مقدمه
در این بخش، با بحث در مورد معیارهای کیفیت دادهها (بخش ۲.۴.۱) شروع میکنیم. سپس، تکنیکهای رایج برای پاکسازی دادهها (بخش ۲.۴.۲) و یکپارچهسازی دادهها (بخش ۲.۴.۳) را معرفی میکنیم.
معیارهای کیفیت دادهها
دادهها در صورتی کیفیت دارند که الزامات کاربرد مورد نظر را برآورده کنند. عوامل زیادی شامل کیفیت دادهها میشوند، از جمله دقت، کامل بودن، سازگاری، بهموقع بودن، باورپذیری و تفسیرپذیری.
تصور کنید که شما مدیر یک فروشگاه اینترنتی آنلاین هستید و وظیفه تجزیه و تحلیل دادههای شرکت در رابطه با فروش شعبه خود را بر عهده دارید. شما بلافاصله برای انجام این کار اقدام میکنید. شما با دقت پایگاه داده و انبار داده شرکت را بررسی میکنید و ویژگیها یا ابعاد (مثلاً کالا، قیمت و واحدهای فروخته شده) را برای گنجاندن در تجزیه و تحلیل خود شناسایی و انتخاب میکنید. افسوس! متوجه میشوید که چندین مورد از ویژگیهای مربوط به تاپلهای مختلف هیچ مقدار ثبت شدهای ندارند. برای تحلیل خود، میخواهید اطلاعاتی در مورد اینکه آیا هر کالای خریداری شده به عنوان کالای حراج تبلیغ شده است یا خیر، اما متوجه میشوید که این اطلاعات ثبت نشده است، ارائه دهید. علاوه بر این، کاربران سیستم پایگاه داده شما خطاها، مقادیر غیرمعمول و ناسازگاریهایی را در دادههای ثبت شده برای برخی از تراکنشها گزارش کردهاند. به عبارت دیگر، دادههایی که میخواهید با تکنیکهای دادهکاوی تجزیه و تحلیل کنید، ناقص هستند (فاقد مقادیر ویژگی یا ویژگیهای خاص مورد نظر، یا فقط شامل دادههای تجمعی هستند)؛ نادرست یا نویزدار هستند (حاوی خطاها یا مقادیری که از حد انتظار منحرف شدهاند)؛ و متناقض هستند (مثلاً حاوی اختلافاتی در کدهای دپارتمان مورد استفاده برای طبقهبندی اقلام). به دنیای واقعی خوش آمدید!
این سناریو سه مورد از عناصر تعریفکننده کیفیت دادهها را نشان میدهد: دقت، کامل بودن و سازگاری. دادههای نادرست، ناقص و ناسازگار، ویژگیهای رایج پایگاههای داده و انبارهای داده بزرگ دنیای واقعی هستند. دلایل احتمالی زیادی برای دادههای نادرست وجود دارد (یعنی داشتن مقادیر ویژگی نادرست). ابزارهای جمعآوری داده مورد استفاده ممکن است معیوب باشند. ممکن است در ورود دادهها خطاهای انسانی یا رایانهای رخ داده باشد. کاربران ممکن است عمداً مقادیر داده نادرستی را برای فیلدهای اجباری ارسال کنند، در حالی که نمیخواهند اطلاعات شخصی خود را ارسال کنند (مثلاً با انتخاب مقدار پیشفرض “۱ ژانویه” که برای تاریخ تولد نمایش داده میشود). این به عنوان دادههای گمشده پنهان شناخته میشود. خطاهایی در انتقال دادهها نیز ممکن است رخ دهد. ممکن است محدودیتهای فناوری مانند اندازه بافر محدود برای هماهنگی انتقال و مصرف دادههای هماهنگ وجود داشته باشد. دادههای نادرست همچنین ممکن است ناشی از ناسازگاری در قراردادهای نامگذاری یا کدهای داده یا قالبهای ناسازگار برای فیلدهای ورودی (مثلاً تاریخ) باشند. تاپلهای تکراری نیز نیاز به پاکسازی دادهها دارند.
دادههای ناقص میتوانند به دلایل مختلفی رخ دهند. ویژگیهای مورد نظر ممکن است همیشه در دسترس نباشند، مانند اطلاعات مشتری برای دادههای تراکنش فروش. سایر دادهها ممکن است صرفاً به این دلیل که در زمان ورود مهم تلقی نشدهاند، گنجانده نشوند. دادههای مرتبط ممکن است به دلیل سوءتفاهم یا به دلیل نقص تجهیزات ثبت نشده باشند. دادههایی که با سایر دادههای ثبت شده مغایرت دارند، ممکن است حذف شده باشند. علاوه بر این، ثبت تاریخچه دادهها یا تغییرات ممکن است نادیده گرفته شده باشد. دادههای از دست رفته، به ویژه برای تاپلهایی با مقادیر از دست رفته برای برخی از ویژگیها، ممکن است نیاز به استنباط داشته باشند.
به یاد داشته باشید که کیفیت دادهها به کاربرد مورد نظر از دادهها بستگی دارد. دو کاربر مختلف ممکن است ارزیابیهای بسیار متفاوتی از کیفیت یک پایگاه داده مشخص داشته باشند. به عنوان مثال، یک تحلیلگر بازاریابی ممکن است برای لیستی از آدرسهای مشتری نیاز به دسترسی به پایگاه داده ذکر شده در بالا داشته باشد. برخی از آدرسها قدیمی یا نادرست هستند، با این حال، به طور کلی، 80٪ از آدرسها دقیق هستند. تحلیلگر بازاریابی این را یک پایگاه داده بزرگ مشتری برای اهداف بازاریابی هدف میداند و از دقت پایگاه داده راضی است، اگرچه به عنوان مدیر فروش، دادهها را نادرست یافتید.
به موقع بودن نیز بر کیفیت دادهها تأثیر میگذارد. فرض کنید که شما بر توزیع پاداشهای فروش ماهانه به نمایندگان برتر فروش در یک شرکت نظارت دارید. با این حال، چندین نماینده فروش، سوابق فروش خود را به موقع در پایان ماه ارائه نمیدهند. همچنین تعدادی اصلاح و تعدیل وجود دارد که پس از پایان ماه انجام میشود. برای مدتی پس از هر ماه، دادههای ذخیره شده در پایگاه داده ناقص هستند. با این حال، پس از دریافت همه دادهها، صحیح هستند. این واقعیت که دادههای پایان ماه به موقع بهروزرسانی نمیشوند، تأثیر منفی بر کیفیت دادهها دارد.
دو عامل دیگر که بر کیفیت دادهها تأثیر میگذارند، باورپذیری و تفسیرپذیری هستند. باورپذیری نشان میدهد که دادهها چقدر توسط کاربران قابل اعتماد هستند، در حالی که تفسیرپذیری نشان میدهد که دادهها چقدر به راحتی قابل درک هستند. فرض کنید که یک پایگاه داده، در یک مقطع، چندین خطا داشته است که همه آنها از آن زمان اصلاح شدهاند. با این حال، خطاهای گذشته مشکلات زیادی را برای کاربران بخش فروش ایجاد کرده است، بنابراین آنها دیگر به دادهها اعتماد ندارند. دادهها همچنین از کدهای حسابداری زیادی استفاده میکنند که بخش فروش نمیداند چگونه آنها را تفسیر کند. اگرچه پایگاه داده اکنون دقیق، کامل، سازگار و بهموقع است، کاربران بخش فروش ممکن است به دلیل باورپذیری و تفسیرپذیری ضعیف، آن را کمکیفیت بدانند.
پاکسازی دادهها
دادههای دنیای واقعی معمولاً ناقص، نویزدار و ناسازگار هستند. روالهای پاکسازی دادهها (یا پالایش دادهها) تلاش میکنند تا مقادیر گمشده را پر کنند، نویز را در حین شناسایی دادههای پرت صاف کنند و ناسازگاریهای دادهها را اصلاح کنند. در این بخش، روشهای اساسی برای پاکسازی دادهها را مطالعه خواهید کرد. ابتدا، به روشهای مدیریت مقادیر گمشده نگاه میکنیم. سپس، تکنیکهای هموارسازی دادهها را توضیح میدهیم. در نهایت، رویکردهای پاکسازی دادهها را به عنوان یک فرآیند مورد بحث قرار میدهیم.
مقادیر گمشده
تصور کنید که باید دادههای فروش و مشتری یک شرکت را تجزیه و تحلیل کنید. متوجه میشوید که بسیاری از تاپلها برای چندین ویژگی مانند درآمد مشتری هیچ مقدار ثبت شدهای ندارند. چگونه میتوانید مقادیر گمشده را برای این ویژگی پر کنید؟ بیایید به روشهای زیر نگاه کنیم.
۱. نادیده گرفتن تاپل: این کار معمولاً زمانی انجام میشود که برچسب کلاس از دست رفته باشد (با فرض اینکه وظیفه کاوش شامل طبقهبندی باشد). این روش خیلی مؤثر نیست، مگر اینکه تاپل شامل چندین ویژگی با مقادیر گمشده باشد. این روش به ویژه زمانی ضعیف است که درصد مقادیر گمشده در هر ویژگی به طور قابل توجهی متفاوت باشد. با نادیده گرفتن تاپل، از مقادیر ویژگیهای باقیمانده در تاپل استفاده نمیکنیم. چنین دادههایی میتوانستند برای کار مورد نظر مفید باشند.
۲. پر کردن دستی مقدار گمشده: به طور کلی، این رویکرد زمانبر است و با توجه به مجموعه دادههای بزرگ با مقادیر گمشده زیاد، ممکن است عملی نباشد.
۳. استفاده از یک ثابت جهانی برای پر کردن مقدار گمشده: تمام مقادیر ویژگی گمشده را با یک ثابت مشابه مانند برچسبی مانند “ناشناخته” یا “نامشخص” جایگزین کنید. اگر مقادیر گمشده با مثلاً “نامشخص” جایگزین شوند، برنامه دادهکاوی ممکن است به اشتباه فکر کند که آنها یک مفهوم جالب را تشکیل میدهند، زیرا همه آنها یک مقدار مشترک دارند – “نامشخص”. از این رو، اگرچه این روش ساده است، اما بیعیب و نقص نیست.
۴. از یک معیار گرایش مرکزی برای ویژگی (مثلاً میانگین یا میانه) برای پر کردن مقدار گمشده استفاده کنید: بخش ۲.۲ معیارهای گرایش مرکزی را مورد بحث قرار داد که نشاندهنده مقدار «میانه» توزیع دادهها هستند. برای توزیع دادههای نرمال (متقارن)، میتوان از میانگین استفاده کرد، در حالی که توزیع دادههای چوله باید از میانه استفاده کند (بخش ۲.۲). به عنوان مثال، فرض کنید توزیع دادهها در مورد درآمد مشتریان متقارن است و میانگین درآمد ۵۶۰۰۰ دلار است. از این مقدار برای جایگزینی مقدار گمشده برای درآمد استفاده کنید.
۵. از میانگین ویژگی یا میانه برای تمام نمونههای متعلق به همان کلاس تاپل داده شده استفاده کنید: به عنوان مثال، اگر مشتریان را بر اساس ریسک اعتباری طبقهبندی میکنیم، میتوانیم مقدار گمشده را با میانگین مقدار درآمد برای مشتریانی که در همان دسته ریسک اعتباری تاپل داده شده قرار دارند، جایگزین کنیم. اگر توزیع دادهها برای یک کلاس داده شده کج باشد، مقدار میانه انتخاب بهتری است.
۶. از محتملترین مقدار برای پر کردن مقدار گمشده استفاده کنید: این مورد را میتوان با رگرسیون، ابزارهای مبتنی بر استنتاج با استفاده از فرمالیسم بیزی یا استنتاج درخت تصمیمگیری تعیین کرد. به عنوان مثال، با استفاده از سایر ویژگیهای مشتری در مجموعه دادههای خود، میتوانید یک درخت تصمیمگیری برای پیشبینی مقادیر گمشده برای درآمد بسازید. درختهای تصمیمگیری، رگرسیون و استنتاج بیزی به تفصیل در فصلهای ۶ و ۷ شرح داده شدهاند
روشهای ۳ تا ۶ دادهها را دچار سوگیری میکنند – مقدار پر شده ممکن است صحیح نباشد. با این حال، روش ۶ یک استراتژی محبوب است. در مقایسه با سایر روشها، از بیشترین اطلاعات از دادههای فعلی برای پیشبینی مقادیر گمشده استفاده میکند. با در نظر گرفتن مقادیر سایر ویژگیها در تخمین مقدار از دست رفته برای درآمد، احتمال بیشتری وجود دارد که روابط بین درآمد و سایر ویژگیها حفظ شود.
لازم به ذکر است که در برخی موارد، یک مقدار از دست رفته ممکن است به معنای خطا در دادهها نباشد! به عنوان مثال، هنگام درخواست کارت اعتباری، ممکن است از داوطلبان خواسته شود شماره گواهینامه رانندگی خود را ارائه دهند. داوطلبانی که گواهینامه رانندگی ندارند، طبیعتاً ممکن است این فیلد را خالی بگذارند. فرمها باید به پاسخدهندگان اجازه دهند مقادیری مانند “قابل اجرا نیست” را مشخص کنند. همچنین میتوان از روالهای نرمافزاری برای کشف سایر مقادیر تهی (مثلاً “نمیدانم”، “؟” یا “هیچکدام”) استفاده کرد. در حالت ایدهآل، هر ویژگی باید یک یا چند قانون در مورد شرط تهی داشته باشد. این قوانین ممکن است مشخص کنند که آیا مقادیر تهی مجاز هستند یا خیر و/یا چگونه باید با چنین مقادیری برخورد یا تبدیل شوند. همچنین اگر قرار باشد فیلدها در مرحله بعدی فرآیند کسب و کار ارائه شوند، ممکن است عمداً خالی گذاشته شوند. از این رو، اگرچه میتوانیم تمام تلاش خود را برای پاکسازی دادهها پس از ضبط آنها انجام دهیم، اما طراحی خوب پایگاه داده و رویه ورود داده باید در وهله اول به حداقل رساندن تعداد مقادیر گمشده یا خطاها کمک کند.
دادههای نویزی
“نویز چیست؟” نویز یک خطای تصادفی یا واریانس در یک متغیر اندازهگیری شده است. با توجه به یک ویژگی عددی مانند مثلاً قیمت، چگونه میتوانیم دادهها را “هموار” کنیم تا نویز حذف شود؟ بیایید به تکنیکهای هموارسازی دادههای زیر نگاهی بیندازیم.
Binning: روشهای Binning با مراجعه به “محله” آن، یعنی مقادیر اطراف آن، یک مقدار داده مرتب شده را هموار میکنند. مقادیر مرتب شده در تعدادی “سطل” یا سطل توزیع میشوند. از آنجا که روشهای Binning به همسایگی مقادیر مراجعه میکنند، هموارسازی محلی را انجام میدهند. شکل 2.11 برخی از تکنیکهای Binning را نشان میدهد. در این مثال، دادههای مربوط به قیمت ابتدا مرتب شده و سپس به سطلهای با فرکانس برابر با اندازه 3 تقسیم میشوند (یعنی هر سطل شامل سه مقدار است). در هموارسازی با استفاده از میانگینهای بین، هر مقدار در یک بین با مقدار میانگین بین جایگزین میشود. به عنوان مثال، میانگین مقادیر ۴، ۸ و ۱۵ در بین ۱ برابر با ۹ است. بنابراین هر مقدار اصلی در این بین با مقدار ۹ جایگزین میشود.
به طور مشابه، هموارسازی با استفاده از میانههای بین میتواند مورد استفاده قرار گیرد، که در آن هر مقدار بین با میانه بین جایگزین میشود. در هموارسازی با استفاده از مرزهای بین، حداقل و حداکثر مقادیر در یک بین مشخص به عنوان مرزهای بین شناسایی میشوند. سپس هر مقدار بین با نزدیکترین مقدار مرزی جایگزین میشود. به طور کلی، هرچه عرض بزرگتر باشد، اثر هموارسازی بیشتر است. به طور جایگزین، بینها ممکن است عرض مساوی داشته باشند، که در آن محدوده فاصله مقادیر در هر بین ثابت است. بینبندی همچنین به عنوان یک تکنیک گسستهسازی استفاده میشود.
دادههای مرتبشده برای قیمت (به دلار): ۴، ۸، ۱۵، ۲۱، ۲۱، ۲۴، ۲۵، ۲۸، ۳۴
| تقسیم به (فرکانس برابر) |
|---|
| :bins |
| Bin 1: 4, 8, 15 |
| Bin 2: 21, 21, 24 |
| Bin 3: 25, 28, 34 |
| Smoothing by bin means: Bin 1: 9, 9, 9 |
| Bin 2: 22, 22, 22 |
| Bin 3: 29, 29, 29 |
| Smoothing by bin boundaries: Bin 1: 4, 4, 15 |
| Bin 2: 21, 21, 24 |
| Bin 3: 25, 25, 34 |
هموارسازی دادهها با روشهای مختلف دستهبندی.
رگرسیون: هموارسازی دادهها همچنین میتواند توسط رگرسیون انجام شود، تکنیکی که مقادیر دادهها را با یک تابع مطابقت میدهد. رگرسیون خطی شامل یافتن «بهترین» خط برای برازش دو ویژگی (یا متغیر) است به طوری که یک ویژگی بتواند برای پیشبینی دیگری استفاده شود. رگرسیون خطی چندگانه، بسطی از رگرسیون خطی است که در آن بیش از دو ویژگی درگیر هستند و دادهها با یک سطح چندبعدی برازش میشوند. رگرسیون در فصل 6 بیشتر توضیح داده شده است.
تحلیل دادههای پرت: دادههای پرت ممکن است با خوشهبندی شناسایی شوند، به عنوان مثال، جایی که مقادیر مشابه در گروهها یا «خوشهها» سازماندهی میشوند. به طور شهودی، مقادیری که خارج از مجموعه خوشهها قرار میگیرند، ممکن است به عنوان دادههای پرت در نظر گرفته شوند (شکل 2.12). فصل 11 به موضوع تحلیل دادههای پرت اختصاص داده شده است.
بسیاری از روشهای هموارسازی دادهها برای گسستهسازی دادهها (شکلی از تبدیل دادهها) و کاهش دادهها نیز استفاده میشوند. به عنوان مثال، تکنیکهای binning که قبلاً توضیح داده شد، تعداد مقادیر متمایز در هر ویژگی را کاهش میدهند. این به عنوان نوعی کاهش داده برای روشهای دادهکاوی مبتنی بر منطق، مانند استنتاج درخت تصمیمگیری، عمل میکند که به طور مکرر مقایسههای ارزشی را روی دادههای مرتبشده انجام میدهد. سلسله مراتب مفهومی نوعی گسستهسازی دادهها است که میتواند برای هموارسازی دادهها نیز استفاده شود. به عنوان مثال، یک سلسله مراتب مفهومی برای قیمت، ممکن است مقادیر قیمت واقعی را به ارزان، با قیمت متوسط و گران نگاشت کند و در نتیجه تعداد مقادیر دادهای را که باید توسط فرآیند دادهکاوی مدیریت شوند، کاهش دهد. گسستهسازی دادهها در بخش 2.5.2 مورد بحث قرار گرفته است. برخی از روشهای طبقهبندی دارای مکانیسمهای هموارسازی دادههای داخلی هستند. طبقهبندی موضوع فصلهای 6 و 7 است.
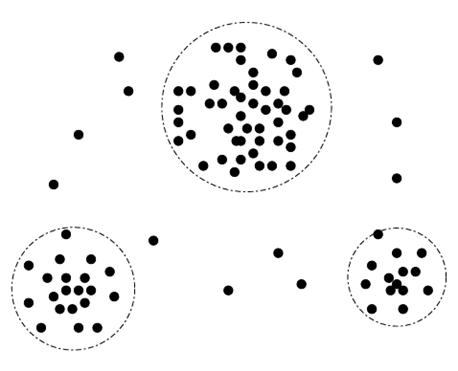
یک نمودار دوبعدی از دادههای مشتری با توجه به موقعیت مکانی مشتریان در یک شهر، که سه خوشه داده را نشان میدهد. دادههای پرت ممکن است به عنوان مقادیری که خارج از مجموعه خوشهها قرار میگیرند، شناسایی شوند.
پاکسازی دادهها به عنوان یک فرآیند
مقادیر گمشده، نویز و ناسازگاریها به دادههای نادرست کمک میکنند. تاکنون، ما به تکنیکهایی برای مدیریت دادههای گمشده و هموارسازی دادهها پرداختهایم. “اما پاکسازی دادهها کار بزرگی است. پاکسازی دادهها به عنوان یک فرآیند چطور؟ دقیقاً چگونه میتوان این کار را انجام داد؟ آیا ابزاری برای کمک وجود دارد؟”
اولین قدم در پاکسازی دادهها به عنوان یک فرآیند، تشخیص اختلاف است. اختلافات میتواند ناشی از عوامل مختلفی باشد، از جمله فرمهای ورود اطلاعات با طراحی ضعیف که فیلدهای اختیاری زیادی دارند، خطای انسانی در ورود اطلاعات، خطاهای عمدی (مثلاً عدم تمایل پاسخدهندگان به افشای اطلاعات در مورد خود) و پوسیدگی دادهها (مثلاً آدرسهای قدیمی). اختلافات همچنین ممکن است از نمایشهای متناقض دادهها و استفاده متناقض از کدها ناشی شود. سایر منابع اختلاف شامل خطاها در دستگاههای ابزار دقیق که دادهها را ثبت میکنند و خطاهای سیستم است. خطاها همچنین میتوانند زمانی رخ دهند که دادهها (به طور ناکافی) برای اهدافی غیر از آنچه در ابتدا در نظر گرفته شده بود، استفاده شوند. همچنین ممکن است به دلیل ادغام دادهها ناسازگاریهایی وجود داشته باشد (مثلاً، جایی که یک ویژگی معین میتواند نامهای مختلفی در پایگاههای داده مختلف داشته باشد).
“بنابراین، چگونه میتوانیم تشخیص اختلاف را ادامه دهیم؟” به عنوان نقطه شروع، از هر دانشی که ممکن است در مورد ویژگیهای دادهها داشته باشید استفاده کنید. چنین دانشی یا “دادههایی درباره دادهها” به عنوان فراداده شناخته میشوند. در اینجا میتوانیم از دانشی که در بخشهای قبلی در مورد دادههای خود به دست آوردهایم استفاده کنیم. به عنوان مثال، نوع داده و دامنه هر ویژگی چیست؟ مقادیر قابل قبول برای هر ویژگی چیست؟ توضیحات اولیه دادههای آماری که در بخش 2.2 مورد بحث قرار گرفت، در اینجا برای درک روند دادهها و شناسایی ناهنجاریها مفید هستند. به عنوان مثال، مقادیر میانگین، میانه و مد را پیدا کنید. آیا دادهها متقارن هستند یا کج؟ دامنه مقادیر چیست؟ آیا همه مقادیر در محدوده مورد انتظار قرار میگیرند؟ انحراف معیار هر ویژگی چیست؟ برای توزیعهای گاوسی مانند، مقادیری که بیش از دو انحراف معیار از میانگین یک ویژگی معین فاصله دارند، ممکن است به عنوان دادههای پرت بالقوه علامتگذاری شوند. آیا وابستگی شناخته شدهای بین ویژگیها وجود دارد؟ در این مرحله، میتوانید اسکریپتهای خودتان را بنویسید و/یا از برخی از ابزارهایی که بعداً در مورد آنها بحث خواهیم کرد، استفاده کنید. از این طریق، ممکن است نویز، دادههای پرت و مقادیر غیرمعمولی پیدا کنید که نیاز به بررسی دارند.
به عنوان یک تحلیلگر داده، باید مراقب استفادهی ناسازگار از کدها و هرگونه نمایش دادهی ناسازگار باشید (مثلاً “2010/12/25” و “25/12/2010” برای تاریخ). بارگذاری بیش از حد فیلد یکی دیگر از منابع خطا است که معمولاً زمانی ایجاد میشود که توسعهدهندگان تعاریف ویژگی جدید را در بخشهای استفاده نشده (بیت) از ویژگیهای از قبل تعریف شده قرار میدهند (مثلاً یک بیت استفاده نشده از یک ویژگی که دارای محدودهی مقداری است که مثلاً فقط از 31 بیت از 32 بیت استفاده میکند).
همچنین دادهها باید از نظر منحصر به فرد بودن، متوالی بودن و شرایط تهی بررسی شوند. یک قانون منحصر به فرد بودن میگوید که هر مقدار از ویژگی داده شده باید با تمام مقادیر دیگر برای آن ویژگی متفاوت باشد. یک قانون توالی میگوید که هیچ مقدار گمشدهای نمیتواند بین کمترین و بیشترین مقدار برای یک ویژگی وجود داشته باشد و همه مقادیر نیز باید منحصر به فرد باشند (مثلاً مانند اعداد کنترلی). یک قانون شرط تهی، استفاده از جاهای خالی، علامت سؤال، کاراکترهای ویژه یا سایر رشتههایی را که ممکن است نشاندهنده شرط تهی باشند (مثلاً جایی که مقداری برای یک ویژگی معین در دسترس نیست) و نحوه برخورد با چنین مقادیری را مشخص میکند. همانطور که قبلاً ذکر شد، دلایل مقادیر گمشده ممکن است شامل موارد زیر باشد: (1) شخصی که در ابتدا از او خواسته شده مقداری برای ویژگی ارائه دهد، امتناع میکند و/یا متوجه میشود که اطلاعات درخواستی قابل اجرا نیست (مثلاً یک ویژگی شماره مجوز توسط افراد غیر راننده خالی گذاشته شده است)؛ (2) فرد واردکننده داده مقدار صحیح را نمیداند؛ یا (3) مقدار قرار است توسط مرحله بعدی فرآیند ارائه شود. قانون تهی باید نحوه ثبت شرط تهی را مشخص کند، به عنوان مثال، مانند ذخیره صفر برای ویژگیهای عددی، خالی برای ویژگیهای دستهبندی یا هر قرارداد دیگری که ممکن است مورد استفاده قرار گیرد (به عنوان مثال، ورودیهایی مانند “نمیدانم” یا “؟” باید به خالی تبدیل شوند). تعدادی ابزار تجاری مختلف وجود دارد که میتوانند در مرحله تشخیص اختلاف کمک کنند. ابزارهای پاکسازی دادهها از دانش ساده دامنه (به عنوان مثال، دانش آدرسهای پستی و بررسی املا) برای تشخیص خطاها و انجام اصلاحات در دادهها استفاده میکنند. این ابزارها هنگام تمیز کردن دادهها از منابع متعدد، به تکنیکهای تجزیه و تطبیق فازی متکی هستند. ابزارهای حسابرسی دادهها با تجزیه و تحلیل دادهها برای کشف قوانین و روابط و تشخیص دادههایی که چنین شرایطی را نقض میکنند، اختلافات را پیدا میکنند. آنها انواع ابزارهای دادهکاوی هستند. به عنوان مثال، آنها ممکن است از تجزیه و تحلیل آماری برای یافتن همبستگیها یا خوشهبندی برای شناسایی دادههای پرت استفاده کنند. آنها همچنین ممکن است از توصیفات آماری اولیه دادههای ارائه شده در بخش 2.2 استفاده کنند.
برخی از ناسازگاریهای دادهها را میتوان به صورت دستی با استفاده از منابع خارجی اصلاح کرد. به عنوان مثال، خطاهای ایجاد شده در ورود دادهها را میتوان با انجام ردیابی کاغذی اصلاح کرد. با این حال، اکثر خطاها نیاز به تبدیل دادهها دارند. یعنی، هنگامی که اختلافاتی را پیدا میکنیم، معمولاً باید (یک سری) تبدیلها را برای اصلاح آنها تعریف و اعمال کنیم.
ابزارهای تجاری میتوانند در مرحله تبدیل دادهها کمک کنند. ابزارهای مهاجرت دادهها امکان مشخص کردن تبدیلهای ساده مانند جایگزینی رشته “جنسیت” با “جنسیت” را فراهم میکنند. ابزارهای ETL (استخراج/تبدیل/بارگذاری) به کاربران اجازه میدهند تبدیلها را از طریق یک رابط کاربری گرافیکی (GUI) مشخص کنند. این ابزارها معمولاً فقط از مجموعهای محدود از تبدیلها پشتیبانی میکنند، بنابراین اغلب ممکن است تصمیم بگیریم اسکریپتهای سفارشی را برای این مرحله از فرآیند پاکسازی دادهها بنویسیم.
فرآیند دو مرحلهای تشخیص اختلاف و تبدیل دادهها (برای اصلاح اختلافات) تکرار میشود. با این حال، این فرآیند مستعد خطا و زمانبر است. برخی از تبدیلها ممکن است اختلافات بیشتری ایجاد کنند. برخی از اختلافات تو در تو ممکن است تنها پس از رفع سایر اختلافات شناسایی شوند. به عنوان مثال، یک غلط املایی مانند “20010” در فیلد سال ممکن است تنها زمانی ظاهر شود که تمام مقادیر تاریخ به یک قالب یکسان تبدیل شده باشند. تبدیلات اغلب به صورت یک فرآیند دستهای انجام میشوند در حالی که کاربر بدون بازخورد منتظر میماند. تنها پس از اتمام تبدیل، کاربر میتواند به عقب برگردد و بررسی کند که هیچ ناهنجاری جدیدی به اشتباه ایجاد نشده باشد. معمولاً، تکرارهای متعددی قبل از رضایت کاربر مورد نیاز است. هر تاپلی که نتواند به طور خودکار توسط یک تبدیل معین مدیریت شود، معمولاً بدون هیچ توضیحی در مورد دلیل عدم موفقیت آنها در یک فایل نوشته میشود. در نتیجه، کل فرآیند پاکسازی دادهها نیز از عدم تعامل رنج میبرد.
رویکردهای جدید به پاکسازی دادهها بر افزایش تعامل تأکید دارند. به عنوان مثال، چرخ پاتر یک ابزار پاکسازی داده در دسترس عموم است که تشخیص و تبدیل اختلاف را ادغام میکند. کاربران به تدریج با ترکیب و اشکالزدایی تبدیلات منفرد، یک گام در هر زمان، در یک رابط کاربری شبیه صفحه گسترده، مجموعهای از تبدیلات را میسازند. تبدیلات را میتوان به صورت گرافیکی یا با ارائه مثال مشخص کرد. نتایج بلافاصله روی رکوردهایی که روی صفحه نمایش قابل مشاهده هستند، نشان داده میشوند. کاربر میتواند تبدیلها را لغو کند، به طوری که تبدیلهایی که خطاهای اضافی ایجاد کردهاند، «پاک» شوند. این ابزار به طور خودکار بررسی اختلاف را در پسزمینه در آخرین نمای تبدیلشده دادهها انجام میدهد. کاربران میتوانند به تدریج تبدیلها را با یافتن اختلافات توسعه داده و اصلاح کنند که منجر به پاکسازی مؤثرتر و کارآمدتر دادهها میشود. بخش 2.5 برخی از تکنیکهای رایج تبدیل دادهها، از جمله نرمالسازی، گسستهسازی، فشردهسازی و نمونهبرداری را معرفی خواهد کرد.
رویکرد دیگر برای افزایش تعامل در پاکسازی دادهها، توسعه زبانهای اعلانی برای تعیین مشخصات عملگرهای تبدیل دادهها است. چنین کاری بر تعریف افزونههای قدرتمند SQL و الگوریتمهایی تمرکز دارد که کاربران را قادر میسازد مشخصات پاکسازی دادهها را به طور مؤثر بیان کنند. همانطور که اطلاعات بیشتری در مورد دادهها کشف میکنیم، بهروزرسانی مداوم فرادادهها برای انعکاس این دانش مهم است. این امر به سرعت بخشیدن به پاکسازی دادهها در نسخههای آینده همان مخزن داده کمک میکند.
ادغام دادهها
دادهکاوی اغلب نیاز به ادغام دادهها دارد – ادغام دادهها از چندین مخزن داده. ادغام دقیق میتواند به کاهش و جلوگیری از افزونگی و ناهماهنگی در مجموعه دادههای حاصل کمک کند. این میتواند به بهبود دقت و سرعت فرآیند دادهکاوی بعدی کمک کند.
ناهمگونی معنایی و ساختار دادهها چالشهای بزرگی را در ادغام دادهها ایجاد میکند. در این بخش، ابتدا مسئله شناسایی موجودیت را معرفی میکنیم که طرحوارهها و اشیاء را از منابع مختلف مطابقت میدهد. سپس، آزمونهای همبستگی را برای تشخیص دادههای عددی و اسمی همبسته ارائه میدهیم. در نهایت، تکثیر تاپلها و تشخیص و حل تعارضات ارزش دادهها را معرفی میکنیم.
مشکل شناسایی موجودیت
احتمالاً وظیفه تجزیه و تحلیل دادههای شما شامل ادغام دادهها خواهد بود که دادهها را از چندین منبع در یک مخزن داده منسجم ترکیب میکند، مانند انبار دادهها. این منابع ممکن است شامل چندین پایگاه داده، مکعبهای داده یا فایلهای مسطح باشند.
در طول یکپارچهسازی دادهها، باید به چندین مسئله توجه کرد. یکپارچهسازی طرحواره و تطبیق شیء میتواند پیچیده باشد. چگونه میتوان موجودیتهای معادل دنیای واقعی را از چندین منبع داده با هم تطبیق داد؟ این موضوع به عنوان مسئله شناسایی موجودیت شناخته میشود. به عنوان مثال، چگونه یک تحلیلگر داده یا یک کامپیوتر میتواند مطمئن شود که customer_id در یک پایگاه داده و cust_number در پایگاه داده دیگر به یک ویژگی اشاره دارند؟ علاوه بر این، میتوان از فراداده برای کمک به شناسایی موجودیت استفاده کرد (به عنوان مثال، کدهای داده برای pay_type در یک پایگاه داده ممکن است “H” و “S” باشند اما در پایگاه داده دیگر 1 و 2 باشند). نمونههایی از فراداده برای هر ویژگی شامل نام، معنی، نوع داده، محدوده مقادیر مجاز برای ویژگی و قوانین null برای مدیریت مقادیر خالی، صفر یا null است (بخش 2.4.2). چنین فرادادههایی میتوانند برای کمک به جلوگیری از خطا در یکپارچهسازی طرحواره استفاده شوند. از این رو، این مرحله همانطور که قبلاً توضیح داده شد، به پاکسازی دادهها نیز مربوط میشود. هنگام تطبیق ویژگیها از یک پایگاه داده به پایگاه داده دیگر در طول یکپارچهسازی، باید به ساختار دادهها توجه ویژهای شود. این امر برای اطمینان از این است که هرگونه وابستگی عملکردی ویژگی و محدودیتهای ارجاعی در سیستم منبع با وابستگیهای عملکردی ویژگیها و محدودیتهای ارجاعی در سیستم هدف مطابقت داشته باشد. به عنوان مثال، در یک سیستم، ممکن است تخفیفی برای سفارش اعمال شود، در حالی که در سیستم دیگر، برای هر یک از اقلام خطی درون سفارش اعمال میشود. اگر این موضوع قبل از ادغام مشخص نشود، اقلام در سیستم هدف ممکن است به طور نامناسبی تخفیف داده شوند.
تحلیل افزونگی و همبستگی
افزونگی یکی دیگر از مسائل مهم در ادغام دادهها است. یک ویژگی (مانند درآمد سالانه، به عنوان مثال) ممکن است اضافی باشد اگر بتوان آن را از ویژگی یا مجموعهای از ویژگیهای دیگر “استخراج” کرد. ناسازگاری در نامگذاری ویژگی یا بُعد نیز میتواند باعث ایجاد افزونگی در مجموعه دادههای حاصل شود.
برخی از افزونگیها را میتوان با تحلیل همبستگی تشخیص داد. با توجه به دو ویژگی، چنین تحلیلی میتواند بر اساس دادههای موجود، میزان تأثیر یک ویژگی بر ویژگی دیگر را اندازهگیری کند. برای دادههای اسمی، میتوانیم از آزمون χ2 (کای دو) استفاده کنیم. برای ویژگیهای عددی، میتوانیم از ضریب همبستگی و کوواریانس استفاده کنیم که هر دو ارزیابی میکنند که چگونه مقادیر یک ویژگی با مقادیر ویژگی دیگر متفاوت است.
تکرار تاپلها
علاوه بر تشخیص افزونگی بین ویژگیها، تکرار باید در سطح تاپلها نیز تشخیص داده شود (مثلاً، جایی که دو یا چند تاپل یکسان برای یک ورودی داده منحصر به فرد وجود دارد). استفاده از جداول غیر نرمال شده (که اغلب برای بهبود عملکرد با اجتناب از اتصال انجام میشود) منبع دیگری از افزونگی دادهها است. ناسازگاریها اغلب بین تکرارهای مختلف، به دلیل ورود نادرست دادهها یا بهروزرسانی برخی از رخدادهای داده (اما نه همه آنها) ایجاد میشوند. به عنوان مثال، اگر یک پایگاه داده سفارش خرید حاوی ویژگیهایی برای نام و آدرس خریدار باشد به جای اینکه کلید این اطلاعات در پایگاه داده خریدار باشد، ممکن است اختلافاتی رخ دهد، مانند اینکه نام خریدار یکسان با آدرسهای مختلف در پایگاه داده سفارش خرید ظاهر شود.
تشخیص و حل تعارض ارزش داده
یکپارچهسازی دادهها همچنین شامل تشخیص و حل تعارض ارزش داده است. به عنوان مثال، برای یک موجودیت در دنیای واقعی، مقادیر ویژگی از منابع مختلف ممکن است متفاوت باشند. این ممکن است به دلیل تفاوت در نمایش، مقیاسبندی یا رمزگذاری باشد. برای مثال، یک ویژگی وزن ممکن است در یک سیستم در واحدهای متریک و در سیستم دیگر در واحدهای امپراتوری بریتانیا ذخیره شود. برای یک زنجیره هتل، قیمت اتاقها در شهرهای مختلف ممکن است نه تنها شامل ارزهای مختلف، بلکه خدمات مختلف (مثلاً صبحانه رایگان) و مالیات نیز باشد. برای مثال، هنگام تبادل اطلاعات بین مدارس، هر مدرسه ممکن است برنامه درسی و طرح نمرهدهی خاص خود را داشته باشد. یک دانشگاه ممکن است سیستم یک چهارم را اتخاذ کند، سه دوره در مورد سیستمهای پایگاه داده ارائه دهد و نمرات را از A+ تا F تعیین کند، در حالی که دانشگاه دیگری ممکن است سیستم ترمی را اتخاذ کند، دو دوره در مورد پایگاه داده ارائه دهد و نمرات را از 1 تا 10 تعیین کند. تعیین قوانین دقیق تبدیل دوره به نمره بین دو دانشگاه دشوار است و تبادل اطلاعات را دشوار میکند.
ویژگیها همچنین ممکن است در سطح انتزاع متفاوت باشند، جایی که یک ویژگی در یک سیستم در سطح انتزاع پایینتری نسبت به ویژگی “مشابه” در سیستم دیگر ثبت میشود. به عنوان مثال، total_sales در یک پایگاه داده ممکن است به یک شعبه از شرکت اشاره داشته باشد، در حالی که یک ویژگی با همان نام در پایگاه داده دیگر ممکن است به کل فروش فروشگاهها در یک منطقه خاص اشاره داشته باشد. موضوع تشخیص اختلاف در بخش ۲.۴.۲ در مورد پاکسازی دادهها به عنوان یک فرآیند توضیح داده شد.


