
مقدمه
دادههای پرت (Outliers) فقط چند عدد عجیبوغریب در جدول دادههای شما نیستند؛ آنها میتوانند یک خطای ویرانگر، نشانهای از یک مشکل پنهان یا حتی سرنخی برای یک کشف علمی بزرگ باشند.
در سادهترین تعریف، دادهٔ پرت مشاهدهای است که رفتاری آنچنان متفاوت دارد که ما را به شک میاندازد: آیا واقعاً به همین مجموعه تعلق دارد؟
اگر چنین دادههایی را در آمار، یادگیری ماشین، تحلیلهای مالی یا امنیت سایبری نادیده بگیریم، تحلیلها ممکن است بهشدت گمراهکننده شوند و تصمیمگیریها را به بیراهه بکشند.
این مقاله یک چارچوب جامع ارائه میدهد تا دادههای پرت را در علم دادهٔ مدرن بهصورت سیستماتیک درک کرده و مدیریت کنیم.
داده پرت چیست؟
شاید در نگاه اول به نظر برسد که دادههای پرت فقط چند مقدار عجیبوغریب یا اشتباه در جدول دادههای شما هستند، اما واقعیت بسیار پیچیدهتر است. داده پرت فقط یک عدد دورافتاده نیست؛ بلکه میتواند منبع خطا، نشانهای از یک مشکل پنهان و یا حتی کلیدی برای یک کشف علمی بزرگ باشد.
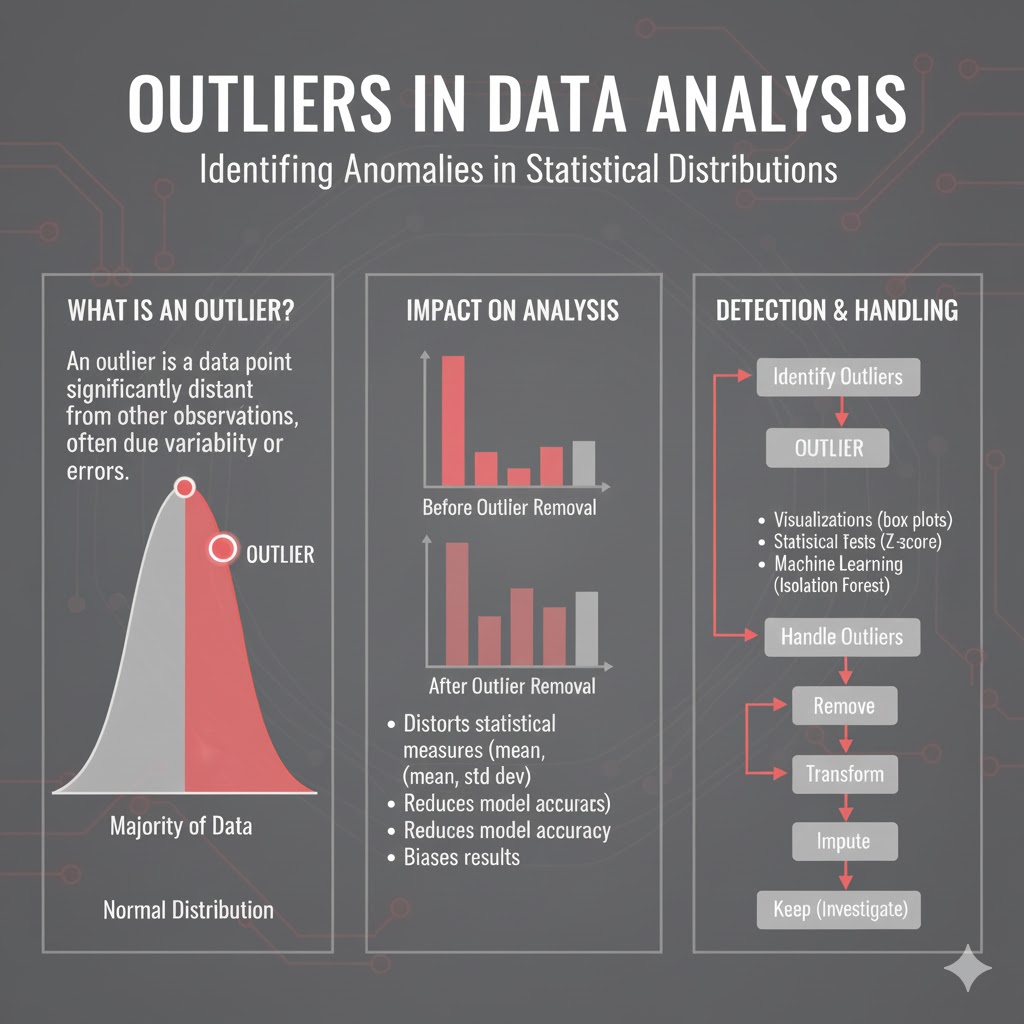
تعریف شهودی Outlier
در سادهترین تعریف، داده پرت (Outlier) مشاهدهای است که رفتار و ویژگیهایش آنقدر با سایر دادهها متفاوت است که ما را به شک میاندازد: آیا این داده واقعاً از جنس بقیه است یا مکانیسم تولیدش فرق میکند؟ در هر مجموعه داده واقعی، تقریباً همیشه مقادیری وجود دارند که به چشم میآیند؛ یعنی بیش از حد بزرگ، بیش از حد کوچک یا بهطور غیرمنتظرهای متفاوت هستند.
چرا دادههای پرت مهماند؟
وجود دادههای پرت میتواند در چند سطح اصلی مشکلساز شود:
تحریف آمار توصیفی:
- یک یا دو مقدار خیلی بزرگ یا کوچک میتوانند میانگین و انحراف معیار را بهطور جدی جابهجا کنند و تصویری غلط از مرکز و پراکندگی داده ارائه دهند. به همین دلیل، در حضور دادههای پرت معمولاً توصیه میشود به معیارهای مقاوم مثل میانه، دامنهی بین چارکی (IQR) و انحراف مطلق میانه (MAD) تکیه کنیم.
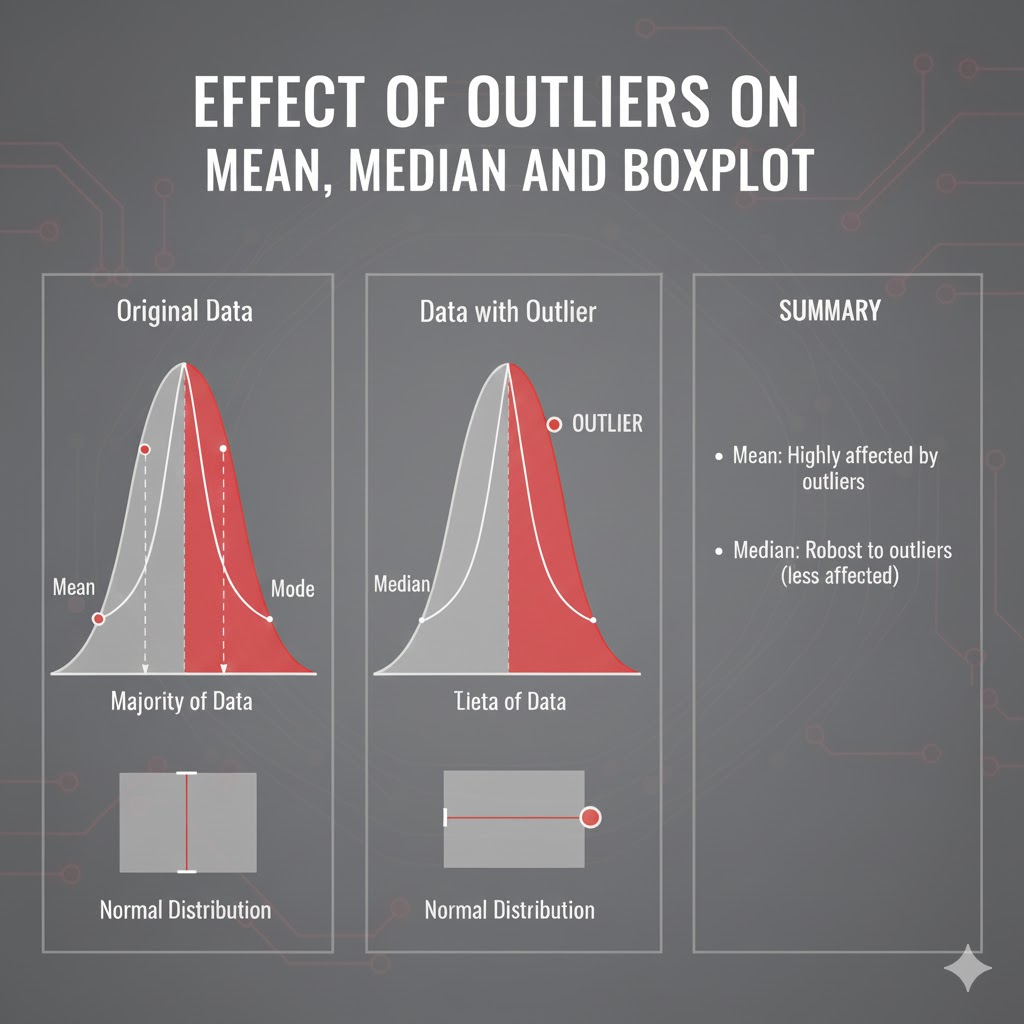
نقض مفروضات استنباط آماری:
- بسیاری از روشهای کلاسیک آماری (رگرسیون حداقل مربعات، آزمون t ، ANOVA و…) روی فرضهایی مثل نرمال بودن خطاها، همسانی واریانس و نبود چند نقطهی بسیار اثرگذار تکیه دارند. دادههای پرت میتوانند این مفروضات را بر هم بزنند و باعث شوند ضریبها، مقادیر p و بازههای اطمینان ظاهراً دقیق اما در واقع گمراهکننده باشند.
کاهش عملکرد مدلهای یادگیری ماشین:
- بسیاری از الگوریتمهای یادگیری ماشین به خصوص آنهایی که بر فاصله یا واریانس متکی هستند مثل KNN، K-Means، SVM، PCA، LDA نسبت به دادههای پرت حساساند. چند نقطهی پرت میتوانند مرز تصمیم را منحرف کنند، مراکز خوشهها را جابهجا کنند، یا جهتهای اصلی در PCA را به سمت خود بکشند؛ در نتیجه مدل روی دادهی جدید ضعیف عمل میکند.
پنهان کردن مسائل واقعی یا سیگنالهای مهم:
- گاهی دادههای پرت دقیقاً همان چیزی هستند که باید رویشان تمرکز کنیم: نشانهی تقلب، حملهی سایبری، خرابی یک دستگاه، بیماری در دادههای پزشکی، یا تغییر حالت در یک سیستم پویا. اگر بیدقت با آنها برخورد کنیم، ممکن است مهمترین اطلاعات را از دست بدهیم.
بنابراین، کار با دادههای پرت فقط یک پیشپردازش ساده نیست؛ بلکه جزئی جداییناپذیر از علم دادهی مسئولانه و قابل اتکا است.
2. سفر تاریخی دادههای پرت: از تلسکوپ تا هوش مصنوعی
برخورد با دادههای عجیب و ناسازگار، پدیدهای مدرن و مختص به عصر کامپیوتر نیست. از روزی که بشر شروع به اندازهگیری جهان کرد، همیشه با چالش عددهای مشکوک روبرو بوده است. این سفر جذاب را میتوان در سه دوره اصلی بررسی کرد:
2.1. عصر اخترشناسان: دور ریختن دادههای مزاحم (قرن ۱۷ تا ۱۹)
داستان از رصدخانههای قدیمی شروع میشود. در قرنهای ۱۷ و ۱۸، اخترشناسان برای تعیین موقعیت دقیق ستارگان تلاش میکردند، اما گاهی با اعدادی روبرو میشدند که با بقیه مشاهدات همخوانی نداشتند. در آن زمان، چون نظریه آماری دقیقی وجود نداشت، راهکار ساده بود: حذف تجربی. دانشمندان صرفاً به حس خود اعتماد کرده و دادههای غیرقابلاعتماد را کنار میگذاشتند.
- نقطه عطف: در اوایل قرن ۱۹، ریاضیدانان بزرگی مثل گاوس (Gauss) و لژاندر با معرفی توزیع نرمال و روش حداقل مربعات، اولین چارچوب علمی را ساختند.
- دیدگاه جدید: آنها پرسیدند: احتمال رخ دادن چنین خطایی چقدر است؟ اگر احتمال خیلی کم بود، آن داده رسماً پرت شناخته میشد
2.2. عصر آمار مقاوم: دیدن دادهها (نیمه قرن ۲۰)
با گذر زمان مشخص شد که روشهای کلاسیک (مثل میانگین) به شدت نسبت به دادههای پرت حساس و شکنندهاند. این دوره، عصر ظهور آمار مقاوم (Robust Statistics) بود.
- قهرمان دوران: جان توکی (John Tukey) با معرفی تحلیل اکتشافی دادهها (EDA) انقلابی به پا کرد. حرف او ساده بود: قبل از فرمولنویسی، نمودار بکشید!. او ابزارهایی مثل نمودار جعبهای (Boxplot) را اختراع کرد تا دادههای پرت با یک نگاه شناسایی شوند.
- تئوریهای جدید: مفاهیمی مثل نقطه شکست (Breakdown Point) مطرح شد؛ یعنی یک مدل تا چه حد میتواند آلودگی دادهها را تحمل کند و خراب نشود.

2.3. عصر مدرن و یادگیری ماشین: کشف ناهنجاری (اواخر قرن ۲۰ تا امروز)
با انفجار کلاندادهها (Big Data)، دیگر نمیشد دادهها را دستی چک کرد. در علوم کامپیوتر، نگاه به داده پرت تغییر کرد: آنها دیگر فقط خطای آزمایش نبودند، بلکه نشانهای از تقلب، حمله سایبری یا خرابی سیستم محسوب میشدند.
الگوریتمهای هوشمند متولد شدند:
- روشهای کلاسترینگ و همسایگی: مثل KNN و Local Outlier Factor (LOF).
- روشهای یادگیری عمیق: استفاده از شبکههای عصبی (Autoencoders, GANs) برای شکار پیچیدهترین ناهنجاریها در تصاویر و سریهای زمانی.
این مسیر تاریخی نشان میدهد که مسئله دادههای پرت از یک دغدغه کوچک در نجوم، به یک حوزه حیاتی و بینرشتهای در قلب هوش مصنوعی تبدیل شده است. امروز ما دیگر دادههای پرت را فقط دور نمیریزیم؛ گاهی آنها ارزشمندترین بخش دادههای ما هستند.
3. منشأ داده های پرت: چرا Outlier ایجاد میشود؟
برای اینکه بدانیم با یک دادهی پرت چه کار کنیم، اول باید بفهمیم چرا به وجود آمده است. منبع یا منشأ دادهی پرت تا حد زیادی تعیینکنندهی نوع واکنش ماست.
3.1. خطاهای اندازهگیری و ابزار
یکی از شایعترین منابع دادههای پرت، خطا در ابزار اندازهگیری است:
- نویز یا خرابی حسگرها: سنسور دما ناگهان صفر درجه گزارش میکند در حالی که محیط گرم است؛ یا حسگر ارتعاش بهخاطر نویز الکترومغناطیس مقادیر غیرواقعی ثبت میکند.
- کالیبراسیون ناقص: اگر یک ترازو درست تنظیم نشده باشد، همهی اندازهگیریها چند گرم یا چند کیلو خطا دارند و بخشی از دادهها نسبت به سایر منابع یا دستگاههای دیگر پرت به نظر میرسند.
- عدم رعایت پروتکل آزمایش: در آزمایشهای شیمی، پزشکی یا مهندسی، تفاوت در دما، زمان، غلظت مواد و آلودگی نمونه میتواند از یک سری آزمایش تا سری دیگر نتایج غیرعادی ایجاد کند.
در این موارد، اگر مطمئن باشیم خطا ابزاری است، معمولاً استراتژی درست اصلاح یا حذف آن داده است.
3.2. خطا در ورود، انتقال و پردازش داده
حتی اگر اندازهگیری صحیح باشد، در مراحل بعدی هم امکان تولید دادهی پرت وجود دارد:
- اشتباه تایپی (۲۵۰ به جای ۲۵، ۱.۲ به جای ۱۲)، جابهجایی اعشار، واحد اشتباه (پوند به جای کیلوگرم)، کدگذاری غلط مقادیر دستهای؛
- خطا در انتقال داده از فرم کاغذی به سیستم، یا در تبدیل بین فرمتهای مختلف؛
- اشتباه در ادغام چند منبع داده ( Join اشتباه، تکراری شدن رکوردها، قاطی شدن رکورد دو نفر با هم).
در یک پروژه فروش چند شعبه، اگر واحد پول شعبهای یورو و شعبهی دیگر دلار باشد ولی بدون تبدیل ادغام شوند، مقادیر یک شعبه به صورت پرت در دیتاست نهایی ظاهر میشوند، در حالی که در واقع خطای پردازش داریم.
3.3. خطاهای نمونهبرداری
گاهی دادهی جمعآوریشده بهدرستی ثبت شده، اما نمونه اصلاً نمایندهی جمعیت هدف نیست:
- وارد شدن اعضای یک جمعیت دیگر در نمونه؛
- استفاده از نمونهگیری در دسترس و جانبدار؛
- آلودگی فیزیکی نمونههای بیولوژیک یا شیمیایی.
در این حالت، نقطهی پرت نسبت به جمعیت مورد نظر ما پرت است، نه نسبت به جمعیت واقعی خودش.
3.4. گزارش نادرست و رفتار مخرب
در برخی حوزهها دادههای پرت عمدی هستند:
- پاسخهای دروغ یا اغراقآمیز در پرسشنامههای حساس (درآمد، مصرف، عقاید).
- تراکنشهای غیرمعمول در کارتهای بانکی، ادعاهای عجیب در بیمه، حملات باتنت و تولید ترافیک غیرعادی در شبکه.
- دادههای دستکاریشده برای گمراه کردن سامانههای تشخیص (نمونههای خصمانه در یادگیری ماشین).
اینجا Outlier نه خطاست، نه چیزی برای حذف؛ بلکه سیگنال اصلی است که باید روی آن متمرکز شویم.
3.5. خرابی داده
خرابی فایل، از کار افتادن رسانهی ذخیرهسازی، نویز روی خطوط ارتباطی و… هم میتواند دادههای بیمعنی تولید کند. معمولاً این نوع دادهها با بررسیهای فنی و کنترلهای صحت (چکسام، لاگها) قابل تشخیصاند.
3.6. رویدادهای نادر اما واقعی
شاید مهمترین و حساسترین دسته، دادههای پرت واقعی و معنادار باشند:
- در توزیع درآمد، چند فرد بسیار ثروتمند.
- در بازار سهام، سقوطها و جهشهای بزرگ.
- در زلزله، چند رخداد با بزرگی بسیار بالا.
- در پزشکی، علائم نادری که بیماری جدید یا وضعیت بحرانی را نشان میدهند.
- در علوم، اندازهگیریهایی که ممکن است حاکی از کشف یک ذرهی جدید یا یک پدیدهی ناشناخته باشند.
در سیستمهای پویا، این نقاط میتوانند نشانهی تغییر فاز یا گذار ناگهانی از یک حالت به حالت دیگر باشند. حذف آنها یعنی کور کردن خود نسبت به اتفاقات مهم.
به همین دلیل، درک منشأ دادههای پرت یک کار صرفاً تکنیکی نیست. بیشتر شبیه کارآگاهبازی است و نیاز به ترکیب نمودارکشی، تشخیصهای آماری، بررسی متادیتا و مشورت با متخصصان حوزه دارد.
4. طبقهبندی دادههای پرت: زبان مشترک تحلیل Outlier ها
از آنجا که دادههای پرت از نظر شکل، منشأ و رفتار بسیار متنوعاند، لازم است یک زبان مشترک برای دستهبندی آنها داشته باشیم. این طبقهبندی مستقیماً روی انتخاب روش تشخیص و نحوهی برخورد اثر میگذارد.
- سراسری (Point)، زمینهای (Contextual) و جمعی (Collective)
- تکمتغیره در برابر چندمتغیره
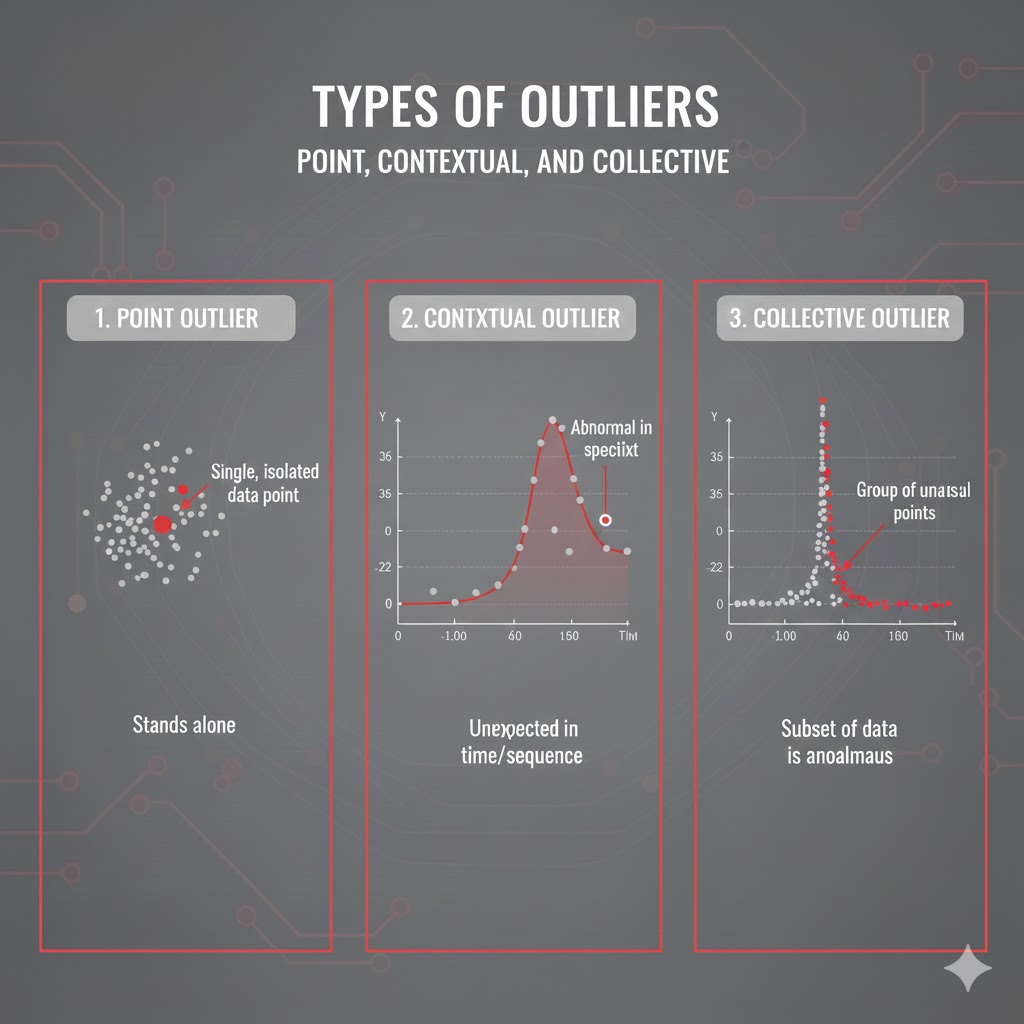
حال به بررسی هر یک می پردازیم.
4.1. سراسری، زمینهای و جمعی
یکی از رایجترین تقسیمبندیها سه دستهی زیر است:
4.1.1. دادههای پرت سراسری (Global / Point Outliers)
این دسته از دادهها، کلاسیکترین نوع پرت هستند. آنها نقاطی هستند که بدون نیاز به هیچ زمینه یا شرط خاصی، نسبت به کل مجموعه داده (Dataset) فاصلهای فاحش و عجیب دارند و به وضوح از بقیه جدا افتادهاند. انگار که متعلق به دنیای دیگری هستند!
مثالها:
برای درک بهتر، بیایید دو سناریوی متفاوت را بررسی کنیم:
- ۱. وزن در کلاس درس (خطای ورود داده): فرض کنید لیستی از وزن دانشآموزان یک مدرسه ابتدایی دارید که همگی بین ۲۰ تا ۴۵ کیلوگرم هستند. ناگهان با عددی مثل ۳۰۰۰ کیلوگرم مواجه میشوید. این عدد نسبت به کل دادهها پرت است (احتمالاً کاربر وزن را به گرم وارد کرده است).
- ۲. زمان پاسخدهی سرور (مشکل فنی): میانگین پینگ (Ping) سرور بازی شما معمولاً بین ۲۰ تا ۵۰ میلیثانیه است. اگر ناگهان یک پینگ ۲۰,۰۰۰ میلیثانیه ثبت شود، این یک داده پرت سراسری است که نشاندهنده قطع لحظهای یا لگ شدید است.
روشهای شکار و چالشهای پنهان
خوشبختانه شناسایی این نوع پرتها نسبتاً ساده است. ابزارهای آماری مشهوری برای به دام انداختن آنها وجود دارد:
- نمره استاندارد (Z-Score)
- دامنهی بینچارکی (IQR)
- الگوریتمهای یادگیری ماشین مثل Isolation Forest .
اما مراقب تلهها باشید! حتی در این حالت ساده هم ممکن است دچار خطای دید شوید:
- پدیده ماسکینگ(Masking): اگر دو یا چند داده پرت خیلی بزرگ کنار هم باشند، ممکن است همدیگر را استتار کنند و تستهای آماری متوجه آنها نشوند.
- پدیده سوامپینگ(Swamping): گاهی وجود دادههای پرت باعث میشود میانگین و واریانس آنقدر جابجا شود که دادههای سالم و نرمال، به اشتباه پرت به نظر برسند.
4.1.2. دادههای پرت زمینهای (Contextual / Conditional Outliers)
در اینجا، مقدار بهتنهایی لزوماً افراطی نیست، بلکه در یک زمینهی خاص غیرعادی میشود.
مثالها:
۱. سرعت رانندگی (زمینه مکانی)
- رفتار عادی: رانندگی با سرعت ۱۰۰ کیلومتر بر ساعت در اتوبان تهران-قم کاملاً قانونی و طبیعی است.
- داده پرت زمینهای: همان سرعت (۱۰۰ کیلومتر بر ساعت) اگر در یک کوچه بنبست یا منطقه مسکونی ثبت شود، یک ناهنجاری شدید و خطرناک است.
- تحلیل: عدد ۱۰۰ به تنهایی مشکلی ندارد (پرت سراسری نیست)، اما زمینه (کوچه) آن را پرت میکند.
۲. ضربان قلب و علائم حیاتی (زمینه فعالیت)
- رفتار عادی: ضربان قلب ۱۴۰ تپش در دقیقه برای یک ورزشکار حرفهای در حین دویدن روی تردمیل کاملاً نرمال است.
- داده پرت زمینهای: اگر همان شخص روی مبل دراز کشیده باشد و در حال استراحت باشد، ضربان ۱۴۰ نشانهی آریتمی قلبی یا یک مشکل جدی پزشکی است.
۳. مصرف انرژی (زمینه زمانی/فصلی)
- رفتار عادی: قبض برق بالا و مصرف زیاد انرژی در مرداد ماه (اوج گرمای تابستان) برای خنکسازی خانه طبیعی است.
- داده پرت زمینهای: اگر همان میزان مصرف برق در دیماه (زمستان) ثبت شود، مشکوک است (شاید دستگاهی خراب شده یا دزدی برق رخ داده است).
4.1.3. دادههای پرت جمعی (Collective Outliers)
گاهی هیچ نقطهای بهتنهایی خیلی غیرعادی نیست، اما مجموعهای از نقاط با هم رفتاری غیرطبیعی دارند.
مثال:
۱. حمله سایبریDDoS (درخواستهای عادی، حجم غیرعادی): فرض کنید یک کاربر وارد صفحه اول سایت شما شود. این یک رفتار کاملاً نرمال است. اما اگر ناگهان ۱۰۰,۰۰۰ کاربر (یا بات) دقیقاً در یک میلیثانیه خاص وارد صفحه اول شوند، سایت از دسترس خارج میشود.
- تحلیل: هر درخواست به تنهایی مجاز است، اما تجمع همزمان آنها یک داده پرت جمعی و نشانهی حمله است.
۲. رباتهای شبکه اجتماعی (Copy-Paste رفتار): کاربری زیر پست شما مینویسد عالی بود. این کامنت نرمال است. اما اگر ۵۰۰ اکانت مختلف، دقیقاً در یک بازه زمانی ۱۰ دقیقهای، دقیقاً همین عبارت عالی بود را پست کنند، شما با یک مزرعه ترول (Troll Farm) یا رباتهای تبلیغاتی طرف هستید.
- تحلیل: متن کامنت عادی است، اما الگوی تکرار جمعی آن غیرعادی است.
۳. افت ناگهانی در خط تولید (فرسایش ابزار): در یک کارخانه، لرزش دستگاه تراش ممکن است هر روز کمی تغییر کند که طبیعی است. اما اگر نمودار لرزش را در طول یک ماه نگاه کنید و ببینید که به آرامی و به صورت توالی پیوسته در حال افزایش است (حتی اگر هنوز به مرز هشدار نرسیده باشد)، این روند نشاندهنده کند شدن تیغه دستگاه است.
- تحلیل: هیچ نقطهای به تنهایی قرمز نیست، اما روند صعودی مجموعه نقاط نشاندهنده یک خرابی قریبالوقوع است.
4.2. تکمتغیره و چندمتغیره
بُعد دیگر طبقهبندی، این است که ناهنجاری در چند ویژگی ظاهر میشود؟
- پرت تکمتغیره: وقتی یک ویژگی بهتنهایی مقدار عجیبی دارد (مثلاً قد ۳ متر). این نوع با نمودار جعبهای، هیستوگرام، Z-Score، IQR و آزمونهای کلاسیک بهخوبی کشف میشود.
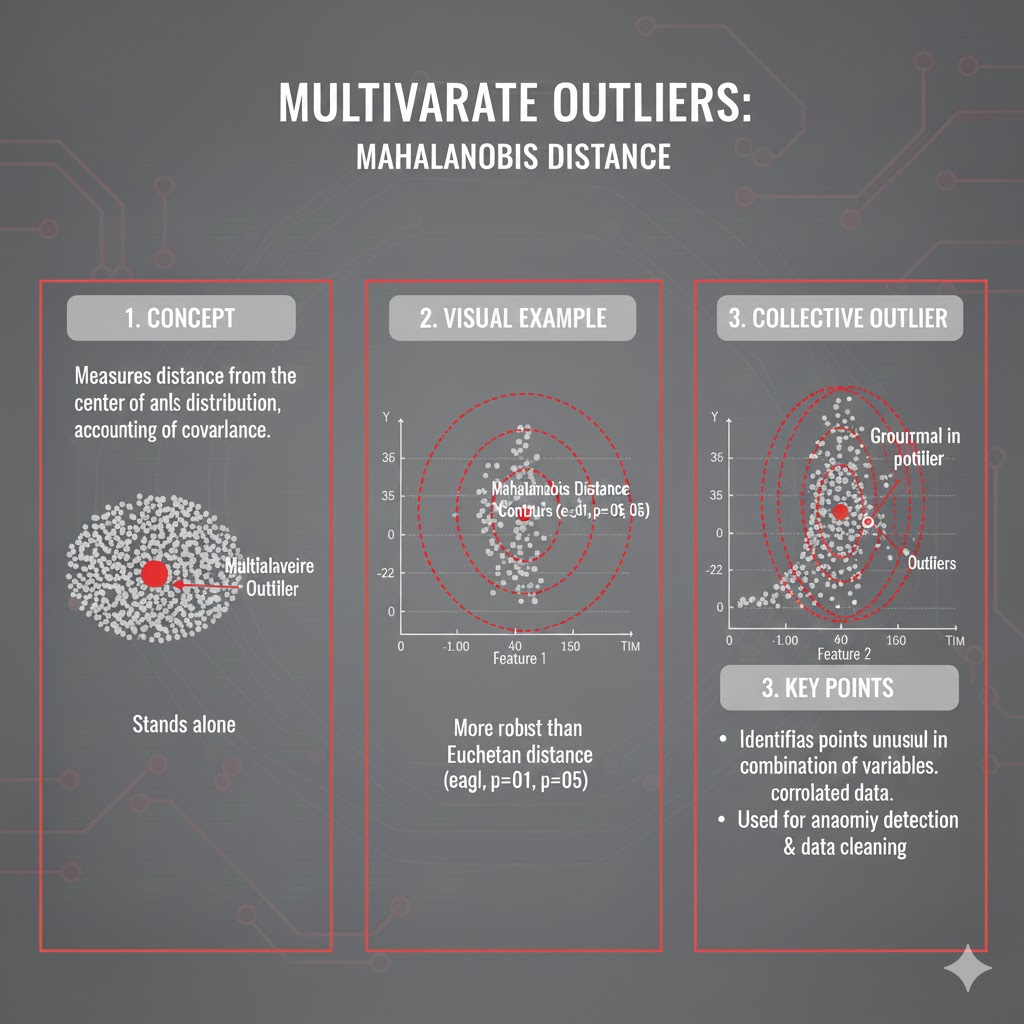
- پرت چندمتغیره: وقتی هر ویژگی بهتنهایی ممکن است در محدودهی عادی باشد، اما ترکیب آنها غیرمنطقی است. مثل فردی با قد ۱۶۰ و وزن ۱۲۰ کیلو؛ یا تراکنشی با مبلغ متوسط و مکان آشنا، اما در زمانی غیرمعمول و با الگویی که هرگز در تاریخ آن حساب دیده نمیشده است.
برای این نوعOutlier ها به روشهایی مثل فاصلهی ماهالانوبیس، کوواریانس مقاوم، PCA، LOF، One-Class SVM، Isolation Forest و سایر الگوریتمهای چندبعدی نیاز داریم.
5. تفاوت: نویز با داده پرت
در دنیای دادهها، هر چیزی که با الگوی معمول نمیخواند، لزوماً داده پرت نیست. بسیاری از تحلیلگران تازهکار، هر نوسان یا بینظمی را Outlier مینامند، اما از نظر فنی، تمایز مهمی بین نویز و پرت وجود دارد. درک این تفاوت تعیین میکند که آیا باید داده را صاف کنید یا آن را بررسی (Investigate) نمایید.
5.1. نویز(Noise) چیست؟
به خطای تصادفی یا واریانس در متغیر اندازهگیریشده اشاره دارد. نویز معمولاً فاقد الگوی مشخص است، معنای خاصی ندارد و صرفاً مانعی برای دیدن الگوی اصلی دادههاست.
- ماهیت: خطای تصادفی سطح پایین.
- منشأ: محدودیتهای فیزیکی ابزار اندازهگیری، تداخلات محیطی، یا نوسانات جزئی و طبیعی.
- ارزش تحلیلی: تقریباً صفر. نویز هیچ اطلاعات مفیدی درباره پدیده مورد مطالعه به ما نمیدهد و سیگنال را مخفی میکند.
- مثال: صدای خشخش در پسزمینه یک فایل صوتی ضبط شده، یا لرزش دست هنگام اندازهگیری وزن یک جسم.
نکته کلیدی: نویز یک شیء (Object) نیست؛ بلکه ویژگی است که روی مقادیر داده سوار میشود. شما نمیتوانید بگویید این سطر نویز است (مگر اینکه کل سطر زباله باشد)، بلکه میگویید این سطر دارای نویز است .
5.2. داده پرت چیست؟
داده پرت مشاهدهای که بهطور معناداری با سایر دادهها متفاوت است. این تفاوت آنقدر زیاد است که شک میکنیم مکانیسم تولید آن با بقیه دادهها یکی باشد.
- ماهیت: انحراف شدید و معنادار.
- منشأ: میتواند ناشی از یک خطای بزرگ (مثل خرابی سنسور) باشد، یا ناشی از یک رویداد واقعی و کمیاب (مثل یک تراکنش بانکی میلیاردی).
- ارزش تحلیلی: بسیار بالا. (اگر نویز نباشد) Outlierها اغلب حاوی مهمترین اطلاعات دیتاست هستند (کشف تقلب، کشف بیماری، کشف علمی).
- مثال: شنیدن صدای جیغ در میان صدای خشخش رادیو. جیغ، خشخش نیست؛ یک رویداد متمایز است.
جدول مقایسه: نویز در برابر داده پرت
| ویژگی (Feature) | داده پرت (Outlier) | نویز (Noise) |
| تعریف اصلی | مشاهدهای که انحراف چشمگیر و معناداری از بقیه دادهها دارد. | خطای تصادفی یا واریانس ناخواسته که فاقد الگوی مشخص است. |
| شدت انحراف | معمولاً زیاد و شدید (مثل یک شوک ناگهانی). | معمولاً کم یا متوسط (مثل لرزشهای ریز). |
| ارزش تحلیلی | بسیار بالا (اگر خطا نباشد). اینها سیگنال اصلی برای کشف تقلب، بیماری یا فرصت هستند. | تقریباً صفر. نویز فقط مانعی برای دیدن اطلاعات است و سیگنال را مخفی میکند. |
| منشأ پیدایش | رویدادهای نادر واقعی (مثل زلزله) یا خطاهای بزرگ سیستمی. | محدودیتهای فیزیکی ابزار، تداخل محیطی یا نوسانات طبیعی. |
| روش برخورد | باید شناسایی، تحلیل و بررسی شود (آیا حذف کنیم یا نگه داریم؟). | باید کاهش، هموارسازی (Smoothing) یا فیلتر شود. |
| مثال شهودی (رادیو) | شنیدن صدای آژیر خطر در میان برنامه (یک رویداد متمایز). | شنیدن صدای خشخش دائم در پسزمینه (مزاحمت صوتی). |
چند مثال شهودی
مثال شهودی 1: آنالوژی استادیوم فوتبال ⚽🏟️
تصور کنید در استادیوم آزادی نشستهاید و بازی دربی در حال برگزاری است. ۹۰ هزار نفر تماشاگر حضور دارند.
- نویز(Noise): همهمهی تماشاگران
- سناریو: صدای دائمی بوقها، طبلها، تشویقها و صحبتهای مردم که به صورت یک صدای ممتد شنیده میشود.
- تحلیل: این صدا لحظهبهلحظه کم و زیاد میشود (واریانس دارد)، اما جزئی از جو ورزشگاه است. شما نمیتوانید بگویید فلان تماشاگر در ردیف ۲۰ صدایش بلندتر بود. این یک صدای پسزمینه است.
- واکنش: گزارشگر بازی سعی میکند صدایش را بالاتر ببرد یا با میکروفونهای خاص این صدا را کم کند (Smoothing) تا صدایش به بینندگان تلویزیونی برسد. کسی بازی را به خاطر همهمه قطع نمیکند.
- داده پرت: جیمی جامپ !
- سناریو: ناگهان وسط بازی، یک تماشاگر (جیمی جامپ) از نردهها میپرد و وسط زمین چمن میدود!
- تحلیل: این فرد بخشی از همهمه نیست. او یک ناهنجاری محض است. رفتار او (دویدن در زمین) با رفتار ۹۰ هزار نفر دیگر (نشستن روی صندلی) کاملاً متفاوت است.
- واکنش: داور بازی را متوقف میکند. دوربینها روی او زوم میکنند (یا سانسور میکنند). ماموران امنیتی وارد عمل میشوند. این یک رخداد است که باید جداگانه مدیریت شود (اخراج از زمین).
مثال شهودی 2: آنالوژی ترافیک صبحگاهی 🚗
برای اینکه تفاوت را کاملاً حس کنید، تصور کنید هر روز صبح با ماشین شخصی به محل کارتان میروید. به طور معمول این مسیر ۳۰ دقیقه زمان میبرد.
- نویز(Noise): چراغ قرمز و رانندههای کند
- سناریو: یک روز رسیدن شما ۲۸ دقیقه طول میکشد، فردا ۳۲ دقیقه و پسفردا ۳۱ دقیقه.
- تحلیل: این بالا و پایین شدنهای جزئی (۲± دقیقه) ناشی از چراغ قرمز، عابران پیاده یا کمی شلوغی است. اینها نویز هستند؛ یعنی نوسانات طبیعی و تصادفی مسیر. شما اینها را نادیده میگیرید و میگویید: حدود نیم ساعت طول میکشد. نیازی به تحلیل نیست.
- داده پرت(Outlier): تصادف بزرگ یا پنچری
- سناریو: یک روز خاص، رسیدن شما ۳ ساعت طول میکشد!
- تحلیل: این عدد دیگر نوسان نیست. شما نمیتوانید بگویید امروز هوا بد بود. این یک داده پرت است که ناشی از یک رویداد خاص (مثل تصادف زنجیرهای در اتوبان یا پنچر شدن لاستیک) است.
- واکنش: شما نمیتوانید این ۳ ساعت را با زمانهای دیگر میانگین بگیرید (چون میانگین کل ماه را خراب میکند). باید جداگانه بررسی کنید که چه اتفاقی افتاد؟.
جمعبندی
در این مقاله، سفر پرفراز و نشیبی را از تعریف سادهی دادههای پرت تا عمیقترین لایههای تشخیص آنها طی کردیم. اکنون زمان آن است که تمام قطعات پازل را کنار هم بگذاریم.
مهمترین درسی که از این بررسی گرفتیم، تغییر نگاه ما به «ناهنجاری» است. دیدیم که دادههای پرت (Outliers) صرفاً چند عدد مزاحم یا اشتباه تایپی نیستند که باید بلافاصله دکمه Delete را برایشان فشار دهیم. آنها میتوانند:
- یک خطای سیستمی باشند که نیاز به تعمیر دارد (مثل سنسور خراب).
- یک فرصت طلایی باشند که نباید از دست داد (مثل کشف یک بیماری جدید یا مشتری خاص).
- یا یک تهدید امنیتی باشند که باید جدی گرفته شود (مثل حمله سایبری).


