجو در یک زمان انجام میشوند. به عبارت دیگر، یک پرسوجوی OLAP احتمالاً بسیاری از ابعاد را نادیده میگیرد (یعنی آنها را نامربوط در نظر میگیرد)، شرایط خاصی را در برخی ابعاد محدود میکند (مثلاً با استفاده از ثابتهای پرسوجو)، و فقط تعداد کمی را برای دستکاری (برای حفاری، چرخش و غیره) باقی میگذارد. دلیل این امر این است که درک هزاران سلول شامل دهها بعد به طور همزمان در یک فضای با ابعاد بالا، نه واقعبینانه است و نه مفید. بر اساس این مشاهده، طبیعی است که ابتدا برخی از مکعبهای کمبعد مورد نظر را در یک مکعب با ابعاد بالا پیدا کنیم و سپس OLAP را روی چنین مکعبهای کمبعدی انجام دهیم. این بدان معناست که اگر بتوان تجمعات چندبعدی را به سرعت در تعداد کمی از ابعاد در یک فضای با ابعاد بالا محاسبه کرد، میتوانیم بدون تحقق مکعب داده با ابعاد بالای اصلی، به OLAP سریع دست یابیم. این منجر به یک رویکرد محاسبه نیمهآنلاین میشود که قطعه پوسته نامیده میشود به شرح زیر: ابتدا، با توجه به یک مکعب پایه، میتوانیم قطعات پوسته مکعب را از قبل (یعنی آفلاین) محاسبه کنیم. سپس، هنگامی که یک پرسوجو (query) میآید، میتوان به سرعت یک مکعب با ابعاد کم را به صورت آنلاین با استفاده از دادههای پیشپردازششده مونتاژ کرد و عملیات OLAP را انجام داد. رویکرد قطعه پوسته میتواند پایگاههای داده با ابعاد بالا را مدیریت کند و به سرعت مکعبهای محلی کوچک را به صورت آنلاین محاسبه کند. این رویکرد، ساختار داده شاخص معکوس را بررسی میکند که در بازیابی اطلاعات و سیستمهای اطلاعاتی مبتنی بر وب محبوب است.
ایده اصلی به شرح زیر است. با توجه به یک مجموعه داده با ابعاد بالا، ابعاد را به مجموعهای از قطعات با ابعاد مجزا تقسیم میکنیم، هر قطعه را به نمایش شاخص معکوس مربوطه تبدیل میکنیم و سپس قطعات پوسته مکعب را در حالی که شاخصهای معکوس مرتبط با سلولهای مکعب را نگه میداریم، میسازیم. با استفاده از قطعات پوسته مکعبهای از پیش محاسبهشده، میتوانیم به صورت پویا سلولهای مکعبی مکعب داده مورد نیاز را به صورت آنلاین مونتاژ و محاسبه کنیم. این کار با عملیات تقاطع مجموعه روی شاخصهای معکوس کارآمد میشود.
برای نشان دادن رویکرد قطعه پوسته، از یک پایگاه داده کوچک جدول 3.4 به عنوان یک مثال در حال اجرا استفاده میکنیم.
فرض کنید سنجه مکعب count() باشد. سایر سنجهها بعداً مورد بحث قرار خواهند گرفت. ابتدا به نحوه ساخت اندیس معکوس برای پایگاه داده داده شده نگاهی میاندازیم.
مثال ۳.۱۵. اندیس معکوس را بسازید. برای هر مقدار ویژگی در هر بعد، شناسههای تاپل (TID) تمام تاپلهایی که آن مقدار را دارند، فهرست کنید. به عنوان مثال، مقدار ویژگی a2 در تاپلهای ۴ و ۵ ظاهر میشود. سپس فهرست TID برای a2 دقیقاً شامل دو مورد، یعنی ۴ و ۵ است. جدول اندیس معکوس حاصل در جدول ۳.۵ نشان داده شده است. این جدول تمام اطلاعات پایگاه داده اصلی را حفظ میکند.
|
جدول ۳.۴ پایگاه داده اصلی. |
|||||
|
TID |
A |
B |
C |
D |
E |
|
1 |
a1 |
b1 |
c1 |
d1 |
e1 |
|
2 |
a1 |
b2 |
c1 |
d2 |
e1 |
|
3 |
a1 |
b2 |
c1 |
d1 |
e2 |
|
4 |
a2 |
b1 |
c1 |
d1 |
e2 |
|
5 |
a2 |
b1 |
c1 |
d1 |
e3 |
«چگونه قطعات پوسته یک مکعب داده را محاسبه کنیم؟» ابتدا تمام ابعاد مجموعه داده داده شده را به گروههای مستقل از ابعاد، به نام قطعات، تقسیم میکنیم. مکعب پایه را اسکن میکنیم و برای هر ویژگی یک شاخص معکوس میسازیم. برای هر قطعه، مکعب داده محلی کامل (یعنی مبتنی بر قطعه) را محاسبه میکنیم و شاخصهای معکوس را حفظ میکنیم. یک پایگاه داده با 60 بعد، یعنی A1، A2،…، A60 را در نظر بگیرید. میتوانیم ابتدا 60 بعد را به 20 قطعه با اندازه 3، مانند (A1، A2، A3)، (A4، A5، A6)، …، (A58، A59، A60) تقسیم کنیم. برای هر قطعه، مکعب داده کامل آن را محاسبه میکنیم و شاخصهای معکوس را ثبت میکنیم. به عنوان مثال، در قطعه (A1، A2، A3)، هفت مکعب داده را محاسبه میکنیم: A1، A2، A3، A1A2، A2A3، A1A3، A1A2A3. علاوه بر این، یک اندیس معکوس برای هر سلول در مکعبهای مستطیلی حفظ میشود. یعنی برای هر سلول، لیست TID مرتبط با آن ثبت میشود.
مزیت محاسبه مکعبهای محلی هر قطعه پوسته به جای محاسبه کل پوسته مکعب را میتوان با یک محاسبه ساده مشاهده کرد. برای یک مکعب مستطیل پایه با ابعاد 60، فقط 7×20=140 مکعب مستطیل وجود دارد که باید طبق پارتیشنبندی قطعه پوسته قبلی محاسبه شوند. این در تضاد با 36050 مکعب مستطیل محاسبه شده برای پوسته مکعب با اندازه 3 است! توجه داشته باشید که پارتیشنبندی قطعه فوق صرفاً بر اساس گروهبندی ابعاد متوالی است. یک رویکرد مطلوبتر، پارتیشنبندی بر اساس گروهبندیهای ابعاد رایج است. این اطلاعات را میتوان از متخصصان حوزه یا تاریخچه گذشته پرسوجوهای OLAP به دست آورد.
بیایید به مثال در حال اجرای خود برگردیم تا ببینیم قطعات پوسته چگونه محاسبه میشوند.
|
جدول ۳.۵ شاخص معکوس. |
||
|
مقدار ویژگی |
لیست TID |
اندازه لیست |
|
a1 |
{1, 2, 3} |
3 |
|
a2 |
{4, 5} |
2 |
|
b1 |
{1, 4, 5} |
3 |
|
b2 |
{2, 3} |
2 |
|
c1 |
{1, 2, 3, 4, 5} |
5 |
|
d1 |
{1, 3, 4, 5} |
4 |
|
d2 |
{2} |
1 |
|
e1 |
{1, 2} |
2 |
|
e2 |
{3, 4} |
2 |
|
e3 |
{5} |
1 |
مثال ۳.۱۶. محاسبه قطعات پوسته. فرض کنید قرار است قطعات پوسته با اندازه ۳ را محاسبه کنیم. ابتدا پنج بعد را به دو قطعه به نامهای (A، B، C) و (D، E) تقسیم میکنیم. برای هر قطعه، مکعب داده محلی کامل را با تقاطع لیستهای TID در جدول ۳.۵ به صورت عمق-اول از بالا به پایین در شبکه مکعب مستطیل محاسبه میکنیم. به عنوان مثال، برای محاسبه سلول (a1، b2،∗)، لیستهای TID مربوط به a1 و b2 را تقاطع میدهیم تا لیست جدیدی از {۲، ۳} به دست آوریم. مکعب AB در جدول ۳.۶ نشان داده شده است.
پس از محاسبه مکعب AB، میتوانیم مکعب ABC را با تقاطع تمام ترکیبهای جفتی بین جدول ۳.۶ و ردیف c1 در جدول ۳.۵ محاسبه کنیم. توجه داشته باشید که از آنجا که سلول (a2, b2) خالی است، میتوان آن را در محاسبات بعدی، بر اساس خاصیت ضدیکنواختی رو به پایین، به طور مؤثر کنار گذاشت. همین فرآیند را میتوان برای محاسبه قطعه (D, E) اعمال کرد که کاملاً مستقل از محاسبه (A,B,C) است. مکعب مستطیل DE در جدول 3.7 نشان داده شده است.
اگر سنجه در شرط کوه یخ، count() باشد (مانند شمارش تاپلها)، نیازی به ارجاع به پایگاه داده اصلی نیست زیرا طول لیست TID معادل تعداد تاپلها است. “آیا در صورت محاسبه سنجههای دیگر مانند average() باید به پایگاه داده اصلی مراجعه کنیم؟” در واقع، میتوانیم به جای آن یک آرایه ID_measure بسازیم و به آن ارجاع دهیم، که آنچه را که برای محاسبه سنجههای دیگر نیاز داریم ذخیره میکند.
به عنوان مثال، برای محاسبه average()، اجازه دهید آرایه ID_measure سه عنصر، یعنی (TID، item_count، sum) را برای هر سلول نگه دارد. سپس میتوان سنجه average() را برای هر سلول تجمیعی با استفاده از sum()/item_count() و با دسترسی به این آرایه ID_measure محاسبه کرد. از آنجایی که آرایه ID_measure ساختار داده فشردهتری نسبت به پایگاه داده با ابعاد بالای مربوطه است، احتمال بیشتری دارد که در حافظه جا شود.
“پس از محاسبه قطعات پوسته، چگونه میتوان از آنها برای پاسخ به پرسوجوهای OLAP استفاده کرد؟”
با توجه به قطعات پوسته از پیش محاسبه شده، فضای مکعب را میتوان به عنوان یک مکعب مجازی برای پشتیبانی از پرسوجوهای OLAP در نظر گرفت. به طور کلی، دو نوع پرسوجو امکانپذیر است: (1) پرسوجوی نقطهای و (2) پرسوجوی زیرمکعب. در پرسوجوی نقطهای، تمام ابعاد مربوطه در مکعب نمونهسازی شدهاند و فقط سنجه مربوطه درخواست میشود، در حالی که در پرسوجوی زیرمکعب، حداقل یکی از ابعاد مربوطه در مکعب درخواست میشود. بیایید فقط پرسوجوی زیرمکعب را بررسی کنیم. در یک مکعب داده n بعدی A1A2…An، یک پرسوجوی زیرمکعب میتواند به شکل A1، A5?، A9، A21?:M? باشد، که در آن A1 ={a11,a18} و A9 =a94، A5 و A21
ابعاد مورد جستجو و M سنجه مورد جستجو است.
پرسوجوی Asubcube یک مکعب داده محلی را بر اساس ابعاد نمونهسازی شده و مورد جستجو برمیگرداند. چنین مکعب دادهای باید به صورت چندبعدی تجمیع شود تا پردازش تحلیلی آنلاین (حفاری، تقسیمبندی، چرخش و غیره) برای دستکاری و تجزیه و تحلیل انعطافپذیر در دسترس کاربران قرار گیرد.
از آنجا که ابعاد نمونهسازی شده معمولاً ثابتهای بسیار انتخابی ارائه میدهند که اندازه لیستهای TID معتبر را به طور چشمگیری کاهش میدهند، باید با یافتن قطعاتی که به بهترین وجه با مجموعه ابعاد نمونهسازی شده مطابقت دارند و واکشی و تقاطع لیستهای TID مرتبط برای استخراج لیست TID کاهشیافته، حداکثر استفاده را از قطعات پوسته از پیش محاسبه شده ببریم. سپس میتوان از این لیست برای تقاطع بهترین قطعات پوسته متشکل از ابعاد مورد جستجو استفاده کرد. این کار مکعب پایه مربوطه و مورد جستجو را ایجاد میکند که سپس میتواند برای محاسبه زیرمکعب مربوطه درجا با استفاده از یک الگوریتم مکعببندی آنلاین کارآمد استفاده شود. فرض کنید جستجوی زیرمکعب به شکل αi، αj، Ak?، αp،Aq?: M? باشد، که در آن αi، αj و αp به ترتیب مجموعهای از مقادیر نمونهسازی شده با ابعاد Ai، Aj و Ap را نشان میدهند و Ak و Aq دو بعد مورد جستجو را نشان میدهند. ابتدا، طرحواره قطعه پوسته را بررسی میکنیم تا مشخص کنیم کدام ابعاد در بین (1) Ai، Aj و Ap و (2) Ak و Aq در یک پارتیشن قطعه قرار دارند. فرض کنید Ai و Aj متعلق به یک قطعه هستند، همانطور که Ak و Aq نیز همینطور هستند، اما Ap در یک قطعه متفاوت است. ما لیستهای TID مربوطه را در قطعه دو بعدی از پیش محاسبه شده برای Ai و Aj با استفاده از نمونهسازیهای αi و αj دریافت میکنیم، سپس لیست TID را روی قطعه یک بعدی از پیش محاسبه شده برای Ap با استفاده از نمونهسازی αp دریافت میکنیم و سپس لیستهای TID را روی قطعات دو بعدی از پیش محاسبه شده برای Ak و Aq به ترتیب با استفاده از هیچ نمونهسازی (یعنی تمام مقادیر ممکن) دریافت میکنیم. لیستهای TID بدست آمده برای استخراج لیستهای TID نهایی تقاطع میشوند، که برای دریافت سنجههای مربوطه از آرایه ID_measure برای استخراج “مکعب پایه” یک زیرمکعب دو بعدی برای دو بعد (Ak,Aq) استفاده میشوند. یک الگوریتم محاسبه مکعب سریع میتواند برای محاسبه این مکعب دو بعدی بر اساس مکعب پایه مشتق شده اعمال شود. سپس مکعب دو بعدی محاسبه شده برای عملیات OLAP آماده است.
|
جدول ۳.۶ مکعب AB. |
|||
|
سلول |
تقاطع |
لیست TID |
اندازه لیست |
|
(a1, b1) |
{1, 2, 3}∩ {1, 4, 5} |
{1} |
1 |
|
(a1, b2) |
{1, 2, 3}∩ {2, 3} |
{2, 3} |
2 |
|
(a2, b1) |
{4, 5}∩ {1, 4, 5} |
{4, 5} |
2 |
|
(a2, b2) |
{4, 5}∩ {2, 3} |
{} |
0 |
پردازش کارآمد پرسوجوهای OLAP با استفاده از مکعبهای داده
هدف از مادیسازی مکعبهای داده و ساخت ساختارهای شاخص OLAP، سرعت بخشیدن به پردازش پرسوجو در مکعبهای داده است. با توجه به نماهای مادیسازیشده، پردازش پرسوجو باید به شرح زیر انجام شود:
۱. تعیین اینکه کدام عملیات باید روی مکعبهای داده موجود انجام شود: این شامل تبدیل هرگونه عملیات انتخاب، تصویرسازی، رولآپ (گروهبندی) و حفاری به پایین مشخص شده در پرسوجو به عملیات SQL و/یا OLAP مربوطه است. به عنوان مثال، برش و ریز کردن یک مکعب داده ممکن است با عملیات انتخاب و/یا تصویرسازی روی یک مکعب داده مادیسازیشده مطابقت داشته باشد.
۲. تعیین اینکه عملیات مربوطه باید روی کدام مکعب(های) مادیسازیشده اعمال شود: این شامل شناسایی تمام مکعبهای مادیسازیشدهای است که ممکن است به طور بالقوه برای پاسخ به پرسوجو استفاده شوند، هرس کردن مجموعه با استفاده از دانش روابط “غلبه” بین مکعبهای داده، تخمین هزینههای استفاده از مکعبهای داده مادیسازیشده باقیمانده و انتخاب مکعب با کمترین هزینه.
مثال ۳.۱۷. پردازش پرسوجوی OLAP. فرض کنید یک مکعب داده برای یک شرکت خردهفروشی به شکل «sales_cube [time, item, location]: sum(sales_in_dollars)» تعریف شده است. سلسله مراتب ابعاد مورد استفاده برای زمان «day < month < quarter < year»؛ برای کالا «item_name < brand < type»؛ و برای مکان «street < city < province_or_state < country» هستند. فرض کنید پرسوجویی که قرار است پردازش شود روی {brand, province_or_state} باشد، با ثابت انتخاب «=year ۲۰۱۰». همچنین، فرض کنید چهار مکعب مستطیل مادی به شرح زیر موجود است:
• مکعب ۱: {سال، نام_کالا، شهر}
• مکعب ۲: {سال، برند، کشور}
• مکعب ۳: {سال، برند، استان_یا_ایالت}
• مکعب ۴: {نام_کالا، استان_یا_ایالت}، که در آن سال = ۲۰۱۰
«کدام یک از این چهار مکعب مستطیل باید برای پردازش پرس و جو انتخاب شود؟» دادههای ریزدانهتر را نمیتوان از دادههای درشتتر تولید کرد. بنابراین، مکعب ۲ را نمیتوان استفاده کرد زیرا کشور مفهومی کلیتر از استان_یا_ایالت است. مکعبهای ۱، ۳ و ۴ میتوانند برای پردازش پرسوجو استفاده شوند، زیرا (۱) آنها مجموعه یا فرامجموعهای از ابعاد موجود در پرسوجو را دارند، (۲) عبارت انتخاب در پرسوجو میتواند نشاندهنده انتخاب در مکعب باشد، و (۳) سطوح انتزاع برای ابعاد کالا و مکان در این مکعبها به ترتیب در سطح ظریفتری نسبت به brand و province_or_state قرار دارند. “اگر برای پردازش پرسوجو استفاده شود، هزینههای هر مکعب چگونه مقایسه میشود؟” احتمالاً استفاده از مکعب ۱ بیشترین هزینه را خواهد داشت زیرا هر دو item_name و city در سطح پایینتری نسبت به مفاهیم brand و province_or_state مشخص شده در پرسوجو هستند. اگر مقادیر سال زیادی مرتبط با اقلام در مکعب وجود نداشته باشد، اما چندین item_name برای هر برند وجود داشته باشد، مکعب ۳ کوچکتر از مکعب ۴ خواهد بود و بنابراین مکعب ۳ باید برای پردازش پرسوجو انتخاب شود. با این حال، اگر شاخصهای کارآمدی برای مکعب مستطیل ۴ در دسترس باشند، مکعب مستطیل ۴ ممکن است انتخاب بهتری باشد. بنابراین، برای تصمیمگیری در مورد اینکه کدام مجموعه از مکعبهای مستطیل باید برای پردازش پرسوجو انتخاب شوند، به تخمین مبتنی بر هزینه نیاز است.
خلاصه
- انبار داده یک مجموعه داده موضوعگرا، یکپارچه، متغیر با زمان و غیرفرار است که برای پشتیبانی از تصمیمگیری مدیریتی سازماندهی شده است. عوامل متعددی انبار داده را از پایگاههای داده عملیاتی متمایز میکند. از آنجا که این دو سیستم عملکردهای کاملاً متفاوتی ارائه میدهند و به انواع مختلفی از دادهها نیاز دارند، لازم است انبارهای داده را جدا از پایگاههای داده عملیاتی نگهداری کرد.
- انبارهای داده اغلب از معماری سه لایه استفاده میکنند. لایه پایین یک سرور پایگاه داده انبار است که معمولاً یک سیستم پایگاه داده رابطهای است. لایه میانی یک سرور OLAP است و لایه بالا یک کلاینت است که شامل ابزارهای پرسوجو و گزارشگیری است.
- انبار داده شامل ابزارها و ابزارهای پشتیبان برای پر کردن و بهروزرسانی انبار است. این ابزارها شامل استخراج دادهها، پاکسازی دادهها، تبدیل دادهها، بارگیری، بهروزرسانی و مدیریت انبار هستند.
- فرادادههای انبار داده، دادههایی هستند که اشیاء انبار را تعریف میکنند. یک مخزن فراداده جزئیاتی در مورد ساختار انبار، تاریخچه دادهها، الگوریتمهای مورد استفاده برای خلاصهسازی، نگاشت پینگها از دادههای منبع به فرم انبار، عملکرد سیستم و اصطلاحات و مسائل تجاری ارائه میدهد.
- دریاچه داده یک مخزن واحد از تمام دادههای سازمانی در قالب طبیعی است. یک دریاچه داده اغلب هم کپیهای دادههای خام و هم دادههای تبدیلشده را ذخیره میکند. بسیاری از وظایف تحلیلی را میتوان روی دریاچههای داده انجام داد. در شرکتها و سازمانها، انبارهای داده و دریاچههای داده اهداف متفاوتی را دنبال میکنند و یکدیگر را تکمیل میکنند.
- لایههای ذخیرهسازی دادهها در دریاچههای داده شامل، از پایین به بالا، لایه دادههای خام، لایه دادههای استاندارد اختیاری، لایه دادههای پاکشده، لایه دادههای کاربردی و لایه دادههای جعبه شنی اختیاری است.
- مدل داده چندبعدی معمولاً برای طراحی انبارهای داده شرکتی و بازارهای داده دپارتمانی استفاده میشود. چنین مدلی میتواند از یک طرح ستارهای، طرح دانه برفی یا طرح صورت فلکی حقایق استفاده کند. هسته مدل چندبعدی، مکعب داده است که از مجموعه بزرگی از حقایق (یا سنجهها) و تعدادی ابعاد تشکیل شده است. ابعاد، موجودیتها یا دیدگاههایی هستند که یک سازمان میخواهد سوابق را نسبت به آنها نگهداری کند و ماهیت سلسله مراتبی دارند.
- مکعب داده شامل شبکهای از مکعبهای دادهای است که هر کدام مربوط به درجه متفاوتی از خلاصهسازی دادههای چندبعدی داده شده است.
- سلسله مراتب مفهومی، مقادیر ویژگیها یا ابعاد را در سطوح انتزاع تدریجی سازماندهی میکند.
- آنها در کاوش در سطوح انتزاع چندگانه مفید هستند.
- سرورهای OLAP ممکن است از یک OLAP رابطهای (ROLAP)، OLAP چندبعدی (MOLAP) یا یک پیادهسازی OLAP ترکیبی (HOLAP) استفاده کنند. سرور AROLAP از یک DBMS رابطهای توسعهیافته استفاده میکند که عملیات OLAP را روی دادههای چندبعدی به عملیات رابطهای استاندارد نگاشت میکند. یک سرور MOLAP نماهای داده چندبعدی را مستقیماً به ساختارهای آرایه نگاشت میکند. یک سرور HOLAP، ROLAP و MOLAP را ترکیب میکند. به عنوان مثال، ممکن است از ROLAP برای دادههای تاریخی استفاده کند در حالی که دادههای پرکاربرد را در یک مخزن MOLAP جداگانه نگهداری میکند.
- سنجه در یک مکعب داده، یک تابع عددی است که میتواند در هر نقطه (یعنی سلول) در فضای مکعب داده ارزیابی شود. سنجهها را میتوان به سه دسته توزیعی، جبری و کلنگر دستهبندی کرد.
- پردازش تحلیلی آنلاین را میتوان در انبارهای داده/بازارها با استفاده از مدل داده چندبعدی انجام داد. عملیات معمول OLAP شامل جمع کردن، و حفاری (پایین، عرضی، از طریق)، برش و تاس، و چرخش (چرخاندن) و همچنین عملیات آماری مانند رتبهبندی و محاسبه میانگینهای متحرک و نرخ رشد است. عملیات OLAP را میتوان با استفاده از ساختار مکعب داده به طور کارآمد پیادهسازی کرد.
- برای تسهیل دسترسی کارآمد به دادهها، اکثر سیستمهای انبار داده از ساختارهای شاخص استفاده میکنند. شاخص bimap یک ویژگی معین با کاردینالیتی پایین را با استفاده از بیتها نشان میدهد و میتواند هزینه ورودی/خروجی را به طور قابل توجهی کاهش داده و محاسبات را برای بسیاری از پرسوجوهای تجمیعی سرعت بخشد. شاخص اتصال، جفتهای شناسه نتایج اتصال را بین یک جدول واقعیت و یک جدول بُعد از پیش محاسبه و ذخیره میکند و بنابراین میتواند هزینه ورودی/خروجی (I/O) را در محاسبات تجمیعی به طور چشمگیری کاهش دهد.
- در بسیاری از برنامهها، یک جدول واقعیت ممکن است شامل ویژگیهای زیادی باشد، اما یک پرسوجوی OLAP ممکن است فقط از چندین ویژگی استفاده کند. یک پایگاه داده مبتنی بر ستون، مقادیر همه رکوردها را به جای ردیف به ردیف، ستون به ستون ذخیره میکند و میتواند در هزینه ورودی/خروجی و زمان پردازش در محاسبات تجمیعی به طور چشمگیری صرفهجویی کند.
- یک مکعب داده ممکن است حاوی اطلاعات اضافی زیادی باشد. یک مکعب خارج قسمت به عنوان یک نمایش مختصر از مکعب داده فقط شامل سلولهای بسته است و اطلاعات اضافی را کاهش میدهد. یک مکعب کوه یخ، مکعب دادهای است که فقط آن دسته از سلولهای مکعبی را ذخیره میکند که مقدار تجمعی (مثلاً تعداد) آنها بالاتر از حداقل آستانه پشتیبانی باشد. برای قطعات پوسته یک مکعب داده، فقط برخی از مکعبهای مکعبی که شامل تعداد کمی از ابعاد هستند محاسبه میشوند و پرسوجوها در مورد ترکیبهای اضافی از ابعاد را میتوان در لحظه محاسبه کرد.
- چندین روش محاسبه مکعب داده کارآمد وجود دارد. در این فصل، ما برخی از روشهای محاسبه مکعب را به تفصیل مورد بحث قرار دادیم: (1) تجمیع آرایه چندوجهی برای تحقق مکعبهای داده کامل در محاسبات اشتراکی، مبتنی بر آرایه پراکنده، از پایین به بالا؛ (2) BUC برای محاسبه مکعبهای کوه یخ با بررسی ترتیب و مرتبسازی برای محاسبات بالا به پایین کارآمد؛ و (3) مکعبسازی قطعه-پوسته، که با پیشمحاسبه فقط قطعات مکعبی پوسته پارتیشنبندیشده، از OLAP با ابعاد بالا پشتیبانی میکند.
تمرینها
3.1. دادههای مربوط به دانشجویان، مدرسان، دورهها و دپارتمانها را در یک محیط دانشگاهی در نظر بگیرید. وقتی چنین دادههایی به عنوان دادههای عملیاتی استفاده میشوند، لطفاً سه عملیات مثال بزنید. اگر بخواهیم با استفاده از چنین دادههایی یک انبار داده بسازیم، چه چیزی میتواند موضوع انبار داده باشد؟
3.2. با یک مثال در مورد چگونگی اتصال و ساخت برنامههای کاربردی بازار داده، انبار داده سازمانی و یادگیری ماشین بر روی یکدیگر بحث کنید.
3.3. آیا ممکن است که یک سازمان هم انبار داده و هم دریاچه داده را اجرا کند؟ اگر چنین است، رابطه بین انبار داده و دریاچه داده چیست؟ آیا میتوانید سناریویی را شرح دهید که در آن حفظ هر دو انبار داده و دریاچه داده ضروری و مفید باشد؟
3.4. فرض کنید یک انبار داده شامل سه بُعد زمان، پزشک و بیمار و دو سنجه شمارش و هزینه است که در آن هزینه، هزینهای است که پزشک برای ویزیت از بیمار دریافت میکند.
- سه کلاس از طرحوارههایی را که به طور رایج برای مدلسازی انبارهای داده استفاده میشوند، برشمارید.
- با استفاده از یکی از کلاسهای طرحواره ذکر شده در (الف)، نمودار شماتیکی برای انبار داده فوق رسم کنید.
- با شروع از مکعب مستطیل پایه [روز، پزشک، بیمار]، چه عملیات OLAP خاصی باید انجام شود تا کل هزینه جمعآوری شده توسط هر پزشک در سال ۲۰۱۰ فهرست شود؟
- برای به دست آوردن همان لیست، یک پرسوجوی SQL بنویسید با فرض اینکه دادهها در یک پایگاه داده رابطهای با طرح هزینه (روز، ماه، سال، پزشک، بیمارستان، بیمار، تعداد، هزینه) ذخیره شدهاند.
۳.۵. فرض کنید یک انبار داده برای دانشگاه بزرگ شامل چهار بُعد دانشجو، دوره، ترم و مربی و دو سنجه شمارش و میانگین نمره است. در پایینترین سطح مفهومی (مثلاً برای یک ترکیب دانشجو، دوره، ترم و استاد معین)، سنجه avg_grade نمره واقعی دانشجو در دوره را ذخیره میکند. در سطوح مفهومی بالاتر، avg_grade نمره میانگین برای ترکیب داده شده را ذخیره میکند.
- نمودار طرحواره دانه برف را برای انبار داده رسم کنید.
- با شروع از مکعب پایه [دانشجو، دوره، ترم، استاد]، چه عملیات OLAP خاصی (مثلاً جمعبندی از ترم به سال) باید انجام دهید تا نمره میانگین دورههای CS را برای هر دانشجوی Big_University فهرست کنید.
- اگر هر بُعد دارای پنج سطح (شامل همه) باشد، مانند «دانشجو < رشته تحصیلی < وضعیت < دانشگاه < همه»، این مکعب شامل چند مکعب مستطیل (شامل مکعبهای پایه و رأس) خواهد بود؟
۳.۶. فرض کنید یک انبار داده شامل چهار بُعد تاریخ، تماشاگر، مکان و بازی و دو سنجه شمارش و هزینه است که در آن هزینه، هزینهای است که یک تماشاگر هنگام تماشای یک بازی در یک تاریخ معین پرداخت میکند. تماشاگران ممکن است دانشجو، بزرگسال یا سالمند باشند و هر دسته نرخ هزینه خاص خود را دارد.
- نمودار طرحواره ستارهای برای انبار داده رسم کنید.
- با شروع از مکعب مستطیل پایه [تاریخ، تماشاگر، مکان، بازی]، چه عملیات OLAP خاصی باید انجام دهید تا کل هزینه پرداخت شده توسط تماشاگران دانشجو درGM_Place در سال ۲۰۱۰ را فهرست کنید؟
- نمایهسازی بیتمپ در انبار داده مفید است. با در نظر گرفتن این مکعب به عنوان مثال، به طور خلاصه مزایا و مشکلات استفاده از ساختار شاخص بیتمپ را مورد بحث قرار دهید.
۳.۷. یک انبار داده را میتوان با طرح ستارهای یا طرح دانه برفی مدلسازی کرد. به طور خلاصه شباهتها و تفاوتهای این دو مدل را شرح دهید و سپس مزایا و معایب آنها را نسبت به یکدیگر تجزیه و تحلیل کنید. نظر خود را در مورد اینکه کدام یک ممکن است از نظر تجربی مفیدتر باشد، بیان کنید و دلایل پاسخ خود را بیان کنید.
۳.۸. یک انبار داده برای یک دفتر هواشناسی منطقهای طراحی کنید. دفتر هواشناسی حدود ۱۰۰۰ کاوشگر دارد که در مناطق مختلف خشکی و اقیانوسی منطقه پراکنده شدهاند تا دادههای اولیه آب و هوا، از جمله فشار هوا، دما و بارندگی را در هر ساعت جمعآوری کنند. همه دادهها به ایستگاه مرکزی ارسال میشوند که بیش از ۱۰ سال است چنین دادههایی را جمعآوری میکند. طراحی شما باید پرسوجوی کارآمد و پردازش تحلیلی آنلاین را تسهیل کند و الگوهای کلی آب و هوا را در فضای چند بعدی استخراج کند.
۳.۹. یک پیادهسازی محبوب انبار داده، ساخت یک پایگاه داده چند بعدی است که به عنوان یک مکعب داده شناخته میشود. متأسفانه، این ممکن است اغلب یک ماتریس چند بعدی بزرگ، اما بسیار پراکنده ایجاد کند.
- مثالی ارائه دهید که چنین مکعب داده عظیم و پراکندهای را نشان دهد.
- یک روش پیادهسازی طراحی کنید که بتواند به زیبایی بر این مشکل ماتریس پراکنده غلبه کند.
توجه داشته باشید که باید ساختارهای داده خود را به تفصیل توضیح دهید و فضای مورد نیاز و همچنین نحوه بازیابی دادهها از ساختارهای خود را مورد بحث قرار دهید.
- طرح خود را در (ب) اصلاح کنید تا بهروزرسانیهای افزایشی دادهها را مدیریت کند. دلیل طراحی جدید خود را بیان کنید.
3.10. در مورد محاسبه سنجهها در یک مکعب داده:
- سه دسته سنجه را بر اساس نوع توابع تجمیعی مورد استفاده در محاسبه یک مکعب داده برشمارید.
- برای یک مکعب داده با سه بعد زمان، مکان و آیتم، واریانس تابع به کدام دسته تعلق دارد؟ نحوه محاسبه آن را در صورت تقسیم مکعب به قطعات زیاد شرح دهید.
راهنمایی: فرمول محاسبه واریانس 1 است.
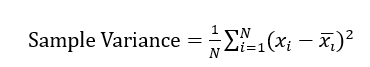
xi2، که در آن ¯xi میانگین … است. فرض کنید تابع «۱۰ فروش برتر» است. در مورد چگونگی محاسبه کارآمد این سنجه در یک مکعب داده بحث کنید.
۳.۱۱. فرض کنید شرکتی میخواهد یک انبار داده طراحی کند تا تجزیه و تحلیل وسایل نقلیه در حال حرکت را به شیوه پردازش تحلیلی آنلاین تسهیل کند. این شرکت حجم عظیمی از دادههای حرکت خودرو را در قالب (Auto_ID، مکان، سرعت، زمان) ثبت میکند. هر Auto_ID نشاندهنده یک وسیله نقلیه مرتبط با اطلاعات (مثلاً، vehicle_category، driver_category) است و هر مکان ممکن است با یک خیابان در یک شهر مرتبط باشد. فرض کنید که یک نقشه خیابان برای شهر در دسترس است.
- چنین انبار دادهای را برای تسهیل پردازش تحلیلی آنلاین مؤثر در فضای چندبعدی طراحی کنید.
- دادههای حرکت ممکن است حاوی نویز باشند. در مورد چگونگی توسعه روشی برای کشف خودکار رکوردهای دادهای که احتمالاً به اشتباه در مخزن دادهها ثبت شدهاند، بحث کنید.
- دادههای حرکت ممکن است پراکنده باشند. بحث کنید که چگونه روشی را توسعه میدهید که با وجود کمبود دادهها، یک انبار داده قابل اعتماد ایجاد کند.
- اگر میخواهید از یک زمان خاص از A به B رانندگی کنید، بحث کنید که چگونه یک سیستم میتواند از دادههای موجود در این انبار برای یافتن یک مسیر سریع استفاده کند.
۳.۱۲. شناسایی فرکانس رادیویی معمولاً برای ردیابی حرکت اشیاء و انجام کنترل موجودی استفاده میشود. یک خواننده RFID میتواند با موفقیت یک برچسب RFID را از فاصله محدود در هر زمان برنامهریزی شده بخواند. فرض کنید شرکتی میخواهد یک انبار داده طراحی کند تا تجزیه و تحلیل اشیاء دارای برچسبهای RFID را به روش پردازش تحلیلی آنلاین تسهیل کند. این شرکت مقادیر عظیمی از دادههای RFID را در قالب (RFID، at_location، time) ثبت میکند و همچنین اطلاعاتی در مورد اشیاء دارای برچسب RFID دارد، به عنوان مثال (RFID، product_name، product_category، manufacturer، date_produced، price).
- یک انبار داده طراحی کنید تا ثبت مؤثر و پردازش تحلیلی آنلاین چنین دادههایی را تسهیل کند.
- دادههای RFID ممکن است حاوی اطلاعات اضافی زیادی باشند. روشی را مورد بحث قرار دهید که افزونگی را در طول ثبت دادهها در انبار داده RFID به حداکثر کاهش دهد.
- دادههای RFID ممکن است حاوی نویز زیادی مانند ثبت نام گمشده و شناسههای اشتباه خوانده شده باشند.
- روشی را مورد بحث قرار دهید که به طور مؤثر دادههای نویزی را در انبار داده RFID پاک کند.
- شما ممکن است بخواهید پردازش تحلیلی آنلاین انجام دهید تا مشخص کنید که چند دستگاه تلویزیون از بندر لسآنجلس به BestBuy در Champaign، IL، بر اساس ماه، برند و محدوده قیمت ارسال شدهاند. توضیح دهید که اگر قرار باشد چنین دادههای RFID را در انبار ذخیره کنید، چگونه میتوان این کار را به طور کارآمد انجام داد.
- اگر مشتری یک پارچ شیر را برگرداند و شکایت کند که قبل از تاریخ انقضا خراب شده است، در مورد چگونگی بررسی چنین موردی در انبار برای یافتن مشکل، چه در حمل و نقل و چه در انبار، بحث کنید.
3.13. در بسیاری از کاربردها، مجموعه دادههای جدید به صورت تدریجی به مجموعه دادههای بزرگ موجود اضافه میشوند. بنابراین، یک نکته مهم این است که آیا یک سنجه میتواند به طور مؤثر به صورت افزایشی محاسبه شود. از تعداد، انحراف سنجه و میانه به عنوان مثال استفاده کنید تا نشان دهید که یک سنجه توزیعی یا جبری، محاسبات افزایشی کارآمد را تسهیل میکند، در حالی که یک سنجه جامع این کار را نمیکند.
3.14. فرض کنید که باید سه سنجه را در یک مکعب داده ثبت کنیم: min()، average() و median(). با توجه به اینکه مکعب امکان حذف تدریجی دادهها (یعنی در بخشهای کوچک در یک زمان) از مکعب را فراهم میکند، یک روش محاسبه و ذخیرهسازی کارآمد برای هر سنجه طراحی کنید.
۳.۱۵. در فناوری انبار داده، یک نمای چندبعدی میتواند توسط یک تکنیک پایگاه داده رابطهای (ROLAP)، توسط یک تکنیک پایگاه داده چندبعدی (MOLAP) یا توسط یک تکنیک پایگاه داده ترکیبی (HOLAP) پیادهسازی شود.
- هر تکنیک پیادهسازی را به طور خلاصه شرح دهید.
- برای هر تکنیک، توضیح دهید که چگونه هر یک از توابع زیر ممکن است پیادهسازی شوند:
- تولید یک انبار داده (شامل تجمیع)
- جمعبندی
- تحلیل عمیق
- بهروزرسانی تدریجی
- کدام تکنیکهای پیادهسازی را ترجیح میدهید و چرا؟
۳.۱۶. فرض کنید یک انبار داده شامل ۲۰ بعد است که هر کدام حدود پنج سطح جزئیات دارند.
- کاربران عمدتاً به چهار بعد خاص علاقهمند هستند که هر کدام سه سطح دسترسی متداول برای جمعبندی و تحلیل عمیق دارند. چگونه یک ساختار مکعب داده را برای پشتیبانی کارآمد از این ترجیح طراحی میکنید؟
- گاهی اوقات، ممکن است کاربر بخواهد مکعب را برای دادههای خام یک یا دو بعد خاص بررسی کند. چگونه این ویژگی را پشتیبانی میکنید؟
۳.۱۷. یک مکعب داده، C، دارای n بعد است و هر بعد دقیقاً p مقدار متمایز در مکعب پایه دارد. فرض کنید هیچ سلسله مراتب مفهومی مرتبط با ابعاد وجود ندارد.
- حداکثر تعداد سلولهای ممکن در مکعب پایه چقدر است؟
- حداقل تعداد سلولهای ممکن در مکعب پایه چقدر است؟
- حداکثر تعداد سلولهای ممکن (شامل سلولهای پایه و سلولهای تجمعی) در مکعب داده C چقدر است؟
- حداقل تعداد سلولهای ممکن در C چقدر است؟
۳.۱۸. فرض کنید یک مکعب پایه 10 بعدی فقط شامل سه سلول پایه است: (1) (a1، d2، d3، d4،…، d9، d10)،
(2) (d1، b2، d3، d4،…، d9، d10) و (3) (d1، d2، c3، d4،…، d9، d10)، که در آن a1 /= d1، b2 /= d2، و
c3 d3. اندازه مکعب count() است.
- الف. یک مکعب داده کامل شامل چند مکعب غیرتهی خواهد بود؟
- ب. یک مکعب کامل شامل چند سلول تجمعی غیرتهی (یعنی غیرپایه) خواهد بود؟
- ج. اگر شرط مکعب کوه یخ “count 2” باشد، یک مکعب کوه یخ شامل چند سلول تجمعی غیرتهی خواهد بود؟
- د. یک سلول، c، یک سلول بسته است اگر هیچ سلولی، d، وجود نداشته باشد به طوری که d یک تخصص از سلول c باشد (یعنی d با جایگزینی a در c با یک مقدار غیر به دست میآید) و d همان مقدار اندازهگیری c را داشته باشد. یک مکعب بسته، یک مکعب داده است که فقط از سلولهای بسته تشکیل شده است. چند سلول بسته در مکعب کامل وجود دارد؟
3.19. چندین روش معمول محاسبه مکعب وجود دارد، مانند MultiWay [ZDN97]، BUC [BR99] و Star-Cubing [XHLW03]. این سه روش را به طور خلاصه شرح دهید (یعنی از یک یا دو خط برای ترسیم نکات کلیدی استفاده کنید) و امکانپذیری و عملکرد آنها را تحت شرایط زیر مقایسه کنید:
- الف. محاسبه یک مکعب کامل متراکم با ابعاد کم (مثلاً کمتر از هشت بعد).
- ب. محاسبه یک مکعب کوه یخ با حدود 10 بعد با توزیع دادههای بسیار چولگی.
- ج. محاسبه یک مکعب کوه یخ پراکنده با ابعاد بالا (مثلاً بیش از ۱۰۰ بعد).
۳.۲۰. فرض کنید یک مکعب داده، C، دارای D بعد است و مکعب پایه شامل k تاپل متمایز است.
- الف. فرمولی برای محاسبه حداقل تعداد سلولهایی که مکعب، C، ممکن است داشته باشد، ارائه دهید.
- ب. فرمولی برای محاسبه حداکثر تعداد سلولهایی که C ممکن است داشته باشد، ارائه دهید.
- ج. به بخشهای (الف) و (ب) طوری پاسخ دهید که گویی تعداد در هر سلول مکعب نباید کمتر از یک آستانه، v، باشد.
- د. به بخشهای (الف) و (ب) طوری پاسخ دهید که گویی فقط سلولهای بسته در نظر گرفته میشوند (با حداقل آستانه شمارش، v).
۳.۲۱. فرض کنید یک مکعب مستطیل پایه دارای سه بعد A، B، C با تعداد سلولهای زیر است:
|= |A۱,۰۰۰,۰۰۰، =|B|۱۰۰، و |=|c۱۰۰۰. فرض کنید هر بعد به طور مساوی به ۱۰ قسمت برای قطعهبندی تقسیم شده است.
- الف. با فرض اینکه هر بعد فقط یک سطح دارد، شبکه کامل مکعب را رسم کنید.
- ب. اگر هر سلول مکعب یک سنجه را با چهار بایت ذخیره کند، اندازه کل مکعب محاسبه شده در صورت چگال بودن مکعب چقدر است؟
- ج. ترتیب محاسبه قطعات در مکعب را که به کمترین مقدار فضا نیاز دارد، بیان کنید،و مقدار کل فضای حافظه اصلی مورد نیاز برای محاسبه دو صفحه را محاسبه کنید.
۳.۲۲. هنگام محاسبه یک مکعب با ابعاد بالا، با مشکل ذاتی نفرین ابعاد مواجه میشویم: تعداد زیادی زیرمجموعه از ترکیبات ابعاد وجود دارد.
- الف. فرض کنید فقط دو سلول پایه، {(a1، a2، a3،…، a100) و (a1، a2، b3،…، b100)}، در یک مکعب پایه ۱۰۰ بعدی وجود دارد. تعداد سلولهای تجمعی غیرتهی را محاسبه کنید. در مورد فضای ذخیرهسازی و زمان مورد نیاز برای محاسبه این سلولها نظر دهید.
- ب. فرض کنید قرار است یک مکعب کوه یخ را از (الف) محاسبه کنیم. اگر حداقل تعداد پشتیبان در شرط کوه یخ ۲ باشد، چند سلول تجمعی در مکعب کوه یخ وجود خواهد داشت؟ سلولها را نشان دهید.
- ج. معرفی مکعبهای کوه یخ، بار محاسبه سلولهای تجمعی بیاهمیت در یک مکعب داده را کاهش میدهد. با این حال، حتی با مکعبهای کوه یخ، هنوز هم ممکن است مجبور شویم تعداد زیادی از سلولهای بیاهمیت و بیاهمیت (یعنی با تعداد کم) را محاسبه کنیم. فرض کنید یک پایگاه داده دارای 20 تاپل است که به دو سلول پایه زیر در یک مکعب مستطیل پایه 100 بعدی نگاشت (یا آنها را پوشش میدهد) که هر کدام تعداد سلول 10 دارند: {(a1, a2, a3,…, a100) 10, (a1, a2, b3,…, b100) 10}.
- فرض کنید حداقل پشتیبانی 10 باشد. چند سلول تجمعی متمایز مانند زیر وجود خواهد داشت: {(a1, a2, a3, a4,…, a99, ∗): 10,…, (a1, a2, ∗, a4,…, a99, a100): 10,…, (a1, a2, a3, ,…, , ) 10}؟
- اگر تمام سلولهای تجمعی را که میتوان با جایگزینی برخی ثابتها با s و در عین حال حفظ مقدار سنجه یکسان به دست آورد، نادیده بگیریم، چند سلول متمایز باقی میماند؟ این سلولها چه هستند؟ ۳.۲۳. الگوریتمی پیشنهاد دهید که مکعبهای کوه یخ بسته را به طور موثر محاسبه کند.
۳.۲۴. فرض کنید میخواهیم یک مکعب کوه یخ را برای ابعاد A، B، C، D محاسبه کنیم، که در آن میخواهیم تمام سلولهایی را که حداقل تعداد پشتیبانی حداقل v را برآورده میکنند، محقق کنیم، و در آن کاردینالیتی(A) < کاردینالیتی(B) < کاردینالیتی(C) < کاردینالیتی(D). درخت پردازش BUC (که ترتیبی را نشان میدهد که الگوریتم BUC شبکه یک مکعب داده را با شروع از همه بررسی میکند) برای ساخت این مکعب کوه یخ نشان دهید.
۳.۲۵. بحث کنید که چگونه میتوانید الگوریتم مکعب ستارهای را برای محاسبه مکعبهای کوه یخ گسترش دهید که در آن شرایط کوه یخ برای میانگینی که بزرگتر از مقداری v نیست، آزمایش میشود.
۳.۲۶. یک انبار داده پرواز برای یک آژانس مسافرتی شامل شش بعد است: مسافر، حرکت (شهر)، زمان حرکت، ورود، زمان ورود و پرواز؛ و دو سنجه: count() و avg_fare()، که در آن avg_fare() کرایه واقعی را در پایینترین سطح و میانگین کرایه را در سایر سطوح ذخیره میکند.
- الف. فرض کنید مکعب کاملاً مادی شده است. با شروع از مکعب مستطیل پایه [مسافر، حرکت، زمان حرکت، ورود، زمان ورود، پرواز]، چه عملیات OLAP خاصی (مثلاً پرواز جمعشونده به خط هوایی) باید انجام شود تا میانگین کرایه ماهانه برای هر مسافر کاری که در سال ۲۰۰۹ با خطوط هوایی American Airlines (AA) از لسآنجلس پرواز میکند، فهرست شود؟
- ب. فرض کنید میخواهیم یک مکعب داده را محاسبه کنیم که شرط آن این است که حداقل تعداد رکوردها 10 و میانگین کرایه بیش از 500 دلار باشد. یک روش محاسبه مکعب کارآمد (بر اساس عقل سلیم در مورد توزیع دادههای پرواز) را شرح دهید.
3.27. (پروژه پیادهسازی) چهار روش معمول محاسبه مکعب داده وجود دارد: MultiWay [ZDN97]، BUC [BR99]، H-Cubing [HPDW01] و Star-Cubing [XHLW03].
- الف. هر یک از این الگوریتمهای محاسبه مکعب را پیادهسازی کنید و پیادهسازی، آزمایش و عملکرد خود را شرح دهید. دانشجوی دیگری را پیدا کنید که الگوریتم متفاوتی را در همان پلتفرم (مثلاً C++ در لینوکس) پیادهسازی کرده است و عملکرد الگوریتم خود را با او مقایسه کنید.
- ورودی:
- یک جدول مکعب پایه n بعدی (برای n < 20)، که اساساً یک جدول رابطهای با n ویژگی است.
- شرط کوه یخ: تعداد (C) k، که k یک عدد صحیح مثبت به عنوان پارامتر است. خروجی:
- مجموعه مکعبهای محاسبهشده که شرط کوه یخ را برآورده میکنند، به ترتیب تولید خروجی شما.
- خلاصهای از مجموعه مکعبهای یخ به شکل “شناسه مکعب: تعداد سلولهای غیرتهی”، که به ترتیب الفبایی مکعبهای یخ مرتب شدهاند (مثلاً A: 155، AB: 120، ABC: 22، ABCD: 4، ABCE: 6، ABD: 36)، که در آن عدد بعد از : نشان دهنده تعداد سلولهای غیرتهی است. (این برای بررسی سریع صحت نتایج شما استفاده میشود.)
- بر اساس پیادهسازی خود، موارد زیر را مورد بحث قرار دهید:
- با افزایش تعداد ابعاد، چه مشکلات محاسباتی چالشبرانگیزی ایجاد میشود؟
- مکعب کوه یخ چگونه میتواند مشکلات قسمت (الف) را برای برخی از مجموعه دادهها حل کند (و چنین مجموعه دادههایی را توصیف کند)؟
- یک مثال ساده بزنید تا نشان دهید که گاهی اوقات مکعبهای کوه یخ نمیتوانند راهحل خوبی ارائه دهند.
- ج. به جای محاسبه یک مکعب داده با ابعاد بالا، میتوانیم مکعبهایی را که فقط تعداد کمی ترکیب ابعاد دارند، به واقعیت تبدیل کنیم. به عنوان مثال، برای یک مکعب داده 30 بعدی، میتوانیم فقط مکعبهای 5 بعدی را برای هر ترکیب 5 بعدی ممکن محاسبه کنیم. مکعبهای حاصل یک مکعب پوستهای تشکیل میدهند. در مورد اینکه اصلاح الگوریتم محاسبه مکعب شما برای تسهیل چنین محاسباتی چقدر آسان یا سخت است، بحث کنید.
3.28. مکعب نمونهگیری برای تجزیه و تحلیل چند بعدی دادههای نمونهگیری (مثلاً دادههای نظرسنجی) پیشنهاد شده است. در بسیاری از کاربردهای واقعی، دادههای نمونهگیری میتوانند ابعاد بالایی داشته باشند (مثلاً داشتن بیش از 50 بعد در یک مجموعه داده نظرسنجی غیرمعمول نیست).
- الف. چگونه میتوانیم یک مکعب نمونهگیری با ابعاد بالا کارآمد و مقیاسپذیر در مجموعه دادههای نمونهگیری بزرگ بسازیم؟
- ب. یک الگوریتم بهروزرسانی افزایشی کارآمد برای چنین مکعب نمونهگیری با ابعاد بالا طراحی کنید.
- ج. با توجه به اینکه برخی از سلولهای سطح پایین ممکن است خالی باشند یا دادههای بسیار کمی برای تجزیه و تحلیل قابل اعتماد داشته باشند، در مورد چگونگی پشتیبانی از جستجوی عمیق با کیفیت بحث کنید.
۳.۲۹. مکعب رتبهبندی برای پشتیبانی از پرسوجوهای k برتر (رتبهبندی) در سیستمهای پایگاه داده رابطهای طراحی شده است. با این حال، پرسوجوهای رتبهبندی نیز در انبارهای داده مطرح میشوند، جایی که رتبهبندی به جای اندازهگیری حقایق پایه، بر اساس مجموعهای چندبعدی است. به عنوان مثال، یک مدیر محصول را در نظر بگیرید که در حال تجزیه و تحلیل یک پایگاه داده فروش است که تاریخچه فروش سراسری را که بر اساس مکان و زمان سازماندهی شده است، ذخیره میکند. برای تصمیمگیری در مورد سرمایهگذاری، مدیر ممکن است پرسوجوی زیر را مطرح کند: “۱۰ سلول برتر (ایالت، سال) که بیشترین فروش کل محصول را دارند، کدامند؟” او ممکن است بیشتر به جزئیات بپردازد و بپرسد، “۱۰ سلول برتر (شهر، ماه) کدامند؟” فرض کنید سیستم میتواند چنین مادیسازی جزئی را برای استخراج دو نوع مکعب مستطیل مادی انجام دهد: یک مکعب مستطیل راهنما و یک مکعب مستطیل پشتیبان، که اولی شامل تعدادی سلول راهنما است که آمار دادههای مختصر و سطح بالایی را برای هدایت پردازش پرسوجوی رتبهبندی ارائه میدهند، در حالی که دومی شاخصهای معکوس را برای تجمیع آنلاین کارآمد فراهم میکند.
- الف) روشی کارآمد برای محاسبه چنین مکعبهای رتبهبندی تجمیعی استخراج کنید
- ب) چارچوب خود را برای مدیریت سنجههای پیشرفتهتر گسترش دهید. یکی از این مثالها میتواند به شرح زیر باشد. یک پایگاه داده اهدای سازمان را در نظر بگیرید، که در آن اهداکنندگان بر اساس “سن”، “درآمد” و سایر ویژگیها گروهبندی شدهاند. سوالات جالب عبارتند از: “کدام گروههای سنی و درآمدی بیشترین میانگین k مقدار اهدایی (به ازای هر اهداکننده) را داشتهاند؟” و “کدام گروه درآمدی اهداکنندگان بیشترین انحراف سنجه را در مقدار اهدایی دارد؟”
3.30. اخیراً، محققان نوع دیگری از پرسوجو را پیشنهاد کردهاند که پرسوجوی خط افق نامیده میشود. یک پرسوجوی خط افق تمام اشیاء pi را برمیگرداند به طوری که pi تحت سلطه هیچ شیء دیگری pj نباشد، که در آن تسلط به شرح زیر تعریف میشود. فرض کنید مقدار pi در بُعد d برابر با v(pi,d) باشد. میگوییم pi تحت سلطه pj است اگر و تنها اگر برای هر بُعد ترجیحی d، v(pj,d) v(pi,d) باشد و حداقل یک d وجود داشته باشد که در آن تساوی برقرار نباشد.
- الف. یک مکعب رتبهبندی طراحی کنید (به سوال قبلی مراجعه کنید) تا بتوان پرسوجوهای خط افق را به طور کارآمد پردازش کرد.
- ب. پرسوجوهای خط افق گاهی اوقات بیش از حد دقیق هستند که برای برخی از کاربران مطلوب باشند. میتوان مفهوم خط افق را به خط افق تعمیمیافته به صورت زیر تعمیم داد: با توجه به یک پایگاه داده d بعدی و یک پرسوجوی q، خط افق تعمیمیافته مجموعهای از اشیاء زیر است: (1) اشیاء خط افق و (2) اشیاء غیرخط افق که همسایههای E یک شیء خط افق هستند، که در آن r همسایه E یک شیء p است اگر فاصله بین p و r بیشتر از E نباشد. یک مکعب رتبهبندی برای پردازش کارآمد پرسوجوهای خط افق تعمیمیافته طراحی کنید.
3.31. مکعب پیشبینی نمونه خوبی از دادهکاوی چندبعدی در فضای مکعب است.
- الف. یک الگوریتم کارآمد پیشنهاد کنید که مکعبهای پیشبینی را در یک پایگاه داده چندبعدی مشخص محاسبه کند.
- ب. الگوریتم شما برای چه نوع مدلهای طبقهبندی قابل استفاده است؟ توضیح دهید
3.32. مکعبهای چندویژگی به ما امکان میدهند مکعبهای داده جالبی را بر اساس شرایط پرسوجوی نسبتاً پیچیده بسازیم. آیا میتوانید مکعب چندویژگی زیر را با ترجمه درخواستهای کاربر زیر به پرسوجوها با استفاده از فرم معرفی شده در این کتاب درسی بسازید؟
- الف. یک مکعب خریدار هوشمند بسازید که در آن یک خریدار هوشمند است اگر حداقل 10٪ از کالاهایی که در هر خرید خریداری میکند، در حراج باشند.
- ب. یک مکعب داده برای محصولات با بهترین معامله بسازید که در آن محصولات با بهترین معامله، محصولاتی هستند که قیمت آنها برای این محصول در ماه معین کمترین است.
3.33. کاوش مکعب مبتنی بر کشف، روشی مطلوب برای علامتگذاری نقاط جالب در میان تعداد زیادی از سلولها در یک مکعب داده است. کاربران ممکن است دیدگاههای متفاوتی در مورد اینکه آیا یک نقطه باید به اندازه کافی جالب در نظر گرفته شود تا علامتگذاری شود، داشته باشند. فرض کنید کسی میخواهد اشیایی را که مقدار مطلق امتیاز z آنها در هر سطر و ستون در یک صفحه d بعدی بیش از 2 است، علامتگذاری کند.
- الف. یک روش محاسباتی کارآمد برای شناسایی چنین نقاطی در طول محاسبه مکعب داده استخراج کنید.
- ب. فرض کنید یک مکعب نیمه مادی دارای مکعبهای (d 1) بعدی و (d 1) بعدی مادی شده است اما مکعب d بعدی مادی نشده است. یک روش کارآمد برای علامتگذاری سلولهای (d 1)بعدی با فرزندان d بعدی که حاوی چنین نقاط علامتگذاری شدهای هستند، استخراج کنید.


