مقدمه
الگوهای پرتکرار، الگوهایی (مثلاً مجموعه اقلام، زیردنبالهها یا زیرساختارها) هستند که به طور پرتکرار در یک مجموعه داده ظاهر میشوند. به عنوان مثال، مجموعهای از اقلام، مانند شیر و نان، که به طور پرتکرار در یک مجموعه داده تراکنش با هم ظاهر میشوند، یک مجموعه اقلام پرتکرار است. یک زیردنباله، مانند خرید اول یک تلفن هوشمند، سپس یک تلویزیون هوشمند و سپس یک دستگاه خانه هوشمند، اگر به طور پرتکرار در یک پایگاه داده تاریخچه خرید رخ دهد، یک الگوی ترتیبی (متکرار) است. یک زیرساختار میتواند به اشکال ساختاری مختلفی مانند زیرگرافها، زیردرختها یا زیرشبکهها اشاره داشته باشد. اگر یک زیرساختار به طور پرتکرار رخ دهد، یک الگوی ساختاریافته (متکرار) نامیده میشود. یافتن الگوهای پرتکرار نقش اساسی در کاوش ارتباطات، همبستگیها و بسیاری از روابط جالب دیگر بین دادهها ایفا میکند. علاوه بر این، به طبقهبندی دادهها، خوشهبندی و سایر وظایف دادهکاوی کمک میکند. بنابراین، کاوش الگوهای پرتکرار به یک وظیفه مهم دادهکاوی و یک موضوع متمرکز در تحقیقات دادهکاوی تبدیل شده است. در این فصل، مفاهیم اساسی الگوهای پرتکرار، ارتباطات و همبستگیها (بخش ۴.۱) را معرفی میکنیم و نحوهی کاوش کارآمد آنها را بررسی میکنیم (بخش ۴.۲). همچنین در مورد چگونگی قضاوت در مورد جالب بودن الگوهای یافتشده بحث میکنیم (بخش ۴.۳). در فصل بعدی، بحث خود را به کاوش پیشرفتهی الگوهای پرتکرار، از جمله کاوش اشکال پیچیدهتر الگوهای پرتکرار و کاربردهای آنها، گسترش میدهیم.
مفاهیم اساسی
کاوش الگوهای پرتکرار، روابط تکرارشونده را در یک مجموعه دادهی معین آشکار میکند. این بخش مفاهیم اساسی کاوش الگوهای پرتکرار را برای کشف ارتباطات و همبستگیهای جالب بین مجموعه اقلام در پایگاههای دادهی تراکنشی و رابطهای معرفی میکند. ما در بخش ۴.۱.۱ با ارائهی مثالی از تحلیل سبد بازار، که اولین شکل کاوش الگوهای پرتکرار برای قوانین وابستگی است، شروع میکنیم. مفاهیم اساسی کاوش الگوها و ارتباطات پرتکرار در بخش ۴.۱.۲ مورد بحث قرار گرفته است.
تحلیل سبد بازار: یک مثال انگیزشی
به مجموعهای از اقلام، مجموعه اقلام گفته میشود. کاوش پرتکرار مجموعه اقلام منجر به کشف ارتباطات و همبستگیها بین اقلام در مجموعه دادههای تراکنشی یا رابطهای بزرگ میشود. با توجه به حجم عظیم دادههایی که به طور مداوم جمعآوری و ذخیره میشوند، بسیاری از صنایع به کاوش چنین الگوهایی از پایگاههای داده خود علاقهمند هستند. کشف روابط همبستگی جالب بین حجم عظیمی از سوابق تراکنشهای تجاری میتواند به بسیاری از فرآیندهای تصمیمگیری تجاری مانند طراحی کاتالوگ، بازاریابی متقابل و تحلیل رفتار خرید مشتری کمک کند.
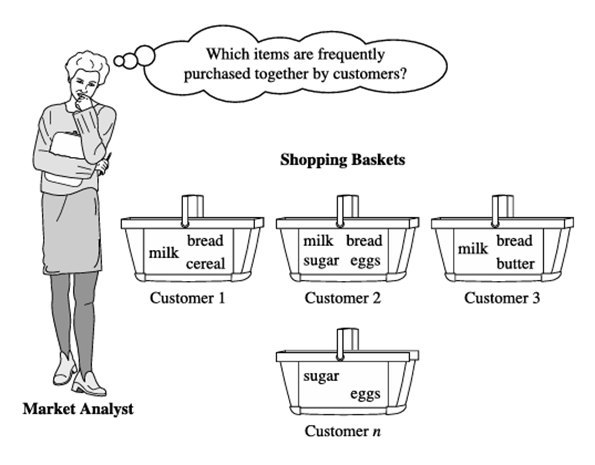
تحلیل سبد بازار.
یک نمونه معمول از کاوش مجموعه اقلام پرتکرار، تحلیل سبد بازار است. این فرآیند با یافتن ارتباط بین اقلام مختلفی که مشتریان در «سبدهای خرید» خود قرار میدهند، عادات خرید مشتری را تجزیه و تحلیل میکند (شکل ۴.۱). کشف این ارتباطها میتواند به خردهفروشان کمک کند تا با کسب بینش در مورد اینکه کدام اقلام اغلب توسط مشتریان با هم خریداری میشوند، استراتژیهای بازاریابی را توسعه دهند. به عنوان مثال، اگر مشتریان شیر میخرند، چقدر احتمال دارد که در همان مراجعه به سوپرمارکت، نان (و چه نوع نانی) نیز بخرند؟ این اطلاعات میتواند با کمک به خردهفروشان در انجام بازاریابی انتخابی و فضای قفسه برنامهریزی شده، منجر به افزایش فروش، درآمد و جذب مشتری شود.
بیایید به مثالی از چگونگی مفید بودن تحلیل سبد بازار نگاهی بیندازیم.
مثال ۴.۱. تحلیل سبد بازار. فرض کنید، به عنوان مدیر یک شرکت خردهفروشی، میخواهید در مورد عادات خرید مشتریان خود اطلاعات بیشتری کسب کنید. به طور خاص، شما به این فکر میکنید که «مشتریان احتمالاً در یک مراجعه خاص به فروشگاه، کدام گروهها یا مجموعههای اقلام را خریداری میکنند؟» برای پاسخ به سوال شما، تحلیل سبد بازار ممکن است بر روی دادههای خردهفروشی تراکنشهای مشتری در فروشگاه شما انجام شود. سپس میتوانید از این نتایج برای انتخاب استراتژیهای بازاریابی و کمک به ایجاد یک کاتالوگ جدید استفاده کنید. برای مثال، تحلیل سبد بازار میتواند به شما در طراحی چیدمانهای مختلف فروشگاه کمک کند. در یک استراتژی، اقلامی که اغلب با هم خریداری میشوند، میتوانند در مجاورت هم قرار داده شوند تا فروش ترکیبی این اقلام بیشتر تشویق شود. اگر مشتریانی که کامپیوتر میخرند، تمایل دارند همزمان نرمافزار آنتیویروس نیز بخرند، قرار دادن نمایشگر سختافزار در نزدیکی نمایشگر نرمافزار میتواند به افزایش فروش هر دو کالا کمک کند.
در یک استراتژی جایگزین، قرار دادن سختافزار و نرمافزار در دو انتهای فروشگاه میتواند مشتریانی را که چنین اقلامی را خریداری میکنند، ترغیب کند تا اقلام دیگری را نیز در طول مسیر تهیه کنند. به عنوان مثال، پس از تصمیمگیری در مورد خرید یک کامپیوتر گرانقیمت، مشتری ممکن است هنگام رفتن به سمت نمایشگر نرمافزار برای خرید نرمافزار آنتیویروس، سیستمهای امنیتی موجود در فروشگاه را مشاهده کند و ممکن است تصمیم به خرید یک سیستم امنیتی خانگی نیز بگیرد. تحلیل سبد بازار همچنین میتواند به خردهفروشان کمک کند تا اقلامی را که با قیمتهای کاهشیافته به فروش میرسانند، برنامهریزی کنند. اگر مشتریان تمایل دارند کامپیوتر و چاپگر را با هم خریداری کنند، کاهش قیمت چاپگرها میتواند فروش چاپگرها و همچنین رایانهها را تشویق کند.
اگر جهان را به عنوان مجموعهای از اقلام موجود در فروشگاه در نظر بگیریم، هر کالا یک متغیر بولی دارد که نشان دهنده وجود یا عدم وجود آن کالا است. سپس هر سبد را میتوان با یک بردار بولی از مقادیر اختصاص داده شده به این متغیرها نشان داد. بردارهای بولی را میتوان برای استخراج الگوهای خریدی که منعکس کننده اقلامی هستند که اغلب با هم مرتبط یا خریداری میشوند، تجزیه و تحلیل کرد. این الگوها را میتوان در قالب قوانین ارتباط نشان داد. به عنوان مثال، اطلاعاتی مبنی بر اینکه مشتریانی که کامپیوتر میخرند، تمایل دارند همزمان نرمافزار آنتی ویروس نیز بخرند، در قانون انجمنی زیر نشان داده شده است:
.computer⇒antivirus_software [support = 2%, confidence = 60%]
پشتیبانی (Support) و اطمینان (Confidence) قانون، دو معیار برای سنجش جذابیت (Interestingness) قانون هستند. آنها بهترتیب منعکسکننده میزان سودمندی و قطعیت قوانینِ کشفشده میباشند .یک پشتیبانی ۲ درصدی برای قانون (۴.۱) بدین معناست که ۲ درصد از کل تراکنشهای تحت تحلیل، نشان میدهند که رایانه و نرمافزار آنتیویروس بهصورت همزمان خریداری شدهاند. یک اطمینان ۶۰ درصدی نیز به این معناست که ۶۰ درصد از مشتریانی که رایانه خریداری کردهاند، آن نرمافزار را نیز خریدهاند. بهطور معمول، قوانین ارتباط (Association Rules) در صورتی جذاب تلقی میشوند که یک حد آستانه حداقل برای پشتیبانی و یک حد آستانه حداقل برای اطمینان را برآورده سازند. این آستانهها میتوانند توسط کاربران یا خبرگان دامنه (Domain Experts) تعیین شوند. تحلیلهای اضافی میتواند برای کشف همبستگیهای آماری جذاب میان اقلام مرتبط انجام پذی
مجموعه اقلام پرتکرار، مجموعه اقلام بسته و قوانین ارتباط
فرض کنید I ={I1,I2,…,Im} یک مجموعه اقلام باشد. فرض کنید D، دادههای مرتبط با وظیفه، مجموعهای از تراکنشهای پایگاه داده باشد که در آن هر تراکنش T یک مجموعه اقلام غیرتهی است به طوری که T ⊆ I. هر تراکنش با یک شناسه به نام TID مرتبط است. فرض کنید A مجموعهای از اقلام باشد. گفته میشود یک تراکنش T شامل A است اگر A⊆T.
یک قانون انجمنی، پیامدی از فرم A ⇒B است، که در آن A⊂I، B ⊂I، A=∅، B =∅ و A∩B=φ. قانون A⇒B در مجموعه تراکنش D با پشتیبانی((support s برقرار است، که در آن s درصد تراکنشهای D است که شامل A∪B هستند (یعنی اجتماع مجموعههای A و B، یا هر دو A و B). این به عنوان احتمال P(A∪B) در نظر گرفته میشود.2 قانون A ⇒B در مجموعه تراکنشهایD دارای اطمینان(confidence) c است، که در آن c درصد تراکنشهای D حاوی A است که حاوی B نیز میباشند. این به عنوان احتمال شرطی P(B|A) در نظر گرفته میشود. یعنی
support(A⇒B) =P(A∪B)
confidence(A⇒B) =P(B|A)
قوانینی که هم حداقل آستانه پشتیبانی (min_sup) و هم حداقل آستانه اطمینان (min_conf) را برآورده میکنند، قوی نامیده میشوند. طبق قرارداد، مقادیر پشتیبانی و اطمینان به صورت درصد سن نمایش داده میشوند.
یک مجموعه آیتم که شامل k آیتم است، یک مجموعه k آیتم است. مجموعه {computer, antivirus_software} یک مجموعه آیتم 2 تایی است. فراوانی وقوع یک مجموعه آیتم، تعداد تراکنشهایی است که شامل آن مجموعه آیتم هستند. فراوانی وقوع همچنین به عنوان فراوانی، تعداد پشتیبانی یا تعداد مجموعه آیتمها شناخته میشود. توجه داشته باشید که پشتیبانی مجموعه آیتم تعریف شده در معادله (4.2) گاهی اوقات به عنوان پشتیبانی نسبی شناخته میشود، در حالی که فراوانی وقوع، پشتیبانی مطلق نامیده میشود. اگر پشتیبانی نسبی یک مجموعه آیتم I، یک آستانه پشتیبانی حداقل از پیش تعیین شده را برآورده کند (یعنی پشتیبانی مطلق I، آستانه تعداد پشتیبانی حداقل مربوطه را برآورده کند)، آنگاه I یک مجموعه آیتم پرتکرار است. مجموعه k مجموعه آیتم پرتکرار معمولاً با Lk نشان داده میشود. از معادله (4.3)، داریم:
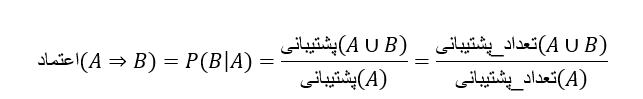
معادله (4.4) نشان میدهد که اطمینان از قانون A⇒B را میتوان به راحتی از تعداد پشتیبانهای A و A∪B استخراج کرد. یعنی، هنگامی که تعداد پشتیبانهای, B A، A∪B مشخص شد، میتوان به راحتی قوانین وابستگی مربوطه A⇒B و B⇒A را استخراج کرد و بررسی کرد که آیا قوی هستند یا خیر. بنابراین، مسئله کاوش قوانین وابستگی را میتوان به مسئله کاوش مجموعه اقلام پرتکرار کاهش داد.
به طور کلی، کاوش قوانین وابستگی را میتوان به عنوان یک فرآیند دو مرحلهای در نظر گرفت:
۱. تمام مجموعههای اقلام پرتکرار را بیابید. طبق تعریف، هر یک از این مجموعههای اقلام حداقل به اندازهی یک تعداد پشتیبانی کمینه از پیش تعیین شده، یا همان min_sup، رخداد خواهند داشت.
۲. قواعد انجمنی قوی را از این مجموعههای اقلام پرتکرار تولید کنید. طبق تعریف، این قواعد باید شرایط پشتیبانی کمینه و اطمینان کمینه را برآورده سازند.
سنجههای جالب توجه دیگری که میتوانند برای کشف روابط همبستگی بین اقلام مرتبط اعمال شوند، در بخش ۴.۳ مورد بحث قرار خواهند گرفت. عملکرد کلی کاوش قوانین ارتباط توسط مرحله اول تعیین میشود، زیرا مرحله دوم بسیار کمهزینهتر از مرحله اول است.
یک چالش عمده در کاوش مجموعه اقلام پرتکرار از یک مجموعه داده بزرگ، این واقعیت است که چنین کاوشی اغلب تعداد زیادی مجموعه اقلام تولید میکند که آستانه حداقل پشتیبانی (min_sup) را برآورده میکنند، به خصوص هنگامی که min_sup کم تنظیم شده باشد. دلیل این امر آن است که اگر یک مجموعه اقلام پرتکرار باشد، هر یک از زیرمجموعههای آن نیز پرتکرار هستند. یک مجموعه اقلام طولانی شامل تعداد ترکیبی از زیرمجموعه اقلام کوتاهتر پرتکرار خواهد بود. به عنوان مثال، یک مجموعه اقلام پرتکرار با طول ۱۰۰، مانند {a، a،…، a}، شامل ۱۰۰ مجموعه اقلام پرتکرار ۱۰۰ تایی است:
{a1}، {a2}، …، {a100}؛ ۱۰۰ مجموعه اقلام تکراری ۲ تایی: {a1, a2}, {a1, a3}, {a1, a4}, …, {a2, a3}, {a2, a4}, …,
{a99, a100}; و غیره. تعداد کل مجموعه اقلام تکراری که شامل میشود به این صورت است:
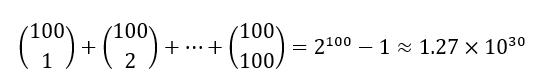
این تعداد مجموعه اقلام برای محاسبه یا ذخیره توسط هر کامپیوتری بسیار زیاد است. برای غلبه بر این مشکل، مفاهیم مجموعه اقلام پرتکرار بسته و مجموعه اقلام پرتکرار حداکثری را معرفی میکنیم.
یک مجموعه اقلام X در مجموعه داده D بسته است اگر هیچ مجموعه اقلام بزرگ مناسب Y وجود نداشته باشد به طوری که Y تعداد پشتیبانی یکسانی با X در D داشته باشد. یک مجموعه اقلام X یک مجموعه اقلام پرتکرار بسته در مجموعه D است اگر X هم بسته باشد و هم پرتکرار در D باشد. یک مجموعه اقلام X یک مجموعه اقلام پرتکرار حداکثری (یا مجموعه اقلام حداکثری) در مجموعه داده D است اگر X پرتکرار باشد و هیچ مجموعه اقلام بزرگ Y وجود نداشته باشد به طوری که X ⊂ Y و Y در D پرتکرار باشند.
فرض کنید C مجموعهای از مجموعه اقلام پرتکرار بسته برای مجموعه داده D باشد که حداقل آستانه پشتیبانی را برآورده میکند، min_sup. فرض کنید M مجموعهای از مجموعه اقلام پرتکرار حداکثری برای D باشد که min_sup را برآورده میکند. فرض کنید که ماتعداد پشتیبانی هر مجموعه اقلام در C و M را داریم. توجه داشته باشید که C و اطلاعات شمارش آن را میتوان برای استخراج کل مجموعه اقلام پرتکرار استفاده کرد. بنابراین میگوییم که C حاوی اطلاعات کاملی در مورد مجموعه اقلام پرتکرار مربوطه خود است. از سوی دیگر، M فقط پشتیبانی از مجموعه اقلام حداکثر را ثبت میکند. معمولاً حاوی اطلاعات پشتیبانی کامل در مورد مجموعه اقلام پرتکرار مربوطه خود نیست. ما این مفاهیم را با مثال ۴.۲ نشان میدهیم.
مثال ۴.۲. مجموعه اقلام پرتکرار بسته و حداکثر. فرض کنید یک پایگاه داده تراکنش فقط دو تراکنش دارد: {a1,a2,…,a100; a1,a2,…,a50}. فرض کنید حداقل آستانه تعداد پشتیبان min_sup=1 باشد. ما دو مجموعه اقلام پرتکرار بسته و تعداد پشتیبان آنها را پیدا میکنیم، یعنی C = {{a1,a2,…,a100}:1; {a1,a2,…,a50}:2}. فقط یک مجموعه اقلام پرتکرار حداکثر وجود دارد: M = {{a1,a2,…,a100}:1}. توجه داشته باشید که نمیتوانیم {a1,a2,…,a50} را به عنوان یک مجموعه اقلام پرتکرار حداکثر در نظر بگیریم زیرا دارای یک فرامجموعه پرتکرار، {a1,a2,…,a100} است. این را با مورد قبلی مقایسه کنید که در آن مشخص کردیم ۲۱۰۰ – ۱ مجموعه اقلام پرتکرار وجود دارد که برای شمارش بسیار زیاد هستند!
مجموعه مجموعه اقلام پرتکرار بسته حاوی اطلاعات کاملی در مورد مجموعه اقلام پرتکرار است.
به عنوان مثال، از C، میتوانیم مثلاً (1) {a2,a45: 2} را استخراج کنیم زیرا {a2,a45} یک زیر مجموعه اقلام از مجموعه اقلام {a1,a2,…,a50: 2} است؛ و (2) {a8,a55: 1} را استخراج کنیم زیرا {a8,a55} زیر مجموعه اقلام قبلی نیست بلکه زیر مجموعه اقلام {a1,a2,…,a100: 1} است. با این حال، از مجموعه اقلام پرتکرار حداکثری، فقط میتوانیم ادعا کنیم که هر دو مجموعه اقلام ({a2,a45} و {a8,a55}) پرتکرار هستند، اما نمیتوانیم تعداد واقعی پشتیبان آنها را ادعا کنیم.


