
مقدمه
در مسائل طبقهبندی چندکلاسه، شبکه عصبی تنها به پیشبینی یک عدد یا فعالسازی یک نورون محدود نمیشود؛ بلکه باید تصمیم بگیرد کدام کلاس محتملتر است و این تصمیم را به شکلی قابلتفسیر ارائه دهد. دقیقاً در همین نقطه است که تابع فعالسازی Softmax نقشی کلیدی ایفا میکند.
Softmax با تبدیل خروجی خام شبکه به یک توزیع احتمالاتی، به مدل این امکان را میدهد که میزان اطمینان خود نسبت به هر کلاس را مشخص کند. برخلاف برخی توابع فعالسازی که خروجیهای مستقل تولید میکنند، Softmax بین کلاسها نوعی رقابت ایجاد میکند و خروجی نهایی را به شکلی منسجم و قابلتحلیل در اختیار ما قرار میدهد.
در این مقاله، تابع Softmax را بهصورت مفهومی، ریاضی و کاربردی بررسی میکنیم. از منطق احتمالاتی و مثالهای عددی گرفته تا تفاوت آن با Sigmoid و نقش آن در شبکههای عصبی عمیق، تلاش شده است این تابع نه بهعنوان یک فرمول، بلکه بهعنوان ابزاری تصمیمساز در خروجی شبکههای عصبی معرفی شود.
تابع فعالسازی SoftMax چیست؟
این تابع فعالسازی SoftMax یکی از پرکاربردترین و کلیدیترین ابزارها در دنیای یادگیری ماشین، بهویژه در لایههای خروجی شبکههای عصبی برای وظایف طبقهبندی (Classification) است. این تابع نقش یک مبدل هوشمند را ایفا میکند که برداری از نمرات خام پیشبینی (که اصطلاحاً به آنها Logits میگویند) را دریافت کرده و آنها را به مجموعهای از احتمالات قابل درک تبدیل مینماید.
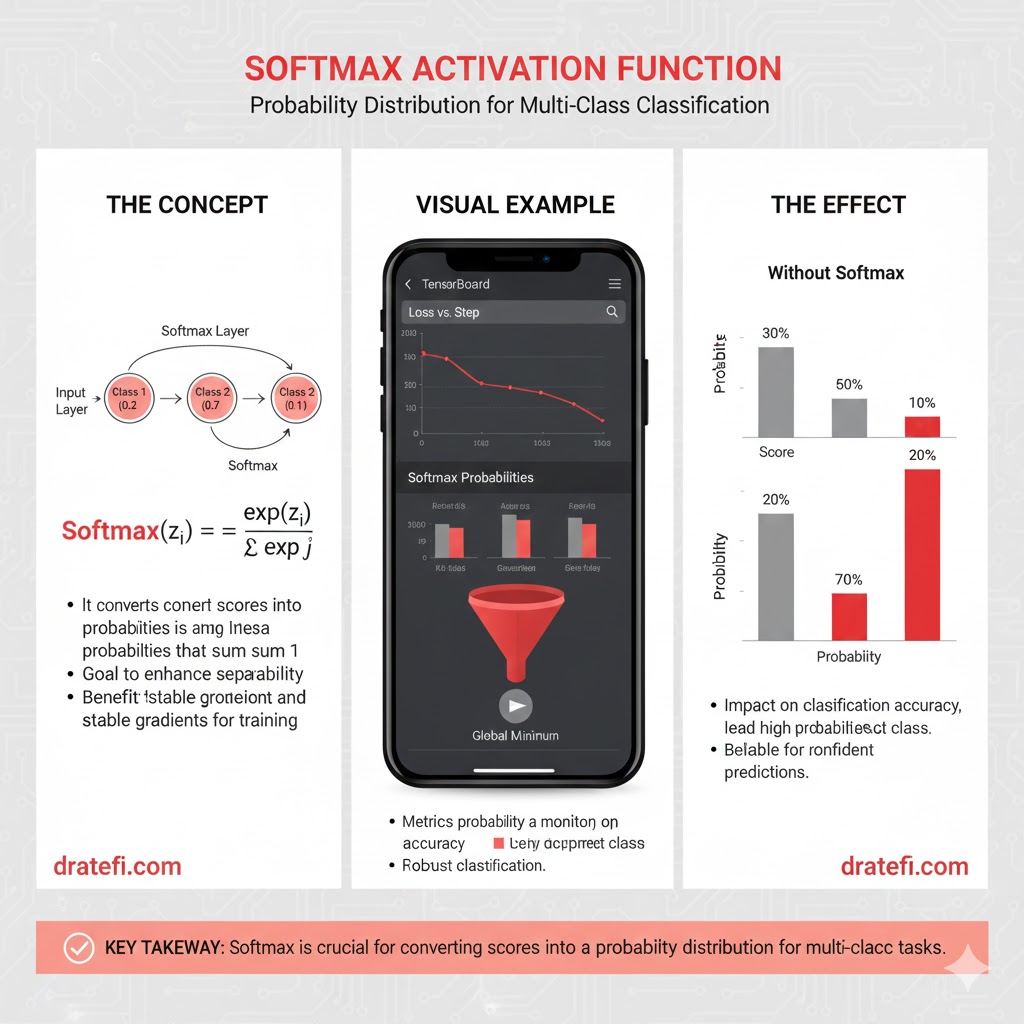
ویژگیهای کلیدی تابع SoftMax
برای درک بهتر قدرت این تابع، باید با سه مشخصه اصلی آن آشنا شویم:
- نرمالسازی: سافتمکس مقادیر ورودی را به یک توزیع احتمالی تبدیل میکند. این فرآیند تضمین میکند که مجموع تمام مقادیر خروجی دقیقاً برابر با ۱ باشد. این ویژگی، سافتمکس را برای مسائلی که خروجی باید نشاندهنده احتمال حضور در کلاسهای مختلف باشد، به گزینهای بیرقیب تبدیل کرده است.
- توانرسانی: این تابع با به توان رساندن ورودیها، تفاوتهای بین نمرات خام را تشدید میکند. این کار باعث میشود بزرگترین مقدار ورودی در خروجی نهایی بسیار برجستهتر دیده شود و مدل با قاطعیت بیشتری کلاس برنده را انتخاب کند.
- مشتقپذیری: یکی از جنبههای فنی حیاتی سافتمکس، مشتقپذیر بودن آن است. این ویژگی برای فرآیند انتشار رو به عقب (Backpropagation) در شبکههای عصبی ضروری است تا مدل بتواند خطاهای خود را محاسبه کرده و وزنها را اصلاح کند.
کاربردهای تابع SoftMax در هوش مصنوعی
سافتمکس تنها به لایه آخر شبکه محدود نمیشود، بلکه در بخشهای مختلفی از هوش مصنوعی نقش ایفا میکند:
- لایههای نهایی شبکههای عصبی: سافتمکس انتخاب استاندارد برای لایه آخر در مسائل طبقهبندی چندکلاسه است. تابع SoftMax نمرات خام لایههای قبل را به احتمالات توزیع شده بین کلاسهای مختلف تبدیل میکند.
- تولید توزیع احتمال: سافتمکس برداری از اعداد را به شکلی تغییر میدهد که هر عنصر نشاندهنده احتمال تعلق ورودی به یک کلاس خاص باشد.
- ترکیب با تابع زیان(Loss Function): در طول آموزش، سافتمکس معمولاً با تابع زیان Cross-Entropy ترکیب میشود. این تابع زیان، تفاوت بین توزیع احتمالی پیشبینی شده توسط سافتمکس و توزیع واقعی (که به صورت کُدگذاری تک-فعال یا One-Hot Encoding است) را اندازهگیری کرده و مدل را برای یادگیری بهتر هدایت میکند.
- مکانیزمهای توجه(Soft Attention): در مدلهای پیشرفتهای مثل Transformers، از سافتمکس برای وزندهی به عناصر مختلف یک توالی استفاده میشود. این کار به مدل کمک میکند تا بر اساس اهمیت هر بخش، توجه خود را تقسیم کند.
- انتخاب اکشن در یادگیری تقویتی: در این حوزه، سافتمکس تخمینهای مربوط به ارزش هر عمل را به احتمالات تبدیل میکند. این موضوع اجازه میدهد تا سیستم به صورت هوشمندانه و تصادفی (Stochastic) بهترین حرکت را انتخاب کند.
- میانگینگیری مدلها: در یادگیری جمعی، سافتمکس میتواند برای ترکیب پیشبینیهای چندین مدل مختلف استفاده شود. با میانگینگیری از توزیعهای احتمالی، پیشبینی نهایی بسیار دقیقتر و مقاومتر (Robust) خواهد بود.
مثال کاربردی:
در این مثال، نحوهی آمادهسازی دادهها برای یک مسئله طبقهبندی سه کلاسه را بررسی میکنیم.
مجموعه داده نمونه
فرض کنید دیتای ما شامل ۵ ویژگی اصلی (X1 تا X5) و یک ستون هدف (Target) با سه کلاس مختلف است:
| ویژگی ۱ | ویژگی ۲ | ویژگی ۳ | ویژگی ۴ | ویژگی ۵ | هدف (Target) |
| ۱ | ۲۲ | ۵۶۹ | ۳۵ | ۰ | کلاس ۱ |
| ۱ | ۷ | ۳۵۱ | ۷۵ | ۱ | کلاس ۲ |
| ۱ | ۴۵ | ۴۵۱ | ۵۴۲ | ۱ | کلاس ۲ |
| ۱ | ۵ | ۵۷۲ | ۸ | ۰ | کلاس ۱ |
| ۰ | ۲۲ | ۵۶۵ | ۴۴ | ۱ | کلاس ۳ |
| ۰ | ۲۴ | ۲۴۳ | ۵۴۶ | ۱ | کلاس ۳ |
| ۱ | ۷۸ | ۹۵۳ | ۴۲ | ۰ | کلاس ۲ |
تحلیل معماری شبکه برای این مسئله:
برای حل این چالش، یک شبکه عصبی ساده با ساختار زیر طراحی میکنیم:
- لایه ورودی: شامل ۵ نورون (مطابق با ۵ ویژگی موجود در دیتا).
- لایه پنهان: دارای ۴ نورون. در اینجا هر نورون با استفاده از ورودیها، وزنها و بایاسها، مقداری را محاسبه میکند که آن را با Zij نشان میدهیم (مثلاً Z11 برای اولین نورون لایه اول).
- پردازش نهایی: ما یک تابع فعالسازی (مانند Tanh) را روی این مقادیر اعمال کرده و خروجی را به لایه نهایی میفرستیم تا احتمالات مربوط به هر کلاس محاسبه شود.
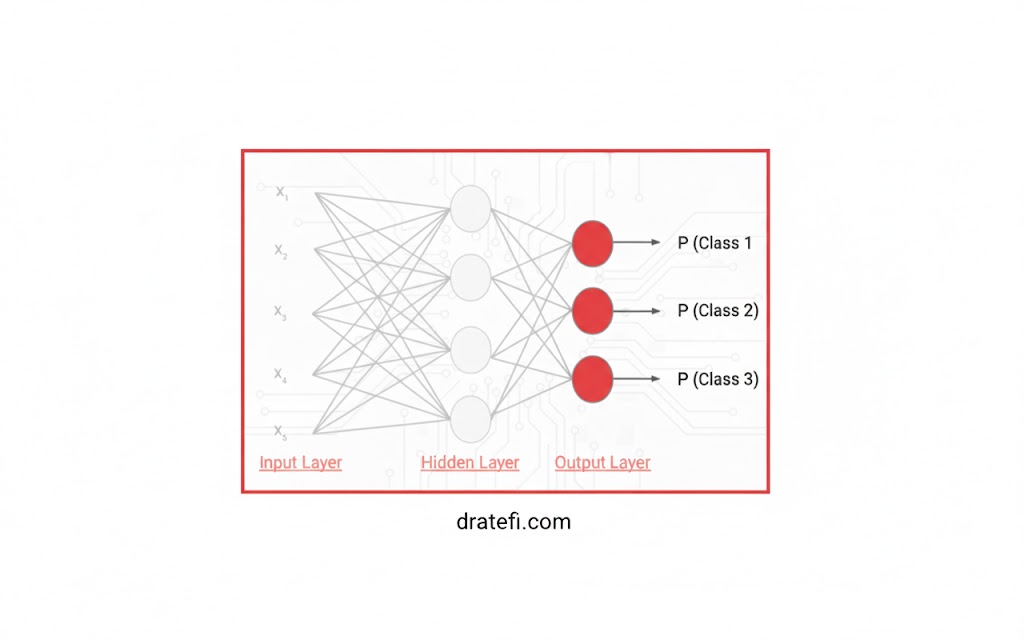
مثالی از ساختار لایهها و نورونها
در لایههای پنهان، هر نورون بر اساس محاسبات داخلی خود یک مقدار تولید میکند. به عنوان مثال، اولین نورون از اولین لایه پنهان با Z11 و دومین نورون با Z12نمایش داده میشود. ما یک تابع فعالسازی (مانند tanh) را روی این مقادیر اعمال کرده و نتایج را به لایه خروجی ارسال میکنیم.
تعداد نورونهای لایه خروجی مستقیماً به تعداد کلاسهای موجود در مجموعهداده بستگی دارد. از آنجایی که در این مثال سه کلاس داریم، لایه خروجی شامل ۳ نورون خواهد بود که هر کدام احتمال تعلق ورودی به یک کلاس خاص را محاسبه میکنند:
- نورون اول: احتمال تعلق داده به کلاس ۱.
- نورون دوم: احتمال تعلق داده به کلاس ۲.
- نورون سوم: احتمال تعلق داده به کلاس ۳.
تابع SoftMax چگونه کار میکند؟
سافتمکس (SoftMax) یک تابع ریاضی هوشمند است که در یادگیری ماشین برای تبدیل برداری از اعداد خام (امتیازات یا Logits) به احتمالات استفاده میشود. این تبدیل باعث میشود خروجی مدل، بهویژه در مسائل طبقهبندی چندکلاسه، به راحتی قابل تفسیر باشد.
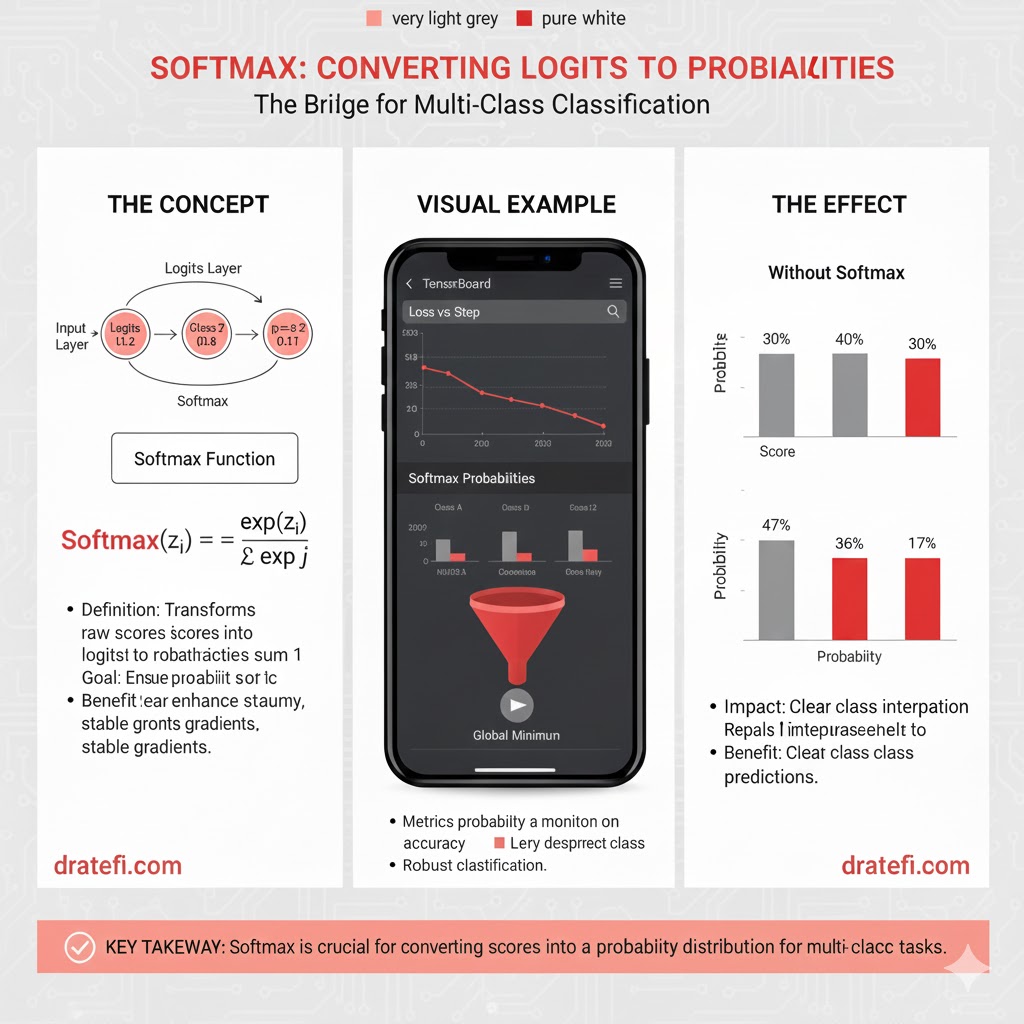
فرآیند عملکرد سافتمکس به زبان ساده شامل مراحل زیر است:
۱. امتیازات ورودی: مدل برداری از امتیازات خام را به عنوان ورودی دریافت میکند.
- مثال: برای ۳ کلاس، ورودی ممکن است به این صورت باشد: [0.1, 1.0, 2.0].
۲. توانرسانی: تابع نمایی (e^x) روی هر امتیاز اعمال میشود. این کار تضمین میکند که تمام مقادیر مثبت شوند و تفاوت بین امتیازات تقویت گردد.
- مثال: مقادیر به [e^(2.0), e^(1.0), e^(0.1)] تبدیل میشوند که تقریباً معادل [1.11, 2.72, 7.39] است.
۳. محاسبه مجموع (Sum of Exponentials): تمام مقادیر به توان رسیده با هم جمع میشوند.
- مثال: مجموع برابر است با: 7.39 + 2.72 + 1.11 = 11.22.
۴. نرمالسازی: هر مقدار بر مجموع کل تقسیم میشود تا توزیعی ساخته شود که جمع اعضای آن دقیقاً ۱ باشد.
- مثال: احتمالات به این صورت محاسبه میشوند: [1.11/11.22, 2.72/11.22, 7.39/11.22] که تقریباً معادل
[0.10, 0.24, 0.66] است.
۵. احتمالات خروجی: خروجی نهایی برداری است که شانس هر کلاس را نشان میدهد.
- نتیجه: خروجی [0.10, 0.24, 0.66] یعنی کلاس اول ۶۶٪، کلاس دوم ۲۴٪ و کلاس سوم ۱۰٪ شانس دارند.
چرا از Softmax در آخرین لایه استفاده میشود؟
دلیل استفاده از این تابع در لایه نهایی شبکههای عصبی، استانداردسازی خروجی برای تصمیمگیری نهایی است:
- دریافت ورودی: تابع برداری از اعداد حقیقی (z) را که خروجی آخرین لایه پنهان است دریافت میکند.
- تثبیت مقادیر مثبت: با استفاده از ثابت ریاضی e (تقریباً ۲.۷۱۸)، تمام خروجیها مثبت میشوند که این موضوع برای محاسبه مشتق در انتشار رو به عقب (Backpropagation) بسیار حیاتی است.
- تولید توزیع واحد: با تقسیم هر مقدار بر مجموع کل، خروجیها بین ۰ و ۱ محدود میشوند. این احتمالات معمولاً توسط تابع زیان Cross-Entropy برای ارزیابی عملکرد مدل استفاده میشوند.
- تصمیمگیری نهایی: در نهایت، از تابع argmax استفاده میشود تا شاخصی (Index) که بالاترین احتمال را دارد به عنوان کلاس پیشبینی شده انتخاب شود.
چرا از تابع سیگموئید (Sigmoid) استفاده نمیکنیم؟
تصور کنید مقادیر Z (خروجی لایه قبل) را با استفاده از وزنها و بایاسهای لایه نهایی محاسبه کردهایم و تصمیم میگیریم به جای سافتمکس، تابع فعالسازی Sigmoid را روی آنها اعمال کنیم. ما میدانیم که خروجی تابع سیگموئید همیشه عددی بین ۰و ۱ است؛ بنابراین در نگاه اول ممکن است برای نشان دادن احتمال مناسب به نظر برسد.
اما در مسائل طبقهبندی چندکلاسه، این رویکرد با دو مشکل اساسی روبرو میشود:
۱. مشکل کلاسهای همپوشان (مجموع نابرابر با ۱)
تابع سیگموئید هر نورون خروجی را به صورت کاملاً مستقل پردازش میکند3. این یعنی اگر ۳ کلاس داشته باشیم، ممکن است خروجی مدل برای یک تصویر به صورت زیر باشد:
- کلاس ۱ (سیب): ۰.۸
- کلاس ۲ (پرتقال): ۰.۷
- کلاس ۳ (موز): ۰.۵
در این حالت، اگر آستانه تصمیمگیری (Threshold) را روی ۰.۵ بگذاریم، شبکه عصبی ادعا میکند که این تصویر همزمان متعلق به هر سه کلاس است! همچنین مجموع این اعداد (2.0) بسیار بیشتر از ۱ است که از نظر قوانین احتمالات، تفسیر خروجی را غیرممکن میکند.
۲. استقلال خروجیها (عدم رقابت)
در مسائل طبقهبندی چندکلاسه، ما به دنبال «بهترین گزینه» هستیم. در سیگموئید، احتمال تعلق داده به کلاس ۱ هیچ توجهی به احتمال کلاسهای دیگر ندارد. اما تابع Softmax با ایجاد یک ساختار رقابتی، از مقادیر تمام نورونها استفاده میکند تا احتمالات «نسبی» بسازد. به عبارت دیگر، در سافتمکس اگر احتمال یک کلاس بالا برود، لزوماً احتمال کلاسهای دیگر پایین میآید تا مجموع همیشه برابر با ۱ باقی بماند.
نتیجهگیری: سافتمکس، نسخه تکاملیافته سیگموئید
در واقع، تابع سیگموئید فقط زمانی ایدهآل است که با یک مسئله طبقهبندی دوتایی (Binary) روبرو باشیم (جایی که فقط یک نورون خروجی داریم). اما به محض اینکه تعداد کلاسها به ۳ یا بیشتر میرسد، باید از سافتمکس استفاده کنیم تا توزیع احتمالی درستی داشته باشیم. جالب است بدانید که از نظر ریاضی، سیگموئید در واقع حالت خاصی از سافتمکس برای دو کلاس است.
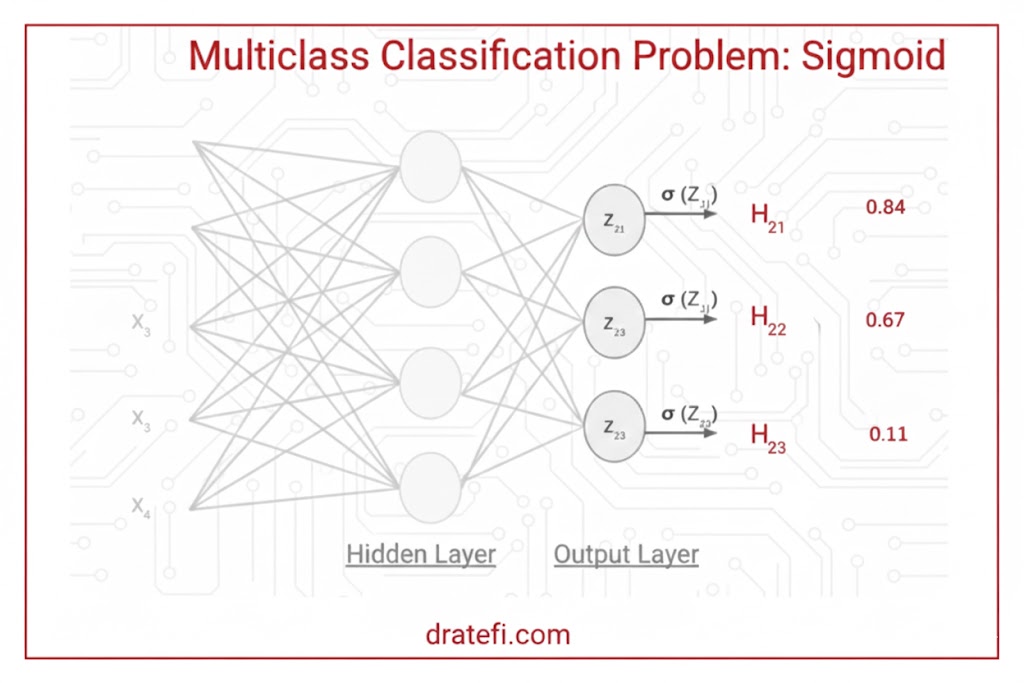
چالشهای استفاده از سیگموئید در طبقهبندی چندکلاسه
در سناریوی استفاده از تابع سیگموئید (Sigmoid) برای خروجیهای چندگانه، با دو مشکل اساسی روبرو هستیم:
۱. تداخل کلاسها: اگر برای تصمیمگیری نهایی، یک حد آستانه (Threshold) مانند ۰.۵ را در نظر بگیریم، ممکن است شبکه عصبی به طور همزمان اعلام کند که دادهی ورودی به دو یا چند کلاس مختلف تعلق دارد. این موضوع در مسائلی که هر داده باید دقیقاً در یک دسته قرار بگیرد، باعث ایجاد ابهام و خطا میشود.
۲. استقلال نادرست خروجیها: در این حالت، مقادیر احتمالی بهدستآمده کاملاً مستقل از یکدیگر هستند. این یعنی احتمال تعلق داده به «کلاس ۱» بدون در نظر گرفتن احتمالات مربوط به دو کلاس دیگر محاسبه میشود. در واقع، هیچ رقابت یا ارتباط منطقی میان خروجیها وجود ندارد و به همین دلیل، استفاده از تابع فعالسازی سیگموئید در مسائل طبقهبندی چندکلاسه به هیچ عنوان توصیه نمیشود.
جایگزینی هوشمند: استفاده از Softmax در لایه خروجی
برای حل مشکلات ذکر شده، در لایه خروجی از تابع فعالسازی Softmax به جای سیگموئید استفاده میکنیم. بر خلاف سیگموئید، تابع Softmax احتمالات نسبی را محاسبه میکند. این یعنی برای تعیین احتمال نهایی هر کلاس، از مقادیر تمام نورونهای لایه خروجی (مثلاً Z21، Z22 و Z23) به صورت همزمان استفاده میشود.
مکانیزم عملکرد Softmax
سافتمکس نیز مانند سیگموئید، احتمال تعلق داده به هر کلاس را بازمیگرداند، اما با یک منطق متفاوت. در اینجا معادلهی ریاضی این تابع را مشاهده میکنید:
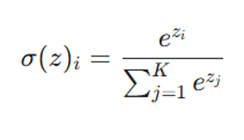
در این فرمول، مقادیر Z نشاندهنده خروجی خام نورونهای لایه آخر هستند. تابع نمایی (e) به عنوان یک فیلتر غیرخطی عمل کرده و در نهایت، تمام مقادیر بر مجموع کل تقسیم میشوند تا نرمالسازی صورت بگیرد و مجموع احتمالات دقیقاً برابر با ۱ شود.
کالبدشکافی فرمولSoftmax و رابطه آن با Sigmoid
در این فرمول، Z نشاندهنده مقادیر خروجی است که مستقیماً از نورونهای لایه آخر به دست میآیند. تابع نمایی (Exponential) در اینجا به عنوان یک تابع غیرخطی عمل میکند. پس از اعمال این تابع، مقادیر به دست آمده بر مجموع تمام مقادیر نمایی تقسیم میشوند تا فرآیند نرمالسازی (Normalization) تکمیل شود. این کار در نهایت اعداد خام را به احتمالات قابل فهم تبدیل میکند.
یک نکته طلایی: رابطه پنهان سافتمکس و سیگموئید
نکته بسیار جالب اینجاست که وقتی تعداد کلاسهای ما برابر با ۲ باشد، تابع Softmax دقیقاً به همان تابع فعالسازی Sigmoid تبدیل میشود. به عبارت دیگر، میتوان گفت تابع سیگموئید صرفاً یک نسخه خاص یا واریانتی از تابع سافتمکس است که برای حالتهای دوتایی بهینهسازی شده است.
درک عمیق با یک مثال ساده
برای اینکه بهتر درک کنیم تابع سافتمکس در قلب یک شبکه عصبی چگونه عمل میکند، بیایید به معماری زیر نگاهی بیندازیم. این مثال به شما نشان میدهد که امتیازات خام چگونه از لایههای پنهان عبور کرده و در نهایت به یک توزیع احتمالی دقیق تبدیل میشوند.
مثال عددی: تبدیل خروجیهای خام به احتمالات واقعی
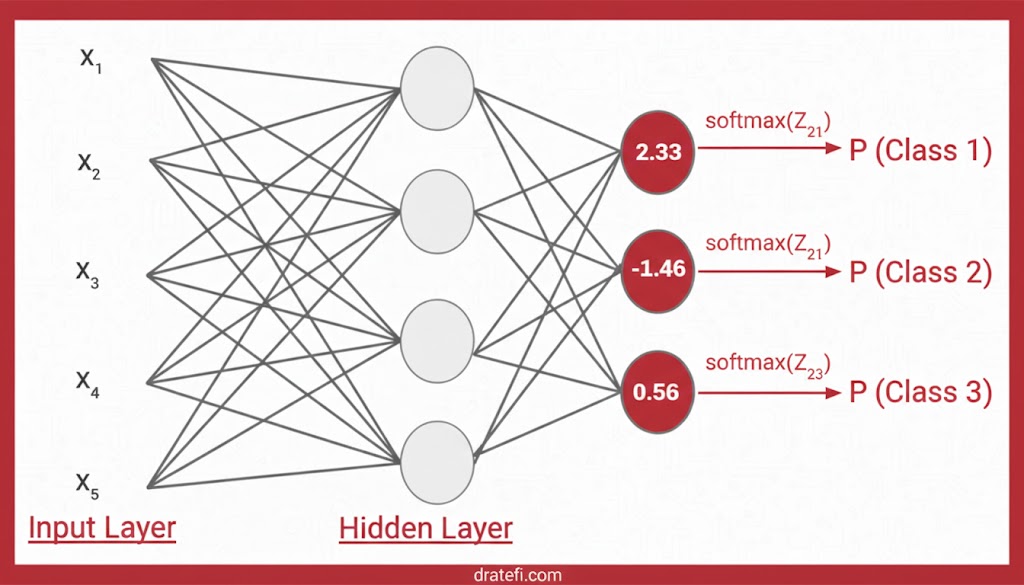
بیایید تصور کنیم در لایه خروجی شبکه عصبی ما، سه نورون مقادیر خام (Logits) زیر را تولید کردهاند:
- نورون اول (Z21): 2.33
- نورون دوم (Z22): 1.46-
- نورون سوم (Z23): 0.56
حالا با اعمال تابع فعالسازی SoftMax روی این مقادیر، فرآیند زیر در قلب مدل اتفاق میافتد:
۱. مرحله توانرسانی (Positive Transformation)
ابتدا هر مقدار به توان عدد نپری (e) میرسد تا تمام اعداد مثبت شده و تفاوتها برجسته شوند:
- e^(2.33) = 10.27
- e^(-1.46) = 0.23
- e^(0.56) = 1.75
۲. مرحله نرمالسازی و خروجی نهایی
با تقسیم هر مقدار بر مجموع کل (12.25)، احتمالات نهایی به دست میآیند:
| کلاس مورد نظر | مقدار نهایی (Probability) | وضعیت خروجی |
| کلاس اول | ۰.۸۳۸ | برنده (بیشترین احتمال) |
| کلاس دوم | ۰.۰۱۹ | کمترین احتمال |
| کلاس سوم | ۰.۱۴۳ | احتمال متوسط |
تفسیر خروجی: چرا همبستگی احتمالات مهم است؟
در مثالی که بررسی کردیم، ورودی به کلاس ۱ تعلق داشت. نکته کلیدی در تابع سافتمکس این است که خروجیها به یکدیگر وابسته هستند؛ یعنی اگر احتمال هر یک از کلاسهای دیگر تغییر کند، مقدار احتمالی کلاس اول نیز به تناسب آن تغییر خواهد کرد. این همبستگی باعث میشود مدل بتواند بین گزینهها «قضاوت» کند.
چرا تابعSoftmax در شبکههایCNN حیاتی است؟
استفاده از سافتمکس به شبکههای عصبی پیچشی (CNN) اجازه میدهد تا به جای ارائه یک جواب خشک و قطعی، یک توزیع احتمالی روی تمام کلاسهای ممکن ارائه دهند. این موضوع از چند جهت اهمیت دارد:
- افزایش دقت پیشبینی: مدل میتواند با بررسی احتمالات نسبی، پیشبینیهای دقیقتری انجام دهد.
- تولید بردار احتمالات: این تابع بردار ورودی را به شکلی نرمالسازی میکند که مجموع تمام اعداد آن برابر با ۱ شود. هر عضو این بردار عددی بین ۰ و ۱ است که نشاندهنده شانس تعلق ورودی به آن کلاس خاص است.
- مثال کاربردی در تصویر: اگر یک شبکه CNN بخواهد تشخیص دهد تصویر ورودی «سگ» است یا «گربه»، سافتمکس مشخص میکند که تصویر با چه احتمالی سگ و با چه احتمالی گربه است (مثلاً ۹۰٪ سگ و ۱۰٪ گربه).

تفاوت کاربرد: Softmax در مقابل ReLU
بسیاری از متخصصان در مورد زمان استفاده از این دو تابع سوال میکنند. تفاوت اصلی در محل قرارگیری و وظیفه آنهاست:
- Softmax: معمولاً فقط در آخرین لایه شبکه برای پیشبینی کلاس نهایی استفاده میشود. همچنین در پردازش زبان طبیعی (NLP) و ترجمه ماشینی کاربرد گستردهای دارد.
- ReLU: به طور معمول در لایههای پنهان برای ایجاد غیرخطی بودن استفاده میشود. این تابع بهینه است و به شبکه کمک میکند روابط پیچیده بین دادههای ورودی و خروجی را بهتر یاد بگیرد.
فرآیند گامبهگام Softmax در قلب یک CNN
یک شبکه CNN برای پیشبینیهای دقیق، به این چرخه هوشمندانه وابسته است:
- پردازش تصویر: شبکه عملیات کانولوشن و استخراج ویژگی را روی تصویر ورودی انجام میدهد.
- تولید امتیازات خام: لایه نهایی مجموعهای از اعداد خام به نام Logits را تولید میکند که نمره اولیه هر کلاس است.
- ورود به مرحله Softmax: این امتیازات به عنوان ورودی به تابع سافتمکس داده میشوند.
- توانرسانی: تابع e^x روی امتیازات اعمال میشود تا تفاوتها برجسته شده و کلاسهای با امتیاز بالا بیشتر نمایان شوند.
- نرمالسازی: هر عدد بر مجموع کل تقسیم میشود تا برآیند خروجیها برابر با ۱ گردد.
- توزیع احتمال: خروجی نهایی برداری از احتمالات است که شانس هر کلاس را تعیین میکند.
- تصمیمگیری: کلاسی که بالاترین احتمال را دارد به عنوان پیشبینی نهایی مدل انتخاب میشود. این مقدار نشاندهنده سطح اعتماد (Confidence) مدل به جواب خود است.
جمع بندی
تابع فعالسازی Softmax یکی از مهمترین اجزای خروجی در شبکههای عصبی طبقهبندی چندکلاسه است که با تبدیل خروجی مدل به توزیع احتمالاتی، فرآیند تصمیمگیری را شفاف و قابلتفسیر میکند. این ویژگی باعث میشود Softmax به انتخابی استاندارد در بسیاری از مدلهای یادگیری عمیق تبدیل شود.
در این مقاله دیدیم که Softmax چگونه با ایجاد رقابت بین کلاسها، برتری هر کلاس را نسبت به سایر گزینهها مشخص میکند و چرا استفاده از آن در مسائل چندکلاسه نسبت به Sigmoid منطقیتر است. مثالهای عددی و مقایسههای مفهومی نشان دادند که Softmax نهتنها خروجی مدل را نرمالسازی میکند، بلکه پایهای مناسب برای استفاده از توابع زیان مانند Cross-Entropy فراهم میآورد.
در نهایت، درک صحیح تابع Softmax به شما کمک میکند خروجی شبکههای عصبی را بهتر تحلیل کنید و انتخابهای آگاهانهتری در طراحی معماری مدل داشته باشید. این آگاهی، پلی میان پیشبینیهای عددی مدل و تصمیمگیریهای احتمالاتی در سیستمهای هوشمند ایجاد میکند و گامی مهم در مسیر تسلط بر یادگیری عمیق بهشمار میرود.



