
مقدمه
وقتی یک شبکهی عصبی در پیشبینی خود دچار خطا میشود، سؤال اصلی این نیست که «خطا چقدر بوده است»، بلکه این است که این خطا دقیقاً از کجا آمده و کدام بخش از مدل باید اصلاح شود. پاسخ به این سؤال، هستهی اصلی فرآیند یادگیری در شبکههای عصبی را شکل میدهد.
الگوریتم انتشار رو به عقب (Backpropagation) مکانیزمی است که این مسئولیت را بر عهده دارد. این الگوریتم با حرکت از خروجی شبکه به سمت لایههای اولیه، سهم هر وزن و بایاس را در ایجاد خطا محاسبه میکند و مشخص میسازد که هر پارامتر باید چه مقدار تغییر کند تا عملکرد مدل بهبود یابد.
هدف این مطلب ارائهی یک توضیح شفاف، مرحلهبهمرحله و قابلفهم از انتشار رو به عقب است؛ بهگونهای که خواننده نهتنها بداند این الگوریتم «چه کاری انجام میدهد»، بلکه درک کند «چرا و چگونه» این فرآیند منجر به یادگیری میشود. برای رسیدن به این هدف، ابتدا چرخهی کلی آموزش را بررسی میکنیم، سپس با یک مثال عددی ساده منطق محاسبات را ملموس میسازیم و در ادامه، کاربردها، مزایا، محدودیتها و مسیرهای آیندهی این الگوریتم را مرور میکنیم.
در پایان این مسیر، انتظار میرود انتشار رو به عقب دیگر یک مفهوم مبهم یا صرفاً یک نام در کتابها نباشد، بلکه بهعنوان یک ابزار تحلیلی قابلدرک در ذهن خواننده جای گیرد.

تعریف
انتشار رو به عقب (Backpropagation) الگوریتمی است که برای آموزش شبکههای عصبی استفاده میشود. وظیفه این الگوریتم، محاسبه سهم خطای هر یک از وزنها و بایاسهای شبکه است. به زبان ساده، وقتی هوش مصنوعی یک پیشبینی اشتباه انجام میدهد، این الگوریتم از انتها (خروجی) به سمت ابتدا (ورودی) حرکت میکند تا بفهمد دقیقاً کدام بخش از شبکه مقصر این اشتباه بوده و باید چقدر تغییر کند.
انتشار رو به عقب (Backpropagation) چگونه کار میکند؟
حالا که با مفهوم کلی آشنا شدید، بیایید غرق در جزئیات شویم و ببینیم در قلب یک شبکه عصبی چه میگذرد. تصور کنید یک مدل ساده با یک ورودی، یک نورون در لایهی پنهان و یک خروجی داریم. این مدل قرار است یاد بگیرد که به هدف (Target) ما نزدیک شود.
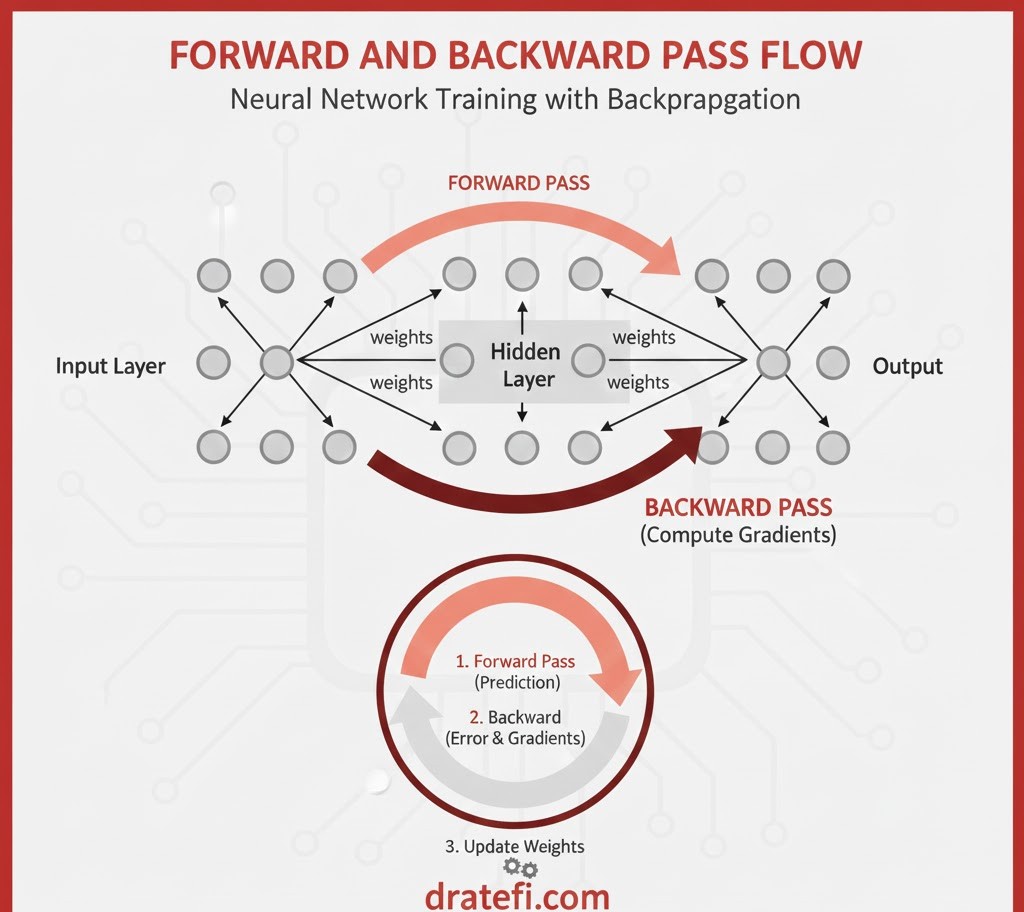
این سفر یادگیری، یک چرخه بیپایان از ۴ گام طلایی است:
۱. گذر رو به جلو(Forward Pass): فرضیهی اولیه
همه چیز با یک حدس شروع میشود. دادههای ورودی وارد شبکه شده و مراحل زیر را طی میکنند:
- تشکیل مجموع وزندار(z): ورودی (x) در وزن (w) ضرب شده و با بایاس (b) جمع میشود.
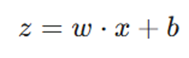
- فعالسازی: خروجی خام (z) از یک تابع فعالساز (مثل سیگموئید) عبور میکند تا خروجی نهایی مدل (y’) به دست آید.
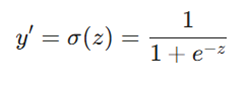
۲. محاسبه خطا(Loss Calculation): لحظهی حقیقت
مدل خروجی خود (‘y) را با واقعیت یا هدف (y) مقایسه میکند. میزان فاصله از حقیقت با استفاده از تابع زیان (مانند MSE) محاسبه میشود:
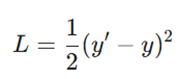
این عدد به ما میگوید که پیشبینی مدل چقدر “بد” بوده است.
۳. گذر رو به عقب(Backward Pass): تقسیم تقصیر
اینجاست که جادوی اصلی اتفاق میافتد. ما از انتهای شبکه به سمت ابتدا حرکت میکنیم تا بفهمیم هر پارامتر چقدر در خطا سهم داشته است. برای این کار از قانون زنجیرهای (Chain Rule) استفاده میکنیم:
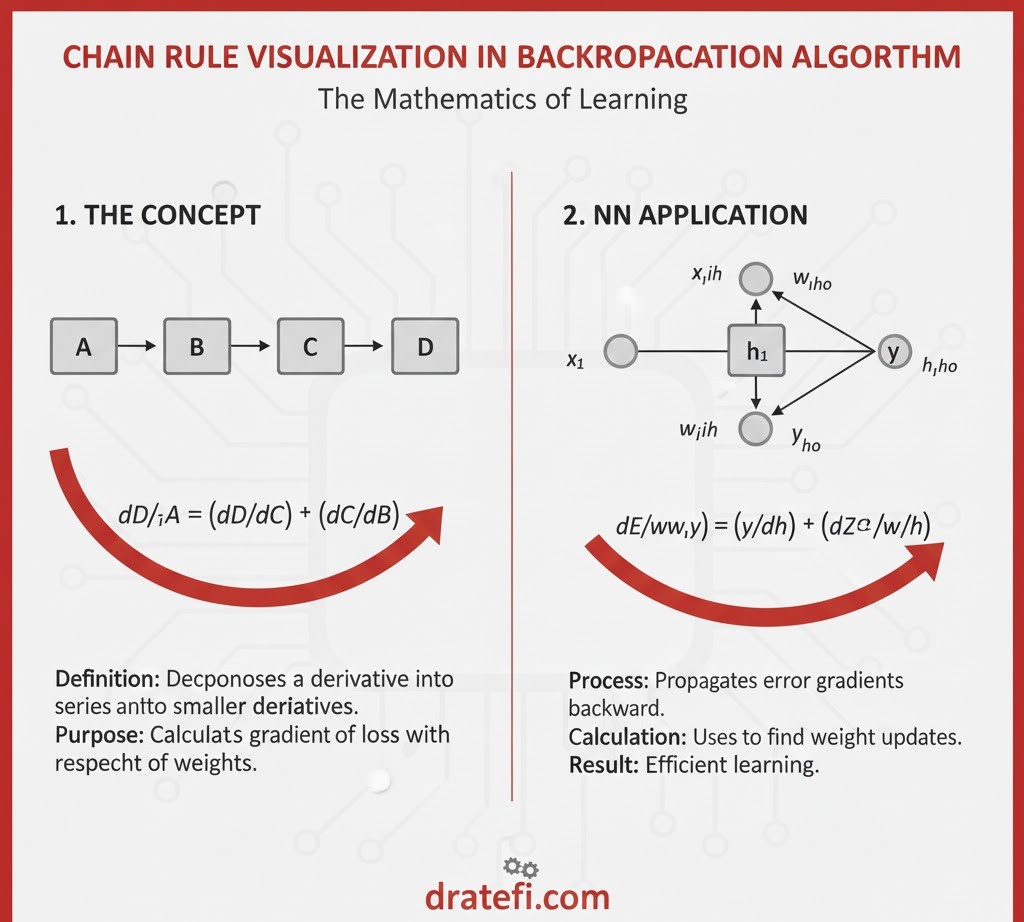
محاسبه گرادیان برای وزن(w):
ما به دنبال این هستیم که بدانیم خطا نسبت به وزن چقدر تغییر میکند(L/∂w∂):
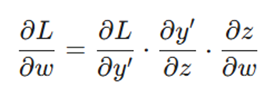
- بخش اول(‘L/∂y∂): میزان حساسیت خطا نسبت به خروجی مدل ←(y’ – y)
- بخش دوم(y’/∂z∂): مشتق تابع سیگموئید← y'(1 – y’)
- بخش سوم(z/∂w∂): تأثیر وزن بر مجموع ورودیها که همان مقدار ورودی است← x
۴. بهروزرسانی(Weights Update): اصلاح هوشمندانه
در گام آخر، بر اساس اطلاعاتی که از مرحله قبل به دست آوردیم، وزنها و بایاسها را اصلاح میکنیم. این کار را نزول گرادیان (Gradient Descent) مینامیم:
بهروزرسانی وزن:
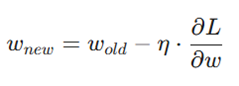
بهروزرسانی بایاس:
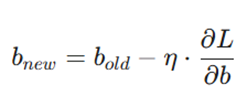
توضیح متغیرهای کلیدی:
- η (نرخ یادگیری): جسارت مدل در تغییر کردن. اگر خیلی بزرگ باشد، مدل از پاسخ درست رد میشود و اگر خیلی کوچک باشد، یادگیری بسیار کُند خواهد بود.
- L/∂w∂: جهت و قدرت تغییر؛ به ما میگوید برای کم کردن خطا، وزن باید چقدر زیاد یا کم شود.
مثال عملی انتشار رو به عقب
برای درک بهتر، فرآیند یادگیری را روی یک تکنورون با تابع فعالساز سیگموئید و با دادههای فرضی زیر پیادهسازی میکنیم:
- ورودی (x): 0.5
- وزن فعلی (w): 0.4
- بایاس (b): 0.1
- خروجی هدف (y): 0.7
- نرخ یادگیری (η): 0.1
گام ۱: گذر رو به جلو (Forward Pass)
در این مرحله، مدل حدس اولیه خود را محاسبه میکند.
۱. محاسبه مجموع وزندار(z):
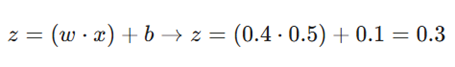
۲. اعمال تابع سیگموئید (خروجی ‘y):
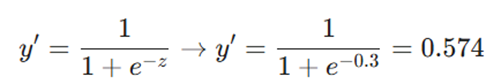
۳. محاسبه خطا(Mean Squared Error):
تفاوت بین پیشبینی مدل (0.574) و هدف واقعی(0.7):
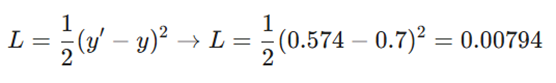
گام ۲: گذر رو به عقب (محاسبه گرادیان)
حالا شبکه باید بفهمد چگونه وزن را تغییر دهد تا خطا کم شود. برای این کار از قانون زنجیرهای (Chain Rule) استفاده میکنیم.
۱. گرادیان خطا نسبت به خروجی:
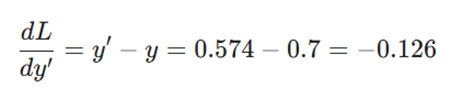
۲. گرادیان خروجی نسبت به z (مشتق سیگموئید):
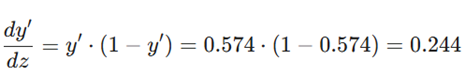
۳. گرادیان z نسبت به وزن w:
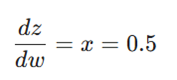
۴. گرادیان کل برای وزن (قانون زنجیرهای):
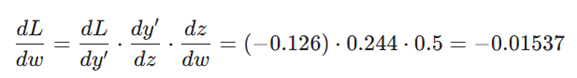
گام ۳: بهروزرسانی وزن (Weighted Update)
اکنون وزن جدید (‘w) را با استفاده از نزول گرادیان محاسبه میکنیم:
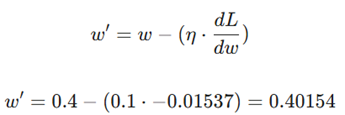
گام ۴: بهروزرسانی بایاس (Bias Update)
مشابه وزن، بایاس جدید را نیز محاسبه میکنیم (با توجه به اینکه dz/db = 1):
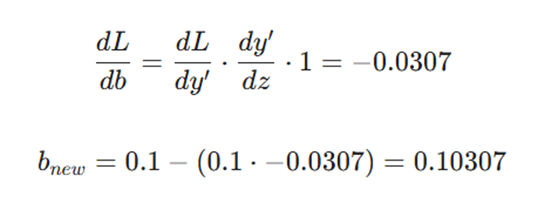
خروجی نهایی این مرحله:
- وزن جدید: 0.40154
- بایاس جدید: 0.10307
- نتیجه: میزان خطا از مقدار اولیه 0.00794 کاهش یافت. با تکرار این چرخه در اپوکهای بعدی، خطا باز هم کمتر شده و خروجی مدل به عدد 0.7 نزدیکتر خواهد شد.
کاربردها
درک زبان انسان
هوش مصنوعیهایی مثل ChatGPT یا مترجم گوگل، با استفاده از انتشار رو به عقب یاد گرفتهاند که کلمات چه ارتباطی با هم دارند. این الگوریتم به مدل میآموزد که اگر در یک جمله اشتباهی در گرامر یا معنا رخ داد، وزنهای مربوط به درک کلمات را اصلاح کند تا دفعه بعد جملهای انسانیتر و دقیقتر بسازد.
بینایی ماشین و تشخیص تصویر
از تشخیص تومورهای سرطانی در عکسهای پزشکی گرفته تا باز شدن قفل گوشی با چهره (FaceID)، همگی مدیون این الگوریتم هستند. انتشار رو به عقب به شبکه عصبی یاد میدهد که کدام پیکسلها مربوط به “لبهی چشم” هستند و کدامها مربوط به “بافت پوست”؛ و اگر مدل یک گربه را اشتباهاً سگ تشخیص داد، با بازگشت به عقب، فیلترهای تصویری خود را اصلاح میکند.
خودروهای خودران
خودروهای تسلا یا ویمو (Waymo) باید در لحظه تصمیم بگیرند که آنچه مقابلشان است یک کیسه پلاستیکی است یا یک کودک. انتشار رو به عقب در مرحله آموزش، هزاران ساعت ویدیو را پردازش میکند تا مدل یاد بگیرد کوچکترین خطا در تشخیص اشیاء میتواند حیاتی باشد؛ بنابراین وزنها را برای رسیدن به دقت بالا تنظیم میکند.
پیشبینیهای مالی و بورس
در بازارهای مالی که نوسانات بسیار پیچیده هستند، شبکههای عصبی با بررسی دادههای تاریخی قیمتها، الگوهای پنهان را کشف میکنند. انتشار رو به عقب کمک میکند تا مدل با کمترین خطا، روندهای آتی بازار را پیشبینی کرده و ریسک سرمایهگذاری را کاهش دهد.
سیستمهای پیشنهادگر
تا به حال فکر کردهاید که چرا نتفلیکس یا اینستاگرام دقیقاً محتوایی را به شما نشان میدهند که دوست دارید؟ این سیستمها با هر کلیک شما، یک مرحله “رفت” انجام میدهند و اگر شما محتوا را نپسندید، با یک مرحله “برگشت”، علایق شما را دوباره کالیبره میکنند تا پیشنهاد بعدی دقیقتر باشد.
مزایا
انتشار رو به عقب تکنیکی بنیادین در آموزش شبکههای عصبی است که به دلیل پیادهسازی مستقیم، سادگی در برنامهنویسی و تطبیقپذیری بالا با معماریهای مختلف، بسیار محبوب است.
سهولت در پیادهسازی و دسترسی همگانی
امروزه دیگر نیاز نیست چرخ را از اول اختراع کنید. به لطف کتابخانههای قدرتمندی مثل PyTorch، Keras و TensorFlow، پیادهسازی این تکنیک به چند خط کد ساده خلاصه شده است. این ابزارها باعث شدهاند تا از توسعهدهندگان مستقل گرفته تا غولهای فناوری، همگی بتوانند از این قدرت در اپلیکیشنهای متنوع استفاده کنند.
سادگی در برنامهنویسی و انتزاع هوشمندانه
در گذشته، پیادهسازی یک شبکه عصبی نیازمند نوشتن دستی هزاران خط کد ریاضی پیچیده بود. اما فریمورکهای مدرن با ایجاد لایههای انتزاعی، بخش سخت ماجرا (محاسبه مشتقات و زنجیرههای ریاضی) را بر عهده گرفتهاند. این یعنی شما روی معماری مدل تمرکز میکنید و ابزارها یادگیری را مدیریت میکنند.
انعطافپذیری خیرهکننده (Versatility)
این الگوریتم یک آچار فرانسه واقعی است. فرقی نمیکند در حال ساخت یک شبکه ساده برای تشخیص اعداد هستید یا یک مدل پیچیده مثل Transformer برای ترجمه همزمان؛ انتشار رو به عقب به راحتی با انواع معماریهای خطی و غیرخطی سازگار میشود.
کارایی بالا در مدیریت پارامترهای عظیم
مدلهای مدرن هوش مصنوعی میلیاردها پارامتر (وزن) دارند. انتشار رو به عقب تنها روشی است که میتواند به طور همزمان و با دقت جراحی، سهم خطای تکتک این میلیاردها نقطه را محاسبه و آنها را اصلاح کند. این سطح از مقیاسپذیری در روشهای قدیمیتر غیرممکن بود.
بهینهسازی مداوم (Iterative Improvement)
این الگوریتم اجازه میدهد مدل به صورت تدریجی (Incremental) یاد بگیرد. یعنی میتوانید آموزش را متوقف کنید، عملکرد را بسنجید و دوباره ادامه دهید. این ویژگی برای مدلهایی که با دادههای در حال تغییر سر و کار دارند، حیاتی است.
پایه و اساسِ بهینهسازهای پیشرفته
الگوریتمهای محبوبی مثل Adam، RMSprop و Adagrad همگی بر شانههای انتشار رو به عقب ایستادهاند. در واقع، این روش زیرساختی را فراهم کرده که تمام نوآوریهای بعدی در سرعت بخشیدن به یادگیری بر روی آن بنا شده است.
محدودیتها
با وجود موفقیتهای چشمگیر، انتشار رو به عقب بدون نقص نیست. این محدودیتها میتوانند بر کارایی و اثربخشی فرآیند آموزش تأثیر بگذارند:
حساسیت شدید به کیفیت دادهها (Garbage In, Garbage Out)
انتشار رو به عقب یک شاگرد بسیار مطیع است؛ او دقیقاً همان چیزی را یاد میگیرد که به او دیکته میکنید. اگر دادههای آموزشی شما شامل نویز، اطلاعات ناقص یا سوگیریهای پنهان (Bias) باشد، مدل نه تنها آنها را یاد میگیرد، بلکه آنها را تقویت میکند. نتیجه، مدلی خواهد بود که در دنیای واقعی پیشبینیهای غیرمنطقی و غیرقابل اعتمادی انجام میدهد.
اشتهای سیریناپذیر برای زمان و منابع
آموزش یک شبکه عصبی با استفاده از این الگوریتم، به ویژه در مدلهای بزرگ (مانند LLMها)، به زمان بسیار طولانی نیاز دارد. این موضوع دو چالش بزرگ ایجاد میکند:
- هزینه محاسباتی: نیاز به پردازندههای گرافیکی (GPU) یا واحدهای پردازش تنسور (TPU) قدرتمند که انرژی و هزینه مالی زیادی میطلبند.
- تاخیر در توسعه: گاهی آموزش یک مدل هفتهها زمان میبرد که در پروژههای حساس به زمان، یک نقطه ضعف بزرگ است.
چالش محاسبات ماتریسی سنگین
هر لایهای که به شبکه اضافه میشود، حجم عملیات ضرب ماتریسی در مرحله بازگشت به صورت تصاعدی بالا میرود. این پیچیدگی محاسباتی باعث میشود که با بزرگ شدن ابعاد شبکه، تقاضا برای حافظه (RAM) و قدرت پردازش، پتانسیل سختافزار موجود را به چالش بکشد.
مشکل محو شدن یا انفجار گرادیان (Vanishing/Exploding Gradients)
در شبکههای بسیار عمیق، وقتی خطا را به لایههای اولیه برمیگردانیم، مقدار گرادیان در طول ضربهای متوالی یا آنقدر کوچک میشود که به صفر میرسد (مدل دیگر یاد نمیگیرد) و یا آنقدر بزرگ میشود که وزنها از کنترل خارج میشوند. این یکی از بزرگترین دردهای سر مهندسان در کار با شبکههای عمیق است.
خطر گیر افتادن در بهینههای محلی (Local Minima)
هدف انتشار رو به عقب پیدا کردن «کمترین میزان خطا» است. اما گاهی اوقات مدل در حفرهای گیر میافتد که کمترین مقدار در آن منطقه است (Local Minimum)، اما کمترین مقدارِ کل نیست. در این حالت، مدل فکر میکند بهترین عملکرد را دارد، در حالی که هنوز پتانسیل بهتری برای یادگیری وجود داشته است.
بیشبرازش (Overfitting)
اگر مدل بیش از حد روی دادههای آموزشی تمرکز کند، به جای یادگیری «مفهوم»، دادهها را «حفظ» میکند. انتشار رو به عقب ممکن است وزنها را به شکلی تنظیم کند که خطا روی دادههای تمرینی صفر شود، اما روی دادههای جدید و واقعی، مدل کاملاً شکست بخورد.
جایگزینها و آیندهی انتشار رو به عقب
هزینههای بالای محاسباتی و محدودیتهای فنی، فضایی را برای جستجوی گزینههای جایگزین فراهم کرده است. برخی از نویدبخشترین این روشها عبارتند از:
۱. انتشار تعادلی (Equilibrium Propagation)
این الگوریتم از تمایل طبیعی شبکههای عصبی برای رسیدن به یک حالت پایدار یا تعادل استفاده میکند. به جای محاسبات پیچیده ریاضی، شبکه را به آرامی به سمت خروجی هدف سوق میدهد و با استفاده از صعود گرادیان در این حالت پایدار، اتصالات را تنظیم میکند.
۲. تراز بازخورد مستقیم (Direct Feedback Alignment)
در این روش، به جای استفاده از گرادیانهای دقیق و ریاضیاتی، از وزنهای بازخورد تصادفی و ثابت برای هدایت بهروزرسانیها استفاده میشود. این متد برای یادگیری، به جای دقت مطلق، بر ترازهای تقریبی خطا تکیه دارد که باعث کاهش چشمگیر بار محاسباتی میشود.
۳. انتشار هدف متفاوت (DTP – Different Target Propagation)
این روش برای شبکههای بسیار عمیق یا به شدت غیرخطی که در آنها بهروزرسانیهای مبتنی بر گرادیان ناکارآمد میشوند، طراحی شده است. DTP به جای محاسبه مقادیر هدف، گرادیانهای مخصوص هر لایه را برای هدایت فرآیند یادگیری محاسبه میکند.
۴. تنگنای HSIC (HSIC Bottleneck)
این تکنیک به جای انتشار رو به عقب، از تقریبی از تنگنای اطلاعاتی (Information Bottleneck) برای آموزش استفاده میکند. هدف این روش افزایش وابستگی بین نمایشهای پنهان و خروجیها، و در عین حال به حداقل رساندن وابستگی آنها به ورودیهاست.
۵. رابطهای عصبی مجزا با استفاده از گرادیانهای مصنوعی (Synthetic Gradients)
این متد به شبکههای عصبی اجازه میدهد تا به صورت مقیاسپذیر و مستقل (Decoupled) یاد بگیرند. با تولید گرادیانهای مصنوعی، مدل دیگر منتظر دریافت سیگنالهای دقیق گرادیان نمیماند؛ این ویژگی به ویژه در مدیریت وابستگیهای طولانیمدت در شبکههای عصبی بازگشتی (RNN) بسیار حیاتی است.
انتشار رو به جلو در برابر انتشار رو به عقب
| پارامتر کلیدی | انتشار رو به جلو (Forward Pass) | انتشار رو به عقب (Backward Pass) |
| تعریف | جریان اطلاعات برای تبدیل ورودی به خروجی | جریان سیگنال خطا برای عیبیابی لایهها |
| منطق عملکردی | استنتاج (Inference): مدل حدس میزند. | یادگیری (Learning): مدل اصلاح میشود. |
| تکنیک ریاضی | ضرب ماتریسی و توابع غیرخطی | مشتقگیری جزئی و قانون زنجیرهای (Chain Rule) |
| نقش وزنها | وزنها ثابت هستند و برای محاسبه استفاده میشوند. | وزنها متغیرند و برای کاهش خطا بهروزرسانی میشوند. |
| وابستگی زمانی | نقطه شروع چرخه یادگیری است. | فقط پس از محاسبه تابع زیان (Loss) آغاز میشود. |
| مفهوم فیزیکی | شبیه به عبور نور از عدسیهای مختلف | شبیه به بازگشت موج برای سنجش عمق (Sonar) |
| توابع درگیر | تابع فعالساز (ReLU, Sigmoid, etc) | تابع بهینهساز (Adam, SGD, etc) |
| میزان پیچیدگی | کمتر؛ محاسبات مستقیم و خطی | بیشتر؛ محاسبات بازگشتی و ذخیرهسازی حافظه |
| خروجی نهایی | بردار احتمال یا یک مقدار عددی (نمره/قیمت) | بردار گرادیان (میزان تغییرات لازم برای هر پارامتر) |
| ارتباط با خطا | خطا را تولید میکند (بدون اطلاع از مقدار آن) | خطا را مصرف کرده و آن را از بین میبرد. |
پیادهسازی انتشار رو به عقب در پایتون برای مسئله XOR
پیادهسازی پایتون برای یک شبکه عصبی ساده جهت حل مسئله XOR با استفاده از الگوریتم انتشار رو به عقب به شرح زیر است:
۱. تعریف ساختار شبکه عصبی
این شبکه دارای دو نورون در لایه ورودی، چهار نورون در لایه پنهان و یک نورون در لایه خروجی است.
- Weights_input_hidden: لایه ورودی را به لایه پنهان متصل میکند.
- Weights_hidden_output: لایه پنهان را به لایه خروجی متصل میکند.
- بایاسها: (Biases): برای جابهجایی تابع فعالساز در صورت نیاز، مقدار اولیه آنها صفر در نظر گرفته شده است.
import numpy as np
class XORNeuralNetwork:
def __init__(self, input_size, hidden_size, output_size):
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.weights_input_hidden = np.random.randn(self.input_size, self.hidden_size)
self.bias_hidden = np.zeros((1, self.hidden_size))
self.weights_hidden_output = np.random.randn(self.hidden_size, self.output_size)
self.bias_output = np.zeros((1, self.output_size))
۲. تابع فعالساز و مشتق آن
تابع سیگموئید (Sigmoid) مقادیر ورودی را فشرده کرده و آنها را در بازهای بین ۰ و ۱ قرار میدهد؛ این ویژگی باعث میشود که این تابع برای خروجیهای دودویی (Binary)، مانند عملیات منطقی XOR، بسیار مناسب باشد. در فرآیند انتشار رو به عقب، از مشتق تابع سیگموئید برای محاسبه گرادیانها و اصلاح خطا استفاده میشود.
def sigmoid(self, x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(self, x):
return x * (1 - x)
۳. فاز پیشخور یا گذر رو به جلو (Feedforward Pass)
در این مرحله، دادهها در طول لایههای شبکه به جریان میافتند تا یک پیشبینی شکل بگیرد:
- از ورودی به لایه پنهان: ابتدا حاصلضرب نقطهای (Dot Product) مقادیر ورودی در وزنهایشان محاسبه شده و با مقدار بایاس جمع میشود. سپس این حاصل برای پردازش، از یک تابع فعالساز سیگموئید (Sigmoid Function) عبور داده میشود.
- در لایه پنهان به خروجی: همین فرآیند تکرار میشود؛ یعنی حاصلضرب نقطهایِ خروجیهای لایه پنهان در وزنهای مربوطه با بایاس جمع شده و مجدداً از تابع سیگموئید رد میشود تا خروجی نهایی به دست آید.
- ذخیرهسازی: تمامی خروجیهای میانی در این مرحله ذخیره میشوند؛ چرا که در فاز انتشار رو به عقب برای محاسبه دقیق خطا و اصلاح وزنها به آنها نیاز حیاتی داریم.
def feedforward(self, X):
self.hidden_input = np.dot(X, self.weights_input_hidden) + self.bias_hidden
self.hidden_output = self.sigmoid(self.hidden_input)
self.final_input = np.dot(self.hidden_output, self.weights_hidden_output) + self.bias_output
self.final_output = self.sigmoid(self.final_input)
return self.final_output
۴. انتشار رو به عقب (Backward Propagation)
def backward(self, X, y, learning_rate):
error = y - self.final_output
d_output = error * self.sigmoid_derivative(self.final_output)
error_hidden = d_output.dot(self.weights_hidden_output.T)
d_hidden = error_hidden * self.sigmoid_derivative(self.hidden_output)
self.weights_hidden_output += self.hidden_output.T.dot(d_output) * learning_rate
self.bias_output += np.sum(d_output, axis=0, keepdims=True) * learning_rate
self.weights_input_hidden += X.T.dot(d_hidden) * learning_rate
self.bias_hidden += np.sum(d_hidden, axis=0, keepdims=True) * learning_rate
۵. آموزش شبکه عصبی
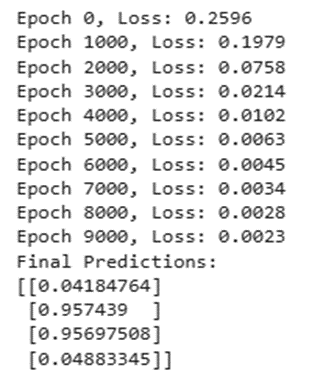
در این مرحله، شبکه عصبی فرآیند انتشار رو به جلو و رو به عقب را برای تعداد دورهای مشخصی (Epochs) به صورت متوالی تکرار میکند. برای اینکه بتوانیم روند یادگیری را زیر نظر بگیریم، میزان خطا یا همان Loss در هر ۱۰۰۰ اپوک چاپ میشود؛ این کار به ما نشان میدهد که مدل چقدر در حال پیشرفت است. در این پیادهسازی، از معیار میانگین مجذور خطا (Mean Squared Error) به عنوان سنجهای برای محاسبه میزان اشتباهات مدل استفاده شده است.
def train(self, X, y, epochs, learning_rate):
for epoch in range(epochs):
self.feedforward(X)
self.backward(X, y, learning_rate)
if epoch % 1000 == 0:
loss = np.mean(np.square(y - self.final_output))
print(f"Epoch {epoch}, Loss: {loss:.4f}")
۶. آموزش و آزمایش (Training and Testing)
فرآیند آموزش این شبکه عصبی برای ۱۰,۰۰۰ اپوک (تکرار) و با نرخ یادگیری (Learning Rate) ۰.۱ انجام میشود. پس از پایان این چرخه طولانیِ یادگیری، مدل پیشبینیهای خود را چاپ میکند؛ در این مرحله، مقادیر خروجی باید کاملاً به ۰ یا ۱ نزدیک شده باشند (که نشاندهنده حل موفقیتآمیز مسئله XOR است).
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[0], [1], [1], [0]])
nn = XORNeuralNetwork(input_size=2, hidden_size=4, output_size=1)
nn.train(X, y, epochs=10000, learning_rate=0.1)
print("Final Predictions:")
print(nn.feedforward(X))
خروجی:
جمع بندی
انتشار رو به عقب، ستون فقرات فرآیند یادگیری در شبکههای عصبی مصنوعی است. در این مطلب دیدیم که چگونه یک مدل با استفاده از گذر رو به جلو خروجی تولید میکند، خطای خود را محاسبه میکند و سپس با حرکت معکوس در شبکه، پارامترهایش را بهصورت هدفمند اصلاح میکند.
بررسی مثال عددی نشان داد که مفاهیمی مانند گرادیان، مشتق و قانون زنجیرهای صرفاً ابزارهای انتزاعی ریاضی نیستند، بلکه بهطور مستقیم تعیین میکنند هر وزن و بایاس چگونه و به چه میزان تغییر کند. همچنین با مرور کاربردها و محدودیتها مشخص شد که با وجود قدرت بالای این الگوریتم، استفادهی مؤثر از آن نیازمند دادهی مناسب، منابع محاسباتی کافی و طراحی آگاهانهی مدل است.
اگرچه پژوهشهای جدید به دنبال جایگزینها یا بهبودهایی برای انتشار رو به عقب هستند، اما این الگوریتم همچنان پایه و اساس آموزش اغلب مدلهای یادگیری عمیق امروزی محسوب میشود. درک دقیق آن، نهتنها فهم شبکههای عصبی را سادهتر میکند، بلکه استفاده از فریمورکها و معماریهای پیشرفته را نیز از یک فعالیت صرفاً اجرایی به تصمیمی آگاهانه و مهندسیشده تبدیل میکند.
گام بعدی پس از تسلط بر این مفاهیم، بررسی رفتار انتشار رو به عقب در شبکههای عمیقتر، توابع فعالساز متنوعتر و بهینهسازهای پیشرفتهتر است؛ جایی که همین اصول ساده، در مقیاسی بسیار بزرگتر به کار گرفته میشوند.



