مقدمه
ضرورت، مادر اختراع است.
– افلاطون
ما در جهانی زندگی میکنیم که حجم عظیمی از دادهها به طور مداوم و سریع تولید میشوند.
“ما در عصر اطلاعات زندگی میکنیم” یک ضربالمثل رایج است؛ با این حال، ما در واقع در عصر دادهها زندگی میکنیم. ترابایتها یا پتابایتها داده هر روز از کسبوکار، آژانسهای خبری، جامعه، علم، مهندسی، پزشکی و تقریباً هر جنبه دیگری از زندگی روزمره وارد شبکههای کامپیوتری ما، وب جهانگستر (WWW) و انواع مختلف دستگاهها میشوند. این رشد انفجاری حجم دادههای موجود، نتیجه کامپیوتری شدن جامعه ما و توسعه سریع ابزارهای قدرتمند محاسبات، حسگرها و جمعآوری، ذخیرهسازی و انتشار دادهها است.
کسبوکارها در سراسر جهان مجموعه دادههای عظیمی از جمله معاملات فروش، سوابق معاملات سهام، توضیحات محصول، تبلیغات فروش، پروفایلها و عملکرد شرکتها و بازخورد مشتری را تولید میکنند. شیوههای علمی و مهندسی، از سنجش از دور گرفته تا اندازهگیری فرآیند، آزمایشهای علمی، عملکرد سیستم، مشاهدات مهندسی و نظارت بر محیط، به طور مداوم مقادیر زیادی پتابایت داده تولید میکنند. تحقیقات زیستپزشکی و صنعت سلامت، حجم عظیمی از دادهها را از دستگاههای توالی ژن، آزمایشها و گزارشهای تحقیقاتی زیستپزشکی، سوابق پزشکی، نظارت بر بیمار و تصویربرداری پزشکی تولید میکنند. میلیاردها جستجوی وب که توسط موتورهای جستجو پشتیبانی میشوند، روزانه دهها پتابایت داده را پردازش میکنند. ابزارهای رسانههای اجتماعی به طور فزایندهای محبوب شدهاند و تعداد زیادی متن، تصویر و ویدیو تولید میکنند و انواع مختلفی از جوامع وب و شبکههای اجتماعی را ایجاد میکنند. فهرست منابعی که حجم عظیمی از دادهها را تولید میکنند، بیپایان است.
این حجم عظیم دادهها که به طور انفجاری در حال رشد، به طور گسترده در دسترس و عظیم است، زمان ما را واقعاً عصر داده میکند. ابزارهای قدرتمند و همهکاره برای کشف خودکار اطلاعات ارزشمند از حجم عظیمی از دادهها و تبدیل چنین دادههایی به دانش سازمانیافته به شدت مورد نیاز هستند. این ضرورت منجر به تولد دادهکاوی شده است.
اساساً، دادهکاوی فرآیند کشف الگوها، مدلها و انواع دیگر دانش جالب در مجموعه دادههای بزرگ است. اصطلاح دادهکاوی، به عنوان دیدگاهی واضح از جستجوی قطعات طلا از دادهها، در دهه 1990 ظاهر شد. با این حال، برای اشاره به استخراج طلا از سنگ یا شن، به جای استخراج سنگ یا شن، میگوییم استخراج طلا. به همین ترتیب، دادهکاوی باید با نام مناسبتری «دانشکاوی از دادهها» نامگذاری میشد که متأسفانه تا حدودی طولانی است. با این حال، اصطلاح کوتاهتر «دانشکاوی» ممکن است تأکید بر استخراج از مقادیر زیادی داده را منعکس نکند. با این وجود، استخراج اصطلاحی واضح است که فرآیندی را توصیف میکند که مجموعهای کوچک از قطعات ارزشمند را از مقدار زیادی مواد خام پیدا میکند.
بنابراین، چنین نام نادرستی که هم «داده» و هم «استخراج» را در بر میگیرد، به انتخابی رایج تبدیل شد. علاوه بر این، بسیاری از اصطلاحات دیگر معنای مشابهی با دادهکاوی دارند – به عنوان مثال، دانشکاوی از دادهها، KDD (یعنی کشف دانش از دادهها)، کشف الگو، استخراج دانش، باستانشناسی دادهها، تجزیه و تحلیل دادهها و برداشت اطلاعات.
دادهکاوی یک حوزه جوان، پویا و امیدوارکننده است. این حوزه در سفر ما از عصر دادهها به سوی عصر اطلاعات آینده، گامهای بزرگی برداشته و همچنان به این کار ادامه خواهد داد.
مثال ۱.۱. دادهکاوی مجموعه بزرگی از دادهها را به دانش تبدیل میکند. یک موتور جستجو (مثلاً گوگل) هر روز میلیاردها پرسوجو دریافت میکند. یک موتور جستجو چه دانش جدید و مفیدی میتواند از چنین مجموعه عظیمی از پرسوجوهای جمعآوریشده از کاربران در طول زمان بیاموزد؟ جالب اینجاست که برخی از الگوهای موجود در پرسوجوهای جستجوی کاربر میتوانند دانش ارزشمندی را فاش کنند که نمیتوان تنها با خواندن اقلام دادهای جداگانه به دست آورد.
به عنوان مثال، Flu Trends گوگل از عبارات جستجوی خاص به عنوان شاخصهای فعالیت آنفولانزا استفاده میکند. این ابزار رابطه نزدیکی بین تعداد افرادی که اطلاعات مربوط به آنفولانزا را جستجو میکنند و تعداد افرادی که واقعاً علائم آنفولانزا دارند، پیدا کرد. وقتی همه پرسوجوهای جستجو مربوط به آنفولانزا جمعآوری میشوند، یک الگو پدیدار میشود. Flu Trends با استفاده از دادههای جستجوی جمعآوریشده گوگل، میتواند فعالیت آنفولانزا را تا دو هفته سریعتر از آنچه سیستمهای سنتی میتوانند تخمین بزنند، تخمین بزند. این مثال نشان میدهد که چگونه دادهکاوی میتواند مجموعه بزرگی از دادهها را به دانشی تبدیل کند که میتواند به رفع یک چالش جهانی فعلی کمک کند.
دادهکاوی: گامی اساسی در کشف دانش
بسیاری از افراد دادهکاوی را مترادف با یک اصطلاح رایج دیگر، کشف دانش از دادهها یا KDD، میدانند، در حالی که برخی دیگر دادهکاوی را صرفاً یک گام اساسی در فرآیند کلی کشف دانش میدانند. فرآیند کلی کشف دانش در شکل 1.1 به صورت یک توالی تکراری از مراحل زیر نشان داده شده است:
1. آمادهسازی دادهها
الف. پاکسازی دادهها (برای حذف نویز و دادههای ناسازگار)
ب. یکپارچهسازی دادهها (که در آن چندین منبع داده ممکن است با هم ترکیب شوند)
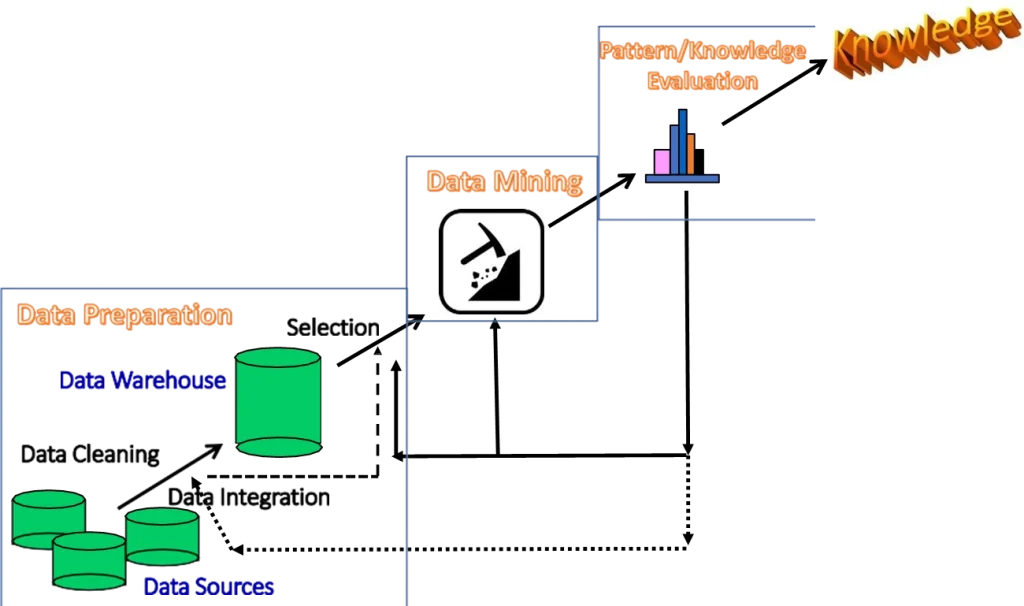
دادهکاوی: یک گام اساسی در فرآیند کشف دانش.
ج. تبدیل دادهها (که در آن دادهها با انجام عملیات خلاصهسازی یا تجمیع، به اشکال مناسب برای کاوش تبدیل و تجمیع میشوند)
د. انتخاب دادهها (که در آن دادههای مرتبط با وظیفه تحلیل از پایگاه داده بازیابی میشوند)
2. دادهکاوی
یک فرآیند اساسی که در آن از روشهای هوشمند برای استخراج الگوها یا ساخت مدلها استفاده میشود.
3. ارزیابی الگو/مدل
برای شناسایی الگوها یا مدلهای واقعاً جالب که نشاندهنده دانش بر اساس معیارهای جالب بودن هستند.
4. ارائه دانش
که در آن از تکنیکهای تجسم و نمایش دانش برای ارائه دانش کاوششده به کاربران استفاده میشود.
مراحل ۱(الف) تا ۱(د) اشکال مختلفی از پیشپردازش دادهها هستند که در آن دادهها برای کاوش آماده میشوند. مرحله دادهکاوی ممکن است با یک کاربر یا یک پایگاه دانش تعامل داشته باشد. الگوهای جالب به کاربر ارائه میشوند و ممکن است به عنوان دانش جدید در پایگاه دانش ذخیره شوند. دیدگاه قبلی، دادهکاوی را به عنوان یک گام در فرآیند کشف دانش نشان میدهد، هرچند گامی ضروری است زیرا الگوها یا مدلهای پنهان را برای ارزیابی آشکار میکند. با این حال، در صنعت، در رسانهها و در محیط تحقیقاتی، اصطلاح دادهکاوی اغلب برای اشاره به کل فرآیند کشف دانش استفاده میشود (شاید به این دلیل که این اصطلاح کوتاهتر از کشف دانش از دادهها است).
بنابراین، ما یک دیدگاه گسترده از عملکرد دادهکاوی را اتخاذ میکنیم: دادهکاوی فرآیند کشف الگوها و دانش جالب از مقادیر زیادی داده است. منابع داده میتوانند شامل پایگاههای داده، انبارهای داده، وب، سایر مخازن اطلاعات یا دادههایی باشند که به صورت پویا به سیستم جریان مییابند.
تنوع انواع دادهها برای دادهکاوی
به عنوان یک فناوری عمومی، دادهکاوی میتواند برای هر نوع دادهای اعمال شود، مادامی که دادهها برای یک کاربرد هدف معنادار باشند. با این حال، انواع مختلف دادهها ممکن است به روشهای دادهکاوی نسبتاً متفاوتی، از ساده تا نسبتاً پیچیده، نیاز داشته باشند که دادهکاوی را به حوزهای غنی و متنوع تبدیل میکند.
دادههای ساختاریافته در مقابل بدون ساختار
بر اساس اینکه آیا دادهها ساختارهای واضحی دارند، میتوانیم دادهها را به عنوان دادههای ساختاریافته در مقابل بدون ساختار طبقهبندی کنیم.
دادههای ذخیره شده در پایگاههای داده رابطهای، مکعبهای داده، ماتریسهای داده و بسیاری از انبارهای داده دارای ساختارهای یکنواخت، رکورد مانند یا جدول مانند هستند که توسط فرهنگ دادههای آنها تعریف میشوند و دارای مجموعهای ثابت از ویژگیها (یا فیلدها، ستونها) هستند که هر کدام مجموعهای ثابت از محدودههای مقادیر و معنای معنایی دارند. این مجموعه دادهها نمونههای معمولی از دادههای بسیار ساختاریافته هستند. در بسیاری از کاربردهای واقعی، چنین الزام ساختاری سختگیرانهای میتواند به روشهای مختلفی تعدیل شود تا ماهیت نیمهساختاریافته دادهها را در خود جای دهد، مانند اینکه به یک شیء داده اجازه داده شود حاوی یک مقدار مشخص، مجموعه کوچکی از مقادیر ناهمگن تایپ شده یا ساختارهای تو در تو باشد یا اینکه ساختار اشیاء یا زیراشیاء به صورت انعطافپذیر و پویا تعریف شود (مثلاً ساختارهای XML).
مجموعه دادههای زیادی وجود دارند که ممکن است به اندازه جداول رابطهای یا ماتریسهای داده ساختاریافته نباشند. با این حال، آنها ساختارهای خاصی با معنای معنایی کاملاً تعریف شده دارند. به عنوان مثال، یک مجموعه داده تراکنشی ممکن است شامل مجموعه بزرگی از تراکنشها باشد که هر کدام شامل مجموعهای از اقلام هستند. یک مجموعه داده توالی ممکن است شامل مجموعه بزرگی از توالیها باشد که هر کدام شامل مجموعهای مرتب از عناصر هستند که میتوانند به نوبه خود شامل مجموعهای از اقلام باشند. بسیاری از مجموعه دادههای کاربردی، مانند دادههای تراکنش خرید، دادههای سری زمانی، دادههای ژن یا پروتئین یا دادههای وبلاگ، به این دسته تعلق دارند.
نوع پیچیدهتری از مجموعه دادههای نیمهساختاریافته، دادههای گراف یا شبکه است که در آن مجموعهای از گرهها توسط مجموعهای از لبهها (که پیوند نیز نامیده میشوند) به هم متصل میشوند. و هر گره/لینک ممکن است توصیف معنایی یا زیرساختارهای خاص خود را داشته باشد.
هر یک از این دستههای مجموعه دادههای ساختاریافته و نیمهساختاریافته ممکن است انواع خاصی از الگوها یا دانش را برای کاوش داشته باشند و بسیاری از روشهای دادهکاوی اختصاصی، مانند کاوش الگوهای ترتیبی، کاوش الگوهای گراف و روشهای دادهکاوی شبکه اطلاعات، برای تجزیه و تحلیل چنین مجموعه دادههایی توسعه داده شدهاند.
فراتر از چنین دادههای ساختاریافته یا نیمهساختاریافته، مقادیر زیادی از دادههای بدون ساختار، مانند دادههای متنی و دادههای چندرسانهای (مانند صدا، تصویر، ویدئو) نیز وجود دارد. اگرچه برخی مطالعات آنها را به عنوان جریانهای بایت یک بعدی یا چند بعدی در نظر میگیرند، اما معانی جالب زیادی را در خود جای دادهاند. روشهای خاص دامنه برای تجزیه و تحلیل چنین دادههایی در زمینههای درک زبان طبیعی، کاوش متن، بینایی کامپیوتر و تشخیص الگو توسعه داده شدهاند. علاوه بر این، پیشرفتهای اخیر در یادگیری عمیق، پیشرفت چشمگیری در پردازش دادههای متن، تصویر و ویدئو ایجاد کرده است. با این وجود، کاوش ساختارهای پنهان از دادههای بدون ساختار میتواند به درک و استفاده خوب از چنین دادههایی کمک زیادی کند
دادههای دنیای واقعی اغلب میتوانند ترکیبی از دادههای ساختاریافته، دادههای نیمهساختاریافته و دادههای بدون ساختار باشند. برای مثال، یک وبسایت خرید آنلاین ممکن است اطلاعات مربوط به مجموعه بزرگی از محصولات را در خود جای دهد که اساساً میتوانند دادههای ساختاریافته ذخیرهشده در یک پایگاه داده رابطهای باشند و مجموعهای ثابت از فیلدها در مورد نام محصول، قیمت، مشخصات و غیره را در خود جای دادهاند. با این حال، برخی از فیلدها اساساً میتوانند دادههای متنی، تصویری و ویدیویی باشند، مانند معرفی محصول، نظرات متخصصان یا کاربران، تصاویر محصول و ویدیوهای تبلیغاتی. روشهای دادهکاوی اغلب برای کاوش نوع خاصی از دادهها توسعه داده میشوند و نتایج آنها میتواند برای دستیابی به هدف کلی، یکپارچه و هماهنگ شود.
دادههای مرتبط با کاربردهای مختلف
کاربردهای مختلف ممکن است مجموعه دادههای بسیار متفاوتی تولید کنند یا نیاز به مدیریت آنها داشته باشند و به روشهای تحلیل دادههای نسبتاً متفاوتی نیاز دارند. بنابراین، هنگام دستهبندی مجموعه دادهها برای دادهکاوی، باید کاربردهای خاص را در نظر بگیریم.
به عنوان مثال، دادههای توالی را در نظر بگیرید. توالیهای بیولوژیکی مانند توالیهای DNA یا پروتئین ممکن است معنای معنایی بسیار متفاوتی از توالیهای تراکنشهای خرید یا جریانهای کلیک وب داشته باشند که مستلزم روشهای کاوش توالی نسبتاً متفاوتی است. نوع خاصی از دادههای توالی، دادههای سری زمانی است که در آن یک سری زمانی ممکن است شامل مجموعهای مرتب از مقادیر عددی با فاصله زمانی برابر باشد، که با توالیهای تراکنشهای خرید که ممکن است فواصل زمانی ثابتی نداشته باشند (یک مشتری ممکن است در هر زمانی که دوست دارد خرید کند) نیز متفاوت است.
دادهها در برخی از کاربردها میتوانند با اطلاعات مکانی، اطلاعات زمانی یا هر دو مرتبط باشند و به ترتیب دادههای مکانی، زمانی و مکانی-زمانی را تشکیل دهند. روشهای دادهکاوی ویژه، مانند دادهکاوی مکانی، دادهکاوی زمانی، دادهکاوی مکانی-زمانی یا کاوش الگوی مسیر، باید برای کاوش چنین مجموعه دادههایی نیز توسعه داده شوند. برای دادههای گراف و شبکه، برنامههای مختلف ممکن است به روشهای دادهکاوی نسبتاً متفاوتی نیز نیاز داشته باشند. به عنوان مثال، شبکههای اجتماعی (مانند دادههای فیسبوک یا لینکدین)، شبکههای ارتباطات کامپیوتری، شبکههای بیولوژیکی و شبکههای اطلاعاتی (مانند نویسندگانی که با کلمات کلیدی لینک میدهند) ممکن است معانی نسبتاً متفاوتی داشته باشند و به روشهای دادهکاوی متفاوتی نیاز داشته باشند.
حتی برای مجموعه دادههای یکسان، یافتن انواع مختلف الگوها یا دانش ممکن است به روشهای دادهکاوی متفاوتی نیاز داشته باشد. به عنوان مثال، برای مجموعه برنامههای نرمافزاری (منبع)، یافتن ماژولهای زیربرنامه سرقت ادبی یا یافتن اشکالات کپی و چسباندن ممکن است به تکنیکهای دادهکاوی نسبتاً متفاوتی نیاز داشته باشد. انواع دادههای غنی و الزامات کاربردی متنوع، روشهای دادهکاوی بسیار متنوعی را میطلبد.
بنابراین، دادهکاوی یک حوزه تحقیقاتی غنی و جذاب است که روشهای جدید زیادی در انتظار مطالعه و توسعه هستند.
دادههای ذخیره شده در مقابل دادههای جریانی
معمولاً، دادهکاوی مجموعه دادههای محدود و ذخیره شده، مانند دادههای ذخیره شده در انواع مختلف مخازن داده بزرگ را مدیریت میکند. با این حال، در برخی از برنامهها مانند نظارت تصویری یا سنجش از دور، دادهها ممکن است به صورت پویا و مداوم، به عنوان جریانهای داده نامحدود، جریان داشته باشند. کاوش دادههای جریانی به روشهای نسبتاً متفاوتی نسبت به دادههای ذخیرهشده نیاز دارد، که ممکن است موضوع جالب دیگری در مطالعه ما باشد.


