مقدمه
یک پایگاه داده متوالی شامل توالیهایی از عناصر یا رویدادهای مرتب است که با یا بدون مفهوم مشخصی از زمان ثبت شدهاند. کاربردهای زیادی در زمینه دادههای متوالی وجود دارد. نمونههای معمول شامل توالیهای خرید مشتری، جریانهای کلیک وب، توالیهای بیولوژیکی و توالیهای رویدادها در علوم و مهندسی و در تحولات طبیعی و اجتماعی است. در این بخش، کاوش الگوهای متوالی در پایگاههای داده تراکنشی را مطالعه میکنیم و با بسطهای مناسب، چنین الگوریتمهای کاوشی میتوانند به یافتن الگوهای متوالی برای بسیاری از کاربردهای دیگر، مانند یافتن الگوهای متوالی برای جریانهای کلیک وب و برای کاوش رویدادهای علمی، مهندسی و اجتماعی، کمک کنند. ما با مفاهیم اولیه کاوش الگوهای متوالی در بخش ۵.۴.۱ شروع میکنیم. بخش ۵.۴.۲ چندین روش مقیاسپذیر برای چنین کاوشی ارائه میدهد. ما در بخش ۵.۴.۳ کاوش الگوهای متوالی مبتنی بر محدودیت را مورد بحث قرار خواهیم داد.
کاوش الگوهای متوالی: مفاهیم و اصول اولیه
“کاوش الگوهای متوالی چیست؟” کاوش الگوهای متوالی، کاوش رویدادها یا زیردنبالههای مرتب حلقهای است که به طور مکرر به عنوان الگو رخ میدهند. مثالی از الگوی ترتیبی عبارت است از: «مشتریانی که یک آیپد پرو میخرند، احتمالاً ظرف ۹۰ روز یک مداد اپل نیز خواهند خرید.» برای دادههای خردهفروشی، الگوهای ترتیبی برای چیدمان قفسهها و تبلیغات مفید هستند. این صنعت، و همچنین مخابرات و سایر کسبوکارها، ممکن است از الگوهای ترتیبی برای بازاریابی هدفمند، حفظ مشتری و بسیاری از کارهای دیگر نیز استفاده کنند. سایر حوزههایی که الگوهای ترتیبی میتوانند در آنها اعمال شوند عبارتند از: تحلیل الگوی دسترسی به وب، فرآیندهای تولید و تشخیص نفوذ شبکه. توجه داشته باشید که اکثر مطالعات مربوط به کاوش الگوهای ترتیبی بر الگوهای دستهبندی یا نمادین متمرکز هستند، در حالی که تحلیل منحنی عددی معمولاً به حوزه تحلیل روند و پیشبینی در تحلیل سریهای زمانی آماری که در بسیاری از کتابهای درسی آمار یا تحلیل سریهای زمانی مورد بحث قرار گرفته است، تعلق دارد.
مسئلهی کاوش الگوهای ترتیبی اولین بار توسط آگراوال و سریکانت در سال ۱۹۹۵ بر اساس مطالعهی آنها روی توالیهای خرید مشتری، به شرح زیر معرفی شد: با توجه به مجموعهای از توالیها، که در آن هر توالی شامل فهرستی از رویدادها (یا عناصر) و هر رویداد شامل مجموعهای از اقلام است، و با توجه به حداقل آستانهی پشتیبانی مشخص شده توسط کاربر min_sup، کاوش الگوهای ترتیبی تمام زیردنبالههای مکرر، یعنی زیردنبالههایی که فراوانی وقوع آنها در مجموعهی توالیها کمتر از min_sup نیست، را پیدا میکند.
بیایید برای بحث خود در مورد کاوش الگوهای ترتیبی، واژگانی ایجاد کنیم. فرض کنید I = {I1,I2,…,Ip} مجموعهی تمام اقلام باشد. Anitemset مجموعهای غیرتهی از اقلام است. یک توالی، فهرستی مرتب از رویدادها است. یک توالی s با e1e2e3···el نشان داده میشود، که در آن رویداد e1 قبل از e2 رخ میدهد، که آن نیز قبل از e3 رخ میدهد و به همین ترتیب. رویداد ej نیز عنصری از s نامیده میشود. در مورد دادههای خرید مشتری، یک رویداد به یک خرید اشاره دارد که در آن مشتری اقلامی را در یک فروشگاه خاص خریداری کرده است. بنابراین، این رویداد یک مجموعه اقلام است، یعنی لیستی نامرتب از اقلامی که مشتری در طول خرید خریداری کرده است. مجموعه اقلام (یا رویداد) به صورت (x1x2 ···xq) نشان داده میشود، که در آن xk یک کالا است. برای اختصار، اگر یک عنصر فقط یک کالا داشته باشد، براکتها حذف میشوند، یعنی عنصر (x) به صورت x نوشته میشود. فرض کنید مشتری چندین خرید به فروشگاه انجام داده است. این رویدادهای مرتب شده یک دنباله برای مشتری تشکیل میدهند. یعنی، مشتری ابتدا اقلام موجود در e1 را خریداری کرده است، سپس بعداً اقلام موجود در e2 را خریداری کرده است و به همین ترتیب. یک کالا میتواند حداکثر یک بار در یک رویداد از یک دنباله رخ دهد، اما میتواند چندین بار در رویدادهای مختلف یک دنباله رخ دهد. تعداد نمونههای اقلام در یک دنباله، طول دنباله نامیده میشود. یک دنباله با طول l، دنباله l نامیده میشود. دنباله α =a1a2···an زیردنبالهای از دنباله دیگر β =b1b2···bm نامیده میشود و β یک ابردنباله از α است که با α β نشان داده میشود، اگر اعداد صحیح 1 ≤ j1 <j2 <···<jn ≤m وجود داشته باشند به طوری که a1 ⊆bj1, a2 ⊆bj2
, …,an ⊆bjn
. به عنوان مثال، اگر α =(ab),d و β =(abc),(de) که در آن a، b، c، d و e آیتم هستند، آنگاه α یک زیردنباله از β و β یک ابردنباله از α است.
یک پایگاه داده دنباله، S، مجموعهای از تاپلها، SID، s است، که در آن SID یک sequence_ID و s یک دنباله است. برای مثال ما، S شامل توالیهایی برای همه مشتریان فروشگاه است. یک تاپل SID,s گفته میشود که شامل توالی α است، اگر α زیردنبالهای از s باشد. پشتیبانی از توالی α در یک پایگاه داده توالیS تعداد تاپلها در پایگاه داده حاوی α است، یعنی supportS(α)=|{SID,s |(SID,s ∈
S)∧(α s)}|. اگر پایگاه داده توالی از متن واضح باشد، میتوان آن را به عنوان support(α) نشان داد.
با توجه به عدد صحیح مثبت min_sup به عنوان حداقل آستانه پشتیبانی، یک توالی α در پایگاه داده توالی S مکرر است اگر supportS(α) ≥ min_sup. یعنی برای اینکه توالی α مکرر باشد، باید حداقل در زمانهای min_sup در S رخ دهد. یک توالی مکرر، الگوی متوالی نامیده میشود. یک الگوی متوالی با طول l، الگوی l نامیده میشود. مثال زیر این مفاهیم را نشان میدهد.
مثال ۵.۱۲. الگوهای ترتیبی. پایگاه داده ترتیبی، S، که در جدول ۵.۴ ارائه شده است را در نظر بگیرید، که در مثالهای این بخش استفاده خواهد شد. فرض کنید min_sup = ۲ باشد. مجموعه اقلام موجود در پایگاه داده عبارت است از {a,b,c,d,e,f,g}. پایگاه داده شامل چهار توالی است. بیایید نگاهی دقیق به توالی ۱ بیندازیم که a(abc)(ac)d(cf) است. این توالی دارای پنج رویداد است، یعنی (a)، (abc)، (ac)، (d) و (cf)، که به ترتیب ذکر شده رخ میدهند. اقلام a و c هر کدام بیش از یک بار در رویدادهای مختلف توالی ظاهر میشوند. نه نمونه از اقلام در توالی ۱ وجود دارد. بنابراین طول آن نه است و یک توالی ۹ تایی نامیده میشود. این عنصر سه بار در توالی ۱ رخ میدهد و بنابراین سه تا به طول توالی کمک میکند. با این حال، کل توالی فقط یک تا به پشتیبانی a کمک میکند. دنباله a(bc)df یک زیردنباله از دنباله ۱ است زیرا رویدادهای اولی هر یک زیرمجموعهای از رویدادهای دنباله ۱ هستند و ترتیب رویدادها حفظ میشود. زیردنباله s =(ab)c را در نظر بگیرید.
با نگاهی به پایگاه داده دنبالهها، S، میبینیم که دنبالههای ۱ و ۳ تنها دنبالههایی هستند که شامل زیردنباله s هستند. بنابراین پشتیبانی s برابر با ۲ است که حداقل پشتیبانی را برآورده میکند. بنابراین s مکرر است و بنابراین آن را یک الگوی متوالی مینامیم. Itisa3-pattern زیرا یک الگوی متوالی با طول سه است.
|
جدول ۵.۴ یک پایگاه داده توالی. |
|
|
شناسه توالی |
توالی |
|
1 |
(a(abc)(ac)d(cf )) |
|
2 |
((ad)c(bc)(ae)) |
|
3 |
((ef )(ab)(df )cb) |
|
4 |
(eg(af )cbc) |
این مدل از کاوش الگوهای متوالی، انتزاعی از تحلیل توالی خرید مشتری است.
روشهای مقیاسپذیر برای کاوش الگوهای متوالی روی چنین دادههایی در بخش 5.4.2 شرح داده شده است که در ادامه میآید. بسیاری از کاربردهای کاوش الگوهای متوالی دیگر ممکن است توسط این مدل پوشش داده نشوند. به عنوان مثال، هنگام تجزیه و تحلیل توالیهای کلیک وب، اگر کسی بخواهد پیشبینی کند که کلیک بعدی چه خواهد بود، شکافهای بین کلیکها مهم میشوند. در تجزیه و تحلیل توالی DNA، الگوهای تقریبی مفید میشوند زیرا توالیهای DNA ممکن است شامل درج (نماد) حذف و جهش باشند. چنین الزامات متنوعی را میتوان به عنوان کاهش یا اعمال محدودیت در نظر گرفت. در بخش 5.4.3، ما در مورد چگونگی گسترش مدل کاوش متوالی پایه به کاوش الگوهای متوالی محدود به منظور رسیدگی به این موارد بحث میکنیم.
روشهای مقیاسپذیر برای کاوش الگوهای متوالی
کاوش الگوهای متوالی از نظر محاسباتی چالش برانگیز است زیرا چنین کاوشی ممکن است تعداد ترکیبی انفجاری از زیرتوالیهای میانی را تولید و/یا آزمایش کند.
“چگونه میتوانیم روشهای کارآمد و مقیاسپذیر برای کاوش الگوهای متوالی توسعه دهیم؟” میتوانیم روشهای کاوش الگوهای متوالی را به دو دسته طبقهبندی کنیم: (1) روشهای کارآمد برای کاوش مجموعه کامل الگوهای متوالی، و (2) روشهای کارآمد برای کاوش فقط مجموعه الگوهای متوالی بسته، که در آن یک الگوی متوالی s بسته است اگر هیچ الگوی متوالی s وجود نداشته باشد که در آن s یک ابردنباله مناسب از s است و s همان پشتیبانی (فرکانس) s را دارد.3 از آنجایی که همه زیردنبالههای یک دنباله مکرر نیز مکرر هستند، کاوش مجموعه الگوهای متوالی بسته ممکن است از تولید زیردنبالههای غیرضروری جلوگیری کند و بنابراین منجر به نتایج فشردهتر و همچنین روشهای کارآمدتری نسبت به کاوش کل مجموعه شود. ابتدا روشهای کاوش مجموعه کامل را بررسی میکنیم و سپس نحوه گسترش آنها را برای کاوش مجموعه بسته مطالعه خواهیم کرد. علاوه بر این، اصلاحاتی را برای کاوش الگوهای متوالی چند سطحی و چند بعدی (یعنی با سطوح مختلف دانهبندی) مورد بحث قرار میدهیم. رویکردهای اصلی برای کاوش مجموعه کامل الگوهای متوالی مشابه رویکردهای معرفی شده برای کاوش مجموعه اقلام پرتکرار در فصل 5 هستند. در اینجا، ما سه رویکرد از این دست را برای کاوش الگوهای متوالی مورد بحث قرار میدهیم که به ترتیب توسط الگوریتمهای GSP، SPADE و PrefixSpan ارائه میشوند. GSP یک رویکرد تولید و آزمایش کاندید را با استفاده از قالب داده افقی (که در آن دادهها به صورت sequence_ID:sequence_of _itemsets نمایش داده میشوند، طبق معمول، که در آن هر مجموعه اقلام یک رویداد است) اتخاذ میکند. SPADE یک رویکرد تولید و آزمایش کاندید را با استفاده از قالب داده عمودی (که در آن دادهها به صورت itemset :(sequence_ID,event_ID) نمایش داده میشوند) اتخاذ میکند. قالب داده عمودی را میتوان با تبدیل از یک پایگاه داده توالی با قالب افقی تنها در یک اسکن به دست آورد. PrefixSpan یک روش رشد الگو است که نیازی به تولید کاندید ندارد.
هر سه رویکرد به طور مستقیم یا غیرمستقیم ویژگی Apriori را که به شرح زیر بیان میشود، بررسی میکنند:
هر زیردنباله غیرتهی از یک الگوی متوالی، یک الگوی متوالی است. (به یاد داشته باشید که برای اینکه یک الگو متوالی نامیده شود، باید مکرر باشد. یعنی باید حداقل پشتیبانی را برآورده کند.) ویژگی Apriori آنتیمانوتونیک (یا رو به پایین بسته) است، به این معنی که اگر یک دنباله نتواند از یک آزمون عبور کند (مثلاً در مورد حداقل پشتیبانی)، تمام سوپردنبالههای آن نیز در آزمون شکست خواهند خورد. استفاده از این ویژگی برای هرس کردن فضای جستجو میتواند به کشف الگوهای متوالی کارآمدتر کمک کند.
GSP: یک الگوریتم کاوش الگوی ترتیبی مبتنی بر تولید و آزمایش کاندید
GSP (الگوهای ترتیبی تعمیمیافته) یک روش کاوش الگوی ترتیبی است که توسط Srikant و Agrawal در سال ۱۹۹۶ توسعه داده شد. این یک بسط از الگوریتم اصلی آنها برای کاوش مجموعه اقلام مکرر، معروف به Apriori (بخش ۵.۲) است. GSP از ویژگی بسته شدن رو به پایین الگوهای ترتیبی استفاده میکند و یک رویکرد تولید و آزمایش کاندید چند مرحلهای را اتخاذ میکند. الگوریتم به شرح زیر خلاصه میشود. در اولین اسکن پایگاه داده، تمام اقلام مکرر، یعنی آنهایی که حداقل پشتیبانی را دارند، پیدا میکند. هر یک از این اقلام، یک توالی مکرر به طول ۱ متشکل از آن آیتم را ارائه میدهد. هر گذر بعدی با یک مجموعه اولیه از الگوهای ترتیبی – مجموعهای از الگوهای ترتیبی که در گذر قبلی یافت شدهاند – شروع میشود. این مجموعه اولیه برای تولید الگوهای بالقوه مکرر جدید، به نام توالیهای کاندید، استفاده میشود.
هر توالی کاندید شامل یک آیتم بیشتر از الگوی ترتیبی اولیهای است که از آن تولید شده است. به یاد داشته باشید که تعداد نمونههای اقلام در یک توالی، طول توالی است. بنابراین، تمام توالیهای کاندید در یک مسیر مشخص، طول یکسانی خواهند داشت. ما به یک توالی با طول k، یک توالی k-کاندیدا اطلاق میکنیم. فرض کنید Ck نشاندهندهی مجموعهی توالیهای k-کاندیدا باشد. یک گذر از پایگاه داده، پشتیبانی برای هر توالی k-کاندیدا را پیدا میکند. کاندیداهای موجود در Ck با حداقل min_sup، Lk را تشکیل میدهند و به k-کاندیداهای مکرر تبدیل میشوند. سپس این مجموعه به عنوان مجموعهی اولیه برای گذر بعدی، k + 1، در نظر گرفته میشود.
الگوریتم زمانی خاتمه مییابد که هیچ الگوی متوالی جدیدی در یک مسیر یافت نشود، یا هیچ توالی کاندیدی نتواند تولید شود.
این روش در مثال زیر نشان داده شده است.
مثال ۵.۱۳. GSP: تولید و آزمایش کاندید (با استفاده از فرمت داده افقی). فرض کنید همان پایگاه داده توالی، S، از جدول ۵.۴ از مثال ۵.۱۲، با min_sup = 2 به ما داده شده است. توجه داشته باشید که دادهها در فرمت داده افقی نمایش داده میشوند. در اولین اسکن (k =1)، GSP پشتیبانی برای هر مورد را جمعآوری میکند. بنابراین، مجموعه توالیهای کاندید ۱ (که در اینجا به شکل «توالی: پشتیبان» نشان داده شده است) به صورت زیر است:
{a :4, b :4, c :4, d :3, e :3, f :3, g :1.}
دنباله g فقط ۱ پشتیبان دارد و تنها دنباله ای است که حداقل پشتیبانی را برآورده نمیکند. با فیلتر کردن آن، اولین مجموعه اولیه، L1 ={a, b, c, d, e, f} را بدست میآوریم. هر عضو در این مجموعه، یک الگوی متوالی با طول ۱ را نشان میدهد. هر مرحله بعدی با مجموعه اولیه یافت شده در مرحله قبلی شروع میشود و از آن برای تولید توالیهای کاندید جدید، که به طور بالقوه مکرر هستند، استفاده میکند. با استفاده از L1 به عنوان مجموعه اولیه، این مجموعه از 6 الگوی متوالی با طول 1، مجموعهای از
که مساوی است با 51 توالی کاندید با طول 2 تولید میکند، C2 ={aa, ab,…, af , ba, bb,…, ff , (ab) , (ac) ,…, (ef) }. توجه داشته باشید که aa نشان میدهد که a دو بار به دنبال هم اتفاق میافتد، و ab نشان میدهد که a و پس از آن b اتفاق میافتد.
به طور کلی، مجموعه کاندیداها توسط خود-پیوندی الگوهای متوالی یافت شده در مرحله قبلی تولید میشود (برای جزئیات به بخش 5.2.1 مراجعه کنید). GSP از ویژگی Apriori برای هرس کردن مجموعه کاندیداها به شرح زیر استفاده میکند. در مرحله kام، یک دنباله تنها در صورتی کاندید است که هر یک از زیردنبالههای با طول (k-1) آن، یک الگوی متوالی یافت شده در مرحله (k-1)ام باشد. یک اسکن جدید از پایگاه داده، پشتیبانی هر دنباله کاندید را جمعآوری کرده و مجموعهای جدید از الگوهای متوالی، Lk، را پیدا میکند. این مجموعه به عنوان بذر برای مرحله بعدی عمل میکند. الگوریتم زمانی خاتمه مییابد که هیچ الگوی متوالی در یک مرحله یافت نشود، یا زمانی که هیچ دنباله کاندیدی تولید نشود. واضح است که تعداد اسکنها حداقل برابر با حداکثر طول الگوهای متوالی است. اگر الگوهای متوالی به دست آمده در آخرین اسکن هنوز کاندیداهای جدیدی تولید کنند، GSP به یک اسکن دیگر نیاز دارد. اگرچه GSP از هرس Apriori بهره میبرد، اما همچنان تعداد زیادی کاندیدا تولید میکند. در این مثال، ۶ الگوی متوالی با طول ۱، ۵۱ کاندید با طول ۲ تولید میکنند؛ ۲۲ الگوی متوالی با طول ۲، ۶۴ کاندید با طول ۳ تولید میکنند؛ و به همین ترتیب. برخی از کاندیدهای تولید شده توسط GSP ممکن است اصلاً در پایگاه داده ظاهر نشوند. در این مثال، ۱۳ مورد از ۶۴ کاندید با طول ۳ در پایگاه داده ظاهر نمیشوند و در نتیجه تلاش جستجو هدر میرود.
این مثال نشان میدهد که اگرچه یک روش کاوش الگوی متوالی شبیه Apriori، مانند GSP، فضای جستجو را کاهش میدهد، اما معمولاً نیاز به اسکن چندین بار پایگاه داده دارد. احتمالاً مجموعه عظیمی از توالیهای کاندید تولید میکند، به خصوص هنگام کاوش توالیهای طولانی. نیاز به روش کاوش کارآمدتری وجود دارد.
SPADE: یک الگوریتم کاوش الگوی متوالی با فرمت دادههای عمودی مبتنی بر Apriori
رویکرد کاوش الگوی متوالی شبیه Apriori (مبتنی بر تولید و آزمایش کاندید) را میتوان با نگاشت یک پایگاه داده توالی به فرمت دادههای عمودی نیز بررسی کرد. در قالب داده عمودی، پایگاه داده به مجموعهای از تاپلها به شکل itemset:(sequence_ID,event_ID) تبدیل میشود. یعنی برای یک itemset مشخص، شناسه توالی و شناسه رویداد مربوطه را که itemset برای آن رخ میدهد، ثبت میکنیم. شناسه رویداد به عنوان یک مهر زمانی در یک توالی عمل میکند. event_ID مربوط به i امین itemset (یا رویداد) در یک توالی، i است. توجه داشته باشید که یک itemset میتواند در بیش از یک توالی رخ دهد. مجموعه جفتهای (sequence_ID,event_ID) برای یک itemset مشخص، ID_list مربوط به itemset را تشکیل میدهد. نگاشت از قالب افقی به عمودی نیاز به یک اسکن از پایگاه داده دارد. مزیت اصلی استفاده از این قالب این است که میتوانیم پشتیبانی هر k-sequence را با اتصال ساده ID_list های هر دو از زیردنبالههای به طول (k-1) آن تعیین کنیم. طول ID_list حاصل (یعنی مقادیر منحصر به فرد sequence_ID) برابر با پشتیبانی از k-sequence است که به ما میگوید آیا دنباله مکرر است یا خیر.
SPADE (کشف الگوی متوالی با استفاده از کلاسهای معادل) یک الگوریتم کاوش الگوی متوالی مبتنی بر Apriori است که از فرمت داده عمودی استفاده میکند. همانند GSP، SPADE برای یافتن توالیهای مکرر ۱- نیاز به یک اسکن دارد. برای یافتن توالیهای کاندید ۲-sequence، اگر جفتهای آیتمهای منفرد مکرر باشند (در اینجا، ویژگی Apriori اعمال میشود)، شناسه توالی یکسانی داشته باشند و شناسههای رویداد آنها از یک ترتیب متوالی پیروی کنند، آنها را به هم متصل میکنیم. یعنی، اولین آیتم در جفت باید به عنوان یک رویداد قبل از آیتم دوم رخ دهد، که در آن هر دو در یک توالی رخ میدهند. به طور مشابه، میتوانیم طول مجموعه آیتمها را از طول ۲ به طول ۳ و غیره افزایش دهیم. این روش زمانی متوقف میشود که هیچ توالی مکرری پیدا نشود یا چنین توالیهایی با چنین اتصالهایی تشکیل نشوند. مثال زیر به توضیح این فرآیند کمک میکند. مثال ۵.۱۴. SPADE: کاندید تولید و آزمایش با استفاده از قالب داده عمودی. فرض کنید min_sup= ۲ باشد.
پایگاه داده توالی نمونه در حال اجرای ما، S، از جدول ۵.۴ در قالب داده افقی است. SPADE ابتدا S را اسکن کرده و آن را به قالب عمودی تبدیل میکند، همانطور که در شکل ۵.۸ (الف) نشان داده شده است. هر مجموعه آیتم (یا رویداد) با ID_list خود مرتبط است، که مجموعهای از جفتهای SID (sequence_ID) و EID (event_ID) است که شامل مجموعه آیتمها میشوند.
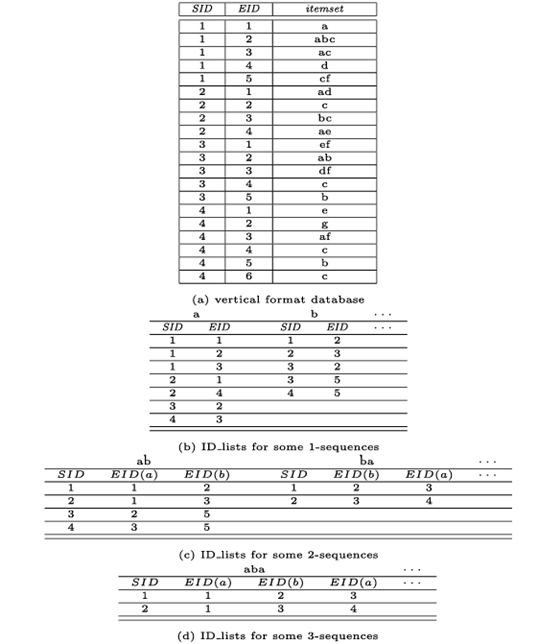
فرآیند کاوش SPADE: (الف) پایگاه داده با فرمت عمودی؛ و (ب) تا (د) نمایش قطعاتی از لیستهای ID به ترتیب برای توالیهای ۱، ۲ و ۳
لیست_شناسه برای آیتمهای منفرد، a، b و غیره، در شکل 5.8(b) نشان داده شده است. به عنوان مثال، لیست_شناسه برای آیتم b شامل جفتهای (SID,EID) زیر است: {(1,2)،(2,3)،(3,2)،(3,5)،(4,5)}، که در آن ورودی(1,2) به این معنی است که b در دنباله 1، رویداد 2 و غیره رخ میدهد. آیتمهای a و b مکرر هستند. آنها را میتوان به هم متصل کرد تا دنباله طول-2، a،b را تشکیل دهند. ما پشتیبانی این دنباله را به شرح زیر مییابیم. ما لیست_شناسههای a و b را با اتصال روی همان شناسه_دنباله، هر جا که طبق شناسه_رویدادها، a قبل از b رخ دهد، به هم متصل میکنیم. یعنی، اتصال باید ترتیب زمانی رویدادهای مربوطه را حفظ کند. نتیجه چنین اتصالی برای
a و b در لیست_شناسه برای ab در شکل 5.8(c) نشان داده شده است. برای مثال، ID_list برای توالی 2-ab مجموعهای از سهتاییها، (SID,EID(a),EID(b))، یعنی {(1,1,2)،(2,1,3)،(3,2,5)،(4,3,5)} است. برای مثال، ورودی (2,1,3) نشان میدهد که هر دو a و b در توالی 2 رخ میدهند و a (رویداد 1 توالی) قبل از b (رویداد 3) رخ میدهد، در صورت نیاز. علاوه بر این، توالیهای 2-متناوب را میتوان (با در نظر گرفتن روش ابتکاری هرس Apriori مبنی بر اینکه (k-1)-زیرتوالیهای یک توالی k کاندید باید مکرر باشند) به هم متصل کرد تا توالیهای 3-متناوب تشکیل دهند، همانطور که در شکل 5.8(d) آمده است، و به همین ترتیب. این فرآیند زمانی پایان مییابد که هیچ توالی مکرری یافت نشود یا هیچ توالی کاندیدی تشکیل نشود. استفاده از قالب داده عمودی، با ایجاد لیستهای ID، اسکنهای پایگاه داده توالی را کاهش میدهد. لیستهای ID اطلاعات لازم برای یافتن پشتیبانی از کاندیداها را حمل میکنند. با افزایش طول یک توالی مکرر، اندازه لیست ID آن کاهش مییابد و در نتیجه اتصال سریع انجام میشود. با این حال، روش جستجوی اساسی SPADE و GSP جستجوی سطح اول (مثلاً کاوش توالیهای ۱، سپس توالیهای ۲ و غیره) و هرس Apriori است. با وجود هرس، هر دو الگوریتم باید مجموعههای بزرگی از کاندیداها را به روش سطح اول تولید کنند تا توالیهای طولانیتر را رشد دهند. بنابراین، بیشتر مشکلاتی که در الگوریتم GSP وجود داشت، در SPADE نیز دوباره رخ خواهد داد.
PrefixSpan: رشد الگوی متوالی پیش بینی شده
رشد الگو روشی برای کاوش الگوهای مکرر است که نیازی به تولید کاندیدا ندارد. این تکنیک از الگوریتم رشد FP برای پایگاههای داده تراکنشی، که در بخش ۵.۶ ارائه شده است، سرچشمه گرفته است. ایده کلی این رویکرد به شرح زیر است: آیتمهای منفرد پرتکرار را پیدا میکند، سپس این اطلاعات را در یک درخت الگوی پرتکرار یا FP-tree فشرده میکند. FP-tree برای تولید مجموعهای از پایگاههای داده پیشبینیشده استفاده میشود که هر کدام با یک آیتم پرتکرار مرتبط هستند. هر یک از این پایگاههای داده به صورت جداگانه و بازگشتی کاوش میشوند و از تولید کاندید جلوگیری میشود. جالب توجه است که رویکرد رشد الگو را میتوان به کاوش الگوهای متوالی تعمیم داد که منجر به یک الگوریتم جدید به نام PrefixSpan میشود که در زیر نشان داده شده است. بدون از دست دادن کلیت، تمام آیتمهای درون یک رویداد را میتوان به صورت الفبایی فهرست کرد. به عنوان مثال، به جای فهرست کردن آیتمها در یک رویداد به عنوان، مثلاً (bac)، میتوانیم آنها را به عنوان (abc) فهرست کنیم. با توجه به یک دنبالهα =e1e2···en (که در آن هر ei مربوط به یک رویداد مکرر در پایگاه داده توالی، S است)، یک دنبالهβ =e1e2···em (m≤n) پیشوند α نامیده میشود اگر و تنها اگر (1) ei =ei برای (i ≤m−1)؛ (2)em ⊆em(3)؛ و همه موارد مکرر در (em −em) به ترتیب حروف الفبا بعد از موارد موجود در em باشند. دنباله
γ = emem+1···en پسوند α نسبت به پیشوند β نامیده میشود که به صورت γ =α/β نشان داده میشود، که در آن
em =(em −em).4 همچنین α =β ·γ را نشان میدهیم. توجه: اگر β زیردنبالهای از α نباشد، پسوند α نسبت به β خالی است. این مفاهیم را با مثال زیر توضیح میدهیم.
مثال ۵.۱۵. پیشوند و پسوند. فرض کنید توالی s =a(abc)(ac)d(cf) باشد که مربوط به توالی ۱ از پایگاه داده توالی نمونه در حال اجرای ما است. a، aa، a(ab) و a(abc) چهار پیشوند s هستند. (abc)(ac)d(cf) پسوند s نسبت به پیشوند a است؛ (_bc)(ac)d(cf) پسوند آن نسبت به پیشوند aa است؛ و (_c)(ac)d(cf) پسوند آن نسبت به پیشوند a(ab) است.
بر اساس مفاهیم پیشوند و پسوند، مسئله کاوش الگوهای متوالی را میتوان به مجموعهای از زیرمسئلهها، همانطور که در زیر نشان داده شده است، تجزیه کرد. ۱. فرض کنید {x1، x2،…، xn} مجموعه کاملی از الگوهای متوالی با طول ۱ در یک پایگاه داده توالی باشد، S. مجموعه کامل الگوهای متوالی در S را میتوان به n زیرمجموعه مجزا تقسیم کرد. زیرمجموعه iام (1 ≤ i ≤n) مجموعهای از الگوهای متوالی با پیشوند xi است.
۲. فرض کنید α الگوی متوالی با طول ۱ و {β1،β2،…،βm} مجموعهای از تمام الگوهای متوالی با طول (l +1) با پیشوند α باشد. مجموعه کامل الگوهای متوالی با پیشوند α، به جز خود α، را میتوان به m زیرمجموعه مجزا تقسیم کرد. زیرمجموعه jام (1 ≤ j ≤ m) مجموعهای از الگوهای متوالی با پیشوند βj است.
بر اساس این مشاهده، مسئله میتواند به صورت بازگشتی تقسیمبندی شود. یعنی، هر زیرمجموعه از الگوهای متوالی میتواند در صورت لزوم بیشتر تقسیمبندی شود. این یک چارچوب تقسیم و حل را تشکیل میدهد.
برای کاوش زیرمجموعههای الگوهای متوالی، پایگاههای داده پیشبینیشده مربوطه را میسازیم و هر یک را به صورت بازگشتی کاوش میکنیم.
بیایید از مثال در حال اجرا خود برای بررسی نحوه استفاده از رویکرد پیشبینی مبتنی بر پیشوند برای کاوش الگوهای متوالی استفاده کنیم.
مثال 5.16. PrefixSpan: یک رویکرد رشد الگو. با استفاده از همان پایگاه داده توالی، S، ازجدول 5.4 با min_sup=2، الگوهای متوالی در S را میتوان با روش پیشبینی پیشوندی در مراحل زیر کاوش کرد.
1. یافتن الگوهای متوالی با طول 1. یک بار S را اسکن کنید تا همه موارد مکرر در توالیها را پیدا کنید. هر یک از این موارد مکرر یک الگوی متوالی با طول 1 است. آنها عبارتند از a :4, b :4, c :4, d :3, e :3,f :3, که در آنها نماد “pattern :count” نشان دهنده الگو و تعداد پشتیبان مرتبط با آن است.
2. فضای جستجو را تقسیم کنید. مجموعه کامل الگوهای متوالی را میتوان بر اساس شش پیشوند به شش زیرمجموعه زیر تقسیم کرد: (1) آنهایی که پیشوند a دارند، (2) آنهایی که پیشوند b ،… دارند، و (6) آنهایی که پیشوند f دارند.
3. زیرمجموعههایی از الگوهای متوالی را پیدا کنید. زیرمجموعههای الگوهای متوالی ذکر شده در مرحله 2 را میتوان با ساخت پایگاههای داده پیشبینی شده مربوطه و کاوش هر یک به صورت بازگشتی، کاوش کرد. پایگاههای داده پیشبینی شده، و همچنین الگوهای متوالی یافت شده در آنها، در جدول 5.5 فهرست شدهاند، در حالی که فرآیند کاوش به شرح زیر توضیح داده شده است.
الف. الگوهای متوالی با پیشوند a را پیدا کنید. فقط توالیهای حاوی a باید جمعآوری شوند. علاوه بر این، در یک دنباله حاوی a، فقط زیردنبالهای که اولین وقوع a در آن پیشوند دارد باید در نظر گرفته شود. برای مثال، در دنباله (ef)(ab)(df)cb، فقط زیردنبالهای که با a پیشوند دارد باید برای کاوش الگوهای متوالی که با a پیشوند دارند در نظر گرفته شود. توجه داشته باشید که (_b) به این معنی است که آخرین رویداد در پیشوند، که a است، همراه با b، یک رویداد را تشکیل میدهند.
دنبالههای S حاوی a نسبت به a تصویر میشوند تا پایگاه داده a-تصویر شده را تشکیل دهند که شامل چهار دنباله پسوندی است: (abc (abc)(ac)d(cf) , (_d)c(bc)(ae) , (_b)(df)cb and (_f)cbc . با یک بار اسکن پایگاه داده a-projected، موارد پرتکرار محلی آن عبارتند از a:2، b:4، _b:2،c:4، d:2، و f:2. بنابراین تمام الگوهای متوالی با طول 2 که با a پیشوند شدهاند، یافت میشوند وآنها عبارتند از aa:2، ab:4، (ab):2، ac:4، ad:2، و af:2.
| جدول ۵.۵ پایگاههای داده پیشبینیشده و الگوهای ترتیبی. | ||
| پیشوند | پایگاه داده پیشبینیشده | الگوهای متوالی |
| (a) | ((abc)(ac)d(cf )), ((_d)c(bc)(ae)), ((_b)(df )cb), ((_f )cbc) | (a), (aa), (ab), (a(bc)), (a(bc)a), (aba), (abc), ((ab)), ((ab)c), ((ab)d), ((ab)f ), ((ab)dc), (ac), (aca), (acb), (acc), (ad), (adc), (af ) |
| (b) | ((_c)(ac)d(cf )), ((_c)(ae)), ((df )cb), (c) | (b), (ba), (bc), ((bc)), ((bc)a), (bd), (bdc), (bf ) |
| (c) | ((ac)d(cf )), ((bc)(ae)), (b), (bc) | (c), (ca), (cb), (cc) |
| (d) | ((cf )), (c(bc)(ae)), ((_f )cb) | (d), (db), (dc), (dcb) |
| (e) | ((_f )(ab)(df )cb), ((af )cbc) | (e), (ea), (eab), (eac), (eacb), (eb), (ebc), (ec), (ecb), (ef ), (ef b), (ef c), (ef cb). |
| (f ) | ((ab)(df )cb), (cbc) | (f ), (fb), (fbc), (fc), (fcb) |
به صورت بازگشتی، تمام الگوهای متوالی با پیشوند a را میتوان به شش زیرمجموعه تقسیم کرد: (1) آنهایی که با aa پیشوند شدهاند، (2) آنهایی که با ab و … پیشوند شدهاند، و در نهایت، (6) آنهایی که با af . این زیرمجموعهها را میتوان با ساخت پایگاههای دادهی projected مربوطه و کاوش بازگشتی هر یک به صورت زیر، کاوش کرد.
i. پایگاه دادهی aa-projected شامل دو زیردنبالهی غیرتهی (پسوندی) با پیشوند aa است: { (_bc)(ac)d(cf )، { (_e) }. از آنجایی که هیچ امیدی به تولید هیچ زیردنبالهی مکرری از این پایگاه دادهی projected وجود ندارد، پردازش پایگاه دادهی aa-projected خاتمه مییابد.
ii. پایگاه دادهی ab-projected شامل سه توالی پسوندی است: (_c)(ac)d(cf )، (_c)a و c. کاوش بازگشتی پایگاه داده ab-projected چهار الگوی متوالی را برمیگرداند: (_c)، (_c)a، a و c (یعنی a(bc)، a(bc)a، aba و abc.) آنها مجموعه کاملی از الگوهای متوالی با پیشوند ab را تشکیل میدهند.
iii. پایگاه داده (ab)-projected فقط شامل دو توالی است: (_c)(ac) d(cf) و(df)cb، که منجر به یافتن الگوهای متوالی زیر با پیشوند (ab) میشود: c، d، f و dc.
iv. پایگاههای داده ac-، ad- و af-projected را میتوان به روشی مشابه ساخت و به صورت بازگشتی کاوش کرد. الگوهای متوالی یافت شده در جدول 5.5 نشان داده شده است.
b. الگوهای متوالی با پیشوند b، c، d، e و f را به ترتیب پیدا کنید. این کار را میتوان با ساخت پایگاههای دادهی b-، c-d-، e- و f-projected و کاوش آنها انجام داد. پایگاههای دادهی projected و الگوهای ترتیبی یافت شده نیز در جدول 5.5 نشان داده شدهاند.
4. مجموعهی الگوهای ترتیبی، مجموعهای از الگوهای یافت شده در فرآیند کاوش بازگشتی فوق است.
روشی که در بالا توضیح داده شد، هیچ توالی کاندیدی در فرآیند کاوش ایجاد نمیکند. با این حال، ممکن است پایگاههای دادهی projected زیادی ایجاد کند، یکی برای هر پیشوند-زیرتوالی مکرر. تشکیل تعداد زیادی پایگاه دادهی projected به صورت بازگشتی، در صورتی که چنین پایگاههای دادهای مجبور به تولید فیزیکی باشند، میتواند به هزینهی اصلی این روش تبدیل شود. یک تکنیک بهینهسازی مهم، pseudo-projection است، همانطور که در شکل 5.9 نشان داده شده است. برای مثال، برای دنباله a(abc)(ac)d(cf)، تصویر a یک زیردنباله تصویر شده (abc)(ac)d(cf) (یعنی پسوند a) تولید میکند و تصویر بعدی روی b یک دنباله تصویر شده ab (_c)(ac)d(cf) تولید میکند. چنین تصویر فیزیکی ممکن است زمان و فضای زیادی برای کپی و ذخیره زیردنبالههای تصویر شده صرف کند، که شامل افزونگی زیادی است. روش شبهتصویر به جای انجام تصویر فیزیکی، اندیس (یا شناسه) دنباله مربوطه و موقعیت شروع پسوند تصویر شده را در دنباله ثبت میکند. یعنی، یک تصویر فیزیکی از یک دنباله با ثبت یک شناسه توالی و نقطه اندیس موقعیت تصویر شده جایگزین میشود. برای مثال، در دو تصویر بالا، به جای تولید دو پسوند تصویر شده فیزیکی، فقط دو اشارهگر ایجاد میشوند (یکی به موقعیت ۲ که با فلش توپر نشان داده شده و دیگری به موقعیت ۵ که با فلش خطچین نشان داده شده اشاره میکند). این ممکن است در زمان کپی و چسباندن پسوندها صرفهجویی کند و فضا را برای ذخیره چنین پسوندهایی ذخیره کند.
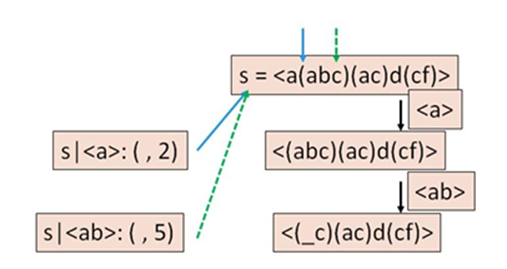
تصویر کاذب در مقابل پروژه فیزیکی در PrefixSpan.


