استخراج انواع مختلف دانش
انواع مختلفی از الگوها و دانش را میتوان از طریق دادهکاوی کشف کرد. به طور کلی، وظایف دادهکاوی را میتوان در دو دسته قرار داد: دادهکاوی توصیفی و دادهکاوی پیشبینیکننده. دادهکاوی توصیفی ویژگیهای مجموعه دادههای مورد نظر را مشخص میکند، در حالی که دادهکاوی پیشبینیکننده، استقراء را روی مجموعه دادهها انجام میدهد تا پیشبینیهایی انجام دهد.
در این بخش، وظایف مختلف دادهکاوی را معرفی میکنیم. این موارد شامل خلاصهسازی دادههای چندبعدی (بخش ۱.۴.۱)؛ استخراج الگوهای مکرر، ارتباطات و همبستگیها (بخش ۱.۴.۲)؛ طبقهبندی و رگرسیون (بخش ۱.۴.۳)؛ تحلیل خوشهای (بخش ۱.۴.۴)؛ و تحلیل دادههای پرت (بخش ۱.۴.۶) میشود. عملکردهای مختلف دادهکاوی انواع مختلفی از نتایج را ایجاد میکنند که اغلب الگوها، مدلها یا دانش نامیده میشوند. در بخش ۱.۴.۷، جذابیت یک الگو یا یک مدل را نیز معرفی خواهیم کرد. در بسیاری از موارد، فقط الگوها یا مدلهای جالب به عنوان دانش در نظر گرفته میشوند.
خلاصهسازی دادههای چندبعدی
اغلب برای کاربر خستهکننده است که جزئیات یک مجموعه بزرگ از دادهها را بررسی کند. بنابراین، مطلوب است که مجموعهای از دادههای مورد نظر را به صورت خودکار خلاصه کرده و آن را با مجموعههای متضاد در سطوح بالا مقایسه کنیم. چنین توصیف خلاصهای از یک مجموعه داده مورد نظر، خلاصهسازی دادهها نامیده میشود. خلاصهسازی دادهها اغلب میتواند در یک فضای چندبعدی انجام شود. اگر فضای چندبعدی به خوبی تعریف شده و به طور مکرر استفاده شود، مانند دسته محصول، تولیدکننده، مکان یا زمان، میتوان حجم عظیمی از دادهها را به شکل مکعبهای داده جمعآوری کرد تا کاربر بتواند با کلیک ماوس، فضای خلاصهسازی را به پایین یا بالا بکشد.
خروجی چنین خلاصهسازی چندبعدی را میتوان به اشکال مختلفی مانند نمودارهای دایرهای، نمودارهای میلهای، منحنیها، مکعبهای داده چندبعدی و جداول چندبعدی، از جمله جدولهای متقاطع، ارائه داد. برای دادههای ساختاریافته، روشهای تجمیع چندبعدی برای تسهیل چنین پیشمحاسباتی یا محاسبه آنلاین تجمیعهای چندبعدی با استفاده از فناوری مکعب داده توسعه داده شدهاند که در فصل ۳ مورد بحث قرار خواهند گرفت. برای دادههای بدون ساختار، مانند متن، این کار چالشبرانگیز میشود. ما در فصل آخر خود بحث مختصری در مورد چنین مرزهای تحقیقاتی ارائه خواهیم داد.
کاوش الگوها، وابستگیها و همبستگیهای مکرر
الگوهای مکرر، همانطور که از نامشان پیداست، الگوهایی هستند که به طور مکرر در دادهها رخ میدهند. انواع مختلفی از الگوهای مکرر وجود دارد، از جمله مجموعه اقلام مکرر، زیردنبالههای مکرر (که به عنوان الگوهای متوالی نیز شناخته میشوند) و زیرساختارهای مکرر. یک مجموعه اقلام مکرر معمولاً به مجموعهای از اقلام اشاره دارد که اغلب در یک مجموعه داده تراکنشی با هم ظاهر میشوند – به عنوان مثال، شیر و نان، که اغلب توسط بسیاری از مشتریان در فروشگاههای مواد غذایی با هم خریداری میشوند. یک زیردنباله مکرر، مانند الگویی که مشتریان تمایل دارند ابتدا یک لپتاپ، سپس یک کیف کامپیوتر و سپس سایر لوازم جانبی را خریداری کنند، یک الگوی متوالی (مکرر) است.
یک زیرساختار میتواند به اشکال ساختاری مختلفی (مثلاً گرافها، درختها یا شبکهها) اشاره داشته باشد که ممکن است با مجموعه اقلام یا زیردنبالهها ترکیب شوند. اگر یک زیرساختار به طور مکرر رخ دهد، به آن یک الگوی ساختاریافته (مکرر) گفته میشود. کاوش الگوهای مکرر منجر به کشف ارتباطات و همبستگیهای جالب در دادهها میشود.
مثال ۱.۲. تحلیل ارتباط. فرض کنید یک مدیر فروشگاه اینترنتی میخواهد بداند کدام اقلام اغلب با هم خریداری میشوند (یعنی در یک تراکنش). مثالی از چنین قانونی که از پایگاه داده تراکنشها استخراج شده است، عبارت است از
buys(X, “computer”) ⇒ buys(X, “webcam”) [support = 1%, confidence = 50%],
که ۱٪ از کل تراکنشهای مورد بررسی نشان میدهد که کامپیوتر و وبکم با هم خریداری شدهاند. این قانون انجمنی شامل یک ویژگی یا گزاره واحد (یعنی خریدها) است که تکرار میشود. به قوانین انجمنی که شامل یک گزاره واحد هستند، قوانین انجمنی تکبعدی گفته میشود. با حذف نمادگذاری گزاره، این قانون را میتوان به سادگی به صورت “وبکم کامپیوتر [۱٪، ۵۰٪]” نوشت.
فرض کنید، کاوش در همان پایگاه داده، یک قانون انجمنی دیگر ایجاد میکند:
age(X, “20..29”) ∧ income(X, “40K..49K”) ⇒ buys(X, “laptop”)
[support = 0.5٪، confidence = 60٪].
این قانون نشان میدهد که از بین تمام مشتریان مورد مطالعه، ۰.۵٪ ۲۰ تا ۲۹ سال سن دارند و درآمدی بین ۴۰۰۰۰ تا ۴۹۰۰۰ دلار دارند و یک لپتاپ (کامپیوتر) خریداری کردهاند. ۶۰٪ احتمال وجود دارد که مشتری در این گروه سنی و درآمدی، لپتاپ خریداری کند. توجه داشته باشید که این یک ارتباط شامل بیش از یک ویژگی یا گزاره (مثلاً سن، درآمد و خرید) است. با اتخاذ اصطلاحات مورد استفاده در پایگاههای داده چندبعدی، که در آن به هر ویژگی به عنوان یک بُعد اشاره میشود، میتوان به قانون فوق به عنوان یک قانون ارتباط چندبعدی اشاره کرد.
معمولاً، قوانین ارتباط اگر هم حداقل آستانه پشتیبانی و هم حداقل آستانه اطمینان را برآورده نکنند، به عنوان قوانین بیاهمیت کنار گذاشته میشوند. تجزیه و تحلیل اضافی میتواند برای کشف همبستگیهای آماری جالب بین جفتهای ویژگی-مقدار مرتبط انجام شود.
کاوش مجموعه اقلام مکرر، شکل اساسی کاوش الگوهای مکرر است. کاوش مجموعه اقلام مکرر، ارتباطات و همبستگیها در فصل ۴ مورد بحث قرار خواهد گرفت. کاوش انواع مختلف الگوهای مکرر، و همچنین کاوش الگوهای متوالی و الگوهای ساختاریافته، در فصل ۵ پوشش داده خواهد شد.
طبقهبندی و رگرسیون برای تحلیل پیشبینی
طبقهبندی فرآیند یافتن یک مدل (یا تابع) است که کلاسها یا مفاهیم داده را توصیف و متمایز میکند. این مدل بر اساس تجزیه و تحلیل مجموعهای از دادههای آموزشی (یعنی اشیاء دادهای که برچسبهای کلاس آنها شناخته شده است) استخراج میشود. این مدل برای پیشبینی برچسبهای کلاس اشیایی که برچسبهای کلاس آنها ناشناخته است، استفاده میشود.
بسته به روشهای طبقهبندی، یک مدل مشتق شده میتواند به اشکال مختلفی مانند مجموعهای از قوانین طبقهبندی (یعنی قوانین IF-THEN)، یک درخت تصمیمگیری، یک فرمول ریاضی یا یک شبکه عصبی یادگیری شده باشد (شکل 1.2). درخت تصمیمگیری یک ساختار درختی شبیه نمودار جریان است که در آن هر گره نشاندهنده یک آزمایش روی یک مقدار ویژگی است، هر شاخه نشاندهنده یک نتیجه آزمایش است و برگهای درخت نشاندهنده کلاسها یا توزیع کلاسها هستند. درختان تصمیمگیری را میتوان به راحتی به قوانین طبقهبندی تبدیل کرد. یک شبکه عصبی، هنگامی که برای طبقهبندی استفاده میشود، معمولاً مجموعهای از واحدهای پردازشی شبیه نورون با اتصالات وزنی بین واحدها است. روشهای بسیار دیگری برای ساخت مدلهای طبقهبندی وجود دارد، مانند طبقهبندی بیزی ساده، ماشینهای بردار پشتیبان و طبقهبندی k-نزدیکترین همسایه.
در حالی که طبقهبندی برچسبهای دستهبندی (گسسته، نامرتب) را پیشبینی میکند، رگرسیون توابع با مقدار پیوسته را مدلسازی میکند. یعنی، رگرسیون برای پیشبینی مقادیر دادههای عددی گمشده یا غیرقابل دسترس به جای برچسبهای کلاس (گسسته) استفاده میشود. اصطلاح پیشبینی به پیشبینی عددی و پیشبینی برچسب کلاس اشاره دارد. تحلیل رگرسیون یک روش آماری است که اغلب برای پیشبینی عددی استفاده میشود، اگرچه روشهای دیگری نیز وجود دارند. رگرسیون همچنین شامل شناسایی روندهای توزیع بر اساس دادههای موجود است.
طبقهبندی و رگرسیون ممکن است نیاز به انتخاب ویژگی یا تحلیل ارتباط داشته باشند که تلاش میکند ویژگیهایی (که اغلب ویژگی نامیده میشوند) را که به طور قابل توجهی به فرآیند طبقهبندی و رگرسیون مرتبط هستند، شناسایی کند. چنین ویژگیهایی برای فرآیند طبقهبندی و رگرسیون انتخاب میشوند. سپس میتوان سایر ویژگیهایی را که بیربط هستند، از بررسی حذف کرد.

یک مدل طبقهبندی میتواند به اشکال مختلف نمایش داده شود: (الف) قوانین IF-THEN، (ب) درخت تصمیمگیری، یا (ج) شبکه عصبی.
مثال ۱.۳. طبقهبندی و رگرسیون. فرض کنید یک مدیر فروش فروشگاه اینترنتی میخواهد مجموعه بزرگی از اقلام موجود در فروشگاه را بر اساس سه نوع پاسخ به یک کمپین فروش طبقهبندی کند: پاسخ خوب، پاسخ ملایم و بدون پاسخ. شما میخواهید برای هر یک از این سه کلاس، بر اساس ویژگیهای توصیفی اقلام، مانند قیمت، برند، مکان ساخته شده، نوع و دسته، مدلی استخراج کنید. طبقهبندی حاصل باید حداکثر تمایز هر کلاس را از سایرین نشان دهد و تصویری سازمانیافته از مجموعه دادهها ارائه دهد.
فرض کنید که طبقهبندی حاصل به صورت یک درخت تصمیمگیری بیان شده است. به عنوان مثال، درخت تصمیمگیری ممکن است قیمت را به عنوان اولین عامل مهمی که به بهترین وجه سه کلاس را متمایز میکند، شناسایی کند. سایر ویژگیهایی که به تمایز بیشتر اشیاء هر کلاس از یکدیگر کمک میکنند شامل برند و مکان ساخته شده است. چنین درخت تصمیمگیری میتواند به مدیر کمک کند تا تأثیر کمپین فروش داده شده را درک کند و یک کمپین مؤثرتر در آینده طراحی کند. در عوض، فرض کنید که به جای پیشبینی برچسبهای پاسخ دستهبندیشده برای هر کالای فروشگاه، میخواهید میزان درآمدی را که هر کالا در طول فروش آینده ایجاد میکند، بر اساس دادههای فروش قبلی پیشبینی کنید. این نمونهای از تحلیل رگرسیون است زیرا مدل رگرسیون ساخته شده یک تابع پیوسته (یا مقدار مرتبشده) را پیشبینی میکند.
فصلهای ۶ و ۷ به تفصیل در مورد طبقهبندی بحث میکنند. تحلیل رگرسیون در این فصلها به طور خلاصه پوشش داده شده است، زیرا معمولاً در دورههای آمار معرفی میشود. منابع اطلاعات بیشتر در یادداشتهای کتابشناختی ارائه شده است.
تحلیل خوشهای
برخلاف طبقهبندی و رگرسیون که مجموعه دادههای دارای برچسب کلاس (آموزشی) را تجزیه و تحلیل میکنند، تحلیل خوشهای (که خوشهبندی نیز نامیده میشود) اشیاء داده را بدون مراجعه به برچسبهای کلاس گروهبندی میکند. در بسیاری از موارد، دادههای دارای برچسب کلاس ممکن است در ابتدا وجود نداشته باشند. خوشهبندی میتواند برای تولید برچسبهای کلاس برای گروهی از دادهها استفاده شود. اشیاء بر اساس اصل به حداکثر رساندن شباهت درون کلاسی و به حداقل رساندن شباهت بین کلاسی، خوشهبندی یا گروهبندی میشوند. یعنی خوشههایی از اشیاء تشکیل میشوند به طوری که اشیاء درون یک خوشه در مقایسه با یکدیگر شباهت بالایی دارند، اما با اشیاء در خوشههای دیگر نسبتاً متفاوت هستند.
هر خوشه تشکیل شده را میتوان به عنوان یک کلاس از اشیاء در نظر گرفت که از آن میتوان قوانین را استخراج کرد. خوشهبندی همچنین میتواند تشکیل طبقهبندی را تسهیل کند، یعنی سازماندهی مشاهدات در سلسله مراتبی از کلاسها که رویدادهای مشابه را در کنار هم گروهبندی میکنند.
مثال ۱.۴. تحلیل خوشهای. تحلیل خوشهای را میتوان بر روی دادههای مشتریان فروشگاه اینترنتی انجام داد تا زیرجمعیتهای همگن مشتریان را شناسایی کرد. این خوشهها ممکن است گروههای هدف فردی را برای بازاریابی نشان دهند. شکل ۱.۳ یک نمودار دوبعدی از مشتریان را با توجه به مکانهای مشتری در یک شهر نشان میدهد. سه خوشه از نقاط داده مشهود است.
تحلیل خوشهای موضوع فصلهای ۸ و ۹ را تشکیل میدهد.
یادگیری عمیق
برای بسیاری از وظایف دادهکاوی، مانند طبقهبندی و خوشهبندی، یک گام کلیدی اغلب در یافتن «ویژگیهای خوب» نهفته است که یک نمایش برداری از هر تاپل داده ورودی است.
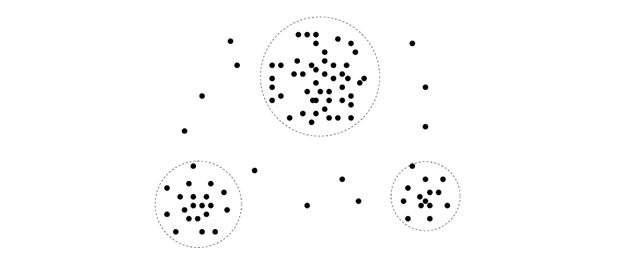
یک نمودار دوبعدی از دادههای مشتری با توجه به مکانهای مشتری در یک شهر، که سه خوشه داده را نشان میدهد.
به عنوان مثال، برای پیشبینی اینکه آیا شیوع بیماری منطقهای رخ خواهد داد یا خیر، ممکن است تعداد زیادی ویژگی از دادههای نظارت بر سلامت جمعآوری شده باشد، از جمله تعداد موارد مثبت روزانه، تعداد آزمایشهای روزانه، تعداد بستریهای روزانه و غیره. به طور سنتی، این مرحله (که مهندسی ویژگی نامیده میشود) اغلب به شدت به دانش دامنه متکی است. تکنیکهای یادگیری عمیق روشی خودکار برای مهندسی ویژگی ارائه میدهند که قادر به تولید ویژگیهای معنادار معنایی (مثلاً نرخ مثبت هفتگی) از ویژگیهای ورودی اولیه است. ویژگیهای تولید شده اغلب عملکرد دادهکاوی (مثلاً دقت طبقهبندی) را به طور قابل توجهی بهبود میبخشند.
یادگیری عمیق مبتنی بر شبکههای عصبی است. یک شبکه عصبی مجموعهای از واحدهای ورودی-خروجی متصل است که در آن هر اتصال دارای وزنی مرتبط با آن است. در طول مرحله یادگیری، شبکه با تنظیم وزنها یاد میگیرد تا بتواند مقادیر هدف صحیح (مثلاً برچسبهای کلاس) تاپلهای ورودی را پیشبینی کند. الگوریتم اصلی برای یادگیری چنین وزنهایی، پسانتشار نامیده میشود که به دنبال مجموعهای از وزنها و مقادیر بایاس است که میتوانند دادهها را مدلسازی کنند تا تابع زیان بین پیشبینی شبکه و خروجی هدف واقعی تاپلهای داده را به حداقل برسانند. اشکال مختلفی (به نام معماری) از شبکههای عصبی توسعه یافتهاند، از جمله شبکههای عصبی پیشخور، شبکههای عصبی کانولوشن، شبکههای عصبی بازگشتی، شبکههای عصبی گراف و بسیاری موارد دیگر.
یادگیری عمیق کاربردهای گستردهای در بینایی کامپیوتر، پردازش زبان طبیعی، ترجمه ماشینی، تحلیل شبکههای اجتماعی و غیره دارد. از آن در انواع وظایف دادهکاوی، از جمله طبقهبندی، خوشهبندی، تشخیص دادههای پرت و یادگیری تقویتی استفاده شده است.
یادگیری عمیق موضوع فصل 10 است.
تحلیل دادههای پرت
یک مجموعه داده ممکن است شامل اشیایی باشد که با رفتار یا مدل کلی دادهها مطابقت ندارند. این اشیاء داده، دادههای پرت هستند. بسیاری از روشهای دادهکاوی، دادههای پرت را به عنوان نویز یا استثنا کنار میگذارند. با این حال، در برخی از کاربردها (به عنوان مثال، تشخیص تقلب) رویدادهای نادر میتوانند جالبتر از رویدادهای منظمتر باشند. تحلیل دادههای پرت، تحلیل دادههای پرت یا کاوش ناهنجاری نامیده میشود. دادههای پرت را میتوان با استفاده از آزمونهای آماری که یک مدل توزیع یا احتمال را برای دادهها فرض میکنند، یا با استفاده از معیارهای فاصله که در آن اشیاء دور از هر خوشه دیگری، دادههای پرت در نظر گرفته میشوند، شناسایی کرد. روشهای مبتنی بر چگالی به جای استفاده از معیارهای آماری یا فاصله، میتوانند دادههای پرت را در یک منطقه محلی شناسایی کنند، اگرچه از دیدگاه توزیع آماری جهانی طبیعی به نظر میرسند.
مثال ۱.۵. تحلیل دادههای پرت. تحلیل دادههای پرت ممکن است با تشخیص خریدهای مبالغ غیرمعمول زیاد برای یک شماره حساب مشخص در مقایسه با هزینههای معمول انجام شده توسط همان حساب، استفاده جعلی از کارتهای اعتباری را کشف کند. مقادیر دادههای پرت همچنین ممکن است با توجه به مکانها و انواع خرید یا فراوانی خرید شناسایی شوند.
تحلیل دادههای پرت در فصل ۱۱ مورد بحث قرار گرفته است.
آیا همه نتایج کاوش جالب هستند؟
دادهکاوی پتانسیل تولید نتایج زیادی را دارد. یک سوال میتواند این باشد: “آیا همه نتایج کاوش جالب هستند؟”
این یک سوال عالی است. هر نوع از توابع دادهکاوی معیارهای خاص خود را برای ارزیابی کیفیت کاوش دارد. با این وجود، برخی فلسفهها و اصول مشترک وجود دارد. به عنوان مثال، کاوش الگو را در نظر بگیرید. کاوش الگو ممکن است هزاران یا حتی میلیونها الگو یا قانون ایجاد کند. ممکن است از خود بپرسید: “چه چیزی یک الگو را جالب میکند؟ آیا یک سیستم دادهکاوی میتواند همه الگوهای جالب را تولید کند؟ یا آیا سیستم میتواند فقط الگوهای جالب را تولید کند؟”
برای پاسخ به سوال اول، یک الگو در صورتی جالب است که (1) به راحتی توسط انسانها قابل درک باشد، (2) روی دادههای جدید یا آزمایشی با درجهای از قطعیت معتبر باشد، (3) به طور بالقوه مفید باشد و (4) بدیع باشد. یک الگو همچنین در صورتی جالب است که فرضیهای را که کاربر به دنبال تأیید آن بوده است، تأیید کند.
چندین معیار عینی برای جالب بودن الگو وجود دارد. این معیارها بر اساس ساختار الگوهای کشف شده و آمار زیربنایی آنها هستند. یک معیار عینی برای قوانین انجمنی به شکل XY، پشتیبانی از قانون است که نشان دهنده درصد تراکنشهای یک پایگاه داده تراکنش است که قانون داده شده آن را برآورده میکند. این احتمال P (XY) در نظر گرفته میشود، که در آن XY نشان میدهد که یک تراکنش شامل X و Y است، یعنی اجتماع مجموعه اقلام X و Y. یکی دیگر از معیارهای عینی برای قوانین انجمنی، اطمینان است که میزان قطعیت ارتباط شناسایی شده را ارزیابی میکند. این احتمال شرطی P(YX) در نظر گرفته میشود، یعنی احتمال اینکه تراکنشی حاوی X، Y را نیز شامل شود. به طور رسمیتر، پشتیبانی و اطمینان به صورت زیر تعریف میشوند.
support(X⇒Y) = P(X∪Y),
confidence(X⇒Y) = P(Y|X).
به طور کلی، هر معیار جالب بودن با یک آستانه مرتبط است که ممکن است توسط کاربر کنترل شود. به عنوان مثال، قوانینی که آستانه اطمینان مثلاً ۵۰٪ را برآورده نمیکنند، میتوانند غیر جالب در نظر گرفته شوند. قوانین زیر آستانه احتمالاً منعکس کننده نویز، استثنائات یا موارد اقلیت هستند و احتمالاً ارزش کمتری دارند.
معیارهای عینی دیگری نیز وجود دارد. به عنوان مثال، ممکن است کسی دوست داشته باشد که مجموعهای از اقلام در یک قانون ارتباط به شدت با هم مرتبط باشند. ما در فصل مربوطه در مورد چنین معیارهایی بحث خواهیم کرد.
اگرچه معیارهای عینی به شناسایی الگوهای جالب کمک میکنند، اما اغلب کافی نیستند مگر اینکه با معیارهای ذهنی که نیازها و علایق یک کاربر خاص را منعکس میکنند، ترکیب شوند. به عنوان مثال، الگوهایی که ویژگیهای مشتریانی را که مرتباً آنلاین خرید میکنند توصیف میکنند، باید برای مدیر بازاریابی جالب باشند، اما ممکن است برای سایر تحلیلگرانی که همان پایگاه داده را برای الگوهای مربوط به عملکرد کارکنان مطالعه میکنند، مورد توجه کمی قرار گیرند. علاوه بر این، بسیاری از الگوهایی که طبق استانداردهای عینی جالب هستند، ممکن است نشان دهنده عقل سلیم باشند و بنابراین در واقع غیر جالب باشند.
معیارهای ذهنی جالب بودن بر اساس باورهای کاربر در مورد دادهها هستند. این معیارها، الگوها را در صورتی جالب میدانند که غیرمنتظره باشند (مغایر با باور کاربر) یا اطلاعات استراتژیکی ارائه دهند که کاربر بتواند بر اساس آنها عمل کند. در حالت دوم، چنین الگوهایی به عنوان الگوهای قابل اقدام شناخته میشوند. به عنوان مثال، الگوهایی مانند «یک زلزله بزرگ اغلب پس از مجموعهای از زلزلههای کوچک رخ میدهد» در صورتی که کاربران بتوانند بر اساس اطلاعات برای نجات جان انسانها اقدام کنند، میتوانند بسیار قابل اقدام باشند. الگوهایی که مورد انتظار هستند، در صورتی میتوانند جالب باشند که فرضیهای را که کاربر میخواهد اعتبارسنجی کند، تأیید کنند یا شبیه حدس کاربر باشند.
سوال دوم – «آیا یک سیستم دادهکاوی میتواند تمام الگوهای جالب را تولید کند؟» – به کامل بودن یک الگوریتم دادهکاوی اشاره دارد. اغلب غیرواقعی و ناکارآمد است که یک سیستم دادهکاوی تمام الگوهای ممکن را تولید کند، زیرا ممکن است تعداد بسیار زیادی از آنها وجود داشته باشد. با این حال، ممکن است نگران این باشید که اگر سیستم متوقف شود، ممکن است برخی از الگوهای مهم را از دست بدهد. برای حل این معضل، باید از محدودیتهای ارائه شده توسط کاربر و معیارهای جالب بودن برای تمرکز جستجو استفاده شود. با معیارهای جالب به خوبی تعریف شده و محدودیتهای ارائه شده توسط کاربر، اطمینان از کامل بودن دادهکاوی الگو کاملاً واقعبینانه است. روشهای مربوطه به تفصیل در فصل ۴ بررسی شدهاند.
در نهایت، سوال سوم – “آیا یک سیستم دادهکاوی میتواند فقط الگوهای جالب تولید کند؟” – یک مسئله بهینهسازی در دادهکاوی است. برای یک سیستم دادهکاوی بسیار مطلوب است که فقط الگوهای جالب تولید کند. این امر هم برای سیستم دادهکاوی و هم برای کاربر کارآمد خواهد بود زیرا سیستم ممکن است زمان بسیار کمتری را برای تولید الگوهای بسیار کمتر اما جالب صرف کند، در حالی که کاربر نیازی به بررسی تعداد زیادی الگو برای شناسایی الگوهای واقعاً جالب نخواهد داشت. الگویکاوی مبتنی بر محدودیت که در فصل ۵ توضیح داده شده است، مثال خوبی در این زمینه است.
روشهای ارزیابی کیفیت یا جالب بودن نتایج دادهکاوی و نحوه استفاده از آنها برای بهبود کارایی دادهکاوی، در سراسر کتاب مورد بحث قرار گرفته است.


