مقدمه
یک انبار داده باید از پرسوجوهای تحلیلی چندبعدی آنلاین پشتیبانی کند. در این بخش، مجموعهای از عملیات معمول OLAP در انبارهای داده (بخش ۳.۳.۱) و نحوه فهرستبندی دادهها برای پشتیبانی از برخی پرسوجوهای OLAP (بخش ۳.۳.۲) را خواهید آموخت. یک مشکل مهم این است که چگونه میتوان دادهها را به درستی ذخیره کرد تا از عملیات OLAP پشتیبانی شود، که در بخش ۳.۳.۳ توضیح داده خواهد شد.
عملیات معمول OLAP
“چگونه میتوان از عملیات OLAP چندبعدی در تجزیه و تحلیل دادهها استفاده کرد؟” در یک مدل چندبعدی، دادهها در ابعاد مختلف سازماندهی میشوند و هر بعد شامل سطوح مختلفی از انتزاع است که توسط سلسله مراتب مفاهیم تعریف میشوند. این سازماندهی به کاربران انعطافپذیری لازم برای مشاهده دادهها از دیدگاههای مختلف را میدهد. تعدادی از عملیات مکعب داده OLAP، پرسوجوی تعاملی و تجزیه و تحلیل دادههای موجود را امکانپذیر میکند. از این رو، OLAP یک محیط کاربرپسند برای تجزیه و تحلیل تعاملی دادهها فراهم میکند.
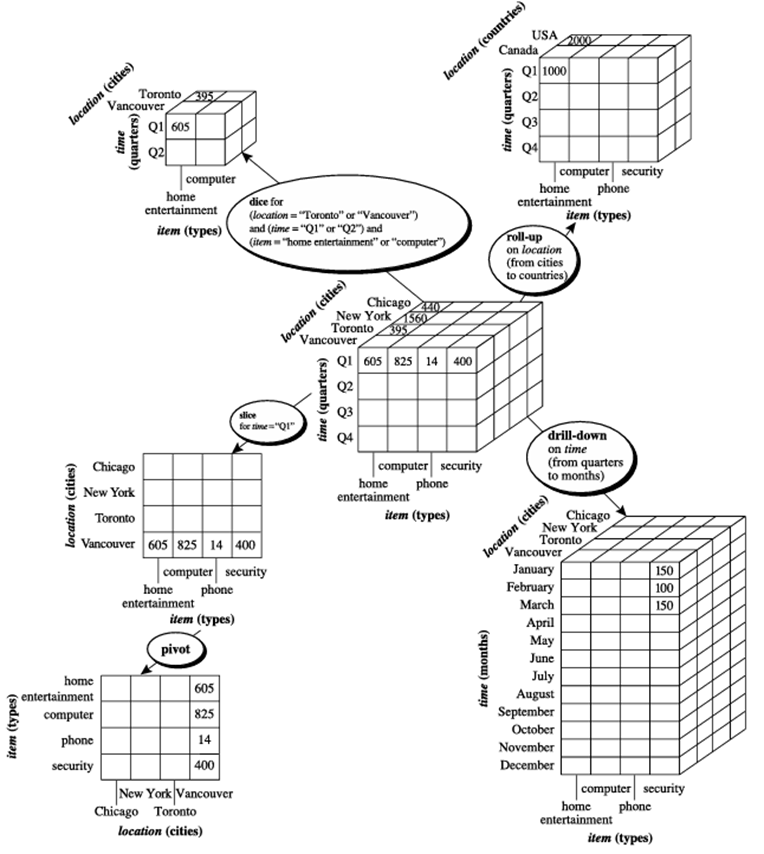
مثال ۳.۴. عملیات OLAP. بیایید به برخی از عملیات معمول OLAP برای دادههای چندبعدی نگاهی بیندازیم. هر یک از عملیات زیر در شکل ۳.۱۳ نشان داده شده است. در مرکز شکل، یک مکعب داده برای فروش در یک شرکت قرار دارد. این مکعب شامل سه بُعد، مکان، زمان و کالا است که در آن مکان با توجه به ارزشهای شهر، زمان با توجه به ربعها و کالا با توجه به انواع کالا تجمیع شده است. برای کمک به توضیح ما، ما به این مکعب به عنوان مکعب مرکزی اشاره میکنیم. سنجه نمایش داده شده، دلار_فروش (به هزار) است. (برای خوانایی، فقط برخی از مقادیر سلولها در مکعبها نشان داده شده است.) دادههای بررسی شده برای شهرهای شیکاگو، نیویورک، تورنتو و ونکوور هستند.
رولآپ
عملیات رولآپ (که توسط برخی از فروشندگان عملیات حفاری نیز نامیده میشود) تجمیع را روی یک مکعب داده انجام میدهد، یا با بالا رفتن از سلسله مراتب مفهومی برای یک بُعد یا با کاهش بُعد. شکل ۳.۱۳ نتیجه یک عملیات رولآپ انجام شده روی مکعب مرکزی را با بالا رفتن از سلسله مراتب مفهومی برای مکان که در شکل ۳.۱۰ داده شده است، نشان میدهد. این سلسله مراتب به صورت ترتیب کلی «خیابان < شهر < استان یا ایالت < کشور» تعریف شده است. عملیات جمعبندی نشان داده شده، دادهها را با افزایش سلسله مراتب مکان از سطح شهر به سطح کشور، تجمیع میکند. به عبارت دیگر، به جای گروهبندی دادهها بر اساس شهر، مکعب حاصل، دادهها را بر اساس کشور گروهبندی میکند.
هنگامی که جمعبندی با کاهش ابعاد انجام میشود، یک یا چند بعد از مکعب داده شده حذف میشود. به عنوان مثال، یک مکعب داده فروش را در نظر بگیرید که فقط شامل ابعاد مکان و زمان است.
مثالهایی از عملیات معمول OLAP روی دادههای چندبعدی.
جمعبندی ممکن است با حذف مثلاً بُعد مکان انجام شود که منجر به تجمیع کل فروش بر اساس زمان کل شرکت، به جای مکان و زمان، میشود.
دریلداون
دریلداون معکوس جمعبندی است. این روش از دادههای کمجزئیاتتر به دادههای باجزئیاتتر حرکت میکند. دریلداون میتواند با کاهش سلسله مراتب مفهومی برای یک بُعد یا معرفی ابعاد اضافی محقق شود. شکل ۳.۱۳ نتیجه عملیات دریلداون انجام شده روی مکعب مرکزی را با کاهش سلسله مراتب مفهومی برای زمان تعریف شده به صورت “روز < ماه < ربع < سال” نشان میدهد. دریلداون با کاهش سلسله مراتب زمانی از سطح ربع به سطح جزئیتر ماه اتفاق میافتد. مکعب داده حاصل، کل فروش در هر ماه را به جای خلاصه کردن آنها بر اساس ربع، جزئیات میکند.
از آنجا که دریلداون جزئیات بیشتری به دادههای داده شده اضافه میکند، میتوان آن را با اضافه کردن ابعاد جدید به یک مکعب نیز انجام داد. به عنوان مثال، دریلداون روی مکعب مرکزی در شکل ۳.۱۳ میتواند با معرفی یک بُعد اضافی مانند customer_group انجام شود.
برش و تاس Slice and dice
عملیات برش، انتخابی را روی یک بُعد از مکعب داده شده انجام میدهد و منجر به یک زیرمکعب میشود. شکل ۳.۱۳ یک عملیات برش را نشان میدهد که در آن دادههای فروش از مکعب مرکزی برای بُعد زمان با استفاده از سنجه زمان “Q1” انتخاب میشوند. عملیات تاس با انجام انتخاب روی دو یا چند بُعد، یک زیرمکعب را تعریف میکند. شکل ۳.۱۳ یک عملیات تاس را روی مکعب مرکزی بر اساس سنجه انتخاب زیر نشان میدهد که شامل سه بُعد است: (مکان “تورنتو” یا “ونکوور”) و (زمان “Q1” یا “Q2”) و (کالا “سرگرمی خانگی” یا “کامپیوتر”).
چرخش
چرخش (که چرخش نیز نامیده میشود) یک عملیات تجسم است که محورهای داده را در نظر میچرخاند تا یک نمایش داده جایگزین ارائه دهد. شکل ۳.۱۳ یک عملیات محوری را نشان میدهد که در آن محورهای کالا و مکان در یک برش دو بعدی چرخانده میشوند. مثالهای دیگر شامل چرخش محورها در یک مکعب سهبعدی یا تبدیل یک مکعب سهبعدی به مجموعهای از صفحات دو بعدی است.
سایر عملیات OLAP
برخی از سیستمهای OLAP عملیات حفاری اضافی ارائه میدهند. به عنوان مثال، drill-across پرسوجوهایی را اجرا میکند که شامل (یعنی، در سراسر) بیش از یک جدول واقعیت هستند. عملیات drill-through از امکانات SQL رابطهای برای حفاری از سطح پایین یک مکعب داده به سمت جداول رابطهای back-end آن استفاده میکند.
سایر عملیات OLAP ممکن است شامل رتبهبندی N مورد برتر یا N مورد پایین در لیستها و همچنین محاسبه میانگینهای متحرک، نرخ رشد، منافع، نرخ بازده داخلی، استهلاک، تبدیل ارز و توابع آماری باشد.
OLAP قابلیتهای مدلسازی تحلیلی، از جمله یک موتور محاسبه برای استخراج نسبتها، واریانس و غیره و برای محاسبه سنجهها در ابعاد مختلف را ارائه میدهد. این سیستم میتواند خلاصهسازیها، تجمیعها و سلسله مراتبها را در هر سطح دانهبندی و در هر تقاطع ابعاد ایجاد کند. OLAP همچنین از مدلهای عملکردی برای پیشبینی، تحلیل روند و تحلیل آماری پشتیبانی میکند. در این زمینه، یک موتور OLAP یک ابزار قدرتمند تحلیل داده است.
فهرستبندی دادههای OLAP
فهرست بیتمپ و فهرست پیوند برای تسهیل دسترسی کارآمد به دادهها، اکثر سیستمهای انبار داده از ساختارهای فهرست و نماهای مادیسازیشده (با استفاده از مکعبها) پشتیبانی میکنند. ما در بخش ۳.۴ روشهای کلی انتخاب مکعبها برای مادیسازی را مورد بحث قرار خواهیم داد. در این زیربخش، نحوه فهرستبندی دادههای OLAP را با استفاده از فهرستبندی بیتمپ و فهرستبندی پیوند بررسی میکنیم.
نمایهسازی بیتمپ
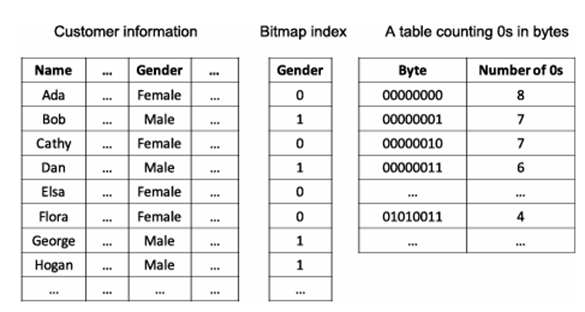
روش نمایهسازی بیتمپ در محصولات OLAP محبوب است زیرا امکان جستجوی سریع در مکعبهای داده را فراهم میکند. نمایه بیتمپ، نمایش جایگزینی از لیست record_ID (RID) است. در نمایه بیتمپ برای یک ویژگی معین، برای هر مقدار v در دامنه ویژگی، یک بردار بیتی مجزا، Bv، وجود دارد. اگر دامنه یک ویژگی معین شامل n مقدار باشد، برای هر ورودی در نمایه بیتمپ به n بیت نیاز است (یعنی n بردار بیتی وجود دارد). اگر ویژگی دارای مقدار v برای یک ردیف معین در جدول دادهها باشد، بیتی که آن مقدار را نشان میدهد در ردیف مربوطه از نمایه بیتمپ روی ۱ تنظیم میشود. تمام بیتهای دیگر برای آن ردیف روی ۰ تنظیم میشوند.
مثال ۳.۵. نمایهسازی بیتمپ. یک جدول اطلاعات مشتری نشان داده شده در شکل ۳.۱۴ را در نظر بگیرید که در آن یک ویژگی جنسیت وجود دارد. برای ساده نگه داشتن بحث، فرض کنید دو مقدار ممکن برای ویژگی جنسیت وجود دارد. میتوانیم برای هر رکورد از یک کاراکتر، یعنی ۸ بیت، برای نمایش مقدار جنسیت استفاده کنیم، مانند F برای زن و M برای مرد. اندیس بیتمپ مقدار جنسیت را با استفاده از یک بیت نمایش میدهد، مانند ۰ برای زن و ۱ برای مرد. این نمایش بلافاصله باعث صرفهجویی هشت برابری در فضای ذخیرهسازی میشود. مهمتر از آن، اندیس بیتمپ میتواند بسیاری از پرسوجوهای تجمیعی را سرعت بخشد. به عنوان مثال، بیایید تعداد مشتریان زن را در جدول اطلاعات مشتری بشماریم. یک روش ساده باید هر رکورد را اسکن کرده و بشمارد. برای جدولی که ۱۰۰۰۰ رکورد دارد و هر رکورد ۱۰۰ بایت فضا اشغال میکند، کل هزینه ورودی/خروجی ۱۰۰۰۰ ۱۰۰ ۱,۰۰۰,۰۰۰ بایت است. یک اندیس بیتمپ فقط از ۱ بیت برای هر رکورد استفاده میکند. این بیتها در حافظه به صورت کلمات بستهبندی میشوند. برای مثال، برای ۸ رکورد اول جدول، مقادیر اندیس بیتمپ در یک بایت ۰۱۰۱۰۰۱۱ بستهبندی شدهاند. اسکن کل اندیس بیتمپ تنها ۱۰۰۰۰ بیت در ورودی/خروجی طول میکشد، یعنی ۱۲۵۰ بایت، ۸۰۰ برابر کمتر از اسکن کل جدول.
برای محاسبه تعداد ۰ها در یک بایت، میتوانیم به سادگی از یک جدول هش از پیش محاسبه شده استفاده کنیم که از مقادیر بایت به عنوان اندیس استفاده میکند و اعداد متناظر ۰ها را ذخیره میکند. به عنوان مثال، جدول هش مقدار ۴ را در ورودی ۸۳ ذخیره میکند، زیرا ۸۳ مقدار اعشاری عدد دودویی ۰۱۰۱۰۰۱۱ است و رشته دودویی ۴ عدد ۰ دارد. با استفاده از بایت ۰۱۰۱۰۰۱۱ که در عدد اعشاری ۵۳ است، برای جستجو در جدول هش، بلافاصله میدانیم که ۴ مشتری زن در ۸ رکورد اول وجود دارند. ما میتوانیم تعداد صفرها را در کل ویژگی جنسیت، بایت به بایت با استفاده از شاخص بیتمپ محاسبه کنیم و تعداد بایتها را جمع کنیم تا تعداد کل مشتریان زن را به دست آوریم. در عمل، میتوان به جای بایتها از کلمات ماشینی استفاده کرد تا روند شمارش را سرعت بیشتری بخشید.
شاخصگذاری دادههای OLAP با استفاده از شاخصهای بیتمپ.
نمایهسازی بیتمپ در مقایسه با شاخصهای هش و درخت در پاسخ به برخی از انواع پرسوجوهای OLAP سودمند است. این روش به ویژه برای دامنههای با کاردینالیتی پایین مفید است زیرا عملیات مقایسه، اتصال و تجمیع به حساب بیتی کاهش مییابند که به طور قابل توجهی زمان پردازش را کاهش میدهد. نمایهسازی بیتمپ منجر به کاهش قابل توجه در فضا و ورودی/خروجی (I/O) میشود زیرا رشتهای از کاراکترها را میتوان با یک بیت واحد نمایش داد.
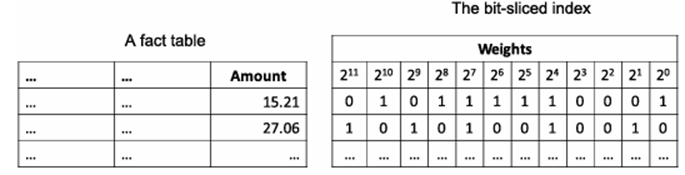
نمایهسازی بیتمپ را میتوان به نمایهسازی برش بیتی برای دادههای عددی تعمیم داد. اجازه دهید ایدهها را با استفاده از یک مثال توضیح دهیم.
مثال ۳.۶. نمایهسازی برش بیتی. فرض کنید میخواهیم مجموع ویژگی مقدار را در جدول واقعیت در شکل ۳.۱۵ محاسبه کنیم. میتوانیم یک مقدار را در یک عدد صحیح از سکه بنویسیم و سپس آن را به صورت یک عدد دودویی از n بیت نمایش دهیم. اگر مبلغی را با استفاده از ۳۲ بیت، یعنی ۴ بایت، نمایش دهیم، برای مبالغ تا سقف ۴۲,۹۴۹,۶۷۲.۹۶ دلار مناسب است و برای بسیاری از سناریوهای کاربردی کافی است. پس از نمایش تمام اعداد مبلغ به صورت دودویی، میتوانیم برای هر بیت یک اندیس بیتمپ بسازیم. برای محاسبه مجموع تمام مبالغ، برای هر بیت تعداد ۱ها را میشماریم. تعداد ۱ها در بیتهای iام مبالغ از راست به چپ را با xi(i 0) نشان میدهیم، که سمت راستترین آنها بیت ۰ است. از آنجایی که یک ۱ در بیت iام وزنی معادل ۲i پنی دارد، xi ۱ها در بیتهای iام تمام مبالغ، نشان دهنده Xᵢ · 2ⁱ پنی در مجموع مبالغ هستند. بنابراین، مجموع مبالغ برابر است با
∑_{i ≥ 0} xᵢ · 2ⁱ پنی یا (∑_{i ≥ 0} xᵢ · 2ⁱ) / 100 دلار.
فهرستبندی پیوند Join indexing
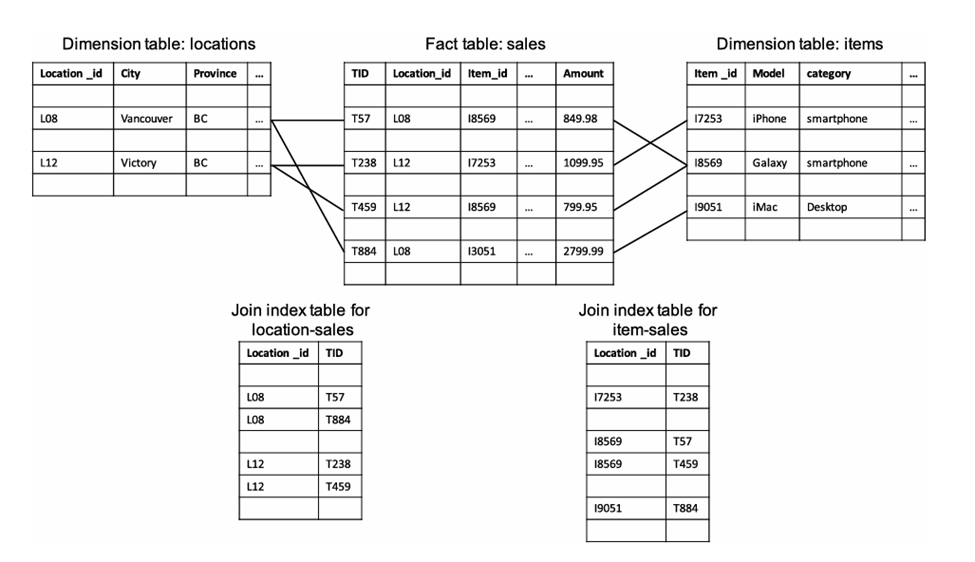
در یک طرح انبار داده مانند طرح ستاره، اغلب نیاز داریم جدول واقعیت و جداول بُعد را به هم پیوند دهیم. پیوند دادن پرتکرار جداول برای پرسوجوهای مختلف قطعاً پرهزینه است. بنابراین، از فهرستبندی پیوند برای پیشمحاسبه و ذخیره جفتهای شناسه نتایج پیوند استفاده میشود تا نتایج پیوند به طور کارآمد قابل دسترسی باشند.
مثال ۳.۷. فهرستبندی پیوند. در مثال ۳.۱، ما یک طرح ستارهای به شکل “sales_star [time, item, branch, location]: dollars_sold sum (sales_in_dollars)” تعریف کردیم. نمونهای از یک فهرست پیوند بین جدول واقعیت فروش و جداول بُعد مکانها و اقلام در شکل ۳.۱۶ نشان داده شده است. پرسوجوی OLAP “کل فروش تلفن هوشمند و دسکتاپ در BC” را در نظر بگیرید. اگر هیچ فهرستی ارائه نشود، باید جدول واقعیت و جداول بُعد مکانها و اقلام را به هم پیوند دهیم و فقط آن نتایج پیوند مربوط به “تلفن هوشمند” و “دسکتاپ” را انتخاب کنیم.
فهرست پیوند.
یک جدول فهرست پیوند، کلیدهای اصلی تاپلهای منطبق را در دو جدول ثبت میکند. به عنوان مثال، در جدول فهرست پیوند برای فروش مکان، جفتهای location_id و TID تاپلهای منطبق در جدول ابعاد مکانها و فروشها ثبت میشوند. از جدول فهرست پیوند، میتوانیم به سرعت TIDهای تاپلها را در جدول واقعیت فروش متعلق به “BC” پیدا کنیم. به طور مشابه، با استفاده از فهرست پیوند برای فروش اقلام، میتوانیم تاپلهای جدول فروش مربوط به “تلفن هوشمند” و “دسکتاپ” را شناسایی کنیم. با استفاده از TIDهای شناسایی شده به این ترتیب، میتوانیم به طور دقیق به تاپلهای جدول واقعیت که برای محاسبه تجمیع OLAP و کاهش هزینه I/O مورد نیاز هستند، دسترسی پیدا کنیم. به طور معمول، یک انبار داده فقط درصد بسیار کمی از تراکنشها را در مورد یک منطقه انتخاب شده و دستههای محصول شامل میشود. به عنوان مثال، ممکن است فقط 0.1٪ از تراکنشهای جدول واقعیت مربوط به تلفنهای هوشمند و دسکتاپهای فروخته شده در BC باشند. بدون استفاده از هیچ شاخصی، ما باید کل جدول حقایق را به حافظه اصلی بخوانیم تا مجموع را محاسبه کنیم. با استفاده از شاخصهای اتصال، حتی هر صفحه شامل ۱۰۰ رکورد تراکنش در جدول حقایق است و تمام آن تراکنشهای تلفنهای هوشمند و کامپیوترهای رومیزی فروخته شده در BC به طور مساوی توزیع شدهاند، ما فقط باید ۱۰٪ از صفحات را به حافظه اصلی بخوانیم و بنابراین ۹۰٪ در ورودی/خروجی صرفهجویی کنیم.
پیادهسازی ذخیرهسازی: پایگاههای داده مبتنی بر ستون
«چگونه دادهها را ذخیره کنیم تا بتوان به طور موثر به پرسوجوهای OLAP پاسخ داد؟» در بسیاری از کاربردها، یک جدول واقعیت ممکن است گسترده باشد و شامل دهها یا حتی صدها ویژگی باشد. اغلب اوقات، یک پرسوجوی OLAP ممکن است مجموع تمام رکوردها یا بخش بزرگی از رکوردها را بر اساس تعداد کمی ویژگی محاسبه کند. اگر دادهها در یک جدول رابطهای سنتی ذخیره شوند که در آن رکوردها ردیف به ردیف ذخیره میشوند، برای پاسخ به یک پرسوجو باید تمام رکوردها را اسکن کنیم، اما فقط از یک بخش کوچک در یک رکورد استفاده میشود. این مشاهده فرصت قابل توجهی را برای توسعه طرح ذخیرهسازی کارآمدتر برای دادههای OLAP ارائه میدهد.
برای کارآمدتر کردن ذخیرهسازی برای پاسخ به پرسوجوهای OLAP، یک پایگاه داده مبتنی بر ستون، یک جدول گسترده را ذخیره میکند که اغلب برای پرسوجوهای تجمیعی به سبک ستون به ستون استفاده میشود. به طور خاص، یک پایگاه داده مبتنی بر ستون، مقادیر تمام رکوردهای یک ستون را در بلوکهای ذخیرهسازی متوالی ذخیره میکند. همه رکوردها به ترتیب یکسان در تمام ستونها فهرست میشوند.
مثال ۳.۸. پایگاه داده مبتنی بر ستون. یک جدول واقعیت در مورد اطلاعات مشتری را در نظر بگیرید که شامل ویژگیها و فضای ذخیرهسازی بر حسب بایت است: شناسه مشتری (2)، نام خانوادگی (20)، نام (20)، جنسیت (1)، تاریخ تولد (2)، خیابان آدرس (50)، شهر آدرس (2)، استان آدرس (1)، کشور آدرس (1)، ایمیل (30)، تاریخ ثبت نام (2) و درآمد خانواده (2). هر رکورد 133 بایت را اشغال میکند. اگر جدول واقعیت شامل 10 میلیون رکورد مشتری باشد، کل فضا بیش از 1 گیگابایت است. اگر دادهها ردیف به ردیف ذخیره شوند و بخواهیم به پرسوجوی OLAP میانگین درآمد خانواده مشتریان زن بر اساس استان پاسخ دهیم، باید کل جدول را اسکن کنیم و همه رکوردها را بخوانیم. هزینه ورودی/خروجی 1 گیگابایت است. در عین حال، برای هر رکورد، فقط باید از 4 بایت از 133 بایت استفاده کنیم، یعنی ویژگیهای جنسیت، استان آدرس و درآمد خانواده. به عبارت دیگر، فقط 4/133 = ۳٪ از دادههای خوانده شده برای پاسخ به پرسوجو مفید هستند.
یک پایگاه داده مبتنی بر ستون، ویژگی دادهها را به صورت جداگانه در ستون ذخیره میکند، همانطور که در شکل ۳.۱۷ نشان داده شده است. برای پاسخ به پرسوجوی فوق، یک پایگاه داده مبتنی بر ستون فقط نیاز به خواندن سه ستون، جنسیت، استان_آدرس و درآمد_خانواده دارد. این پایگاه داده مقادیر مربوط به جنسیت را بررسی میکند و بر این اساس، مجموع و تعداد را برای استان_آدرس افزایش میدهد. در مجموع، مقدار کل ورودی/خروجی وارد شده به یک پایگاه داده مبتنی بر ستون در این مورد ۴ *10 میلیون ۴۰ مگابایت است. صرفهجویی زیادی در ورودی/خروجی حاصل میشود.
در پیادهسازی، ترجیحاً یک پایگاه داده مبتنی بر ستون، یک ستون را در یک زمان پردازش میکند و از بیتمپها برای حفظ نتایج میانی استفاده میکند تا بتوان آنها را به ستون بعدی منتقل کرد. در این مثال، میتوانیم ابتدا جنسیت ستون را پردازش کنیم و از یک بیتمپ برای حفظ لیست مشتریان زن استفاده کنیم. یعنی، هر مشتری با یک بیت مرتبط است، زن ۰ و مرد ۱. در مرحله بعد، میتوانیم ستون address_province را پردازش کنیم و برای هر استان یک بیتمپ تشکیل دهیم. برای مثال، اگر مشتری در BC زندگی میکند، بیت مرتبط در بیتمپ BC روی ۱ تنظیم میشود، در غیر این صورت، روی ۰ تنظیم میشود. در نهایت، برای محاسبه میانگین درآمد خانواده مشتریان در BC، فقط باید عملیات بیتی AND را بین بیتمپ مربوط به جنسیت و بیتمپ مربوط به استان BC انجام دهیم. بیتمپ حاصل برای انتخاب ورودیهای ستون family_income برای محاسبه میانگین استفاده میشود.

ذخیرهسازی مبتنی بر ستون.
پایگاههای داده مبتنی بر ستون به طور گسترده در انبار دادههای صنعتی و پایگاههای داده OLAP پیادهسازی شدهاند. پایگاههای داده مبتنی بر ستون مزایای قابل توجهی برای بارهای کاری مشابه OLAP دارند، مانند پرسوجوهای تجمیعی که چند ستون از تمام رکوردها را در یک جدول گسترده جستجو میکنند. در عین حال، پایگاههای داده مبتنی بر ستون باید تراکنشها را به ستونها تقسیم کرده و تراکنشها را هنگام ذخیره فشرده کنند، که باعث میشود پایگاههای داده مبتنی بر ستون برای بارهای کاری OLTP پرهزینه باشند.


