
مقدمه
پس از بررسی روشهای سنتی تشخیص دادههای پرت — از جمله آماری، غیرپارامتریک، فاصلهای و خوشهبندی — به سراغ ابزارهای پیشرفته میرویم، چون در دنیای واقعی دادهها اغلب چندبعدی، حجیم، پیچیده یا دارای وابستگیهای زمانی هستند و در چنین شرایطی، روشهای کلاسیک دیگر پاسخگو نیستند؛ درنتیجه نیاز به مدلهای هوشمندِ مبتنی بر یادگیری ماشین و یادگیری عمیق افزایش مییابد.
برای مواجهه مؤثر با این چالشها، از روشهای مبتنی بر مدل، یادگیری یککلاسه و نیمهنظارتی استفاده میشود.همچنین، الگوریتمهای فاصلهای و هستهای در حوزه یادگیری ماشین نقش مهمی ایفا میکنند.مدلهای بازسازیکننده، شبکههای عمیقی مانند Autoencoder و LSTM و روشهای Ensemble نیز برجستهاند.این تکنیکهای مدرن، بهویژه در دادههای پُربُعد، سریزمانی، مالی، سنسوری یا امنیتی، عملکرد بهتری دارند.آنها انعطاف و دقت بیشتری در شناسایی الگوهای ناهنجار فراهم میکنند.
این مقاله راهنمای عملیِ تشخیص پرتهای پیچیدهای است که روشهای سنتی در برابر آنها ناتوان میمانند.
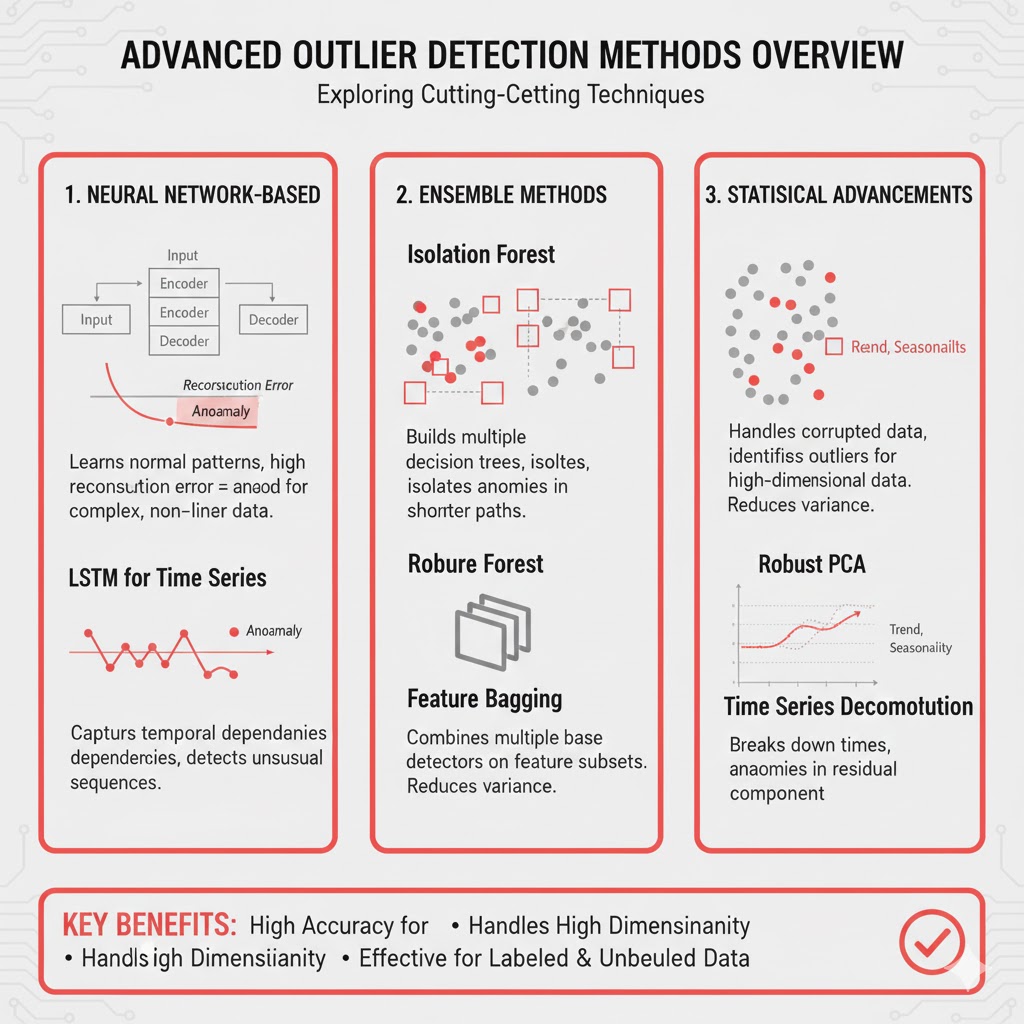
۵. روشهای مبتنی بر مدل (Model-Based Outlier Detection)
در این رویکرد، ابتدا یک مدل آماری یا پیشبینیکننده روی دادهها برازش میشود.
اگر یک مشاهده:
- احتمال بسیار کمی طبق مدل داشته باشد،
- یا پسماند بزرگ و غیرعادی ایجاد کند،
- یا پارامترهای مدل را تغییر زیادی دهد،
آن مشاهده به عنوان داده پرت (Outlier) شناسایی میشود.
این روشها زمانی بسیار مؤثرند که دادهها دارای رابطه ساختاری، روند یا وابستگی زمانی باشند.
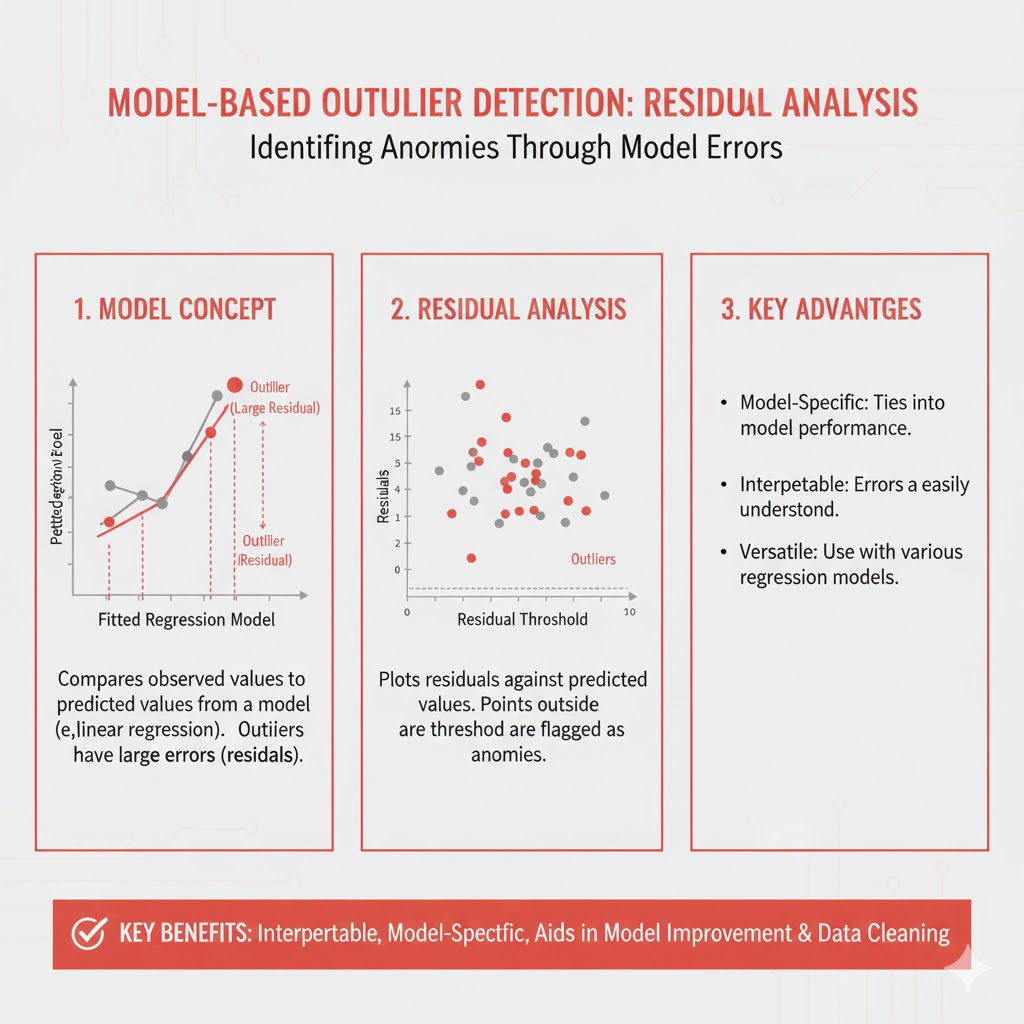
۵.۱. تحلیل پسماند (Residual Analysis)
سادهترین و عمومیترین روش مدلمحور.
ایده اصلی
مدل روی داده برازش میشود.اگر مقدار واقعی با مقدار پیشبینی شده فاصله زیادی داشته باشد ⭠ پرت.
فرمول

معیار پرت بودن
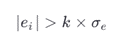
مزایا
- ساده و قابل اجرا روی هر مدلی
- ایدهآل برای سری زمانی و رگرسیون
معایب
- به کیفیت مدل وابسته است
- چند پرت شدید میتوانند مدل را خراب کنند
۵.۲. روشهای مبتنی بر رگرسیون (Regression-Based Detection)
این روشها بهدنبال نقاطی هستند که:
- مقدارشان غیرعادی است
- و تأثیر شدیدی بر تخمین پارامترهای مدل دارند
۵.۲.۱. Cook’s Distance
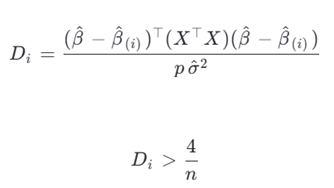
۵.۲.۲. پسماندهای دانشجوییشده (Studentized Residuals)
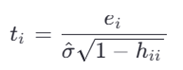
اگر
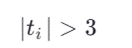
۵.۳. روشهای احتمالاتی (Probabilistic / Likelihood-Based)
این گروه بر پایه احتمال رخداد یک مشاهده طبق مدل است.
۵.۳.۱. روش مبتنی بر درستنمایی (Likelihood-Based)
ایده: اگر احتمال رخداد یک مشاهده تحت مدل بسیار کم باشد، آن مشاهده پرت است.
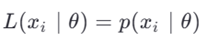
اگر

۵.۳.۲. مدلهای آمیخته گوسی (GMM)
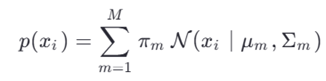
اگر p(xi) کوچک باشد ⭠ پرت
اگر نقطه به هیچ مؤلفهای تعلق زیاد نداشته باشد ⭠ پرت
مزایا
- مناسب دادههای چندبعدی
- خروجی احتمالاتی
معایب
- انتخاب تعداد مؤلفهها سخت
- حساس به initialization
۵.۳.۳. روشهای بیزی (Bayesian Outlier Detection)
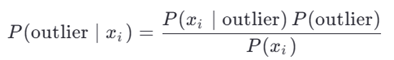
نقطه پرت است اگر:
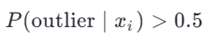
۵.۴. روشهای مبتنی بر سری زمانی (Time-Series Model-Based)
در دادههایی که وابستگی زمانی دارند، تشخیص پرت باید با مدلهای پویای زمانی انجام شود.
۵.۴.۱. پسماند مدل ARIMA
ایده اصلی
در سریزمانی، مدل ARIMA برای در نظر گرفتن روند، فصلی بودن و خودهمبستگی برازش میشود. مشاهداتی که پسماند بزرگی دارند، پرت هستند.
فرمول

معیار پرت بودن
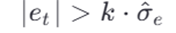
یا با روش غیرپارامتریک:
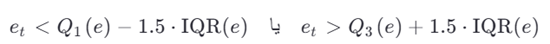
مزایا
- در نظر گرفتن وابستگی زمانی
- جلوگیری از تشخیص کاذب در دادههای با روند
معایب
- به انتخاب صحیح p,d,q وابسته است
- در حضور پرتهای زیاد، مدل مخدوش میشود
- برای ساختارهای غیرخطی (مثل volatility clustering) مناسب نیست
6. روشهای مبتنی بر یادگیری ماشین
در روشهای مبتنی بر یادگیری ماشین، هدف این است که مدلها مرز دادههای عادی را یاد بگیرند . نقاطی را که از این مرز خارج میشوند، پرت تشخیص دهند.این روشها برخلاف روشهای آماری یا فاصلهای، قادرند الگوهای غیرخطی، پیچیده و چندبُعدی را یاد بگیرند.
این دسته روشها در تشخیص تقلب، امنیت شبکه، تحلیل رفتار کاربران، شناسایی تراکنشهای مشکوک و یادگیری بدون نظارت کاربرد گسترده دارند.
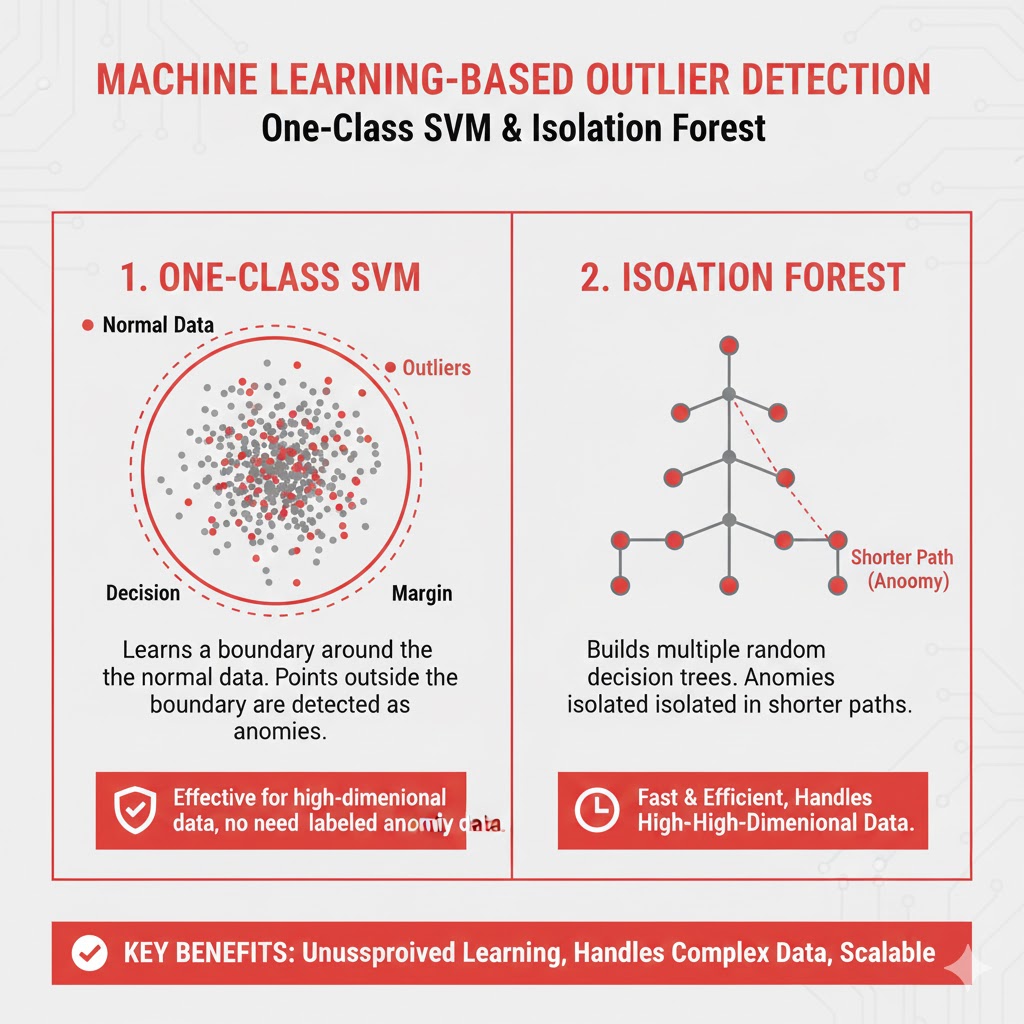
6.1روشهای مبتنی بر بردار پشتیبان (One-Class SVM)
One-Class SVM یکی از مهمترین روشهای تشخیص ناهنجاری در دادههای پیچیده است.
ایده اصلی One-Class SVM
این مدل یک «مرز» در فضای ویژگی میسازد که:
- نقاط نرمال داخل مرز قرار میگیرند
- نقاط پرت خارج مرز قرار میگیرند
و همه اینها فقط با «دادههای نرمال» انجام میشود.
فرمول سادهشده:
مدل SVM توزیع داده را با یک منحنی (Hyperplaneیا شکل منحنیدار در فضای کرنل) محصور میکند:
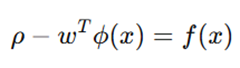
مزایا
- مناسب دادههایی که پرتها بسیار کماند
- فقط به داده عادی نیاز دارد
- پیادهسازی در sklearn آماده است
معایب
- بسیار حساس به انتخاب پارامترها
- با دادههای پُربعد ضعیف میشود (Curse of Dimensionality)
۶.۲ Isolation Forest (نسخه ML)
ایده:
پرتها «سریعتر» از سایر نقاط در یک درخت تصادفی منزوی میشوند.
مدل یک جنگل از درختها میسازد و عمق جداسازی را اندازه میگیرد.
- عمق کوتاه ⭠ پرت
- عمق بلند ⭠ عادی
مزایا
- کارایی بالا روی دادههای بزرگ
- بینیاز از فرض توزیع
- مناسب دادههای پُربعد
معایب
- پارامتر contamination مهم است
- پرتهای ساختاری ظریف را گاهی از دست میدهد
۶.۳. روشهای مبتنی بر کرنل (Kernel-Based Anomaly Detection)
ایده اصلی
با نگاشت داده به فضای ویژگی با ابعاد بالا (Kernel Trick) مدل سعی میکند شکل مرز داده عادی را بهتر یاد بگیرد.
روشها:
- Kernel Density Estimation (KDE) نسخه ML
- Kernel PCA Outlier Detection
- Kernel-based One-Class models
مثال: (Kernel PCA)
اگر بازسازی نقطه در فضای PCA هستهای با خطا همراه باشد، مقدار بازسازی نشده ⭠ پرت.
۶.۴. روشهای نیمهنظارتی (Semi-Supervised Anomaly Detection)
وقتی بخشی از دادهها برچسب عادی دارند (اما پرتها برچسب ندارند).
مدلها:
- Semi-supervised SVM
- Label propagation
- Pseudo-labeling + Isolation Forest
- Autoencoder + ML hybrid
مزایا
- عملکرد بهتر از unsupervised
- مناسب سامانههای تشخیص تقلب بانکی و امنیت شبکه
معایب
- نیاز به داده عادی با برچسب
- خطر آلودگی برچسب (Label Contamination)
۶.۵. روشهای مبتنی بر خوشهبندی+ ML
این دسته ترکیبی از خوشهبندی و ماشین لرنینگ است.
مثالها:
- K-Means + SVM برای تشخیص رفتارهای غیرعادی
- DBSCAN + Random Forest برای دادههای تراکنش
- LOF + ML برای دادههای شبکه
مزایا
- عملکرد پایدارتر
- مناسب دادههای پیچیده با ساختار چندخوشهای
معایب
- نیاز به تنظیم چند مدل همزمان
- هزینه محاسباتی بیشتر
۶.۶چه زمانی از روشهایML استفاده کنیم؟
✔ وقتی شکل توزیع داده ناشناخته است
✔ وقتی پرتها الگوی غیرخطی دارند
✔ وقتی داده چندبُعدیاست
✔ وقتی روشهای آماری و فاصله/چگالی کافی نیستند
✔ برای کاربردهای بانکی، مالی، امنیت شبکه، رفتار کاربران
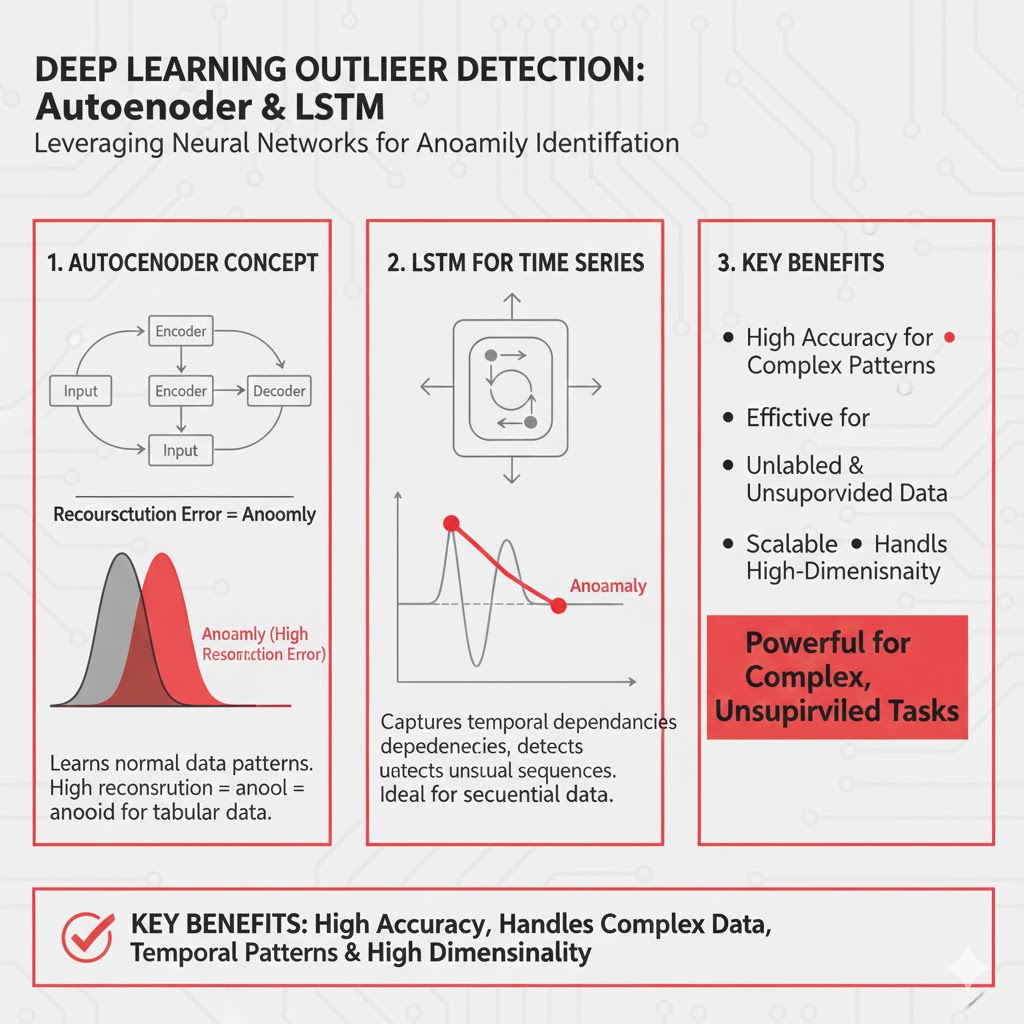
۷. روشهای یادگیری عمیق (Deep Learning–Based Methods)
ایده اصلی
استفاده از معماریهای عصبی عمیق برای یادگیری ساختار غیرخطی و پیچیده دادهها. این روشها مخصوصاً زمانی برتری چشمگیری دارند که دادهها دارای الگوهای پنهان، وابستگیهای بلندمدت (سریزمانی)، یا ساختار چندلایه (مانند روابط بین سپرده، تسهیلات، NPL و سود) باشند.
۷.۱. Deep SVDD (Deep Support Vector Data Description)
ایده اصلی
تعمیم One-Class SVM به فضای عمیق: یک شبکه عصبی دادهها را به فضای ویژگی غیرخطی میبرد و سعی میکند تمام نقاط عادی در یک کره کمینهالحجم قرار گیرند.
فرمول
هدف: یافتن مرکز c و پارامترهای شبکه ϕθ که:
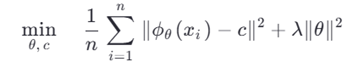
امتیاز پرت:
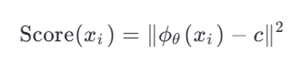
معیار پرت بودن
- اگر Score(xi)>R2 ⭠ پرت
- که R2 میتواند چارک ۹۵-ام امتیازها باشد یا از طریق اعتبارسنجی تنظیم شود.
مزایا
- بدون نیاز به داده پرت در آموزش
- مدلسازی غیرخطی قوی
- خروجی پیوسته و قابل رتبهبندی
معایب
- حساس به انتخاب معماری شبکه و λ
- پیچیدگی آموزش بالا نسبت به Isolation Forest
۷.۲. خودرمزنمای عمیق (Deep Autoencoder)
ایده اصلی
تعمیم Autoencoder ساده با لایههای پنهان عمیق (معمولاً ۳+ لایه در هر سمت) برای یادگیری نمایشهای فشردهتر و معنادارتر.
فرمول

معیار پرت بودن
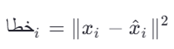
انواع:
- Denoising Deep AE: ورودیها را با نویز تزریقشده تغذیه میکنند تا مدل در برابر دادههای پرت مقاومتر شود.
. - Sparse Deep AE: اعمال محدودیت تنکی (sparsity) روی لایه میانی — تمرکز بر ویژگیهای اصلی.
مزایا
- قابلیت مدلسازی الگوهای پیچیده در دادههای جدولی و ساختاریافته
- سازگاری با pipelineهای موجود (مثل پردازش دادههای مالی)
معایب
- ریسک بیشبرازش (overfitting) ⭠ نیاز به Dropout، Early Stopping
- خطای بازسازی برای متغیرهای با واریانس متفاوت ناعادلانه است ⭠ استانداردسازی ضروری
۷.۳ LSTM Autoencoder- برای سریزمانی
ایده اصلی
برای دادههای سریزمانی (مثل سود روزانه، نقدینگی، نرخ NPL)، استفاده از لایههای LSTM در Encoder و برای مدلسازی وابستگیهای زمانی کوتاه و بلندمدت.
فرمول
برای یک سری زمانی با طول T:
- Encoder (LSTM):
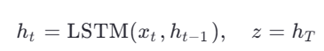
- (LSTM یا Dense):
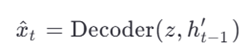
- تابع زیان:
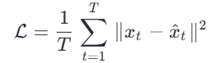
مزایا
- مدلسازی دقیق روندها، فصلی بودن و وابستگیهای غیرخطی
- مناسب برای تشخیص رویدادهای غیرعادی موقت )مثلاً کاهش ناگهانی سپرده در یک شعبه)
معایب
- آموزش کند و حساس به نرخ یادگیری
- در صورت وجود چند پرت در یک پنجره، ممکن است آنها را بازسازی کند
۷.۴. روشهای مبتنی بر GAN
ایده اصلی
یک شبکه مولد (Generator) سعی میکند داده واقعی را تقلید کند؛ یک شبکه تشخیصدهنده (Discriminator) سعی میکند تفاوت داده واقعی و مصنوعی را بفهمد. پرتها دادههایی هستند که مولد نمیتواند آنها را تولید کند و تشخیصدهنده بهراحتی آنها را شناسایی میکند.
روشهای رایج:
AnoGAN
- مولد پس از آموزش ثابت میماند.
- برای یک داده جدید x ، به دنبال کُد پنهان z میگردیم که x^=G(z) به x نزدیک باشد:
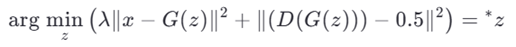
نمره پرت:

f-AnoGAN
- افزودن یک Encoder برای تخمین مستقیم z ⭠ سرعت بسیار بالاتر.
معیار پرت بودن
اگر Anomaly Score در دُم بالا باشد (مثلاً صدک ۹۹) → پرت.
مزایا
- تولید داده واقعگرایانه ⭠ خطاها معنادارند
- مناسب برای دادههای غیرساختاریافته (تصویر، متن) و در صورت تنظیم، سریزمانی
معایب
- ناپایداری آموزش GAN
- پیچیدگی پیادهسازی و تنظیم هایپرپارامترها
۷.۵. روشهای مبتنی بر توجه (Transformer-Based Anomaly Detection)
ایده اصلی
استفاده از مکانیزم توجه (Self-Attention) برای مدلسازی وابستگیهای بلندمدت در سریزمانی بدون نیاز به بازگشت (recurrence). روشهایی مانند Anomaly Transformer یا TranAD در سالهای اخیر معرفی شدهاند.
فرمول (ایده TranAD)
- Encoder: Transformer برای نمایش جهانی داده
- Decoder: تولید خطا
- استفاده از Adversarial Training برای افزایش حساسیت به انحرافات کوچک
امتیاز پرت:
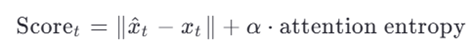
مزایا
- عملکرد بالا در سریهای زمانی طولانی
- موازیسازی کامل ⭠ سرعت بالاتر از LSTM
- تفسیرپذیری نسبی از طریق نقشههای توجه
معایب
- منابع محاسباتی زیاد (GPU قوی)
- در دادههای کوتاهمدت ممکن است بیشبرازش شود
۸. روشهای ترکیبی وEnsemble
روشهای Ensemble با ترکیب چندین آشکارساز ناهنجاری عملکرد بهتری نسبت به استفاده از یک روش تکی ارائه میدهند.
ایده اصلی این است که هر آشکارساز—چه آماری، چه فاصلهای، چه یادگیری عمیق—نقاط قوت و ضعف خاص خودش را دارد.
ترکیب این روشها باعث میشود مدل نهایی:
- پایدارتر
- دقیقتر
- کمریسکتر
- و کاهشدهنده خطاهای نوع اول و دوم باشد.

۸.۱. تجمیع ویژگیها (Feature Bagging)
ایده اصلی
بهجای استفاده از تمام ویژگیها در یک آشکارساز واحد،چندین آشکارساز مستقل بر روی زیرمجموعههای مختلف ویژگیها آموزش داده میشوند.این کار بهویژه در دادههای پُربعد (High-Dimensional) مؤثر است.
مزایا
- کاهش curse of dimensionality
- پایداری بالا
- جلوگیری از تسلط چند ویژگی خاص
معایب
- نیاز به انتخاب اندازه زیرمجموعهها
- افزایش هزینهی محاسباتی
مثال کاربردی
۱۰ زیرمجموعه ویژگی ⭠ روی هرکدام یک LOF ⭠ میانگین امتیاز ⭠ ناهنجاری نهایی.
۸.۲. تجمیع امتیاز (Score-Level Fusion)
هر آشکارساز یک امتیاز ناهنجاری تولید میکند.این امتیازها با یکی از روشهای زیر ترکیب میشوند:
روشها:
- میانگین ساده (Average)
- حداکثر — اگر یکی از مدلها پرت تشخیص دهد، قبول میشود
- حداقل — مناسب مدلهای محافظهکار
- میانگین وزنی (Weighted Average)
- نرمالسازی امتیاز + ادغام
مزایا
- ساده و قابل تفسیر
- قابل تنظیم بر اساس حساسیت مدل
معایب
- انتخاب وزنها و آستانه حساس است
- کیفیت آن به کیفیت مدلهای پایه وابسته است
۸.۳. رأیگیری (Majority / Hard Voting)
در این روش، هر مدل رأی میدهد که آیا نقطه پرت است یا نه.اگر تعداد رأیهای پرت از یک آستانه بیشتر باشد ⭠ پرت.
مثال:
- LOF ⭠ پرت
- iForest ⭠ نرمال
- SVM ⭠ پرت
⭠ ۲ از ۳ ⭠ پرت
مزایا
- آسان و قابل فهم
- مناسب برای ترکیب چند مدل ناهمگون
معایب
- حساسیت به تعداد مدلها
- مدلهای ضعیف میتوانند رأی نهایی را خراب کنند
۸.۴. انباشتگی (Stacking / Cascading)
در این روش، خروجی یک آشکارساز بهعنوان ورودی مدل بعدی استفاده میشود.
Cascading
ابتدا یک مدل سریع و کمهزینه (مثلاً KNN یا Z-Score)
دادهها را فیلتر میکند؛
سپس روی نقاط مشکوکتر یک مدل دقیقتر (مثل Autoencoder یا iForest) اعمال میشود.
Stacking
چندین مدل ⭠ خروجی آنها ⭠ مدل Meta-Learner (مثلاً Logistic Regression یا XGBoost) ⭠ خروجی نهایی.
مزایا
- دقت بالا
- کاهش محاسبه برای دادههای بزرگ (در حالت Cascading)
معایب
- پیادهسازی و تنظیم دشوار
- ریسک بیشبرازش
۸.۵. روشهای Hybrid (ترکیبی)
در این رویکرد، دو یا چند روش غیرهمخانواده با هم ترکیب میشوند برای بهرهگیری از نقاط قوت هر دسته.
مثالهای متداول
- LOF + Autoencoder
(عمق ⭠ ویژگیهای غیرخطی + چگالی محلی) - Isolation Forest + LSTM
(درخت ⭠ ساختار کلی + پیشبینی سری زمانی) - GMM + SVM
(احتمال + مرز غیرخطی) - KMeans + One-Class SVM
(خوشهبندی ⭠ پیشپردازش ML/ ⭠ تشخیص پرت)
۸.۶. چه زمانی از Ensemble استفاده کنیم؟
✔ وقتی دقت خیلی مهم است (مثلاً کشف تقلب بانکی)
✔ وقتی روشهای منفرد رفتار ناپایدار دارند
✔ وقتی انواع مختلف پرت وجود دارد
✔ وقتی میخواهیم ریسک خطا را کاهش دهیم
جدول خلاصه مهمترین روشهای تشخیص دادههای پرت
| روش | ایده اصلی | قویترین کاربرد |
| Z-Score / IQR | فاصله زیاد از مرکز توزیع | دادههای ساده و یکبعدی |
| KNN Distance | پرتها از همسایهها دورند | دادههای رفتاری/مکانی |
| LOF | چگالی کم نسبت به همسایگان | خوشههای با چگالی متفاوت |
| Isolation Forest | پرتها سریع جدا میشوند | دیتاستهای بزرگ و پُربعد |
| K-Means Outlier | فاصله زیاد از مرکز خوشه | دادههای خوشهای ساده |
| DBSCAN / HDBSCAN | نقاط= Noise پرت | خوشههای پیچیده و غیرخطی |
| Residual Analysis | پسماند بزرگ = پرت | مدلسازی مالی، سریزمانی |
| Cook’s Distance | نقطه روی مدل اثر زیاد دارد | رگرسیون و اقتصاد |
| / GMMاحتمالمحور | احتمال بسیار کم = پرت | دادههای چندبعدی |
| One-Class SVM | یادگیری مرز داده عادی | تقلب، امنیت شبکه |
| Autoencoder | خطای بازسازی زیاد | دادههای پُربعد و پیچیده |
| LSTM Autoencoder | خطای پیشبینی زمانی | سریزمانی (حسگر، مالی) |
| GAN-Based | ناتوانی در تولید/بازسازی | تصویر و رفتار کاربر |
| Ensemble | ترکیب چند مدل | کاربردهای بسیار حساس |
جمعبندی نهایی
تشخیص دادههای پرت یکی از حیاتیترین مراحل در تحلیل داده است.وجود این نقاط میتواند نتایج آماری را تحریف کند، عملکرد مدلهای یادگیری ماشین را کاهش دهد و حتی تصمیمگیریهای استراتژیک را به خطر بیندازد.
روشهای آماری برای دادههای ساده و توزیعیافته مناسباند، در حالیکه روشهای فاصله و چگالی برای دادههای پیچیدهتر و چندخوشهای بهتر عمل میکنند. رویکردهای خوشهبندی توان تشخیص پرتهای ساختاری و رفتاری را دارند و روشهای مدلمحور برای محیطهایی که الگوی توزیع یا رابطه بین متغیرها قابل مدلسازی باشد، بسیار مفید هستند. روشهای یادگیری ماشین عملکرد بهتری در دادههای غیرخطی و چندبُعدی دارند و روشهای یادگیری عمیق، قدرتمندترین گزینه برای دادههای حجیم، پیچیده یا زمانی هستند.
در نهایت، روشهای Ensemble ثابت کردهاند که ترکیب چند رویکرد متفاوت میتواند بهترین تعادل ممکن بین دقت، پایداری و انعطافپذیری را فراهم کند. انتخاب روش مناسب باید بر اساس ماهیت داده، هدف کاربردی، هزینه محاسباتی، و میزان حساسیت سیستم به خطا انجام شود. این فصل یک نقشه جامع برای تصمیمگیری در این حوزه ارائه میدهد و میتواند مبنای طراحی یک سیستم عملی تشخیص ناهنجاری در زمینههای اقتصادی، بانکی، صنعتی، پزشکی یا دادههای سازمانی قرار گیرد.


