
مقدمه
آموزش یک شبکه عصبی در بسیاری از مواقع شبیه کار کردن با یک «جعبه سیاه» است؛ دادهها را وارد میکنیم، مدل را آموزش میدهیم و منتظر نتیجه میمانیم. اما زمانی که مدل عملکرد خوبی ندارد یا اصلاً یاد نمیگیرد، سؤال اصلی این است: مشکل دقیقاً کجاست؟ معماری شبکه؟ دادهها؟ نرخ یادگیری؟ یا خود فرآیند آموزش؟
در چنین شرایطی، حدس و آزمونوخطای کورکورانه میتواند بسیار زمانبر و خستهکننده باشد. اینجاست که ابزارهایی مانند TensorBoard اهمیت پیدا میکنند. TensorBoard به ما اجازه میدهد روند آموزش شبکه عصبی را بهصورت بصری مشاهده کنیم و بهجای حدس زدن، بر اساس شواهد و نمودارهای واقعی تصمیم بگیریم.
در این مقاله، یاد میگیریم چگونه با استفاده از TensorBoard فرآیند آموزش شبکه عصبی را عیبیابی، تحلیل و بهینهسازی کنیم. از بررسی نمودار زیان و دقت گرفته تا تحلیل وزنها، ساختار شبکه و توزیع دادهها، این مطلب به شما کمک میکند شبکه عصبی را از حالت جعبه سیاه خارج کرده و با دیدی مهندسی و آگاهانه مشکلات آن را شناسایی کنید.
چرا به ابزاری مثل TensorBoard نیاز داریم؟
آموزش یک شبکه عصبی اغلب شبیه به یک “جعبه سیاه” است؛ شما دادهها را میدهید و منتظر خروجی میمانید. اما وقتی مدل خوب کار نمیکند، از کجا بفهمیم مشکل کجاست؟
- آیا نرخ یادگیری (Learning Rate) خیلی زیاد است؟
- آیا وزنها دچار انفجار شدهاند؟
- آیا مدل در حال حفظ کردن دادهها (Overfitting) است؟
اینجاست که TensorBoard وارد میشود. این ابزار قدرتمندِ گوگل، به شما اجازه میدهد تمام اتفاقات درونی شبکه را به صورت گرافیکی و زنده تماشا کنید.
قابلیتهای کلیدی TensorBoard در عیبیابی
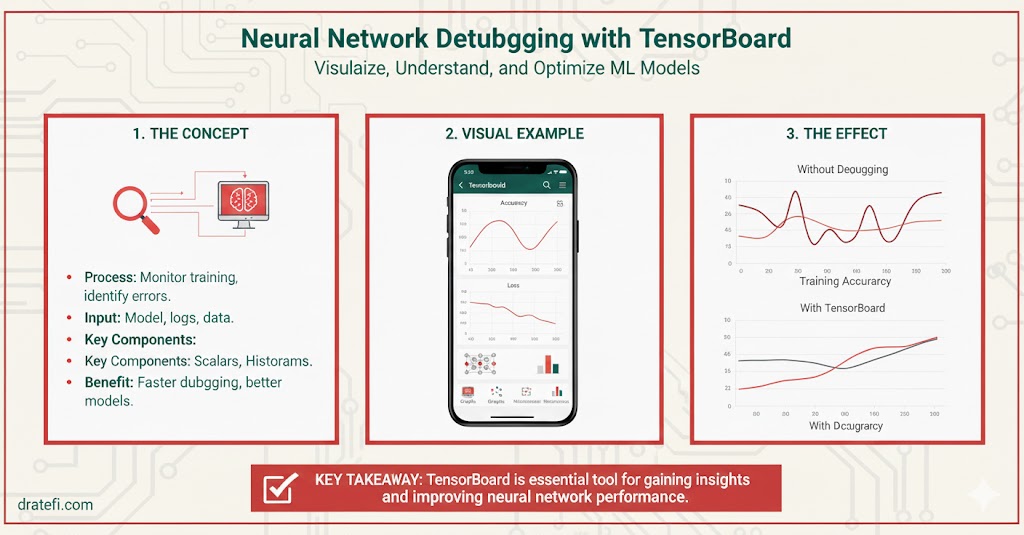
استفاده از این ابزار فقط برای دیدن نمودارهای زیبا نیست، بلکه برای درک عمیق رفتار مدل است:
- ردیابی معیارها: میتوانید نمودار Loss (زیان) و Accuracy (دقت) را به صورت لحظهای ببینید و متوجه شوید که آیا مدل در مسیر درستی حرکت میکند یا خیر.
- تجسم ساختار مدل: لایههای شبکه، نحوه اتصال آنها و جریان دادهها را به صورت گرافیکی مشاهده کنید تا مطمئن شوید معماری شبکه را درست چیده اید.
- بررسی هیستوگرام وزنها: ببینید وزنها و بایاسها در طول زمان چگونه تغییر میکنند. این کار برای تشخیص مشکلاتی مثل محو شدن گرادیان عالی است.
- نمایش تصاویر و دادهها: اگر روی پروژههای تصویری کار میکنید، میتوانید ورودیهای مدل را در مراحل مختلف ببینیم.
جریان کار (Workflow) پیشنهادی برای عیبیابی
برای اینکه فرآیند آموزش مدل از حالت حدس و گمان خارج شود، این مراحل را دنبال کنید:

- ثبت وقایع (Logging): در هنگام استفاده از کتابخانه Keras، یک “Callback” برای TensorBoard تعریف کنید تا تمام دادهها را در یک فایل ذخیره کند.
- تحلیل نمودار زیان: اگر نمودار زیان نوسانات شدیدی دارد، احتمالاً باید نرخ یادگیری را کاهش دهید.
- مقایسه نسخهها: TensorBoard به شما اجازه میدهد چندین اجرای مختلف (با پارامترهای متفاوت) را همزمان روی یک نمودار مقایسه کنید تا بهترین تنظیمات را پیدا کنید.
آموزش شبکه عصبی: فرصت یا نفرین؟
معمولاً آموزش یک شبکه عصبی یک استراتژی با «ریسک بالا و پاداش بالا» است. اگر بتوانید تنظیمات آن را به درستی انجام دهید، به یک مدل پیشرفته و کارآمد دست مییابید که از پسِ کارهای دشوار برمیآید. برای مثال، تولید تصویر یکی از موفقیتهای اخیر شبکههای عصبی است؛ جایی که تنها با چند حرکت قلمموی مصنوعی، میتوان تصویری کاملاً واقعی از مناظر طبیعی خلق کرد.
اما از سوی دیگر، آموزش یک شبکه عصبی فوقالعاده دشوار است. برای اینکه همهچیز درست پیش برود، باید مرحلهای سختگیرانه از آزمون و خطا را پشت سر بگذارید.
وقتی شبکه عصبی از حرکت باز میماند!
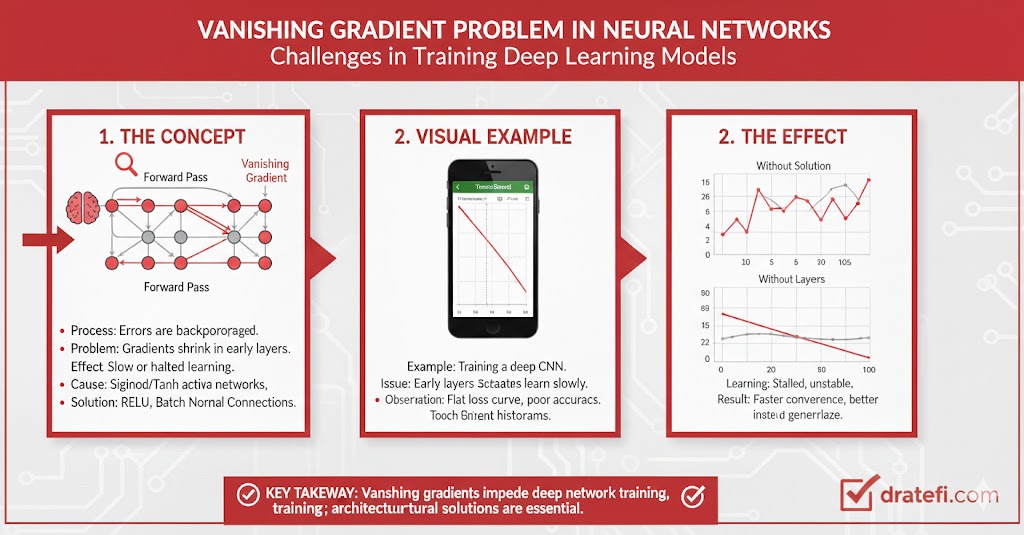
گاهی شبکه اصلاً آموزش نمیبیند و هیچ تغییری در نرخ دقت (Accuracy) دیده نمیشود؛ حتی اگر اجازه دهید مدل ساعتها برای صدها تکرار (Iteration) آموزش ببیند.
واضح است که در چنین شرایطی یک جای کار میلنگد. اگر با این بنبست روبرو شدید، معمولاً دو دلیل اصلی وجود دارد که باعث میشود شبکه عصبی شما به درستی کار نکند:
۱. معماری شبکه عصبی شما اشتباه است: لایهها، تعداد نورونها یا توابع فعالسازی به درستی انتخاب نشدهاند. ۲. دادههای ورودی مشکل دارند: دادهها به درستی پاکسازی، نرمالسازی یا برچسبگذاری نشدهاند.
بیایید این دلایل را یکییکی بررسی کرده و گزینههای غیرمحتمل را حذف کنیم تا به ریشه مشکل برسیم.
گام اول: بررسی معماری
اولین چیزی که هنگام ساخت یک شبکه عصبی باید بررسی کنید، این است که آیا معماری مدل را به درستی تعریف کردهاید یا خیر. در اینجا، ما با یک مسئله دستهبندی سه کلاسه روبرو هستیم که تصاویر موجود در دیتاست آن ابعاد متفاوتی دارند. برای سادهتر شدن کار، ما تمام تصاویر را به اندازه ۳۲×۳۲ تغییر دادیم.
در این مرحله، باید مطمئن شویم که لایه ورودی شبکه با ابعاد تصاویر (۳۲×۳۲) همخوانی دارد و لایه خروجی نیز دقیقاً دارای ۳ واحد (نورون) است تا بتواند احتمالات مربوط به این سه کلاس را به درستی محاسبه کند. هرگونه عدم تطابق در این بخش، میتواند فرآیند یادگیری را در همان ابتدا متوقف کند.
temp = []
for img_name in train.ID:
img_path = os.path.join(data_dir, 'Train', img_name)
img = imread(img_path)
img = imresize(img, (32, 32))
temp.append(img.astype('float32'))
train_x = np.stack(temp)
بنابراین با توجه به این موارد، ما معماری شبکه را به صورت زیر تعریف کردیم:
در واقع، برای اینکه مدل بتواند این تصاویر ۳۲×۳۲ را پردازش کند و در نهایت آنها را در یکی از سه دستهی مورد نظر ما قرار دهد، لایهها را طوری چیدم که گامبهگام ویژگیهای تصویر را استخراج کنند. لایهی خروجی را هم دقیقاً با ۳ نورون تنظیم کردم تا با تعداد کلاسهای مسئلهمان همخوانی کامل داشته باشد.
# define vars
input_num_units = 32 * 32 * 3 # image is 3D (RGB) that is why multiply by 3
hidden_num_units = 500
output_num_units = 3
epochs = 50
batch_size = 128
model = Sequential([
InputLayer(input_shape=(input_num_units,)),
Dense(units=hidden_num_units, activation='relu'),
Dense(units=output_num_units, activation='softmax'),
])
گام دوم: بررسی ابرپارامترهای شبکه عصبی
به عقیدهی من، این حیاتیترین مرحله در کار با شبکههای عصبی است. دلیلش هم ساده است: آنقدر پارامترهای مختلف برای تنظیم کردن وجود دارد که گاهی امتحان کردن تکتک آنها میتواند واقعاً کلافهکننده باشد.
خوشبختانه، ما از یک شبکه عصبی بسیار ساده استفاده کرده بودیم؛ شبکهای که تنها یک لایهی پنهان داشت و با الگوریتم کلاسیک گرادیان کاهشی تصادفی (SGD) آموزش میدید.
وقتی با چنین مدل سادهای کار میکنید، فضای جستجو برای یافتن مشکل کوچکتر میشود، اما هنوز هم تنظیم دقیق ابرپارامترها (مثل نرخ یادگیری) نقشی کلیدی در موفقیت یا شکست نهایی مدل ایفا میکند.
model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['accuracy'])نکتهای که باید به آن توجه کنید این است: گفته میشود وقتی یک شبکه عصبی را با روش SGD (گرادیان کاهشی تصادفی) آموزش میدهید، ممکن است سرعت یادگیری بسیار پایین باشد. برای غلبه بر این مشکل و افزایش سرعت آموزش شبکه، میتوانیم از الگوریتمهای گرادیان کاهشی تطبیقی (Adaptive Gradient Descent) استفاده کنیم.
این بهینهسازهای تطبیقی (مثل Adam یا RMSprop) بهجای استفاده از یک نرخ یادگیری ثابت برای تمام وزنها، نرخ یادگیری را بهصورت هوشمند و لحظهای تنظیم میکنند. این کار باعث میشود مدل بسیار سریعتر از بنبست خارج شده و به سمت کمترین میزان خطا حرکت کند.
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])نکته عجیب اینجا بود که حتی با تغییر الگوریتم از SGD به Adam (که همان روش گرادیان کاهشی تطبیقی است)، شبکه باز هم هیچ تمایلی به یادگیری نشان نداد! این یعنی یک جای کار به صورت بنیادی ایراد داشت.
میانبرنامه: نگاهی به ابزار قدرتمند TensorBoard
در طول مسیری که برای درک شبکههای عصبی طی کردهایم، با ابزارهای مختلفی برای ساخت و تجسم مدلها کار کردهایم؛ اما در میان همهی آنها، TensorBoard را یک دارایی حیاتی میدانیم. این ابزار میتواند در حین آموزش شبکه، بینشهای بسیار ارزشمندی به شما بدهد.
علاوه بر این، TensorBoard یک نمای داشبوردمانند و حرفهای از یافتههایتان به شما ارائه میدهد که برای توضیح نتایج به ذینفعان و مدیران پروژه بسیار کلیدی است. در واقع، آن تصویری که بالاتر به عنوان مدرک از وضعیت شبکه دیدید، خروجیِ همین داشبورد TensorBoard بود.
نحوه نصب TensorBoard
حتماً این ابزار را شخصاً امتحان کنید. شما میتوانید به راحتی و با استفاده از مدیریت بستهی پایتون (pip)، TensorBoard را روی سیستم خود نصب کنید. کافی است دستور زیر را در ترمینال خود اجرا نمایید:
pip install tensorboardپس از نصب، میتوانید برای باز کردن TensorBoard به ترمینال بروید و دستور زیر را تایپ کنید:
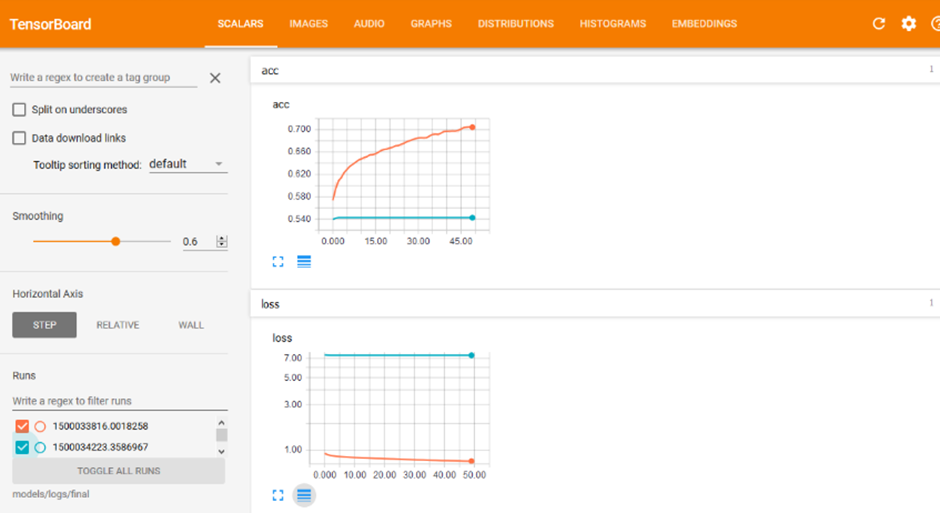
tensorboard --logdir=logs/با اجرای این دستور، یک لینک محلیدر اختیار شما قرار میگیرد که با کپی کردن آن در مرورگر، میتوانید داشبورد مدیریتی مدل خود را مشاهده کنید. در ادامه، تصویری از نمای کلی این ابزار در مرورگر را میبینید که به شما اجازه میدهد تمام جزئیات آموزش را به صورت زنده رصد کنید:
در این محیط، شما میتوانید نمودارهای مربوط به میزان خطا و دقت را تحلیل کنید .
پوشهی “logs/” که در بالا به آن اشاره کردیم، باید حاوی تاریخچهی کامل نحوهی آموزش شبکه عصبی شما باشد. شما میتوانید به سادگی و با اضافه کردن یک کالبک مربوط به TensorBoard در کتابخانه Keras، این اطلاعات را ذخیره کنید:
model.fit(train_x, train_y, batch_size=batch_size,epochs=epochs,verbose=1, validation_split=0.2, callbacks=[keras.callbacks.TensorBoard(log_dir="logs/final/{}".format(time()), histogram_freq=1, write_graph=True, write_images=True)])write_graph:
این گزینه نمودار (گراف) شبکه عصبی رو دقیقاً همونطور که در لایههای داخلی تعریف شده، برای شما ترسیم و چاپ میکند.
با فعال کردن این گزینه، شما میتونید بصورت بصری چک کنید که آیا اتصال بین لایهها، ورودیها و خروجیها درست برقرار شده یا نه. این کار به شما کمک میکند تا از صحت ساختار داخلی مدلتان کاملاً مطمئن بشوید.
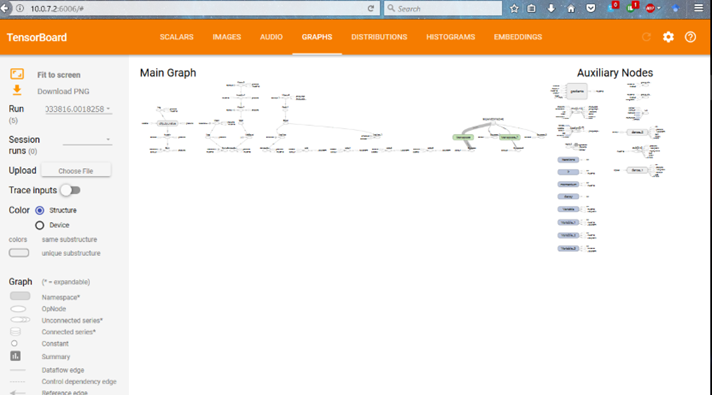
write_images:
این گزینه با ترکیب مقادیر وزنهای شبکه عصبی، یک تصویر گرافیکی ایجاد میکند.
در واقع، این پارامتر به شما اجازه میدهد تا وزنهای لایههای مختلف را به جای اعداد خشک و بیروح، به صورت بصری مشاهده کنید. این کار به خصوص در مدلهای پردازش تصویر بسیار مفید است، زیرا میتوانید متوجه شوید که فیلترهای شبکه دقیقاً روی چه ویژگیهایی (مثل لبهها یا بافتها) تمرکز کردهاند.
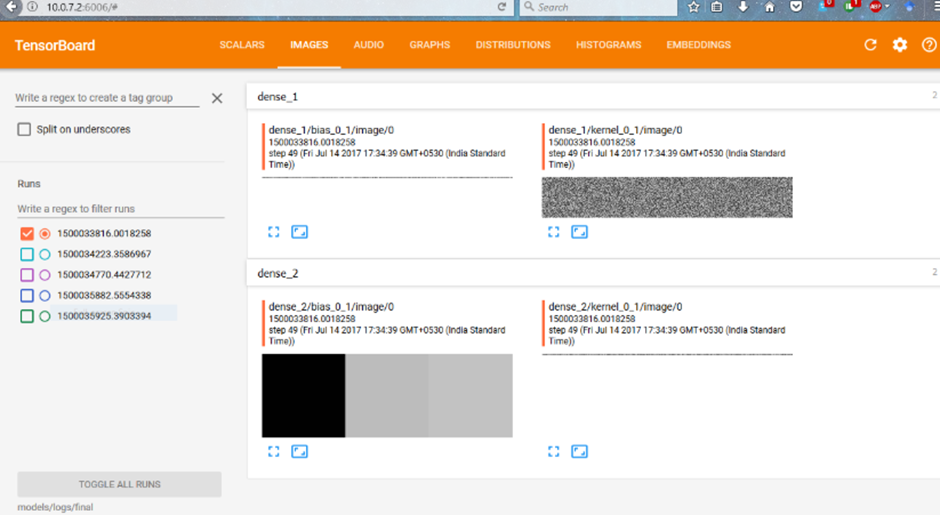
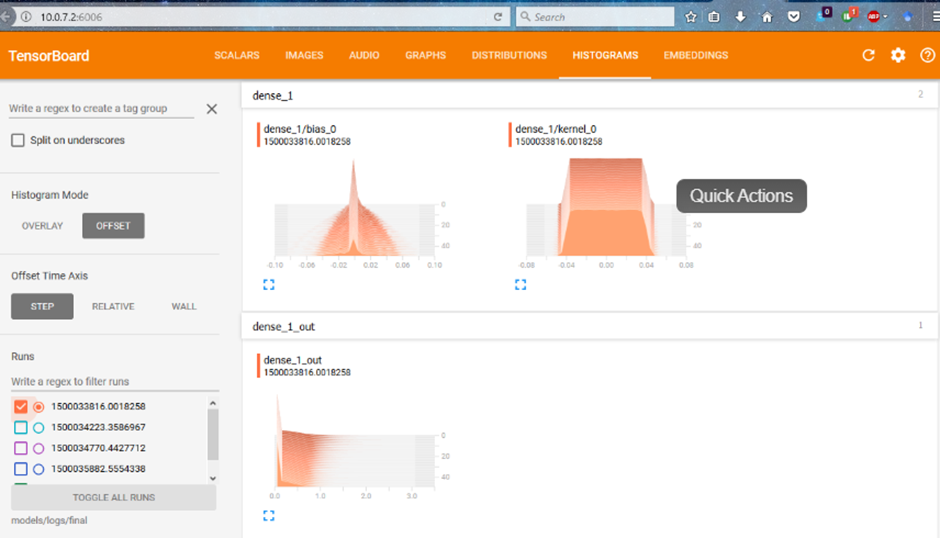
histogram_freq:
این گزینه نمودار توزیع وزنها و بایاسها را در لایههای مختلف شبکه عصبی رسم میکند.
در واقع با تنظیم این پارامتر، شما میتوانید ببینید که مقادیر عددی داخل شبکه در طول زمان چطور تغییر میکنند. اگر هیستوگرامها در طول دورههای مختلف آموزش تغییری نکنند، یعنی شبکه شما عملاً چیزی یاد نمیگیرد و وزنها ثابت ماندهاند؛ این یکی از بهترین روشها برای تشخیص زودهنگام مشکلاتی مثل «ایستایی شبکه» است.
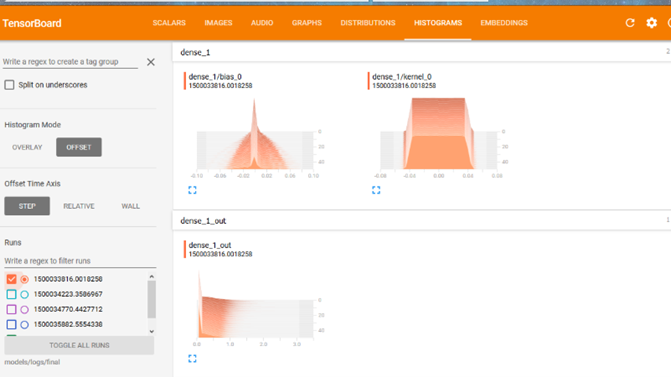
بازگشت به حل مسئله
گام سوم: بررسی پیچیدگی شبکه
بعد از این گشتوگذار کوتاه در دنیای ابزارها، سراغ مرحله بعدی رفتیم: بررسی اینکه آیا شبکهای که ساختهایم، اصلاً توانایی و ظرفیت لازم برای یادگیری الگوها و توزیعهای این مسئله را دارد یا خیر.
برای آزمایش این موضوع، به جای استفاده از یک شبکه عصبی ساده، معماری مدل را به یک شبکه عصبی کانولوشنی (CNN) تغییر دادم. نتیجه این تغییر شگفتانگیز بود: دقت مدل از همان ابتدا جهش بزرگی کرد و از ۳۳٪ به ۵۴٪ رسید. اما با این حال، مشکل اصلی همچنان پابرجا بود؛ یعنی دقت بعد از رسیدن به این عدد، ثابت میماند و با ادامه آموزش هیچ پیشرفتی نمیکرد.
این نشان میداد که اگرچه مدل جدید پتانسیل بیشتری دارد، اما هنوز یک مانع بزرگ جلوی یادگیری کامل آن را گرفته است.
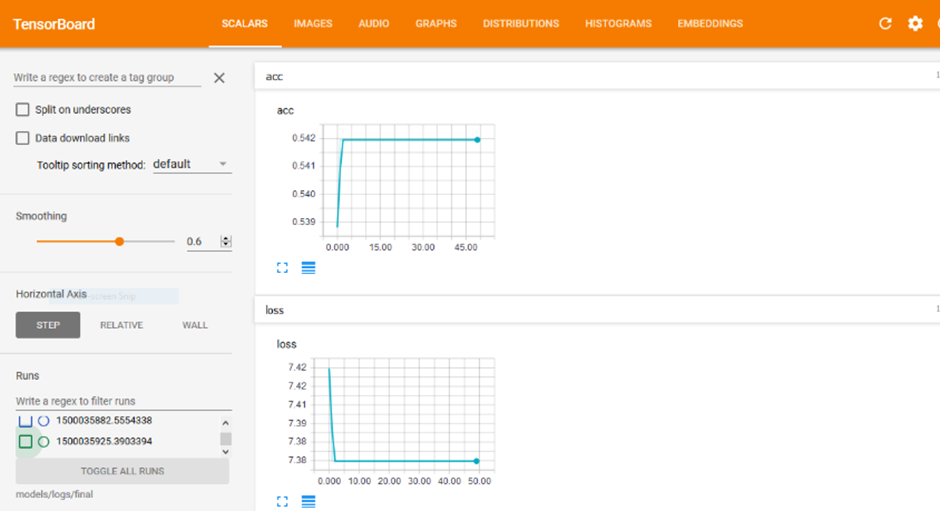
به نظر میرسید آزمایش کوچک ما شکست خورده است! 🙁
تست دادهها (Testing the Data)
گام چهارم: بررسی ساختار دادههای ورودی
بعد از اینکه معماری شبکه را به دقت و از تمام زوایا بررسی کردیم، زمان آن رسیده بود که به سراغ خودِ مجموعهداده برویم و ببینیم آیا اصلاً دیتای مناسبی در اختیار داریم یا خیر. در این مرحله، چند مورد کلیدی وجود دارد که باید حتماً چک شوند:
- آیا تمام رکوردها هماندازه هستند؟ همانطور که در گام اول صحبت کردیم، ما قبلاً اطمینان حاصل کرده بودیم که تمام تصاویر پیش از ارسال به شبکه، همسایز شدهاند؛ بنابراین این مورد از دایره احتمالات خارج است.
- آیا مسئله با نابرابری کلاسها (Imbalanced Data) روبروست؟ گاهی اوقات اگر تعداد نمونههای یک کلاس خیلی بیشتر از بقیه باشد، مدل دچار سوگیری میشود. اما مجموعهداده ما چندان نابرابر نیست و برای هر کلاس، تعداد تصاویر کافی و مناسبی در اختیار داریم.

آیا پیشپردازش (Preprocessing) به درستی انجام شده است؟
در این مرحله باید بررسی کنیم که آیا ورودیها به شکل صحیح آمادهسازی شدهاند یا خیر. برای مثال، در مسائل پردازش تصویر، اگر تصاویر را طوری پردازش کنید که نسبت ابعاد (Aspect Ratio) آنها بههمریخته و نامنظم شود، شبکه عصبی قطعاً گیج خواهد شد و نمیتواند الگوها را تشخیص دهد. اما از آنجایی که مدل ما یک شبکه ساده بود، ما واقعاً گامهای پیچیدهای برای پیشپردازش بر نداشته بودیم؛ بنابراین این مورد هم نمیتوانست علت مشکل باشد.
گام پنجم: بررسی توزیع دادهها
بعد از اینکه تقریباً تمام احتمالات و مشکلاتی که ممکن بود با آنها روبرو شویم را امتحان کردیم، دیگر داشتیم از پیدا کردن علت اصلی ناامید و کلافه میشدیم.
مشکل اینجا بود که دادههای ورودی که ما به شبکه ارسال میکردیم، در بازهی ۰ تا ۲۵۵ بودند. در حالی که در حالت ایدهآل، این بازه باید بین ۰ و ۱ باشد. توزیع دادههای ورودی ما به این شکل بود:
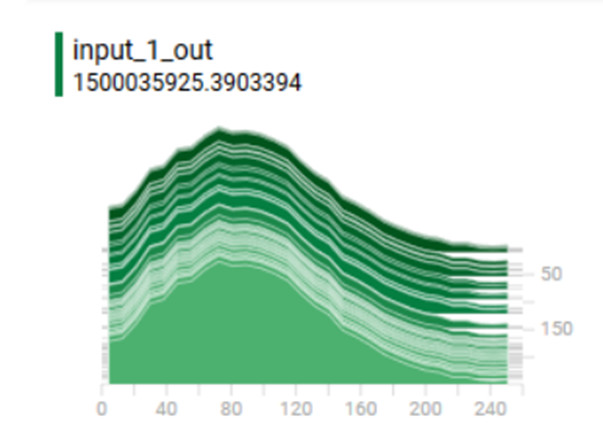
وقتی دادهها در بازهی بزرگی مثل ۰ تا ۲۵۵ هستند، محاسبات ریاضی لایههای شبکه عصبی به شدت سنگین و ناپایدار میشود. در واقع، وزنهای شبکه مجبورند برای جبران این اعداد بزرگ، تغییرات بسیار شدیدی داشته باشند که باعث میشود فرآیند یادگیری عملاً متوقف شود یا در یک نقطه گیر کند.
با نرمالسازی و تبدیل اعداد به بازهی ۰ و ۱، شما در واقع دارید یک زبان مشترک و استاندارد برای تمام نورونها ایجاد میکنید. این کار باعث میشود:
- سرعت آموزش به شدت بالا برود.
- الگوریتمهای بهینهساز مثل Adam یا SGD خیلی راحتتر مسیر رسیدن به کمترین خطا را پیدا کنند.
- شبکه دچار مشکلاتی مثل انفجار گرادیان نشود.
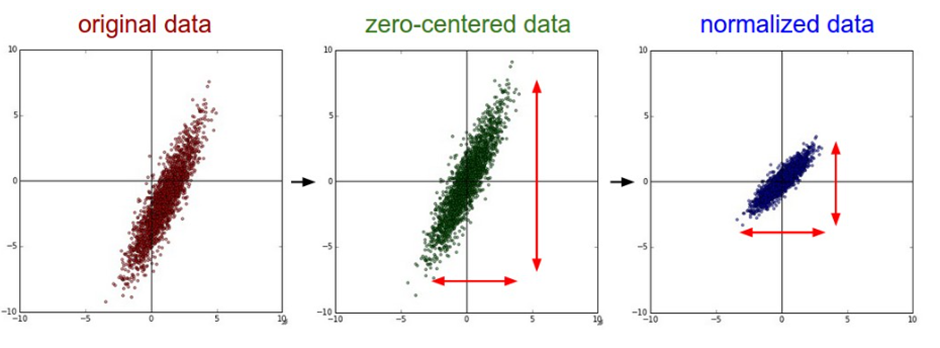
میتوانید ببینید که اگر دادههای شما توزیع سادهای نداشته باشند، شبکه عصبی ممکن است برای یادگیری این توزیع به سختی بیفتد. در چنین حالتی، شبکه قطعا برای همگرا شدن (رسیدن به پاسخ) تلاش میکند، اما تضمینی برای همگرایی کامل وجود نخواهد داشت.
نسخهی پیشرفتهتر این مفهوم، Batch Normalization است. این تکنیک تضمین میکند که دادهها حتی پس از عبور از یک لایهی شبکه عصبی، دوباره نرمالسازی شوند. این کار باعث پایداری فوقالعادهی شبکه در طول آموزش میشود.
temp = []
for img_name in train.ID:
img_path = os.path.join(data_dir, 'Train', img_name)
img = imread(img_path)
img = imresize(img, (32, 32))
temp.append(img.astype('float32'))
train_x = np.stack(temp)
train_x = train_x / 255. # normalization step
به محض اینکه همین مرحلهی سادهی نرمالسازی را به پروژه اضافه کردیم، دیدیم که شبکه عصبی بالاخره شروع به یادگیری کرد.
نتیجهگیری: نقشهی راه عیبیابی شبکههای عصبی
برای جمعبندی، اگر در مسیر آموزش مدل خود به بنبست رسیدید، این ۵ گام حیاتی را به ترتیب دنبال کنید تا ریشهی مشکل را پیدا کنید:
- گام اول: بررسی معماری (Architecture) مطمئن شوید که تعداد لایهها، ابعاد ورودی و بهویژه تعداد نورونهای لایه خروجی با تعداد کلاسهای مسئله شما کاملاً همخوانی دارد.
- گام دوم: بررسی ابرپارامترها (Hyper-parameters) نرخ یادگیری (Learning Rate) و الگوریتمهای بهینهسازی را بازنگری کنید. گاهی یک تغییر کوچک در میزان حساسیت بهینهساز، کل فرآیند را تغییر میدهد.
- گام سوم: بررسی پیچیدگی شبکه (Complexity) آیا مدل شما به اندازه کافی قدرتمند هست؟ گاهی برای دادههای پیچیدهتر، نیاز دارید از مدلهای ساده به سمت مدلهای عمیقتر مثل CNN حرکت کنید.
- گام چهارم: بررسی ساختار دادههای ورودی (Input Structure) ابعاد دادهها، توازن بین کلاسها و کیفیت برچسبگذاریها را چک کنید. دادههای نامنظم، شبکه را گیج میکنند.
- گام پنجم: بررسی توزیع دادهها (Distribution) مهمترین درس این پروژه! همیشه مطمئن شوید که دادههای ورودی را نرمالسازی کردهاید (بازه ۰ تا ۱). این گام ساده معمولاً تفاوت بین شکست و موفقیت مدل است.



