مقدمه
برای موفقیتآمیز بودن پیشپردازش دادهها، داشتن یک تصویر کلی از دادههایتان ضروری است. توصیفات آماری پایه میتوانند برای شناسایی ویژگیهای دادهها و برجسته کردن اینکه کدام مقادیر داده باید به عنوان نویز یا دادههای پرت در نظر گرفته شوند، استفاده شوند.
این بخش سه حوزه از توصیفات آماری پایه را مورد بحث قرار میدهد. ما با معیارهای گرایش مرکزی (بخش ۲.۲.۱) شروع میکنیم که موقعیت وسط یا مرکز توزیع دادهها را اندازهگیری میکنند.
به طور شهودی، با توجه به یک ویژگی، بیشتر مقادیر آن در کجا قرار میگیرند؟ به طور خاص، ما در مورد میانگین، میانه، مد و میانهدامنه بحث میکنیم.
علاوه بر ارزیابی گرایش مرکزی مجموعه دادههایمان، میخواهیم ایدهای از پراکندگی دادهها نیز داشته باشیم. یعنی، دادهها چگونه پراکنده شدهاند؟ رایجترین معیارهای پراکندگی دادهها عبارتند از دامنه، چارکها (مثلاً Q1 که چارک اول، یعنی صدک ۲۵ است) و دامنه بین چارکها؛ خلاصه پنج عددی و نمودارهای جعبهای؛ و واریانس و انحراف معیار دادهها. این معیارها برای شناسایی دادههای پرت مفید هستند و در بخش ۲.۲.۲ شرح داده شدهاند.
برای تسهیل توصیف روابط بین متغیرهای متعدد، مفاهیم کوواریانس و ضریب همبستگی برای دادههای عددی و آزمون همبستگی χ2 برای دادههای اسمی در بخش ۲.۲.۳ معرفی شدهاند.
در نهایت، میتوانیم از نمایشهای گرافیکی بسیاری از توصیفات آماری پایه برای بررسی بصری دادههای خود استفاده کنیم (بخش ۲.۲.۴). بیشتر بستههای نرمافزاری آماری یا گرافیکی ارائه دادهها شامل نمودارهای میلهای، نمودارهای دایرهای و نمودارهای خطی هستند. سایر نمایشهای رایج خلاصهها و توزیع دادهها شامل نمودارهای چندکی، نمودارهای چندکی-چندکی، هیستوگرامها و نمودارهای پراکندگی است.
اندازهگیری گرایش مرکزی
در این بخش، روشهای مختلفی برای اندازهگیری گرایش مرکزی دادهها بررسی میکنیم. فرض کنید که ما یک ویژگی X مانند حقوق داریم که برای مجموعهای از اشیاء ثبت شده است. فرض کنید x1، x2،…، xN مجموعهای از N مقدار مشاهده شده یا مشاهدات برای X باشند. در اینجا، این مقادیر ممکن است به عنوان مجموعه دادهها (برای X) نیز نامیده شوند. اگر قرار باشد مشاهدات مربوط به حقوق را رسم کنیم، بیشتر مقادیر در کجا قرار میگیرند؟ این به ما ایدهای از گرایش مرکزی دادهها میدهد. معیارهای گرایش مرکزی شامل میانگین، میانه، مد و میانه دامنه است.
رایجترین و مؤثرترین معیار عددی “مرکز” مجموعهای از دادهها، میانگین (حسابی) است. فرض کنید x1، x2،…، xN مجموعهای از N مقدار یا مشاهده باشند، مثلاً برای یک ویژگی عددی X، مانند حقوق. میانگین این مجموعه از مقادیر برابر است با
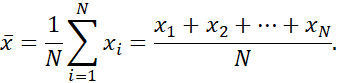
این مربوط به تابع تجمیع داخلی، میانگین (avg) در SQL))، است که در سیستمهای پایگاه داده رابطهای ارائه میشود.
مثال 2.6. میانگین. فرض کنید مقادیر زیر را برای حقوق (به هزار دلار) داریم که به ترتیب صعودی نشان داده شدهاند: 30، 36، 47، 50، 52، 52، 56، 60، 63، 70، 70، 110. با استفاده از معادله (2.1)، داریم:
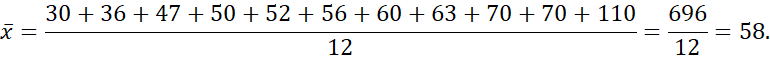
بنابراین، میانگین حقوق ۵۸۰۰۰ دلار است.
گاهی اوقات، هر مقدار xi در یک مجموعه ممکن است با وزن wi برای i 1,…,N مرتبط باشد. وزنها نشاندهنده اهمیت، درجه اهمیت یا فراوانی وقوع مربوط به مقادیر مربوطه خود هستند. در این مورد، به این میانگین حسابی وزنی یا میانگین وزنی گفته میشود.
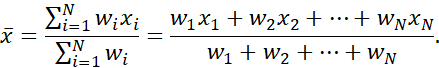
اگرچه میانگین مفیدترین کمیت برای توصیف یک مجموعه داده است، اما همیشه بهترین راه برای اندازهگیری مرکز دادهها نیست. یک مشکل عمده در مورد میانگین، حساسیت آن به مقادیر افراطی (مثلاً دادههای پرت) است. حتی تعداد کمی از مقادیر افراطی نیز میتوانند میانگین را خراب کنند. به عنوان مثال، میانگین حقوق در یک شرکت ممکن است توسط حقوق چند مدیر پردرآمد به طور قابل توجهی افزایش یابد. به طور مشابه، میانگین نمره یک کلاس در یک امتحان میتواند به دلیل چند نمره بسیار پایین، به میزان قابل توجهی کاهش یابد. برای جبران اثر ناشی از تعداد کمی از مقادیر افراطی، میتوانیم از میانگین اصلاحشده استفاده کنیم، که میانگینی است که پس از جدا کردن مقادیر در بالاترین و پایینترین مقادیر به دست میآید.
به عنوان مثال، میتوانیم مقادیر مشاهده شده برای حقوق را مرتب کنیم و قبل از محاسبه میانگین، 2٪ بالا و پایین را حذف کنیم. باید از حذف بخش خیلی بزرگ (مانند 20٪) در هر دو انتها خودداری کنیم، زیرا این امر میتواند منجر به از دست رفتن اطلاعات ارزشمند شود. برای دادههای کج (نامتقارن)، معیار بهتری برای مرکز دادهها، میانه است که مقدار میانی در مجموعهای از مقادیر دادههای مرتب شده است. این مقداری است که نیمه بالایی یک مجموعه داده را از نیمه پایینی جدا میکند.
در احتمال و آمار، میانه عموماً برای دادههای عددی کاربرد دارد؛ با این حال، میتوانیم این مفهوم را به دادههای ترتیبی نیز تعمیم دهیم. فرض کنید یک مجموعه داده داده شده از N مقدار برای یک ویژگی X به ترتیب صعودی مرتب شده است. اگر N فرد باشد، میانه مقدار میانی مجموعه مرتب شده است. در صورتی که N زوج باشد، میانه منحصر به فرد نیست؛ این دو مقدار میانی و هر مقداری بین آنهاست. اگر X در این مورد یک ویژگی عددی باشد، طبق قرارداد، میانه به عنوان میانگین دو مقدار میانی در نظر گرفته میشود.
مثال ۲.۷. میانه. بیایید میانه دادههای مثال ۲.۶ را پیدا کنیم. دادهها از قبل به ترتیب صعودی مرتب شدهاند. تعداد مشاهدات زوج است (یعنی ۱۲). بنابراین، میانه منحصر به فرد نیست. میتواند هر مقداری بین دو مقدار میانی ۵۲ و ۵۶ باشد (یعنی بین مقادیر ششم و هفتم در لیست). طبق قرارداد، میانگین دو مقدار میانی را به عنوان میانه تعیین میکنیم؛ یعنی:
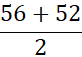
بنابراین، میانه ۵۴۰۰۰ دلار است.
فرض کنید که فقط ۱۱ مقدار اول در لیست را داریم. با توجه به تعداد فرد مقادیر، میانه میانهترین مقدار است. این ششمین مقدار در این لیست است که مقدار آن ۵۲۰۰۰ دلار است.
محاسبهی میانه زمانی که تعداد مشاهدات زیادی داریم، پرهزینه است. با این حال، برای ویژگیهای عددی، میتوانیم به راحتی مقدار را تخمین بزنیم. فرض کنید دادهها بر اساس مقادیر دادهی xi خود در بازهها گروهبندی شدهاند و فراوانی (یعنی تعداد مقادیر داده) هر بازه مشخص است. به عنوان مثال، کارمندان ممکن است بر اساس حقوق سالانهشان در بازههایی مانند 10001 تا 20000 دلار، 20001 تا 50000 دلار و غیره گروهبندی شوند. (یک مثال مشابه و ملموس را میتوان در جدول دادههای تمرین 2.3 مشاهده کرد.) فرض کنید بازهای که شامل فراوانی میانه است، بازه میانه باشد. میتوانیم میانه کل مجموعه دادهها (مثلاً حقوق میانه) را با درونیابی با استفاده از تقریب بزنیم که در آن L1 مرز پایینی بازه میانه، N تعداد مقادیر در کل مجموعه دادهها، freq l مجموع فراوانیهای تمام بازههایی است که از بازه میانه پایینتر هستند، freqmedian فراوانی بازه میانه و width پهنای بازه میانه است.
مد یکی دیگر از معیارهای گرایش مرکزی است. مد برای مجموعهای از دادهها، مقداری است که در مقایسه با تمام مقادیر همسایه در مجموعه، بیشترین فراوانی را دارد. بنابراین، میتوان آن را برای ویژگیهای کیفی و کمی تعیین کرد. این امکان وجود دارد که بیشترین فراوانی مربوط به چندین مقدار مختلف باشد که منجر به بیش از یک مد میشود. مجموعه دادههایی با یک، دو یا سه مد به ترتیب تکمدهای، دومدهای و سهمدهای نامیده میشوند. به طور کلی، یک مجموعه داده با دو یا چند مد، چندمدهای است.
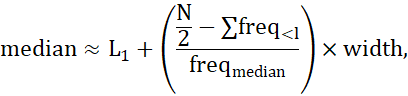
مثال ۲.۸. مد. دادههای مثال ۲.۶ دو مدی هستند. دو مد ۵۲۰۰۰ و ۷۰۰۰۰ دلار هستند.
برای دادههای عددی تک مدی که کمی چولگی (نامتقارن) دارند، رابطه تجربی زیر را داریم:
میانگین – مد ≈ ۳ × (میانگین – میانه). (۲.۴)
این نشان میدهد که مد برای منحنیهای فراوانی تک مدی که کمی چولگی دارند، در صورت مشخص بودن مقادیر میانگین و میانه، به راحتی قابل تقریب است.
میانبرد همچنین میتواند برای ارزیابی گرایش مرکزی یک مجموعه داده عددی استفاده شود. این میانگین، میانگین بزرگترین و کوچکترین مقادیر در مجموعه است. محاسبه این معیار با استفاده از توابع تجمیعی SQL، max() و min()، آسان است.
مثال ۲.۹. میانبرد(midrange). محدوده میانی دادههای مثال ۲.۶، ۳۰،۰۰۰ + ۱۱۰،۰۰۰ = ۷۰،۰۰۰ دلار است. در یک منحنی فرکانس تکوجهی با توزیع دادههای متقارن کامل، میانگین، میانه و مد، همانطور که در شکل ۲.۱a نشان داده شده است، همگی در یک مقدار مرکزی قرار دارند.
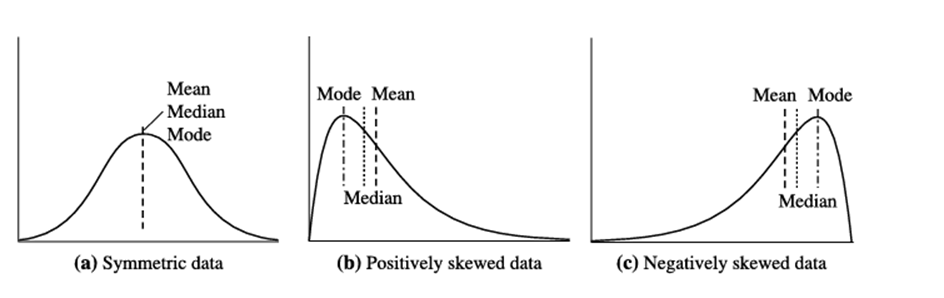
میانگین، میانه و مد دادههای متقارن در مقابل دادههای با چولگی مثبت و منفی.
دادهها در اکثر کاربردهای واقعی متقارن نیستند. در عوض، ممکن است چولگی مثبت داشته باشند، که در آن مد در مقداری کوچکتر از میانه رخ میدهد (شکل ۲.۱ب)، یا چولگی منفی داشته باشند، که در آن مد در مقداری بزرگتر از میانه رخ میدهد (شکل ۲.۱ج).
اندازهگیری پراکندگی دادهها
اکنون به معیارهایی برای ارزیابی پراکندگی یا پراکندگی دادههای عددی میپردازیم. این معیارها شامل دامنه، چندکها، چارکها، صدکها و دامنه بین چارکی هستند. خلاصه پنج عددی، که میتواند به صورت نمودار جعبهای نمایش داده شود، در شناسایی دادههای پرت مفید است. واریانس و انحراف معیار نیز نشاندهنده پراکندگی توزیع دادهها هستند. دامنه، چارکها و دامنه بین چارکی برای شروع، بیایید دامنه، چندکها، چارکها، صدکها و دامنه بین چارکی را به عنوان معیارهای پراکندگی دادهها بررسی کنیم.
دامنه، چارکها، و دامنه بین چارکی
برای شروع، بیایید دامنه (Range)، چندکها (Quantiles)، چارکها (Quartiles)، صدکها (Percentiles) و دامنه بین چارکی (Interquartile Range) را به عنوان معیارهایی برای پراکندگی دادهها (measures of data dispersion) بررسی کنیم.
فرض کنید x1، x2،…، xN مجموعهای از مشاهدات برای یک ویژگی عددی، X باشند. دامنه این مجموعه، تفاوت بین بزرگترین (max()) و کوچکترین (min()) مقادیر است.
فرض کنید دادههای مربوط به ویژگی X به ترتیب عددی صعودی مرتب شدهاند. تصور کنید که میتوانیم نقاط داده خاصی را انتخاب کنیم تا توزیع دادهها را به مجموعههای متوالی با اندازه مساوی تقسیم کنیم، همانطور که در شکل 2.2 نشان داده شده است. این نقاط داده، چندک نامیده میشوند.
چندکها نقاطی هستند که در فواصل منظم از توزیع دادهها گرفته میشوند و آن را به مجموعههای متوالی با اندازه اساساً مساوی تقسیم میکنند. (ما میگوییم «اساساً» زیرا ممکن است مقادیر دادهای از X وجود نداشته باشند که دادهها را به زیرمجموعههای دقیقاً مساوی تقسیم کنند. برای خوانایی، ما آنها را مساوی مینامیم.) kامین q-quantile برای یک توزیع داده معین، مقداری x است به طوری که حداکثر k/q از مقادیر دادهها کمتر از x و حداکثر (q k)/q از مقادیر دادهها بیشتر از x باشند، که در آن k یک عدد صحیح است به طوری که 0 < k < q. تعداد q-quantiles q 1 وجود دارد.
دومین چندک، نقطه دادهای است که نیمههای پایین و بالای توزیع دادهها را تقسیم میکند. این مربوط به میانه است. چهار چندکها، سه نقطه دادهای هستند که توزیع دادهها را به چهار قسمت مساوی تقسیم میکنند. هر قسمت نشان دهنده یک چهارم توزیع دادهها است. آنها معمولاً به عنوان چارکها شناخته میشوند. صدمین چندکها معمولاً به عنوان صدکها شناخته میشوند. آنها را بر … تقسیم میکنند.
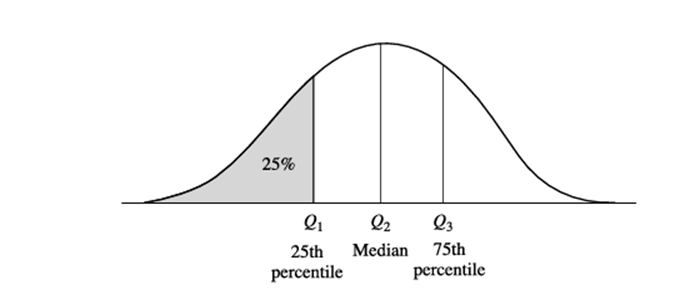
نموداری از توزیع دادهها برای یک ویژگی X. کوارتیلهای رسم شده، چارکها هستند. سه چارک، توزیع را به چهار زیرمجموعه متوالی با اندازه مساوی تقسیم میکنند. چارک دوم مربوط به میانه است.
توزیع دادهها به ۱۰۰ مجموعه متوالی با اندازه مساوی. میانه، چارکها و صدکها پرکاربردترین اشکال کوارتیلها هستند.
چارکها نشاندهنده مرکز، پراکندگی و شکل توزیع هستند. چارک اول، که با Q1 نشان داده میشود، صدک ۲۵ است. این چارک، ۲۵٪ پایینترین دادهها را جدا میکند. چارک سوم، که با Q3 نشان داده میشود، صدک ۷۵ است – ۷۵٪ پایینترین (یا ۲۵٪ بالاترین) دادهها را جدا میکند. چارک دوم، صدک ۵۰ است. به عنوان میانه، مرکز توزیع دادهها را نشان میدهد. فاصله بین چارک اول و سوم، معیار سادهای از پراکندگی است که دامنه پوشش داده شده توسط نیمه میانی دادهها را نشان میدهد. این فاصله، دامنه بین چارکی (IQR) نامیده میشود و به صورت زیر تعریف میشود:
IQR = Q3 − Q1.
مثال 2.10. دامنه بین چارکی. چارکها سه مقداری هستند که مجموعه دادههای مرتب شده را به چهار قسمت مساوی تقسیم میکنند. دادههای مثال 2.6 شامل 12 مشاهده هستند که از قبل به ترتیب صعودی مرتب شدهاند. از آنجایی که تعداد عناصر در این لیست زوج است، میانه لیست باید میانگین دو عنصر مرکزی باشد، یعنی (52000$ + 56000$)/2 = 54000$. سپس چارک اول باید میانگین عناصر سوم و چهارم باشد، یعنی ($47,000 + $50,000)/2 = $48,500، در حالی که چارک سوم باید میانگین عناصر نهم و دهم باشد، یعنی ($63,000 + $70,000)/2 = $66,500. بنابراین دامنه بین چارکی IQR = $66,500 − $48,500 = $18,000 است.
خلاصه پنج عددی، نمودارهای جعبهای و دادههای پرت
هیچ معیار عددی واحدی برای پراکندگی (مثلاً IQR) برای توصیف توزیعهای چوله خیلی مفید نیست. به توزیعهای دادههای متقارن و چوله شکل ۲.۱ نگاهی بیندازید. در توزیع متقارن، میانه (و سایر معیارهای گرایش مرکزی) دادهها را به نیمههای مساوی تقسیم میکند. این اتفاق برای توزیعهای چوله رخ نمیدهد. بنابراین، ارائه دو چارک Q1 و Q3 به همراه میانه، آموزندهتر است. یک قاعده کلی رایج برای شناسایی دادههای پرت مشکوک، جدا کردن مقادیری است که حداقل ۱.۵ IQR بالاتر از چارک سوم یا پایینتر از چارک اول قرار دارند.
از آنجا که Q1، میانه و Q3 با هم هیچ اطلاعاتی در مورد نقاط پایانی (مثلاً دنبالهها) دادهها ندارند، میتوان با ارائه کمترین و بیشترین مقادیر داده، خلاصه کاملتری از شکل توزیع به دست آورد. این به عنوان خلاصه پنج عددی شناخته میشود. خلاصه پنج عددی یک توزیع شامل میانه (Q2)، چارکهای Q1 و Q3 و کوچکترین و بزرگترین مشاهدات منفرد است که به ترتیب حداقل، Q1، میانه، Q3 و حداکثر نوشته میشوند.
نمودارهای جعبهای روشی محبوب برای تجسم یک توزیع هستند. یک نمودار جعبهای خلاصه پنج عددی را به شرح زیر در بر میگیرد:
- معمولاً انتهای جعبه در چارکها قرار دارند به طوری که طول جعبه، محدوده بین چارکی است.
- میانه با یک خط درون جعبه مشخص میشود.
- دو خط (به نام ویسکرها) در خارج از جعبه تا کوچکترین (مینیمم) و بزرگترین (ماکزیمم) مشاهدات امتداد مییابند.
هنگام برخورد با تعداد متوسطی از مشاهدات، رسم جداگانه دادههای پرت بالقوه ارزشمند است. برای انجام این کار در یک نمودار جعبهای، ویسکرها تنها در صورتی به مشاهدات بسیار پایین و بسیار بالا گسترش مییابند که این مقادیر کمتر از x1.5 IQR فراتر از چارکها باشند. در غیر این صورت، ویسکرها در شدیدترین مشاهداتی که در محدوده x1.5 IQR چارکها رخ میدهند، خاتمه مییابند. موارد باقیمانده به صورت جداگانه رسم میشوند. نمودارهای جعبهای را میتوان در مقایسه چندین مجموعه از دادههای سازگار استفاده کرد.
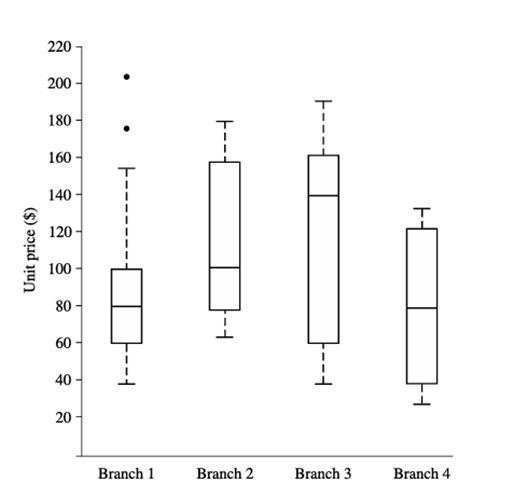
نمودار جعبهای برای دادههای قیمت واحد برای اقلام فروخته شده در چهار شعبه یک فروشگاه آنلاین در یک دوره زمانی معین.
مثال ۲.۱۱. نمودار جعبهای. شکل ۲.۳ نمودارهای جعبهای برای دادههای قیمت واحد برای اقلام فروخته شده در چهار شعبه یک فروشگاه آنلاین در یک دوره زمانی معین را نشان میدهد. برای شعبه ۱، میبینیم که میانگین قیمت اقلام فروخته شده ۸۰ دلار، Q1 برابر با ۶۰ دلار و Q3 برابر با ۱۰۰ دلار است. توجه داشته باشید که دو مشاهده پرت برای این شعبه به صورت جداگانه رسم شدهاند، زیرا مقادیر ۱۷۵ و ۲۰۲ آنها بیش از ۱.۵ برابر IQR در اینجا یعنی ۴۰ است.
واریانس و انحراف معیار
واریانس و انحراف معیار معیارهای پراکندگی دادهها هستند. آنها نشان میدهند که توزیع دادهها چقدر گسترده است. انحراف معیار پایین به این معنی است که مشاهدات دادهها تمایل دارند بسیار نزدیک به میانگین باشند، در حالی که انحراف معیار بالا نشان میدهد که دادهها در طیف وسیعی از مقادیر پراکنده شدهاند. واریانس N مشاهده، x1، x2،…، xN (وقتی N بزرگ باشد)، برای یک ویژگی عددی X برابر است با
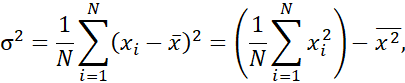
که در آن x مقدار میانگین مشاهدات است، همانطور که در معادله (2.1) تعریف شده است. انحراف معیار، σ، مشاهدات، جذر واریانس، σ^2، است.
مثال ۲.۱۲. واریانس و انحراف معیار. در مثال ۲.۶، با استفاده از معادله (۲.۱) برای میانگین، x $۵۸۰۰۰ را بدست آوردیم. برای تعیین واریانس و انحراف معیار دادهها از آن مثال، =N ۱۲ را در نظر میگیریم و با استفاده از معادله (۲.۶) به دست میآوریم.
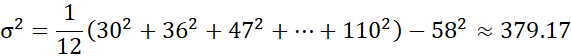
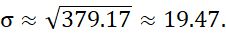
ویژگیهای اساسی انحراف معیار، σ، به عنوان معیار پراکندگی به شرح زیر است:
• σ پراکندگی را در مورد میانگین اندازهگیری میکند و فقط زمانی باید در نظر گرفته شود که میانگین به عنوان معیار مرکز انتخاب شود.
• σ= 0 فقط زمانی که هیچ پراکندگی وجود نداشته باشد، یعنی زمانی که همه مشاهدات مقدار یکسانی داشته باشند. در غیر این صورت،
σ > 0.
نکته مهم این است که بعید است یک مشاهده بیش از چندین انحراف معیار از میانگین فاصله داشته باشد. از نظر ریاضی، با استفاده از نابرابری چبیشف، میتوان نشان داد که حداقل 1 تا 1 × 100% از مشاهدات بیش از k انحراف معیار از میانگین ندارند. بنابراین، انحراف معیار شاخص خوبی برای پراکندگی یک مجموعه داده است.
محاسبه واریانس و انحراف معیار در مجموعه دادههای بزرگ قابل مقیاسبندی است.
تحلیل کوواریانس و همبستگی
در این قسمت به تحلیل کوواریانس و همبستگی میپردازیم.
کوواریانس دادههای عددی
در نظریه احتمال و آمار، همبستگی و کوواریانس دو معیار مشابه برای ارزیابی میزان تغییر دو ویژگی با هم هستند. دو ویژگی عددی A و B و مجموعهای از n مشاهده با مقادیر حقیقی} (a1, b1)، bn)، …، {(an، را در نظر بگیرید. مقادیر میانگین A و B، به ترتیب، به عنوان مقادیر مورد انتظار روی A و B نیز شناخته میشوند، یعنی:
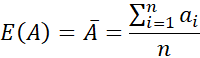
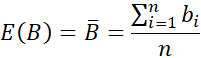
کوواریانس بین A و B به صورت زیر تعریف میشود:
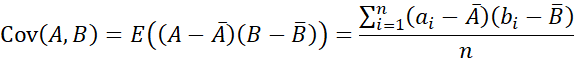
از نظر ریاضی نیز میتوان نشان داد که
Cov(A, B) = E(A · B) − A¯B¯
برای دو ویژگی A و B که تمایل به تغییر با هم دارند، اگر مقدار ai برای A بزرگتر از A¯ (مقدار مورد انتظار A) باشد، احتمالاً مقدار متناظر bi برای ویژگی B بزرگتر از B¯ (مقدار مورد انتظار B) خواهد بود. بنابراین کوواریانس بین A و B مثبت است. از سوی دیگر، اگر یکی از ویژگیها تمایل به بالاتر بودن از مقدار مورد انتظار خود داشته باشد در حالی که ویژگی دیگر پایینتر از مقدار مورد انتظار خود است، کوواریانس A و B منفی است.
اگر A و B مستقل باشند (یعنی همبستگی نداشته باشند)، آنگاه E(A · B) = E(A) · E(B). بنابراین کوواریانس
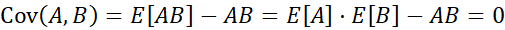
است. با این حال، عکس این قضیه صادق نیست. برخی از جفت متغیرهای تصادفی (ویژگیها) ممکن است کوواریانس 0 داشته باشند اما مستقل نیستند. تنها تحت برخی فرضیات اضافی (مثلاً، دادهها از توزیع نرمال چند متغیره پیروی میکنند) کوواریانس ۰ دلالت بر استقلال دارد.
مثال ۲.۱۳. تحلیل کوواریانس ویژگیهای عددی. جدول ۲.۱ را در نظر بگیرید که مثال سادهای از قیمت سهام مشاهده شده در پنج نقطه زمانی برای AllElectronics و HighTech، یک شرکت فناوری پیشرفته، را ارائه میدهد. اگر سهام تحت تأثیر روندهای صنعت یکسانی قرار گیرند، آیا قیمت آنها با هم افزایش مییابد یا کاهش مییابد؟
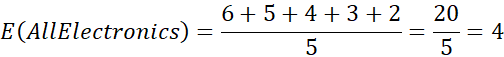
و
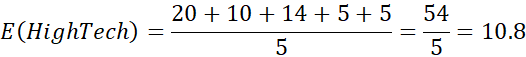
بنابراین، با استفاده از معادله (2.7)، محاسبه میکنیم
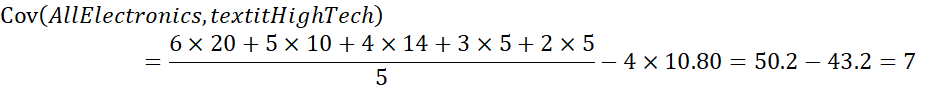
بنابراین، با توجه به کوواریانس مثبت، میتوانیم بگوییم که قیمت سهام هر دو شرکت با هم افزایش مییابد.
واریانس حالت خاصی از کوواریانس است که در آن دو ویژگی یکسان هستند (یعنی کوواریانس یک ویژگی با خودش).
|
Table 2.1 Stock prices for tronics and HighTech. |
AllElec- |
|
|
Time point |
AllElectronics |
HighTech |
|
t1 |
6 |
20 |
|
t2 |
5 |
10 |
|
t3 |
4 |
14 |
|
t4 |
3 |
5 |
|
t5 |
2 |
5 |
ضریب همبستگی برای دادههای عددی
برای ویژگیهای عددی، میتوانیم همبستگی بین دو ویژگی، A و B، را با محاسبه ضریب همبستگی (که به عنوان ضریب گشتاور ضرب پیرسون نیز شناخته میشود و به نام مخترع آن، کارل پیرسون، نامگذاری شده است) ارزیابی کنیم. در این ضریب، n تعداد تاپلها، ai و bi مقادیر مربوط به A و B در تاپل i، A¯ و B¯ میانگین مقادیر مربوط به A و B، σA و σB انحراف معیار مربوط به A و B (مطابق تعریف در بخش 2.2.2) و ‘B(aibi) مجموع ضرب متقاطع AB است (یعنی برای هر تاپل، مقدار A در مقدار B در آن تاپل ضرب میشود).
توجه داشته باشید که 1 rA,B 1. اگر rA,B بزرگتر از 0 باشد، A و B همبستگی مثبت دارند، به این معنی که مقادیر A با افزایش مقادیر B افزایش مییابد. هرچه مقدار بیشتر باشد، همبستگی قویتر است (یعنی هر ویژگی بیشتر بر دیگری دلالت دارد). از این رو، مقدار بالاتر ممکن است نشان دهد که A (یا B) ممکن است به عنوان افزونگی حذف شود.
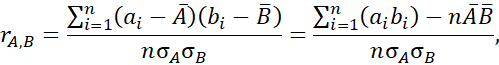
اگر مقدار حاصل برابر با 0 باشد، A و B مستقل هستند و هیچ همبستگی بین آنها وجود ندارد. اگر مقدار حاصل کمتر از 0 باشد، A و B همبستگی منفی دارند، که در آن مقادیر یک ویژگی با کاهش مقادیر ویژگی دیگر افزایش مییابد. این بدان معناست که هر ویژگی، دیگری را تضعیف میکند. نمودارهای پراکندگی همچنین میتوانند برای مشاهده همبستگی بین ویژگیها استفاده شوند (بخش 2.2.3). به عنوان مثال، نمودارهای پراکندگی شکل 2.8 به ترتیب دادههای با همبستگی مثبت و دادههای با همبستگی منفی را نشان میدهند، در حالی که شکل 2.9 دادههای غیر همبسته را نشان میدهد.
توجه داشته باشید که همبستگی به معنای علیت نیست. یعنی، اگر A و B با هم همبستگی داشته باشند، لزوماً به این معنی نیست که A باعث B میشود یا B باعث A میشود. برای مثال، در تجزیه و تحلیل یک پایگاه داده جمعیتی، ممکن است متوجه شویم که ویژگیهایی که نشان دهنده تعداد بیمارستانها و تعداد سرقت خودرو در یک منطقه هستند، با هم همبستگی دارند. این بدان معنا نیست که یکی باعث دیگری میشود. هر دو در واقع به صورت علّی با یک ویژگی سوم، یعنی جمعیت، مرتبط هستند.
آزمون همبستگی χ2 برای دادههای اسمی
برای دادههای اسمی، رابطه همبستگی بین دو ویژگی، A و B، میتواند توسط آزمون χ2 (کای اسکوئر) کشف شود. فرض کنید A دارای c مقدار متمایز، یعنی a1، a2،… ac، و B دارای r مقدار متمایز، یعنی b1، b2،… br باشد. تاپلهای دادهای که توسط A و B توصیف میشوند را میتوان به صورت یک جدول احتمالی نشان داد، که c مقدار A ستونها و r مقدار B ردیفها را تشکیل میدهند. فرض کنید (Ai, Bj) نشان دهنده رویداد مشترکی است که ویژگی A مقدار ai و ویژگی B مقدار bj را به خود میگیرد، یعنی، که در آن (Ai,B bj). هر رویداد مشترک ممکن (Ai, Bj) سلول (یا جایگاه) خاص خود را در جدول دارد. مقدار χ2 (که به عنوان آماره پیرسون χ2 نیز شناخته میشود) به صورت زیر محاسبه میشود:
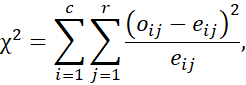
که در آن oij فراوانی مشاهدهشده (یعنی تعداد واقعی) رویداد مشترک (Ai, Bj) و eij فراوانی مورد انتظار (Ai, Bj) است که میتوان آن را به صورت زیر محاسبه کرد
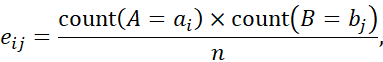
که در آن n تعداد تاپلهای داده، count(A ai) تعداد تاپلهایی با مقدار ai برای A و count(B bj) تعداد تاپلهایی با مقدار bj برای B است. مجموع در معادله (2.10) روی تمام سلولهای rc c محاسبه میشود. توجه داشته باشید که سلولهایی که بیشترین سهم را در مقدار χ2 دارند، سلولهایی هستند که تعداد واقعی آنها با تعداد مورد انتظار بسیار متفاوت است.
آمار χ2 این فرضیه را آزمایش میکند که A و B مستقل هستند، یعنی هیچ همبستگی بین آنها وجود ندارد. این آزمون بر اساس سطح معنیداری، با درجه آزادی (r1) (c1) است. ما استفاده از این آمار را در مثال 2.14 نشان میدهیم. اگر فرضیه قابل رد باشد، میگوییم که A و B از نظر آماری همبستگی دارند.
مثال 2.14. تحلیل همبستگی ویژگیهای اسمی با استفاده از χ2. فرض کنید گروهی متشکل از 1500 نفر مورد بررسی قرار گرفتهاند. جنسیت هر فرد ذکر شده است. از هر فرد در مورد اینکه نوع مطالب خواندنی مورد علاقهاش داستان است یا غیرداستان، نظرسنجی شد. بنابراین، ما دو ویژگی داریم، جنسیت و مطالعهی ترجیحی. فراوانی (یا تعداد) مشاهدهشدهی هر رویداد مشترک ممکن در جدول احتمال نشان داده شده در جدول 2.2 خلاصه شده است، که در آن اعداد داخل پرانتز، فراوانیهای مورد انتظار هستند. فراوانیهای مورد انتظار بر اساس توزیع دادهها برای هر دو ویژگی با استفاده از معادله (2.11) محاسبه میشوند.
با استفاده از معادله (2.11)، میتوانیم فراوانیهای مورد انتظار برای هر سلول را تأیید کنیم. به عنوان مثال، فراوانی مورد انتظار برای سلول (مرد، داستان) برابر است با
e11 = تعداد (مرد) × تعداد (داستان) = 300 × 450 = 90،
و به همین ترتیب. توجه داشته باشید که در هر سطر، مجموع فراوانیهای مورد انتظار باید برابر با کل فراوانی مشاهدهشده برای آن سطر باشد، و مجموع فراوانیهای مورد انتظار در هر ستون نیز باید برابر با کل فراوانی مشاهدهشده برای آن ستون باشد.
با استفاده از معادله (2.10) برای محاسبهی χ2، به دست میآوریم:
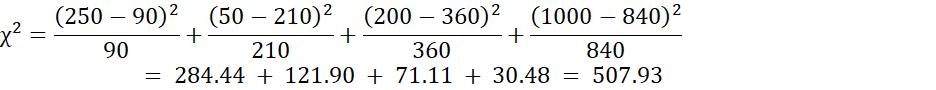
برای این جدول ۲ ۲، درجات آزادی عبارتند از (۲ ۱) (2 1) ۱. برای ۱ درجه آزادی، مقدار χ۲ مورد نیاز برای رد فرضیه در سطح معنیداری ۰.۰۰۱، ۱۰.۸۲۸ است (برگرفته از جدول درصدهای بالای توزیع χ۲، که معمولاً از هر کتاب درسی آمار در دسترس است). از آنجایی که مقدار محاسبهشده ما بالاتر از این است، میتوانیم فرضیه جنسیت و ترجیح_مطالعه را رد کنیم.
|
جدول ۲.۲ دادههای جدول توافقی ۲ × ۲ مثال ۲.۱. |
|||
|
|
مرد |
زن |
مجموع |
|
fiction |
250 (90) |
200 (360) |
450 |
|
non_fiction |
50 (210) |
1000 (840) |
1050 |
|
Total |
300 |
1200 |
1500 |
|
نکته کلی: آیا جنسیت و ترجیحات مطالعه با هم مرتبط هستند؟ |
|||
مستقل هستند و نتیجه میگیرند که دو ویژگی برای گروه معینی از افراد (به شدت) با هم همبستگی دارند.
نمایش گرافیکی آمار پایه دادهها
در این بخش، نمایش گرافیکی توصیفات آماری پایه را مطالعه میکنیم. این موارد شامل نمودارهای چندکی، نمودارهای چندکی-چندکی، هیستوگرامها و نمودارهای پراکندگی است. چنین نمودارهایی برای بررسی بصری دادهها مفید هستند که برای پیشپردازش دادهها مفید است. سه نمودار اول توزیعهای تک متغیره (یعنی دادههای مربوط به یک ویژگی) را نشان میدهند، در حالی که نمودارهای پراکندگی توزیعهای دو متغیره (یعنی شامل دو ویژگی) را نشان میدهند.
نمودار چندکی
نمودار چندکی روشی ساده و مؤثر برای بررسی اولیه توزیع دادههای تک متغیره است. اول، تمام دادهها را برای ویژگی داده شده نمایش میدهد (به کاربر اجازه میدهد هم رفتار کلی و هم رویدادهای غیرمعمول را ارزیابی کند). دوم، اطلاعات چندکی را رسم میکند (به بخش ۲.۲.۲ مراجعه کنید). فرض کنید xi، برای i از ۱ تا N، دادههایی باشند که به ترتیب صعودی مرتب شدهاند، به طوری که x1 کوچکترین مشاهده و xN بزرگترین مشاهده برای یک ویژگی ترتیبی یا عددی X باشد. هر مشاهده، xi، با یک درصد، fi، جفت شده است که نشان میدهد تقریباً fi، ۱۰۰٪ دادهها زیر مقدار xi هستند. ما میگوییم «تقریباً» زیرا ممکن است مقداری با دقیقاً کسری، fi، از دادههای زیر xi وجود نداشته باشد. توجه داشته باشید که چندک ۰.۲۵ مربوط به چارک Q1، چندک ۰.۵۰ میانه و چندک ۰.۷۵ مربوط به Q3 است.
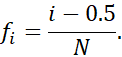
این اعداد با گامهای مساوی 1/N افزایش مییابند، که از 1 (که کمی بالاتر از 0 است) تا 1 – 1 (که کمی پایینتر از 1 است) متغیر است. در یک نمودار کوانتایل، xi در مقابل fi رسم میشود. این به ما امکان میدهد توزیعهای مختلف را بر اساس کوانتایلهایشان مقایسه کنیم. به عنوان مثال، با توجه به نمودارهای کوانتایل دادههای فروش برای دو دوره زمانی مختلف، میتوانیم مقادیر Q1، میانه، Q3 و سایر مقادیر fi آنها را در یک نگاه مقایسه کنیم.
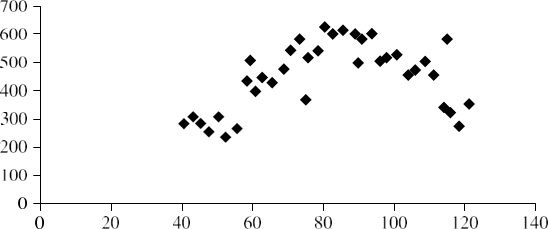
مثال 2.15. نمودار کوانتایل. شکل 2.4 یک نمودار کوانتایل برای دادههای قیمت واحد جدول 2.3 نشان میدهد.
| جدول ۲.۳ مجموعهای از دادههای قیمت واحد برای اقلام فروخته شده در شعبهای از فروشگاه آنلاین. | |
| قیمت واحد (دلار) | تعداد اقلام فروخته شده |
| 40 | 275 |
| 43 | 300 |
| 47 | 250 |
| . | . |
| 74 | 360 |
| 75 | 515 |
| 78 | 540 |
| . | . |
| 115 | 320 |
| 117 | 270 |
| 120 | 350 |
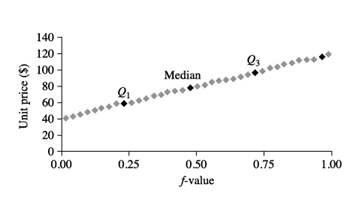
نمودار چندک برای دادههای قیمت واحد در جدول ۲.۳.
نمودار چندک-چندک
نمودار چندک-چندک یا نمودار q-q، چندکهای یک توزیع تک متغیره را در مقابل چندکهای متناظر توزیع دیگر نشان میدهد. این یک ابزار تجسم قدرتمند است زیرا به کاربر اجازه میدهد تا مشاهده کند که آیا در رفتن از یک توزیع به توزیع دیگر تغییری وجود دارد یا خیر.
فرض کنید دو مجموعه مشاهدات برای ویژگی یا متغیر قیمت واحد داریم که از دو مکان شاخه مختلف گرفته شدهاند. فرض کنید x1,…, xN دادههای شاخه اول و y1,…, yM دادههای شاخه دوم باشند، که در آن هر مجموعه داده به ترتیب صعودی مرتب شده است. اگر M N (یعنی تعداد نقاط در هر مجموعه یکسان باشد)، آنگاه به سادگی yi را در مقابل xi رسم میکنیم، که در آن yi و xi هر دو (i 0.5)/N چندک از مجموعه دادههای مربوطه خود هستند. اگر M < N (یعنی شاخه دوم مشاهدات کمتری نسبت به شاخه اول دارد)، فقط M نقطه میتواند در نمودار q-q وجود داشته باشد. در اینجا، yi چندک (i 0.5)/M دادههای y است که در مقابل چندک (i 0.5)/M دادههای x رسم میشود. این محاسبه معمولاً شامل درونیابی است.
مثال ۲.۱۶. نمودار چندک-چندک. شکل ۲.۵ یک نمودار چندک-چندک برای دادههای قیمت واحد اقلام فروخته شده در دو شعبه فروشگاه آنلاین در یک دوره زمانی معین را نشان میدهد. هر نقطه مربوط به چندک یکسان برای هر مجموعه داده است و قیمت واحد اقلام فروخته شده در شعبه ۱ در مقابل شعبه ۲ را برای آن چندک نشان میدهد. (برای کمک به مقایسه، خط مستقیم نشاندهنده حالتی است که برای هر چندک مشخص، قیمت واحد در هر شعبه یکسان است. نقاط تیرهتر به ترتیب مربوط به دادههای Q1، میانه و Q3 هستند.)
برای مثال، میبینیم که در Q1، قیمت واحد اقلام فروخته شده در شعبه 1 کمی کمتر از شعبه 2 بود. به عبارت دیگر، 25٪ از اقلام فروخته شده در شعبه 1 کمتر یا مساوی 60 دلار بودند، در حالی که 25٪ از اقلام فروخته شده در شعبه 2 کمتر یا مساوی 64 دلار بودند. در صدک پنجاهم (که با میانه مشخص شده است، که آن هم Q2 است)، میبینیم که 50٪ از اقلام فروخته شده در شعبه 1 کمتر از 78 دلار بودند، در حالی که 50٪ از اقلام در شعبه 2 کمتر از 85 دلار بودند. به طور کلی، متوجه میشویم که یک تغییر در توزیع شعبه 1 نسبت به شعبه 2 وجود دارد، به این صورت که قیمت واحد اقلام فروخته شده در شعبه 1 تمایل به کمتر بودن از شعبه 2 دارد.
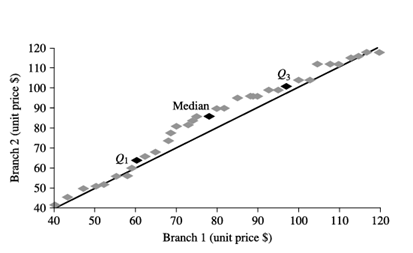
نمودار q-q برای دادههای قیمت واحد از دو شعبه فروشگاه آنلاین.
هیستوگرامها
هیستوگرامها (یا هیستوگرامهای فراوانی) حداقل یک قرن قدمت دارند و به طور گسترده مورد استفاده قرار میگیرند. “هیستوس” به معنی قطب یا دکل و “گرام” به معنی نمودار است، بنابراین هیستوگرام نموداری از قطبها است. رسم هیستوگرامها یک روش گرافیکی برای خلاصه کردن توزیع یک ویژگی معین، X، است. بر اساس تعداد قطبهای مورد نظر در نمودار، محدوده مقادیر X به مجموعهای از زیرمحدودههای متوالی مجزا تقسیم میشود.
زیرمحدودهها، که به عنوان سطل یا دسته شناخته میشوند، زیرمجموعههای مجزایی از توزیع دادهها برای X هستند. محدوده یک سطل به عنوان عرض شناخته میشود. معمولاً سطلها دارای عرض مساوی هستند. برای مثال، یک ویژگی قیمت با محدودهی مقداری ۱ تا ۲۰۰ دلار (گرد شده به نزدیکترین دلار) میتواند به زیرمحدودههای ۱ تا ۲۰، ۲۱ تا ۴۰، ۴۱ تا ۶۰ و غیره تقسیم شود. برای هر زیرمحدوده، یک میله با ارتفاعی رسم میشود که نشاندهندهی تعداد کل اقلام مشاهدهشده در آن زیرمحدوده است.
لطفاً توجه داشته باشید که هیستوگرام با یکی دیگر از نمایشهای نموداری رایج به نام نمودار میلهای متفاوت است. نمودار میلهای از مجموعهای از میلهها (که اغلب با فاصله از هم جدا میشوند) استفاده میکند که در آن X نشاندهندهی مجموعهای از دادههای دستهبندیشده، مانند automobile_model یا item_type است و ارتفاع میله (ستون) نشاندهندهی اندازهی گروه تعریفشده توسط دستهها است.
از سوی دیگر، هیستوگرام دادههای کمی را با محدودهای از مقادیر X که در دستهها یا فواصل گروهبندی شدهاند، رسم میکند. هیستوگرامها برای نشان دادن توزیعها (در امتداد محور X) استفاده میشوند، در حالی که نمودارهای میلهای برای مقایسهی دستهها استفاده میشوند. همیشه صحبت در مورد چولگی هیستوگرام مناسب است؛ یعنی، تمایل مشاهدات برای قرار گرفتن بیشتر در انتهای پایین یا انتهای بالای محور X. با این حال، محور X نمودار میلهای انتهای پایین یا انتهای بالا ندارد؛ زیرا برچسبهای روی محور X دستهبندی شدهاند – نه کمی. بنابراین، میلهها را میتوان در نمودارهای میلهای تغییر ترتیب داد اما در هیستوگرامها خیر.
مثال ۲.۱۷. هیستوگرام. شکل ۲.۶ یک هیستوگرام برای مجموعه دادههای توزیع جوایز تحقیقاتی برای یک منطقه را نشان میدهد، که در آن سطلها (یا دستهها) توسط محدودههای با عرض مساوی که نشاندهنده افزایش ۱۰۰۰ دلاری هستند تعریف میشوند و فراوانی تعداد جوایز تحقیقاتی در سطلهای مربوطه است.
اگرچه هیستوگرامها به طور گسترده مورد استفاده قرار میگیرند، اما ممکن است به اندازه روشهای نمودار کوانتایل، نمودار q-q و نمودار جعبهای در مقایسه گروههای مشاهدات تک متغیره مؤثر نباشند.
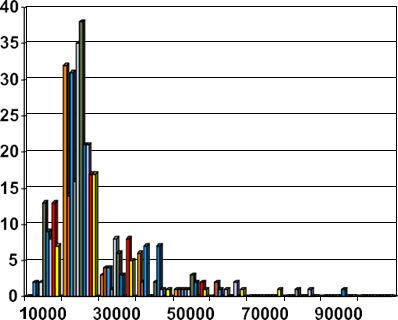
هیستوگرام توزیع جوایز تحقیقاتی برای یک منطقه.
نمودارهای پراکندگی و همبستگی دادهها
نمودار پراکندگی یکی از مؤثرترین روشهای گرافیکی برای تعیین وجود رابطه، الگو یا روند بین دو ویژگی عددی است. برای ساخت یک نمودار پراکندگی، هر جفت از مقادیر به عنوان یک جفت مختصات به معنای جبری در نظر گرفته میشوند و به صورت نقاطی در صفحه رسم میشوند. شکل ۲.۷ نمودار پراکندگی را برای مجموعه دادههای جدول ۲.۳ نشان میدهد.
نمودار پراکندگی روشی مفید برای ارائه اولین نگاه به دادههای دو متغیره برای مشاهده خوشههایی از نقاط و دادههای پرت یا بررسی امکان روابط همبستگی است. دو ویژگی، X و Y، در صورتی که دانش یک ویژگی امکان پیشبینی دیگری را با کمی دقت فراهم کند، همبستگی دارند. همبستگیها میتوانند مثبت، منفی یا صفر (غیرهمبسته) باشند. شکل ۲.۸ نمونههایی از همبستگیهای مثبت و منفی بین دو ویژگی را نشان میدهد.
نمودار پراکندگی برای مجموعه دادههای جدول ۲.۳.
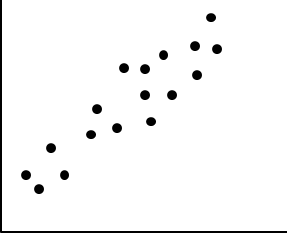

شکل ۲.۸
از نمودارهای پراکندگی میتوان برای یافتن (الف) همبستگیهای مثبت یا (ب) همبستگیهای منفی بین ویژگیها استفاده کرد.



شکل ۲.۹
سه حالت که در آنها هیچ همبستگی مشاهده شدهای بین دو ویژگی رسم شده در هر یک از مجموعه دادهها وجود ندارد.
اگر الگوی نقاط رسم شده از پایین سمت چپ به بالا سمت راست شیب داشته باشد، این بدان معناست که مقادیر X با افزایش مقادیر Y افزایش مییابند که نشاندهنده همبستگی مثبت است (شکل ۲.۸a). اگر الگوی نقاط رسم شده از بالا سمت چپ به پایین سمت راست شیب داشته باشد، مقادیر X با کاهش مقادیر Y افزایش مییابند که نشاندهنده همبستگی منفی است (شکل ۲.۸b). میتوان یک خط با بهترین برازش برای مطالعه همبستگی بین متغیرها رسم کرد. آزمونهای آماری برای همبستگی در پیوست الف معرفی شدهاند.
شکل ۲.۹ سه حالت را نشان میدهد که در آنها هیچ رابطه همبستگی بین دو ویژگی در هر یک از مجموعه دادههای داده شده وجود ندارد. نمودارهای پراکندگی را میتوان به n ویژگی نیز تعمیم داد که منجر به یک ماتریس نمودار پراکندگی میشود. به طور خلاصه، توصیفات اولیه دادهها (مثلاً معیارهای گرایش مرکزی و معیارهای پراکندگی) و نمایشهای آماری گرافیکی (مثلاً نمودارهای چندکی، هیستوگرامها و نمودارهای پراکندگی) بینش ارزشمندی در مورد رفتار کلی دادههای شما ارائه میدهند. آنها با کمک به شناسایی نویز و دادههای پرت، به ویژه برای پاکسازی دادهها مفید هست


