
مقدمه
در دنیای امروز که دادهها قلب تپندهی تحلیل، تصمیمگیری و توسعه سامانههای هوشمند هستند، کیفیت داده مهمتر از هر زمان دیگری شده است. حتی پیشرفتهترین مدلهای یادگیری ماشین نیز در صورتی که با دادههای ناقص، ناهماهنگ یا پرخطا تغذیه شوند، خروجی نادرست تولید میکنند. همین واقعیت، پاکسازی دادهها (Data Cleaning) را به یک گام حیاتی تبدیل میکند—فرآیندی که دادهها را دقیق، یکپارچه، قابلاعتماد و آمادهٔ تحلیل میسازد.
پاکسازی دادهها شامل شناسایی و اصلاح خطاهای ساختاری، حذف دادههای تکراری، مدیریت مقادیر گمشده، استانداردسازی فرمتها و رسیدگی به دادههای پرت است. این گام حیاتی نهتنها باعث افزایش دقت تحلیل و مدلسازی میشود، بلکه بهرهوری، سرعت پردازش و قابلیت تصمیمسازی در سازمانها را نیز بهبود میبخشد. بدون داده تمیز، هیچ تصمیم مدیریتی، تحلیل علمی یا مدل هوش مصنوعی نمیتواند قابلاعتماد باشد.
در این مقاله، با مفهوم پاکسازی دادهها، اهمیت آن، روشها و مراحل عملی اجرای آن، ابزارهای موجود و چالشهای رایج کیفیت داده آشنا میشویم. هدف این است که خواننده در پایان بتواند در هر پروژه دادهای، دادههای خام را به اطلاعات ارزشمند و قابل استفاده تبدیل کند.
پاکسازی دادهها چیست؟
پاکسازی دادهها فرآیند شناسایی و برطرف کردن خطاها یا ناهمخوانیهای موجود در مجموعه داده (Dataset) است. در این فرآیند، دادهها با حذف (Scrapping) یا اصلاح موارد معیوب، به استاندارد کیفی لازم برای تحلیل میرسند.
این فعالیت، بخش جداییناپذیر پیشپردازش دادهها است، زیرا نحوه استفاده و پردازش دادهها در سایر فرآیندهای مدلسازی را تعیین میکند.
اهمیت پاکسازی دادهها:
- ارتقای کیفیت دادهها: پاکسازی دادهها بسیار حیاتی است، زیرا احتمال خطاها، تناقضات و مقادیر گمشده را کاهش میدهد و در نهایت باعث میشود دادهها برای تحلیل دقیقتر و قابلاعتمادتر باشند.
- تصمیمگیری بهتر: دادههای تمیز و یکدست، بینشی جامع و واقعی به سازمان میدهند و از تصمیمگیریهای غلط مدیران که بر پایه اطلاعات ناقص یا قدیمی بنا شدهاند، جلوگیری میکنند.
- افزایش بهرهوری: تحلیل، مدلسازی و گزارشگیری روی دادههای باکیفیت بسیار کارآمدتر است؛ در حالی که دادههای تمیز از هدررفت زمان و انرژی قابلتوجهی که صرف سروکله زدن با دادههای بیکیفیت میشود، جلوگیری میکنند.
- رعایت الزامات قانونی و مقررات: صنایع و نهادهای نظارتی سیاستهای مشخصی برای کیفیت داده دارند. با پاکسازی دادهها، میتوان با این استانداردها همسو شد و از جریمهها و خطرات قانونی اجتناب کرد.
وظایف اصلی در پاکسازی دادهها
پاکسازی دادهها شامل چندین وظیفه کلیدی است که هرکدام برای رفع مشکل خاصی طراحی شدهاند:
۱. مدیریت دادههای گمشده (Handling Missing Data)
دادههای گمشده مشکلی رایج هستند. استراتژیهای مدیریت آنها شامل موارد زیر است:
- حذف رکوردها: پاک کردن ردیفهای دارای مقدار خالی، اگر تعدادشان کم و کماهمیت باشد.
- جایگزینی مقادیر: پر کردن جاهای خالی با مقادیر تخمینی مانند میانگین ، میانه یا مُد.
- استفاده از الگوریتمها: بهکارگیری تکنیکهای پیشرفته مثل رگرسیون یا مدلهای یادگیری ماشین برای پیشبینی و پر کردن مقادیر.
۲. حذف موارد تکراری :
تکراریها تحلیل را منحرف میکنند. شناسایی و حذف آنها تضمین میکند که هر نقطه داده یکتاست و به درستی نمایندگی میشود.
۳. اصلاح بیدقتیها :
خطاهای ورود اطلاعات (مثل تایپ اشتباه یا اعداد غلط) باید شناسایی و اصلاح شوند. این کار میتواند شامل تطبیق با سایر منابع داده یا استفاده از قوانین اعتبارسنجی باشد.
۴. استانداردسازی فرمتها:
دادهها ممکن است با فرمتهای گوناگون وارد شده باشند. استانداردسازی مواردی مثل تاریخ، آدرس و شماره تلفن، کار با دادهها را آسانتر و سازگارتر میکند.
۵. مدیریت دادههای پرت :
دادههای پرت میتوانند نتایج گمراهکنندهای ایجاد کنند. شناسایی و مدیریت آنها (چه از طریق حذف و چه از طریق تبدیل داده) به حفظ یکپارچگی دیتاست کمک میکند.
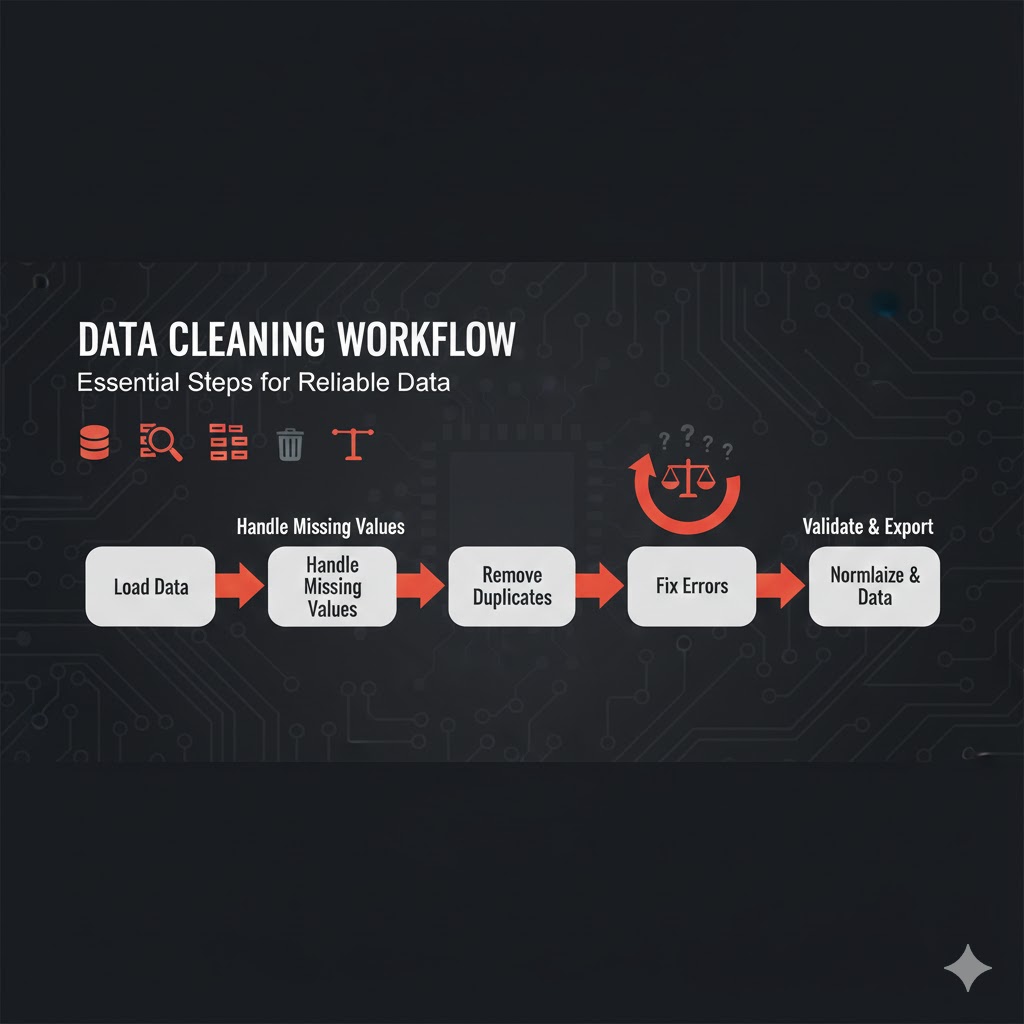
گامهای اجرایی پاکسازی دادهها
این فرآیند معمولاً شامل مراحل زیر است:
۱. ارزیابی کیفیت دادهها (Assess Data Quality)
اولین قدم، بررسی وضعیت فعلی دادههاست. این ارزیابی شامل موارد زیر است:
- مقادیر گمشده: شناسایی سلولهای خالی یا. Null این موارد ممکن است ناشی از جمعآوری ناقص، خطای اپراتور یا از دست رفتن داده هنگام انتقال باشند.
- مقادیر نادرست: بررسی مقادیری که خارج از بازه مورد انتظار هستند یا با نوع داده همخوانی ندارند (مثلاً تاریخ نامعتبر یا وجود کاراکتر غیرعددی در فیلد عددی).
- ناسازگاری در فرمت: اطمینان از اینکه فرمت دادهها در سراسر دیتاست یکسان است (مثلاً همه تاریخها به صورت YYYY-MM-DD باشند) و متغیرهای دستهای برچسبهای یکسانی دارند.
با شناسایی زودهنگام این مشکلات، میتوانید میزان پاکسازی مورد نیاز را تعیین کرده و برنامه خود را تنظیم کنید.
برای مثال،
جدول نمونه: نمرات دانشجویان
| نام (Name) | سن (Age) | نمره (Score) | تاریخ (Date) |
|---|---|---|---|
| علی | 25 | 90 | ۱۴۰۲/۱۰/۱۱ |
| سارا | 31 | 80 | ۱۴۰۲/۱۰/۱۲ |
| مریم | 22 | 70 | ۱۴۰۲/۱۰/۱۳ |
| رضا | 35 | 95 | ۱۴۰۲/۱۰/۱۴ |
| نگین | 28 | 85 | ۱۴۰۲/۱۰/۱۵ |
| علی | 25 | 90 | ۱۴۰۲/۱۰/۱۱ |
| سارا | 31 | 80 | ۱۴۰۲/۱۰/۱۲ |
| NaN (نامشخص) | 40 | 100 | ۱۴۰۲/۱۰/۱۶ |
تحلیل ایرادات دیتافریم (DataFrame Faults)
بیایید نگاهی دقیق به مشکلات موجود در جدول نمرات بیندازیم:
- ردیفهای تکراری: ردیفهای مربوط به علی و سارا دقیقاً تکرار شدهاند. این نشاندهنده مشکل تکثیر ناخواسته دادهها است که باید برطرف شود.
- مقادیر گمشده :در ردیف آخر، ستون نام خالی است. (NaN) این فقدان اطلاعات میتواند بر تحلیل و تفسیر نهایی تأثیر منفی بگذارد.
- فرمت تاریخ: اگرچه فرمت تاریخها در ظاهر یکدست است (سال-ماه-روز)، اما در دادههای واقعی باید تضمین کنیم که تمام ورودیها از یک استاندارد واحد پیروی میکنند.
- داده پرت احتمالی :نمره ۱۰۰ در ردیف آخر مشکوک است. بسته به سیستم نمرهدهی (مثلاً اگر سقف نمره ۲۰ باشد)، عدد ۱۰۰ قطعاً یک داده پرت محسوب میشود و باید بررسی شود.
۲. حذف دادههای نامربوط
وجود رکوردهای تکراری میتواند نتایج تحلیل را منحرف کرده و منجر به نتیجهگیریهای غلط شود. فرآیند تکرارزدایی شامل مراحل زیر است:
- شناسایی ورودیهای تکراری: استفاده از تکنیکهای فنی مانند مرتبسازی ، گروهبندی یا هشینگ (Hashing) برای پیدا کردن رکوردهایی که دقیقاً مشابه هم هستند.
- حذف رکوردهای تکراری: پس از شناسایی، باید نسخههای اضافی را حذف کنیم تا اطمینان حاصل شود که هر نقطه داده یکتاست و به درستی نمایندگی میشود.
- شناسایی مشاهدات زائد: جستجو برای رکوردهای کپی یا یکسانی که هیچ اطلاعات جدیدی به دیتاست اضافه نمیکنند.
- حذف اطلاعات بیفایده: حذف متغیرها یا ستونهایی که هیچ ارتباطی با هدف تحلیل ندارند یا بینش مفیدی ارائه نمیدهند.
نکته کلیدی: دادههای نامربوط باعث شلوغی و آشفتگی دیتاست میشوند. حذف دادههایی که سهم معناداری در تحلیل ندارند، به چابکسازی دیتاست و بهبود کیفیت کلی نتایج کمک میکند.
الف) دیتافریم ناقص (Imperfect DataFrame) – قبل از اصلاح: (شامل تکراریها و خطاها)
| نام (Name) | سن (Age) | نمره (Score) | تاریخ (Date) |
|---|---|---|---|
| علی | 25 | 90 | ۱۴۰۲/۱۰/۱۱ |
| سارا | 31 | 80 | ۱۴۰۲/۱۰/۱۲ |
| مریم | 22 | 70 | ۱۴۰۲/۱۰/۱۳ |
| رضا | 35 | 95 | ۱۴۰۲/۱۰/۱۴ |
| نگین | 28 | 85 | ۱۴۰۲/۱۰/۱۵ |
| علی | 25 | 90 | ۱۴۰۲/۱۰/۱۱ |
| سارا | 31 | 80 | ۱۴۰۲/۱۰/۱۲ |
| NaN (نامشخص) | 40 | 100 | ۱۴۰۲/۱۰/۱۶ |
ب) دیتافریم تکرارزدایی شده (Deduplicated DataFrame)- بعد از اصلاح: (تکراریها حذف شدند، اما دادههای پرت و گمشده هنوز هستند تا در مراحل بعد مدیریت شوند).
| نام | سن | نمره | تاریخ |
|---|---|---|---|
| علی | ۲۵ | ۹۰ | ۱۴۰۲/۱۰/۱۱ |
| سارا | ۳۱ | ۸۰ | ۱۴۰۲/۱۰/۱۲ |
| مریم | ۲۲ | ۷۰ | ۱۴۰۲/۱۰/۱۳ |
| رضا | ۳۵ | ۹۵ | ۱۴۰۲/۱۰/۱۴ |
| نگین | ۲۸ | ۸۵ | ۱۴۰۲/۱۰/۱۵ |
| NaN | ۴۰ | ۱۰۰ | ۱۴۰۲/۱۰/۱۶ |
وضعیت فعلی: حذف تکراریها
همانطور که اشاره کردید، در مرحله قبل ردیفهای تکراری (مربوط به علی و سارا) حذف شدند و حالا دیتافریم ما خلوتتر شده است. اکنون نوبت گام سوم است.
۳. اصلاح خطاهای ساختاری (Fix Structural Errors)
خطاهای ساختاری شامل مواردی مثل ناهمخوانی در فرمت دادهها، قراردادهای نامگذاری یا نوع متغیرها هستند. استانداردسازی فرمتها و تضمین یکنواختی در نحوه نمایش دادهها برای انجام یک تحلیل دقیق ضروری است.
این مرحله شامل اقدامات زیر است:
- استانداردسازی فرمت دادهها: اطمینان از اینکه تاریخها، زمانها و سایر انواع داده در سراسر دیتاست با یک فرمت واحد نوشته شدهاند.
- در مثال ما: همه تاریخها باید فرمت YYYY/MM/DD (مثلاً ۱۴۰۲/۱۰/۱۱) داشته باشند. اگر جایی یازدهم دی ماه نوشته شده باشد، باید اصلاح شود.
- اصلاح تناقضات نامگذاری: بررسی نام ستونها یا متغیرها برای یافتن غلطهای املایی یا فاصلههای اضافی و یکسانسازی آنها.
- تضمین یکنواختی در نمایش دادهها: تایید اینکه دادهها با واحدهای یکسان (مثلاً همه کیلوگرم) یا مقیاسهای یکسان سنجیده شدهاند.
- در مثال ما: نمره ۱۰۰ در ردیف آخر یک خطای ساختاری در مقیاس (Scale) است. چون سیستم نمرهدهی در این مثال بر مبنای ۲۰ است، نمره ۱۰۰ (که احتمالاً بر مبنای درصد بوده) باید به ۲۰ تبدیل شود تا با بقیه دادهها همجنس شود.
جدول نمرات دانشجویان با فرمت استاندارد شده
| نام (Name) | سن (Age) | نمره (Score) | تاریخ (Date) |
|---|---|---|---|
| علی | ۲۵ | ۱۸ | 1402-10-11 00:00:00 |
| سارا | ۳۱ | ۱۶ | 1402-10-12 00:00:00 |
| مریم | ۲۲ | ۱۴ | 1402-10-13 00:00:00 |
| رضا | ۳۵ | ۱۹ | 1402-10-14 00:00:00 |
| نگین | ۲۸ | ۱۷ | 1402-10-15 00:00:00 |
| nan | ۴۰ | ۲۰ | 1402-10-16 00:00:00 |
وضعیت فعلی: استانداردسازی تاریخ
همانطور که در جدول مرحله قبل دیدیم، ستون تاریخ (Date) اکنون در تمام ورودیها به فرمت استاندارد YYYY-MM-DD یکدست شده است . این کار سازگاری زمانی دادهها را تضمین میکند.
۵. مدیریت دادههای گمشده
دادههای گمشده میتوانند باعث ایجاد سوگیری (Bias) شوند و یکپارچگی تحلیل شما را به خطر بیندازند . برای مدیریت این دادهها چندین استراتژی وجود دارد:
- جایگزینی مقادیر: استفاده از روشهای آماری مانند میانگین ، میانه یا مُد برای پر کردن جاهای خالی .
- حذف رکوردهای ناقص: اگر دادههای گمشده گسترده هستند یا نمیتوان آنها را با دقت مناسب تخمین زد، بهتر است کل آن رکورد حذف شود .
- بکارگیری تکنیکهای پیشرفته: استفاده از روشهایی مانند رگرسیون، K-نزدیکترین همسایه (KNN) یا درخت تصمیم برای تخمین هوشمندانه مقادیر گمشده.
انتخاب استراتژی درست، کاملاً به ماهیت دادههای شما و نیازهای تحلیلیتان بستگی دارد.
مدیریت مقدار گمشده: مقدار گمشده در ستون نام (ردیف ۷) با واژه Unknown (ناشناس) جایگزین شده است تا نشان دهد که نام فرد نامشخص یا در دسترس نیست. این اقدام به حفظ یکپارچگی و کامل بودن دادهها کمک میکند.
۶. نرمالسازی دادهها
نرمالسازی دادهها شامل سازماندهی دادهها با هدف کاهش افزونگی (Redundancy) و بهبود کارایی ذخیرهسازی است. این فرآیند معمولاً شامل موارد زیر است:
- تقسیم دادهها به چندین جدول: تقسیم دادهها به جداول مجزا، به طوری که هر جدول نوع خاصی از اطلاعات را ذخیره کند.
- تضمین سازگاری دادهها: اطمینان از اینکه ساختار دادهها به گونهای است که عملیات پرسوجو (Querying) و تحلیل را تسهیل و کارآمد میکند.
مقایسه فرآیند تکرارزدایی (Deduplication)
۱. دیتافریم ناقص (Imperfect DataFrame)
| نام (Name) | سن (Age) | نمره (Score) | تاریخ (Date) |
|---|---|---|---|
| علی | ۲۵ | ۹۰ | ۱۴۰۲/۱۰/۱۱ |
| سارا | ۳۱ | ۸۰ | ۱۴۰۲/۱۰/۱۲ |
| مریم | ۲۲ | ۷۰ | ۱۴۰۲/۱۰/۱۳ |
| رضا | ۳۵ | ۹۵ | ۱۴۰۲/۱۰/۱۴ |
| نگین | ۲۸ | ۸۵ | ۱۴۰۲/۱۰/۱۵ |
| علی | ۲۵ | ۹۰ | ۱۴۰۲/۱۰/۱۱ |
| سارا | ۳۱ | ۸۰ | ۱۴۰۲/۱۰/۱۲ |
| NaN | ۴۰ | ۱۰۰ | ۱۴۰۲/۱۰/۱۶ |
۲. دیتافریم تکرارزدایی شده (Deduplicated DataFrame)
| نام (Name) | سن (Age) | نمره (Score) | تاریخ (Date) |
|---|---|---|---|
| علی | ۲۵ | ۹۰ | ۱۴۰۲/۱۰/۱۱ |
| سارا | ۳۱ | ۸۰ | ۱۴۰۲/۱۰/۱۲ |
| مریم | ۲۲ | ۷۰ | ۱۴۰۲/۱۰/۱۳ |
| رضا | ۳۵ | ۹۵ | ۱۴۰۲/۱۰/۱۴ |
| نگین | ۲۸ | ۸۵ | ۱۴۰۲/۱۰/۱۵ |
| NaN | ۴۰ | ۱۰۰ | ۱۴۰۲/۱۰/۱۶ |
۷. شناسایی و مدیریت دادههای پرت
دادههای پرت نقاطی از داده هستند که انحراف چشمگیری از حد نرمال دارند و میتوانند نتایج تحلیل را تحریف کنند. بسته به زمینه ، شما میتوانید یکی از روشهای زیر را انتخاب کنید:
- حذف دادههای پرت: اگر این دادهها ناشی از خطای ورود اطلاعات هستند یا نماینده درستی از جامعه آماری نیستند، آنها را از دیتاست حذف کنید.
- تبدیل دادههای پرت: اگر دادهها معتبر اما افراطی هستند، آنها را تغییر دهید (Transform) تا تاثیر شدیدشان بر تحلیل به حداقل برسد.
مدیریت دادههای پرت برای دستیابی به بینشهای دقیق و قابل اعتماد بسیار حیاتی است.
اعمال روی مثال نمرات دانشجویان (Outlier Management)
بیایید به جدول خودمان نگاه کنیم.
- مشکل شناسایی شده: در دادههای اولیه، نمرهای برابر با ۱۰۰ داشتیم، در حالی که سایر نمرات در بازه ۰ تا ۲۰ بودند.
- تحلیل: این عدد قطعاً یک داده پرت است. اما آیا باید حذف شود؟ خیر، زیرا احتمالاً دانشجو نمره کامل گرفته و سیستم به جای ۲۰، عدد ۱۰۰ (درصد) را ثبت کرده است.
- اقدام: ما در مراحل قبل (بخش خطاهای ساختاری)، این داده پرت را تبدیل کردیم (۱۰۰ → ۲۰). اگر این کار را نکرده بودیم، میانگین کلاس به شدت بالا میرفت و غلط میشد.
بررسی سایر ستونها:
- سن: سنها عبارتند از: ۲۵، ۳۱، ۲۲، ۳۵، ۲۸، ۴۰.
- عدد ۴۰ کمی بالاتر از بقیه است، اما برای یک دانشجو غیرممکن نیست. بنابراین آن را به عنوان یک داده واقعی میپذیریم و حذف نمیکنیم.
۱. دادههای نرمالسازی شده (اطلاعات دانشجویان)
| نام (Name) | سن (Age) | تاریخ (Date) |
|---|---|---|
| علی | ۲۵ | 1402-10-11 00:00:00 |
| سارا | ۳۱ | 1402-10-12 00:00:00 |
| مریم | ۲۲ | 1402-10-13 00:00:00 |
| رضا | ۳۵ | 1402-10-14 00:00:00 |
| نگین | ۲۸ | 1402-10-15 00:00:00 |
۲. دادههای نرمالسازی شده (نمرات)
| نام (Name) | نمره (Score) |
|---|---|
| علی | ۱۸ |
| سارا | ۱۶ |
| مریم | ۱۴ |
| رضا | ۱۹ |
| نگین | ۱۷ |
ابزارها و تکنیکهای پاکسازی دادهها
ابزارهای نرمافزاری (Software Tools)
چندین ابزار برای کمک به این فرآیند وجود دارد:
- Microsoft Excel: عملکردهای پایه مثل حذف تکراریها و استانداردسازی فرمت را ارائه میدهد.
- OpenRefine: یک ابزار متنباز (Open-source) که اختصاصاً برای تمیزکردن و تبدیل دادههای بهمریخته طراحی شده است.
- کتابخانههای پایتون: کتابخانههای قدرتمندی مثل Pandas و NumPy که توابع پیشرفتهای برای دستکاری داده دارند.
تکنیکهای فنی
پاکسازی موثر شامل تکنیکهای زیر است:
- عبارتهای باقاعده: بسیار مفید برای تطبیق الگوهای متنی (مثلاً یافتن ایمیلهای نامعتبر).
- پروفایلسازی دادهها: بررسی دادهها برای درک ساختار، محتوا و کیفیت آنها.
- ممیزی دادهها: چک کردن سیستماتیک دادهها برای یافتن خطاها.
چالشهای پاکسازی دادهها
- حجم دادهها: تمیز کردن دیتاستهای عظیم (Big Data) به دلیل اندازه بزرگشان چالشبرانگیز است و نیاز به ابزارهای کارآمد دارد.
- پیچیدگی: دادههای منابع مختلف، ساختارها و فرمتهای متفاوتی دارند که ادغام آنها را دشوار میکند.
- فرآیند مداوم: پاکسازی یک کار یکبارمصرف نیست؛ با ورود دادههای جدید، این پروسه باید تکرار شود.
بهترین روشها برای تضمین کیفیت
برای اطمینان از پاکسازی موثر، رعایت این موارد توصیه میشود:
- درک دادهها: باید منشأ دادهها و ویژگیهای دامنه کسبوکار را بشناسید تا بفهمید خطاها از کجا ناشی میشوند.
- مستندسازی فرآیند: تمام تصمیمات، تغییرات و فرضیات اعمال شده را ثبت کنید تا فرآیند قابل پیگیری باشد.
- اولویتبندی مسائل حیاتی: ابتدا روی خطاهایی تمرکز کنید که بیشترین تاثیر منفی را روی تصمیمگیری میگذارند.
- خودکارسازی: کارهای تکراری را با اسکریپتنویسی یا ابزارها اتوماتیک کنید تا بهرهوری بالا برود.
- همکاری با متخصصان: از متخصصان دامنه (Domain Experts) کمک بگیرید تا تایید کنند دادههای پاکشده با قوانین کسبوکار همخوانی دارند.
- پایش و نگهداری: کیفیت دادهها را در طول زمان رصد کنید.
نتیجه گیری
پاکسازی دادهها یکی از اساسیترین مراحل در چرخهٔ تحلیل داده و ساخت مدلهای هوش مصنوعی است؛ مرحلهای که کیفیت خروجی را بهطور چشمگیری بهبود میبخشد یا در صورت بیتوجهی، کل پروژه را به شکست میکشاند. تحلیلگر داده با حذف رکوردهای تکراری، اصلاح خطاهای ساختاری، مدیریت مقادیر گمشده و رسیدگی به دادههای پرت، دیتاستی دقیق و قابلاتکا میسازد.
ابزارها و روشهای مختلفی برای پاکسازی دادهها وجود دارند.از Excel و OpenRefine گرفته تا کتابخانههای قدرتمند پایتون مانند Pandas و NumPyاما موفقیت نهایی وابسته به درک صحیح ماهیت دادهها و نیازهای تحلیل است. علاوه بر این، پاکسازی دادهها یک فرآیند یکباره نیست؛ بلکه فعالیتی پیوسته است که با ورود دادههای جدید باید تکرار شود.
در نهایت، دادههای تمیز به تصمیمگیری بهتر، تحلیل قابلاعتمادتر و مدلهای دقیقتر منجر میشوند. هر سازمان یا تحلیلگری که به ارزش واقعی دادهها آگاه است، میداند که پاکسازی دادهها نه یک مرحله اضافی، بلکه پایهایترین گام در مسیر تبدیل دادههای خام به بینشهای عمیق و قابل اجراست.


