
مقدمه
دادههای پرت (Outliers) همیشه بخشی از واقعیتهای یک دیتاست هستند. گاهی بیخطر و قابلچشمپوشی، گاهی هم مخرب و گمراهکننده است. اهمیت این دادهها فقط در مقدار غیرعادیشان نیست، بلکه در تأثیری است که میتوانند بر تحلیل، تصمیمگیری و مدلهای یادگیری ماشین داشته باشند. در این بخش بررسی میکنیم که دادههای پرت چگونه میتوانند نتایج تحلیل را تغییر دهند و چرا شناخت درست آنها برای هر تحلیلگر حرفهای ضروری است.
شناسایی و مدیریت دادههای پرت، یک کار تزئینی یا مرحله جانبیِ تمیزکاری داده نیست؛ بلکه بخشی حیاتی از تحلیل داده مسئولانه در همهی رشتههای کمی است. اگر با دادههای پرت درست و آگاهانه برخورد نشود، میتوانند:
- خلاصههای توصیفی را بهشدت تحریف کنند،
- مفروضات کلیدی مدلهای آماری را نقض کنند،
- عملکرد و پایداری الگوریتمهای یادگیری ماشین را کاهش دهند،
- مشکلات اساسی کیفیت داده را پنهان کنند،
- و مهمتر از همه، باعث شوند سیگنالهای بسیار مهمی که در قالب نقاط ظاهراً عجیب ظاهر میشوند، نادیده گرفته شوند
در ادامه، این اثرات را بهصورت لایهبهلایه مرور میکنیم.
1. تحریف شدید آمار توصیفی کلاسیک
بسیاری از معیارهایی که در تحلیل مقدماتی استفاده میکنیم – مثل میانگین و انحراف معیار – ذاتاً غیرمقاوم هستند و با حضور چند مقدار پرت، بهسرعت از واقعیت دور میشوند.
1.1 معیارهای گرایش مرکزی
میانگین حسابی نقطهی شکست صفر درصد دارد؛ یعنی یک مقدار پرتِ بسیار بزرگ یا بسیار کوچک میتواند میانگین را به هر سمتی که بخواهد بکشد. در دادههای چوله یا آلوده، این یعنی میانگین دیگر نمایندهی رفتار معمول نیست.
در مقابل:
- میانه نقطهی شکست ۵۰٪ دارد و در برابر وجود حتی تعداد قابلتوجهی دادهی پرت، پایدار میماند.
- میانگین پیرایششده (Trimmed Mean) با حذف مثلاً ۵ یا ۱۰ درصد از مقادیر انتهایی، اثر نقاط بسیار دور را کاهش میدهد.
- میانگین وینسورایزشده (Winsorized Mean) بهجای حذف مقادیر انتهایی، آنها را با مقادیر نزدیکتر جایگزین میکند و سپس میانگین میگیرد.
این رویکردها، تصویر بسیار واقعیتری از مرکز داده در حضور Outlierها میدهند.
1.2 معیارهای پراکندگی
واریانس و انحراف معیار به مربع فاصله از میانگین وابستهاند؛ بنابراین دادههای پرت، سهم بسیار بزرگی در آنها دارند نتیجه:
- برآورد پراکندگی بهطور غیرواقعی بزرگ میشود،
- دادهی ما پرنوسانتر از آنچه واقعاً هست بهنظر میرسد.
به همین دلیل، در حضور دادههای پرت، بهتر است از معیارهای مقاوم استفاده کنیم، مثل:
- دامنه بین چارکی (IQR)
- انحراف مطلق میانه (MAD)
- سایر تخمینگرهای مقیاس مبتنی بر چندکها یا تخمینگرهای مقاوم نوع M
1.3 معیارهای شکل (چولگی و کشیدگی)
وجود یک یا چند مقدار بسیار شدید در دمهای توزیع، بهراحتی میتواند:
- چولگی محاسبهشده را بزرگ کند،
- کشیدگی (Kurtosis) را بالا ببرد و توزیع را دمسنگین نشان دهد،
و این در حالی است که شاید واقعاً توزیع آنقدر هم غیرعادی نباشد. معیارهای مقاوم برای چولگی و کشیدگی وجود دارند ، اما در عمل کمتر استفاده میشوند؛ در حالیکه در حضور Outlier، بسیار مفیدترند.
2. نقض مفروضات اساسی در استنباط و مدلسازی آماری
بخش عمدهای از آمار استنباطی روی مفروضاتی بنا شده که دادههای پرت بهراحتی آنها را نقض میکنند.
2.1 فرض نرمال بودن
آزمونهای t، ANOVA و رگرسیون کلاسیک (OLS) غالباً فرض میکنند که:
- خطاها (Residualها) نرمالاند،
- یا خود دادهها تقریباً توزیع نرمال دارند.
دادههای پرت معمولاً در دمهای توزیع قرار میگیرند و باعث:
- چولگی،
- دمهای سنگین،
- و انحراف آشکار از نرمال بودن
میشوند. نتیجه: مقادیر p و بازههای اطمینان میتوانند بهطور جدی غلطانداز باشند.
ابزارهایی مثل Q-Q Plot، هیستوگرام پسماند، و آزمونهای Shapiro-Wilk یا Kolmogorov–Smirnov هم خودشان به دادههای پرت حساساند و اگر بدون توجه به Outlier استفاده شوند، تشخیص را پیچیدهتر میکنند.
2.2 فرض همسانی واریانس (Homoscedasticity)
در رگرسیون OLS و ANOVA، فرض میشود واریانس خطاها در تمام سطوح پیشبینها ثابت است دادههای پرت میتوانند:
- نواحی موضعی با واریانس بسیار بالا ایجاد کنند،
- و باعث ناهمسانی واریانس (Heteroscedasticity) شوند.
نمودار پسماند در برابر مقادیر برازششده و آزمونهایی مثل Breusch–Pagan یا White به تشخیص کمک میکنند؛ اما باز هم اگر دادههای پرت کنترل نشده باشند، این تشخیصها ممکن است گمراهکننده شوند.
2.3 فرض خطی بودن
در رگرسیون، معمولاً فرض میکنیم رابطه بین پیشبینها و متغیر پاسخ تقریباً خطی است. دادههای پرت با اهرم بالا (مقادیر بسیار دور در متغیرهای X) میتوانند:
- خط رگرسیون را به سمت خود خم کنند،
- رابطهی واقعی را پنهان کنند،
- یا در جایی که رابطهای غیرخطی وجود دارد، ظاهر خطیِ جعلی بسازند.
شاخصهایی مثل فاصلهی کوک (Cook’s Distance)، DFFITS و DFBETAS برای شناسایی همین نقاط نفوذی طراحی شدهاند.
2.4 فرض استقلال
خود دادههای پرت لزوماً استقلال را نقض نمیکنند، اما اگر Outlierها در زمانها، مکانها یا دستههای خاصی متمرکز شده باشند، میتوانند:
- الگوهای ظاهری خودهمبستگی یا خوشهبندی در پسماندها ایجاد کنند،
- و باعث شوند تحلیلگر بهاشتباه به وجود ساختار وابستگی در خطاها مشکوک شود.
در هر حال، نقض هر یک از این مفروضات، یعنی نتایج استنباطی غیرقابلاعتماد و مدلهایی که روی دادهی جدید عملکرد خوبی ندارند.
3. کاهش عملکرد و پایداری مدلهای یادگیری ماشین
در یادگیری ماشین، دادههای پرت میتوانند هم دقت را پایین بیاورند، هم مدل را ناپایدار کنند.
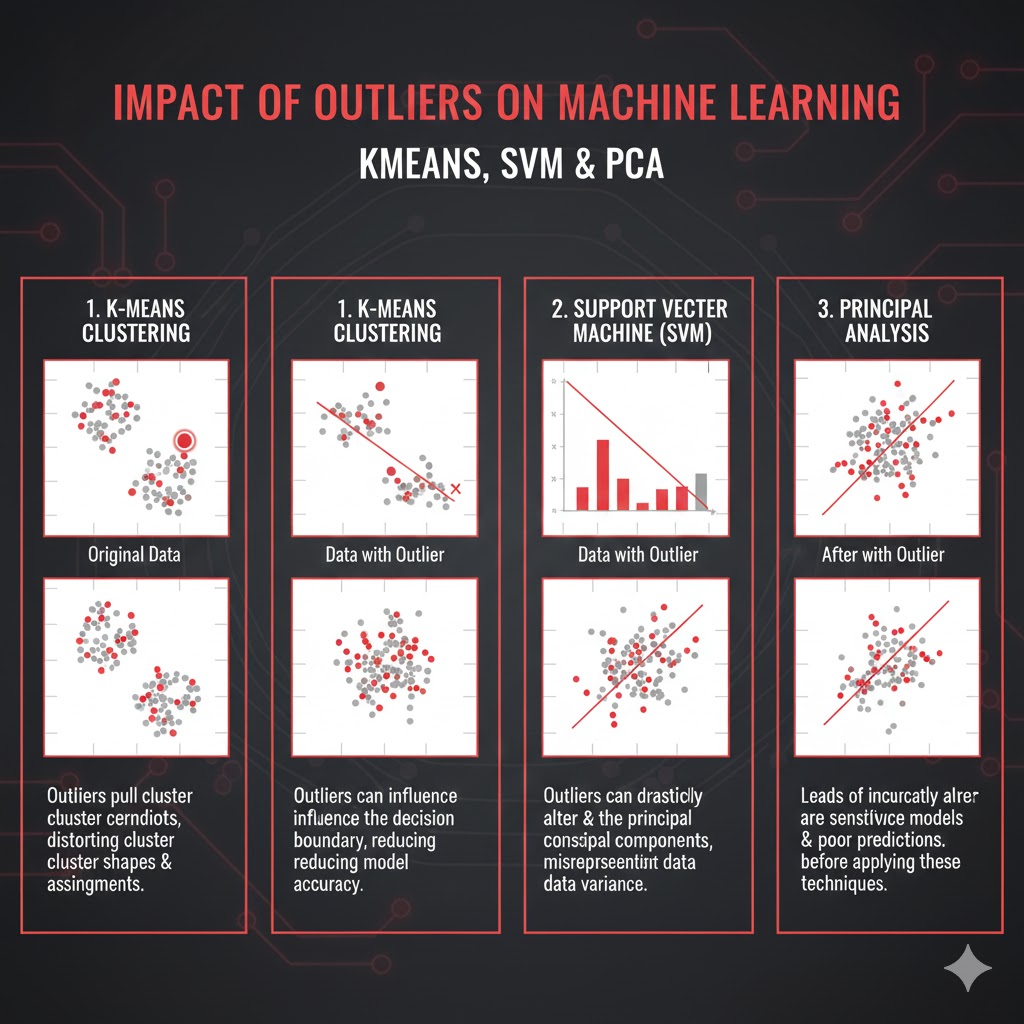
3.1 الگوریتمهای مبتنی بر فاصله (K-Means، KNN، SVM)
- K-Means: چند نقطهی پرت میتوانند مراکز خوشهها را از مرکز واقعی دادهها دور کنند .
- KNN: همسایگی یک نقطهی عادی میتواند توسط چند Outlier اشغال شود، و در نتیجه طبقهبندی یا رگرسیون کاملاً منحرف شود.
- SVM: نقاط پرت نزدیک یا آنسوی مرز تصمیم، میتوانند بهطور نامتناسبی روی ابرصفحهی جداکننده تأثیر بگذارند و حاشیه را کوچک و تعمیمپذیری را ضعیف کنند.
در روشهای کرنلمحور، این حساسیت گاهی حتی بیشتر هم میشود.
3.2 مدلهای خطی (رگرسیون خطی/لاجستیک، LDA)
پیادهسازیهای کلاسیک که بر حداقل مربعات یا حداکثر درستنمایی تحت مفروضات استاندارد تکیه دارند، همچنان نسبت به دادههای پرت آسیبپذیرند.
در LDA، تخمین میانگین کلاسها و ماتریس کوواریانس تجمیعی – که هر دو غیرمقاوم هستند – باعث میشوند چند نقطهی پرت بتوانند مرزهای تفکیک را بهطور جدی جابهجا کنند.
3.3 کاهش ابعاد (PCA و …)
PCA بهدنبال جهتهایی است که بیشترین واریانس را توضیح میدهند. از آنجا که Outlierها سهم بزرگی در واریانس دارند، میتوانند:
- محورهای اصلی را به سمت خود بکشند،
- و ساختار واقعیِ بخش عمدهی دادهها را پنهان کنند.
در نتیجه، نمایش دوبعدی/سهبعدی که از PCA به دست میآید، ممکن است بیش از آنکه ساختار نرمال داده را نشان دهد، توسط چند Outlier کنترل شود.
(در کنار PCA، روشهای دیگری مثل t-SNE برای تجسم دادههای با ابعاد بالا استفاده میشوند، اما آنها نیز در برابر نقاط بسیار دور میتوانند رفتار غیرمنتظره داشته باشند).
3.4 مدلهای مبتنی بر درخت (درخت تصمیم، جنگل تصادفی)
درخت تصمیم از بسیاری مدلهای خطی مقاومتر است، اما:
- اگر یک دادهی پرت روی معیارهای ناخالصی (مثل جینی یا آنتروپی) اثر بگذارد،
- یا در سطوح بالای درخت منجر به تقسیمهای نامناسب شود،
میتواند ساختار درخت را خراب کند.
جنگل تصادفی با میانگینگیری روی درختهای متعدد و استفاده از نمونهگیری تصادفی ویژگیها، اثر تکنقطهها را کاهش میدهد ، اما اگر پرتها بسیار شدید باشند، هنوز هم اثر باقیمانده خواهند داشت.
3.5 شبکههای عصبی و روشهای عمیق
در شبکههای عصبی:
- خطاهای بزرگ مرتبط با Outlierها میتوانند باعث انفجار گرادیان شوند و بهینهسازی را ناپایدار کنند .
- مقادیر بسیار بزرگ میتوانند بعضی نورونها را بهطور کامل در نواحی اشباع توابع فعالسازی ببرند و یادگیری را مختل کنند.
برای کاهش این اثرات، معمولاً از:
- برش گرادیان (Gradient Clipping)
- توابع زیان مقاوم (مثل Huber Loss)
- نرمالسازی درست ورودیها
استفاده میشود، اما مسئلهی Outlier کاملاً از بین نمیرود .
در عین حال، از همین شبکهها میتوان برای تشخیص ناهنجاری هم استفاده کرد:
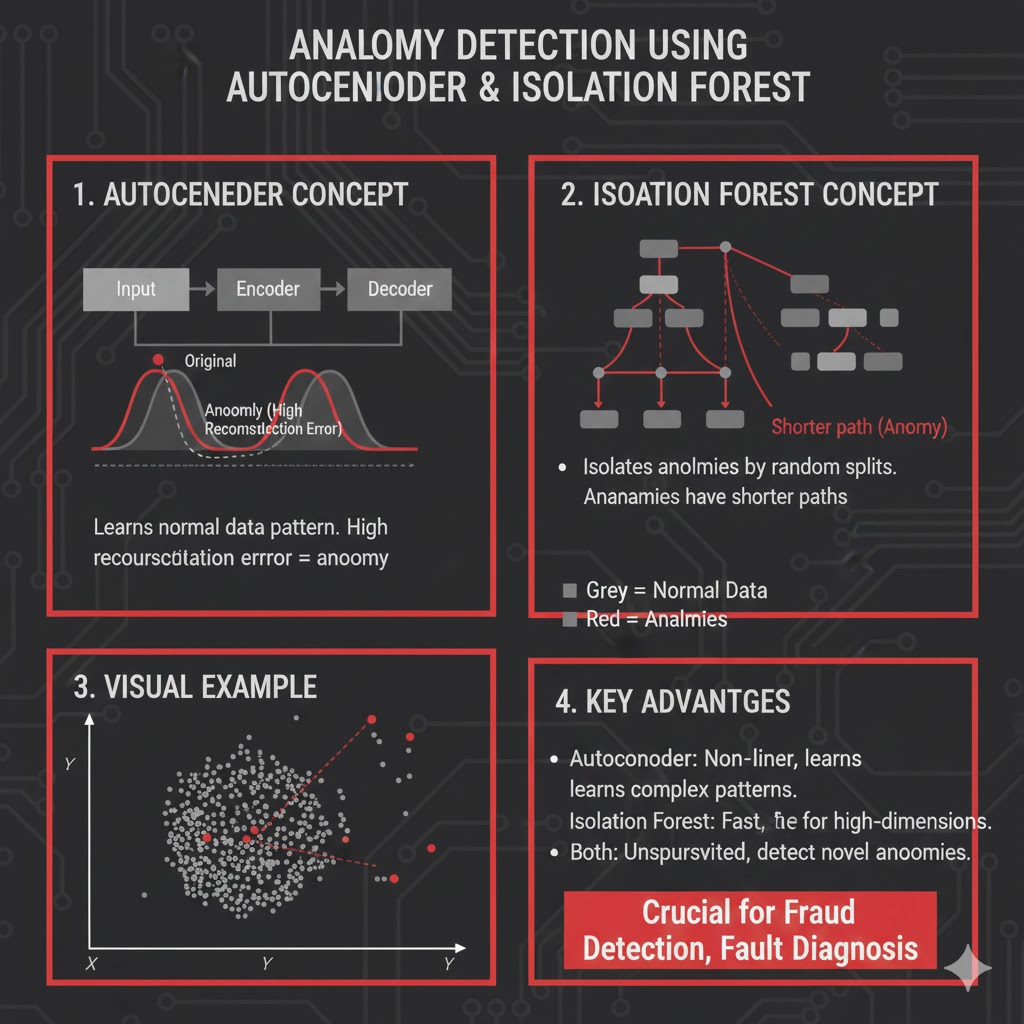
Autoencoderها:
- روی دادههای عادی آموزش میبینند تا ورودی را بازسازی کنند.
- نقاطی که خطای بازسازی آنها خیلی بزرگ است، بهعنوان Outlier علامتگذاری میشوند.
- نسخههای مختلف مثل VAE و Denoising Autoencoder، در مواجهه با نویز و ناهنجاری رفتار بهتری دارند.
GANها:
- یک شبکه تولیدکننده و یک شبکه تمایزدهنده دارند.
- اگر دادهای بهخوبی توسط مدل یادگرفتهشده قابل تولید یا بازشناسی نباشد، میتواند ناهنجار تلقی شود .
RNN / LSTM برای سریهای زمانی:
- روی توالیهای نرمال آموزش میبینند تا مقدار بعدی را پیشبینی کنند.
- اختلاف زیاد بین مقدار واقعی و پیشبینی شده، نشانهی ناهنجاری است.
4. پنهان کردن مسائل مهم کیفیت داده
اغلب، تشخیص دادههای پرت اولین آژیر خطری است که به ما میگوید:
- جایی در اندازهگیری، ثبت، تبدیل واحد، یا ادغام دادهها ایراد وجود دارد.
اگر بدون بررسی، این نقاط را نادیده بگیریم یا کورکورانه حذف کنیم، خطاهای جدی دادهای به مراحل بعدی تحلیل و مدلسازی نشت میکنند و تمام نتایج را آلوده میسازند.
بنابراین، استفاده از روالهای تشخیص Outlier بخشی از کنترل کیفیت داده (Data Quality Assurance) است، نه فقط یک کار آماری جانبی.
5.نادیده گرفتن دادههای پرت سیگنال
از آنطرف، بدترین سناریو این است که دادههای پرت، نه خطا، بلکه سیگنالهای حیاتی باشند و ما با حذف مکانیکیشان آنها را نابود کنیم. نمونهها:
- در تشخیص تقلب، دقیقاً همان تراکنشهای غیرعادی هستند که اهمیت دارند.
- در امنیت شبکه، الگوهای ترافیکی عجیب، نشانهی نفوذ یا حملهاند.
- در پزشکی، تغییر ناگهانی علائم حیاتی یا یک لکهی غیرطبیعی در تصویر پزشکی میتواند مربوط به وضعیت بحرانی بیمار باشد.
- در نگهداری پیشگویانه، قرائتهای غیرعادی حسگر، هشدار قبل از خرابی بزرگ تجهیزات است .
- در کشف علمی، بسیاری از پیشرفتهای بزرگ دقیقاً از مشاهدهی یک مقدار غیرمنتظره شروع شدهاند.
اگر با این نوع دادههای پرت مثل نویز رفتار کنیم، فرصتهای مهمی را از دست میدهیم و حتی ممکن است تبعات سنگینی مثل عدم شناسایی تقلب یا از دست دادن تشخیص حیاتی را تجربه کنیم. اینجا نقش تخصص دامنه و درک زمینه کاملاً کلیدی است.
6.تأثیرات دادههای پرت بر تحلیل دادهها
جدول زیر چند اثر مهم دادههای پرت را بهصورت خلاصه نشان میدهد:
| نوع تأثیر (Impact) | چکیده آسیب (چه میشود؟) | مثال ملموس (فلشبک) |
| ۱. فریب آماری | میانگین و انحراف معیار را به دروغ تغییر میدهد و تصویری غلط از نرمال میسازد. | حقوق مدیرعامل: حقوق نجومی او باعث میشود میانگین درآمد کارمندان به دروغ بالا به نظر برسد. |
| ۲. انحراف مدل (ML) | خطای مدل را بالا برده و دقت پیشبینی را نابود میکند (Bad Fit). | قیمت مسکن: وجود یک «قصر تاریخی» در دیتاست، مدل را در قیمتگذاری آپارتمانهای معمولی گیج میکند. |
| ۳. توهم الگو | روندی را نشان میدهد که وجود خارجی ندارد (روند کاذب). | فروش جعلی: یک خطای تایپی (صفر اضافی) نمودار فروش را صعودی نشان میدهد، در حالی که رشدی در کار نیست. |
| ۴. کوری آماری | واریانس را زیاد کرده و باعث میشود تفاوتهای واقعی در آزمونها دیده نشوند. | تست دارو: واکنش عجیب چند بیمار باعث میشود تأثیر مثبت دارو روی بقیه، از نظر آماری بیمعنی شود. |
| ۵. تخریب نمودار | مقیاس محورها (Scale) را به هم میریزد و دادههای دیگر را ناخوانا میکند. | نمودار وزن: وجود عدد ۳۰۰۰ کیلوگرم باعث میشود بقیه افراد مثل یک نقطه ریز و فشرده دیده شوند. |
| ۶. زیان مالی | تحلیل غلط منجر به استراتژی غلط و ضرر سنگین میشود. | تولید اشتباه: کارخانه بر اساس تقاضای کاذب (ناشی از داده پرت) تولید انبوه میکند و کالا روی دستش میماند. |
7.مطالعات موردی
مطالعه موردی ۱: نگهداری پیشگویانه در خط تولید خودرو 🤖
سناریو: سنسورهای لرزشسنج روی بازوهای رباتیک کارخانه نصب شدهاند تا سلامت دستگاه را پایش کنند.
۱. منشأهای احتمالی:
- نویز محیطی: عبور لیفتراک سنگین از کنار ربات که باعث لرزش لحظهای سنسور شده است (نویز).
- خرابی سنسور: قطع و وصل شدن کابل سنسور که اعداد پرت و پلا ثبت میکند.
- خرابی واقعی: شکستگی جزئی در بلبرینگ داخلی ربات که باعث ایجاد پیکهای لرزشی متوالی میشود (سیگنال مهم).
۲. تأثیر دادههای پرت:
- در مانیتورینگ: اگر نویزها حذف نشوند، سیستم مدام آلارم غلط میدهد و اپراتورها نسبت به هشدارها بیتفاوت میشوند.
- در مدل پیشبینی: اگر دادههای خرابی واقعی به اشتباه حذف شوند (به تصور اینکه نویز هستند)، ربات ناگهان میشکند و خط تولید ۴۸ ساعت متوقف میشود.
۳. راهکار مدیریت:
- تشخیص: استفاده از تحلیلهای سری زمانی و چک کردن تداوم ناهنجاری (آیا فقط یک لحظه بود یا ادامه دارد؟).
- بررسی منشأ: مقایسه با دادههای سنسورهای مجاور. اگر فقط یک سنسور جیغ میکشد، احتمالاً سنسور خراب است; اگر همه میلرزند، عامل محیطی است.
- تصمیم:
- اگر نویز لحظهای است ← استفاده از فیلترهای هموارسازی (Smoothing) مثل میانگین متحرک.
- اگر الگوی تکرارشونده است ← توقف برنامهریزی شده دستگاه برای بازرسی فنی (قبل از شکست کامل).
- تحلیل حساسیت: شبیهسازی هزینهی بازرسی بیمورد در برابر هزینهی توقف خط تولید برای تعیین نقطه بهینه هشدار.
مطالعه موردی ۲: پیشبینی قیمت مسکن (مشاور املاک هوشمند) 🏠
سناریو: مدل هوش مصنوعی در حال تخمین قیمت خانهها بر اساس متراژ، منطقه و سال ساخت است.
۱. منشأهای احتمالی:
- خطای تایپی: وارد کردن یک صفر اضافی در قیمت (مثلاً ۱۰ میلیارد به جای ۱ میلیارد).
- ملک خاص: وجود یک عمارت تاریخی ثبتشده یا یک قصر لوکس در محلهای معمولی.
- فروش اضطراری: فروش خانه زیر قیمت بازار به دلیل نیاز فوری به پول.
۲. تأثیر دادههای پرت:
- در آمار توصیفی: میانگین قیمت منطقه به شدت بالا میرود و خریداران معمولی را فراری میدهد.
- در مدل رگرسیون: خط رگرسیون به سمت آن قصر لوکس کشیده میشود (اثر اهرمی). نتیجه این است که مدل قیمت آپارتمانهای معمولی را هم گرانتر از واقعیت تخمین میزند.
۳. راهکار مدیریت:
- تشخیص: استفاده از فاصله کوک (Cook’s Distance) برای پیدا کردن نقاطی که خط رگرسیون را کج کردهاند، یا نمودار. Scatter Plot
- بررسی منشأ: بررسی آگهی فروش و توضیحات ملک توسط کارشناس انسانی.
- تصمیم:
- اگر خطای تایپی است ← اصلاح عدد بر اساس متراژ و میانگین منطقه.
- اگر ملک خاص است ← حذف از مدل عمومی و ساخت یک مدل جداگانه برای املاک لوکس (Segmentation).
- تحلیل حساسیت: اجرای مدل با و بدون آن عمارت تاریخی برای دیدن اینکه ضریب خطای مدل (RMSE) چقدر بهبود مییابد
نتیجه گیری
در این مقاله، سفر پرفراز و نشیبی را طی کردیم؛ از تاثیرات مخرب دادههای پرت بر سادهترین میانگینها تا قدرت آنها در به زانو درآوردن پیچیدهترین شبکههای عصبی.
ما دیدیم که دادههای پرت (Outliers) شمشیر دولبهی علم داده هستند. آنها همزمان میتوانند «قاتل مدل» و «منجی کسبوکار» باشند. اگر آنها را نادیده بگیرید، مدلهایتان دروغ میگویند ؛ و اگر کورکورانه حذفشان کنید، ممکن است گنجینههایی مثل کشف تقلب یا پیشبینی خرابی دستگاه را دور بریزید.
خلاصه درسهای کلیدی:
- آمار فریبنده است: به میانگین و واریانس اعتماد نکنید. آنها در برابر پرتها بیدفاعاند. همیشه نیمنگاهی به معیارهای مقاوم مثل میانه و IQR داشته باشید.
- مدلها شکنندهاند: از رگرسیون خطی گرفته تا K-Means، بسیاری از الگوریتمها با یک دادهی اشتباه گمراه میشوند. شناخت نقاط ضعف هر مدل، وظیفه شماست.
- زمینه (Context) پادشاه است: یک عدد به تنهایی «پرت» نیست. این «شرایط» است که تعیین میکند آیا خرید ۵۰۰ دلاری یک دانشجو، طبیعی است یا کلاهبرداری.


