
مقدمه
شبکههای عصبی تنها مجموعهای از فرمولها یا چند خط کد نیستند؛ آنها سیستمهایی هستند که از طریق تکرار، ارزیابی خطا و اصلاح تدریجی پارامترها یاد میگیرند. با وجود گسترش کتابخانههای آماده و چارچوبهای قدرتمند، درک واقعی شبکههای عصبی زمانی شکل میگیرد که بدانیم در هر مرحله از آموزش، دقیقاً چه محاسباتی انجام میشود و هر پارامتر چه نقشی در شکلگیری خروجی نهایی دارد.
هدف این مطلب ارائهی یک مسیر آموزشی شفاف و عملی برای فهم شبکههای عصبی است؛ مسیری که از شهود اولیه و مفاهیم پایه آغاز میشود و به فرمولبندی ریاضی و پیادهسازی گامبهگام یک شبکه عصبی ساده با پایتون میرسد. تمرکز اصلی بر این است که شبکه عصبی بهعنوان یک «جعبه سیاه» در نظر گرفته نشود، بلکه فرآیندهایی مانند انتشار رو به جلو، انتشار رو به عقب، محاسبه خطا و بهروزرسانی وزنها بهصورت قابلدرک و مرحلهبهمرحله بررسی شوند.
در طول این مسیر، با ساخت و آموزش یک پرسپترون چندلایه از صفر، مشاهده خواهیم کرد که مدل چگونه از خطاهای خود یاد میگیرد و بهتدریج به خروجیهای دقیقتر نزدیک میشود. هدف نهایی این است که پس از مطالعه این مطلب، خواننده بتواند منطق درونی شبکههای عصبی ساده را تحلیل کند و با دیدی آگاهانهتر به سراغ معماریها و ابزارهای پیشرفتهتر برود.
نقشه راه یادگیری: تئوری یا شهود؟
شما میتوانید هر مفهومی را به دو روش یاد بگیرید:
- (تئوریمحور): ابتدا تمام ریاضیات، فرضیات، محدودیتها و جزئیات دقیق الگوریتم را مطالعه کنید و سپس به سراغ کاربرد بروید. این روش بسیار مستحکم اما بسیار زمانبر است.
- (شهودمحور): با مبانی ساده شروع کنید و یک شهود (Intuition) قوی نسبت به موضوع پیدا کنید. سپس یک مسئله واقعی را انتخاب کرده و در حین حل آن، مفاهیم را یاد بگیرید. مدام مدل را تغییر دهید، پارامترها را جابهجا کنید و با آزمون و خطا، درک خود را عمیقتر کنید.
درک شهودی و ساده از شبکههای عصبی
اگر تا به حال برنامهنویسی کرده باشید، احتمالاً با فرآیند پیدا کردن باگ آشنا هستید: ورودی را تغییر میدهید، خروجی را بررسی میکنید و از روی اختلاف خروجیِ مورد انتظار و خروجی واقعی، محل خطا را حدس میزنید. سپس کد را اصلاح میکنید و این چرخه را تکرار میکنید تا برنامه به رفتار مطلوب برسد.
شبکههای عصبی نیز از منطق مشابهی پیروی میکنند. آنها خروجی تولید میکنند، میزان خطا را محاسبه میکنند و با اصلاح پارامترها، در تکرارهای بعدی عملکرد خود را بهبود میدهند.
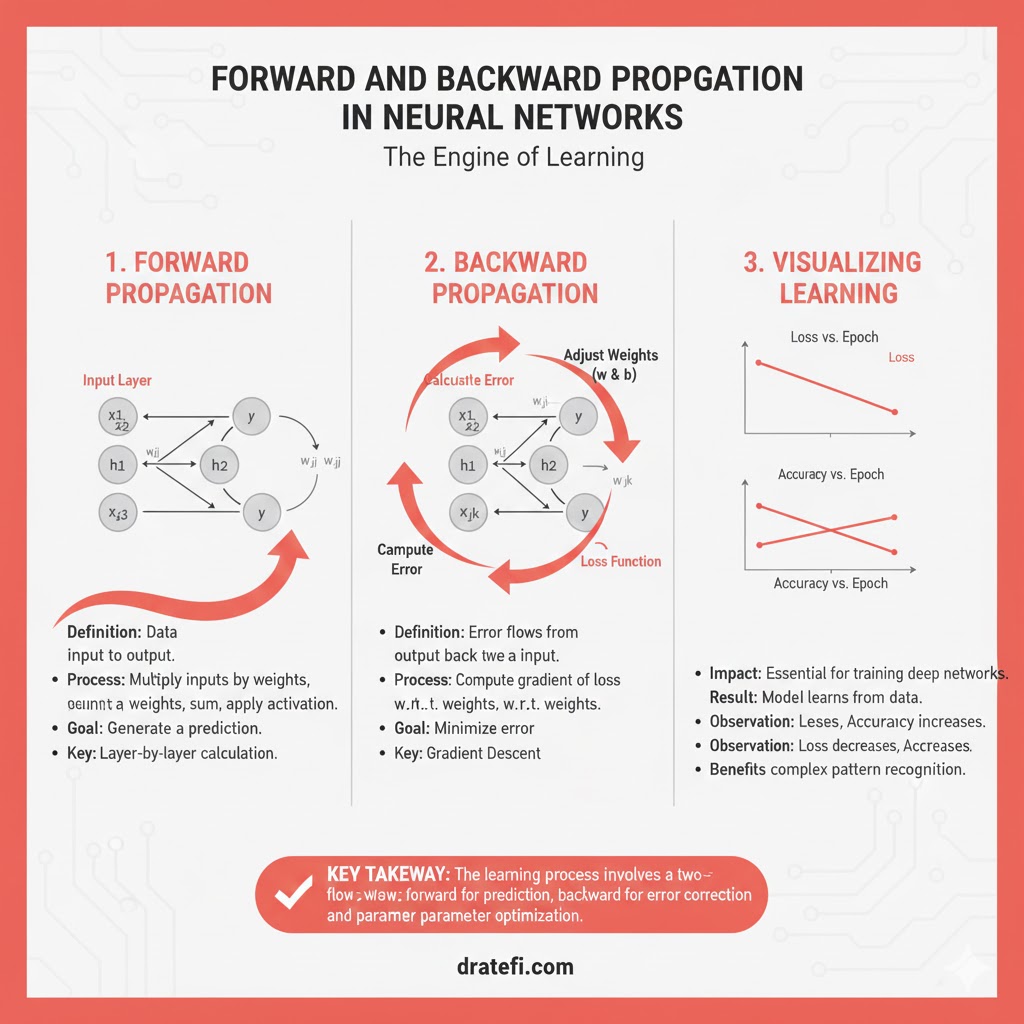
شبکههای عصبی دقیقاً به همین صورت عمل میکنند:
- انتشار رو به جلو(Forward Propagation): شبکه چندین ورودی را میگیرد، آنها را از طریق نورونهای موجود در لایههای پنهان پردازش میکند و نتیجه را در لایه خروجی برمیگرداند. این فرآیند تخمین نتیجه، “انتشار رو به جلو” نامیده میشود.
- مقایسه و تشخیص خطا: ما نتیجه را با خروجی واقعی مقایسه میکنیم. هدف این است که خروجی شبکه تا حد ممکن به خروجی مطلوب (واقعی) نزدیک شود. هر نورون سهمی در خطای نهایی دارد.
- انتشار رو به عقب(Backward Propagation): برای کاهش خطا، ما به عقب برمیگردیم تا بفهمیم خطا کجاست و وزن نورونهایی که سهم بیشتری در خطا دارند را کاهش دهیم. این فرآیند “انتشار رو به عقب” نام دارد.
- بهینهسازی با گرادیان کاهشی: برای اینکه این تکرارها کمتر شود و سریعتر به حداقل خطا برسیم، از الگوریتمی به نام گرادیان کاهشی (Gradient Descent) استفاده میشود که وظیفه بهینهسازی کارآمد مدل را بر عهده دارد.
پرسپترون چندلایه و مفاهیم پایه
همانطور که اتمها واحد سازنده تمام مواد روی زمین هستند، پرسپترون (Perceptron) نیز واحد اصلی سازنده یک شبکه عصبی است. پرسپترون چیزی است که چندین ورودی میگیرد و یک خروجی تولید میکند.
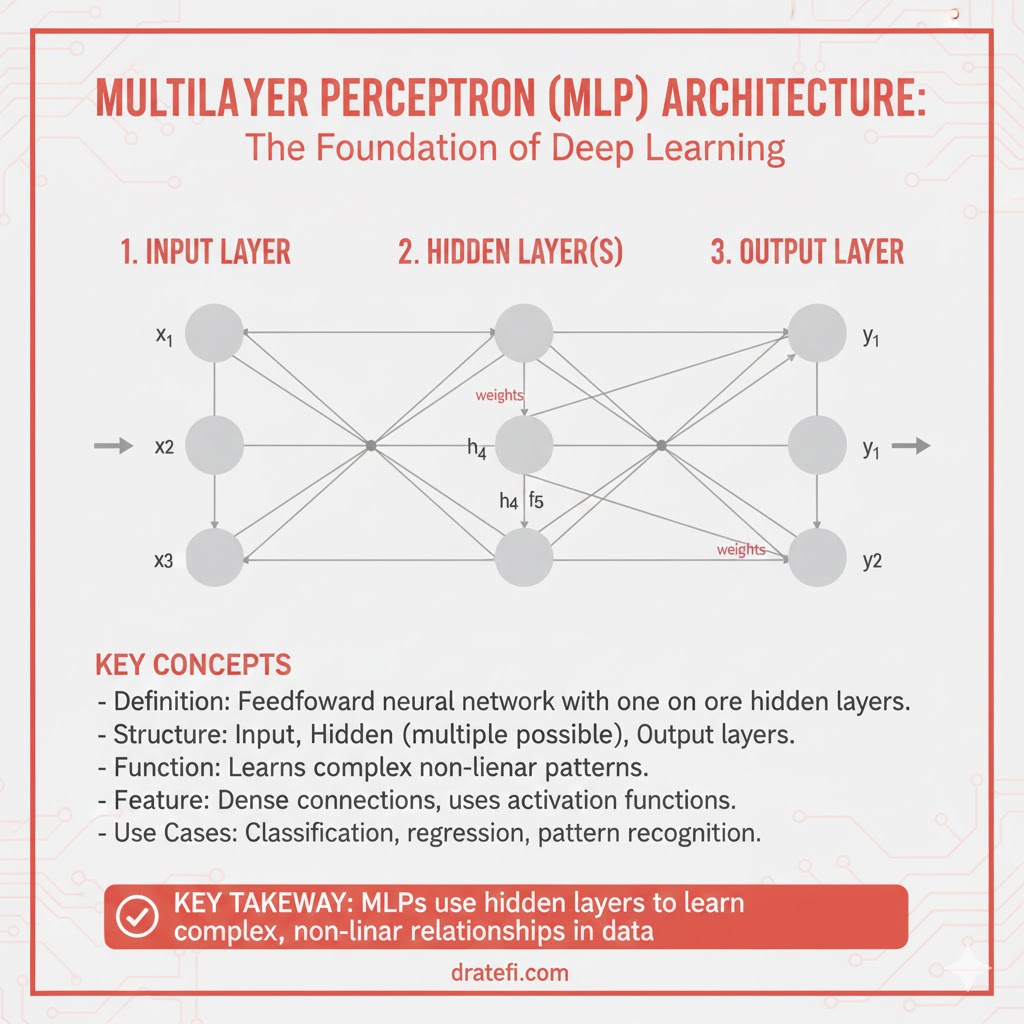
روابط بین ورودی و خروجی در یک پرسپترون طی سه مرحله تکامل یافته است:
- ترکیب مستقیم و آستانه(Threshold): در سادهترین حالت، ورودیها با هم ترکیب میشوند و اگر مجموع آنها از یک مقدار آستانه بیشتر بود، خروجی ۱ و در غیر این صورت ۰ خواهد بود. (مثلاً اگر مجموع x1+x2+x3 بزرگتر از ۰ باشد، خروجی ۱ است).
- افزودن وزنها(Weights): وزنها به ورودیها اهمیت میدهند. ما هر ورودی را در وزن مخصوص به خود ضرب میکنیم . (w1*x1 + w2*x2 + …) این کار باعث میشود برخی ورودیها تأثیر بیشتری بر نتیجه نهایی داشته باشند.
- افزودن بایاس (Bias): بایاس نشاندهنده میزان انعطافپذیری پرسپترون است. این پارامتر مشابه عدد ثابت b در تابع خطی y = ax + b است و به ما اجازه میدهد خط پیشبینی را بالا و پایین ببریم تا بهتر روی دادهها برازش شود. بدون بایاس، خط پیشبینی همیشه از مبدأ مختصات (۰,۰) میگذرد که دقت مدل را کاهش میدهد. البته در برخی پیادهسازیهای ساده یا آموزشی، ممکن است پارامتر بایاس برای سادهسازی محاسبات حذف شود، اما در مسائل واقعی معمولاً نقش مهمی در افزایش انعطافپذیری مدل دارد.
ظهور نورون مصنوعی
تمامی موارد بالا هنوز در محدوده خطی هستند. اما دنیای واقعی غیرخطی است. بنابراین پرسپترون تکامل یافت و به نورون مصنوعی (Artificial Neuron) تبدیل شد. یک نورون، توابع فعالسازی (Activation Functions) غیرخطی را روی مجموع ورودیها و بایاسها اعمال میکند تا بتواند الگوهای پیچیده را درک کند.
تابع فعالسازی (Activation Function) چیست؟
تابع فعالسازی، مجموع وزندار ورودیها به همراه بایاس را به عنوان آرگومان دریافت کرده و خروجی نهایی نورون را برمیگرداند. اگر ورودیها را با x، وزنها را با w و بایاس را با b در نظر بگیریم، فرمول کلی به صورت زیر است:
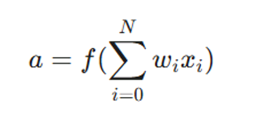
- a: خروجی (فعالسازی) نورون.
- f: تابع فعالسازی.
- x0 و w0: در اینجا مقدار ۱ به عنوان x0 و بایاس (b) به عنوان w0 در نظر گرفته شده است.
چرا به آن نیاز داریم؟
هدف اصلی استفاده از توابع فعالسازی، ایجاد تغییرات غیرخطی در دادههاست. این کار به شبکه اجازه میدهد تا فرضیات پیچیده و غیرخطی را مدلسازی کرده و الگوهای دشوار را تخمین بزند.
پرسپترون چندلایه (MLP) و ساختار لایههای پنهان
یک پرسپترون ساده محدودیتهای زیادی دارد. برای کاربردهای عملی، ما از لایههای پنهان (Hidden Layers) استفاده میکنیم که بین لایه ورودی و خروجی قرار میگیرند.
- در یک MLP، تمامی لایهها تماممتصل (Fully Connected) هستند؛ یعنی هر نود در یک لایه به تمامی نودهای لایه قبل و بعد خود متصل است.
استراتژیهای آپدیت وزن: Full Batch vs SGD
دو روش اصلی برای بهروزرسانی پارامترها با استفاده از گرادیان کاهشی وجود دارد:
- Full Batch Gradient Descent: از تمام دادههای آموزشی برای یک بار آپدیت کردن وزنها استفاده میکند.
- Stochastic Gradient Descent (SGD): از یک یا چند نمونه (و نه کل دادهها) برای هر بار آپدیت استفاده میکند. این روش سریعتر است زیرا پس از دیدن هر نمونه، وزنها بلافاصله اصلاح میشوند.
مراحل گامبهگام پیادهسازی شبکه عصبی با تجسم عددی و بصری
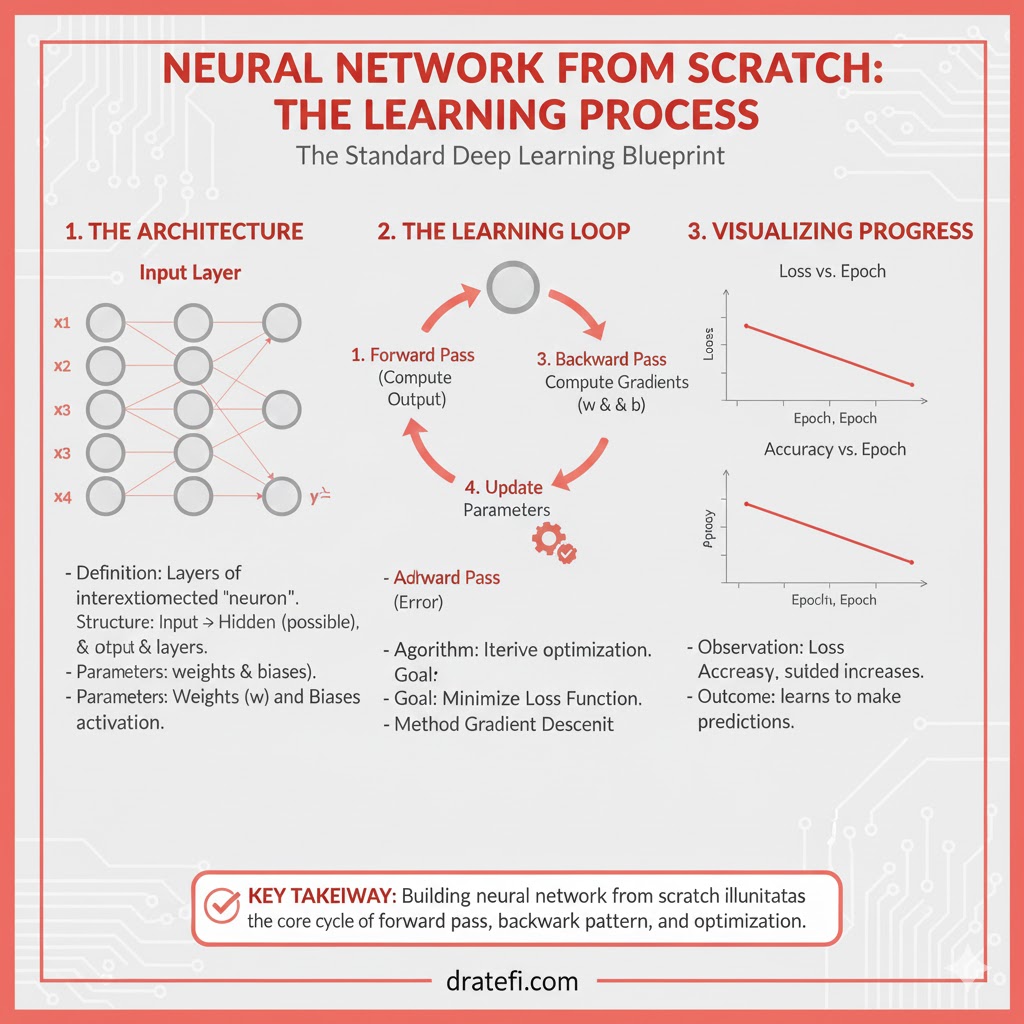
برای ساخت یک MLP با یک لایه پنهان جهت حل یک مسئله طبقهبندی دوتایی (خروجی ۰ یا ۱)، این مراحل طی میشود:
نکات مهم در تصاویر بصری:
- سلولهای زرد رنگ: نشاندهنده سلول فعال در گام فعلی هستند.
- سلولهای نارنجی رنگ: نشاندهنده ورودیهایی هستند که برای محاسبه مقدار سلول فعلی استفاده شدهاند.
۱. مقداردهی اولیه: وزنها (wh, wout) و بایاسها (bh, bout) را با مقادیر تصادفی مقداردهی میکنیم.

۲. تحول خطی لایه پنهان: حاصلضرب ماتریسی ورودی و وزنها را محاسبه کرده و بایاس را اضافه میکنیم:
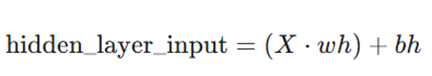

۳. تحول غیرخطی: اعمال تابع سیگموئید بر خروجی مرحله قبل:
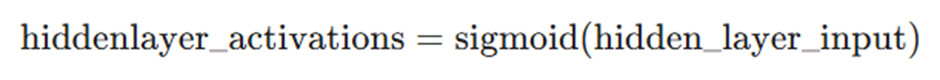

۴. تکرار برای لایه خروجی: مشابه لایه پنهان، یک تحول خطی و سپس غیرخطی روی فعالسازهای لایه پنهان در لایه خروجی انجام میشود تا پیشبینی نهایی (output) حاصل شود.
فرمول:

محاسبه:

۵. محاسبه خطا: تفاوت پیشبینی با خروجی واقعی (معمولاً با خطای میانگین مربعات):
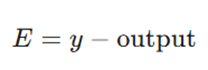

۶. محاسبه شیب(Gradient): محاسبه مشتق تابع فعالسازی در هر لایه.
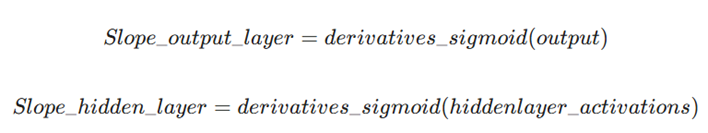
محاسبه:
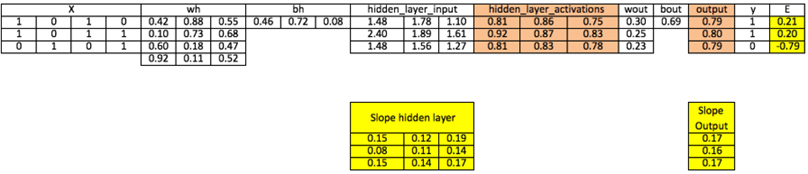
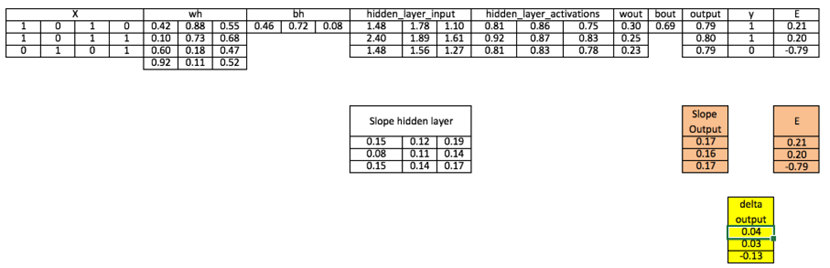
۷. محاسبه فاکتور تغییر(Delta): ضرب خطا در شیب لایه خروجی.
فرمول:
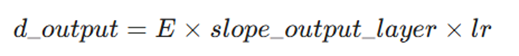
محاسبه:
۸. پسانتشار خطا: انتقال خطا به لایه پنهان با استفاده از ترانهاده ماتریس وزنها.
فرمول:
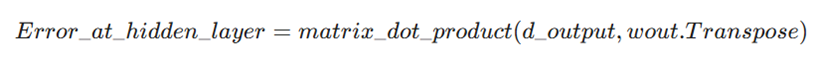
محاسبه:
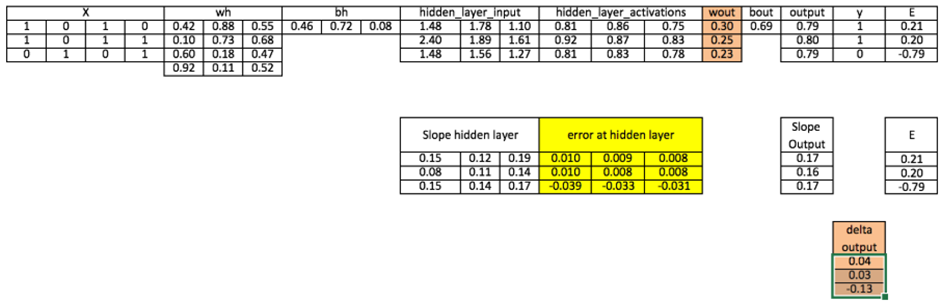
۹. بهروزرسانی وزنها و بایاسها:دلتای لایه پنهان از حاصلضرب خطای لایه پنهان در شیب فعالسازهای همان لایه بهدست میآید:
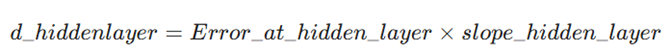
محاسبه:
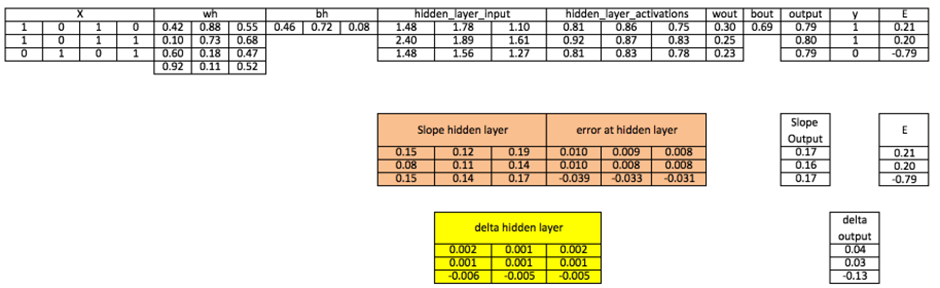
۱۰. بهروزرسانی وزنها
وزنهای شبکه با استفاده از خطاهای محاسبه شده برای نمونههای آموزشی تغییر میکنند. میزان این تغییر توسط پارامتری به نام نرخ یادگیری کنترل میشود که سرعت همگرایی مدل را تعیین میکند.
- بهروزرسانی وزنهای لایه خروجی:
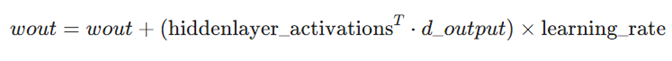
- در این مرحله، حاصلضرب ترانهاده فعالسازهای لایه پنهان در دلتای خروجی، جهت تغییر وزنها را مشخص میکند.
- بهروزرسانی وزنهای لایه پنهان:
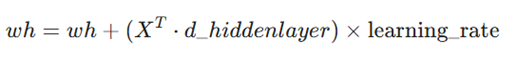
- در اینجا نیز ترانهاده ماتریس ورودی (X) در دلتای لایه پنهان ضرب میشود تا وزنهای اولیه اصلاح شوند.
محاسبه:
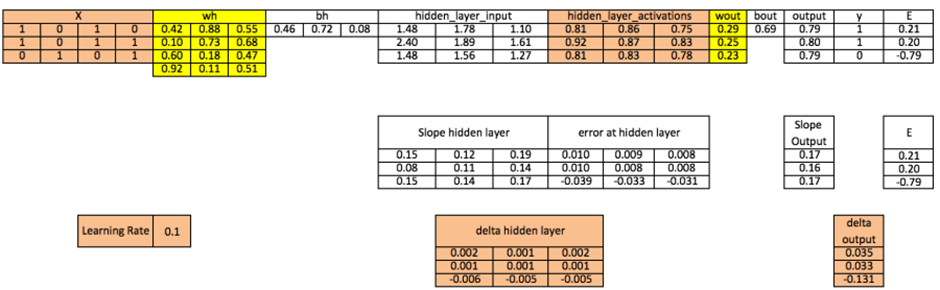
۱۱. بهروزرسانی بایاسها (Update Biases)
بایاسها نیز مشابه وزنها، اما بر اساس مجموع خطاهای انباشته شده در هر نورون آپدیت میشوند:
- بهروزرسانی بایاس لایه خروجی:
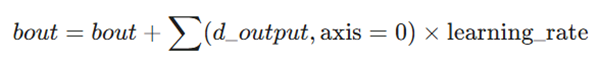
- بایاس جدید برابر است با بایاس قبلی به اضافه مجموع مقادیر دلتای خروجی در هر سطر که در نرخ یادگیری ضرب شده است.
- بهروزرسانی بایاس لایه پنهان:

- مشابه لایه خروجی، مجموع دلتاهای لایه پنهان برای اصلاح مقدار بایاس این لایه به کار میرود.
محاسبه:
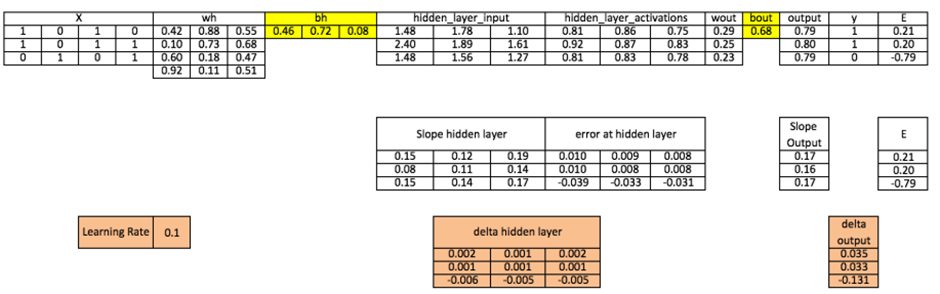
جمعبندی فرآیند
مراحل ۵ تا ۱۱ در مجموع به عنوان انتشار رو به عقب (Backward Propagation) شناخته میشوند. ترکیب یک دور انتشار رو به جلو و یک دور انتشار رو به عقب، یک چرخه کامل آموزشی یا همان اپوک (Epoch) را میسازد. در اپوک دوم، مدل از همین وزنها و بایاسهای آپدیت شده برای پیشبینی دقیقتر استفاده خواهد کرد.
کد پایتون این مثال:
# importing the library
import numpy as np
# creating the input array
X=np.array([[1,0,1,0],[1,0,1,1],[0,1,0,1]])
print ('\n Input:')
print(X)
# creating the output array
y=np.array([[1],[1],[0]])
print ('\n Actual Output:')
print(y)
# defining the Sigmoid Function
def sigmoid (x):
return 1/(1 + np.exp(-x))
# derivative of Sigmoid Function
def derivatives_sigmoid(x):
return x * (1 - x)
# initializing the variables
epoch=5000 # number of training iterations
lr=0.1 # learning rate
inputlayer_neurons = X.shape[1] # number of features in data set
hiddenlayer_neurons = 3 # number of hidden layers neurons
output_neurons = 1 # number of neurons at output layer
# initializing weight and bias
wh=np.random.uniform(size=(inputlayer_neurons,hiddenlayer_neurons))
bh=np.random.uniform(size=(1,hiddenlayer_neurons))
wout=np.random.uniform(size=(hiddenlayer_neurons,output_neurons))
bout=np.random.uniform(size=(1,output_neurons))
# training the model
for i in range(epoch):
#Forward Propogation
hidden_layer_input1=np.dot(X,wh)
hidden_layer_input=hidden_layer_input1 + bh
hiddenlayer_activations = sigmoid(hidden_layer_input)
output_layer_input1=np.dot(hiddenlayer_activations,wout)
output_layer_input= output_layer_input1+ bout
output = sigmoid(output_layer_input)
#Backpropagation
E = y-output
slope_output_layer = derivatives_sigmoid(output)
slope_hidden_layer = derivatives_sigmoid(hiddenlayer_activations)
d_output = E * slope_output_layer
Error_at_hidden_layer = d_output.dot(wout.T)
d_hiddenlayer = Error_at_hidden_layer * slope_hidden_layer
wout += hiddenlayer_activations.T.dot(d_output) *lr
bout += np.sum(d_output, axis=0,keepdims=True) *lr
wh += X.T.dot(d_hiddenlayer) *lr
bh += np.sum(d_hiddenlayer, axis=0,keepdims=True) *lr
print ('\n Output from the model:')
print (output)
پیاده سازی گام به گام در پایتون
راهاندازی محیط کدنویسی و فراخوانی کتابخانهها
برای شروع پیادهسازی، ابتدا باید ابزارهای مورد نیازمان را وارد میدان کنیم. در پایتون، پادشاه محاسبات عددی Numpy است و برای جان بخشیدن به دادهها و ترسیم نمودارها از Matplotlib استفاده میکنیم.
# importing required libraries
import numpy as np
import matplotlib.pyplot as plt
ایجاد ورودیهای مدل
برای شروع، از یک مجموعه داده فرضی استفاده میکنیم؛ در این دادهها، تنها ستون اول به عنوان ستون مفید و تأثیرگذار در نظر گرفته میشود، در حالی که باقی ستونها ممکن است مفید باشند یا نباشند و پتانسیل این را دارند که صرفاً به عنوان نویز (Noise) در محاسبات عمل کنند.
# creating the input array
X = np.array([[1, 0, 0, 0], [1, 0, 1, 1], [0, 1, 0, 1]])
print("Input:\n", X)
# shape of input array
print("\nShape of Input:", X.shape)
خروجی:

حالا ما باید ترانهادهی (Transpose) ورودی را بگیریم تا بتوانیم شبکهمان را آموزش دهیم.
# converting the input in matrix form
X = X.T
print("Input in matrix form:\n", X)
# shape of input matrix
print("\nShape of Input Matrix:", X.shape)
خروجی:

ایجاد و آمادهسازی ماتریس خروجی
حالا باید آرایه خروجی (Output Array) خود را بسازیم و برای هماهنگی با محاسبات ماتریسی شبکه، آن را نیز ترانهاده (Transpose) کنیم.
در دنیای ریاضیاتِ شبکههای عصبی، ترانهاده کردن ماتریسها به ما کمک میکند تا ابعاد دادهها را با وزنها تراز کنیم و عملیات ضرب ماتریسی (Dot Product) به درستی انجام شود.
# creating the output array
y = np.array([[1], [1], [0]])
print("Actual Output:\n", y)
# output in matrix form
y = y.T
print("\nOutput in matrix form:\n", y)
# shape of input array
print("\nShape of Output:", y.shape)
خروجی:

حالا که دادههای ورودی و خروجی ما آماده شدهاند، بیایید شبکه عصبی خود را تعریف کنیم. ما یک معماری بسیار ساده را در نظر میگیریم که دارای یک لایه پنهان با تنها سه نورون است.
inputLayer_neurons = X.shape[0] # number of features in data set
hiddenLayer_neurons = 3 # number of hidden layers neurons
outputLayer_neurons = 1 # number of neurons at output layer
مقدار دهی اولیه به شبکه عصبی
در ادامه، فرآیند مقداردهی اولیه به شبکه عصبی را با تمرکز بر وزنها بررسی میکنیم:
سپس، ما وزنهای مربوط به هر نورون در شبکه را مقداردهی اولیه میکنیم. وزنهایی که ایجاد میکنیم دارای مقادیری بین ۰ تا ۱ هستند که در شروع کار به صورت تصادفی تعیین میشوند.
به منظور سادهسازی، در این محاسبات پارامتر بایاس (Bias) را لحاظ نخواهیم کرد، اما برای درک نحوه عملکرد آن میتوانید به پیادهسازی سادهای که پیش از این انجام دادیم مراجعه کنید.
# initializing weight
# Shape of weights_input_hidden should number of neurons at input layer * number of neurons at hidden layer
weights_input_hidden = np.random.uniform(size=(inputLayer_neurons, hiddenLayer_neurons))
# Shape of weights_hidden_output should number of neurons at hidden layer * number of neurons at output layer
weights_hidden_output = np.random.uniform(
size=(hiddenLayer_neurons, outputLayer_neurons)
)
برای اینکه در هر مرحله از کدنویسی بدانیم ابعاد ماتریسهایمان دقیقاً به چه صورت است، از این دستور استفاده میکنیم:
# shape of weight matrix
weights_input_hidden.shape, weights_hidden_output.shape# We are using sigmoid as an activation function so defining the sigmoid function here
پس از این مرحله، ما تابع فعالساز خود را به عنوان سیگموئید (Sigmoid) تعریف خواهیم کرد؛ تابعی که از آن هم در لایه پنهان و هم در لایه خروجی شبکه استفاده میکنیم.
# defining the Sigmoid Function
def sigmoid(x):
return 1 / (1 + np.exp(-x))
فرآیند انتشار رو به جلو
در ادامه، فرآیند انتشار رو به جلو(Forward Pass) را پیادهسازی خواهیم کرد؛ ابتدا برای بهدست آوردن مقادیر فعالسازی لایه پنهان و سپس برای لایه خروجی. فرآیند انتشار رو به جلو در کد ما چیزی شبیه به این خواهد بود:
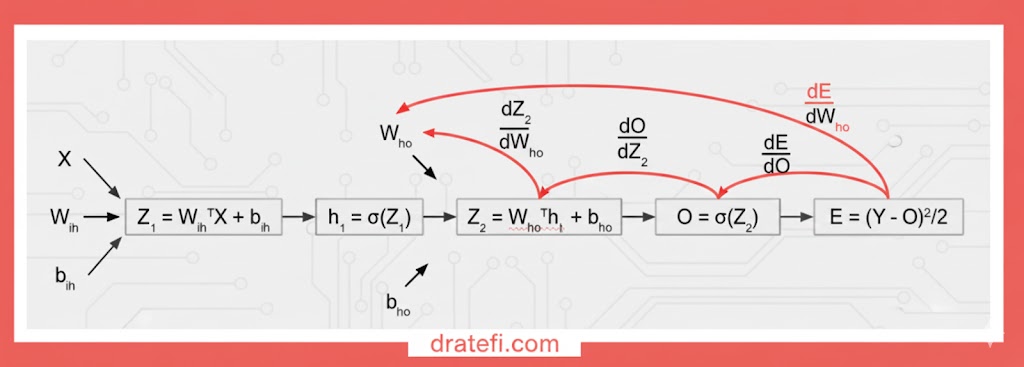
# hidden layer activations
hiddenLayer_linearTransform = np.dot(weights_input_hidden.T, X)
hiddenLayer_activations = sigmoid(hiddenLayer_linearTransform)
# calculating the output
outputLayer_linearTransform = np.dot(weights_hidden_output.T, hiddenLayer_activations)
output = sigmoid(outputLayer_linearTransform)
بررسی عملکرد اولیه؛ مدل آموزشندیده چه خروجی میدهد؟
بیایید ببینیم مدل ما در حالی که هنوز هیچ آموزشی ندیده و کاملاً خام است، چه خروجیای تولید میکند.
در این مرحله، از آنجایی که وزنها و بایاسها به صورت کاملاً تصادفی مقداردهی شدهاند، شبکه صرفاً یک حدس تصادفی میزند. مشاهده این خروجی به ما کمک میکند تا بفهمیم مدل پیش از شروع فرآیند یادگیری و اعمال انتشار رو به عقب، چقدر با واقعیت فاصله دارد.
# output
output
خروجی:
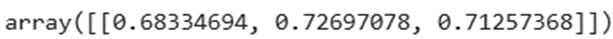
ما برای هر یک از نمونههای دادههای ورودی، یک خروجی دریافت میکنیم. در این مورد، بیایید خطا را برای هر نمونه با استفاده از تابع زیان مجموع مربعات خطا (Squared Error Loss) محاسبه کنیم.
# calculating error
error = np.square(y - output) / 2
error
خروجی:
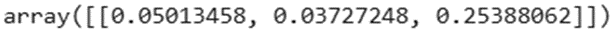
ما گام انتشار رو به جلو را به پایان رسانده و مقدار خطا را بهدست آوردهایم. اکنون بیایید انتشار رو به عقب را انجام دهیم تا میزان خطا را نسبت به هر یک از وزنهای نورون محاسبه کرده و سپس این وزنها را با استفاده از روش ساده گرادیان کاهشی بهروزرسانی کنیم.
در مرحله اول، ما خطا را نسبت به وزنهای بین لایههای پنهان و خروجی محاسبه خواهیم کرد. اساساً عملیاتی مشابه تصویر زیر را انجام میدهیم:
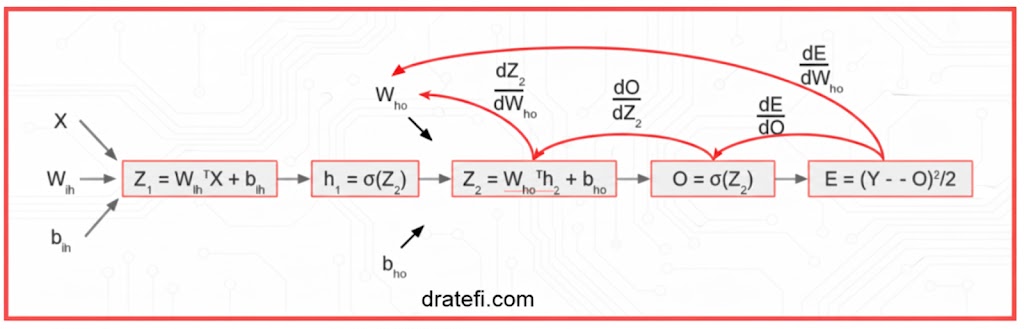
برای محاسبه این مقدار، مراحل میانی زیر را با استفاده از قاعده زنجیرهای (Chain Rule) طی خواهیم کرد:
- نرخ تغییرات خطا نسبت به خروجی.
- نرخ تغییرات خروجی نسبت به متغیر میانجی. Z2
- نرخ تغییرات Z2 نسبت به وزنهای بین لایه پنهان و خروجی.
بیایید این عملیات را اجرا کنیم.
# rate of change of error w.r.t. output
error_wrt_output = -(y - output)
# rate of change of output w.r.t. Z2
output_wrt_outputLayer_LinearTransform = np.multiply(output, (1 - output))
# rate of change of Z2 w.r.t. weights between hidden and output layer
outputLayer_LinearTransform_wrt_weights_hidden_output = hiddenLayer_activations
# checking the shapes of partial derivatives
error_wrt_output.shape, output_wrt_outputLayer_LinearTransform.shape, outputLayer_LinearTransform_wrt_weights_hidden_output.shape
# shape of weights of output layer
weights_hidden_output.shape
همانطور که پیش از این مشاهده کردیم، میتوانیم این عملیات را به صورت رسمی با استفاده از معادله زیر تعریف کنیم:
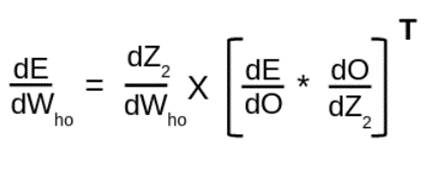
بیایید مراحل را گامبهگام اجرا کنیم.
# rate of change of error w.r.t weight between hidden and output layer
error_wrt_weights_hidden_output = np.dot(
outputLayer_LinearTransform_wrt_weights_hidden_output,
(error_wrt_output * output_wrt_outputLayer_LinearTransform).T,
)
error_wrt_weights_hidden_output.shape
در این بخش، گامهای نهایی برای محاسبه خطا نسبت به وزنهای اولیه را بررسی میکنیم. خروجی دقیقاً همانطور که انتظار داشتیم بهدست میآید.
در ادامه، همان مراحل را برای محاسبه میزان خطا نسبت به وزنهای بین لایه ورودی و لایه پنهان به این صورت انجام میدهیم:
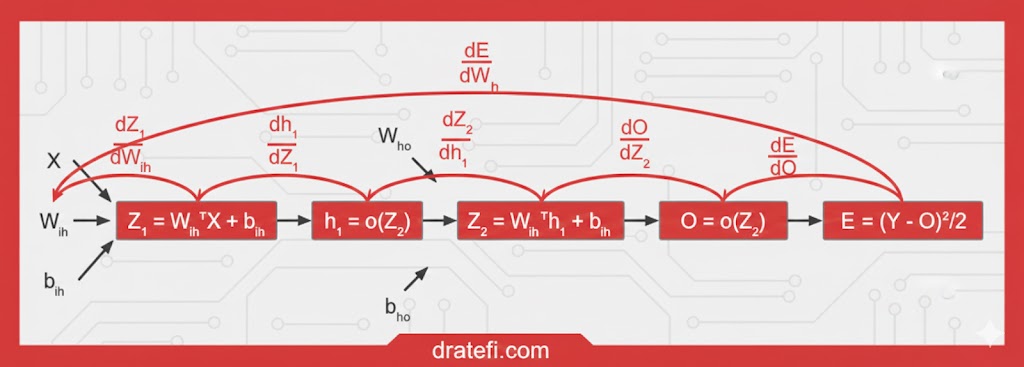
قاعده زنجیرهای (Chain Rule)
گامهای میانی زیر را برای رسیدن به هدف نهایی محاسبه خواهیم کرد:
- نرخ تغییرات خطا نسبت به خروجی
- نرخ تغییرات خروجی نسبت به Z2 (مقدار قبل از تابع فعالساز در لایه خروجی)
- نرخ تغییرات Z2 نسبت به فعالسازهای لایه پنهان
- نرخ تغییرات فعالسازهای لایه پنهان نسبت به Z1 (مقدار قبل از تابع فعالساز در لایه پنهان)
- نرخ تغییرات Z1 نسبت به وزنهای بین لایه ورودی و پنهان
این زنجیره به ما اجازه میدهد تا دقیقاً بفهمیم لرزشهای کوچک در وزنهای اولیه، چه تأثیری بر خطای نهایی در انتهای شبکه میگذارند.
# rate of change of error w.r.t. output
error_wrt_output = -(y - output)
# rate of change of output w.r.t. Z2
output_wrt_outputLayer_LinearTransform = np.multiply(output, (1 - output))
# rate of change of Z2 w.r.t. hidden layer activations
outputLayer_LinearTransform_wrt_hiddenLayer_activations = weights_hidden_output
# rate of change of hidden layer activations w.r.t. Z1
hiddenLayer_activations_wrt_hiddenLayer_linearTransform = np.multiply(
hiddenLayer_activations, (1 - hiddenLayer_activations)
)
# rate of change of Z1 w.r.t. weights between input and hidden layer
hiddenLayer_linearTransform_wrt_weights_input_hidden = X
# checking the shapes of partial derivatives
print(
error_wrt_output.shape,
output_wrt_outputLayer_LinearTransform.shape,
outputLayer_LinearTransform_wrt_hiddenLayer_activations.shape,
hiddenLayer_activations_wrt_hiddenLayer_linearTransform.shape,
hiddenLayer_linearTransform_wrt_weights_input_hidden.shape,
)
خروجی:
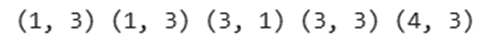
اما آنچه ما به آن نیاز داریم، آرایهای با این شکل (Shape) است:
# shape of weights of hidden layer
weights_input_hidden.shape
خروجی:
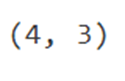
بنابراین، ما آنها را با استفاده از معادله زیر با یکدیگر ترکیب میکنیم:
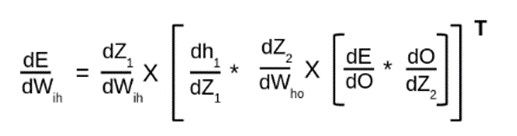
# rate of change of error w.r.t weights between input and hidden layer
error_wrt_weights_input_hidden = np.dot(
hiddenLayer_linearTransform_wrt_weights_input_hidden,
(
hiddenLayer_activations_wrt_hiddenLayer_linearTransform
* np.dot(
outputLayer_LinearTransform_wrt_hiddenLayer_activations,
(output_wrt_outputLayer_LinearTransform * error_wrt_output),
)
).T,
)
error_wrt_weights_input_hidden.shape
گام بعدی، بهروزرسانی پارامترهای مدل است. برای این کار، ما از تابع بهروزرسانی گرادیان کاهشی ساده (Vanilla Gradient Descent) استفاده خواهیم کرد که به شرح زیر است:
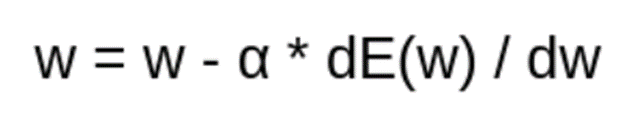
# defining the learning rate
lr = 0.01
# initial weights_hidden_output
weights_hidden_output
# initial weights_input_hidden
weights_input_hidden
# updating the weights of output layer
weights_hidden_output = weights_hidden_output - lr * error_wrt_weights_hidden_output
# updating the weights of hidden layer
weights_input_hidden = weights_input_hidden - lr * error_wrt_weights_input_hidden
# updated weights_hidden_output
weights_hidden_output
# updated weights_input_hidden
weights_input_hidden
اثر تکرار اپوکها (Epochs)
تا به اینجای کار، ما فقط یک تکرار (تکاپوک) از مراحل انتشار رو به جلو و انتشار رو به عقب را انجام دادیم. اما همانطور که در نتایج دیدیم، یک بار تکرار برای رسیدن به یک مدل هوشمند کافی نیست.
برای اینکه مدل ما بتواند الگوها را به درستی یاد بگیرد و عملکرد خود را بهبود ببخشد، باید این چرخه را بارها و بارها تکرار کنیم. بیایید تمام مراحلی که پیشتر بررسی کردیم را برای ۱۰۰۰ اپوک (تکرار) اجرا کنیم تا شاهد کاهش چشمگیر خطا و همگرایی مدل باشیم.
# defining the model architecture
inputLayer_neurons = X.shape[0] # number of features in data set
hiddenLayer_neurons = 3 # number of hidden layers neurons
outputLayer_neurons = 1 # number of neurons at output layer
# initializing weight
weights_input_hidden = np.random.uniform(size=(inputLayer_neurons, hiddenLayer_neurons))
weights_hidden_output = np.random.uniform(
size=(hiddenLayer_neurons, outputLayer_neurons)
)
# defining the parameters
lr = 0.1
epochs = 1000
losses = []
for epoch in range(epochs):
## Forward Propogation
# calculating hidden layer activations
hiddenLayer_linearTransform = np.dot(weights_input_hidden.T, X)
hiddenLayer_activations = sigmoid(hiddenLayer_linearTransform)
# calculating the output
outputLayer_linearTransform = np.dot(
weights_hidden_output.T, hiddenLayer_activations
)
output = sigmoid(outputLayer_linearTransform)
## Backward Propagation
# calculating error
error = np.square(y - output) / 2
# calculating rate of change of error w.r.t weight between hidden and output layer
error_wrt_output = -(y - output)
output_wrt_outputLayer_LinearTransform = np.multiply(output, (1 - output))
outputLayer_LinearTransform_wrt_weights_hidden_output = hiddenLayer_activations
error_wrt_weights_hidden_output = np.dot(
outputLayer_LinearTransform_wrt_weights_hidden_output,
(error_wrt_output * output_wrt_outputLayer_LinearTransform).T,
)
# calculating rate of change of error w.r.t weights between input and hidden layer
outputLayer_LinearTransform_wrt_hiddenLayer_activations = weights_hidden_output
hiddenLayer_activations_wrt_hiddenLayer_linearTransform = np.multiply(
hiddenLayer_activations, (1 - hiddenLayer_activations)
)
hiddenLayer_linearTransform_wrt_weights_input_hidden = X
error_wrt_weights_input_hidden = np.dot(
hiddenLayer_linearTransform_wrt_weights_input_hidden,
(
hiddenLayer_activations_wrt_hiddenLayer_linearTransform
* np.dot(
outputLayer_LinearTransform_wrt_hiddenLayer_activations,
(output_wrt_outputLayer_LinearTransform * error_wrt_output),
)
).T,
)
# updating the weights
weights_hidden_output = weights_hidden_output - lr * error_wrt_weights_hidden_output
weights_input_hidden = weights_input_hidden - lr * error_wrt_weights_input_hidden
# print error at every 100th epoch
epoch_loss = np.average(error)
if epoch % 100 == 0:
print(f"Error at epoch {epoch} is {epoch_loss:.5f}")
# appending the error of each epoch
losses.append(epoch_loss)
خروجی:
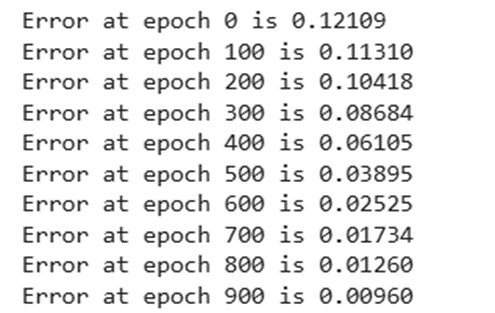
به نظر میرسد با ادامه روند آموزش، عملکرد مدل ما لحظه به لحظه در حال بهبود است. بیایید نگاهی به مقادیر نهایی وزنها پس از اتمام کامل فرآیند آموزش بیندازیم.
# updated w_ih
weights_input_hidden
# updated w_ho
weights_hidden_output
ترسیم نمودار برای تجسم روند آموزش
# visualizing the error after each epoch
plt.plot(np.arange(1, epochs + 1), np.array(losses))
ارزیابی نهایی: چقدر به هدف نزدیک شدهایم؟
در آخرین مرحله از این فرآیند، ما بررسی خواهیم کرد که پیشبینیهای مدل ما تا چه حد به خروجیهای واقعی (Actual Output) نزدیک شدهاند. این کار به ما کمک میکند تا بفهمیم شبکهی عصبی که از صفر طراحی کردهایم، چقدر توانسته است الگوهای موجود در دادهها را با موفقیت استخراج و یاد بگیرد.
# final output from the model
output
# actual target
y
خطا بهطور محسوسی کاهش یافته است
ارزیابی مدل و ترسیم Decision Boundary
در قدم بعدی، مدل خود را روی یک مجموعهداده متفاوت آموزش خواهیم داد و با ترسیم مرز تصمیمگیری (Decision Boundary) پس از پایان آموزش، عملکرد آن را به صورت بصری مشاهده و تحلیل خواهیم کرد.
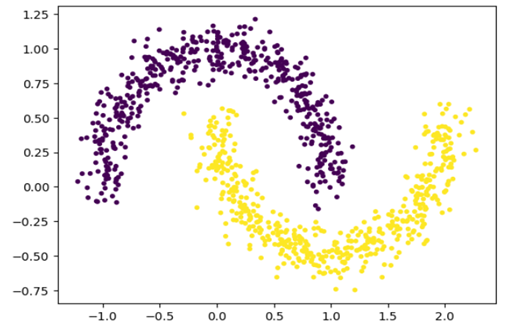
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=1000, random_state=42, noise=0.1)
plt.scatter(X[:, 0], X[:, 1], s=10, c=y)
خروجی:
ما ورودیها را نرمالسازی (Normalize) میکنیم تا مدل ما با سرعت بیشتری آموزش ببیند.
x
X -= X.min()
X /= X.max()
X.min(), X.max()
np.unique(y)
X.shape, y.shape
X = X.T
y = y.reshape(1, -1)
X.shape, y.shape
حالا زمان آن رسیده است که ساختار شبکه خود را دقیقتر تعریف کنیم. ما برای بهینهسازی مدل، سه فراپارامتر (Hyperparameter) کلیدی زیر را بهروزرسانی خواهیم کرد:
- تعداد نورونهای لایه پنهان را به ۱۰ عدد تغییر میدهیم.
- نرخ یادگیری (Learning Rate) را روی ۰.۱ تنظیم میکنیم.
- و فرآیند آموزش را برای تعداد اپوکهای (Epochs) بیشتری ادامه میدهیم.
# defining the model architecture
inputLayer_neurons = X.shape[0] # number of features in data set
hiddenLayer_neurons = 10 # number of hidden layers neurons
outputLayer_neurons = 1 # number of neurons at output layer
# initializing weight
weights_input_hidden = np.random.uniform(size=(inputLayer_neurons, hiddenLayer_neurons))
weights_hidden_output = np.random.uniform(
size=(hiddenLayer_neurons, outputLayer_neurons)
)
# defining the parameters
lr = 0.1
epochs = 10000
losses = []
for epoch in range(epochs):
## Forward Propogation
# calculating hidden layer activations
hiddenLayer_linearTransform = np.dot(weights_input_hidden.T, X)
hiddenLayer_activations = sigmoid(hiddenLayer_linearTransform)
# calculating the output
outputLayer_linearTransform = np.dot(
weights_hidden_output.T, hiddenLayer_activations
)
output = sigmoid(outputLayer_linearTransform)
## Backward Propagation
# calculating error
error = np.square(y - output) / 2
# calculating rate of change of error w.r.t weight between hidden and output layer
error_wrt_output = -(y - output)
output_wrt_outputLayer_LinearTransform = np.multiply(output, (1 - output))
outputLayer_LinearTransform_wrt_weights_hidden_output = hiddenLayer_activations
error_wrt_weights_hidden_output = np.dot(
outputLayer_LinearTransform_wrt_weights_hidden_output,
(error_wrt_output * output_wrt_outputLayer_LinearTransform).T,
)
# calculating rate of change of error w.r.t weights between input and hidden layer
outputLayer_LinearTransform_wrt_hiddenLayer_activations = weights_hidden_output
hiddenLayer_activations_wrt_hiddenLayer_linearTransform = np.multiply(
hiddenLayer_activations, (1 - hiddenLayer_activations)
)
hiddenLayer_linearTransform_wrt_weights_input_hidden = X
error_wrt_weights_input_hidden = np.dot(
hiddenLayer_linearTransform_wrt_weights_input_hidden,
(
hiddenLayer_activations_wrt_hiddenLayer_linearTransform
* np.dot(
outputLayer_LinearTransform_wrt_hiddenLayer_activations,
(output_wrt_outputLayer_LinearTransform * error_wrt_output),
)
).T,
)
# updating the weights
weights_hidden_output = weights_hidden_output - lr * error_wrt_weights_hidden_output
weights_input_hidden = weights_input_hidden - lr * error_wrt_weights_input_hidden
# print error at every 100th epoch
epoch_loss = np.average(error)
if epoch % 1000 == 0:
print(f"Error at epoch {epoch} is {epoch_loss:.5f}")
# appending the error of each epoch
losses.append(epoch_loss)
# visualizing the error after each epoch
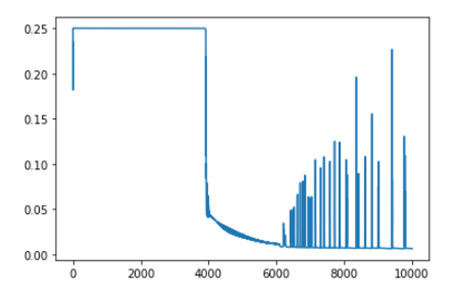
plt.plot(np.arange(1, epochs + 1), np.array(losses))
# final output from the model
output[:, :5]
حالا اگر نگاهی به خروجیها بیندازیم و پیشبینیهای مدل را به صورت دستی بررسی کنیم، میبینیم که نتایج به به مقادیر واقعی نزدیک شدهاند.
y[:, :5]در این بخش، قصد داریم عملکرد مدل را با ترسیم مرز تصمیمگیری (Decision Boundary) به تصویر بکشیم.
# Define region of interest by data limits
steps = 1000
x_span = np.linspace(X[0, :].min(), X[0, :].max(), steps)
y_span = np.linspace(X[1, :].min(), X[1, :].max(), steps)
xx, yy = np.meshgrid(x_span, y_span)
# forward pass for region of interest
hiddenLayer_linearTransform = np.dot(
weights_input_hidden.T, np.c_[xx.ravel(), yy.ravel()].T
)
hiddenLayer_activations = sigmoid(hiddenLayer_linearTransform)
outputLayer_linearTransform = np.dot(weights_hidden_output.T, hiddenLayer_activations)
output_span = sigmoid(outputLayer_linearTransform)
# Make predictions across region of interest
labels = (output_span > 0.5).astype(int)
# Plot decision boundary in region of interest
z = labels.reshape(xx.shape)
fig, ax = plt.subplots()
ax.contourf(xx, yy, z, alpha=0.2)
# Get predicted labels on training data and plot
train_labels = (output > 0.5).astype(int)
# create scatter plot
ax.scatter(X[0, :], X[1, :], s=10, c=y.squeeze())
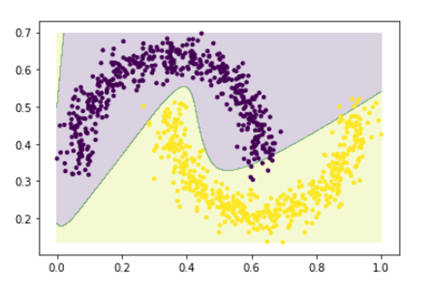
این معیار به ما نشان میدهد که شبکه عصبی ما تا چه اندازه در شناسایی الگوهای موجود در دادهها و سپس دستهبندی صحیح آنها مهارت پیدا کرده است.
تا اینجا، تمرکز ما بر درک شهودی فرآیند یادگیری و مشاهده آن در قالب پیادهسازی عملی بود. در ادامه، همان فرآیند را از زاویهای رسمیتر و ریاضی بررسی میکنیم تا مشخص شود محاسباتی که در کد انجام دادیم، دقیقاً بر چه اصول ریاضی استوار هستند و چگونه قاعده زنجیرهای نقش اصلی را در انتشار رو به عقب ایفا میکند.
دیدگاه ریاضی به الگوریتم انتشار رو به عقب (Back Propagation)
بیایید فرض کنیم Wi وزنهای بین لایه ورودی و لایه پنهان، و Wh وزنهای بین لایه پنهان و لایه خروجی باشند.
مطابق با محاسبات لایهها:
۱.
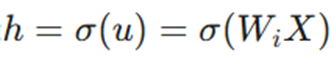
یعنی h تابعی از u است و u خود تابعی از Wi و. X در اینجا σ نشاندهنده تابع فعالساز ماست.
۲.
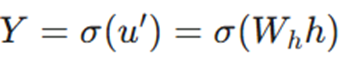
یعنی Y تابعی از u’ است و u’ نیز تابعی از Wh و h.
هدف اصلی ما پیدا کردن دو عبارت کلیدی است:
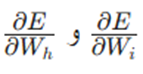
و به زبان ساده، میخواهیم بدانیم با تغییر وزنهای هر لایه، میزان خطای نهایی (E) چقدر تغییر میکند.
استفاده از قاعده زنجیرهای (Chain Rule)
از آنجایی که خطا (E) تابعی از Y، و Y تابعی از u’، و u’ تابعی از وزنهاست، باید از قاعده زنجیرهای در مشتقگیری استفاده کنیم:
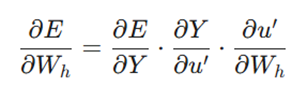
با دانستن اینکه تابع خطا به صورت E = (Y-t)^2 / 2 تعریف میشود، مشتقات را به دست میآوریم:
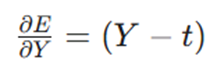
مشتق تابع سیگموئید به صورت جذاب σ (1-σ) است، پس
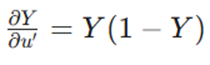
و در نهایت
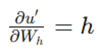
با جایگذاری این مقادیر، گرادیان لایه خروجی بهدست میآید:
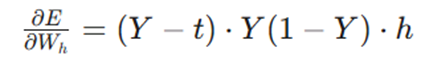
محاسبه گرادیان برای لایه ورودی
حالا به سراغ وزنهای بین لایه ورودی و پنهان میرویم:
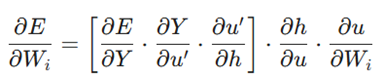
همانطور که میبینید، ما قبلاً عبارات زیر
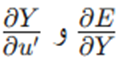
را محاسبه کردهایم. با جایگذاری مقادیر باقیمانده، فرمول نهایی وزنهای ورودی به دست میآید:
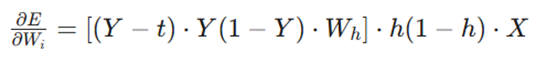
بهروزرسانی وزنها
در نهایت وزنها با استفاده از نرخ یادگیری (η) اصلاح میشوند:
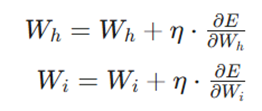
چرا به آن «انتشار رو به عقب» میگوییم؟
اگر به فرمولهای نهایی دقت کنید، هر دو شامل عبارت (Y-t) یا همان خطای خروجی هستند. ما از خروجی شروع کردیم و این خطا را لایهبهلایه به سمت ورودیها عقب راندیم تا وزنها را اصلاح کنیم؛ به همین دلیل نام آن را «انتشار رو به عقب» گذاشتهاند.
انطباق ریاضیات با کد پایتون:
- h همان hiddenlayer_activations است.
- Y-t همان E (خطا) است.
- Y(1-Y) همان Slope_output_layer است.
- η همان lr (نرخ یادگیری) است.
جمع بندی
در این مطلب، فرآیند آموزش یک شبکه عصبی از زاویه شهودی، محاسباتی و پیادهسازی عملی بررسی شد. دیدیم که چگونه یک مدل با انتشار رو به جلو خروجی تولید میکند، میزان خطا را محاسبه میکند و سپس با استفاده از انتشار رو به عقب و گرادیان کاهشی، پارامترهای خود را اصلاح میکند.
تطبیق گامبهگام مفاهیم ریاضی با کد پایتون نشان داد که مفاهیمی مانند مشتق، قاعده زنجیرهای و نرخ یادگیری چگونه بهصورت عملی در فرآیند یادگیری نقش دارند. همچنین مشاهده کردیم که تکرار این چرخه در قالب اپوکها، به کاهش تدریجی خطا و همگرایی مدل منجر میشود.
این مسیر آموزشی، پایهای مناسب برای ورود به معماریهای پیشرفتهتر مانند پرسپترونهای چندلایه عمیق، شبکههای کانولوشنی و چارچوبهای یادگیری عمیق فراهم میکند. با درک این مفاهیم بنیادین، استفاده از ابزارهای آماده دیگر صرفاً اجرای کد نخواهد بود، بلکه تصمیمی آگاهانه و مهندسیشده خواهد بود.



