مقدمه
در این بخش، روشهایی برای کاوش سادهترین شکل الگوهای پرتکرار، مانند مواردی که برای تحلیل سبد بازار در بخش ۴.۱.۱ مورد بحث قرار گرفت، خواهید آموخت. ما با ارائه Apriori، الگوریتم پایه برای یافتن مجموعه اقلام پرتکرار در بخش ۴.۲.۱، شروع میکنیم. در بخش ۴.۲.۲، به چگونگی تولید قوانین وابستگی قوی از مجموعه اقلام پرتکرار میپردازیم. بخش ۴.۲.۳ چندین تغییر در الگوریتم Apriori را برای بهبود کارایی و مقیاسپذیری شرح میدهد. بخش ۴.۲.۴ روشهای رشد الگو را برای کاوش مجموعه اقلام پرتکرار ارائه میدهد که فضای جستجوی بعدی را فقط به مجموعه دادههای حاوی مجموعه اقلام پرتکرار فعلی محدود میکنند. بخش ۴.۲.۵ روشهایی را برای کاوش مجموعه اقلام پرتکرار ارائه میدهد که از قالب داده عمودی بهره میبرند.
الگوریتم Apriori: یافتن مجموعه اقلام پرتکرار با استفاده از تولید محدود کاندیدا
Apriori یک الگوریتم بنیادی است که توسط R. Agrawal و R. Srikant در سال ۱۹۹۴ برای کاوش مجموعه اقلام پرتکرار برای قوانین وابستگی بولی [AS94b] ارائه شده است. نام این الگوریتم بر اساس این واقعیت است که الگوریتم از دانش قبلی در مورد ویژگیهای مجموعه اقلام پرتکرار استفاده میکند، همانطور که بعداً خواهیم دید. Apriori از یک رویکرد تکراری معروف به جستجوی سطح-محور استفاده میکند، که در آن از k-itemset برای کاوش (k 1)-itemset استفاده میشود. ابتدا، مجموعه 1-itemsetهای پرتکرار با اسکن پایگاه داده برای جمعآوری تعداد هر آیتم و جمعآوری آیتمهایی که حداقل پشتیبانی را برآورده میکنند، پیدا میشوند. مجموعه حاصل با L1 نشان داده میشود. سپس، از L1 برای یافتن L2، مجموعه 2-itemsetهای پرتکرار، که برای یافتن L3 استفاده میشود، استفاده میشود و به همین ترتیب، تا زمانی که دیگر k-itemset پرتکرار دیگری پیدا نشود. یافتن هر Lk نیاز به یک اسکن کامل پایگاه داده دارد. برای بهبود کارایی تولید مجموعه اقلام پرتکرار به صورت سطحی، از یک ویژگی مهم به نام ویژگی Apriori برای کاهش فضای جستجو استفاده میشود.
ویژگی Apriori: همه زیرمجموعههای غیرتهی یک مجموعه اقلام پرتکرار نیز باید پرتکرار باشند.
ویژگی Apriori بر اساس مشاهده زیر است. طبق تعریف، اگر یک مجموعه اقلام I حداقل آستانه پشتیبانی، min_sup، را برآورده نکند، آنگاه I پرتکرار نیست، یعنی P(I) < min_sup. اگر یک آیتم A به مجموعه اقلام I اضافه شود، آنگاه مجموعه اقلام حاصل (یعنی I A) نمیتواند بیشتر از I تکرار شود. بنابراین I A نیز پرتکرار نیست، یعنی P(I A) < min_sup.
این ویژگی متعلق به دسته خاصی از ویژگیها به نام ضدیکنواختی است، به این معنا که اگر یک مجموعه نتواند از یک آزمون عبور کند، همه فرامجموعههای آن نیز در همان آزمون شکست خواهند خورد. به این ویژگی ضدیکنواختی میگویند زیرا این ویژگی در زمینه شکست در یک آزمون، تکنواخت است. «ویژگی آپریوری چگونه در الگوریتم استفاده میشود؟» برای درک این موضوع، بیایید نگاهی به نحوه استفاده از Lk-1 برای یافتن Lk برای k ≥ 2 بیندازیم. یک فرآیند دو مرحلهای دنبال میشود که شامل اقدامات اتصال و هرس است.
۱. مرحلهی پیوند join step. برای یافتن Lk، مجموعهی اقلام کاندید k با پیوند Lk-1 با خودش تولید میشود.
این مجموعه از نامزدها با Ck نشان داده میشوند. بگذارید l1 و l2 مجموعه اقلام در Lk-1 باشند. نمادگذاری li[j] به j امین مورد در li اشاره دارد (به عنوان مثال، l1[k-2] به دومین مورد از آخرین مورد در l1 اشاره دارد). برای پیادهسازی کارآمد، Apriori فرض میکند که اقلام درون یک تراکنش یا مجموعه اقلام به ترتیب لغوی مرتب شدهاند. برای مجموعه اقلام (k-1)، li، این بدان معناست که اقلام به گونهای مرتب شدهاند که li[1] <li[2] < ···<li[k-1]. عمل پیوند، Lk−1 ⋊⋉Lk−1، انجام میشود، که در آن اعضای Lk−1 در صورتی قابل پیوند هستند که اولین (k −2) مورد آنها مشترک باشد. یعنی، اعضای l1 و l2 از Lk−1 در صورتی به هم متصل میشوند که (l1[1]=l2[1])∧(l1[2]=l2[2]) ∧···∧(l1[k −2]=l2[k −2]) ∧(l1[k −1]<l2[k −1]). شرط l1[k −1]<l2[k −1]
به سادگی تضمین میکند که هیچ تکراری ایجاد نمیشود. مجموعه اقلام حاصل که با اتصال l1 و l2 تشکیل میشود، عبارت است از
{l1[1],l1[2],…,l1[k − 2],l1[k − 1],l2[k − 1]}.
2. مرحله هرس prune step . Ck یک فرامجموعه از Lk است، یعنی اعضای آن ممکن است پرتکرار باشند یا نباشند، اما همه k-item های پرتکرار در Ck گنجانده شدهاند. یک اسکن پایگاه داده برای تعیین تعداد هر نامزد در Ck منجر به تعیین Lk میشود (یعنی همه نامزدهایی که تعدادشان کمتر از حداقل تعداد پشتیبان نباشد، طبق تعریف پرتکرار هستند و بنابراین به Lk تعلق دارند). با این حال، Ck میتواند بسیار بزرگ باشد و بنابراین این میتواند محاسبات سنگینی را شامل شود. برای کاهش اندازه Ck، از ویژگی Apriori به شرح زیر استفاده میشود. هر (k − 1)-item set که پرتکرار نباشد، نمیتواند زیرمجموعهای از یک k-item set پرتکرار باشد. از این رو، اگر هر (k-1)-زیرمجموعه از یک مجموعه اقلام k کاندید در Lk-1 نباشد، آنگاه کاندید نمیتواند پرتکرار باشد و بنابراین میتواند از Ck حذف شود. آزمایش این زیرمجموعه را میتوان به سرعت با نگهداری یک درخت هش از تمام مجموعه اقلام پرتکرار انجام داد.
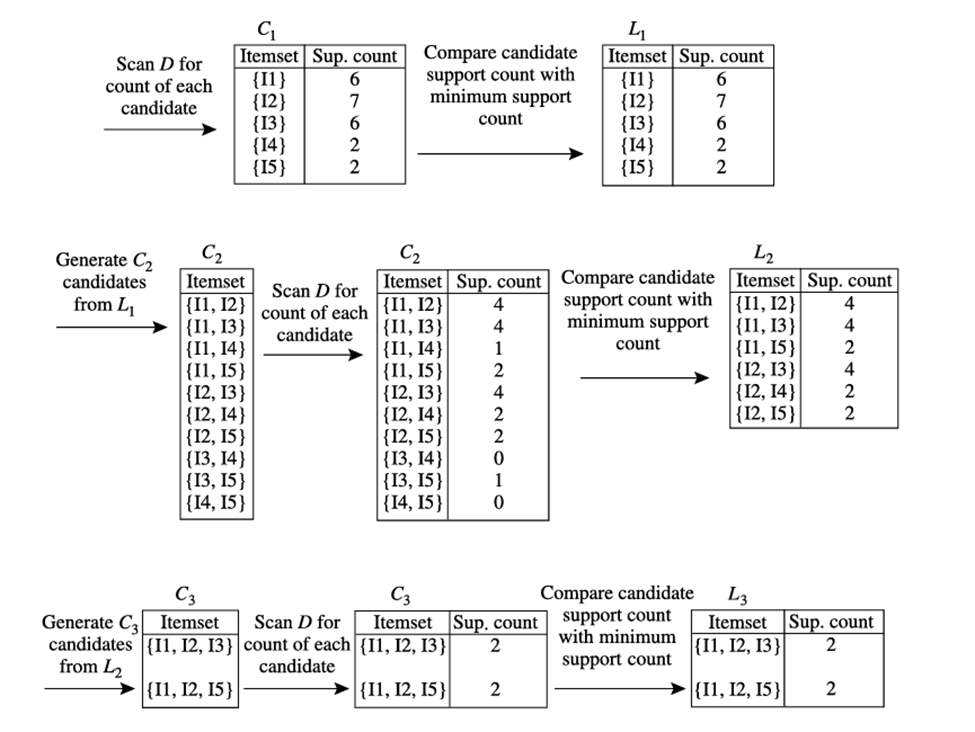
مثال ۴.۳. Apriori. بیایید به یک مثال عینی، بر اساس پایگاه داده تراکنشها، D، از جدول ۴.۱، نگاهی بیندازیم. در این پایگاه داده نه تراکنش وجود دارد، یعنی |= | D ۹. ما از شکل ۴.۲ برای نشان دادن الگوریتم Apriori برای یافتن مجموعه اقلام پرتکرار در D استفاده میکنیم.
۱. در اولین تکرار الگوریتم، هر آیتم عضوی از مجموعه اقلام کاندید ۱، C1، است.
الگوریتم به سادگی تمام تراکنشها را اسکن میکند تا تعداد وقوع هر آیتم را بشمارد.
۲. فرض کنید که حداقل تعداد پشتیبانی مورد نیاز ۲ باشد، یعنی =min_sup ۲. (در اینجا، ما به پشتیبانی مطلق اشاره میکنیم زیرا از تعداد پشتیبانی استفاده میکنیم. پشتیبانی نسبی مربوطه ۲/۹ = ۲۲٪ است.) سپس میتوان مجموعه اقلام کاندید ۱، L1، را تعیین کرد. این مجموعه شامل اقلام کاندید ۱ است که حداقل پشتیبانی را برآورده میکنند. در مثال ما، همه کاندیداها در C1 حداقل پشتیبانی را برآورده میکنند.
۳. برای کشف مجموعه مجموعههای ۲-آیتمی پرتکرار، L2، الگوریتم از پیوند L1 ⋊⋉L1 برای تولید یک مجموعه کاندید از مجموعههای ۲-آیتمی، C2.6 استفاده میکند. C2 شامل |L1|۲-آیتمی است. توجه داشته باشید که هیچ کاندیدی در طول مرحله هرس از C2 حذف نمیشود زیرا هر زیرمجموعه از کاندیدها نیز پرتکرار است.
۴. در مرحله بعد، تراکنشهای D اسکن میشوند و تعداد پشتیبانی هر مجموعه آیتم کاندید در C2، همانطور که در جدول میانی ردیف دوم در شکل ۴.۲ نشان داده شده است، جمع میشود.
۵. سپس مجموعه مجموعههای ۲-آیتمی پرتکرار، L2، تعیین میشود که شامل آن دسته از مجموعههای ۲-آیتمی کاندید در C2 است که حداقل پشتیبانی را دارند.
۶. تولید مجموعه مجموعههای ۳-آیتمی کاندید، C3، در شکل ۴.۳ به تفصیل شرح داده شده است. از مرحلهی اتصال، ابتدا C3 =L2 ⋊⋉L2 ={{I1, I2, I3}, {I1, I2, I5}, {I1, I3, I5}, {I2, I3, I4}, {I2, I3, I5}, {I2, I4,I5}} را بدست میآوریم. بر اساس ویژگی Apriori که همه زیرمجموعههای یک مجموعه اقلام پرتکرار نیز باید پرتکرار باشند، میتوانیم تعیین کنیم که چهار نامزد اخیر نمیتوانند پرتکرار باشند. بنابراین آنها را از C3 حذف میکنیم و در نتیجه تلاش برای بدست آوردن تعداد آنها در طول اسکن بعدی D برای تعیین L3 را صرفهجویی میکنیم. توجه داشته باشید که وقتی یک مجموعه اقلام k کاندید داده میشود، فقط باید بررسی کنیم که آیا زیرمجموعههای (k-1) آن پرتکرار هستند یا خیر، زیرا الگوریتم Apriori از یک استراتژی جستجوی سطح-محور استفاده میکند. نسخه هرس شده C3 در جدول اول ردیف پایین شکل 4.2 نشان داده شده است.
۷. تراکنشهای موجود در D برای تعیین L3 اسکن میشوند، که شامل آن دسته از مجموعههای ۳ آیتمی کاندید در C3 است که حداقل پشتیبانی را دارند (شکل ۴.۲)
|
جدول ۴.۱ مجموعه دادههای تراکنشی. |
|
|
TID |
List of item_IDs |
|
T100 |
I1, I2, I5 |
|
T200 |
I2, I4 |
|
T300 |
I2, I3 |
|
T400 |
I1, I2, I4 |
|
T500 |
I1, I3 |
|
T600 |
I2, I3 |
|
T700 |
I1, I3 |
|
T800 |
I1, I2, I3, I5 |
|
T900 |
I1, I2, I3 |
تولید مجموعه اقلام کاندید و مجموعه اقلام پرتکرار، که در آن حداقل تعداد پشتیبان ۲ است.
۸. الگوریتم از L3 ⋊⋉L3 برای تولید یک مجموعه کاندید از مجموعههای ۴ آیتمی، C4، استفاده میکند. اگرچه نتیجه پیوند به {{I1، I2، I3، I5}} میرسد، مجموعه آیتمهای {I1، I2، I3، I5} هرس میشود زیرا زیرمجموعه آن {I2، I3، I5} پرتکرار نیست.
بنابراین، C4 =φ است و الگوریتم با یافتن تمام مجموعه آیتمهای پرتکرار خاتمه مییابد.
شکل ۴.۴ شبهکد الگوریتم Apriori و رویههای مرتبط با آن را نشان میدهد. مرحله ۱ Apriori
مجموعه آیتمهای پرتکرار ۱ آیتمی، L1، را پیدا میکند. در مراحل ۲ تا ۱۰، Lk−۱ برای تولید کاندیداهای Ck برای یافتن Lk برای k ≥۲ استفاده میشود. رویه apriori_gen کاندیداها را تولید میکند و سپس از ویژگی Aprioriبرای حذف آنهایی که زیرمجموعهای غیر پرتکرار دارند استفاده میکند (مرحله ۳). پس از تولید همه کاندیداها، پایگاه داده اسکن میشود (مرحله ۴). برای هر تراکنش، از یک تابع زیرمجموعه برای یافتن همه زیرمجموعههای تراکنش که کاندیدا هستند استفاده میشود (مرحله ۵)، و تعداد هر یک از این کاندیداها جمع میشود (مراحل ۶ و ۷). در نهایت، همه کاندیداهایی که حداقل پشتیبانی را برآورده میکنند (مرحله ۹) مجموعه مجموعه اقلام پرتکرار، L (مرحله ۱۱) را تشکیل میدهند. سپس میتوان روشی را برای تولید قوانین ارتباط از مجموعه اقلام پرتکرار فراخوانی کرد. چنین روشی در بخش ۴.۲.۲ شرح داده شده است.

تولید و هرس مجموعههای ۳-آیتمی کاندید، C3، از L2 با استفاده از ویژگی Apriori.
رویه apriori_gen دو نوع عمل انجام میدهد، یعنی اتصال و هرس، همانطور که قبلاً توضیح داده شد. در مؤلفه اتصال، Lk−1 با Lk−1 ترکیب میشود تا نامزدهای بالقوه تولید شوند (مراحل 1-4). مؤلفه هرس (مراحل 5-7) از ویژگی Apriori برای حذف نامزدهایی که زیرمجموعهای غیرمتکرار دارند استفاده میکند. آزمون زیرمجموعههای نادر در رویه has_infrequent_subset نشان داده شده است.
تولید قوانین ارتباط از مجموعه اقلام پرتکرار
پس از یافتن مجموعه اقلام پرتکرار از تراکنشها در پایگاه داده D، تولید قوانین ارتباط قوی از آنها (که در آن قوانین ارتباط قوی هم حداقل پشتیبانی و هم حداقل اطمینان را برآورده میکنند) ساده است. این کار را میتوان با استفاده از معادله (4.4) برای اطمینان انجام داد، که ما آن را دوباره در اینجا برای کامل بودن نشان میدهیم:
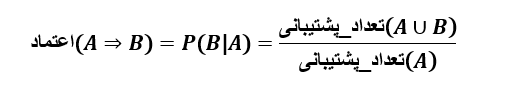
احتمال شرطی بر حسب تعداد پشتیبان مجموعه اقلام بیان میشود، که در آنsupport_count(A∪B) تعداد تراکنشهای حاوی مجموعه اقلام A∪B وsupport_count(A) تعداد تراکنشهای حاوی مجموعه اقلام A است. بر اساس این معادله،
قوانین ارتباط میتوانند به صورت زیر تولید شوند.
- برای هر مجموعه اقلام پرتکرار l، تمام زیرمجموعههای غیرتهی l را تولید کنید.
- برای هر زیرمجموعه غیرتهی s از l، اگر:
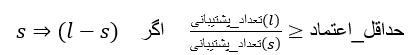
را در خروجی بنویسید.
که در آن حداقل آستانه اطمینان است.

الگوریتم Apriori برای کشف مجموعه اقلام پرتکرار برای کاوش قوانین ارتباط بولی.
از آنجا که قوانین از مجموعه اقلام پرتکرار تولید میشوند، هر یک به طور خودکار حداقل پشتیبانی را برآورده میکند. مجموعه اقلام پرتکرار را میتوان از قبل در جداول هش به همراه تعدادشان ذخیره کرد تا بتوان به سرعت به آنها دسترسی داشت.
مثال ۴.۴. تولید قوانین ارتباط. بیایید مثالی را بر اساس دادههای تراکنشی که قبلاً در جدول ۴.۱ نشان داده شده است، امتحان کنیم. دادهها شامل مجموعه اقلام پرتکرار X = {I1, I2, I5} هستند. قوانین ارتباط که میتوانند از X تولید شوند کدامند؟ زیرمجموعههای غیرتهی X عبارتند از {I1,I2},{I1,I5},{I2,I5},{I1}, {I2}, {I5}, {I2}, {I5}. قوانین ارتباط حاصل در زیر نشان داده شده است، که هر کدام با اطمینان خود فهرست شدهاند:

اگر حداقل آستانه اطمینان، مثلاً ۷۰٪ باشد، فقط قوانین دوم، سوم و آخر خروجی داده میشوند، زیرا اینها تنها قوانین تولید شدهای هستند که قوی هستند. توجه داشته باشید که برخلاف قوانین طبقهبندی مرسوم، قوانین ارتباط میتوانند شامل بیش از یک پیوستگی در سمت راست قانون باشند.
بهبود کارایی Apriori
“چگونه میتوانیم کارایی استخراج مبتنی بر Apriori را بیشتر بهبود بخشیم؟” بسیاری از تغییرات الگوریتم Aprioriپیشنهاد شدهاند که بر بهبود کارایی الگوریتم اصلی تمرکز دارند. چندین مورد از این تغییرات به شرح زیر خلاصه شدهاند.
تکنیک مبتنی بر هش
هش کردن مجموعه اقلام به سطلهای مربوطه. یک تکنیک مبتنی بر هش میتواند برای کاهش اندازه مجموعه اقلام k کاندید، Ck,fork>1، استفاده شود. برای مثال، هنگام اسکن هر تراکنش (مثلاً فرض کنید t ={i1,i2,i4}) در پایگاه داده برای تولید مجموعه اقلام تکراری ۱، L1، میتوانیم تمام مجموعه اقلام تکراری ۲ را برای هر تراکنش (مثلاً سه مجموعه اقلام تکراری {i1,i2}، {i1,i4} و {i2,i4} برای تراکنش t) تولید کنیم، آنها را در سطلهای مختلف ساختار جدول هش هش کنیم (یعنی نگاشت کنیم) و تعداد سطلهای مربوطه را همانطور که در شکل ۴.۵ نشان داده شده است، افزایش دهیم. یک مجموعه اقلام تکراری ۲ با تعداد سطل مربوطه در جدول هش که زیر آستانه پشتیبانی است، نمیتواند پرتکرار باشد و بنابراین باید از مجموعه کاندید حذف شود. چنین تکنیک مبتنی بر هش ممکن است تعداد مجموعه اقلام تکراری k مورد بررسی شده را به طور قابل توجهی کاهش دهد (به خصوص وقتی k = 2 باشد).
کاهش تراکنش
کاهش تعداد تراکنشهای اسکن شده در تکرارهای آینده. تراکنشی که حاوی هیچ مجموعه اقلام k تکراری نباشد، نمیتواند شامل هیچ مجموعه اقلام (k + 1) تکراری باشد. بنابراین، چنین تراکنشی را میتوان علامتگذاری یا از بررسی بیشتر حذف کرد، زیرا اسکنهای بعدی پایگاه داده برای مجموعه اقلام j، که در آن j>k است، نیازی به بررسی چنین تراکنشی نخواهند داشت.
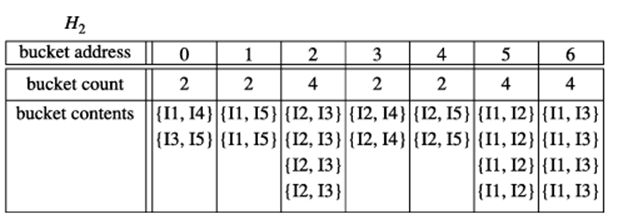
جدول درهمسازی H₂ را با استفاده از تابع درهمسازی زیر ایجاد کنید:
h(x, y) = ((ترتیب x) × ۱۰ + ترتیب y) mod
جدول هش، H2، برای مجموعه اقلام کاندید ۲. این جدول هش با اسکن تراکنشهای جدول ۴.۱ هنگام تعیین L1 ایجاد شده است. اگر حداقل تعداد پشتیبان، مثلاً ۳ باشد، آنگاه مجموعه اقلام موجود در سطلهای ۰، ۱، ۳ و ۴ نمیتوانند پرتکرار باشند و بنابراین نباید در C2 گنجانده شوند.
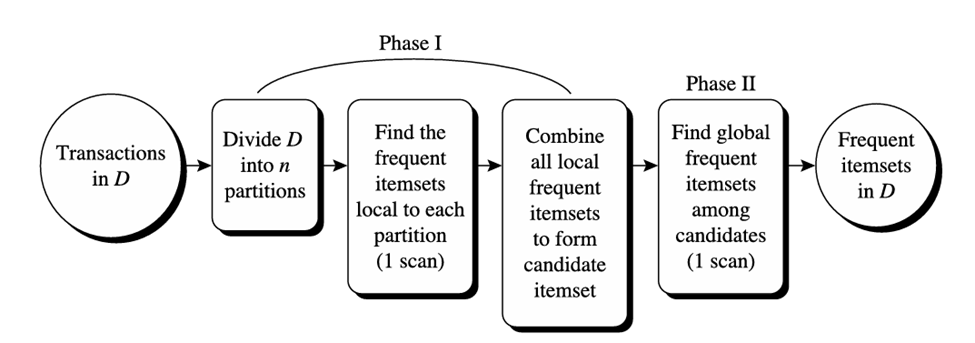
کاوش با تقسیمبندی دادهها.
پارتیشنبندی
پارتیشنبندی دادهها برای یافتن مجموعه اقلام کاندید. میتوان از یک تکنیک تقسیمبندی استفاده کرد که فقط به دو اسکن پایگاه داده برای کاوش مجموعه اقلام پرتکرار نیاز دارد (شکل ۴.۶). این تکنیک شامل دو مرحله است. در مرحله اول، الگوریتم تراکنشهای D را به n پارتیشن غیر همپوشان تقسیم میکند.
اگر حداقل آستانه پشتیبانی نسبی برای تراکنشها در D برابر با min_sup باشد، آنگاه حداقل تعداد پشتیبانی برای یک پارتیشن برابر با min_sup × تعداد تراکنشها در آن پارتیشن است. برای هر پارتیشن، تمام مجموعه اقلام پرتکرار محلی (یعنی مجموعه اقلام پرتکرار درون پارتیشن) یافت میشوند.
مجموعه اقلام پرتکرار محلی ممکن است نسبت به کل پایگاه داده D پرتکرار باشد یا نباشد. با این حال، هر مجموعه اقلامی که به طور بالقوه نسبت به D پرتکرار باشد، باید حداقل در یکی از پارتیشنها به عنوان یک مجموعه اقلام پرتکرار رخ دهد. بنابراین، همه مجموعه اقلام پرتکرار محلی، مجموعه اقلام کاندید نسبت به D هستند. مجموعه اقلام پرتکرار از همه پارتیشنها، مجموعه اقلام کاندید سراسری نسبت به D را تشکیل میدهد. در مرحله دوم، اسکن دوم D انجام میشود که در آن پشتیبانی واقعی هر کاندید برای تعیین مجموعه اقلام پرتکرار سراسری ارزیابی میشود. اندازه پارتیشن و تعداد پارتیشنها طوری تنظیم میشوند که هر پارتیشن بتواند در حافظه اصلی جا شود و بنابراین فقط یک بار در هر مرحله خوانده شود.
نمونهبرداری
کاوش روی زیرمجموعهای از دادههای داده شده. ایده اصلی رویکرد نمونهبرداری، انتخاب یک نمونه تصادفی S از دادههای داده شده D و سپس جستجوی مجموعه اقلام پرتکرار در S به جای D است. به این ترتیب، ما مقداری از دقت را در مقابل کارایی معامله میکنیم. اندازه نمونه S به گونهای است که جستجوی مجموعه اقلام پرتکرار در S میتواند در حافظه اصلی انجام شود و بنابراین فقط یک اسکن از تراکنشها در S مورد نیاز است. از آنجا که ما به جای D، در S به دنبال مجموعه اقلام پرتکرار هستیم، ممکن است برخی از مجموعه اقلام پرتکرار سراسری را از دست بدهیم. برای کاهش این احتمال، از یک آستانه پشتیبانی پایینتر از حداقل پشتیبانی برای یافتن مجموعه اقلام پرتکرار محلی S (که با LS نشان داده میشود) استفاده میکنیم. سپس بقیه پایگاه داده برای محاسبه پرتکرارهای واقعی هر مجموعه اقلام در LS استفاده میشود. از مکانیزمی برای تعیین اینکه آیا همه مجموعه اقلام پرتکرار جهانی در LS گنجانده شدهاند یا خیر، استفاده میشود. اگر LS در واقع شامل همه مجموعه اقلام پرتکرار در D باشد، فقط یک اسکن از D مورد نیاز است. در غیر این صورت، میتوان یک مرحله دوم برای یافتن مجموعه اقلام پرتکراری که در مرحله اول از دست رفتهاند، انجام داد. رویکرد نمونهگیری به ویژه زمانی مفید است که کارایی از اهمیت بالایی برخوردار باشد، مانند برنامههای کاربردی با محاسبات فشرده که باید مرتباً اجرا شوند.
شمارش پویای مجموعه اقلام
اضافه کردن مجموعه اقلام کاندید در نقاط مختلف در طول اسکن. یک تکنیک شمارش پویای مجموعه اقلام پیشنهاد شده است که در آن پایگاه داده به بلوکهایی که با نقاط شروع مشخص شدهاند، تقسیم میشود. در این تغییر، مجموعه اقلام کاندید جدید را میتوان در هر نقطه شروع اضافه کرد، برخلاف Apriori که مجموعه اقلام کاندید جدید را تنها پس از هر اسکن کامل پایگاه داده تعیین میکند. این تکنیک از شمارش تا کنون به عنوان حد پایین شمارش واقعی استفاده میکند. اگر شمارش تا کنون از حداقل پشتیبانی عبور کند، مجموعه اقلام به مجموعه اقلام پرتکرار اضافه میشود و میتواند برای تولید نامزدهای طولانیتر استفاده شود. این امر منجر به اسکنهای کمتر پایگاه داده نسبت به Apriori برای یافتن همه مجموعه اقلام پرتکرار میشود.سایر تغییرات در فصل بعدی مورد بحث قرار گرفته یا به عنوان تمرین باقی مانده است.
یک رویکرد رشد الگو برای کاوش مجموعه اقلام پرتکرار
همانطور که مشاهده کردیم، در بسیاری از موارد، روش تولید و آزمایش کاندید Apriori به طور قابل توجهی اندازه مجموعههای کاندید را کاهش میدهد و منجر به افزایش عملکرد خوب میشود. با این حال، میتواند از دو هزینه غیر بدیهی رنج ببرد.
- ممکن است هنوز نیاز به تولید تعداد زیادی مجموعه کاندید باشد. برای مثال، اگر 104 مجموعه آیتم 1-متکرار وجود داشته باشد، الگوریتم Apriori باید بیش از 107 مجموعه آیتم 2-کاندیدا تولید کند.
- ممکن است نیاز باشد که کل پایگاه داده را بارها اسکن کرده و مجموعه بزرگی از کاندیدها را با تطبیق الگو بررسی کند. بررسی هر تراکنش در پایگاه داده برای تعیین پشتیبانی مجموعه آیتمهای کاندید پرهزینه است.
“آیا میتوانیم روشی طراحی کنیم که مجموعه کامل مجموعه آیتمهای پرتکرار را بدون چنین فرآیند تولید داده پرهزینهای استخراج کند؟” یک روش جالب در این تلاش، رشد الگوی پرتکرار یا به طور ساده FP-growth نامیده میشود که از یک استراتژی تقسیم و غلبه به شرح زیر استفاده میکند. ابتدا، پایگاه دادهای را که نشاندهنده آیتمهای پرتکرار است در یک درخت الگوی پرتکرار یا FP-tree فشرده میکند که اطلاعات ارتباط مجموعه آیتمها را حفظ میکند. سپس پایگاه داده فشرده شده را به مجموعهای از پایگاههای داده شرطی (نوع خاصی از پایگاه داده پیشبینی شده) تقسیم میکند که هر کدام با یک مجموعه آیتم یافت شده تاکنون یا “قطعه الگو” مرتبط هستند و هر پایگاه داده را جداگانه کاوش میکند. برای هر “قطعه الگو”، فقط مجموعه دادههای مرتبط با آن باید بررسی شوند. بنابراین، این رویکرد ممکن است اندازه مجموعه دادههای مورد جستجو را به همراه “رشد” الگوهای مورد بررسی، به طور قابل توجهی کاهش دهد. نحوه کار آن را در مثال ۴.۵ خواهید دید.
مثال ۴.۵. رشد FP (یافتن مجموعه آیتمهای پرتکرار بدون تولید کاندید). ما کاوش پایگاه داده تراکنش، D، جدول ۴.۱ در مثال ۴.۳ را با استفاده از رویکرد رشد الگوی پرتکرار دوباره بررسی میکنیم.
اولین اسکن پایگاه داده همان Apriori است که مجموعه آیتمهای پرتکرار (۱ مجموعه آیتم) و تعداد پشتیبانی آنها (فرکانسها) را استخراج میکند. فرض کنید حداقل تعداد پشتیبانی ۲ باشد. مجموعه آیتمهای پرتکرار به ترتیب نزولی تعداد پشتیبانی مرتب شدهاند. این مجموعه یا لیست حاصل با L نشان داده میشود. بنابراین، داریم {{I2: 7}، {I1: 6}، {I3: 6}، {I4: 2}، {I5: 2}}. L=
سپس درخت AnFP به صورت زیر ساخته میشود. ابتدا، ریشه درخت را که با “null” برچسبگذاری شده است، ایجاد کنید. پایگاه داده D را برای بار دوم اسکن کنید. موارد موجود در هر تراکنش به ترتیب L پردازش میشوند (یعنی بر اساس تعداد پشتیبان نزولی مرتب میشوند) و برای هر تراکنش یک شاخه ایجاد میشود. به عنوان مثال، اسکن اولین تراکنش، ” T100: I1, I2, I5″ که شامل سه مورد (I2، I1، I5 به ترتیب L) است، منجر به ساخت اولین شاخه درخت با سه گره، (I2: 1)، (I1: 1) و (I5: 1) میشود، که در آن I2 به عنوان فرزند به ریشه، I1 به I2 و I5 به I1 متصل است. تراکنش دوم، T200، شامل آیتمهای I2 و I4 به ترتیب L است که منجر به شاخهای میشود که در آن I2 به ریشه و I4 به I2 پیوند خورده است. با این حال، این شاخه یک پیشوند مشترک، I2، با مسیر موجود برای T100 به اشتراک میگذارد. بنابراین، ما به جای آن، تعداد گره I2 را ۱ واحد افزایش میدهیم و یک گره جدید، I4:1، ایجاد میکنیم که به عنوان فرزند به I2:2 پیوند خورده است. به طور کلی، هنگام بررسی شاخهای که قرار است برای یک تراکنش اضافه شود، تعداد هر گره در امتداد یک پیشوند مشترک ۱ واحد افزایش مییابد و گرههای مربوط به آیتمهای پس از پیشوند ایجاد شده و بر این اساس پیوند داده میشوند.
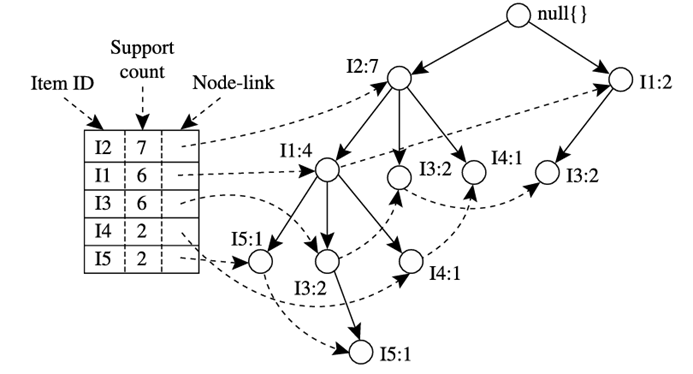
یک درخت FP اطلاعات الگوهای پرتکرار فشرده را ثبت میکند.
برای تسهیل پیمایش درخت، یک جدول سرآیند آیتم ساخته میشود به طوری که هر آیتم از طریق زنجیرهای از گره-پیوندها به رخدادهای خود در درخت اشاره میکند. درختی که پس از اسکن تمام تراکنشها به دست میآید در شکل ۴.۷ با گره-پیوندهای مرتبط نشان داده شده است. به این ترتیب، مسئله کاوش الگوهای پرتکرار در پایگاههای داده به مسئله کاوش درخت FP تبدیل میشود.
درخت FP به شرح زیر کاوش میشود. از هر الگوی پرتکرار با طول ۱ (به عنوان یک الگوی پسوند اولیه) شروع کنید، پایگاه الگوی شرطی آن (یک “زیرپایگاه داده” که شامل مجموعهای از مسیرهای پیشوندی در درخت FP است که با الگوی پسوند همزمان رخ میدهد) را بسازید، سپس درخت FP (شرطی) آن را بسازید و کاوش را به صورت بازگشتی روی درخت انجام دهید. رشد الگو با الحاق الگوی پسوند با الگوهای پرتکرار تولید شده از یک درخت FP شرطی حاصل میشود. کاوش درخت FP در جدول ۴.۲ خلاصه شده و به شرح زیر شرح داده شده است.
- ابتدا I5 را در نظر میگیریم که آخرین مورد در L است، نه اولین مورد. دلیل شروع از انتهای لیست، با توضیح فرآیند کاوش درخت FP آشکار خواهد شد. I5 در دو شاخه درخت FP شکل 4.7 رخ میدهد. (وقوع I5 را میتوان به راحتی با دنبال کردن زنجیره گره-پیوندهای آن پیدا کرد.) مسیرهای تشکیل شده توسط این شاخهها I2, I1, I5: 1> > و I2, I1, I3, I5: 1 هستند. بنابراین، با در نظر گرفتن I5 به عنوان پسوند، دو مسیر پیشوندی مربوطه آن I2, I1: 1 و I2, I1, I3: 1 هستند که پایه الگوی شرطی آن را تشکیل میدهند. با استفاده از این پایه الگوی شرطی به عنوان یک پایگاه داده تراکنش، ما یک درخت FP شرطی I5 میسازیم که فقط شامل یک مسیر واحد، I2: 2، I1: 2 است. I3 شامل نمیشود، زیرا تعداد پشتیبانی آن 1 کمتر از حداقل تعداد پشتیبانی است. این مسیر واحد، تمام ترکیبات الگوهای پرتکرار را تولید میکند: {I2, I5: 2}، {I1, I5: 2}، {I2, I1, I5: 2}
|
جدول ۴.۲ کاوش درخت FP با ایجاد پایگاههای (زیر)الگوی شرطی. |
|||
|
مورد |
الگوی شرطی پایه |
درخت FP شرطی |
الگوهای پرتکرار تولید شده |
|
I5 |
{{I2, I1: 1}, {I2, I1, I3: 1}} |
(I2: 2, I1: 2) |
{I2, I5: 2}, {I1, I5: 2}, {I2, I1, I5: 2} |
|
I4 |
{{I2, I1: 1}, {I2: 1}} |
(I2: 2) |
{I2, I4: 2} |
|
I3 |
{{I2, I1: 2}, {I2: 2}, {I1: 2}} |
(I2: 4, I1: 2), (I1: 2) |
{I2, I3: 4}, {I1, I3: 4}, {I2, I1, I3: 2} |
|
I1 |
{{I2: 4}} |
(I2: 4) |
{I2, I1: 4} |

الگوریتم رشد FP برای کشف مجموعه اقلام پرتکرار بدون تولید کاندید.
- برای I4، دو مسیر پیشوندی آن، پایه الگوی شرطی، {{I2 I1: 1}، {I2: 1}} را تشکیل میدهند که یک درخت FP شرطی تک گرهای، I2: 2، تولید میکند و یک الگوی پرتکرار، {I2، I4: 2}، را مشتق میکند.
- مشابه تحلیل قبلی، پایه الگوی شرطی I3، {{I2، I1: 2}، {I2: 2}، {I1: 2}} است. درخت FP شرطی آن دارای دو شاخه است، I2: 4، I1: 2 و I1: 2، همانطور که در شکل ۴.۹ نشان داده شده است، که مجموعه الگوهای {{I2، I3: 4}، {I1، I3: 4}، {I2، I1، I3: 2}} را تولید میکند.
- در نهایت، الگوی شرطی I1 بر اساس {{I2: 4}} است، با یک درخت FP که فقط شامل یک گره است، I2: 4، که یک الگوی پرتکرار تولید میکند، {I2، I1: 4}.
این فرآیند دادهکاوی در شکل 4.8 خلاصه شده است.
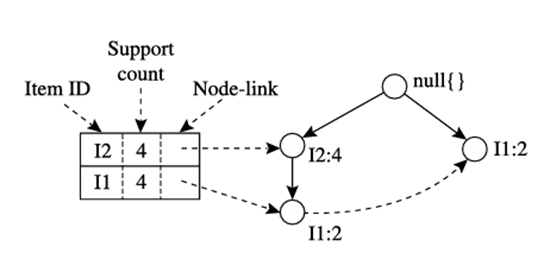
درخت FP شرطی مرتبط با گره شرطی I3.
روش رشد FP، مشکل یافتن الگوهای طولانی و پرتکرار را به جستجوی الگوهای کوتاهتر در پایگاههای داده شرطی بسیار کوچکتر به صورت بازگشتی و سپس الحاق پسوند تبدیل میکند. این روش از موارد کمتکرار به عنوان پسوند استفاده میکند و گزینشپذیری خوبی را ارائه میدهد. این روش به طور قابل توجهی هزینههای جستجو را کاهش میدهد.
وقتی پایگاه داده بزرگ است، گاهی اوقات ساخت یک درخت FP مبتنی بر حافظه اصلی غیرواقعی است.
یک جایگزین جالب این است که ابتدا پایگاه داده را به مجموعهای از پایگاههای داده پیشبینیشده تقسیم کنید و سپس یک درخت FP بسازید و آن را در هر پایگاه داده پیشبینیشده کاوش کنید. این فرآیند را میتوان به صورت بازگشتی برای هر پایگاه داده پیشبینیشدهای اعمال کرد، اگر درخت FP آن هنوز در حافظه اصلی جا نشود.
کاوش مجموعه اقلام پرتکرار با استفاده از قالب داده عمودی
هر دو روش Apriori و FP-growth الگوهای پرتکرار را از مجموعهای از تراکنشها در قالب مجموعه اقلام TID (یعنی {TID: itemset}) کاوش میکنند، که در آن TID شناسه تراکنش و مجموعه اقلام، مجموعهای از اقلام خریداری شده در TID تراکنش است. این به عنوان قالب داده افقی شناخته میشود. به طور جایگزین، دادهها میتوانند در قالب مجموعه اقلام-TID (یعنی {item: TID_set}) ارائه شوند، که در آن item نام یک آیتم است و TID_set مجموعهای از شناسههای تراکنش حاوی آیتم است. این به عنوان قالب داده عمودی شناخته میشود.
در این زیربخش، بررسی میکنیم که چگونه میتوان مجموعه اقلام پرتکرار را با استفاده از قالب داده عمودی، که اساس الگوریتم Eclat (تبدیل کلاس همارزی) است، به طور موثر کاوش کرد.
مثال ۴.۶. کاوش مجموعه اقلام پرتکرار با استفاده از قالب داده عمودی. قالب داده افقی پایگاه داده تراکنش، D، از جدول ۴.۱ در مثال ۴.۳ را در نظر بگیرید. این را میتوان با یک بار اسکن مجموعه دادهها به قالب داده عمودی نشان داده شده در جدول ۴.۳ تبدیل کرد.
|
جدول ۴.۳ قالب داده عمودی مجموعه داده تراکنش D از جدول ۴.۱. |
|
|
مجموعه اقلام |
مجموعه TID |
|
I1 |
{T100, T400, T500, T700, T800, T900} |
|
I2 |
{T100, T200, T300, T400, T600, T800, T900} |
|
I3 |
{T300, T500, T600, T700, T800, T900} |
|
I4 |
{T200, T400} |
|
I5 |
{T100, T800} |
|
جدول ۴.۴ ۲- مجموعه اقلام در قالب داده عمودی. |
|
|
مجموعه اقلام |
مجموعه TID |
|
{I1, I2} |
{T100, T400, T800, T900} |
|
{I1, I3} |
{T500, T700, T800, T900} |
|
{I1, I4} |
{T400} |
|
{I1, I5} |
{T100, T800} |
|
{I2, I3} |
{T300, T600, T800, T900} |
|
{I2, I4} |
{T200, T400} |
|
{I2, I5} |
{T100, T800} |
|
{I3, I5} |
{T800} |
|
جدول ۴.۵ مجموعه اقلام ۳- در قالب داده عمودی. |
|
itemset TID_set |
|
{I1, I2, I3} {T800, T900} {I1, I2, I5} {T100, T800} |
کاوش را میتوان روی این مجموعه داده با تقاطع مجموعههای TID هر جفت از اقلام منفرد پرتکرار انجام داد. حداقل تعداد پشتیبان ۲ است. از آنجا که هر قلم در جدول ۴.۳ پرتکرار است، در مجموع ۱۰ تقاطع انجام میشود که منجر به هشت مجموعه ۲-آیتمی غیرتهی میشود، همانطور که در جدول ۴.۴ نشان داده شده است.
توجه داشته باشید که از آنجا که مجموعههای اقلام {I1، I4} و {I3، I5} هر کدام فقط شامل یک تراکنش هستند، به مجموعه مجموعههای ۲-آیتمی پرتکرار تعلق ندارند.
بر اساس ویژگی Apriori، یک مجموعه ۳-آیتمی داده شده تنها در صورتی یک مجموعه ۳-آیتمی کاندید است که هر یک از زیرمجموعههای ۲-آیتمی آن پرتکرار باشد. فرآیند تولید کاندید در اینجا فقط دو مجموعه ۳-آیتمی تولید میکند:
{I1، I2، I3} و {I1، I2، I5}. با تقاطع مجموعههای TID هر دو مجموعه ۲ آیتمی متناظر از این مجموعههای ۳ آیتمی کاندید، جدول ۴.۵ حاصل میشود که در آن فقط دو مجموعه ۳ آیتمی پرتکرار وجود دارد: {I1، I2، I3: 2} و {I1، I2، I5: 2}.
مثال ۴.۶ فرآیند کاوش مجموعههای آیتم پرتکرار را با بررسی فرمت دادههای عمودی نشان میدهد.
ابتدا، دادههای با فرمت افقی را با یک بار اسکن مجموعه دادهها به فرمت عمودی تبدیل میکنیم. تعداد پشتیبان یک مجموعه آیتم به سادگی طول مجموعه TID مجموعه آیتم است. با شروع ازk = 1، میتوان از مجموعههای آیتم k پرتکرار برای ساخت مجموعه آیتمهای کاندید (k +1) بر اساس ویژگی Apriori استفاده کرد. محاسبه با تقاطع مجموعههای TID مجموعههای آیتم k پرتکرار برای محاسبه مجموعههای TID مجموعههای آیتم (k +1) متناظر انجام میشود. این فرآیند تکرار میشود، با افزایش k هر بار ۱، تا زمانی که هیچ مجموعه آیتم پرتکرار یا مجموعه آیتم کاندیدی پیدا نشود.
علاوه بر بهرهگیری از ویژگی Apriori در تولید مجموعه آیتمهای کاندید (k +1) از مجموعه آیتمهای پرتکرار k، مزیت دیگر این روش این است که نیازی به اسکن پایگاه داده برای یافتن پشتیبانی از مجموعه آیتمهای (k +1) نیست (برای k ≥ 1). این به این دلیل است که مجموعه TID هر مجموعه k حاوی اطلاعات کامل مورد نیاز برای شمارش چنین پشتیبانی است. با این حال، مجموعههای TID میتوانند بسیار طولانی باشند و فضای حافظه قابل توجهی و همچنین زمان محاسبه برای تقاطع مجموعههای طولانی را اشغال کنند.
برای کاهش بیشتر هزینه ثبت مجموعههای TID طولانی و همچنین هزینههای بعدی تقاطعها، میتوانیم از تکنیکی به نام diffset استفاده کنیم که فقط تفاوتهای مجموعههای TID یک مجموعه آیتم (k +1) و یک مجموعه آیتم k مربوطه را ردیابی میکند. برای مثال، در مثال ۴.۶ داریم {I1} = {T100,T400, T500, T700, T800, T900} و {I1, I2} = {T100, T400, T800, T900}. تفاضل بین این دو diffset({I1, I2}, {I1}) = {T500, T700} است. بنابراین، به جای ثبت چهار TID که محل تقاطع {I1} و {I2} را تشکیل میدهند، میتوانیم از diffset برای ثبت فقط دو TID استفاده کنیم که نشاندهنده تفاوت بین {I1} و {I1, I2} است. با چنین حسابداری فشردهای، فراوانی مجموعه اقلام همچنان میتواند به درستی محاسبه شود. آزمایشها نشان میدهد که در موقعیتهای خاص، مانند زمانی که مجموعه دادهها شامل الگوهای متراکم و طولانی زیادی است، این تکنیک میتواند هزینه کل استخراج قالب عمودی مجموعه اقلام پرتکرار را به میزان قابل توجهی کاهش دهد.
کاوش الگوهای بسته و حداکثر
در بخش ۴.۱.۲ دیدیم که چگونه کاوش مجموعه اقلام پرتکرار ممکن است تعداد زیادی مجموعه اقلام پرتکرار ایجاد کند، به خصوص زمانی که آستانه min_sup پایین تنظیم شده باشد یا زمانی که الگوهای طولانی در مجموعه دادهها وجود داشته باشد.
مثال ۴.۲ نشان داد که مجموعه اقلام پرتکرار بسته۸ میتواند تعداد الگوهای تولید شده در کاوش مجموعه اقلام پرتکرار را به طور قابل توجهی کاهش دهد و در عین حال اطلاعات کامل مربوط به مجموعه اقلام پرتکرار را حفظ کند. یعنی، از مجموعه مجموعه اقلام پرتکرار بسته، میتوانیم به راحتی مجموعه مجموعه اقلام پرتکرار و پشتیبانی آنها را استخراج کنیم. بنابراین در عمل، در بیشتر موارد، کاوش مجموعه مجموعه اقلام پرتکرار بسته مطلوبتر از مجموعه همه مجموعه اقلام پرتکرار است.
“چگونه میتوانیم مجموعه اقلام پرتکرار بسته را کاوش کنیم؟” یک رویکرد ساده این است که ابتدا مجموعه کامل مجموعه اقلام پرتکرار را کاوش کنیم و سپس هر مجموعه اقلام پرتکراری را که زیرمجموعه مناسبی از یک مجموعه اقلام پرتکرار موجود است و پشتیبانی مشابه آن را دارد، حذف کنیم. با این حال، این کار بسیار پرهزینه است. همانطور که در مثال ۴.۲ نشان داده شده است،این روش ابتدا باید ۲۱۰۰ -۱ مجموعه اقلام پرتکرار را استخراج کند تا یک مجموعه اقلام پرتکرار با طول ۱۰۰ به دست آورد، قبل از اینکه بتواند شروع به حذف مجموعه اقلام اضافی کند. این کار بسیار پرهزینه است. در واقع، فقط تعداد بسیار کمی مجموعه اقلام پرتکرار بسته در مجموعه داده مثال ۴.۲ وجود دارد.
یک روش پیشنهادی این است که به محض اینکه بتوانیم مورد مجموعه اقلام بسته را در حین کاوش شناسایی کنیم، فضای جستجو را هرس کنیم. به عنوان مثال، یک روش ادغام مجموعه اقلام به شرح زیر معرفی میشود.
ادغام مجموعه اقلام. اگر هر تراکنشی که شامل یک مجموعه اقلام پرتکرار X است، شامل یک مجموعه اقلام Y نیز باشد اما هیچ فرامجموعه مناسبی از Y نداشته باشد، آنگاه X ∪Y یک مجموعه اقلام بسته پرتکرار تشکیل میدهد و نیازی به جستجوی هر مجموعه اقلامی که حاوی X است اما Y ندارد، نیست.
برای مثال، در جدول 4.2 از مثال 4.5، پایگاه داده شرطی پیشبینی شده برای مجموعه اقلام پیشوندی {I5:2} به صورت {{I2, I1}, {I2, I1, I3}} است که از آن میتوانیم ببینیم که هر یک از تراکنشهای آن شامل مجموعه اقلام {I2, I1} است اما هیچ فرامجموعه مناسبی از {I2, I1} ندارد. مجموعه اقلام {I2, I1} را میتوان با {I5} ادغام کرد تا مجموعه اقلام بسته {I5, I2, I1: 2} را تشکیل دهد و نیازی به کاوش برای مجموعه اقلام بستهای که شامل I5 هستند اما {I2, I1} نیستند، نداریم.
روشهای هرس و بررسی بسته شدن فضای جستجو زیادی برای کاوش مجموعه اقلام بسته پرتکرار توسعه داده شدهاند. علاوه بر این، از آنجا که مجموعه اقلام با حداکثر فراوانی شباهتهای زیادی با مجموعه اقلام با حداکثر فراوانی دارند، بسیاری از تکنیکهای بهینهسازی توسعهیافته برای کاوش مجموعه اقلام بسته را میتوان به کاوش مجموعه اقلام با حداکثر فراوانی تعمیم داد. خوانندگان علاقهمند میتوانند با مطالعه مقالات تحقیقاتی مرتبط، عمیقتر کاوش کنند.


