- محتویات این فصل
- این فصل به موارد زیر میپردازد:
- ساخت مدلهای کراس (Keras) با استفاده از کلاس Sequential، Functional API و مدلهای زیرکلاس (subclassing).
- استفاده از حلقههای توکار آموزش و ارزیابی کراس.
- بهرهگیری از کالبکهای کراس (Keras callbacks) برای سفارشیسازی آموزش.
- استفاده از تنسوربورد (TensorBoard) برای نظارت بر معیارهای آموزش و ارزیابی.
- نوشتن حلقههای آموزش و ارزیابی از ابتدا.
مقدمه
شما تا اینجا با Keras تجربه کسب کردهاید؛ با مدل Sequential، لایههای Dense، و APIهای توکار برای آموزش، ارزیابی، و استنتاج (شامل () compile ، () fit ، () evaluate ، و () predict) آشنا هستید. حتی در فصل 3 یاد گرفتید که چگونه از کلاس Layer ارثبری کنید تا لایههای سفارشی بسازید و چگونه از TensorFlow GradientTape برای پیادهسازی یک حلقه آموزشی گامبهگام استفاده کنید.
در فصلهای آینده، ما به بررسی بینایی کامپیوتر (computer vision)، پیشبینی سریهای زمانی (timeseries forecasting)، پردازش زبان طبیعی (natural language processing)، و یادگیری عمیق مولد (generative deep learning) خواهیم پرداخت. این کاربردهای پیچیده به چیزی فراتر از یک معماری Sequential و حلقه () fit پیشفرض نیاز دارند. پس بیایید ابتدا شما را به یک متخصص Keras تبدیل کنیم! در این فصل، یک بررسی کامل از روشهای کلیدی کار با APIهای Keras را خواهید داشت: هر آنچه برای مدیریت موارد پیشرفته یادگیری عمیق که در ادامه با آنها روبرو خواهید شد، نیاز دارید.
طیفی از جریان های کاری
طراحی API کراس بر اساس اصل افشای تدریجی پیچیدگی است: شروع کار را آسان کنید، اما در عین حال امکان مدیریت موارد استفاده با پیچیدگی بالا را فراهم کنید، و در هر مرحله فقط به یادگیری تدریجی نیاز داشته باشید. موارد استفاده ساده باید آسان و قابل دسترس باشند، و گردش کارهای پیشرفته به صورت دلخواه باید امکانپذیر باشند: مهم نیست که کار مورد نظر شما چقدر خاص و پیچیده باشد، باید یک مسیر واضح برای رسیدن به آن وجود داشته باشد. مسیری که بر اساس چیزهای مختلفی که از گردش کارهای سادهتر یاد گرفتهاید، ساخته میشود. این یعنی میتوانید از یک مبتدی به یک متخصص تبدیل شوید و همچنان از ابزارهای یکسانی استفاده کنید – فقط به روشهای متفاوت.
به این ترتیب، یک روش “واقعی” واحد برای استفاده از Keras وجود ندارد. در عوض، Keras طیفی از گردش کارها را ارائه میدهد، از بسیار ساده تا بسیار منعطف. روشهای مختلفی برای ساخت مدلهای Keras و روشهای مختلفی برای آموزش آنها وجود دارد که نیازهای متفاوتی را پاسخ میدهند. از آنجایی که تمام این گردش کارها بر اساس APIهای مشترک مانند Layer و Model هستند، مؤلفهها از هر گردش کاری میتوانند در هر گردش کار دیگری استفاده شوند – همه آنها میتوانند با هم “صحبت” کنند.
روشهای مختلف برای ساخت مدلهای کراس
سه API برای ساخت مدلها در Keras وجود دارد (به شکل 7.1 مراجعه کنید):
- مدل Sequential: این مدل قابل دسترسترین API است – اساساً یک لیست پایتون است. به همین دلیل، به پشتههای سادهای از لایهها محدود میشود.
- Functional API: این API بر معماریهای مدل گرافمانند تمرکز دارد. این یک نقطه میانی خوب بین قابلیت استفاده و انعطافپذیری را نشان میدهد، و به همین دلیل، متداولترین API برای ساخت مدلها است.
- Model subclassing: این یک گزینه سطح پایین است که در آن همه چیز را از ابتدا خودتان مینویسید. این گزینه ایدهآل است اگر میخواهید کنترل کامل بر روی کوچکترین جزئیات داشته باشید. با این حال، به بسیاری از ویژگیهای توکار Keras دسترسی نخواهید داشت و بیشتر در معرض خطر اشتباه کردن خواهید بود.
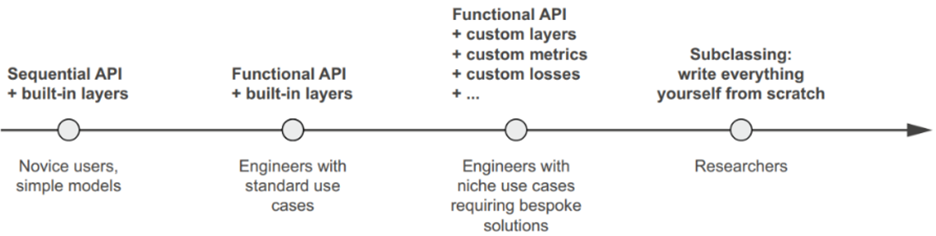
شکل 7.1. سیر پیشرفت پیچیدگی در ساخت مدل
مدل Sequential یا ترتیبی
سادهترین راه برای ساخت یک مدل کراس استفاده از مدل ترتیبی ( Sequential) است، که شما قبلاً با آن آشنا هستید.
قطعه کد 7.1 کلاس Sequential
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(64, activation=”relu” layers.Dense(10, activation=”softmax”)
])
توجه داشته باشید که میتوان همین مدل را به صورت افزایشی از طریق متد add() ساخت، که مشابه متد append() در لیستهای پایتون است.
قطعه کد 7.2 ساخت افزایشی یک مدل Sequential
model = keras.Sequential()
model.add(layers.Dense(64, activation=”relu”)) model.add(layers.Dense(10, activation=”softmax”))
در فصل 4 دیدید که لایهها تنها زمانی ساخته میشوند (به عبارت دیگر، وزنهای خود را ایجاد میکنند) که برای اولین بار فراخوانی شوند. این به این دلیل است که شکل وزنهای لایهها به شکل ورودی آنها بستگی دارد: تا زمانی که شکل ورودی مشخص نشود، نمیتوان آنها را ایجاد کرد.
به این ترتیب، مدل Sequential قبلی هیچ وزنی ندارد (قطعه کد 7.3) تا زمانی که آن را واقعاً روی دادهای فراخوانی کنید، یا متد build() آن را با یک شکل ورودی فراخوانی کنید (قطعه کد 7.4).
قطعه کد 7.3 مدلهایی که هنوز ساخته نشدهاند، وزنی ندارند
>>> model.weights
در آن مرحله، مدل هنوز ساخته نشده است.
ValueError: Weights for model sequential_1 have not yet been created.
قطعه کد 7.4 فراخوانی مدل برای اولین بار جهت ساخت آن
>>> model.build(input_shape=(None, 3))
مدل را میسازد — اکنون مدل انتظار نمونههایی با شکل (3,) را خواهد داشت. مقدار None در شکل ورودی نشان میدهد که اندازه دسته (batch size) میتواند هر چیزی باشد.
>>> model.weights
حالا میتوانید وزنهای مدل را بازیابی کنید.
[<tf.Variable “dense_2/kernel:0” shape=(3, 64) dtype=float32, … >,
<tf.Variable “dense_2/bias:0” shape=(64,) dtype=float32, … >
<tf.Variable “dense_3/kernel:0” shape=(64, 10) dtype=float32, … >,
<tf.Variable “dense_3/bias:0” shape=(10,) dtype=float32, … >]
پس از اینکه مدل ساخته شد، میتوانید محتویات آن را از طریق متد summary() نمایش دهید، که برای اشکالزدایی بسیار کاربردی است.
قطعه کد 7.5 متد summary()
>>> model.summary()
Model: “sequential_1”
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 64) 256
dense_3 (Dense) (None, 10) 650
=================================================================
Total params: 906
Trainable params: 906
Non-trainable params: 0
همانطور که میبینید، نام این مدل به طور اتفاقی “sequential_1” است. شما میتوانید به هر چیزی در Keras نام بدهید – هر مدل، هر لایه.
قطعه کد 7.6 نامگذاری مدلها و لایهها با آرگومان name
>>> model = keras.Sequential(name=”my_example_model”)
>>> model.add(layers.Dense(64, activation=”relu”, name=”my_first_layer”))
>>> model.add(layers.Dense(10, activation=”softmax”, name=”my_last_layer”))
>>> model.build((None, 3))
>>> model.summary() Model: “my_example_model”
Layer (type) Output Shape Param #
=================================================================
my_first_layer (Dense) (None, 64) 256
my_last_layer (Dense) (None, 10) 650
=================================================================
Total params: 906
Trainable params: 906
Non-trainable params: 0
هنگام ساخت یک مدل Sequential به صورت افزایشی، مفید است که بتوانید خلاصهای از ظاهر مدل فعلی را پس از افزودن هر لایه چاپ کنید. اما تا زمانی که مدل ساخته نشده باشد، نمیتوانید خلاصهای را چاپ کنید!
در واقع راهی برای ساخت مدل Sequential شما به صورت “on the fly” (در لحظه) وجود دارد: کافیست شکل ورودیهای مدل را از قبل اعلام کنید. میتوانید این کار را از طریق کلاس Input انجام دهید.
قطعه کد 7.7 تعیین شکل ورودی مدل از قبل
model = keras.Sequential()
model.add(keras.Input(shape=(3,)))
model.add(layers.Dense(64, activation=”relu”))
از Input برای اعلام شکل ورودیها استفاده کنید. توجه داشته باشید که آرگومان shape باید شکل هر نمونه باشد، نه شکل یک batch .
حالا میتوانید از summary() استفاده کنید تا دنبال کنید که چگونه شکل خروجی مدل شما با افزودن لایههای بیشتر تغییر میکند:
>>> model.summary()
Model: “sequential_2”
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 64) 256
=================================================================
Total params: 256
Trainable params: 256
Non-trainable params: 0
>>> model.add(layers.Dense(10, activation=”softmax”))
>>> model.summary() Model: “sequential_2”
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 64) 256
dense_5 (Dense) (None, 10) 650
=================================================================
Total params: 906
Trainable params: 906
Non-trainable params: 0
این یک گردش کار اشکالزدایی بسیار رایج است، به خصوص هنگام کار با لایههایی که ورودیهای خود را به روشهای پیچیده تبدیل میکنند، مانند لایههای کانولوشنال که در فصل 8 با آنها آشنا خواهید شد.
Functional API
مدل Sequential برای استفاده آسان است، اما کاربرد آن بسیار محدود است: تنها میتواند مدلهایی با یک ورودی و یک خروجی را بیان کند که لایهها را به صورت متوالی و یکی پس از دیگری اعمال میکند. در عمل، مشاهده مدلهایی با ورودیهای متعدد (مثلاً، یک تصویر و ابردادههای آن)، خروجیهای متعدد (چیزهای مختلفی که میخواهید درباره دادهها پیشبینی کنید)، یا یک توپولوژی غیرخطی بسیار رایج است.
در چنین مواردی، مدل خود را با استفاده از Functional API خواهید ساخت. این همان چیزی است که بیشتر مدلهای Keras که در عمل با آنها روبرو میشوید، از آن استفاده میکنند. این روش سرگرمکننده و قدرتمند است – حس بازی کردن با آجرهای لگو را میدهد.
یک مثال ساده
بیایید با چیزی ساده شروع کنیم: پشتهای از دو لایه که در بخش قبلی استفاده کردیم. نسخه Functional API آن شبیه قطعه کد زیر است.
قطعه کد ۷.۸: یک مدل Functional ساده با دو لایه متراکم
inputs = keras.Input(shape=(3,), name=”my_input”)
features = layers.Dense(64, activation=”relu”)(inputs)
outputs = layers.Dense(10, activation=”softmax”)(features)
model = keras.Model(inputs=inputs, outputs=outputs)
بیایید این را گام به گام بررسی کنیم.
ما با اعلان یک Input شروع کردیم (توجه داشته باشید که میتوانید به این اشیاء ورودی هم نام دهید، درست مثل هر چیز دیگری):
inputs = keras.Input(shape=(3,), name=”my_input”)
این شیء inputs، اطلاعاتی درباره شکل و نوع داده (dtype) دادههایی که مدل پردازش خواهد کرد، در خود نگه میدارد:
>>> inputs.shape (None, 3)
مدل، دستههایی را پردازش خواهد کرد که در آنها هر نمونه دارای شکل (3,) است. تعداد نمونهها در هر دسته متغیر است (که با اندازه دسته None نشان داده شده است)
>>> inputs.dtype float32
این دستهها نوع داده float32 خواهند داشت.
ما چنین شیئی را یک تنسور نمادین (symbolic tensor) مینامیم. این تنسور هیچ داده واقعی ندارد، اما مشخصات تنسورهای واقعی داده را که مدل هنگام استفاده از آن خواهد دید، کدگذاری میکند. این شیء نشاندهنده تنسورهای داده آینده است.
در مرحله بعد، یک لایه ایجاد کردیم و آن را روی ورودی فراخوانی کردیم:
features = layers.Dense(64, activation=”relu”)(inputs)
همه لایههای Keras را میتوان هم بر روی تنسورهای واقعی داده و هم بر روی تنسورهای نمادین فراخوانی کرد. در حالت دوم، آنها یک تنسور نمادین جدید را با اطلاعات شکل و نوع داده (dtype) بهروز شده برمیگردانند:
>>>features.shape
(None, 64)
پس از به دست آوردن خروجیهای نهایی، مدل را با مشخص کردن ورودیها و خروجیهای آن در سازنده Model نمونهسازی کردیم:
outputs = layers.Dense(10, activation=”softmax”)(features)
model = keras.Model(inputs=inputs, outputs=outputs)
این خلاصه مدل ماست:
>>> model.summary() Model: “functional_1”
Layer (type) Output Shape Param #
=================================================================
my_input (InputLayer) [(None, 3)] 0
dense_6 (Dense) (None, 64) 256
dense_7 (Dense) (None, 10) 650
=================================================================
Total params: 906
Trainable params: 906
Non-trainable params: 0
مدلهای چند ورودی، چند خروجی
برخلاف این مدل ساده، بیشتر مدلهای یادگیری عمیق شبیه لیست نیستند—بلکه شبیه نمودار هستند. برای مثال، ممکن است چندین ورودی یا چندین خروجی داشته باشند. برای این نوع مدل است که Functional API واقعاً میدرخشد.
فرض کنید در حال ساخت سیستمی هستید که درخواستهای پشتیبانی مشتری را بر اساس اولویت رتبهبندی کرده و به بخش مناسب هدایت میکند. مدل شما سه ورودی دارد:
- عنوان درخواست (ورودی متنی)
- متن اصلی درخواست (ورودی متنی)
- هر گونه برچسب اضافه شده توسط کاربر ورودی دستهای، که در اینجا فرض میشود به صورت One-Hot کدگذاری شده است
ما میتوانیم ورودیهای متنی را به صورت آرایههایی از صفر و یک با اندازه vocabulary_size کدگذاری کنیم (برای اطلاعات دقیق در مورد تکنیکهای کدگذاری متن به فصل ۱۱ مراجعه کنید). مدل شما همچنین دو خروجی دارد:
- امتیاز اولویت درخواست، یک اسکالر بین ۰ و ۱ (خروجی سیگموئید)
- بخشی که باید درخواست را رسیدگی کند (یک سافتمکس بر روی مجموعه بخشها)
شما میتوانید این مدل را در چند خط با Functional API بسازید.
قطعه کد ۷.۹: یک مدل Functional چند ورودی، چند خروجی
vocabulary_size = 10000
num_tags = 100
num_departments = 4
title = keras.Input(shape=(vocabulary_size,), name=”title”)
text_body = keras.Input(shape=(vocabulary_size,), name=”text_body”)
tags = keras.Input(shape=(num_tags,), name=”tags”)
ورودیهای مدل را تعریف کنید.
features = layers.Concatenate()([title, text_body, tags])
ویژگیهای ورودی را با الحاق (concatenating) آنها، در یک تنسور واحد به نام features ترکیب کنید.
features = layers.Dense(64, activation=”relu”)(features)
priority = layers.Dense(1, activation=”sigmoid”, name=”priority”)(features)
department = layers.Dense(
num_departments, activation=”softmax”, name=”department”)(features)
خروجیهای مدل را تعریف کنید.
model = keras.Model(inputs=[title, text_body, tags],
مدل را با مشخص کردن ورودیها و خروجیهای آن ایجاد کنید.
outputs=[priority, department])
یک لایه میانی را اعمال کنید تا ویژگیهای ورودی را در بازنماییهای غنیتر بازترکیب کند.
Functional API روشی ساده، شبیه لگو، اما بسیار انعطافپذیر برای تعریف نمودارهای دلخواه از لایهها مانند اینهاست.
آموزش یک مدل چند ورودی، چند خروجی
میتوانید مدل خود را تقریباً به همان روشی که یک مدل Sequential را آموزش میدهید، با فراخوانی fit() به همراه لیستهایی از دادههای ورودی و خروجی آموزش دهید. این لیستهای داده باید به همان ترتیبی باشند که ورودیها را به سازنده Model پاس دادید.
قطعه کد ۷.۱۰: آموزش یک مدل با ارائه لیستهایی از آرایههای ورودی و هدف
import numpy as np
num_samples = 1280
title_data = np.random.randint(0, 2, size=(num_samples, vocabulary_size))
text_body_data = np.random.randint(0, 2, size=(num_samples, vocabulary_size))
tags_data = np.random.randint(0, 2, size=(num_samples, num_tags))
دادههای ورودی ساختگی (Dummy input data)
priority_data = np.random.random(size=(num_samples, 1))
department_data = np.random.randint(0, 2, size=(num_samples, num_departments))
دادههای هدف ساختگی (Dummy target data)
model.compile(optimizer=”rmsprop”,
loss=[“mean_squared_error”, “categorical_crossentropy”],
metrics=[[“mean_absolute_error”], [“accuracy”]])
model.fit([title_data, text_body_data, tags_data],
[priority_data, department_data],
epochs=1)
model.evaluate([title_data, text_body_data, tags_data],
[priority_data, department_data])
priority_preds, department_preds = model.predict(
[title_data, text_body_data, tags_data])
اگر نمیخواهید به ترتیب ورودیها متکی باشید (برای مثال، به دلیل اینکه ورودیها یا خروجیهای زیادی دارید)، میتوانید از نامهایی که به اشیاء Input و لایههای خروجی دادهاید نیز استفاده کنید و دادهها را از طریق دیکشنریها (dictionaries) پاس دهید.
قطعه کد ۷.۱۱: آموزش یک مدل با ارائه دیکشنریهایی از آرایههای ورودی و هدف
model.compile(optimizer=”rmsprop”,
loss={“priority”: “mean_squared_error”, “department”:
“categorical_crossentropy”},
metrics={“priority”: [“mean_absolute_error”], “department”:
[“accuracy”]})
model.fit({“title”: title_data, “text_body”: text_body_data,
“tags”: tags_data},
{“priority”: priority_data, “department”: department_data},
epochs=1)
model.evaluate({“title”: title_data, “text_body”: text_body_data,
“tags”: tags_data},
{“priority”: priority_data, “department”: department_data})
priority_preds, department_preds = model.predict(
{“title”: title_data, “text_body”: text_body_data, “tags”: tags_data})
قدرت Functional API : دسترسی به اتصال لایهها
یک مدل Functional یک ساختار داده نموداری صریح است. این امر امکان بررسی نحوه اتصال لایهها و استفاده مجدد از گرههای نمودار قبلی (که خروجیهای لایه هستند) را به عنوان بخشی از مدلهای جدید فراهم میکند. همچنین به خوبی با “مدل ذهنی” که اکثر محققان هنگام تفکر در مورد یک شبکه عصبی عمیق استفاده میکنند: یک نمودار از لایهها، مطابقت دارد. این امر دو مورد استفاده مهم را ممکن میسازد: بصریسازی مدل و استخراج ویژگی. بیایید اتصال مدل را که همین الان تعریف کردیم (توپولوژی مدل) بصریسازی کنیم. میتوانید یک مدل Functional را به عنوان یک نمودار با ابزار plot_model() رسم کنید (به شکل ۷.۲ مراجعه کنید).
keras.utils.plot_model(model, “ticket_classifier.png”)
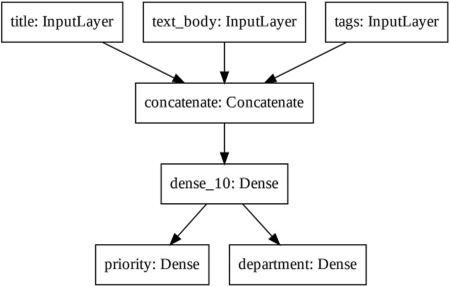
شکل ۷.۲: نمودار تولید شده توسط plot_model() بر روی مدل طبقهبندی درخواست ما
میتوانید به این نمودار، شکلهای ورودی و خروجی هر لایه را در مدل اضافه کنید که میتواند در حین عیبیابی مفید باشد (به شکل ۷.۳ مراجعه کنید).
keras.utils.plot_model(
model, “ticket_classifier_with_shape_info.png”, show_shapes=True)
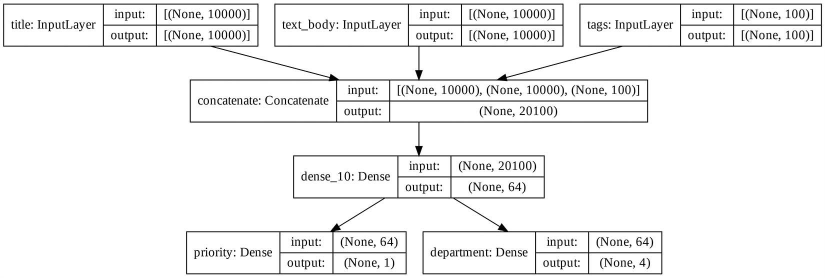
شکل ۷.۳: نمودار مدل با اطلاعات شکل اضافه شده
None در شکلهای تنسور نشاندهنده اندازه دسته (batch size) است: این مدل امکان استفاده از دستههایی با هر اندازهای را میدهد.
دسترسی به اتصال لایهها همچنین به این معنی است که میتوانید گرههای جداگانه (فراخوانیهای لایه) را در نمودار بازرسی و دوباره استفاده کنید. خصوصیت model.layers لیستی از لایههایی را که مدل را تشکیل میدهند، فراهم میکند، و برای هر لایه میتوانید layer.input و layer.output را پرسوجو کنید.
قطعه کد ۷.۱۲: بازیابی ورودیها یا خروجیهای یک لایه در یک مدل Functional
>>> model.layers
[<tensorflow.python.keras.engine.input_layer.InputLayer at 0x7fa963f9d358>,
<tensorflow.python.keras.engine.input_layer.InputLayer at 0x7fa963f9d2e8>,
<tensorflow.python.keras.engine.input_layer.InputLayer at 0x7fa963f9d470>,
<tensorflow.python.keras.layers.merge.Concatenate at 0x7fa963f9d860>,
<tensorflow.python.keras.layers.core.Dense at 0x7fa964074390>,
<tensorflow.python.keras.layers.core.Dense at 0x7fa963f9d898>,
<tensorflow.python.keras.layers.core.Dense at 0x7fa963f95470>]
>>> model.layers[3].input
[<tf.Tensor “title:0” shape=(None, 10000) dtype=float32>,
<tf.Tensor “text_body:0” shape=(None, 10000) dtype=float32>,
<tf.Tensor “tags:0” shape=(None, 100) dtype=float32>]
>>> model.layers[3].output
<tf.Tensor “concatenate/concat:0” shape=(None, 20100) dtype=float32>
این به شما امکان میدهد تا استخراج ویژگی (feature extraction) انجام دهید و مدلهایی ایجاد کنید که از ویژگیهای میانی یک مدل دیگر استفاده مجدد میکنند.
فرض کنید میخواهید یک خروجی دیگر به مدل قبلی اضافه کنید — میخواهید تخمین بزنید که حل یک درخواست (ticket) چقدر طول میکشد، نوعی رتبهبندی دشواری. میتوانید این کار را از طریق یک لایه طبقهبندی روی سه دسته انجام دهید: “سریع”، “متوسط” و “دشوار”. نیازی به بازسازی و آموزش مجدد یک مدل از ابتدا ندارید. میتوانید از ویژگیهای میانی مدل قبلی خود شروع کنید، چون به آنها دسترسی دارید، به این صورت.
قطعه کد ۷.۱۳: ایجاد یک مدل جدید با استفاده مجدد از خروجیهای لایه میانی
features = model.layers[4].output
layers[4] لایه Dense میانی ما است.
difficulty = layers.Dense(3, activation=”softmax”, name=”difficulty”)(features)
new_model = keras.Model(
inputs=[title, text_body, tags],
outputs=[priority, department, difficulty])
بیایید مدل جدیدمان را رسم کنیم (به شکل ۷.۴ مراجعه کنید):
keras.utils.plot_model(
new_model, “updated_ticket_classifier.png”, show_shapes=True)
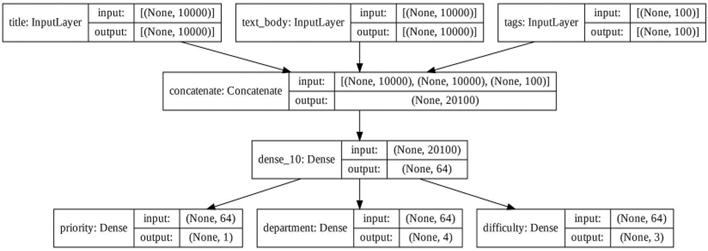
شکل ۷.۴: نمودار مدل جدید ما
زیرکلاس کردن(بندی) کلاس Model
آخرین الگوی ساخت مدل که باید با آن آشنا شوید، پیشرفتهترین آنهاست: زیرکلاس کردن Model (Model subclassing). شما در فصل ۳ یاد گرفتید چگونه کلاس Layer را زیرکلاس کنید تا لایههای سفارشی ایجاد کنید. زیرکلاس کردن Model بسیار شبیه به آن است:
- در متد __init__()، لایههایی را که مدل استفاده خواهد کرد، تعریف کنید.
- در متد call()، گذر رو به جلو (forward pass) مدل را با استفاده مجدد از لایههایی که قبلاً ایجاد شدهاند، تعریف کنید.
- زیرکلاس خود را نمونهسازی (instantiate) کنید و آن را روی داده فراخوانی کنید تا وزنهایش را ایجاد کنید.
بازنویسی مثال قبلی ما به عنوان یک مدل زیرکلاسشده بیایید به یک مثال ساده نگاه کنیم: ما مدل مدیریت درخواست پشتیبانی مشتری را با استفاده از یک زیرکلاس Model دوباره پیادهسازی خواهیم کرد.
قطعه کد ۷.۱۴: یک مدل زیرکلاسشده ساده
class CustomerTicketModel(keras.Model):
def init (self, num_departments):
super(). init ()
فراموش نکنید که سازنده super() را فراخوانی کنید!
self.concat_layer = layers.Concatenate()
self.mixing_layer = layers.Dense(64, activation=”relu”)
self.priority_scorer = layers.Dense(1, activation=”sigmoid”) self.department_classifier = layers.Dense(
num_departments, activation=”softmax”)
زیرلایهها را در سازنده (constructor) تعریف کنید.
def call(self, inputs):
گذر رو به جلو (forward pass) را در متد call() تعریف کنید.
title = inputs[“title”]
text_body = inputs[“text_body”]
tags = inputs[“tags”]
features = self.concat_layer([title, text_body, tags])
features = self.mixing_layer(features)
priority = self.priority_scorer(features)
department = self.department_classifier(features)
return priority, department
هنگامی که مدل را تعریف کردید، میتوانید آن را نمونهسازی (instantiate) کنید. توجه داشته باشید که این مدل فقط اولین باری که آن را بر روی مقداری داده فراخوانی کنید، وزنهای خود را ایجاد خواهد کرد، دقیقاً مانند زیرکلاسهای Layer:
model = CustomerTicketModel(num_departments=4)
priority, department = model(
{“title”: title_data, “text_body”: text_body_data, “tags”: tags_data})
تا اینجا، همه چیز بسیار شبیه به زیرکلاس کردن Layer به نظر میرسد، گردش کاری که در فصل ۳ با آن برخورد کردید. پس، تفاوت بین زیرکلاس Layer و زیرکلاس Model چیست؟ ساده است: یک “لایه” بلوک ساختمانی است که برای ایجاد مدلها از آن استفاده میکنید، و یک “مدل” شیء سطح بالایی است که شما واقعاً آن را آموزش میدهید، برای استنباط (inference) صادر میکنید و غیره. به طور خلاصه، یک Model دارای متدهای fit()، evaluate() و predict() است. لایهها این متدها را ندارند. به غیر از این، دو کلاس عملاً یکسان هستند. (تفاوت دیگر این است که میتوانید یک مدل را در فایلی روی دیسک ذخیره کنید، که در چند بخش آینده به آن خواهیم پرداخت.)
میتوانید یک زیرکلاس Model را دقیقاً مانند یک مدل Sequential یا Functional کامپایل و آموزش دهید:
model.compile(optimizer=”rmsprop”,
loss=[“mean_squared_error”, “categorical_crossentropy”],
metrics=[[“mean_absolute_error”], [“accuracy”]])
ساختار آنچه شما به عنوان آرگومانهای loss و metrics پاس میدهید، باید دقیقاً با آنچه توسط call() برگردانده میشود — در اینجا، لیستی از دو عنصر — مطابقت داشته باشد.
model.fit({“title”: title_data,
“text_body”: text_body_data,
“tags”: tags_data},
ساختار دادههای ورودی باید دقیقاً با آنچه متد call() انتظار دارد، مطابقت داشته باشد — در اینجا، یک دیکشنری با کلیدهای title، text_body و tags.
[priority_data, department_data],
epochs=1)
ساختار دادههای هدف باید دقیقاً با آنچه توسط متد call() برگردانده میشود — در اینجا، لیستی از دو عنصر — مطابقت داشته باشد.
model.evaluate({“title”: title_data,
“text_body”: text_body_data,
“tags”: tags_data},
[priority_data, department_data])
priority_preds, department_preds = model.predict({“title”: title_data,
“text_body”: text_body_data,
“tags”: tags_data})
گردش کار زیرکلاس کردن Model انعطافپذیرترین راه برای ساخت یک مدل است. این روش شما را قادر میسازد مدلهایی را بسازید که نمیتوانند به عنوان نمودارهای جهتدار غیرمدور (directed acyclic graphs) از لایهها بیان شوند—تصور کنید، برای مثال، مدلی که متد call() آن از لایهها درون یک حلقه for استفاده میکند، یا حتی آنها را به صورت بازگشتی فراخوانی میکند. هر چیزی ممکن است—شما مسئول هستید.
مراقب باشید: آنچه مدلهای زیرکلاسشده پشتیبانی نمیکنند
این آزادی هزینهای دارد: با مدلهای زیرکلاسشده، شما مسئول بخش بیشتری از منطق مدل هستید، به این معنی که فضای خطای بالقوه شما بسیار بزرگتر است. در نتیجه، کار بیشتری برای عیبیابی خواهید داشت. شما در حال توسعه یک شیء پایتون جدید هستید، نه فقط اتصال آجرهای لگو به یکدیگر.
مدلهای Functional و زیرکلاسشده نیز از نظر ماهیت تفاوتهای اساسی دارند. یک مدل Functional یک ساختار داده صریح است — یک گراف از لایهها، که میتوانید آن را مشاهده، بازرسی و تغییر دهید. یک مدل زیرکلاسشده یک قطعه بایتکد است — یک کلاس پایتون با متد call() که حاوی کد خام است. این منبع انعطافپذیری گردش کار زیرکلاسینگ است — میتوانید هر قابلیتی را که دوست دارید کدنویسی کنید — اما محدودیتهای جدیدی را نیز معرفی میکند. برای مثال، از آنجایی که نحوه اتصال لایهها به یکدیگر در داخل بدنه متد call() پنهان شده است، نمیتوانید به آن اطلاعات دسترسی پیدا کنید. فراخوانی summary() اتصال لایهها را نمایش نمیدهد، و نمیتوانید توپولوژی مدل را از طریق plot_model() رسم کنید. به همین ترتیب، اگر یک مدل زیرکلاسشده دارید، نمیتوانید به گرههای گراف لایهها برای استخراج ویژگی دسترسی پیدا کنید زیرا به سادگی هیچ گرافی وجود ندارد. هنگامی که مدل نمونهسازی شود، گذر رو به جلو آن به یک جعبه سیاه کامل تبدیل میشود.
ترکیب و تطبیق اجزای مختلف
نکته مهم این است که انتخاب یکی از این الگوها — مدل Sequential، Functional API یا زیرکلاس کردن Model — شما را از بقیه محروم نمیکند. تمام مدلها در Keras API میتوانند به طور هموار با یکدیگر کار کنند، چه مدلهای Sequential باشند، چه مدلهای Functional، و چه مدلهای زیرکلاسشده که از ابتدا نوشته شدهاند. همه آنها بخشی از یک طیف از گردش کارها هستند. برای مثال، میتوانید از یک لایه یا مدل زیرکلاسشده در یک مدل Functional استفاده کنید.
قطعه کد ۷.۱۵: ایجاد یک مدل Functional که شامل یک مدل زیرکلاسشده است
class Classifier(keras.Model):
def init (self, num_classes=2):
super(). init ()
if num_classes == 2:
num_units = 1
activation = “sigmoid”
else:
num_units=num_classes
activation = “softmax”
self.dense = layers.Dense(num_units, activation=activation)
def call(self, inputs):
return self.dense(inputs)
inputs = keras.Input(shape=(3,))
features = layers.Dense(64, activation=”relu”)(inputs)
outputs = Classifier(num_classes=10)(features)
model = keras.Model(inputs=inputs, outputs=outputs)
برعکس، میتوانید از یک مدل Functional به عنوان بخشی از یک لایه یا مدل زیرکلاسشده استفاده کنید
قطعه کد ۷.۱۶: ایجاد یک مدل زیرکلاسشده که شامل یک مدل Functional است
inputs = keras.Input(shape=(64,))
outputs = layers.Dense(1, activation=”sigmoid”)(inputs)
binary_classifier = keras.Model(inputs=inputs, outputs=outputs)
class MyModel(keras.Model):
def init (self,num_classes=2):
super(). init ()
self.dense = layers.Dense(64, activation=”relu”) self.classifier = binary_classifier
def call(self, inputs):
features = self.dense(inputs)
return self.classifier(features) model
MyModel()
به یاد داشته باشید: از ابزار مناسب برای کار استفاده کنید
شما با طیف وسیعی از گردشکارهای ساخت مدل Keras آشنا شدید، از سادهترین گردش کار، مدل Sequential، تا پیشرفتهترین آن، زیرکلاس کردن مدل. چه زمانی باید از یکی به جای دیگری استفاده کرد؟ هر کدام مزایا و معایب خاص خود را دارند—موردی را انتخاب کنید که برای کار مورد نظر مناسبتر است.
به طور کلی، Functional API تعادل بسیار خوبی بین سهولت استفاده و انعطافپذیری ارائه میدهد. همچنین به شما دسترسی مستقیم به اتصال لایهها میدهد که برای موارد استفادهای مانند رسم نمودار مدل یا استخراج ویژگی بسیار قدرتمند است. اگر میتوانید از Functional API استفاده کنید — یعنی، اگر مدل شما میتواند به صورت یک نمودار جهتدار غیرمدور از لایهها بیان شود — توصیه میکنم آن را بر زیرکلاس کردن مدل ترجیح دهید.
در ادامه، تمام مثالهای این کتاب از Functional API استفاده خواهند کرد، صرفاً به این دلیل که تمام مدلهایی که با آنها کار خواهیم کرد به صورت نمودار لایهها قابل بیان هستند. با این حال، ما به طور مکرر از لایههای زیرکلاسشده استفاده خواهیم کرد. به طور کلی، استفاده از مدلهای Functional که شامل لایههای زیرکلاسشده هستند، بهترین هر دو جهان را فراهم میکند: انعطافپذیری بالای توسعه در عین حفظ مزایای Functional API .
استفاده از حلقههای آموزش و ارزیابی داخلی
اصل افشای تدریجی پیچیدگی — دسترسی به طیفی از گردش کارها که از بسیار آسان تا به طور دلخواه انعطافپذیر، گام به گام پیش میروند — در مورد آموزش مدل نیز صدق میکند. Keras گردش کارهای مختلفی را برای آموزش مدلها در اختیار شما قرار میدهد. آنها میتوانند به سادگی فراخوانی fit() روی دادههای شما باشند، یا به پیشرفتهگی نوشتن یک الگوریتم آموزشی جدید از ابتدا.
شما قبلاً با گردش کار compile()، fit()، evaluate()، predict() آشنا هستید. به عنوان یادآوری، به قطعه کد زیر نگاه کنید.
قطعه کد ۷.۱۷: گردش کار استاندارد: compile()، fit()، evaluate()، predict()
from tensorflow.keras.datasets import mnist
def get_mnist_model():
inputs = keras.Input(shape=(28 * 28,))
features = layers.Dense(512, activation=”relu”)(inputs) features = layers.Dropout(0.5)(features)
outputs = layers.Dense(10, activation=”softmax”)(features)
model = keras.Model(inputs, outputs)
return model
(images, labels), (test_images, test_labels) = mnist.load_data()
دادههای خود را بارگذاری کنید و بخشی از آن را برای اعتبارسنجی (validation) نگه دارید.
images = images.reshape((60000, 28 * 28)).astype(“float32”) / 255
test_images = test_images.reshape((10000, 28 * 28)).astype(“float32”) / 255
train_images, val_images = images[10000:], images[:10000]
train_labels, val_labels = labels[10000:], labels[:10000]
model = get_mnist_model()
model.compile(optimizer=”rmsprop”,
loss=”sparse_categorical_crossentropy”,
metrics=[“accuracy”])
مدل را با مشخص کردن بهینهساز آن، تابع زیان برای حداقل کردن، و معیارهای قابل پایش کامپایل کنید.
model.fit(train_images, train_labels,
epochs=3,
validation_data=(val_images, val_labels))
از () fit برای آموزش مدل استفاده کنید و به صورت اختیاری دادههای اعتبارسنجی را برای پایش عملکرد روی دادههای دیدهنشده ارائه دهید.
test_metrics = model.evaluate(test_images, test_labels)
از evaluate() برای محاسبه زیان و معیارهای روی دادههای جدید استفاده کنید.
predictions = model.predict(test_images)
از predict() برای محاسبه احتمالات طبقهبندی روی دادههای جدید استفاده کنید.
چندین راه وجود دارد که میتوانید این گردش کار ساده را سفارشیسازی کنید:
- معیارهای سفارشی خود را ارائه دهید.
- Callbacks را به متد fit() ارسال کنید تا اقداماتی را برای انجام در نقاط خاصی در طول آموزش برنامهریزی کنید. بیایید به اینها نگاهی بیندازیم.
نوشتن معیارهای خودتان
معیارها برای اندازهگیری عملکرد مدل شما کلیدی هستند — به ویژه، برای اندازهگیری تفاوت بین عملکرد آن روی دادههای آموزشی و عملکرد آن روی دادههای آزمایشی. معیارهای رایج مورد استفاده برای طبقهبندی و رگرسیون قبلاً بخشی از ماژول داخلی keras.metrics هستند، و بیشتر اوقات این همان چیزی است که شما استفاده خواهید کرد. اما اگر کار غیرمعمولی انجام میدهید، باید بتوانید معیارهای خود را بنویسید. این کار ساده است! یک معیار Keras یک زیرکلاس از کلاس keras.metrics.Metric است. مانند لایهها، یک معیار دارای یک وضعیت داخلی است که در متغیرهای TensorFlow ذخیره میشود. برخلاف لایهها، این متغیرها از طریق پسانتشار (backpropagation) بهروزرسانی نمیشوند، بنابراین شما باید منطق بهروزرسانی وضعیت را خودتان بنویسید، که در متد update_state() اتفاق میافتد. برای مثال، در اینجا یک معیار سفارشی ساده آورده شده است که خطای میانگین مربعات ریشه (RMSE) را اندازهگیری میکند.
قطعه کد ۷.۱۸: پیادهسازی یک معیار سفارشی با زیرکلاس کردن کلاس Metric
import tensorflow as tf
class RootMeanSquaredError(keras.metrics.Metric):
کلاس Metric را زیرکلاس کنید.
def init (self, name=”rmse”, **kwargs):
super(). init (name=name, **kwargs)
self.mse_sum = self.add_weight(name=”mse_sum”, initializer=”zeros”)
self.total_samples = self.add_weight(
name=”total_samples”, initializer=”zeros”, dtype=”int32″)
متغیرهای وضعیت را در سازنده (constructor) تعریف کنید. مانند لایهها، به متد add_weight() دسترسی دارید.
def update_state(self, y_true, y_pred, sample_weight=None):
منطق بهروزرسانی وضعیت (state update logic) را در update_state() پیادهسازی کنید. آرگومان y_true هدفها (یا برچسبها) برای یک دسته است، در حالی که y_pred پیشبینیهای متناظر از مدل را نشان میدهد. میتوانید آرگومان sample_weight را نادیده بگیرید — ما اینجا از آن استفاده نخواهیم کرد.
y_true = tf.one_hot(y_true, depth=tf.shape(y_pred)[1])
برای تطبیق با مدل MNIST ما، پیشبینیهای دستهای (categorical predictions) و برچسبهای عددی (integer labels) را انتظار داریم.
mse = tf.reduce_sum(tf.square(y_true – y_pred)) self.mse_sum.assign_add(mse)
num_samples = tf.shape(y_pred)[0] self.total_samples.assign_add(num_samples)
شما از متد result() برای برگرداندن مقدار فعلی معیار استفاده میکنید:
def result(self):
return tf.sqrt(self.mse_sum / tf.cast(self.total_samples, tf.float32))
در همین حال، شما همچنین باید راهی را برای بازنشانی وضعیت معیار (reset the metric state) بدون نیاز به نمونهسازی مجدد آن، فراهم کنید—این کار باعث میشود بتوان از همان اشیاء معیار در طول دورههای مختلف آموزش یا در هر دو فرآیند آموزش و ارزیابی استفاده کرد. این کار را با متد reset_state() انجام میدهید:
def reset_state(self):
self.mse_sum.assign(0.) self.total_samples.assign(0)
معیارهای سفارشی را میتوان درست مانند معیارهای داخلی استفاده کرد. بیایید معیار خودمان را آزمایش کنیم:
model = get_mnist_model() model.compile(optimizer=”rmsprop”,
loss=”sparse_categorical_crossentropy”,
metrics=[“accuracy”, RootMeanSquaredError()])
model.fit(train_images, train_labels,
epochs=3,
validation_data=(val_images, val_labels))
test_metrics = model.evaluate(test_images, test_labels)
اکنون میتوانید نوار پیشرفت fit() را مشاهده کنید که RMSE مدل شما را نمایش میدهد.
استفاده از Callbackها
اجرای یک مرحله آموزشی بر روی یک مجموعه داده بزرگ برای دهها دوره با استفاده از model.fit()، کمی شبیه به پرتاب یک هواپیمای کاغذی است: پس از نیروی اولیه، هیچ کنترلی بر مسیر یا محل فرود آن ندارید. اگر میخواهید از نتایج بد (و در نتیجه هدر رفتن هواپیماهای کاغذی) جلوگیری کنید، هوشمندانهتر است که به جای هواپیمای کاغذی، از یک پهپاد استفاده کنید که میتواند محیط خود را حس کند، دادهها را به اپراتور خود بازگرداند و به طور خودکار بر اساس وضعیت فعلی خود تصمیمات هدایتی بگیرد. API Callback در Keras به شما کمک میکند تا فراخوانی model.fit() خود را از یک هواپیمای کاغذی به یک پهپاد هوشمند و خودکار تبدیل کنید که میتواند خوداندیشی کند و به صورت پویا عمل کند.
یک Callback یک شیء (یک نمونه کلاس که متدهای خاصی را پیادهسازی میکند) است که در فراخوانی fit() به مدل ارسال میشود و توسط مدل در نقاط مختلفی در طول آموزش فراخوانی میشود. این شیء به تمام دادههای موجود در مورد وضعیت مدل و عملکرد آن دسترسی دارد و میتواند اقداماتی را انجام دهد: آموزش را قطع کند، یک مدل را ذخیره کند، مجموعه وزنهای متفاوتی را بارگذاری کند، یا به نحو دیگری وضعیت مدل را تغییر دهد.
در اینجا چند مثال از روشهایی که میتوانید از Callbackها استفاده کنید آورده شده است:
- ذخیرهسازی وضعیت مدل (Model checkpointing) : ذخیره وضعیت فعلی مدل در نقاط مختلف در طول آموزش.
- توقف زودهنگام (Early stopping) : قطع آموزش زمانی که زیان اعتبارسنجی دیگر بهبود نمییابد (و البته، بهترین مدل به دست آمده در طول آموزش را ذخیره میکند).
- تنظیم پویا مقدار پارامترهای خاص در طول آموزش: مانند نرخ یادگیری بهینهساز.
- ثبت معیارهای آموزش و اعتبارسنجی در طول آموزش، یا بصریسازی بازنماییهای آموخته شده توسط مدل هنگام بهروزرسانی: نوار پیشرفت fit() که با آن آشنا هستید، در واقع یک Callback است!
ماژول keras.callbacks شامل تعدادی Callback داخلی است (این یک لیست جامع نیست):
keras.callbacks.ModelCheckpoint keras.callbacks.EarlyStopping keras.callbacks.LearningRateScheduler keras.callbacks.ReduceLROnPlateau keras.callbacks.CSVLogger
بیایید دو مورد از آنها را بررسی کنیم تا ایدهای از نحوه استفاده از آنها به شما بدهیم: EarlyStopping و ModelCheckpoint.
توقف زودهنگام و ذخیره سازی وضعیت مدل
هنگامی که یک مدل را آموزش میدهید، بسیاری از چیزها را نمیتوانید از ابتدا پیشبینی کنید. به ویژه، نمیتوانید بگویید چند دوره (epoch) برای رسیدن به یک زیان اعتبارسنجی بهینه نیاز خواهد بود. مثالهای ما تاکنون استراتژی آموزش برای تعداد کافی از دورهها را اتخاذ کردهاند که شروع به بیشبرازش میکنید، از اولین اجرا برای تعیین تعداد مناسب دورهها برای آموزش استفاده میکنید، و سپس در نهایت یک اجرای آموزشی جدید را از ابتدا با استفاده از این تعداد بهینه راهاندازی میکنید. البته، این رویکرد هدردهنده است. راه بسیار بهتر برای مدیریت این موضوع، توقف آموزش زمانی است که متوجه میشوید زیان اعتبارسنجی دیگر بهبود نمییابد. این کار را میتوان با استفاده از Callback EarlyStopping به دست آورد.
Callback EarlyStopping آموزش را به محض اینکه یک معیار هدف در حال پایش، برای تعداد ثابتی از دورهها از بهبود باز میایستد، قطع میکند. برای مثال، این Callback به شما امکان میدهد به محض شروع بیشبرازش، آموزش را قطع کنید، بنابراین از نیاز به آموزش مجدد مدل خود برای تعداد کمتری از دورهها جلوگیری میکند. این Callback معمولاً در ترکیب با ModelCheckpoint استفاده میشود، که به شما امکان میدهد مدل را به طور مداوم در طول آموزش ذخیره کنید (و، به صورت اختیاری، فقط بهترین مدل فعلی را ذخیره کنید: نسخهای از مدل که بهترین عملکرد را در پایان یک دوره به دست آورده است).
قطعه کد ۷.۱۹: استفاده از آرگومان callbacks در متد ()fit
callbacks_list = [
Callbackها از طریق آرگومان callbacks در متد () fit به مدل ارسال میشوند که لیستی از callbackها را میپذیرد. میتوانید هر تعداد callback را ارسال کنید.
keras.callbacks.EarlyStopping(
آموزش را زمانی که دقت برای دو دوره بهبود نیافته است، قطع میکند.
monitor=”val_accuracy”,
شما دقت (accuracy) را پایش میکنید، بنابراین باید بخشی از معیارهای مدل باشد.
patience=2,
آموزش را زمانی که بهبود متوقف میشود، قطع میکند.
),
keras.callbacks.ModelCheckpoint(
وزنهای فعلی را بعد از هر دوره ذخیره میکند.
filepath=”checkpoint_path.keras”,
مسیر فایل مدل مقصد.
monitor=”val_loss”,
save_best_only=True,
این دو آرگومان به این معنی هستند که شما فایل مدل را بازنویسی نخواهید کرد مگر اینکه val_loss بهبود یافته باشد، که به شما امکان میدهد بهترین مدل دیده شده در طول آموزش را حفظ کنید.
)
]
model = get_mnist_model()
model.compile(optimizer=”rmsprop”,
loss=”sparse_categorical_crossentropy”,
metrics=[“accuracy”])
model.fit(train_images, train_labels,
epochs=10,
callbacks=callbacks_list,
validation_data=(val_images, val_labels))
توجه داشته باشید که از آنجایی که callback زیان اعتبارسنجی و دقت اعتبارسنجی را پایش میکند، باید validation_data را به فراخوانی () fit ارسال کنید.
توجه داشته باشید که همیشه میتوانید مدلها را به صورت دستی پس از آموزش نیز ذخیره کنید — فقط کافیست model.save(‘my_checkpoint_path’) را فراخوانی کنید. برای بارگذاری مجدد مدلی که ذخیره کردهاید، فقط از model = keras.models.load_model(“checkpoint_path.keras”) استفاده کنید.
نوشتن Callbackهای خودتان
اگر نیاز دارید که یک اقدام خاص را در طول آموزش انجام دهید که توسط هیچ یک از Callbackهای داخلی پوشش داده نمیشود، میتوانید Callback خودتان را بنویسید. Callbackها با زیرکلاس کردن کلاس keras.callbacks.Callback پیادهسازی میشوند. سپس میتوانید هر تعدادی از متدهای با نامهای واضح زیر را پیادهسازی کنید، که در نقاط مختلفی در طول آموزش فراخوانی میشوند:
on_epoch_begin(epoch, logs)
در ابتدای هر دوره (epoch) فراخوانی میشود.
on_epoch_end(epoch, logs)
در انتهای هر دوره (epoch) فراخوانی میشود.
on_batch_begin(batch, logs)
درست قبل از پردازش هر دسته (batch) فراخوانی میشود.
on_batch_end(batch, logs)
درست بعد از پردازش هر دسته (batch) فراخوانی میشود.
on_train_begin(logs)
در ابتدای آموزش فراخوانی میشود.
on_train_end(logs)
در انتهای آموزش فراخوانی میشود.
این متدها همگی با آرگومان logs فراخوانی میشوند، که یک دیکشنری حاوی اطلاعات مربوط به دسته قبلی، دوره، یا اجرای آموزشی — معیارهای آموزش و اعتبارسنجی و غیره — است. متدهای on_epoch_* و on_batch_* نیز شاخص دوره یا دسته را به عنوان اولین آرگومان خود (یک عدد صحیح) میپذیرند.
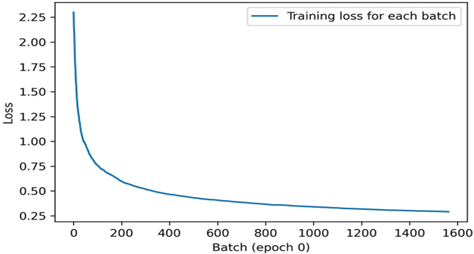
در اینجا یک مثال ساده آورده شده است که لیستی از مقادیر زیان به ازای هر دسته را در طول آموزش ذخیره میکند و در پایان هر دوره، نموداری از این مقادیر را ذخیره میکند.
قطعه کد ۷.۲۰: ایجاد یک Callback سفارشی با زیرکلاس کردن کلاس Callback
from matplotlib import pyplot as plt
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self, logs): self.per_batch_losses = []
def on_batch_end(self, batch, logs): self.per_batch_losses.append(logs.get(“loss”))
def on_epoch_end(self, epoch, logs):
plt.clf()
plt.plot(range(len(self.per_batch_losses)), self.per_batch_losses,
label=”Training loss for each batch”)
plt.xlabel(f”Batch (epoch {epoch})”)
plt.ylabel(“Loss”)
plt.legend()
plt.savefig(f”plot_at_epoch_{epoch}”) self.per_batch_losses = []
بیایید آن را آزمایش کنیم:
model = get_mnist_model() model.compile(optimizer=”rmsprop”,
loss=”sparse_categorical_crossentropy”,
metrics=[“accuracy”])
model.fit(train_images, train_labels,
epochs=10,
callbacks=[LossHistory()],
validation_data=(val_images, val_labels))
نمودارهایی به دست میآوریم که شبیه شکل 7.5 هستند.
نظارت و تجسمسازی با تنسوربورد tensor board
برای انجام تحقیقات خوب یا توسعه مدلهای خوب، به بازخورد غنی و مکرر درباره آنچه در مدلهای شما در طول آزمایشها میگذرد، نیاز دارید. هدف اجرای آزمایشها همین است: کسب اطلاعات در مورد عملکرد مدل – تا حد امکان اطلاعات بیشتر. پیشرفت یک فرآیند تکراری و یک حلقه است – شما با یک ایده شروع میکنید و آن را به عنوان یک آزمایش بیان میکنید و سعی میکنید ایده خود را تأیید یا رد کنید. این آزمایش را اجرا میکنید و اطلاعاتی را که تولید میکند پردازش میکنید. این کار ایده بعدی شما را الهام میبخشد. هر چه تعداد دفعات بیشتری بتوانید این حلقه را اجرا کنید، ایدههای شما دقیقتر و قدرتمندتر میشوند. Keras به شما کمک میکند در کمترین زمان ممکن از ایده به آزمایش برسید، و GPUهای سریع میتوانند به شما کمک کنند در سریعترین زمان ممکن از آزمایش به نتیجه برسید. اما پردازش نتایج آزمایش چه؟ اینجا جایی است که TensorBoard وارد میشود (به شکل 7.6 مراجعه کنید).
TensorBoard (www.tensorflow.org/tensorboard) یک برنامه مبتنی بر مرورگر است که میتوانید به صورت محلی آن را اجرا کنید. این بهترین راه برای پایش همه چیزهایی است که در طول آموزش در داخل مدل شما اتفاق میافتد. با TensorBoard، میتوانید:
- معیارهای را در طول آموزش به صورت بصری پایش کنید.
- معماری مدل خود را بصریسازی کنید.
- هیستوگرامهای فعالسازیها و گرادیانها را بصریسازی کنید.
- جاسازیها را به صورت 3 بعدی کاوش کنید.
اگر اطلاعات بیشتری غیر از زیان نهایی مدل را پایش میکنید، میتوانید دید واضحتری از آنچه مدل انجام میدهد و نمیدهد، ایجاد کنید، و میتوانید سریعتر پیشرفت کنید.
آسانترین راه برای استفاده از TensorBoard با یک مدل Keras و متد fit()، استفاده از callback keras.callbacks.TensorBoard است.
در سادهترین حالت، فقط کافی است مشخص کنید که میخواهید callback گزارشها را کجا بنویسد، و آمادهاید:
model = get_mnist_model() model.compile(optimizer=”rmsprop”,
loss=”sparse_categorical_crossentropy”,
metrics=[“accuracy”])
tensorboard = keras.callbacks.TensorBoard(
log_dir=”/full_path_to_your_log_dir”,
)
model.fit(train_images, train_labels,
epochs=10,
validation_data=(val_images, val_labels),
callbacks=[tensorboard])
هنگامی که مدل شروع به اجرا کرد، گزارشها را در مکان مورد نظر مینویسد. اگر اسکریپت پایتون خود را روی یک ماشین محلی اجرا میکنید، میتوانید سرور محلی TensorBoard را با استفاده از دستور زیر راهاندازی کنید (توجه داشته باشید که اگر TensorFlow را از طریق pip نصب کرده باشید، فایل اجرایی tensorboard باید از قبل موجود باشد؛ در غیر این صورت، میتوانید TensorBoard را به صورت دستی از طریق pip install tensorboard نصب کنید):
tensorboard –logdir /full_path_to_your_log_dir
سپس میتوانید به URL که دستور برمیگرداند بروید تا به رابط TensorBoard دسترسی پیدا کنید.
اگر اسکریپت خود را در یک نوتبوک Colab اجرا میکنید، میتوانید یک نمونه TensorBoard تعبیهشده را به عنوان بخشی از نوتبوک خود، با استفاده از دستورات زیر، اجرا کنید:
%load_ext tensorboard
%tensorboard –logdir /full_path_to_your_log_dir
در رابط TensorBoard، میتوانید نمودارهای زنده معیارهای آموزش و ارزیابی خود را پایش کنید (به شکل 7.7 مراجعه کنید).
نوشتن حلقههای آموزش و ارزیابی خودتان
گردش کار fit() تعادل خوبی بین سهولت استفاده و انعطافپذیری برقرار میکند. این چیزی است که بیشتر اوقات از آن استفاده خواهید کرد. با این حال، قرار نیست از هر کاری که یک محقق یادگیری عمیق ممکن است بخواهد انجام دهد، حتی با معیارهای سفارشی، زیانهای سفارشی و Callbackهای سفارشی، پشتیبانی کند.
در نهایت، گردش کار داخلی fit() صرفاً بر یادگیری نظارتشده (supervised learning) تمرکز دارد: یک تنظیم که در آن هدفهای شناختهشدهای (که برچسبها یا حاشیهنویسی نیز نامیده میشوند) با دادههای ورودی شما مرتبط هستند، و در آن زیان خود را به عنوان تابعی از این هدفها و پیشبینیهای مدل محاسبه میکنید. با این حال، هر شکلی از یادگیری ماشین در این دسته قرار نمیگیرد. تنظیمات دیگری نیز وجود دارد که در آنها هدفهای صریحی وجود ندارند، مانند یادگیری مولد (generative learning) (که در فصل 12 بحث خواهیم کرد)، یادگیری خودنظارتی (self-supervised learning) (که در آن هدفها از ورودیها به دست میآیند)، و یادگیری تقویتی (reinforcement learning) (که در آن یادگیری توسط “پاداشهای” گاه به گاه هدایت میشود، بسیار شبیه آموزش یک سگ). حتی اگر در حال انجام یادگیری نظارتشده معمولی هستید، به عنوان یک محقق، ممکن است بخواهید ویژگیهای جدیدی را اضافه کنید که نیاز به انعطافپذیری سطح پایین دارند.
هر زمان که خود را در موقعیتی یافتید که fit() داخلی کافی نیست، باید منطق آموزش سفارشی خود را بنویسید. شما قبلاً مثالهای سادهای از حلقههای آموزش سطح پایین را در فصلهای 2 و 3 دیدهاید. به عنوان یادآوری، محتویات یک حلقه آموزش معمولی به این شکل است:
- گذر رو به جلو (خروجی مدل را محاسبه کنید) را در داخل یک نوار گرادیان (gradient tape) اجرا کنید تا یک مقدار زیان برای دسته فعلی داده به دست آورید.
- گرادیانهای زیان را نسبت به وزنهای مدل بازیابی کنید.
- وزنهای مدل را بهروزرسانی کنید تا مقدار زیان را در دسته فعلی داده کاهش دهید.
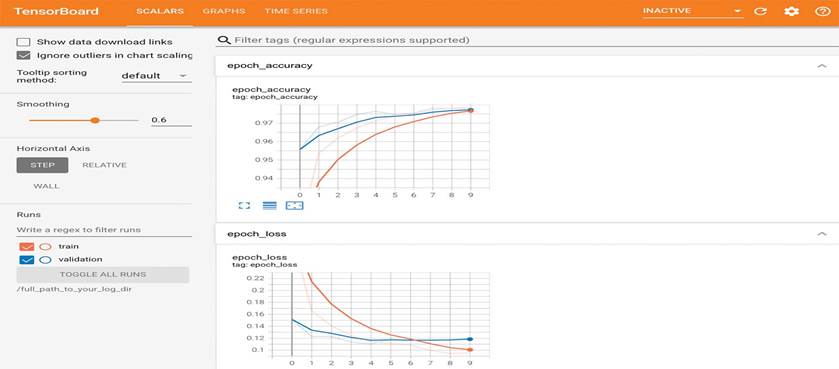
شکل 7.7: TensorBoard را میتوان برای پایش آسان معیارهای آموزش و ارزیابی استفاده کرد.
این مراحل به تعداد دستههای لازم تکرار میشوند. این اساساً همان کاری است که fit() در پشت پرده انجام میدهد. در این بخش، یاد میگیرید که fit() را از ابتدا پیادهسازی کنید، که تمام دانش لازم برای نوشتن هر الگوریتم آموزشی که ممکن است به ذهنتان برسد را به شما میدهد.
بیایید جزئیات را بررسی کنیم.
آموزش در مقابل استنباط
در مثالهای حلقه آموزش سطح پایینی که تا کنون دیدهاید، گام 1 (گذر رو به جلو) از طریق predictions = model(inputs) انجام میشد، و گام 2 (بازیابی گرادیانهای محاسبه شده توسط نوار گرادیان) از طریق gradients = tape.gradient(loss, model.weights) انجام میشد. در حالت کلی، در واقع دو ظرافت وجود دارد که باید آنها را در نظر بگیرید.
برخی از لایههای Keras، مانند لایه Dropout، در طول آموزش و در طول استنباط (هنگامی که از آنها برای تولید پیشبینی استفاده میکنید) رفتارهای متفاوتی دارند. چنین لایههایی یک آرگومان Boolean training را در متد call() خود ارائه میدهند. فراخوانی dropout(inputs, training=True) برخی از ورودیهای فعالسازی را حذف میکند، در حالی که فراخوانی dropout(inputs, training=False) هیچ کاری انجام نمیدهد. به تبع آن، مدلهای Functional و Sequential نیز این آرگومان training را در متدهای call() خود ارائه میدهند. به یاد داشته باشید که هنگام فراخوانی یک مدل Keras در طول گذر رو به جلو، training = True را ارسال کنید! بنابراین گذر رو به جلو ما به predictions = model(inputs, training=True) تبدیل میشود.
علاوه بر این، توجه داشته باشید که هنگامی که گرادیانهای وزنهای مدل خود را بازیابی میکنید، نباید از tape.gradients(loss, model.weights) استفاده کنید، بلکه باید از tape.gradients(loss, model.trainable_weights) استفاده کنید. در واقع، لایهها و مدلها دو نوع وزن دارند:
- وزنهای قابل آموزش (Trainable weights) : اینها قرار است از طریق پسانتشار بهروزرسانی شوند تا زیان مدل را حداقل کنند، مانند کرنل و بایاس یک لایه Dense.
- وزنهای غیرقابل آموزش (Non-trainable weights) : اینها قرار است در طول گذر رو به جلو توسط لایههایی که صاحب آنها هستند، بهروزرسانی شوند. برای مثال، اگر میخواستید یک لایه سفارشی تعداد دستههایی را که تاکنون پردازش کرده است، نگه دارد، آن اطلاعات در یک وزن غیرقابل آموزش ذخیره میشد، و در هر دسته، لایه شما شمارنده را یک واحد افزایش میداد.
در میان لایههای داخلی Keras، تنها لایهای که دارای وزنهای غیرقابل آموزش است، لایه BatchNormalization است که در فصل 9 در مورد آن بحث خواهیم کرد. لایه BatchNormalization برای ردیابی اطلاعات مربوط به میانگین و انحراف معیار دادههایی که از آن عبور میکنند، به وزنهای غیرقابل آموزش نیاز دارد، تا یک تقریب آنلاین از نرمالسازی ویژگی (مفهومی که در فصل 6 در مورد آن آموختید) انجام دهد.
با در نظر گرفتن این دو جزئیات، یک مرحله آموزش یادگیری نظارتشده به این شکل خواهد بود:
def train_step(inputs, targets):
with tf.GradientTape() as tape:
predictions = model(inputs, training=True) loss = loss_fn(targets, predictions)
gradients = tape.gradients(loss, model.trainable_weights)
optimizer.apply_gradients(zip(model.trainable_weights, gradients))
استفاده سطح پایین از معیارها
در یک حلقه آموزشی سطح پایین، احتمالاً میخواهید از معیارهای Keras (چه سفارشی و چه داخلی) استفاده کنید. شما قبلاً در مورد API معیارها آموختهاید: به سادگی update_state(y_true, y_pred) را برای هر دسته از هدفها و پیشبینیها فراخوانی کنید، و سپس از result() برای پرسوجو از مقدار معیار فعلی استفاده کنید:
metric = keras.metrics.SparseCategoricalAccuracy()
targets = [0, 1, 2]
predictions = [[1, 0, 0], [0, 1, 0], [0, 0, 1]]
metric.update_state(targets, predictions) current_result = metric.result()
print(f”result: {current_result:.2f}”)
ممکن است لازم باشد میانگین یک مقدار اسکالر، مانند زیان مدل، را نیز پایش کنید. میتوانید این کار را از طریق معیار keras.metrics.Mean انجام دهید:
values = [0, 1, 2, 3, 4]
mean_tracker = keras.metrics.Mean()
for value in values:
mean_tracker.update_state(value)
print(f”Mean of values: {mean_tracker.result():.2f}”)
به یاد داشته باشید که هر زمان که میخواهید نتایج فعلی را بازنشانی کنید (در ابتدای یک دوره آموزشی یا در ابتدای ارزیابی)، از metric.reset_state() استفاده کنید.
یک حلقه آموزش و ارزیابی کامل
بیایید گذر رو به جلو، گذر رو به عقب و ردیابی معیارها را در یک تابع گام آموزشی شبیه fit() ترکیب کنیم که یک دسته از دادهها و هدفها را میگیرد و گزارشهایی را که توسط نوار پیشرفت fit() نمایش داده میشوند، برمیگرداند.
قطعه کد ۷.۲۱: نوشتن یک حلقه آموزش گام به گام: تابع گام آموزشی
model = get_mnist_model()
loss_fn = keras.losses.SparseCategoricalCrossentropy()
تابع زیان را آماده کنید.
optimizer = keras.optimizers.RMSprop()
بهینهساز را آماده کنید.
metrics = [keras.metrics.SparseCategoricalAccuracy()]
لیست معیارهای قابل پایش را آماده کنید.
loss_tracking_metric = keras.metrics.Mean()
یک ردیاب معیار Mean را آماده کنید تا میانگین زیان را پیگیری کند.
def train_step(inputs, targets):
with tf.GradientTape() as tape:
predictions = model(inputs, training=True)
loss = loss_fn(targets, predictions)
گذر رو به جلو (forward pass) را اجرا کنید. توجه داشته باشید که training=True را ارسال میکنیم.
gradients = tape.gradient(loss, model.trainable_weights)
optimizer.apply_gradients(zip(gradients, model.trainable_weights))
گذر رو به عقب (backward pass) را اجرا کنید. توجه داشته باشید که از model.trainable_weights استفاده میکنیم.
logs = {}
for metric in metrics:
metric.update_state(targets, predictions)
logs[metric.name] = metric.result()
معیارها را پیگیری کنید.
loss_tracking_metric.update_state(loss)
logs[“loss”] = loss_tracking_metric.result()
میانگین زیان را پیگیری کنید.
return logs
مقادیر فعلی معیارها و زیان را برگردانید.
ما باید وضعیت معیارهای خود را در ابتدای هر دوره و قبل از اجرای ارزیابی بازنشانی کنیم. در اینجا یک تابع کمکی برای انجام این کار آورده شده است.
قطعه کد ۷.۲۲: نوشتن یک حلقه آموزش گام به گام: بازنشانی معیارها
def reset_metrics():
for metric in metrics: metric.reset_state()
loss_tracking_metric.reset_state()
اکنون میتوانیم حلقه آموزش کامل خود را برنامهریزی کنیم. توجه داشته باشید که از یک شیء tf.data.Dataset استفاده میکنیم تا دادههای NumPy خود را به یک iterator تبدیل کنیم که بر روی دادهها در دستههای 32 تایی تکرار میشود.
قطعه کد ۷.۲۳: نوشتن یک حلقه آموزش گام به گام: خود حلقه
training_dataset = tf.data.Dataset.from_tensor_slices(
(train_images, train_labels))
training_dataset = training_dataset.batch(32)
epochs = 3
for epoch in range(epochs): reset_metrics()
for inputs_batch, targets_batch in training_dataset:
logs = train_step(inputs_batch, targets_batch)
print(f”Results at the end of epoch {epoch}”)
for key, value in logs.items():
print(f”…{key}: {value:.4f}”)
و این هم حلقه ارزیابی: یک حلقه for ساده که به طور مکرر تابع test_step() را فراخوانی میکند، تابعی که یک دسته واحد از دادهها را پردازش میکند. تابع test_step() فقط زیرمجموعهای از منطق train_step() است. این تابع کدی را که با بهروزرسانی وزنهای مدل سروکار دارد — یعنی هر چیزی که شامل GradientTape و بهینهساز است — حذف میکند.
قطعه کد ۷.۲۴: نوشتن یک حلقه ارزیابی گام به گام
def test_step(inputs, targets):
predictions = model(inputs, training=False)
loss = loss_fn(targets, predictions)
logs = {}
for metric in metrics:
metric.update_state(targets, predictions)
logs[“val_” + metric.name] = metric.result()
loss_tracking_metric.update_state(loss)
logs[“val_loss”] = loss_tracking_metric.result()
return logs
val_dataset = tf.data.Dataset.from_tensor_slices((val_images,
val_labels)) val_dataset = val_dataset.batch(32)
reset_metrics()
for inputs_batch, targets_batch in val_dataset:
logs = test_step(inputs_batch, targets_batch)
print(“Evaluation results:”)
for key, value in logs.items():
print(f”…{key}: {value:.4f}”)
تبریک میگویم—شما همین الان fit() و evaluate() را دوباره پیادهسازی کردید! یا تقریباً: fit() و evaluate() از ویژگیهای بسیار بیشتری، از جمله محاسبات توزیعشده در مقیاس بزرگ که کمی کار بیشتری میطلبد، پشتیبانی میکنند. همچنین شامل چندین بهینهسازی عملکرد کلیدی نیز هستند.
بیایید نگاهی به یکی از این بهینهسازیها بیندازیم: کامپایل کردن تابع TensorFlow.
سریع کردن کار با tf.function
شاید متوجه شده باشید که حلقههای سفارشی شما به طور قابل توجهی کندتر از fit() و evaluate() داخلی اجرا میشوند، با وجود اینکه اساساً منطق یکسانی را پیادهسازی میکنند. این به این دلیل است که به طور پیشفرض، کد TensorFlow خط به خط و با ولع اجرا میشود، درست مانند کد NumPy یا کد پایتون معمولی.
اجرای ولع باعث میشود اشکالزدایی کد شما آسانتر شود، اما از نظر عملکرد بسیار دور از حد بهینه است.
عملکرد بهتر این است که کد TensorFlow خود را به یک گراف محاسباتی کامپایل کنید که میتواند به طور جهانی بهینهسازی شود، به گونهای که کد تفسیر شده خط به خط نمیتواند. نحو انجام این کار بسیار ساده است: فقط یک @tf.function را به هر تابعی که میخواهید قبل از اجرا کامپایل کنید، اضافه کنید، همانطور که در قطعه کد زیر نشان داده شده است.
قطعه کد ۷.۲۵: افزودن دکوراتور @tf.function به تابع گام ارزیابی ما
@tf.function
این تنها خطی است که تغییر کرده است.
def test_step(inputs, targets):
predictions = model(inputs, training=False)
loss = loss_fn(targets, predictions)
logs = {}
for metric in metrics:
metric.update_state(targets, predictions)
logs[“val_” + metric.name] = metric.result()
loss_tracking_metric.update_state(loss)
logs[“val_loss”] = loss_tracking_metric.result()
return logs
val_dataset = tf.data.Dataset.from_tensor_slices((val_images, val_labels))
val_dataset = val_dataset.batch(32)
reset_metrics()
for inputs_batch, targets_batch in val_dataset:
logs = test_step(inputs_batch, targets_batch)
print(“Evaluation results:”)
for key, value in logs.items():
print(f”…{key}: {value:.4f}”)
در Colab CPU، از 1.80 ثانیه برای اجرای حلقه ارزیابی به تنها 0.8 ثانیه کاهش مییابیم. خیلی سریعتر! به یاد داشته باشید، هنگامی که در حال اشکالزدایی کد خود هستید، ترجیح دهید آن را با ولع (eagerly) و بدون هیچ دکوراتور tf.function@ اجرا کنید. ردیابی باگها به این روش آسانتر است. هنگامی که کد شما کار میکند و میخواهید آن را سریع کنید، یک دکوراتور tf.function@ به مرحله آموزش و مرحله ارزیابی خود — یا هر تابع حیاتی دیگر از نظر عملکرد — اضافه کنید.
بهرهبرداری از fit() با یک حلقه آموزشی سفارشی
در بخشهای قبلی، ما حلقه آموزشی خود را به طور کامل از صفر مینوشتیم. انجام این کار بیشترین انعطافپذیری را به شما میدهد، اما در نهایت کد زیادی مینویسید در حالی که بسیاری از ویژگیهای راحت fit()، مانند callbackها یا پشتیبانی داخلی برای آموزش توزیعشده را از دست میدهید.
اگر به یک الگوریتم آموزشی سفارشی نیاز دارید، اما همچنان میخواهید از قدرت منطق آموزش داخلی Keras بهرهمند شوید، چه؟ در واقع یک راه میانه بین fit() و یک حلقه آموزشی نوشته شده از صفر وجود دارد: میتوانید یک تابع گام آموزشی سفارشی ارائه دهید و بگذارید چارچوب بقیه کارها را انجام دهد.
میتوانید این کار را با بازنویسی (overriding) متد train_step() کلاس Model انجام دهید. این تابعی است که توسط fit() برای هر دسته از دادهها فراخوانی میشود. سپس میتوانید fit() را طبق معمول فراخوانی کنید، و این تابع الگوریتم یادگیری خود شما را در پشت صحنه اجرا خواهد کرد.
در اینجا یک مثال ساده آورده شده است:
- ما یک کلاس جدید ایجاد میکنیم که از keras.Model زیرکلاس میشود.
- ما متد train_step(self, data) را بازنویسی میکنیم. محتویات آن تقریباً با آنچه در بخش قبلی استفاده کردیم، یکسان است. این متد یک دیکشنری را برمیگرداند که نامهای معیار (شامل زیان) را به مقادیر فعلی آنها نگاشت میکند.
- ما یک ویژگی metrics را پیادهسازی میکنیم که نمونههای Metric مدل را ردیابی میکند. این کار به مدل امکان میدهد تا به طور خودکار reset_state() را در معیارهای مدل در ابتدای هر دوره و در ابتدای فراخوانی evaluate() فراخوانی کند، بنابراین نیازی نیست که این کار را به صورت دستی انجام دهید.
قطعه کد ۷.۲۶: پیادهسازی یک گام آموزشی سفارشی برای استفاده با fit()
loss_fn = keras.losses.SparseCategoricalCrossentropy()
loss_tracker = keras.metrics.Mean(name=”loss”)
این شیء معیار برای ردیابی میانگین زیانهای هر دسته در طول آموزش و ارزیابی استفاده خواهد شد.
class CustomModel(keras.Model):
def train_step(self, data):
ما متد train_step را بازنویسی میکنیم.
inputs, targets = data
with tf.GradientTape() as tape:
predictions = self(inputs, training=True)
ما از self(inputs, training=True) به جای model(inputs, training=True) استفاده میکنیم، زیرا مدل ما خودِ کلاس است.
loss = loss_fn(targets, predictions)
gradients = tape.gradient(loss, model.trainable_weights) optimizer.apply_gradients(zip(gradients,
model.trainable_weights))
loss_tracker.update_state(loss)
ما معیار ردیاب زیان را که میانگین زیان را پیگیری میکند، بهروزرسانی میکنیم.
return {“loss”: loss_tracker.result()}
میانگین زیان را تا اینجا با پرسوجو از معیار ردیاب زیان، برمیگردانیم.
@property
def metrics(self):
هر معیاری که میخواهید در طول دورهها (epochs) بازنشانی شود، باید در اینجا لیست شود.
return [loss_tracker]
اکنون میتوانیم مدل سفارشی خود را نمونهسازی کنیم، آن را کامپایل کنیم (فقط بهینهساز را پاس میدهیم، زیرا زیان از قبل خارج از مدل تعریف شده است)، و آن را با استفاده از fit() طبق معمول آموزش دهیم:
inputs = keras.Input(shape=(28 * 28,))
features = layers.Dense(512, activation=”relu”)(inputs)
features = layers.Dropout(0.5)(features)
outputs = layers.Dense(10, activation=”softmax”)(features)
model = CustomModel(inputs, outputs)
model.compile(optimizer=keras.optimizers.RMSprop())
model.fit(train_images, train_labels, epochs=3)
چند نکته وجود دارد که باید به آنها توجه کرد:
- این الگو شما را از ساخت مدلها با Functional API منع نمیکند. میتوانید این کار را چه در حال ساخت مدلهای Sequential، چه مدلهای Functional API یا مدلهای زیرکلاسشده باشید، انجام دهید.
- شما نیازی به استفاده از دکوراتور @tf.function هنگام بازنویسی train_step ندارید—چارچوب این کار را برای شما انجام میدهد.
حالا، در مورد معیارها و پیکربندی زیان از طریق compile() چه؟ پس از فراخوانی compile()، به موارد زیر دسترسی پیدا میکنید:
- self.compiled_loss — تابع زیانی که به compile() ارسال کردید.
- self.compiled_metrics — یک پوشش برای لیستی از معیارهایی که ارسال کردید، که به شما امکان میدهد self.compiled_metrics.update_state() را فراخوانی کنید تا همه معیارهای خود را به یکباره بهروزرسانی کنید.
- self.metrics — لیست واقعی معیارهایی که به compile() ارسال کردید. توجه داشته باشید که این لیست شامل معیاری برای پیگیری زیان نیز هست، شبیه به کاری که قبلاً به صورت دستی با loss_tracking_metric خود انجام دادیم.
بنابراین میتوانیم بنویسیم:
class CustomModel(keras.Model):
def train_step(self, data):
inputs, targets = data
with tf.GradientTape() as tape:
predictions = self(inputs, training=True)
loss = self.compiled_loss(targets, predictions)
زیان را از طریق self.compiled_loss محاسبه کنید.
gradients = tape.gradient(loss, model.trainable_weights)
optimizer.apply_gradients(zip(gradients, model.trainable_weights)) self.compiled_metrics.update_state(targets, predictions)
معیارهای مدل را از طریق self.compiled_metrics بهروزرسانی کنید.
return {m.name: m.result() for m in self.metrics}
یک دیکشنری را برگردانید که نامهای معیار را به مقدار فعلی آنها نگاشت میکند.
بیایید آن را امتحان کنیم:
inputs = keras.Input(shape=(28 * 28,))
features = layers.Dense(512, activation=”relu”)(inputs)
features = layers.Dropout(0.5)(features)
outputs = layers.Dense(10, activation=”softmax”)(features)
model = CustomModel(inputs, outputs)
model.compile(optimizer=keras.optimizers.RMSprop(), loss=keras.losses.SparseCategoricalCrossentropy(), metrics=[keras.metrics.SparseCategoricalAccuracy()])
model.fit(train_images, train_labels, epochs=3)
این حجم زیادی از اطلاعات بود، اما اکنون شما به اندازه کافی میدانید که میتوانید با Keras تقریباً هر کاری انجام دهید.
خلاصه
- Keras طیفی از گردشکارهای مختلف را بر اساس اصل افشای تدریجی پیچیدگی ارائه میدهد. همه آنها به صورت یکپارچه با یکدیگر کار میکنند.
- شما میتوانید مدلها را از طریق کلاس Sequential، از طریق Functional API، یا با زیرکلاس کردن کلاس Model بسازید. بیشتر اوقات، از Functional API استفاده خواهید کرد.
- سادهترین راه برای آموزش و ارزیابی یک مدل، از طریق متدهای پیشفرض fit() و evaluate() است.
- Callbacks در Keras راهی ساده برای پایش مدلها در طول فراخوانی fit() شما و انجام خودکار اقدامات بر اساس وضعیت مدل را فراهم میکنند.
- شما همچنین میتوانید با بازنویسی متد train_step()، کنترل کاملی بر آنچه fit() انجام میدهد، داشته باشید.
- فراتر از fit()، میتوانید حلقههای آموزشی خود را به طور کامل از صفر نیز بنویسید. این برای محققانی که الگوریتمهای آموزشی کاملاً جدیدی را پیادهسازی میکنند، مفید است.



