- این فصل پوشش میدهد:
- اولین مثالهای شما از گردشکارهای یادگیری ماشینی در دنیای واقعی
- پردازش مسائل طبقهبندی روی دادههای برداری
- پردازش مسائل رگرسیون پیوسته روی دادههای برداری
مقدمه
این فصل برای شروع استفاده شما از شبکههای عصبی برای حل مسائل واقعی طراحی شده است. شما دانش کسبشده از فصلهای ۲ و ۳ را تثبیت خواهید کرد و آنچه را که آموختهاید در سه کار جدید که سه مورد استفاده رایج شبکههای عصبی را پوشش میدهند، به کار خواهید گرفت—طبقهبندی دودویی، طبقهبندی چندکلاسه، و رگرسیون اسکالر:
- طبقهبندی نقدهای فیلم به مثبت یا منفی (طبقهبندی دودویی)
- طبقهبندی خبرها بر اساس موضوع (طبقهبندی چندکلاسه)
- تخمین قیمت یک خانه، با توجه به دادههای املاک و مستغلات (رگرسیون اسکالر)
این مثالها اولین تماس شما با گردشکارهای یادگیری ماشینی سرتاسری خواهد بود: شما با پیشپردازش دادهها، اصول معماری پایه مدل، و ارزیابی مدل آشنا خواهید شد.
واژهنامه طبقهبندی و رگرسیون
طبقهبندی و رگرسیون شامل اصطلاحات تخصصی بسیاری است. شما با برخی از آنها در مثالهای قبلی برخورد کردهاید و در فصلهای آینده بیشتر آنها را خواهید دید. این اصطلاحات تعاریف دقیق و مختص یادگیری ماشینی دارند و باید با آنها آشنا باشید:
- نمونه یا ورودی (Sample or input) :یک نقطه داده که وارد مدل شما میشود.
- پیشبینی یا خروجی (Prediction or output) : آنچه از مدل شما خارج میشود.
- هدف(Target) : حقیقت. آنچه که مدل ایدهآل شما باید طبق یک منبع داده خارجی پیشبینی میکرد.
- خطای پیشبینی یا مقدار زیان (Prediction error or loss value) : معیاری برای سنجش فاصله بین پیشبینی مدل شما و هدف.
- کلاسها (Classes) : مجموعهای از برچسبهای ممکن برای انتخاب در یک مسئله طبقهبندی. برای مثال، هنگام طبقهبندی تصاویر گربه و سگ، “سگ” و “گربه” دو کلاس هستند.
- برچسب (Label) : یک نمونه خاص از حاشیهنویسی کلاس در یک مسئله طبقهبندی. برای مثال، اگر تصویر شماره ۱۲۳۴ به عنوان شامل کلاس “سگ” حاشیهنویسی شده باشد، آنگاه “سگ” یک برچسب برای تصویر شماره ۱۲۳۴ است.
- حقیقت زمینی یا حاشیهنویسیها (Ground-truth or annotations) : تمام اهداف برای یک مجموعه داده، که معمولاً توسط انسانها جمعآوری میشوند.
- طبقهبندی دودویی (Binary classification) : یک وظیفه طبقهبندی که در آن هر نمونه ورودی باید به دو دسته انحصاری طبقهبندی شود.
- طبقهبندی چندکلاسه (Multiclass classification) : یک وظیفه طبقهبندی که در آن هر نمونه ورودی باید به بیش از دو دسته طبقهبندی شود؛ برای مثال، طبقهبندی ارقام دستنویس.
- طبقهبندی چندبرچسبی (Multilabel classification) : یک وظیفه طبقهبندی که در آن به هر نمونه ورودی میتوان چندین برچسب اختصاص داد. برای مثال، یک تصویر ممکن است هم شامل گربه و هم سگ باشد و باید هم با برچسب “گربه” و هم با برچسب “سگ” حاشیهنویسی شود. تعداد برچسبها در هر تصویر معمولاً متغیر است.
- رگرسیون اسکالر (Scalar regression) : وظیفهای که در آن هدف یک مقدار اسکالر پیوسته است. پیشبینی قیمت خانه یک مثال خوب است: قیمتهای هدف مختلف یک فضای پیوسته را تشکیل میدهند.
- رگرسیون برداری (Vector regression) : وظیفهای که در آن هدف مجموعهای از مقادیر پیوسته است؛ برای مثال، یک بردار پیوسته. اگر رگرسیون را برای چندین مقدار (مانند مختصات یک کادر محدودکننده در یک تصویر) انجام میدهید، در حال انجام رگرسیون برداری هستید.
- مینی-بچ یا بچ (Mini-batch or batch) : مجموعهای کوچک از نمونهها (معمولاً بین ۸ تا ۱۲۸) که همزمان توسط مدل پردازش میشوند. تعداد نمونهها اغلب توانی از ۲ است تا تخصیص حافظه در GPU را تسهیل کند. هنگام آموزش، یک مینی-بچ برای محاسبه یک بهروزرسانی گرادیان کاهشی واحد که بر وزنهای مدل اعمال میشود، استفاده میگردد.
تا پایان این فصل، شما قادر خواهید بود از شبکههای عصبی برای انجام وظایف ساده طبقهبندی و رگرسیون بر روی دادههای برداری استفاده کنید. سپس آماده خواهید بود تا در فصل ۵، درک اصولیتر و نظریتری از یادگیری ماشینی را شروع کنید.
طبقهبندی نقدهای فیلم: یک مثال طبقهبندی دودویی
طبقهبندی دوکلاسه، یا طبقهبندی دودویی، یکی از رایجترین انواع مسائل یادگیری ماشینی است. در این مثال، شما یاد میگیرید که نقدهای فیلم را بر اساس محتوای متنی آنها به عنوان مثبت یا منفی طبقهبندی کنید.
مجموعه داده IMDB
شما با مجموعه داده IMDB کار خواهید کرد: مجموعهای شامل ۵۰,۰۰۰ نقد بسیار قطبیشده از پایگاه داده فیلم اینترنت. این نقدها به ۲۵,۰۰۰ نقد برای آموزش و ۲۵,۰۰۰ نقد برای آزمایش تقسیم شدهاند که هر مجموعه شامل ۵۰٪ نقد منفی و ۵۰٪ نقد مثبت است.
درست مانند مجموعه داده MNIST، مجموعه داده IMDB همراه با Keras ارائه میشود. این مجموعه داده قبلاً پیشپردازش شده است: نقدها (دنبالهای از کلمات) به دنبالهای از اعداد صحیح تبدیل شدهاند، که در آن هر عدد صحیح نشاندهنده یک کلمه خاص در یک دیکشنری است. این کار ما را قادر میسازد تا بر روی ساخت مدل، آموزش و ارزیابی تمرکز کنیم. در فصل ۱۱، یاد خواهید گرفت که چگونه ورودی متن خام را از ابتدا پردازش کنید.
کد زیر مجموعه داده را بارگذاری میکند (هنگامی که برای اولین بار آن را اجرا میکنید، حدود ۸۰ مگابایت داده روی دستگاه شما دانلود میشود).
قطعه کد ۴.۱ بارگذاری مجموعه داده IMDB
from tensorflow.keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(
num_words=10000)
آرگومان num_words=10000 به این معنی است که شما فقط ۱۰,۰۰۰ کلمه پرتکرار را در دادههای آموزشی نگه میدارید. کلمات کمیاب حذف خواهند شد. این کار به ما اجازه میدهد با دادههای برداری با اندازهای قابل مدیریت کار کنیم. اگر این محدودیت را تعیین نمیکردیم، با ۸۸,۵۸۵ کلمه منحصربهفرد در دادههای آموزشی سروکار داشتیم که به طور غیرضروری بزرگ است. بسیاری از این کلمات فقط در یک نمونه ظاهر میشوند و بنابراین نمیتوانند به طور معناداری برای طبقهبندی استفاده شوند.
متغیرهای train_data و test_data لیستی از نقدها هستند؛ هر نقد لیستی از شاخصهای کلمات (که یک دنباله از کلمات را کدگذاری میکنند) است. train_labels و test_labels لیستی از ۰ و ۱ هستند که ۰ به معنای منفی و ۱ به معنای مثبت است.
>>> train_data[0]
[1, 14, 22, 16, … 178, 32]
>>> train_labels[0]
1
چون خودمان را به ۱۰,۰۰۰ کلمه پرتکرار محدود کردهایم، هیچ شاخص کلمهای از ۱۰,۰۰۰ بیشتر نخواهد شد:
>>> max([max(sequence) for sequence in train_data])
9999
برای اینکه یک ایده بگیرید، در اینجا روشی سریع برای بازگرداندن (decode) یکی از این نقدها به کلمات انگلیسی آورده شده است.
قطعه کد ۴.۲ بازگرداندن نقدها به متن
word_index = imdb.get_word_index()
word_index یک دیکشنری است که کلمات را به یک شاخص عددی (عدد صحیح) نگاشت میکند.
reverse_word_index = dict(
[(value, key) for (key, value) in word_index.items()])
آن را برعکس میکند، یعنی شاخصهای عددی (صحیح) را به کلمات نگاشت میکند.
decoded_review = ” “.join(
[reverse_word_index.get(i – 3, “?”) for i in train_data[0]])
نقد را رمزگشایی (decode) میکند. توجه داشته باشید که شاخصها ۳ واحد آفست دارند زیرا ۰، ۱ و ۲ شاخصهای رزرو شده برای «padding»، «شروع دنباله» و «نامعلوم» هستند.
آمادهسازی دادهها
شما نمیتوانید مستقیماً لیستهایی از اعداد صحیح را به یک شبکه عصبی وارد کنید. همه آنها طولهای متفاوتی دارند، اما یک شبکه عصبی انتظار دارد دستههای پیوسته داده را پردازش کند. شما باید لیستهای خود را به تنسور تبدیل کنید. دو راه برای انجام این کار وجود دارد:
- لیستهای خود را پدگذاری (pad) کنید تا همگی طول یکسانی داشته باشند، آنها را به یک تنسور عدد صحیح با شکل (نمونهها، حداکثر_طول) تبدیل کنید، و مدل خود را با لایهای که قادر به مدیریت چنین تنسورهای عدد صحیحی است لایه Embedding، که بعداً در کتاب به تفصیل آن را پوشش خواهیم داد شروع کنید.
- لیستهای خود را به روش multi-hot encode تبدیل کنید تا به بردارهایی از ۰ و ۱ تبدیل شوند. این بدان معناست، برای مثال، تبدیل دنباله[8,5] به یک بردار ۱۰,۰۰۰ بعدی که به جز شاخصهای ۸ و ۵ (که ۱ خواهند بود)، همگی ۰ خواهند بود. سپس میتوانید از یک لایه Dense، که قادر به مدیریت دادههای برداری با ممیز شناور است، به عنوان اولین لایه در مدل خود استفاده کنید.
بیایید راه حل دوم را برای برداری کردن دادهها انتخاب کنیم، که برای حداکثر وضوح، آن را به صورت دستی انجام خواهید داد.
قطعه کد ۴.۳: رمزگذاری دنبالههای عدد صحیح از طریق رمزگذاری multi-hot
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
یک ماتریس کاملاً صفر با شکل (len(sequences), dimension) ایجاد میکند.
for i, sequence in enumerate(sequences):
for j in sequence:
results[i, j] = 1.
شاخصهای خاصی از results[i] را به ۱ تغییر میدهد.
return results
x_train = vectorize_sequences(train_data)
دادههای آموزشی برداریشده
x_test = vectorize_sequences(test_data)
دادههای آزمایشی برداریشده
نمونهها اکنون به این شکل هستند:
>>> x_train[0]
array([ 0., 1., 1., …, 0., 0., 0.])
شما همچنین باید برچسبهای خود را برداری کنید، که کار سادهای است:
y_train = np.asarray(train_labels).astype(“float32”)
y_test = np.asarray(test_labels).astype(“float32”)
حالا دادهها آماده هستند تا به یک شبکه عصبی وارد شوند.
ساخت مدل
دادههای ورودی بردار هستند و برچسبها اسکالر (۱ و ۰): این یکی از سادهترین تنظیمات مسئلهای است که تا به حال با آن روبرو خواهید شد. نوعی از مدل که روی چنین مسئلهای خوب عمل میکند، یک پشته ساده از لایههای کاملاً متصل (Dense) با فعالسازیهای ReLU است.
دو تصمیم کلیدی معماری در مورد چنین پشتهای از لایههای Dense وجود دارد که باید گرفته شوند:
- چند لایه استفاده شود
- چند واحد برای هر لایه انتخاب شود
در فصل ۵، اصول رسمی را برای راهنمایی شما در گرفتن این انتخابها یاد خواهید گرفت. فعلاً، باید در مورد انتخابهای معماری زیر به من اعتماد کنید:
- دو لایه میانی که هر کدام ۱۶ واحد دارند
- یک لایه سوم که پیشبینی اسکالر مربوط به احساس نقد فعلی را خروجی میدهد
شکل ۴.۱ نشان میدهد که مدل چگونه به نظر میرسد. و لیست زیر پیادهسازی Keras را نشان میدهد، مشابه مثال MNIST که قبلاً دیدید.
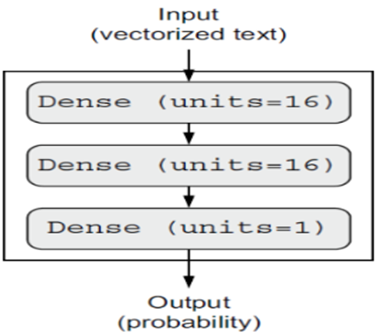
قطعه کد ۴.۴: تعریف مدل
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(16, activation=”relu”), layers.Dense(16, activation=”relu”), layers.Dense(1, activation=”sigmoid”)
])
اولین آرگومانی که به هر لایه Dense پاس داده میشود، تعداد واحدها در آن لایه است: بُعد فضای بازنمایی آن لایه. از فصلهای ۲ و ۳ به خاطر دارید که هر لایه Dense با فعالسازی ReLU، زنجیره عملیات تنسور زیر را پیادهسازی میکند:
output = relu(dot(input, W) + b)
داشتن ۱۶ واحد به این معنی است که ماتریس وزن W شکلی معادل (بعد ورودی، ۱۶) خواهد داشت: ضرب نقطهای با W، داده ورودی را بر روی یک فضای بازنمایی ۱۶ بعدی نگاشت میکند (و سپس بردار بایاس b را اضافه کرده و عملیات ReLU را اعمال خواهید کرد). شما میتوانید به طور شهودی بُعد فضای بازنمایی خود را به عنوان «میزان آزادی که به مدل برای یادگیری بازنماییهای داخلی میدهید» درک کنید. داشتن واحدهای بیشتر (یک فضای بازنمایی با ابعاد بالاتر) به مدل شما اجازه میدهد بازنماییهای پیچیدهتری را یاد بگیرد، اما مدل را از نظر محاسباتی پرهزینهتر میکند و ممکن است منجر به یادگیری الگوهای ناخواسته شود (الگوهایی که عملکرد را در دادههای آموزشی بهبود میبخشند اما در دادههای آزمایشی نه).
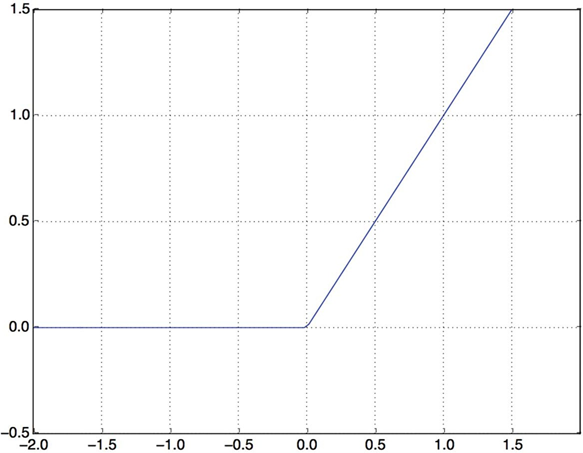
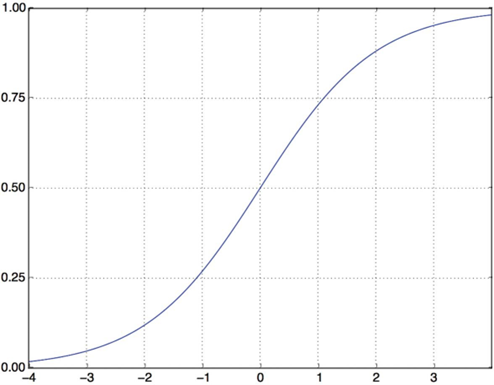
لایههای میانی از ReLU به عنوان تابع فعالسازی خود استفاده میکنند و لایه نهایی از فعالسازی سیگموئید استفاده میکند تا یک احتمال را خروجی دهد (امتیازی بین ۰ و ۱ که نشان میدهد چقدر احتمال دارد نمونه دارای هدف “۱” باشد: چقدر احتمال دارد نقد مثبت باشد). یک ReLU (واحد خطی یکسوساز) تابعی است که مقادیر منفی را صفر میکند (به شکل ۴.۲ مراجعه کنید)، در حالی که یک سیگموئید مقادیر دلخواه را به بازه [۰, ۱] “فشرده” میکند (به شکل ۴.۳ مراجعه کنید) و چیزی را خروجی میدهد که میتواند به عنوان یک احتمال تفسیر شود.
در نهایت، باید یک تابع زیان (loss function) و یک بهینهساز (optimizer) انتخاب کنید. از آنجایی که با یک مسئله طبقهبندی دودویی روبرو هستید و خروجی مدل شما یک احتمال است (شما مدل خود را با یک لایه تکواحدی با فعالسازی سیگموئید به پایان میرسانید)، بهترین کار استفاده از تابع زیان binary_crossentropy است. این تنها انتخاب ممکن نیست؛ برای مثال، میتوانید از mean_squared_error نیز استفاده کنید. اما cross-entropy معمولاً بهترین انتخاب هنگام کار کردن با…
———————————————————————————
توابع فعالسازی چه هستند و چرا ضروریاند؟
بدون یک تابع فعالسازی مانند ReLU (که به آن غیرخطی بودن نیز گفته میشود)، لایه Dense شامل دو عملیات خطی خواهد بود—یک ضرب نقطهای و یک جمع:
output = dot(input, W) + b
این لایه تنها میتوانست تبدیلات خطی (تبدیلات افاین) از دادههای ورودی را یاد بگیرد: فضای فرضیه این لایه مجموعه تمام تبدیلات خطی ممکن دادههای ورودی به یک فضای ۱۶ بعدی خواهد بود. چنین فضای فرضیهای بسیار محدود است و از چندین لایه بازنمایی بهرهای نمیبرد، زیرا یک پشته عمیق از لایههای خطی باز هم یک عملیات خطی را پیادهسازی میکرد: افزودن لایههای بیشتر فضای فرضیه را گسترش نمیداد همانطور که در فصل ۲ دیدید.
برای دستیابی به یک فضای فرضیه بسیار غنیتر که از بازنماییهای عمیق بهره ببرد، به یک غیرخطی بودن، یا تابع فعالسازی نیاز دارید. ReLU محبوبترین تابع فعالسازی در یادگیری عمیق است، اما بسیاری از کاندیداهای دیگر نیز وجود دارند که همگی با نامهای عجیب و غریب مشابهی همراه هستند: PReLU، ELU و غیره.
—————————————————————————————-
با مدلهایی که احتمالات را خروجی میدهند. Cross-entropy کمیتی از حوزه نظریه اطلاعات است که فاصله بین توزیعهای احتمال یا در این مورد، بین توزیع حقیقت زمینی و پیشبینیهای شما را اندازهگیری میکند.
در مورد انتخاب بهینهساز، ما rmsprop را انتخاب میکنیم، که معمولاً یک گزینه پیشفرض خوب برای تقریباً هر مسئلهای است.
این گامی است که در آن مدل را با بهینهساز rmsprop و تابع زیان binary_crossentropy پیکربندی میکنیم. توجه داشته باشید که دقت (accuracy) را نیز در طول آموزش پایش خواهیم کرد.
قطعه کد ۴.۵: کامپایل کردن مدل
model.compile(optimizer=”rmsprop”,
loss=”binary_crossentropy”,
metrics=[“accuracy”])
اعتبار سنجی رویکرد
همانطور که در فصل ۳ آموختید، یک مدل یادگیری عمیق هرگز نباید بر روی دادههای آموزشی خود ارزیابی شود – رویه استاندارد استفاده از یک مجموعه اعتبارسنجی برای پایش دقت مدل در طول آموزش است. در اینجا، ما یک مجموعه اعتبارسنجی با کنار گذاشتن ۱۰,۰۰۰ نمونه از دادههای آموزشی اصلی ایجاد خواهیم کرد.
قطعه کد ۴.۶: اختصاص یک مجموعه اعتبارسنجی
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
اکنون مدل را برای ۲۰ دوره (epoch) (۲۰ بار تکرار روی تمام نمونهها در دادههای آموزشی) در مینی-بچهایی با اندازه ۵۱۲ نمونه آموزش خواهیم داد. همزمان، زیان (loss) و دقت (accuracy) را بر روی ۱۰,۰۰۰ نمونهای که کنار گذاشتیم، پایش میکنیم. این کار را با ارسال دادههای اعتبارسنجی به عنوان آرگومان validation_data انجام میدهیم.
قطعه کد ۴.۷: آموزش مدل
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
روی CPU، این کار کمتر از ۲ ثانیه در هر epoch طول میکشد—آموزش در ۲۰ ثانیه به پایان میرسد. در پایان هر epoch، مکث کوتاهی وجود دارد زیرا مدل زیان و دقت خود را بر روی ۱۰,۰۰۰ نمونه از دادههای اعتبارسنجی محاسبه میکند.
توجه داشته باشید که فراخوانی model.fit() یک شیء History را برمیگرداند، همانطور که در فصل ۳ دیدید. این شیء یک عضو history دارد که دیکشنری حاوی دادههایی درباره هر آنچه در طول آموزش اتفاق افتاده است. بیایید به آن نگاهی بیندازیم:
>>> history_dict = history.history
>>> history_dict.keys()
[u”accuracy”, u”loss”, u”val_accuracy”, u”val_loss”]
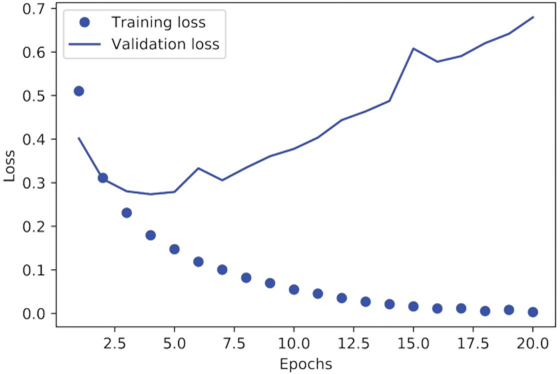
این دیکشنری شامل چهار ورودی است: یکی برای هر معیار که در طول آموزش و در طول اعتبارسنجی پایش میشد. در دو لیست زیر، بیایید از Matplotlib برای رسم همزمان زیان آموزش و اعتبارسنجی (به شکل ۴.۴ مراجعه کنید) و همچنین دقت آموزش و اعتبارسنجی (به شکل ۴.۵ مراجعه کنید) استفاده کنیم. توجه داشته باشید که نتایج شما ممکن است به دلیل مقداردهی اولیه تصادفی متفاوت مدل شما کمی فرق کند.
قطعه کد ۴.۸ – رسم نمودار خطای آموزش و اعتبارسنجی (Training and Validation Loss)
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict[“loss”]
val_loss_values = history_dict[“val_loss”]
epochs = range(1, len(loss_values) + 1)
plt.plot(epochs, loss_values, “bo”, label=”Training loss”)
“bo” به معنای “نقطه آبی” است.
plt.plot(epochs, val_loss_values, “b”, label=”Validation loss”)
“b” به معنای “خط آبی پررنگ” است.
plt.title(“Training and validation loss”)
plt.xlabel(“Epochs”)
plt.ylabel(“Loss”)
plt.legend()
plt.show()
قطعه کد ۴.۹ – رسم نمودار دقت آموزش و دقت اعتبارسنجی(Training and Validation Accuracy)
plt.clf()
شکل را پاک میکند.
acc = history_dict[“accuracy”]
val_acc = history_dict[“val_accuracy”]
plt.plot(epochs, acc, “bo”, label=”Training acc”)
plt.plot(epochs, val_acc, “b”, label=”Validation acc”) plt.title(“Training and validation accuracy”)
plt.xlabel(“Epochs”)
plt.ylabel(“Accuracy”) plt.legend() plt.show()
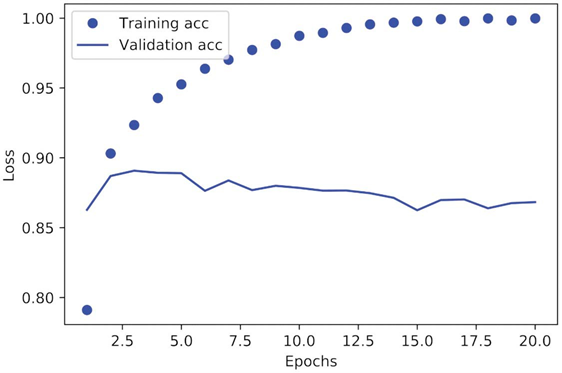
همانطور که میبینید، زیان آموزش با هر دوره کاهش مییابد و دقت آموزش با هر دوره افزایش مییابد. این همان چیزی است که هنگام اجرای بهینهسازی گرادیان کاهشی انتظار میرود – کمیتی که سعی در حداقل کردن آن دارید باید با هر تکرار کمتر شود. اما این مورد برای زیان و دقت اعتبارسنجی صادق نیست: به نظر میرسد آنها در دوره چهارم به اوج خود میرسند.
این نمونهای از چیزی است که قبلاً در مورد آن هشدار دادیم: مدلی که بر روی دادههای آموزشی عملکرد بهتری دارد، لزوماً مدلی نیست که بر روی دادههایی که قبلاً ندیده است، بهتر عمل کند. به عبارت دقیقتر، آنچه شما میبینید بیشبرازش (overfitting) است: پس از دوره چهارم، شما بیش از حد روی دادههای آموزشی بهینهسازی میکنید و در نهایت بازنماییهایی را یاد میگیرید که مختص دادههای آموزشی هستند و به دادههای خارج از مجموعه آموزشی تعمیم نمییابند.
در این حالت، برای جلوگیری از بیشبرازش، میتوانید آموزش را پس از چهار دوره متوقف کنید. به طور کلی، میتوانید از طیف وسیعی از تکنیکها برای کاهش بیشبرازش استفاده کنید که در فصل ۵ آنها را پوشش خواهیم داد.
بیایید یک مدل جدید را از ابتدا برای چهار دوره آموزش دهیم و سپس آن را روی دادههای آزمایش ارزیابی کنیم.
قطعه کد ۴.۱۰ – بازآموزی (آموزش مجدد) یک مدل از ابتدا(Retraining a model from scratch)
model = keras.Sequential([
layers.Dense(16, activation=”relu”),
layers.Dense(16, activation=”relu”),
layers.Dense(1, activation=”sigmoid”)
])
model.compile(optimizer=”rmsprop”,
loss=”binary_crossentropy”,
metrics=[“accuracy”])
model.fit(x_train, y_train, epochs=4, batch_size=512)
results = model.evaluate(x_test, y_test)
نتایج نهایی به شرح زیر است:
>>> results
[0.2929924130630493, 0.88327999999999995]
عدد اول، ۰.۲۹، زیان آزمایش (test loss) است و عدد دوم، ۰.۸۸، دقت آزمایش (test accuracy) است.
این رویکرد نسبتاً سادهانگارانه به دقت ۸۸% دست مییابد. با رویکردهای پیشرفته (state-of-the-art)، باید بتوانید به حدود ۹۵% نزدیک شوید.
استفاده از یک مدل آموزشدیده برای تولید پیشبینی روی دادههای جدید
پس از آموزش یک مدل، میخواهید از آن در یک محیط عملی استفاده کنید. میتوانید با استفاده از متد predict، همانطور که در فصل ۳ آموختید، احتمال مثبت بودن نقدها را تولید کنید:
>>> model.predict(x_test)
array([[ 0.98006207]
[ 0.99758697]
[ 0.99975556]
…,
[ 0.82167041]
[ 0.02885115]
[ 0.65371346]], dtype=float32)
همانطور که میبینید، مدل برای برخی نمونهها (۰.۹۹ یا بیشتر، یا ۰.۰۱ یا کمتر) مطمئن است، اما برای برخی دیگر) ۰.4، ۰.6 (اطمینان کمتری دارد.
آزمایشهای بیشتر
آزمایشهای زیر به شما کمک میکند متقاعد شوید که انتخابهای معماری شما کاملاً منطقی هستند، هرچند هنوز جای بهبود وجود دارد:
- شما از دو لایه بازنمایی قبل از لایه طبقهبندی نهایی استفاده کردید. سعی کنید از یک یا سه لایه بازنمایی استفاده کنید و ببینید این کار چگونه بر دقت اعتبارسنجی و آزمایش تأثیر میگذارد.
- سعی کنید از لایههایی با واحدهای بیشتر یا کمتر استفاده کنید: ۳۲ واحد، ۶۴ واحد و غیره.
- سعی کنید به جای binary_crossentropy از تابع زیان mse استفاده کنید.
- سعی کنید به جای relu از فعالسازی tanh (یک فعالسازی که در اوایل ظهور شبکههای عصبی محبوب بود) استفاده کنید.
جمعبندی
آنچه باید از این مثال برداشت کنید:
- شما معمولاً باید پیشپردازش نسبتاً زیادی را روی دادههای خام خود انجام دهید تا بتوانید آنها را — به صورت تنسور — به یک شبکه عصبی وارد کنید. دنبالههای کلمات میتوانند به عنوان بردارهای دودویی کدگذاری شوند، اما گزینههای کدگذاری دیگری نیز وجود دارد.
- پشتههایی از لایههای Dense با فعالسازیهای ReLU میتوانند طیف وسیعی از مسائل (از جمله طبقهبندی احساسات) را حل کنند و احتمالاً شما به طور مکرر از آنها استفاده خواهید کرد.
- در یک مسئله طبقهبندی دودویی (دو کلاس خروجی)، مدل شما باید با یک لایه Dense با یک واحد و یک فعالسازی سیگموئید به پایان برسد: خروجی مدل شما باید یک اسکالر بین ۰ و ۱ باشد که یک احتمال را کدگذاری میکند.
- با چنین خروجی سیگموئید اسکالر در یک مسئله طبقهبندی دودویی، تابع زیانی که باید استفاده کنید binary_crossentropy است.
- بهینهساز rmsprop عموماً یک انتخاب به اندازه کافی خوب است، هر مسئلهای که داشته باشید. این یکی از دغدغههایی است که کمتر نگران آن خواهید بود.
- همانطور که شبکههای عصبی در دادههای آموزشی خود بهتر میشوند، در نهایت شروع به بیشبرازش (overfitting) میکنند و نتایج بدتری را روی دادههایی که قبلاً ندیدهاند، به دست میآورند. همیشه از پایش عملکرد روی دادههایی که خارج از مجموعه آموزشی هستند، اطمینان حاصل کنید.
طبقهبندی خبرها: یک مثال طبقهبندی چندکلاسه
در بخش قبلی، دیدید که چگونه ورودیهای برداری را به دو کلاس متقابلاً انحصاری با استفاده از یک شبکه عصبی کاملاً متصل طبقهبندی کنید. اما وقتی بیش از دو کلاس داشته باشید چه اتفاقی میافتد؟
در این بخش، ما یک مدل برای طبقهبندی اخبار رویترز به ۴۶ موضوع متقابلاً انحصاری خواهیم ساخت. از آنجایی که ما کلاسهای زیادی داریم، این مسئله نمونهای از طبقهبندی چندکلاسه است، و از آنجایی که هر نقطه داده باید فقط در یک دسته طبقهبندی شود، این مسئله به طور خاص نمونهای از طبقهبندی چندکلاسه تکبرچسبی است. اگر هر نقطه داده میتوانست به چندین دسته (در این حالت، موضوعات) تعلق داشته باشد، ما با یک مسئله طبقهبندی چندکلاسه چندبرچسبی روبرو بودیم.
مجموعه داده رویترز
شما با مجموعه داده رویترز کار خواهید کرد، مجموعهای از خبرهای کوتاه و موضوعات آنها که توسط رویترز در سال ۱۹۸۶ منتشر شده است. این یک مجموعه داده نمونه ساده و پرکاربرد برای طبقهبندی متن است. ۴۶ موضوع مختلف وجود دارد؛ برخی موضوعات بیشتر از دیگران بازنمایی شدهاند، اما هر موضوع حداقل ۱۰ مثال در مجموعه آموزشی دارد.
مانند IMDB و MNIST، مجموعه داده رویترز به عنوان بخشی از Keras بستهبندی شده است. بیایید نگاهی بیندازیم.
قطعه کد ۴.۱۱ – بارگذاری دیتاست(مجموع داده های ) رویترز
from tensorflow.keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(
num_words=10000)
مانند مجموعه داده IMDB، آرگومان num_words=10000 دادهها را به ۱۰,۰۰۰ کلمه پرتکرار یافت شده در دادهها محدود میکند.
شما ۸,۹۸۲ نمونه آموزشی و ۲,۲۴۶ نمونه آزمایشی دارید:
>>> len(train_data)
8982
>>> len(test_data)
2246
مانند نقدهای IMDB، هر مثال لیستی از اعداد صحیح (شاخصهای کلمات) است:
>>> train_data[10]
[1, 245, 273, 207, 156, 53, 74, 160, 26, 14, 46, 296, 26, 39, 74, 2979,
3554, 14, 46, 4689, 4329, 86, 61, 3499, 4795, 14, 61, 451, 4329, 17, 12]
اگر کنجکاو هستید، در اینجا نحوه بازگرداندن (decode) آن به کلمات آورده شده است.
قطعه کد ۴.۱۲ – بازگردانی خبرها به متن قابلخواندن
word_index = reuters.get_word_index() reverse_word_index = dict(
[(value, key) for (key, value) in word_index.items()])
decoded_newswire = ” “.join(
[reverse_word_index.get(i – 3, “?”) for i in train_data[0]])
توجه داشته باشید که شاخصها ۳ واحد آفست دارند زیرا ۰، ۱ و ۲ شاخصهای رزرو شده برای «پدگذاری (padding)»، «شروع دنباله (start of sequence)» و «نامعلوم (unknown)» هستند.
برچسب مرتبط با یک مثال، یک عدد صحیح بین ۰ تا ۴۵ است — یک شاخص موضوع:
>>> train_labels[10]
3
آمادهسازی دادهها
میتوانید دادهها را با دقیقاً همان کدی که در مثال قبلی استفاده شد، برداری کنید.
قطعه کد ۴.۱۳ – رمزگذاری دادههای ورودی
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
برای برداری کردن برچسبها، دو امکان وجود دارد: میتوانید لیست برچسبها را به یک تنسور عدد صحیح تبدیل کنید، یا میتوانید از کدگذاری یک-داغ (one-hot encoding) استفاده کنید. کدگذاری یک-داغ یک فرمت پرکاربرد برای دادههای دستهای (categorical data) است که به آن کدگذاری دستهای نیز گفته میشود. در این حالت، کدگذاری یک-داغ برچسبها شامل جاسازی هر برچسب به عنوان یک بردار تمام-صفر است که در محل شاخص برچسب، یک (۱) قرار میگیرد. لیست زیر یک مثال را نشان میدهد.
قطعه کد ۴.۱۴ – رمزگذاری برچسبها (Encoding the Labels)
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
y_train = to_one_hot(train_labels)
y_test = to_one_hot(test_labels)
برچسبهای آموزش برداریشده
برچسبهای آزمایش برداریشده
توجه داشته باشید که یک روش داخلی برای انجام این کار در Keras وجود دارد:
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(train_labels)
y_test = to_categorical(test_labels)
ساخت مدل
این مسئله طبقهبندی موضوعی شبیه به مسئله قبلی طبقهبندی نقدهای فیلم به نظر میرسد: در هر دو مورد، ما سعی داریم قطعات کوتاه متن را طبقهبندی کنیم. اما در اینجا یک محدودیت جدید وجود دارد: تعداد کلاسهای خروجی از ۲ به ۴۶ افزایش یافته است. بعد فضای خروجی بسیار بزرگتر است.
در پشتهای از لایههای Dense مانند آنچه که ما استفاده کردهایم، هر لایه فقط میتواند به اطلاعات موجود در خروجی لایه قبلی دسترسی داشته باشد. اگر یک لایه اطلاعاتی را که به مسئله طبقهبندی مربوط است از دست بدهد، این اطلاعات هرگز نمیتواند توسط لایههای بعدی بازیابی شود: هر لایه به طور بالقوه میتواند به یک گلوگاه اطلاعاتی (information bottleneck) تبدیل شود. در مثال قبلی، ما از لایههای میانی ۱۶ بعدی استفاده کردیم، اما یک فضای ۱۶ بعدی ممکن است برای یادگیری جدا کردن ۴۶ کلاس مختلف بسیار محدود باشد: چنین لایههای کوچکی ممکن است به عنوان گلوگاههای اطلاعاتی عمل کرده و اطلاعات مربوطه را برای همیشه حذف کنند.
به همین دلیل، ما از لایههای بزرگتر استفاده خواهیم کرد. بیایید با ۶۴ واحد ادامه دهیم.
قطعه کد ۴.۱۵ – تعریف مدل
model = keras.Sequential([
layers.Dense(64, activation=”relu”), layers.Dense(64, activation=”relu”), layers.Dense(46, activation=”softmax”)
])
دو نکته دیگر درباره این معماری وجود دارد که باید به آنها توجه کنید.
اولاً، مدل را با یک لایه Dense به اندازه ۴۶ به پایان میرسانیم. این بدان معناست که برای هر نمونه ورودی، شبکه یک بردار ۴۶ بعدی را خروجی خواهد داد. هر ورودی در این بردار (هر بعد) یک کلاس خروجی متفاوت را کدگذاری میکند.
ثانیاً، لایه آخر از فعالسازی Softmax استفاده میکند. این الگو را در مثال MNIST مشاهده کردید. این به این معنی است که مدل یک توزیع احتمال را روی ۴۶ کلاس خروجی متفاوت تولید خواهد کرد—برای هر نمونه ورودی، مدل یک بردار خروجی ۴۶ بعدی تولید میکند که در آن output[i] احتمال تعلق نمونه به کلاس i است. مجموع ۴۶ امتیاز به ۱ خواهد رسید.
بهترین تابع زیان برای استفاده در این حالت، categorical_crossentropy است. این تابع فاصله بین دو توزیع احتمال را اندازهگیری میکند: در اینجا، بین توزیع احتمال خروجی توسط مدل و توزیع واقعی برچسبها. با حداقل کردن فاصله بین این دو توزیع، مدل را آموزش میدهید تا چیزی تا حد امکان نزدیک به برچسبهای واقعی را خروجی دهد.
قطعه کد ۴.۱۶ – کامپایل کردن مدل
model.compile(optimizer=”rmsprop”,
loss=”categorical_crossentropy”,
metrics=[“accuracy”])
اعتبار سنجی رویکرد
بیایید ۱,۰۰۰ نمونه از دادههای آموزشی را برای استفاده به عنوان یک مجموعه اعتبارسنجی جدا کنیم.
قطعه کد ۴.۱۷ – جدا کردن مجموعه اعتبارسنجی
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = y_train[:1000]
partial_y_train = y_train[1000:]
حالا، بیایید مدل را برای ۲۰ دوره آموزش دهیم.
قطعه کد ۴.۱۸ – آموزش مدل
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
و در نهایت، بیایید نمودارهای زیان و دقت آن را نمایش دهیم (به اشکال ۴.۶ و ۴.۷ مراجعه کنید).
قطعه کد ۴.۱۹ – رسم نمودار خطای آموزش و اعتبارسنجی
loss = history.history[“loss”]
val_loss = history.history[“val_loss”]
epochs = range(1, len(loss) + 1)
plt.plot(epochs, loss, “bo”, label=”Training loss”)
plt.plot(epochs, val_loss, “b”, label=”Validation loss”) plt.title(“Training and validation loss”)
plt.xlabel(“Epochs”)
plt.ylabel(“Loss”) plt.legend() plt.show()
قطعه کد ۴.۲۰ – رسم نمودار دقت آموزش و دقت اعتبارسنجی
plt.clf()
acc = history.history[“accuracy”]
val_acc = history.history[“val_accuracy”]
plt.plot(epochs, acc, “bo”, label=”Training accuracy”)
plt.plot(epochs, val_acc, “b”, label=”Validation accuracy”) plt.title(“Training and validation accuracy”)
plt.xlabel(“Epochs”)
plt.ylabel(“Accuracy”) plt.legend()
plt.show()
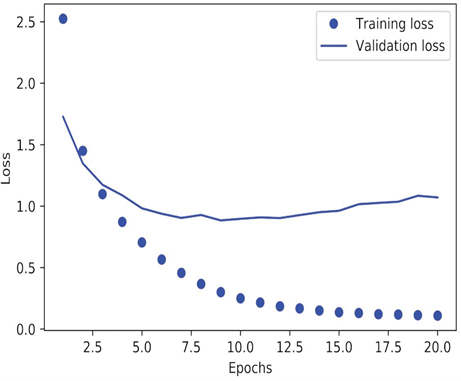
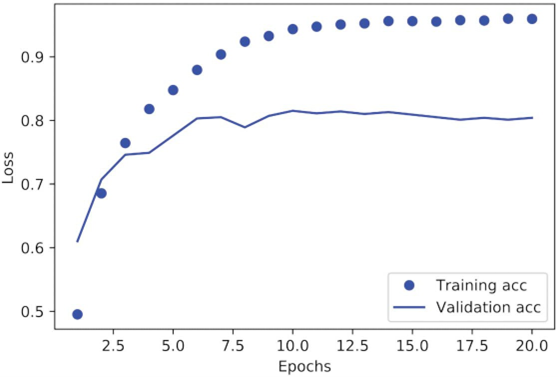
مدل پس از ۹ دوره شروع به بیشبرازش (overfit) میکند. بیایید یک مدل جدید را از ابتدا برای ۹ دوره آموزش دهیم و سپس آن را روی مجموعه آزمایش ارزیابی کنیم.
قطعه کد ۴.۲۱ – آموزش مجدد مدل از ابتدا
model = keras.Sequential([
layers.Dense(64, activation=”relu”),
layers.Dense(64, activation=”relu”),
layers.Dense(46, activation=”softmax”)
])
model.compile(optimizer=”rmsprop”,
loss=”categorical_crossentropy”,
metrics=[“accuracy”])
model.fit(x_train,
y_train,
epochs=9, batch_size=512)
results = model.evaluate(x_test, y_test)
نتایج نهایی به شرح زیر است:
>>> results
[0.9565213431445807, 0.79697239536954589]
این رویکرد به دقت تقریباً ۸۰٪ میرسد. در یک مسئله طبقهبندی دودویی متوازن، دقتی که توسط یک طبقهبندی کاملاً تصادفی به دست میآید، ۵۰٪ خواهد بود. اما در این مورد، ما ۴۶ کلاس داریم و ممکن است به طور یکسان نمایش داده نشده باشند. دقت یک معیار تصادفی چقدر خواهد بود؟ میتوانیم برای بررسی تجربی این موضوع، به سرعت یکی را پیادهسازی کنیم:
>>> import copy
>>> test_labels_copy = copy.copy(test_labels)
>>> np.random.shuffle(test_labels_copy)
>>> hits_array = np.array(test_labels) == np.array(test_labels_copy)
>>> hits_array.mean()
0.18655387355298308
همانطور که میبینید، یک طبقهبند تصادفی حدود ۱۹٪ دقت طبقهبندی کسب میکند، بنابراین نتایج مدل ما با توجه به این موضوع کاملاً خوب به نظر میرسد.
تولید پیشبینی روی دادههای جدید
فراخوانی متد predict مدل روی نمونههای جدید، یک توزیع احتمال کلاس را بر روی هر ۴۶ موضوع برای هر نمونه برمیگرداند. بیایید پیشبینیهای موضوع را برای تمام دادههای آزمایشی تولید کنیم:
predictions = model.predict(x_test)
هر ورودی در «predictions» یک بردار به طول ۴۶ است:
>>> predictions[0].shape
(46,)
ضرایب این بردار به ۱ میرسند، زیرا یک توزیع احتمال را تشکیل میدهند:
>>> np.sum(predictions[0])
1.0
بزرگترین ورودی، کلاس پیشبینیشده است — کلاسی که بالاترین احتمال را دارد:
>>> np.argmax(predictions[0])
4
روشی متفاوت برای مدیریت برچسبها و تابع زیان
پیشتر اشاره کردیم که راه دیگری برای کدگذاری برچسبها، تبدیل آنها به یک تنسور از اعداد صحیح، به این صورت، خواهد بود:
y_train = np.array(train_labels)
y_test = np.array(test_labels)
تنها چیزی که این رویکرد تغییر میدهد، انتخاب تابع زیان است. تابع زیان مورد استفاده در لیست ۴.۲۱، categorical_crossentropy، انتظار دارد که برچسبها از یک کدگذاری دستهای (categorical encoding) پیروی کنند. با برچسبهای عددی (integer labels)، باید از sparse_categorical_crossentropy استفاده کنید:
model.compile(optimizer=”rmsprop”,
loss=”sparse_categorical_crossentropy”,
metrics=[“accuracy”])
این تابع زیان جدید از نظر ریاضی همچنان همانند categorical_crossentropy است؛ فقط یک رابط متفاوت دارد.
اهمیت داشتن لایههای میانی به اندازه کافی بزرگ
قبلاً اشاره کردیم که چون خروجیهای نهایی ۴۶ بعدی هستند، باید از لایههای میانی با تعداد واحد بسیار کمتر از ۴۶ پرهیز کنید. حالا بیایید ببینیم چه اتفاقی میافتد وقتی با داشتن لایههای میانی که به طور قابل توجهی کمتر از ۴۶ بعد هستند – برای مثال، ۴ بعدی – یک گلوگاه اطلاعاتی ایجاد میکنیم.
قطعه کد ۴.۲۲ – مدلی با گلوگاه اطلاعاتی
model = keras.Sequential([
layers.Dense(64, activation=”relu”), layers.Dense(4, activation=”relu”), layers.Dense(46, activation=”softmax”)
])
model.compile(optimizer=”rmsprop”,
loss=”categorical_crossentropy”,
metrics=[“accuracy”])
model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=128,
validation_data=(x_val, y_val))
مدل اکنون در دقت اعتبارسنجی تقریباً ۷۱٪ به اوج خود میرسد که یک افت مطلق ۸٪ است. این افت عمدتاً به این دلیل است که ما سعی داریم حجم زیادی از اطلاعات (اطلاعات کافی برای بازیابی ابرصفحههای تفکیک ۴۶ کلاس) را در یک فضای میانی که ابعاد بسیار پایینی دارد، فشرده کنیم. مدل قادر است بیشتر اطلاعات لازم را در این بازنماییهای چهار بعدی جا دهد، اما نه همه آن را.
آزمایشهای بیشتر
همانند مثال قبلی، شما را تشویق میکنم آزمایشهای زیر را انجام دهید تا شهود خود را در مورد انواع تصمیمات پیکربندی که باید با چنین مدلهایی بگیرید، تقویت کنید:
- سعی کنید از لایههای بزرگتر یا کوچکتر استفاده کنید: ۳۲ واحد، ۱۲۸ واحد و غیره.
- شما از دو لایه میانی قبل از لایه نهایی طبقهبندی Softmax استفاده کردید. اکنون سعی کنید از یک لایه میانی واحد، یا سه لایه میانی استفاده کنید.
جمعبندی
آنچه باید از این مثال برداشت کنید:
- اگر قصد طبقهبندی نقاط داده در میان N کلاس را دارید، مدل شما باید با یک لایه Dense به اندازه N به پایان برسد.
- در یک مسئله طبقهبندی چندکلاسه تکبرچسبی، مدل شما باید با فعالسازی Softmax به پایان برسد تا یک توزیع احتمال را بر روی N کلاس خروجی ارائه دهد.
- Categorical Crossentropy تقریباً همیشه تابع زیانی است که باید برای چنین مسائلی استفاده کنید. این تابع فاصله بین توزیعهای احتمال خروجی مدل و توزیع واقعی هدفها را به حداقل میرساند.
- دو روش برای مدیریت برچسبها در طبقهبندی چندکلاسه وجود دارد:
- رمزگذاری برچسبها از طریق کدگذاری دستهای (categorical encoding) (که به عنوان One-Hot Encoding نیز شناخته میشود) و استفاده از categorical_crossentropy به عنوان تابع زیان.
- رمزگذاری برچسبها به عنوان اعداد صحیح و استفاده از تابع زیان sparse_categorical_crossentropy.
- اگر نیاز به طبقهبندی دادهها در تعداد زیادی از دستهها دارید، باید از ایجاد گلوگاههای اطلاعاتی در مدل خود به دلیل لایههای میانی که بسیار کوچک هستند، اجتناب کنید.
پیشبینی قیمت خانه: یک مثال رگرسیون
دو مثال قبلی، مسائل طبقهبندی بودند، که در آنها هدف پیشبینی یک برچسب گسسته واحد برای یک نقطه داده ورودی بود. نوع رایج دیگری از مسائل یادگیری ماشینی رگرسیون است که شامل پیشبینی یک مقدار پیوسته به جای یک برچسب گسسته است: برای مثال، پیشبینی دمای فردا با توجه به دادههای هواشناسی یا پیشبینی زمان لازم برای تکمیل یک پروژه نرمافزاری با توجه به مشخصات آن.
نکته: رگرسیون و الگوریتم رگرسیون لجستیک را با هم اشتباه نگیرید. به طور گیجکننده، رگرسیون لجستیک یک الگوریتم رگرسیون نیست – بلکه یک الگوریتم طبقهبندی است.
مجموعه داده قیمت مسکن بوستون
در این بخش، قصد داریم قیمت متوسط خانهها را در یک حومه خاص بوستون در اواسط دهه ۱۹۷۰ پیشبینی کنیم، با توجه به نقاط داده مربوط به آن حومه در آن زمان، مانند نرخ جرم و جنایت، نرخ مالیات محلی بر دارایی و غیره.
مجموعه دادهای که استفاده خواهیم کرد، تفاوت جالبی با دو مثال قبلی دارد. این مجموعه داده نسبتاً نقاط داده کمی دارد: فقط ۵۰۶ نمونه، که بین ۴۰۴ نمونه آموزشی و ۱۰۲ نمونه آزمایشی تقسیم شدهاند. و هر ویژگی در دادههای ورودی (برای مثال، نرخ جرم و جنایت) مقیاس متفاوتی دارد. به عنوان مثال، برخی مقادیر نسبت هستند که بین ۰ و ۱ قرار میگیرند، برخی دیگر بین ۱ و ۱۲، برخی دیگر بین ۰ و ۱۰۰ و غیره.
قطعه کد ۴.۲۳ – بارگذاری دیتاست مسکن بوستون
from tensorflow.keras.datasets import boston_housing (train_data, train_targets), (test_data, test_targets) = (
boston_housing.load_data())
بیایید به دادهها نگاهی بیندازیم:
>>> train_data.shape
(404, 13)
>>> test_data.shape
(102, 13)
همانطور که میبینید، ما ۴۰۴ نمونه آموزشی و ۱۰۲ نمونه آزمایشی داریم که هر کدام ۱۳ ویژگی عددی دارند، مانند نرخ جرم و جنایت سرانه، میانگین تعداد اتاق در هر اقامتگاه، دسترسی به بزرگراهها و غیره.
هدفها، مقادیر میانه خانههای تحت مالکیت ساکنین، به هزار دلار هستند:
>>> train_targets
[ 15.2, 42.3, 50. … 19.4, 19.4, 29.1]
قیمتها معمولاً بین ۱۰,۰۰۰ و ۵۰,۰۰۰ دلار هستند. اگر این ارقام ارزان به نظر میرسند، به یاد داشته باشید که این مربوط به اواسط دهه ۱۹۷۰ بود و این قیمتها برای تورم تعدیل نشدهاند.
آمادهسازی دادهها
وارد کردن مقادیری به یک شبکه عصبی که همگی دامنههای بسیار متفاوتی دارند، مشکلساز خواهد بود. مدل ممکن است بتواند به طور خودکار با چنین دادههای ناهمگونی سازگار شود، اما قطعاً یادگیری را دشوارتر خواهد کرد. یک بهترین روش رایج برای مقابله با چنین دادههایی، انجام نرمالسازی ویژگی به ویژگی (feature-wise normalization) است: برای هر ویژگی در دادههای ورودی (یک ستون در ماتریس دادههای ورودی)، میانگین ویژگی را کم میکنیم و بر انحراف معیار تقسیم میکنیم، به طوری که ویژگی حول ۰ متمرکز شده و دارای انحراف معیار واحد باشد. این کار به راحتی در NumPy انجام میشود.
قطعه کد ۴.۲۴ – نرمالسازی دادهها
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std
توجه داشته باشید که مقادیر مورد استفاده برای نرمالسازی دادههای آزمایشی با استفاده از دادههای آموزشی محاسبه میشوند. شما هرگز نباید از هیچ کمیتی که بر روی دادههای آزمایشی محاسبه شده است در جریان کار خود استفاده کنید، حتی برای چیزی به سادگی نرمالسازی دادهها.
ساخت مدل
به دلیل در دسترس بودن نمونههای بسیار کم، ما از یک مدل بسیار کوچک با دو لایه میانی، هر کدام با ۶۴ واحد، استفاده خواهیم کرد. به طور کلی، هرچه داده آموزشی کمتری داشته باشید، بیشبرازش (overfitting) بدتر خواهد بود، و استفاده از یک مدل کوچک یکی از راههای کاهش بیشبرازش است.
قطعه کد ۴.۲۵ – تعریف مدل
def build_model():
model = keras.Sequential([
layers.Dense(64, activation=”relu”),
layers.Dense(64, activation=”relu”),
layers.Dense(1)
])
model.compile(optimizer=”rmsprop”, loss=”mse”, metrics=[“mae”])
return model
چون نیاز داریم که یک مدل را چندین بار نمونه سازی کنیم ، از یک تابع برای ساخت آن استفاده کنیم.
مدل با یک واحد و بدون فعالسازی (یک لایه خطی خواهد بود) به پایان میرسد. این یک تنظیمات معمول برای رگرسیون اسکالر (رگرسیونی که در آن سعی در پیشبینی یک مقدار پیوسته واحد دارید) است. اعمال یک تابع فعالسازی محدوده خروجی را محدود میکند؛ برای مثال، اگر یک تابع فعالسازی سیگموئید را به لایه آخر اعمال میکردید، مدل فقط میتوانست مقادیر بین ۰ و ۱ را پیشبینی کند. در اینجا، چون لایه آخر کاملاً خطی است، مدل آزاد است که یاد بگیرد مقادیر را در هر دامنهای پیشبینی کند.
توجه داشته باشید که مدل را با تابع زیان— mse میانگین مربعات خطا (mean squared error)، مربع تفاوت بین پیشبینیها و هدفها — کامپایل میکنیم. این یک تابع زیان پرکاربرد برای مسائل رگرسیون است.
ما همچنین یک معیار جدید را در طول آموزش پایش میکنیم: میانگین خطای مطلق (MAE). این مقدار مطلق تفاوت بین پیشبینیها و هدفها است. برای مثال، یک MAE برابر با ۰.۵ در این مسئله به این معنی است که پیشبینیهای شما به طور متوسط ۵۰۰ دلار خطا دارند.
اعتبارسنجی رویکرد با استفاده از اعتبارسنجی متقاطع ( K-fold تایی)
برای ارزیابی مدل خود در حالی که پارامترهای آن (مانند تعداد دورههای استفاده شده برای آموزش) را تنظیم میکنیم، میتوانستیم دادهها را به یک مجموعه آموزشی و یک مجموعه اعتبارسنجی تقسیم کنیم، همانطور که در مثالهای قبلی انجام دادیم. اما چون ما نقاط داده بسیار کمی داریم، مجموعه اعتبارسنجی بسیار کوچک خواهد بود (برای مثال، حدود ۱۰۰ نمونه). در نتیجه، امتیازات اعتبارسنجی ممکن است بسته به اینکه کدام نقاط داده را برای اعتبارسنجی و کدام را برای آموزش انتخاب کردیم، تغییر زیادی کند: امتیازات اعتبارسنجی ممکن است واریانس بالایی نسبت به تقسیم اعتبارسنجی داشته باشند. این امر ما را از ارزیابی قابل اعتماد مدلمان باز میدارد.
بهترین روش در چنین شرایطی استفاده از اعتبارسنجی متقاطع K-fold است (به شکل ۴.۸ مراجعه کنید).
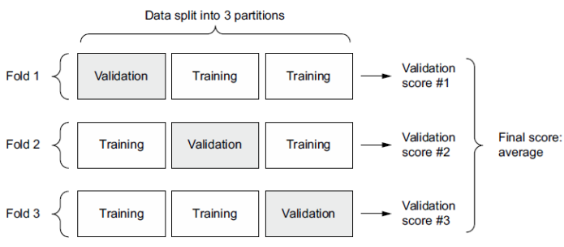
این روش شامل تقسیم دادههای موجود به K بخش معمولاً ۴ یا۵ K=، نمونهسازی K مدل یکسان و آموزش هر کدام بر روی ۱ K–بخش و ارزیابی بر روی بخش باقیمانده است. امتیاز اعتبارسنجی برای مدل مورد استفاده، سپس میانگین K امتیاز اعتبارسنجی به دست آمده خواهد بود.
از نظر کدنویسی، این کار ساده است.
قطعه کد ۴.۲۶ – اعتبارسنجی K-بخشی (K-fold Validation)
k = 4
num_val_samples = len(train_data) // k
num_epochs = 100
all_scores = []
for i in range(k):
print(f”Processing fold #{i}”)
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
دادههای اعتبارسنجی را آماده میکند: دادهها از بخش شماره k.
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
partial_train_data = np.concatenate(
دادههای آموزشی را آماده میکند: دادهها از تمام بخشهای دیگر.
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
model = build_model()
مدل Keras را میسازد (که از قبل کامپایل شده است).
model.fit(partial_train_data, partial_train_targets,
مدل را آموزش میدهد (در حالت بیصدا، verbose =0).
epochs=num_epochs, batch_size=16, verbose=0)
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0)
all_scores.append(val_mae)
اجرای این با num_epochs=100 نتایج زیر را به دست میدهد:
>>> all_scores
[2.112449, 3.0801501, 2.6483836, 2.4275346]
>>> np.mean(all_scores)
2.5671294
اجراهای مختلف در واقع نمرات اعتبارسنجی نسبتاً متفاوتی را نشان میدهند، از ۲.۱ تا ۳.۱. میانگین (۲.۶) یک معیار بسیار قابل اعتمادتر از هر امتیاز واحدی است – این تمام هدف اعتبارسنجی متقاطع K-fold است.
در این مورد، ما به طور متوسط ۲,۶۰۰ دلار خطا داریم، که با توجه به اینکه قیمتها از ۱۰,۰۰۰ دلار تا ۵۰,۰۰۰ دلار متغیر هستند، قابل توجه است.
بیایید سعی کنیم مدل را کمی طولانیتر آموزش دهیم: ۵۰۰ دوره. برای ثبت سوابق عملکرد مدل در هر دوره، حلقه آموزشی را تغییر خواهیم داد تا گزارش امتیاز اعتبارسنجی برای هر دوره و برای هر fold (تقسیم) را ذخیره کند.
قطعه کد ۴.۲۷ – ذخیره لاگهای اعتبارسنجی در هر بخش (fold)
num_epochs = 500
all_mae_histories = []
for i in range(k):
print(f”Processing fold #{i}”)
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
دادههای اعتبارسنجی را آماده میکند: دادهها از بخش شماره k.
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
partial_train_data = np.concatenate(
دادههای آموزشی را آماده میکند: دادهها از تمام بخشهای دیگر.
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
model = build_model()
مدل Keras را میسازد (که از قبل کامپایل شده است).
history = model.fit(partial_train_data, partial_train_targets,
مدل را آموزش میدهد (در حالت بیصدا، verbose=0).
validation_data=(val_data, val_targets),
epochs=num_epochs, batch_size=16, verbose=0)
mae_history = history.history[“val_mae”]
all_mae_histories.append(mae_history)
سپس میتوانیم میانگین امتیازات MAE در هر دوره را برای تمام folds محاسبه کنیم.
قطعه کد ۴.۲۸ – ساخت تاریخچهی میانگین متوالی از امتیازهای اعتبارسنجی K-بخشی
average_mae_history = [
np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
بیایید این را رسم کنیم؛ به شکل ۴.۹ نگاه کنید.
قطعه کد ۴.۲۹ – رسم نمودار امتیازهای اعتبارسنجی
plt.plot(range(1, len(average_mae_history) + 1), average_mae_history)
plt.xlabel(“Epochs”)
plt.ylabel(“Validation MAE”)
plt.show()
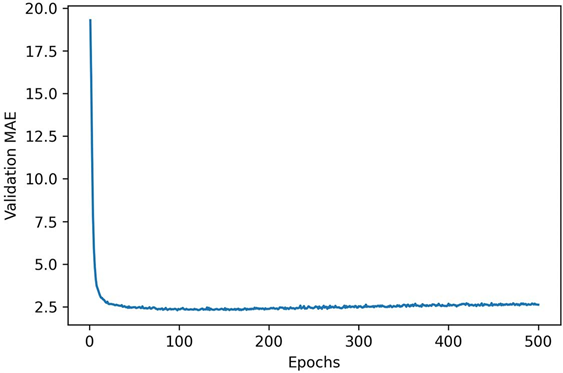
ممکن است خواندن نمودار کمی دشوار باشد، به دلیل مشکل مقیاسبندی: MAE اعتبارسنجی برای چند دوره اول به طور چشمگیری بالاتر از مقادیر بعدی است. بیایید ۱۰ نقطه داده اول را که در مقیاسی متفاوت از بقیه منحنی هستند، حذف کنیم.
قطعه کد ۴.۳۰ – رسم امتیازهای اعتبارسنجی با حذف ۱۰ نقطهی ابتدایی
truncated_mae_history = average_mae_history[10:]
plt.plot(range(1, len(truncated_mae_history) + 1), truncated_mae_history)
plt.xlabel(“Epochs”)
plt.ylabel(“Validation MAE”)
plt.show()
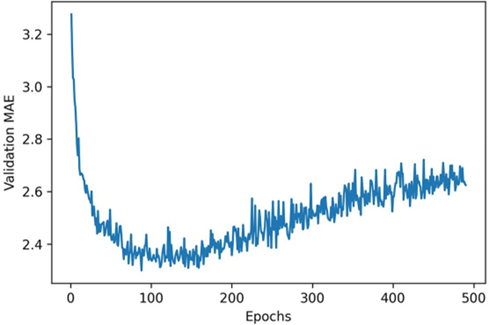
همانطور که در شکل ۴.۱۰ میبینید، MAE اعتبارسنجی پس از ۱۲۰ تا ۱۴۰ دوره (epoch) (این تعداد شامل ۱۰ دورهای که حذف کردیم میشود) به طور قابل توجهی بهبود نمییابد. پس از آن نقطه، مدل شروع به بیشبرازش (overfitting) میکند.
پس از اینکه تنظیم پارامترهای دیگر مدل (علاوه بر تعداد دورهها، میتوانید اندازه لایههای میانی را نیز تنظیم کنید) را به پایان رساندید، میتوانید یک مدل نهایی تولید را بر روی تمام دادههای آموزشی، با بهترین پارامترها، آموزش دهید و سپس عملکرد آن را بر روی دادههای آزمایشی مشاهده کنید.
قطعه کد ۴.۳۱ – آموزش مدل نهایی
model = build_model()
یک مدل تازه و کامپایلشده به دست میآورد.
model.fit(train_data, train_targets,
epochs=130, batch_size=16, verbose=0)
آن را بر تمامیت دادهها آموزش میدهد.
test_mse_score, test_mae_score = model.evaluate(test_data, test_targets)
نتیجه نهایی اینجاست:
>>> test_mae_score
2.4642276763916016
ما همچنان کمی کمتر از ۲,۵۰۰ دلار خطا داریم. این یک بهبود است! درست مانند دو وظیفه قبلی، میتوانید با تغییر تعداد لایهها در مدل، یا تعداد واحدها در هر لایه، سعی کنید خطای آزمایش کمتری را به دست آورید.
ایجاد پیشبینی روی دادههای جدید
هنگام فراخوانی predict() روی مدل طبقهبندی دودویی خود، برای هر نمونه ورودی یک امتیاز اسکالر بین ۰ و ۱ به دست آوردیم. با مدل طبقهبندی چندکلاسه خود، یک توزیع احتمال روی همه کلاسها برای هر نمونه به دست آوردیم. اکنون، با این مدل رگرسیون اسکالر، predict() حدس مدل را برای قیمت نمونه بر حسب هزار دلار برمیگرداند:
>>> predictions = model.predict(test_data)
>>> predictions[0]
array([9.990133], dtype=float32)
اولین خانه در مجموعه آزمایش، با قیمت تقریبی ۱۰,۰۰۰ دلار پیشبینی شده است.
جمعبندی
آنچه باید از این مثال رگرسیون اسکالر برداشت کنید:
- رگرسیون با توابع زیان متفاوتی نسبت به آنچه برای طبقهبندی استفاده کردیم، انجام میشود. میانگین مربعات خطا (MSE) یک تابع زیان است که معمولاً برای رگرسیون استفاده میشود.
- به طور مشابه، معیارهای ارزیابی مورد استفاده برای رگرسیون با معیارهای مورد استفاده برای طبقهبندی تفاوت دارند؛ به طور طبیعی، مفهوم دقت برای رگرسیون کاربرد ندارد. یک معیار رایج رگرسیون میانگین خطای مطلق (MAE) است.
- هنگامی که ویژگیها در دادههای ورودی دارای مقادیری در دامنههای متفاوت هستند، هر ویژگی باید به عنوان یک مرحله پیشپردازش به طور مستقل مقیاسبندی شود.
- هنگامی که دادههای کمی در دسترس است، استفاده از اعتبارسنجی K-fold یک راه عالی برای ارزیابی قابل اعتماد مدل است.
- هنگامی که داده آموزشی کمی در دسترس است، برای جلوگیری از بیشبرازش (overfitting) شدید، ترجیح داده میشود از یک مدل کوچک با لایههای میانی کم (معمولاً فقط یک یا دو لایه) استفاده شود.
خلاصه
- سه نوع رایج وظایف یادگیری ماشینی روی دادههای برداری عبارتند از: طبقهبندی دودویی، طبقهبندی چندکلاسه و رگرسیون اسکالر.
- بخشهای “جمعبندی” در ابتدای فصل، نکات مهمی را که در مورد هر وظیفه آموختهاید، خلاصه میکند.
- رگرسیون از توابع زیان و معیارهای ارزیابی متفاوتی نسبت به طبقهبندی استفاده میکند.
- معمولاً باید دادههای خام را قبل از ورود به یک شبکه عصبی پیشپردازش کنید.
- هنگامی که ویژگیهای دادههای شما دارای دامنههای متفاوتی هستند، هر ویژگی را به طور مستقل به عنوان بخشی از پیشپردازش مقیاسبندی کنید.
- با پیشرفت آموزش، شبکههای عصبی در نهایت شروع به بیشبرازش میکنند و نتایج بدتری را روی دادههایی که قبلاً دیده نشدهاند، به دست میآورند.
- اگر داده آموزشی زیادی ندارید، برای جلوگیری از بیشبرازش شدید، از یک مدل کوچک با تنها یک یا دو لایه میانی استفاده کنید.
- اگر دادههای شما به دستههای زیادی تقسیم شدهاند، در صورت کوچک کردن بیش از حد لایههای میانی، ممکن است باعث ایجاد گلوگاههای اطلاعاتی شوید.
- هنگامی که با دادههای کم کار میکنید، اعتبارسنجی K-fold میتواند به ارزیابی قابل اعتماد مدل شما کمک کند.



