مقدمه
چالش اصلی در کاوش الگوهای پرتکرار، تعداد زیاد الگوهای کشف شده است. استفاده از یک آستانه حداقلی برای کنترل تعداد الگوهای یافت شده، تأثیر محدودی دارد. مقدار خیلی کم میتواند منجر به تولید تعداد زیادی الگوی خروجی شود، در حالی که مقدار خیلی زیاد میتواند منجر به کشف فقط الگوهای رایج شود.
برای کاهش مجموعه عظیم الگوهای پرتکرار تولید شده در کاوش و در عین حال حفظ الگوهای با کیفیت بالا، میتوانیم مجموعهای فشرده یا تقریبی از الگوهای پرتکرار را کاوش کنیم. الگوهای پرتکرار برتر برای متمرکز کردن فرآیند کاوش فقط بر روی مجموعه k الگوی پرتکرار پیشنهاد شدهاند. اگرچه جالب هستند، اما معمولاً به دلیل توزیع فرکانس ناهموار در بین مجموعه اقلام، k الگوی پرتکرار را به طور خلاصه نشان نمیدهند. کاوش مبتنی بر محدودیت الگوهای پرتکرار(بخش ۵.۳) شامل محدودیتهای مشخص شده توسط کاربر برای فیلتر کردن الگوهای غیر جالب است. معیارهای جالب بودن الگو/قانون و همبستگی (بخش ۵.۳) نیز میتوانند برای کمک به محدود کردن جستجو به الگوها/قوانین مورد علاقه استفاده شوند.
به یاد داشته باشید که در فصل قبل، دو شکل اولیه از «فشردهسازی» الگوهای پرتکرار را معرفی کردیم: الگوی بسته، که فشردهسازی بدون اتلاف مجموعه الگوهای پرتکرار است، و الگوی حداکثر، که فشردهسازی با اتلاف است. در این بخش، دو شکل پیشرفته از «فشردهسازی» الگوهای پرتکرار را که بر اساس مفاهیم الگوهای بسته و الگوهای حداکثر ساخته شدهاند، بررسی میکنیم. بخش 5.2.1 فشردهسازی مبتنی بر خوشهبندی الگوهای پرتکرار را بررسی میکند که الگوها را بر اساس شباهت و پشتیبانی فرکانسی آنها گروهبندی میکند. بخش 5.2.2 یک رویکرد «خلاصهسازی» را در نظر میگیرد، که در آن هدف، استخراج الگوهای نماینده برتر آگاه از افزونگی است که کل مجموعه اقلام پرتکرار (بسته) را پوشش میدهند. این رویکرد نه تنها نمایندگی الگوها، بلکه استقلال متقابل آنها را نیز برای جلوگیری از افزونگی در مجموعه الگوهای تولید شده در نظر میگیرد. k نماینده، فشردهسازی فشردهای را بر روی مجموعه الگوهای پرتکرار ارائه میدهند و تفسیر و استفاده از آنها را آسانتر میکنند.
کاوش الگوهای فشردهشده با استفاده از خوشهبندی الگو
فشردهسازی الگو را میتوان با خوشهبندی الگو انجام داد. تکنیکهای خوشهبندی به تفصیل در فصلهای ۸ و ۹ شرح داده شدهاند. در این بخش، دانستن جزئیات دقیق خوشهبندی ضروری نیست. در عوض، یاد خواهید گرفت که چگونه میتوان مفهوم خوشهبندی را برای فشردهسازی الگوهای پرتکرار به کار برد. خوشهبندی فرآیند خودکار گروهبندی اشیاء مشابه با یکدیگر است، به طوری که اشیاء درون یک خوشه مشابه یکدیگر و متفاوت از اشیاء در خوشههای دیگر باشند. در این حالت، اشیاء الگوهای پرتکرار هستند.
الگوهای پرتکرار با استفاده از یک معیار سنجش به نام δ-خوشه خوشهبندی میشوند. یک الگوی نماینده برای هر خوشه انتخاب میشود و در نتیجه یک نسخه فشرده از مجموعه الگوهای پرتکرار ارائه میشود.
قبل از شروع، بیایید برخی از تعاریف را مرور کنیم. یک مجموعه اقلام X یک مجموعه اقلام مکرر بسته در مجموعه داده D است اگر X مکرر باشد و هیچ مجموعه اقلام بزرگ مناسب Y از X وجود نداشته باشد به طوری که Y تعداد پشتیبانی یکسانی با X در D داشته باشد. یک مجموعه اقلام X یک مجموعه اقلام مکرر حداکثری در مجموعه داده D است اگر X مکرر باشد و هیچ مجموعه اقلام بزرگ Y وجود نداشته باشد به طوری که X ⊂ Y و Y در D مکرر باشد. همانطور که در مثال 5.7 میبینیم، استفاده از این مفاهیم به تنهایی برای به دست آوردن یک فشردهسازی نماینده خوب از یک مجموعه داده کافی نیست.
|
جدول ۵.۲ زیرمجموعهای از مجموعه اقلام مکرر. |
||
|
ID |
مجموعه اقلام |
پشتیبانی |
|
P1 |
{b, c, d, e} |
205,227 |
|
P2 |
{b, c, d, e, f } |
205,211 |
|
P3 |
{a, b, c, d, e, f } |
101,758 |
|
P4 |
{a, c, d, e, f } |
161,563 |
|
P5 |
{a, c, d, e} |
161,576 |
مثال ۵.۷. کاستیهای مجموعه اقلام بسته و مجموعه اقلام حداکثری برای فشردهسازی. جدول ۵.۲
زیرمجموعهای از مجموعه اقلام مکرر را در یک مجموعه داده بزرگ نشان میدهد، که در آن a، b، c، d، e، f نشاندهنده اقلام منفرد هستند.
در اینجا هیچ مجموعه اقلام غیربستهای وجود ندارد؛ بنابراین نمیتوانیم از مجموعه اقلام مکرر بسته برای فشردهسازی دادهها استفاده کنیم. تنها مجموعه اقلام مکرر حداکثری P3 است. با این حال، مشاهده میکنیم که مجموعه اقلام P2، P3 و P4 از نظر تعداد پشتیبانی خود تفاوت قابل توجهی دارند. اگر قرار بود از P3 برای نمایش یک نسخه فشردهشده از دادهها استفاده کنیم، این اطلاعات تعداد پشتیبانی را به طور کامل از دست میدادیم. دو جفت (P1، P2) و (P4، P5) را در نظر بگیرید. از نظر بصری، الگوهای درون هر جفت از نظر پشتیبانی و بیان آنها بسیار مشابه هستند. بنابراین، به طور شهودی، P2، P3 و P4، در مجموع، باید به عنوان یک نسخه فشردهشده بهتر از دادهها عمل کنند.
بیایید ببینیم آیا میتوانیم راهی برای خوشهبندی الگوهای پرتکرار به عنوان وسیلهای برای به دست آوردن یک نمایش فشرده از آنها پیدا کنیم. ما باید یک معیار شباهت خوب تعریف کنیم، الگوها را بر اساس این معیار خوشهبندی کنیم و سپس فقط یک الگوی نماینده برای هر خوشه انتخاب و خروجی دهیم. از آنجایی که مجموعه الگوهای پرتکرار بسته، فشردهسازی بدون اتلاف روی مجموعه الگوهای پرتکرار اصلی است، ایده خوبی است که الگوهای نماینده را در اطراف مجموعهای از الگوهای تقریباً بسته کشف کنیم. میتوانیم از معیار فاصله زیر بین الگوهای بسته استفاده کنیم. فرض کنید P1 و P2 دو الگوی بسته باشند. مجموعه تراکنشهای پشتیبان آنها به ترتیب T(P1) و T(P2) هستند. فاصله الگوی P1 و P2، Pat_Dist(P1,P2)، به صورت زیر تعریف میشود.
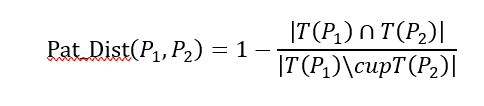
فاصله الگو یک معیار فاصله است که روی مجموعه تراکنشها تعریف میشود. این معیار، اطلاعات پشتیبانی الگوها را، همانطور که قبلاً مورد نظر بود، در بر میگیرد.مثال ۵.۸. فاصله الگو. فرض کنید P1 و P2 دو الگو هستند که T(P1) ={t1,t2,t3,t4,t5} و T(P2) ={t1,t2,t3,t4,t6}، که در آن ti یک تراکنش در پایگاه داده است. فاصله بین P1 و P2 برابر است با
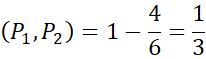
حال، بیایید بیان الگوها را بررسی کنیم. با توجه به دو الگوی A و B، فرض میکنیم B را میتوان با A بیان کرد اگر O(B)⊂O(A)، که در آن O(A) مجموعه اقلام مربوط به الگوی A است. با پیروی از این تعریف، فرض کنید الگوهای P1، P2،…،Pk در یک خوشه هستند. الگوی نماینده Pr خوشه باید بتواند تمام الگوهای دیگر موجود در خوشه را بیان کند. واضح است که داریم
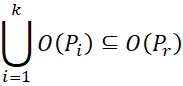
با استفاده از معیار فاصله، میتوانیم به سادگی یک روش خوشهبندی، مانند k-means (بخش 9.2)، را روی مجموعهای از الگوهای مکرر اعمال کنیم. با این حال، این دو مشکل را ایجاد میکند. اول، کیفیت خوشهها را نمیتوان تضمین کرد. دوم، ممکن است نتواند الگوی نمایندهای برای هر خوشه پیدا کند (یعنی الگوی Pr ممکن است متعلق به یک خوشه نباشد). برای غلبه بر این مشکلات، اینجاست که مفهوم δ-خوشه مطرح میشود، که در آن δ (0 ≤ δ ≤ 1) میزان تنگی یک خوشه را اندازهگیری میکند.
یک الگوی P توسط الگوی P دیگری δ-پوشش داده میشود اگر
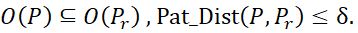
مجموعهای از الگوها یک δ-خوشه تشکیل میدهند اگر یک الگوی نماینده Pr وجود داشته باشد به طوری که برای هر الگوی Pدر مجموعه، P توسط Pr δ-پوشش داده شود.
توجه داشته باشید که طبق مفهوم δ-خوشه، یک الگو میتواند به چندین خوشه تعلق داشته باشد. همچنین، با استفاده از δ-خوشه، ما فقط باید فاصله بین هر الگو و الگوی نماینده خوشه را محاسبه کنیم. از آنجا که یک الگوی P فقط در صورتی توسط یک الگوی نماینده Pr δ-پوشش داده میشود که O(P)⊆ O(Pr)، میتوانیم محاسبه فاصله را با در نظر گرفتن تنها تکیهگاههای الگوها ساده کنیم:
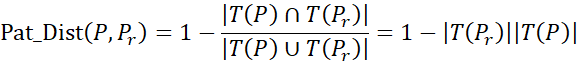
اگر الگوی نماینده را به پرتکرار بودن محدود کنیم، تعداد الگوهای نماینده (یعنی خوشهها) کمتر از تعداد الگوهای با حداکثر پرتکرار نخواهد بود. دلیل این امر آن است که یک الگوی با حداکثر پرتکرار فقط میتواند توسط خودش پوشش داده شود. برای دستیابی به فشردهسازی مختصرتر، محدودیتهای الگوهای نماینده را کاهش میدهیم، یعنی اجازه میدهیم پشتیبانی الگوهای نماینده تا حدودی کمتر از min_sup باشد. برای هر الگوی نماینده Pr، فرض میکنیم پشتیبانی آن k است. از آنجایی که باید حداقل یک الگوی پرتکرار (یعنی P) را با پشتیبانی که حداقل min_sup است پوشش دهد، داریم
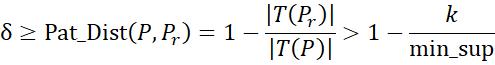
یعنی، k ≥(1−δ)×min_sup. این حداقل پشتیبانی برای یک الگوی نماینده است که با min_supr نشان داده میشود.
بر اساس بحث قبلی، مسئله فشردهسازی الگو را میتوان به صورت زیر تعریف کرد:
با توجه به یک پایگاه داده تراکنش، حداقل پشتیبانی min_sup و معیار کیفیت خوشه δ، مسئله فشردهسازی الگو یافتن مجموعهای از الگوهای نماینده R است به طوری که برای هر الگوی مکرر P (نسبت به min_sup)، یک الگوی نماینده Pr ∈ R (نسبت به min_supr) وجود داشته باشد که P را پوشش دهد و مقدار |R| به حداقل برسد. یافتن حداقل مجموعه الگوهای نماینده یک مسئله NP-Hard است. با این حال، روشهای کارآمدی توسعه یافتهاند که تعداد الگوهای مکرر بسته تولید شده را با توجه به مجموعه اصلی الگوهای بسته، به میزان زیادی کاهش میدهند. این روشها در یافتن فشردهسازی با کیفیت بالا از مجموعه الگو موفق هستند.
استخراج الگوهای برتر آگاه از افزونگی
استخراج الگوهای برتر آگاه از افزونگی، راهبردی برای کاهش تعداد الگوهای بازگردانده شده در طول کاوش است. با این حال، در بسیاری از موارد، الگوهای پرتکرار مستقل از هم نیستند، بلکه اغلب در مناطق کوچک خوشهبندی شدهاند. این تا حدودی مانند یافتن ۲۰ مرکز جمعیتی در جهان است که ممکن است منجر به خوشهبندی شهرها در تعداد کمی از کشورها شود، نه اینکه به طور مساوی در سراسر جهان توزیع شده باشند. در عوض، اکثر کاربران ترجیح میدهند k الگوی جالبتر را استخراج کنند، الگوهایی که نه تنها مهم هستند، بلکه مستقل از هم نیز هستند و افزونگی کمی دارند. مجموعه کوچکی از k الگوی نماینده که نه تنها اهمیت بالایی دارند، بلکه افزونگی کمی نیز دارند، الگوهای برتر آگاه از افزونگی نامیده میشوند.
مثال ۵.۹. استراتژی top-k آگاه از افزونگی در مقایسه با سایر استراتژیهای top-k. شکل ۵.۷ شهود پشت الگوهای top-k آگاه از افزونگی در مقایسه با الگوهای top-k سنتی و الگوهای k-خلاصهشده را نشان میدهد. فرض کنید مجموعه الگوهای مکرر نشان داده شده در شکل ۵.۷(الف) را داریم که در آن هر دایره نشان دهنده الگویی است که اهمیت آن به صورت خاکستری رنگآمیزی شده است. فاصله بین دو دایره نشان دهنده افزونگی دو الگوی مربوطه است: هرچه دایرهها به هم نزدیکتر باشند، الگوهای مربوطه نسبت به یکدیگر افزونگی بیشتری دارند. فرض کنید میخواهیم سه الگویی پیدا کنیم که به بهترین شکل مجموعه داده شده، یعنی k = ۳ را نشان دهند. کدام سه را باید انتخاب کنیم؟ از فلشها برای نشان دادن الگوهای انتخاب شده در صورت استفاده از الگوهای top-k آگاه از افزونگی (شکل ۵.۷ب)، الگوهای top-k سنتی (شکل ۵.۷ج) یا الگوهای k-خلاصهشده (شکل ۵.۷د) استفاده میشود. در شکل 5.7(c)، استراتژی سنتی k-top صرفاً بر اهمیت متکی است: این استراتژی سه الگوی با بیشترین اهمیت را برای نمایش مجموعه انتخاب میکند.
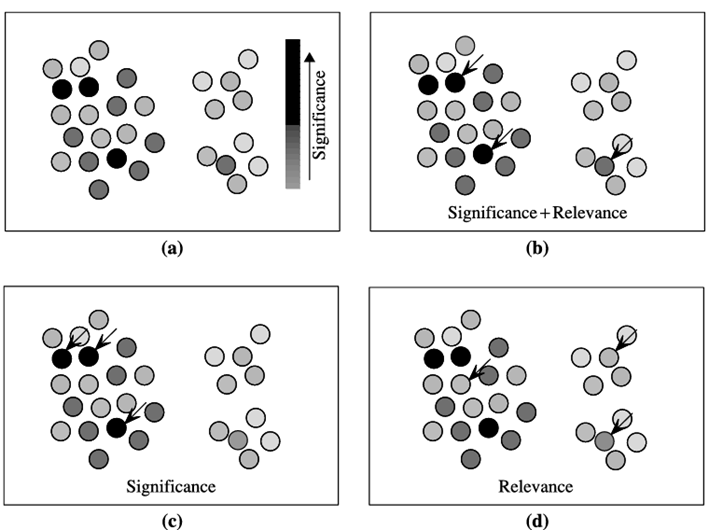
نمای مفهومی مقایسه روشهای top-k (که در آن سطوح خاکستری نشاندهنده اهمیت الگو هستند و هرچه دو الگو به هم نزدیکتر نمایش داده شوند، افزونگی بیشتری نسبت به یکدیگر دارند): (الف) الگوهای اصلی، (ب) الگوهای top-k آگاه از افزونگی، (ج) الگوهای top-k سنتی، و (د) الگوهای k-خلاصه شده
در شکل 5.7(d)، استراتژی الگوی k-خلاصه، الگوها را صرفاً بر اساس عدم افزونگی انتخاب میکند.
این استراتژی سه خوشه را شناسایی میکند و الگوهایی را که بیشترین نماینده را دارند، به عنوان الگوی “مرکزیترین” از هر خوشه پیدا میکند. این الگوها برای نمایش دادهها انتخاب میشوند. الگوهای انتخاب شده به این معنا که نمایانگر یا “خلاصهای” از خوشههایی که نماینده آنها هستند، در نظر گرفته میشوند.
در مقابل، در شکل 5.7(b) الگوهای k-top آگاه از افزونگی، بین اهمیت و افزونگی، بدهبستانی برقرار میکنند. سه الگوی انتخاب شده در اینجا دارای اهمیت بالا و افزونگی پایین هستند.
به عنوان مثال، دو الگوی بسیار مهم را مشاهده کنید که بر اساس افزونگیشان، در کنار یکدیگر نمایش داده میشوند. استراتژی k-top آگاه از افزونگی، تنها یکی از آنها را انتخاب میکند، با در نظر گرفتن اینکه دو مورد زائد خواهند بود. برای رسمی کردن تعریف الگوهای k برتر آگاه از افزونگی، باید مفاهیم اهمیت و افزونگی را تعریف کنیم.
یک معیار معنادار S تابعی است که الگوی p ∈P را به یک مقدار واقعی نگاشت میکند به طوری که S(p) درجه جالب بودن (یا مفید بودن) الگوی p است. به طور کلی، معیارهای اهمیت میتوانند عینی یا ذهنی باشند. معیارهای عینی فقط به ساختار الگوی داده شده و دادههای اساسی مورد استفاده در فرآیند کشف بستگی دارند. معیارهای عینی رایج شامل پشتیبانی، اطمینان، همبستگی و tf-idf (یا فراوانی اصطلاح در مقابل فراوانی معکوس سند) هستند، که مورد دوم اغلب در بازیابی اطلاعات استفاده میشود. معیارهای ذهنی بر اساس باورهای کاربر در مورد دادهها هستند. بنابراین، آنها به کاربرانی که الگوها را بررسی میکنند بستگی دارند. یک معیار ذهنی معمولاً یک امتیاز نسبی است که بر اساس دانش قبلی کاربر یا یک مدل پسزمینه ساخته شده است. این معیار اغلب غیرمنتظره بودن یک الگو را با محاسبه واگرایی آن از مدل پسزمینه اندازهگیری میکند. فرض کنید S(p,q) اهمیت ترکیبی الگوهای p و q باشد، و S(p|q)= S(p,q)−S(q) اهمیت نسبی p با فرض q باشد. توجه داشته باشید که اهمیت ترکیبی، S(p,q)، به معنای اهمیت جمعی دو الگوی منفرد p و q است، نه اهمیت یک الگوی برتر p ∪q. با توجه به معیار اهمیت S، افزونگی R بین دو الگوی p و q به صورت R(p,q)=S(p)+S(q)−S(p,q) تعریف میشود. در نتیجه، داریم S(p|q)=S(p)−R(p,q). فرض میکنیم که اهمیت ترکیبی دو الگو کمتر از اهمیت هر الگوی منفرد نیست (زیرا این یک اهمیت جمعی از دو الگو است) و از مجموع دو الگوی منفرد تجاوز نمیکند (زیرا افزونگی وجود دارد). یعنی افزونگی بین دو الگو باید را برآورده کند.
0 ≤R(p,q)≤min(S(p),S(q))
معمولاً به دست آوردن معیار افزونگی ایدهآل R(p,q) دشوار است. با این حال، میتوانیم افزونگی را با استفاده از فاصله بین الگوها، مانند معیار فاصله تعریف شده در بخش 5.2.1، تخمین بزنیم.
بنابراین، مسئله یافتن الگوهای k برتر آگاه از افزونگی میتواند به یافتن مجموعهای از الگوهای k تبدیل شود که اهمیت حاشیهای را به حداکثر میرساند، که یک مسئله به خوبی مطالعه شده در بازیابی اطلاعات است. در این زمینه، یک سند اگر هم به پرسوجو مرتبط باشد و هم حداقل شباهت حاشیهای را با اسناد انتخاب شده قبلی داشته باشد، ارتباط حاشیهای بالایی دارد، که در آن شباهت حاشیهای با انتخاب مرتبطترین سند انتخاب شده محاسبه میشود. روش محاسباتی دقیق در اینجا حذف شده است. مطالعات تجربی نشان دادهاند که محاسبه مبتنی بر این اصل کارآمد است و قادر به یافتن الگوهای k برتر با اهمیت بالا و افزونگی کم است.


