
9.1. مقدمه: از ثبت داده تا کشف دانش
در دهههای گذشته، مدیریت HSE عمدتاً بر پایه ثبت رخدادها، محاسبه نرخها و تحلیلهای توصیفی ساده شکل گرفته بود. سازمانها تعداد حوادث، روزهای از دسترفته، دفعات بازرسی، میزان آلایندهها یا نتایج معاینات شغلی را ثبت میکردند و سپس با استفاده از شاخصهایی مانند نرخ تکرار حادثه، نرخ شدت، تعداد شبهحادثهها یا درصد عدمانطباقها، تصویری کلی از عملکرد خود به دست میآوردند. این رویکرد اگرچه ضروری و ارزشمند است، اما برای فهم پیچیدگیهای امروز HSE کافی نیست.
در محیطهای صنعتی جدید، دادهها بسیار متنوع، پرحجم و چندمنبعی شدهاند. دادههای حاصل از حسگرها، سامانههای گزارشدهی، نرمافزارهای مدیریت HSE، سیستمهای نگهداشت، دوربینهای هوشمند، تجهیزات پوشیدنی، گزارشهای متنی، دادههای آبوهوایی، دادههای تولید و اطلاعات منابع انسانی، همگی میتوانند در کنار هم تصویری عمیقتر از وضعیت ریسک ارائه دهند. مسئله اصلی این نیست که سازمان داده دارد یا نه؛ مسئله اصلی این است که آیا سازمان میتواند از میان این دادهها، الگوهای معنادار و قابل اقدام استخراج کند یا خیر.
دادهکاوی در چنین زمینهای معنا پیدا میکند. دادهکاوی را میتوان فرایند کشف الگوها، روابط، ساختارها و دانش پنهان در دادهها دانست؛ دانشی که در نگاه نخست آشکار نیست، اما میتواند برای پیشگیری از حادثه، کنترل بیماریهای شغلی، کاهش آلودگی، بهبود فرهنگ ایمنی و افزایش تابآوری سازمانی مورد استفاده قرار گیرد.
.
در HSE، ارزش دادهکاوی تنها در «پیشبینی» نیست. گاهی مهمترین نقش دادهکاوی، کمک به فهم بهتر گذشته و حال است؛ یعنی اینکه سازمان دریابد حوادث در چه شرایطی بیشتر رخ میدهند، کدام ترکیب عوامل با افزایش ریسک همراه است، چه الگوهایی در گزارشهای متنی تکرار میشود، کدام واحدها از نظر رفتار ریسکی مشابهاند، یا چه تغییراتی در فرایند میتواند نشانه شکلگیری یک وضعیت غیرعادی باشد.
بنابراین، دادهکاوی را باید حلقهای میان داده، تحلیل، تفسیر و اقدام دانست. اگر دادهکاوی به تصمیم مدیریتی، اصلاح فرایند، طراحی مداخله یا یادگیری سازمانی منجر نشود، صرفاً یک تمرین فنی باقی میماند.
.
9.2. ماهیت دادهکاوی در HSE
9.2.1. دادهکاوی چیست
دادهکاوی بخشی از فرایند گستردهتر «کشف دانش از دادهها» است. در این فرایند، دادههای خام پس از گردآوری، پاکسازی، آمادهسازی، تحلیل و تفسیر، به دانش قابل استفاده تبدیل میشوند. دادهکاوی بهطور خاص بر مرحله کشف الگوها و روابط تمرکز دارد.
در ادبیات علمی، دادهکاوی معمولاً به عنوان استخراج الگوهای معتبر، جدید، مفید و قابل فهم از دادهها تعریف میشود. این تعریف چند نکته مهم دارد:
- معتبر بودن: الگو نباید صرفاً حاصل تصادف یا خطای داده باشد.
- جدید بودن: الگو باید چیزی فراتر از دانستههای بدیهی سازمان ارائه کند.
- مفید بودن: الگو باید در تصمیمگیری یا اقدام مدیریتی کاربرد داشته باشد.
- قابل فهم بودن: خروجی تحلیل باید برای متخصصان HSE، مدیران و کاربران قابل تفسیر باشد.
در HSE، این چهار ویژگی اهمیت ویژهای دارند. برای مثال، اگر الگوریتمی نشان دهد که «رخدادها در روزهای کاری بیشتر از تعطیلات رخ میدهند»، این یافته احتمالاً جدید یا مفید نیست؛ زیرا حجم فعالیت در روزهای کاری بیشتر است. اما اگر مدل نشان دهد که ترکیب «شیفت شب، کار پیمانکاری، تأخیر در صدور مجوز کار و دمای محیط بالا» با افزایش شبهحادثههای جدی همراه است، این الگو میتواند از نظر مدیریتی بسیار ارزشمند باشد.

9.2.2. تفاوت دادهکاوی با آمار سنتی
آمار سنتی و دادهکاوی رقیب یکدیگر نیستند، بلکه مکملاند. آمار کلاسیک معمولاً با فرضیه مشخص آغاز میشود. پژوهشگر یا تحلیلگر ابتدا سؤالی طرح میکند، سپس دادهها را برای آزمون آن فرضیه تحلیل میکند. برای مثال: «آیا نرخ حادثه در واحد الف بیشتر از واحد ب است؟» یا «آیا آموزش ایمنی باعث کاهش رفتار ناایمن شده است؟»
اما دادهکاوی اغلب با هدف اکتشاف آغاز میشود. در اینجا ممکن است تحلیلگر نداند دقیقاً چه الگویی وجود دارد. او دادهها را بررسی میکند تا روابط پنهان، گروهبندیهای غیرمنتظره، ناهنجاریها یا ترکیبهای پرریسک را کشف کند.
به بیان ساده:
- آمار سنتی بیشتر به دنبال پاسخ به پرسشهای مشخص است.
- دادهکاوی بیشتر به دنبال کشف پرسشها و الگوهای جدید است.
البته این تمایز مطلق نیست. بسیاری از روشهای دادهکاوی ریشه آماری دارند و بسیاری از تحلیلهای آماری نیز میتوانند اکتشافی باشند. نکته مهم آن است که دادهکاوی در محیطهای دادهمحور جدید، به سازمان کمک میکند از چارچوبهای تحلیلی محدود فراتر رود.
9.2.3. ضرورت دادهکاوی در HSE
چند تحول مهم باعث شدهاند دادهکاوی در HSE اهمیت روزافزون پیدا کند:
نخست، افزایش حجم دادهها است. سازمانها امروزه حجم بزرگی از دادههای عملیاتی، ایمنی، بهداشتی و محیطزیستی تولید میکنند. تحلیل دستی این دادهها عملاً ممکن نیست.
دوم، پیچیدگی روابط علّی در HSE است. حوادث و بیماریهای شغلی معمولاً نتیجه یک عامل منفرد نیستند، بلکه از تعامل عوامل فنی، انسانی، سازمانی، محیطی و مدیریتی شکل میگیرند. دادهکاوی میتواند الگوهای چندعاملی را بهتر آشکار کند.
سوم، نیاز به پیشگیری پیشدستانه است. مدیریت HSE دیگر نمیتواند صرفاً پس از وقوع حادثه واکنش نشان دهد. سازمانها نیاز دارند نشانههای اولیه خطر را شناسایی کنند و پیش از تبدیل شدن آنها به حادثه جدی، اقدام اصلاحی انجام دهند.
چهارم، توسعه فناوریهای دیجیتال است. حسگرها، اینترنت اشیا، سامانههای گزارشدهی موبایلی، تجهیزات پوشیدنی و نرمافزارهای یکپارچه HSE، فرصتهای تازهای برای تحلیل داده ایجاد کردهاند.
.
9.3. دادههای HSE به عنوان ورودی دادهکاوی
9.3.1. تنوع دادههای HSE
دادههای HSE از نظر ماهیت بسیار متنوعاند. این تنوع، هم فرصت ایجاد میکند و هم چالش. برخی از مهمترین انواع داده در HSE عبارتاند از:
- دادههای رخداد و شبهرخداد: شامل حوادث، آسیبها، شبهحادثهها، رویدادهای فرایندی، آتشسوزی، نشت، سقوط، برخورد، برقگرفتگی و سایر رخدادهای ناخواسته.
- دادههای رفتاری: شامل مشاهده رفتار ایمن و ناایمن، استفاده از تجهیزات حفاظت فردی، رعایت دستورالعملها، نحوه انجام کار و تعامل کارکنان با تجهیزات.
- دادههای بهداشت حرفهای: شامل مواجهه با عوامل شیمیایی، فیزیکی، زیستی، ارگونومیک و روانی؛ نتایج پایش فردی؛ معاینات سلامت شغلی؛ و دادههای بیماریهای مرتبط با کار.
- دادههای محیطزیستی: شامل آلایندههای هوا، آب و خاک، پسماند، مصرف انرژی، مصرف آب، انتشار گازهای گلخانهای، پساب، صدای محیطی و دادههای انطباق با الزامات قانونی.
- دادههای عملیاتی و فرایندی: شامل فشار، دما، جریان، سطح، وضعیت تجهیزات، توقفهای اضطراری، هشدارهای سیستم کنترل و دادههای نگهداشت.
- دادههای سازمانی و مدیریتی: شامل آموزشها، صلاحیتها، ساعات کار، شیفتها، پیمانکاران، حجم تولید، تغییرات سازمانی، نتایج ممیزی، اقدامات اصلاحی و فرهنگ ایمنی.
9.3.2. چالشهای دادههای HSE
دادههای HSE معمولاً با چند مشکل اساسی همراهاند.
نخست، ناقص بودن دادهها است. بسیاری از رخدادها، بهویژه شبهحادثهها و رفتارهای ناایمن، بهطور کامل ثبت نمیشوند. اگر فرهنگ گزارشدهی ضعیف باشد، دادهها تصویر واقعی ریسک را نشان نمیدهند.
دوم، سوگیری گزارشدهی است. ممکن است برخی واحدها بیشتر گزارش کنند و برخی کمتر. در چنین شرایطی، تعداد بالای گزارشها لزوماً به معنای خطر بیشتر نیست؛ ممکن است نشانه فرهنگ گزارشدهی بهتر باشد.
سوم، نامتوازن بودن دادهها است. در HSE، رخدادهای شدید خوشبختانه کمفراواناند. این ویژگی از نظر اخلاقی و انسانی مطلوب است، اما از نظر مدلسازی یک چالش محسوب میشود. الگوریتمها ممکن است به دلیل کم بودن نمونههای حادثه شدید، در شناسایی آنها ضعیف عمل کنند.
چهارم، کیفیت پایین دادههای متنی است. گزارشهای حادثه و شبهحادثه گاهی کوتاه، مبهم، غیرساختاریافته یا دارای اصطلاحات محلی هستند. تحلیل چنین دادههایی نیازمند پاکسازی و استانداردسازی است.
پنجم، گسست میان سامانهها است. دادههای HSE ممکن است در نرمافزارهای مختلف، فایلهای اکسل، سامانههای عملیاتی، سیستمهای منابع انسانی و اسناد کاغذی پراکنده باشند. این پراکندگی، مانع تحلیل جامع میشود.
.
9.4. متدولوژی CRISP-DM در پروژههای دادهکاوی HSE
برای اجرای موفق پروژههای دادهکاوی، داشتن الگوریتم کافی نیست. سازمان باید از یک فرایند نظاممند پیروی کند. یکی از شناختهشدهترین چارچوبها در این زمینه، CRISP-DM است. این مدل شامل شش مرحله اصلی است.
9.4.1. درک مسئله کسبوکار و ریسک
در HSE، نخستین و مهمترین مرحله، تعریف دقیق مسئله ریسک است. پروژه دادهکاوی نباید با این سؤال شروع شود که «چه الگوریتمی استفاده کنیم؟» بلکه باید با این سؤال آغاز شود که «چه تصمیمی را میخواهیم بهتر بگیریم؟»
برای مثال:
- آیا میخواهیم واحدهای پرریسک را شناسایی کنیم؟
- آیا میخواهیم علل تکرارشونده شبهحادثهها را کشف کنیم؟
- آیا میخواهیم احتمال عبور آلاینده از حد مجاز را پیشبینی کنیم؟
- آیا میخواهیم الگوهای پنهان در گزارشهای متنی حادثه را استخراج کنیم؟
- آیا میخواهیم گروههای شغلی با مواجهه مشابه را شناسایی کنیم؟
تعریف مسئله باید به زبان HSE انجام شود، نه صرفاً زبان داده. اگر مسئله بهدرستی تعریف نشود، حتی پیشرفتهترین تحلیلها نیز ممکن است خروجیهایی تولید کنند که برای مدیریت بیفایدهاند.
9.4.2. درک داده
در این مرحله، تحلیلگر باید بداند چه دادههایی وجود دارد، از کجا آمدهاند، چگونه ثبت شدهاند، چه محدودیتهایی دارند و تا چه حد قابل اعتمادند.
برای نمونه، اگر دادههای شبهحادثه بررسی میشود، باید پرسید:
- آیا همه واحدها شبهحادثهها را به یک شکل تعریف میکنند؟
- آیا شدت بالقوه شبهحادثه ثبت شده است؟
- آیا گزارشها داوطلبانه بودهاند یا اجباری؟
- آیا تغییرات مدیریتی یا کمپینهای گزارشدهی باعث افزایش مصنوعی تعداد گزارشها شدهاند؟
- آیا دادهها شامل زمان، مکان، نوع فعالیت، نوع خطر و اقدامات کنترلی هستند؟
بدون پاسخ به این پرسشها، احتمال تفسیر نادرست خروجی مدل زیاد است.
9.4.3. آمادهسازی داده
آمادهسازی داده معمولاً زمانبرترین بخش پروژه است. در این مرحله دادهها پاکسازی، یکپارچه، کدگذاری، تبدیل و برای تحلیل آماده میشوند.
اقداماتی مانند حذف رکوردهای تکراری، تکمیل دادههای ناقص، استانداردسازی نام واحدها، یکسانسازی کدهای حادثه، تبدیل متن به ویژگیهای قابل تحلیل، نرمالسازی مقادیر و ساخت متغیرهای جدید در این مرحله انجام میشود.
برای مثال، ممکن است متغیر «زمان وقوع حادثه» به متغیرهای معنادارتری مانند «شیفت»، «روز هفته»، «فصل»، «ساعت از شروع شیفت» یا «همزمانی با تعمیرات» تبدیل شود. این تبدیلها میتوانند ارزش تحلیلی داده را بهشدت افزایش دهند.
9.4.4. مدلسازی
در مرحله مدلسازی، الگوریتمهای مناسب انتخاب و اجرا میشوند. انتخاب الگوریتم باید تابع هدف تحلیل باشد. اگر هدف پیشبینی یک طبقه باشد، روشهای دستهبندی مناسباند. حالا اگر هدف گروهبندی دادهها بدون برچسب قبلی باشد، خوشهبندی کاربرد دارد. هدف کشف الگوهای همآیی باشد، قوانین وابستگی مفیدند. اگر دادهها متنی باشند، روشهای پردازش زبان طبیعی به کار میروند.
در HSE، انتخاب مدل باید علاوه بر دقت، بر قابلیت تفسیر نیز توجه کند. مدلی که خروجی آن برای مدیر HSE قابل فهم نباشد، ممکن است در عمل به تصمیم منجر نشود.
9.4.5. ارزیابی
ارزیابی مدل صرفاً به معنای بررسی شاخصهای فنی مانند دقت نیست. در HSE باید پرسید:
- آیا مدل از نظر فنی معتبر است؟
- آیا خروجی آن با دانش کارشناسان سازگار است؟
- آیا مدل میتواند تصمیم عملی را بهبود دهد؟
- آیا احتمال سوگیری یا آسیب اخلاقی وجود دارد؟
- آیا مدل در دادههای جدید نیز عملکرد مناسبی دارد؟
برای مثال، در پیشبینی رخدادهای نادر، شاخص «دقت کلی» ممکن است گمراهکننده باشد. اگر فقط یک درصد دادهها مربوط به حوادث شدید باشد، مدلی که همیشه پیشبینی کند «حادثه شدید رخ نمیدهد»، ممکن است ۹۹ درصد دقت ظاهری داشته باشد، اما از نظر HSE کاملاً بیارزش باشد.
9.4.6. استقرار و اقدام
آخرین مرحله، تبدیل خروجی تحلیل به اقدام سازمانی است. این مرحله اغلب نادیده گرفته میشود. دادهکاوی زمانی ارزشمند است که در فرایندهای مدیریتی ادغام شود؛ مانند برنامهریزی بازرسی، اولویتبندی اقدامات اصلاحی، طراحی آموزش، اصلاح مجوز کار، بهبود نگهداشت، کنترل مواجهه یا بازنگری در ارزیابی ریسک.
استقرار موفق نیازمند آموزش کاربران، تعریف مسئولیتها، تعیین آستانههای اقدام، پایش عملکرد مدل و بازنگری دورهای است.
.
9.5. دستهبندی و پیشبینی طبقات در HSE
9.5.1. مفهوم دستهبندی
دستهبندی یکی از روشهای مهم یادگیری نظارتشده است. در این روش، مدل با استفاده از دادههایی که برچسب مشخص دارند آموزش میبیند و سپس تلاش میکند برچسب دادههای جدید را پیشبینی کند.
در HSE، برچسب میتواند مواردی مانند «حادثه شدید / غیرشدید»، «رفتار ایمن / ناایمن»، «مواجهه قابل قبول / غیرقابل قبول»، «عدمانطباق بحرانی / غیر بحرانی» یا «ریسک بالا / متوسط / پایین» باشد.
9.5.2. کاربرد در ایمنی
در حوزه ایمنی، دستهبندی میتواند برای شناسایی فعالیتهای پرخطر استفاده شود. برای مثال، با استفاده از دادههای گذشته میتوان مدلی ساخت که احتمال وقوع شبهحادثه جدی را در فعالیتهای مختلف پیشبینی کند.
متغیرهای ورودی میتوانند شامل موارد زیر باشند:
- نوع فعالیت؛
- نوع پیمانکار؛
- ساعت انجام کار؛
- وضعیت آبوهوا؛
- تجربه تیم کاری؛
- وجود یا عدم وجود مجوز کار؛
- تعداد اقدامات اصلاحی باز؛
- نتایج بازرسی قبلی؛
- سابقه رخداد در همان واحد.
چنین مدلی میتواند به سازمان کمک کند قبل از اجرای کارهای پرریسک، کنترلهای بیشتری اعمال کند.
9.5.3. کاربرد در بهداشت حرفهای
در بهداشت حرفهای، دستهبندی میتواند برای شناسایی گروههای شغلی با احتمال مواجهه بالا یا احتمال بروز اختلالات اسکلتیعضلانی، افت شنوایی، تنش گرمایی یا مشکلات تنفسی استفاده شود.
برای مثال، با ترکیب دادههای مواجهه، سوابق شغلی، نتایج معاینات دورهای و ویژگیهای محیط کار، میتوان کارکنان یا گروههای شغلی را از نظر نیاز به مداخله بهداشتی اولویتبندی کرد. البته در این حوزه باید بهشدت مراقب محرمانگی دادههای سلامت و جلوگیری از استفاده تنبیهی از اطلاعات بود.
9.5.4. کاربرد در محیطزیست
در محیطزیست، دستهبندی میتواند برای پیشبینی وضعیت انطباق یا عدمانطباق استفاده شود. برای مثال، دادههای عملیاتی واحد، شرایط آبوهوایی، وضعیت تجهیزات کنترل آلودگی و سوابق تعمیرات میتوانند برای پیشبینی احتمال عبور از حدود مجاز انتشار به کار روند.
چنین تحلیلی به سازمان اجازه میدهد اقدامات اصلاحی را پیش از وقوع عدمانطباق انجام دهد.
9.5.5. درخت تصمیم، جنگل تصادفی و SVM
درخت تصمیم یکی از قابل فهمترین روشهاست. این روش دادهها را بر اساس مجموعهای از قواعد ساده تقسیم میکند. مزیت آن در HSE، قابلیت توضیح برای مدیران و کارشناسان است.
جنگل تصادفی از ترکیب تعداد زیادی درخت تصمیم تشکیل میشود و معمولاً دقت بالاتری دارد. این روش برای دادههای پیچیده و چندمتغیره مناسب است، اما نسبت به درخت تصمیم ساده، تفسیر آن دشوارتر است.
ماشین بردار پشتیبان یا SVM برای مسائل طبقهبندی پیچیده کاربرد دارد، اما ممکن است برای کاربران غیرمتخصص کمتر قابل فهم باشد. بنابراین در کاربردهای HSE، باید میان دقت و تفسیرپذیری تعادل برقرار کرد.

.
9.6. رگرسیون و پیشبینی مقادیر پیوسته
9.6.1. مفهوم رگرسیون در دادهکاوی
رگرسیون زمانی به کار میرود که هدف، پیشبینی یک مقدار عددی باشد. در HSE، بسیاری از متغیرهای مهم پیوستهاند؛ مانند غلظت آلاینده، سطح صدا، میزان مواجهه، تعداد رخدادها، زمان توقف، شدت پیامد یا شاخص ریسک.
9.6.2. کاربرد در محیطزیست
یکی از کاربردهای مهم رگرسیون در محیطزیست، پیشبینی غلظت آلایندههاست. برای مثال، میتوان میزان انتشار یک آلاینده را بر اساس دمای فرایند، نرخ خوراک، وضعیت فیلتر، فشار سیستم، شرایط سوخت و دادههای هواشناسی پیشبینی کرد.
اگر مدل نشان دهد که در شرایط خاص، احتمال افزایش آلاینده زیاد است، سازمان میتواند پیش از وقوع عدمانطباق اقدام کند؛ مثلاً ظرفیت کنترل آلودگی را افزایش دهد، فرایند را تنظیم کند یا برنامه تعمیرات را جلو بیندازد.
9.6.3. کاربرد در بهداشت حرفهای
در بهداشت حرفهای، رگرسیون میتواند برای پیشبینی مواجهه شغلی استفاده شود. برای نمونه، میتوان سطح مواجهه با گردوغبار، بخارات شیمیایی یا صدا را بر اساس نوع فعالیت، مدت تماس، فاصله از منبع، تهویه، نوع ابزار و شرایط محیطی تخمین زد.
این رویکرد بهویژه زمانی مفید است که اندازهگیری مستقیم برای همه کارکنان یا همه شرایط ممکن نباشد.
9.6.4. کاربرد در ایمنی
در ایمنی، رگرسیون میتواند برای پیشبینی تعداد شبهحادثهها، تعداد رفتارهای ناایمن یا شاخصهای ترکیبی ریسک استفاده شود. البته باید توجه داشت که دادههای شمارشی، مانند تعداد رخدادها، معمولاً با رگرسیون خطی ساده بهخوبی مدل نمیشوند و روشهایی مانند رگرسیون پواسون یا نگاتیو بینومیال مناسبترند.
.
9.7. قوانین وابستگی: کشف بستههای ریسک

9.7.1. مفهوم قوانین وابستگی
قوانین وابستگی برای کشف الگوهای هموقوعی در دادهها استفاده میشوند. این روش ابتدا در تحلیل سبد خرید در فروشگاهها مشهور شد؛ اما در HSE نیز کاربرد بسیار ارزشمندی دارد.
در این روش، تحلیلگر میخواهد بداند چه شرایطی معمولاً با هم رخ میدهند. برای مثال:
اگر «کار در ارتفاع» و «پیمانکار جدید» و «نقص در داربست» همزمان باشند، احتمال ثبت رفتار ناایمن افزایش مییابد.
یا:
اگر «شیفت شب» و «تعمیرات اضطراری» و «کمبود نفرات باتجربه» همزمان باشند، احتمال شبهحادثه جدی بیشتر میشود.
9.7.2. شاخصهای اصلی در قوانین وابستگی
سه شاخص مهم در تحلیل قوانین وابستگی عبارتاند از:
حمایت یا Support: نشان میدهد یک الگو چند بار در کل دادهها رخ داده است. اگر الگویی بسیار نادر باشد، ممکن است از نظر آماری قابل اعتماد نباشد.
اطمینان یا Confidence: نشان میدهد وقتی بخش اول قانون رخ داده، بخش دوم قانون با چه احتمالی رخ داده است.
Lift: نشان میدهد رابطه مشاهدهشده چقدر فراتر از انتظار تصادفی است. Lift بالاتر از یک نشاندهنده ارتباط مثبت میان اجزای قانون است.
در HSE، Lift بسیار مهم است؛ زیرا ممکن است برخی رویدادها بهطور کلی زیاد رخ دهند، اما رابطه خاصی با عامل موردنظر نداشته باشند.
9.7.3. کاربرد در تحلیل حوادث
تحلیل قوانین وابستگی میتواند از نگاه تکعلتی به حادثه جلوگیری کند. بسیاری از گزارشهای حادثه به دنبال یک علت اصلی هستند؛ مثلاً «بیاحتیاطی فرد»، «نقص ابزار» یا «عدم رعایت دستورالعمل». اما حوادث معمولاً از ترکیب چند عامل شکل میگیرند.
قوانین وابستگی کمک میکنند «بستههای ریسک» شناسایی شوند. این بستهها ممکن است شامل عوامل انسانی، فنی، سازمانی و محیطی باشند. برای مثال:
- کار پیمانکاری؛
- تغییر برنامه کاری؛
- فشار زمانی؛
- نبود سرپرست باتجربه؛
- عدم بهروزرسانی ارزیابی ریسک؛
- نقص در تحویل شیفت.
چنین ترکیبهایی برای مدیریت پیشگیرانه بسیار ارزشمندتر از تحلیلهای تکعاملی هستند.
.
9.8. خوشهبندی: کشف گروههای پنهان در دادههای HSE
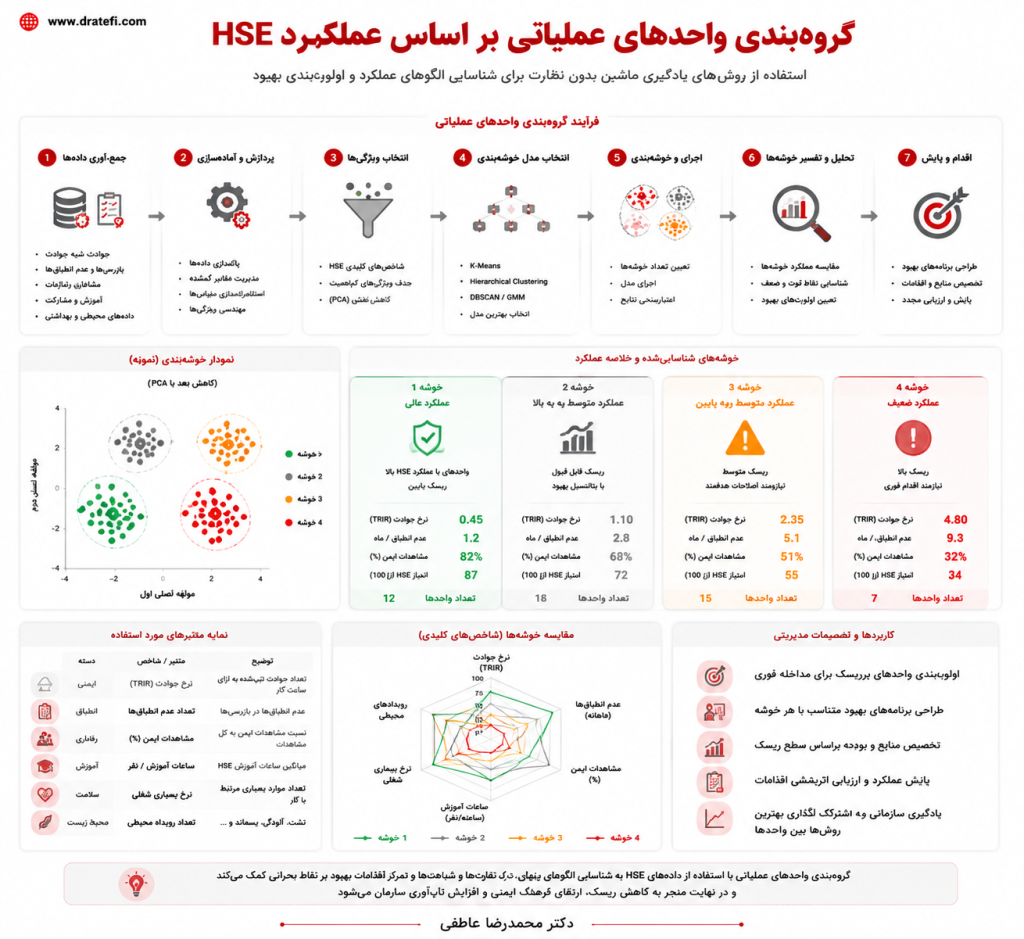
9.8.1. مفهوم خوشهبندی
خوشهبندی یکی از روشهای یادگیری بدون نظارت است. در این روش، دادهها بدون برچسب قبلی به گروههایی تقسیم میشوند که اعضای هر گروه به یکدیگر شبیهترند و با اعضای گروههای دیگر تفاوت بیشتری دارند.
در HSE، خوشهبندی میتواند برای شناسایی الگوهایی استفاده شود که از قبل تعریف نشدهاند. این ویژگی آن را به ابزاری مناسب برای اکتشاف تبدیل میکند.
9.8.2. خوشهبندی واحدهای عملیاتی
فرض کنید سازمانی چندین واحد تولیدی دارد. هر واحد از نظر تعداد حوادث، شبهحادثهها، نتایج بازرسی، سطح آموزش، اقدامات اصلاحی، وضعیت نگهداشت و شاخصهای محیطزیستی دادههایی تولید میکند. به جای رتبهبندی ساده واحدها بر اساس یک شاخص، میتوان از خوشهبندی استفاده کرد تا واحدها بر اساس الگوی کلی عملکرد HSE گروهبندی شوند.
ممکن است تحلیل نشان دهد:
- یک خوشه شامل واحدهایی است که حادثه کم دارند، اما گزارش شبهحادثه نیز پایین است؛ این وضعیت ممکن است نشانه ضعف گزارشدهی باشد.
- خوشه دیگر حادثه کم و شبهحادثه زیاد دارد؛ این میتواند نشانه فرهنگ گزارشدهی فعال باشد.
- خوشه سوم حادثه زیاد، اقدام اصلاحی باز زیاد و تأخیر در بستن اقدامات دارد؛ این خوشه نیازمند مداخله مدیریتی فوری است.
این نگاه از رتبهبندی ساده دقیقتر است.
9.8.3. خوشهبندی کارکنان یا گروههای شغلی
در بهداشت حرفهای، خوشهبندی میتواند گروههای مواجهه مشابه را شناسایی کند. برای مثال، کارکنانی که از نظر نوع فعالیت، مدت مواجهه، سطح صدا، وضعیت تهویه و استفاده از وسایل حفاظت فردی مشابهاند، میتوانند در یک خوشه قرار گیرند.
این روش به طراحی برنامههای پایش سلامت، نمونهبرداری و کنترل مواجهه کمک میکند.
9.8.4. تشخیص ناهنجاری
تشخیص ناهنجاری یکی از کاربردهای مهم خوشهبندی و روشهای مشابه است. در اینجا هدف، شناسایی نقاطی است که از الگوی معمول فاصله دارند. در HSE، ناهنجاری میتواند نشانه خطر باشد.
برای مثال:
- افزایش غیرعادی دمای یک تجهیز؛
- الگوی غیرمعمول انتشار آلاینده؛
- افزایش ناگهانی رفتارهای ناایمن در یک شیفت؛
- کاهش غیرمنتظره گزارش شبهحادثه؛
- تغییر الگوی مصرف مواد شیمیایی؛
- افزایش صدای غیرعادی در یک دستگاه.
البته هر ناهنجاری لزوماً خطرناک نیست، اما هر ناهنجاری مهم باید بررسی شود. دادهکاوی میتواند نقش سیستم هشدار اولیه را ایفا کند.
.
9.9. دادهکاوی متنی در گزارشهای HSE

9.9.1. اهمیت دادههای متنی
بخش بزرگی از دانش HSE در قالب متن ذخیره شده است: گزارش حادثه، شرح شبهحادثه، یافتههای ممیزی، گزارش بازدید، مصاحبه با کارکنان، صورتجلسات کمیته HSE، گزارش تحلیل ریشهای، شرح اقدامات اصلاحی و حتی پیامهای ثبتشده در سامانههای داخلی.
این دادهها معمولاً ساختار عددی ندارند، اما از نظر معنایی بسیار غنیاند. اگر سازمان فقط به فیلدهای عددی توجه کند و متن گزارشها را نادیده بگیرد، بخش بزرگی از واقعیت را از دست میدهد.
9.9.2. پردازش زبان طبیعی در HSE
دادهکاوی متنی با استفاده از روشهای پردازش زبان طبیعی تلاش میکند متن را به داده قابل تحلیل تبدیل کند. مراحل معمول آن شامل پاکسازی متن، حذف کلمات کماهمیت، ریشهیابی، تبدیل متن به بردارهای عددی، استخراج کلیدواژهها، شناسایی موضوعات و تحلیل الگوهاست.
در گزارشهای HSE، این روش میتواند پاسخ دهد:
- چه خطراتی بیشتر در گزارشها تکرار میشوند؟
- چه واژههایی در گزارشهای حوادث شدید بیشتر دیده میشوند؟
- آیا برخی علل ریشهای بهطور مکرر ظاهر میشوند؟
- آیا لحن گزارشها نشاندهنده سرزنش فردی است یا نگاه سیستمی؟
- آیا در برخی واحدها گزارشها مبهمتر یا کوتاهتر نوشته میشوند؟
- چه موضوعاتی در شبهحادثهها در حال افزایشاند؟
9.9.3. تحلیل موضوعات
تحلیل موضوعات یا Topic Modeling روشی است که میتواند تمهای پنهان در مجموعه بزرگی از متون را استخراج کند. برای مثال، از میان هزاران گزارش شبهحادثه، ممکن است چند موضوع اصلی شناسایی شود:
- نقص در مجوز کار؛
- مشکل در جداسازی انرژی؛
- ضعف ارتباطات شیفتی؛
- ناکافی بودن نظارت پیمانکار؛
- چیدمان نامناسب محل کار؛
- خطاهای مرتبط با لیفتینگ.
این تحلیل به مدیران کمک میکند به جای خواندن تکتک گزارشها، تصویر کلی از موضوعات پرتکرار و در حال رشد داشته باشند.
9.9.4. تحلیل احساسات و فرهنگ ایمنی
در برخی موارد، تحلیل احساسات میتواند برای بررسی نگرشها، نگرانیها و فضای روانی کارکنان استفاده شود. البته کاربرد آن در HSE باید با احتیاط فراوان همراه باشد. هدف از تحلیل احساسات نباید کنترل یا نظارت فردی باشد، بلکه باید فهم بهتر جو سازمانی و فرهنگ ایمنی باشد.
برای مثال، اگر در گزارشها یا نظرسنجیهای متنی، واژههایی مانند «فشار»، «عجله»، «ترس»، «بیتوجهی»، «گزارش نکردم» یا «فایده ندارد» زیاد دیده شود، ممکن است نشانه مشکلات عمیقتر در فرهنگ ایمنی باشد.
.
9.10. دادهکاوی و تحلیل پیشرفته در سه حوزه HSE
9.10.1. کاربرد در ایمنی
در حوزه ایمنی، دادهکاوی میتواند در چند محور استفاده شود:
تحلیل حوادث و شبهحوادث: کشف الگوهای تکرارشونده، شناسایی ترکیب عوامل خطر، اولویتبندی اقدامات اصلاحی و بررسی اثربخشی مداخلات.
پایش رفتار ایمنی: تحلیل دادههای مشاهده رفتار، شناسایی واحدها یا فعالیتهایی که رفتارهای پرخطر بیشتری دارند و تشخیص روندهای نگرانکننده.
ایمنی فرایند: تحلیل دادههای آلارم، توقف اضطراری، انحرافات عملیاتی و نشانههای اولیه خرابی سیستمهای کنترلی.
مدیریت پیمانکاران: شناسایی الگوهای ریسک مرتبط با نوع پیمانکار، مدت حضور، نوع فعالیت، سطح آموزش و سابقه عملکرد.
پیشگیری از حوادث بزرگ: ترکیب دادههای نگهداشت، فرایند، بازرسی، شبهحادثه و تغییرات عملیاتی برای تشخیص سیگنالهای ضعیف.
9.10.2. کاربرد در بهداشت حرفهای
در بهداشت حرفهای، دادهکاوی میتواند به حرکت از پایش مقطعی به مدیریت هوشمند مواجهه کمک کند.
کاربردهای مهم عبارتاند از:
- شناسایی گروههای مواجهه مشابه؛
- پیشبینی مواجهه با عوامل زیانآور؛
- تحلیل روند نتایج معاینات دورهای؛
- شناسایی الگوهای اختلالات اسکلتیعضلانی؛
- ارتباط میان شرایط کاری و پیامدهای سلامت؛
- اولویتبندی اقدامات کنترلی در محیط کار.
البته دادههای سلامت کارکنان حساساند و استفاده از آنها باید با رعایت محرمانگی، رضایت آگاهانه، حداقلگرایی داده و هدف پیشگیرانه انجام شود.
9.10.3. کاربرد در محیطزیست
در حوزه محیطزیست، دادهکاوی میتواند نقش بسیار مهمی در عبور از پایش صرف به سوی فهم الگوهای انتشار، مصرف و عدمانطباق ایفا کند. در بسیاری از سازمانها، دادههای محیطزیستی بهصورت دورهای جمعآوری میشوند، اما ظرفیت تحلیلی آنها بهطور کامل مورد استفاده قرار نمیگیرد. غلظت آلایندهها، کیفیت پساب، مصرف آب، مصرف انرژی، تولید پسماند، انتشار گازهای گلخانهای، دادههای هواشناسی، دادههای فرایندی و سوابق نگهداشت تجهیزات کنترل آلودگی، در صورت تحلیل یکپارچه میتوانند تصویری بسیار غنیتر از عملکرد محیطزیستی سازمان ارائه دهند.
یکی از مهمترین کاربردهای دادهکاوی در این حوزه، شناسایی الگوهای پنهان در نوسانات آلایندهها است. بهعنوان مثال، ممکن است بررسی ساده دادهها فقط نشان دهد که غلظت یک آلاینده در برخی روزها افزایش یافته است. اما تحلیل دادهکاوانه میتواند آشکار کند که این افزایش عمدتاً زمانی رخ میدهد که چند شرط همزمان برقرار میشوند: تغییر نوع خوراک، افت راندمان تجهیز کنترل، افزایش بار تولید، دمای خاص محیط و تأخیر در تعمیرات. چنین تحلیلی به سازمان اجازه میدهد بهجای واکنش پس از تخلف محیطزیستی، از قبل شرایط پرریسک را شناسایی و مدیریت کند.
.
کاربرد دیگر، تحلیل مصرف منابع است. سازمانها معمولاً دادههای آب، انرژی، بخار، سوخت و مواد مصرفی را ثبت میکنند، اما تحلیل این دادهها در بسیاری موارد در سطح گزارشهای ماهانه باقی میماند. دادهکاوی میتواند الگوهای غیرعادی مصرف، نقاط اتلاف، تفاوتهای غیرموجه میان واحدها، یا ارتباط میان رفتار عملیاتی و شدت مصرف منابع را آشکار کند. برای مثال، ممکن است مشخص شود که در برخی شیفتها یا در برخی الگوهای بهرهبرداری، مصرف انرژی بدون افزایش متناسب در تولید بالا میرود. این یافته میتواند به مداخله فنی و مدیریتی بینجامد.
همچنین دادهکاوی در پایش انطباق زیستمحیطی نیز اهمیت دارد. اگر دادههای بازرسی، نتایج نمونهبرداری، وضعیت مجوزها، سوابق عدمانطباق و دادههای فرایندی در کنار هم قرار گیرند، میتوان الگوهایی را شناسایی کرد که پیشدرآمد تخلف یا ضعف در کنترلاند. این رویکرد بهویژه برای صنایعی که با الزامات سختگیرانه قانونی یا نظارت شدید بیرونی روبهرو هستند، ارزش عملی بسیار بالایی دارد.
..
9.11. چالشهای روششناختی در دادهکاوی HSE
هرچند دادهکاوی امکانات چشمگیری برای تحلیل HSE فراهم میکند، اما استفاده نادرست از آن میتواند به نتایج گمراهکننده، تصمیمهای ضعیف و حتی مخاطرات جدید منجر شود. از اینرو، فهم محدودیتها و چالشهای روششناختی، بخشی جداییناپذیر از سواد تحلیلی در این حوزه است.
9.11.1. مسئله کیفیت داده
اساسیترین چالش در دادهکاوی HSE، کیفیت داده است. الگوریتمها هرقدر پیشرفته باشند، اگر دادههای ورودی ناقص، ناسازگار، متناقض یا سوگیرانه باشند، خروجی نیز قابل اعتماد نخواهد بود. این همان اصل شناختهشده «زباله در ورودی، زباله در خروجی» است.
در HSE، کیفیت پایین داده میتواند اشکال گوناگونی داشته باشد:
- ثبت نشدن کامل شبهحادثهها؛
- گزارش گزینشی برخی انواع رخداد؛
- تفاوت در تعریف مفاهیم میان واحدها؛
- کدگذاری نامنسجم علل و پیامدها؛
- خطاهای ورود داده؛
- دادههای متنی مبهم یا کلی؛
- نبود زمانسنجی دقیق؛
- ثبت نشدن شدت بالقوه رخدادها؛
- نبود ارتباط میان رخداد و شرایط عملیاتی همزمان.
برای مثال، اگر یک واحد صنعتی فرهنگ گزارشدهی فعالی داشته باشد و واحد دیگر رخدادها را کمتر گزارش کند، تحلیل خام دادهها ممکن است به اشتباه واحد اول را پرخطرتر نشان دهد. در واقع آنچه مشاهده میشود، شاید نه خطر بیشتر، بلکه شفافیت بیشتر باشد. از اینرو، تحلیلگر باید همواره میان «داده ثبتشده» و «واقعیت زیرین» تمایز قائل شود.
9.11.2. نامتوازن بودن دادهها
بسیاری از مسائل HSE با دادههای نامتوازن روبهرو هستند. رخدادهای شدید، انفجارها، مواجهههای بحرانی یا بیماریهای نادر خوشبختانه فراوانی کمی دارند. اما همین کمیابی، کار مدلسازی را دشوار میکند. الگوریتمها معمولاً تمایل دارند طبقههای پرتعداد را بهتر یاد بگیرند و در شناسایی موارد نادر ضعیف باشند.
برای نمونه، اگر از ده هزار رکورد فقط پنجاه مورد مربوط به حادثه شدید باشد، مدلی که تقریباً همه موارد را «غیرشدید» طبقهبندی کند، ممکن است از نظر عددی دقت بالایی داشته باشد، اما از نظر عملی هیچ ارزشی نداشته باشد. در چنین شرایطی باید از راهکارهایی مانند بازنمونهگیری، وزندهی، استفاده از معیارهای ارزیابی مناسبتر و ترکیب روشهای آماری و کارشناسی استفاده کرد.
9.11.3. خطر همبستگی کاذب
یکی از مخاطرات جدی در دادهکاوی، یافتن الگوهایی است که از نظر آماری وجود دارند اما از نظر مفهومی یا علّی بیمعنا هستند. در دادههای بزرگ، همیشه میتوان همبستگیهایی یافت که صرفاً حاصل تصادف، متغیرهای پنهان یا ساختار خاص مجموعهدادهاند.
در HSE، تفسیر نادرست چنین الگوهایی میتواند خطرناک باشد. اگر سازمان بر اساس یک همبستگی کاذب اقدام اصلاحی طراحی کند، نهتنها منابع را هدر میدهد، بلکه ممکن است از عوامل واقعی خطر غافل بماند. بنابراین، هر الگوی کشفشده باید با دانش فرایندی، تجربه کارشناسان، منطق علّی و در صورت امکان شواهد تکمیلی اعتبارسنجی شود.
9.11.4. مسئله تفسیرپذیری
همه مدلهای دادهکاوی به یک اندازه قابل توضیح نیستند. برخی الگوریتمها مانند درخت تصمیم، از نظر مفهومی سادهتر و برای مدیران قابل فهمترند. برخی دیگر، مانند مدلهای پیچیدهتر یادگیری ماشین، ممکن است دقت بالاتری داشته باشند اما تفسیر آنها دشوارتر باشد.
در HSE، تفسیرپذیری صرفاً یک مزیت نیست، بلکه در بسیاری موارد یک ضرورت است. وقتی خروجی مدل قرار است مبنای تصمیمهایی درباره سلامت کارکنان، اولویتهای ایمنی، توقف عملیات یا تغییر فرایند قرار گیرد، باید بتوان توضیح داد که مدل بر چه مبنایی به این نتیجه رسیده است. استفاده از مدلهای غیرشفاف بدون سازوکارهای توضیحپذیری میتواند اعتماد سازمانی را کاهش دهد و از منظر اخلاقی نیز مسئلهساز باشد.
9.11.5. پویایی و تغییرپذیری محیط
مدلهای دادهکاوی معمولاً بر اساس دادههای گذشته ساخته میشوند، اما محیط HSE ثابت نیست. تغییر در فناوری، تجهیزات، مواد، نیروی انسانی، پیمانکاران، حجم تولید، سیاستهای گزارشدهی، الزامات قانونی یا فرهنگ سازمانی میتواند باعث شود الگوهای گذشته دیگر معتبر نباشند.
از این رو، مدلهای HSE نباید به عنوان ابزارهای یکبار ساختهشده دیده شوند. آنها نیازمند بازآموزی، بازبینی و پایش مستمرند. مدلی که یک سال پیش عملکرد خوبی داشته، ممکن است امروز به دلیل تغییر شرایط، بخشی از اعتبار خود را از دست داده باشد.
.
9.12. ملاحظات اخلاقی، حریم خصوصی و مشروعیت سازمانی
دادهکاوی در HSE صرفاً یک مسئله فنی نیست؛ بلکه بهطور مستقیم با انسان، اعتماد، عدالت و مشروعیت سازمانی نیز پیوند دارد. هرچه دادهکاوی بیشتر به سمت دادههای رفتاری، سلامت فردی، پایش لحظهای و تحلیل الگوهای شخصی حرکت کند، اهمیت ملاحظات اخلاقی نیز بیشتر میشود.
9.12.1. مرز میان پیشگیری و نظارت
یکی از مسائل مهم این است که دادهکاوی در HSE میتواند بهراحتی از ابزار پیشگیری به ابزار نظارت افراطی تبدیل شود. برای مثال، اگر دادههای پوشیدنی، دادههای مکانی، رفتارهای فردی یا دادههای سلامت بدون چارچوب روشن تحلیل شوند، کارکنان ممکن است احساس کنند که بهجای حفاظت، تحت مراقبت تنبیهی قرار گرفتهاند.
برای پرهیز از این وضعیت، سازمان باید بهروشنی مشخص کند:
- چه دادههایی جمعآوری میشوند؛
- چرا جمعآوری میشوند؛
- چه کسانی به آنها دسترسی دارند؛
- چگونه محافظت میشوند؛
- برای چه نوع تصمیمهایی به کار میروند؛
- و چگونه از سوءاستفاده از آنها جلوگیری میشود.
9.12.2. محرمانگی دادههای سلامت
در حوزه بهداشت حرفهای، حساسیت بیشتر است. دادههای پزشکی و سلامت شغلی از خصوصیترین انواع دادهاند. استفاده از این دادهها برای تحلیل جمعی و پیشگیرانه ممکن است مفید باشد، اما باید با اصولی چون حداقلگرایی داده، ناشناسسازی، کنترل دسترسی، رضایت آگاهانه و تفکیک میان کاربرد بالینی و مدیریتی همراه باشد.
اصل بنیادی این است که دادهکاوی نباید به برچسبزنی، حذف فرصت شغلی، تبعیض یا آسیب به شأن کارکنان منجر شود. در این زمینه، همکاری نزدیک میان HSE، منابع انسانی، واحد حقوقی، فناوری اطلاعات و نمایندگان کارکنان ضروری است.
9.12.3. عدالت اطلاعاتی
عدالت اطلاعاتی به این معناست که نحوه تولید، دسترسی، تفسیر و استفاده از دادهها، منصفانه و غیرتبعیضآمیز باشد. اگر برخی واحدها یا گروهها بهطور نامتناسب زیر ذرهبین تحلیلی قرار گیرند، یا اگر مدلها بر اساس دادههای سوگیرانه آموزش ببینند، نتایج میتوانند ناعادلانه باشند.
برای مثال، اگر دادههای تاریخی بهطور سیستماتیک بیشتر درباره برخی گروههای شغلی ثبت شده باشد، مدل نیز ممکن است همان سوگیری را بازتولید کند. بنابراین، ارزیابی عدالت و سوگیری مدلها باید بخشی از فرایند طراحی و استقرار آنها باشد.
9.12.4. اعتماد کارکنان به عنوان پیششرط موفقیت
هیچ پروژه دادهکاوی در HSE بدون اعتماد کارکنان پایدار نخواهد بود. اگر کارکنان احساس کنند دادهها علیه آنها استفاده میشود، احتمال کاهش گزارشدهی، پنهانکاری، مقاومت و حتی تخریب کیفیت داده افزایش مییابد. در مقابل، اگر روشن باشد که هدف از تحلیل، پیشگیری، یادگیری و بهبود شرایط کار است، کارکنان بیشتر با سامانههای دادهمحور همکاری میکنند.
به همین دلیل، مشروعیت اجتماعی و سازمانی دادهکاوی به اندازه دقت فنی آن اهمیت دارد.
.
9.13. استراتژی پیادهسازی دادهکاوی در سازمانهای HSE
دادهکاوی زمانی موفق میشود که به صورت مرحلهای، مسئلهمحور و در تعامل با واقعیت سازمانی پیادهسازی شود. تلاش برای اجرای ناگهانی پروژههای پیچیده بدون بلوغ دادهای و آمادگی سازمانی، معمولاً به شکست منجر میشود.
9.13.1. شروع از مسئله، نه از فناوری
نخستین اصل آن است که سازمان باید از یک مسئله واقعی شروع کند. مثلاً:
- چرا شبهحادثههای مرتبط با لیفتینگ در حال افزایشاند؟
- کدام ترکیب عوامل با بیشترین احتمال عدمانطباق زیستمحیطی همراه است؟
- چگونه میتوان مواجهه با صدا را در گروههای شغلی بهتر پیشبینی کرد؟
- آیا میتوان الگوهای فرسودگی سازمانی را از گزارشهای متنی استخراج کرد؟
شروع از مسئله واقعی، باعث میشود دادهکاوی به اقدام منتهی شود و از تبدیل شدن به نمایش فناوری جلوگیری گردد.
9.13.2. اجرای پایلوت و یادگیری مرحلهای
پیشنهاد عملی آن است که دادهکاوی ابتدا در قالب پروژههای پایلوت کوچک آغاز شود. این پروژهها باید دامنه محدود، داده قابل دسترس، مسئله روشن و امکان ارزیابی داشته باشند.
برای مثال، تحلیل گزارشهای شبهحادثه یک واحد مشخص در بازه ششماهه، یا بررسی الگوهای مواجهه شغلی در یک گروه شغلی خاص، میتواند نقطه شروع خوبی باشد. موفقیت در چنین پروژههایی به سازمان امکان میدهد دانش، اعتماد و ظرفیت لازم برای پروژههای بزرگتر را بهتدریج ایجاد کند.
9.13.3. تشکیل تیمهای چندتخصصی
دادهکاوی HSE را نمیتوان صرفاً به متخصص داده یا صرفاً به کارشناس HSE سپرد. این حوزه ذاتاً میانرشتهای است. تیم موفق معمولاً شامل ترکیبی از افراد زیر است:
- متخصص HSE با درک عمیق از مسئله؛
- تحلیلگر داده یا دانشمند داده؛
- متخصص فناوری اطلاعات یا پایگاه داده؛
- در صورت نیاز، متخصص فرایند یا نگهداشت؛
- نماینده کاربران نهایی یا مدیر عملیاتی.
این تنوع تخصصی باعث میشود هم مسئله درست تعریف شود، هم داده بهدرستی فهم شود، هم خروجیها قابلیت استفاده پیدا کنند.
9.13.4. ادغام با نظام مدیریت HSE
خروجی دادهکاوی نباید جدا از ساختار مدیریتی سازمان باقی بماند. نتایج باید به فرایندهای رسمی مانند ارزیابی ریسک، برنامهریزی بازرسی، جلسات بازنگری مدیریت، تعیین اقدامات اصلاحی، آموزش، مدیریت تغییر و پایش شاخصها متصل شود.
برای مثال، اگر تحلیل نشان دهد ترکیب خاصی از شرایط با افزایش خطر همراه است، این یافته باید وارد دستورالعملهای عملیاتی، برنامههای کنترلی یا ماتریسهای ارزیابی ریسک شود. در غیر این صورت، دانش تولیدشده اثر واقعی بر عملکرد نخواهد داشت.
9.13.5. آموزش و سواد دادهای
بسیاری از پروژههای دادهمحور نه به دلیل ضعف الگوریتم، بلکه به دلیل نبود سواد دادهای در کاربران شکست میخورند. مدیران و کارشناسان HSE باید بدانند که دادهکاوی چه میتواند بکند و چه نمیتواند بکند. آنها باید با مفاهیمی مانند کیفیت داده، عدمقطعیت، همبستگی، سوگیری، اعتبارسنجی و تفسیر نتایج آشنا باشند.
این آموزش لزوماً به معنای تربیت همه افراد بهعنوان برنامهنویس یا متخصص یادگیری ماشین نیست، بلکه به معنای ایجاد توانایی فهم انتقادی و استفاده مسئولانه از تحلیلهاست.
.
9.14. از تحلیل توصیفی پیشرفته تا یادگیری سازمانی
یکی از مهمترین نکات در کاربرد دادهکاوی در HSE آن است که هدف نهایی نباید صرفاً تولید مدل باشد، بلکه باید ارتقای یادگیری سازمانی باشد. سازمانی که فقط گزارش تولید میکند اما چیزی نمیآموزد، عملاً از ظرفیت دادههای خود استفاده نکرده است.
9.14.1. دادهکاوی به عنوان ابزار یادگیری
دادهکاوی میتواند به سازمان کمک کند تا الگوهای نامرئی را ببیند، فرضیات نادرست را به چالش بکشد، علل سیستمی را بهتر درک کند و از تجربههای پراکنده، دانش منسجم بسازد. این همان جوهره یادگیری سازمانی است.
برای مثال، اگر تحلیل دادهها نشان دهد که بسیاری از رخدادها نه به دلیل نقص فنی مستقیم، بلکه در شرایط تغییر برنامه، فشار زمانی و اختلال در ارتباطات رخ میدهند، سازمان به درک عمیقتری از ریشههای سیستمی ریسک دست مییابد. این فهم میتواند به اصلاحات بنیادیتری منجر شود تا صرفاً تکرار آموزشهای عمومی.
9.14.2. پیوند با رویکردهای نوین ایمنی
رویکردهای نوین ایمنی، بهویژه دیدگاههای سیستممحور، بر این تأکید دارند که ایمنی فقط حاصل حذف خطا نیست، بلکه نتیجه فهم تعاملات پیچیده در سیستم است. دادهکاوی با قابلیت کشف الگوهای چندعاملی، همآیی شرایط و رفتارهای emergent، میتواند مکمل مهمی برای این رویکردها باشد.
از این منظر، دادهکاوی فقط ابزاری برای پیشبینی حادثه نیست، بلکه ابزاری برای دیدن بهتر «چگونگی کارکرد واقعی سیستم» است.
9.14.3. محدودیت یادگیری صرفاً دادهمحور
در عین حال، باید تأکید کرد که یادگیری سازمانی را نمیتوان به داده تقلیل داد. همه واقعیتهای HSE در دادههای ثبتشده ظاهر نمیشوند. تجربههای ضمنی کارکنان، روایتهای میدانی، مشاهده مستقیم، شناخت زمینه عملیاتی و گفتوگوی حرفهای همچنان جایگاه اساسی دارند.
به همین دلیل، دادهکاوی باید در کنار روشهای کیفی، تحلیل کارشناسی و گفتوگوهای بینرشتهای به کار رود. بهترین سازمانها آنهایی نیستند که فقط داده بیشتری دارند، بلکه آنهایی هستند که بهتر میتوانند میان داده، تجربه و قضاوت حرفهای پیوند برقرار کنند.
.
9.15. آینده دادهکاوی در HSE
آینده دادهکاوی در HSE با چند روند مهم گره خورده است. نخست، افزایش دادههای بلادرنگ از طریق حسگرها، اینترنت اشیا صنعتی و تجهیزات پوشیدنی است. این تحول باعث میشود دادهکاوی از تحلیل پسینی به سمت پایش و هشدار نزدیک به زمان واقعی حرکت کند.
دوم، ترکیب دادهکاوی با هوش مصنوعی و یادگیری عمیق است. این همگرایی میتواند در تحلیل تصویر، ویدئو، متن، صدا و دادههای پیچیده فرایندی ظرفیتهای تازهای ایجاد کند؛ هرچند نیاز به اعتبارسنجی و شفافیت در این مدلها بسیار بالاست.
سوم، حرکت به سمت دوقلوهای دیجیتال و مدلهای پیشبینیگر پیچیدهتر است. در چنین سامانههایی، دادههای HSE میتوانند با دادههای عملیات، نگهداشت و پایداری در یک محیط شبیهسازیشده ترکیب شوند تا رفتار سیستم و سناریوهای ریسک بهتر فهم شوند.
چهارم، ادغام بیشتر HSE با حوزههایی مانند قابلیت اطمینان، نگهداشت، بهرهوری، پایداری و تابآوری سازمانی است. در این آینده، دادهکاوی دیگر ابزاری صرفاً متعلق به HSE نخواهد بود، بلکه بخشی از معماری هوشمندی کل سازمان خواهد شد.
با این حال، هرچه فناوری پیچیدهتر میشود، نیاز به حکمرانی بهتر، اخلاق قویتر، شایستگی تحلیلی بالاتر و قضاوت حرفهای عمیقتر نیز بیشتر میشود.
.
9.16. جمعبندی
دادهکاوی در HSE را باید یکی از نشانههای گذار از مدیریت مبتنی بر ثبت و واکنش، به مدیریت مبتنی بر کشف، پیشگیری و یادگیری دانست. این رویکرد به سازمانها امکان میدهد از دل دادههای پراکنده و گاه خاموش، الگوهای معناداری استخراج کنند که میتوانند به فهم بهتر ریسک، طراحی مداخلات هدفمندتر و ارتقای اثربخشی نظام HSE منجر شوند.
در این فصل دیدیم که دادهکاوی صرفاً مجموعهای از الگوریتمها نیست، بلکه یک رویکرد مسئلهمحور، میانرشتهای و نیازمند بلوغ سازمانی است. دستهبندی، رگرسیون، قوانین وابستگی، خوشهبندی و دادهکاوی متنی، هر یک میتوانند در ایمنی، بهداشت حرفهای و محیطزیست کاربردهای مهمی داشته باشند؛ اما ارزش آنها زمانی آشکار میشود که بر داده باکیفیت، طراحی روشمند، تفسیر حرفهای و استقرار مسئولانه تکیه کنند.
همچنین روشن شد که دادهکاوی، با وجود ظرفیت بالا، محدودیتها و مخاطرات خود را نیز دارد: کیفیت داده، نامتوازن بودن رخدادها، همبستگیهای کاذب، دشواری تفسیر، مسائل اخلاقی، حریم خصوصی و خطر استفاده ابزاری یا تنبیهی از دادهها. از این رو، دادهکاوی در HSE تنها زمانی مشروع و مفید است که در خدمت یادگیری، پیشگیری، عدالت و بهبود واقعی شرایط کار قرار گیرد.
در نهایت، شاید مهمترین نکته این باشد که دادهکاوی قرار نیست جایگزین قضاوت حرفهای شود. ارزش واقعی آن در این است که توان دیدن ما را گسترش دهد؛ یعنی الگوهایی را نشان دهد که پیشتر پنهان بودند، پرسشهایی را مطرح کند که پیشتر به آنها نیندیشیده بودیم، و سازمان را یک گام به سوی فهم عمیقتر و تصمیمگیری هوشمندانهتر سوق دهد. در جهان پیچیده امروز، این توانایی نه یک تجمل تحلیلی، بلکه بخشی از بلوغ مدیریتی در HSE است.
.
منابع
Agrawal, R., & Srikant, R. (1994). Fast algorithms for mining association rules. Proceedings of the 20th International Conference on Very Large Data Bases, 487–499.
Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5–32
Chandola, V., Banerjee, A., & Kumar, V. (2009). Anomaly detection: A survey. ACM Computing Surveys, 41(3), 1–58
Fayyad, U., Piatetsky-Shapiro, G., & Smyth, P. (1996). From data mining to knowledge discovery in databases. AI Magazine, 17(3), 37–54
Floridi, L., & Taddeo, M. (2016). What is data ethics? Philosophical Transactions of the Royal Society A, 374(2083), 20160360
Han, J., Kamber, M., & Pei, J. (2012). Data Mining: Concepts and Techniques (3rd ed.). Morgan Kaufmann
Hand, D. J., Mannila, H., & Smyth, P. (2001). Principles of Data Mining. MIT Press
Hollnagel, E. (2014). Safety-I and Safety-II: The Past and Future of Safety Management. Ashgate
Jain, A. K. (2010). Data clustering: 50 years beyond K-means. Pattern Recognition Letters, 31(8), 651–666
Kotsiantis, S. B., Zaharakis, I., & Pintelas, P. (2007). Supervised machine learning: A review of classification techniques. Informatica, 31, 249–268
Pearl, J., & Mackenzie, D. (2018). The Book of Why. Basic Books
Provost, F., & Fawcett, T. (2013). Data Science for Business. O’Reilly Media
Wickham, H. (2014). Tidy data. Journal of Statistical Software, 59(10), 1–23
Wirth, R., & Hipp, J. (2000). CRISP-DM: Toward a standard process model for data mining. Proceedings of the 4th International Conference on the Practical Applications of Knowledge Discovery and Data Mining, 29–39


