مقدمه
کاوش الگوهای پرتکرار به دلیل تحقیقات قابل توجه، گسترشهای متعدد دامنه مسئله و مطالعات کاربردی گسترده، فراتر از اصول اولیه رفته است. در این فصل، روشهایی را برای کاوش الگوهای پیشرفته خواهیم آموخت. ابتدا روشهایی را برای کاوش انواع مختلف الگوها، از جمله کاوش الگوهای چندسطحی، الگوهای چندبعدی، الگوهای موجود در دادههای پیوسته، الگوهای نادر، الگوهای منفی و الگوهای پرتکرار در دادههای با ابعاد بالا، معرفی میکنیم. همچنین روشهایی را برای کاوش الگوهای فشرده و تقریبی بررسی میکنیم. سپس روشهای استفاده از محدودیتها را برای کاهش هزینه کاوش الگوهای پرتکرار بررسی میکنیم. از آنجایی که الگوهای ترتیبی و الگوهای ساختاری به طور گسترده دیده میشوند اما به روشهای کاوش نسبتاً متفاوتی نیاز دارند، مفاهیم و روشهایی را برای کاوش الگوهای ترتیبی در مجموعه دادههای توالی و کاوش الگوهای زیرگراف در مجموعه دادههای گراف معرفی میکنیم. برای درک چگونگی گسترش روشهای کاوش الگو برای تسهیل کاربردهای متنوع، یک مثال در مورد کاوش اشکالات کپی و پیست در برنامههای نرمافزاری بزرگ را بررسی میکنیم. توجه داشته باشید که کاوش الگو اصطلاحی کلیتر از کاوش الگوهای پرتکرار است، زیرا اولی الگوهای نادر و منفی را نیز پوشش میدهد. با این حال، هنگامی که هیچ ابهامی وجود ندارد، این دو اصطلاح به جای یکدیگر استفاده میشوند.
کاوش انواع مختلف الگوها
در فصل گذشته، روشهای کاوش الگوها و ارتباطات در سطح یک مفهوم واحد و فضای تک بعدی (مثلاً محصولات خریداری شده) را مطالعه کردیم. با این حال، در بسیاری از کاربردها، افراد ممکن است دوست داشته باشند الگوهای پیچیدهتری را از دادههای حجیم کشف کنند. به عنوان مثال، ممکن است کسی دوست داشته باشد ارتباطات چند سطحی را پیدا کند که شامل مفاهیمی در سطوح انتزاع مختلف باشد، ارتباطات چند بعدی که شامل بیش از یک بعد یا گزاره باشد (مثلاً قوانینی که آنچه مشتری میخرد را به سن او مرتبط میکنند)، قوانین ارتباط کمی که شامل ویژگیهای عددی هستند (مثلاً سن، حقوق)، الگوهای نادر که ممکن است ترکیبات اقلام جالب اما نادر را نشان دهند، و الگوهای منفی که همبستگیهای منفی بین اقلام را نشان میدهند. در این بخش، روشهای کاوش الگوها و ارتباطات در سطوح انتزاعی چندگانه (بخش 5.1.1) و در فضاهای چندبعدی (بخش 5.1.2)، مدیریت دادهها با ویژگیهای کمی (بخش 5.1.3)، کاوش الگوها در فضای با ابعاد بالا (بخش 5.1.4) و کاوش الگوهای نادر و الگوهای منفی (بخش 5.1.5) را بررسی میکنیم.
کاوش ارتباطات چندسطحی
برای بسیاری از کاربردها، ارتباطات قوی کشفشده در سطوح انتزاعی بالا، اگرچه اغلب دارای پشتیبانی بالایی هستند، میتوانند دانش عمومی باشند (مثلاً خرید مکرر نان و شیر با هم).
ممکن است بخواهیم برای یافتن الگوهای جدید در سطوح جزئیتر، عمیقتر شویم (مثلاً خرید مکرر چه نوع نان و چه نوع شیر با هم). از سوی دیگر، ممکن است الگوهای پراکنده زیادی در سطوح انتزاعی پایین یا اولیه وجود داشته باشد که برخی از آنها صرفاً تخصصهای جزئی الگوها در سطوح بالاتر هستند. بنابراین، بررسی چگونگی توسعه روشهای مؤثر برای کاوش الگوهای معنادار در سطوح انتزاعی چندگانه، با انعطافپذیری کافی برای پیمایش آسان در میان فضاهای انتزاعی مختلف، جالب است.
مثال ۵.۱. کاوش قوانین وابستگی چندسطحی. فرض کنید مجموعه دادههای تراکنشی مرتبط با وظیفه در جدول ۵.۱ برای فروش در یک فروشگاه الکترونیکی به ما داده شده است که اقلام خریداری شده برای هر تراکنش را نشان میدهد. سلسله مراتب مفاهیم برای اقلام در شکل ۵.۱ نشان داده شده است. یک سلسله مراتب مفهومی، توالی نگاشتها را از مجموعهای از مفاهیم سطح پایین به یک مجموعه مفهوم سطح بالاتر و عمومیتر تعریف میکند. دادهها را میتوان با جایگزینی مفاهیم سطح پایین در دادهها با مفاهیم سطح بالاتر مربوطه یا اجداد آنها، از یک سلسله مراتب مفهومی، تعمیم داد.
سلسله مراتب مفاهیم در شکل ۵.۱ به ترتیب دارای پنج سطح است که به ترتیب سطوح ۰ تا ۴ نامیده میشوند و از سطح ۰ در گره ریشه برای همه (عمومیترین سطح انتزاع) شروع میشوند. در اینجا، سطح ۱ شامل کامپیوتر، نرمافزار، چاپگر و دوربین و لوازم جانبی کامپیوتر است. سطح ۲ شامل کامپیوتر لپتاپ، کامپیوتر رومیزی، نرمافزار اداری، نرمافزار آنتیویروس و غیره است. و سطح ۳ شامل کامپیوتر رومیزی Dell، …، نرمافزار اداری مایکروسافت و غیره است. سطح ۴ خاصترین سطح انتزاع این سلسله مراتب است. این سطح شامل محصولات ملموس است.
|
جدول ۵.۱ دادههای مرتبط با وظیفه، D. |
|
TID اقلام خریداری شده |
|
T100 Apple 1511 MacBook Pro, HP Photosmart 7520 printer T200 Microsoft Office Professional 2020, Microsoft Surface Mobile Mouse T300 Logitech MX Master 2S Wireless Mouse, Gimars GEL Wrist Rest T400 Dell Studio XPS 16 Notebook, Canon PowerShot SX70 HS Digital Camera T500 Apple iPad Air (10.5-inch, Wi-Fi, 256GB), Norton Security Premium … … |
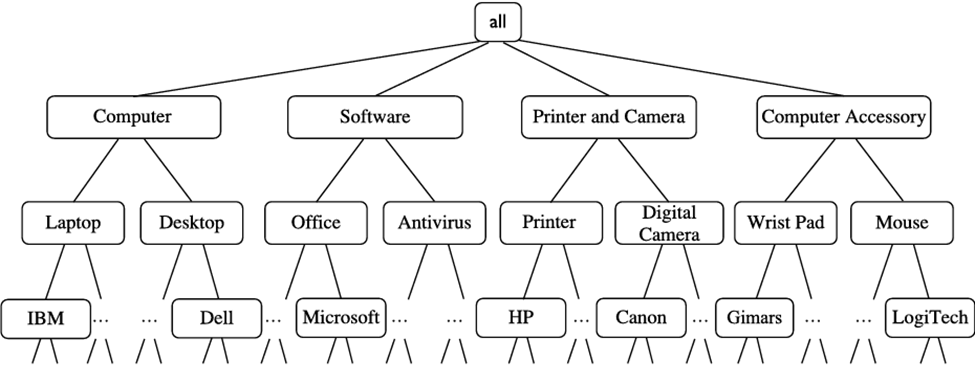
سلسله مراتب مفهومی برای اقلام کامپیوتری یک فروشگاه الکترونیکی
سلسله مراتب مفهومی برای ویژگیهای اسمی ممکن است توسط کاربرانی که با دادهها آشنا هستند مانند مدیران فروشگاه مشخص شود. به طور جایگزین، میتوان آنها را از دادهها، بر اساس تجزیه و تحلیل مشخصات محصول، مقادیر ویژگی یا توزیع دادهها، تولید کرد. سلسله مراتب مفهومی برای ویژگیهای عددی را میتوان با استفاده از تکنیکهای گسستهسازی، مانند تکنیکهای معرفی شده در فصل ۲، تولید کرد. برای مثال، سلسله مراتب مفهومی شکل ۵.۱ ارائه شده است.
اقلام موجود در جدول ۵.۱ در پایینترین سطح سلسله مراتب مفهومی شکل ۵.۱ قرار دارند. یافتن الگوهای خرید جالب در چنین دادههای سطح اولیه دشوار است. به عنوان مثال، اگر “نوت بوک Dell Studio XPS 16” یا “ماوس لیزری بیسیم Logitech VX Nano” در بخش بسیار کوچکی از تراکنشها رخ دهد، یافتن ارتباطات قوی بین این اقلام خاص میتواند دشوار باشد. افراد کمی ممکن است این اقلام را با هم خریداری کنند، که بعید است مجموعه اقلام حداقل پشتیبانی را برآورده کند. با این حال، انتظار داریم که یافتن ارتباطات قوی بین انتزاعهای تعمیمیافته این اقلام، مانند بین «لپتاپ دل» و «ماوس بیسیم»، آسانتر باشد.
قوانین وابستگی تولید شده از کاوش دادهها در سطوح انتزاع چندگانه، قوانین وابستگی چندسطحی یا چند-سطحی نامیده میشوند. قوانین وابستگی چندسطحی را میتوان با استفاده از سلسله مراتب مفاهیم تحت یک چارچوب پشتیبانی-اطمینان، به طور کارآمد کاوش کرد. به طور کلی، میتوان از یک استراتژی بالا به پایین استفاده کرد، که در آن شمارشها برای محاسبه مجموعه اقلام مکرر در هر سطح مفهوم، از سطح مفهوم ۱ شروع شده و در سلسله مراتب به سمت سطوح مفهوم خاصتر به سمت پایین حرکت میکنند، تا زمانی که هیچ مجموعه اقلام مکرر دیگری یافت نشود. برای هر سطح، میتوان از هر الگوریتمی برای کشف مجموعه اقلام مکرر، مانند Apriori یا انواع آن، استفاده کرد.
تعدادی از انواع این رویکرد در ادامه شرح داده شده است، که در آن هر نوع شامل «بازی» با آستانه پشتیبانی به روشی کمی متفاوت است. این تغییرات در شکلها نشان داده شده است. 5.2 و 5.3، که در آن گرهها نشاندهنده یک آیتم یا مجموعه آیتمی هستند که بررسی شده است، و گرههای با حاشیههای ضخیم نشان میدهند که یک آیتم یا مجموعه آیتم بررسی شده مکرر است.
• استفاده از حداقل پشتیبانی یکنواخت برای همه سطوح (که به عنوان پشتیبانی یکنواخت شناخته میشود): هنگام کاوش در هر سطح انتزاعی، از آستانه پشتیبانی حداقل 5٪ استفاده میشود. به عنوان مثال، در شکل 5.2، در کل از یک آستانه پشتیبانی حداقل 5٪ استفاده میشود (مثلاً برای کاوش از “کامپیوتر” به سمت پایین به “کامپیوتر لپتاپ”). هم “کامپیوتر” و هم “کامپیوتر لپتاپ” مکرر هستند، در حالی که “کامپیوتر رومیزی” مکرر نیست.
هنگامی که از آستانه پشتیبانی حداقل یکنواخت استفاده میشود، روش جستجو ساده میشود. این روش همچنین از این نظر ساده است که کاربران ملزم به مشخص کردن فقط یک آستانه پشتیبانی حداقل هستند. میتوان یک تکنیک بهینهسازی شبیه به Apriori را بر اساس این دانش که یک جد، ابرمجموعهای از فرزندان خود است، اتخاذ کرد: جستجو از بررسی مجموعه آیتمهایی که حاوی هر آیتم یا مجموعه آیتمی هستند که اجداد آنها حداقل پشتیبانی ندارند، اجتناب میکند.
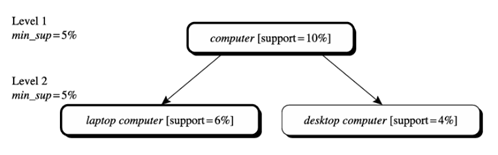
استخراج چند سطحی با پشتیبانی یکنواخت
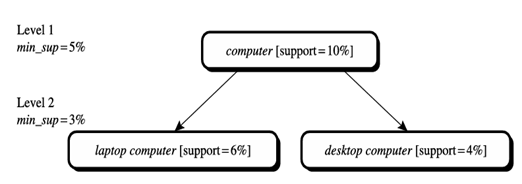
کاوش چندسطحی با پشتیبانی کاهشیافته
با این حال، رویکرد پشتیبانی یکنواخت دارای برخی اشکالات است. بعید است که موارد در سطوح انتزاع پایینتر به اندازه موارد در سطوح انتزاع بالاتر رخ دهند. اگر آستانه حداقل پشتیبانی خیلی بالا تنظیم شود، میتواند برخی از ارتباطات معنادار که در سطوح انتزاع پایین رخ میدهند را از دست بدهد. اگر آستانه خیلی پایین تنظیم شود، ممکن است ارتباطات بیاهمیت زیادی را که در سطوح انتزاع بالا رخ میدهند، ایجاد کند. این انگیزهای برای رویکرد بعدی فراهم میکند.
• استفاده از حداقل پشتیبانی کاهشیافته در سطوح پایینتر (که به عنوان پشتیبانی کاهشیافته شناخته میشود): هر سطح انتزاع آستانه پشتیبانی حداقل خود را دارد. هرچه سطح انتزاع عمیقتر باشد، آستانه مربوطه کوچکتر است. به عنوان مثال، در شکل 5.3، حداقل آستانههای پشتیبانی برای سطوح 1 و 2 به ترتیب 5٪ و 3٪ هستند. به این ترتیب، “کامپیوتر”، “کامپیوتر لپتاپ” و “کامپیوتر رومیزی” همگی مکرر در نظر گرفته میشوند. برای کاوش الگوهای چندسطحی با پشتیبانی کاهشیافته، باید در طول فرآیند کاوش، از حداقل آستانه پشتیبانی در پایینترین سطح انتزاع استفاده شود تا کاوش به پایینترین سطح انتزاع نفوذ کند. با این حال، برای استخراج نهایی الگو/قانون، آستانههای مرتبط با موارد مربوطه باید اعمال شوند تا فقط ارتباطات جالب چاپ شوند.
• استفاده از حداقل پشتیبانی مبتنی بر آیتم یا گروه (که به عنوان پشتیبانی مبتنی بر گروه شناخته میشود): از آنجا که کاربران یا متخصصان اغلب در مورد اینکه کدام گروهها از سایرین مهمتر هستند، بینش دارند، گاهی اوقات مطلوب است که هنگام کاوش قوانین چندسطحی، آستانههای پشتیبانی حداقل مختص کاربر، مبتنی بر آیتم یا مبتنی بر گروه تنظیم شوند. به عنوان مثال، یک کاربر میتواند حداقل آستانههای پشتیبانی را بر اساس قیمت محصول یا موارد مورد علاقه تنظیم کند، مانند تنظیم آستانههای پشتیبانی بسیار پایین برای “دوربین با قیمت بیش از 1000 دلار”، تا توجه ویژهای به الگوهای ارتباطی حاوی موارد در این دستهها داشته باشد.
برای کاوش الگوهایی با موارد مختلط از گروههایی با آستانههای پشتیبانی مختلف، معمولاً کمترین آستانه پشتیبانی در بین تمام گروههای شرکتکننده به عنوان آستانه پشتیبانی در کاوش در نظر گرفته میشود. این کار از فیلتر کردن الگوهای ارزشمند حاوی اقلامی از گروه با کمترین آستانه پشتیبانی جلوگیری میکند. در عین حال، حداقل آستانه پشتیبانی برای هر گروه جداگانه باید حفظ شود تا از تولید مجموعه اقلام غیرجذاب از هر گروه جلوگیری شود. سایر معیارهای جذابیت را میتوان پس از کاوش مجموعه اقلام برای استخراج قوانین واقعاً جالب استفاده کرد.
یک عارضه جانبی جدی کاوش قوانین ارتباط چندسطحی، تولید بسیاری از قوانین زائد در سطوح انتزاعی متعدد به دلیل روابط “اجداد” بین اقلام است. به عنوان مثال، قوانین زیر را در نظر بگیرید که در آن “کامپیوتر لپ تاپ” جد “کامپیوتر لپ تاپ Dell” بر اساس سلسله مراتب مفهومی شکل 5.1 است و در آن X متغیری است که نشان دهنده مشتریانی است که اقلام را خریداری کردهاند.
خرید(X، “چاپگر HP”)⇒ خرید(X، “کامپیوتر لپ تاپ”)
[پشتیبانی = 8%، اطمینان = 70%]
خرید(X، “چاپگر HP”)⇒ خرید(X، “کامپیوتر لپ تاپ Dell”)
[پشتیبانی = 2%، اطمینان = 72%]
buys(X, “laptop computer”)⇒buys(X, “HP printer”)
[support = 8%, confidence = 70%] (5.1)
buys(X, “Dell laptop computer”)⇒buys(X, “HP printer”) [support = 2%, confidence = 72%](5.2)
«اگر قوانین (5.1) و (5.2) هر دو استخراج شوند، آیا قانون (5.2) اطلاعات جدیدی ارائه میدهد؟» فرض کنید یک قانون R1 جد یک قانون R2 است، اگر R1 را بتوان با جایگزینی موارد موجود در R2 با اجدادشان در یک سلسله مراتب مفهومی به دست آورد. به عنوان مثال، قانون (5.1) جد قانون (5.2) است زیرا «کامپیوتر لپ تاپ» جد «کامپیوتر لپ تاپ Dell» است. بر اساس این تعریف، یک قانون را میتوان زائد در نظر گرفت اگر پشتیبانی و اطمینان آن نزدیک به مقادیر «مورد انتظار» آنها، بر اساس جد قانون باشد.
مثال 5.2. بررسی افزونگی در میان قوانین ارتباط چند سطحی. فرض کنید حدود یک چهارم از کل فروش «کامپیوتر لپ تاپ» مربوط به «کامپیوترهای لپ تاپ Dell» باشد. از آنجایی که قانون (5.1) دارای 70٪ اطمینان و 8٪ پشتیبانی است، میتوانیم انتظار داشته باشیم که قانون (5.2) دارای اطمینان حدود 70٪ (از آنجا که همه نمونههای داده “کامپیوتر لپتاپ دل” نمونههایی از “کامپیوتر لپتاپ” نیز هستند) و پشتیبانی حدود 2٪ (یعنی 8٪ × 1/4) باشد. اگر واقعاً چنین باشد، قانون (5.2) جالب نیست زیرا هیچ اطلاعات اضافی ارائه نمیدهد و از قانون (5.1) عمومیت کمتری دارد.
کاوش در انجمنهای چندبعدی
تاکنون، ما قوانین انجمنی را مطالعه کردهایم که حاکی از یک گزاره واحد هستند، یعنی گزاره buys. به عنوان مثال، در کاوش در یک مجموعه داده، ممکن است قانون انجمنی بولی ] خرید(X، “چاپگر HP”)⇒ خرید (X، “اپل آیپد ایر”) [را کشف کنیم. (5.3)
با پیروی از اصطلاحات مورد استفاده در پایگاههای داده چندبعدی، به هر گزاره متمایز در یک قانون، به عنوان یک بُعد اشاره میکنیم. از این رو، میتوانیم به قانون (5.3) به عنوان یک قانون ارتباط تکبعدی یا درونبعدی اشاره کنیم زیرا شامل یک گزاره متمایز (مثلاً خرید) با چندین رخداد است (یعنی گزاره بیش از یک بار در داخل قانون رخ میدهد). چنین قوانینی معمولاً از دادههای تراکنشی استخراج میشوند.
به جای در نظر گرفتن فقط دادههای تراکنشی، فروش و اطلاعات مرتبط اغلب با دادههای رابطهای مرتبط میشوند یا در یک انبار داده ادغام میشوند. چنین انبارهای دادهای ماهیت چندبعدی دارند.
به عنوان مثال، علاوه بر پیگیری اقلام خریداری شده در تراکنشهای فروش، یک پایگاه داده رابطهای ممکن است ویژگیهای دیگری مرتبط با اقلام و/یا تراکنشها مانند شرح کالا یا محل شعبه فروش را ثبت کند. اطلاعات رابطهای اضافی در مورد مشتریانی که اقلام را خریداری کردهاند (مثلاً سن مشتری، شغل، رتبه اعتباری، درآمد و آدرس) نیز ممکن است ذخیره شود. با در نظر گرفتن هر ویژگی پایگاه داده یا بُعد انبار به عنوان یک گزاره، میتوانیم قوانین انجمنی شامل گزارههای چندگانه مانند سن(X، “18…25”)∧شغل(X، “دانشجو”)⇒خرید(X، “لپتاپ”).را استخراج کنیم.
قوانین انجمنی که شامل دو یا چند بعد یا گزاره هستند را میتوان به عنوان قوانین انجمنی چندبعدی نامید. قانون (5.4) شامل سه گزاره (سن، شغل و خرید) است که هر کدام فقط یک بار در قانون رخ میدهند. از این رو، میگوییم که هیچ گزاره تکراری ندارد. قوانین انجمنی چندبعدی بدون گزارههای تکراری، قوانین انجمنی بینبعدی نامیده میشوند. ما همچنین میتوانیم قوانین انجمنی چندبعدی با گزارههای تکراری را که شامل تکرارهای متعدد برخی از گزارهها هستند، استخراج کنیم. این قوانین، قوانین انجمنی ترکیبی-بعدی نامیده میشوند. مثالی از چنین قانونی به شرح زیر است که در آن گزاره خرید تکرار میشود:
سن(X، “۱۸…۲۵”) ∧خرید(X، “لپتاپ”)⇒خرید(X، “چاپگر HP”)
(5.5)
ویژگیهای پایگاه داده میتوانند اسمی یا کمی باشند. مقادیر ویژگیهای اسمی (یا طبقهبندیشده)
“نام چیزها” هستند. ویژگیهای اسمی تعداد محدودی از مقادیر ممکن را دارند، بدون هیچ ترتیبی بین مقادیر (مثلاً شغل، برند، رنگ). ویژگیهای کمی عددی هستند و ترتیب ضمنی بین مقادیر دارند (مثلاً سن، درآمد، قیمت). تکنیکهای کاوش قوانین وابستگی چندبعدی را میتوان در مورد نحوه برخورد با ویژگیهای کمی به دو رویکرد اساسی طبقهبندی کرد.
در رویکرد اول، ویژگیهای کمی با استفاده از سلسله مراتب مفاهیم از پیش تعریف شده گسستهسازی میشوند.
این گسستهسازی قبل از کاوش انجام میشود. به عنوان مثال، ممکن است از یک سلسله مراتب مفهومی برای درآمد برای جایگزینی مقادیر عددی اصلی این ویژگی با برچسبهای بازه مانند “31K..40K,” “0..20K,” “21K..30K,”و غیره استفاده شود. در اینجا، گسستهسازی ایستا و از پیش تعیین شده است. فصل 2 در مورد پیشپردازش دادهها، چندین تکنیک برای گسستهسازی ویژگیهای عددی ارائه داد. ویژگیهای عددی گسستهشده، با برچسبهای بازهشان، میتوانند به عنوان ویژگیهای اسمی در نظر گرفته شوند (که در آن هر بازه یک دسته در نظر گرفته میشود). ما به این روش، کاوش قوانین وابستگی چندبعدی با استفاده از گسستهسازی استاتیک ویژگیهای کمی میگوییم. در رویکرد دوم، ویژگیهای کمی بر اساس توزیع دادهها گسستهسازی یا در “سطلها” خوشهبندی میشوند. این سطلها ممکن است در طول فرآیند کاوش بیشتر ترکیب شوند. فرآیند گسستهسازی پویا است و برای برآورده کردن برخی از معیارهای کاوش مانند به حداکثر رساندن اطمینان قوانین کاوششده ایجاد شده است. از آنجا که این استراتژی با مقادیر ویژگیهای عددی به عنوان کمیتها به جای محدودهها یا دستههای از پیش تعریفشده رفتار میکند، قوانین وابستگی استخراجشده از این رویکرد نیز به عنوان قوانین وابستگی کمی (پویا) شناخته میشوند.
بیایید هر یک از این رویکردها را برای کاوش قوانین وابستگی چندبعدی مطالعه کنیم. برای سادگی، بحث خود را به قوانین وابستگی بینبعدی محدود میکنیم. توجه داشته باشید که به جای جستجوی مجموعه اقلام پرتکرار (همانطور که برای کاوش قوانین وابستگی تک بعدی انجام میشود)، در کاوش قوانین وابستگی چند بعدی، ما به دنبال مجموعههای گزارهای پرتکرار میگردیم. مجموعه گزارههای Ak-مجموعهای است که شامل k گزاره عطفی است. به عنوان مثال، مجموعه گزارههای {سن، شغل، خرید} از Rule(5.4) یک مجموعه گزارهای 3-است.
کاوش قوانین وابستگی کمی
همانطور که قبلاً بحث شد، دادههای رابطهای و انبار داده اغلب شامل ویژگیها یا معیارهای کمی هستند. ما میتوانیم ویژگیهای کمی را در فواصل مختلف گسستهسازی کنیم و سپس آنها را به عنوان دادههای اسمی در کاوش وابستگی در نظر بگیریم. با این حال، چنین گسستهسازی سادهای ممکن است منجر به تولید تعداد زیادی قانون شود که بسیاری از آنها ممکن است مفید نباشند. در اینجا سه روش را معرفی میکنیم که میتوانند به غلبه بر این مشکل برای کشف روابط وابستگی جدید کمک کنند: (1) یک روش مکعب داده، (2) یک روش مبتنی بر خوشهبندی، و (3) یک روش تحلیل آماری برای کشف رفتارهای استثنایی.
کاوش وابستگیهای کمی مبتنی بر مکعب داده
در بسیاری از موارد، ویژگیهای کمی را میتوان قبل از کاوش با استفاده از سلسله مراتب مفاهیم از پیش تعریف شده یا تکنیکهای گسستهسازی دادهها، که در آن مقادیر عددی با برچسبهای فاصلهای جایگزین میشوند، گسستهسازی کرد. ویژگیهای اسمی نیز در صورت تمایل میتوانند به سطوح مفهومی بالاتر تعمیم داده شوند. اگر دادههای مربوط به وظیفه حاصل در یک جدول رابطهای ذخیره شوند، میتوان هر یک از الگوریتمهای کاوش مجموعه اقلام مکرر که در مورد آنها بحث کردیم را به راحتی اصلاح کرد تا همه مجموعههای گزارههای مکرر را پیدا کند. به طور خاص، به جای جستجو فقط روی یک ویژگی مانند خریدها، باید تمام ویژگیهای مربوطه را جستجو کنیم و هر جفت ویژگی-مقدار را به عنوان یک مجموعه اقلام در نظر بگیریم. به طور جایگزین، میتوان از دادههای چندبعدی تبدیل شده برای ساخت یک مکعب داده استفاده کرد. مکعبهای داده برای کاوش قوانین وابستگی چندبعدی بسیار مناسب هستند: آنها مجموعها (مثلاً تعدادها) را در فضای چندبعدی ذخیره میکنند که برای محاسبه پشتیبانی و اطمینان قوانین وابستگی چندبعدی ضروری است. مروری بر فناوری مکعب داده و الگوریتمهای محاسبه مکعب داده در فصل 3 ارائه شد. شکل 5.4 شبکه مکعبهای دادهای را نشان میدهد که یک مکعب داده را برای ابعاد سن، درآمد و خرید تعریف میکند. سلولهای یک مکعب n بعدی میتوانند برای ذخیره تعداد پشتیبان مجموعههای n-محمولی مربوطه استفاده شوند. مکعب پایه، دادههای مرتبط با وظیفه را بر اساس سن، درآمد و خرید تجمیع میکند؛ مکعب دو بعدی (سن، درآمد)، بر اساس سن و درآمد و غیره تجمیع میکند؛ مکعب صفر بعدی (راس) شامل تعداد کل تراکنشها در دادههای مرتبط با وظیفه است. با توجه به استفاده روزافزون از انبار داده و فناوری OLAP، این امکان وجود دارد که یک مکعب دادهای حاوی ابعادی که مورد توجه کاربر هستند، از قبل وجود داشته باشد، به طور کامل یا جزئی تحقق یابد. در این صورت، میتوانیم به سادگی مقادیر تجمعی مربوطه را دریافت کنیم یا آنها را با استفاده از تجمعهای تحققیافته سطح پایینتر محاسبه کنیم و قوانین مورد نیاز را با استفاده از یک الگوریتم تولید قانون برگردانیم. توجه داشته باشید که حتی در این حالت، ویژگی Apriori همچنان میتواند برای هرس کردن فضای جستجو استفاده شود. اگر یک مجموعه k-predicate داده شده دارای پشتیبانی sup باشد که حداقل پشتیبانی را برآورده نمیکند، کاوش بیشتر این مجموعه باید خاتمه یابد. دلیل این امر این است که هر نسخه تخصصیتر از مجموعه k-item پشتیبانی بیشتر از sup نخواهد داشت و بنابراین، حداقل پشتیبانی را نیز برآورده نمیکند. در مواردی که هیچ مکعب دادهای مرتبط برای کار کاوش وجود ندارد، باید یکی را در حال اجرا ایجاد کنیم. این به یک مسئله محاسبه مکعب کوه یخ تبدیل میشود، که در آن آستانه حداقل پشتیبانی به عنوان شرط کوه یخ در نظر گرفته میشود (فصل 3).
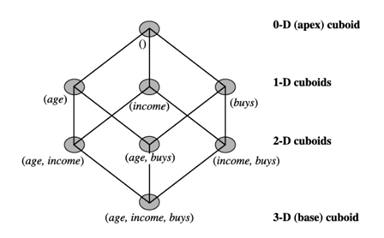
شبکهای از مکعبهای مستطیلی، که یک مکعب داده سهبعدی را تشکیل میدهند. هر مکعب مستطیل نشان دهنده یک گروه متفاوت است. مکعب مستطیل پایه شامل سه گزاره سن، درآمد و خرید است.
کاوش در مورد ارتباطات کمی مبتنی بر خوشهبندی
علاوه بر استفاده از مجموعه دادههای مبتنی بر گسستهسازی یا مبتنی بر مکعب داده برای تولید قوانین ارتباط کمی، میتوانیم با خوشهبندی دادهها در ابعاد کمی، قوانین ارتباط کمی نیز تولید کنیم. (به یاد داشته باشید که اشیاء درون یک خوشه مشابه یکدیگر و متفاوت از اشیاء درون خوشههای دیگر هستند.) فرض کلی این است که الگوهای مکرر جالب یا قوانین ارتباط به طور کلی در خوشههای نسبتاً متراکم از ویژگیهای کمی یافت میشوند. در اینجا، ما یک رویکرد بالا به پایین و یک رویکرد پایین به بالا برای خوشهبندی را توصیف میکنیم که ارتباطات کمی را پیدا میکند.
یک رویکرد معمول بالا به پایین برای یافتن الگوهای مکرر کمی مبتنی بر خوشهبندی به شرح زیر است. برای هر بعد کمی، میتوان از یک الگوریتم خوشهبندی استاندارد (مثلاً k-means یا یک الگوریتم خوشهبندی مبتنی بر چگالی، همانطور که در فصل ۸ توضیح داده شد) برای یافتن خوشههایی در این بعد که حداقل آستانه پشتیبانی را برآورده میکنند، استفاده کرد. برای هر خوشه، سپس فضاهای دوبعدی تولید شده توسط ترکیب خوشه با یک خوشه یا مقدار اسمی از بُعد دیگر را بررسی میکنیم تا ببینیم آیا چنین ترکیبی از حداقل آستانه پشتیبانی عبور میکند یا خیر. اگر عبور کند، به جستجوی خوشهها در این ناحیه دوبعدی ادامه میدهیم و به سمت ترکیبات با ابعاد بالاتر پیش میرویم. هرس Apriori همچنان در این فرآیند اعمال میشود: اگر در هر نقطهای، پشتیبانی یک ترکیب حداقل پشتیبانی را نداشته باشد، تقسیمبندی بیشتر آن یا ترکیب با ابعاد دیگر نیز نمیتواند حداقل پشتیبانی را داشته باشد.
یک رویکرد پایین به بالا برای یافتن الگوهای مکرر مبتنی بر خوشهبندی با خوشهبندی اولیه در فضای با ابعاد بالا برای تشکیل خوشههایی با پشتیبانی که حداقل آستانه پشتیبانی را برآورده میکند، و سپس آن خوشهها را در فضایی که حاوی ترکیبات با ابعاد کمتر است، پیشبینی و ادغام میکنیم. با این حال، برای مجموعه دادههای با ابعاد بالا، یافتن خوشهبندی با ابعاد بالا خود یک مشکل دشوار است. بنابراین، این رویکرد کمتر واقعبینانه است.
استفاده از نظریه آماری برای آشکارسازی رفتار استثنایی
میتوان قوانین ارتباط کمی را کشف کرد که رفتار استثنایی را آشکار میکنند، که در آن “استثنایی” بر اساس یک نظریه آماری تعریف میشود. به عنوان مثال، قانون ارتباط زیر ممکن است نشاندهنده رفتار استثنایی باشد:
جنسیت = زن ⇒ میانگین دستمزد = 7.90 دلار در ساعت (میانگین دستمزد کلی = 9.02 دلار در ساعت).
این قانون بیان میکند که میانگین دستمزد زنان فقط 7.90 دلار در ساعت است. این قانون (به طور ذهنی) جالب است زیرا گروهی از افراد را نشان میدهد که دستمزدی به طور قابل توجهی پایینتر از میانگین دستمزد 9.02 دلار در ساعت دریافت میکنند.
یک جنبه جداییناپذیر از تعریف ما شامل اعمال آزمونهای آماری برای تأیید اعتبار قوانین ما است. یعنی، قانون (5.6) تنها در صورتی پذیرفته میشود که یک آزمون آماری (در این مورد، آزمون Z) تأیید کند که با اطمینان بالا میتوان استنباط کرد که میانگین دستمزد جمعیت زنان در واقع کمتر از میانگین دستمزد بقیه جمعیت است.
کاوش دادههای با ابعاد بالا
بحثهای ما در مورد کاوش الگوهای چندبعدی در دو زیربخش فوق به الگوهایی با تعداد کمی از ابعاد محدود میشود. با این حال، برخی از برنامهها ممکن است نیاز به کاوش دادههای با ابعاد بالا (یعنی دادههایی با صدها یا هزاران بعد) داشته باشند. با این حال، گسترش روشهای کاوش الگوهای چندبعدی قبلی به کاوش دادههای با ابعاد بالا آسان نیست زیرا فضاهای جستجوی چنین روشهایی با تعداد ابعاد به صورت نمایی رشد میکنند.
یک جهت جالب برای مدیریت دادههای با ابعاد بالا، گسترش یک رویکرد رشد الگو با بررسی قالب دادههای عمودی برای مدیریت مجموعه دادههایی با تعداد زیادی از ابعاد (همچنین ویژگیها یا اقلام نامیده میشوند، مانند ژنها) اما تعداد کمی ردیف (همچنین تراکنشها یا تاپلها نامیده میشوند، مانند نمونهها) است. این امر در کاربردهایی مانند تجزیه و تحلیل بیان ژن در بیوانفورماتیک مفید است، به عنوان مثال، جایی که اغلب نیاز به تجزیه و تحلیل دادههای ریزآرایهای داریم که حاوی تعداد زیادی ژن (مثلاً 10،000 تا 100،000) هستند، اما فقط تعداد کمی نمونه (مثلاً دهها تا صدها) دارند.
جهتگیری دیگر، توسعه یک روش جدید است که تلاش دادهکاوی خود را بر روی الگوهای عظیم، یعنی الگوهایی با طول نسبتاً طولانی، به جای مجموعه کامل الگوها متمرکز کند. یکی از این روشهای جالب، Pattern-Fusion نام دارد که در فضای جستجوی الگو جهشهایی ایجاد میکند و منجر به تقریب خوبی از مجموعه کامل الگوهای عظیم و مکرر میشود. ما در اینجا به طور خلاصه ایده ادغام الگو را شرح میدهیم و خوانندگان علاقهمند را به مقاله فنی مفصل ارجاع میدهیم. در برخی کاربردها (مثلاً بیوانفورماتیک)، یک محقق میتواند بیشتر به یافتن الگوهای عظیم (مثلاً توالیهای طولانی DNA و پروتئین) علاقهمند باشد تا یافتن الگوهای کوچک (یعنی کوتاه)، زیرا الگوهای عظیم معمولاً معانی مهمتری دارند. یافتن الگوهای عظیم چالشبرانگیز است زیرا در کاوش افزایشی، قبل از اینکه حتی بتواند به الگوهای کاندید با اندازه بزرگ برسد، توسط تعداد انفجاری از الگوهای متوسط ”به دام” میافتد.
تمام استراتژیهای کاوش الگو که تاکنون مطالعه کردهایم، مانند Apriori و FP-growth، ذاتاً از یک استراتژی رشد افزایشی استفاده میکنند، یعنی طول الگوهای کاندید را یکی یکی افزایش میدهند. روشهای جستجوی سطح اول مانند Apriori نمیتوانند از تولید تعداد انفجاری از الگوهای متوسط تولید شده جلوگیری کنند، و رسیدن به الگوهای عظیم را غیرممکن میکنند. حتی روشهای جستجوی عمق اول مانند FP-growth را میتوان به راحتی قبل از رسیدن به الگوهای عظیم در تعداد زیادی از زیردرختها به دام انداخت. واضح است که برای غلبه بر چنین مانعی، به یک روش کاوش کاملاً جدید نیاز است. همانطور که در شکل ۵.۵ مشاهده کردیم، ممکن است تعداد کمی الگوی عظیم (مثلاً الگوهایی با اندازه نزدیک به ۱۰۰) وجود داشته باشد، اما چنین الگوهایی ممکن است تعداد نمایی از الگوهای متوسط ایجاد کنند.
به جای کاوش در یک مجموعه کامل از الگوهای متوسط، الگوریتم ادغام الگو، تعداد کمی از الگوهای کوتاهتر را به الگوهای عظیمتر تبدیل میکند و با مجموعه دادهها مقایسه میکند تا ببیند کدام یک از این الگوها، الگوهای پرتکرار واقعی هستند که میتوانند با ترکیب بیشتر، الگوهای عظیمتری را تولید کنند. چنین ادغام گام به گامی، جهشهایی را در فضای جستجوی الگو ایجاد میکند و از مشکلات هر دو جستجوی اول-سطح و اول-عمق، همانطور که در شکل ۵.۶ نشان داده شده است، جلوگیری میکند.
توجه داشته باشید که یک الگوی عظیم مانند {a1,a2,…,a100}:55 به این معنی است که مجموعه دادهها شامل زیرالگوهای کوتاه بسیار زیادی مانند {a1,a2,a9,…,a30}:55+; …, {a1,a9,…,a40}:55+; …), که در آن 55+به معنای تعداد پشتیبانی حداقل 55 است. یعنی، یک الگوی عظیم باید الگوهای کوچک بسیار بیشتری نسبت به الگوهای کوچکتر تولید کند. بنابراین، یک الگوی عظیم از این نظر قویتر است که اگر تعداد کمی از موارد از الگو حذف شوند، الگوی حاصل مجموعه پشتیبانی مشابهی خواهد داشت.
هرچه اندازه الگو بزرگتر باشد، این مقاومت برجستهتر است. چنین رابطه مقاومتی بین یک الگوی عظیم و الگوهای کوتاه مربوطه آن را میتوان به چندین سطح گسترش داد.
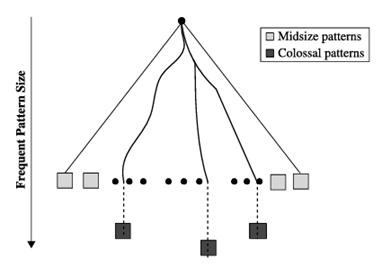
مجموعه دادههای با ابعاد بالا ممکن است شامل مجموعه کوچکی از الگوهای عظیم باشد، اما به صورت نمایی شامل الگوهای متوسط زیادی باشد
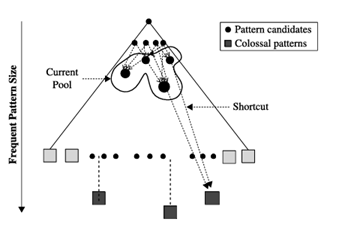
پیمایش درخت الگو: کاندیداها از مجموعهای از الگوها گرفته میشوند که منجر به میانبرهایی از طریق فضای الگو به الگوهای عظیم میشود.
بنابراین، Pattern-Fusion قابلیت شناسایی کاندیداهای ادغام خوب را دارد، که الگوهایی هستند که برخی از زیرالگوها را به اشتراک میگذارند و برخی از مجموعههای پشتیبانی مشابه دارند. این امر به جستجو کمک میکند تا از طریق فضای الگو به طور مستقیمتری به سمت الگوهای عظیم جهش کند.
به صورت نظری نشان داده شده است که Pattern-Fusion منجر به تقریب خوبی از الگوهای عظیم میشود (به [ZYH+07] مراجعه کنید). این روش بر روی مجموعه دادههای مصنوعی و واقعی ساخته شده از دادههای ردیابی برنامه و دادههای ریزآرایه آزمایش شده است. آزمایشها نشان میدهد که این روش میتواند اکثر الگوهای عظیم را با راندمان بالا پیدا کند.
کاوش الگوهای نادر و الگوهای منفی
تمام روشهای ارائه شده تاکنون در این فصل برای کاوش الگوهای مکرر بودهاند. با این حال، گاهی اوقات، یافتن الگوهایی که به جای مکرر، نادر هستند یا الگوهایی که همبستگی منفی بین موارد را نشان میدهند، جالب است. این الگوها به ترتیب به عنوان الگوهای نادر و الگوهای منفی شناخته میشوند. در این زیربخش، روشهای مختلفی برای تعریف الگوهای نادر و الگوهای منفی را بررسی میکنیم که برای ماین نیز مفید هستند.
مثال ۵.۳. الگوهای نادر و الگوهای منفی. در دادههای فروش جواهرات، فروش ساعتهای الماس نادر است؛ با این حال، الگوهای مربوط به فروش ساعتهای الماس میتواند جالب باشد. در دادههای سوپرمارکت، اگر متوجه شویم که مشتریان اغلب کوکاکولا کلاسیک یا کوکاکولا رژیمی میخرند اما نه هر دو، پس خرید کوکاکولا کلاسیک و خرید کوکاکولا رژیمی با هم یک الگوی منفی (همبسته) در نظر گرفته میشود. در دادههای فروش خودرو، یک فروشنده چند وسیله نقلیه پرمصرف (مثلاً SUV) را به یک مشتری خاص میفروشد و سپس بعداً خودروهای الکتریکی را به همان مشتری میفروشد. اگرچه خرید SUV و خرید خودروهای الکتریکی ممکن است رویدادهایی با همبستگی منفی باشند، کشف و بررسی چنین موارد استثنایی میتواند جالب باشد.
الگوی نادر (یا کمیاب) الگویی است که پشتیبانی فراوانی آن کمتر (یا بسیار کمتر) از حداقل آستانه پشتیبانی (نسبی) تعیینشده توسط کاربر است. با این حال، از آنجایی که فراوانی وقوع اکثر مجموعه اقلام معمولاً کمتر یا حتی بسیار کمتر از حداقل آستانه پشتیبانی است، در عمل مطلوب است که کاربران شرایط دیگری را برای الگوهای نادر مشخص کنند. به عنوان مثال، اگر بخواهیم الگوهایی را پیدا کنیم که حاوی حداقل یک مورد با مقداری بیش از 500 دلار هستند، باید چنین محدودیتی را به صراحت مشخص کنیم. کاوش کارآمد چنین مجموعه اقلامی تحت کاوش انجمنهای چندبعدی (بخش 5.1.1) مورد بحث قرار میگیرد، که در آن استراتژی، اتخاذ چندین آستانه پشتیبانی حداقل (مثلاً مبتنی بر مورد یا گروه) است. سایر روشهای کاربردی تحت کاوش الگوی مبتنی بر محدودیت (بخش 5.3) مورد بحث قرار میگیرند، که در آن محدودیتهای تعیینشده توسط کاربر در فرآیند کاوش تکراری قرار میگیرند. روشهای مختلفی برای تعریف یک الگوی منفی وجود دارد. ما سه تعریف از این دست را در نظر خواهیم گرفت.
تعریف 5.1. اگر مجموعه اقلام X و Y هر دو مکرر باشند اما به ندرت با هم رخ دهند (یعنی sup(X ∪Y)< sup(X) ×sup(Y)))، آنگاه مجموعه اقلام X و Y همبستگی منفی دارند و الگوی X ∪Y یک الگوی با همبستگی منفی است. اگر sup(X ∪ Y) sup(X)×sup(Y))، آنگاه X و Y همبستگی منفی قوی دارند و الگوی X ∪Y یک الگوی با همبستگی منفی قوی است.
این تعریف را میتوان به راحتی برای الگوهای حاوی k-itemset برای k>2 گسترش داد.
با این حال، یک مشکل این تعریف این است که نسبت به صفر ثابت نیست. یعنی، مقدار آن میتواند به طور گمراهکنندهای تحت تأثیر تراکنشهای صفر قرار گیرد، که در آن یک تراکنش صفر تراکنشی است که شامل هیچ یک از مجموعه اقلام مورد بررسی نیست (بخش 4.3.3). این موضوع در مثال 5.4 نشان داده شده است.
مثال 5.4. مسئله تراکنش صفر با تعریف 5.1. اگر تعداد زیادی تراکنش تهی در مجموعه دادهها وجود داشته باشد، تعداد تراکنشهای تهی به جای الگوهای مشاهده شده، ممکن است به شدت بر ارزیابی معیار در مورد اینکه آیا یک الگو همبستگی منفی دارد یا خیر، تأثیر بگذارد. به عنوان مثال، فرض کنید یک فروشگاه خیاطی بستههای سوزن A و B را میفروشد. این فروشگاه ۱۰۰ بسته از هر کدام از A و B را فروخته است، اما فقط یک تراکنش شامل A و B است. به طور شهودی، A با B همبستگی منفی دارد زیرا خرید یکی به نظر نمیرسد خرید دیگری را تشویق کند.
بیایید ببینیم تعریف بالا چگونه این سناریو را مدیریت میکند. اگر ۲۰۰ تراکنش وجود داشته باشد، داریمsup(A∪B)=1/200=0.005 و
sup(A)×sup(B)=100/200×100/200=0.25. بنابراین، sup(A∪ B) sup(A)×sup(B)و بنابراین تعریف ۵.۱ نشان میدهد که A و B همبستگی منفی قوی دارند. چه میشود اگر به جای فقط ۲۰۰ تراکنش در پایگاه داده، 106تراکنش وجود داشته باشد؟ در این حالت، تراکنشهای تهی زیادی وجود دارد، یعنی بسیاری از آنها نه شامل A هستند و نه B. تعریف چگونه برقرار است؟ این تعریف A∪B)=1/106 و sup(X)×sup(Y)=100/106 ×100/106 =1/108 را محاسبه میکند.
بنابراین،
sup(A∪B)>>sup(X)×sup(Y)، که با یافته قبلی در تضاد است، حتی اگر تعداد وقوع A و B تغییر نکرده باشد. معیار در تعریف 5.1 ناوردای تهی نیست، که در آن ناوردای تهی برای معیارهای جالب بودن کیفیت ضروری است، همانطور که در بخش 4.3.3 بحث شده است.
تعریف 5.2. اگر X و Y به شدت همبستگی منفی داشته باشند، آنگاه
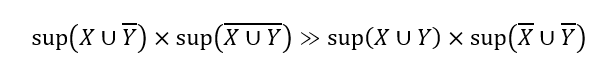
به طور شهودی، این قانون میگوید که دو مجموعه اقلام X و Y به شدت همبستگی منفی دارند اگر احتمال اینکه یک تراکنش شامل X یا Y باشد بسیار بزرگتر از احتمال این باشد که شامل هر دو X و Y باشد یا اینکه نه X و نه Y را شامل شود.
مثال ۵.۵. مسئله تراکنش پوچ با تعریف ۵.۲. با توجه به مثال بسته سوزن ما، وقتی در مجموع ۲۰۰ تراکنش در پایگاه داده وجود داشته باشد، داریم
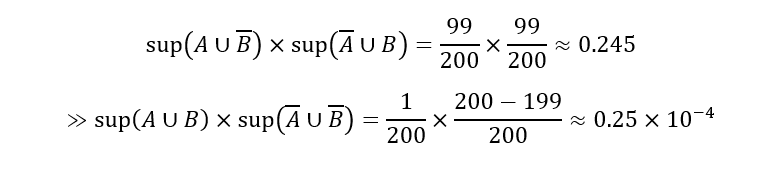
که طبق تعریف ۵.۲، نشان میدهد که A و B به شدت همبستگی منفی دارند. با این حال، اگر ۱۰۶ تراکنش در پایگاه داده وجود داشته باشد، این معیار محاسبه خواهد شد
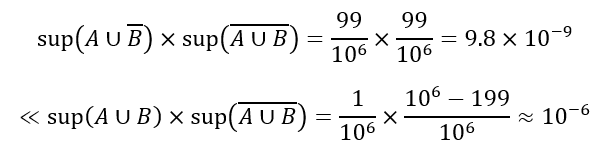
این بار، معیار نشان میدهد که A و B همبستگی مثبت دارند، از این رو، یک تناقض وجود دارد. این معیار، ثابت-صفر نیست.
به عنوان یک جایگزین سوم، تعریف 5.3 را در نظر بگیرید که مبتنی بر معیار کولچینسکی (یعنی میانگین احتمالات شرطی) است. این تعریف از روح معیارهای جالب بودن که در بخش 4.3.3 معرفی شدهاند، پیروی میکند.
تعریف 5.3. فرض کنید مجموعه اقلام X و Y هر دو مکرر هستند، یعنی sup(X)≥min_sup و sup(Y) ≥min_sup، که در آن min_sup حداقل آستانه پشتیبانی است. اگر (P(X|Y)+P(Y|X))/2 < ,که در آن
یک آستانه الگوی منفی است، آنگاه الگوی X ∪Y یک الگوی با همبستگی منفی است.
مثال 5.6. الگوهای با همبستگی منفی با استفاده از تعریف 5.3، بر اساس معیار کولچینسکی. بیایید مثال بسته سوزن خود را دوباره بررسی کنیم. فرض کنید min_sup برابر با 0.01% و =0.02 باشد. وقتی200 تراکنش در پایگاه داده وجود داشته باشد، داریم
sup(A) = sup(B) = 100/200 =0.5 >0.01% , (P(B|A)+P(A|B))/2=(0.01+0.01)/2<0.02 بنابراین A و B همبستگی منفی دارند. آیا اگر تراکنشهای بیشتری داشته باشیم، این همچنان صادق است؟ وقتی 106 تراکنش در پایگاه داده وجود داشته باشد، معیار محاسبه میکند
sup(A) =sup(B)=100/106 =0.01%≥0.01% , (P(B|A)+P(A|B))/2= (0.01 +0.01)/2 <0.02 ، که دوباره نشان میدهد A و B همبستگی منفی دارند. این با شهود ما مطابقت دارد. این معیار، مشکل عدم تغییر صفر دو تعریف اول مورد بررسی را ندارد.
بیایید حالت دیگری را بررسی کنیم: فرض کنید در بین ۱۰۰۰۰۰ تراکنش، فروشگاه ۱۰۰۰ بسته سوزن از جنس B فروخته است؛ اما هر بار که بسته B فروخته میشود، بسته A نیز فروخته میشود (یعنی در همان تراکنش ظاهر میشوند). در این حالت، معیار (P(B|A) + P(A|B))/2 = (0.01 +1)/2 =0.505 0.02, را محاسبه میکند که نشان میدهد A و B به جای همبستگی منفی، همبستگی مثبت دارند. این نیز با شهود ما مطابقت دارد.
با این تعریف جدید از همبستگی منفی، میتوان به راحتی روشهای کارآمدی برای کاوش الگوهای منفی در پایگاههای داده بزرگ استخراج کرد. این به عنوان یک تمرین برای خوانندگان علاقهمند باقی مانده است.


