مقدمه
تجزیه و تحلیل دادهها، که اغلب به عنوان هوش تجاری نیز شناخته میشود، استراتژیها و فناوریهایی است که شرکتها را قادر میسازد تا بینش عمیق و عملی در مورد دادههای تجاری به دست آورند. دادهکاوی نقش اصلی را در تجزیه و تحلیل دادهها و هوش تجاری ایفا میکند. اساساً، انبارهای داده، دادهها را در فضای چندبعدی تعمیم و تجمیع میکنند. ساخت انبارهای داده شامل پاکسازی دادهها، ادغام دادهها و تبدیل دادهها است و میتواند به عنوان یک مرحله مهم آمادهسازی برای دادهکاوی در نظر گرفته شود. علاوه بر این، انبارهای داده ابزارهای پردازش تحلیلی آنلاین (OLAP) را برای تجزیه و تحلیل تعاملی دادههای چندبعدی با جزئیات متنوع ارائه میدهند که تعمیم مؤثر دادهها و دادهکاوی را تسهیل میکند. بسیاری از عملکردهای دادهکاوی دیگر، مانند ارتباط، طبقهبندی، پیشبینی و خوشهبندی، میتوانند با عملیات OLAP ادغام شوند تا کاوش تعاملی دانش در سطوح مختلف انتزاع را بهبود بخشند. ابزارهای OLAP معمولاً از مکعب داده، یک مدل داده چندبعدی، برای ارائه دسترسی انعطافپذیر به دادههای خلاصه شده استفاده میکنند. دریاچههای داده به عنوان زیرساخت اطلاعات سازمانی، دادههای گستردهای را در شرکتها جمعآوری کرده و فرادادهها را ادغام میکنند تا کاوش دادهها به طور مؤثر انجام شود. از این رو، انبارهای داده، OLAP، مکعبهای داده و دریاچههای داده به ستون فقرات ضروری دادهها و اطلاعات برای شرکتها تبدیل شدهاند. این فصل مقدمهای عمیق و جامع بر انبار داده، OLAP، مکعب داده و فناوری دریاچه داده ارائه میدهد. این مرور کلی برای درک کلی فرآیند دادهکاوی و کشف دانش و کاربردهای عملی ضروری است. علاوه بر این، میتواند به عنوان مقدمهای آگاهانه برای تجزیه و تحلیل دادهها و هوش تجاری عمل کند.
در این فصل، ابتدا تعریف پذیرفتهشدهای از انبار داده را مطالعه میکنیم، معماری را معرفی میکنیم و مفهوم دریاچه داده را مورد بحث قرار میدهیم (بخش 3.1). سپس طراحی منطقی یک انبار داده را به عنوان یک مدل داده چندبعدی مطالعه میکنیم (بخش 3.2). سپس، به عملیات OLAP و نحوه فهرستبندی دادههای OLAP برای تجزیه و تحلیل کارآمد میپردازیم (بخش 3.3). در نهایت، تکنیکهای ساخت مکعب داده را به عنوان راهی برای پیادهسازی یک انبار داده معرفی میکنیم (بخش 3.4).
انبار داده
این بخش انبارهای داده را معرفی میکند. ما با تعریف انبارهای داده شروع میکنیم و توضیح میدهیم که چگونه انبارهای داده میتوانند به عنوان پایه و اساس هوش تجاری عمل کنند (بخش ۳.۱.۱). سپس، معماری مخزن داده را مورد بحث قرار میدهیم (بخش ۳.۱.۲). در نهایت، دریاچههای داده را مورد بحث قرار میدهیم (بخش ۳.۱.۳).
انبار داده: چیستی و چرا؟
اغلب اوقات، دادهها در سازمانها در سطح عملیاتی ثبت میشوند. به عنوان مثال، برای کارایی کسب و کار، یک شرکت تجارت الکترونیک اغلب جزئیات تراکنشهای مشتری را در یک جدول، اطلاعات مربوط به مشتریان را در جدول دیگری و اطلاعات مربوط به تأمینکنندگان محصول را در جدول سوم ثبت میکند. دادههای عملیاتی عمدتاً مربوط به عملکردهای تجاری فردی، مانند تراکنش خرید، ثبت مشتری جدید و ارسال دستهای از محصولات به فروشگاه هستند. مزیت اصلی این است که عملیات تجاری، مانند خرید یک محصول توسط مشتری، میتواند با درج، حذف یا تغییر تنها یک یا چند رکورد در یک یا تعداد کمی از جداول، به طور کارآمد انجام شود و بنابراین بسیاری از عملیات تجاری میتوانند به طور همزمان انجام شوند.
در عین حال، تحلیلگران و مدیران تجاری اغلب بر دیدگاههای تاریخی، فعلی و پیشبینیکننده عملیات تجاری به جای جزئیات تراکنشهای فردی تمرکز میکنند. به عنوان مثال، یک تحلیلگر تجاری در یک شرکت تجارت الکترونیک ممکن است بخواهد دستههای مشتریان، مانند گروههای جمعیتی آنها، که بیشترین هزینه را در ماه گذشته داشتهاند و دستههای اصلی محصولاتی که خریداری میکنند را بررسی کند. محاسبه پاسخ به چنین سوالات تحلیلی اغلب زمانبر و منابعبر است، زیرا باید چندین جدول داده را به هم متصل کند و تعداد زیادی عملیات تجمیع گروهی انجام دهد و بنابراین نیاز به دسترسی انحصاری به دادهها دارد. بسیاری از وظایف تجزیه و تحلیل ممکن است دورهای و برخی ممکن است موقت باشند و بنابراین ممکن است به شدت بر عملیات تجاری که انتظار میرود آنلاین، پرتکرار و همزمان باشند، تأثیر بگذارند. برای پر کردن شکاف بین عملیات تجاری و تجزیه و تحلیل، انبار داده معماریها و ابزارهایی را برای تحلیلگران تجاری و مدیران فراهم میکند تا به طور سیستماتیک دادههای خود را سازماندهی، درک و از آنها برای تصمیمگیریهای استراتژیک استفاده کنند. سیستمهای انبار داده ابزارهای ارزشمندی در دنیای رقابتی و به سرعت در حال تحول امروز هستند. در دو دهه گذشته، بسیاری از شرکتها میلیاردها دلار برای ساخت انبارهای داده در سطح سازمانی هزینه کردهاند. به خوبی شناخته شده است که با افزایش رقابت در هر صنعتی، انبار داده زیرساخت ضروری کسب و کار است – راهی برای حفظ مشتریان با کسب اطلاعات بیشتر در مورد خواستهها و رفتار آنها.
“پس، انبار داده دقیقاً چیست؟” به طور کلی، انبار داده به مخزن دادهای اشاره دارد که مخصوص تجزیه و تحلیل است و جدا از پایگاههای داده عملیاتی یک سازمان نگهداری میشود. سیستمهای انبار داده با ارائه یک پلتفرم محکم از دادههای تاریخی تلفیقی برای تجزیه و تحلیل، از پردازش اطلاعات پشتیبانی میکنند.
به گفته ویلیام اچ. اینمون، معمار پیشرو در ساخت سیستمهای انبار داده، «انبار داده مجموعهای از دادههای موضوعگرا، یکپارچه، متغیر با زمان و غیرفرار است که از فرآیند تصمیمگیری مدیریت پشتیبانی میکند» [Inm96]. این تعریف کوتاه اما جامع، ویژگیهای اصلی یک انبار داده را ارائه میدهد. چهار کلمه کلیدی – موضوعگرا، یکپارچه، متغیر با زمان و غیرفرار – انبارهای داده را از سایر سیستمهای مخزن داده، مانند سیستمهای پایگاه داده رابطهای، سیستمهای پردازش تراکنش و سیستمهای فایل، متمایز میکنند.
• موضوعگرا: یک انبار داده حول موضوعات اصلی سازماندهی شده است که اغلب به صورت سازمانی یا بخشی شناسایی میشوند، مانند مشتری، تأمینکننده، محصول و فروش. یک انبار داده به جای تمرکز بر عملیات روزانه و پردازش تراکنشهای یک سازمان، بر مدلسازی و تجزیه و تحلیل دادهها برای تصمیمگیرندگان تمرکز میکند. از این رو، انبارهای داده معمولاً با حذف دادههایی که در فرآیند پشتیبانی تصمیمگیری مفید نیستند، یک نمای ساده و مختصر از موضوعات خاص ارائه میدهند. • یکپارچه: یک انبار داده معمولاً با ادغام چندین منبع ناهمگن، مانند پایگاههای داده رابطهای، فایلهای مسطح و سوابق تراکنشهای آنلاین ساخته میشود. تکنیکهای پاکسازی دادهها و یکپارچهسازی دادهها برای اطمینان از سازگاری در قراردادهای نامگذاری، ساختارهای رمزگذاری، سنجههای ویژگی و غیره اعمال میشوند.
• متغیر با زمان: دادهها برای ارائه اطلاعات از یک دیدگاه تاریخی (مثلاً ۵ تا ۱۰ سال گذشته) ذخیره میشوند. هر ساختار کلیدی در یک انبار داده، به طور ضمنی یا صریح، شامل یک عنصر زمان است. به عبارت دیگر، یک انبار داده معمولاً دادههایی را که از یک تاریخچه زمانی قابل توجه عبور میکنند، ثبت میکند.
• غیرفرار: یک انبار داده همیشه یک مخزن فیزیکی جداگانه از دادههای تبدیلشده از دادههای کاربردی موجود در محیط عملیاتی است. به دلیل این جداسازی، یک انبار داده نیازی به مکانیسمهای قوی پردازش تراکنش، بازیابی و کنترل همزمانی ندارد و بنابراین هیچ تداخلی با سیستمهای عملیاتی ندارد. معمولاً فقط به دو عملیات در دسترسی به دادهها نیاز دارد: بارگذاری اولیه دادهها و دسترسی به دادهها. به عبارت دیگر، دادههای ذخیرهشده در یک انبار داده معمولاً حذف نمیشوند.
به طور خلاصه، یک انبار داده یک مخزن داده از نظر معنایی سازگار و پایدار است که به عنوان یک پیادهسازی فیزیکی از یک مدل داده پشتیبانی تصمیمگیری عمل میکند. این انبار، اطلاعاتی را که یک شرکت برای تصمیمگیریهای استراتژیک نیاز دارد، ذخیره میکند. یک انبار داده همچنین اغلب به عنوان یک معماری در نظر گرفته میشود که با ادغام دادهها از منابع ناهمگن متعدد برای پشتیبانی از پرسوجوهای ساختاریافته و/یا موردی، گزارشدهی تحلیلی و تصمیمگیری ساخته شده است. به همین ترتیب، انبار داده فرآیند ساخت و استفاده از انبارهای داده است. ساخت یک انبار داده نیاز به پاکسازی دادهها، ادغام دادهها و ادغام دادهها دارد.
“سازمانها چگونه از اطلاعات انبارهای داده استفاده میکنند؟” بسیاری از سازمانها از این اطلاعات برای پشتیبانی از فعالیتهای تصمیمگیری تجاری استفاده میکنند. به عنوان مثال، با شناسایی گروههایی از فعالترین مشتریان، یک شرکت تجارت الکترونیک میتواند کمپینهای تبلیغاتی را برای حفظ پایدار آن مشتریان طراحی کند. با تجزیه و تحلیل الگوهای فروش محصولات در فصول مختلف، یک شرکت میتواند استراتژیهای زنجیره تأمین را برای کاهش هزینه انبارداری محصولات فصلی طراحی کند. نتایج تحلیلی از انبارهای داده اغلب از طریق گزارشهای دورهای یا موردی، مانند گزارشهای تحلیل فروش روزانه، هفتگی و ماهانه که الگوهای فروش را در گروههای مشتری، مناطق، محصولات و تبلیغات تجزیه و تحلیل میکنند، به تحلیلگران و تصمیمگیرندگان ارائه میشود.
“تفاوتهای عمده بین سیستمهای پایگاه داده عملیاتی و انبارهای داده چیست؟” وظیفه اصلی سیستمهای پایگاه داده عملیاتی سنتی انجام پردازش تراکنشهای آنلاین (OLTP) است. این سیستمهای OLTP بیشتر عملیات روزانه یک سازمان، مانند خرید، موجودی، تولید، بانکداری، حقوق و دستمزد، ثبت نام و حسابداری را پوشش میدهند. سیستمهای انبار داده به تحلیلگران و مدیران کسبوکار (که بهطورکلی به عنوان کارکنان دانش نیز شناخته میشوند) در نقش کسب بینشهای تجاری و تصمیمگیری با سازماندهی و ارائه دادهها در دیدگاههای مختلف به منظور برآورده کردن نیازهای متنوع کاربران مختلف، خدمت میکنند. این سیستمها به عنوان سیستمهای پردازش تحلیلی آنلاین (OLAP) شناخته میشوند.
ویژگیهای اصلی متمایز OLTP و OLAP
• جهتگیری کاربران و سیستم: یک سیستم OLTP تراکنشمحور است و برای اجرای عملیات توسط کارمندان و مشتریان استفاده میشود. یک سیستم OLAP بینشمحور است و برای خلاصهسازی و تحلیل دادهها توسط کارکنان دانش، از جمله مدیران، مدیران اجرایی و تحلیلگران استفاده میشود.
• محتوای دادهها: یک سیستم OLTP دادههای فعلی را که معمولاً بسیار دقیق هستند و به راحتی برای تصمیمگیری تجاری قابل استفاده نیستند، مدیریت میکند. یک سیستم OLAP مقادیر زیادی از دادههای تاریخی را مدیریت میکند، امکاناتی را برای خلاصهسازی و تجمیع فراهم میکند و اطلاعات را در سطوح مختلف جزئیات، مانند هفتگی-ماهانه-سالانه، ذخیره و مدیریت میکند. این ویژگیها استفاده از دادهها را برای تصمیمگیری آگاهانه آسانتر میکند.
• طراحی پایگاه داده: یک سیستم OLTP معمولاً از یک مدل داده رابطه-موجودیت (ER) و یک طراحی پایگاه داده مبتنی بر برنامه استفاده میکند. یک سیستم OLAP معمولاً از یک مدل ستارهای یا یک مدل دانه برفی (به بخش 3.2.2 مراجعه کنید) و یک طراحی پایگاه داده مبتنی بر موضوع استفاده میکند.
• مشاهده: یک سیستم OLTP عمدتاً بر دادههای فعلی در یک شرکت یا بخش تمرکز دارد، بدون اینکه به دادههای تاریخی یا دادههای سازمانهای مختلف اشاره کند. در مقابل، یک سیستم OLAP اغلب به دلیل فرآیند تکاملی یک سازمان، چندین نسخه از یک طرح پایگاه داده را در بر میگیرد. سیستمهای OLAP همچنین با اطلاعاتی که از سازمانهای مختلف سرچشمه میگیرند، سر و کار دارند و اطلاعات را از بسیاری از انبارهای داده ادغام میکنند.
• الگوهای دسترسی: الگوهای دسترسی یک سیستم OLTP عمدتاً از تراکنشهای کوتاه و اتمیک، مانند انتقال مبلغ از یک حساب به حساب دیگر، تشکیل شده است. چنین سیستمی نیاز به مکانیسمهای کنترل و بازیابی همزمان دارد. با این حال، دسترسیها به سیستمهای OLAP عمدتاً عملیات فقط خواندنی هستند (زیرا اکثر انبارهای داده به جای اطلاعات بهروز، اطلاعات تاریخی را ذخیره میکنند). بسیاری از دسترسیها ممکن است پرسوجوهای پیچیده باشند.
«چرا OLAP را مستقیماً روی پایگاههای داده عملیاتی اجرا نکنیم به جای اینکه یک انبار داده جداگانه بسازیم؟» دلیل اصلی جداسازی، تضمین عملکرد بالای هر دو سیستم است. یک پایگاه داده عملیاتی از وظایف و حجم کاری شناختهشدهای مانند نمایهسازی و هش کردن با استفاده از کلیدهای اصلی، جستجوی رکوردهای خاص و بهینهسازی پرسوجوهای «مخفی» که پرسوجوهای از پیش برنامهریزیشده و پرکاربرد در کسبوکار هستند، طراحی و تنظیم میشود. با این حال، پرسوجوهای OLAP اغلب پیچیده هستند. آنها شامل محاسبه گروههای داده بزرگ در سطوح خلاصهشده هستند و ممکن است نیاز به استفاده از روشهای خاص سازماندهی، دسترسی و پیادهسازی دادهها بر اساس دیدگاههای چندبعدی داشته باشند. پردازش پرسوجوهای OLAP به طور مستقیم در پایگاههای داده عملیاتی ممکن است عملکرد وظایف عملیاتی را به طور قابل توجهی به خطر بیندازد. یک پایگاه داده عملیاتی از پردازش همزمان چندین تراکنش پشتیبانی میکند. مکانیسمهای کنترل و بازیابی همزمان (مانند قفل کردن و ثبت وقایع) برای اطمینان از سازگاری و استحکام تراکنشها مورد نیاز هستند. یک پرسوجوی OLAP اغلب برای خلاصهسازی و تجمیع، نیاز به دسترسی فقط خواندنی به رکوردهای داده حجیم دارد. مکانیسمهای کنترل و بازیابی همزمانی، در صورت اعمال برای چنین عملیات OLAP، ممکن است اجرای تراکنشهای همزمان را به طور جدی به تأخیر بیندازند و در نتیجه به طور قابل توجهی توان عملیاتی یک سیستم OLTP را کاهش دهند.
در نهایت، جداسازی پایگاههای داده عملیاتی از انبارهای داده بر اساس ساختارها، محتواها و کاربردهای مختلف دادهها در این دو نوع سیستم است. پشتیبانی تصمیمگیری به دادههای تاریخی نیاز دارد، در حالی که پایگاههای داده عملیاتی معمولاً دادههای تاریخی را نگهداری نمیکنند. در این زمینه، دادهها در پایگاههای داده عملیاتی معمولاً برای تصمیمگیری کامل نیستند. پشتیبانی تصمیمگیری نیاز به تجمیع (مثلاً تجمیع و خلاصهسازی) دادهها از منابع ناهمگن دارد که منجر به دادههای با کیفیت بالا، تمیز و یکپارچه میشود. در مقابل، پایگاههای داده عملیاتی فقط حاوی دادههای خام دقیق، مانند تراکنشها هستند که باید قبل از تجزیه و تحلیل تجمیع شوند. از آنجا که این دو سیستم عملکردهای کاملاً متفاوتی ارائه میدهند و به انواع مختلفی از دادهها نیاز دارند، در حال حاضر نگهداری پایگاههای داده جداگانه ضروری است.
معماری انبارهای داده: انبارهای داده سازمانی و مراکز داده
«معماری یک انبار داده چگونه است؟» برای پاسخ به این سوال، ابتدا معماری سه لایه عمومی انبارهای داده را معرفی میکنیم و سپس دو مدل اصلی انبار داده را مورد بحث قرار میدهیم: انبار سازمانی و مرکز داده.
معماری سه لایه
انبارهای داده اغلب از معماری سه لایه استفاده میکنند، همانطور که در شکل ۳.۱ نشان داده شده است.
سطح پایین یک سرور پایگاه داده انبار است که معمولاً یک سیستم پایگاه داده جریان اصلی، مانند یک پایگاه داده رابطهای یا یک فروشگاه کلید-مقدار است. ابزارهای back-end و ابزارهای استخراج/تبدیل/بارگذاری داده (ETL) برای تغذیه دادهها به سطح پایین از پایگاههای داده عملیاتی یا سایر منابع خارجی (به عنوان مثال، اطلاعات پروفایل مشتری ارائه شده توسط شرکای خارجی) استفاده میشوند. این ابزارها و ابزارها، استخراج، پاکسازی و تبدیل دادهها و همچنین توابع بارگذاری و بهروزرسانی را برای بهروزرسانی انبار داده انجام میدهند. این سطح همچنین شامل یک مخزن فراداده است که اطلاعات مربوط به انبار داده و محتویات آن را ذخیره میکند. لایه میانی یک سرور OLAP است که معمولاً با استفاده از یک مدل OLAP رابطهای (ROLAP) (یعنی یک DBMS رابطهای توسعهیافته که عملیات روی دادههای چندبعدی را به عملیات رابطهای استاندارد نگاشت میکند) یا یک مدل OLAP چندبعدی (MOLAP) (یعنی یک سرور خاص منظوره که مستقیماً دادهها و عملیات چندبعدی را پیادهسازی میکند) پیادهسازی میشود. به زودی در مورد سرورهای OLAP به تفصیل بحث خواهیم کرد.
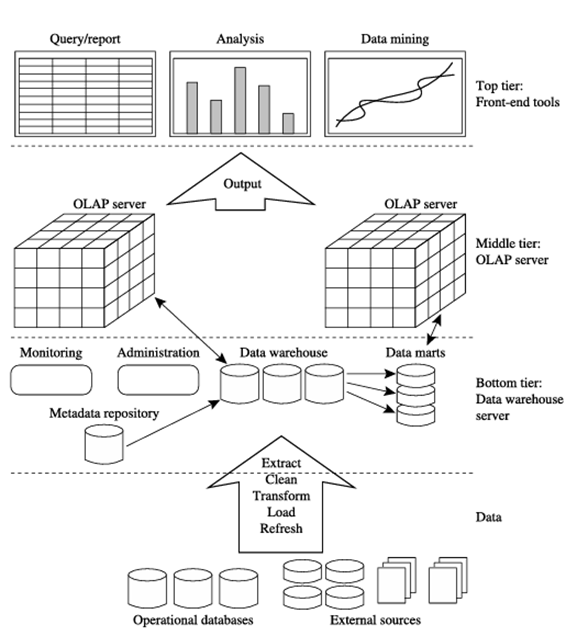
لایه میانی یک سرور OLAP است که معمولاً با استفاده از یک مدل OLAP رابطهای (ROLAP) (یعنی یک DBMS رابطهای توسعهیافته که عملیات روی دادههای چندبعدی را به عملیات رابطهای استاندارد نگاشت میکند) یا یک مدل OLAP چندبعدی (MOLAP) (یعنی یک سرور خاص منظوره که مستقیماً دادهها و عملیات چندبعدی را پیادهسازی میکند) پیادهسازی میشود. به زودی در مورد سرورهای OLAP به تفصیل بحث خواهیم کرد. لایه بالایی یک لایه کلاینت front-end است که شامل ابزارهایی برای پرسوجو، گزارشدهی، تجسم، تجزیه و تحلیل و/یا دادهکاوی، مانند تجزیه و تحلیل روند و پیشبینی است.
“فراداده در یک سرور پایگاه داده انبار چیست؟” فرادادهها دادههایی درباره دادهها هستند. هنگامی که در یک انبار داده استفاده میشوند، فرادادهها دادههایی هستند که اشیاء انبار را تعریف میکنند. فرادادهها برای نامها و تعاریف دادههای انبار داده ایجاد میشوند. فرادادههای اضافی ممکن است برای مهر زمانی هر داده استخراج شده، منبع دادههای استخراج شده و فیلدهای گمشده که توسط فرآیندهای پاکسازی یا ادغام دادهها اضافه شدهاند، ایجاد و ضبط شوند.
… علاوه بر این، یک مخزن فراداده ممکن است شامل شرحی از ساختار انبار داده (مثلاً طرحواره، نما، ابعاد، تعریف دادههای مشتقشده و غیره)، فراداده عملیاتی (مثلاً تبار تبدیل دادهها، تازگی دادهها)، تعاریف خلاصهسازی دادهها، نگاشت از دادههای عملیاتی به انبار داده، اطلاعات سیستم و اطلاعات تجاری مرتبط باشد.
فرادادهها نقش بسیار متفاوتی نسبت به سایر دادههای انبار داده ایفا میکنند و به دلایل زیادی مهم هستند. به عنوان مثال، فرادادهها به عنوان یک فهرست راهنما برای کمک به تحلیلگران در یافتن محتویات یک انبار داده و به عنوان راهنمایی برای نگاشت دادهها هنگام تبدیل دادهها از محیط عملیاتی به محیط انبار داده استفاده میشوند. فراداده همچنین به عنوان راهنمایی برای الگوریتمهای مورد استفاده برای خلاصهسازی بین دادههای دقیق فعلی و دادههای کمی خلاصهشده و بین دادههای کمی خلاصهشده و دادههای بسیار خلاصهشده عمل میکند. فرادادهها باید به طور مداوم (یعنی روی دیسک) ذخیره و مدیریت شوند.
سیستمهای انبار داده از ابزارها و ابزارهای پشتیبان برای پر کردن و بهروزرسانی دادههای خود استفاده میکنند (شکل 3.1). این ابزارها و خدمات شامل عملکردهای استخراج دادهها (جمعآوری دادهها از منابع متعدد، ناهمگن و خارجی)، پاکسازی دادهها (تشخیص خطاها در دادهها و اصلاح آنها در صورت امکان)، تبدیل دادهها (تبدیل دادهها از قالب قدیمی یا میزبان به قالب انبار)، بارگیری (مرتبسازی، خلاصهسازی، ادغام، محاسبه نماها، بررسی یکپارچگی و ساخت شاخصها و پارتیشنها) و تازهسازی (انتشار بهروزرسانیها از منابع داده به انبار) میشوند. علاوه بر این، سیستمهای انبار داده معمولاً مجموعه خوبی از ابزارهای مدیریت انبار داده را ارائه میدهند.
ETL برای انبارهای داده
به منظور بارگیری و بهروزرسانی دورهای محتوا در انبارهای داده، معمولاً سیستمهای انبار داده برخی از ماژولهای ETL را پیادهسازی میکنند. ما در فصل 2 در مورد تکنیکها و روشهای ضروری برای استخراج، تبدیل و بارگیری دادهها که در خدمت انبار دادهها نیز هستند، بحث میکنیم. در اینجا، به طور خلاصه برخی از وظایف اصلی ETL را برای انبارهای داده معرفی میکنیم.
استخراج دادهها
یک فرآیند استخراج دادهها، دادهها را از منابع خارجی استخراج میکند و اغلب مهمترین جنبه ETL است. برای مثال، یک انبار داده ممکن است نیاز به استخراج دادههای تراکنش از یک پایگاه داده OLTP و همچنین دادههای نقد کاربر از مخزن رسانههای اجتماعی داشته باشد. برای کپسولهسازی جزئیات منابع داده مختلف، اغلب بستهبندیهایی توسعه داده و مستقر میشوند که با منابع داده تعامل دارند و دادههای استخراج شده را به ماژول ETL ارائه میدهند. با توجه به تنوع و پویایی منابع داده، توسعه دستی بستهبندیها اغلب از نظر کیفیت ناکارآمد و بیاثر است. اخیراً، بستهبندیهای بیشتری دادهمحور هستند و میتوانند به طور خودکار با تغییرات منابع داده، مانند تغییرات در طرحواره، فرکانس بهروزرسانی، طرحبندی و کدگذاری، سازگار شوند. به عنوان مثال، یک بستهبندی برای یک پایگاه داده OLTP میتواند بهروزرسانیهای طرحواره را نظارت و با آنها سازگار شود. یک بستهبندی برای یک رسانه اجتماعی میتواند دادهها را از رسانههای اجتماعی خزش کند و فیلدهای کلیدی را از متن، مانند نام محصول و احساسات نقد کاربر، استخراج کند. علاوه بر این، بستهبندی ممکن است بتواند با تغییرات در طرحبندیهای رسانههای اجتماعی سازگار شود و در برابر هرزنامه مقاوم بماند.
تبدیل دادهها
اغلب اوقات، دادههای استخراجشده از منابع ممکن است الزامات یک انبار داده را فوراً برآورده نکنند. ممکن است برخی شکافها، مانند عدم تطابق در قالب دادهها، اعمال محدودیتهای یکپارچگی کسبوکار و الزامات مربوط به کیفیت دادهها، وجود داشته باشد. تبدیل دادهها، قوانین و توابعی را برای تبدیل دادههای استخراجشده، اعمال منطق کسبوکار و بهبود کیفیت اعمال میکند، به طوری که دادههای تبدیلشده آماده بارگذاری در انبار داده باشند. به عنوان مثال، در مرحله تبدیل، دادههای مربوط به آدرسها میتوانند پاکسازی شوند تا نمایش استاندارد آدرسها استفاده شود و اطلاعات صحیح در مورد کشور، استان، شهر و کد پستی شناسایی و کدگذاری شود. علاوه بر این، از طریق تبدیل، میتوانیم منطق کسبوکار را اعمال کنیم، مانند الزام به اینکه هر تراکنش با مبلغ بیش از 1 میلیون دلار باید با نماینده مشتری مرتبط باشد. پاکسازی دادهها و بهبود کیفیت نیز وظایف مهمی در مرحله تبدیل دادهها هستند.
تبدیل دادهها یک فرآیند پویا است. تکنیکهای دادهکاوی اغلب در تبدیل دادهها استفاده میشوند. به عنوان مثال، تکنیکهای دادهکاوی میتوانند برای تشخیص مشکلات کیفیت دادهها و بهبود پاکسازی دادهها استفاده شوند. علاوه بر این، با پیشرفت کسبوکار، منطق کسبوکار نیز به طور متناسب تکامل مییابد. فرآیند تبدیل دادهها باید بر این اساس بهروزرسانی شود. بارگذاری دادهها
پس از استخراج دادهها از منابع و تبدیل آنها، مرحله بارگذاری، دادهها را در انبارهای داده بارگذاری میکند. بارگذاری ممکن است به روشهای مختلفی انجام شود. به عنوان مثال، یک انبار داده نسبتاً کوچک ممکن است دادهها را به صورت متمرکز و دورهای بارگذاری کند (مثلاً بارگیری روزانه، هفتگی یا ماهانه). یک انبار داده بزرگ که از سرورهای توزیعشده زیادی عبور میکند، ممکن است مجبور باشد دادهها را به صورت توزیعشده بارگذاری کند. اگر یک انبار داده از یک کسبوکار بسیار حساس به زمان پشتیبانی کند، انبار داده ممکن است مجبور شود دادهها را به صورت پرتکرار یا حتی در زمان واقعی بارگذاری کند. بارگذاری دادهها اغلب زمانبر و کندترین بخش یک فرآیند ETL است. بارگذاری همچنین ممکن است بر در دسترس بودن، قابلیت استفاده و پهنای باند یک انبار داده تأثیر بگذارد. تکنیکهای مختلفی برای دستیابی به عملکرد بالا در بارگذاری دادهها در انبارهای داده و به حداقل رساندن تداخل با خدمات منظم ارائه شده توسط انبارهای داده توسعه داده شدهاند.
انبار داده سازمانی و بازار داده
از دیدگاه معماری، دو مدل اصلی انبار داده وجود دارد، یعنی انبار سازمانی و بازار داده.
انبار سازمانی: یک انبار سازمانی تمام اطلاعات مربوط به موضوعاتی را که کل سازمان را در بر میگیرد، جمعآوری میکند. این سیستم، یکپارچهسازی دادهها در سطح شرکت، معمولاً از یک یا چند سیستم عملیاتی یا ارائهدهندگان اطلاعات خارجی، را فراهم میکند و دامنه آن بینبخشی است. معمولاً حاوی دادههای دقیق و دادههای خلاصهشده است و میتواند از صدها گیگابایت تا ترابایت یا فراتر از آن متغیر باشد. این سیستم به مدلسازی گسترده کسبوکار در سطح سازمانی نیاز دارد و طراحی و ساخت آن ممکن است سالها طول بکشد.
مارت داده: یک مارت داده شامل زیرمجموعهای از دادههای کل شرکت است که برای گروه خاصی از کاربران، مانند کاربران یک بخش تجاری، ارزشمند است. دامنه آن به موضوعات خاص انتخابشده محدود میشود. به عنوان مثال، یک مارت داده بازاریابی ممکن است موضوعات خود را به مشتری، کالا، کانال بازاریابی و فروش محدود کند. یک مارت داده کنترل ریسک ممکن است بر اعتبار مشتری، ریسک و انواع مختلف کلاهبرداری تمرکز کند. دادههای موجود در مارتهای داده معمولاً خلاصه میشوند. چرخه پیادهسازی یک مارت داده به احتمال زیاد در هفتهها اندازهگیری میشود تا ماهها یا سالها. با این حال، اگر طراحی و برنامهریزی آن در سطح شرکت نباشد، ممکن است در درازمدت شامل یکپارچهسازی پیچیدهای باشد. بسته به منبع دادهها، میتوان دیتا مارتها را به صورت مستقل یا وابسته طبقهبندی کرد. دیتا مارتهای مستقل از دادههای گرفته شده از یک یا چند سیستم عملیاتی یا ارائه دهندگان اطلاعات خارجی، یا از دادههای تولید شده محلی در یک بخش یا منطقه جغرافیایی خاص، تهیه میشوند. دیتا مارتهای وابسته مستقیماً از انبارهای داده سازمانی تهیه میشوند. در عمل، بسیاری از دیتا مارتها، دادهها را هم از انبارهای داده سازمانی و هم از منابع داده داخلی خارجی یا خاص بارگیری میکنند.
در برخی شرایط، از یک انبار مجازی نیز استفاده میشود که مجموعهای از نماها بر روی پایگاههای داده عملیاتی است. برای پردازش پرس و جو کارآمد، فقط برخی از نماهای خلاصه ممکن ممکن است قابل اجرا باشند. ساخت یک انبار مجازی آسان است، اما سربار اضافی را بر روی سرورهای پایگاه داده عملیاتی تحمیل میکند.
“اغلب گفته میشود که شرکتها بیشتر و بیشتر از هوش مصنوعی (به اختصار AI) در تجارت استفاده میکنند و دادهها پایه و اساس هوش مصنوعی هستند. رابطه بین انبارهای داده و هوش مصنوعی چیست؟” به طور کلی، انبارهای داده میتوانند از استقرار قابلیتهای هوش مصنوعی و یادگیری ماشین پشتیبانی کنند. در عین حال، میتوان از ابزارهای هوش مصنوعی و یادگیری ماشین بر روی انبارهای داده برای بهترین بهرهگیری از انبارهای داده استفاده کرد.
هوش مصنوعی به سیستمهای کامپیوتری مختلفی اشاره دارد که میتوانند وظایفی را انجام دهند که معمولاً به هوش انسانی نیاز دارند، مانند بازیهای تختهای، رانندگی خودکار و گفتگو با انسانها. یادگیری ماشین، یکی از فناوریهای اصلی در هوش مصنوعی، ساخت سیستمهای کامپیوتری است که میتوانند بدون برنامهریزی صریح دستورالعملهای خاص، یاد بگیرند. بسیاری از تکنیکهای یادگیری ماشین توسط دادهکاوی استفاده میشوند، مانند طبقهبندی و خوشهبندی، که بعداً در این کتاب به تفصیل مورد بحث قرار خواهند گرفت.
ابزارهای هوش مصنوعی و یادگیری ماشین برای ساخت مدلهای مختلف برای وظایف پیچیده، نیاز به مصرف مقادیر قابل توجهی داده دارند. انبارهای داده، دادهها را در سطوح مناسب سازماندهی و خلاصه میکنند و بنابراین میتوانند از استقرار قابلیتهای هوش مصنوعی و یادگیری ماشین پشتیبانی کنند. به عنوان مثال، یک شرکت تجارت الکترونیک ممکن است بخواهد یک مدل هوش مصنوعی بسازد تا مشتریان را برای مدیریت بهتر ارتباط با مشتری، در گروههای مختلف دستهبندی کند. این کار پیچیده میتواند به طور قابل توجهی از یک بازار داده اطلاعات مشتری بهرهمند شود که میتواند دادههای تمیز، یکپارچه و خلاصه شده در مورد مشتریان را ارائه دهد.
در عین حال، تکنیکهای هوش مصنوعی و یادگیری ماشین به طور گسترده در مراحل مختلف انبار دادهها استفاده میشوند. برای مثال، تکنیکهای یادگیری ماشین میتوانند در ساخت انبارهای داده، مانند پر کردن مقادیر گمشده و شناسایی موجودیتها در پاکسازی دادهها (به فصل 2 مراجعه کنید) استفاده شوند. علاوه بر این، خروجی مدلهای هوش مصنوعی ممکن است در یک انبار داده گنجانده شود. به عنوان مثال، یک بازار داده از اطلاعات مشتری احتمالاً شامل پروفایلهای مشتری است که در آن مشتریان و گروههای مشتری اغلب بر اساس رفتارشان، مانند گروههای سنی، سطح درآمد و ترجیحات مصرف، برچسبگذاری میشوند. این برچسبها اغلب توسط مدلهای یادگیری ماشینی آموزش دیده از دادههای مشتری پیشبینی میشوند. سوم، تکنیکهای هوش مصنوعی و یادگیری ماشینی میتوانند برای بهینهسازی عملکرد انبار داده استفاده شوند. به عنوان مثال، تکنیکهای یادگیری ماشینی میتوانند برای تنظیم عملکرد نمایهسازی دادهها و اجرای وظایف در انبارهای داده توزیع شده در مراکز داده بزرگ استفاده شوند و همچنین میتوانند به کاهش قابل توجه مصرف برق کمک کنند. در نهایت، تکنیکهای هوش مصنوعی و یادگیری ماشینی برای کارکنان دانش ضروری هستند تا دادهها را در انبارهای داده کاوش و درک کنند و تصمیمات آگاهانه بگیرند. به عنوان مثال، یک تحلیلگر میتواند مدلهای یادگیری ماشینی را برای بررسی رابطه بین نرخ رشد کسب و کار در مناطق مختلف و هزینه بازاریابی بسازد. مثالهای بیشتر در بخش بعدی این کتاب ارائه خواهد شد.
دریاچههای داده
«در برخی سازمانها، مردم از «دریاچههای داده» یاد میکنند. دریاچههای داده چیستند و روابط و تفاوتهای بین دریاچههای داده و انبارهای داده چیست؟» در یک سازمان بزرگ، اغلب تعداد زیادی منبع داده پیچیده با تنوع زیاد در انواع، قالبها و کیفیت دادهها وجود دارد، مانند دادههای تجاری در پایگاههای داده رابطهای، سوابق ارتباطی بین مشتریان و سازمان، مقررات، تحلیل بازار و اطلاعات بازار خارجی. بسیاری از تحلیلهای اکتشاف داده یکباره هستند و ممکن است مجبور به استفاده از دادهها از گوشه و کنار مختلف باشند. طراحی و توسعه یک انبار داده، جایی که دادهها بر اساس کاربردهای تعریفشده یکپارچه، تبدیل، ساختاریافته و بارگذاری میشوند، ممکن است زمان زیادی طول بکشد. علاوه بر این، بسیاری از کاوشهای مبتنی بر داده باید هوش تجاری سلف سرویس باشند تا دانشمندان داده بتوانند خودشان دادهها را تجزیه و تحلیل و کاوش کنند. برای رسیدگی به تقاضاهای گسترده استفاده از دادهها در سازمان، به عنوان یک جایگزین، میتوان یک دریاچه داده ساخت.
از نظر مفهومی، دریاچه داده یک مخزن واحد از تمام دادههای سازمانی در قالب طبیعی، مانند دادههای رابطهای، دادههای نیمهساختاریافته (مانند XML، CSV، JSON)، دادههای بدون ساختار (مانند ایمیلها، فایلهای PDF) و حتی دادههای دودویی (مانند تصاویر، صدا، ویدیو) است. اغلب اوقات، یک دریاچه داده به شکل بلوکهای شیء یا فایلها است و با استفاده از یک مخزن داده مبتنی بر ابر یا توزیعشده میزبانی میشود. یک دریاچه داده اغلب هم نسخههای خام داده و هم دادههای تبدیلشده را ذخیره میکند. بسیاری از وظایف تحلیلی، مانند گزارشدهی، تجسم، تجزیه و تحلیل و دادهکاوی، میتوانند در دریاچههای داده انجام شوند.
تفاوتهای بنیادین انبارهای داده و دریاچههای داده
نخست، برای ساخت یک انبار داده، لازم است که منابع داده تحلیل شوند، فرآیندهای کسبوکار درک گردند و مدلهای دادهای متناظر با آنها توسعه یابند. موضوعات موجود در انبار دادهها بازتابدهندهی فاکتورهای موجود در تحلیل کسبوکار و فرآیندهای تصمیمسازیِ مرتبط هستند. در نقطه مقابل، یک دریاچه داده تمامی دادههای یک سازمان را، شامل دادههای جاری و تاریخی ، و همچنین دادههایی که هماکنون در حال استفاده هستند و دادههایی که در حال حاضر مورد استفاده نیستند، حفظ میکند. منطق حاکم بر این رویکرد آن است که دریاچه داده به عنوان یک مخزن جامع، میتواند به عنوان پایهای برای تمامی وظایف مرتبط با داده در حال و آینده مورد بهرهبرداری قرار گیرد.
دوم، یک انبار داده معمولاً دادههای استخراجشده از دادههای تراکنشی را ذخیره میکند که شامل سنجههای کمی و مقادیر ویژگی است و دادههای غیر رابطهای نظیر متن، تصویر و ویدئو را چندان پوشش نمیدهد. دادهها بر اساس طرحوارههای از پیش تعریفشده در انبارهای داده بارگذاری میشوند. در مقابل، یک دریاچه داده به صورت بومی پذیرای تمامی انواع داده است. در اینجا، دادهها تنها زمانی که مورد استفاده قرار میگیرند، دچار تبدیل میشوند اشاره به مفهوم.
سوم، انبار داده برای تحلیلگران داده و مدیران اجرایی طراحی شده است. پرسوجوهای روی انبار داده معمولاً پشتیبانِ فرایند تصمیمسازی هستند. در مقابل، از آنجا که دریاچه داده شامل تمامی دادهها به فرم طبیعی است، میتواند از تمامی کاربران در یک سازمان، شامل کاربران عملیاتی، تحلیلگران و مدیران اجرایی پشتیبانی کند.
چهارم، ساختارهای خوشطراحیشده در یک انبار داده، پشتیبانی با کیفیت بالایی را برای وظایف تحلیلی هدف فراهم میکنند. با این حال، برای پرسوجوهای جدید یا تغییرات کسبوکار که توسط طراحی فعلی انبار داده پوشش داده نشدهاند، ارتقای انبار داده برای پاسخگویی به تقاضاهای جدید زمانبر است، که این مورد نقطه درد اصلی در انبارداری داده محسوب میشود. در مقابل، یک دریاچه داده تمامی دادهها را به فرم خام ذخیره میکند و بنابراین همواره برای کاوش هرگونه کاربرد نوین در دسترس است. دانشمندان داده میتوانند مستقیماً روی دریاچههای داده کار کنند تا تحلیل داده را انجام دهند. نتایج این تحلیلها نیز ممکن است خود به بخشی از دریاچه داده تبدیل شوند.
در آخر، از آنجایی که ساخت یک انبار داده به زمان و منابع نیاز دارد، یک انبار داده معمولاً نمیتواند همه کاربران تجاری و تحلیلی در یک سازمان را پوشش دهد. برای آن دسته از کسبوکارها و کاربرانی که توسط یک انبار داده پشتیبانی نمیشوند، همچنان میتوانند از یک دریاچه داده برای دستیابی به بینشهای سریعتر استفاده کنند.
انبارهای داده و دریاچههای داده دو دیدگاه در مورد تجزیه و تحلیل دادهها را نشان میدهند. انبارهای داده بیشتر از بالا به پایین، ساختاریافته و متمرکز هستند. در مقابل، دریاچههای داده بیشتر از پایین به بالا، نمونهسازی سریع و دموکراتیک هستند. در عمل سازمانی، اغلب ترکیبی برای برداشت بهترین سود اعمال میشود.
“از آنجایی که یک دریاچه داده باید تمام دادههای سازمانی را ذخیره کند، که اغلب از نظر اندازه بسیار بزرگ و از نظر نوع و قالب متنوع هستند، دادهها در یک دریاچه داده چگونه ذخیره و سازماندهی میشوند؟” معمولاً دریاچههای داده دارای یک لایه ذخیرهسازی اصلی هستند که دادههای خام و/یا با پردازش سبک را ذخیره میکند. چندین ملاحظه مهم در طراحی و پیادهسازی ذخیرهسازی دریاچه داده وجود دارد. اول، از آنجایی که دریاچههای داده به عنوان مخزن داده متمرکز برای کل یک سازمان عمل میکنند، ذخیرهسازی دادهها باید فوقالعاده مقیاسپذیر باشد. دوم، از آنجایی که دریاچههای داده باید به طیف گستردهای از پرسوجوها و وظایف تحلیلی پاسخ دهند، استحکام دادهها بسیار مهم است. در نتیجه، لایه ذخیرهسازی داده باید از دوام بالایی برخوردار باشد. به عبارت دیگر، دادههای ذخیره شده در دریاچه داده باید همیشه دستنخورده و بکر باشند. سوم، برای پرداختن به تنوع دادهها در شرکتها، ذخیرهسازی دریاچه داده باید از انواع مختلف دادهها در قالبهای مختلف، از جمله دادههای ساختاریافته، دادههای نیمهساختاریافته و دادههای بدون ساختار، پشتیبانی کند. همه این دادهها باید به طور مداوم و هماهنگ در یک مخزن ذخیره و مدیریت شوند. چهارم، از آنجایی که دریاچههای داده برای پشتیبانی از انواع مختلف پرسوجوها، تحلیلها و برنامهها استفاده میشوند، ذخیرهسازی داده باید بتواند از طرحوارههای داده مختلفی پشتیبانی کند که بسیاری از آنها ممکن است هنگام طراحی دریاچههای داده شناخته شده یا در دسترس نباشند. به عبارت دیگر، ذخیرهسازی دریاچه داده باید مستقل از هرگونه طرحواره ثابت باشد. در نهایت، برخلاف بسیاری از برنامههایی که دادهها و محاسبات مربوط به شرکتها هستند، لایه ذخیرهسازی دریاچههای داده باید از منابع محاسباتی جدا شود، به طوری که منابع محاسباتی مختلف، از سرورهای اصلی قدیمی گرفته تا ابرها، بتوانند به دادهها در دریاچههای داده دسترسی داشته باشند. این جداسازی میتواند حداکثر مقیاسپذیری را هم در دریاچههای داده و هم در برنامههای پشتیبانیشده توسط دریاچههای داده فراهم کند.
از نظر مفهومی، یک دریاچه داده دارای یک لایه ذخیرهسازی به عنوان یک مخزن واحد است. در پیادهسازی، مخزن داده همچنان به چندین لایه تقسیم میشود. معمولاً مخزن دارای سه لایه اجباری است: دادههای خام، دادههای پاکسازیشده و دادههای برنامه. به صورت اختیاری، یک لایه داده استاندارد و یک لایه جعبه شنی ممکن است اضافه شود. اجازه دهید لایهها را از پایین به بالا توضیح دهیم. شکل 3.2 لایهها را خلاصه میکند.
لایه داده خام پایینترین لایه است و همچنین به عنوان لایه دریافت یا ناحیه فرود شناخته میشود. در این لایه، دادههای خام با فرمت بومی بارگذاری میشوند. هیچ پردازش دادهای مانند پاکسازی، حذف دادههای تکراری یا تبدیل دادهها انجام نمیشود. دادهها معمولاً بر اساس مناطق، منابع داده، اشیاء و زمان دریافت در پوشهها سازماندهی میشوند. دادهها در این سطح هنوز برای استفاده آماده نیستند و بنابراین کاربران نهایی دریاچههای داده نباید اجازه دسترسی به لایه داده خام را داشته باشند.
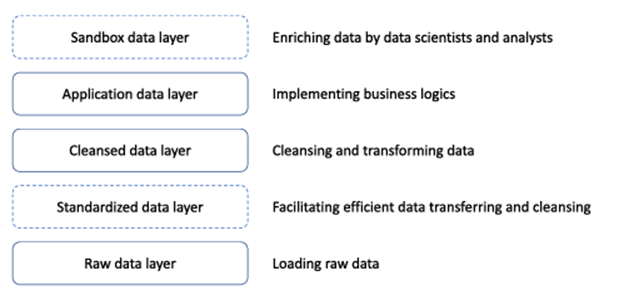
لایههای ذخیرهسازی دادهها در دریاچههای داده.
به صورت اختیاری، یک دریاچه داده میتواند یک لایه داده استاندارد شده در بالای لایه داده خام داشته باشد. هدف اصلی لایه داده استاندارد شده، تسهیل عملکرد بالا در انتقال و پاکسازی دادهها است. به عنوان مثال، در لایه داده خام، دادهها در قالب اصلی خود ذخیره میشوند. در لایه داده استاندارد شده، دادهها ممکن است به قالبهایی تبدیل شوند که برای پاکسازی بهترین هستند. علاوه بر این، دادهها ممکن است برای دسترسی و پردازش کارآمدتر به ساختارهایی با دانههای ریزتر تقسیم شوند.
لایه بعدی، لایه داده پاک شده است که به عنوان لایه مرتب شده یا لایه مطابق نیز شناخته میشود. در این لایه، دادهها پاک و تبدیل میشوند، مانند غیر نرمال شدن یا تجمیع. علاوه بر این، دادهها در مجموعه دادهها سازماندهی شده و در جداول یا فایلها ذخیره میشوند. کاربران نهایی دریاچههای داده اجازه دسترسی به دادهها را در این لایه دارند.
در بالای لایه داده پاک شده، لایه داده برنامه قرار دارد که به عنوان لایه قابل اعتماد، لایه امن یا لایه تولید نیز شناخته میشود. منطقهای تجاری در این لایه پیادهسازی میشوند. بنابراین، بسیاری از برنامهها، از جمله برنامههای دادهکاوی و یادگیری ماشین، میتوانند بر اساس این لایه ساخته شوند.
در برخی سازمانها، دانشمندان و تحلیلگران داده ممکن است آزمایشهایی انجام دهند و الگوها و همبستگیهایی را بیابند. پروژههای آنها ممکن است دادهها را به طور قابل توجهی غنیتر کند و در نتیجه دادههای جدیدی ایجاد کند. چنین دادههایی ممکن است در لایه داده جعبه شنی اختیاری ذخیره شوند. “معماری دریاچههای داده که توسط ذخیرهسازی دریاچه داده متمرکز شده است، چیست؟ علاوه بر ذخیرهسازی دادهها، اجزای مهم دیگر در دریاچههای داده چیست؟” شکل 3.3 معماری مفهومی دریاچههای داده را نشان میدهد. یک دریاچه داده، دادهها را از طیف گستردهای از مخازن داده در یک شرکت یا سازمان، مانند پایگاههای داده، مخزن اسناد، دادههای خزششده از وب، رسانههای اجتماعی، تصاویر (مثلاً محصولات) و احتمالاً منابع داده خارجی، دریافت میکند. دادههای این منابع داده از طریق رابطها به صورت پیوسته در دریاچه داده بارگذاری میشوند. پس از ورود دادهها به دریاچه داده، دادهها از لایههایی که قبلاً در مورد آنها بحث کردیم، عبور میکنند.
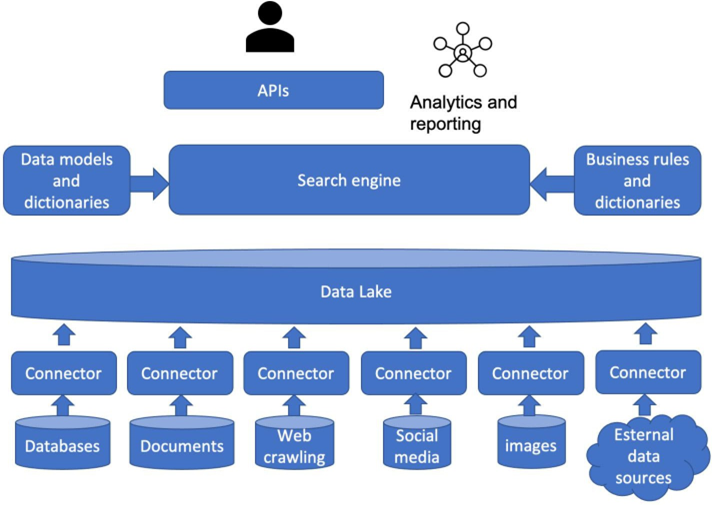
معماری مفهومی دریاچههای داده.
دریاچههای داده به عنوان مخازن داده متمرکز شرکتها و سازمانها عمل میکنند. کاربران نهایی، مانند تحلیلگران و دانشمندان داده، میتوانند به مجموعه دادههای موجود در دریاچههای داده، در لایه داده پاکسازی شده و لایههای بالایی دسترسی داشته باشند. یکی از انواع اصلی دسترسی، کشف مجموعه دادههایی است که میتوانند برای انجام وظایف تحلیلی استفاده شوند. این وظایف «کشف دادهها» از طریق یک موتور جستجوی سازمانی انجام میشود. به عنوان مثال، یک دانشمند داده که یک کمپین بازاریابی را طراحی میکند، ممکن است بخواهد تمام دادههای مربوط به مشتریان در بخش صنعت «تولید الکترونیک» را پیدا کند. از طریق موتور جستجو، دانشمند داده ممکن است مجموعه دادههایی مانند تراکنشهای خرید از پایگاههای داده عملیاتی، اسناد ارتباطی با آن مشتریان مرتبط، دستههای محصول آن مشتریان که از وب خزش شدهاند، بررسی محصولات از رسانههای اجتماعی و تصاویر محصول و دادههای در دسترس بودن محصول که توسط آن مشتریان به عنوان دادههای خارجی ارائه میشود را پیدا کند. واضح است که بدون دریاچه داده به عنوان یک مخزن داده متمرکز، دانشمند داده ممکن است مجبور شود زمان زیادی را برای یافتن چنین دادههایی که در بخشهای مختلف شرکت پراکنده شدهاند و دسترسی به آن مجموعه دادهها صرف کند. به منظور تسهیل استفاده بهتر از دادهها در دریاچههای داده، مدلهای داده و فرهنگ لغتها و قوانین و فرهنگ لغتهای تجاری به عنوان پایگاههای دانش تجاری دامنه برای موتور جستجوی سازمانی به کار گرفته میشوند تا جستجوی مجموعه دادهها به جای فنی، مبتنی بر تجارت باشد. در نهایت، بسیاری از برنامهها میتوانند بر اساس خدمات دادهای ارائه شده توسط دریاچههای داده از طریق رابطهای برنامهنویسی کاربردی (API) مربوطه ساخته شوند. سرویسهای تحلیلی و گزارشدهی منظم نیز میتوانند بر این اساس توسعه داده و نگهداری شوند.
دریاچههای داده به عنوان مخازن داده متمرکز در شرکتها، کارایی و مزیت زیادی را در عملیات تجاری و تصمیمگیری مبتنی بر داده به ارمغان میآورند. در عین حال، دریاچههای داده چالشهای بزرگی را در مدیریت و اجرا نیز ایجاد میکنند. دریاچههای داده علاوه بر لایه ذخیرهسازی داده، باید به مجموعهای از جنبههای مهم نیز بپردازند. در میان موارد دیگر، امنیت یک بخش مرکزی است. دسترسی به دریاچههای داده باید به درستی تعریف و برای دورههای مناسب به افراد مناسب اختصاص داده شود. دادههای ذخیره شده در دریاچههای داده باید به درستی محافظت شوند. احراز هویت، پاسخگویی، مجوز و حفاظت از دادهها باید به طور مداوم و جامع نگهداری شوند. برای اطمینان از امنیت و تنظیم عملکرد بالا، دریاچههای داده باید تحت مدیریت سیستماتیک باشند. به عنوان مثال، نظارت، ثبت وقایع و ردهبندی دادهها باید به طور منظم انجام شود. دسترسی، قابلیت استفاده، امنیت و یکپارچگی دریاچههای داده باید همواره تحت نظارت و مدیریت باشند. علاوه بر این، کیفیت دادهها، حسابرسی دادهها، بایگانی و نظارت از دیگر جنبههای مهم در دریاچههای داده هستند.


