مقدمه
انبارهای داده حاوی حجم عظیمی از دادهها هستند. سرورهای OLAP نیاز دارند که به پرسوجوهای پشتیبانی تصمیمگیری در عرض چند ثانیه پاسخ داده شود. مکعبهای داده هسته انبارهای داده هستند. بنابراین، برای سیستمهای انبار داده بسیار مهم است که از محاسبات، دسترسی و پردازش پرسوجو با کارایی بالا در مکعب داده پشتیبانی کنند. در این بخش، مروری بر ایدههای پشت محاسبات مکعب داده ارائه میدهیم. بخش 3.4.1 اصطلاحات اساسی را معرفی میکند. بخش ۳.۴.۲ ایدههای مختلفی را در مورد تحقق کامل یا جزئی یک مکعب داده مورد بحث قرار میدهد. بخش ۳.۴.۳ توضیح میدهد که چگونه مکعبهای داده ممکن است با استفاده از معماریهای مختلف ذخیره شوند. بخش ۳.۴.۴ استراتژیهای کلی مورد استفاده در محاسبات مکعب داده را مرور میکند. الگوریتمهای دقیق برای محاسبات مکعب داده در بخش ۳.۵ معرفی خواهند شد.
اصطلاحات محاسبات مکعب داده
یک رویکرد برای محاسبات مکعب، محاسبه مجموعها روی تمام زیرمجموعههای ابعاد مشخص شده توسط کاربر است. این میتواند به فضای ذخیرهسازی بیش از حد، به ویژه برای تعداد زیادی از ابعاد، نیاز داشته باشد. برای بحث در مورد جزئیات مربوط به محاسبه و تحلیل مکعب داده، به برخی اصطلاحات نیاز داریم.
شکل ۳.۱۸ یک مکعب داده سهبعدی را برای سه بعد، A، B و C، و یک سنجه تجمعی، M، نشان میدهد. از این پس در این فصل، ما همیشه از اصطلاح مکعب داده برای اشاره به شبکهای از مکعبهای مستطیلی به جای یک مکعب مستطیل منفرد استفاده میکنیم. یک تاپل در یک مکعب مستطیل، سلول نیز نامیده میشود که نشاندهنده یک نقطه در فضای مکعب داده است. یک سلول در مکعب مستطیل پایه، یک سلول پایه است. یک سلول از یک مکعب مستطیل غیر پایه، یک سلول تجمعی است. یک سلول تجمعی روی یک یا چند بعد تجمع میکند، که هر بعد تجمعی با یک * در نمادگذاری سلول نشان داده میشود. فرض کنید یک مکعب داده n بعدی داریم. فرض کنیدa1) =a، a2،…، an، )measures
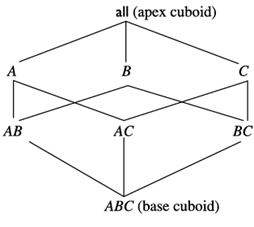
شبکهای از مکعبهای مستطیلی که یک مکعب داده سهبعدی با ابعاد A، B و C برای یک سنجه تجمعی، M، را تشکیل میدهند.
سلولی از یکی از مکعبهای مستطیلی تشکیلدهنده مکعب داده است. میگوییم a یک سلول m بعدی است (یعنی از یک مکعب داده) اگر دقیقاً m (m n) مقدار بین a1، a2،… و an وجود نداشته باشد. اگر m n باشد، آنگاه a یک سلول پایه است؛ در غیر این صورت، یک سلول تجمعی است (یعنی، که در آن m< n).
مثال ۳.۹. سلولهای پایه و تجمعی. یک مکعب داده با سه بعد، ماه، شهر و گروه مشتری و سنجه فروش را در نظر بگیرید. (J an، ، ، ۲۸۰۰) و ( ، شیکاگو، ، ۱۲۰۰) سلولهای یک بعدی هستند؛ (Jan، ، کسب و کار، ۱۵۰) یک سلول دو بعدی است؛ و (Jan, Chicago, Business, 45) یک سلول سهبعدی است. در اینجا، از آنجایی که مکعب داده دارای ۳ بعد است، تمام سلولهای پایه سهبعدی هستند، در حالی که سلولهای ۱ بعدی و ۲ بعدی سلولهای تجمعی هستند.
(ماه h، شهر، ) یک مکعب مستطیل ۲ بعدی است که شامل تمام سلولهای ۲ بعدی دارای مقادیر غیرمقداری روی ویژگیهای month و city است. مکعب مستطیل پایه (ماه، شهر، گروه مشتری) شامل تمام سلولهای پایه است. مکعب مستطیل رأسی ALL فقط شامل یک سلول ۰ بعدی است (∗، ∗، ∗).ممکن است رابطه جد-فرزند بین سلولها وجود داشته باشد. در یک مکعب داده n بعدی، یک سلول i-D به نام a = (a1, a2,…, an, measuresa) جد یک سلول j-D به نام b = (b1, b2,…, bn, measuresb) است و b از نسل a است، اگر و تنها اگر (1) i < j باشد، و (2) برای 1 ≤ k ≤ n، ak = bk باشد هر زمان که ak /= ∗ باشد. به طور خاص، سلول a والد سلول b نامیده میشود و b فرزند a است، اگر و تنها اگر j = i + 1 باشد.
مثال 3.10. سلولهای جد و نسل. با اشاره به مثال 3.9، سلول 1-D a (J an, , , 2800) و سلول 2-D b (J an, ,Business, 150) اجداد سلول 3-D c (J an, Chicago, Business, 45) هستند. c از نسل هر دو a و b است. b والد c است؛ و c فرزند b است.
“چند مکعب مستطیل در یک مکعب داده n بعدی وجود دارد؟” اگر هیچ سلسله مراتبی با هیچ بعدی مرتبط نباشد، تعداد کل مکعبهای مستطیل برای یک مکعب داده n بعدی، همانطور که دیدهایم، (n) + (n) + ··· + (n) = 2n است. با این حال، در عمل، بسیاری از ابعاد دارای سلسله مراتب هستند. به عنوان مثال، زمان اغلب در سطوح مفهومی متعددی مانند سلسله مراتب “روز < ماه < ربع < سال” بررسی میشود. در بعدی که با سطوح L مرتبط است، مکعب مستطیل دارای L 1 انتخاب ممکن است، یعنی یکی از سطوح L یا سطح بالای مجازی که همه به معنای بعد در گروه بندی نیست. بنابراین، برای یک مکعب داده n بعدی، تعداد کل مکعبهایی که میتوانند تولید شوند (از جمله مکعبهای ایجاد شده با بالا رفتن از سلسله مراتب در امتداد هر بعد) برابر است با
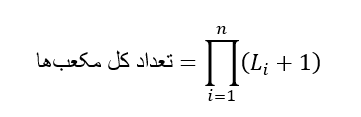
که در آن Li تعداد سطوح مرتبط با بُعد i است. به عنوان مثال، بُعد زمان همانطور که قبلاً مشخص شد، چهار سطح مفهومی دارد، یا اگر سطح مجازی all را در نظر بگیریم، پنج سطح دارد. اگر مکعب 10 بعد داشته باشد و هر بعد پنج سطح (شامل همه) داشته باشد، تعداد کل مکعبهای قابل تولید
است. اندازه هر مکعب، یعنی تعداد سلولهای یک مکعب، به کاردینالیتی (یعنی تعداد مقادیر متمایز) هر بُعد نیز بستگی دارد. به عنوان مثال، اگر هر کالا در هر شهر فروخته شود، فقط در گروه (شهر، کالا) تاپلهای کالای شهر وجود خواهد داشت. با افزایش تعداد ابعاد، تعداد سلسله مراتب مفهومی یا کاردینالیتی، فضای ذخیرهسازی مورد نیاز برای بسیاری از گروهها به طور قابل توجهی از اندازه (محدود) رابطه ورودی فراتر خواهد رفت. در واقع، با توجه به یک جدول پایه و مجموعهای از ابعاد، چگونگی محاسبه یا تخمین سریع تعداد تاپلها در مکعب داده حاصل، همچنان یک چالش حل نشده است.
تجسم مکعب داده: ایدهها
تا الان، احتمالاً متوجه شدهاید که در برنامههای کاربردی در مقیاس بزرگ، ممکن است پیشمحاسبه و تجسم تمام مکعبهای قابل تولید برای یک مکعب داده (یعنی از یک مکعب پایه) مطلوب یا واقعبینانه نباشد. اگر مکعبهای زیادی وجود داشته باشند و این مکعبها اندازه بزرگی داشته باشند، گزینه معقولتر، تجسم جزئی است؛ یعنی، تجسم فقط برخی از مکعبهای ممکن که میتوانند تولید شوند.
سه انتخاب ممکن برای تجسم مکعب داده وجود دارد.
۱. عدم تجسم: هیچ یک از مکعبهای “غیر پایه” را پیشمحاسبه نکنید. این منجر به محاسبه تجمعهای چندبعدی گرانقیمت در حال اجرا میشود که میتواند بسیار کند باشد.
۲. تجسم کامل: تمام مکعبها را پیشمحاسبه کنید. شبکه حاصل از مکعبهای محاسبهشده، مکعب کامل نامیده میشود. این انتخاب معمولاً به فضای حافظه بسیار زیادی برای ذخیره تمام مکعبهای از پیش محاسبهشده نیاز دارد.
۳. مادیسازی جزئی: به صورت انتخابی یک زیرمجموعه مناسب از کل مجموعه مکعبهای ممکن را محاسبه کنید، مانند زیرمجموعهای از مکعب که فقط شامل سلولهایی است که سنجه مشخص شده توسط کاربر را برآورده میکنند (مثلاً تعداد کل هر سلول بالاتر از یک آستانه است). ما از اصطلاح زیرمکعب برای اشاره به مورد دوم استفاده میکنیم، که در آن فقط برخی از سلولها ممکن است برای مکعبهای مختلف از پیش محاسبه شوند. مادیسازی جزئی مکعبهای داده، یک بدهبستان جالب بین فضای ذخیرهسازی و زمان پاسخ برای OLAP ارائه میدهد. به جای محاسبه مکعب کامل، میتوانیم فقط زیرمجموعهای از مکعبهای داده یا زیرمکعبهایی متشکل از زیرمجموعههایی از سلولها از مکعبهای مختلف را محاسبه کنیم.
با این وجود، الگوریتمهای محاسبه مکعب کامل مهم هستند. ما میتوانیم از چنین الگوریتمهایی برای محاسبه مکعبهای کوچکتر، متشکل از زیرمجموعهای از مجموعه ابعاد داده شده یا محدوده کوچکتری از مقادیر ممکن برای برخی از ابعاد، استفاده کنیم. در این موارد، مکعب کوچکتر یک مکعب کامل برای زیرمجموعه داده شده از ابعاد و/یا مقادیر ابعاد است. درک کامل روشهای محاسبه مکعب کامل به ما کمک میکند تا روشهای کارآمدی برای محاسبه مکعبهای جزئی توسعه دهیم. از این رو، بررسی روشهای مقیاسپذیر برای محاسبه تمام مکعبهای تشکیلدهنده یک مکعب داده، یعنی برای تحقق کامل، مهم است. این روشها باید مقدار محدود حافظه اصلی موجود برای محاسبه مکعب، اندازه کل مکعب داده محاسبه شده و همچنین زمان مورد نیاز برای چنین محاسباتی را در نظر بگیرند.
بسیاری از سلولهای یک مکعب ممکن است در واقع برای تحلیلگران داده کم یا بیاهمیت باشند. به یاد بیاورید که هر سلول در یک مکعب کامل یک مقدار کل مانند تعداد یا مجموع را ثبت میکند. برای بسیاری از سلولهای یک مکعب، مقدار سنجه صفر خواهد بود. به عنوان مثال، اگر کالای “لاستیک برفی” در ماه ژوئن به هیچ وجه در شهر “فینیکس” فروخته نشود، سلول کل مربوطه مقدار سنجه 0 را برای تعداد یا مجموع خواهد داشت. در یک مکعب مستطیل، وقتی بیشتر سلولها اندازه ۰ دارند، یعنی حاصلضرب کاردینالیتیها برای ابعاد در مکعب مستطیل بسیار بزرگتر از تعداد تاپلهای غیر صفر ذخیره شده در مکعب مستطیل باشد، میگوییم که مکعب مستطیل پراکنده است. اگر یک مکعب شامل مکعبهای پراکنده زیادی باشد، میگوییم که مکعب پراکنده است.
در بسیاری از موارد، مقدار قابل توجهی از فضای مکعب میتواند توسط تعداد زیادی سلول با مقادیر اندازه بسیار پایین اشغال شود. دلیل این امر این است که سلولهای مکعب اغلب به طور پراکنده در یک فضای چند بعدی توزیع شدهاند. به عنوان مثال، یک مشتری ممکن است فقط چند کالا را در یک فروشگاه در یک زمان خریداری کند. چنین رویدادی فقط چند سلول غیر خالی ایجاد میکند و بیشتر سلولهای مکعب دیگر را خالی میگذارد. در چنین شرایطی، مفید است که فقط آن سلولها را در یک مکعب مستطیل (گروهبندی شده توسط) با مقدار اندازه بالاتر از حداقل آستانه، قابل استفاده کنیم. مثلاً در یک مکعب داده در مورد فروش، ممکن است بخواهیم فقط سلولهایی را که تعدادشان >=10 است (یعنی حداقل 10 تاپل برای ترکیب ابعاد داده شده سلول وجود دارد) یا فقط سلولهایی را که فروش >=100 دلار را نشان میدهند، در نظر بگیریم. این کار نه تنها در زمان پردازش و فضای دیسک صرفهجویی میکند، بلکه منجر به تجزیه و تحلیل متمرکزتری نیز میشود. سلولهایی که نمیتوانند از آستانه عبور کنند، احتمالاً برای توجیه تجزیه و تحلیل بیشتر، بسیار ناچیز هستند.
چنین مکعبهای نیمهمتمرکزی به عنوان مکعبهای کوه یخ شناخته میشوند. آستانه حداقل، آستانه حداقل پشتیبانی یا به اختصار حداقل پشتیبانی (min_sup) نامیده میشود. با تحقق تنها کسری از سلولهای یک مکعب داده، نتیجه به عنوان “نوک کوه یخ” دیده میشود، که در آن “کوه یخ” مکعب کامل بالقوه شامل تمام سلولها است. یک مکعب کوه یخ را میتوان با استفاده از یک پرسوجوی SQL، همانطور که در مثال 3.11 نشان داده شده است، مشخص کرد.
مثال 3.11. مکعب کوه یخ. پرسوجوی مکعب کوه یخ زیر را در نظر بگیرید.
compute cube sales_iceberg as
select month, city, customer_group, count(*)
from salesInfo
cube by month, city, customer_group
have count(*) >= min_sup
جمله compute cube پیشمحاسبه مکعب کوه یخ، sales_iceberg، را با سه بعد، ماه، شهر و گروه مشتری، و سنجه تجمعی count() مشخص میکند. تاپلهای ورودی در رابطه salesInfo هستند. بند cube by مشخص میکند که برای هر یک از زیرمجموعههای ممکن از ابعاد داده شده، باید مجموعهایی (group-by) تشکیل شود. اگر ما مکعب کامل را محاسبه میکردیم، هر group-by معادل یک مکعب مستطیل در شبکه مکعب داده خواهد بود. محدودیت مشخص شده در بند having به عنوان شرط iceberg شناخته میشود. در اینجا، سنجه iceberg، count() است. توجه داشته باشید که مکعب iceberg محاسبه شده در اینجا میتواند برای پاسخ به پرسوجوهای group-by در هر ترکیبی از ابعاد مشخص شده فرم با count(*) > v، که v min_sup است، استفاده شود. به جای count()، شرط iceberg ممکن است سنجههای پیچیدهتری مانند average() را مشخص کند.
اگر بند having را حذف کنیم، در نهایت مکعب کامل را خواهیم داشت. بیایید این مکعب را sales_cube بنامیم. مکعب iceberg، sales_iceberg، تمام سلولهای sales_cube را که تعداد آنها کمتر از min_sup است، حذف میکند. بدیهی است که اگر حداقل پشتیبانی را در sales_iceberg روی ۱ تنظیم کنیم، مکعب حاصل، مکعب کامل، sales_cube، خواهد بود.
یک رویکرد ساده برای محاسبه مکعب کوه یخ این است که ابتدا مکعب کامل را محاسبه کنیم و سپس سلولهایی را که شرط کوه یخ را برآورده نمیکنند، هرس کنیم. با این حال، این هنوز هم بسیار گران است. یک رویکرد کارآمد، محاسبه مستقیم فقط مکعب کوه یخ بدون محاسبه مکعب کامل است. بخش ۳.۵.۲ روشهایی را برای محاسبه کارآمد مکعب کوه یخ مورد بحث قرار میدهد.
معرفی مکعبهای کوه یخ، بار محاسبه سلولهای تجمیعی بیاهمیت در یک مکعب داده را کاهش میدهد. با این حال، ممکن است هنوز تعداد زیادی سلول بیاهمیت برای محاسبه داشته باشیم. برای مثال، فرض کنید دو سلول پایه برای یک پایگاه داده با ۱۰۰ بعد وجود دارد که به صورت {(a1, a2, a3,…, a100) 10, (a1, a2, b3,…, b100) 10} نشان داده میشوند، که در آن هر کدام تعداد سلول ۱۰ دارند. اگر حداقل پشتیبانی روی ۱۰ تنظیم شود، هنوز تعداد غیرمجازی سلول برای محاسبه و ذخیره وجود دارد، اگرچه اکثر آنها جالب نیستند. برای مثال، ۲۱۰۱ ۶ سلول تجمعی مجزا وجود دارد، ۲ مانند {(a1, a2, a3, a4,…, a99, ) 10,…, (a1, a2, , a4,…, a99, a100) 10,…, (a1, a2, a3, ,…, , ) 10}، اما اکثر آنها حاوی اطلاعات جدید زیادی نیستند. اگر تمام سلولهای تجمیعی را که میتوان با جایگزینی برخی ثابتها با * و با حفظ مقدار سنجه یکسان به دست آورد، نادیده بگیریم، تنها سه سلول مجزا باقی میماند: {(a1, a2, a3,…, a100) : 10, (a1, a2, b3,…, b100) : 10, (a1, a2, ∗,…, ∗) : 20}. یعنی از بین 2101 تا 4 سلول پایه و تجمیعی مجزا، تنها سه سلول واقعاً اطلاعات ارزشمندی ارائه میدهند.
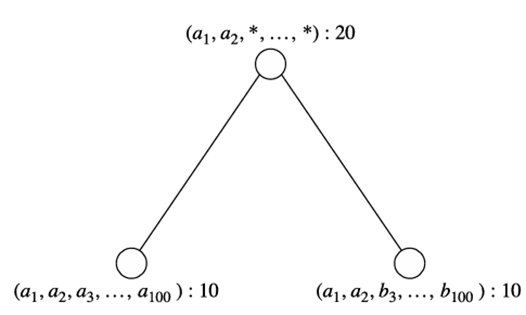
سه سلول بسته که شبکه یک مکعب بسته را تشکیل میدهند.
برای فشردهسازی سیستماتیک یک مکعب داده، باید مفهوم پوشش بسته را معرفی کنیم. پوشش یک سلول c مجموعهای از سلولهای پایه است که از نسل c هستند. اندازه c توسط سلولهای پایهای که از نسل c هستند محاسبه میشود. به عبارت دیگر، اندازه c توسط پوشش c تعیین میشود. واضح است که اگر دو سلول c1 و c2 پوشش یکسانی داشته باشند، صرف نظر از اینکه از چه توابع تجمیعی استفاده میشود، اندازه یکسانی دارند. بر اساس این مشاهده، اگر هیچ سلولی، d، وجود نداشته باشد، یک سلول بسته است، به طوری که d از نسل c باشد (یعنی d با جایگزینی حداقل یک سلول در c با یک مقدار غیر- به دست میآید) و d پوششی مشابه c داشته باشد. یک مکعب خارج قسمت، یک مکعب داده است که فقط از سلولهای بسته تشکیل شده است. برای مثال، سه سلول مشتق شده در پاراگراف قبل، سه سلول بسته مکعب داده برای مجموعه داده {(a1، a2، a3،…، a100) 10، (a1، a2، b3،…، b100) 10} هستند. آنها شبکه یک مکعب بسته را همانطور که در شکل 3.19 نشان داده شده است، تشکیل میدهند. سایر سلولهای غیربسته را میتوان از سلولهای بسته مربوطه در این شبکه مشتق کرد. به عنوان مثال، “(a1، ، ،…، ) 20” را میتوان از “(a1، a2، ،…، ) 20” مشتق کرد زیرا اولی یک سلول غیربسته تعمیم یافته از دومی است. به طور مشابه، ما )”a1، a2، b3، ،…، 10″( را داریم.
استراتژی دیگر برای تجسم جزئی، پیش محاسبه فقط مکعبهای شامل تعداد کمی از ابعاد مانند سه تا پنج است. این مکعبها یک پوسته مکعب برای مکعب داده مربوطه تشکیل میدهند. پرسوجوهای مربوط به ترکیبهای اضافی از ابعاد باید درجا محاسبه شوند. برای مثال، میتوانیم تمام مکعبهای با سه بعد یا کمتر را در یک مکعب داده n بعدی محاسبه کنیم که منجر به یک پوسته مکعبی با اندازه ۳ میشود. با این حال، این کار همچنان میتواند منجر به تعداد زیادی مکعب برای محاسبه شود، به خصوص وقتی n بزرگ باشد. از طرف دیگر، میتوانیم فقط بخشها یا قطعاتی از پوسته مکعب را بر اساس مکعبهای مورد نظر از قبل محاسبه کنیم. بخش 3.5.3 روشی را برای محاسبه قطعات پوسته مورد بحث قرار میدهد و نحوه استفاده از آنها را برای پردازش کارآمد پرسوجوی OLAP بررسی میکند.
معماریهای سرور OLAP: ROLAP در مقابل MOLAP در مقابل HOLAP
روشهای زیادی برای محاسبه کارآمد مکعب داده وجود دارد که بر اساس انواع مختلف مکعبهایی که قبلاً در این بخش توضیح داده شدهاند، هستند. به طور کلی، دو ساختار داده اساسی برای ذخیره مکعبها استفاده میشود. پیادهسازی OLAP رابطهای (ROLAP) از جداول رابطهای استفاده میکند، در حالی که آرایههای چندبعدی در OLAP چندبعدی (MOLAP) استفاده میشوند. در برخی شرایط، ممکن است ROLAP و MOLAP را نیز ترکیب کنیم تا رویکرد ترکیبی OLAP (HOLAP) را به دست آوریم. بیایید جزئیات را در اینجا بررسی کنیم. از نظر منطقی، سرورهای OLAP دادههای چندبعدی را از انبارهای داده یا مراکز داده در اختیار کاربران تجاری قرار میدهند، بدون اینکه نگرانی در مورد نحوه یا محل ذخیره دادهها داشته باشند. با این حال، معماری فیزیکی و پیادهسازی سرورهای OLAP باید مسائل مربوط به ذخیرهسازی دادهها را در نظر بگیرد. پیادهسازیهای یک سرور انبار داده برای پردازش OLAP ممکن است گزینههای زیر را داشته باشد.
سرورهای OLAP رابطهای (ROLAP)
اینها سرورهای میانی هستند که بین یک سرور back-end رابطهای و ابزارهای front-end کلاینت قرار میگیرند. آنها از یک DBMS رابطهای یا رابطهای توسعهیافته برای ذخیره و مدیریت دادههای انبار و از میانافزار OLAP برای پشتیبانی از قطعات گمشده استفاده میکنند. سرورهای ROLAP شامل بهینهسازی برای هر بخش پشتی DBMS، پیادهسازی منطق ناوبری تجمیعی و ابزارها و خدمات اضافی هستند. فناوری ROLAP معمولاً مقیاسپذیری بیشتری نسبت به فناوری MOLAP دارد.
سرورهای OLAP چندبعدی (MOLAP)
این سرورها از طریق موتورهای ذخیرهسازی چندبعدی مبتنی بر آرایه، از نماهای داده چندبعدی پشتیبانی میکنند. آنها نماهای چندبعدی را مستقیماً به ساختارهای آرایه مکعب داده نگاشت میکنند. مزیت استفاده از مکعب داده این است که امکان نمایهسازی سریع برای دادههای خلاصهشده از پیش محاسبهشده را فراهم میکند. توجه داشته باشید که با انبارهای داده چندبعدی، اگر مجموعه داده پراکنده باشد، ممکن است استفاده از فضای ذخیرهسازی کم باشد. در چنین مواردی، باید تکنیکهای فشردهسازی ماتریس پراکنده بررسی شوند.
بسیاری از سرورهای MOLAP از یک نمایش ذخیرهسازی دو سطحی برای مدیریت مجموعه دادههای متراکم و پراکنده استفاده میکنند: زیرمکعبهای متراکمتر به عنوان ساختارهای آرایه شناسایی و ذخیره میشوند، در حالی که زیرمکعبهای پراکنده از فناوری فشردهسازی برای استفاده کارآمد از فضای ذخیرهسازی استفاده میکنند.
سرورهای OLAP ترکیبی (HOLAP)
رویکرد OLAP ترکیبی، فناوری ROLAP و MOLAP را ترکیب میکند و از مقیاسپذیری بیشتر ROLAP و محاسبه سریعتر MOLAP بهره میبرد. به عنوان مثال، یک سرور HOLAP ممکن است امکان ذخیره حجم زیادی از دادههای دقیق را در یک پایگاه داده رابطهای فراهم کند، در حالی که دادههای تجمیعی در یک مخزن MOLAP جداگانه نگهداری میشوند.
سرورهای SQL تخصصی
برای پاسخگویی به تقاضای رو به رشد پردازش OLAP در پایگاههای داده رابطهای، برخی از فروشندگان سیستم پایگاه داده، سرورهای SQL تخصصی را پیادهسازی میکنند که زبان پرسوجوی پیشرفته و پشتیبانی از پردازش پرسوجو را برای پرسوجوهای SQL بر روی طرحهای ستارهای و دانه برفی در یک محیط فقط خواندنی ارائه میدهند.
“دادهها در معماریهای ROLAP و MOLAP چگونه ذخیره میشوند؟” بیایید ابتدا به ROLAP نگاهی بیندازیم. همانطور که از نامش پیداست، ROLAP از جداول رابطهای برای ذخیره دادهها برای پردازش تحلیلی آنلاین استفاده میکند. به یاد بیاورید که جدول واقعیت مرتبط با یک مکعب پایه، جدول واقعیت پایه نامیده میشود. جدول واقعیت پایه، دادهها را در سطح انتزاعی که توسط کلیدهای اتصال در طرح برای مکعب داده داده شده نشان داده میشود، ذخیره میکند. دادههای تجمیعشده را میتوان در جداول واقعیت نیز ذخیره کرد که به آنها جداول واقعیت خلاصه گفته میشود. برخی از جداول واقعیت خلاصه، هم دادههای جدول واقعیت پایه و هم دادههای تجمیعشده را ذخیره میکنند. به عنوان یک جایگزین، میتوان از جداول واقعیت خلاصه جداگانه برای هر سطح انتزاع استفاده کرد تا فقط دادههای تجمیعشده را ذخیره کند.
مثال ۳.۱۲. یک مخزن داده ROLAP. جدول ۳.۳ یک جدول واقعیت خلاصه را نشان میدهد که شامل دادههای واقعیت پایه و دادههای تجمیعشده است. طرحواره آن «شناسه رکورد (RID)، کالا، …، روز، ماه، ربع، سال، دلار_فروش» است که در آن روز، ماه، ربع و سال تاریخ فروش را تعریف میکنند و دلار_فروش مقدار فروش است. تاپلهایی را با RID 1001 و 1002 به ترتیب در نظر بگیرید. دادههای این تاپلها در سطح واقعیت پایه هستند که در آن تاریخهای فروش به ترتیب ۱۵ اکتبر ۲۰۱۰ و ۲۳ اکتبر ۲۰۱۰ هستند. تاپل با RID برابر با ۵۰۰۱ را در نظر بگیرید. این تاپل در سطح انتزاعیتری نسبت به تاپلهای ۱۰۰۱ و ۱۰۰۲ قرار دارد. مقدار روز به همه تعمیم داده شده است، به طوری که مقدار زمانی مربوطه اکتبر ۲۰۱۰ است. یعنی، مقدار dollars_sold نشان داده شده، یک تجمیع است که کل ماه اکتبر ۲۰۱۰ را نشان میدهد، نه فقط ۱۵ یا ۲۳ اکتبر ۲۰۱۰. مقدار ویژه all برای نمایش جمعهای فرعی در دادههای خلاصه شده استفاده میشود.
|
جدول ۳.۳ جدول واحد برای حقایق پایه و خلاصه. |
|||||||
|
RID |
مورد |
… |
روز |
ماه |
ربع |
سال |
دلار_فروخته شد |
|
1001 |
TV |
. . . |
15 |
10 |
Q4 |
2010 |
250.60 |
|
1002 |
TV |
. . . |
23 |
10 |
Q4 |
2010 |
175.00 |
|
… |
… |
… |
… |
… |
… |
… |
… |
|
5001 |
TV |
. . . |
all |
10 |
Q4 |
2010 |
45,786.08 |
|
… |
… |
… |
… |
… |
… |
… |
… |
MOLAP از ساختارهای آرایهای چندبعدی برای ذخیره دادهها جهت پردازش تحلیلی آنلاین استفاده میکند. اکثر سیستمهای انبار داده از معماری کلاینت-سرور استفاده میکنند. یک انبار داده رابطهای همیشه در سایت سرور انبار داده/مارت داده قرار دارد. یک انبار داده چندبعدی میتواند در سایت سرور پایگاه داده یا سایت کلاینت قرار گیرد.
استراتژیهای کلی برای محاسبه مکعب داده
اگرچه ROLAP و MOLAP ممکن است هر کدام تکنیکهای مختلف محاسبه مکعب را بررسی کنند، اما برخی از تکنیکهای بهینهسازی به طور گسترده مورد استفاده قرار میگیرند.
تکنیک بهینهسازی ۱: مرتبسازی، درهمسازی و گروهبندی
عملیات مرتبسازی، درهمسازی و گروهبندی باید بر روی ویژگیهای ابعاد اعمال شوند تا تاپلهای مرتبط با هم مرتبسازی و خوشهبندی شوند.
در محاسبه مکعب، تجمیع روی تاپلها (یا سلولهایی) انجام میشود که مجموعه یکسانی از مقادیر ابعاد را به اشتراک میگذارند. بنابراین، بررسی عملیات مرتبسازی، درهمسازی و گروهبندی برای دسترسی و گروهبندی چنین دادههایی با هم برای تسهیل محاسبه چنین تجمیعهایی مهم است. برای محاسبه کل فروش بر اساس شاخه، روز و کالا، به عنوان مثال، مرتبسازی تاپلها یا سلولها ابتدا بر اساس شاخه، سپس بر اساس روز و در آخر بر اساس کالا میتواند کارآمدتر باشد. با استفاده از دادههای مرتبشده، گروهبندی آنها بر اساس نام کالا آسان است. پیادهسازیهای کارآمد چنین عملیاتی در مجموعه دادههای بزرگ، به طور گسترده در جوامع تحقیقاتی الگوریتم و پایگاه داده، مانند مرتبسازی شمارشی، مورد مطالعه قرار گرفتهاند. چنین پیادهسازیهایی را میتوان به محاسبات مکعب داده تعمیم داد.
این تکنیک همچنین میتواند برای انجام مرتبسازیهای مشترک (یعنی به اشتراکگذاری هزینههای مرتبسازی در چندین مکعب مستطیل هنگام استفاده از روشهای مبتنی بر مرتبسازی) یا انجام پارتیشنهای مشترک (یعنی به اشتراکگذاری هزینه پارتیشنبندی در چندین مکعب مستطیل هنگام استفاده از الگوریتمهای مبتنی بر هش) گسترش یابد. به عنوان مثال، با استفاده از دادههایی که ابتدا بر اساس شاخه، سپس بر اساس روز و در آخر بر اساس کالا مرتب شدهاند، میتوانیم نه تنها مکعب مستطیل (شاخه، روز، کالا) بلکه مکعبهای (شاخه، روز، ∗)، (شاخه، ∗، ∗) و () را نیز محاسبه کنیم.
تکنیک بهینهسازی ۲: تجمیع و ذخیرهسازی همزمان نتایج میانی در محاسبات مکعبی
محاسبه تجمیعهای سطح بالاتر از تجمیعهای سطح پایینتر که قبلاً محاسبه شدهاند، به جای جدول واقعیت پایه، کارآمدتر است، زیرا تعداد تاپلهای تجمیعهای سطح بالاتر بسیار کمتر از تعداد تاپلهای جدول واقعیت پایه است. به عنوان مثال، برای محاسبه کل مبلغ فروش یک سال، تجمیع از زیرجمع اقلام مختلف سال کارآمدتر است. علاوه بر این، تجمیع همزمان از نتایج محاسبات میانی ذخیره شده ممکن است منجر به کاهش عملیات ورودی/خروجی (I/O) پرهزینه دیسک شود. این تکنیک را میتوان برای انجام اسکنهای سرشکن شده (یعنی محاسبه حداکثر تعداد مکعبهای ممکن در یک زمان برای سرشکن کردن خواندنهای دیسک) بیشتر گسترش داد.
تکنیک بهینهسازی ۳: تجمیع از کوچکترین فرزند وقتی چندین مکعب فرزند وجود دارد
وقتی چندین مکعب فرزند وجود دارد، معمولاً محاسبه مکعب والد مورد نظر (یعنی تعمیمیافتهتر) از کوچکترین مکعب فرزند محاسبهشده قبلی، کارآمدتر است. به عنوان مثال، برای محاسبه مکعب فروش، Cbranch، وقتی دو مکعب از قبل محاسبهشده، C{branch,year} و C branch,item وجود دارد، بدیهی است که محاسبه Cbranch از اولی کارآمدتر از دومی است اگر تعداد اقلام متمایز بسیار بیشتر از سالهای متمایز باشد.
تکنیک بهینهسازی ۴: میتوان از آنتیمانوتونیک رو به پایین برای هرس کردن فضای جستجو در محاسبه مکعب کوه یخ استفاده کرد.
برای بسیاری از سنجههای تجمیع، آنتیمانوتونیک رو به پایین ممکن است برقرار باشد. اگر یک سلول معین شرط کوه یخ را برآورده نکند، هیچ فرزندی از سلول (یعنی سلول تخصصیتر) نمیتواند شرط کوه یخ را برآورده کند.
به عنوان مثال، شرط کوه یخ “count(*) > 1000” را در نظر بگیرید. اگر یک سلول (*، Bellingham، *): 800 در شرط کوه یخ شکست بخورد، هر یک از فرزندان این سلول، مانند (March، Bellingham، *) و (*، Bellingham، small-business)، نیز باید در شرط شکست بخورد و بنابراین نمیتواند در مکعب کوه یخ گنجانده شود.
ویژگی ضدیکنواختی میتواند برای کاهش قابل توجه محاسبات مکعبهای کوه یخ استفاده شود. یک شرط رایج کوه یخ این است که سلولها باید حداقل آستانه پشتیبانی مانند حداقل تعداد یا مجموع را برآورده کنند. در این شرایط، میتوان از ویژگی ضدیکنواختی برای حذف کاوش فرزندان سلول استفاده کرد.
در بخش بعدی، چندین روش محبوب برای محاسبه کارآمد مکعب را معرفی میکنیم که این استراتژیهای بهینهسازی را بررسی میکنند.


