- فصل اول این کتاب شامل مباحث زیر است:
- تعاریف سطح بالا از مفاهیم اساسی
- جدول زمانی توسعه یادگیری ماشین
- عوامل کلیدی پشت محبوبیت روزافزون و پتانسیل آینده یادگیری عمیق
مقدمه
در چند سال گذشته، هوش مصنوعی (AI) موضوع تبلیغات رسانهای شدیدی بوده است. یادگیری ماشین، یادگیری عمیق و هوش مصنوعی در مقالات بیشماری، اغلب خارج از نشریات با رویکرد فناوری، مطرح میشوند. به ما آیندهای از چتباتهای هوشمند، خودروهای خودران و دستیاران مجازی وعده داده شده است—آیندهای که گاهی در نور تیره و تار و گاهی به عنوان آرمانشهر به تصویر کشیده میشود، جایی که مشاغل انسانی کمیاب خواهند شد و بیشتر فعالیتهای اقتصادی توسط رباتها یا عاملهای هوش مصنوعی انجام خواهد شد. برای یک متخصص فعلی یا آینده یادگیری ماشین، مهم است که بتواند سیگنال را در میان نویز تشخیص دهد، تا بتواند تحولات تغییردهنده جهان را از بیانیههای مطبوعاتی بیش از حد تبلیغ شده تشخیص دهد. آینده ما در خطر است و این آیندهای است که شما نقش فعالی در آن دارید: پس از خواندن این کتاب، شما یکی از کسانی خواهید بود که آن سیستمهای هوش مصنوعی را توسعه میدهند. بنابراین بیایید به این سؤالات بپردازیم: یادگیری عمیق تاکنون به چه دستاوردهایی رسیده است؟ چقدر اهمیت دارد؟ بعد به کجا میرویم؟ آیا باید این تبلیغات را باور کنید؟
این فصل زمینه اساسی در مورد هوش مصنوعی، یادگیری ماشین و یادگیری عمیق را فراهم میکند.
هوش مصنوعی، یادگیری ماشین و یادگیری عمیق
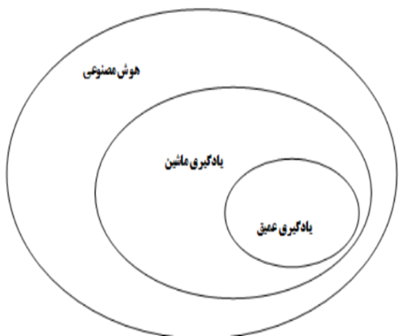
ابتدا باید به طور واضح تعریف کنیم که وقتی از هوش مصنوعی صحبت میکنیم، منظورمان چیست. هوش مصنوعی، یادگیری ماشین و یادگیری عمیق (شکل ۱.۱ را ببینید) چه هستند؟ چگونه با یکدیگر ارتباط دارند؟
هوش مصنوعی
هوش مصنوعی در دهه ۱۹۵۰ متولد شد، زمانی که معدودی از پیشگامان حوزه نوپای علوم کامپیوتر شروع به پرسیدن این سؤال کردند که آیا میتوان رایانهها را به “فکر کردن” واداشت—سؤالی که پیامدهای آن را هنوز هم امروز بررسی میکنیم.
در حالی که بسیاری از ایدههای اساسی در سالها و حتی دهههای قبل در حال شکلگیری بودند، “هوش مصنوعی” سرانجام در سال ۱۹۵۶ به عنوان یک حوزه تحقیقاتی متبلور شد، زمانی که جان مک کارتی، که در آن زمان استادیار جوان ریاضیات در کالج دارتموث بود، یک کارگاه تابستانی را با پیشنهاد زیر سازماندهی کرد:
مطالعه بر اساس این فرضیه پیش خواهد رفت که هر جنبهای از یادگیری یا هر ویژگی دیگر هوش، در اصل میتواند به قدری دقیق توصیف شود که یک ماشین بتواند آن را شبیهسازی کند. تلاشی برای یافتن چگونگی استفاده ماشینها از زبان، شکلگیری انتزاعات و مفاهیم، حل انواع مشکلاتی که اکنون مختص انسانها است و بهبود خودشان صورت خواهد گرفت. ما فکر میکنیم که اگر گروهی از دانشمندان با دقت انتخاب شده برای یک تابستان با هم روی آن کار کنند، میتوان پیشرفت قابل توجهی در یک یا چند مورد از این مشکلات به دست آورد.
در پایان تابستان، کارگاه بدون حل کامل معمایی که برای بررسی آن تعیین شده بود، به پایان رسید. با این وجود، بسیاری از افرادی که بعدها به پیشگامان این حوزه تبدیل شدند، در آن شرکت کردند و یک انقلاب فکری را به راه انداخت که تا به امروز ادامه دارد.
به طور خلاصه، هوش مصنوعی را میتوان به عنوان تلاش برای خودکارسازی وظایف فکری که معمولاً توسط انسانها انجام میشود، توصیف کرد. به این ترتیب، هوش مصنوعی یک حوزه کلی است که یادگیری ماشین و یادگیری عمیق را در بر میگیرد، اما همچنین شامل بسیاری از رویکردهای دیگر است که ممکن است هیچ یادگیری در آنها دخیل نباشد. در نظر بگیرید که تا دهه ۱۹۸۰، بیشتر کتابهای درسی هوش مصنوعی اصلاً به “یادگیری” اشاره نمیکردند.
برای مثال، برنامههای اولیه شطرنج فقط شامل قوانین سختکد شدهای بودند که توسط برنامهنویسان ساخته شده بودند و به عنوان یادگیری ماشین واجد شرایط نبودند. در واقع، برای مدت نسبتاً طولانی، بیشتر کارشناسان معتقد بودند که هوش مصنوعی در سطح انسان میتواند با داشتن برنامهنویسانی که مجموعه کافی بزرگی از قوانین صریح برای دستکاری دانش ذخیره شده در پایگاههای داده صریح را دستی میسازند، به دست آید. این رویکرد به عنوان هوش مصنوعی نمادین شناخته میشود. این پارادایم غالب در هوش مصنوعی از دهه ۱۹۵۰ تا اواخر دهه ۱۹۸۰ بود و در طول رونق سیستمهای خبره در دهه ۱۹۸۰ به اوج محبوبیت خود رسید.
اگرچه هوش مصنوعی نمادین برای حل مسائل منطقی و خوشتعریف مانند بازی شطرنج مناسب بود، اما مشخص شد که یافتن قوانین صریح برای حل مسائل پیچیدهتر و مبهمتر مانند طبقهبندی تصویر، تشخیص گفتار یا ترجمه زبان طبیعی غیرممکن است. رویکرد جدیدی برای جایگزینی هوش مصنوعی نمادین ظهور کرد: یادگیری ماشین.
یادگیری ماشین
در انگلستان ویکتوریا، لیدی آدا لاولیس دوست و همکار چارلز بابیج، مخترع موتور تحلیلی: اولین رایانه مکانیکی همهمنظوره شناخته شده بود. اگرچه موتور تحلیلی رویایی و بسیار جلوتر از زمان خود بود، اما زمانی که در دهههای ۱۸۳۰ و ۱۸۴۰ طراحی شد، به عنوان یک رایانه همهمنظوره در نظر گرفته نشده بود، زیرا مفهوم محاسبات همهمنظوره هنوز اختراع نشده بود. این صرفاً به عنوان راهی برای استفاده از عملیات مکانیکی برای خودکارسازی محاسبات معینی از حوزه تحلیل ریاضی در نظر گرفته شده بود—از این رو نام موتور تحلیلی. به این ترتیب، این موتور از نظر فکری نواده تلاشهای قبلی برای رمزگذاری عملیات ریاضی در قالب چرخ دنده، مانند پاسکالین یا ماشین حساب پلهای لایبنیتس، نسخه اصلاح شده پاسکالین بود. پاسکالین که توسط بلیز پاسکال در سال ۱۶۴۲ (در سن ۱۹ سالگی!) طراحی شد، اولین ماشین حساب مکانیکی جهان بود—میتوانست ارقام را جمع، تفریق، ضرب یا حتی تقسیم کند.
در سال ۱۸۴۳، آدا لاولیس در مورد اختراع موتور تحلیلی اظهار داشت:
موتور تحلیلی به هیچ وجه ادعای ایجاد چیزی را ندارد. این موتور میتواند هر آنچه را که ما میدانیم چگونه به آن دستور دهیم انجام دهد… وظیفه آن کمک به ما در دسترس قرار دادن چیزهایی است که قبلاً با آنها آشنا هستیم.
حتی با ۱۷۸ سال دیدگاه تاریخی، مشاهده لیدی لاولیس همچنان تکان دهنده است. آیا یک رایانه همهمنظوره میتواند چیزی را “ایجاد” کند، یا همیشه محکوم به اجرای بیروح فرآیندهایی خواهد بود که ما انسانها کاملاً آنها را درک میکنیم؟ آیا هرگز میتواند قادر به هیچ فکر اصیلی باشد؟ آیا میتواند از تجربه بیاموزد؟ آیا میتواند خلاقیت نشان دهد؟
اظهار نظر او بعدها توسط پیشگام هوش مصنوعی، آلن تورینگ، به عنوان “اعتراض لیدی لاولیس” در مقاله مهم خود در سال ۱۹۵۰ با عنوان “ماشینهای محاسباتی و هوش” نقل شد، که آزمون تورینگ و همچنین مفاهیم کلیدی که بعدها هوش مصنوعی را شکل دادند، معرفی کرد. تورینگ بر این عقیده بود—که در آن زمان بسیار تحریکآمیز بود—که رایانهها در اصل میتوانند تمام جنبههای هوش انسانی را شبیهسازی کنند.
۱ آ.م. تورینگ، «ماشینهای محاسباتی و هوش»، Mind 59، شماره ۲۳۶ (۱۹۵۰): ۴۳۳–۴۶۰.1
۲ اگرچه آزمون تورینگ گاهی به عنوان یک آزمون واقعی—هدفی که حوزه هوش مصنوعی باید برای رسیدن به آن تعیین کند—تفسیر شده است، اما تورینگ صرفاً آن را به عنوان یک ابزار مفهومی در یک بحث فلسفی در مورد ماهیت شناخت در نظر گرفته بود.
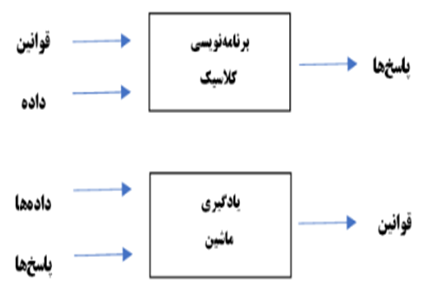
روش معمول برای وادار کردن یک رایانه به انجام کار مفید این است که یک برنامهنویس انسانی قوانینی را بنویسد—یک برنامه رایانهای—که باید برای تبدیل دادههای ورودی به پاسخهای مناسب دنبال شود، درست مانند لیدی لاولیس که دستورالعملهای گام به گام را برای موتور تحلیلی مینوشت تا آنها را اجرا کند. یادگیری ماشین این روند را معکوس میکند: ماشین به دادههای ورودی و پاسخهای مربوطه نگاه میکند و تشخیص میدهد که قوانین باید چه باشند (شکل ۱.۲ را ببینید). یک سیستم یادگیری ماشین آموزش داده میشود نه اینکه به طور صریح برنامهریزی شود. به آن مثالهای زیادی مربوط به یک وظیفه ارائه میشود و ساختار آماری را در این مثالها پیدا میکند که در نهایت به سیستم اجازه میدهد تا قوانینی برای خودکارسازی وظیفه ارائه دهد. برای مثال، اگر میخواستید وظیفه برچسبگذاری عکسهای تعطیلات خود را خودکار کنید، میتوانید مثالهای زیادی از عکسهایی که قبلاً توسط انسانها برچسبگذاری شدهاند را به یک سیستم یادگیری ماشین ارائه دهید و سیستم قوانین آماری را برای مرتبط کردن عکسهای خاص با برچسبهای خاص یاد میگیرد.
اگرچه یادگیری ماشین تنها در دهه ۱۹۹۰ شکوفا شد، اما به سرعت به محبوبترین و موفقترین زیرشاخه هوش مصنوعی تبدیل شده است، روندی که ناشی از در دسترس بودن سختافزار سریعتر و مجموعهدادههای بزرگتر است. یادگیری ماشین با آمار ریاضی مرتبط است، اما از جهات مهمی با آمار تفاوت دارد، به همان معنا که پزشکی با شیمی مرتبط است اما نمیتوان آن را به شیمی تقلیل داد، زیرا پزشکی با سیستمهای متمایز خود با ویژگیهای متمایز خود سروکار دارد. برخلاف آمار، یادگیری ماشین تمایل دارد با مجموعهدادههای بزرگ و پیچیده (مانند مجموعهدادهای از میلیونها تصویر که هر کدام از دهها هزار پیکسل تشکیل شدهاند) سروکار داشته باشد که برای آنها تحلیل آماری کلاسیک مانند تحلیل بیزی غیرعملی خواهد بود. در نتیجه، یادگیری ماشین، و به ویژه یادگیری عمیق، در مقایسه با آن نظریه ریاضی نسبتاً کمی از خود نشان میدهد—شاید خیلی کم—و اساساً یک رشته مهندسی است. برخلاف فیزیک نظری یا ریاضیات، یادگیری ماشین یک حوزه بسیار عملی است که ناشی از یافتههای تجربی است و عمیقاً به پیشرفتهای نرمافزار و سختافزار متکی است.
یادگیری قوانین و بازنماییها از دادهها
برای تعریف یادگیری عمیق و درک تفاوت بین یادگیری عمیق و سایر رویکردهای یادگیری ماشین، ابتدا به درکی از عملکرد الگوریتمهای یادگیری ماشین نیاز داریم. ما به تازگی بیان کردیم که یادگیری ماشین قوانینی را برای اجرای یک وظیفه پردازش داده، با توجه به مثالهایی از آنچه انتظار میرود، کشف میکند. بنابراین، برای انجام یادگیری ماشین، به سه چیز نیاز داریم:
- نقاط داده ورودی— برای مثال، اگر وظیفه تشخیص گفتار باشد، این نقاط داده میتوانند فایلهای صوتی افراد در حال صحبت باشند. اگر وظیفه برچسبگذاری تصویر باشد، میتوانند تصاویر باشند.
- نمونههایی از خروجی مورد انتظار— در یک وظیفه تشخیص گفتار، اینها میتوانند رونوشتهای ایجاد شده توسط انسان از فایلهای صوتی باشند. در یک وظیفه تصویر، خروجیهای مورد انتظار میتوانند برچسبهایی مانند “سگ”، “گربه” و غیره باشند.
- راهی برای اندازهگیری اینکه آیا الگوریتم کار خوبی انجام میدهد— این برای تعیین فاصله بین خروجی فعلی الگوریتم و خروجی مورد انتظار آن ضروری است. این اندازهگیری به عنوان یک سیگنال بازخورد برای تنظیم نحوه عملکرد الگوریتم استفاده میشود. این مرحله تنظیم همان چیزی است که ما آن را یادگیری مینامیم.
یک مدل یادگیری ماشین دادههای ورودی خود را به خروجیهای معنادار تبدیل میکند، فرآیندی که از طریق قرار گرفتن در معرض مثالهای شناخته شده از ورودیها و خروجیها “یاد گرفته” میشود. بنابراین، مشکل اصلی در یادگیری ماشین و یادگیری عمیق، تبدیل معنادار دادهها است: به عبارت دیگر، یادگیری بازنماییهای مفید از دادههای ورودی موجود—بازنماییهایی که ما را به خروجی مورد انتظار نزدیکتر میکنند.
قبل از اینکه جلوتر برویم: بازنمایی چیست؟ در هسته خود، این یک روش متفاوت برای نگاه کردن به دادهها است—برای نمایش یا رمزگذاری دادهها. برای مثال، یک تصویر رنگی میتواند در قالب RGB (قرمز-سبز-آبی) یا در قالب HSV (مقدار-اشباع-رنگ) رمزگذاری شود: اینها دو بازنمایی متفاوت از یک داده یکسان هستند. برخی از وظایفی که ممکن است با یک بازنمایی دشوار باشند، میتوانند با بازنمایی دیگر آسان شوند. برای مثال، وظیفه “انتخاب تمام پیکسلهای قرمز در تصویر” در قالب RGB سادهتر است، در حالی که “کم کردن اشباع تصویر” در قالب HSV سادهتر است. مدلهای یادگیری ماشین همگی در مورد یافتن بازنماییهای مناسب برای دادههای ورودی خود هستند—تبدیلاتی از دادهها که آنها را برای وظیفه مورد نظر مناسبتر میکند.
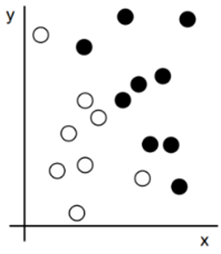
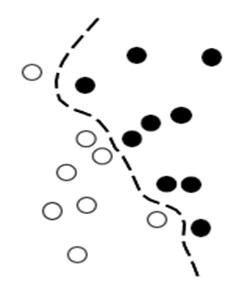
بیایید این را ملموس کنیم. یک محور x، یک محور y و چند نقطه را در نظر بگیرید که با مختصاتشان در سیستم (x, y) نشان داده شدهاند، همانطور که در شکل ۱.۳ نشان داده شده است.
همانطور که میبینید، چند نقطه سفید و چند نقطه سیاه داریم. فرض کنید میخواهیم الگوریتمی توسعه دهیم که بتواند مختصات (x, y) یک نقطه را بگیرد و خروجی دهد که آیا آن نقطه احتمالاً سیاه است یا سفید. در این حالت،
- ورودیها مختصات نقاط ما هستند.
- خروجیهای مورد انتظار رنگ نقاط ما هستند.
- راهی برای اندازهگیری اینکه آیا الگوریتم ما کار خوبی انجام میدهد میتواند، برای مثال، درصد نقاطی باشد که به درستی طبقهبندی میشوند.
آنچه در اینجا به آن نیاز داریم، یک بازنمایی جدید از دادههای ما است که نقاط سفید را از نقاط سیاه به طور واضح جدا کند. یکی از تبدیلاتی که میتوانیم از آن استفاده کنیم، در میان بسیاری از احتمالات دیگر، تغییر مختصات است که در شکل ۱.۴ نشان داده شده است.
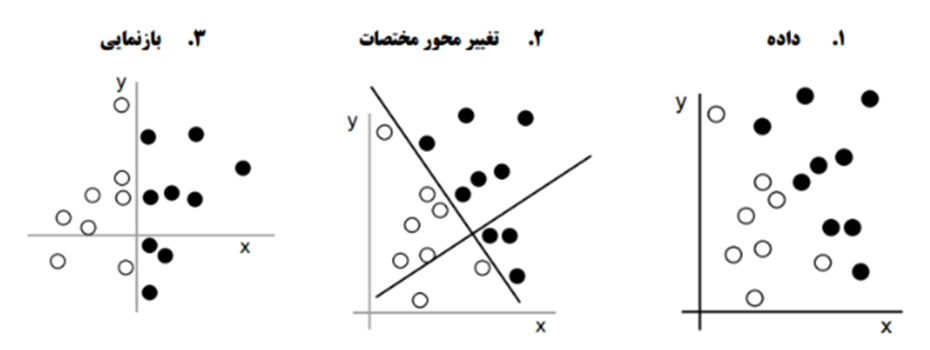
در این سیستم مختصات جدید، میتوان گفت که مختصات نقاط ما یک بازنمایی جدید از دادههای ما هستند. و بازنمایی خوبی است! با این بازنمایی، مسئله طبقهبندی سیاه/سفید را میتوان به عنوان یک قانون ساده بیان کرد: “نقاط سیاه نقاطی هستند که x > 0” یا “نقاط سفید نقاطی هستند که x < 0”. این بازنمایی جدید، همراه با این قانون ساده، به طور مرتب مسئله طبقهبندی را حل میکند.
در این مورد، ما تغییر مختصات را به صورت دستی تعریف کردیم: از هوش انسانی خود برای ارائه یک بازنمایی مناسب از دادهها استفاده کردیم. این برای چنین مسئله بسیار سادهای خوب است، اما آیا میتوانید همین کار را انجام دهید اگر وظیفه طبقهبندی تصاویر ارقام دستنویس بود؟ آیا میتوانید تبدیلهای صریح و قابل اجرای رایانهای برای تصویر بنویسید که تفاوت بین ۶ و ۸، بین ۱ و ۷ را در انواع مختلف دستخط روشن کند؟
تا حدودی این امکان وجود دارد. قوانینی مبتنی بر بازنمایی ارقام مانند “تعداد حلقههای بسته” یا هیستوگرامهای پیکسلی عمودی و افقی میتوانند کار مناسبی در تشخیص ارقام دستنویس انجام دهند. اما یافتن چنین بازنماییهای مفیدی به صورت دستی کار دشواری است و همانطور که میتوانید تصور کنید، سیستم مبتنی بر قانون حاصل شکننده است—نگهداری از آن یک کابوس است. هر بار که با یک مثال جدید از دستخط مواجه میشوید که قوانین با دقت اندیشیده شده شما را نقض میکند، باید تبدیلهای داده و قوانین جدیدی اضافه کنید، در حالی که تعامل آنها با هر قانون قبلی را در نظر میگیرید.
احتمالاً فکر میکنید، اگر این فرآیند آنقدر دردناک است، آیا میتوانیم آن را خودکار کنیم؟ چه میشود اگر به طور سیستماتیک به دنبال مجموعههای مختلفی از بازنماییهای داده و قوانینی مبتنی بر آنها بگردیم که به طور خودکار ایجاد شدهاند، و با استفاده از درصد ارقامی که به درستی در یک مجموعه داده توسعه طبقهبندی میشوند به عنوان بازخورد، موارد خوب را شناسایی کنیم؟ در این صورت ما در حال انجام یادگیری ماشین خواهیم بود. یادگیری، در زمینه یادگیری ماشین، یک فرآیند جستجوی خودکار برای تبدیلهای داده را توصیف میکند که بازنماییهای مفیدی از برخی دادهها ایجاد میکنند، که توسط یک سیگنال بازخورد هدایت میشوند—بازنماییهایی که برای قوانین سادهتری که وظیفه مورد نظر را حل میکنند، مناسب هستند.
این تبدیلها میتوانند تغییرات مختصات باشند (مانند مثال طبقهبندی مختصات دوبعدی ما)، یا گرفتن هیستوگرام پیکسلها و شمارش حلقهها (مانند مثال طبقهبندی ارقام ما)، اما همچنین میتوانند نگاشت (بازنمایی،نمایش)های خطی، انتقالها، عملیات غیرخطی (مانند “انتخاب تمام نقاطی که x > 0 هستند”) و غیره باشند.
الگوریتمهای یادگیری ماشین معمولاً در یافتن این تبدیلها خلاق نیستند؛ آنها صرفاً در یک مجموعه از پیش تعریف شده از عملیات، که فضای فرضیه نامیده میشود، جستجو میکنند. برای مثال، فضای تمام تغییرات مختصات ممکن، فضای فرضیه ما در مثال طبقهبندی مختصات دوبعدی خواهد بود.
بنابراین، این خلاصه یادگیری ماشین است: جستجو برای بازنماییها و قوانین مفید بر روی برخی دادههای ورودی، در یک فضای از پیش تعریف شده از احتمالات، با استفاده از راهنمایی از یک سیگنال بازخورد. این ایده ساده امکان حل طیف بسیار گستردهای از وظایف فکری، از تشخیص گفتار گرفته تا رانندگی خودکار را فراهم میکند. اکنون که درک کردهاید منظور ما از یادگیری چیست، بیایید نگاهی به آنچه یادگیری عمیق را خاص میکند بیندازیم.
“عمیق یا عمق” در “یادگیری عمیق”
یادگیری عمیق یک زیرشاخه خاص از یادگیری ماشین است: رویکردی جدید به یادگیری بازنماییها از دادهها که بر یادگیری لایههای متوالی از بازنماییهای به طور فزاینده معنادار تأکید دارد. “عمیق یا عمق” در “یادگیری عمیق” اشارهای به هیچ نوع درک عمیقتری که توسط این رویکرد به دست میآید نیست؛ بلکه، مخفف این ایده از لایههای متوالی بازنماییها است. تعداد لایههایی که در یک مدل از دادهها نقش دارند، عمق مدل نامیده میشود. نامهای مناسب دیگر برای این حوزه میتوانست یادگیری بازنماییهای لایهای یا یادگیری بازنماییهای سلسله مراتبی باشد. یادگیری عمیق مدرن اغلب شامل دهها یا حتی صدها لایه متوالی از بازنماییها است و همه آنها به طور خودکار از طریق قرار گرفتن در معرض دادههای آموزشی یاد گرفته میشوند. در همین حال، سایر رویکردهای یادگیری ماشین تمایل دارند بر یادگیری تنها یک یا دو لایه از بازنماییهای دادهها تمرکز کنند (مثلاً گرفتن هیستوگرام پیکسل و سپس اعمال یک قانون طبقهبندی)؛ از این رو، گاهی اوقات به آنها یادگیری سطحی گفته میشود.
در یادگیری عمیق، این بازنماییهای لایهای از طریق مدلهایی به نام شبکههای عصبی یاد گرفته میشوند که در لایههای واقعی که روی هم چیده شدهاند، ساختار یافتهاند. اصطلاح “شبکه عصبی” به عصبشناسی اشاره دارد، اما اگرچه برخی از مفاهیم اصلی در یادگیری عمیق تا حدودی با الهام گرفتن از درک ما از مغز (به ویژه، قشر بینایی) توسعه یافتهاند، مدلهای یادگیری عمیق مدلهای مغز نیستند. هیچ مدرکی وجود ندارد که نشان دهد مغز چیزی شبیه به مکانیسمهای یادگیری مورد استفاده در مدلهای یادگیری عمیق مدرن را پیادهسازی میکند. ممکن است در مقالات علمی-تخیلی با این ادعا مواجه شوید که یادگیری عمیق مانند مغز کار میکند یا از مغز الگوبرداری شده است، اما اینطور نیست. برای تازهواردان این حوزه، فکر کردن به اینکه یادگیری عمیق به هر نحوی با عصبشناسی مرتبط است، گیجکننده و مضر خواهد بود؛ شما به آن پوشش رمز و راز “دقیقاً مانند ذهن ما” نیاز ندارید و بهتر است هر آنچه را که ممکن است در مورد پیوندهای فرضی بین یادگیری عمیق و زیستشناسی خواندهاید، فراموش کنید. برای اهداف ما، یادگیری عمیق یک چارچوب ریاضی برای یادگیری بازنماییها از دادهها است.
بازنماییهایی که توسط یک الگوریتم یادگیری عمیق یاد گرفته میشوند چگونه به نظر میرسند؟ بیایید بررسی کنیم که چگونه یک شبکه چند لایه عمیق (شکل ۱.۵ را ببینید) یک تصویر از یک رقم را برای تشخیص اینکه چه رقمی است، تبدیل میکند.
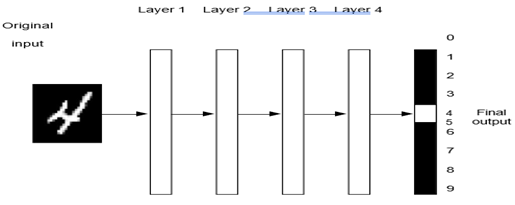
همانطور که در شکل ۱.۶ میبینید، شبکه تصویر رقم را به بازنماییهایی تبدیل میکند که به طور فزایندهای با تصویر اصلی متفاوت هستند و به طور فزایندهای در مورد نتیجه نهایی اطلاعات میدهند. میتوانید یک شبکه عمیق را به عنوان یک فرآیند تقطیر اطلاعات چند مرحلهای در نظر بگیرید، جایی که اطلاعات از فیلترهای متوالی عبور میکنند و به طور فزایندهای خالصتر (یعنی برای یک کار خاص مفیدتر) بیرون میآیند.
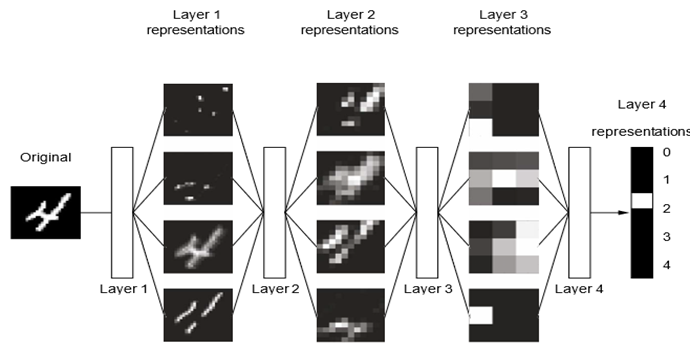
بنابراین، از نظر فنی، یادگیری عمیق یک روش چند مرحلهای برای یادگیری بازنماییهای داده است. این یک ایده ساده است—اما، همانطور که معلوم شده است، مکانیسمهای بسیار ساده، در مقیاس کافی، میتوانند در نهایت شبیه جادو به نظر برسند.
درک نحوه عملکرد یادگیری عمیق در سه شکل
در این مرحله میدانید که یادگیری ماشین درباره نگاشت ورودیها (مانند تصاویر) به اهداف (مانند برچسب “گربه”) است که با مشاهده مثالهای زیادی از ورودی و هدف انجام میشود. همچنین میدانید که شبکههای عصبی عمیق این نگاشت ورودی به هدف را از طریق یک دنباله عمیق از تبدیلهای داده ساده (لایهها) انجام میدهند و این تبدیلهای داده با قرار گرفتن در معرض مثالها یاد گرفته میشوند. اکنون بیایید به طور مشخص نگاهی به چگونگی این یادگیری بیندازیم.
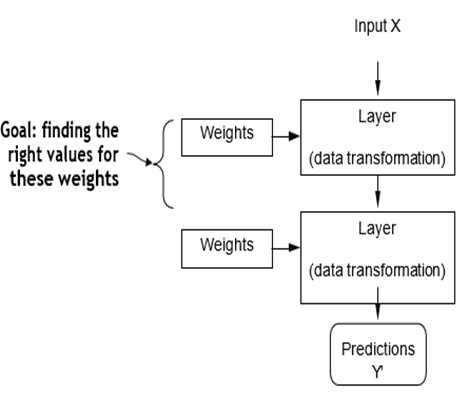
مشخصات آنچه یک لایه با دادههای ورودی خود انجام میدهد در وزنهای لایه ذخیره میشود که در اصل مجموعهای از اعداد هستند. از نظر فنی، میگوییم که تبدیل پیادهسازی شده توسط یک لایه توسط وزنهای آن پارامتریزه میشود (شکل ۱.۷ را ببینید). (وزنها گاهی اوقات پارامترهای یک لایه نیز نامیده میشوند.) در این زمینه، یادگیری به معنای یافتن مجموعهای از مقادیر برای وزنهای تمام لایههای یک شبکه است، به طوری که شبکه به درستی ورودیهای مثال را به اهداف مرتبط با آنها نگاشت کند. اما نکته اینجاست: یک شبکه عصبی عمیق میتواند شامل دهها میلیون پارامتر باشد. یافتن مقادیر درست برای همه آنها ممکن است یک کار دشوار به نظر برسد، به خصوص با توجه به اینکه تغییر مقدار یک پارامتر بر رفتار همه پارامترهای دیگر تأثیر میگذارد!
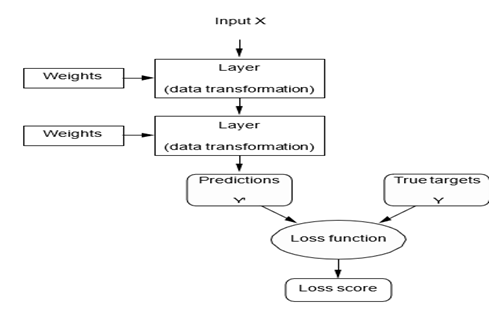
برای کنترل چیزی، ابتدا باید بتوانید آن را مشاهده کنید. برای کنترل خروجی یک شبکه عصبی، باید بتوانید اندازهگیری کنید که این خروجی چقدر از آنچه انتظار داشتید دور است. این وظیفه تابع زیان شبکه است که گاهی اوقات تابع هدف یا تابع هزینه نیز نامیده میشود. تابع زیان، پیشبینیهای شبکه و هدف واقعی (آنچه میخواستید شبکه خروجی دهد) را میگیرد و یک امتیاز فاصله محاسبه میکند که نشان میدهد شبکه در این مثال خاص چقدر خوب عمل کرده است (شکل ۱.۸ را ببینید).
ترفند اساسی در یادگیری عمیق استفاده از این امتیاز به عنوان یک سیگنال بازخورد برای تنظیم جزئی مقدار وزنها در جهتی است که امتیاز زیان را برای مثال فعلی کاهش دهد (شکل ۱.۹ را ببینید). این تنظیم وظیفه بهینهساز است که الگوریتمی به نام پسانتشار را پیادهسازی میکند: الگوریتم اصلی در یادگیری عمیق. فصل بعد نحوه عملکرد پسانتشار را با جزئیات بیشتری توضیح میدهد.
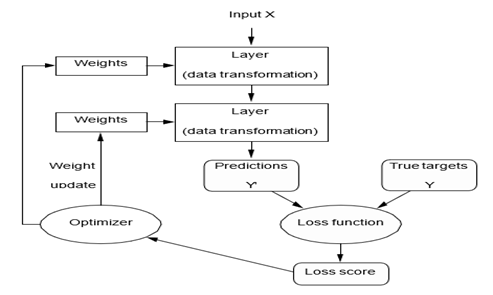
در ابتدا، وزنهای شبکه مقادیر تصادفی میگیرند، بنابراین شبکه صرفاً مجموعهای از تبدیلهای تصادفی را پیادهسازی میکند. طبیعتاً، خروجی آن بسیار دور از آنچه که باید باشد است و امتیاز زیان نیز به تبع آن بسیار بالا است. اما با هر مثالی که شبکه پردازش میکند، وزنها کمی در جهت درست تنظیم میشوند و امتیاز زیان کاهش مییابد. این حلقه آموزش است که با تکرار تعداد دفعات کافی (معمولاً دهها تکرار بر روی هزاران مثال)، مقادیر وزنی را به دست میدهد که تابع زیان را به حداقل میرساند. شبکهای با حداقل زیان، شبکهای است که خروجیهای آن تا حد امکان به اهداف نزدیک هستند: یک شبکه آموزشدیده. بار دیگر، این یک مکانیسم ساده است که پس از مقیاسبندی، در نهایت شبیه جادو به نظر میرسد.
دستاوردهای یادگیری عمیق تاکنون
اگرچه یادگیری عمیق یک زیرشاخه نسبتاً قدیمی از یادگیری ماشین است، اما تنها در اوایل دهه ۲۰۱۰ به شهرت رسید. در چند سال پس از آن، انقلابی تمام عیار در این حوزه ایجاد کرده و نتایج قابل توجهی در وظایف ادراکی و حتی وظایف پردازش زبان طبیعی به دست آورده است—مسائلی که شامل مهارتهایی هستند که برای انسانها طبیعی و شهودی به نظر میرسند اما برای ماشینها مدتها دست نیافتنی بودهاند.
به طور خاص، یادگیری عمیق امکان دستیابی به پیشرفتهای زیر را فراهم کرده است، همه در زمینههایی از یادگیری ماشین که از نظر تاریخی دشوار بودهاند:
- طبقهبندی تصویر در سطح نزدیک به انسان
- رونویسی گفتار در سطح نزدیک به انسان
- رونویسی دستنوشته در سطح نزدیک به انسان
- بهبود چشمگیر ترجمه ماشینی
- بهبود چشمگیر تبدیل متن به گفتار
- دستیاران دیجیتال مانند Google Assistant و Amazon Alexa
- رانندگی خودکار در سطح نزدیک به انسان
- بهبود هدفگیری تبلیغات، همانطور که توسط گوگل، بایدو یا بینگ استفاده میشود
- بهبود نتایج جستجو در وب
- توانایی پاسخ دادن به سؤالات زبان طبیعی
- بازی Go در سطح فراانسانی
ما هنوز در حال بررسی دامنه کامل تواناییهای یادگیری عمیق هستیم. با موفقیت چشمگیری شروع به استفاده از آن در طیف گستردهای از مشکلاتی کردهایم که تا چند سال پیش حلنشدنی تصور میشدند—رونویسی خودکار دهها هزار نسخه خطی باستانی موجود در آرشیو آپوستولیک واتیکان، تشخیص و طبقهبندی بیماریهای گیاهی در مزارع با استفاده از یک تلفن هوشمند ساده، کمک به متخصصان سرطان یا رادیولوژیستها در تفسیر دادههای تصویربرداری پزشکی، پیشبینی بلایای طبیعی مانند سیل، طوفان یا حتی زلزله، و غیره. با هر نقطه عطف، ما به عصری نزدیکتر میشویم که یادگیری عمیق در هر فعالیت و هر زمینه تلاش انسانی—علم، پزشکی، ایجاد، انرژی، حمل و نقل، توسعه نرمافزار، کشاورزی و حتی آفرینش هنری—به ما کمک میکند.
تبلیغات کوتاهمدت را باور نکنید
اگرچه یادگیری عمیق در سالهای اخیر به دستاوردهای قابل توجهی منجر شده است، اما انتظارات از آنچه این حوزه در دهه آینده قادر به دستیابی به آن خواهد بود، به طور کلی بسیار بالاتر از آنچه احتمالاً ممکن خواهد بود، پیش میرود. اگرچه برخی از کاربردهای تغییردهنده جهان مانند خودروهای خودران در حال حاضر در دسترس هستند، بسیاری دیگر احتمالاً برای مدت طولانی دست نیافتنی باقی خواهند ماند، مانند سیستمهای گفتگوی باورپذیر، ترجمه ماشینی در سطح انسان در بین زبانهای دلخواه و درک زبان طبیعی در سطح انسان. به طور خاص، صحبت از هوش عمومی در سطح انسان نباید خیلی جدی گرفته شود. خطر انتظارات بالا در کوتاه مدت این است که با عدم تحقق فناوری، سرمایهگذاری تحقیقاتی خشک خواهد شد و پیشرفت برای مدت طولانی کند خواهد شد.
این قبلاً اتفاق افتاده است. دو بار در گذشته، هوش مصنوعی یک چرخه خوشبینی شدید و به دنبال آن ناامیدی و شک و تردید را با کمبود بودجه در نتیجه آن تجربه کرده است.
این با هوش مصنوعی نمادین در دهه ۱۹۶۰ آغاز شد. در آن روزهای اولیه، پیشبینیها در مورد هوش مصنوعی بسیار بالا بود. یکی از مشهورترین پیشگامان و طرفداران رویکرد هوش مصنوعی نمادین، ماروین مینسکی بود که در سال ۱۹۶۷ ادعا کرد: «در عرض یک نسل… مشکل ایجاد “هوش مصنوعی” به طور اساسی حل خواهد شد.» سه سال بعد، در سال ۱۹۷۰، او پیشبینی دقیقتری ارائه کرد: «بین سه تا هشت سال دیگر ماشینی با هوش عمومی یک انسان متوسط خواهیم داشت.» در سال ۲۰۲۱ چنین دستاوردی هنوز بسیار دور از آینده به نظر میرسد—آنقدر دور که هیچ راهی برای پیشبینی مدت زمان لازم برای آن نداریم—اما در دهههای ۱۹۶۰ و اوایل دهه ۱۹۷۰، چندین متخصص معتقد بودند که این امر بسیار نزدیک است (همانطور که بسیاری از مردم امروز معتقدند). چند سال بعد، با عدم تحقق این انتظارات بالا، محققان و بودجههای دولتی از این حوزه روی گرداندند و آغاز اولین زمستان هوش مصنوعی (اشاره به زمستان هستهای، زیرا این مدت کوتاهی پس از اوج جنگ سرد بود) را رقم زدند.
این آخرین مورد نبود. در دهه ۱۹۸۰، رویکرد جدیدی به هوش مصنوعی نمادین، سیستمهای خبره، در میان شرکتهای بزرگ شروع به اوج گرفتن کرد. چند داستان موفقیت اولیه موجی از سرمایهگذاری را به راه انداخت و شرکتها در سراسر جهان بخشهای هوش مصنوعی داخلی خود را برای توسعه سیستمهای خبره تأسیس کردند. در حدود سال ۱۹۸۵، شرکتها سالانه بیش از ۱ میلیارد دلار برای این فناوری هزینه میکردند؛ اما در اوایل دهه ۱۹۹۰، این سیستمها پرهزینه برای نگهداری، دشوار برای مقیاسبندی و محدود در دامنه ثابت شدند و علاقه به آنها فروکش کرد. بدین ترتیب دومین زمستان هوش مصنوعی آغاز شد.
ما ممکن است در حال حاضر شاهد سومین چرخه تبلیغات و ناامیدی هوش مصنوعی باشیم و هنوز در مرحله خوشبینی شدید قرار داریم. بهتر است انتظارات خود را در کوتاه مدت تعدیل کنیم و اطمینان حاصل کنیم که افرادی که آشنایی کمتری با جنبه فنی این حوزه دارند، درک روشنی از آنچه یادگیری عمیق میتواند و نمیتواند ارائه دهد، داشته باشند.
وعده هوش مصنوعی
اگرچه ممکن است انتظارات غیرواقعی کوتاهمدتی از هوش مصنوعی داشته باشیم، اما تصویر بلندمدت روشن به نظر میرسد. ما تازه شروع به استفاده از یادگیری عمیق در بسیاری از مسائل مهم کردهایم که میتواند تحولآفرین باشد، از تشخیصهای پزشکی گرفته تا دستیاران دیجیتال. تحقیقات هوش مصنوعی در ده سال گذشته با سرعتی شگفتانگیز پیشرفت کرده است، که عمدتاً به دلیل سطح بودجهای است که در تاریخ کوتاه هوش مصنوعی بیسابقه بوده است، اما تاکنون نسبتاً کمی از این پیشرفت به محصولات و فرآیندهایی که دنیای ما را شکل میدهند، راه یافته است. بیشتر یافتههای تحقیقاتی یادگیری عمیق هنوز به کار گرفته نشدهاند، یا حداقل به طیف کاملی از مشکلاتی که میتوانند در تمام صنایع حل کنند، اعمال نشدهاند. پزشک شما هنوز از هوش مصنوعی استفاده نمیکند و حسابدار شما نیز همینطور. شما احتمالاً در زندگی روزمره خود اغلب از فناوریهای هوش مصنوعی استفاده نمیکنید. البته، میتوانید سؤالات سادهای از تلفن هوشمند خود بپرسید و پاسخهای معقولی دریافت کنید، میتوانید توصیههای نسبتاً مفیدی برای محصولات در Amazon.com دریافت کنید و میتوانید “تولد” را در Google Photos جستجو کنید و فوراً عکسهای جشن تولد دخترتان از ماه گذشته را پیدا کنید. این بسیار متفاوت از جایی است که چنین فناوریهایی قبلاً در آن قرار داشتند. اما چنین ابزارهایی هنوز فقط لوازم جانبی زندگی روزمره ما هستند. هوش مصنوعی هنوز به مرحلهای نرسیده است که در نحوه کار، فکر و زندگی ما محوری باشد.
در حال حاضر، ممکن است باور اینکه هوش مصنوعی میتواند تأثیر زیادی بر دنیای ما داشته باشد دشوار به نظر برسد، زیرا هنوز به طور گسترده مستقر نشده است—همانطور که در سال ۱۹۹۵، باور به تأثیر آینده اینترنت دشوار بود. در آن زمان، بیشتر مردم نمیدیدند که اینترنت چگونه به آنها مربوط است و چگونه زندگی آنها را تغییر خواهد داد. همین امر در مورد یادگیری عمیق و هوش مصنوعی امروز نیز صادق است. اما اشتباه نکنید: هوش مصنوعی در راه است. در آیندهای نه چندان دور، هوش مصنوعی دستیار شما، حتی دوست شما خواهد بود؛ به سؤالات شما پاسخ خواهد داد، به آموزش فرزندانتان کمک خواهد کرد و مراقب سلامتی شما خواهد بود. مواد غذایی شما را به در منزل تحویل خواهد داد و شما را از نقطه A به نقطه B خواهد رساند. این رابط شما با دنیایی خواهد بود که به طور فزایندهای پیچیده و پر از اطلاعات است. و مهمتر از آن، هوش مصنوعی به بشریت به طور کلی کمک خواهد کرد تا پیشرفت کند، با کمک به دانشمندان انسانی در اکتشافات جدید در تمام زمینههای علمی، از ژنومیک گرفته تا ریاضیات.
در این راه، ممکن است با چند شکست و شاید حتی یک زمستان هوش مصنوعی جدید روبرو شویم—به همان روشی که صنعت اینترنت در سالهای ۱۹۹۸–۹۹ بیش از حد تبلیغ شد و از یک سقوط رنج برد که سرمایهگذاری را در اوایل دهه ۲۰۰۰ خشک کرد. اما ما در نهایت به آنجا خواهیم رسید. هوش مصنوعی در نهایت در تقریباً هر فرآیندی که جامعه و زندگی روزمره ما را تشکیل میدهد، به کار گرفته خواهد شد، درست مانند اینترنت امروز.
تبلیغات کوتاهمدت را باور نکنید، اما به چشمانداز بلندمدت ایمان داشته باشید. ممکن است مدتی طول بکشد تا هوش مصنوعی به پتانسیل واقعی خود برسد—پتانسیلی که هیچکس هنوز جرأت تصور کامل آن را نداشته است—اما هوش مصنوعی در راه است و دنیای ما را به شکلی خارقالعاده تغییر خواهد داد.
پیش از یادگیری عمیق: تاریخچه مختصری از یادگیری ماشین
یادگیری عمیق به سطحی از توجه عمومی و سرمایهگذاری صنعتی رسیده است که در تاریخ هوش مصنوعی بیسابقه بوده است، اما اولین شکل موفق یادگیری ماشین نیست. به جرات میتوان گفت که بیشتر الگوریتمهای یادگیری ماشینی که امروزه در صنعت استفاده میشوند، الگوریتمهای یادگیری عمیق نیستند. یادگیری عمیق همیشه ابزار مناسب برای کار نیست—گاهی اوقات داده کافی برای کاربرد یادگیری عمیق وجود ندارد و گاهی اوقات مشکل با یک الگوریتم متفاوت بهتر حل میشود. اگر یادگیری عمیق اولین آشنایی شما با یادگیری ماشین است، ممکن است خود را در موقعیتی بیابید که تنها چکش یادگیری عمیق را در اختیار دارید و هر مسئله یادگیری ماشینی شبیه یک میخ به نظر برسد. تنها راه برای نیفتادن در این دام، آشنایی با رویکردهای دیگر و تمرین آنها در صورت لزوم است.
بحث مفصل در مورد رویکردهای کلاسیک یادگیری ماشین خارج از محدوده این کتاب است، اما من به طور خلاصه آنها را مرور میکنم و زمینه تاریخی توسعه آنها را شرح میدهم. این به ما امکان میدهد یادگیری عمیق را در زمینه وسیعتر یادگیری ماشین قرار دهیم و بهتر درک کنیم که یادگیری عمیق از کجا آمده و چرا اهمیت دارد.
مدلسازی احتمالی
مدلسازی احتمالی کاربرد اصول آمار در تحلیل دادهها است. این یکی از قدیمیترین اشکال یادگیری ماشین است و امروزه نیز به طور گسترده مورد استفاده قرار میگیرد. یکی از شناختهشدهترین الگوریتمها در این دسته، الگوریتم بیز ساده است.
بیز ساده نوعی طبقهبندیکننده یادگیری ماشین است که بر اساس اعمال قضیه بیز و در عین حال فرض مستقل بودن تمام ویژگیهای دادههای ورودی (یک فرض قوی یا “سادهلوحانه”، که نام از آن گرفته شده است) بنا شده است. این شکل از تحلیل دادهها پیش از رایانهها وجود داشته و دهها سال قبل از اولین پیادهسازی رایانهای آن (احتمالاً مربوط به دهه ۱۹۵۰) به صورت دستی اعمال میشده است. قضیه بیز و مبانی آمار به قرن هجدهم باز میگردند و این تمام چیزی است که برای شروع استفاده از طبقهبندیکنندههای بیز ساده نیاز دارید.
یک مدل نزدیک به آن رگرسیون لجستیک (به اختصار logreg) است که گاهی اوقات به عنوان “Hello World” یادگیری ماشین مدرن در نظر گرفته میشود. فریب نام آن را نخورید—logreg یک الگوریتم طبقهبندی است نه یک الگوریتم رگرسیون.
مانند بیز ساده، logreg مدتها قبل از محاسبات وجود داشته است، اما به لطف ماهیت ساده و چندمنظورهاش، هنوز هم امروزه مفید است. این اغلب اولین چیزی است که یک دانشمند داده برای درک وظیفه طبقهبندی موجود در یک مجموعه داده امتحان میکند.
شبکههای عصبی اولیه
تکرارهای اولیه شبکههای عصبی به طور کامل توسط گونههای مدرن که در این صفحات پوشش داده شدهاند، جایگزین شدهاند، اما آگاهی از چگونگی پیدایش یادگیری عمیق مفید است. اگرچه ایدههای اصلی شبکههای عصبی در اشکال ساده از دهه ۱۹۵۰ مورد بررسی قرار گرفتند، اما این رویکرد دههها طول کشید تا شروع شود. برای مدت طولانی، قطعه گمشده یک روش کارآمد برای آموزش شبکههای عصبی بزرگ بود. این در اواسط دهه ۱۹۸۰ تغییر کرد، زمانی که چندین نفر به طور مستقل الگوریتم پسانتشار را دوباره کشف کردند—روشی برای آموزش زنجیرههایی از عملیات پارامتری با استفاده از بهینهسازی گرادیان کاهشی (ما این مفاهیم را بعداً در کتاب به طور دقیق تعریف خواهیم کرد)—و شروع به اعمال آن بر روی شبکههای عصبی کردند.
اولین کاربرد عملی موفقیتآمیز شبکههای عصبی در سال ۱۹۸۹ از آزمایشگاههای بل به دست آمد، زمانی که یان لکان ایدههای اولیه شبکههای عصبی کانولوشنال و پسانتشار را با هم ترکیب کرد و آنها را در مسئله طبقهبندی ارقام دستنویس به کار برد. شبکه حاصل، LeNet نامیده شد و توسط سرویس پستی ایالات متحده در دهه ۱۹۹۰ برای خودکارسازی خواندن کدهای پستی روی پاکتهای نامه استفاده میشد.
روشهای کرنل
همانطور که شبکههای عصبی در دهه ۱۹۹۰، به لطف اولین موفقیت خود، مورد توجه محققان قرار گرفتند، رویکرد جدیدی به یادگیری ماشین شهرت یافت و به سرعت شبکههای عصبی را به فراموشی سپرد: روشهای کرنل. روشهای کرنل گروهی از الگوریتمهای طبقهبندی هستند که شناختهشدهترین آنها ماشین بردار پشتیبان (SVM) است. فرمولبندی مدرن یک SVM توسط ولادیمیر واپیک و کورینا کورتس در اوایل دهه ۱۹۹۰ در آزمایشگاههای بل توسعه یافت و در سال ۱۹۹۵ منتشر شد، اگرچه یک فرمولبندی خطی قدیمیتر توسط واپیک و الکسی چروننکیس در اوایل سال ۱۹۶۳ منتشر شده بود.
SVM یک الگوریتم طبقهبندی است که با یافتن “مرزهای تصمیمگیری” که دو کلاس را از هم جدا میکنند، کار میکند (شکل ۱.۱۰ را ببینید). SVM ها این مرزها را در دو مرحله پیدا میکنند:
۱. دادهها به یک بازنمایی جدید با ابعاد بالا نگاشت میشوند که در آن مرز تصمیمگیری را میتوان به عنوان یک ابرصفحه بیان کرد (اگر دادهها دو بعدی بودند، همانطور که در شکل ۱.۱۰، یک ابرصفحه یک خط مستقیم خواهد بود).
۲. یک مرز تصمیمگیری خوب (یک ابرصفحه جداسازی) با تلاش برای حداکثر کردن فاصله بین ابرصفحه و نزدیکترین نقاط داده از هر کلاس محاسبه میشود، گامی که به آن حداکثر کردن حاشیه میگویند. این امکان را میدهد که مرز به خوبی به نمونههای جدید خارج از مجموعه داده آموزشی تعمیم یابد.
تکنیک نگاشت دادهها به یک بازنمایی با ابعاد بالا که در آن یک مسئله طبقهبندی سادهتر میشود، شاید روی کاغذ خوب به نظر برسد، اما در عمل اغلب از نظر محاسباتی غیرقابل حل است. اینجاست که ترفند کرنل وارد میشود (ایده کلیدی که روشهای کرنل نام خود را از آن گرفتهاند). اصل مطلب این است: برای یافتن ابرصفحههای تصمیمگیری خوب در فضای بازنمایی جدید، نیازی نیست که مختصات نقاط خود را در فضای جدید به صراحت محاسبه کنید؛ فقط کافی است فاصله بین جفت نقاط در آن فضا را محاسبه کنید، که میتوان آن را به طور کارآمد با استفاده از تابع کرنل انجام داد. تابع کرنل یک عملیات قابل محاسبه است که هر دو نقطه را در فضای اولیه شما به فاصله بین این نقاط در فضای بازنمایی هدف شما نگاشت میکند و به طور کامل از محاسبه صریح بازنمایی جدید جلوگیری میکند. توابع کرنل معمولاً به صورت دستی ساخته میشوند تا از دادهها یاد گرفته شوند—در مورد یک SVM، تنها ابرصفحه جداسازی یاد گرفته میشود.
در زمان توسعه، SVMها عملکردی پیشرفته در مسائل طبقهبندی ساده از خود نشان دادند و یکی از معدود روشهای یادگیری ماشین بودند که توسط نظریه گسترده پشتیبانی میشدند و قابل تحلیل ریاضی جدی بودند، که باعث شد به خوبی درک شوند و به راحتی قابل تفسیر باشند. به دلیل این ویژگیهای مفید، SVMها برای مدت طولانی در این حوزه بسیار محبوب شدند.
اما SVMها در مقیاسبندی به مجموعه دادههای بزرگ دشوار بودند و نتایج خوبی برای مشکلات ادراکی مانند طبقهبندی تصویر ارائه نمیدادند. از آنجا که یک SVM یک روش سطحی است، اعمال یک SVM بر روی مشکلات ادراکی ابتدا نیاز به استخراج دستی بازنماییهای مفید دارد (گامی به نام مهندسی ویژگی)، که دشوار و شکننده است. برای مثال، اگر میخواهید از یک SVM برای طبقهبندی ارقام دستنویس استفاده کنید، نمیتوانید از پیکسلهای خام شروع کنید؛ ابتدا باید بازنماییهای مفیدی را به صورت دستی پیدا کنید که مسئله را قابل حلتر کنند، مانند هیستوگرامهای پیکسلی که قبلاً ذکر کردم.
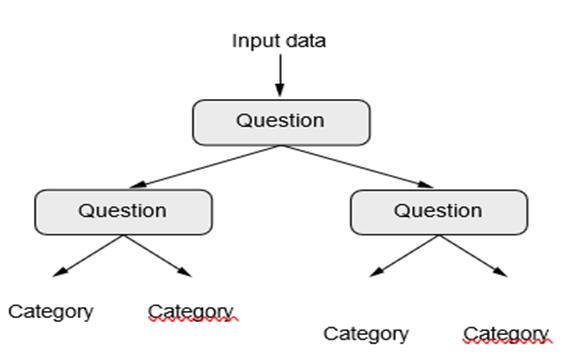
درختان تصمیم، جنگلهای تصادفی و ماشینهای تقویت گرادیان
درختان تصمیم ساختارهایی شبیه نمودار جریان هستند که به شما امکان میدهند نقاط داده ورودی را طبقهبندی کنید یا مقادیر خروجی را با توجه به ورودیها پیشبینی کنید (شکل ۱.۱۱ را ببینید). دیدن و تفسیر آنها آسان است. درختان تصمیم یادگرفته شده از دادهها در دهه ۲۰۰۰ توجه تحقیقاتی قابل توجهی را به خود جلب کردند و تا سال ۲۰۱۰ اغلب به روشهای کرنل ترجیح داده میشدند.
الگوریتمهای درخت تصمیم، جنگلهای تصادفی و ماشینهای تقویت گرادیان
به طور خاص، الگوریتم جنگل تصادفی (Random Forest) رویکردی قوی و عملی به یادگیری درخت تصمیم را معرفی کرد که شامل ساخت تعداد زیادی درخت تصمیم تخصصی و سپس ترکیب خروجیهای آنهاست. جنگلهای تصادفی برای طیف وسیعی از مسائل قابل استفاده هستند—میتوان گفت که آنها تقریباً همیشه دومین بهترین الگوریتم برای هر کار یادگیری ماشین سطحی هستند. هنگامی که وبسایت محبوب رقابتهای یادگیری ماشین Kaggle (http://kaggle.com) در سال ۲۰۱۰ شروع به کار کرد، جنگلهای تصادفی به سرعت به یکی از محبوبترینها در این پلتفرم تبدیل شدند—تا سال ۲۰۱۴، زمانی که ماشینهای تقویت گرادیان (Gradient Boosting Machines) جای آنها را گرفتند.
یک ماشین تقویت گرادیان، بسیار شبیه به جنگل تصادفی، یک تکنیک یادگیری ماشین مبتنی بر ترکیب مدلهای پیشبینی ضعیف، معمولاً درختان تصمیم، است. این الگوریتم از تقویت گرادیان (Gradient Boosting) استفاده میکند، روشی برای بهبود هر مدل یادگیری ماشین با آموزش تکراری مدلهای جدیدی که در رفع نقاط ضعف مدلهای قبلی تخصص دارند. با اعمال بر روی درختان تصمیم، استفاده از تکنیک تقویت گرادیان منجر به مدلهایی میشود که در بیشتر مواقع عملکردی به مراتب بهتر از جنگلهای تصادفی دارند، در حالی که ویژگیهای مشابهی نیز دارند. این الگوریتم ممکن است یکی از بهترین، اگر نه بهترین، الگوریتمها برای کار با دادههای غیرادراکی امروزی باشد. در کنار یادگیری عمیق، این یکی از رایجترین تکنیکهای مورد استفاده در رقابتهای Kaggle است.
بازگشت به شبکههای عصبی
حدود سال ۲۰۱۰، با وجود اینکه شبکههای عصبی تقریباً به طور کامل از سوی جامعه علمی کنار گذاشته شده بودند، تعدادی از پژوهشگران که همچنان روی آنها کار میکردند، شروع به دستیابی به موفقیتهای بزرگی کردند: گروههای جفری هینتون در دانشگاه تورنتو، یوشوا بنجیو در دانشگاه مونترال، یان لکان در دانشگاه نیویورک، و IDSIA در سوئیس.
در سال ۲۰۱۱، دن شیرسان از IDSIA با استفاده از شبکههای عصبی عمیق آموزشدیده با GPU (واحد پردازش گرافیکی) شروع به برنده شدن در رقابتهای آکادمیک طبقهبندی تصاویر کرد—این اولین موفقیت عملی یادگیری عمیق مدرن بود. اما نقطه عطف اصلی در سال ۲۰۱۲ رخ داد، با ورود گروه هینتون به چالش سالانه طبقهبندی تصویر در مقیاس بزرگ ایمیجنت (ImageNet Large Scale Visual Recognition Challenge، یا به اختصار ILSVRC). چالش ایمیجنت در آن زمان به شدت دشوار بود، زیرا شامل طبقهبندی ۱.۴ میلیون تصویر رنگی با وضوح بالا به ۱۰۰۰ دسته مختلف بود. در سال ۲۰۱۱، دقت پنج برتر مدل برنده، که بر پایه رویکردهای کلاسیک بینایی کامپیوتر بود، تنها ۷۴.۳٪ بود. اما در سال ۲۰۱۲، تیمی به رهبری الکس کریزفسکی و با مشاوره جفری هینتون توانست به دقت ۸۳.۶٪ در پنج برتر دست یابد—این یک پیشرفت چشمگیر بود. از آن سال به بعد، این رقابت هر ساله تحت سلطه شبکههای عصبی پیچشی عمیق بوده است. تا سال ۲۰۱۵، برنده به دقتی معادل ۹۶.۴٪ رسید و وظیفه طبقهبندی در ایمیجنت به عنوان یک مشکل کاملاً حلشده در نظر گرفته شد.
از سال ۲۰۱۲، شبکههای عصبی پیچشی عمیق (Convnet) به الگوریتم اصلی برای تمام وظایف بینایی کامپیوتر تبدیل شدهاند؛ به طور کلیتر، آنها بر روی تمام وظایف ادراکی کار میکنند. در هر کنفرانس بزرگ بینایی کامپیوتر پس از سال ۲۰۱۵، تقریباً غیرممکن بود که ارائههایی را بیابید که به نوعی شامل Convnet نباشند.
در همین زمان، یادگیری عمیق کاربردهایی در انواع دیگر مسائل نیز پیدا کرده است، مانند پردازش زبان طبیعی. این روش به طور کامل SVMها و درختان تصمیم را در طیف وسیعی از کاربردها جایگزین کرده است. برای مثال، برای چندین سال، سازمان اروپایی تحقیقات هستهای، سرن (CERN)، از روشهای مبتنی بر درخت تصمیم برای تجزیه و تحلیل دادههای ذرات از آشکارساز ATLAS در برخورددهنده بزرگ هادرون (LHC) استفاده میکرد، اما سرن در نهایت به دلیل عملکرد بالاتر و سهولت آموزش بر روی مجموعهدادههای بزرگ، به شبکههای عصبی عمیق مبتنی بر Keras روی آورد.
چه چیزی یادگیری عمیق را متفاوت میکند
دلیل اصلی پیشرفت سریع یادگیری عمیق این است که برای بسیاری از مشکلات عملکرد بهتری ارائه میدهد. اما این تنها دلیل نیست. یادگیری عمیق همچنین حل مسئله را بسیار آسانتر میکند، زیرا آنچه قبلاً حیاتیترین گام در یک گردش کار یادگیری ماشین بود—یعنی مهندسی ویژگی (Feature Engineering)—را به طور کامل خودکار میکند.
تکنیکهای یادگیری ماشین قبلی—یادگیری سطحی—فقط شامل تبدیل دادههای ورودی به یک یا دو فضای بازنمایی متوالی بود، معمولاً از طریق تبدیلهای ساده مانند نگاشتهای غیرخطی با ابعاد بالا (در SVMها) یا درختان تصمیم. اما بازنماییهای تصفیه شده مورد نیاز برای مسائل پیچیده معمولاً با چنین تکنیکهایی قابل دستیابی نیستند. به این ترتیب، انسانها باید تلاش زیادی میکردند تا دادههای ورودی اولیه را برای پردازش توسط این روشها مناسبتر کنند: آنها باید به صورت دستی لایههای خوبی از بازنماییها را برای دادههای خود مهندسی میکردند. این همان مهندسی ویژگی است. از سوی دیگر، یادگیری عمیق این مرحله را به طور کامل خودکار میکند: با یادگیری عمیق، شما تمام ویژگیها را در یک مرحله یاد میگیرید و نیازی به مهندسی آنها توسط خودتان ندارید. این امر گردش کارهای یادگیری ماشین را به شدت ساده کرده است، و اغلب خطوط لوله پیچیده چند مرحلهای را با یک مدل یادگیری عمیق ساده و سرتاسری جایگزین میکند.
شاید بپرسید، اگر گره اصلی مسئله داشتن چندین لایه متوالی از بازنماییها است، آیا میتوان روشهای سطحی را به طور مکرر برای تقلید اثرات یادگیری عمیق به کار برد؟ در عمل، کاربردهای متوالی روشهای یادگیری سطحی بازدهی به سرعت کاهشی ایجاد میکنند، زیرا لایه بازنمایی بهینه اول در یک مدل سهلایه، لایه بهینه اول در یک مدل تکلایه یا دو لایه نیست. آنچه در مورد یادگیری عمیق تحولآفرین است این است که به مدل اجازه میدهد تمام لایههای بازنمایی را به صورت مشترک و همزمان یاد بگیرد، نه به صورت متوالی (که به آن حریصانه گفته میشود). با یادگیری ویژگی مشترک، هر زمان که مدل یکی از ویژگیهای داخلی خود را تنظیم میکند، تمام ویژگیهای دیگری که به آن وابسته هستند به طور خودکار با تغییر سازگار میشوند، بدون نیاز به دخالت انسانی. همه چیز توسط یک سیگنال بازخورد واحد نظارت میشود: هر تغییری در مدل به هدف نهایی خدمت میکند. این بسیار قدرتمندتر از انباشتن حریصانه مدلهای سطحی است، زیرا به بازنماییهای پیچیده و انتزاعی اجازه میدهد تا با تقسیم آنها به مجموعهای طولانی از فضاهای میانی (لایهها) یاد گرفته شوند؛ هر فضا تنها یک تبدیل ساده با فضای قبلی فاصله دارد.
اینها دو ویژگی اساسی نحوه یادگیری یادگیری عمیق از دادهها هستند: روش تدریجی، لایه به لایه که در آن بازنماییهای پیچیدهتر توسعه مییابند، و این واقعیت که این بازنماییهای تدریجی میانی به صورت مشترک یاد گرفته میشوند، یعنی هر لایه به گونهای به روز میشود که هم
نیازهای بازنمایی لایه بالاتر و هم نیازهای لایه پایینتر را برآورده کند. این دو ویژگی با هم، یادگیری عمیق را به مراتب موفقتر از رویکردهای قبلی در یادگیری ماشین کردهاند.
5 «دقت پنج برتر» معیاری است که نشان میدهد مدل، پاسخ صحیح را چند بار در میان پنج حدس برتر خود (از میان ۱۰۰۰ پاسخ ممکن، در مورد ایمیجنت) انتخاب میکند.
چشمانداز مدرن یادگیری ماشین
یک راه عالی برای درک وضعیت فعلی الگوریتمها و ابزارهای یادگیری ماشین، نگاهی به رقابتهای یادگیری ماشین در Kaggle است. به دلیل محیط بسیار رقابتی آن (برخی مسابقات هزاران شرکتکننده و جوایز میلیونی دارند) و تنوع گسترده مسائل یادگیری ماشینی پوشش داده شده، Kaggle راهی واقعبینانه برای ارزیابی اینکه چه چیزی کار میکند و چه چیزی کار نمیکند، ارائه میدهد. پس، چه نوع الگوریتمی به طور قابل اعتماد در حال برنده شدن در رقابتهاست؟ برترین شرکتکنندگان از چه ابزارهایی استفاده میکنند؟
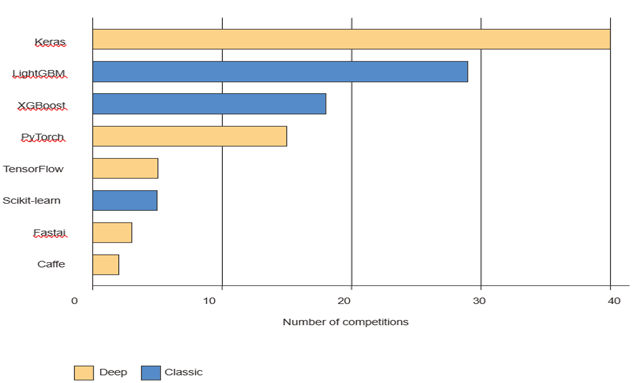
در اوایل سال ۲۰۱۹، Kaggle نظرسنجیای را انجام داد که از تیمهایی که از سال ۲۰۱۷ در هر رقابتی در پنج رتبه برتر قرار گرفته بودند، پرسید که کدام ابزار نرمافزاری اصلی را در رقابت استفاده کردهاند (شکل ۱.۱۲ را ببینید). مشخص شد که تیمهای برتر تمایل دارند از روشهای یادگیری عمیق (اغلب از طریق کتابخانه Keras) یا درختان تقویتیافته با گرادیان (اغلب از طریق کتابخانههای LightGBM یا XGBoost) استفاده کنند.
فقط قهرمانان رقابتها نیستند که اینطور عمل میکنند. Kaggle همچنین یک نظرسنجی سالانه در میان متخصصان یادگیری ماشین و علم داده در سراسر جهان انجام میدهد. با دهها هزار پاسخدهنده، این نظرسنجی یکی از معتبرترین منابع ما در مورد وضعیت این صنعت است. شکل ۱.۱۳ درصد استفاده از فریمورکهای مختلف نرمافزاری یادگیری ماشین را نشان میدهد.
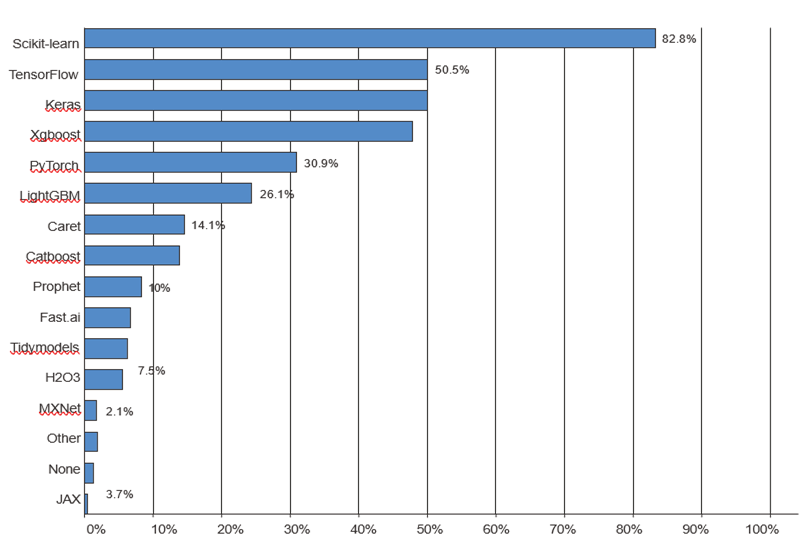
از سال ۲۰۱۶ تا ۲۰۲۰، کل صنعت یادگیری ماشین و علم داده تحت سلطه این دو رویکرد بوده است: یادگیری عمیق و درختان تقویت شده با گرادیان. به طور خاص، درختان تقویت شده با گرادیان برای مسائلی که دادههای ساختاریافته در دسترس است، استفاده میشوند، در حالی که یادگیری عمیق برای مسائل ادراکی مانند طبقهبندی تصویر به کار میرود.
کاربران درختان تقویت شده با گرادیان معمولاً از Scikit-learn، XGBoost، یا LightGBM استفاده میکنند. در همین حال، بیشتر متخصصان یادگیری عمیق از Keras استفاده میکنند، که اغلب در ترکیب با فریمورک اصلی آن، TensorFlow، به کار میرود. نقطه مشترک این ابزارها این است که همگی کتابخانههای پایتون هستند: پایتون تا حد زیادی پرکاربردترین زبان برای یادگیری ماشین و علم داده است.
اینها دو تکنیکی هستند که برای موفقیت در یادگیری ماشین کاربردی امروز باید بیشترین آشنایی را با آنها داشته باشید: درختان تقویت شده با گرادیان، برای مسائل یادگیری سطحی؛ و یادگیری عمیق، برای مسائل ادراکی. از نظر فنی، این بدان معناست که شما باید با Scikit-learn، XGBoost و Keras آشنا باشید—سه کتابخانهای که در حال حاضر بر رقابتهای Kaggle تسلط دارند. با این کتاب در دست، شما همین حالا یک گام بزرگ به جلو برداشتهاید.
چرا یادگیری عمیق؟ چرا اکنون؟
دو ایده کلیدی یادگیری عمیق برای بینایی کامپیوتر—شبکههای عصبی پیچشی و پسانتشار—تا سال ۱۹۹۰ به خوبی درک شده بودند. الگوریتم حافظه بلندمدت کوتاه (LSTM)، که برای یادگیری عمیق در سریهای زمانی بنیادی است، در سال ۱۹۹۷ توسعه یافت و از آن زمان تاکنون به ندرت تغییر کرده است. پس چرا یادگیری عمیق تنها پس از سال ۲۰۱۲ اوج گرفت؟ چه چیزی در این دو دهه تغییر کرد؟
به طور کلی، سه نیروی فنی باعث پیشرفت در یادگیری ماشین میشوند:
- سختافزار
- مجموعهدادهها و معیارهای سنجش
- پیشرفتهای الگوریتمی
از آنجا که این حوزه بیشتر توسط یافتههای تجربی هدایت میشود تا نظریه، پیشرفتهای الگوریتمی تنها زمانی امکانپذیر میشوند که دادهها و سختافزار مناسب برای آزمایش ایدههای جدید (یا مقیاسبندی ایدههای قدیمی، که اغلب اتفاق میافتد) در دسترس باشند. یادگیری ماشین ریاضیات یا فیزیک نیست که پیشرفتهای بزرگ را بتوان با قلم و کاغذ انجام داد. این یک علم مهندسی است.
محدودیتهای واقعی در طول دهههای ۱۹۹۰ و ۲۰۰۰ دادهها و سختافزار بودند. اما در آن زمان اتفاقی افتاد: اینترنت اوج گرفت و تراشههای گرافیکی با عملکرد بالا برای نیازهای بازار بازیها توسعه یافتند.
چشم، متوجه شدم. عذرخواهی میکنم بابت تکرار این مورد. از این به بعد، مطمئن خواهم شد که هیچ خطی در بالا یا پایین متن ترجمه شده قرار نگیرد.
سختافزار
بین سالهای ۱۹۹۰ تا ۲۰۱۰، سرعت پردازندههای مرکزی (CPU) رایج تقریباً ۵۰۰۰ برابر افزایش یافت. در نتیجه، امروزه امکان اجرای مدلهای کوچک یادگیری عمیق روی لپتاپ شما وجود دارد، در حالی که ۲۵ سال پیش این کار غیرممکن بود.
اما مدلهای معمول یادگیری عمیق که در بینایی کامپیوتر یا تشخیص گفتار استفاده میشوند، به توان محاسباتی به مراتب بیشتری از آنچه لپتاپ شما میتواند ارائه دهد، نیاز دارند. در طول دهه ۲۰۰۰، شرکتهایی مانند NVIDIA و AMD میلیاردها دلار برای توسعه تراشههای سریع و بسیار موازی (واحد پردازش گرافیکی یا GPU) سرمایهگذاری کردند تا گرافیک بازیهای ویدیویی فوتورئالیستیتر را تأمین کنند—ابَرکامپیوترهای ارزان و تکمنظوره که برای رندر صحنههای سهبعدی پیچیده روی صفحه نمایش شما در زمان واقعی طراحی شده بودند. این سرمایهگذاری زمانی به نفع جامعه علمی تمام شد که در سال ۲۰۰۷، NVIDIA نرمافزار CUDA (https://developer.nvidia.com/about-cuda) را راهاندازی کرد، یک رابط برنامهنویسی برای خط ایجاد GPUهای خود. تعداد کمی از GPUها شروع به جایگزینی خوشههای عظیم CPU در کاربردهای بسیار موازیپذیر مختلف، از جمله مدلسازی فیزیک، کردند. شبکههای عصبی عمیق که عمدتاً از ضربهای ماتریسی کوچک بسیاری تشکیل شدهاند، نیز به شدت موازیپذیر هستند، و حدود سال ۲۰۱۱ برخی از محققان شروع به نوشتن پیادهسازیهای CUDA از شبکههای عصبی کردند—دن شیرسان و الکس کریزفسکی از اولین نفرات بودند.
آنچه اتفاق افتاد این بود که بازار بازیها، ابرکامپیوترهای مورد نیاز نسل بعدی کاربردهای هوش مصنوعی را یارانهبندی کرد. گاهی اوقات، چیزهای بزرگ با بازیها شروع میشوند. امروزه، NVIDIA Titan RTX، یک GPU با قیمت ۲۵۰۰ دلار در پایان سال ۲۰۱۹، میتواند به اوج ۱۶ ترافلاپس در دقت تکی (۱۶ تریلیون عملیات float32 در ثانیه) دست یابد. این حدود ۵۰۰ برابر توان محاسباتی سریعترین ابرکامپیوتر جهان در سال ۱۹۹۰، یعنی Intel Touchstone Delta، است. روی یک Titan RTX، آموزش یک مدل ImageNet از نوعی که در حدود سال ۲۰۱۲ یا ۲۰۱۳ برنده رقابت ILSVRC میشد، تنها چند ساعت طول میکشد. در همین حال، شرکتهای بزرگ مدلهای یادگیری عمیق را روی خوشههایی از صدها GPU آموزش میدهند.
علاوه بر این، صنعت یادگیری عمیق فراتر از GPUها رفته و در حال سرمایهگذاری بر روی تراشههای هرچه تخصصیتر و کارآمدتر برای یادگیری عمیق است. در سال ۲۰۱۶، گوگل در کنفرانس سالانه I/O خود از پروژه واحد پردازش تنسور (TPU) رونمایی کرد: طراحی تراشه جدیدی که از ابتدا برای اجرای شبکههای عصبی عمیق به طور قابلتوجهی سریعتر و بسیار کارآمدتر از GPUهای ردهبالا توسعه یافته است. امروز، در سال ۲۰۲۰، سومین تکرار کارت TPU نشاندهنده ۴۲۰ ترافلاپس توان محاسباتی است. این ۱۰,۰۰۰ برابر Intel Touchstone Delta از سال ۱۹۹۰ است.
این کارتهای TPU برای مونتاژ در پیکربندیهای بزرگ، به نام «پاد» طراحی شدهاند. یک پاد (۱۰۲۴ کارت TPU) به اوج ۱۰۰ پتافلاپس میرسد. برای مقایسه، این حدود ۱۰ درصد از اوج توان محاسباتی بزرگترین ابرکامپیوتر فعلی، IBM Summit در آزمایشگاه ملی Oak Ridge است که از ۲۷,۰۰۰ GPU انویدیا تشکیل شده و به اوج حدود ۱.۱ اگزافلاپس میرسد.
داده
هوش مصنوعی گاهی اوقات به عنوان انقلاب صنعتی جدید معرفی میشود. اگر یادگیری عمیق موتور بخار این انقلاب باشد، پس داده زغال سنگ آن است: ماده خامی که ماشینهای هوشمند ما را تغذیه میکند و بدون آن هیچ چیز ممکن نخواهد بود. در مورد داده، علاوه بر پیشرفت تصاعدی در سختافزار ذخیرهسازی در ۲۰ سال گذشته (پیروی از قانون مور)، عامل تغییردهنده بازی، ظهور اینترنت بوده است که جمعآوری و توزیع مجموعهدادههای بسیار بزرگ برای یادگیری ماشین را امکانپذیر کرده است. امروزه، شرکتهای بزرگ با مجموعهدادههای تصویری، ویدیویی و زبان طبیعی کار میکنند که بدون اینترنت قابل جمعآوری نبودند. برای مثال، برچسبهای تصاویر ایجاد شده توسط کاربران در فلیکر (Flickr)، گنجینهای از دادهها برای بینایی کامپیوتر بودهاند. ویدیوهای یوتیوب نیز همینطور. و ویکیپدیا یک مجموعهداده کلیدی برای پردازش زبان طبیعی است.
اگر یک مجموعهداده وجود داشته باشد که کاتالیزوری برای خیزش یادگیری عمیق بوده، آن مجموعهداده ایمیجنت (ImageNet) است که شامل ۱.۴ میلیون تصویر است که به صورت دستی با ۱۰۰۰ دسته تصویری (یک دسته برای هر تصویر) حاشیهنویسی شدهاند. اما آنچه ایمیجنت را خاص میکند فقط اندازه بزرگ آن نیست، بلکه رقابت سالانه مرتبط با آن نیز هست.
همانطور که Kaggle از سال ۲۰۱۰ نشان داده است، رقابتهای عمومی راهی عالی برای ترغیب محققان و مهندسان به پیشبرد مرزهای دانش هستند. داشتن معیارهای مشترک که محققان برای شکست دادن آنها رقابت میکنند، با برجسته کردن موفقیت یادگیری عمیق در برابر رویکردهای کلاسیک یادگیری ماشین، به پیشرفت آن بسیار کمک کرده است.
الگوریتمها
علاوه بر سختافزار و داده، تا اواخر دهه ۲۰۰۰، ما فاقد یک راه مطمئن برای آموزش شبکههای عصبی بسیار عمیق بودیم. در نتیجه، شبکههای عصبی هنوز نسبتاً سطحی بودند و فقط از یک یا دو لایه بازنمایی استفاده میکردند؛ بنابراین، آنها نمیتوانستند در برابر روشهای سطحی تصفیهشدهتر مانند SVMها و جنگلهای تصادفی خودنمایی کنند. مسئله اصلی، انتشار گرادیان در میان پشتههای عمیق لایهها بود. سیگنال بازخوردی که برای آموزش شبکههای عصبی استفاده میشد، با افزایش تعداد لایهها، از بین میرفت.
این وضعیت در حدود سالهای ۲۰۰۹–۲۰۱۰ با ظهور چندین بهبود الگوریتمی ساده اما مهم تغییر کرد که امکان انتشار گرادیان بهتر را فراهم آوردند:
- توابع فعالسازی بهتر برای لایههای عصبی
- روشهای بهتر برای مقداردهی اولیه وزنها، که با پیشآموزش لایهبهلایه آغاز شد، و سپس به سرعت کنار گذاشته شد.
- روشهای بهینهسازی بهتر، مانند RMSProp و Adam
تنها زمانی که این بهبودها شروع به امکان آموزش مدلها با ۱۰ لایه یا بیشتر را دادند، یادگیری عمیق شروع به درخشش کرد.
در نهایت، در سالهای ۲۰۱۴، ۲۰۱۵ و ۲۰۱۶، روشهای پیشرفتهتری برای بهبود انتشار گرادیان کشف شد، مانند نرمالسازی دستهای (Batch Normalization)، اتصالات باقیمانده (Residual Connections)، و پیچشهای جداشدنی عمقی (Depthwise Separable Convolutions).
امروزه، ما میتوانیم مدلهایی با عمق دلخواه را از ابتدا آموزش دهیم. این امر استفاده از مدلهای بسیار بزرگ را ممکن ساخته است که قدرت بازنمایی قابل توجهی دارند—یعنی فضاهای فرضیه بسیار غنی را کدگذاری میکنند. این مقیاسپذیری افراطی یکی از ویژگیهای تعیینکننده یادگیری عمیق مدرن است. معماریهای مدل در مقیاس بزرگ، که دارای دهها لایه و دهها میلیون پارامتر هستند، پیشرفتهای حیاتی را هم در بینایی کامپیوتر (به عنوان مثال، معماریهایی مانند ResNet، Inception، یا Xception) و هم در پردازش زبان طبیعی (به عنوان مثال، معماریهای بزرگ مبتنی بر ترنسفورمر مانند BERT، GPT-3، یا XLNet) به ارمغان آوردهاند.
موج جدیدی از سرمایهگذاری
هنگامی که یادگیری عمیق در سالهای ۲۰۱۲ تا ۲۰۱۳ به جدیدترین سطح پیشرفت در بینایی کامپیوتر، و در نهایت برای تمام وظایف ادراکی تبدیل شد، رهبران صنعت به آن توجه کردند. به دنبال آن، موجی تدریجی از سرمایهگذاری صنعتی آغاز شد که به مراتب فراتر از هر آنچه پیش از آن در تاریخ هوش مصنوعی دیده شده بود، رفت (شکل ۱.۱۴ را ببینید).
جمع کل سرمایهگذاریهای تخمینی در استارتآپهای هوش مصنوعی، ۲۰۱۱-۱۷ و نیمه اول ۲۰۱۸
بر اساس موقعیت مکانی استارتآپ
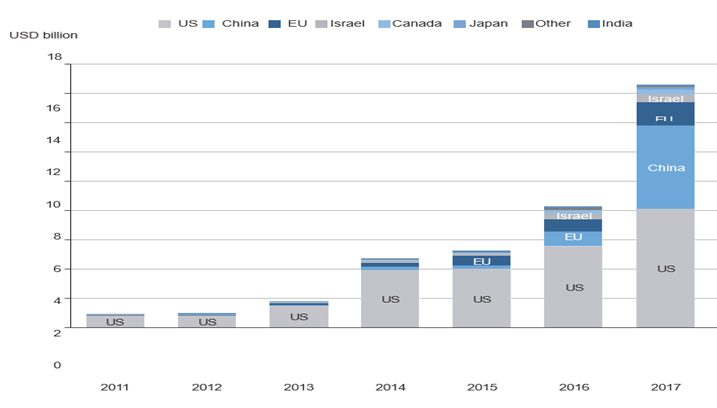
در سال ۲۰۱۱، درست پیش از آنکه یادگیری عمیق در کانون توجه قرار گیرد، مجموع سرمایهگذاری خطرپذیر در هوش مصنوعی در سراسر جهان کمتر از یک میلیارد دلار بود که تقریباً تمام آن به کاربردهای عملی رویکردهای یادگیری ماشین سطحی اختصاص مییافت. در سال ۲۰۱۵، این رقم به بیش از ۵ میلیارد دلار و در سال ۲۰۱۷ به ۱۶ میلیارد دلار خیرهکننده افزایش یافت. صدها استارتآپ در این چند سال راهاندازی شدند و تلاش کردند تا از هیجان یادگیری عمیق سرمایهگذاری کنند. در همین حال، شرکتهای بزرگ فناوری مانند گوگل، آمازون و مایکروسافت در دپارتمانهای تحقیقات داخلی خود به میزانی سرمایهگذاری کردهاند که به احتمال زیاد جریان پول سرمایههای خطرپذیر را تحتالشعاع قرار میدهد.
یادگیری ماشین—به ویژه یادگیری عمیق—به هسته استراتژی محصول این غولهای فناوری تبدیل شده است. در اواخر سال ۲۰۱۵، ساندار پیچای، مدیرعامل گوگل، اظهار داشت: “یادگیری ماشین یک راهکار اصلی و تحولآفرین است که ما با آن نحوه انجام همه کارها را دوباره ارزیابی میکنیم. ما آن را به طور متفکرانه در تمام محصولات خود، اعم از جستجو، تبلیغات، یوتیوب، یا پلی، به کار میبریم. و ما در مراحل اولیه هستیم، اما خواهید دید که ما—به روشی سیستماتیک—یادگیری ماشین را در تمام این زمینهها به کار خواهیم برد.”
در نتیجه این موج سرمایهگذاری، تعداد افرادی که روی یادگیری عمیق کار میکنند در کمتر از ۱۰ سال از چند صد نفر به دهها هزار نفر رسید و پیشرفت تحقیقات به سرعت دیوانهواری دست یافت.
دموکراتیزه شدن(دموکراتیک کردن) یادگیری عمیق
یکی از عوامل کلیدی که باعث سرازیر شدن نیروهای جدید به حوزه یادگیری عمیق شد، دموکراتیزه شدن ابزارهای مورد استفاده در این زمینه بوده است. در روزهای اولیه، انجام یادگیری عمیق نیازمند تخصص قابل توجهی در ++ C و CUDA بود که تنها تعداد کمی از افراد از آن برخوردار بودند.
امروزه، مهارتهای پایهای اسکریپتنویسی پایتون برای انجام تحقیقات پیشرفته یادگیری عمیق کافی است. این امر به ویژه با توسعه کتابخانه اکنون منسوخ شده Theano، و سپس کتابخانه TensorFlow—دو فریمورک نمادین برای دستکاری تنسورها در پایتون که از خودکارسازی مشتقگیری (autodifferentiation) پشتیبانی میکنند و پیادهسازی مدلهای جدید را به شدت ساده میکنند—و با ظهور کتابخانههای کاربرپسند مانند Keras به وقوع پیوست. Keras یادگیری عمیق را به سادگی دستکاری قطعات لگو میکند. پس از انتشار آن در اوایل سال ۲۰۱۵، Keras به سرعت به راهحل اصلی یادگیری عمیق برای تعداد زیادی از استارتآپهای جدید، دانشجویان تحصیلات تکمیلی و محققانی که به این حوزه روی میآوردند، تبدیل شد.
آیا دوام خواهد آورد؟
آیا ویژگی خاصی در شبکههای عصبی عمیق وجود دارد که آنها را رویکرد «درست» برای سرمایهگذاری شرکتها و سرازیر شدن محققان به این حوزه تبدیل میکند؟ یا یادگیری عمیق صرفاً یک مد گذرا است که ممکن است دوام نیاورد؟ آیا ما در ۲۰ سال آینده همچنان از شبکههای عصبی عمیق استفاده خواهیم کرد؟
یادگیری عمیق چندین ویژگی دارد که جایگاه آن را به عنوان یک انقلاب هوش مصنوعی توجیه میکند و نشان میدهد که این حوزه ماندگار است. ممکن است ما دو دهه دیگر از شبکههای عصبی استفاده نکنیم، اما هر آنچه که استفاده خواهیم کرد، مستقیماً از یادگیری عمیق مدرن و مفاهیم اصلی آن به ارث خواهد برد. این ویژگیهای مهم را میتوان به طور کلی در سه دسته طبقهبندی کرد:
- سادگی: یادگیری عمیق نیاز به مهندسی ویژگی را از بین میبرد و خطوط لوله پیچیده، شکننده، و نیازمند مهندسی سنگین را با مدلهای ساده و سرتاسری قابل آموزش جایگزین میکند که معمولاً فقط با پنج یا شش عملیات تنسور مختلف ساخته میشوند.
- مقیاسپذیری: یادگیری عمیق به شدت برای موازیسازی روی GPUها یا TPUها مناسب است، بنابراین میتواند از مزایای کامل قانون مور بهرهمند شود. علاوه بر این، مدلهای یادگیری عمیق با تکرار روی دستههای کوچک داده آموزش میبینند و این امکان را میدهد که روی مجموعهدادههایی با اندازه دلخواه آموزش داده شوند. (تنها گلوگاه، مقدار توان محاسباتی موازی در دسترس است که به لطف قانون مور، یک مانع به سرعت در حال جابجایی است.)
- تطبیقپذیری و قابلیت استفاده مجدد: برخلاف بسیاری از رویکردهای قبلی یادگیری ماشین، مدلهای یادگیری عمیق را میتوان روی دادههای اضافی بدون شروع مجدد از ابتدا آموزش داد، که آنها را برای یادگیری آنلاین پیوسته مناسب میسازد—یک ویژگی مهم برای مدلهای ایجادی بسیار بزرگ. علاوه بر این، مدلهای یادگیری عمیق آموزشدیده قابل تغییر هدف و بنابراین قابل استفاده مجدد هستند: برای مثال، میتوان یک مدل یادگیری عمیق آموزشدیده برای طبقهبندی تصویر را برداشت و آن را در یک خط لوله پردازش ویدیو قرار داد. این به ما امکان میدهد که کارهای قبلی را در مدلهای پیچیدهتر و قدرتمندتر سرمایهگذاری مجدد کنیم. این همچنین یادگیری عمیق را برای مجموعهدادههای نسبتاً کوچک نیز قابل استفاده میکند.
یادگیری عمیق تنها چند سال است که در کانون توجه قرار گرفته، و ما هنوز ممکن است دامنه کامل تواناییهای آن را مشخص نکرده باشیم. با گذشت هر سال، ما درباره کاربردهای جدید و بهبودهای مهندسی که محدودیتهای قبلی را برطرف میکنند، میآموزیم. پس از یک انقلاب علمی، پیشرفت معمولاً از یک منحنی سیگموئید پیروی میکند: با یک دوره پیشرفت سریع آغاز میشود، که به تدریج با رسیدن محققان به محدودیتهای سخت، تثبیت میشود، و سپس بهبودهای بیشتر به صورت تدریجی (incremental) میشوند.
هنگامی که من ویرایش اول این کتاب را در سال ۲۰۱۶ مینوشتم، پیشبینی کردم که یادگیری عمیق هنوز در نیمه اول آن سیگموئید قرار دارد و پیشرفتهای تحولآفرین بیشتری در چند سال آینده در راه است. این پیشبینی در عمل درست از آب درآمد، زیرا در سالهای ۲۰۱۷ و ۲۰۱۸ شاهد ظهور مدلهای یادگیری عمیق مبتنی بر ترنسفورمر برای پردازش زبان طبیعی بودیم که انقلابی در این حوزه ایجاد کردند، در حالی که یادگیری عمیق همچنان پیشرفت ثابتی را در بینایی کامپیوتر و تشخیص گفتار ارائه میداد. امروزه، در سال ۲۰۲۱، به نظر میرسد یادگیری عمیق وارد نیمه دوم آن سیگموئید شده است. ما باید همچنان انتظار پیشرفت قابل توجهی را در سالهای آینده داشته باشیم، اما احتمالاً از فاز اولیه پیشرفت انفجاری خارج شدهایم.
امروز، من از بهکارگیری فناوری یادگیری عمیق برای هر مشکلی که میتواند حل کند—لیست بیپایان است—بسیار هیجانزده هستم. یادگیری عمیق هنوز یک انقلاب در حال شکلگیری است، و سالها طول خواهد کشید تا پتانسیل کامل آن به وقوع بپیوندد.



