- این فصل پوشش میدهد:
- درک کشمکش بین تعمیم و بهینهسازی، که مسئله اساسی در یادگیری ماشین است.
- روشهای ارزیابی برای مدلهای یادگیری ماشین.
- بهترین شیوهها برای بهبود برازش مدل.
- بهترین شیوهها برای دستیابی به تعمیم بهتر.
مقدمه
پس از سه مثال عملی در فصل ۴، شما باید با چگونگی رویکرد به مسائل طبقهبندی و رگرسیون با استفاده از شبکههای عصبی آشنا شده باشید و با مشکل اصلی یادگیری ماشین: بیشبرازش (overfitting)، مواجه شدهاید. این فصل برخی از شهود جدید شما در مورد یادگیری ماشین را به یک چارچوب مفهومی مستحکم رسمی میکند و بر اهمیت ارزیابی دقیق مدل و تعادل بین آموزش و تعمیم تأکید میکند.
تعمیم: هدف یادگیری ماشین
در سه مثال ارائه شده در فصل ۴ — پیشبینی نقدهای فیلم، طبقهبندی موضوع و رگرسیون قیمت خانه — ما دادهها را به یک مجموعه آموزشی، یک مجموعه اعتبارسنجی و یک مجموعه آزمایش تقسیم کردیم. دلیل ارزیابی نکردن مدلها بر روی همان دادههایی که آموزش دیدهاند به سرعت آشکار شد: پس از تنها چند دوره (epoch)، عملکرد بر روی دادههای هرگز دیدهنشده شروع به واگرایی از عملکرد بر روی دادههای آموزشی کرد، که همیشه با پیشرفت آموزش بهبود مییابد. مدلها شروع به بیشبرازش کردند. بیشبرازش در هر مسئله یادگیری ماشین اتفاق میافتد.
مسئله اساسی در یادگیری ماشین، کشمکش بین بهینهسازی (optimization) و تعمیم (generalization) است. بهینهسازی به فرآیند تنظیم یک مدل برای به دست آوردن بهترین عملکرد ممکن بر روی دادههای آموزشی (همان یادگیری در یادگیری ماشین) اشاره دارد، در حالی که تعمیم به این اشاره دارد که مدل آموزشدیده چقدر بر روی دادههایی که قبلاً ندیده است خوب عمل میکند. هدف بازی البته به دست آوردن تعمیم خوب است، اما شما تعمیم را کنترل نمیکنید؛ شما فقط میتوانید مدل را با دادههای آموزشی آن برازش دهید. اگر این کار را بیش از حد خوب انجام دهید، بیشبرازش شروع میشود و تعمیم آسیب میبیند.
اما چه چیزی باعث بیشبرازش میشود؟ چگونه میتوانیم به تعمیم خوب دست یابیم؟
کمبرازش (Underfitting) و بیشبرازش (Overfitting)
برای مدلهایی که در فصل قبل دیدید، عملکرد بر روی دادههای اعتبارسنجی کنار گذاشته شده با ادامه آموزش بهبود یافت و سپس به ناچار پس از مدتی به اوج رسید. این الگو (که در شکل ۵.۱ نشان داده شده است) جهانی است. شما آن را با هر نوع مدل و هر مجموعه دادهای مشاهده خواهید کرد.
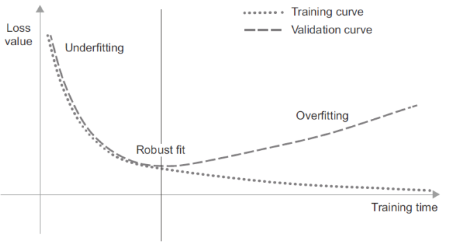
در ابتدای آموزش، بهینهسازی و تعمیم با هم همبستگی دارند: هرچه زیان روی دادههای آموزشی کمتر باشد، زیان روی دادههای آزمایش نیز کمتر است. در حالی که این اتفاق میافتد، گفته میشود مدل شما کمبرازش (underfit) است: هنوز جای پیشرفت وجود دارد؛ شبکه هنوز تمام الگوهای مرتبط در دادههای آموزشی را مدلسازی نکرده است. اما پس از تعداد مشخصی از تکرارها روی دادههای آموزشی، تعمیم متوقف میشود، معیارهای اعتبارسنجی ثابت میمانند و سپس شروع به افت میکنند: مدل در حال بیشبرازش (overfitting) است. یعنی شروع به یادگیری الگوهایی میکند که مختص دادههای آموزشی هستند اما در مورد دادههای جدید گمراهکننده یا بیربط هستند.
بیشبرازش به ویژه زمانی احتمال وقوع بیشتری دارد که دادههای شما نویزدار باشند، اگر شامل عدم قطعیت باشند، یا اگر شامل ویژگیهای کمیاب باشند. بیایید به مثالهای ملموس نگاهی بیندازیم.
دادههای آموزشی نویزدار
در مجموعهدادههای دنیای واقعی، کاملاً معمول است که برخی از ورودیها نامعتبر باشند. شاید یک رقم MNIST بتواند یک تصویر کاملاً سیاه باشد، برای مثال، یا چیزی شبیه شکل ۵.۲.

شکل ۵.۲: چند نمونه آموزش MNIST نسبتاً عجیب و غریب
اینها چیست؟ من هم نمیدانم. اما همه اینها بخشی از مجموعه آموزشی MNIST هستند. با این حال، چیزی که حتی بدتر است، داشتن ورودیهای کاملاً معتبری است که در نهایت اشتباه برچسبگذاری شدهاند، مانند مواردی که در شکل ۵.۳ نشان داده شده است.

شکل ۵.۳: نمونههای آموزشی MNIST با برچسبگذاری اشتباه
اگر یک مدل بیش از حد تلاش کند تا چنین دادههای پرت (outliers) را در خود جای دهد، عملکرد تعمیم (generalization) آن کاهش مییابد، همانطور که در شکل ۵.۴ نشان داده شده است. برای مثال، عددی ۴ که بسیار شبیه به ۴ اشتباه برچسبگذاری شده در شکل ۵.۳ به نظر میرسد، ممکن است در نهایت به عنوان ۹ طبقهبندی شود.
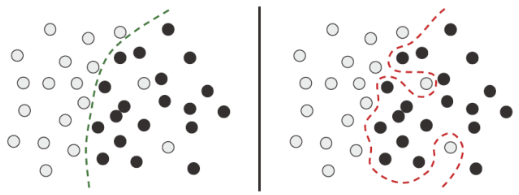
شکل ۵.۴: مقابله با دادههای پرت (Outliers): برازش مقاوم در مقابل بیشبرازش
ویژگیهای مبهم
همه نویزهای دادهای از عدم دقت ناشی نمیشوند—حتی دادههای کاملاً تمیز و دقیقاً برچسبگذاری شده نیز میتوانند نویزدار باشند، زمانی که مسئله شامل عدم قطعیت و ابهام باشد. در وظایف طبقهبندی، اغلب اوقات مناطقی از فضای ویژگی ورودی با چندین کلاس به طور همزمان مرتبط هستند. فرض کنید در حال توسعه مدلی هستید که تصویری از یک موز را میگیرد و پیشبینی میکند که موز نرسیده، رسیده یا فاسد است. این دستهها مرزهای عینی ندارند، بنابراین ممکن است یک تصویر مشابه توسط برچسبگذاران انسانی مختلف، هم نرسیده و هم رسیده طبقهبندی شود. به طور مشابه، بسیاری از مسائل شامل تصادفی بودن هستند. شما میتوانید از دادههای فشار اتمسفر برای پیشبینی اینکه آیا فردا باران خواهد بارید یا خیر استفاده کنید، اما دقیقاً همان اندازهگیریها ممکن است گاهی با باران و گاهی با آسمان صاف، با احتمالی معین، دنبال شوند.
یک مدل میتواند با اطمینان بیش از حد نسبت به مناطق مبهم فضای ویژگی، به چنین دادههای احتمالی بیشبرازش کند، مانند شکل ۵.۵. یک برازش مقاومتر، نقاط داده منفرد را نادیده میگیرد و به تصویر کلیتر نگاه میکند.
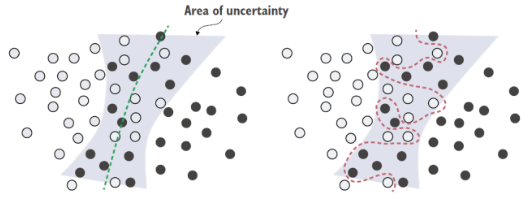
شکل ۵.۵: برازش مقاوم در مقابل بیشبرازش در یک منطقه مبهم از فضای ویژگی
ویژگیهای کمیاب و همبستگیهای کاذب
اگر در زندگیتان تنها دو گربه نارنجی راهراه دیدهاید و هر دوی آنها اتفاقاً به شدت ضداجتماعی بودهاند، ممکن است نتیجه بگیرید که گربههای نارنجی راهراه عموماً احتمالاً ضداجتماعی هستند. این بیشبرازش (overfitting) است: اگر در معرض طیف وسیعتری از گربهها، از جمله گربههای نارنجی بیشتر، قرار گرفته بودید، یاد میگرفتید که رنگ گربه با شخصیت آن همبستگی خوبی ندارد.
به همین ترتیب، مدلهای یادگیری ماشین که بر روی مجموعهدادههایی آموزش دیدهاند که شامل مقادیر ویژگیهای کمیاب هستند، به شدت مستعد بیشبرازش هستند. در یک وظیفه طبقهبندی احساسات، اگر کلمه “چریمویا”[1](یک میوه بومی آند) فقط در یک متن در دادههای آموزشی ظاهر شود، و این متن اتفاقاً از نظر احساسی منفی باشد، یک مدل با نظمدهی(regularized) ضعیف (poorly regularized) ممکن است وزن بسیار بالایی به این کلمه بدهد و همیشه متون جدیدی را که به چریمویا اشاره میکنند، به عنوان منفی طبقهبندی کند، در حالی که از نظر عینی، هیچ چیز منفی در مورد چریمویا وجود ندارد.
مهمتر اینکه، یک مقدار ویژگی نیازی نیست فقط چند بار اتفاق بیفتد تا به همبستگیهای کاذب (spurious correlations) منجر شود. کلمهای را در نظر بگیرید که در ۱۰۰ نمونه از دادههای آموزشی شما وجود دارد و در ۵۴٪ مواقع با احساس مثبت و در ۴۶٪ مواقع با احساس منفی مرتبط است. این تفاوت ممکن است یک شانس آماری کامل (complete statistical fluke) باشد، با این حال مدل شما احتمالاً یاد میگیرد که از آن ویژگی برای وظیفه طبقهبندی خود بهره ببرد. این یکی از رایجترین منابع بیشبرازش است.
در اینجا یک مثال چشمگیر آورده شده است. MNIST را در نظر بگیرید. یک مجموعه آموزشی جدید با الحاق ۷۸۴ بعد نویز سفید به ۷۸۴ بعد موجود داده ایجاد کنید، به طوری که نیمی از دادهها اکنون نویز باشند. برای مقایسه، یک مجموعه داده معادل نیز با الحاق ۷۸۴ بعد تمامصفر ایجاد کنید. الحاق ویژگیهای بیمعنی ما، محتوای اطلاعاتی دادهها را به هیچ وجه تحت تأثیر قرار نمیدهد: ما فقط چیزی را اضافه میکنیم. دقت طبقهبندی انسانی به هیچ وجه تحت تأثیر این تبدیلها قرار نمیگرفت.
قطعه کد ۵.۱ – افزودن کانالهای نویز سفید یا صفر به تصاویر MNIST
from tensorflow.keras.datasets import mnist
import numpy as np
(train_images, train_labels), _ = mnist.load_data() train_images = train_images.reshape((60000, 28 * 28)) train_images = train_images.astype(“float32”) / 255
train_images_with_noise_channels = np.concatenate(
[train_images, np.random.random((len(train_images), 784))], axis=1)
train_images_with_zeros_channels = np.concatenate(
[train_images, np.zeros((len(train_images), 784))], axis=1)
حالا، بیایید مدل فصل ۲ را بر روی هر دوی این مجموعههای آموزشی آموزش دهیم.
قطعه کد ۵.۲ – آموزش همان مدل روی دادههای MNIST با کانال نویز یا صفر
from tensorflow import keras
from tensorflow.keras import layers
def get_model():
model = keras.Sequential([
layers.Dense(512, activation=”relu”), layers.Dense(10, activation=”softmax”)
])
model.compile(optimizer=”rmsprop”,
loss=”sparse_categorical_crossentropy”,
metrics=[“accuracy”])
return model
model = get_model()
history_noise = model.fit(
train_images_with_noise_channels, train_labels,
epochs=10,
batch_size=128,
validation_split=0.2)
model = get_model()
history_zeros = model.fit(
train_images_with_zeros_channels, train_labels,
epochs=10,
batch_size=128,
validation_split=0.2)
بیایید بررسی کنیم که دقت اعتبارسنجی هر مدل چگونه در طول زمان تغییر میکند.
قطعه کد ۵.۳ – رسم نمودار مقایسه دقت اعتبارسنجی
import matplotlib.pyplot as plt
val_acc_noise=history_noise.history[“val_accuracy”] val_acc_zeros = history_zeros.history[“val_accuracy”]
epochs = range(1, 11)
plt.plot(epochs, val_acc_noise, “b-“,
label=”Validation accuracy with noise channels”)
plt.plot(epochs, val_acc_zeros, “b–“,
label=”Validation accuracy with zeros channels”)
plt.title(“Effect of noise channels on validation accuracy”)
plt.xlabel(“Epochs”)
plt.ylabel(“Accuracy”)
plt.legend()
با وجود اینکه دادهها در هر دو مورد اطلاعات یکسانی دارند، دقت اعتبارسنجی مدل آموزشدیده با کانالهای نویز در نهایت حدود یک درصد پایینتر است (به شکل ۵.۶ مراجعه کنید)—که صرفاً به دلیل همبستگیهای کاذب (spurious correlations) است. هر چه کانالهای نویز بیشتری اضافه کنید، دقت بیشتر کاهش مییابد.
ویژگیهای نویزدار به ناچار منجر به بیشبرازش (overfitting) میشوند. به همین دلیل، در مواردی که مطمئن نیستید آیا ویژگیهای موجود شما آموزنده هستند یا حواسپرتکننده، معمولاً قبل از آموزش، انتخاب ویژگی (feature selection) انجام میشود. محدود کردن دادههای IMDB به ۱۰,۰۰۰ کلمه پرتکرار، به عنوان مثال، یک شکل خام از انتخاب ویژگی بود. روش معمول برای انجام انتخاب ویژگی، محاسبه یک امتیاز مفید بودن برای هر ویژگی موجود است—معیاری که نشاندهنده میزان آموزنده بودن ویژگی نسبت به وظیفه است، مانند اطلاعات متقابل (mutual information) بین ویژگی و برچسبها—و تنها حفظ ویژگیهایی که بالاتر از یک آستانه مشخص هستند. انجام این کار کانالهای نویز سفید را در مثال قبلی فیلتر میکند.
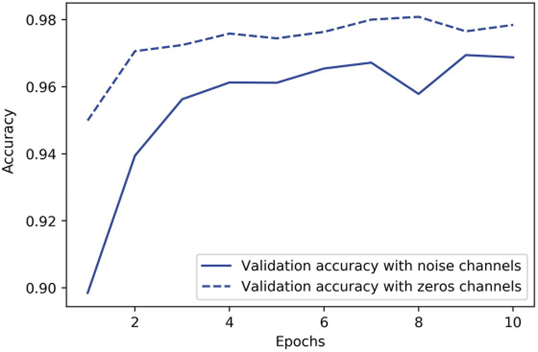
شکل ۵.۶: تأثیر کانالهای نویز بر دقت اعتبارسنجی
ماهیت تعمیم در یادگیری عمیق
یک واقعیت قابل توجه در مورد مدلهای یادگیری عمیق این است که میتوان آنها را برای برازش هر چیزی آموزش داد، به شرطی که قدرت بازنمایی کافی داشته باشند.
باور نمیکنید؟ سعی کنید برچسبهای MNIST را به هم بریزید (shuffle کنید) و یک مدل را روی آن آموزش دهید. حتی با وجود اینکه هیچ ارتباطی بین ورودیها و برچسبهای به هم ریخته وجود ندارد، زیان آموزش به خوبی کاهش مییابد، حتی با یک مدل نسبتاً کوچک. طبیعتاً، زیان اعتبارسنجی در طول زمان اصلاً بهبود نمییابد، زیرا در این تنظیمات امکان تعمیم وجود ندارد.
قطعه کد ۵.۴ – آموزش مدل MNIST با برچسبهای تصادفی (شُفلشده)
(train_images, train_labels), _ = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype(“float32”) / 255
random_train_labels = train_labels[:] np.random.shuffle(random_train_labels)
model = keras.Sequential([
layers.Dense(512, activation=”relu”),
layers.Dense(10, activation=”softmax”)
])
model.compile(optimizer=”rmsprop”,
loss=”sparse_categorical_crossentropy”,
metrics=[“accuracy”])
model.fit(train_images, random_train_labels,
epochs=100,
batch_size=128, validation_split=0.2)
در واقع، حتی نیازی نیست که این کار را با دادههای MNIST انجام دهید—میتوانید صرفاً ورودیهای نویز سفید و برچسبهای تصادفی تولید کنید. شما میتوانید یک مدل را روی آن هم برازش دهید، به شرطی که پارامترهای کافی داشته باشد. در این صورت، مدل صرفاً ورودیهای خاصی را حفظ (memorize) میکند، بسیار شبیه به یک دیکشنری پایتون.
اگر اینطور است، پس چطور مدلهای یادگیری عمیق اصلاً تعمیم پیدا میکنند؟ آیا نباید صرفاً یک نگاشت اختصاصی (ad hoc) بین ورودیهای آموزشی و هدفها یاد بگیرند، شبیه یک دیکشنری فانتزی؟ چه انتظاری میتوانیم داشته باشیم که این نگاشت برای ورودیهای جدید کار کند؟
همانطور که مشخص است، ماهیت تعمیم در یادگیری عمیق ارتباط نسبتاً کمی با خود مدلهای یادگیری عمیق دارد و بیشتر به ساختار اطلاعات در دنیای واقعی مربوط میشود. بیایید ببینیم واقعاً چه اتفاقی میافتد.
فرضیه مانیفولد (The Manifold Hypothesis)
ورودی یک طبقهبندیکننده MNIST (قبل از پیشپردازش) یک آرایه ۲۸ × ۲۸ از اعداد صحیح بین ۰ تا ۲۵۵ است. بنابراین، تعداد کل مقادیر ورودی ممکن، ۲۵۶ به توان ۷۸۴ است — بسیار بیشتر از تعداد اتمهای موجود در جهان. با این حال، تعداد بسیار کمی از این ورودیها شبیه نمونههای معتبر MNIST به نظر میرسند: ارقام دستنویس واقعی تنها یک زیرفضای بسیار کوچک از فضای والد تمام آرایههای ۲۸ × ۲۸ از نوع uint8 را اشغال میکنند. علاوه بر این، این زیرفضا فقط مجموعهای از نقاط پراکنده تصادفی در فضای والد نیست: بسیار ساختاریافته است.
اولاً، زیرفضای ارقام دستنویس معتبر پیوسته است: اگر یک نمونه را بگیرید و کمی آن را تغییر دهید، همچنان به عنوان همان رقم دستنویس قابل تشخیص خواهد بود. علاوه بر این، تمام نمونهها در زیرفضای معتبر توسط مسیرهای هموار به هم متصل هستند که از طریق زیرفضا عبور میکنند. این بدان معناست که اگر دو رقم تصادفی MNIST A و B را بگیرید، توالیای از تصاویر “میانی” وجود دارد که A را به B تبدیل میکند، به طوری که دو رقم متوالی بسیار به یکدیگر نزدیک هستند (به شکل ۵.۷ مراجعه کنید). شاید چند شکل مبهم نزدیک به مرز بین دو کلاس وجود داشته باشد، اما حتی این اشکال نیز همچنان بسیار شبیه به یک رقم خواهند بود.
در اصطلاح فنی، شما میگویید که ارقام دستنویس یک مانیفولد (manifold) را در فضای آرایههای ۲۸ × ۲۸ از نوع uint8 ممکن تشکیل میدهند. این کلمه بزرگی است، اما مفهوم آن کاملاً شهودی است. “مانیفولد” یک زیرفضای با ابعاد کمتر از یک فضای والد است که به صورت محلی شبیه به یک فضای خطی (اقلیدسی) است. برای مثال، یک منحنی هموار در صفحه، یک مانیفولد ۱ بعدی در یک فضای ۲ بعدی است، زیرا برای هر نقطه از منحنی، میتوانید یک مماس رسم کنید (منحنی را میتوان در هر نقطه با یک خط تقریب زد). یک سطح هموار در یک فضای ۳ بعدی، یک مانیفولد ۲ بعدی است. و به همین ترتیب.

شکل ۵.۷: تبدیل تدریجی ارقام مختلف MNIST به یکدیگر، نشاندهنده اینکه فضای ارقام دستنویس یک “مانیفولد” را تشکیل میدهد. این تصویر با استفاده از کد فصل ۱۲ تولید شده است.
به طور کلیتر، فرضیه مانیفولد (manifold hypothesis) بیان میکند که تمام دادههای طبیعی در یک مانیفولد کمبعد درون فضای پرابعادی که در آن کدگذاری شدهاند، قرار دارند. این یک گزاره بسیار قوی درباره ساختار اطلاعات در جهان است. تا آنجا که میدانیم، این گزاره دقیق است و دلیل کارکرد یادگیری عمیق نیز همین است. این موضوع برای ارقام MNIST صادق است، اما برای چهرههای انسان، ریختشناسی درختان، صداهای گفتار انسان، و حتی زبان طبیعی نیز صدق میکند.
فرضیه مانیفولد اشاره دارد به اینکه:
مدلهای یادگیری ماشین فقط باید زیرفضاهای نسبتاً ساده، کمبعد و بسیار ساختاریافتهای را درون فضای ورودی پتانسیل خود (مانیفولدهای نهفته) برازش دهند.
درون یکی از این مانیفولدها، همیشه امکان درونیابی (interpolate) بین دو ورودی وجود دارد؛ یعنی میتوان یکی را از طریق یک مسیر پیوسته که تمام نقاط آن بر روی مانیفولد قرار میگیرند، به دیگری تبدیل کرد.
توانایی درونیابی بین نمونهها کلید درک تعمیم در یادگیری عمیق است.
درونیابی به عنوان منبع تعمیم
اگر با نقاط دادهای کار میکنید که میتوانند درونیابی شوند، میتوانید با ربط دادن آنها به نقاط دیگری که در مانیفولد نزدیک هستند، به درک نقاطی که قبلاً ندیدهاید، دست یابید. به عبارت دیگر، میتوانید کل فضا را تنها با استفاده از نمونهای از آن فضا درک کنید. میتوانید از درونیابی برای پر کردن جاهای خالی استفاده کنید.
توجه داشته باشید که درونیابی در مانیفولد نهفته با درونیابی خطی در فضای والد متفاوت است، همانطور که در شکل ۵.۸ نشان داده شده است. برای مثال، میانگین پیکسلها بین دو رقم MNIST معمولاً یک رقم معتبر نیست.
مهمتر اینکه، در حالی که یادگیری عمیق تعمیم را از طریق درونیابی بر روی یک تقریب یادگرفتهشده از مانیفولد داده به دست میآورد، اشتباه است که فرض کنیم درونیابی تمام چیزی است که در تعمیم وجود دارد. این فقط نوک کوه یخ است. درونیابی تنها میتواند به شما کمک کند تا چیزهایی را که بسیار نزدیک به آنچه قبلاً دیدهاید هستند، درک کنید: این قابلیت، تعمیم محلی را فعال میکند. اما به طور قابل توجهی، انسانها همیشه با نوآوریهای شدید مواجه میشوند و به خوبی از عهده آن برمیآیند. شما نیازی ندارید که از قبل روی هزاران مثال از هر موقعیتی که ممکن است با آن روبرو شوید، آموزش ببینید. تکتک روزهای شما با هر روزی که قبلاً تجربه کردهاید متفاوت است، و با هر روزی که هر کسی از طلوع بشریت تجربه کرده است، تفاوت دارد. شما میتوانید بین گذراندن یک هفته در نیویورک، یک هفته در شانگهای و یک هفته در بنگلور بدون نیاز به هزاران عمر یادگیری و تمرین برای هر شهر، جابهجا شوید.
انسانها قادر به تعمیم افراطی هستند، که توسط مکانیسمهای شناختی دیگری غیر از درونیابی فعال میشود: انتزاع، مدلهای نمادین جهان، استدلال، منطق، عقل سلیم، پیشفرضهای ذاتی درباره جهان — آنچه عموماً استدلال (reason) مینامیم، در مقابل شهود و تشخیص الگو. دومیها عمدتاً ماهیت درونیابی دارند، اما اولیها اینگونه نیستند. هر دو برای هوش ضروری هستند. در فصل ۱۴ بیشتر در مورد این موضوع صحبت خواهیم کرد.
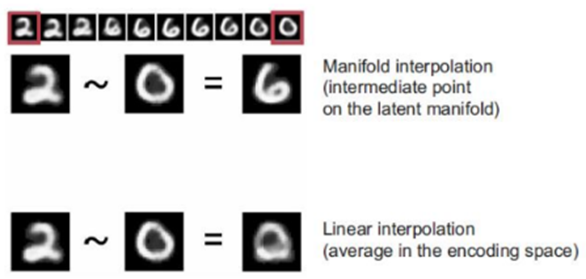
شکل ۵.۸: تفاوت بین درونیابی خطی و درونیابی در مانیفولد نهفته. هر نقطه روی مانیفولد نهفته ارقام یک رقم معتبر است، اما میانگین دو رقم معمولاً اینطور نیست.
چرا یادگیری عمیق کار میکند
استعاره توپ کاغذی مچاله شده از فصل ۲ را به خاطر بیاورید؟ یک ورق کاغذ نشاندهنده یک مانیفولد ۲ بعدی در فضای ۳ بعدی است (به شکل ۵.۹ مراجعه کنید). یک مدل یادگیری عمیق ابزاری برای باز کردن توپهای کاغذی مچاله شده است، یعنی برای جدا کردن مانیفولدهای نهفته (disentangling latent manifolds).
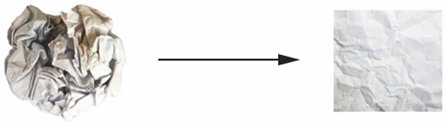
شکل ۵.۹: باز کردن یک مانیفولد پیچیده داده
یک مدل یادگیری عمیق اساساً یک منحنی بسیار پربعد است—منحنیای که هموار و پیوسته است (با محدودیتهای اضافی بر ساختار آن، ناشی از پیشفرضهای معماری مدل)، زیرا باید مشتقپذیر باشد. و آن منحنی از طریق گرادیان کاهشی، به صورت هموار و تدریجی، بر نقاط داده برازش مییابد. یادگیری عمیق اساساً درباره گرفتن یک منحنی بزرگ و پیچیده—یک مانیفولد—و تنظیم تدریجی پارامترهای آن تا زمانی که بر نقاط داده آموزشی برازش یابد، است.
این منحنی پارامترهای کافی دارد که میتواند هر چیزی را برازش دهد—در واقع، اگر به مدل خود اجازه دهید به اندازه کافی آموزش ببیند، در نهایت صرفاً دادههای آموزشی خود را حفظ خواهد کرد و اصلاً تعمیم نخواهد یافت. با این حال، دادههایی که شما روی آنها برازش میدهید، از نقاط گسسته که به ندرت در سراسر فضای زیرین توزیع شدهاند، ساخته نشدهاند. دادههای شما یک مانیفولد بسیار ساختاریافته و کمبعد را در فضای ورودی تشکیل میدهند—این همان فرضیه مانیفولد است. و از آنجایی که برازش منحنی مدل شما به این دادهها به تدریج و به صورت هموار در طول زمان و با پیشرفت گرادیان کاهشی اتفاق میافتد، یک نقطه میانی در طول آموزش وجود خواهد داشت که در آن مدل به طور تقریبی مانیفولد طبیعی دادهها را تقریب میزند، همانطور که در شکل ۵.۱۰ مشاهده میکنید.
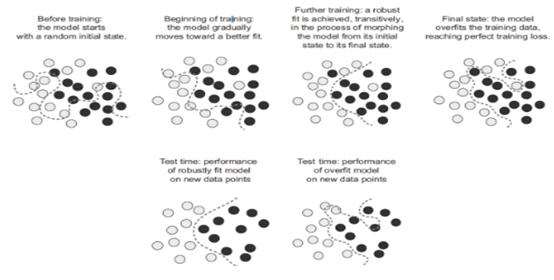
شکل ۵.۱۰: رفتن از یک مدل تصادفی به یک مدل بیشبرازششده و دستیابی به برازش مقاوم به عنوان یک حالت میانی
حرکت در امتداد منحنی یادگرفته شده توسط مدل در آن نقطه، نزدیک به حرکت در امتداد مانیفولد نهفته واقعی دادهها خواهد بود—به این ترتیب، مدل قادر خواهد بود ورودیهای هرگز دیدهنشده را از طریق درونیابی (interpolation) بین ورودیهای آموزشی درک کند.
جدا از این واقعیت بدیهی که مدلهای یادگیری عمیق قدرت بازنمایی کافی دارند، چند ویژگی دیگر نیز در آنها وجود دارد که آنها را به ویژه برای یادگیری مانیفولدهای نهفته مناسب میسازد:
- مدلهای یادگیری عمیق یک نگاشت هموار و پیوسته از ورودیهای خود به خروجیهای خود را پیادهسازی میکنند. این نگاشت باید هموار و پیوسته باشد زیرا لزوماً باید مشتقپذیر باشد (در غیر این صورت نمیتوان گرادیان کاهشی انجام داد).
این همواری به تقریب مانیفولدهای نهفته کمک میکند که خود دارای همین ویژگیها هستند.
- مدلهای یادگیری عمیق تمایل دارند به گونهای ساختاربندی شوند که “شکل” اطلاعات موجود در دادههای آموزشی خود را منعکس کنند (از طریق پیشفرضهای معماری). این امر به ویژه در مورد مدلهای پردازش تصویر (که در فصلهای ۸ و ۹ مورد بحث قرار گرفتهاند) و مدلهای پردازش دنباله (فصل ۱۰) صادق است. به طور کلیتر، شبکههای عصبی عمیق، بازنماییهای آموختهشده خود را به روشی سلسلهمراتبی و ماژولار ساختار میدهند، که روش سازماندهی دادههای طبیعی را تداعی میکند.
دادههای آموزشی حیاتی هستند
در حالی که یادگیری عمیق واقعاً برای یادگیری مانیفولد مناسب است، قدرت تعمیم بیشتر پیامد ساختار طبیعی دادههای شماست تا پیامد هر ویژگی خاصی از مدل شما. شما تنها زمانی قادر به تعمیم خواهید بود که دادههایتان یک مانیفولد را تشکیل دهند که نقاط در آن قابل درونیابی باشند. هرچه ویژگیهای شما آموزندهتر و کمنویزتر باشند، بهتر قادر به تعمیم خواهید بود، زیرا فضای ورودی شما سادهتر و ساختارمندتر خواهد بود. سازماندهی دادهها (Data curation) و مهندسی ویژگی (feature engineering) برای تعمیم ضروری هستند.
علاوه بر این، از آنجایی که یادگیری عمیق نوعی برازش منحنی است، برای عملکرد خوب یک مدل، باید بر روی یک نمونهبرداری چگال (dense sampling) از فضای ورودی خود آموزش ببیند. “نمونهبرداری چگال” در این زمینه به این معنی است که دادههای آموزشی باید تمامیت مانیفولد دادههای ورودی را به طور چگال پوشش دهند (به شکل ۵.۱۱ مراجعه کنید). این امر به ویژه در نزدیکی مرزهای تصمیمگیری صادق است. با یک نمونهبرداری به اندازه کافی چگال، درک ورودیهای جدید از طریق درونیابی بین ورودیهای آموزشی گذشته امکانپذیر میشود، بدون اینکه نیازی به استفاده از عقل سلیم، استدلال انتزاعی یا دانش بیرونی در مورد جهان باشد — همه چیزهایی که مدلهای یادگیری ماشین به آنها دسترسی ندارند.
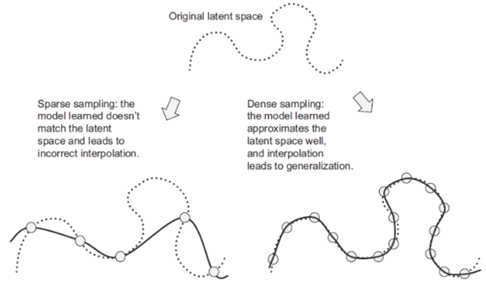
شکل ۵.۱۱: نمونهبرداری چگال از فضای ورودی برای یادگیری مدلی که قادر به تعمیم دقیق باشد، ضروری است.
به همین دلیل، همیشه باید به خاطر داشته باشید که بهترین راه برای بهبود یک مدل یادگیری عمیق، آموزش آن با دادههای بیشتر یا دادههای بهتر است (البته، اضافه کردن دادههای بیش از حد نویزدار یا نادرست به تعمیم آسیب میرساند). پوشش چگالتر مانیفولد دادههای ورودی، مدلی را به ارمغان میآورد که بهتر تعمیم مییابد. شما هرگز نباید از یک مدل یادگیری عمیق انتظار داشته باشید که چیزی فراتر از درونیابی خام بین نمونههای آموزشی خود انجام دهد، و بنابراین باید هر کاری که میتوانید انجام دهید تا درونیابی را تا حد امکان آسان کنید. تنها چیزی که در یک مدل یادگیری عمیق پیدا خواهید کرد، همان چیزی است که خودتان در آن قرار دادهاید: پیشفرضهای کدگذاری شده در معماری آن و دادههایی که روی آن آموزش دیده است.
هنگامی که دسترسی به دادههای بیشتر امکانپذیر نیست، بهترین راهحل بعدی، تنظیم کمیت اطلاعاتی است که مدل شما مجاز به ذخیره آن است، یا افزودن محدودیتهایی بر همواری منحنی مدل. اگر یک شبکه تنها بتواند تعداد کمی از الگوها، یا الگوهای بسیار منظم را حفظ کند، فرآیند بهینهسازی آن را مجبور میکند تا بر برجستهترین الگوها تمرکز کند، که شانس بهتری برای تعمیم خوب دارند. فرآیند مقابله با بیشبرازش به این روش را نظمدهی (regularization) مینامند. ما تکنیکهای نظمدهی را به طور عمیق در بخش ۵.۴.۴ بررسی خواهیم کرد.
قبل از اینکه بتوانید مدل خود را برای بهبود تعمیم آن تنظیم کنید، به راهی برای ارزیابی عملکرد فعلی مدل خود نیاز خواهید داشت. در بخش بعدی، یاد میگیرید که چگونه میتوانید تعمیم را در طول توسعه مدل نظارت کنید: ارزیابی مدل.
ارزیابی مدلهای یادگیری ماشین
شما فقط میتوانید آنچه را که مشاهده میکنید کنترل کنید. از آنجایی که هدف شما توسعه مدلهایی است که بتوانند با موفقیت به دادههای جدید تعمیم یابند، اندازهگیری قابل اعتماد قدرت تعمیم مدل شما ضروری است. در این بخش، من به طور رسمی روشهای مختلفی را که میتوانید مدلهای یادگیری ماشین را ارزیابی کنید، معرفی خواهم کرد. شما قبلاً بیشتر آنها را در فصل قبلی در عمل دیدهاید.
مجموعههای آموزشی، اعتبارسنجی و آزمایش
ارزیابی یک مدل همیشه به تقسیم دادههای موجود به سه مجموعه خلاصه میشود: آموزش، اعتبارسنجی و آزمایش. شما روی دادههای آموزشی آموزش میدهید و مدل خود را روی دادههای اعتبارسنجی ارزیابی میکنید. هنگامی که مدل شما برای زمان اصلی آماده شد، آن را برای آخرین بار روی دادههای آزمایش، که قرار است تا حد امکان شبیه دادههای تولیدی باشد، آزمایش میکنید. سپس میتوانید مدل را در محیط تولید مستقر کنید.
ممکن است بپرسید، چرا دو مجموعه نداشته باشیم: یک مجموعه آموزشی و یک مجموعه آزمایش؟ روی دادههای آموزشی آموزش دهید و روی دادههای آزمایش ارزیابی کنید. بسیار سادهتر!
دلیل این است که توسعه یک مدل همیشه شامل تنظیم پیکربندی آن است: برای مثال، انتخاب تعداد لایهها یا اندازه لایهها (که فراپارامترهای (hyperparameters) مدل نامیده میشوند، تا آنها را از پارامترها که وزنهای شبکه هستند متمایز کنیم). شما این تنظیم را با استفاده از عملکرد مدل بر روی دادههای اعتبارسنجی به عنوان سیگنال بازخورد انجام میدهید. در اصل، این تنظیم نوعی یادگیری است: جستجو برای یک پیکربندی خوب در یک فضای پارامتری. در نتیجه، تنظیم پیکربندی مدل بر اساس عملکرد آن بر روی مجموعه اعتبارسنجی میتواند به سرعت منجر به بیشبرازش روی مجموعه اعتبارسنجی شود، حتی با وجود اینکه مدل شما هرگز به طور مستقیم روی آن آموزش ندیده است.
محور اصلی این پدیده، مفهوم نشت اطلاعات (information leaks) است. هر بار که یک فراپارامتر (hyperparameter) مدل خود را بر اساس عملکرد مدل در مجموعه اعتبارسنجی تنظیم میکنید، مقداری اطلاعات از دادههای اعتبارسنجی به مدل نشت (leak) میکند. اگر این کار را فقط یک بار، برای یک پارامتر انجام دهید، بیتهای بسیار کمی از اطلاعات نشت میکنند و مجموعه اعتبارسنجی شما برای ارزیابی مدل قابل اعتماد باقی میماند. اما اگر این کار را بارها تکرار کنید—یک آزمایش را اجرا کنید، روی مجموعه اعتبارسنجی ارزیابی کنید، و در نتیجه مدل خود را تغییر دهید—آنگاه مقدار فزایندهای از اطلاعات درباره مجموعه اعتبارسنجی به مدل نشت خواهد کرد.
در نهایت، با مدلی روبرو خواهید شد که به طور مصنوعی روی دادههای اعتبارسنجی خوب عمل میکند، زیرا شما آن را برای همین بهینهسازی کردهاید. شما به عملکرد روی دادههای کاملاً جدید اهمیت میدهید، نه روی دادههای اعتبارسنجی، بنابراین باید از یک مجموعه داده کاملاً متفاوت و هرگز دیدهنشده برای ارزیابی مدل استفاده کنید: مجموعه داده آزمایش (test dataset). مدل شما نباید به هیچ اطلاعاتی از مجموعه آزمایش، حتی به طور غیرمستقیم، دسترسی داشته باشد. اگر هر چیزی در مورد مدل بر اساس عملکرد مجموعه آزمایش تنظیم شده باشد، آنگاه معیار تعمیم شما ناقص خواهد بود.
تقسیم دادههای خود به مجموعههای آموزشی، اعتبارسنجی و آزمایش ممکن است ساده به نظر برسد، اما چند روش پیشرفته برای انجام این کار وجود دارد که وقتی داده کمی در دسترس باشد، میتوانند مفید باشند.
بیایید سه روش ارزیابی کلاسیک را بررسی کنیم: اعتبارسنجی ساده هولدآوت (simple holdout validation)، اعتبارسنجی K-fold و اعتبارسنجی K-fold تکراری با درهمسازی (iterated K-fold validation with shuffling). همچنین در مورد استفاده از معیارهای پایه عقل سلیم برای بررسی اینکه آموزش شما به سمتی درست پیش میرود، صحبت خواهیم کرد.
اعتبارسنجی ساده هولدآوت
بخشی از دادههای خود را به عنوان مجموعه آزمایش جدا کنید. روی دادههای باقیمانده آموزش دهید و روی مجموعه آزمایش ارزیابی کنید. همانطور که در بخشهای قبلی دیدید، برای جلوگیری از نشت اطلاعات، نباید مدل خود را بر اساس مجموعه آزمایش تنظیم کنید، و بنابراین باید یک مجموعه اعتبارسنجی نیز کنار بگذارید.
از نظر شماتیک، اعتبارسنجی هولدآوت شبیه شکل ۵.۱۲ است. لیست ۵.۵ یک پیادهسازی ساده را نشان میدهد.
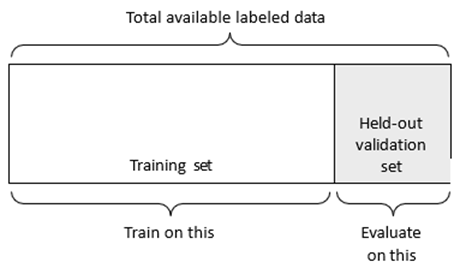
شکل ۵.۱۲: تقسیمبندی اعتبارسنجی ساده هولدآوت
قطعه کد ۵.۵ – اعتبارسنجی با جداسازی (Holdout Validation)
num_validation_samples = 10000
np.random.shuffle(data)
درهمسازی (shuffling) دادهها معمولاً مناسب است.
validation_data = data[:num_validation_samples]
مجموعه اعتبارسنجی را تعریف میکند.
training_data = data[num_validation_samples:]
مجموعه آموزشی را تعریف میکند.
model = get_model()
model.fit(training_data, …)
validation_score = model.evaluate(validation_data, …)
مدلی را بر روی دادههای آموزشی آموزش میدهد و آن را بر روی دادههای اعتبارسنجی ارزیابی میکند.
…
در این مرحله میتوانید مدل خود را تنظیم کنید، دوباره آموزش دهید، ارزیابی کنید و دوباره آن را تنظیم کنید.
model = get_model()
model.fit(np.concatenate([training_data,
validation_data]), …)
test_score = model.evaluate(test_data, …)
هنگامی که فراپارامترهای خود را تنظیم کردید، معمولاً مدل نهایی خود را از ابتدا روی تمام دادههای غیرآزمایشی موجود آموزش میدهید.
این سادهترین پروتکل ارزیابی است و از یک نقص رنج میبرد: اگر داده کمی در دسترس باشد، آنگاه مجموعههای اعتبارسنجی و آزمایش شما ممکن است شامل نمونههای بسیار کمی باشند که از نظر آماری نماینده دادههای موجود نباشند. تشخیص این مورد آسان است: اگر درهمسازیهای تصادفی مختلف دادهها قبل از تقسیم منجر به معیارهای بسیار متفاوتی از عملکرد مدل شود، آنگاه شما با این مشکل روبرو هستید. اعتبارسنجی K-fold و اعتبارسنجی K-fold تکراری دو راه برای رفع این مشکل هستند که در ادامه مورد بحث قرار میگیرند.
اعتبارسنجی K-fold
با این رویکرد، دادههای خود را به K بخش با اندازه مساوی تقسیم میکنید. برای هر بخش i، یک مدل را روی1 K− بخش باقیمانده آموزش میدهید و آن را روی بخش i ارزیابی میکنید. امتیاز نهایی شما سپس میانگین K امتیاز به دست آمده است. این روش زمانی مفید است که عملکرد مدل شما واریانس قابل توجهی بر اساس تقسیم آموزش-آزمایش شما نشان میدهد. مانند اعتبارسنجی هولدآوت، این روش شما را از استفاده از یک مجموعه اعتبارسنجی مجزا برای کالیبراسیون مدل معاف نمیکند.
از نظر شماتیک، اعتبارسنجی متقاطع K-fold شبیه شکل ۵.۱۳ است. لیست ۵.۶ یک پیادهسازی ساده را نشان میدهد.
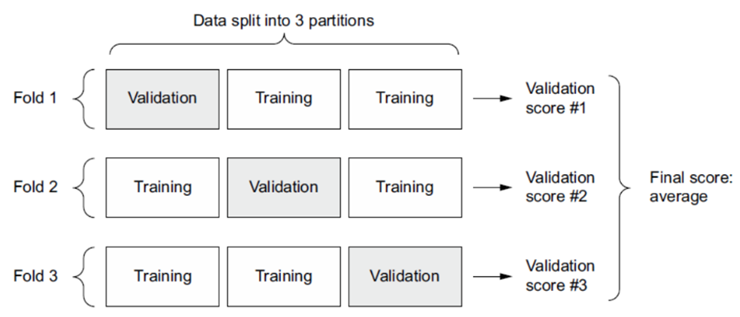
شکل ۵.۱۳ – اعتبارسنجی K-بخشی با K = 3
قطعه کد ۵.۶ – اعتبارسنجی K-بخشی (K-fold Cross-Validation)
k = 3
num_validation_samples = len(data) // k
np.random.shuffle(data)
validation_scores = []
for fold in range(k):
validation_data = data[num_validation_samples * fold:
num_validation_samples * (fold + 1)]
بخش دادههای اعتبارسنجی را انتخاب میکند.
training_data = np.concatenate(
data[:num_validation_samples * fold],
data[num_validation_samples * (fold + 1):])
باقیمانده دادهها را به عنوان دادههای آموزشی استفاده میکند. توجه داشته باشید که عملگر + نشاندهنده الحاق لیستها است، نه جمع.
model = get_model()
یک نمونه کاملاً جدید از مدل (آموزشندیده) ایجاد میکند.
model.fit(training_data, …)
validation_score = model.evaluate(validation_data,
validation_scores.append(validation_score)
validation_score = np.average(validation_scores)
امتیاز اعتبارسنجی: میانگین امتیازات اعتبارسنجی از k folds.
model = get_model()
model.fit(data, …)
test_score = model.evaluate(test_data, …)
مدل نهایی را بر روی تمام دادههای غیرآزمایشی موجود آموزش میدهد.
اعتبارسنجی K-fold تکراری با درهمسازی
این روش برای شرایطی است که دادههای نسبتاً کمی در دسترس دارید و نیاز به ارزیابی مدل خود با دقیقترین حالت ممکن دارید. من آن را در رقابتهای Kaggle بسیار مفید یافتهام. این روش شامل اعمال چندین باره اعتبارسنجی K-fold است، به طوری که هر بار قبل از تقسیم دادهها به K بخش، آنها را درهمسازی (shuffle) میکنید. امتیاز نهایی، میانگین امتیازات به دست آمده در هر اجرای اعتبارسنجی K-fold است. توجه داشته باشید که در نهایت P×K مدل را آموزش داده و ارزیابی میکنید (که P تعداد تکرارهایی است که استفاده میکنید)، که میتواند بسیار پرهزینه باشد.
غلبه بر یک مبنای عقل سلیم
علاوه بر پروتکلهای ارزیابی مختلفی که در دسترس دارید، آخرین نکتهای که باید بدانید، استفاده از خطوط پایه عقل سلیم (common-sense baselines) است.
آموزش یک مدل یادگیری عمیق کمی شبیه فشار دادن دکمهای است که موشکی را در دنیایی موازی پرتاب میکند. شما نمیتوانید آن را بشنوید یا ببینید. نمیتوانید فرآیند یادگیری مانیفولد را مشاهده کنید—این فرآیند در فضایی با هزاران بعد اتفاق میافتد، و حتی اگر آن را به ۳ بعدی نگاشت کنید، نمیتوانید آن را تفسیر کنید. تنها بازخوردی که دارید، معیارهای اعتبارسنجی شماست—مانند یک ارتفاعسنج روی موشک نامرئی شما.
اینکه بتوانید تشخیص دهید آیا اصلاً از زمین بلند میشوید یا خیر، از اهمیت ویژهای برخوردار است. ارتفاعی که از آن شروع کردید چقدر بود؟ مدل شما به نظر میرسد ۱۵٪ دقت دارد—آیا این خوب است؟ قبل از شروع کار با یک مجموعه داده، همیشه باید یک خط پایه بدیهی را انتخاب کنید که سعی در شکست دادن آن دارید. اگر از آن آستانه عبور کنید، خواهید دانست که کار درستی انجام میدهید: مدل شما در واقع از اطلاعات موجود در دادههای ورودی برای انجام پیشبینیهایی که تعمیم مییابند، استفاده میکند و میتوانید ادامه دهید. این خط پایه میتواند عملکرد یک طبقهبند تصادفی، یا عملکرد سادهترین تکنیک غیر یادگیری ماشین که میتوانید تصور کنید، باشد.
برای مثال، در مثال طبقهبندی ارقام MNIST، یک خط پایه ساده دقت اعتبارسنجی بیشتر از ۰.۱ (طبقهبند تصادفی) خواهد بود؛ در مثال IMDB، دقت اعتبارسنجی بیشتر از ۰.۵ خواهد بود. در مثال رویترز، به دلیل عدم توازن کلاس، حدود ۰.۱۸-۰.۱۹ خواهد بود. اگر یک مسئله طبقهبندی دودویی دارید که در آن ۹۰٪ نمونهها به کلاس A و ۱۰٪ به کلاس B تعلق دارند، یک طبقهبند که همیشه A را پیشبینی میکند، در حال حاضر به دقت ۰.۹ در اعتبارسنجی دست مییابد، و شما باید بهتر از آن عمل کنید.
داشتن یک خط پایه عقل سلیم که بتوانید به آن مراجعه کنید، هنگام شروع یک مسئله که قبلاً کسی آن را حل نکرده است، ضروری است. اگر نتوانید یک راهحل بدیهی را شکست دهید، مدل شما بیارزش است—شاید از مدل اشتباهی استفاده میکنید، یا شاید مسئلهای که با آن سروکار دارید، اصلاً با یادگیری ماشین قابل حل نیست. وقت آن است که به نقطه شروع برگردید.
نکاتی که باید در مورد ارزیابی مدل به خاطر بسپارید
هنگام انتخاب یک پروتکل ارزیابی، به موارد زیر توجه داشته باشید:
- نمایندگی داده (Data representativeness) : شما میخواهید هم مجموعه آموزشی و هم مجموعه آزمایش شما نماینده دادههای موجود باشند. برای مثال، اگر در حال تلاش برای طبقهبندی تصاویر ارقام هستید، و از یک آرایه از نمونهها شروع میکنید که نمونهها بر اساس کلاسشان مرتب شدهاند، گرفتن ۸۰٪ اول آرایه به عنوان مجموعه آموزشی و ۲۰٪ باقیمانده به عنوان مجموعه آزمایش منجر به این میشود که مجموعه آموزشی شما فقط شامل کلاسهای ۰ تا ۷ باشد، در حالی که مجموعه آزمایش شما فقط شامل کلاسهای ۸ تا ۹ خواهد بود. این اشتباهی مضحک به نظر میرسد، اما به طرز شگفتآوری رایج است. به همین دلیل، شما معمولاً باید دادههای خود را قبل از تقسیم آنها به مجموعههای آموزشی و آزمایش، به صورت تصادفی درهمسازی (shuffle) کنید.
- پیکان زمان (The arrow of time) : اگر در تلاش برای پیشبینی آینده با استفاده از گذشته هستید (مثلاً آب و هوای فردا، حرکات سهام و غیره)، نباید دادههای خود را قبل از تقسیم تصادفی درهمسازی کنید، زیرا این کار باعث ایجاد یک نشت زمانی (atemporal leak) میشود: مدل شما به طور مؤثر بر روی دادههایی از آینده آموزش میبیند. در چنین شرایطی، همیشه باید اطمینان حاصل کنید که تمام دادههای موجود در مجموعه آزمایش شما پس از (posterior) دادههای موجود در مجموعه آموزشی قرار دارند.
- افزونگی در دادههای شما (Redundancy in your data) : اگر برخی از نقاط داده در دادههای شما دو بار ظاهر میشوند (که در دادههای دنیای واقعی بسیار رایج است)، درهمسازی دادهها و تقسیم آنها به یک مجموعه آموزشی و یک مجموعه اعتبارسنجی منجر به اضافهگویی بین مجموعههای آموزشی و اعتبارسنجی خواهد شد. در واقع، شما بر روی بخشی از دادههای آموزشی خود آزمایش خواهید کرد، که بدترین کاری است که میتوانید انجام دهید! اطمینان حاصل کنید که مجموعه آموزشی و مجموعه اعتبارسنجی شما جدا از هم (disjoint) هستند.
داشتن یک راه قابل اعتماد برای ارزیابی عملکرد مدل شما، نحوه نظارت بر کشمکش در قلب یادگیری ماشین است—بین بهینهسازی و تعمیم، کمبرازش و بیشبرازش.
بهبود برازش مدل
برای دستیابی به یک برازش عالی، ابتدا باید بیشبرازش (overfit) را تجربه کنید. از آنجایی که از قبل نمیدانید مرز کجاست، باید از آن عبور کنید تا پیدایش کنید. بنابراین، هدف اولیه شما هنگامی که شروع به کار بر روی یک مسئله میکنید، دستیابی به مدلی است که قدرت تعمیم داشته باشد و بتواند بیشبرازش کند. هنگامی که چنین مدلی را در اختیار داشتید، با مبارزه با بیشبرازش، بر بهبود تعمیم تمرکز خواهید کرد.
در این مرحله، سه مشکل رایج با آنها روبرو خواهید شد:
- آموزش شروع نمیشود: زیان (loss) آموزش شما در طول زمان کاهش نمییابد.
- آموزش به خوبی شروع میشود، اما مدل شما به طور معناداری تعمیم نمییابد: نمیتوانید از خط پایه عقل سلیم (common-sense baseline) که تعیین کردهاید، بهتر عمل کنید.
- زیان آموزش و اعتبارسنجی هر دو در طول زمان کاهش مییابند و میتوانید از خط پایه خود بهتر عمل کنید، اما به نظر نمیرسد قادر به بیشبرازش باشید، که نشاندهنده این است که هنوز در حال کمبرازش (underfitting) هستید.
بیایید ببینیم چگونه میتوانید این مسائل را حل کنید تا به اولین نقطه عطف بزرگ یک پروژه یادگیری ماشین دست یابید: دستیابی به مدلی که قدرت تعمیم داشته باشد (میتواند از یک خط پایه بدیهی بهتر عمل کند) و قادر به بیشبرازش باشد.
تنظیم پارامترهای کلیدی گرادیان کاهشی
گاهی اوقات آموزش شروع نمیشود، یا خیلی زود متوقف میشود. زیان شما ثابت میماند. این همیشه چیزی است که میتوانید بر آن غلبه کنید: به یاد داشته باشید که میتوانید یک مدل را با دادههای تصادفی نیز برازش دهید. حتی اگر هیچ چیز در مورد مسئله شما منطقی نباشد، باز هم باید بتوانید چیزی را آموزش دهید—حتی فقط با حفظ دادههای آموزشی.
وقتی این اتفاق میافتد، همیشه مشکلی در پیکربندی فرآیند گرادیان کاهشی وجود دارد: انتخاب بهینهساز (optimizer)، توزیع مقادیر اولیه در وزنهای مدل شما، نرخ یادگیری (learning rate) شما، یا اندازه دستهای (batch size) شما. همه این پارامترها به هم وابسته هستند، و به همین دلیل معمولاً کافی است نرخ یادگیری و اندازه دسته را تنظیم کنید در حالی که بقیه پارامترها را ثابت نگه میدارید.
بیایید به یک مثال عینی نگاه کنیم: بیایید مدل MNIST از فصل ۲ را با نرخ یادگیری نامناسب بزرگ به مقدار ۱ آموزش دهیم.
قطعه کد ۵.۷ – آموزش مدل MNIST با نرخ یادگیری بیشازحد بالا
(train_images, train_labels), _ = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype(“float32”) / 255
model = keras.Sequential([
layers.Dense(512, activation=”relu”), layers.Dense(10, activation=”softmax”)
])
model.compile(optimizer=keras.optimizers.RMSprop(1.), loss=”sparse_categorical_crossentropy”, metrics=[“accuracy”])
model.fit(train_images, train_labels,
epochs=10,
batch_size=128, validation_split=0.2)
مدل به سرعت به دقت آموزش و اعتبارسنجی در محدوده ۳۰٪ تا ۴۰٪ میرسد، اما نمیتواند از آن فراتر رود.
بیایید سعی کنیم نرخ یادگیری را به یک مقدار معقولتر، یعنی 2e-1، کاهش دهیم.
قطعه کد ۵.۸ – همان مدل با نرخ یادگیری مناسبتر
model = keras.Sequential([
layers.Dense(512, activation=”relu”), layers.Dense(10, activation=”softmax”)
])
model.compile(optimizer=keras.optimizers.RMSprop(1e-2), loss=”sparse_categorical_crossentropy”,
metrics=[“accuracy”])
model.fit(train_images, train_labels,
epochs=10,
batch_size=128, validation_split=0.2)
مدل اکنون قادر به آموزش دیدن است.
اگر خود را در موقعیتی مشابه یافتید، موارد زیر را امتحان کنید:
- کاهش یا افزایش نرخ یادگیری. نرخ یادگیری خیلی بالا ممکن است منجر به بهروزرسانیهایی شود که بسیار فراتر از یک برازش مناسب حرکت میکنند، همانند مثال قبلی، و نرخ یادگیری خیلی پایین ممکن است آموزش را آنقدر کند کند که به نظر برسد متوقف شده است.
- افزایش اندازه دسته (batch size). یک دسته با نمونههای بیشتر منجر به گرادیانهایی میشود که آموزندهتر و کمنویزتر هستند (واریانس کمتر).
شما، در نهایت، یک پیکربندی پیدا خواهید کرد که آموزش را آغاز میکند.
بهرهبرداری ازدانش قبلی معماری بهتر
شما یک مدل دارید که برازش میشود، اما به دلایلی معیارهای اعتبارسنجی شما اصلاً بهبود نمییابند. آنها بهتر از آنچه یک طبقهبند تصادفی به دست میآورد، نیستند: مدل شما آموزش میبیند اما تعمیم نمییابد. چه اتفاقی در حال رخ دادن است؟
این شاید بدترین وضعیتی باشد که میتوانید در یادگیری ماشین خود را در آن بیابید. این نشان میدهد که چیزی به طور اساسی در رویکرد شما اشتباه است و ممکن است تشخیص آن آسان نباشد. در اینجا چند نکته وجود دارد.
اولاً، ممکن است دادههای ورودی که استفاده میکنید به سادگی اطلاعات کافی برای پیشبینی هدفهای شما را نداشته باشند: مسئله به شکلی که فرموله شده است، قابل حل نیست. این همان چیزی است که قبلاً زمانی اتفاق افتاد که ما سعی کردیم یک مدل MNIST را آموزش دهیم که برچسبهای آن به هم ریخته بودند: مدل به خوبی آموزش میدید، اما دقت اعتبارسنجی در ۱۰٪ ثابت میماند، زیرا تعمیم با چنین مجموعه دادهای به وضوح غیرممکن بود.
همچنین ممکن است نوع مدلی که استفاده میکنید برای مسئله موجود مناسب نباشد. برای مثال، در فصل ۱۰، مثالی از یک مسئله پیشبینی سری زمانی را خواهید دید که در آن یک معماری کاملاً متصل قادر به شکست دادن یک خط پایه بدیهی نیست، در حالی که یک معماری بازگشتی مناسبتر به خوبی تعمیم مییابد. استفاده از مدلی که فرضیات درستی در مورد مسئله دارد، برای دستیابی به تعمیم ضروری است: شما باید از پیشفرضهای معماری (architecture priors) صحیح بهره ببرید.
در فصلهای بعدی، با بهترین معماریها برای انواع روشهای دادهای — تصاویر، متن، سریهای زمانی و غیره — آشنا خواهید شد. به طور کلی، همیشه باید مطمئن شوید که بهترین شیوههای معماری برای نوع وظیفهای که در حال حمله به آن هستید را مطالعه کردهاید — به احتمال زیاد شما اولین نفری نیستید که آن را امتحان میکنید.
افزایش ظرفیت مدل
اگر موفق شدید به مدلی دست یابید که برازش میشود، معیارهای اعتبارسنجی آن رو به کاهش است، و به نظر میرسد حداقل به سطحی از قدرت تعمیم دست مییابد، تبریک میگویم: تقریباً موفق شدهاید. در مرحله بعد، باید مدل خود را وادار به شروع بیشبرازش (overfitting) کنید.
مدل کوچک زیر را در نظر بگیرید — یک رگرسیون لجستیک ساده — که بر روی پیکسلهای MNIST آموزش دیده است.
قطعه کد ۵.۹ – یک رگرسیون لجستیک ساده روی دادههای MNIST
model = keras.Sequential([layers.Dense(10, activation=”softmax”)]) model.compile(optimizer=”rmsprop”,
loss=”sparse_categorical_crossentropy”,
metrics=[“accuracy”])
history_small_model = model.fit(
train_images, train_labels,
epochs=20,
batch_size=128, validation_split=0.2)
شما منحنیهای زیانی را به دست میآورید که شبیه شکل ۵.۱۴ هستند:
import matplotlib.pyplot as plt
val_loss = history_small_model.history[“val_loss”]
epochs = range(1, 21)
plt.plot(epochs, val_loss, “b–“, label=”Validation loss”)
plt.title(“Effect of insufficient model capacity on validation loss”) plt.xlabel(“Epochs”)
plt.ylabel(“Loss”)
plt.legend()
معیارهای اعتبارسنجی به نظر میرسد متوقف شدهاند یا بسیار کند بهبود مییابند، به جای اینکه به اوج برسند و مسیر معکوس را طی کنند. زیان اعتبارسنجی به ۰.۲۶ میرسد و همانجا میماند. شما میتوانید برازش دهید، اما نمیتوانید به وضوح بیشبرازش کنید، حتی پس از تکرارهای زیاد بر روی دادههای آموزشی.
شما احتمالاً در طول فعالیت حرفهای خود اغلب با منحنیهای مشابهی روبرو خواهید شد.
به یاد داشته باشید که همیشه باید امکان بیشبرازش (overfit) وجود داشته باشد. مانند مشکلی که در آن زیان آموزش کاهش نمییابد، این نیز مسئلهای است که همیشه قابل حل است. اگر به نظر نمیرسد قادر به بیشبرازش باشید، احتمالاً مشکلی در قدرت بازنمایی (representational power) مدل شما وجود دارد: شما به یک مدل بزرگتر نیاز دارید، مدلی با ظرفیت بیشتر، یعنی مدلی که قادر به ذخیره اطلاعات بیشتری باشد. میتوانید قدرت بازنمایی را با افزودن لایههای بیشتر، استفاده از لایههای بزرگتر (لایههایی با پارامترهای بیشتر)، یا استفاده از انواع لایههای مناسبتر برای مسئله موجود (پیشفرضهای معماری بهتر) افزایش دهید.
بیایید سعی کنیم یک مدل بزرگتر را آموزش دهیم، مدلی با دو لایه میانی که هر کدام ۹۶ واحد دارند:
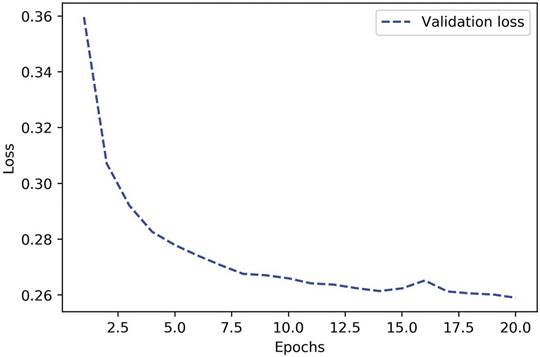
شکل ۵.۱۴: تأثیر ظرفیت ناکافی مدل بر منحنیهای زیان
model = keras.Sequential([
layers.Dense(96, activation=”relu”), layers.Dense(96, activation=”relu”), layers.Dense(10, activation=”softmax”),
])
model.compile(optimizer=”rmsprop”,
loss=”sparse_categorical_crossentropy”,
metrics=[“accuracy”])
history_large_model = model.fit(
train_images, train_labels,
epochs=20,
batch_size=128,
validation_split=0.2)
منحنی اعتبارسنجی اکنون دقیقاً همانطور که باید به نظر میرسد: مدل سریع برازش میشود و پس از ۸ دوره (epoch) شروع به بیشبرازش میکند (به شکل ۵.۱۵ مراجعه کنید).
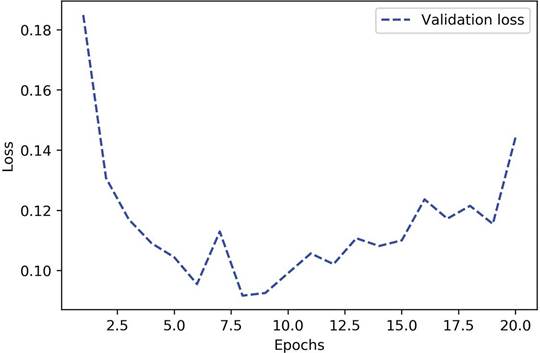
شکل ۵.۱۵: زیان اعتبارسنجی برای مدلی با ظرفیت مناسب
بهبود تعمیم
هنگامی که مدل شما نشان داد که دارای قدرت تعمیم است و قادر به بیشبرازش (overfit) است، زمان آن رسیده که تمرکز خود را به حداکثر رساندن تعمیم معطوف کنید.
سازماندهی مجموعه داده (Dataset Curation)
شما قبلاً یاد گرفتهاید که تعمیم در یادگیری عمیق از ساختار نهفته دادههای شما نشأت میگیرد. اگر دادههای شما امکان درونیابی هموار بین نمونهها را فراهم کنند، قادر خواهید بود یک مدل یادگیری عمیق را آموزش دهید که تعمیم مییابد. اگر مشکل شما بیش از حد نویزدار یا اساساً گسسته باشد، مانند مرتبسازی لیست، یادگیری عمیق به شما کمکی نخواهد کرد. یادگیری عمیق برازش منحنی است، نه جادو.
به همین دلیل، بسیار مهم است که اطمینان حاصل کنید با یک مجموعه داده مناسب کار میکنید. صرف هزینه و تلاش بیشتر برای جمعآوری داده تقریباً همیشه بازگشت سرمایه بسیار بیشتری نسبت به صرف همین میزان برای توسعه یک مدل بهتر به همراه دارد.
- اطمینان حاصل کنید که داده کافی دارید. به یاد داشته باشید که به یک نمونهبرداری چگال از فضای ورودی-خروجی نیاز دارید. دادههای بیشتر، مدل بهتری را به ارمغان میآورد. گاهی اوقات، مسائلی که در ابتدا غیرممکن به نظر میرسند، با یک مجموعه داده بزرگتر قابل حل میشوند.
- خطاهای برچسبگذاری را به حداقل برسانید—ورودیهای خود را بصریسازی کنید تا ناهنجاریها را بررسی کنید و برچسبهای خود را بازخوانی کنید.
- دادههای خود را پاک کنید و با مقادیر از دست رفته کنار بیایید (این مورد را در فصل بعدی پوشش خواهیم داد).
- اگر ویژگیهای زیادی دارید و مطمئن نیستید که کدام یک واقعاً مفید هستند، انتخاب ویژگی (feature selection) انجام دهید.
یک راه بهویژه مهم برای بهبود پتانسیل تعمیم دادههای شما، مهندسی ویژگی (feature engineering) است. برای بیشتر مسائل یادگیری ماشین، مهندسی ویژگی یک عنصر کلیدی برای موفقیت است. بیایید نگاهی بیندازیم.
مهندسی ویژگی (Feature Engineering)
مهندسی ویژگی فرآیندی است که در آن از دانش خود در مورد دادهها و الگوریتم یادگیری ماشین مورد استفاده (در این مورد، یک شبکه عصبی) بهره میبرید تا با اعمال تبدیلهای از پیش کدگذاری شده (غیرقابل یادگیری) بر روی دادهها، قبل از ورودشان به مدل، عملکرد الگوریتم را بهبود بخشید. در بسیاری از موارد، منطقی نیست که از یک مدل یادگیری ماشین انتظار داشته باشیم که بتواند از دادههای کاملاً دلخواه یاد بگیرد. دادهها باید به گونهای به مدل ارائه شوند که کار مدل را آسانتر کند.
بیایید به یک مثال شهودی نگاه کنیم. فرض کنید در حال توسعه مدلی هستید که میتواند تصویری از یک ساعت را به عنوان ورودی بگیرد و زمان روز را خروجی دهد (به شکل ۵.۱۶ مراجعه کنید).
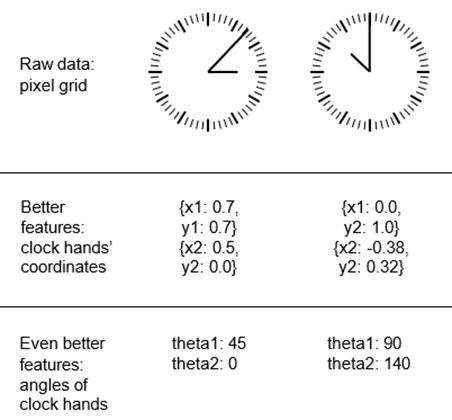
شکل ۵.۱۶: مهندسی ویژگی برای خواندن زمان روی ساعت
اگر انتخاب کنید که از پیکسلهای خام تصویر به عنوان داده ورودی استفاده کنید، یک مسئله دشوار یادگیری ماشین در دست دارید. برای حل آن به یک شبکه عصبی کانولوشنی (convolutional neural network) نیاز خواهید داشت و باید منابع محاسباتی زیادی را برای آموزش شبکه صرف کنید.
اما اگر از قبل مسئله را در سطح بالایی درک میکنید (میدانید که انسانها چگونه زمان را از روی یک ساعت میخوانند)، میتوانید ویژگیهای ورودی بسیار بهتری را برای یک الگوریتم یادگیری ماشین ارائه دهید: برای مثال، نوشتن یک اسکریپت پایتون پنج خطی برای ردیابی پیکسلهای سیاه عقربههای ساعت و خروجی دادن مختصات (x,y) نوک هر عقربه آسان است. سپس یک الگوریتم ساده یادگیری ماشین میتواند یاد بگیرد که این مختصات را با زمان مناسب روز مرتبط کند.
حتی میتوانید فراتر بروید: یک تغییر مختصات انجام دهید و مختصات (x,y) را به صورت مختصات قطبی نسبت به مرکز تصویر بیان کنید. ورودی شما به زاویه تتا (theta) هر عقربه ساعت تبدیل خواهد شد. در این مرحله، ویژگیهای شما مسئله را آنقدر آسان میکنند که هیچ یادگیری ماشینی مورد نیاز نیست؛ یک عملیات گرد کردن ساده و جستجو در دیکشنری برای بازیابی زمان تقریبی روز کافی است.
این همان جوهر مهندسی ویژگی است: آسانتر کردن یک مسئله با بیان آن به روشی سادهتر. مانیفولد نهفته را هموارتر، سادهتر و منظمتر کنید. انجام این کار معمولاً به درک عمیق مسئله نیاز دارد.
قبل از یادگیری عمیق، مهندسی ویژگی مهمترین بخش گردش کار یادگیری ماشین بود، زیرا الگوریتمهای کلاسیک کمعمق (shallow) فضای فرضیه کافی برای یادگیری ویژگیهای مفید به تنهایی را نداشتند. نحوه ارائه دادهها به الگوریتم برای موفقیت آن کاملاً حیاتی بود. برای مثال، قبل از اینکه شبکههای عصبی کانولوشنی در مسئله طبقهبندی ارقام MNIST موفق شوند، راهحلها معمولاً بر اساس ویژگیهای کدگذاریشده مانند تعداد حلقهها در تصویر یک رقم، ارتفاع هر رقم در یک تصویر، هیستوگرام مقادیر پیکسل و غیره بودند.
خوشبختانه، یادگیری عمیق مدرن نیاز به اکثر مهندسی ویژگی را از بین میبرد، زیرا شبکههای عصبی قادر به استخراج خودکار ویژگیهای مفید از دادههای خام هستند. آیا این بدان معناست که تا زمانی که از شبکههای عصبی عمیق استفاده میکنید، نیازی نیست نگران مهندسی ویژگی باشید؟ خیر، به دو دلیل:
- ویژگیهای خوب همچنان به شما این امکان را میدهند که مسائل را با ظرافت بیشتری و با استفاده از منابع کمتر حل کنید. برای مثال، حل مسئله خواندن ساعت با استفاده از یک شبکه عصبی کانولوشنی مضحک خواهد بود.
- ویژگیهای خوب به شما امکان میدهند یک مسئله را با دادههای بسیار کمتری حل کنید. توانایی مدلهای یادگیری عمیق در یادگیری ویژگیها به تنهایی، متکی بر در دسترس بودن حجم زیادی از دادههای آموزشی است؛ اگر فقط چند نمونه دارید، ارزش اطلاعاتی ویژگیهای آنها حیاتی میشود.
استفاده از توقف زودهنگام (Early Stopping)
در یادگیری عمیق، ما همیشه از مدلهایی استفاده میکنیم که به شدت بیشپارامترسازی (overparameterized) شدهاند: آنها درجه آزادی بسیار بیشتری از حداقل لازم برای برازش با مانیفولد نهفته دادهها دارند. این بیشپارامترسازی مشکلی ایجاد نمیکند، زیرا شما هرگز یک مدل یادگیری عمیق را به طور کامل برازش نمیکنید. چنین برازشی اصلاً تعمیم نمییابد. شما همیشه آموزش را مدتها قبل از رسیدن به حداقل زیان آموزشی ممکن قطع خواهید کرد.
یافتن نقطه دقیق در طول آموزش که در آن به برازش قابل تعمیمترین حالت رسیدهاید — مرز دقیق بین یک منحنی کمبرازش و یک منحنی بیشبرازش — یکی از موثرترین کارهایی است که میتوانید برای بهبود تعمیم انجام دهید.
در مثالهای فصل قبلی، ما ابتدا مدلهای خود را برای مدت طولانیتری آموزش میدادیم تا تعداد دورههایی که بهترین معیارهای اعتبارسنجی را به ارمغان میآوردند، مشخص کنیم، و سپس یک مدل جدید را دقیقاً برای همان تعداد دوره دوباره آموزش میدادیم. این روش بسیار استاندارد است، اما نیاز به انجام کارهای تکراری دارد که گاهی اوقات میتواند پرهزینه باشد. طبیعتاً، میتوانید مدل خود را در پایان هر دوره ذخیره کنید، و هنگامی که بهترین دوره را پیدا کردید، از نزدیکترین مدل ذخیره شده استفاده کنید. در Keras، معمولاً این کار با یک callback EarlyStopping انجام میشود، که به محض توقف بهبود معیارهای اعتبارسنجی، آموزش را قطع میکند، در حالی که بهترین حالت شناخته شده مدل را به خاطر میسپارد.
در فصل ۷ یاد میگیرید که چگونه از callbacks استفاده کنید.
منظم کردن مدل شما (Regularizing your model)
تکنیکهای منظمسازی (Regularization techniques) مجموعهای از بهترین شیوهها هستند که فعالانه توانایی مدل برای برازش کامل با دادههای آموزشی را محدود میکنند، با هدف اینکه مدل در طول اعتبارسنجی بهتر عمل کند. این کار را “منظمسازی” مدل مینامند، زیرا تمایل دارد مدل را سادهتر، “منظمتر”، منحنی آن را هموارتر و “عمومیتر” کند؛ بنابراین، مدل کمتر به مجموعه آموزشی خاص میشود و بهتر میتواند با تقریب زدن دقیقتر مانیفولد نهفته دادهها، تعمیم یابد.
به خاطر داشته باشید که منظم کردن یک مدل فرآیندی است که همیشه باید توسط یک روش ارزیابی دقیق هدایت شود. شما تنها در صورتی به تعمیم دست خواهید یافت که بتوانید آن را اندازهگیری کنید.
بیایید برخی از رایجترین تکنیکهای منظمسازی را بررسی کرده و آنها را در عمل برای بهبود مدل طبقهبندی فیلم از فصل ۴ به کار ببریم.
کاهش اندازه شبکه
شما قبلاً یاد گرفتهاید که یک مدل بیش از حد کوچک بیشبرازش نخواهد کرد. سادهترین راه برای کاهش بیشبرازش، کاهش اندازه مدل است (تعداد پارامترهای قابل یادگیری در مدل، که توسط تعداد لایهها و تعداد واحدها در هر لایه تعیین میشود). اگر مدل منابع حافظهای محدودی داشته باشد، نمیتواند صرفاً دادههای آموزشی خود را حفظ کند؛ بنابراین، برای حداقل کردن زیان خود، مجبور به یادگیری بازنماییهای فشردهای خواهد شد که قدرت پیشبینی در مورد هدفها را دارند—دقیقاً همان نوع بازنماییهایی که به آنها علاقهمندیم. در عین حال، به خاطر داشته باشید که باید از مدلهایی استفاده کنید که پارامترهای کافی دارند تا کمبرازش نکنند: مدل شما نباید از منابع حافظهای محروم شود. باید مصالحهای بین ظرفیت زیاد و ظرفیت کم پیدا شود.
متأسفانه، هیچ فرمول جادویی برای تعیین تعداد صحیح لایهها یا اندازه صحیح برای هر لایه وجود ندارد. شما باید آرایهای از معماریهای مختلف را (البته بر روی مجموعه اعتبارسنجی خود، نه بر روی مجموعه آزمایش) ارزیابی کنید تا اندازه مدل صحیح برای دادههای خود را بیابید. روند کلی برای یافتن اندازه مدل مناسب این است که با لایهها و پارامترهای نسبتاً کم شروع کنید و اندازه لایهها را افزایش دهید یا لایههای جدیدی اضافه کنید تا زمانی که بازده کاهشی را در مورد زیان اعتبارسنجی مشاهده کنید.
بیایید این را بر روی مدل طبقهبندی نقدهای فیلم امتحان کنیم. لیست زیر مدل اصلی ما را نشان میدهد.
قطعه کد ۵.۱۰ – مدل اصلی
from tensorflow.keras.datasets import imdb
(train_data, train_labels), _ = imdb.load_data(num_words=10000)
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
train_data = vectorize_sequences(train_data)
model = keras.Sequential([
layers.Dense(16, activation=”relu”), layers.Dense(16, activation=”relu”), layers.Dense(1, activation=”sigmoid”)
])
model.compile(optimizer=”rmsprop”,
loss=”binary_crossentropy”,
metrics=[“accuracy”])
history_original = model.fit(train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)
حالا بیایید سعی کنیم آن را با این مدل کوچکتر جایگزین کنیم
قطعه کد ۵.۱۱ – نسخهای از مدل با ظرفیت پایینتر
model = keras.Sequential([
layers.Dense(4, activation=”relu”), layers.Dense(4, activation=”relu”), layers.Dense(1, activation=”sigmoid”)
])
model.compile(optimizer=”rmsprop”,
loss=”binary_crossentropy”,
metrics=[“accuracy”])
history_smaller_model = model.fit(
train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)
شکل ۵.۱۷ مقایسه زیانهای اعتبارسنجی (validation losses) مدل اصلی و مدل کوچکتر را نشان میدهد.
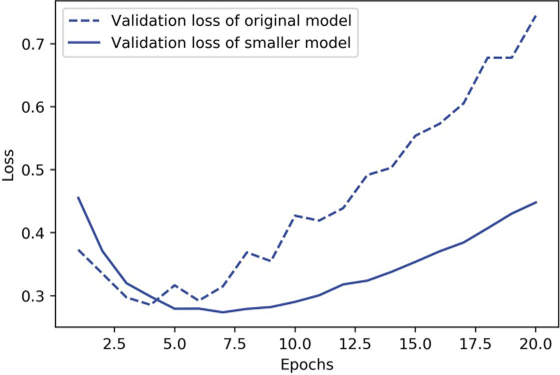
شکل ۵.۱۷: مدل اصلی در مقابل مدل کوچکتر در طبقهبندی نقدهای IMDB
همانطور که میبینید، مدل کوچکتر دیرتر از مدل مرجع شروع به بیشبرازش میکند (بعد از شش دوره به جای چهار دوره)، و عملکرد آن پس از شروع بیشبرازش کندتر افت میکند.
حالا، بیایید به معیار خود مدلی را اضافه کنیم که ظرفیت بسیار بیشتری دارد – بسیار بیشتر از آنچه که مسئله ایجاب میکند. در حالی که معمول است با مدلهایی کار کنیم که برای آنچه سعی در یادگیری آن دارند به طور قابل توجهی بیشپارامترسازی شدهاند، قطعاً چیزی به نام ظرفیت حفظ بیش از حد وجود دارد. شما زمانی متوجه میشوید که مدل شما بیش از حد بزرگ است که بلافاصله شروع به بیشبرازش کند و منحنی زیان اعتبارسنجی آن ناهموار و با واریانس بالا به نظر برسد (اگرچه معیارهای اعتبارسنجی ناهموار میتوانند نشانه استفاده از یک فرآیند اعتبارسنجی غیرقابل اعتماد نیز باشند، مانند تقسیم اعتبارسنجی که خیلی کوچک است).
قطعه کد ۵.۱۲ – نسخهای از مدل با ظرفیت بالاتر
model = keras.Sequential([
layers.Dense(512, activation=”relu”), layers.Dense(512, activation=”relu”), layers.Dense(1, activation=”sigmoid”)
])
model.compile(optimizer=”rmsprop”,
loss=”binary_crossentropy”,
metrics=[“accuracy”])
history_larger_model = model.fit(
train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)
شکل ۵.۱۸ نشان میدهد که مدل بزرگتر در مقایسه با مدل مرجع چگونه عمل میکند.
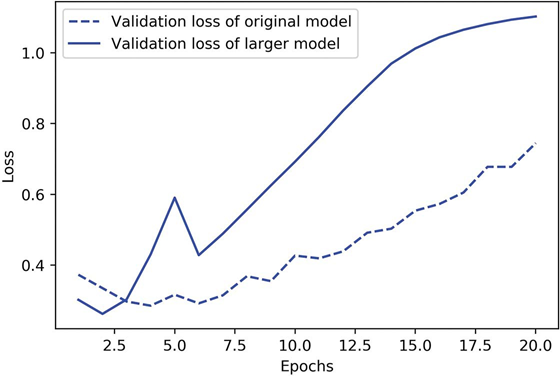
شکل ۵.۱۸: مدل اصلی در مقابل مدل بسیار بزرگتر در طبقهبندی نقدهای IMDB
مدل بزرگتر تقریباً بلافاصله، پس از تنها یک دوره، شروع به بیشبرازش (overfit) میکند و به مراتب شدیدتر بیشبرازش میکند. زیان اعتبارسنجی آن نیز نویزدارتر است. این مدل زیان آموزشی را خیلی سریع به نزدیکی صفر میرساند. هرچه مدل ظرفیت بیشتری داشته باشد، سریعتر میتواند دادههای آموزشی را مدلسازی کند (که منجر به زیان آموزشی پایین میشود)، اما بیشتر مستعد بیشبرازش است (که منجر به تفاوت زیادی بین زیان آموزشی و زیان اعتبارسنجی میشود).
افزودن منظمسازی وزن (Weight Regularization)
شاید با اصل “تیغ اوکام” آشنا باشید: با فرض دو توضیح برای یک چیز، توضیحی که به احتمال زیاد صحیح است، سادهترین آن است—همانی که مفروضات کمتری دارد. این ایده در مورد مدلهای یادگرفتهشده توسط شبکههای عصبی نیز صدق میکند: با توجه به برخی دادههای آموزشی و یک معماری شبکه، چندین مجموعه از مقادیر وزن (مدلهای متعدد) میتوانند دادهها را توضیح دهند. مدلهای سادهتر کمتر از مدلهای پیچیده مستعد بیشبرازش هستند.
یک مدل ساده در این زمینه، مدلی است که توزیع مقادیر پارامتر آن آنتروپی کمتری دارد (یا مدلی با پارامترهای کمتر، همانطور که در بخش قبلی دیدید). بنابراین، یک راه رایج برای کاهش بیشبرازش، اعمال محدودیتهایی بر پیچیدگی یک مدل است با اجبار وزنهای آن به پذیرش فقط مقادیر کوچک، که توزیع مقادیر وزن را منظمتر میکند. این عمل منظمسازی وزن (weight regularization) نامیده میشود و با اضافه کردن یک هزینه مرتبط با وزنهای بزرگ به تابع زیان مدل انجام میشود. این هزینه در دو نوع است:
- منظمسازی (L1 regularization): L1هزینه اضافهشده متناسب با مقدار مطلق ضرایب وزن نرم L1 وزنها است.
- منظمسازی (L2 regularization): L2هزینه اضافهشده متناسب با مربع مقدار ضرایب وزن نرم L2 وزنها است. منظمسازی L2 در زمینه شبکههای عصبی، کاهش وزن (weight decay) نیز نامیده میشود. اجازه ندهید نامهای متفاوت شما را گیج کنند: کاهش وزن از نظر ریاضی همان منظمسازی L2 است.
در Keras، منظمسازی وزن با پاس دادن نمونههای منظمساز وزن به لایهها به عنوان آرگومانهای کلمهکلیدی اضافه میشود. بیایید منظمسازی وزن L2 را به مدل طبقهبندی اولیه نقدهای فیلم خود اضافه کنیم.
قطعه کد ۵.۱۳ – افزودن منظمسازی وزن با L2 به مدل
from tensorflow.keras import regularizers
model = keras.Sequential([
layers.Dense(16,
kernel_regularizer=regularizers.l2(0.002),
activation=”relu”),
layers.Dense(16,
kernel_regularizer=regularizers.l2(0.002),
activation=”relu”),
layers.Dense(1, activation=”sigmoid”)
])
model.compile(optimizer=”rmsprop”,
loss=”binary_crossentropy”,
metrics=[“accuracy”])
history_l2_reg = model.fit(
train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)
در لیست قبلی، l2(0.002) به این معنی است که هر ضریب در ماتریس وزن لایه،2(مقدار ضریب وزن)* ۰.۰۰۲ را به کل زیان مدل اضافه خواهد کرد. توجه داشته باشید که از آنجایی که این جریمه فقط در زمان آموزش اضافه میشود، زیان این مدل در زمان آموزش بسیار بیشتر از زمان آزمایش خواهد بود.
شکل ۵.۱۹ تأثیر جریمه منظمسازی L2 را نشان میدهد. همانطور که میبینید، مدل با منظمسازی L2 در برابر بیشبرازش بسیار مقاومتر از مدل مرجع شده است، حتی با وجود اینکه هر دو مدل تعداد پارامترهای یکسانی دارند.
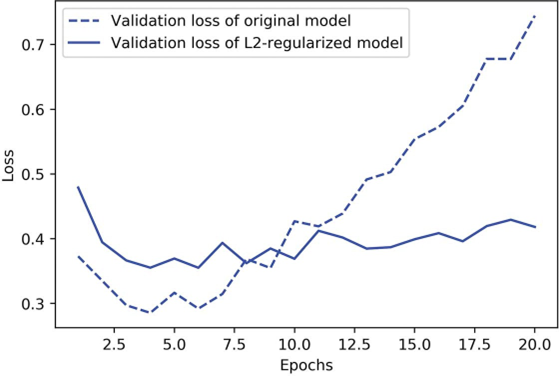
شکل ۵.۱۹: تأثیر منظمسازی وزن L2 بر زیان اعتبارسنجی
به عنوان جایگزینی برای منظمسازی L2، میتوانید از یکی از منظمسازهای وزن Keras زیر استفاده کنید.
قطعه کد ۵.۱۴ – انواع منظمسازهای وزن (Weight Regularizers) در Keras
from tensorflow.keras import regularizers
regularizers.l1(0.001)
منظمسازی L1 (L1 regularization)
regularizers.l1_l2(l1=0.001, l2=0.001)
منظمسازی همزمان L1 و L2
توجه داشته باشید که منظمسازی وزن معمولاً برای مدلهای یادگیری عمیق کوچکتر استفاده میشود. مدلهای بزرگ یادگیری عمیق تمایل دارند آنقدر بیشپارامترسازی (overparameterized) باشند که اعمال محدودیت بر مقادیر وزن تأثیر زیادی بر ظرفیت مدل و تعمیم ندارد. در این موارد، یک تکنیک منظمسازی متفاوت ترجیح داده میشود: دراپاوت (dropout).
افزودن دراپاوت (Dropout)
دراپاوت یکی از مؤثرترین و رایجترین تکنیکهای منظمسازی برای شبکههای عصبی است؛ این تکنیک توسط جفری هینتون و دانشجویانش در دانشگاه تورنتو توسعه یافت.
دراپاوت که به یک لایه اعمال میشود، شامل به طور تصادفی صفر کردن (حذف) تعدادی از ویژگیهای خروجی لایه در طول آموزش است. فرض کنید یک لایه معین به طور معمول برای یک نمونه ورودی مشخص در طول آموزش، بردار [0.2, 0.5, 1.3, 0.8, 1.1]را برمیگرداند. پس از اعمال دراپاوت، این بردار چند ورودی صفر خواهد داشت که به طور تصادفی توزیع شدهاند: برای مثال، [0, 0.5, 1.3, 0, 1.1]. نرخ دراپاوت (dropout rate) کسری از ویژگیهایی است که صفر میشوند؛ معمولاً بین ۰.۲ تا ۰.۵ تنظیم میشود. در زمان آزمایش، هیچ واحدی حذف نمیشود؛ در عوض، مقادیر خروجی لایه با ضریبی برابر با نرخ دراپاوت مقیاسبندی میشوند، تا این واقعیت که واحدهای بیشتری نسبت به زمان آموزش فعال هستند، جبران شود.
یک ماتریس NumPy شامل خروجی یک لایه، layer_output، با شکل (batch_size, features) را در نظر بگیرید. در زمان آموزش، کسری از مقادیر در ماتریس را به طور تصادفی صفر میکنیم:
layer_output *= np.random.randint(0, high=2, size=layer_output.shape)
در زمان آموزش، ۵۰٪ از واحدها را در خروجی حذف میکند.
در زمان آزمایش، خروجی را با نرخ دراپاوت مقیاسبندی میکنیم. در اینجا، با ۰.۵ مقیاسبندی میکنیم (زیرا قبلاً نیمی از واحدها را حذف کرده بودیم):
layer_output *= 0.5
در زمان آزمایش
توجه داشته باشید که این فرآیند را میتوان با انجام هر دو عملیات در زمان آموزش و دست نخورده گذاشتن خروجی در زمان آزمایش پیادهسازی کرد، که اغلب روشی است که در عمل پیادهسازی میشود (به شکل ۵.۲۰ مراجعه کنید):
layer_output *= np.random.randint(0, high=2, size=layer_output.shape)
layer_output /= 0.5
توجه داشته باشید که در این حالت، ما به جای کاهش مقیاس (scaling down)، در حال افزایش مقیاس (scaling up) هستیم.
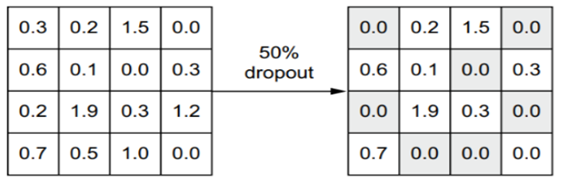
شکل ۵.۲۰: دراپاوت اعمالشده بر یک ماتریس فعالسازی در زمان آموزش، همراه با تغییر مقیاس در طول آموزش. در زمان آزمایش، ماتریس فعالسازی بدون تغییر میماند.
این تکنیک ممکن است عجیب و دلبخواهی به نظر برسد. چرا باید به کاهش بیشبرازش کمک کند؟ هینتون میگوید که از جمله چیزهای دیگر، از یک مکانیسم جلوگیری از تقلب که توسط بانکها استفاده میشود، الهام گرفته است. به قول خودش، “به بانک رفتم. تحویلداران مرتب عوض میشدند و از یکی از آنها پرسیدم چرا. او گفت نمیدانم، اما آنها زیاد جابهجا میشوند.”
فکر کردم باید به این دلیل باشد که برای تقلب موفقیتآمیز از بانک، نیاز به همکاری بین کارمندان است. این باعث شد متوجه شوم که به طور تصادفی حذف کردن زیرمجموعههای متفاوتی از نورونها در هر مثال، از “توطئهها” جلوگیری کرده و در نتیجه بیشبرازش را کاهش میدهد.” ایده اصلی این است که معرفی نویز در مقادیر خروجی یک لایه میتواند الگوهای اتفاقی که معنیدار نیستند (آنچه هینتون به آن “توطئه” میگوید) را درهم بشکند، الگوهایی که مدل در صورت عدم وجود نویز، شروع به حفظ کردنشان میکند.
در Keras، میتوانید دراپاوت را در یک مدل از طریق لایه Dropout معرفی کنید، که به خروجی لایه درست قبل از آن اعمال میشود.
بیایید دو لایه Dropout را به مدل IMDB اضافه کنیم تا ببینیم چقدر در کاهش بیشبرازش خوب عمل میکنند.
قطعه کد ۵.۱۵ – افزودن Dropout به مدل IMDB
model = keras.Sequential([
layers.Dense(16, activation=”relu”), layers.Dropout(0.5),
layers.Dense(16, activation=”relu”), layers.Dropout(0.5),
layers.Dense(1, activation=”sigmoid”)
])
model.compile(optimizer=”rmsprop”,
loss=”binary_crossentropy”,
metrics=[“accuracy”])
history_dropout = model.fit(
train_data, train_labels,
epochs=20, batch_size=512, validation_split=0.4)
شکل ۵.۲۱ نموداری از نتایج را نشان میدهد. این یک پیشرفت آشکار نسبت به مدل مرجع است — همچنین به نظر میرسد بسیار بهتر از منظمسازی L2 عمل میکند، زیرا کمترین زیان اعتبارسنجی به دست آمده بهبود یافته است.
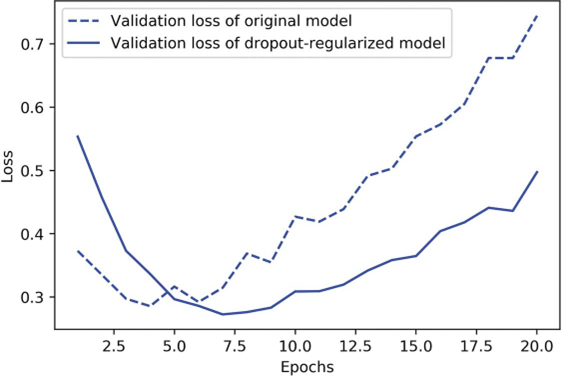
شکل ۵.۲۱: تأثیر دراپاوت (Dropout) بر زیان اعتبارسنجی
برای جمعبندی، اینها رایجترین راهها برای به حداکثر رساندن تعمیم و جلوگیری از بیشبرازش در شبکههای عصبی هستند:
- دادههای آموزشی بیشتر یا دادههای آموزشی بهتر به دست آورید.
- ویژگیهای بهتر توسعه دهید.
- ظرفیت مدل را کاهش دهید.
- منظمسازی وزن (weight regularization) اضافه کنید (برای مدلهای کوچکتر).
- دراپاوت (dropout) اضافه کنید.
خلاصه
- هدف یک مدل یادگیری ماشین، تعمیم (generalize) است: عملکرد دقیق بر روی ورودیهایی که قبلاً دیده نشدهاند. این کار دشوارتر از آن چیزی است که به نظر میرسد.
- یک شبکه عصبی عمیق با یادگیری یک مدل پارامتری که میتواند با موفقیت بین نمونههای آموزشی درونیابی (interpolate) کند، به تعمیم دست مییابد؛ میتوان گفت چنین مدلی “مانیفولد نهفته” دادههای آموزشی را یاد گرفته است. به همین دلیل مدلهای یادگیری عمیق تنها میتوانند ورودیهایی را که بسیار نزدیک به آنچه در طول آموزش دیدهاند هستند، درک کنند.
- مسئله اساسی در یادگیری ماشین، کشمکش بین بهینهسازی و تعمیم است: برای دستیابی به تعمیم، ابتدا باید به یک برازش خوب با دادههای آموزشی دست یابید، اما بهبود برازش مدل شما با دادههای آموزشی به ناچار پس از مدتی شروع به آسیب رساندن به تعمیم خواهد کرد. هر تکتک بهترین شیوه یادگیری عمیق با مدیریت این کشمکش سروکار دارد.
- توانایی مدلهای یادگیری عمیق در تعمیم از این واقعیت ناشی میشود که آنها موفق میشوند مانیفولد نهفته دادههای خود را تقریب بزنند و بنابراین میتوانند ورودیهای جدید را از طریق درونیابی درک کنند.
- ارزیابی دقیق قدرت تعمیم مدل شما در حین توسعه آن ضروری است. شما آرایهای از روشهای ارزیابی در اختیار دارید، از اعتبارسنجی ساده هولدآوت (simple holdout validation) گرفته تا اعتبارسنجی متقاطع K-fold و اعتبارسنجی متقاطع K-fold تکراری با درهمسازی. به خاطر داشته باشید که همیشه یک مجموعه آزمایش کاملاً جداگانه برای ارزیابی نهایی مدل نگه دارید، زیرا ممکن است نشت اطلاعات از دادههای اعتبارسنجی شما به مدل اتفاق افتاده باشد.
- هنگامی که کار بر روی یک مدل را شروع میکنید، هدف شما ابتدا دستیابی به مدلی است که دارای قدرت تعمیم باشد و بتواند بیشبرازش کند. بهترین شیوهها برای انجام این کار شامل تنظیم نرخ یادگیری و اندازه دسته (batch size)، استفاده از پیشفرضهای معماری بهتر، افزایش ظرفیت مدل، یا صرفاً آموزش طولانیتر است.
- هنگامی که مدل شما شروع به بیشبرازش میکند، هدف شما به بهبود تعمیم از طریق منظمسازی مدل (model regularization) تغییر میکند. میتوانید ظرفیت مدل خود را کاهش دهید، دراپاوت یا منظمسازی وزن اضافه کنید و از توقف زودهنگام (early stopping) استفاده کنید. و به طور طبیعی، یک مجموعه داده بزرگتر یا بهتر همیشه بهترین راه برای کمک به تعمیم مدل است.



