
مقدمه
پرسپترون نقطهی آغاز داستان شبکههای عصبی و یادگیری عمیق است؛ مدلی ساده اما تأثیرگذار که برای نخستینبار ایدهی «یادگیری ماشینی الهامگرفته از مغز انسان» را بهصورت عملی مطرح کرد. هرچند پرسپترون از نظر ساختار بسیار ابتدایی به نظر میرسد، اما مفاهیمی که در دل آن شکل گرفتند، پایهی بسیاری از پیشرفتهای بعدی در هوش مصنوعی را بنا نهادند.
درک پرسپترون صرفاً به معنای شناخت یک الگوریتم قدیمی نیست، بلکه راهی برای فهم چرایی تولد شبکههای عصبی چندلایه، الگوریتم پسانتشار و معماریهای عمیق امروزی است. مفاهیمی مانند وزن، بایاس، تابع فعالسازی و تصمیمگیری خطی، همگی نخستینبار در قالب پرسپترون معنا پیدا کردند.
در این متن، پرسپترون از منظر تاریخی، مفهومی و فنی بررسی میشود؛ از ریشههای زیستشناختی و مدلهای اولیه گرفته تا محدودیتهای بنیادی و نقش آن در شکلگیری شبکههای عصبی مدرن. هدف این است که خواننده، پرسپترون را نه بهعنوان مدلی منسوخ، بلکه بهعنوان سنگبنای یادگیری عمیق امروز درک کند.
سفری در اعماق تاریخچه پرسپترون
دنیای هوش مصنوعی مسیری شبیه به یک رمان علمی-تخیلی و پرفراز و نشیب را طی کرده است تا به تکامل امروزی برسد. درک این تاریخچه، کلید فهم چرایی قدرت شبکههای عصبی مدرن است.
۱۹۴۳: جرقه ریاضی؛ ذهن به مثابه ماشین
همه چیز از یک ایده جسورانه توسط وارن مککالک و والتر پیتس آغاز شد. آنها ثابت کردند که عملکرد نورونهای مغز انسان را میتوان با گیتهای منطقی ریاضی مدلسازی کرد. این کشف بزرگ یک پیام ساده اما تکاندهنده داشت: هوش، فرمولپذیر است.
۱۹۵۸: تولد یادگیری؛ رویای بیپایان روزنبلات
فرانک روزنبلات با معرفی Mark I Perceptron، ایده یادگیری ماشین را به واقعیت تبدیل کرد. این اولین باری بود که یک الگوریتم میتوانست با دیدن دادهها، خودش را اصلاح کند. هیجان به قدری بالا بود که نیویورک تایمز در آن زمان پیشبینی کرد: بزودی شاهد ماشینهایی خواهیم بود که راه میروند، حرف میزنند و آگاه هستند. اما این موفقیت یک پاشنه آشیل داشت: سادگی بیش از حد در مواجهه با پیچیدگی.
۱۹۶۹: عصر یخبندان؛ ضربه فنی هوش مصنوعی
در سال ۱۹۶۹، ماروین مینسکی و سیمور پاپرت در کتاب مشهور خود ثابت کردند که پرسپترون ساده در برابر یک چالش منطقی به نام XOR (جداسازی غیرخطی) کاملاً ناتوان است. این نقد علمی مانند سطل آبی بر پیکر داغ هوش مصنوعی بود و منجر به زمستان اول هوش مصنوعی شد؛ دورانی که بودجههای تحقیقاتی قطع شد و بسیاری از دانشمندان این حوزه را ترک کردند.

۱۹۸۶: رنسانس؛ بازگشت قهرمانانه هینتون
پس از سالها سکوت، جفری هینتون با معرفی الگوریتم انتشار رو به عقب ورق را برگرداند. او نشان داد که اگر نورونها را در لایههای پنهان روی هم بچینیم، بنبست XOR فرو میریزد. این تولد دوباره، زیربنای چیزی شد که امروزه به آن یادگیری عمیق (Deep Learning) میگوییم و جهان را تسخیر کرده است.
پرسپترون: سنگبنای شبکههای عصبی
در دنیای شبکههای عصبی، پرسپترون (Perceptron) یک واحد یا الگوریتم پایه است که مقادیر ورودی، وزنها و بایاسها را دریافت کرده و محاسبات پیچیدهای را برای شناسایی ویژگیهای درون دادههای ورودی انجام میدهد.
دیدگاه بیولوژیکی:
الهام از طبیعت پرسپترون صرفاً یک کد برنامهنویسی نیست؛ بلکه تلاشی جسورانه برای مدلسازی ریاضی عملکرد یک نورون واقعی در مغز انسان است. در این مدل:
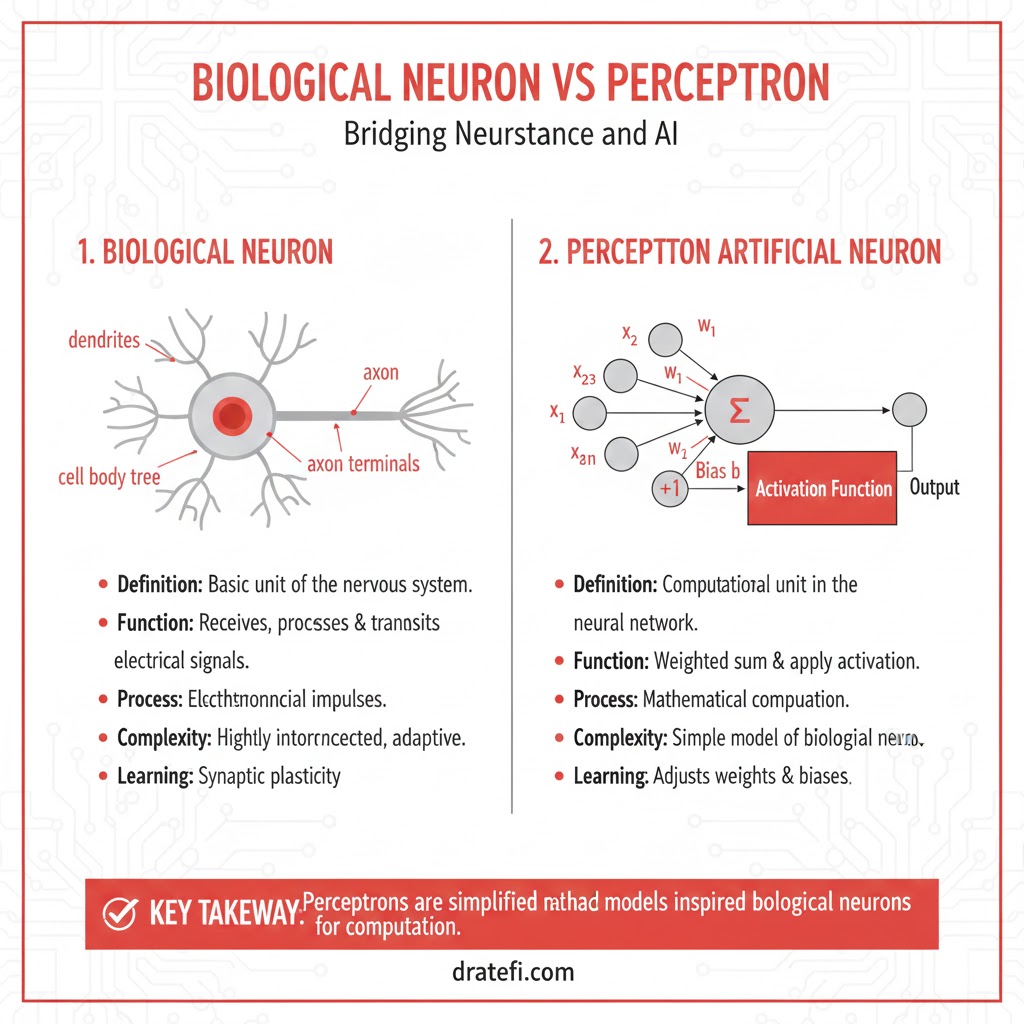
- دندریتها (ورودی): نقش کانالهای ورودی را دارند که سیگنالها را دریافت میکنند.
- بدنه سلولی (تابع جمعکننده): جایی که تمام سیگنالهای دریافتی با هم ترکیب میشوند تا شدت کل پیام مشخص شود.
- آکسون (خروجی): مسیری که اگر شدت سیگنال از حد مجاز فراتر رفت، پیام نهایی را به نورونهای دیگر مخابره میکند.
مفهوم خطای بازگشتی:
سیستم خود اصلاحگر پرسپترون فراتر از یک فرمول ثابت، یک سیستم زنده و پویا است. قدرت اصلی آن در یادگیری از اشتباهات نهفته است. این یعنی پرسپترون پس از هر پیشبینی، خروجی خود را با واقعیت مقایسه کرده و از طریق یک حلقه بازخورد، وزنهای داخلیاش را طوری تغییر میدهد که در دفعه بعد اشتباه کمتری مرتکب شود.
ویژگیهای کلیدی پرسپترون:
- حل مسائل تحت نظارت: این واحد برای حل مسائل یادگیری ماشین تحت نظارت (Supervised Learning) مانند طبقهبندی (Classification) و رگرسیون (Regression) به کار میرود.
- واحد سازنده: اگرچه پرسپترون به عنوان یک الگوریتم طراحی شده است، اما به دلیل سادگی و نتایج دقیق، به عنوان واحد سازنده (Building Block) اصلی شبکههای عصبی شناخته میشود.
- توصیف چندگانه: ما میتوانیم پرسپترون را یک مدل یادگیری ماشین یا حتی یک تابع ریاضی بنامیم که دادههای خام را به نتایج معنادار تبدیل میکند.
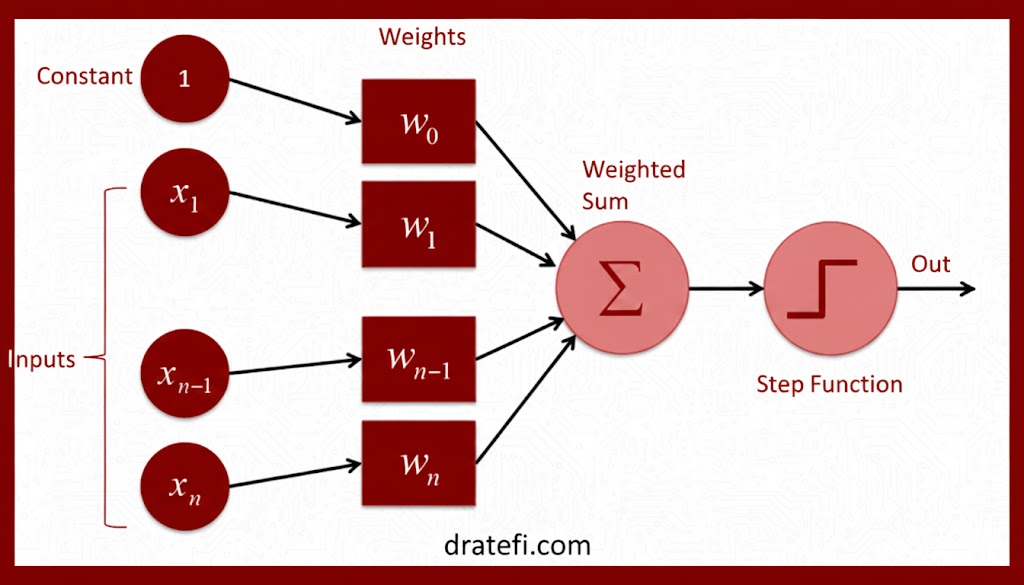
در ساختار شبکههای عصبی، وزنها و بایاسها (که با w و b نشان داده میشوند) پارامترهای قابل یادگیری مدل هستند که تعیین میکنند شبکه چگونه دادهها را پردازش و تفسیر کند.
در ادامه، جزئیات فنی این مفاهیم و نحوه تعامل آنها در یک واحد پرسپترون را بررسی میکنیم:
پارامترهای قابل یادگیری: وزن و بایاس
- وزنها(Weights): پارامترهایی هستند که دادههای ورودی را به لایه بعدی منتقل میکنند و وزن یا اهمیت اطلاعات را با خود حمل میکنند؛ به این معنا که وزن بیشتر به معنای اهمیت بالاتر آن ویژگی ورودی است.
- بایاس(Bias): میتوان بایاس را به عنوان یک تابع خطی در نظر گرفت که به طور موثری توسط یک مقدار ثابت جابهجا (Transposed) شده است.
نورونها: واحدهای عملیاتی
نورونها واحدهای اصلی شبکههای عصبی مصنوعی هستند که وزنها و بایاسها را از لایه قبلی دریافت کرده و به لایه بعدی منتقل میکنند.
- افزایش دقت: در برخی مسائل پیچیده، افزایش تعداد نورونها در هر لایه پنهان برای دستیابی به دقت بالاتر در نظر گرفته میشود، زیرا گرههای بیشتر به معنای کسب اطلاعات بیشتر از مجموعه داده است.
- محدودیت گرهها: پس از رسیدن به تعداد مشخصی از گرهها در هر لایه، دقت مدل دیگر افزایش نمییابد. در این مرحله باید روشهای دیگر مانند افزایش لایههای پنهان، افزایش تعداد دورههای آموزشی (Epochs) یا امتحان کردن توابع فعالسازی و بهینهسازهای مختلف را امتحان کرد.
معماری محاسباتی پرسپترون
یک پرسپترون ساده دارای ورودیهای Xn و یک مقدار ثابت است. هر ورودی وزن مخصوص به خود را دارد و مقدار ثابت نیز وزن خود را خواهد داشت که همان بایاس (b) یا W0 نامیده میشود.
روند محاسبات:
۱. وزنها و بایاسها وارد تابع جمعکننده (Summation) میشوند.
فرمول این تابع به صورت زیر است:
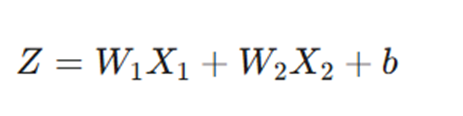
۲. سپس مقدار Z به یک تابع فعالسازی (مانند Step Function در این مثال) منتقل میشود تا خروجی نهایی دادههای تغذیه شده را ارائه دهد.
نقش تابع فعالسازی
تابع فعالسازی، مقدار حاصل از جمع (Z) را به عنوان ورودی دریافت کرده و آن را به یک محدوده خاص میبرد. توابع فعالسازی مختلف از متدهای متفاوتی برای این فرآیند استفاده میکنند.
تکامل از پرسپترون ساده به شبکههای چندلایه: عبور از مرز خطی بودن
بزرگترین چالش پرسپترونهای تکلایه این است که نمیتوانند غیرخطی بودن (Non-linearity) مجموعهدادهها را درک کنند؛ به همین دلیل در مواجهه با دادههای پیچیده، نتایج ضعیفی ارائه میدهند. این بنبست با ظهور پرسپترونهای چندلایه (MLP) شکسته شد که عملکرد خیرهکنندهای در تحلیل دادههای غیرخطی دارند.

شبکههای عصبی تماممتصل (Fully Connected)
در معماری شبکههای تماممتصل (FCNN)، هر گره یا نورون در یک لایه به تمامی نورونهای لایه بعدی متصل است. یک MLP استاندارد شامل یک لایه ورودی، یک لایه خروجی و یک یا چند لایه پنهان است که نورونها در آنها روی هم چیده شدهاند.
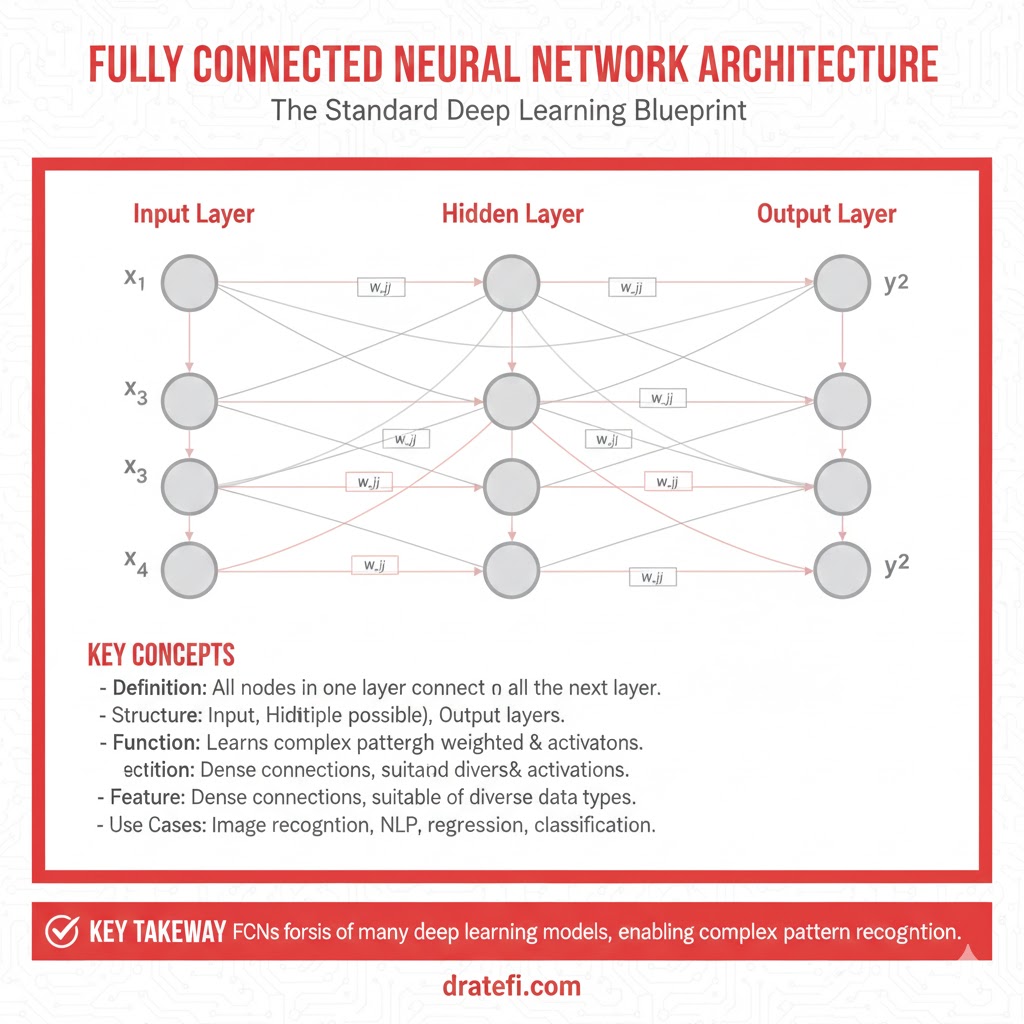
- نقش لایههای پنهان: افزایش تعداد لایههای پنهان و گرهها به مدل کمک میکند تا رفتارهای غیرخطی دیتاست را شکار کرده و نتایج قابلاتکایی ارائه دهد.
- توابع فعالسازی: در MLP میتوان از هر تابع فعالسازی دلخواهی (مانند ReLU یاSigmoid) استفاده کرد تا آستانههای تصمیمگیری غیرخطی روی دادهها اعمال شود.
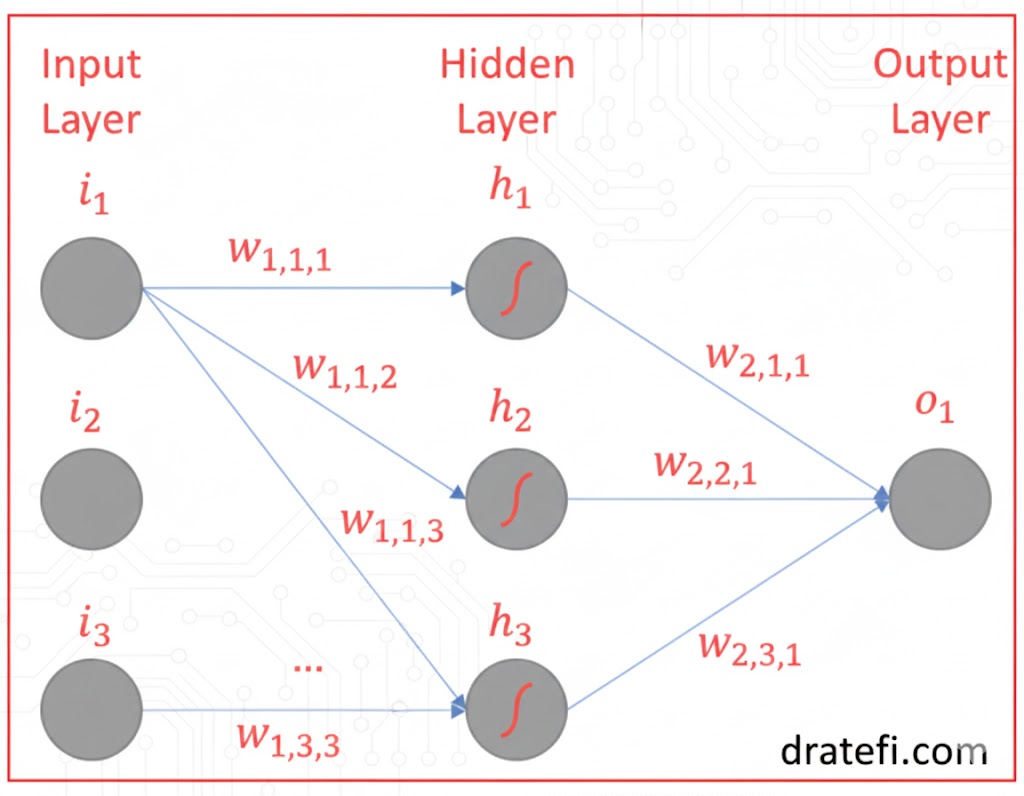
الف) رمزگشایی از نمادگذاریهای MLP (Notations)
سختترین بخش در آموزش شبکههای عصبی، درک الگوریتم انتشار رو به عقب (Backpropagation) برای آپدیت وزنها و بایاسهاست. از آنجایی که هزاران پارامتر در یک شبکه وجود دارد، تسلط بر نمادگذاریها برای درک شهود این الگوریتم ضروری است.
۱. نمادگذاری وزنها (Wij^h)
وزنها پلهای ارتباطی بین لایهها هستند. نماد Wij^h به این صورت تفسیر میشود:
- i: شماره گرهای در لایه قبل که وزن از آن صادر میشود.
- j: شماره گرهای در لایه بعد که وزن به آن وارد میشود.
- h: شماره لایهای که وزن به آن وارد شده است.
مثال: W23^1 یعنی وزنی که از گره ۲ لایه قبل به گره ۳ از اولین لایه پنهان وارد شده است.
۲. نمادگذاری بایاسها (bij)
بایاسها به هر گره انعطافپذیری میدهند:
- i: لایهای که بایاس به آن تعلق دارد.
- j: گرهای که بایاس در آن قرار دارد.
مثال: b23 یعنی مقدار بایاس گره ۳ در دومین لایه پنهان.
۳. نمادگذاری خروجیها (Oij)
- Oij: نشاندهنده خروجی گره j در لایه i است.
ب) محاسبه کل پارامترهای قابل آموزش (Trainable Parameters)
تعداد کل پارامترهای قابل آموزش بین دو لایه، برابر است با مجموع تمام وزنها و بایاسهای موجود بین آن دو لایه.
فرمول محاسبه:
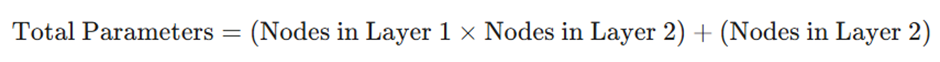
مثال عملی: برای یک شبکه با معماری [۳، ۴، ۲،۲]
- بین لایه ورودی (۳ گره) و لایه پنهان اول (۴ گره):
- وزنها: 3 ✕ 4 = 12
- بایاسها: 4 (به تعداد گرههای مقصد)
- مجموع: 16 پارامتر
- بین لایه پنهان اول (۴ گره) و لایه پنهان دوم (۲ گره):
- وزنها: 4 ✕ 2 = 8
- بایاسها: 2
- مجموع: 10 پارامتر
- بین لایه پنهان دوم (۲ گره) و لایه خروجی (۲ گره):
- وزنها :2 ✕ 2 = 4
- بایاسها: 2
- مجموع: 6 پارامتر
کاربردهای پرسپترون چندلایه (MLP)
امروزه MLP فراتر از محیطهای آزمایشگاهی، در حال تغییر دادن نحوه تعامل ما با تکنولوژی هستند. این شبکهها به دلیل توانایی در یادگیری ویژگیها به صورت خودکار، در خط مقدم حل مسائل پیچیده قرار دارند.
۱. پردازش زبان طبیعی (NLP) و درک احساسات
دیگر متون برای ماشینها فقط مشتی از کلمات نیستند؛ MLPها به ماشینها قدرت «درک لحن» دادهاند.
- تحلیل احساسات: کسبوکارها با استفاده از MLP میتوانند هزاران نظر کاربران را در لحظه تحلیل کرده و متوجه شوند که جو کلی حاکم بر برند آنها مثبت است یا منفی.
۲. سیستمهای توصیهگر
آیا تا به حال فکر کردهاید که یوتیوب یا نتفلیکس چگونه دقیقاً محتوای مورد علاقه شما را حدس میزنند؟
- پیشبینی رفتار کاربر: MLP با تحلیل تاریخچه بازدیدها، لایکها و حتی مدت زمانی که روی یک عکس مکث کردهاید، الگوی رفتاری شما را استخراج میکند.
- فیلترینگ مشارکتی :این مدلها شباهت بین سلیقه شما و میلیونها کاربر دیگر را پیدا کرده و دقیقترین پیشنهاد را ارائه میدهند.
۳. پزشکی هوشمند؛ تشخیص پیش از وقوع
در حوزه سلامت، MLPها نقش فرشته نجات را ایفا میکنند.
- تحلیل دادههای بیومتریک: با بررسی دادههای آزمایشگاهی (مانند قند خون، فشار و چربی)، این مدلها میتوانند احتمال ابتلا به بیماریهایی نظیر دیابت یا نارساییهای قلبی را با دقت بسیار بالایی پیشبینی کنند.
۴. امنیت سایبری و مبارزه با کلاهبرداری
در دنیای دیجیتال، امنیت یک اولویت است و MLPها بیدارترین نگهبانان هستند.
- تشخیص نفوذ: این شبکهها ترافیک شبکه را به صورت لحظهای رصد کرده و هرگونه الگوی غیرعادی که شبیه به حملات سایبری باشد را مسدود میکنند.
۵. پیشبینی سریهای زمانی و بازارهای مالی
اقتصاددانان از MLP برای پیشبینی آینده استفاده میکنند.
- بازار سهام و ارز دیجیتال: اگرچه بازارها غیرقابل پیشبینی به نظر میرسند، اما MLPها با تحلیل روند قیمتهای گذشته، الگوهای تکرارشونده را برای پیشبینی قیمتهای آینده استخراج میکنند.
- تخمین تقاضا: کارخانههای بزرگ برای مدیریت انبار خود، از این مدلها استفاده میکنند تا بدانند در ماههای آینده بازار به چه مقدار از محصول آنها نیاز خواهد داشت.
مطالعه موردی1: هوش مصنوعی در بازار املاک (پیشبینی قیمت با MLP)
چرا به MLP نیاز داریم؟
در بازار مسکن، قیمت یک خانه صرفاً تابع متراژ نیست؛ بلکه ترکیبی پیچیده و غیرخطی از پارامترهایی مانند سن بنا، دسترسیهای محلی، تعداد اتاقها و نوسانات بازار است. مدلهای خطی ساده معمولاً در درک این روابط درهمتنیده ناتوان هستند. اما یک پرسپترون چندلایه (MLP) با لایههای پنهان خود میتواند الگوهای پنهان در دادههای املاک را شناسایی کرده و تخمینی دقیق از قیمت ارائه دهد.
معماری شبکه برای رگرسیون
برای حل این مسئله، ساختار MLP ما تفاوتهای کلیدی با مدلهای طبقهبندی دارد:
- لایه ورودی: شامل ویژگیهایی مثل متراژ، تعداد اتاق و سن بنا.
- لایههای پنهان: از تابع فعالساز ReLU استفاده میکنیم تا روابط غیرخطی را مدلسازی کنیم.
- لایه خروجی: برخلاف طبقهبندی که از Softmax استفاده میکرد، در اینجا لایه خروجی فقط یک نورون دارد و معمولاً بدون تابع فعالساز (یا با تابع خطی) است تا بتواند هر عدد مثبتی را به عنوان قیمت برگرداند.
- تابع زیان :از MSE (میانگین مربعات خطا) استفاده میکنیم تا فاصله عددی بین قیمت واقعی و قیمت پیشبینی شده را به حداقل برسانیم.
پیادهسازی عملی با پایتون
در این بخش، کدی طراحی شده است که یک مدل MLP را برای پیشبینی قیمت آموزش میدهد:
import numpy as np
from sklearn.neural_network import MLPRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error
# ۱. آمادهسازی دادهها (متراژ، تعداد اتاق، سن بنا)
# ورودیها (X): [متراژ، تعداد اتاق، سن بنا]
X = np.array([
[50, 1, 20], [80, 2, 10], [120, 3, 5],
[150, 3, 2], [65, 1, 15], [200, 4, 1],
[90, 2, 12], [110, 2, 8], [180, 4, 3]
])
# هدف (y): قیمت به میلیون تومان
y = np.array([500, 900, 1800, 2500, 700, 4000, 1100, 1500, 3200])
# ۲. نرمالسازی دادهها (بسیار حیاتی برای شبکههای عصبی)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# ۳. تقسیم دادهها به دو بخش آموزش (۸۰٪) و تست (۲۰٪)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# ۴. تعریف مدل MLP برای رگرسیون
# ساختار: دو لایه پنهان با ۵۰ نورون، تابع فعالساز ReLU
# از solver='lbfgs' استفاده شده تا روی دادههای کم، سریعتر به جواب برسیم
mlp_reg = MLPRegressor(hidden_layer_sizes=(50, 50),
activation='relu',
solver='lbfgs',
max_iter=2000,
random_state=42)
# ۵. شروع فرآیند آموزش (یادگیری وزنها و بایاسها)
print("در حال آموزش شبکه عصبی... لطفاً کمی صبر کنید.")
mlp_reg.fit(X_train, y_train)
# ۶. پیشبینی بر روی دادههای جدید (تست)
predictions = mlp_reg.predict(X_test)
# ۷. نمایش نتایج نهایی
print("-" * 30)
print("نتایج نهایی مدل:")
for i in range(len(y_test)):
print(f"نمونه شماره {i+1}:")
print(f" قیمت واقعی: {y_test[i]} میلیون تومان")
print(f" پیشبینی مدل: {predictions[i]:.2f} میلیون تومان")
# محاسبه خطای مدل
mae = mean_absolute_error(y_test, predictions)
print("-" * 30)
print(f"خطای میانگین مطلق (MAE): {mae:.2f} میلیون تومان")
مطالعه موردی2:تشخیص تقلب در تراکنشهای بانکی
چالش: در سیستمهای بانکی، بیش از ۹۹٪ تراکنشها سالم هستند و تنها بخش بسیار کوچکی تقلب محسوب میشوند. مدل باید بتواند این الگوهای نادر (Minority Class) را بدون ایجاد مزاحمت برای کاربران عادی شناسایی کند.
تمرکز فنی: مدیریت عدم توازن کلاس(Class Imbalance). ما از وزندهی به کلاسها استفاده میکنیم تا شبکه عصبی بابت نادیده گرفتن تقلب، جریمه سنگینتری شود.
کد پایتون:
import numpy as np
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.preprocessing import StandardScaler
# ۱. شبیهسازی دادههای نامتوازن (۱۰۰۰ تراکنش که فقط ۱۰ تای آنها تقلب است)
X = np.random.randn(1000, 10) # ۱۰ ویژگی برای هر تراکنش
y = np.zeros(1000)
y[:10] = 1 # ۱۰ مورد تقلب
# ۲. تقسیم دادهها و نرمالسازی
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# ۳. آموزش MLP (استفاده از لایههای پنهان برای شناسایی الگوهای پیچیده تقلب)
# در لایههای پنهان از ReLU استفاده میکنیم تا روابط غیرخطی را پیدا کنیم
fraud_mlp = MLPClassifier(hidden_layer_sizes=(32, 16), activation='relu', solver='adam', max_iter=500)
fraud_mlp.fit(X_train, y_train)
# ۴. ارزیابی مدل
y_pred = fraud_mlp.predict(X_test)
print("گزارش عملکرد مدل در تشخیص تقلب:")
print(classification_report(y_test, y_pred))
مطالعه موردی3:تشخیص زودهنگام دیابت
چالش: پیشبینی بیماری بر اساس دادههای عددی بیومتریک (مانند سطح انسولین، گلوکز و BMI). در اینجا دقت (Accuracy) بسیار حیاتی است، زیرا تشخیص اشتباه میتواند بر سلامت بیمار تأثیر بگذارد.
تمرکز فنی: کار با دادههای عددی (Numerical) و بهینهسازی توابع فعالساز برای رسیدن به بالاترین حساسیت (Sensitivity)
کد پایتون:
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import make_classification # برای شبیهسازی دادههای پزشکی
from sklearn.preprocessing import MinMaxScaler
# ۱. ایجاد دادههای شبیهسازی شده پزشکی (۸ ویژگی مثل سن، وزن، قند خون)
X_med, y_med = make_classification(n_samples=500, n_features=8, n_classes=2, random_state=1)
# ۲. مقیاسگذاری دادهها بین ۰ و ۱ (مناسب برای دادههای بیومتریک)
scaler_med = MinMaxScaler()
X_med_scaled = scaler_med.fit_transform(X_med)
# ۳. تعریف MLP با تمرکز بر دقت بالا
# استفاده از ۳ لایه پنهان برای استخراج ویژگیهای عمیقتر پزشکی
diabetes_mlp = MLPClassifier(hidden_layer_sizes=(64, 32, 16),
activation='tanh', # Tanh برای دادههای پزشکی که حول صفر هستند عالی عمل میکند
solver='lbfgs', # برای دادههای با حجم متوسط بسیار دقیق است
max_iter=1000)
diabetes_mlp.fit(X_med_scaled, y_med)
# ۴. پیشبینی برای یک بیمار جدید (فرضی)
new_patient = np.random.rand(1, 8)
prediction = diabetes_mlp.predict(scaler_med.transform(new_patient))
probability = diabetes_mlp.predict_proba(scaler_med.transform(new_patient))
print(f"وضعیت پیشبینی: {'دیابتی' if prediction[0] == 1 else 'سالم'}")
print(f"احتمال ابتلا: {probability[0][1] * 100:.2f}%")
جمع بندی
پرسپترون سادهترین شکل یک شبکه عصبی مصنوعی است، اما تأثیر آن بر تاریخ هوش مصنوعی بسیار فراتر از سادگی ظاهریاش است. این مدل نشان داد که ماشینها میتوانند با تنظیم وزنها و یادگیری از دادهها، تصمیمگیری کنند و همین ایده، مسیر توسعه شبکههای عصبی را هموار کرد.
در این فایل دیدیم که پرسپترون تکلایه با وجود توانایی در حل مسائل خطی، با محدودیتهای جدی مانند ناتوانی در حل مسئله XOR مواجه است. همین محدودیتها زمینهساز تولد شبکههای عصبی چندلایه (MLP) و الگوریتم پسانتشار شدند؛ تحولاتی که باعث جهش واقعی در یادگیری ماشین و یادگیری عمیق گردیدند.
در نهایت، پرسپترون را میتوان نقطه اتصال مفاهیم زیستشناسی، ریاضیات و مهندسی دانست؛ مدلی که اگرچه بهتنهایی برای مسائل پیچیده کافی نیست، اما فهم آن برای درک معماریهای پیشرفتهتر مانند MLP، CNN و RNN کاملاً ضروری است. تسلط بر پرسپترون، درک عمیقتری از منطق درونی شبکههای عصبی فراهم میکند و پایهای محکم برای ورود به دنیای یادگیری عمیق مدرن بهشمار میرود.



