
داده گمشده(Missing Value) چیست و چرا مهم است؟
در دنیای واقعی، دادهها هرگز تمیز و کامل نیستند. داده گمشده (Missing Value) به مقادیری اطلاق میشود که برای یک یا چند ویژگی (ستون) از یک یا چند مشاهده (سطر) در دسترس نیستند. این مقادیر گمشده، که اغلب با NULL، NaN (Not a Number)، ? یا یک خانه خالی نمایش داده میشوند، یکی از رایجترین مشکلات در کیفیت داده (Data Quality) هستند.
چرا اهمیت دارد؟
- الگوریتمهای خرابکار: بسیاری از الگوریتمهای یادگیری ماشین (مانند رگرسیون خطی یا SVM) نمیتوانند مستقیماً با مقادیر گمشده کار کنند و اجرای آنها با خطا مواجه میشود.
- نتایج مغرضانه (Biased): اگر دادههای گمشده به درستی مدیریت نشوند، میتوانند الگوهای آماری داده را به هم ریخته و منجر به نتایج تحلیلی نادرست و مدلهای پیشبینی ضعیف شوند.
چرا دادهها گم میشوند؟
دلایل اصلی گم شدن دادهها عبارتند از:
جمعآوری نشدن اطلاعات (Information not collected):
- مثال (اطلاعات حساس): یک فرد در نظرسنجی سلامت، فیلد مربوط به «وزن» یا «میزان درآمد ماهانه» را به دلیل عدم تمایل به اشتراکگذاری، خالی میگذارد.
- مثال (خطای کاربر): یک مشتری هنگام ثبتنام در وبسایت، پر کردن فیلد «کد پستی» را فراموش میکند.
عدم کاربرد ویژگی (Attribute not applicable):
- مثال: در یک پایگاه داده جمعیتی، ویژگی سابقه شغلی یا درآمد سالانه برای یک کودک ۶ ساله، اساساً معنایی ندارد و باید گمشده در نظر گرفته شود
گم شدن خود داده (Data is lost):
- مثال (نقص فنی):دستگاه سنجش دمای یک ایستگاه هواشناسی به دلیل نقص فنی، به مدت ۴ ساعت هیچ دادهای ثبت نمیکند.
- مثال (مشکل شبکه) :دادههای جمعآوری شده توسط یک سنسور هوشمند، به دلیل قطع ارتباط شبکه هرگز به سرور مرکزی ارسال نمیشوند.
الگوهای داده گمشده
برای انتخاب بهترین روش، ابتدا باید الگوی گم شدن دادهها را بشناسیم. در منابع آکادمیک، سه الگوی اصلی تعریف میشود:
MCAR: کاملاً تصادفی.
- توضیح: گم شدن داده به مقدار آن متغیر یا متغیرهای دیگر وابستگی ندارد؛ یک اتفاق شانسی است.
- مثال: مسئول ورود دادهها به دلیل یک حواسپرتی ناگهانی، به صورت تصادفی چند خانه از ستون «امتیاز مشتری» را خالی میگذارد.
- اهمیت: بهترین سناریو است؛ حذف سطرها (در حجم کم) بایاس زیادی ایجاد نمیکند.
MAR: تصادفی (اما وابسته).
- توضیح: گم شدن داده به مقدار سایر متغیرهای مشاهدهشده در همان سطر وابسته است، نه به مقدار خودش.
- مثال: در یک نظرسنجی، مردان (متغیر مشاهدهشده) کمتر از زنان به سوال نمره اضطراب (متغیر گمشده) پاسخ میدهند. در اینجا، گم شدن نمره اضطراب به جنسیت وابسته است.
MNAR: غیر تصادفی (بدترین حالت).
- توضیح: گم شدن داده به مقدار خود همان متغیر گمشده بستگی دارد.
- مثال: افرادی که میزان درآمد بسیار بالا یا بسیار پایینی دارند، بیشتر تمایل دارند که این فیلد را پر نکنند.
- اهمیت: پیچیدهترین حالت است؛ دادههای موجود نماینده کل جامعه آماری نیستند و نیاز به روشهای تخمین پیشرفته دارد.
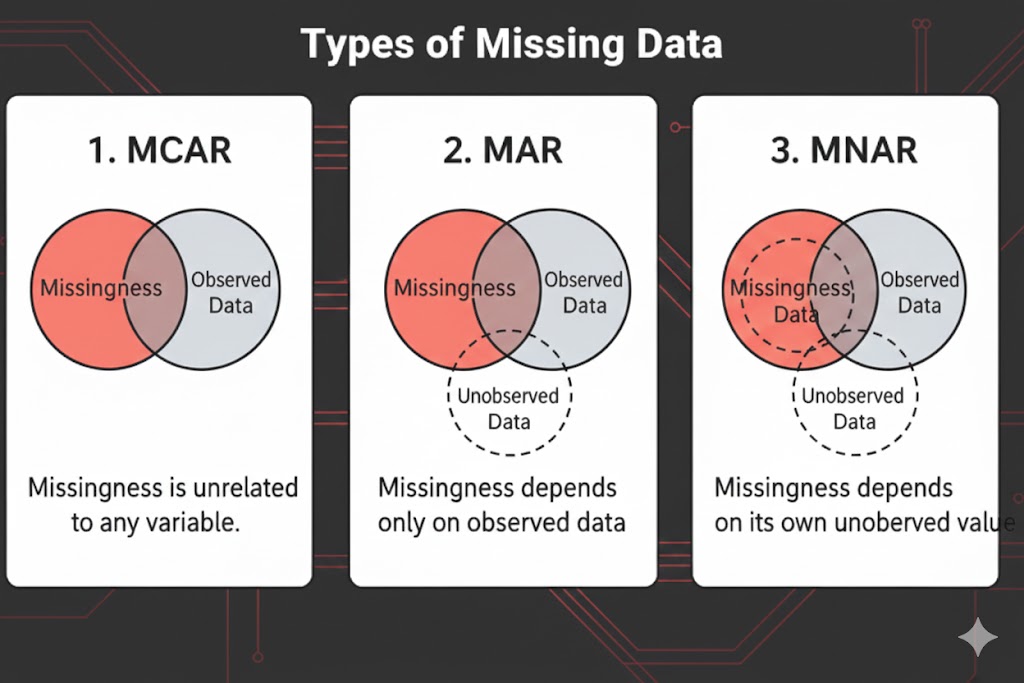
این تصویر سه الگوی اصلی گمشدگی داده را نشان میدهد.
1. MCAR گمشدن کاملاً تصادفی است.
2. MAR گمشدن به دادههای مشاهدهشده بستگی دارد.
3. MNAR گمشدن به مقدار واقعیِ همان متغیر گمشده وابسته است.
شناخت این الگوها اولین قدم برای انتخاب روش مناسب برخورد با Missing Data است.
چطور نوع گمشدگی داده را تشخیص دهیم؟
برای انتخاب روش درست، فقط دانستن مفاهیم MCAR، MAR و MNAR کافی نیست؛باید بتوانیم تشخیص دهیم دادهها واقعاً در کدام دسته قرار میگیرند.
چند روش رایج برای تشخیص:
۱. آزمون Little’s MCAR Test
اگر نتیجه آزمون نشان دهد دادهها MCAR هستند، یعنی گمشدن کاملاً تصادفی است و روشهایی مانند حذف سطر آسیب جدی نمیزند.
۲. ایجاد ستون کمکی
یک ستون کمکی (Indicator) میسازیم:
Missing_Age = 1 → اگر سن گمشده است
Missing_Age = 0 → اگر موجود است
اگر Missing_Age با سایر ویژگیها (مثل جنسیت، درآمد، تحصیلات) رابطه داشته باشد → دادهها MAR هستند.
۳. تحلیل الگوها و منطق دادهها
اگر دلیل گمشدن وابسته به خود مقدار باشد (مثلاً درآمدهای بسیار بالا ثبت نمیشوند) → معمولاً MNAR است.
4.روش های تصویری (Visualization)
نمایش گرافیکی میزان و الگوی گمشدگی، درک بسیار خوبی از مشکل میدهد و انتخاب روش مناسب را راحت میکند.
چند روش رایج:
- Heatmap: نمایش سطرهای کامل در مقابل سطرهای ناقص
- Matrix Plot: نمایش بلوکی دادههای گمشده و موجود
- Bar Plot: تعداد مقادیر گمشده در هر ستون
- Missingno Library در پایتون:ابزار آماده برای تولید نمودارهای missingness
این نمودارها کمک میکنند بفهمیم آیا دادههای گمشده الگوی خاصی دارند یا نه.
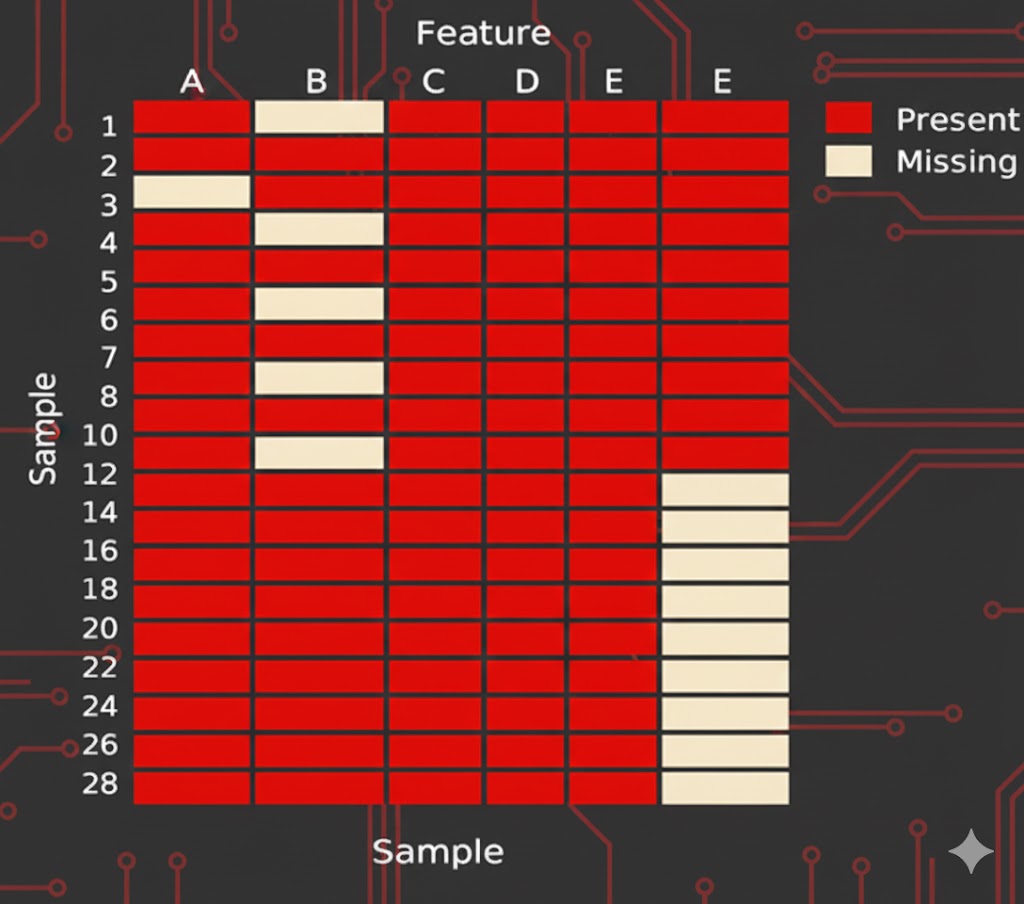
این تصویر یک مثال از نمایش گرافیکی دادههای گمشده است. رنگهای روشن بخشهای خالی (Missing) و رنگهای تیره مقادیر موجود را نشان میدهند. با چنین نمایشهایی میتوان الگوی گمشدگی، نقاط پرت و ستونهای دارای مشکل را سریع تشخیص داد.
استراتژیهای برخورد با دادههای گمشده
انتخاب روش مناسب به کاربرد و شرایط بستگی دارد. سه رویکرد اصلی وجود دارد:
الف) حذف (Deletion)
سادهترین راهکار، حذف کردن دادههای مشکلدار است.
۱. حذف سطر (Listwise Deletion):
- توضیح: کل سطر (Data Object یا نمونه) که حاوی حداقل یک مقدار گمشده است، حذف میشود.
- مشکل: اگر دادههای گمشده زیاد باشند (مثلاً ۱۰٪ دادهها)، حجم زیادی از دادههای آموزشی ارزشمند را از دست میدهیم.
۲. حذف ستون (Column Deletion):
- توضیح: کل ستون (Feature یا متغیر) که حاوی داده گمشده است، حذف میشود.
- چه زمانی؟ فقط زمانی که درصد بسیار زیادی (مثلاً بالای ۶۰-۷۰٪) از مقادیر یک ستون خاص گم شده باشد و آن ستون اهمیت حیاتی نداشته باشد.
ب) تخمین یا جایگزینی (Imputation / Estimation)
رویکرد هوشمندانهتر و ارجح، تلاش برای تخمین زدن و پر کردن مقادیر گمشده است.
۱. جایگزینی آماری ساده (Simple Imputation):
- توضیح: استفاده از یک مقدار آماری مرکزی برای پر کردن تمام جاهای خالی آن ستون.
- میانگین (Mean): برای دادههای عددی (مثلاً پر کردن «سن» گمشده با میانگین سنی بقیه).
- سناریو: پر کردن ۱۰ مورد گمشده در ستون «وزن بدن».
- روش: محاسبه میانگین وزن برای ۹۹۰ مورد موجود و جایگزینی آن میانگین در ۱۰ خانه خالی.
- میانه (Median): برای دادههای عددی که داده پرت (Outlier) دارند، بسیار بهتر از میانگین است.
- سناریو: پر کردن مقادیر گمشده در ستون «حقوق ماهانه» که دارای دادههای پرت (Outlier) زیادی است.
- روش: محاسبه میانه حقوق (که کمتر تحت تأثیر دادههای پرت قرار میگیرد) و جایگزینی آن.
- نما (Mode): برای دادههای دستهای (Nominal) (مثلاً پر کردن «رنگ چشم» گمشده با رایجترین رنگ).
- سناریو: پر کردن ۵ مورد گمشده در ستون «رنگ چشم» (داده دستهای).
- روش: انتخاب رایجترین رنگ چشم (مثلاً قهوهای) و جایگزینی آن در ۵ خانه خ
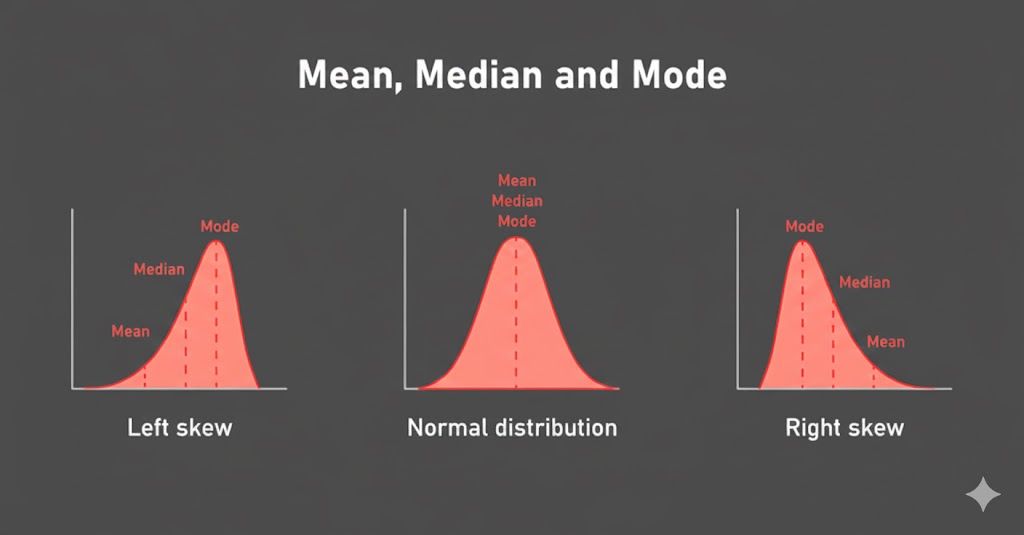
نمودار بالا نشان میدهد که چگونه یک داده پرت (Outlier) میتواند میانگین (Mean) را به شدت منحرف کند، در حالی که میانه (Median) ثابت و مقاوم باقی میماند.
۲. جایگزینی مبتنی بر مدل (Model-based Imputation):
- توضیح: استفاده از الگوریتمهای یادگیری ماشین برای پیشبینی مقدار گمشده.
- رگرسیون (Regression): متغیری که داده گمشده دارد را به عنوان “هدف (y)” و سایر متغیرها را به عنوان “ویژگی (X)” در نظر میگیریم. یک مدل رگرسیون روی دادههای کامل آموزش داده و سپس مقدار گمشده را پیشبینی میکنیم.
- مثال (سری زمانی): اگر داده آلودگی هوا در ساعت ۳:۰۰ بعد از ظهر گم شده، میتوان از مقادیر ساعات قبلی (۱۲، ۱، ۲) برای پیشبینی (Time Series Prediction) آن استفاده کرد.
مثال (فضایی): میتوان از اطلاعات ایستگاههای سنجش آلودگی در اطراف (ایستگاههای A و C) برای تخمین مقدار گمشده ایستگاه B استفاده کرد.
۳. جایگزینی مبتنی بر شباهت (Similarity-based):
- توضیح: پیدا کردن نمونههای (سطرهای) مشابه با نمونهای که داده گمشده دارد و استفاده از مقادیر آنها.
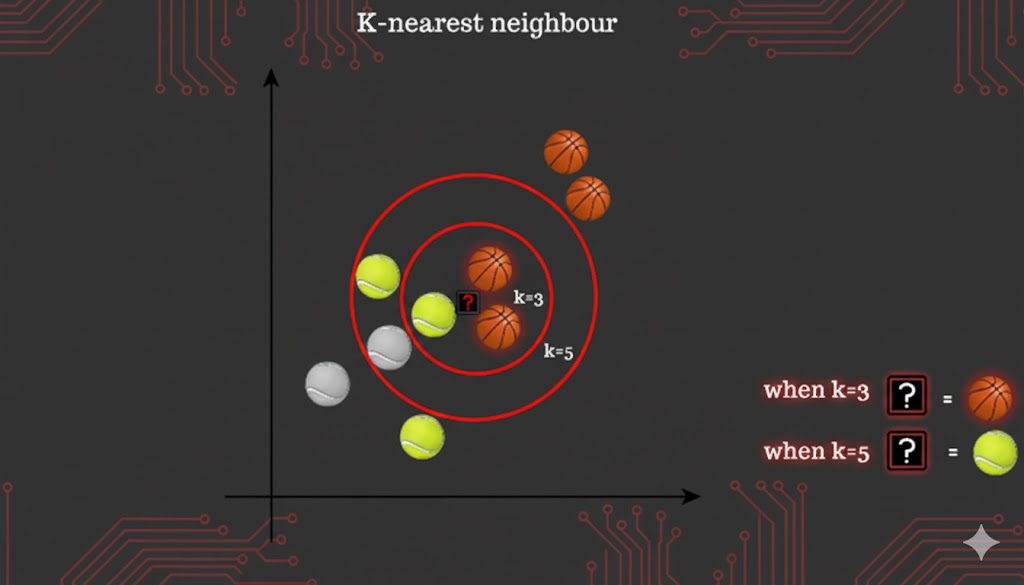
- مثال (KNN Imputation): k همسایه نزدیک (K-Nearest Neighbors) به سطر مورد نظر را (بر اساس سایر ویژگیها) پیدا میکنیم و مقدار گمشده را با میانگین (یا میانه) مقادیر آن ویژگی در بین k همسایه، پر میکنیم.
- سناریو: مقدار «قد» برای یک فرد (A) گمشده است.
- روش:
- 1. پیدا کردن ۳ فرد (k=3) دیگر در مجموعه داده که از نظر ویژگیهای موجود (مثلاً سن، وزن، جنسیت) بیشترین شباهت را به فرد A دارند.
- 2. محاسبه میانگین قد آن ۳ فرد مشابه.
- 3. پر کردن مقدار گمشده قد فرد A با این میانگین محاسبه شده.
ج) نادیده گرفتن (Ignoring)
در برخی موارد، میتوانیم مقدار گمشده را رها کنیم، به شرطی که الگوریتم ما توانایی مدیریت آن را داشته باشد.
- توضیح: در حین محاسبات، آن داده گمشده نادیده گرفته میشود.
- مثال: اگر هنگام محاسبه شباهت بین دو فرد، ویژگی «سن» برای یکی از آنها گمشده بود، میتوان این ویژگی را از محاسبه شباهت کنار گذاشت و شباهت را بر اساس باقی ویژگیها محاسبه کرد.
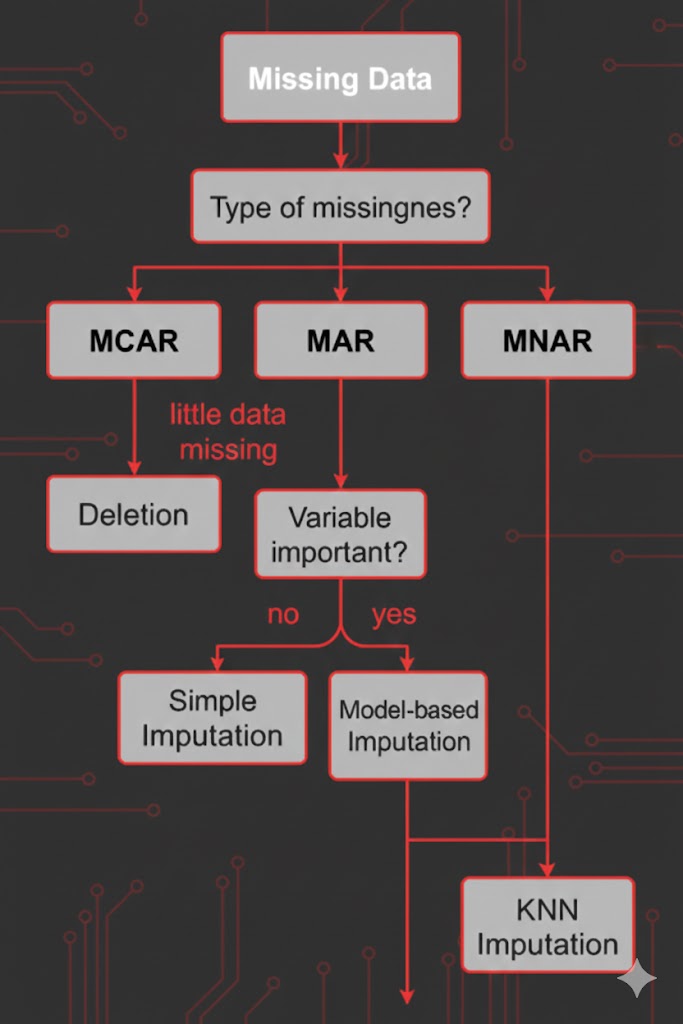
این فلوچارت یک راهنمای ساده برای انتخاب روش مناسب برخورد با دادههای گمشده است.با توجه به نوع گمشدگی (MCAR، MAR، MNAR)، مقدار دادههای خالی و اهمیت متغیر، تصمیم گرفته میشود که از حذف، جایگزینی ساده، روشهای مدلمحور یا KNN Imputation استفاده شود.هدف این نمودار کمک به انتخاب سریع و منطقی بهترین روش مدیریت Missing Data است.
د) روشهای تکمیلی
1- رفتار الگوریتمهای یادگیری ماشین با داده های گمشده
هریک از الگوریتمها رفتار متفاوتی دارند:
- درخت تصمیم (Decision Tree)
خودش میتواند با مقادیر گمشده کنار بیاید و آنها را در بهترین شاخه هدایت کند. - XGBoost ،LightGBM ،CatBoost
این مدلها بهطور داخلی مقدار گمشده را مدیریت میکنند و لازم نیست قبل از آن Impute کنیم. - KNN، SVM، Regression، Logistic Regression
این الگوریتمها نمیتوانند با داده گمشده کار کنند و قبل از استفاده باید Imputation انجام شود. - K-Means
وجود داده گمشده باعث خطا میشود؛ قبل از خوشهبندی باید ستون یا سطر کامل شود.
این بخش کمک میکند انتخاب کنیم که چه زمانی باید Imputation انجام دهیم و چه زمانی الگوریتم خودش مدیریت میکند.
چرا Imputation گاهی خطرناک است؟
هرچند پر کردن دادهها ضروری است، اما میتواند مشکلاتی ایجاد کند:
- کاهش واریانس دادهها
چون مقادیر مشابه به داده تزریق میشود. - ایجاد الگوهای مصنوعی
ممکن است روابطی شکل بگیرد که در داده واقعی وجود نداشته است. - افزایش Bias
مخصوصاً در روشهای ساده مثل میانگین یا میانه. - وابستگی شدید مدل به دادههای فرضی
داده پرشده همیشه واقعی نیست؛ مدل ممکن است فریب بخورد.
به همین دلیل، همیشه باید کیفیت Imputation کنترل و گزارش شود.
نکات مهم در برخورد با داده های گمشده
- قبل از هرکار، الگوی Missingness را بررسی کن.
- برای دادههای دارای Outlier از میانه استفاده کن، نه میانگین.
- اگر ستون بیش از ۷۰٪ گمشدگی دارد، حذف آن معمولاً بهتر است.
- از نشت اطلاعات (Data Leakage) جلوگیری کن: Imputation را جداگانه روی train و test انجام بده.
- برای دادههای دستهای، اگر تعداد دسته زیاد باشد، مود همیشه بهترین گزینه نیست.
- همیشه درصد و نحوهی مدیریت دادههای گمشده را مستند کن.
مثال حل شده
مطالعه موردی کامل: مدیریت دادههای گمشده در مجموعه داده مشتریان بانک
هدف: ساخت مدل پیشبینی ریسک وام
فرض کنید یک بانک اطلاعات ۵۰۰۰ مشتری را دارد و میخواهد یک مدل یادگیری ماشین برای پیشبینی اینکه آیا مشتریان وامهای خود را پس خواهند داد (ریسک پایین) یا خیر (ریسک بالا)، بسازد.
وضعیت اولیه دادهها:
| ستون (ویژگی) | نوع داده | درصد گمشده | اهمیت ویژگی برای مدل |
| سن (Age) | عددی | ۰٪ | حیاتی |
| میزان بدهی فعلی (Debt Amount) | عددی | ۶٪ | حیاتی |
| وضعیت تأهل (Marital Status) | دستهای | ۰٪ | متوسط |
| درآمد ماهانه (Monthly Income) | عددی | ۳۰٪ | بسیار حیاتی |
| نوع مسکن (Housing Type) | دستهای | ۱٪ | کم |
گام ۱: شناسایی الگوی گمشدگی (Missingness) و تحلیل اولیه
| ستون | درصد گمشدگی | الگو / علت فرضی | نوع گمشدگی | تصمیمگیری اولیه |
| نوع مسکن | ۱٪ | خطای تصادفی در ثبت توسط کارمند بانک | MCAR (Missing Completely At Random) | حذف سطر (Listwise Deletion) |
| میزان بدهی | ۶٪ | وابستگی به درآمد (افرادی با درآمد پایینتر، میزان بدهی خود را کمتر اعلام میکنند) | MAR (Missing At Random) | جایگزینی مبتنی بر مدل/شباهت (زیرا متغیر حیاتی است) |
| درآمد ماهانه | ۳۰٪ | وابستگی به مقدار خود درآمد (افراد با درآمد بالا یا پایینتر تمایل بیشتری به وارد نکردن دارند) | MNAR (Missing Not At Random) | جایگزینی مبتنی بر مدل/شباهت (زیرا بسیار حیاتی و پیچیدهترین حالت است) |
گام ۲: اجرای استراتژیهای برخورد و جایگزینی (Imputation)
۱. حذف دادهها (Deletion)
- نوع مسکن (۱٪ گمشدگی، MCAR): از آنجایی که گمشدگی کاملاً تصادفی است و بسیار کم است، سطرهای مربوط به این متغیر حذف میشوند. (حذف ۵۰ سطر از ۵۰۰۰ سطر)
۲. جایگزینی پیشرفته (Imputation)
متغیرهای حیاتی (درآمد و بدهی) که MAR یا MNAR هستند، باید با روشهای دقیق جایگزین شوند تا ساختار دادهها حفظ شود.
- روش انتخابی:. KNN Imputation (K-Nearest Neighbors)
- توجیه: این روش برای MAR و MNAR مقاومتر از میانگین است و از سایر ویژگیها (سن، وضعیت تأهل، فشار خون) برای پیدا کردن مشتریان مشابه و تخمین مقدار گمشده استفاده میکند.
- اجرای Best Practice: قبل از اجرای KNN Imputation، دادهها به Train و Test تقسیم میشوند و Imputer جداگانه روی هر مجموعه اعمال میگردد تا از نشت اطلاعات (Data Leakage) جلوگیری شود.
۳. جایگزینیهای جایگزین (اگر متغیرها گمشده زیادی داشتند)
فرض کنید وضعیت تأهل (داده دستهای) ۵۰٪ گمشده داشت:
| متغیر (مثال) | نوع داده | روش پیشنهادی | توجیه |
| وضعیت تأهل | دستهای | نما (Mode) یا ایجاد دسته جدید | اگر درصد گمشدگی بالا نباشد، نما (رایجترین مقدار) سادهترین است. اگر از نوع MNAR باشد، میتوان یک دسته جدید به نام “نامشخص” ایجاد کرد. |
گام ۳: اعتبارسنجی و نتیجهگیری نهایی
| مرحله | عمل انجام شده | توجیه نهایی |
| حذفهای انجامشده | حذف ۱٪ از سطرها (به دلیل گمشده بودن نوع مسکن) | چون MCAR بود، بایاس ایجاد نشد و حجم داده قابل قبولی حفظ شد. |
| اجرای Imputation | KNN Imputation برای درآمد (MNAR) و بدهی (MAR) | جلوگیری از کاهش واریانس و حفظ ساختار دادهها (برخلاف روش میانگین). |
| آمادگی مدل | دادههای نهایی برای اجرای الگوریتمهای حساس به Missing Data (مانند رگرسیون لجستیک) آماده شدند. | اگر از الگوریتم مقاوم (مانند CatBoost) استفاده میشد، ممکن بود از Imputation چشمپوشی کنیم. |
| مستندسازی | همه مراحل، از تشخیص MNAR برای درآمد تا انتخاب KNN و جلوگیری از Data Leakage، مستندسازی شد. | تضمین شفافیت و قابلیت بازتولید نتایج. |
با اجرای این سه گام، مجموعه داده کاملاً پاکسازی شده و با کمترین بایاس ممکن، برای آموزش مدل پیشبینی ریسک وام آماده است.
خلاصه روش ها و مزایا و معایب
| روش برخورد | مزایا | معایب |
| حذف سطر | ساده، سریع. | از دست دادن دادههای ارزشمند، احتمال ایجاد بایاس (Bias). |
| حذف ستون | ساده. | از دست دادن اطلاعات یک ویژگی به طور کامل. |
| جایگزینی ساده (Mean/Median/Mode) | سریع، قابل فهم، حفظ اندازه داده. | واریانس دادهها را کم میکند، روابط بین متغیرها را نادیده میگیرد. |
| جایگزینی مبتنی بر مدل/شباهت | دقیقترین روش، حفظ ساختار و روابط دادهها. | پیچیدگی محاسباتی، زمانبر بودن. |
| نادیده گرفتن | ساده، نیازی به تغییر داده نیست. | همه الگوریتمها این قابلیت را ندارند. |
جمع بندی
دادههای گمشده یکی از اساسیترین چالشهای مرحلهی پیشپردازش داده هستند و تقریباً در همهی مجموعهدادههای واقعی دیده میشوند. کیفیت برخورد با دادههای گمشده میتواند دقت تحلیل، اعتبار نتایج آماری و عملکرد نهایی مدلهای یادگیری ماشین را بهشدت تحت تأثیر قرار دهد.
برای مدیریت درست دادههای گمشده باید:
- نوع گمشَدگی (MCAR، MAR، MNAR) را شناسایی کنیم
- الگوی Missingness را با روشهای گرافیکی بررسی کنیم
- روش مناسب را بر اساس نوع داده، مقدار گمشده و اهمیت ویژگی انتخاب کنیم
- بدانیم هر الگوریتم یادگیری ماشین چه رفتاری با دادهی گمشده دارد
- از خطرات Imputation مثل کاهش واریانس یا ایجاد الگوهای مصنوعی آگاه باشیم
- در نهایت با رعایت Best Practices مثل جلوگیری از Data Leakage و انتخاب روشهای مقاوم، کیفیت داده را بالا ببریم


