
مقدمه
در دنیای امروز که حجم عظیمی از دادهها از منابع مختلف تولید میشود، کیفیت و ساختار این دادهها نقش تعیینکنندهای در موفقیت تحلیلها و مدلهای دادهکاوی دارد. دادههای خام معمولاً شامل خطا، مقادیر گمشده، نویز، تناقض و ناهمگونی هستند؛ بنابراین قبل از هرگونه تحلیل، باید آنها را به شکل قابل اعتماد و ساختیافته تبدیل کرد. این مرحله حیاتی «پیشپردازش دادهها» نام دارد.
پیشپردازش دادهها در واقع پلی میان دادههای خام و الگوریتمهای دادهکاوی است. بدون این مرحله، حتی پیشرفتهترین مدلها نیز عملکرد ضعیفی خواهند داشت، زیرا ورودی نادرست همیشه خروجی اشتباه ایجاد میکند. این فرآیند شامل پاکسازی، یکپارچهسازی، تبدیل و کاهش دادههاست. مراحلی که دقت، انسجام و کارایی مجموعه داده را تضمین کرده و بستر لازم را برای استخراج الگوها، ساخت مدلهای پیشبینی و تحلیلهای هوشمند فراهم میکنند.
این مقاله با تمرکز بر مفاهیم اصلی پیشپردازش، تکنیکها، کاربردهای عملی و مثالهای واقعی، تلاش میکند تصویری شفاف و کاربردی از این گام بنیادی ارائه دهد.
تعریف
پیشپردازش دادهها فرآیند آمادهسازی دادههای خام برای تحلیل، از طریق پاکسازی و تبدیل آنها به یک فرمت قابل استفاده است. در دادهکاوی، این مفهوم به آمادهسازی دادههای خام برای کاوش از طریق انجام وظایفی مانند پاکسازی، تبدیل و سازماندهی آنها در فرمتی مناسب برای الگوریتمهای کاوش اشاره دارد.
- هدف، بهبود کیفیت دادهها است.
- به مدیریت مقادیر گمشده، حذف موارد تکراری و نرمالسازی دادهها کمک میکند.
- دقت و سازگاری مجموعه داده را تضمین میکند.
گامهای پیشپردازش دادهها
برخی از گامهای کلیدی در پیشپردازش دادهها عبارتند از: پاکسازی دادهها، یکپارچهسازی دادهها، تبدیل دادهها و کاهش دادهها.

۱. پاکسازی دادهها(Data Cleaning):
این فرآیند شناسایی و اصلاح خطاها یا ناهمخوانیها در مجموعه داده است. این کار شامل مدیریت مقادیر گمشده، حذف موارد تکراری و اصلاح دادههای نادرست یا پرت است تا اطمینان حاصل شود که مجموعه داده دقیق و قابل اعتماد است. دادههای پاک برای تحلیل موثر ضروری هستند، زیرا کیفیت نتایج را بهبود میبخشند و عملکرد مدلهای داده را ارتقا میدهند.
مثال :
مسئله: فرض کنید دادههای سن ۵ مشتری به صورت زیر است:
[25, 30, NaN, 28, 150]
- مشکل ۱: مقدار NaN (داده گمشده).
- مشکل ۲: مقدار 150 (داده پرت/نویزی – چون انسان ۱۵۰ سال عمر نمیکند).
راهحل عملی:
- مدیریت مقدار گمشده: طبق متن، میتوانیم از میانگین استفاده کنیم.
- میانگین سنهای سالم: 28 ≈ 27.6= 3 / (25+30+28)
- جایگزینی: NaN → 28
- مدیریت داده پرت: حذف یا اصلاح با روشهای خوشهبندی یا مرزی.
- در اینجا عدد ۱۵۰ را حذف میکنیم.
- داده پاکسازی شده نهایی: [25, 30, 28, 28]
A. مقادیر گمشده(Missing Values):
این حالت زمانی رخ میدهد که دادهای در مجموعه داده وجود نداشته باشد. شما میتوانید ردیفهای دارای داده گمشده را نادیده بگیرید یا جاهای خالی را به صورت دستی، با میانگین ویژگی ، یا با استفاده از محتملترین مقدار پر کنید. این کار تضمین میکند که مجموعه داده برای تحلیل دقیق و کامل باقی بماند.
B. دادههای نویزی(Noisy Data):
به دادههای نامربوط یا نادرستی اشاره دارد که تفسیر آنها برای ماشینها دشوار است و اغلب ناشی از خطا در جمعآوری یا ورود دادهها است. این دادهها را میتوان به چندین روش مدیریت کرد:
- روش دستهبندی: دادهها به بخشهای مساوی مرتب میشوند و هر بخش با جایگزینی مقادیر با میانگین یا مقادیر مرزی هموار میشود.
- رگرسیون: دادهها با برازش به یک تابع رگرسیون، چه خطی و چه چندگانه، برای پیشبینی مقادیر هموار میشوند.
- خوشهبندی: این روش نقاط داده مشابه را با هم گروهبندی میکند، به طوری که دادههای پرت یا شناسایی نمیشوند یا خارج از خوشهها قرار میگیرند. این تکنیکها به حذف نویز و بهبود کیفیت دادهها کمک میکنند.
C.حذف موارد تکراری:
شامل شناسایی و حذف ورودیهای داده تکراری برای اطمینان از دقت و سازگاری در مجموعه داده است. این فرآیند از خطاها جلوگیری میکند و با نگه داشتن تنها سوابق منحصربهفرد، تحلیل قابل اعتماد را تضمین میکند.
۲. یکپارچهسازی دادهها:
شامل ادغام دادهها از منابع مختلف در یک مجموعه داده واحد و یکپارچه است. این کار به دلیل تفاوت در فرمتها، ساختارها و معانی دادهها میتواند چالشبرانگیز باشد. تکنیکهایی مانند پیوند رکوردها و تلفیق دادهها به ترکیب کارآمد دادهها کمک کرده و سازگاری و دقت را تضمین میکنند.
A. پیوند رکوردها:
فرآیند شناسایی و تطبیق رکوردهایی از مجموعه دادههای مختلف است که به یک موجودیت واحد اشاره دارند، حتی اگر به شکل متفاوتی نمایش داده شده باشند. این کار با یافتن رکوردهای مربوطه بر اساس شناسهها یا ویژگیهای مشترک، به ترکیب دادهها از منابع مختلف کمک میکند.
B. تلفیق دادهها(Data Fusion):
شامل ترکیب دادهها از منابع متعدد برای ایجاد یک مجموعه داده جامعتر و دقیقتر است. این روش اطلاعاتی را که ممکن است از منابع مختلف ناسازگار یا ناقص باشند، یکپارچه کرده و یک مجموعه داده واحد و غنیتر برای تحلیل تضمین میکند.
۳. تبدیل دادهها(Data Transformation):
شامل تبدیل دادهها به فرمتی مناسب برای تحلیل است. تکنیکهای رایج شامل نرمالسازی است که دادهها را به یک محدوده مشترک مقیاسبندی میکند؛ استانداردسازی که دادهها را تنظیم میکند تا دارای میانگین صفر و واریانس واحد باشند؛ و گسستهسازی که دادههای پیوسته را به دستههای گسسته تبدیل میکند. این تکنیکها به آمادهسازی دادهها برای تحلیل دقیقتر کمک میکنند.
مثال:
مسئله: ما دو ویژگی داریم:
- سن: بین ۲۰ تا ۶۰ سال.
- درآمد: بین ۱۰,۰۰۰,۰۰۰ تا ۱۰۰,۰۰۰,۰۰۰ تومان.
- مشکل: اعداد درآمد بسیار بزرگتر از سن هستند و بر مدل غلبه میکنند.
راهحل (نرمالسازی Min-Max)
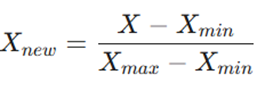
فرض کنید درآمد یک شخص ۴۰,۰۰۰,۰۰۰ تومان است. میخواهیم آن را به بازه [0, 1] ببریم:
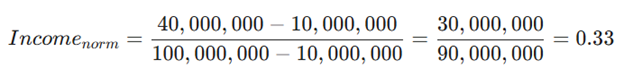
حالا درآمد این شخص به عدد 0.33 تبدیل شد که برای الگوریتم قابلفهمتر است.
A. نرمالسازی دادهها(Data Normalization):
فرآیند مقیاسبندی دادهها به یک محدوده مشترک برای اطمینان از سازگاری در بین متغیرها.
B. گسستهسازی(Discretization):
تبدیل دادههای پیوسته به دستههای گسسته برای تحلیل آسانتر.
C.تجمیع دادهها(Data Aggregation):
ترکیب چندین نقطه داده به یک فرم خلاصهشده، مانند میانگینها یا مجموعها، برای سادهسازی تحلیل.
D.تولید سلسلهمراتب مفاهیم:
سازماندهی دادهها در یک سلسلهمراتب از مفاهیم برای ارائه یک نمای سطح بالاتر جهت درک و تحلیل بهتر.
۴. کاهش دادهها:
اندازه مجموعه داده را کاهش میدهد در حالی که اطلاعات کلیدی را حفظ میکند. این کار میتواند از طریق انتخاب ویژگی انجام شود که مرتبطترین ویژگیها را انتخاب میکند، و استخراج ویژگی که دادهها را به یک فضای با ابعاد پایینتر تبدیل میکند در حالی که جزئیات مهم را حفظ مینماید. این روش از تکنیکهای کاهش مختلفی استفاده میکند مانند:
مثال:
هدف کاهش متغیرها بدون از دست دادن اطلاعات کلیدی است.
مسئله: در یک دیتابیس املاک، دو ستون داریم:
- طول زمین (Length)
- عرض زمین (Width)
راهحل (استخراج ویژگی): به جای اینکه هر دو ستون را به مدل بدهیم، یک ستون جدید به نام مساحت (Area) میسازیم:
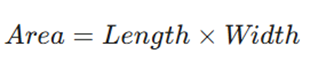
حالا دو ستون قبلی را حذف میکنیم. ما ابعاد را از ۲ به ۱ کاهش دادیم، اما اطلاعات حفظ شد.
A.کاهش ابعاد:
تکنیکی که تعداد متغیرها را در یک مجموعه داده کاهش میدهد در حالی که اطلاعات اساسی آن را حفظ میکند.
B.کاهش تعداد:
کاهش تعداد نقاط داده با روشهایی مانند نمونهگیری برای سادهسازی مجموعه داده بدون از دست دادن الگوهای حیاتی.
C.فشردهسازی دادهها:
کاهش اندازه دادهها با کدگذاری آنها در فرمی فشردهتر، که ذخیرهسازی و پردازش آن را آسانتر میکند.
کاربردهای پیشپردازش دادهها
پیشپردازش دادهها در حوزههای متنوعی به کار گرفته میشود تا تضمین کند که دادههای خام به فرمتی کارآمد برای تحلیل و تصمیمگیری تبدیل شدهاند. در ادامه حوزههای کلیدی کاربرد آن را بررسی میکنیم:
۱. انبار داده(Data Warehousing): در انبار داده، پیشپردازش برای پاکسازی، یکپارچهسازی و ساختاردهی دادهها قبل از ذخیره در یک مخزن مرکزی ضروری است. این کار تضمین میکند که دادهها برای پرسوجوها (Queries) و گزارشگیریهای آینده، سازگار و قابل اعتماد باشند.
۲. دادهکاوی: پیشپردازش در دادهکاوی شامل تمیز کردن و تغییر شکل دادههای خام است تا برای تحلیل مناسب شوند. این گام برای شناسایی الگوها و استخراج بینش از مجموعه دادههای بزرگ حیاتی است.
۳. ML: در یادگیری ماشین، پیشپردازش دادههای خام را برای آموزش مدل آماده میکند. این شامل مدیریت مقادیر گمشده، نرمالسازی ویژگیها، کدگذاری متغیرهای دستهای و تقسیم دادهها به مجموعههای آموزش و تست برای بهبود عملکرد و دقت مدل است.
۴. علم داده: پیشپردازش یک گام بنیادین در پروژههای علم داده است که تضمین میکند دادههای مورد استفاده برای تحلیل یا ساخت مدلهای پیشبینی، تمیز، ساختاریافته و مرتبط هستند. این کار کیفیت کلی بینشهای بهدستآمده از دادهها را ارتقا میدهد.
۵. وبکاوی(Web Mining): در وبکاوی، پیشپردازش به تحلیل لاگهای استفاده از وب کمک میکند تا الگوهای رفتاری معنادار کاربران استخراج شود. این امر میتواند استراتژیهای بازاریابی را آگاه کرده و تجربه کاربری را از طریق پیشنهادات شخصیسازیشده بهبود بخشد.
۶. هوش تجاری: پیشپردازش با سازماندهی و پاکسازی دادهها از BI پشتیبانی میکند تا داشبوردها و گزارشهایی ایجاد شود که بینشهای عملی (Actionable) برای تصمیمگیرندگان فراهم کنند.
مطالعات موردی
مطالعه موردی اول: سیستم تشخیص بیماری قلبی در یک بیمارستان
هدف: پیشبینی احتمال سکته قلبی در بیماران با استفاده از سوابق پزشکی ۱۰ ساله.
در این پروژه، بیمارستان با انبوهی از پروندههای کاغذی و دیجیتالی روبرو بود که پر از خطا و نواقص بودند. برای آمادهسازی این دادهها، چهار مرحله اصلی پیشپردازش به شرح زیر انجام شد:
۱. پاکسازی دادهها
دادههای پزشکی بسیار حساس هستند و وجود خطا در آنها میتواند منجر به تشخیص اشتباه شود.
- مدیریت دادههای گمشده: در بسیاری از پروندهها، فیلد «وزن بیمار» خالی بود. به جای حذف این پروندهها (که باعث از دست رفتن اطلاعات میشد)، تیم تصمیم گرفت جاهای خالی را با میانگین وزن سایر بیماران همسن و همجنس پر کند.
- مدیریت دادههای نویزی و پرت: در ستون فشار خون، عددی مانند «۱۸۰۰» ثبت شده بود (احتمالاً خطای تایپی به جای ۱۸). با استفاده از روشهای آماری، این دادههای پرت شناسایی و با مقدار میانگین اصلاح شدند.
- حذف تکراریها: برخی بیماران دو بار پذیرش شده بودند و سیستم دو پرونده با یک کد ملی برایشان ساخته بود. این رکوردهای تکراری شناسایی و حذف شدند تا آمار بیماران غلط از آب درنیاید.
۲. یکپارچهسازی دادهها
اطلاعات بیماران در دو جای مختلف بود: «سیستم پذیرش» (مشخصات فردی) و «سیستم آزمایشگاه» (نتایج خون).
- پیوند رکوردها: چالش این بود که در سیستم پذیرش نام بیمار «محمدی» و در آزمایشگاه «محمدیاصل» ثبت شده بود. با استفاده از کد ملی به عنوان کلید مشترک، این دو دیتابیس به هم متصل شدند تا برای هر بیمار یک پرونده کامل شامل مشخصات و نتایج آزمایش وجود داشته باشد.
۳. تبدیل دادهها
دادههای خام باید برای الگوریتمهای هوش مصنوعی قابلفهم میشدند .
- گسستهسازی: سن بیماران عددی پیوسته بود . برای تحلیل بهتر، این اعداد به دستههای کیفی تبدیل شدند: «جوان» (۲۰-۳۵)، «میانسال» (۳۶-۵۵) و «سالمند» (۵۵+).
- نرمالسازی: پارامترهایی مثل «کلسترول» (مثلاً ۲۰۰) و «سن» (مثلاً ۵۰) مقیاسهای متفاوتی داشتند. تمام اعداد به بازه بین ۰ تا ۱ تبدیل شدند تا سن یا کلسترول بر دیگری تسلط پیدا نکند.
۴. کاهش دادهها
بیمارستان بیش از ۱۰۰ ستون اطلاعات برای هر بیمار داشت (شامل آدرس دقیق، نام پدر، رنگ چشم و…).
- انتخاب ویژگی: برای پیشبینی سکته قلبی، رنگ چشم یا آدرس منزل تاثیری نداشت. با استفاده از تکنیک انتخاب ویژگی، تنها ۲۰ فیلد حیاتی (مانند سن، فشار خون، سابقه دیابت) نگه داشته شد و بقیه حذف شدند تا سرعت پردازش بالا برود.
نتیجه مطالعه موردی بیمارستان (تشخیص بیماری قلبی)
پس از انجام مراحل پاکسازی و یکپارچهسازی، خروجی نهایی به شرح زیر بود:
- افزایش چشمگیر دقت تشخیص: قبل از پیشپردازش، به دلیل وجود دادههای نویزی (مثل فشار خون ۱۸۰۰) و مقادیر گمشده، الگوریتم هوش مصنوعی خطای زیادی داشت. اما پس از اصلاح دادهها، نویز و دادههای نامربوط کاهش یافت که منجر به پیشبینیهای دقیقتر شد. مدل توانست با دقت بالای ۹۰٪ بیماران در معرض خطر را شناسایی کند.
- کاهش هزینههای آزمایشگاهی: با استفاده از تکنیک «کاهش دادهها» و «انتخاب ویژگی» ، بیمارستان متوجه شد که برخی آزمایشهای گرانقیمت تاثیر چندانی در پیشبینی سکته ندارند. در نتیجه، این آزمایشها از پروتکل غربالگری حذف شدند که باعث صرفهجویی در هزینه و زمان شد.
- اعتماد پزشکان به سیستم: دادههای پاک و یکپارچه، تحلیلها را قابلاعتماد کردند. پزشکان که قبلاً به سیستم بدبین بودند، حالا به عنوان یک دستیار هوشمند به هشدارهای سیستم توجه میکردند، زیرا میدانستند دادهها دقیق و بدون تناقض هستند.
مطالعه موردی دوم: تحلیل رفتار مشتریان در فروشگاه زنجیرهای (Retail)
هدف: دستهبندی مشتریان برای ارسال پیشنهادات تخفیف شخصیسازی شده.
یک فروشگاه زنجیرهای بزرگ (مثل هایپراستار) میخواست بداند کدام مشتریان «وفادار» هستند و کدامیک در حال «ریزش» هستند. دادهها از صندوقهای فروش و اپلیکیشن موبایل جمعآوری میشد.
۱. پاکسازی دادهها
- اصلاح ناهنجاریها: در برخی فاکتورها، مبلغ خرید منفی ثبت شده بود. تیم تحلیلگر این دادهها را جدا کرد تا میانگین فروش روزانه را خراب نکنند.
- یکسانسازی فرمتها: تاریخ خرید در برخی صندوقها به شمسی و در برخی به میلادی بود. تمام تاریخها به یک فرمت واحد استاندارد تبدیل شدند.
۲. یکپارچهسازی دادهها
فروشگاه میخواست بداند آیا کسانی که در اینستاگرام تبلیغ را دیدهاند، خرید حضوری هم کردهاند یا خیر.
- تلفیق دادهها: دادههای «باشگاه مشتریان» (خرید حضوری) با دادههای «رفتار در وبسایت» (کلیکها) ترکیب شد. این کار باعث شد فروشگاه بفهمد مشتری دقیقاً چه مسیری را طی کرده تا خرید کند.
۳. تبدیل دادهها
- تجمیع دادهها: به جای بررسی تکتک خریدهای چیپس و پفک، دادهها تجمیع شدند تا «مجموع خرید ماهانه» هر مشتری محاسبه شود. این کار تحلیل را بسیار سادهتر کرد.
- تولید سلسلهمراتب مفاهیم: کالاهای جزئی مثل «شیر کمچرب کاله» و «شیر پرچرب دامداران» همگی زیرمجموعه دسته کلیتر «لبنیات» قرار گرفتند تا تحلیل مدیریتی امکانپذیر شود.
۴. کاهش دادهها
دیتابیس فروشگاه شامل میلیاردها رکورد تراکنش از ۱۰ سال گذشته بود.
- نمونهگیری: برای تست اولیه مدل، نیازی به تحلیل ۱۰ سال داده نبود. تیم تحلیلگر یک نمونه تصادفی شامل ۵٪ از دادههای سال اخیر را انتخاب کرد که همان الگوها را نشان میداد اما سرعت تحلیل را ۲۰ برابر کرد.
- فشردهسازی: دادههای قدیمیتر آرشیو و فشرده شدند تا فضای سیستم اشغال نشود.
نتیجه مطالعه موردی فروشگاه زنجیرهای (تحلیل رفتار مشتری)
در پروژه فروشگاهی، پیشپردازش دادهها مستقیماً روی سودآوری و استراتژی بازاریابی تاثیر گذاشت:
- کمپینهای تبلیغاتی هدفمند: با تلفیق دادههای وبسایت و فروشگاه (یکپارچهسازی)، الگوهای رفتاری معنادار مشتریان استخراج شد. فروشگاه توانست دقیقاً بفهمد چه کسانی در خطر ریزش هستند. به جای ارسال پیامک تبلیغاتی انبوه به همه (که هزینه بالایی داشت)، کوپنهای تخفیف فقط برای این افراد ارسال شد.
- افزایش فروش و کاهش ریزش: دادههای شفاف و سازمانیافته، امکان تصمیمگیری تجاری بهتر را فراهم کرد. مدیران با دیدن گزارشهای دقیق (که دیگر تحت تاثیر فاکتورهای مرجوعی یا تکراری نبودند)، استراتژیهای اشتباه را اصلاح کردند. نتیجه، بازگشت ۳۰٪ از مشتریانی بود که قصد ترک فروشگاه را داشتند.
- سرعت بالای گزارشگیری : به لطف تکنیکهای «کاهش تعداد» (مثل نمونهگیری) و «تجمیع دادهها» ، زمان پردازش گزارشهای ماهانه از «چند روز» به «چند دقیقه» کاهش یافت. این یعنی دادهها برای پردازش سریعتر و آسانتر سادهسازی شدند و مدیران میتوانستند به صورت لحظهای تصمیم بگیرند.
خلاصه تاثیر پیشپردازش در هر دو مورد
در هر دو مورد، اگر پیشپردازش انجام نمیشد، با مشکل «احتمال از دست رفتن دادهها» یا تحلیلهای غلط مواجه میشدیم. پیشپردازش تضمین کرد که دادهها برای تحلیل، تمیز، سازگار و قابل اعتماد هستند.
مزایای پیشپردازش دادهها
- بهبود کیفیت داده: تضمین میکند که دادهها برای تحلیل، تمیز، سازگار و قابل اعتماد هستند.
- عملکرد بهتر مدل: نویز و دادههای نامربوط را کاهش میدهد که منجر به پیشبینیها و بینشهای دقیقتر میشود.
- تحلیل داده کارآمد: دادهها را برای پردازش سریعتر و آسانتر سادهسازی میکند.
- تصمیمگیری ارتقایافته: دادههای شفاف و سازمانیافتهای را برای تصمیمات تجاری بهتر فراهم میکند.
معایب پیشپردازش دادهها
- زمانبر: پاکسازی، تغییر شکل و سازماندهی دادهها نیازمند صرف زمان و تلاش قابل توجهی است.
- احتمال از دست رفتن دادهها: مدیریت نادرست ممکن است منجر به حذف اطلاعات ارزشمند شود.
- پیچیدگی: مدیریت مجموعه دادههای بزرگ یا فرمتهای متنوع میتواند چالشبرانگیز باشد.
جمع بندی
پیشپردازش دادهها یکی از اساسیترین مراحل در دادهکاوی، یادگیری ماشین و علم داده است؛ زیرا کیفیت خروجی هر مدل یا تحلیل، مستقیماً وابسته به کیفیت ورودی آن است. با اجرای صحیح تکنیکهایی مانند پاکسازی دادهها، مدیریت مقادیر گمشده، حذف دادههای نویزی، یکپارچهسازی منابع مختلف، نرمالسازی، گسستهسازی و کاهش ابعاد، میتوان دادههایی تمیز، سازگار و قابل اتکا ایجاد کرد. نتیجه این فرآیند، مدلهایی دقیقتر، تحلیلهایی سریعتر و تصمیمگیریهایی آگاهانهتر است.
مطالعات موردی ارائهشده در این مقاله نشان میدهد که پیشپردازش نه یک کار حاشیهای، بلکه عامل موفقیت پروژههای بزرگ است. بدون پیشپردازش، دادههای غلط و نامنظم میتوانند کل یک پروژه را به بیراهه ببرند؛ اما با آمادهسازی اصولی دادهها، میتوان بینشهای ارزشمند استخراج کرد که مستقیماً در بهبود عملکرد تجاری، افزایش دقت مدلها و کاهش هزینهها نقش دارند.
در نهایت، پیشپردازش دادهها نهتنها دقت و کارایی دادهکاوی را تضمین میکند، بلکه پایهای مطمئن برای ساخت سیستمهای هوشمند و تحلیلهای پیشرفته فراهم میسازد—پایهای که بدون آن هیچ پروژه علمی و کاربردی موفق نخواهد بود.


