روشهای ارزیابی الگو
اکثر الگوریتمهای کاوش قوانین ارتباط از یک چارچوب پشتیبانی-اطمینان استفاده میکنند. اگرچه حداقل آستانههای پشتیبانی و اطمینان به حذف یا حذف کاوش تعداد زیادی از قوانین غیرجذاب کمک میکنند، اما بسیاری از قوانین تولید شده هنوز برای بسیاری از کاربران جالب نیستند. این امر به ویژه هنگام کاوش در آستانههای پشتیبانی پایین یا کاوش برای الگوهای طولانی صادق است. این یک تنگنای بزرگ برای کاربرد موفقیتآمیز کاوش قوانین ارتباط بوده است.
در این بخش، ابتدا به این موضوع میپردازیم که چگونه حتی قوانین ارتباط قوی میتوانند غیرجذاب و گمراهکننده باشند (بخش ۴.۳.۱). سپس بحث میکنیم که چگونه میتوان چارچوب پشتیبانی-اطمینان را با سنجههای جالب اضافی بر اساس تحلیل همبستگی تکمیل کرد (بخش ۴.۳.۲). بخش ۴.۳.۳ سنجههای ارزیابی الگوی اضافی را ارائه میدهد. سپس یک مقایسه کلی از تمام سنجههای مورد بحث در اینجا ارائه میدهد. در پایان، خواهید آموخت که کدام سنجههای ارزیابی الگو برای کشف فقط قوانین جالب، مؤثرتر هستند.
قوانین قوی لزوماً جالب نیستند
جالب بودن یک قانون را میتوان به صورت ذهنی یا عینی ارزیابی کرد. در نهایت، فقط کاربر میتواند قضاوت کند که آیا یک قانون مشخص جالب است یا خیر، و این قضاوت، به دلیل ذهنی بودن، ممکن است از کاربری به کاربر دیگر متفاوت باشد. با این حال، سنجههای عینی جالب بودن، بر اساس آمار «پشت» دادهها، میتوانند به عنوان گامی به سوی هدف حذف قوانین بیاهمیت که در غیر این صورت به کاربر ارائه میشوند، استفاده شوند.
«چگونه میتوانیم تشخیص دهیم که کدام قوانین ارتباط قوی واقعاً جالب هستند؟» بیایید مثال زیر را بررسی کنیم.
مثال ۴.۷. یک قانون انجمنی «قوی» گمراهکننده. فرض کنید ما علاقهمند به تجزیه و تحلیل تراکنشهای مربوط به خرید بازیهای کامپیوتری و ویدیوها هستیم. فرض کنید game به تراکنشهای حاوی بازیهای کامپیوتری و video به تراکنشهای حاوی ویدیو اشاره دارد. از 10000 تراکنش مورد تجزیه و تحلیل، دادهها نشان میدهند که 6000 تراکنش مشتری شامل بازیهای کامپیوتری، 7500 تراکنش شامل ویدیو و 4000 تراکنش شامل بازیهای کامپیوتری و ویدیو بوده است. فرض کنید یک برنامه دادهکاوی برای کشف قوانین ارتباط روی دادهها اجرا میشود و از حداقل پشتیبانی مثلاً 30٪ و حداقل اطمینان 60٪ استفاده میکند. قانون انجمنی زیر کشف میشود..
buys (X, “computer games”)⇒buys (X, “videos”)
.[support = 40%, confidence = 66%]
قانون (4.6) یک قانون وابستگی قوی است و بنابراین گزارش میشود، زیرا مقدار پشتیبانی آن 10000/4000 = 40% و مقدار اطمینان 6000/4000 = 66% به ترتیب آستانههای پشتیبانی حداقل و حداقل اطمینان را برآورده میکنند. با این حال، قانون (4.6) گمراهکننده است زیرا احتمال خرید ویدیوها 75% است که حتی بزرگتر از 66% است. در واقع، بازیهای کامپیوتری و ویدیوها به صورت منفی مرتبط هستند زیرا خرید یکی از این اقلام در واقع احتمال خرید دیگری را کاهش میدهد. بدون درک کامل این پدیده، میتوانیم به راحتی بر اساس قانون (4.6) تصمیمات تجاری غیرعاقلانهای بگیریم.
مثال 4.7 همچنین نشان میدهد که اطمینان یک قانون A ⇒ B میتواند فریبنده باشد. این قانون قدرت واقعی (یا عدم قدرت) همبستگی و دلالت بین A و B را اندازهگیری نمیکند. از این رو، جایگزینهایی برای چارچوب پشتیبانی-اطمینان میتوانند در کاوش روابط جالب دادهها مفید باشند.
مثال ۴.۷ همچنین نشان میدهد که اطمینان یک قانون A ⇒ B میتواند فریبنده باشد. این قانون قدرت واقعی (یا عدم قدرت) همبستگی و دلالت بین A و B را اندازهگیری نمیکند. از این رو، جایگزینهایی برای چارچوب پشتیبانی-اطمینان میتوانند در کاوش روابط جالب دادهها مفید باشند.
از تحلیل ارتباط تا تحلیل همبستگی
همانطور که تاکنون دیدهایم، سنجههای پشتیبانی و اطمینان در فیلتر کردن قوانین ارتباطی غیرجذاب کافی نیستند. برای مقابله با این ضعف، میتوان یک سنجه همبستگی را به چارچوب پشتیبانی-اطمینان برای قوانین ارتباطی اضافه کرد. این منجر به قوانین همبستگی به شکل
[پشتیبانی، اطمینان، همبستگی] A⇒B میشود.
.A⇒B [support, confidence, correlation]
یعنی، یک قانون همبستگی نه تنها با پشتیبانی و اطمینان آن، بلکه با همبستگی بین مجموعه اقلام A و B نیز اندازهگیری میشود. سنجههای همبستگی مختلفی برای انتخاب ما وجود دارد. در این زیربخش، چندین سنجه همبستگی را مطالعه میکنیم تا مشخص کنیم کدام یک برای کاوش مجموعه دادههای بزرگ مناسب است.
Lift یک سنجه همبستگی ساده است که به شرح زیر ارائه میشود. وقوع مجموعه اقلام A مستقل از وقوع مجموعه اقلام B است اگر P(A∪B)=P(A)P(B)؛ در غیر این صورت، مجموعه اقلام A و B وابسته و همبسته هستند. این تعریف را میتوان به راحتی به بیش از دو مجموعه اقلام تعمیم داد. ضریب افزایش Lift بین وقوع A و B را میتوان با محاسبه اندازهگیری کرد.
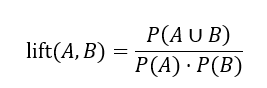
اگر مقدار حاصل از معادله (4.8) کمتر از 1 باشد، آنگاه وقوع A با وقوع B همبستگی منفی دارد، به این معنی که وقوع یکی احتمالاً منجر به عدم وجود دیگری میشود. اگر مقدار حاصل بزرگتر از 1 باشد، A و B همبستگی مثبت دارند، به این معنی که وقوع یکی به معنای وقوع دیگری است. اگر مقدار حاصل برابر با 1 باشد، A و B مستقل هستند و هیچ همبستگی بین آنها وجود ندارد.
معادله (4.8) معادل P(B|A)/P(B) یا conf(A ⇒ B)/P(B) است که به آن تقویت قانون ارتباط (یا همبستگی) A ⇒ B نیز گفته میشود. به عبارت دیگر، این معادله میزان «تقویت» وقوع یکی از موارد دیگر را ارزیابی میکند. برای مثال، اگر A مربوط به فروش بازیهای کامپیوتری و B مربوط به فروش ویدیو باشد، با توجه به شرایط فعلی بازار، گفته میشود که فروش بازیها احتمال فروش ویدیوها را به اندازه ضریبی از مقدار برگردانده شده توسط معادله (4.8) افزایش یا «بالا» میبرد.
بیایید به دادههای بازی کامپیوتری و ویدیویی مثال 4.7 برگردیم.
مثال 4.8. تحلیل همبستگی با استفاده از lift. برای کمک به فیلتر کردن ارتباطات «قوی» گمراهکننده به شکل A⇒B از دادههای مثال 4.7، باید بررسی کنیم که چگونه دو مجموعه آیتم، A و B، با هم همبستگی دارند. فرض کنید game به تراکنشهای مثال 4.7 که شامل بازیهای کامپیوتری نیستند اشاره دارد و video به تراکنشهایی که شامل ویدیو نیستند اشاره دارد. تراکنشها را میتوان در یک جدول احتمالی، همانطور که در جدول 4.6 نشان داده شده است، خلاصه کرد. از جدول، میتوانیم ببینیم که احتمال خرید یک بازی کامپیوتری P({game}) = 0.60، احتمال خرید یک ویدیو P({video}) = 0.75 و احتمال خرید هر دو P({game,video}) = 0.40 است. طبق معادله (4.8)، افزایش قانون (4.6) برابر است با P({game,video})/(P({game})× P({video})) = 0.40/(0.60×0.75) = 0.89. از آنجا که این مقدار کمتر از 1 است، همبستگی منفی بین وقوع {game} و {video} وجود دارد. صورت کسر، احتمال خرید هر دو توسط مشتری است، در حالی که مخرج، احتمال این است که اگر دو خرید کاملاً مستقل بودند، چه اتفاقی میافتاد. چنین همبستگی منفی را نمیتوان با چارچوب پشتیبانی-اطمینان شناسایی کرد.
|
جدول ۴.۶ جدول احتمالی ۲ × ۲ که خلاصهای از تراکنشهای مربوط به خرید بازی و ویدیو را نشان میدهد. |
|
game game !:-row |
|
video 4000 3500 7500 video 2000 500 2500 “Ecol 6000 4000 10, 000 |
|
جدول ۴.۷ جدول ۴.۶ جدول احتمال، اکنون با مقادیر مورد انتظار |
|||
|
|
game |
game |
!:-row |
|
video |
4000 (4500) |
3500 (3000) |
7500 |
|
video |
2000 (1500) |
500 (1000) |
2500 |
|
“Ecol |
6000 |
4000 |
10,000 |
دومین سنجه همبستگی که ما مطالعه میکنیم، سنجه χ2 است که در فصل 3 معرفی شد (معادله (3.1)). برای محاسبه مقدار χ2، اختلاف مربع بین مقدار مشاهده شده و مورد انتظار برای یک بازه (جفت A و B) در جدول توافقی را بر مقدار مورد انتظار تقسیم میکنیم. این مقدار برای همه بازههای جدول توافقی جمع میشود. بیایید یک تحلیل χ2 از مثال 4.8 انجام دهیم.
مثال 4.9. تحلیل همبستگی با استفاده از χ2. برای محاسبه همبستگی با استفاده از تحلیل χ2 برای دادههای اسمی، به مقدار مشاهده شده و مقدار مورد انتظار (نمایش داده شده در پرانتز) برای هر بازه از جدول توافقی، همانطور که در جدول 4.7 نشان داده شده است، نیاز داریم. از جدول، میتوانیم مقدار χ2 را به صورت زیر محاسبه کنیم:
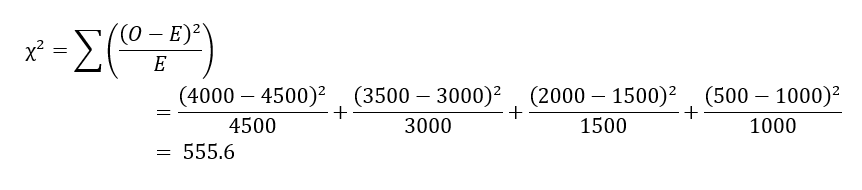
از آنجا که مقدار χ2 بزرگتر از ۱ است و مقدار مشاهده شده اسلات (بازی، ویدیو) = ۴۰۰۰ است که کمتر از مقدار مورد انتظار ۴۵۰۰ است، خرید بازی و خرید ویدیو همبستگی منفی دارند. این با نتیجه حاصل از تحلیل سنجه لیفت در مثال ۴.۸ سازگار است.
مقایسه سنجههای ارزیابی الگو
بحث فوق نشان میدهد که به جای استفاده از چارچوب ساده پشتیبانی-اطمینان برای ارزیابی الگوهای پرتکرار، سنجههای دیگری مانند لیفت و χ2 اغلب روابط الگوی ذاتیتری را آشکار میکنند.
این سنجهها چقدر مؤثر هستند؟ آیا باید جایگزینهای دیگری را نیز در نظر بگیریم؟
محققان حتی قبل از شروع تحقیقات عمیق در مورد روشهای مقیاسپذیر برای کاوش الگوهای پرتکرار، سنجههای ارزیابی الگوی بسیاری را مطالعه کردهاند. در جامعه دادهکاوی، چندین سنجه ارزیابی الگوی دیگر مورد توجه قرار گرفتهاند. در این زیربخش، چهار سنجه از این دست را ارائه میدهیم:
all_confidence، max_confidence، Kulczynski و cosine. هر یک از این چهار سنجه یک ویژگی جالب دارد: مقدار هر سنجه فقط تحت تأثیر پشتیبانهای A، B و A∪B، یا به طور دقیقتر، تحت تأثیر احتمالات شرطی P(A|B) و P(B|A) قرار میگیرد، اما تحت تأثیر تعداد کل تراکنشها نیست. ویژگی مشترک دیگر این است که هر سنجه از 0 تا 1 متغیر است و هرچه مقدار آن بیشتر باشد، رابطه بین A و B نزدیکتر است. با توجه به دو مجموعه آیتم، A و B، سنجه تمام اطمینان A و B به صورت زیر تعریف میشود:
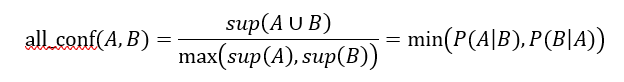
که در آن max{sup(A), sup(B)} حداکثر پشتیبانی از مجموعه اقلام A و B است. بنابراین all_conf(A,B) همچنین حداقل اطمینان دو قانون انجمنی مربوط به A و B، یعنی “A ⇒ B” و “B ⇒A” است.
با توجه به دو مجموعه اقلام A و B، سنجه حداکثر اطمینان A و B به صورت زیر تعریف میشود:
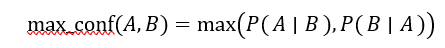
سنجه max_conf حداکثر میزان اطمینان دو قانون انجمنی «A ⇒ B» و «B ⇒A» است. با توجه به دو مجموعه آیتم A و B، سنجه کولچینسکی A و B (به اختصار Kulc) به صورت زیر تعریف میشود.
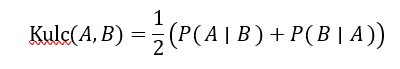
این در سال ۱۹۲۷ توسط ریاضیدان لهستانی، اس. کولچینسکی، پیشنهاد شد. میتوان آن را به عنوان میانگین دو سنجه اطمینان در نظر گرفت. یعنی، میانگین دو احتمال شرطی است: احتمال مجموعه اقلام B با توجه به مجموعه اقلام A، و احتمال مجموعه اقلام A با توجه به مجموعه اقلام B. در نهایت، با توجه به دو مجموعه اقلام A و B، سنجه کسینوس A و B به صورت زیر تعریف میشود:
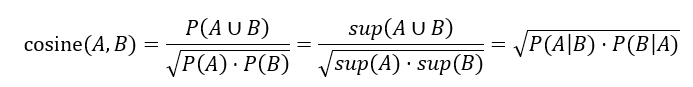
سنجه کسینوس را میتوان به عنوان یک سنجه هماهنگ لیفت در نظر گرفت. این دو فرمول مشابه هستند، به جز اینکه برای کسینوس، جذر از حاصلضرب احتمالات A و B گرفته میشود. با این حال، این یک تفاوت مهم است، زیرا با گرفتن جذر، مقدار کسینوس فقط تحت تأثیر پشتیبانیهای A، B و A∪B قرار میگیرد و نه تحت تأثیر تعداد کل تراکنشها.
اکنون، همراه با لیفت و χ2، در مجموع شش سنجه ارزیابی الگو معرفی کردهایم. ممکن است از خود بپرسید: “کدام یک در ارزیابی روابط الگوی کشف شده بهترین است؟” برای پاسخ به این سوال، عملکرد آنها را در برخی از مجموعه دادههای معمولی بررسی میکنیم.
مثال ۴.۱۰. مقایسه شش سنجه ارزیابی الگو در مجموعه دادههای معمولی. رابطه بین خرید دو کالا، شیر و قهوه، را میتوان با خلاصه کردن تاریخچه خرید آنها در جدول ۴.۸، جدول احتمالی a2×2، که در آن ورودی مانند mc نشان دهنده تعداد تراکنشهای حاوی شیر و قهوه است، بررسی کرد.
|
جدول ۴.۸ جدول پیشایندی ۲ × ۲ برای دو مورد. |
|||
|
|
milk |
milk |
!:-row |
|
coffee coffee “Ecol |
mc mc m |
mc mc m |
c c “E |
|
جدول ۴.۹ مقایسه شش سنجه ارزیابی الگو با استفاده از جداول توافقی برای مجموعه دادههای متنوع . |
||||||||||
|
مجموعه دادهها |
mc |
mc |
mc |
mc |
χ2 |
lift |
all_conf. |
max_conf. |
Kulc. |
cosine |
|
D1 |
10,000 |
1000 |
1000 |
100,000 |
90,557 |
9.26 |
0.91 |
0.91 |
0.91 |
0.91 |
|
D2 |
10,000 |
1000 |
1000 |
100 |
0 |
1 |
0.91 |
0.91 |
0.91 |
0.91 |
|
D3 |
100 |
1000 |
1000 |
100,000 |
670 |
8.44 |
0.09 |
0.09 |
0.09 |
0.09 |
|
D4 |
1000 |
1000 |
1000 |
100,000 |
24,740 |
25.75 |
0.5 |
0.5 |
0.5 |
0.5 |
|
D5 |
1000 |
100 |
10,000 |
100,000 |
8173 |
9.18 |
0.09 |
0.91 |
0.5 |
0.29 |
|
D6 |
1000 |
10 |
100,000 |
100,000 |
965 |
1.97 |
0.01 |
0.99 |
0.5 |
0.10 |
جدول ۴.۹ مجموعهای از مجموعه دادههای تراکنشی را به همراه جداول احتمالی مربوطه و مقادیر مرتبط برای هر یک از شش سنجه ارزیابی نشان میدهد. ابتدا چهار مجموعه داده اول، D1 تا D4، را بررسی میکنیم. از جدول، میبینیم که m و c در D1 و D2 ارتباط مثبت، در D3 ارتباط منفی و در D4 خنثی دارند. برای D1 و D2، m و c ارتباط مثبت دارند زیرا mc (10,000) به طور قابل توجهی بزرگتر از mc(1000) و mc(1000) است. به طور شهودی، برای افرادی که شیر خریدهاند (m=10,000 + 1000=11,000)، بسیار محتمل است که قهوه نیز خریدهاند (mc/m = 10/11=91%)، و برعکس. نتایج چهار سنجه جدید معرفی شده نشان میدهد که m و c در هر دو مجموعه داده با تولید مقدار سنجه ۰.۹۱، ارتباط مثبت قوی دارند. با این حال، lift و χ2 به دلیل حساسیتشان به narios، mc، مقادیر سنجه بسیار متفاوتی برای D1 و D2 ایجاد میکنند. در واقع، در بسیاری از ساختارهای دنیای واقعی، mc معمولاً بسیار بزرگ و ناپایدار است. به عنوان مثال، در یک پایگاه داده سبد بازار، تعداد کل تراکنشها میتواند روزانه نوسان داشته باشد و به طور چشمگیری از تعداد تراکنشهای حاوی هر مجموعه اقلام خاص فراتر رود. بنابراین، یک سنجه جالب بودن خوب نباید تحت تأثیر تراکنشهایی قرار گیرد که حاوی مجموعه اقلام مورد نظر نیستند. در غیر این صورت، همانطور که در D1 و D2 نشان داده شده است، نتایج ناپایداری ایجاد میکند. به طور مشابه، در D3، چهار سنجه جدید به درستی نشان میدهند که m و c به شدت با هم مرتبط هستند زیرا نسبت mc به c برابر با نسبت mc به m است، یعنی 100/1100 = 9.1٪. با این حال، lift و χ2 هر دو به روشی نادرست با این موضوع در تضاد هستند: مقادیر آنها برای D2 بین مقادیر D1 و D3 است. برای مجموعه داده D4، هر دو متغیر lift و χ2 نشاندهنده ارتباط بسیار مثبت بین m و c هستند، در حالی که سایر متغیرها نشاندهنده ارتباط «خنثی» هستند زیرا نسبت mc به mc برابر با نسبت mc به mc است که برابر با ۱ است. این بدان معناست که اگر مشتری قهوه (یا شیر) بخرد، احتمال اینکه او شیر (یا قهوه) نیز بخرد دقیقاً ۵۰٪ است.
“چرا lift و χ2 در تشخیص روابط ارتباط الگو در مجموعه دادههای تراکنشی قبلی بسیار ضعیف هستند؟” برای پاسخ به این سوال، باید تراکنشهای پوچ را در نظر بگیریم. تراکنش پوچ تراکنشی است که شامل هیچ یک از مجموعه اقلام مورد بررسی نیست. در مثال ما، mc نشاندهنده تعداد تراکنشهای پوچ است. Lift و χ2 در تشخیص روابط ارتباط الگو جالب مشکل دارند زیرا هر دو به شدت تحت تأثیر mc قرار دارند. معمولاً تعداد تراکنشهای پوچ میتواند از تعداد خریدهای فردی بیشتر باشد زیرا، به عنوان مثال، بسیاری از افراد ممکن است نه شیر بخرند و نه قهوه. از سوی دیگر، چهار سنجه دیگر شاخصهای خوبی برای الگوهای جالب توجه هستند، زیرا تعاریف آنها تأثیر mc را حذف میکند (یعنی تحت تأثیر تعداد تراکنشهای تهی قرار نمیگیرند).
این بحث نشان میدهد که داشتن سنجهی که مستقل از تعداد تراکنشهای تهی باشد، بسیار مطلوب است. یک سنجه در صورتی ثابت-تهی است که مقدار آن از تأثیر تراکنشهای تهی آزاد باشد. ثابت-تهی بودن یک ویژگی مهم برای اندازهگیری الگوهای ارتباط در پایگاههای داده تراکنش بزرگ است. در میان شش سنجه مورد بحث در این زیربخش، تنها lift و χ2 سنجههای ثابت-تهی نیستند.
“از میان سنجههای all_confidence، max_confidence، Kulczynski و cosine، کدام یک در نشان دادن روابط جالب توجه الگوها بهترین است؟”
برای پاسخ به این سوال، نسبت عدم تعادل (IR) را معرفی میکنیم که عدم تعادل دو مجموعه آیتم، A و B، را در مفاهیم قانون ارزیابی میکند. این سنجه به صورت زیر تعریف میشود:
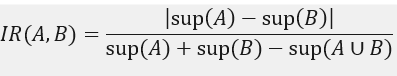
که در آن صورت، قدر مطلق اختلاف بین پشتیبانی مجموعه اقلام A و B و مخرج، تعداد تراکنشهای حاوی A یا B است. اگر دو دلالت جهتدار بین A و B یکسان باشند، IR(A,B) صفر خواهد بود. در غیر این صورت، هر چه اختلاف بین این دو بیشتر باشد، نسبت عدم تعادل بیشتر است. این نسبت مستقل از تعداد تراکنشهای صفر و مستقل از تعداد کل تراکنشها است.
بیایید به بررسی مجموعه دادههای باقیمانده در مثال ۴.۱۰ ادامه دهیم.
مثال ۴.۱۱. مقایسه سنجههای بدون تغییر صفر در ارزیابی الگو. اگرچه چهار سنجه معرفیشده در این بخش بدون تغییر صفر هستند، اما ممکن است مقادیر بسیار متفاوتی را روی برخی از مجموعه دادههای کاملاً متفاوت ارائه دهند. بیایید مجموعه دادههای D5 و D6 را که قبلاً در جدول ۴.۹ نشان داده شده است، بررسی کنیم، که در آن دو رویداد m و c احتمالات شرطی نامتوازن دارند. یعنی نسبت mc به c بزرگتر از ۰.۹ است. این بدان معناست که دانستن اینکه c رخ میدهد، قویاً نشان میدهد که m نیز رخ میدهد. نسبت mc به mis کمتر از 0.1 است که نشان میدهد m دلالت بر این دارد که c کاملاً بعید است که رخ دهد. سنجههای all_confidence و cosine هر دو مورد را به عنوان ارتباط منفی در نظر میگیرند و سنجه Kulc هر دو را خنثی میداند. سنجه max_confidence ادعا میکند که ارتباط مثبت قوی برای این موارد وجود دارد. این سنجهها نتایج بسیار متنوعی ارائه میدهند!
“کدام سنجه به طور شهودی رابطه واقعی بین خرید شیر و هزینه قهوه را منعکس میکند؟” در واقع، در این مورد، بحث در مورد اینکه آیا دو مجموعه داده ارتباط مثبت یا منفی دارند، دشوار است. از یک دیدگاه، فقط mc/(mc +mc)=1000/(1000+10,000)=9.09% از تراکنشهای مربوط به شیر حاوی قهوه در D5 هستند و این درصد در D6 برابر با 1000/(1000 + 100,000) = 0.99% است که هر دو نشان دهنده ارتباط منفی هستند. از سوی دیگر، ۹۰.۹٪ از تراکنشها در D5 (یعنی،mc/(mc+mc)=1000/(1000+100)) و ۹٪ در D6 (یعنی، ۱۰۰۰/(1000+10)) حاوی قهوه، حاوی شیر نیز هستند که نشاندهندهی ارتباط مثبت بین شیر و قهوه است، که نتیجهگیری بسیار متفاوتی است.
در این مورد، منصفانه است که آن را خنثی در نظر بگیریم، همانطور که کولک انجام میدهد. در عین حال، خوب است که چولگی آن را نیز با استفاده از نسبت عدم تعادل (IR) نشان دهیم. طبق معادله (۴.۱۳)، برای D4 داریمIR(m,c)=0، یک مورد کاملاً متعادل؛ برای D5، IR(m,c)=0.89، یک مورد نسبتاً نامتعادل؛ در حالی که برای D6، IR(m,c)=0.99، یک مورد بسیار چولگی. بنابراین، دو سنجه، Kulc و IR، با هم کار میکنند و تصویری واضح برای هر سه مجموعه داده، D4 تا D6، ارائه میدهند.
به طور خلاصه، استفاده از تنها سنجههای پشتیبانی و اطمینان برای کاوش ارتباطات ممکن است تعداد زیادی قانون ایجاد کند که بسیاری از آنها میتوانند برای کاربران جالب نباشند. در عوض، میتوانیم چارچوب پشتیبانی-اطمینان را با یک سنجه جالب بودن الگو تقویت کنیم، که به تمرکز کاوش به سمت قوانینی با روابط الگوی قوی کمک میکند. سنجه اضافه شده به طور قابل توجهی تعداد قوانین تولید شده را کاهش میدهد و منجر به کشف قوانین معنادارتر میشود. علاوه بر مواردی که در این بخش معرفی شدهاند، سنجههای جالب بودن بسیاری دیگر در ادبیات مورد مطالعه قرار گرفتهاند. متأسفانه، اکثر آنها ویژگی تغییرناپذیری تهی را ندارند. از آنجا که مجموعه دادههای بزرگ معمولاً تراکنشهای تهی زیادی دارند، در نظر گرفتن ویژگی تغییرناپذیری تهی هنگام انتخاب سنجههای جالب بودن مناسب برای ارزیابی الگو مهم است. از میان چهار سنجه تغییرناپذیری تهی مورد مطالعه در اینجا، یعنی all_confidence، max_confidence، Kulc و cosine، توصیه میکنیم از Kulc همراه با نسبت عدم تعادل استفاده کنید.
خلاصه
- کشف الگوها، ارتباطات و روابط همبستگی پرتکرار در میان مقادیر عظیمی از دادهها در بازاریابی انتخابی، تحلیل تصمیمگیری و مدیریت کسبوکار مفید است. یک حوزه کاربردی محبوب، تحلیل سبد بازار است که عادات خرید مشتریان را با جستجوی مجموعه اقلامی که پرتکراراً با هم (یا به ترتیب) خریداری میشوند، مطالعه میکند.
- کاوش قوانین ارتباط شامل یافتن اولیه مجموعه اقلام پرتکرار (مجموعههایی از اقلام، مانند A و B، که حداقل آستانه پشتیبانی یا درصد تاپلهای مربوط به وظیفه را برآورده میکنند) است که از آن قوانین ارتباط قوی به شکل A ⇒ B تولید میشوند. این قوانین همچنین حداقل آستانه اطمینان (احتمال از پیش تعیینشدهای برای برآورده شدن B تحت شرایطی که A برآورده شده باشد) را برآورده میکنند. ارتباطات را میتوان بیشتر تجزیه و تحلیل کرد تا قوانین همبستگی را کشف کرد که همبستگیهای آماری بین مجموعه اقلام A و B را منتقل میکنند.
- الگوریتمهای کارآمد و مقیاسپذیر زیادی برای کاوش مجموعه اقلام پرتکرار توسعه داده شدهاند که از آنها میتوان قوانین ارتباط و همبستگی را استخراج کرد. این الگوریتمها را میتوان به سه دسته طبقهبندی کرد: (1) الگوریتمهای شبه Apriori، (2) الگوریتمهای مبتنی بر رشد الگوهای پرتکرار مانند رشد FP، و (3) الگوریتمهایی که از قالب دادههای عمودی استفاده میکنند.
- الگوریتم Apriori یک الگوریتم اصلی برای کاوش مجموعه اقلام پرتکرار برای قوانین ارتباط بولی است. این الگوریتم، ویژگی Apriori کاوش سطح به سطح را بررسی میکند که همه زیرمجموعههای غیرتهی از یک مجموعه اقلام پرتکرار نیز باید پرتکرار باشند. در تکرار kام (برای k ≥ 2)، این الگوریتم، نامزدهای مجموعه اقلام k پرتکرار را بر اساس مجموعه اقلام پرتکرار (k-1) تشکیل میدهد و یک بار پایگاه داده را اسکن میکند تا مجموعه کامل مجموعه اقلام k پرتکرار، Lk، را پیدا کند. میتوان از تغییراتی شامل هشینگ و کاهش تراکنش برای کارآمدتر کردن این روش استفاده کرد. سایر تغییرات شامل پارتیشنبندی دادهها (کاوش در هر پارتیشن و سپس ترکیب نتایج) و نمونهبرداری از دادهها (کاوش در یک زیرمجموعه داده) است. این تغییرات میتواند تعداد اسکنهای داده مورد نیاز را به حداقل دو یا حتی یک کاهش دهد.
- رشد الگوی پرتکرار روشی برای کاوش مجموعه اقلام پرتکرار بدون تولید کاندید است.این روش یک ساختار داده بسیار فشرده (یک درخت FP) برای فشردهسازی پایگاه داده تراکنش اصلی میسازد. به جای استفاده از استراتژی تولید و آزمایش روشهای مشابه Apriori، بر رشد الگوی پرتکرار (قطعه) تمرکز میکند که از تولید کاندید پرهزینه جلوگیری میکند و منجر به کارایی بیشتر میشود.
- کاوش مجموعه اقلام پرتکرار با استفاده از فرمت داده عمودی (Eclat) روشی است که یک مجموعه داده معین از تراکنشها را در فرمت داده افقی TID-itemset به فرمت داده عمودی item-TID_set تبدیل میکند. این روش مجموعه دادههای تبدیل شده توسط تقاطعهای TID_set را بر اساس ویژگی Apriori و تکنیکهای بهینهسازی اضافی مانند diffset کاوش میکند.
- قوانین ارتباط کاملاً قوی جالب نیستند. بنابراین، چارچوب پشتیبانی-اطمینان باید با یک سنجه ارزیابی الگو تکمیل شود که کاوش قوانین جالب را ارتقا میدهد. یک سنجه در صورتی صفر-ثابت است که مقدار آن از تأثیر تراکنشهای صفر (یعنی تراکنشهایی که هیچ یک از مجموعه اقلام مورد بررسی را شامل نمیشوند) عاری باشد. در میان بسیاری از سنجههای ارزیابی الگو، ما lift، χ2، all_confidence، max_confidence، Kulczynski و cosine را بررسی کردیم و نشان دادیم که فقط چهار مورد آخر صفر-ثابت هستند. ما استفاده از سنجه Kulczynski، همراه با نسبت عدم تعادل، را برای ارائه روابط الگو بین مجموعه اقلام پیشنهاد میکنیم.
تمرینها
۴.۱. فرض کنید مجموعه C از تمام مجموعه اقلام بسته پرتکرار روی مجموعه داده D و همچنین تعداد پشتیبان برای هر مجموعه اقلام بسته پرتکرار را دارید. الگوریتمی را شرح دهید که تعیین کند آیا مجموعه اقلام X داده شده پرتکرار است یا خیر، و در صورت پرتکرار بودن، پشتیبانی X را تعیین کند.
۴.۲. مجموعه اقلام X در مجموعه داده D یک مولد نامیده میشود اگر زیرمجموعه اقلام مناسب Y ⊂ X وجود نداشته باشد به طوری که support(X)=support(Y). یک مولد X در صورتی مولد پرتکرار است که support(X) از حداقل آستانه پشتیبانی عبور کند. فرض کنید G مجموعه تمام مولدهای پرتکرار روی مجموعه داده D باشد.
- الف. آیا میتوانید با استفاده از G و تعداد پشتیبان همه مولدهای پرتکرار، تعیین کنید که آیا مجموعه اقلام A پرتکرار است و پشتیبانی A، در صورت پرتکرار بودن، چیست؟ اگر بله، الگوریتم خود را ارائه دهید. در غیر این صورت، چه اطلاعات دیگری مورد نیاز است؟ آیا میتوانید الگوریتمی ارائه دهید که فرض کند اطلاعات مورد نیاز در دسترس است؟
- ب. رابطه بین مجموعه اقلام بسته و مولدها چیست؟
۴.۳. الگوریتم Apriori از دانش قبلی در مورد ویژگیهای پشتیبانی زیرمجموعهها استفاده میکند.
- الف. ثابت کنید که همه زیرمجموعههای غیرتهی از یک مجموعه اقلام پرتکرار نیز باید پرتکرار باشند.
- ب. ثابت کنید که پشتیبانی هر زیرمجموعه غیرتهی s از مجموعه اقلام s باید حداقل به بزرگی پشتیبانی s باشد.
- ج. با توجه به مجموعه اقلام پرتکرار l و زیرمجموعه s از l، ثابت کنید که اطمینان قانون “s⇒(l −s)” نمیتواند بیشتر از اطمینان “s ⇒(l −s)” باشد، که در آن s زیرمجموعهای از s است.
- د. یک نوع پارتیشنبندی Apriori، تراکنشهای یک پایگاه داده D را به n پارتیشن غیر همپوشان تقسیم میکند. ثابت کنید که هر مجموعه اقلامی که در D پرتکرار است، باید حداقل در یک پارتیشن از D پرتکرار باشد.
۴.۴. فرض کنید c یک مجموعه اقلام کاندید در Ck باشد که توسط الگوریتم Apriori تولید شده است. چند زیرمجموعه با طول (k-1) باید در مرحله هرس بررسی کنیم؟ طبق پاسخ قبلی شما، آیا میتوانید یک نسخه بهبود یافته از روال has_infrequent_subset در شکل ۴.۴ ارائه دهید؟
۴.۵. بخش ۴.۲.۲ روشی را برای تولید قوانین ارتباط از مجموعه اقلام پرتکرار توصیف میکند. یک روش کارآمدتر پیشنهاد دهید. توضیح دهید که چرا این روش از روش پیشنهادی در آنجا کارآمدتر است. (راهنمایی: در نظر بگیرید که ویژگیهای تمرینهای ۴.۳ (ب) و (ج) را در طراحی خود بگنجانید.)
۴.۶. یک پایگاه داده پنج تراکنش دارد. فرض کنید = min_sup۶۰٪ و =min_conf۸۰٪
| TID | items_bought |
| T100 | {M, O, N, K, E, Y} |
| T200 | {D, O, N, K, E,Y} |
| T300 | {M, A, K, E} |
| T400 | {M, U, C, K, Y} |
| T500 | {C, O, O, K, I, E} |
- الف. به ترتیب با استفاده از Apriori و FP-growth، تمام مجموعه اقلام پرتکرار را پیدا کنید. کارایی دو فرآیند کاوش را مقایسه کنید.
- ب. تمام قوانین ارتباط قوی (با پشتیبانی s و اطمینان c) را که با متاروال زیر مطابقت دارند، فهرست کنید، که در آن X متغیری است که مشتریان را نشان میدهد و itemi متغیرهایی را نشان میدهد که اقلام را نشان میدهند (مثلاً “A”، “B”):
∀x ∈ transaction, buys(X, item1) ∧ buys(X, item2) ⇒ buys(X, item3) [s, c]
4.7. (پروژه پیادهسازی) با استفاده از یک زبان برنامهنویسی که با آن آشنا هستید، مانند C++ یا جاوا، سه الگوریتم کاوش مجموعه اقلام پرتکرار معرفی شده در این فصل را پیادهسازی کنید:
(1) Apriori [AS94b]، (2) FP-growth [HPY00]، و (3) Eclat [Zak00] (کاوش با استفاده از فرمت داده عمودی). عملکرد هر الگوریتم را با انواع مختلف مجموعه دادههای بزرگ مقایسه کنید.
گزارشی برای تجزیه و تحلیل موقعیتها (مثلاً اندازه دادهها، توزیع دادهها، حداقل تنظیمات آستانه پشتیبانی و چگالی الگو) بنویسید که در آن یک الگوریتم ممکن است بهتر از سایرین عمل کند ودلیل آن را بیان کنید.
۴.۸. یک پایگاه داده چهار تراکنش دارد. فرض کنید =min_sup ۶۰٪ و =min_conf ۸۰٪ باشد.
| cust_ID | TID | items_bought (به شکل brand-item_category) |
| 01 | T100 | {King’s-Crab, Sunset-Milk, Dairyland-Cheese, Best-Bread} |
| 02 | T200 | {Best-Cheese, Dairyland-Milk, Goldenfarm-Apple, Tasty-Pie, Wonder-Bread} |
| 01 | T300 | {Westcoast-Apple, Dairyland-Milk, Wonder-Bread, Tasty-Pie} |
| 03 | T400 | {Wonder-Bread, Sunset-Milk, Dairyland-Cheese} |
در دانهبندی item_category (مثلاً، itemi میتواند “شیر” باشد)، برای الگوی قانون،X∈transaction, buys(X,item1)∧buys(X,item2)⇒buys(X,item3) [s,c] ∀،
مجموعه اقلام k پرتکرار را برای بزرگترین k و تمام قوانین ارتباط قوی (با پشتیبانی s و اطمینان c آنها) حاوی k پرتکرار را برای بزرگترین k فهرست کنید.
ب. در دانهبندی brand-item_category (مثلاً، itemi میتواند “شیر غروب آفتاب” باشد)، برای الگوی قانون،
X∈customer, buys(X,item1)∧buys(X,item2)⇒buys(X,item3) ∀ ،
مجموعه اقلام k پرتکرار را برای بزرگترین k فهرست کنید (اما هیچ قانونی چاپ نکنید).
۴.۹. فرض کنید یک فروشگاه بزرگ دارای یک پایگاه داده تراکنشی است که بین چهار مکان توزیع شده است. تراکنشها در هر پایگاه داده مولفهای دارای قالب یکسانی هستند، یعنی Tj:{i1,…,im}، که در آن Tj یک شناسه تراکنش است و ik (1 ≤ k ≤ m) شناسه یک آیتم خریداری شده در تراکنش است. یک الگوریتم کارآمد برای کاوش قوانین ارتباط سراسری پیشنهاد دهید. الگوریتم شما نباید نیاز به ارسال تمام دادهها به یک سایت داشته باشد و نباید باعث سربار ارتباطی شبکه بیش از حد شود.
۴.۱۰. فرض کنید مجموعه اقلام پرتکرار برای یک پایگاه داده تراکنشی بزرگ، DB، ذخیره شدهاند. در مورد چگونگی کاوش کارآمد قوانین ارتباط (سراسری) تحت همان آستانه پشتیبانی حداقل، در صورتی که
مجموعهای از تراکنشهای جدید، که با DB نشان داده میشوند، (به صورت افزایشی) اضافه شوند، بحث کنید؟
۴.۱۱. اکثر الگوریتمهای کاوش الگوهای پرتکرار فقط آیتمهای متمایز در یک تراکنش را در نظر میگیرند. با این حال، وقوع چندین مورد از یک کالا در یک سبد خرید، مانند چهار کیک و سه بطری شیر، میتواند در تجزیه و تحلیل دادههای تراکنشی مهم باشد. چگونه میتوان با در نظر گرفتن وقوع چندین مورد، مجموعه اقلام پرتکرار را به طور موثر کاوش کرد؟ اصلاحاتی را در الگوریتمهای شناخته شده، مانند Apriori و FP-growth، برای سازگاری با چنین موقعیتی پیشنهاد دهید.
۴.۱۲. (پروژه پیادهسازی) تکنیکهای زیادی برای بهبود بیشتر عملکرد الگوریتمهای کاوش مجموعه اقلام پرتکرار پیشنهاد شده است. با در نظر گرفتن الگوریتمهای رشد الگوی پرتکرار مبتنی بر درخت FP (به عنوان مثال، FP-growth)، یکی از تکنیکهای بهینهسازی زیر را پیادهسازی کنید. عملکرد پیادهسازی جدید خود را با نسخه بهینهسازی نشده مقایسه کنید.
- الف. روش کاوش الگوی پرتکرار بخش ۴.۲.۴ از یک درخت FP برای تولید پایگاههای الگوی شرطی با استفاده از تکنیک پیشبینی پایین به بالا (یعنی، پیشبینی روی مسیر پیشوند یک کالای p) استفاده میکند. با این حال، میتوان یک تکنیک تصویرسازی بالا به پایین توسعه داد، یعنی تصویرسازی روی مسیر پسوند یک آیتم p در تولید یک پایگاه الگوی شرطی. چنین روش کاوش درخت FP از بالا به پایین را طراحی و پیادهسازی کرد. عملکرد آن را با روش تصویرسازی پایین به بالا مقایسه کنید.
- ب. گرهها و اشارهگرها به طور یکنواخت در یک درخت FP در طراحی الگوریتم رشد FP استفاده میشوند.
- با این حال، چنین ساختاری ممکن است وقتی دادهها پراکنده باشند، فضای زیادی مصرف کند. یک طرح جایگزین ممکن، بررسی پیادهسازی ترکیبی مبتنی بر آرایه و اشارهگر است، که در آن یک گره ممکن است چندین آیتم را ذخیره کند وقتی که هیچ نقطه تقسیمی به زیرشاخههای متعدد ندارد.
چنین پیادهسازی را توسعه داده و آن را با پیادهسازی اصلی مقایسه کنید.
- ج. تولید پایگاههای الگوی شرطی متعدد در طول کاوش رشد الگو، زمان و فضا مصرف میکند. یک جایگزین جالب، هل دادن شاخههایی است که برای یک آیتم خاص p کاوش شدهاند، یعنی هل دادن آنها به شاخه(های) باقیمانده درخت FP. این کار به این صورت انجام میشود که پایگاههای الگوی شرطی کمتری تولید شوند و اشتراکگذاریهای اضافی هنگام کاوش شاخههای باقیمانده درخت FP قابل بررسی باشند. چنین روشی را طراحی و پیادهسازی کنید و یک مطالعه عملکرد روی آن انجام دهید.
۴.۱۳. یک مثال کوتاه ارائه دهید تا نشان دهد که اقلام موجود در یک قانون ارتباط قوی در واقع ممکن است همبستگی منفی داشته باشند.
| هات داگ | هات داگ | !:-row | |
| همبرگر | 2000 | 500 | 2500 |
| همبرگر | 1000 | 1500 | 2500 |
| “Ecol | 3000 | 2000 | 5000 |
۴.۱۴. جدول احتمالی زیر دادههای تراکنش سوپرمارکت را خلاصه میکند، که در آن هات داگ به تراکنشهای حاوی هات داگ، هات داگ به تراکنشهایی که حاوی هات داگ نیستند، همبرگر به تراکنشهای حاوی همبرگر و همبرگر به تراکنشهایی که حاوی همبرگر نیستند اشاره دارد.
- الف. فرض کنید که قانون وابستگی «هات داگ ⇒ همبرگر» استخراج شده است. با توجه به حداقل آستانه پشتیبانی ۲۵٪ و حداقل آستانه اطمینان ۵۰٪، آیا این قانون وابستگی قوی است؟
- ب. بر اساس دادههای داده شده، آیا خرید هات داگ مستقل از خرید همبرگر است؟ اگر نه، چه نوع رابطه همبستگی بین این دو وجود دارد؟
- ج. استفاده از سنجههای all_confidence، max_confidence، Kulczynski و cosine را با lift و correlation روی دادههای داده شده مقایسه کنید.
۴.۱۵. (پروژه پیادهسازی) مجموعه دادههای DBLP (https://dblp.uni-trier.de/xml/) شامل بیش از سه میلیون ورودی از مقالات تحقیقاتی منتشر شده در کنفرانسها و مجلات علوم کامپیوتر است. در میان این ورودیها، تعداد قابل توجهی از نویسندگان وجود دارند که روابط همنویسندگی دارند.
- الف. روشی را برای کاوش کارآمد مجموعهای از روابط همنویسندگی که همبستگی نزدیکی دارند (مثلاً اغلب مقالات همنویسندگی با هم) پیشنهاد دهید.
- ب. بر اساس نتایج دادهکاوی و سنجههای ارزیابی الگو که در این فصل مورد بحث قرار گرفتهاند، بحث کنید که کدام سنجه میتواند الگوهای همکاری نزدیک را به طور قانعکنندهای بهتر از سایرین آشکار کند.
- ج. بر اساس مطالعهی (الف)، روشی را توسعه دهید که بتواند روابط مشاور و مشاورپذیر و دورهی تقریبی چنین نظارت مشاورهای را به طور تقریبی پیشبینی کند.


