
مقدمه
در پروژههای یادگیری ماشین، همیشه «دادهی بیشتر» به معنای «مدل بهتر» نیست. در بسیاری از مواقع، وجود ویژگیهای زیاد، نامرتبط یا تکراری نهتنها کمکی به بهبود مدل نمیکند، بلکه باعث افزایش پیچیدگی، کاهش دقت و افت توان تعمیمپذیری میشود. اینجاست که انتخاب ویژگی (Feature Selection) بهعنوان یکی از مهمترین مراحل پیشپردازش دادهها مطرح میشود.
انتخاب ویژگی فرآیندی است که طی آن، مهمترین و مؤثرترین متغیرها از میان مجموعهای بزرگ از ویژگیها انتخاب میشوند تا مدل بتواند با دادهای سادهتر، سریعتر و قابلاعتمادتر آموزش ببیند. این کار به کاهش ابعاد داده، جلوگیری از بیشبرازش، افزایش تفسیرپذیری مدل و بهبود عملکرد نهایی کمک میکند—بهویژه در مسائل با دادههای پُربعد یا حجیم.
در این مقاله، با مفهوم انتخاب ویژگی، اهمیت آن در یادگیری ماشین، چالشهای دادههای پُربعد و مهمترین دستهبندیها و تکنیکها از جمله روشهای Filter، Wrapper، Embedded و Hybrid آشنا میشویم. هدف این است که خواننده بتواند با درک درست این روشها، در هر پروژه دادهمحور، هوشمندانهترین انتخاب را میان دقت، سرعت و پیچیدگی انجام دهد.
تعریف
انتخاب ویژگی (Feature Selection) فرآیند هوشمندانهی غربالگری است؛ یعنی انتخابِ تنها مفیدترین و مرتبطترین ویژگیهای ورودی برای یک مدل یادگیری ماشین. این کار نه تنها عملکرد مدل را بهبود میبخشد، بلکه نویز را کاهش داده و نتایج را قابلفهمتر میکند.
مثال آشپزی: تصور کنید میخواهید قورمهسبزی بپزید. در کابینت شما ۱۰۰ نوع ادویه وجود دارد.
- بدون انتخاب ویژگی: اگر همه ۱۰۰ ادویه را در غذا بریزید، طعم اصلی گم میشود و غذا خراب میشود (مدل گیج میشود).
- با انتخاب ویژگی: شما فقط ۴ یا ۵ ادویه اصلی و مرتبط را انتخاب میکنید. نتیجه؟ غذایی خوشطعم و اصیل.
چرا انتخاب ویژگی حیاتی است؟
این فرآیند ۴ فایدهی اصلی دارد که هر مهندس دادهای باید بداند:
۱. حذف ویژگیهای نامربوط و تکراری (Irrelevant and Redundant)
بسیاری از دادههایی که جمعآوری میکنیم، هیچ کمکی به پیشبینی نمیکنند یا اطلاعات تکراری دارند.
- ویژگی نامربوط: فرض کنید میخواهیم قیمت خانه را پیشبینی کنیم. دانستن رنگ چشم صاحبخانه هیچ ربطی به قیمت خانه ندارد و فقط نویز است.
- ویژگی تکراری(Redundant): اگر در دادهها هم ستون سن خانه را داشته باشیم و هم سال ساخت، این دو عملاً یک حرف را میزنند. نگه داشتن هر دو، فقط محاسبات را سنگین میکند.
۲. بهبود دقت و کاهش بیشبرازش (Overfitting)
وقتی مدل را با دادههای بیهوده بمباران میکنیم، مدل شروع به یادگیری نویزها به جای الگوها میکند (بیشبرازش). با حذف این دادههای اضافی، مدل روی الگوهای واقعی متمرکز میشود و دقتش در دنیای واقعی بالا میرود.
۳. افزایش سرعت آموزش مدل (Speed)
ساده است: دادههای کمتر = محاسبات کمتر. وقتی تعداد ستونهای جدول داده (Features) را از ۱۰۰ به ۱۰ میرسانید، زمان آموزش مدل ممکن است از چند ساعت به چند دقیقه کاهش یابد. این در پروژههای بزرگ حیاتی است.
۴. سادهسازی و تفسیرپذیری مدل (Interpretability)
توضیح دادن مدلی که فقط با ۳ عامل کار میکند برای مدیران و ذینفعان بسیار سادهتر از مدلی است که با ۳۰۰ عامل پیچیده کار میکند.
- مثال: راحتتر است بگوییم مشتری وام را پس نمیدهد چون ۱. درآمدش کم است و ۲. بدهی قبلی دارد تا اینکه دلایل ریاضی پیچیدهای بر اساس ۵۰ متغیر مختلف بیاوریم.
ضرورت و اهمیت انتخاب ویژگی
روشهای انتخاب ویژگی در علم داده و یادگیری ماشین، صرفاً یک گزینه اختیاری نیستند، بلکه به دلایل کلیدی زیر، یک ضرورت اجتنابناپذیر محسوب میشوند:
۱. بهبود دقت مدل: مدلها زمانی بهتر یاد میگیرند که روی سیگنالهای اصلی تمرکز کنند، نه نویزها. حذف دادههای بیفایده باعث میشود مدل گمراه نشود و الگوهای واقعی را بهتر ببیند.
۲. آموزش سریعتر: ریاضیات ساده است: ویژگیهای کمتر یعنی محاسبات کمتر. این موضوع زمان آموزش مدل را به شدت کاهش میدهد (بهویژه در کلاندادهها).
۳. تفسیرپذیری بهتر: هرچه ورودیها کمتر باشند، درک رفتار مدل آسانتر میشود. توضیح دادن مدلی که با ۵ فاکتور کلیدی کار میکند، بسیار راحتتر از مدلی است که ۱۰۰ فاکتور مبهم دارد.
۴. فرار از نفرین ابعاد :این یکی از مهمترین مفاهیم است. وقتی تعداد ویژگیها (ابعاد) خیلی زیاد میشود، دادهها در فضا رقیق و پراکنده میشوند و مدل برای پیدا کردن الگوها به حجم وحشتناکی از داده نیاز پیدا میکند. انتخاب ویژگی، پیچیدگی را کم کرده و مدل را از غرق شدن در این فضای چندبعدی نجات میدهد.
انواع روشهای انتخاب ویژگی
الگوریتمهای متنوعی برای این کار وجود دارد که معمولاً در 4 دسته گروهبندی میشوند. هر کدام قوتها و سبکسنگینیهای (Trade-offs) خاص خود را دارند که بسته به نوع پروژه انتخاب میشوند.
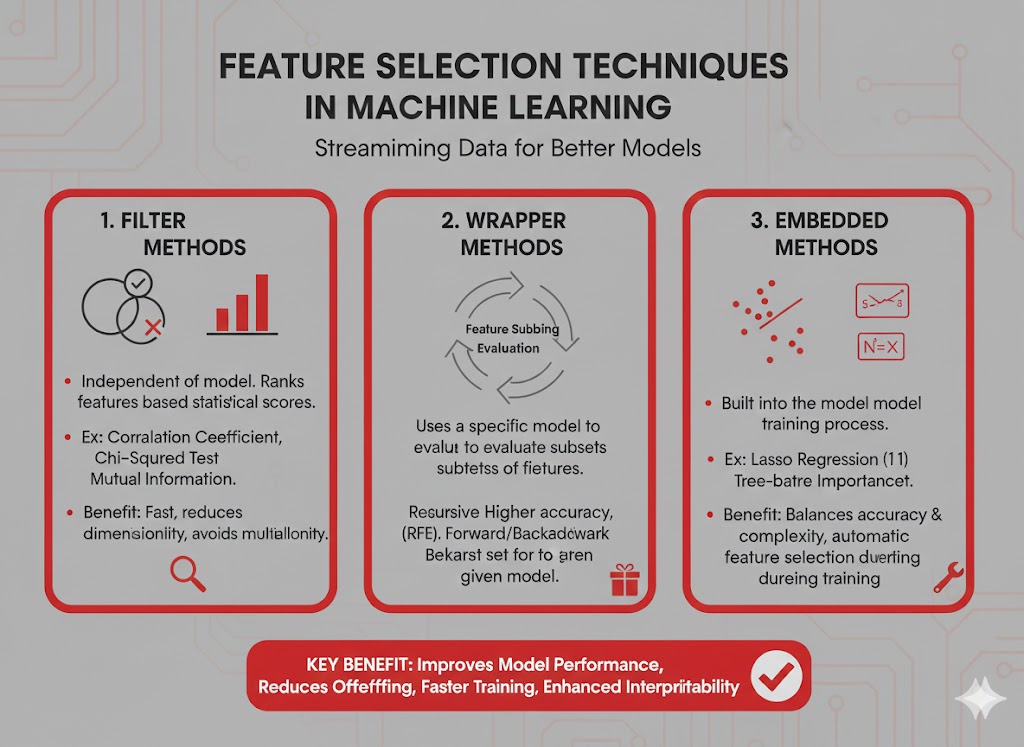
در اینجا به بررسی اولین و سریعترین دسته میپردازیم:
- روشهای فیلتر (Filter Methods)
- روشهای پوششی (Wrapper Methods)
- روشهای تعبیهشده (Embedded Methods)
- روشهای ترکیبی (Hybrid Methods)
۱. روشهای فیلتر (Filter Methods)
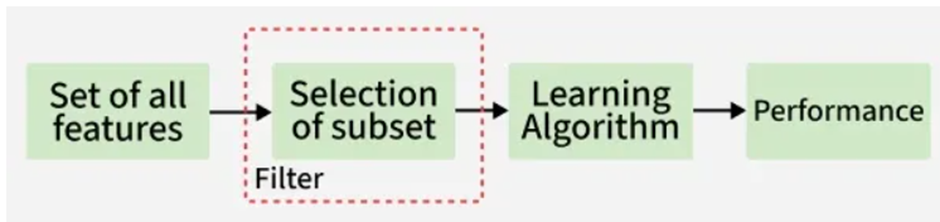
روشهای فیلتر مانند یک دروازهبان سختگیر در ورودی یک کلوپ عمل میکنند. آنها قبل از اینکه مدل یادگیری ماشین اصلا درگیر شود (در مرحله پیشپردازش)، ویژگیها را غربال میکنند.

نحوه عملکرد: این روشها هر ویژگی را به صورت مستقل و جداگانه با متغیر هدف (Target Variable) ارزیابی میکنند.
- منطق: ویژگی که همبستگی (Correlation) بالایی با متغیر هدف داشته باشد، انتخاب میشود. چرا؟ چون این همبستگی بالا یعنی آن ویژگی حاوی اطلاعات ارزشمندی است که میتواند در پیشبینیِ هدف به ما کمک کند.
مکانیسم: این روشها بر پایه آزمونهای آماری عمل میکنند تا ویژگیهای نامربوط (Irrelevant) یا تکراری (Redundant) را شناسایی و حذف کنند.
مثال کاربردی (پیشبینی قیمت خودرو): فرض کنید میخواهیم قیمت خودرو (متغیر هدف) را پیشبینی کنیم.
- ویژگی ۱ (قدرت موتور): آزمون آماری نشان میدهد که هرچه قدرت موتور بیشتر شود، قیمت هم بالا میرود (همبستگی بالا). <– تایید میشود.
- ویژگی ۲ (رنگ روکش صندلی): آزمون نشان میدهد تغییر رنگ روکش تاثیر خاصی روی قیمت ندارد (همبستگی پایین). <– توسط فیلتر حذف میشود.
- این کار بدون اینکه هیچ مدل هوش مصنوعیای آموزش ببیند، و صرفاً با آمار و ریاضیات انجام میشود.
مزیت اصلی: این روشها بسیار سریع هستند و قدرت محاسباتی کمی نیاز دارند.
الف) تکنیکهای رایج فیلتر (Common Filter Techniques)
روشهای فیلتر از معیارهای آماری و ریاضی برای سنجش ارتباط (Relevance) هر ویژگی با متغیر هدف استفاده میکنند. برخی از رایجترین این تکنیکها عبارتند از:
| تکنیک فیلتر | عملکرد اصلی | مثال کاربردی |
| ۱. بهره اطلاعاتی (Information Gain) | کاهش آنتروپی (Entropy) یا همان میزان ابهام را هنگامی که یک ویژگی خاص استفاده میشود، اندازهگیری میکند. | در تصمیمگیریهای پیچیده (مانند درختهای تصمیم) ویژگیای که بیشترین کاهش ابهام را به ارمغان میآورد، انتخاب میشود. |
| ۲. آزمون کای-دو (Chi-square test) | رابطه بین ویژگیهای دستهبندیشده (Categorical Features) را بررسی میکند تا ببیند آیا دو ویژگی به صورت تصادفی از هم مستقل هستند یا با هم مرتبطاند. | بررسی ارتباط بین جنسیت (دسته) و نتیجه درمان (دسته) برای انتخاب ویژگیهای مرتبط در تحلیلهای پزشکی. |
| ۳. نمره فیشر (Fisher’s Score) | ویژگیها را بر اساس میزان قابلیت تفکیک کلاسها رتبهبندی میکند. ویژگیهایی که دادههای یک کلاس را از دادههای کلاس دیگر بهتر جدا میکنند، نمره بالاتری میگیرند. | در تشخیص چهره، ویژگیای که بهتر میتواند تفاوت بین چهره A و چهره B را مشخص کند، مهمتر است. |
| ۴. ضریب همبستگی پیرسون (Pearson’s Correlation) | یک رابطه خطی بین دو متغیر پیوسته (Continuous) را اندازهگیری میکند. | بررسی همبستگی بین متراژ خانه و قیمت نهایی. (اگر همبستگی به صفر نزدیک باشد، ویژگی حذف میشود). |
| ۵. آستانه واریانس (Variance Threshold) | ویژگیهایی که واریانس (تغییرپذیری) بسیار پایینی دارند (یعنی تقریباً برای همه نمونهها یکسان هستند)، حذف میکند. | اگر ستونی مثل کشور برای یک مجموعه داده که همه متعلق به ایران هستند، ۹۹٪ یکسان باشد، آن ستون حذف میشود زیرا اطلاعات جدیدی ندارد. |
مزایای روشهای فیلتر
- سرعت و کارایی بالا (Fast and efficient): از آنجایی که محاسبات آنها ساده و آماری است و نیازی به آموزش مدل ندارند، از نظر محاسباتی ارزان هستند و برای مجموعه دادههای بزرگ (Big Data) ایدهآل هستند.
- پیادهسازی آسان (Easy to implement): این روشها معمولاً در کتابخانههای معروف یادگیری ماشین (مانند Scikit-learn) به صورت توابع آماده موجود هستند و نیاز به کدنویسی پیچیده ندارند.
- مستقل از مدل (Model Independence): روشهای فیلتر با هر نوع مدل یادگیری ماشینی (درخت تصمیم، رگرسیون، شبکه عصبی و…) سازگار هستند و از این نظر بسیار کاربردی و انعطافپذیرند.
محدودیتهای روشهای فیلتر
- توجه محدود به تعاملات (Limited Interaction): چون این روشها هر ویژگی را به صورت مجزا ارزیابی میکنند، نمیتوانند تعاملات پیچیده بین ویژگیها را که ممکن است برای پیشبینی مدل حیاتی باشند، تشخیص دهند.
- مثال: ممکن است هیچکدام از ویژگیهای درآمد یا سن به تنهایی با بازگشت وام همبستگی نداشته باشند، اما ترکیب (تعامل) درآمد پایین و سن بالا یک ریسک بسیار بزرگ باشد که فیلتر آن را از دست میدهد.
- انتخاب معیار مناسب (Choosing the right metric): انتخاب معیار آماری مناسب (مانند کای-دو در مقابل پیرسون) برای نوع داده و وظیفه ما حیاتی است و نیاز به دانش فنی دارد.
۲. روشهای پوششی (Wrapper Methods)
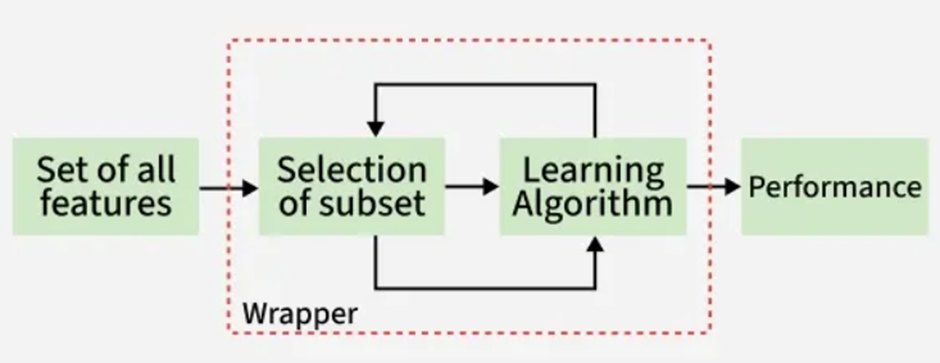
روشهای پوششی (Wrapper Methods) که گاهی به آنها الگوریتمهای حریص (Greedy Algorithms) نیز گفته میشود، رویکرد کاملاً متفاوتی دارند. آنها دیگر به آمار مستقل ویژگیها تکیه نمیکنند؛ بلکه از خود مدل یادگیری ماشین برای سنجش کیفیت یک زیرمجموعه از ویژگیها استفاده میکنند.
نحوه عملکرد:
این روشها به صورت آزمون و خطا عمل میکنند:
- زیرمجموعههای مختلفی از ویژگیها را انتخاب میکنند (مثلاً [A, B, C] یا [B, D, F]).
- مدل یادگیری ماشین را با آن زیرمجموعه آموزش میدهند.
- عملکرد مدل (دقت پیشبینی) را محاسبه میکنند.
- بر اساس نتیجه (عملکرد خوب یا بد)، تصمیم به اضافه کردن یا حذف کردن یک ویژگی دیگر میگیرند.
معیار توقف (Stopping Criteria):
فرد آموزشدهنده مدل باید معیارهای توقف را از قبل تعریف کند، مثلاً:
- هنگامی که عملکرد مدل شروع به کاهش کرد (یعنی ویژگیهای بد اضافه کردیم).
- یا هنگامی که به تعداد مشخصی از ویژگیها (مثلاً ۵ ویژگی) رسیدیم.
مثال ملموس (سفر جادهای):
این روش مثل این است که در حال رانندگی به سمت شیراز هستید (آموزش مدل).
- شما هر بار یک مسیر جدید (زیرمجموعه ویژگی) را امتحان میکنید.
- سرعت خود را در مسیر جدید میسنجید (عملکرد مدل).
- اگر مسیر بهتر بود، برای مرحله بعدی از آن استفاده میکنید (بهرهبرداری).
این فرآیند حریصانه است؛ زیرا در هر مرحله، بهترین گزینه در دسترس را انتخاب میکند، بدون اینکه به آینده دور نگاه کند.
الف) تکنیکهای رایج روشهای پوششی (Common Wrapper Techniques)
همانطور که گفته شد، این روشها حریص هستند و به دنبال بهترین ترکیب ممکن میگردند. سه استراتژی اصلی آنها عبارتند از:
۱. انتخاب رو به جلو (Forward Selection)
- استراتژی: خشت اول چون نهد معمار کج….
- روش کار: با یک مدل خالی (بدون هیچ ویژگی) شروع میکنیم. سپس ویژگیها را یکییکی تست کرده و آن ویژگیای را که بیشترین بهبود را ایجاد میکند، اضافه میکنیم. این کار تا زمانی که بهبود متوقف شود، ادامه مییابد.
۲. حذف رو به عقب (Backward Elimination)
- استراتژی: هرس کردن شاخ و برگ اضافه.
- روش کار: برعکس قبلی، ابتدا تمام ویژگیها را وارد مدل میکنیم. سپس در هر مرحله، بیفایدهترین ویژگی (آنکه کمترین تاثیر مثبت را دارد) حذف میکنیم تا به هسته اصلی برسیم.
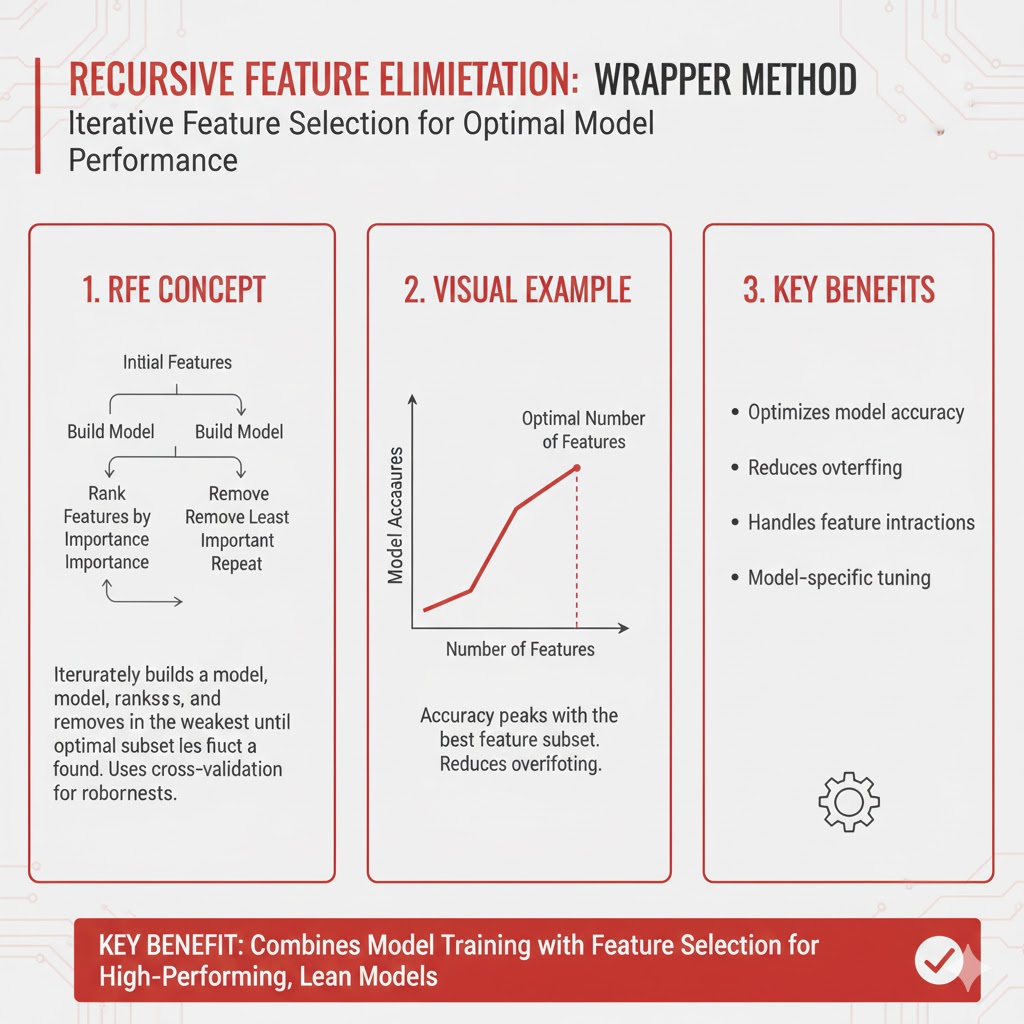
۳. حذف بازگشتی ویژگی (Recursive Feature Elimination – RFE)
- استراتژی: بازی بقا.
- روش کار: یک فرآیند تکرارشونده و هوشمند است. مدل بارها ساخته میشود و در هر دور، ضعیفترین ویژگیها کنار گذاشته میشوند. این کار آنقدر تکرار میشود تا تعداد ویژگیها به حد مطلوب برسد.
مزایای روشهای پوششی
- بهینهسازی مخصوص مدل (Model-specific optimization): این روشها مستقیماً بررسی میکنند که ویژگیها چگونه روی مدل خاص شما تاثیر میگذارند.
- نتیجه: معمولاً عملکرد (Performance) بهتری نسبت به روشهای فیلتر دارند، چون دقیقا برای همان مدل خیاطی شدهاند.
- انعطافپذیری (Flexible): این روشها را میتوان با انواع مختلف مدلها و معیارهای ارزیابی تطبیق داد و محدود به الگوریتم خاصی نیستند.
محدودیتهای روشهای پوششی
- بسیار پرهزینه و سنگین (Computationally expensive): بررسی تمام ترکیبات مختلف ویژگیها زمانبر است. اگر مجموعه داده بزرگی داشته باشید، این روش ممکن است روزها طول بکشد!
- خطر بیشبرازش (Risk of overfitting): چون ویژگیها خیلی دقیق برای یک مدل خاص تنظیم (Fine-tune) میشوند، این خطر وجود دارد که مدل روی دادههای آموزشی حفظ کند و روی دادههای جدید و نادیده (Unseen Data) عملکرد ضعیفی داشته باشد.
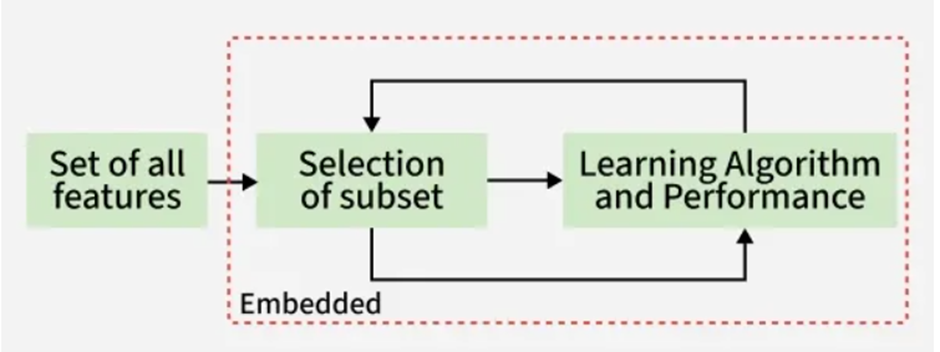
۳. روشهای تعبیهشده (Embedded Methods)
روشهای تعبیهشده، راهحل هوشمندانهای هستند که سعی میکنند بهترینهای هر دو دنیا (روش فیلتر و پوششی) را ترکیب کنند.
نحوه عملکرد: در این روشها، انتخاب ویژگی یک مرحله جداگانه نیست؛ بلکه بخشی از خودِ فرآیند آموزش مدل است.
- ادغام: انتخاب ویژگی در دلِ الگوریتم آموزش مدل تعبیه شده است (Integrated).
- پویایی: مدل در حین یادگیری، به صورت خودکار و پویا تصمیم میگیرد که کدام ویژگیها مهم هستند و به آنها وزن میدهد و کدامیک را باید نادیده بگیرد (یا وزن صفر بدهد).
مثال ملموس (مجسمهسازی):
- روش فیلتر: سنگهای نامناسب را قبل از شروع کار دور میریزید.
- روش پوششی: چندین مجسمه میسازید و بهترین را انتخاب میکنید (زمانبر).
- روش تعبیهشده: همانطور که دارید مجسمه را میتراشید (آموزش میبینید)، بخشهای اضافی سنگ را هم جدا میکنید. این کار همزمان و بهینه انجام میشود.
مثالهای فنی:
- Lasso Regression (L1 Regularization): ویژگیهای کماهمیت را با صفر کردن ضریبشان عملاً حذف میکند.
- Tree-based methods: الگوریتمهایی مثل Random Forest یا XGBoost به صورت ذاتی در حین ساخت درخت تصمیم، ویژگیهای مهمتر را در گرههای بالاتر قرار میدهند.
الف) تکنیکهای رایج روشهای تعبیهشده (Common Embedded Techniques)
این روشها هوشمندانه عمل میکنند و انتخاب ویژگی را بخشی از ذاتِ فرآیند یادگیری قرار میدهند. سه تکنیک مشهور در این دسته عبارتند از:
۱. رگرسیون لاسو یا تنظیم L1 (Lasso / L1 Regularization)
- مکانیسم: این روش یک جریمه (Penalty) به مدل اضافه میکند که باعث میشود ضریب ویژگیهای کماهمیت به صفر برسد.
- نتیجه: ویژگیهایی که ضریبشان صفر شده، عملاً از معادله حذف میشوند و فقط ویژگیهای مهم باقی میمانند.
مثال: مثل یک ویراستار سختگیر که کلمات اضافی یک متن را خط میزند تا جمله کوتاهتر و مفیدتر شود.
۲. درختهای تصمیم و جنگلهای تصادفی (Decision Trees & Random Forests)
- مکانیسم: این الگوریتمها در هر گره (Node) از درخت، سوالی میپرسند که دادهها را بهتر جدا کند (کاهش ناخالصی یا Impurity Reduction).
- نتیجه: ویژگیهایی که در بالای درخت قرار میگیرند یا بیشتر استفاده میشوند، به عنوان مهمترین ویژگیها شناخته میشوند.
۳. گرادیان بوستینگ (Gradient Boosting)
- مکانیسم: این روش (مانند XGBoost یا LightGBM) به صورت مرحلهای مدلهایی میسازد که خطای مدلهای قبلی را اصلاح کنند.
- نتیجه: ویژگیهایی را انتخاب میکند که بیشترین تاثیر را در کاهش خطای پیشبینی دارند.
مزایای روشهای تعبیهشده
- کارآمد و موثر (Efficient and effective): این روشها نتایج بسیار خوبی میدهند بدون اینکه بار محاسباتی سنگینِ روشهای پوششی (که صدها بار مدل را اجرا میکنند) را داشته باشند.
- یادگیری مخصوص مدل (Model-specific learning): مشابه روشهای پوششی، این تکنیکها ویژگیهایی را پیدا میکنند که دقیقاً برای همان الگوریتم خاص مفید هستند.
محدودیتهای روشهای تعبیهشده
- تفسیرپذیری محدود (Limited interpretability): درک اینکه چرا یک ویژگی انتخاب شده، در این روشها سختتر از روشهای فیلتر (که با یک عدد همبستگی ساده کار میکنند) است. گاهی اوقات فرآیند انتخاب مثل یک جعبه سیاه عمل میکند.
- عدم کاربرد جهانی (Not universally applicable): همه الگوریتمهای یادگیری ماشین قابلیت انتخاب ویژگیِ داخلی ندارند (مثلاً الگوریتم K-NN این قابلیت را ندارد)، بنابراین نمیتوان همیشه از روش تعبیهشده استفاده کرد.
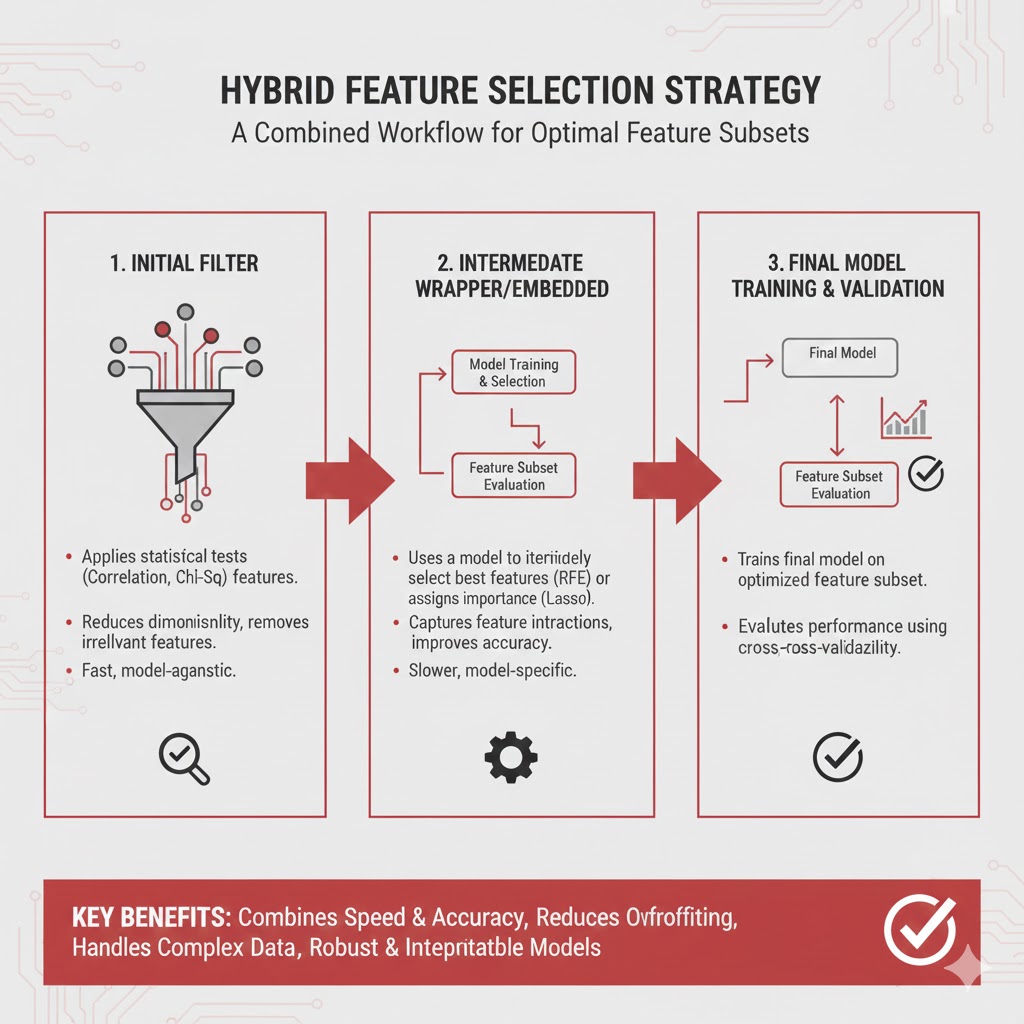
۴. روشهای ترکیبی (Hybrid Methods)
تا بدینجا روشهای فیلتر (سریع اما کمدقت) و پوششی (دقیق اما کند) را جداگانه بررسی کردیم. اما در پروژههای واقعی و سنگین صنعتی، مهندسان داده اغلب از یک استراتژی دو مرحلهای استفاده میکنند تا از مزایای هر دو روش بهرهمند شوند (سرعتِ فیلتر + دقتِ پوششی).
منطق پشت روش ترکیبی (The Logic)
بیایید با یک مثال ملموس غیرفنی شروع کنیم: تصور کنید کارگردانی هستید که میخواهید از بین ۱۰,۰۰۰ داوطلب، بهترین بازیگر را برای نقش اول فیلمتان انتخاب کنید.
- مرحله اول (فیلتر): شما وقت ندارید از همه تست بگیرید. پس ابتدا بر اساس رزومه و عکس چهره، ۹,۹۰۰ نفر را رد میکنید. این کار سریع و کمهزینه است.
- مرحله دوم (پوششیWrapper/): حالا فقط ۱۰۰ نفر باقی ماندهاند. از این تعداد محدود، تست بازیگری دقیق و طولانی میگیرید تا همان یک ستاره را پیدا کنید. این کار زمانبر اما دقیق است.
نکته: اگر از همان اول میخواستید از همه ۱۰,۰۰۰ نفر تست بازیگری بگیرید (فقط روش Wrapper)، انتخاب بازیگر سالها طول میکشید!
نحوه اجرا در یادگیری ماشین
این استراتژی در علم داده دقیقاً به همین شکل پیاده میشود:
- گام اول (کاهش ابعاد): با استفاده از یک روش فیلتر (مثل همبستگی یا Information Gain)، ابعاد داده را به شدت کاهش میدهیم.
- مثال: تعداد ویژگیها را از ۲۰۰۰ به ۵۰ میرسانیم.
- گام دوم (بهینهسازی دقیق): روی آن ۵۰ ویژگی انتخابشده، از یک روش دقیق و سنگین مثل «حذف بازگشتی» (RFE) استفاده میکنیم تا بهترینها را گلچین کنیم.
- مثال: از ۵۰ ویژگی به ۱۰ ویژگی طلایی میرسیم.
مثالهای کاربردی و سناریوهای واقعی
برای اینکه کاربرد این روش را بهتر درک کنیم، در اینجا دو سناریوی تخصصی که در آنها استفاده از روش ترکیبی حیاتی است را بررسی میکنیم:
سناریوی ۱: تحلیل دادههای ژنتیکی (Genomics)
در تحقیقات سرطان، ما با تعداد بسیار زیادی ویژگی روبرو هستیم.
- دادهها: اطلاعات ۲۰,۰۰۰ ژن برای هر بیمار.
- مشکل: اگر بخواهیم روش Wrapper (مثل RFE) را روی ۲۰,۰۰۰ ستون اجرا کنیم، پردازش آن ماهها طول میکشد.
- راهکار ترکیبی:
- فیلتر: ابتدا با استفاده از آزمون آنالیز واریانس (ANOVA)، ژنهایی را که تغییراتشان بین بیماران سالم و بیمار ناچیز است، حذف میکنیم. (کاهش از ۲۰,۰۰۰ به ۱,۰۰۰ ژن).
- پوششی: حالا روی ۱,۰۰۰ ژن باقیمانده، الگوریتم RFE را اجرا میکنیم تا ۵ ژن خاصی که مستقیماً عامل بیماری هستند را پیدا کنیم.
سناریوی ۲: پردازش متن و نظرات مشتریان
فرض کنید میخواهید نظرات مشتریان را به دو دسته «راضی» و «ناراضی» تقسیم کنید.
- دادهها: هزاران کلمه مختلف در متن نظرات وجود دارد (هر کلمه یک ویژگی است).
- مشکل: بسیاری از کلمات (مثل “است”، “که”، “در”) بیارزش هستند و فقط فضا را اشغال کردهاند.
- راهکار ترکیبی:
- فیلتر: با استفاده از آزمون کای-دو (Chi-Square)، کلماتی که تکرارشان تصادفی است یا ربطی به رضایت ندارند را حذف میکنیم.
- پوششی: از روش انتخاب رو به جلو (Forward Selection) استفاده میکنیم تا ترکیب کلماتی را پیدا کنیم (مثلاً ترکیب “کیفیت” + “پایین”) که بیشترین دقت را در تشخیص مشتری ناراضی دارند.
راهنمای انتخاب روش مناسب
هیچ بهترین روش مطلقی وجود ندارد؛ انتخاب شما باید بر اساس شرایط پروژه باشد. این چکلیست به شما کمک میکند تصمیم بگیرید:
۱. اندازه مجموعه داده (Dataset size)
- دادههای عظیم (Big Data): سراغ روشهای فیلتر بروید (چون سریع هستند).
- دادههای کوچک تا متوسط: روشهای پوششی (Wrapper) میتوانند دقت بالاتری به شما بدهند، چون زمان پردازش قابل مدیریت است.
۲. نوع مدل (Model type)
- آیا از مدلهای درختی (Tree-based) مثل Random Forest استفاده میکنید؟ تبریک میگویم! شما نیازی به کار اضافه ندارید، چون این مدلها قابلیت تعبیهشده دارند.
۳. نیاز به تفسیرپذیری (Interpretability)
- آیا باید به رئیستان توضیح دهید چرا این ویژگیها مهم هستند؟ روشهای فیلتر (مثل همبستگی) بهترین گزینه هستند چون منطق شفاف و آماری دارند.
۴. منابع محاسباتی (Computational resources)
- آیا ابررایانه دارید یا لپتاپ معمولی؟ روشهای پوششی زمانبر و سنگین هستند. اگر منابع محدود دارید، از روشهای فیلتر یا تعبیهشده استفاده کنید.
نتیجهگیری نهایی: با استفاده هوشمندانه از این روشها، میتوانیم عملکرد مدل را به سادگی بهبود بخشیم، هزینههای محاسباتی را کاهش دهیم و از شر دادههای مزاحم خلاص شویم.
مطالعه موردی جامع :پیشبینی ریزش مشتری
برای اینکه قدرت انتخاب ویژگی را به طور کامل لمس کنید، بیایید یک پروژه واقعی در صنعت مخابرات را از ابتدا تا انتها بررسی کنیم.

صورت مسئله:
یک شرکت مخابراتی متوجه شده است که مشتریانش را از دست میدهد. آنها میخواهند مدلی بسازند که پیشبینی کند کدام مشتریان احتمالاً ماه بعد قراردادشان را لغو میکنند (Churn) تا به آنها پیشنهاد تخفیف بدهند.
وضعیت دادهها (قبل از شروع):
- تعداد رکوردها: ۱۰۰,۰۰۰ مشتری.
- تعداد ویژگیها: ۵۰ ستون (شامل سن، جنسیت، آدرس، کد پستی، دقیقههای مکالمه روزانه/شبانه، تعداد تماس با پشتیبانی، نوع پرداخت، داشتن خط اینترنت، مدل گوشی و…).
گام ۱: پاکسازی اولیه و اجرای روش فیلتر
مهندس داده ابتدا نگاهی به ۵۰ ویژگی میاندازد و از روشهای آماری استفاده میکند:
- حذف واریانس صفر: ستونی به نام کشور وجود دارد که برای همه ۱۰۰٪ مشتریان ایران است. این ستون هیچ اطلاعاتی ندارد. (حذف شد)
- حذف همبستگی بالا: دو ستون داریم: مبلغ قبض ماهانه و مجموع پرداختی سالانه. این دو ۹۸٪ همبستگی دارند. نگه داشتن هر دو باعث گیج شدن مدل میشود. یکی را نگه میداریم. (۱ ستون حذف شد)
- فیلتر آماری: ستون کد پستی و رنگ مورد علاقه (که در فرم نظرسنجی بوده) هیچ همبستگی معناداری با ریزش مشتری ندارند. (۱۰ ستون حذف شد)
- نتیجه گام ۱: تعداد ویژگیها از ۵۰ به ۲۰ رسید.
گام ۲: اجرای روش پوششی دقیق
حالا با ۲۰ ویژگی باقیمانده که همگی نسبتاً خوب به نظر میرسند، از الگوریتم RFE (حذف بازگشتی) استفاده میکنیم تا بهترینِ بهترینها را پیدا کنیم.
مدل بارها اجرا میشود و ویژگیهایی مثل جنسیت یا داشتن خط ثابت را که تاثیر کمی دارند، حذف میکند.
- نتیجه نهایی: رسیدن به ۶ ویژگی طلایی.
ویژگیهای انتخاب شده نهایی:
- نوع قرارداد: (ماهانه یا سالانه؟ مشتریان ماهانه بیشتر ریزش میکنند).
- تعداد تماس با پشتیبانی: (مشتری که ۵ بار زنگ زده و شاکی است، حتماً میرود).
- هزینه ماهانه: (هزینه بالا = ریسک بیشتر).
- مدت زمان عضویت: (مشتریهای قدیمی وفادارترند).
- امنیت آنلاین: (کسانی که سرویس امنیت خریدهاند، کمتر میروند).
- پشتیبانی فنی: (کسانی که این سرویس را ندارند، بیشتر میروند).
جدول مقایسه عملکرد (قبل و بعد از انتخاب ویژگی)
این جدول نشان میدهد چرا این فرآیند حیاتی است:
| معیار (Metric) | مدل خام (همه ۵۰ ویژگی) | مدل بهینه (۶ ویژگی منتخب) | تحلیل تغییرات |
| دقت (Accuracy) | ۷۸٪ | ۹۲٪ | ۱۴٪ افزایش. نویزهایی مثل کد پستی باعث میشدند مدل الگوهای غلط یاد بگیرد. |
| زمان آموزش (Time) | ۴۵ دقیقه | ۳ دقیقه | ۱۵ برابر سریعتر. کاهش حجم محاسبات به شدت ملموس است. |
| پیچیدگی مدل | بسیار پیچیده (Black Box) | شفاف و قابل تفسیر | حالا مدیر بازاریابی میداند دقیقاً چرا مشتری میرود (چون با پشتیبانی تماس گرفته). |
| بیشبرازش (Overfitting) | زیاد (High) | بسیار کم (Low) | مدل قبلی روی دادههای آموزشی عالی بود اما در تست واقعی شکست میخورد؛ مدل جدید پایدار است. |
تحلیل مدیریتی و نتیجهگیری
با انتخاب ویژگی، ما نه تنها یک مدل ریاضی بهتر ساختیم، بلکه استراتژی کسبوککار را تغییر دادیم:
- قبل از انتخاب ویژگی: مدیر نمیدانست مشکل کجاست. شاید فکر میکرد باید قیمت را پایین بیاورد.
- بعد از انتخاب ویژگی: مدل فریاد میزند که تعداد تماس با پشتیبانی مهمترین عامل ریزش است.
- اقدام عملی: به جای تخفیف دادن به همه (هزینه زیاد)، شرکت روی آموزش پرسنل پشتیبانی سرمایهگذاری میکند تا مشکلات مشتریان در تماس اول حل شود.
این یعنی انتخاب ویژگی، دادهها را به دانش قابل اجرا (Actionable Insight) تبدیل کرد.
نتیجه گیری
انتخاب ویژگی یکی از کلیدیترین مراحل در ساخت مدلهای یادگیری ماشین است که تأثیر مستقیمی بر دقت، پایداری و کارایی مدل دارد. با حذف ویژگیهای غیرضروری و تمرکز بر متغیرهای مؤثر، میتوان مدلهایی سادهتر، سریعتر و قابلتفسیرتر ساخت که روی دادههای جدید نیز عملکرد بهتری دارند.
روشهای مختلف انتخاب ویژگی—از Filter که سریع و مقیاسپذیر است، تا Wrapper که دقت بالاتری دارد و Embedded که انتخاب ویژگی را در دل فرآیند آموزش مدل انجام میدهد—هرکدام مزایا و محدودیتهای خاص خود را دارند. انتخاب روش مناسب به عواملی مانند حجم داده، نوع مدل، منابع محاسباتی و هدف پروژه بستگی دارد و در بسیاری از کاربردهای واقعی، ترکیب این روشها (Hybrid) بهترین نتیجه را به همراه دارد.
در نهایت، انتخاب ویژگی صرفاً یک گام فنی نیست، بلکه یک تصمیم استراتژیک در مسیر ساخت مدلهای هوشمند است. هرچه این انتخاب آگاهانهتر انجام شود، مسیر رسیدن از دادههای خام به بینشهای دقیق و قابلاعتماد کوتاهتر و مطمئنتر خواهد بود.


