
مقدمه
الگوریتم گرادیان کاهشی (Gradient Descent) یکی از حیاتیترین مفاهیم در یادگیری ماشین و شبکههای عصبی است. همانطور که در مراحل قبلی یاد گرفتیم، پس از انجام انتشار رو به جلو (Forward Propagation) و محاسبه میزان خطا، حالا نوبت به اصلاح وزنها میرسد. گرادیان کاهشی ابزاری است که به ما میگوید وزنها را چقدر و در چه جهتی تغییر دهیم تا خطا به حداقل برسد.
تعریف گرادیان کاهشی
تصور کنید در بالای یک کوه (نقطه حداکثر خطا) هستید و میخواهید به پایینترین نقطه دره (حداقل خطا) برسید، اما چشمان شما بسته است. شما با پاهای خود شیب زمین را احساس میکنید و در جهتی قدم برمیدارید که بیشترین شیب را به سمت پایین دارد.
در دنیای ریاضیات:
- کوه: تابع زیان یا همان خطا (Loss Function) است.
- قدمها: تغییراتی است که در وزنها (W) ایجاد میکنیم.
- شیب: همان مشتق یا گرادیان تابع نسبت به وزنهاست.
ایده اصلی الگوریتم گرادیان کاهشی (Gradient Descent) را میتوان با یک مثال شهودی درک کرد. تصور کنید در بالای یک تپه سرسبز ایستادهاید و میخواهید در سریعترین زمان ممکن به پایینترین نقطه (پایه تپه) برسید.
فرآیند گامبهگام سقوط از تپه
برای رسیدن به پایین، شما مراحل زیر را تکرار میکنید:
- ابتدا به اطراف نگاه میکنید تا جهت مناسب برای برداشتن یک «گام کوچک» به سمت پایین را پیدا کنید.
- در جهتی که تندترین شیب به سمت پایین را دارد، یک قدم برمیدارید و در نقطه جدیدی مستقر میشوید.
- در نقطه جدید، دوباره به اطراف نگاه میکنید تا جهت گام بعدی را بیابید.
- این فرآیند «تصمیمگیری برای جهت» و «برداشتن گام» را تا زمانی ادامه میدهید که به پایین تپه یا همان مینیمم مطلق (Global Minimum) برسید.
هسته اصلی الگوریتم بهینهسازی گرادیان کاهشی
گرادیان کاهشی یک حلکننده تکرار شونده (Iterative Solver) است. در دنیای ریاضیات و شبکههای عصبی، همیشه نمیتوان به راه حل دقیق دست یافت؛ بنابراین از این روش برای رسیدن به یک راه حل تقریبی استفاده میکنیم تا تابع هدف را کمینه کنیم.
دو مفهوم حیاتی در این الگوریتم وجود دارد:
۱. اندازه گام: که به آن نرخ یادگیری (Learning Rate) نیز گفته میشود.
۲. کنترل حرکت: نرخ یادگیری تعیین میکند که گامهای ما به سمت پایین چقدر بزرگ یا کوچک باشند تا به راه حل دقیق نزدیک شویم.
قانون بهروزرسانی (Update Rule)
در هر مرحله از آموزش (تکرار)، مدل سعی میکند با استفاده از شیب خط (مشتق)، وزنها را اصلاح کند تا به کمترین میزان خطا برسد. فرمول اصلی:
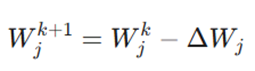
تحلیل اجزای فرمول:
- W_j^{k+1}: موقعیت بعدی یا وزن جدید در تکرار k+1.
- W_j^k: موقعیت فعلی یا وزن موجود در تکرار فعلی k.
- ΔW_j: مقدار تغییر، که همان شیب یا مشتق تابع نسبت به وزن است.
فرمول تفصیلی بهینهسازی
فرمول زیر در برنامهنویسی شبکههای عصبی برای محاسبه مقدار تغییر وزن استفاده میشود:
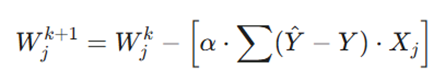
تشریح پارامترهای عملیاتی:
- α (نرخ یادگیری): ضریبی که تعیین میکند قدمهای ما به سمت پایین تپه چقدر بزرگ باشد.
- Y ^- Y (مقدار خطا): تفاوت بین پیشبینی مدل (Y^) و مقدار واقعی هدف .(Y)
- X_j: مقدار ورودی مربوط به آن وزن خاص.
- Σ: مجموع خطاها برای تمام نمونههای آموزشی (رکوردهای مشتریان).
خلاصه عملکرد
این فرمول قلب تپندهی بخش انتشار رو به عقب (Backward Propagation) است. شبکه با محاسبه تفاوت پیشبینی و واقعیت، متوجه میشود که وزن W_j چقدر در ایجاد خطا نقش داشته است. سپس با کسر کردن این خطا (ضربدر نرخ یادگیری) از وزن قبلی، وزن جدید و دقیقتری برای تکرار بعدی میسازد.
ما این محاسبات را به صورت مکرر تا زمان همگرایی (Convergence) انجام میدهیم. همگرایی زمانی رخ میدهد که تغییرات در تابع زیان بسیار ناچیز شود و مدل به بهینهترین حالت خود برسد.
انواع گرادیان کاهشی
فرمول گرادیان کاهشی از مفاهیم مشتق در ریاضیات مشتق شده است تا جهت و اندازه تغییرات وزنها را مشخص کند. همچنین، انواع مختلفی از این الگوریتم وجود دارد که بسته به حجم دادهها استفاده میشوند:
- گرادیان کاهشی دستهای(Batch Gradient Descent): استفاده از کل دادهها برای هر بهروزرسانی.
- گرادیان کاهشی تصادفی(Stochastic Gradient Descent): بهروزرسانی وزنها پس از هر نمونه داده.
- گرادیان کاهشی دستهای کوچک(Mini-batch Gradient Descent): استفاده از بخشهای کوچک داده برای ایجاد تعادل بین سرعت و پایداری.
شروع با یک مدل ساده یادگیری ماشین (رگرسیون خطی)
برای درک بهتر، یک مدل رگرسیون خطی (Linear Regression) را در نظر بگیرید. فرض کنید مجموعهای از نقاط داده در یک فضای دو بعدی دارید. هدف ما رسم خطی است که به بهترین شکل از بین این نقاط عبور کند.
در این مدل:
- نقاط داده: ورودیهای واقعی ما هستند.
- خط: پیشبینی مدل ما را نشان میدهد که معادله آن همان Z = W_1X_1 + W_0 است که پیشتر بررسی کردیم.
- هدف: تنظیم وزنها (W) به گونهای که مجموع فاصله (خطا) بین این خط و نقاط به حداقل برسد.
چرا این مثال مهم است؟
در رگرسیون خطی، تابع زیان معمولاً به شکل یک کاسه (محدب) است. این یعنی همیشه یک «پایینترین نقطه» یا مینیمم مطلق وجود دارد که الگوریتم گرادیان کاهشی با برداشتن گامهای کوچک به سمت آن حرکت میکند.
رگرسیون خطی و مفهوم تابع هزینه (Cost Function)
در ادامه بررسی مدلهای یادگیری ماشین، به سراغ تحلیل ریاضی خطی میرویم که قرار است بهترین پیشبینی را برای ما انجام دهد. معادله یک خط به صورت Y = mX + b تعریف میشود که در آن m شیب خط و b عرض از مبدأ (محل برخورد با محور Y) است.
۱. فرآیند پیشبینی و محاسبه خطا
زمانی که مدل شما سعی میکند پیشبینی انجام دهد، ورودی X را میگیرد و یک حدس میزند. این حدس یا مقدار پیشبینی شده را (Y-hat) مینامیم. از طرفی، ما مقدار واقعی Y را که متناظر با آن X است، از قبل میدانیم.
خطا تفاوت بین این دو مقدار است:
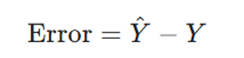
این خطا نشاندهنده میزان انحراف حدس مدل از واقعیت است و اساس مفهوم تابع هزینه یا زیان را تشکیل میدهد.
۲. تفاوت تابع زیان (Loss) و تابع هزینه (Cost)
اگرچه این دو اصطلاح اغلب به جای یکدیگر به کار میروند، اما تفاوت ظریفی با هم دارند:
- تابع زیان(Loss Function): خطا را فقط برای یک نمونه آموزشی محاسبه میکند.
- تابع هزینه(Cost Function): میانگین یا مجموع خطاهای تمام نمونههای آموزشی در کل مجموعهداده است.
برای ارزیابی عملکرد یک الگوریتم روی دادههای بزرگ، مجموع تمام خطاها را محاسبه میکنیم تا خطای کل مدل که وابسته به مقادیر m و b است، مشخص شود.
۳. هدف: کمینهسازی
هدف نهایی ما این است که این زیان را به حداقل برسانیم. ما به دنبال بهترین مقادیر برای m و b هستیم که کمترین میزان خطا را تولید کنند.
از نظر ریاضی، تابع هزینه در اینجا مشابه تابع Y = f(x) = X^2 عمل میکند. اگر نمودار Y = X^2 را در دستگاه مختصات دکارتی رسم کنید، یک شکل سهمی (Uشکل) ایجاد میشود:
این نمودار به ما نشان میدهد که یک نقطه بهینه (مینیمم) وجود دارد که در آن خطا در کمترین سطح خود قرار دارد. الگوریتم گرادیان کاهشی با حرکت روی این منحنی، سعی میکند دقیقاً به همین نقطه برسد.
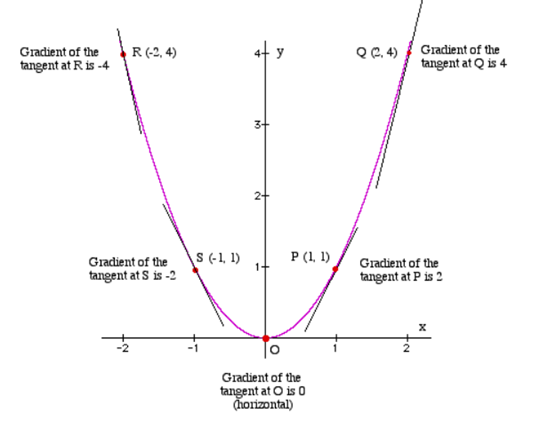
بر اساس مفاهیم الگوریتم گرادیان کاهشی و مدل رگرسیون خطی که تا اینجا بررسی کردیم، برای رسیدن به نقطه بهینه (مینیمم) باید دو تصمیم حیاتی بگیریم.
تعیین مسیر و اندازه گام در جستجوی نقطه بهینه
فرض کنید در نقطه فعلی Q هستیم و هدف ما رسیدن به نقطه O (کمترین مقدار خطا) است. برای این کار به دو فاکتور نیاز داریم:
- جهت حرکت: باید بدانیم به کدام سمت حرکت کنیم تا خطا کاهش یابد.
- اندازه گام: باید تعیین کنیم هر بار چقدر تغییر در پارامترها ایجاد کنیم.
مفهوم مشتق (گرادیان) در یافتن مینیمم
راه یافتن مینیمم، استفاده از مشتق یا گرادیان است. گرادیان یک منحنی در هر نقطه، برابر با شیب خط مماس بر آن نقطه است.
- تغییر گرادیان: همانطور که در تصویر مشخص است، گرادیان در نقاط مختلف (مانند P، Q، R و S) متفاوت است.
- تعریف مشتق: مشتق را میتوان به دو صورت دید:
- شیب خط مماس بر نمودار تابع.
- نرخ تغییرات تابع.
یافتن پارامترهای بهینه
هدف ما یافتن خطی است که کمترین میزان خطا را داشته باشد. به عبارت دیگر، مینیمم کردن یک تابع یعنی پیدا کردن مقدار X (پارامترها) به گونهای که کمترین مقدار Y (خطا) حاصل شود. دانستن شیب (مشتق) به ما میگوید که چگونه برای یافتن این نقطه بهینه جستجو کنیم.
استاندارد سازی پارامترها برای محاسبات شبکه عصبی
در دنیای شبکههای عصبی و یادگیری ماشین، پارامترهای m (شیب) و b (عرض از مبدأ) را معمولاً برای استانداردسازی با نمادهای جدیدی مینویسیم:
- پارامتر b (بایاس): به عنوان θ_0 شناخته میشود.
- پارامتر m (وزن): به عنوان θ _1 شناخته میشود.
با این نامگذاری جدید، مدل ما به فرمت استانداردتری برای اعمال الگوریتمهای بهینهسازی تبدیل میشود.
فرمول بهروزرسانی پارامترها
این معادلات نشاندهنده نحوه اصلاح m (شیب خط) و b (عرض از مبدأ) برای کاهش خطا در هر مرحله از یادگیری هستند:
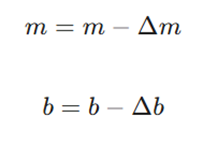
تعریف متغیرها:
- Δm: تغییرات کوچک در مقدار m (مشتق تابع هزینه نسبت به شیب).
- Δb: تغییرات کوچک در مقدار b (مشتق تابع هزینه نسبت به عرض از مبدأ).
تحلیل مفهوم ریاضی
در این فرآیند، مدل با کم کردن مقدار تغییرات (Δ) از مقادیر فعلی، سعی میکند به سمت نقطهای حرکت کند که کمترین میزان خطا را دارد. این دقیقاً همان مفهوم برداشتن «گامهای کوچک» به سمت پایین تپه در الگوریتم گرادیان کاهشی است.
پس از اینکه متوجه شدیم برای کاهش خطا باید مقادیر m و b را در معادله y = mx + b تغییر دهیم، هدف ما یافتن مقادیری است که کمترین میزان خطا را تولید کنند. این کار از طریق محاسبه مشتق (گرادیان) تابع هزینه انجام میشود تا جهت حرکت به سمت مینیمم مشخص شود.
برای محاسبه این مشتقات، از دو قاعده اساسی در حساب دیفرانسیل استفاده میکنیم:
استخراج ریاضی فرمول گرادیان کاهشی
برای محاسبه میزان تغییرات وزنها (Δm و Δb)، از دو قاعده کلیدی زیر استفاده میکنیم:

۱. قاعده توان (Power Rule):
این قاعده برای مشتقگیری از توابع توانی به کار میرود. در تابع هزینه(مانند MSE) که با توان دوم خطا سروکار داریم، این فرمول بسیار حیاتی است:
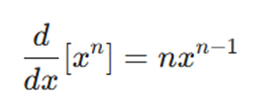
۲. قاعده زنجیرهای(Chain Rule):
از آنجایی که پیشبینی مدل (^Y) خودش نتیجهی ترکیبی از چندین عملیات ریاضی (وزنها، بایاس و تابع فعالسازی) است، برای پیدا کردن سهم هر پارامتر در خطای نهایی، از این قاعده استفاده میکنیم:
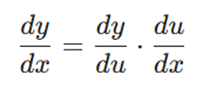
تعریف نمادها:
- :dy/dx مشتق تابع y نسبت به متغیر x .
- :dy/du مشتق تابع y نسبت به متغیر واسطه u .
- :du/dx مشتق متغیر واسطه u نسبت به متغیر اصلی x .
چرا به این فرمولها نیاز داریم؟
در شبکه عصبی، ما میخواهیم بدانیم “اگر وزن W را کمی تغییر دهیم، خطای کل چقدر تغییر میکند؟”.
- قاعده توان به ما کمک میکند تا از عبارت “مربع خطا” مشتق بگیریم.
- قاعده زنجیرهای مانند یک پل ارتباطی عمل میکند که اجازه میدهد خطا را از لایه خروجی، مرحله به مرحله به سمت لایههای عقبتر منتقل کنیم تا به وزن مورد نظر برسیم.
محاسبه مشتق تابع هزینه (Cost Function)
بیایید فرض کنیم J_{(m,b)} نشاندهنده تابع هزینه یا زیان بر حسب پارامترهای m (شیب) و b (عرض از مبدأ) باشد. فرمول کلی میانگین مجموع مربعات خطا به صورت زیر است:
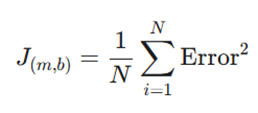
سادهسازی برای یک خطا
برای درک بهتر، فرض میکنیم در لحظه فقط روی خطای یک نمونه تمرکز کردهایم. در این صورت علامت مجموع (Σ) حذف شده و رابطه به این شکل در میآید:
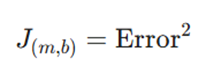
مشتقگیری نسبت به m
اکنون با مشتقگیری از تابع J نسبت به m و با استفاده از قاعده توان (Power Rule) و قاعده زنجیرهای (Chain Rule)، تغییرات را محاسبه میکنیم. ما از قاعده زنجیرهای استفاده میکنیم چون J تابعی از “خطا” (Error) است و خودِ “خطا” تابعی از m و b است.

طبق قاعده توان، مشتق Error^2 برابر است با 2 .Error. بنابراین فرمول به صورت زیر ساده میشود:

چرا این فرمول حیاتی است؟
این نتیجه به ما نشان میدهد که شیب تغییرات تابع هزینه نسبت به وزن m، مستقیماً با مقدار خودِ خطا در آن لحظه در ارتباط است. هر چه خطا بزرگتر باشد، مقدار مشتق بزرگتر شده و در نتیجه گامهای بلندتری برای اصلاح وزنها برداشته میشود.
۱. مشتق تابع هزینه نسبت به عرض از مبدأ (b)
به روشی مشابه مشتقگیری نسبت به m، مشتق تابع هزینه (J) نسبت به b نیز با استفاده از قاعده زنجیرهای محاسبه میشود:

این فرمول نشان میدهد که تغییر در b نیز مستقیماً با میزان خطای فعلی مدل در ارتباط است.
۲. محاسبه جزئیات خطا (Error Definition)
همانطور که قبلاً اشاره شد، خطا تفاوت بین پیشبینی مدل (^Y) و مقدار واقعی (Y) است. با جایگذاری معادله خط در پیشبینی، داریم:
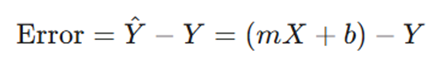
۳. مشتق نهایی خطا نسبت به شیب (m)
اکنون باید مشتق عبارت خطا را نسبت به m محاسبه کنیم:
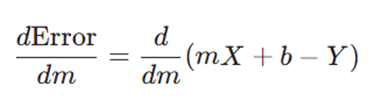
تحلیل متغیرها:
- X: دادههای ورودی است.
- b: در اینجا به عنوان یک مقدار ثابت در نظر گرفته میشود.
- Y: خروجی واقعی است که ثابت میباشد.
نتیجه مهم: از آنجایی که مشتق یک مقدار ثابت صفر است (چون ثابتها تغییر نمیکنند)، مشتق b و Y نسبت به m برابر با صفر میشود. تنها عبارت باقیمانده mX است که مشتق آن نسبت به m برابر با X میشود.
مراحل استخراج فرمول گرادیان کاهشی (Gradient Descent)
۱. محاسبه مشتق تابع هزینه نسبت به پارامترها
هدف ما این است که بدانیم با تغییر پارامترهای مدل (m و b)، میزان خطا (تابع هزینه J) چقدر تغییر میکند.
- فرمول هزینه برای یک رکورد: فرض میکنیم J_{(m,b)} = Error^2 باشد.
- مشتق نسبت به شیب (m): با استفاده از قاعده زنجیرهای، مشتق تابع نسبت به m به صورت زیر است:
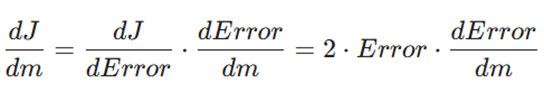
- مشتق نسبت به عرض از مبدأ (b): به همین ترتیب مشتق نسبت به b برابر است با:
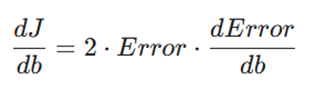
۲. تعریف خطا و استخراج مشتقات جزئی
خطا تفاوت بین پیشبینی (mX + b) و واقعیت (Y) است: Error = mX + b – Y.
- مشتق خطا نسبت به m: چون b و Y نسبت به m ثابت هستند (مشتق ثابت صفر است)، داریم:
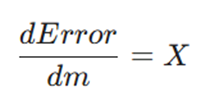
- مشتق خطا نسبت به b: چون mX و Y نسبت به b ثابت هستند، داریم:
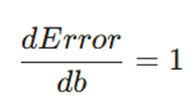
۳. فرمول نهایی تغییرات (Δ)
با ترکیب مراحل بالا و در نظر گرفتن نرخ یادگیری (Learning Rate)، مقدار تغییرات به دست میآید. ضریب 2 حذف میشود چون تأثیری در جهت حرکت ندارد و فقط مقیاس نرخ یادگیری را تغییر میدهد.
- تغییر در شیب:
- d Error/dm = Error . X . Learning Rate
- تغییر در عرض از مبدأ: dJ/db = Error . Learning Rate
نکته: حاصلضرب (Error . X) جهت حرکت (شیب) را مشخص میکند و نرخ یادگیری اندازه گام را تعیین میکند.
۴. قانون بهروزرسانی نهایی (قانون گرادیان کاهشی)
در هر مرحله از تکرار (k)، وزنهای جدید (m^1 و b^1) از وزنهای قبلی (m^0 و b^0) به دست میآیند:
- بهروزرسانی شیب: m^1 = m^0 – (Error . X . Learning Rate)
- بهروزرسانی عرض از مبدأ: b^1 = b^0 – (Error . Learning Rate)
فرمول کلی (معادل فرمول گرادیان کاهشی):
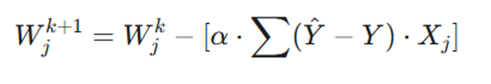
جمع بندی
الگوریتم گرادیان کاهشی یکی از بنیادیترین و در عین حال حیاتیترین مفاهیم در یادگیری ماشین و یادگیری عمیق است. این الگوریتم با حرکت تدریجی در جهت کاهش مقدار تابع هزینه، به مدل اجازه میدهد پارامترهای خود را بهگونهای تنظیم کند که خطای پیشبینی به حداقل برسد. درک این فرآیند، پایهی فهم نحوه یادگیری مدلها از دادههاست.
در این مقاله دیدیم که گرادیان کاهشی صرفاً یک فرمول ریاضی نیست، بلکه یک فرآیند تصمیمگیری تکرارشونده است که به عواملی مانند نرخ یادگیری، شکل تابع هزینه و نحوه محاسبه مشتقها وابسته است. مثالهای شهودی و ریاضی نشان دادند که چرا انتخاب نادرست این پارامترها میتواند منجر به همگرایی کند، واگرایی ایجاد کند یا مدل را در کمینههای نامطلوب گرفتار سازد.
در نهایت، گرادیان کاهشی نقطه اتصال ریاضیات به یادگیری واقعی در شبکههای عصبی است. این الگوریتم پایهی روشهایی مانند پسانتشار (Backpropagation) و بهینهسازهای پیشرفتهتر بهشمار میرود. تسلط بر مفهوم گرادیان کاهشی، گامی ضروری برای درک عمیقتر فرآیند آموزش شبکههای عصبی و حرکت از یادگیری سطحی به تحلیل مهندسی مدلهای یادگیری ماشین است.



