
مقدمه
پیشرفت هوش مصنوعی بیش از آنکه حاصل ظهور ابزارهای جدید باشد، نتیجهی تثبیت و تکامل مفاهیم بنیادینی است که در طول زمان بارها بازتعریف شدهاند. در میان این مفاهیم، الگوریتم انتشار رو به عقب (Backpropagation) نقشی محوری ایفا میکند؛ الگوریتمی که با وجود تغییر نسل فریمورکها، همچنان هستهی اصلی فرآیند یادگیری در شبکههای عصبی باقی مانده است.
بررسی تاریخچهی فریمورکهای یادگیری عمیق نشان میدهد که تحول ابزارها همواره بازتابی از تغییر اولویتها بوده است: از دقت ریاضی و کنترل کامل بر محاسبات، به سمت سرعت توسعه، مقیاسپذیری و سهولت استفاده در محیطهای صنعتی. در این مسیر، کتابخانهی Theano نمایندهی نسلی است که یادگیری عمیق را با رویکردی کاملاً ریاضیمحور و سمبلیک بنا نهاد، در حالی که TensorFlow نماد گذار به فریمورکهایی است که همان مفاهیم را در قالب انتزاعهای سطح بالا و قابل استفاده در مقیاس وسیع ارائه میکنند.
هدف این مقاله، مقایسهی صرف دو ابزار نیست؛ بلکه تلاش میکند تقابل دو نگرش مهندسی را نشان دهد: نگرشی که در آن پژوهشگر مستقیماً با ساختارهای ریاضی درگیر است و نگرشی که پیچیدگیهای محاسباتی را به فریمورک میسپارد تا تمرکز بر طراحی معماری و حل مسئله حفظ شود. با بررسی فلسفهی طراحی، مزایا، محدودیتها و یک مثال مشترک (مسئله XOR)، تلاش میکنیم درک روشنتری از این تحول نسلی و پیامدهای آن برای مهندسان هوش مصنوعی امروز به دست آوریم.
کتابخانه Theano
Theano که در سال ۲۰۰۷ در آزمایشگاه MILA دانشگاه مونترال متولد شد . در روزگاری که یادگیری عمیق هنوز یک اصطلاحِ عمومی نبود، Theano جاده را برای انجام محاسبات سنگین روی کارتهای گرافیک (GPU) هموار کرد.
- فلسفه طراحی: تیانو فراتر از یک کتابخانه معمولی است؛ آن را مثل یک کامپایلر ریاضی تصور کنید. شما مستقیماً با اعداد بازی نمیکنید، بلکه ابتدا روابط ریاضی را به صورت سمبلیک (نمادین) تعریف میکنید. تیانو این روابط را کالبدشکافی کرده، ساده میکند و به کدهای بسیار بهینه C++ تبدیل میکند تا با بیشترین سرعت ممکن اجرا شوند.
- ویژگی منحصربهفرد: جادوی واقعی این کتابخانه در مشتقگیری سمبلیک نهفته است. شما فقط فرمول اصلی را مینویسید و تیانو تمام زنجیرههای ریاضی پیچیده برای انتشار رو به عقب را خودش استخراج میکند.
مزایا:
- بهینهسازی ریاضی فوقالعاده: تیانو روابط ریاضی را قبل از اجرا تحلیل کرده و آنها را ساده میکند (مثلاً اگر در فرمول شما x/x باشد، آن را حذف میکند تا سرعت بالا برود).
- پایداری عددی: در محاسبه مشتقثسات بسیار دقیق عمل میکند و از بروز خطاهای محاسباتی در اعداد بسیار کوچک جلوگیری میکند.
- خروجی ++C: مدلها را به کد ++C تبدیل میکند که باعث میشود روی پردازندههای مختلف با سرعت خوبی اجرا شوند.
معایب:
- زمان کامپایل طولانی: هر بار که تغییری در مدل ایجاد میکنید، باید منتظر بمانید تا تیانو دوباره کد را کامپایل کند؛ این موضوع در پروژههای بزرگ کلافهکننده است.
- اشکالزدایی (Debug) بسیار دشوار: چون کدها به صورت سمبلیک هستند، اگر خطایی رخ دهد، پیدا کردن خط دقیق در کد پایتون تقریباً غیرممکن است.
- توقف توسعه: این کتابخانه دیگر بهروزرسانی نمیشود و از تکنولوژیهای جدید سختافزاری پشتیبانی نمیکند.
- یادگیری سخت: برای استفاده از آن باید دانش ریاضی بالایی داشته باشید؛ خبری از لایههای آماده و ساده نیست.

کتابخانه TensorFlow؛ و معمار هوشمند
گوگل در سال ۲۰۱۵ با معرفی TensorFlow، انقلابی را که تیانو آغاز کرده بود، به کمال رساند. این کتابخانه میراثدار قدرت تیانو بود، اما آن را با قابلیتهایی ترکیب کرد که برای تولید در مقیاس صنعتی حیاتی بودند.
- فلسفه طراحی (جریان داده): تمرکز اصلی بر جریان دادهها (Data Flow) است. در نسخههای مدرن (TensorFlow 2.x)، این کتابخانه با ادغام کامل Keras، پیچیدگیهای ریاضی را پشت لایههای انتزاعی پنهان کرد تا مهندسان بر روی معماری تمرکز کنند، نه محاسبات دیفرانسیل.
ویژگیهای کلیدی:
- Eager Execution: اجرای فوری کدها (برخلاف مدل تاخیری تیانو) که عیبیابی را مثل آب خوردن ساده کرده است.
- TensorBoard: ابزاری بینظیر برای دیدنِ زنده و بصریِ روند یادگیری و سقوط خطاها.
مزایا:
- اکوسیستم کامل و قدرتمند: از مرحله تحقیق و طراحی تا مرحله اجرا روی موبایل (TF Lite) و مرورگر (TF.js)، همه چیز را پوشش میدهد.
- پشتیبانی از Keras: یادگیری عمیق را به سادگیِ چیدن قطعات لگو کرده است؛ شما با چند خط کد، مدلهای غولآسا میسازید.
- ابزار TensorBoard: بهترین ابزار بصریسازی در دنیاست که به شما اجازه میدهد روند یادگیری و کاهش خطا را به صورت زنده و در نمودارهای زیبا ببینید.
- پشتیبانی از TPU: علاوه بر کارتهای گرافیک (GPU)، از واحدهای پردازش تنسور گوگل (TPU) نیز پشتیبانی میکند که سرعت آموزش را ۱۰۰ برابر میکند.
- جامعه کاربری عظیم: هر مشکلی داشته باشید، قبلاً کسی در اینترنت به آن پاسخ داده است.
معایب:
- ساختار پیچیده در نسخههای قدیمی: نسخه ۱ تنسورفلو بسیار سخت بود (چیزی شبیه تیانو)، اما در نسخه ۲ بسیار بهتر شد.
- مصرف حافظه زیاد: به دلیل ساختار سنگین و ابزارهای جانبی، نسبت به فریمورکهای سبکتر، حافظه RAM و گرافیک بیشتری اشغال میکند.
- بهروزرسانیهای مکرر: گاهی اوقات تغییرات سریع در نسخهها باعث میشود کدهای قدیمی دیگر اجرا نشوند و نیاز به بازنویسی داشته باشند.
جدول مقایسه جامع
| پارامتر مقایسه | Theano (سنت و دقت) | TensorFlow (مدرنیته و قدرت) |
| رویکرد پیادهسازی | تعریف دستی و سمبلیک روابط ریاضی | استفاده از لایههای پیشساخته (High-level) |
| محاسبه گرادیان | سمبلیک (بسیار دقیق اما صلب) | خودکار (Autograd) و بسیار منعطف |
| سرعت توسعه | پایین (نیازمند زمان زیاد برای پیادهسازی) | بسیار بالا (ساخت مدل در چند دقیقه) |
| اشکالزدایی (Debug) | دشوار (به دلیل ماهیت سمبلیک کدها) | ساده (مشابه برنامهنویسی عادی پایتون) |
| پشتیبانی سختافزاری | محدود به GPUهای خاص و CPU | پشتیبانی گسترده از CPU, GPU, TPU |
| جامعه کاربری | محدود به محققان و دانشگاهیان | وسیعترین جامعه کاربری در کل دنیا |
نقشه راه عملی: حل معمای XOR
برای اینکه تفاوت فلسفی این دو رویکرد را با تمام وجود لمس کنید، ما یک هدف واحد را دنبال میکنیم: آموزش یک شبکه عصبی برای حل منطق. XOR شاید بپرسید چرا XOR؟ چون این مسئله، کوچکترین چالشِ «غیرخطی» است که هوش مصنوعی را به مبارزه میطلبد؛ مسئلهای که شبکههای عصبی ساده (بدون لایه پنهان) هرگز نمیتوانند آن را حل کنند.
- آمادهسازی زمین: مقداردهی اولیه وزنها با اعداد تصادفی (شروع از نقطه صفر).
- گذر رو به جلو(Forward Pass): ترسیم مسیر حرکت دادهها از ورودی به خروجی.
- انتشار رو به عقب(Backward Pass): محاسبه میزان اشتباه و بازگشت برای یافتن مقصر اصلی (محاسبه گرادیان).
- بهروزرسانی (Update): اصلاح هوشمندانه وزنها و تکرار چرخه تا رسیدن به هوشمندی کامل.
هدف از ارائه کدهای مبتنی بر کتابخانه Theano در این مقاله، اجرای عملی مدلها در محیطهای امروزی نیست، بلکه نمایش رویکرد تاریخی و فلسفه اولیه پیادهسازی شبکههای عصبی است. Theano بهعنوان یکی از نخستین فریمورکهای یادگیری عمیق، بستری را فراهم میکرد که در آن پژوهشگر ناگزیر بود تمامی مراحل محاسباتی، از تعریف گراف سمبلیک تا محاسبه گرادیانها، را بهصورت صریح و ریاضیمحور طراحی کند. این سطح از درگیری مستقیم با ساختار ریاضی مدلها، نقش مهمی در شکلگیری درک عمیق از مفاهیمی مانند انتشار رو به عقب و بهینهسازی پارامترها داشته است.
پیادهسازی شبکه عصبی باTheano
در این بخش، ما یک شبکه عصبی کلاسیک را از پایه میسازیم. توجه داشته باشید که در تیانو، ما ابتدا «نقشه» را طراحی میکنیم و سپس دادهها را در آن جریان میدهیم.
۱. راهاندازی و تعریف متغیرهای سمبلیک
ابتدا ظرفهایی را برای ورودیها و وزنها رزرو میکنیم.
import theano
import theano.tensor as T
import numpy as np
# ۱. تعریف متغیرهای سمبلیک (ورودی و خروجی مطلوب)
x = T.dmatrix('x') # ماتریس ورودی (ویژگیها)
y = T.dvector('y') # بردار خروجی (برچسبها)
# ۲. مقداردهی اولیه وزنها به صورت Shared
# این پارامترها در طول آموزش تغییر میکنند
w = theano.shared(np.random.randn(3), name='w') # فرض بر ۳ ویژگی ورودی
b = theano.shared(0., name='b')
۲. تعریف فرآیند محاسباتی (Forward Pass)
در اینجا منطق ریاضی شبکه را تعریف میکنیم.
# محاسبه مجموع وزندار و اعمال تابع فعالساز سیگموئید
z = T.dot(x, w) + b
prediction = 1 / (1 + T.exp(-z)) # تابع سیگموئید دستی
۳. تعریف تابع خطا و گرادیان (The Magic Part)
اینجاست که تیانو قدرت خود را در مشتقگیری خودکار نشان میدهد.
# تعریف تابع خطا (Cross-Entropy)
# ما میخواهیم فاصله بین پیشبینی و واقعیت را به حداقل برسانیم
cost = -y * T.log(prediction) - (1 - y) * T.log(1 - prediction)
cost = cost.mean()
# محاسبه خودکار مشتقات (گرادیانها) نسبت به وزن و بایاس
gw, gb = T.grad(cost, [w, b])
۴. تنظیمات بهروزرسانی و کامپایل تابع
حالا همه قطعات را به هم متصل میکنیم تا یک تابع قابل اجرا بسازیم.
learning_rate = 0.01
# تعریف قانون بهروزرسانی (نزول گرادیان)
updates = [
(w, w - learning_rate * gw),
(b, b - learning_rate * gb)
]
# کامپایل تابع آموزش: ورودی میگیرد و خطا را برمیگرداند
train = theano.function(
inputs=[x, y],
outputs=[prediction, cost],
updates=updates
)
لازم به تأکید است که کتابخانه Theano امروزه بهصورت رسمی منسوخ (Deprecated) شده و توسعه آن متوقف گردیده است. این کتابخانه دیگر با نسخههای جدید پایتون و سختافزارهای مدرن سازگاری کامل ندارد و استفاده از آن در پروژههای عملی و صنعتی توصیه نمیشود. با این حال، ارزش Theano نه در کاربرد امروزی، بلکه در نقش تاریخی و آموزشی آن نهفته است؛ نقشی که بهعنوان زیربنای مفهومی بسیاری از فریمورکهای مدرن یادگیری عمیق شناخته میشود.
گذار مفهومی از Theano به TensorFlow
با رشد نیاز به سرعت توسعه، سهولت اشکالزدایی و مقیاسپذیری در محیطهای واقعی، فریمورکهایی مانند TensorFlow ظهور کردند که بسیاری از پیچیدگیهای سطح پایین Theano را در قالب لایهها و رابطهای سطح بالا پنهان کردند. در حالی که در Theano پژوهشگر مستقیماً گراف محاسباتی و قوانین بهروزرسانی را تعریف میکرد، TensorFlow این فرآیندها را بهصورت خودکار و پویا مدیریت میکند. با این حال، باید توجه داشت که مفاهیم بنیادین مانند تابع هزینه، گرادیان و بهینهسازی، بدون تغییر باقی ماندهاند و تنها نحوه بیان آنها دچار تحول شده است.
پیادهسازی هوشمند با TensorFlow
تنسورفلو مانند یک مهندس معمار عمل میکند. شما لایهها را تعریف میکنید و سیستم خودش میداند که چگونه دادهها را منتقل کند و چطور اشتباهات را اصلاح نماید.
مرحله ۱: آمادهسازی دادهها (The Inputs)
ابتدا ورودیها و خروجیهای مطلوب مسئله XOR را تعریف میکنیم. از آنجایی که تنسورفلو با اعداد اعشاری بهتر کار میکند، نوع داده را float32 قرار میدهیم.
import tensorflow as tf
import numpy as np
# دادههای ورودی XOR: [0,0], [0,1], [1,0], [1,1]
X = np.array([[0,0], [0,1], [1,0], [1,1]], dtype="float32")
# پاسخهای صحیح متناظر: 0, 1, 1, 0
y = np.array([[0], [1], [1], [0]], dtype="float32")
مرحله ۲: معماری لایه به لایه (Sequential Model)
در اینجا، ما شبکه عصبی را مثل قطعات لگو روی هم میچینیم. برای حل XOR، حداقل به یک لایه پنهان نیاز داریم تا بتواند پیچیدگی غیرخطی مسئله را درک کند.
model = tf.keras.Sequential([
# لایه پنهان: دارای 4 نورون. تابع فعالساز ReLU به مدل کمک میکند الگوهای سخت را یاد بگیرد.
tf.keras.layers.Dense(4, input_dim=2, activation='relu'),
# لایه خروجی: دارای 1 نورون. تابع سیگموئید خروجی را بین 0 و 1 (احتمال) نگه میدارد.
tf.keras.layers.Dense(1, activation='sigmoid')
])
مرحله ۳: کامپایل؛ تعیین استراتژی یادگیری
در این مرحله، ما به مدل میگوییم که چطور خطا را بسنجد (loss) و با چه روشی وزنها را اصلاح کند. (optimizer)برخلاف تیانو، نیازی به نوشتن دستیِ مشتقات نیست.
# استفاده از بهینهساز Adam که یکی از هوشمندترین روشهای انتشار رو به عقب است
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.05),
loss='binary_crossentropy',
metrics=['accuracy'])
مرحله ۴: تمرین و یادگیری
حالا شبکه را وارد مرحله آموزش میکنیم. epochs=500 یعنی مدل ۵۰۰ بار کل دادهها را مرور میکند تا به بهترین وزنها برسد.
print("در حال آموزش شبکه... لطفا کمی صبر کنید.")
history = model.fit(X, y, epochs=500, verbose=0) # verbose=0 برای جلوگیری از شلوغی خروجی
print("آموزش با موفقیت به پایان رسید!")
مرحله ۵: راستی آزمایی
پس از پایان ۵ مرحله تمرین، حالا وقت آن است که شبکه عصبی را به چالش بکشیم. ما دادههای اصلی XOR را به مدل میدهیم و از آن میخواهیم خروجی را پیشبینی کند. در اینجا خروجیها به صورت احتمال (عددی بین ۰ و ۱) هستند، بنابراین با استفاده از تابع round آنها را به اعداد صحیح تبدیل میکنیم تا نتیجه نهایی مشخص شود.
# گرفتن پیشبینیها از مدل برای دادههای اصلی XOR
predictions = model.predict(X)
print("\n--- 🎯 نتایج نهایی و تست هوشمندی شبکه ---")
for i in range(len(X)):
probability = predictions[i][0]
final_result = round(probability)
print(f"ورودی: {X[i]} | احتمال خروجی: {probability:.4f} -> خروجی نهایی: {final_result}")
خروجی:

مرحله ۶: تحلیل بصری؛ تماشای سقوط خطا (Loss Curve)
یک مهندس هوش مصنوعی حرفهای هرگز فقط به اعداد نهایی اکتفا نمیکند. ما باید بدانیم در طول آن ۵۰۰ مرحله، «انتشار رو به عقب» چطور وزنها را اصلاح کرده است. بهترین راه برای درک این موضوع، رسم نمودار Loss (میزان خطا) است.
import matplotlib.pyplot as plt
# تنظیمات گرافیکی برای رسم نمودار
plt.figure(figsize=(10, 6))
plt.plot(history.history['loss'], color='#E63946', linewidth=2.5, label='Loss')
# استفاده از عبارات انگلیسی برای خوانایی بهتر در محیطهای برنامهنویسی
plt.title('Model Convergence and Loss Reduction during Training', fontsize=14)
plt.xlabel('Epoch', fontsize=12)
plt.ylabel('Loss Value', fontsize=12)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5)
# نمایش نمودار
plt.show()
خروجی:
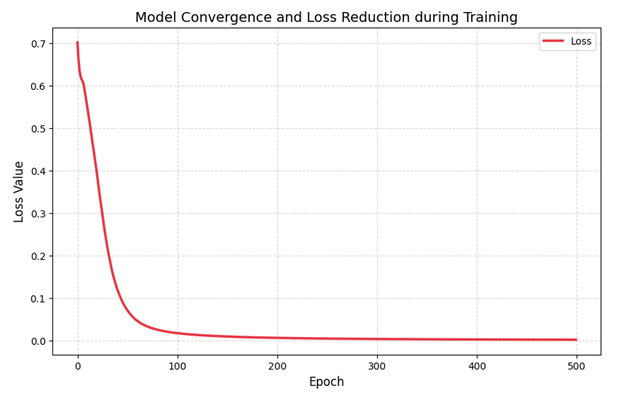
جمع بندی
مقایسهی Theano و TensorFlow نشان میدهد که تحول فریمورکهای یادگیری عمیق، بیش از آنکه تغییر در اصول یادگیری باشد، تغییر در شیوهی تعامل ما با آن اصول است Theano. با تأکید بر تعریف سمبلیک روابط ریاضی و کنترل کامل بر فرآیند انتشار رو به عقب، بستری فراهم میکرد که در آن درک عمیق مفاهیم پایه اجتنابناپذیر بود؛ هرچند این دقت، هزینهی بالایی در سرعت توسعه و سهولت استفاده داشت.
در مقابل، TensorFlow با پنهانسازی پیچیدگیهای سطح پایین و ارائهی رابطهای لایهمحور، امکان توسعهی سریع، اشکالزدایی سادهتر و مقیاسپذیری صنعتی را فراهم کرده است. با این حال، این سادگی ظاهری نباید ما را از این واقعیت غافل کند که همان مفاهیم بنیادین—تابع هزینه، گرادیان، و انتشار رو به عقب—در قلب این فریمورک نیز بدون تغییر حضور دارند.
ارزش مطالعهی ابزارهایی مانند Theano امروز، نه در استفادهی عملی از آنها، بلکه در نقشی است که در شکلگیری فهم مفهومی عمیق از یادگیری عصبی ایفا میکنند. مهندس هوش مصنوعی موفق کسی است که بتواند از انتزاعهای مدرن بهره ببرد، بدون آنکه منطق ریاضی و محدودیتهای درونی مدلها را نادیده بگیرد.
آیندهی یادگیری عمیق احتمالاً شاهد فریمورکهای سادهتر، خودکارتر و مقیاسپذیرتر خواهد بود، اما تسلط بر مفاهیم بنیادی—که در نسلهایی مانند Theano شفاف بودند—همچنان عامل تمایز میان «استفادهکننده ابزار» و «طراح آگاه سیستمهای هوشمند» باقی خواهد ماند.



