
۱۰-۱. مقدمه: از شناخت گذشته تا پیشبینی آینده
در فصل پیشین، دادهکاوی در HSE بیشتر از منظر اکتشاف الگوها، تحلیل توصیفی پیشرفته و کشف روابط پنهان در دادههای گذشته بررسی شد. آن رویکرد کمک میکرد بفهمیم در گذشته چه رخ داده است، چه الگوهایی تکرار شدهاند و کدام فعالیتها، واحدها یا شرایط، بیشتر با رخدادهای ناخواسته همراه بودهاند.
اما مدیریت پیشرفته HSE تنها به شناخت گذشته محدود نمیشود. سازمانهای بالغ باید بتوانند از دادههای گذشته و حال برای پیشبینی آینده استفاده کنند. پرسش اصلی در این مرحله آن نیست که «چه اتفاقی افتاده است؟»، بلکه این است که «چه اتفاقی ممکن است رخ دهد؟»، «احتمال وقوع آن چقدر است؟» و «پیش از وقوع پیامد، چه مداخلهای باید انجام شود؟».
دادهکاوی پیشبینانه و یادگیری ماشین، ابزارهایی برای پاسخ به همین پرسشها هستند. این رویکردها با استفاده از دادههای تاریخی، متغیرهای عملیاتی، اطلاعات انسانی، سوابق بازرسی، دادههای حسگری و شاخصهای محیطی، احتمال رخدادهای آینده را برآورد میکنند.
.
در HSE، پیامد قابل پیشبینی میتواند وقوع حادثه، افزایش شدت ریسک، بروز شبهحادثه، خرابی تجهیز ایمنیحساس، مواجهه بیش از حد مجاز با آلاینده، عدم انطباق زیستمحیطی یا شکلگیری شرایط عملیاتی ناایمن باشد.
البته پیشبینی در HSE به معنای قطعیت نیست. هیچ مدل آماری یا یادگیری ماشینی نمیتواند با اطمینان کامل اعلام کند که حادثهای دقیقاً در زمان و مکان مشخص رخ خواهد داد. مدلها معمولاً با احتمالها، سناریوها و سطح اطمینان کار میکنند.
بنابراین، ارزش اصلی این مدلها در آن است که تصمیمگیرندگان را زودتر، دقیقتر و هدفمندتر نسبت به شرایط پرخطر آگاه میکنند. به بیان سادهتر، دادهکاوی پیشبینانه جایگزین قضاوت حرفهای نیست؛ بلکه آن را تقویت میکند.
در این فصل، تمرکز اصلی بر کاربردهای پیشبینانه دادهکاوی، یادگیری ماشین، کلانداده، تحلیل جریان داده و هوش مصنوعی در HSE است. هدف فصل آن است که نشان دهد چگونه میتوان از دادهها برای هشدار زودهنگام، اولویتبندی ریسک، تصمیمسازی مدیریتی و حرکت به سوی HSE پیشنگر و تابآور استفاده کرد.
۱۰-۲. ماهیت دادهکاوی پیشبینانه در HSE

دادهکاوی پیشبینانه به مجموعهای از روشها گفته میشود که با استفاده از دادههای موجود، احتمال یا مقدار یک پیامد آینده را برآورد میکنند. این پیامد ممکن است دودویی باشد؛ مانند وقوع یا عدم وقوع حادثه. همچنین ممکن است عددی و پیوسته باشد؛ مانند میزان آلاینده، شدت مواجهه یا نرخ انتشار.
در HSE، دادهکاوی پیشبینانه معمولاً با سه هدف اصلی بهکار میرود. هدف نخست، شناسایی موقعیتهایی است که احتمال رخداد نامطلوب در آنها بیشتر است. سپس هدف دوم، اولویتبندی منابع محدود سازمان برای کنترل ریسک است. هدف سوم، فراهم کردن هشدار زودهنگام پیش از تبدیل شرایط خطرناک به حادثه، بیماری یا آسیب زیستمحیطی است.
این رویکرد از نظر فلسفه مدیریتی اهمیت زیادی دارد. در نظامهای سنتی HSE، بسیاری از اقدامات پس از وقوع حادثه یا مشاهده عدم انطباق انجام میشدند. اما در رویکرد پیشبینانه، سازمان تلاش میکند نشانههای اولیه خطر را قبل از وقوع پیامد شناسایی کند.
برای مثال، افزایش تدریجی شبهحوادث، تأخیر در بستن اقدامات اصلاحی، افت کیفیت مجوزهای کاری، افزایش خرابیهای جزئی تجهیزات، فشار تولید، تغییر شیفتها یا کاهش مشارکت کارکنان در گزارشدهی میتوانند نشانههایی از افزایش ریسک باشند. مدل پیشبینانه این نشانهها را بهصورت جداگانه و ترکیبی تحلیل میکند.
مزیت مدلهای پیشبینانه آن است که میتوانند روابط پیچیده و غیرخطی را بهتر از روشهای ساده آماری تشخیص دهند. بسیاری از حوادث HSE نتیجه یک علت منفرد نیستند، بلکه حاصل تعامل چند عامل فنی، انسانی، سازمانی و محیطیاند.
با این حال، استفاده از این مدلها نیازمند احتیاط است. اگر دادهها ناقص، سوگیرانه یا نامعتبر باشند، خروجی مدل نیز قابل اعتماد نخواهد بود. همان اصل مشهور «ورودی نامناسب، خروجی نامناسب» در اینجا کاملاً صادق است.
بنابراین، دادهکاوی پیشبینانه در HSE فقط یک فعالیت فنی نیست. این کار باید با فهم عمیق از ریسک، شناخت فرایندهای عملیاتی، مشارکت خبرگان HSE و درک زمینه سازمانی همراه باشد.
۱۰-۳. دادههای مورد استفاده در مدلهای پیشبینانه HSE
مدلهای پیشبینانه به داده وابستهاند. کیفیت، تنوع و ساختار دادهها نقش تعیینکنندهای در عملکرد مدل دارند. در HSE، دادهها معمولاً از منابع متنوعی گردآوری میشوند و همین تنوع، هم فرصت ایجاد میکند و هم چالش.
- نخستین گروه، دادههای رخدادمحور است. این دادهها شامل حوادث، شبهحوادث، آسیبها، بیماریهای شغلی، نشتها، آتشسوزیها، خرابیها و عدم انطباقها هستند. این دادهها برای آموزش مدلهای پیشبینی حادثه و تحلیل شدت پیامد بسیار مهماند.
- گروه دوم، دادههای بازرسی و ممیزی است. نتایج بازرسیهای ایمنی، مشاهدات رفتاری، ممیزیهای HSE، چکلیستهای کنترلی و وضعیت اقدامات اصلاحی میتوانند نشانههای ارزشمندی از وضعیت واقعی کنترل ریسک ارائه دهند.
- گروه سوم، دادههای عملیاتی و فرایندی است. این دادهها شامل فشار، دما، جریان، ارتعاش، سطح مخازن، سرعت تولید، توقفات فرایندی، وضعیت تجهیزات و دادههای نگهداشت است. این نوع دادهها بهویژه برای پیشبینی خرابی و هشدار زودهنگام اهمیت دارند.
.
- گروه چهارم، دادههای بهداشت حرفهای است. اطلاعات مربوط به مواجهه با عوامل شیمیایی، فیزیکی، زیستی، ارگونومیک و روانی ـ اجتماعی در این گروه قرار میگیرند. این دادهها برای پیشبینی مواجهه بیش از حد مجاز و شناسایی گروههای پرریسک کاربرد دارند.
- گروه پنجم، دادههای زیستمحیطی است. دادههایی مانند میزان انتشار، کیفیت پساب، مصرف انرژی، تولید پسماند، آلودگی هوا، آلودگی آب و شاخصهای پایش محیطی میتوانند برای پیشبینی عدم انطباقهای زیستمحیطی بهکار روند.
- گروه ششم، دادههای انسانی و سازمانی است. آموزش، تجربه، نوع قرارداد، وضعیت پیمانکاری، تغییرات شیفت، اضافهکاری، بار کاری، فرهنگ گزارشدهی و مشارکت کارکنان، متغیرهایی هستند که میتوانند بر ریسک HSE اثر بگذارند.
در سالهای اخیر، دادههای حسگری و بلادرنگ نیز اهمیت زیادی پیدا کردهاند. حسگرهای صنعتی، سامانههای اینترنت اشیای صنعتی، ابزارهای پوشیدنی و سامانههای پایش آنلاین میتوانند دادههایی با سرعت بالا و حجم زیاد تولید کنند.
با وجود این، همه دادهها به یک اندازه مفید نیستند. دادهای ارزشمند است که معتبر، مرتبط، قابل تفسیر، بهموقع و متناسب با مسئله ریسک باشد. گردآوری حجم عظیم داده بدون مسئله روشن، به بهبود تصمیمگیری منجر نمیشود.
۱۰-۴. کلانداده و نقش آن در پیشبینی HSE
کلانداده در HSE به دادههایی اشاره دارد که از نظر حجم، سرعت، تنوع و پیچیدگی فراتر از ظرفیت روشهای سنتی تحلیل هستند. این دادهها میتوانند از سامانههای عملیاتی، حسگرها، تجهیزات هوشمند، گزارشهای متنی، تصاویر، ویدئوها، سامانههای نگهداشت و پایگاههای داده سازمانی تولید شوند.
در محیطهای صنعتی، کلانداده فقط به معنای «داده زیاد» نیست. اهمیت اصلی آن در امکان مشاهده پیوستهتر و دقیقتر وضعیت سیستم است. هرچه دادهها نزدیکتر به زمان واقعی تولید شوند، امکان شناسایی زودهنگام انحرافات افزایش مییابد.
برای مثال، در یک واحد فرایندی، دادههای دما، فشار، ارتعاش و جریان میتوانند بهصورت لحظهای تحلیل شوند. اگر الگوی این متغیرها از وضعیت عادی فاصله بگیرد، مدل میتواند احتمال خرابی، نشت یا شرایط عملیاتی ناایمن را هشدار دهد.
در حوزه بهداشت حرفهای، ابزارهای پوشیدنی میتوانند اطلاعاتی درباره مواجهه با صدا، گرما، گازهای خطرناک یا فشار فیزیولوژیک کارکنان فراهم کنند. این دادهها اگر بهدرستی مدیریت شوند، میتوانند به پیشبینی زودهنگام مواجهه نامطلوب کمک کنند.
.
در محیطزیست نیز سامانههای پایش آنلاین انتشار، کیفیت هوا، کیفیت آب و مصرف انرژی میتوانند تغییرات غیرعادی را زودتر از گزارشهای دورهای آشکار کنند. این موضوع برای پیشگیری از عدم انطباقهای زیستمحیطی بسیار ارزشمند است.
با این حال، کلانداده بهتنهایی مزیت ایجاد نمیکند. اگر حکمرانی داده، کیفیتسنجی، امنیت اطلاعات، استانداردسازی و قابلیت تفسیر وجود نداشته باشد، حجم زیاد داده حتی میتواند تصمیمگیری را دشوارتر کند.
بنابراین، نقش کلانداده در HSE زمانی مهم است که در خدمت پیشبینی باشد. هدف، انباشتن داده نیست؛ هدف، تبدیل داده به هشدار قابل اعتماد و اقدام مدیریتی مؤثر است.
۱۰-۵. تحلیل جریان داده و هشدار زودهنگام

تحلیل جریان داده یا Stream Analytics به معنای پردازش دادهها در همان زمانی است که تولید میشوند. در این رویکرد، دادهها منتظر گزارشهای ماهانه یا تحلیلهای دورهای نمیمانند، بلکه بهصورت پیوسته تحلیل میشوند.
در HSE، این قابلیت اهمیت زیادی دارد. بسیاری از شرایط خطرناک، ماهیت لحظهای یا سریعالتغییر دارند. اگر سازمان فقط پس از پایان شیفت، هفته یا ماه دادهها را بررسی کند، فرصت مداخله زودهنگام از دست میرود.
برای مثال، افزایش ناگهانی غلظت یک گاز سمی، افت فشار غیرعادی، افزایش ارتعاش تجهیز، افزایش دمای غیرمعمول، یا عبور موقت از حدود مجاز زیستمحیطی ممکن است در لحظه به اقدام نیاز داشته باشد. تحلیل جریان داده میتواند این وضعیتها را سریعتر شناسایی کند.
مدلهای هشدار زودهنگام بر اساس همین منطق عمل میکنند. این مدلها تلاش میکنند نشانههایی را شناسایی کنند که پیش از حادثه، خرابی یا عدم انطباق ظاهر میشوند. این نشانهها گاهی آشکار و گاهی بسیار ضعیفاند.
برای طراحی هشدار زودهنگام، تعیین آستانه هشدار اهمیت زیادی دارد. اگر آستانه بیش از حد پایین باشد، هشدارهای کاذب زیاد میشوند و کاربران دچار خستگی از هشدار میگردند. اگر آستانه بیش از حد بالا باشد، سیستم ممکن است خطر واقعی را دیر تشخیص دهد.
در HSE، خطای از دست دادن هشدار واقعی معمولاً پیامد سنگینتری دارد. اما هشدارهای کاذب فراوان نیز اعتماد کاربران را کاهش میدهد. بنابراین، تنظیم آستانه باید با ترکیب تحلیل داده، نظر خبرگان و سطح تحمل ریسک سازمان انجام شود.
نکته مهم آن است که هشدار باید به اقدام وصل شود. اگر سامانه فقط هشدار تولید کند، اما مشخص نباشد چه کسی، چه زمانی و چگونه باید واکنش نشان دهد، مدل ارزش عملیاتی خود را از دست میدهد.
به همین دلیل، برای هر سطح هشدار باید پروتکل اقدام تعریف شود. این پروتکل باید مشخص کند دریافتکننده هشدار کیست، سطح فوریت چیست، چه کنترلی لازم است و چگونه اثربخشی اقدام بررسی میشود.
۱۰-۶. انواع مدلهای یادگیری ماشین در پیشبینی HSE
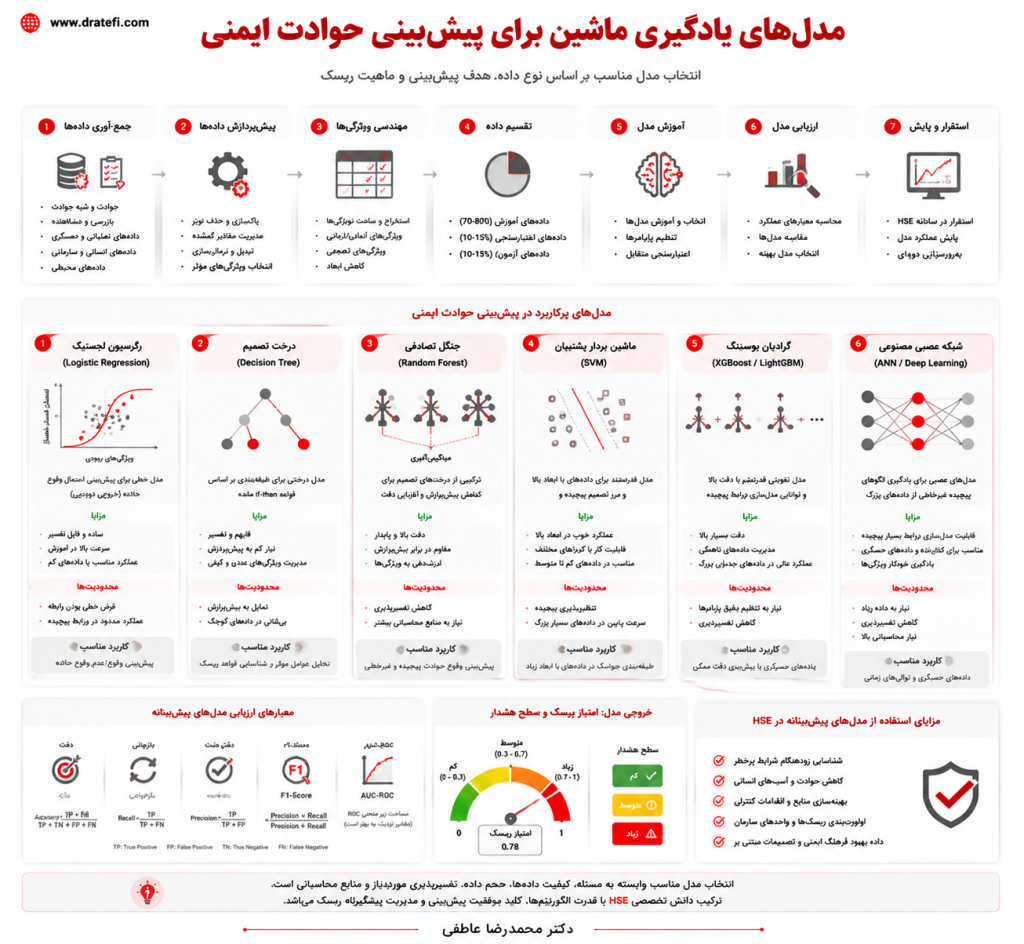
یادگیری ماشین مجموعهای از روشهاست که به مدلها امکان میدهد از دادهها الگو بیاموزند و بر اساس آن درباره موارد جدید پیشبینی انجام دهند. در HSE، این روشها معمولاً در سه گروه اصلی استفاده میشوند: طبقهبندی، رگرسیون و پیشبینی زمانی.
در مسائل طبقهبندی، هدف پیشبینی تعلق یک مورد به یک گروه است. برای مثال، مدل ممکن است پیشبینی کند یک فعالیت در طبقه ریسک پایین، متوسط یا بالا قرار دارد. همچنین ممکن است احتمال وقوع یا عدم وقوع حادثه را برآورد کند.
در مسائل رگرسیون، هدف پیشبینی یک مقدار پیوسته است. برای مثال، مدل میتواند میزان مواجهه با صدا، غلظت آلاینده، نرخ انتشار یا شاخص شدت ریسک را پیشبینی کند.
در پیشبینی زمانی، روند آینده بر اساس دادههای وابسته به زمان برآورد میشود. این نوع مدلها برای پیشبینی افت عملکرد تجهیزات، تغییرات مواجهه، روند شبهحوادث و نوسان شاخصهای زیستمحیطی کاربرد دارند.
یکی از مدلهای ساده و قابل استفاده، رگرسیون لجستیک است. این مدل برای پیشبینی احتمال وقوع یک پیامد دودویی، مانند وقوع حادثه یا عبور از حد مجاز، کاربرد دارد. مزیت مهم آن تفسیرپذیری است.
.
درخت تصمیم نیز در HSE کاربرد فراوان دارد. این مدل با مجموعهای از قواعد شرطی، مسیر تصمیم را نشان میدهد. برای مثال، ممکن است نشان دهد که ترکیب فعالیت در ارتفاع، تجربه پایین پیمانکار و سابقه بازرسی نامطلوب، احتمال رخداد را افزایش میدهد.
جنگل تصادفی و گرادیان بوستینگ از مدلهای تجمیعی هستند. این مدلها معمولاً دقت بالاتری نسبت به یک درخت تصمیم ساده دارند، زیرا از ترکیب چندین مدل استفاده میکنند. با این حال، تفسیر آنها دشوارتر است.
ماشین بردار پشتیبان یا SVM نیز برای مسائل طبقهبندی پیچیده قابل استفاده است. این مدل زمانی مفید است که مرز میان وضعیتهای پرخطر و کمخطر ساده و خطی نباشد.
شبکههای عصبی و یادگیری عمیق ظرفیت بالایی برای تحلیل دادههای پیچیده دارند. این مدلها در پیشبینی خرابی، تحلیل دادههای حسگری، تشخیص الگوهای غیرعادی و پردازش تصویر کاربرد دارند. با این حال، استفاده از آنها باید با دقت، اعتبارسنجی و توضیحپذیری همراه باشد.
در انتخاب الگوریتم، پیچیدگی نباید هدف اصلی باشد. در HSE، مدل مناسب مدلی است که علاوه بر دقت، قابل فهم، قابل دفاع، قابل استقرار و قابل اتصال به تصمیم مدیریتی باشد.
۱۰-۷. پیشبینی حوادث و ریسکهای ایمنی
پیشبینی حادثه یکی از مهمترین کاربردهای یادگیری ماشین در HSE است. هدف این نیست که زمان دقیق حادثه با قطعیت اعلام شود، بلکه هدف شناسایی شرایطی است که احتمال رخداد را افزایش میدهند.
برای این منظور، مدل میتواند از متغیرهایی مانند نوع فعالیت، مکان عملیات، سابقه رخداد، وضعیت مجوز کار، نتایج بازرسی، تجربه کارکنان، وضعیت پیمانکار، زمان انجام کار، شرایط آبوهوایی و وضعیت تجهیزات استفاده کند.
برای مثال، در یک پروژه ساختمانی یا صنعتی، مدل میتواند فعالیتهای روز آینده را بر اساس سطح ریسک پیشبینیشده رتبهبندی کند. سپس تیم HSE میتواند منابع نظارتی خود را بر فعالیتهای پرریسکتر متمرکز کند.
در صنایع فرایندی، مدلهای پیشبینانه میتوانند شرایطی را تشخیص دهند که احتمال نشت، آتشسوزی، انفجار یا از دست رفتن کنترل فرایند را افزایش میدهند. این مدلها معمولاً از دادههای عملیاتی و نگهداشت استفاده میکنند.
در حوزه حملونقل سازمانی، مدل میتواند احتمال رخدادهای رانندگی را بر اساس سرعت، مسیر، ساعت حرکت، خستگی، سابقه راننده و شرایط محیطی برآورد کند. این نوع پیشبینی میتواند به طراحی برنامههای پیشگیرانه کمک کند.
با این حال، پیشبینی حادثه با چالش مهمی روبهروست: حوادث شدید معمولاً نادرند. این نامتوازن بودن دادهها باعث میشود مدلها بهاشتباه بیشتر موارد را کمخطر تشخیص دهند. بنابراین، باید از معیارهای ارزیابی مناسب و روشهای ویژه برای دادههای نامتوازن استفاده شود.
همچنین باید مراقب بود که مدل پیشبینی حادثه به ابزار سرزنش تبدیل نشود. هدف، شناسایی شرایط خطرناک و اصلاح سیستم است، نه برچسبزدن به افراد یا گروهها.
۱۰-۸. پیشبینی مواجهههای شغلی و پیامدهای بهداشتی
در بهداشت حرفهای، پیشبینی میتواند نقش مهمی در هدفمند کردن پایش و کنترل مواجهه داشته باشد. بسیاری از سازمانها منابع محدودی برای نمونهبرداری، معاینات، پایش و مداخله دارند. مدلهای پیشبینانه میتوانند این منابع را به سمت گروهها و فعالیتهای پرریسکتر هدایت کنند.
برای مثال، مدل میتواند احتمال مواجهه بیش از حد مجاز با گردوغبار، بخارات شیمیایی، صدا، گرما یا عوامل ارگونومیک را پیشبینی کند. این پیشبینی میتواند بر اساس نوع شغل، مدت مواجهه، تهویه، شرایط فرایندی، مواد مصرفی و نتایج نمونهبرداری گذشته انجام شود.
در محیطهایی که دادههای حسگری وجود دارد، امکان پیشبینی دقیقتر فراهم میشود. برای نمونه، پایش لحظهای صدا یا گازهای خطرناک میتواند نشان دهد چه زمانی احتمال عبور از حدود مجاز افزایش مییابد.
در ارگونومی نیز مدلها میتوانند احتمال بروز اختلالات اسکلتی ـ عضلانی را بر اساس وضعیت بدن، تکرار حرکت، نیروی اعمالشده، مدت فعالیت و سابقه شکایات پیشبینی کنند.
با این حال، استفاده از دادههای سلامت کارکنان حساسیت بالایی دارد. دادههای پزشکی، زیستی و مواجهه فردی باید با رعایت محرمانگی، حداقلگرایی داده و رضایت آگاهانه مدیریت شوند.
مدلهای پیشبینانه در بهداشت حرفهای باید در خدمت پیشگیری و حفاظت از سلامت باشند. اگر کارکنان احساس کنند دادهها برای کنترل تنبیهی یا ارزیابی ناعادلانه استفاده میشود، اعتماد آسیب میبیند و کیفیت دادهها کاهش مییابد.
۱۰-۹. پیشبینی عدم انطباقهای زیستمحیطی
در حوزه محیطزیست، مدلهای پیشبینانه میتوانند به سازمان کمک کنند پیش از وقوع عدم انطباق، نشانههای آن را تشخیص دهد. این موضوع بهویژه در صنایع دارای انتشار هوا، پساب، پسماند خطرناک و مصرف بالای انرژی اهمیت دارد.
برای مثال، مدل میتواند احتمال عبور غلظت آلاینده از حد مجاز را بر اساس شرایط تولید، وضعیت تجهیزات کنترلی، دما، رطوبت، کیفیت سوخت، نرخ خوراک و سوابق نگهداشت پیشبینی کند.
در تصفیهخانههای صنعتی، مدلهای پیشبینانه میتوانند کیفیت پساب خروجی را بر اساس بار ورودی، pH، دما، اکسیژن محلول، مواد شیمیایی مصرفی و عملکرد واحدهای تصفیه برآورد کنند.
در مدیریت پسماند، مدل میتواند مقدار پسماند تولیدی یا احتمال افزایش پسماند خطرناک را بر اساس نوع تولید، مواد اولیه و تغییرات فرایندی پیشبینی کند. این پیشبینی به برنامهریزی بهتر برای ذخیرهسازی، حمل و دفع کمک میکند.
در مدیریت انرژی و کربن نیز مدلها میتوانند مصرف آینده انرژی یا شدت انتشار را پیشبینی کنند. این موضوع برای سازمانهایی که به دنبال بهبود عملکرد زیستمحیطی و کاهش هزینهها هستند، اهمیت راهبردی دارد.
نکته مهم آن است که پیشبینی زیستمحیطی باید به تصمیمهای عملیاتی متصل شود. برای مثال، اگر مدل احتمال افزایش آلاینده را نشان دهد، سازمان باید بداند آیا باید ظرفیت تصفیه را افزایش دهد، تولید را تنظیم کند، نگهداشت انجام دهد یا کنترل فرایند را اصلاح کند.
۱۰-۱۰. تشخیص ناهنجاری و پیشبینی خرابی

تشخیص ناهنجاری یکی از کاربردهای مهم یادگیری ماشین در HSE است. ناهنجاری به وضعیتی گفته میشود که از الگوی عادی دادهها فاصله دارد. این فاصله ممکن است نشانه اولیه خرابی، خطای عملیاتی، نشت، آلودگی یا شرایط ناایمن باشد.
در بسیاری از موارد، رخدادهای جدی پیش از وقوع، علائم کوچکی از خود نشان میدهند. افزایش تدریجی ارتعاش، نوسان غیرعادی دما، تغییر فشار، افزایش مصرف انرژی یا تغییر الگوی توقفات میتواند نشانهای از مشکل باشد.
مدلهای تشخیص ناهنجاری تلاش میکنند این تغییرات را زودتر از روشهای معمول شناسایی کنند. این مدلها بهویژه زمانی مفیدند که داده برچسبدار کافی از حوادث وجود ندارد، اما دادههای عادی سیستم در دسترس است.
پیشبینی خرابی نیز با تشخیص ناهنجاری ارتباط نزدیک دارد. در اینجا هدف برآورد احتمال خرابی تجهیز یا زمان باقیمانده تا خرابی است. این موضوع برای تجهیزات ایمنیحساس اهمیت ویژهای دارد.
خرابی یک تجهیز در صنایع نفت، گاز، پتروشیمی، معدن، انرژی یا حملونقل فقط یک مسئله نگهداشت نیست. چنین خرابیای میتواند به حادثه، توقف تولید، نشت، آتشسوزی یا آلودگی محیطزیست منجر شود.
مدلهای پیشبینی خرابی معمولاً از دادههای ارتعاش، دما، فشار، جریان، سوابق تعمیرات، شرایط بهرهبرداری و نتایج بازرسی استفاده میکنند. خروجی این مدلها میتواند به برنامهریزی نگهداشت پیشبینانه کمک کند.
اتصال نگهداشت پیشبینانه به نظام مدیریت HSE اهمیت زیادی دارد. اگر پیشبینی خرابی فقط در واحد تعمیرات باقی بماند و با ریسکهای ایمنی و زیستمحیطی پیوند نخورد، بخشی از ارزش خود را از دست میدهد.
۱۰-۱۱. هوش مصنوعی، یادگیری عمیق و بینایی ماشین در HSE پیشبینانه
هوش مصنوعی مفهومی گستردهتر از یادگیری ماشین است و شامل روشهایی میشود که به سامانهها امکان تحلیل، یادگیری، تصمیمیاری و گاه خودکارسازی رفتار را میدهند. در HSE، هوش مصنوعی زمانی ارزشمند است که به پیشبینی بهتر، هشدار زودهنگام و تصمیمگیری ایمنتر کمک کند.
یادگیری عمیق یکی از شاخههای مهم یادگیری ماشین است. این روشها بهویژه در تحلیل دادههای پیچیده مانند تصویر، ویدئو، صوت و دادههای حسگری چندبعدی عملکرد بالایی دارند.
در HSE، بینایی ماشین میتواند برای شناسایی رفتارهای ناایمن، استفاده نکردن از تجهیزات حفاظت فردی، ورود به مناطق ممنوعه، وضعیت نامناسب تجهیزات، نشتی قابل مشاهده یا شرایط محیطی خطرناک استفاده شود.
برای مثال، دوربینهای صنعتی میتوانند با کمک مدلهای بینایی ماشین، نبود کلاه ایمنی، حضور فرد در محدوده خطر یا رفتار ناایمن در نزدیکی ماشینآلات را تشخیص دهند. اگر این تشخیص در زمان مناسب انجام شود، میتواند به هشدار فوری منجر شود.
با این حال، این کاربردها باید با احتیاط اخلاقی همراه باشند. پایش تصویری کارکنان نباید به نظارت افراطی، کنترل تنبیهی یا نقض حریم خصوصی تبدیل شود. هدف باید پیشگیری از آسیب و بهبود ایمنی باشد، نه ایجاد فضای بیاعتمادی.
.
هوش مصنوعی همچنین میتواند در تحلیل گزارشهای متنی حوادث و شبهحوادث بهکار رود. پردازش زبان طبیعی میتواند موضوعات تکرارشونده، عوامل زمینهای، ضعفهای کنترلی و نشانههای فرهنگ ایمنی را شناسایی کند.
ترکیب دادههای متنی با دادههای عددی و حسگری میتواند قدرت پیشبینی را افزایش دهد. برای مثال، اگر گزارشهای متنی از افزایش فشار کاری یا نقصهای تکراری سخن بگویند و همزمان دادههای عملیاتی نیز نوسان غیرعادی نشان دهند، احتمال ریسک میتواند جدیتر تلقی شود.
در آینده، دوقلوهای دیجیتال نیز نقش مهمی در HSE پیشبینانه خواهند داشت. دوقلوی دیجیتال نسخهای مجازی از یک فرایند، تجهیز یا سیستم است که با دادههای واقعی بهروزرسانی میشود. این ابزار میتواند سناریوهای خطر را پیش از وقوع در محیط واقعی شبیهسازی کند.
با وجود این ظرفیتها، هوش مصنوعی نباید بهعنوان راهحل جادویی معرفی شود. کاربرد موفق آن نیازمند داده معتبر، مسئله روشن، ارزیابی دقیق، حکمرانی مناسب و نظارت انسانی است.
۱۰-۱۲. ارزیابی عملکرد مدلهای پیشبینانه
ارزیابی مدلهای پیشبینانه در HSE اهمیت بنیادین دارد. یک مدل ضعیف یا بداعتبار میتواند تصمیمهای مدیریتی را منحرف کند و پیامدهای انسانی، زیستمحیطی و حقوقی داشته باشد.
نخستین اصل، تفکیک دادههای آموزش و آزمون است. مدل باید روی بخشی از دادهها آموزش ببیند و روی دادههایی ارزیابی شود که قبلاً ندیده است. این کار کمک میکند عملکرد واقعیتر مدل سنجیده شود.
اگر مدل فقط روی دادههای آموزشی عملکرد خوبی داشته باشد، ممکن است دچار بیشبرازش شده باشد. بیشبرازش یعنی مدل به جای یادگیری الگوی عمومی، جزئیات و نویزهای دادههای گذشته را حفظ کرده است.
در مدلهای طبقهبندی، دقت کلی یا Accuracy همیشه معیار مناسبی نیست. در HSE، رخدادهای مهم معمولاً نادرند. بنابراین، مدلی که همیشه پیشبینی کند «حادثه رخ نمیدهد» ممکن است دقت ظاهری بالایی داشته باشد، اما از نظر پیشگیری بیارزش باشد.
به همین دلیل، معیارهایی مانند Recall، Precision، F1 و AUC اهمیت بیشتری پیدا میکنند. Recall نشان میدهد مدل چه نسبتی از موارد واقعاً پرخطر را شناسایی کرده است. Precision نشان میدهد هشدارهای مدل تا چه اندازه درست بودهاند.
F1 توازنی میان Precision و Recall ایجاد میکند. AUC نیز توان مدل را در تفکیک موارد پرخطر از کمخطر در آستانههای مختلف نشان میدهد.
.
در مدلهای رگرسیونی، معیارهایی مانند MAE، RMSE و R² استفاده میشوند. اما در HSE، این معیارها باید با معنای عملیاتی خطا تفسیر شوند. خطای کوچک در نزدیکی حد مجاز ممکن است از نظر مدیریتی بسیار مهم باشد.
کالیبراسیون مدل نیز اهمیت دارد. اگر مدل احتمال ۳۰ درصدی برای رخداد اعلام کند، در بلندمدت باید تقریباً همین نسبت رخداد در موارد مشابه مشاهده شود. مدل غیرکالیبره ممکن است تصمیمگیری را گمراه کند.
ارزیابی مدل فقط در زمان ساخت کافی نیست. محیطهای HSE پویا هستند. تغییر فرایند، تغییر پیمانکار، تغییر فرهنگ گزارشدهی، تغییر تجهیزات یا تغییر شرایط تولید میتواند عملکرد مدل را کاهش دهد.
به همین دلیل، مدل پس از استقرار نیز باید پایش شود. افت عملکرد، افزایش هشدارهای کاذب، کاهش شناسایی خطرهای واقعی و تغییر توزیع دادهها باید بهطور دورهای بررسی شوند.
۱۰-۱۳. تفسیرپذیری و تصمیمگیری مدیریتی
تفسیرپذیری در مدلهای HSE اهمیت ویژهای دارد. در این حوزه، تصمیمها با جان انسانها، سلامت کارکنان، محیطزیست، مسئولیت قانونی و اعتبار سازمان ارتباط دارند. بنابراین، مدیران باید بدانند مدل چرا یک وضعیت را پرخطر تشخیص داده است.
برخی مدلها مانند رگرسیون لجستیک و درخت تصمیم ذاتاً قابل فهمترند. در مقابل، مدلهایی مانند جنگل تصادفی، گرادیان بوستینگ و شبکههای عصبی معمولاً پیچیدهترند و نیاز به روشهای توضیحپذیری دارند.
توضیحپذیری کمک میکند خروجی مدل به اقدام اصلاحی تبدیل شود. اگر مدل فقط اعلام کند یک فعالیت پرخطر است، اما دلیل آن روشن نباشد، تصمیمگیری دشوار میشود.
برای مثال، اگر مدل نشان دهد احتمال حادثه در یک فعالیت بالاست، باید مشخص شود کدام عوامل اثرگذار بودهاند. آیا مسئله مربوط به پیمانکار است؟ یا آیا فشار زمانی، سابقه رخداد یا نقص تجهیز نقش داشته است؟
این توضیحها به مدیر کمک میکند اقدام مناسبتری انتخاب کند. اقدام ممکن است افزایش نظارت، بازآموزی، اصلاح برنامه کاری، تقویت کنترل مهندسی، توقف موقت فعالیت یا بازنگری فرایند باشد.
با این حال، خروجی مدل نباید بهصورت مکانیکی اجرا شود. مدل پیشبینی میکند، اما تصمیم نهایی باید با قضاوت حرفهای، دانش فنی، الزامات قانونی و شرایط واقعی کار ترکیب شود.
اصل انسان در حلقه تصمیم در HSE بسیار مهم است. یعنی مدل باید تصمیم را پشتیبانی کند، اما تصمیم نهایی نباید بدون نظارت و مسئولیتپذیری انسانی گرفته شود.
۱۰-۱۴. ملاحظات اخلاقی، حقوقی و سازمانی
کاربرد دادهکاوی پیشبینانه و هوش مصنوعی در HSE با ملاحظات اخلاقی مهمی همراه است. این فناوریها میتوانند به پیشگیری از آسیب کمک کنند، اما اگر نادرست بهکار روند، میتوانند اعتماد سازمانی را تضعیف کنند.
یکی از مهمترین نگرانیها، مرز میان پیشگیری و نظارت افراطی است. گردآوری دادههای رفتاری، مکانی، تصویری یا زیستی کارکنان باید محدود، هدفمند و شفاف باشد.
اصل حداقلگرایی داده اهمیت زیادی دارد. سازمان نباید بیش از آنچه برای هدف HSE لازم است، داده گردآوری کند. هر دادهای که جمعآوری میشود باید دلیل روشن، مبنای قانونی و سازوکار حفاظت داشته باشد.
محرمانگی دادههای سلامت کارکنان نیز بسیار مهم است. دادههای پزشکی و مواجهه فردی نباید برای تبعیض، تنبیه یا تصمیمهای ناعادلانه استفاده شوند. هدف اصلی باید حفاظت از سلامت باشد.
سوگیری الگوریتمی نیز از چالشهای جدی است. اگر دادههای گذشته سوگیرانه باشند، مدل ممکن است همان سوگیری را بازتولید کند. برای مثال، واحدی که فرهنگ گزارشدهی بهتری دارد، ممکن است در دادهها پرحادثهتر دیده شود، در حالی که الزاماً ناایمنتر نیست.
شفافیت با کارکنان اهمیت اساسی دارد. کارکنان باید بدانند چه دادههایی، برای چه هدفی، با چه سطحی از دسترسی و با چه ضمانتهایی استفاده میشوند. بدون اعتماد، حتی بهترین مدلها نیز در عمل با مقاومت روبهرو میشوند.
از نظر سازمانی، پروژههای پیشبینانه نباید صرفاً پروژه فناوری اطلاعات باشند. این پروژهها باید با مشارکت HSE، عملیات، نگهداشت، منابع انسانی، حقوقی، فناوری اطلاعات و نمایندگان کارکنان طراحی شوند.
۱۰-۱۵. استقرار مدلهای پیشبینانه در نظام مدیریت HSE
ارزش مدل پیشبینانه زمانی آشکار میشود که در نظام مدیریت HSE مستقر شود. مدل جداافتاده، حتی اگر از نظر فنی دقیق باشد، اثر پایداری بر عملکرد سازمان نخواهد داشت.
نخستین گام، تعریف مسئله است. سازمان باید دقیقاً بداند میخواهد چه چیزی را پیشبینی کند. پیشبینی حادثه، مواجهه، خرابی، عدم انطباق یا افزایش ریسک، هرکدام دادهها و مدلهای متفاوتی میخواهند.
گام دوم، آمادهسازی داده است. دادهها باید پاکسازی، یکپارچه، استاندارد و معتبر شوند. در بسیاری از پروژهها، بخش عمده زمان صرف همین مرحله میشود.
گام سوم، انتخاب مدل مناسب است. انتخاب مدل باید بر اساس هدف، کیفیت داده، نیاز به تفسیرپذیری، پیامد خطا و قابلیت استقرار انجام شود. همیشه پیچیدهترین مدل بهترین گزینه نیست.
گام چهارم، ارزیابی و اعتبارسنجی است. مدل باید از نظر آماری و عملیاتی آزمون شود. همچنین باید مشخص شود خروجی مدل چگونه به تصمیم مدیریتی تبدیل میشود.
گام پنجم، استقرار کنترلشده است. بهتر است پروژه ابتدا بهصورت پایلوت در یک واحد، فرایند یا نوع ریسک اجرا شود. اجرای پایلوت امکان یادگیری، اصلاح و افزایش پذیرش سازمانی را فراهم میکند.
گام ششم، پایش و بازآموزی مدل است. مدلها در طول زمان فرسوده میشوند، زیرا شرایط عملیاتی و سازمانی تغییر میکند. بنابراین، بازآموزی و پایش دورهای ضروری است.
در نهایت، مدل باید با فرایندهای موجود HSE پیوند بخورد. این فرایندها شامل ارزیابی ریسک، مدیریت اقدامات اصلاحی، بازرسی، مجوز کار، مدیریت پیمانکاران، نگهداشت، آموزش و بازنگری مدیریتی هستند.
۱۰-۱۶. آینده دادهکاوی پیشبینانه و هوش مصنوعی در HSE

آینده HSE بهطور فزایندهای با داده، پیشبینی و هوش مصنوعی پیوند خواهد خورد. با گسترش حسگرهای صنعتی، اینترنت اشیای صنعتی، ابزارهای پوشیدنی و سامانههای پایش آنلاین، حجم و سرعت دادههای HSE افزایش مییابد.
این تحول میتواند مدیریت HSE را از گزارشدهی پسینی به پیشگیری فعال نزدیکتر کند. سازمانها خواهند توانست نشانههای اولیه خطر را زودتر ببینند و منابع خود را دقیقتر تخصیص دهند.
دوقلوهای دیجیتال یکی از مسیرهای مهم آینده هستند. این فناوری میتواند امکان شبیهسازی سناریوهای خطر، آزمون اقدامات کنترلی و پیشبینی پیامدهای عملیاتی را پیش از اجرای واقعی فراهم کند.
هوش مصنوعی مولد و مدلهای پیشرفته زبانی نیز میتوانند در تحلیل گزارشهای HSE، استخراج درسآموختهها، خلاصهسازی رخدادها و پشتیبانی از تصمیم کارشناسی نقش داشته باشند. البته این کاربردها نیازمند کنترل کیفیت، محرمانگی و نظارت انسانی هستند.
با این حال، آینده مطلوب HSE صرفاً فناورانه نیست. فناوری زمانی ارزشمند است که با فرهنگ ایمنی، رهبری مسئولانه، مشارکت کارکنان، اخلاق داده و قضاوت حرفهای همراه باشد.
بنابراین، HSE هوشمند به معنای حذف انسان از تصمیمگیری نیست. برعکس، به معنای تجهیز انسان به دادههای بهتر، هشدارهای دقیقتر و بینش عمیقتر برای تصمیمگیری مسئولانهتر است.
جمعبندی فصل
در این فصل، دادهکاوی پیشبینانه، یادگیری ماشین، کلانداده، تحلیل جریان داده و هوش مصنوعی در HSE بهصورت یکپارچه بررسی شد. محور اصلی فصل، پیشبینی آینده و پشتیبانی از تصمیمگیری پیشگیرانه بود.
تأکید شد که دادهکاوی پیشبینانه به سازمان کمک میکند احتمال وقوع حوادث، مواجهههای شغلی، عدم انطباقهای زیستمحیطی، خرابی تجهیزات و افزایش ریسکهای عملیاتی را پیش از وقوع پیامد شناسایی کند.
همچنین نشان داده شد که کلانداده و تحلیل جریان داده میتوانند سرعت و دقت هشدارهای HSE را افزایش دهند. با این حال، حجم زیاد داده بهتنهایی کافی نیست. داده باید معتبر، مرتبط، قابل تفسیر و متصل به اقدام مدیریتی باشد.
مدلهای یادگیری ماشین، از رگرسیون لجستیک و درخت تصمیم تا جنگل تصادفی، گرادیان بوستینگ، شبکههای عصبی و روشهای تشخیص ناهنجاری، هرکدام میتوانند در شرایط خاص مفید باشند. انتخاب مدل باید بر اساس مسئله، داده، پیامد خطا و نیاز سازمان انجام شود.
ارزیابی مدل نیز بخش جداییناپذیر کار است. معیارهایی مانند Recall، Precision، F1، AUC، MAE و RMSE باید با معنای عملیاتی خطا در HSE تفسیر شوند. در رخدادهای نادر، اتکا به دقت کلی میتواند گمراهکننده باشد.
از سوی دیگر، تفسیرپذیری، اخلاق داده، محرمانگی، عدالت و اصل انسان در حلقه تصمیم، برای استفاده مسئولانه از مدلهای پیشبینانه ضروریاند. فناوری نباید به ابزار نظارت افراطی یا تصمیمگیری غیرپاسخگو تبدیل شود.
پیام اصلی فصل آن است که آینده HSE، آیندهای پیشبینانه، دادهمحور و هوشمند است؛ اما این آینده فقط زمانی مطلوب خواهد بود که فناوری در کنار قضاوت حرفهای، تجربه میدانی، مشارکت کارکنان و مسئولیت اخلاقی قرار گیرد. دادهکاوی پیشبینانه و هوش مصنوعی میتوانند توان سازمان را برای دیدن نشانههای خطر افزایش دهند. اما تصمیم درست، همچنان نیازمند انسان آگاه، مسئول و متعهد به ایمنی، سلامت و پایداری است.
منابع
دادهکاوی پیشبینانه، یادگیری ماشین و هوش مصنوعی در HSE
Aggarwal, C. C. (2017). Outlier analysis (2nd ed.). Springer. https://doi.org/10.1007/978-3-319-47578-3
Bishop, C. M. (2006). Pattern recognition and machine learning. Springer
Box, G. E. P., Jenkins, G. M., Reinsel, G. C., & Ljung, G. M. (2015). Time series analysis: Forecasting and control (5th ed.). Wiley
Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5–32. https://doi.org/10.1023/A:1010933404324
Burdorf, A., Schantz, S., & Descatha, A. (2013). Monitoring and management of occupational exposure to hazardous agents. Occupational and Environmental Medicine, 70(12), 845–846. https://doi.org/10.1136/oemed-2013-101806
Chandola, V., Banerjee, A., & Kumar, V. (2009). Anomaly detection: A survey. ACM Computing Surveys, 41(3), Article 15. https://doi.org/10.1145/1541880.1541882
Dekker, S. (2014). The field guide to understanding human error (3rd ed.). Ashgate
Floridi, L., Cowls, J., Beltrametti, M., Chatila, R., Chazerand, P., Dignum, V., Luetge, C., Madelin, R., Pagallo, U., Rossi, F., Schafer, B., Valcke, P., & Vayena, E. (2018). AI4People—An ethical framework for a good AI society: Opportunities, risks, principles, and recommendations. Minds and Machines, 28, 689–707. https://doi.org/10.1007/s11023-018-9482-5
Gama, J., Žliobaitė, I., Bifet, A., Pechenizkiy, M., & Bouchachia, A. (2014). A survey on concept drift adaptation. ACM Computing Surveys, 46(4), Article 44. https://doi.org/10.1145/2523813
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT Press
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning: Data mining, inference, and prediction (2nd ed.). Springer. https://doi.org/10.1007/978-0-387-84858-7
He, H., & Garcia, E. A. (2009). Learning from imbalanced data. IEEE Transactions on Knowledge and Data Engineering, 21(9), 1263–1284. https://doi.org/10.1109/TKDE.2008.239
Hollnagel, E. (2014). Safety-I and Safety-II: The past and future of safety management. Ashgate.
ISO. (2018). ISO 45001:2018 Occupational health and safety management systems—Requirements with guidance for use. International Organization for Standardization.
ISO. (2015). ISO 14001:2015 Environmental management systems—Requirements with guidance for use. International Organization for Standardization.
.
ISO. (2018). ISO 31000:2018 Risk management—Guidelines. International Organization for Standardization
Jardine, A. K. S., Lin, D., & Banjevic, D. (2006). A review on machinery diagnostics and prognostics implementing condition-based maintenance. Mechanical Systems and Signal Processing, 20(7), 1483–1510. https://doi.org/10.1016/j.ymssp.2005.09.012
Kelleher, J. D., Namee, B. M., & D’Arcy, A. (2020). Fundamentals of machine learning for predictive data analytics: Algorithms, worked examples, and case studies (2nd ed.). MIT Press.
Kuhn, M., & Johnson, K. (2013). Applied predictive modeling. Springer. https://doi.org/10.1007/978-1-4614-6849-3
Lee, J., Bagheri, B., & Kao, H.-A. (2015). A cyber-physical systems architecture for Industry 4.0-based manufacturing systems. Manufacturing Letters, 3, 18–23. https://doi.org/10.1016/j.mfglet.2014.12.001
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521, 436–444. https://doi.org/10.1038/nature14539
Lundberg, S. M., & Lee, S.-I. (2017). A unified approach to interpreting model predictions. In I. Guyon, U. von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, & R. Garnett (Eds.), Advances in neural information processing systems 30 (pp. 4765–4774). Curran Associates.
Mitchell, T. M. (1997). Machine learning. McGraw-Hill
Molnar, C. (2022). Interpretable machine learning: A guide for making black box models explainable (2nd ed.). https://christophm.github.io/interpretable-ml-book/
Murphy, K. P. (2012). Machine learning: A probabilistic perspective. MIT Press
National Academies of Sciences, Engineering, and Medicine. (2019). Reproducibility and replicability in science. National Academies Press. https://doi.org/10.17226/25303
Pasman, H. J., & Rogers, W. J. (2014). How can we use the information provided by process safety performance indicators? Possibilities and limitations. Journal of Loss Prevention in the Process Industries, 30, 197–206. https://doi.org/10.1016/j.jlp.2013.06.001
Pearl, J., & Mackenzie, D. (2018). The book of why: The new science of cause and effect. Basic Books
Rasmussen, J. (1997). Risk management in a dynamic society: A modelling problem. Safety Science, 27(2–3), 183–213. https://doi.org/10.1016/S0925-7535(97)00052-0
.
Rausand, M. (2011). Risk assessment: Theory, methods, and applications. Wiley
Reason, J. (1997). Managing the risks of organizational accidents. Ashgate
Russell, S., & Norvig, P. (2021). Artificial intelligence: A modern approach (4th ed.). Pearson
Sarkar, S., Vinay, S., Raj, R., Maiti, J., & Mitra, P. (2019). Application of optimized machine learning techniques for prediction of occupational accidents. Computers & Operations Research, 106, 210–224. https://doi.org/10.1016/j.cor.2018.02.021
Shalev-Shwartz, S., & Ben-David, S. (2014). Understanding machine learning: From theory to algorithms. Cambridge University Press. https://doi.org/10.1017/CBO9781107298019
Susto, G. A., Schirru, A., Pampuri, S., McLoone, S., & Beghi, A. (2015). Machine learning for predictive maintenance: A multiple classifier approach. IEEE Transactions on Industrial Informatics, 11(3), 812–820. https://doi.org/10.1109/TII.2014.2349359
Wachter, S., Mittelstadt, B., & Russell, C. (2018). Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harvard Journal of Law & Technology, 31(2), 841–887
Witten, I. H., Frank, E., Hall, M. A., & Pal, C. J. (2016). Data mining: Practical machine learning tools and techniques (4th ed.). Morgan Kaufmann
Zhou, Z.-H. (2021). Machine learning. Springer. https://doi.org/10.1007/978-981-15-1967-3


