- این فصل شامل موارد زیر است:
- اولین مثال از یک شبکه عصبی
- تنسورها و عملیات تنسور
- چگونگی یادگیری شبکههای عصبی از طریق پسانتشار (backpropagation) و گرادیان کاهشی (gradient descent)
مقدمه
برای درک یادگیری عمیق، آشنایی با بسیاری از مفاهیم ریاضی ساده ضروری است: تنسورها، عملیات تنسور، مشتقگیری، گرادیان کاهشی و غیره. هدف ما در این فصل، ساختن شهود شما در مورد این مفاهیم بدون ورود بیش از حد به جزئیات فنی است. به طور خاص، ما از نمادهای ریاضی دوری خواهیم کرد، چرا که میتوانند موانع غیرضروری برای کسانی که پیشزمینه ریاضی ندارند ایجاد کنند و برای توضیح خوب مطالب لازم نیستند. دقیقترین و بدون ابهامترین توصیف یک عملیات ریاضی، کد اجرایی آن است.
برای فراهم آوردن بستر کافی جهت معرفی تنسورها و گرادیان کاهشی، فصل را با یک مثال عملی از یک شبکه عصبی آغاز خواهیم کرد. سپس، به بررسی تک تک مفاهیم جدیدی که معرفی شدهاند، خواهیم پرداخت. به خاطر داشته باشید که این مفاهیم برای درک مثالهای عملی در فصول بعدی ضروری خواهند بود!
پس از مطالعه این فصل، درک شهودی از نظریه ریاضی پشت یادگیری عمیق خواهید داشت و آماده خواهید بود تا در فصل ۳ به Keras و TensorFlow بپردازید.
۸. چالش تشخیص بصری در مقیاس بزرگ ایمیجنت (ILSVRC)، در وبسایت www.image-net.org/challenges/LSVRC.
اولین نگاه به یک شبکه عصبی
بیایید نگاهی به یک مثال عملی از یک شبکه عصبی بیندازیم که از کتابخانه پایتون Keras برای یادگیری طبقهبندی ارقام دستنویس بهره میبرد. اگرچه ممکن است در ابتدا تمام جزئیات این مثال را درک نکنید (مگر اینکه از قبل با Keras یا کتابخانههای مشابه کار کرده باشید)، جای نگرانی نیست. در فصل بعدی، هر بخش از این مثال را به دقت بررسی کرده و به تفصیل توضیح خواهیم داد. پس اگر برخی مراحل در نگاه اول کمی غیرمنطقی یا حتی جادویی به نظر میرسند، نگران نباشید! هر آغازی نیاز به نقطهای دارد.
مسئلهای که در اینجا قصد حل آن را داریم، طبقهبندی تصاویر خاکستری ارقام دستنویس (در ابعاد ۲۸ × ۲۸ پیکسل) به ۱۰ دسته مجزا (از ۰ تا ۹) است. برای این منظور، از مجموعهداده MNIST استفاده خواهیم کرد. این مجموعه یک مرجع کلاسیک در جامعه یادگیری ماشین است که تقریباً به قدمت خود این حوزه قدمت دارد و به طور گستردهای مورد مطالعه قرار گرفته است. MNIST شامل ۶۰,۰۰۰ تصویر برای آموزش و ۱۰,۰۰۰ تصویر برای آزمایش است که در دهه ۱۹۸۰ توسط مؤسسه ملی استانداردها و فناوری (NIST در MNIST) گردآوری شده است. میتوانید “حل کردن” MNIST را مانند “Hello World” در برنامهنویسی برای یادگیری عمیق در نظر بگیرید—این اولین قدمی است که برمیدارید تا مطمئن شوید الگوریتمهایتان طبق انتظار عمل میکنند. به عنوان یک متخصص یادگیری ماشین، بارها و بارها با MNIST در مقالات علمی، پستهای وبلاگ و منابع دیگر روبرو خواهید شد. میتوانید چند نمونه از تصاویر MNIST را در شکل ۲.۱ ببینید.

توجه: در یادگیری ماشین، یک دسته در یک مسئله طبقهبندی کلاس نامیده میشود. نقاط داده نمونه نام دارند. کلاسی که با یک نمونه خاص مرتبط است برچسب نامیده میشود.
نیازی نیست که همین الان تلاش کنید این مثال را روی دستگاه خود بازتولید کنید. اگر میخواهید این کار را انجام دهید، ابتدا باید یک فضای کاری یادگیری عمیق راهاندازی کنید که در فصل ۳ به آن پرداخته شده است.
مجموعهداده MNIST به صورت پیشفرض در Keras، در قالب مجموعهای از چهار آرایه NumPy، بارگذاری شده است.
فهرست ۲.۱ بارگذاری مجموعهداده MNIST در Keras
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images و train_labels مجموعه آموزشی را تشکیل میدهند، یعنی دادههایی که مدل از آنها یاد میگیرد. سپس، مدل روی مجموعه آزمایشی، شامل test_images و test_labels، آزمایش خواهد شد.
تصاویر به صورت آرایههای نامپای (NumPy) کدگذاری شدهاند و برچسبها نیز آرایهای از ارقام هستند که از ۰ تا ۹ متغیرند. تصاویر و برچسبها یک تناظر یکبهیک دارند.
بیایید نگاهی به دادههای آموزشی بیندازیم:
>>>train_images.shape
(60000,28,28)
>>> len(train_labels)
60000
>>> train_labels
array([5, 0, 4, …, 5, 6, 8], dtype=uint8)
و در اینجا دادههای آزمایشی آمدهاند:
>>>test_images.shape
(10000,28,28)
>>> len(test_labels)
10000
>>> test_labels
array([7, 2, 1, …, 4, 5, 6], dtype=uint8)
گردش کار به این صورت خواهد بود: ابتدا، دادههای آموزشی، یعنی train_images و train_labels را به شبکه عصبی میدهیم. سپس، شبکه یاد میگیرد که تصاویر و برچسبها را به هم مرتبط کند. در نهایت، از شبکه میخواهیم که پیشبینیهایی برای test_images انجام دهد، و ما بررسی میکنیم که آیا این پیشبینیها با برچسبهای موجود در test_labels مطابقت دارند یا خیر.
حالا بیایید شبکه را بسازیم—باز هم به یاد داشته باشید که انتظار نمیرود فعلاً همه چیز را در مورد این مثال درک کنید.
فهرست ۲.۲: معماری شبکه
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(512, activation=”relu”), layers.Dense(10, activation=”softmax”)
])
بلوکهای سازنده اصلی: لایهها
هسته اصلی سازنده شبکههای عصبی، لایه است. میتوانید لایه را به عنوان یک فیلتر برای دادهها تصور کنید: دادهای وارد آن میشود و به شکلی مفیدتر خارج میگردد. به طور خاص، لایهها بازنماییهایی را از دادههای ورودی استخراج میکنند—که امیدواریم برای مسئله مورد نظر معنادارتر باشند. بیشتر یادگیری عمیق شامل زنجیرهای از لایههای ساده است که نوعی تصفیه تدریجی دادهها را پیادهسازی میکنند. یک مدل یادگیری عمیق مانند یک الک برای پردازش دادههاست که از توالی فیلترهای دادهای با پالایش فزاینده—یعنی همان لایهها—ساخته شده است.
در اینجا، مدل ما از توالی دو لایه Dense تشکیل شده است. این لایهها به طور متراکم متصل (یا کاملاً متصل) هستند. لایه دوم (و آخر) یک لایه طبقهبندی سافتمکس (softmax) ۱۰-طرفه است، به این معنی که آرایهای از ۱۰ نمره احتمال (با مجموع ۱) را برمیگرداند. هر نمره، احتمال تعلق تصویر رقم فعلی به یکی از ۱۰ کلاس رقم ما خواهد بود.
برای آمادهسازی مدل برای آموزش، باید سه چیز دیگر را به عنوان بخشی از مرحله کامپایل انتخاب کنیم:
- یک بهینهساز (Optimizer): سازوکاری که مدل از طریق آن خود را بر اساس دادههای آموزشی که میبیند، بهروزرسانی میکند تا عملکردش را بهبود بخشد.
- یک تابع زیان یا ضرر(Loss Function): نحوه اندازهگیری عملکرد مدل بر روی دادههای آموزشی، و در نتیجه، نحوه هدایت خود در مسیر درست.
- معیارهایی برای نظارت در طول آموزش و آزمایش: در اینجا، ما فقط به دقت (درصد تصاویری که به درستی طبقهبندی شدهاند) اهمیت خواهیم داد.
هدف دقیق تابع زیان و بهینهساز در دو فصل بعدی روشن خواهد شد.
فهرست ۲.۳: مرحله کامپایل
model.compile(optimizer=”rmsprop”,
loss=”sparse_categorical_crossentropy”,
metrics=[“accuracy”])
قبل از آموزش، دادهها را پیشپردازش میکنیم. این کار با تغییر شکل (reshaping) دادهها به فرمی که مدل انتظار دارد و همچنین مقیاسبندی آنها انجام میشود تا تمام مقادیر در بازه [1, 0] قرار گیرند. پیش از این، تصاویر آموزشی ما در یک آرایه با شکل (28, 28, 60000) و از نوع uint8 با مقادیر در بازه [255, 0] ذخیره شده بودند. ما این آرایه را به یک آرایه float32 با شکل (28 * 28, 60000) و مقادیری بین ۰ و ۱ تبدیل خواهیم کرد.
فهرست ۲.۴: آمادهسازی دادههای تصویر
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype(“float32”) / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype(“float32”) / 255
اکنون آماده آموزش مدل هستیم که در Keras از طریق فراخوانی متد fit() مدل انجام میشود—ما مدل را با دادههای آموزشیش تطبیق میدهیم.
فهرست ۲.۵: «تطبیق» مدل
>>> model.fit(train_images, train_labels, epochs=5, batch_size=128)
Epoch 1/5
60000/60000 [===========================] – 5s – loss: 0.2524 – acc: 0.9273
Epoch 2/5
51328/60000 [=====================>…..] – ETA: 1s – loss: 0.1035 – acc: 0.9692
در طول آموزش، دو کمیت نمایش داده میشود: میزان زیان (loss) مدل بر روی دادههای آموزشی و دقت (accuracy) مدل بر روی دادههای آموزشی. ما به سرعت به دقتی معادل ۰.۹۸۹ (۹۸.۹٪) در دادههای آموزشی دست پیدا میکنیم.
اکنون که یک مدل آموزشدیده داریم، میتوانیم از آن برای پیشبینی احتمالات کلاس برای ارقام جدید—تصاویری که بخشی از دادههای آموزشی نبودهاند، مانند تصاویر موجود در مجموعه آزمایشی—استفاده کنیم.
فهرست ۲.۶: استفاده از مدل برای انجام پیشبینیها
>>> test_digits = test_images[0:10]
>>> predictions = model.predict(test_digits)
>>> predictions[0]
array([1.0726176e-10, 1.6918376e-10, 6.1314843e-08, 8.4106023e-06, 2.9967067e-11, 3.0331331e-09, 8.3651971e-14, 9.9999106e-01,
2.6657624e-08, 3.8127661e-07], dtype=float32)
هر عدد با شاخص i در آن آرایه، متناظر با احتمالی است که تصویر رقم test_digits[0] به کلاس i تعلق دارد.
این اولین رقم آزمایشی بالاترین امتیاز احتمال (۰.۹۹۹۹۹۱۰۶، تقریباً ۱) را در شاخص ۷ دارد، بنابراین طبق مدل ما، باید یک رقم ۷ باشد:
>>> predictions[0].argmax() 7
>>> predictions[0][7] 0.99999106
میتوانیم بررسی کنیم که برچسب آزمایشی نیز تأیید میکند:
>>> test_labels[0] 7
به طور میانگین، مدل ما در طبقهبندی چنین ارقامی که قبلاً هرگز دیده نشدهاند، چقدر خوب عمل میکند؟ بیایید با محاسبه میانگین دقت در کل مجموعه آزمایشی بررسی کنیم.
فهرست ۲.۷: ارزیابی مدل روی دادههای جدید
>>> test_loss, test_acc = model.evaluate(test_images, test_labels)
>>> print(f”test_acc: {test_acc}”) test_acc: 0.9785
دقت مجموعه آزمایشی ۹۷.۸٪ است—این رقم کمی پایینتر از دقت مجموعه آموزشی (۹۸.۹٪) است. این شکاف بین دقت آموزش و دقت آزمایش، نمونهای از بیشبرازش (overfitting) است: این واقعیت که مدلهای یادگیری ماشین روی دادههای جدید نسبت به دادههای آموزشی خود عملکرد بدتری دارند. بیشبرازش یک موضوع اصلی در فصل ۳ است.
اینجا اولین مثال ما به پایان میرسد—شما همین الان دیدید که چگونه میتوانید یک شبکه عصبی را برای طبقهبندی ارقام دستنویس در کمتر از ۱۵ خط کد پایتون بسازید و آموزش دهید. در این فصل و فصل بعدی، به جزئیات هر بخش متحرکی که اکنون مشاهده کردیم، خواهیم پرداخت و آنچه را که در پشت صحنه اتفاق میافتد، روشن خواهیم کرد. شما درباره تنسورها، یعنی اشیاء ذخیرهسازی داده که وارد مدل میشوند؛ عملیات تنسور، که لایهها از آنها ساخته شدهاند؛ و گرادیان کاهشی، که به مدل شما اجازه میدهد از نمونههای آموزشیش یاد بگیرد، خواهید آموخت.
نمایش دادهها برای شبکههای عصبی
در مثال قبلی، ما از دادههایی شروع کردیم که در آرایههای چندبعدی NumPy ذخیره شده بودند که به آنها تنسور نیز گفته میشود. به طور کلی، تمام سیستمهای یادگیری ماشین کنونی از تنسورها به عنوان ساختار داده پایه خود استفاده میکنند. تنسورها برای این حوزه بنیادی هستند—آنقدر بنیادی که نام TensorFlow از آنها گرفته شده است. پس تنسور چیست؟
در هسته خود، یک تنسور محفظهای برای دادهها است—معمولاً دادههای عددی. پس، آن یک محفظه برای اعداد است. ممکن است از قبل با ماتریسها آشنا باشید، که تنسورهای مرتبه-۲ هستند: تنسورها تعمیمی از ماتریسها به تعداد دلخواهی از ابعاد هستند (توجه داشته باشید که در زمینه تنسورها، یک بُعد اغلب محور نامیده میشود).
اسکالرها (تنسورهای مرتبه-۰)
یک تنسور که تنها شامل یک عدد باشد، اسکالر (یا تنسور اسکالر، یا تنسور مرتبه-۰، یا تنسور 0D) نامیده میشود. در نامپای (NumPy)، یک عدد float32 یا float64 یک تنسور اسکالر (یا آرایه اسکالر) است. میتوانید تعداد محورهای یک تنسور نامپای را از طریق ویژگی ndim نمایش دهید؛ یک تنسور اسکالر دارای ۰ محور است (ndim == 0). تعداد محورهای یک تنسور نیز مرتبه آن نامیده میشود. در اینجا یک اسکالر نامپای آورده شده است:
>>> import numpy as np
>>> x = np.array(12)
>>> xarray(12)
>>> x.ndim
0
بردارها (تنسورهای مرتبه-۱)
آرایهای از اعداد را بردار، یا تنسور مرتبه-۱، یا تنسور 1D مینامند. یک تنسور مرتبه-۱ دقیقاً یک محور دارد. در ادامه یک بردار نامپای آورده شده است:
>>> x = np.array([12, 3, 6, 14, 7])
>>> x array([12, 3, 6, 14, 7])
>>> x.ndim
1
این بردار دارای پنج ورودی است و بنابراین یک بردار ۵-بعدی نامیده میشود. یک بردار ۵-بعدی را با یک تنسور ۵-بعدی اشتباه نگیرید! یک بردار ۵-بعدی تنها یک محور دارد و در طول این محور پنج بُعد (ورودی) دارد، در حالی که یک تنسور ۵-بعدی دارای پنج محور است (و میتواند هر تعداد بُعد در طول هر محور داشته باشد). ابعاد (dimensionality) میتواند هم به تعداد ورودیها در طول یک محور خاص (مانند مورد بردار ۵-بعدی ما) و هم به تعداد محورها در یک تنسور (مانند یک تنسور ۵-بعدی) اشاره داشته باشد که گاهی اوقات میتواند گیجکننده باشد. در حالت دوم، از نظر فنی صحیحتر است که درباره یک تنسور با مرتبه ۵ (مرتبه یک تنسور، تعداد محورهای آن است) صحبت کنیم، اما اصطلاح مبهم تنسور ۵-بعدی بدون توجه به این موضوع رایج است.
ماتریسها (تنسورهای مرتبه-۲)
آرایهای از بردارها یک ماتریس، یا تنسور مرتبه-۲، یا تنسور 2D نامیده میشود. یک ماتریس دو محور دارد (که اغلب به عنوان سطرها و ستونها از آنها یاد میشود). میتوانید یک ماتریس را به صورت بصری به عنوان یک شبکه مستطیلی از اعداد تفسیر کنید. این یک ماتریس نامپای (NumPy) است:
>>> x = np.array([[5, 78, 2,34,0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]])
>>> x.ndim
2
مقادیر محور اول سطرها و مقادیر محور دوم ستونها نامیده میشوند. در مثال قبلی، [0, 34, 2, 78, 5] سطر اول x و [7, 6, 5] ستون اول آن است.
تنسورهای مرتبه-۳و بالاتر
اگر چنین ماتریسهایی را در یک آرایه جدید بستهبندی کنید، یک تنسور مرتبه-۳ (یا تنسور 3D) به دست میآورید که میتوانید آن را به صورت بصری به عنوان یک مکعب از اعداد تفسیر کنید. در ادامه یک تنسور مرتبه-۳ نامپای آورده شده است:
>>> x = np.array([[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]],
[[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]]])
>>> x.ndim 3
با بستهبندی تنسورهای مرتبه-۳ در یک آرایه، میتوانید یک تنسور مرتبه-۴ و به همین ترتیب تنسورهای با مراتب بالاتر ایجاد کنید. در یادگیری عمیق، شما به طور کلی با تنسورهایی با مرتبه ۰ تا ۴ کار خواهید کرد، اگرچه اگر دادههای ویدیویی را پردازش کنید، ممکن است تا مرتبه ۵ نیز پیش بروید.
ویژگیهای کلیدی
یک تنسور با سه ویژگی کلیدی تعریف میشود:
- تعداد محورها (مرتبه): برای مثال، یک تنسور مرتبه-۳ دارای سه محور و یک ماتریس دارای دو محور است. به این مورد در کتابخانههای پایتون مانند NumPy یا TensorFlow، ndim تنسور نیز گفته میشود.
- شکل (Shape): این یک تاپل (tuple) از اعداد صحیح است که نشان میدهد تنسور در امتداد هر محور چند بُعد دارد. برای مثال، ماتریس مثال قبلی دارای شکل (5, 3) و تنسور مرتبه-۳ مثال ما دارای شکل (5, 3, 3) است. یک بردار دارای شکلی با یک عنصر مانند (5,) است، در حالی که یک اسکالر دارای شکل خالی () است.
- نوع داده (معمولاً در کتابخانههای پایتون dtype نامیده میشود): این نوع دادهای است که در تنسور موجود است؛ برای مثال، نوع یک تنسور میتواند float16، float32، float64، uint8 و غیره باشد. در TensorFlow، احتمالاً با تنسورهای رشتهای نیز روبرو خواهید شد.
برای ملموستر کردن این موضوع، بیایید به دادههایی که در مثال MNIST پردازش کردیم، نگاهی بیندازیم. ابتدا، مجموعه داده MNIST را بارگذاری میکنیم:
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
اکنون، تعداد محورهای تنسور train_images، یعنی ویژگی ndim، را نمایش میدهیم:
>>> train_images.ndim 3
این هم شکل (shape) آن:
>>> train_images.shape (60000, 28, 28)
این هم نوع داده آن، یعنی ویژگی dtype:
>>> train_images.dtype uint8
پس، چیزی که اینجا داریم، یک تنسور مرتبه-۳ از اعداد صحیح ۸ بیتی است. دقیقتر بگوییم، این یک آرایه شامل ۶۰,۰۰۰ ماتریس ۲۸ × ۲۸ از اعداد صحیح است. هر یک از این ماتریسها یک تصویر خاکستری است، با ضرایبی بین ۰ تا ۲۵۵.
بیایید رقم چهارم این تنسور مرتبه-۳ را با استفاده از کتابخانه Matplotlib (یک کتابخانه معروف بصریسازی داده پایتون که در Colab به صورت پیشفرض نصب شده است) نمایش دهیم؛ شکل ۲.۲ را ببینید
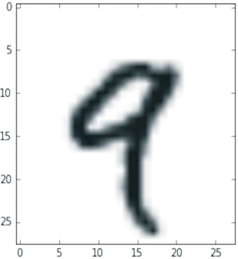
فهرست ۲.۸: نمایش رقم چهارم
import matplotlib.pyplot as plt digit = train_images[4]
plt.imshow(digit, cmap=plt.cm.binary)
plt.show()
طبیعتاً، برچسب مربوطه عدد صحیح ۹ است:
>>> train_labels[4]
9
دستکاری تنسورها در NumPy
در مثال قبلی، ما یک رقم خاص را در امتداد محور اول با استفاده از نحو train_images[i] انتخاب کردیم. انتخاب عناصر خاص در یک تنسور را برشزنی تنسور (tensor slicing) مینامند. بیایید به عملیات برشزنی تنسور که میتوانید روی آرایههای NumPy انجام دهید، نگاهی بیندازیم.
مثال زیر ارقام #۱۰ تا #۱۰۰ (۱۰۰# شامل نمیشود) را انتخاب کرده و آنها را در یک آرایه با شکل (90, 28, 28) قرار میدهد:
>>> my_slice = train_images[10:100]
>>> my_slice.shape (90,28,28)
این کار معادل با این نمادگذاری دقیقتر است که یک شاخص شروع و یک شاخص توقف برای برش در امتداد هر محور تنسور مشخص میکند. توجه داشته باشید که : معادل انتخاب کل محور است:
>>> my_slice = train_images[10:100, :, :]
این عبارت معادل مثال قبلی است.
>>> my_slice.shape (90, 28, 28)
همچنین معادل مثال قبلی است.
>>> my_slice = train_images[10:100, 0:28, 0:28]
>>> my_slice.shape (90, 28, 28)
به طور کلی، میتوانید برشهایی را بین هر دو شاخص در امتداد هر محور تنسور انتخاب کنید. برای مثال، برای انتخاب ۱۴ × ۱۴ پیکسل در گوشه پایین سمت راست تمام تصاویر، به این صورت عمل میکنید:
my_slice = train_images[:, 14:, 14:]
همچنین میتوان از شاخصهای منفی استفاده کرد. درست مانند شاخصهای منفی در لیستهای پایتون، آنها موقعیتی را نسبت به انتهای محور جاری نشان میدهند. برای بریدن تصاویر به تکههای ۱۴ × ۱۴ پیکسلی که در مرکز قرار دارند، به این صورت عمل میکنید:
my_slice = train_images[:, 7:-7, 7:-7]
مفهوم دستههای داده (Data Batches)
به طور کلی، در تمام تنسورهای دادهای که در یادگیری عمیق با آنها روبرو میشوید، محور اول (محور ۰، چون ایندکسگذاری از ۰ شروع میشود)، محور نمونهها (samples axis) خواهد بود (گاهی اوقات به آن بعد نمونهها نیز گفته میشود). در مثال MNIST، “نمونهها” همان تصاویر ارقام هستند.
علاوه بر این، مدلهای یادگیری عمیق کل یک مجموعه داده را یکباره پردازش نمیکنند؛ بلکه دادهها را به دستههای کوچک تقسیم میکنند. به طور خاص، در اینجا یک دسته از ارقام MNIST ما را میبینید که اندازه دسته آن ۱۲۸ است:
batch = train_images[:128]
و این هم دسته بعدی:
batch = train_images[128:256]
و n-اُمین دسته:
n = 3
batch = train_images[128 * n:128 * (n + 1)]
هنگام بررسی چنین تنسور دستهای، محور اول (محور ۰) را محور دسته (batch axis) یا بُعد دسته (batch dimension) مینامند. این اصطلاحی است که هنگام استفاده از Keras و سایر کتابخانههای یادگیری عمیق، مکرراً با آن مواجه خواهید شد.
مثالهای واقعی از تنسورهای داده
بیایید تنسورهای داده را با چند مثال مشابه آنچه بعداً با آنها روبرو خواهید شد، ملموستر کنیم. دادههایی که دستکاری خواهید کرد تقریباً همیشه در یکی از دستههای زیر قرار میگیرند:
- دادههای برداری: تنسورهای مرتبه-۲ با شکل (samples, features)، که در آنها هر نمونه یک بردار از ویژگیهای عددی است.
- دادههای سری زمانی یا دادههای توالی: تنسورهای مرتبه-۳ با شکل (samples, timesteps, features)، که در آنها هر نمونه یک توالی (به طول timesteps) از بردارهای ویژگی است.
- تصاویر: تنسورهای مرتبه-۴ با شکل (samples, height, width, channels)، که در آنها هر نمونه یک شبکه دوبعدی از پیکسلها است و هر پیکسل با یک بردار از مقادیر (“کانالها”) نمایش داده میشود.
- ویدئو: تنسورهای مرتبه-۵ با شکل (samples, frames, height, width, channels)، که در آنها هر نمونه یک توالی (به طول frames) از تصاویر است.
دادههای برداری (Vector Data)
این یکی از رایجترین موارد است. در چنین مجموعه دادهای، هر نقطه داده منفرد را میتوان به عنوان یک بردار کدگذاری کرد، و بنابراین یک دسته از دادهها به عنوان یک تنسور مرتبه-۲ (یعنی آرایهای از بردارها) کدگذاری میشوند، که در آن محور اول، محور نمونهها (samples axis) و محور دوم، محور ویژگیها (features axis) است.
بیایید به دو مثال نگاهی بیندازیم:
- مجموعه داده بیمه: فرض کنید یک مجموعه داده از افراد داریم که در آن سن، جنسیت و درآمد هر شخص را در نظر میگیریم. هر فرد را میتوان با یک بردار از ۳ مقدار مشخص کرد. بنابراین، یک مجموعه داده کامل شامل ۱۰۰,۰۰۰ نفر را میتوان در یک تنسور مرتبه-۲ با شکل (3, 100000) ذخیره کرد.
- مجموعه داده اسناد متنی: فرض کنید هر سند را با تعداد دفعات تکرار هر کلمه در آن (از یک دیکشنری شامل ۲۰,۰۰۰ کلمه رایج) نمایش میدهیم. هر سند را میتوان به عنوان یک بردار با ۲۰,۰۰۰ مقدار (یک شمارش برای هر کلمه در دیکشنری) کدگذاری کرد، و بنابراین یک مجموعه داده کامل از ۵۰۰ سند را میتوان در یک تنسور با شکل (2000, 500) ذخیره کرد.
دادههای سری زمانی یا دادههای توالی
هرگاه زمان در دادههای شما اهمیت داشته باشد (یا مفهوم ترتیب توالی)، منطقی است که آن را در یک تنسور مرتبه-۳ با یک محور زمانی مشخص ذخیره کنید. هر نمونه را میتوان به عنوان توالیای از بردارها (یک تنسور مرتبه-۲) کدگذاری کرد، و بنابراین یک دسته از دادهها به عنوان یک تنسور مرتبه-۳ کدگذاری میشوند (شکل ۲.۳ را ببینید).
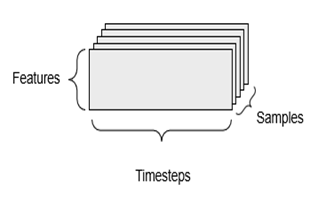
محور زمان همیشه طبق قرارداد، محور دوم (محور با شاخص ۱) است. بیایید به چند مثال نگاهی بیندازیم:
- مجموعه داده قیمت سهام: هر دقیقه، ما قیمت فعلی سهام، بالاترین قیمت در دقیقه گذشته، و پایینترین قیمت در دقیقه گذشته را ذخیره میکنیم. بنابراین، هر دقیقه به عنوان یک بردار سهبعدی کدگذاری میشود. یک روز کامل معاملاتی به عنوان یک ماتریس با شکل ( 390 و3) کدگذاری میشود (زیرا ۳۹۰ دقیقه در یک روز معاملاتی وجود دارد)، و دادههای مربوط به ۲۵۰ روز را میتوان در یک تنسور مرتبه-۳ با شکل (250, 390, 3) ذخیره کرد. در این حالت، هر نمونه، دادههای یک روز کامل خواهد بود.
- مجموعه داده توییتها: در این سناریو، هر توییت را به عنوان دنبالهای از ۲۸۰ کاراکتر از الفبایی شامل ۱۲۸ کاراکتر منحصربهفرد کدگذاری میکنیم. هر کاراکتر را میتوان به عنوان یک بردار باینری با اندازه ۱۲۸ کدگذاری کرد (یک بردار تمام صفر به جز یک ورودی ۱ در شاخص مربوط به کاراکتر). سپس هر توییت را میتوان به عنوان یک تنسور مرتبه-۲ با شکل (128و280) کدگذاری کرد، و یک مجموعه داده شامل ۱ میلیون توییت را میتوان در یک تنسور با شکل (128و280و1000000) ذخیره کرد.
دادههای تصویری (Image Data)
تصاویر معمولاً سه بعد دارند: ارتفاع، عرض و عمق رنگ. اگرچه تصاویر سیاه و سفید (مانند ارقام MNIST ما) تنها یک کانال رنگی دارند و بنابراین میتوانستند در تنسورهای مرتبه-2 ذخیره شوند، اما طبق قرارداد، تنسورهای تصویری همیشه مرتبه-3 هستند، حتی برای تصاویر سیاه و سفید که یک کانال رنگی تکبعدی دارند.
بنابراین، یک دسته شامل 128 تصویر سیاه و سفید با اندازه 256 × 256 را میتوان در یک تنسور با شکل (1,256,256,128) ذخیره کرد. همچنین، یک دسته شامل 128 تصویر رنگی را میتوان در یک تنسور با شکل (3,256,256,128) ذخیره کرد (شکل 2.4 را ببینید).
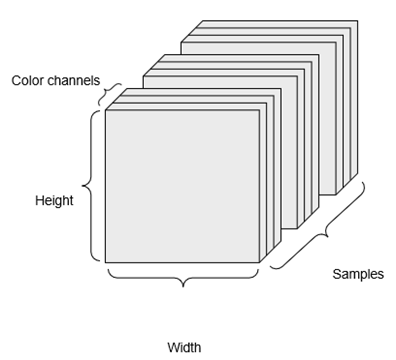
دو قرارداد برای اشکال تنسورهای تصویری وجود دارد: قرارداد “کانالها-آخر” (channels-last) (که در TensorFlow استاندارد است) و قرارداد “کانالها-اول” (channels-first) (که به تدریج در حال منسوخ شدن است).
قرارداد “کانالها-آخر” محور عمق رنگ را در انتها قرار میدهد: (samples, height, width, color_depth). در حالی که، قرارداد “کانالها-اول” محور عمق رنگ را بلافاصله پس از محور دسته قرار میدهد: (samples, color_depth, height, width). با قرارداد “کانالها-اول”، مثالهای قبلی به (256, 256, 1, 128) و (256, 256, 3, 128) تبدیل میشدند. API کراس (Keras) از هر دو فرمت پشتیبانی میکند.
دادههای ویدئویی (Video Data)
دادههای ویدئویی یکی از معدود انواع دادههای واقعی هستند که برای آنها به تنسورهای مرتبه-۵ نیاز پیدا میکنید. یک ویدئو را میتوان به عنوان دنبالهای از فریمها در نظر گرفت، که هر فریم یک تصویر رنگی است. از آنجایی که هر فریم را میتوان در یک تنسور مرتبه-۳ (ارتفاع، عرض، عمق رنگ) ذخیره کرد، یک دنباله از فریمها را میتوان در یک تنسور مرتبه-۴ (فریمها، ارتفاع، عرض، عمق رنگ) ذخیره کرد. بنابراین، یک دسته از ویدئوهای مختلف را میتوان در یک تنسور مرتبه-۵ با شکل (samples, frames, height, width, color_depth) ذخیره کرد.
به عنوان مثال، یک کلیپ ویدیویی ۶۰ ثانیهای یوتیوب با اندازه 256 × 144 پیکسل و نرخ نمونهبرداری 4 فریم در ثانیه، دارای 240 فریم خواهد بود. یک دسته شامل چهار کلیپ ویدیویی اینچنینی، در یک تنسور با شکل (3, 256, 144, 240, 2) ذخیره میشود. این مقدار در مجموع 106,168,320 مقدار است! اگر dtype تنسور float32 باشد، هر مقدار در 32 بیت ذخیره میشود، بنابراین تنسور 405 مگابایت (MB) حجم خواهد داشت. حجیم است! ویدئوهایی که در زندگی واقعی با آنها روبرو میشوید بسیار سبکتر هستند، زیرا در فرمت float32 ذخیره نمیشوند و معمولاً با نسبت فشردهسازی بالایی (مانند فرمت MPEG) فشردهسازی شدهاند.
چرخدندههای شبکههای عصبی: عملیات تنسور
همانطور که هر برنامه کامپیوتری را میتوان در نهایت به مجموعهای کوچک از عملیات باینری بر روی ورودیهای باینری (AND، OR، NOR و غیره) تقلیل داد، تمام تبدیلاتی که توسط شبکههای عصبی عمیق آموخته میشوند را میتوان به تعداد انگشتشماری از عملیات تنسور (tensor operations) (یا توابع تنسور) که بر روی تنسورهای دادههای عددی اعمال میشوند، تقلیل داد.
به عنوان مثال، امکان جمع کردن تنسورها، ضرب کردن تنسورها و غیره وجود دارد.
در مثال اولیه ما، مدل خود را با روی هم قرار دادن لایههای Dense ساختیم. یک نمونه لایه کراس (Keras) به این صورت است:
keras.layers.Dense(512, activation=”relu”)
این لایه را میتوان به عنوان یک تابع تفسیر کرد که یک ماتریس را به عنوان ورودی میگیرد و ماتریس دیگری را بازمیگرداند – یک نمایش جدید برای تنسور ورودی. به طور خاص، این تابع به شرح زیر است (که در آن W یک ماتریس و b یک بردار است که هر دو از ویژگیهای لایه هستند):
output = relu(dot(input, W) + b)
این را بررسی کنیم. ما در اینجا سه عملیات تنسور داریم:
- یک ضرب نقطهای (dot) بین تنسور ورودی و تنسور W
- یک جمع (+) بین ماتریس حاصل و بردار b
- یک عملیات relu: relu(x) برابر است با max(x, 0)؛ “relu” مخفف “واحد خطی اصلاحشده” (rectified linear unit) است.
نکته: اگرچه این بخش به طور کامل به عبارات جبر خطی میپردازد، اما هیچ نماد ریاضی در اینجا پیدا نخواهید کرد. من متوجه شدهام که مفاهیم ریاضی میتوانند توسط برنامهنویسانی که پیشزمینه ریاضی ندارند، راحتتر درک شوند، اگر به جای معادلات ریاضی، به عنوان قطعه کدهای کوتاه پایتون بیان شوند.
بنابراین، ما در سراسر این بخش از کدهای NumPy و TensorFlow استفاده خواهیم کرد.
عملیاتهای عنصر به عنصر(Element-wise Operations)
عملیات relu و جمع، عملیاتهای عنصر به عنصر هستند: عملیاتی که به طور مستقل بر روی هر ورودی در تنسورهای مورد نظر اعمال میشوند. این بدان معناست که این عملیاتها به شدت برای پیادهسازیهای موازی عظیم (پیادهسازیهای وکتورایز شده، اصطلاحی که از معماری ابررایانههای پردازشگر وکتوری در دوره 1970 تا 1990 میآید) مناسب هستند. اگر میخواهید یک پیادهسازی ساده پایتون از یک عملیات عنصر به عنصر بنویسید، از یک حلقه for استفاده میکنید، همانطور که در این پیادهسازی ساده از یک عملیات relu عنصر به عنصر نشان داده شده است
def naive_relu(x):
assert len(x.shape) == 2
x یک تنسور NumPy مرتبه-2 است.
تنسور ورودی را بازنویسی نکنید.
for i in range(x.shape[0]):
for j in range(x.shape[1]): x[i, j] = max(x[i, j], 0)
return x
شما میتوانید همین کار را برای جمع نیز انجام دهید:
def naive_add(x, y):
x و y تنسورهای NumPy مرتبه-2 هستند.
assert len(x.shape) == 2
assert x.shape == y.shape x = x.copy()
for i in range(x.shape[0]):
for j in range(x.shape[1]): x[i, j] += y[i, j]
پرهیز از بازنویسی تنسور ورودی.
return x
به همین صورت، میتوان عملیاتی مانند ضرب، تفریق و سایر عملیات عنصر به عنصر (element-wise) را نیز انجام داد. در عمل، هنگام کار با آرایههای NumPy، این عملیات بهصورت توابع بهینهشده و داخلی در خود NumPy پیادهسازی شدهاند. این توابع نیز اجرای محاسبات سنگین را به کتابخانهای به نام BLAS (برنامههای زیرمجموعه جبر خطی پایه) واگذار میکنند. BLAS شامل رویههایی سطح پایین، بسیار موازی و کارآمد برای دستکاری تانسورها است که معمولاً به زبان Fortran یا C نوشته میشوند.
پس در NumPy میتوانید عملیات عنصر به عنصر (element-wise) زیر را انجام دهید، و این کار با سرعتی بسیار بالا انجام خواهد شد:
import numpy as np
z = x + y
جمع عنصر به عنصر(درایه به درایه)
z = np.maximum(z, 0.)
تابع ReLU بهصورت عنصر به عنصر(اعمال ReLU بهصورت درایه به درایه)
بیایید زمان اجرای این دو را با هم مقایسه کنیم.
import time
x = np.random.random((20, 100))
y = np.random.random((20, 100))
t0 = time.time()
for _ in range(1000):
z = x + y
z = np.maximum(z, 0.)
print(“Took: {0:.2f} s”.format(time.time() – t0))
«این نسخه تنها ۰٫۰۲ ثانیه زمان میبرد. در مقابل، نسخهی ساده و ابتدایی بهطرز شگفتانگیزی ۲٫۴۵ ثانیه طول میکشد.»
t0 = time.time()
for _ in range(1000):
z = naive_add(x, y)
z = naive_relu(z)
print(“Took: {0:.2f} s”.format(time.time() – t0))
به همین ترتیب، هنگام اجرای کدهای TensorFlow روی یک GPU، عملیات عنصر به عنصر از طریق پیادهسازیهای کاملاً برداریشدهی CUDA انجام میشوند که میتوانند به بهترین شکل از معماری بهشدت موازی تراشهی GPU بهرهبرداری کنند.
انتشار(Broadcasting)
پیادهسازی ساده قبلی ما از naive_add تنها از جمع تنسورهای مرتبه-2 با اشکال یکسان پشتیبانی میکند. اما در لایه Dense که قبلاً معرفی شد، ما یک تنسور مرتبه-2 را با یک بردار جمع کردیم. چه اتفاقی برای جمع میافتد وقتی اشکال دو تنسوری که جمع میشوند، متفاوت باشند؟
در صورت امکان و در صورت عدم ابهام، تنسور کوچکتر منتشر (broadcast) میشود تا با شکل تنسور بزرگتر مطابقت یابد. انتشار شامل دو مرحله است:
- محورها (که محورهای انتشار نامیده میشوند) به تنسور کوچکتر اضافه میشوند تا با ndim تنسور بزرگتر مطابقت داشته باشند.
- تنسور کوچکتر در امتداد این محورهای جدید تکرار میشود تا با شکل کامل تنسور بزرگتر مطابقت یابد.
بیایید به یک مثال عینی نگاه کنیم. X را با شکل (10, 32) و y را با شکل (,10) در نظر بگیرید.
import numpy as np
X = np.random.random((32, 10))
X یک ماتریس تصادفی با شکل (10, 32) است.
y = np.random.random((10,))
y یک بردار تصادفی با شکل (,10) است.
ابتدا، یک محور اول خالی به y اضافه میکنیم که شکل آن (10, 1) میشود:
y = np.expand_dims(y, axis=0)
شکل y اکنون (10, 1) است.
سپس، y را 32 بار در امتداد این محور جدید تکرار میکنیم، به طوری که در نهایت یک تنسور Y با شکل (10, 32) داشته باشیم، که در آن Y[i, :] == y برای i در بازه (32, 0) است:
Y = np.concatenate([y] * 32, axis=0)
y را 32 بار در امتداد محور 0 تکرار کنید تا Y به دست آید، که دارای شکل (10, 32) است.
در این مرحله، میتوانیم به جمع کردن X و Y بپردازیم، زیرا آنها شکل یکسانی دارند.
از نظر پیادهسازی، هیچ تنسور مرتبه-2 جدیدی ایجاد نمیشود، زیرا این کار به شدت ناکارآمد خواهد بود. عملیات تکرار کاملاً مجازی است: این عملیات در سطح الگوریتمی رخ میدهد تا در سطح حافظه. اما فکر کردن به اینکه بردار 10 بار در کنار یک محور جدید تکرار میشود، یک مدل ذهنی مفید است. در اینجا یک پیادهسازی ساده نشان داده شده است:
def naive_add_matrix_and_vector(x, y):
assert len(x.shape) == 2
x یک تنسور NumPy مرتبه-2 است.
assert len(y.shape) == 1
y یک بردار NumPy است.
assert x.shape[1] == y.shape[0]
x = x.copy()
پرهیز از بازنویسی تنسور ورودی.
for i in range(x.shape[0]):
for j in range(x.shape[1]): x[i, j] += y[j]
return x
با استفاده از انتشار (broadcasting)، شما معمولاً میتوانید عملیاتهای عنصر به عنصری را انجام دهید که دو تنسور ورودی را میپذیرند، اگر یکی از تنسورها دارای شکل (a,b,…,n,n+1,…,m) و دیگری دارای شکل (n,n+1,…,m) باشد. در این صورت، انتشار به طور خودکار برای محورهای a تا n−1 اتفاق خواهد افتاد.
مثال زیر عملیات حداکثر عنصر به عنصر را با استفاده از انتشار، بر روی دو تنسور با اشکال متفاوت اعمال میکند:
import numpy as np
x = np.random.random((64, 3, 32, 10))
x یک تنسور تصادفی با شکل (10, 32, 3, 64) است.
y = np.random.random((32, 10))
y یک تنسور تصادفی با شکل (10, 32) است.
z = np.maximum(x, y)
خروجی z شکلی مشابه x دارد: (10, 32, 3, 64).
ضرب تنسور (Tensor Product)
ضرب تنسور، یا ضرب نقطهای (که نباید با ضرب عنصر به عنصر، عملگر *، اشتباه گرفته شود)، یکی از رایجترین و مفیدترین عملیاتهای تنسور است.
در نامپای (NumPy)، ضرب تنسور با استفاده از تابع np.dot انجام میشود (زیرا نماد ریاضی برای ضرب تنسور معمولاً یک نقطه است):
x = np.random.random((32,))
y = np.random.random((32,))
z = np.dot(x, y)
در نماد ریاضی، این عملیات را با یک نقطه (•) نشان میدهید:
z = x • y
از نظر ریاضی، عملیات نقطهای (dot product) یا ضرب داخلی بین دو بردار چه کاری انجام میدهد؟
بیایید با ضرب نقطهای بین دو بردار x و y شروع کنیم. این ضرب به صورت زیر محاسبه میشود:
def naive_vector_dot(x, y):
assert len(x.shape) == 1
assert len(y.shape) == 1
بردارهای x و y بردارهایی از نوع NumPy باشند
assert x.shape[0] == y.shape[0]
z = 0.
for i in range(x.shape[0]):
z += x[i] * y[i]
return z
احتمالاً متوجه شدهای که ضرب نقطهای بین دو بردار، حاصلش یک عدد اسکالر (عدد ساده) است، و اینکه فقط بردارهایی که تعداد مؤلفههایشان برابر باشد برای ضرب نقطهای با یکدیگر سازگار هستند.
همچنین میتوان ضرب نقطهای بین یک ماتریس x و یک بردار y را نیز انجام داد.
در این حالت، نتیجهی ضرب نقطهای یک بردار جدید خواهد بود که هر مؤلفهی آن، ضرب نقطهای بردار y با یکی از سطرهای ماتریس x است.
def naive_matrix_vector_dot(x, y):
assert len(x.shape) == 2
x یک ماتریس NumPy است
assert len(y.shape) == 1
y یک ماتریس NumPy است
assert x.shape[1] == y.shape[0]
بعد اول ماتریس x که نشاندهنده تعداد ستونهای آن است باید با بعد صفرم y که نشاندهنده تعداد عناصر آن اگر y بردار باشد، یا تعداد سطرهای آن اگر y ماتریس باشد یکسان باشد!
z = np.zeros(x.shape[0])
این عملیات یک بردار از ۰ها با همان شکل y را برمیگرداند.
for i in range(x.shape[0]):
for j in range(x.shape[1]):
z[i] += x[i, j] * y[j]
return z
همچنین میتوانی از کدی که قبلاً نوشتیم دوباره استفاده کنی، کدی که ارتباط بین ضرب ماتریس-بردار و ضرب بردار-بردار را نشان میدهد.
def naive_matrix_vector_dot(x, y):
z = np.zeros(x.shape[0])
for i in range(x.shape[0]):
z[i] = naive_vector_dot(x[i, :], y)
return z
توجه داشته باش که بهمحض اینکه یکی از دو تنسور تعداد ابعادی بیشتر از ۱ داشته باشد، تابع dot دیگر متقارن نیست؛ یعنی dot(x, y) لزوماً برابر با dot(y, x) نخواهد بود.
البته، ضرب داخلی به تنسورها (تنسورها آرایههایی با تعداد دلخواه محورها هستند) با تعداد دلخواه محورها تعمیم پیدا میکند. رایجترین کاربردها ممکن است ضرب داخلی بین دو ماتریس باشد. شما میتوانید ضرب داخلی دو ماتریس x و y (dot(x, y)) را انجام دهید، اگر و تنها اگر x.shape[1] == y.shape[0] باشد. نتیجه یک ماتریس با شکل (x.shape[0], y.shape[1]) است که ضرایب آن، ضرب داخلی (حاصلضرب برداری) بین سطرهای x و ستونهای y هستند. پیادهسازی ساده آن به این صورت است:
def naive_matrix_dot(x, y):
assert len(x.shape) == 2
x و y هر دو ماتریسهایی از نوع NumPy هستند.
assert len(y.shape) == 2
assert x.shape[1] == y.shape[0]
بعد اولِ x باید با بعد صفرمِ y برابر باشد!
z = np.zeros((x.shape[0], y.shape[1]))
این عملیات، ماتریسی از صفرها با شکلی (ابعادی) مشخص برمیگرداند.
for i in range(x.shape[0]):
بر روی سطرهای ماتریس x تکرار میکند.
for j in range(y.shape[1]):
و بر روی ستونهای ماتریس y تکرار میکند.
row_x = x[i, :] column_y = y[:, j]
z[i, j] = naive_vector_dot(row_x, column_y)
return z
برای درک سازگاری شکل ضرب داخلی (dot-product shape compatibility)، کمک میکند تا تنسورهای ورودی و خروجی را با همتراز کردن آنها، همانطور که در شکل ۲.۵ نشان داده شده است، بصریسازی کنیم.
در این شکل، x، y و z به صورت مستطیل (جعبههای واقعی ضرایب) به تصویر کشیده شدهاند. از آنجایی که سطرهای x و ستونهای y باید اندازه یکسانی داشته باشند، نتیجه میشود که عرض x باید با ارتفاع y مطابقت داشته باشد. اگر به توسعه الگوریتمهای جدید یادگیری ماشین بپردازید، احتمالاً اغلب چنین نمودارهایی را رسم خواهید کرد.
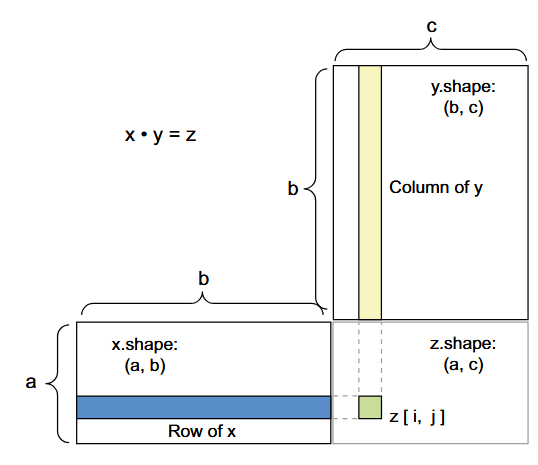
به طور کلیتر، شما میتوانید ضرب داخلی را بین تنسورهای با ابعاد بالاتر انجام دهید و همان قوانین سازگاری شکل را که پیشتر برای حالت ۲ بعدی (ماتریسها) توضیح داده شد، دنبال کنید:
(a, b, c, d) • (d,) ® (a, b, c)
(a, b, c, d) • (d, e) ® (a, b, c, e)
و غیره (به همین ترتیب ادامه مییابد).
تغییر شکل تنسور(Tensor Reshaping)
سومین نوع از عملیات تنسور که درک آن ضروری است، تغییر شکل تنسور (tensor reshaping) است. اگرچه در لایههای Dense در اولین مثال شبکه عصبی ما استفاده نشد، اما ما از آن هنگام پیشپردازش دادههای ارقام قبل از وارد کردن آنها به مدلمان استفاده کردیم:
train_images = train_images.reshape((60000, 28 * 28))
تغییر شکل دادن یک تنسور به معنای مرتب کردن مجدد سطرها و ستونهای آن برای تطابق با یک شکل هدف است. به طور طبیعی، تنسور تغییر شکل یافته همان تعداد کل ضرایب را با تنسور اولیه دارد. تغییر شکل از طریق مثالهای ساده بهتر درک میشود:
>>> x = np.array([[0., 1.],
[2., 3.],
[4., 5.]])
>>> x.shape
(3, 2)
>>> x = x.reshape((6, 1))
>>> x
array([[ 0.],
[ 1.],
[ 2.],
[ 3.],
[ 4.],
[ 5.]])
>>> x = x.reshape((2, 3))
>>> x
array([[ 0., 1., 2.],
[ 3., 4., 5.]])
یک حالت خاص از تغییر شکل که به طور رایج با آن مواجه میشویم، جابهجایی (transposition) است. جابهجا کردن یک ماتریس به معنای جابهجا کردن سطرها و ستونهای آن است، به طوری که x[i, :] به x[:, i] تبدیل میشود:
>>> x = np.zeros((300, 20))
برای ایجاد یک ماتریس تماماً صفر با شکل (2۰، 300)
>>> x = np.transpose(x)
>>> x.shape (20, 300)
تفسیر هندسی عملیاتهای تنسور
از آنجا که محتویات تنسورهایی که با عملیاتهای تنسور دستکاری میشوند، میتوانند به عنوان مختصات نقاطی در یک فضای هندسی تفسیر شوند، تمام عملیاتهای تنسور دارای یک تفسیر هندسی هستند. به عنوان مثال، بیایید جمع را در نظر بگیریم. با بردار زیر شروع میکنیم:
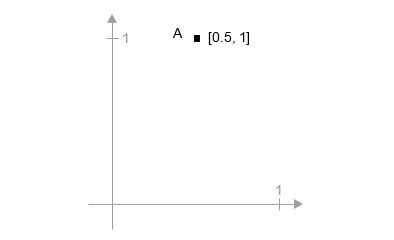
A = [0.5, 1]
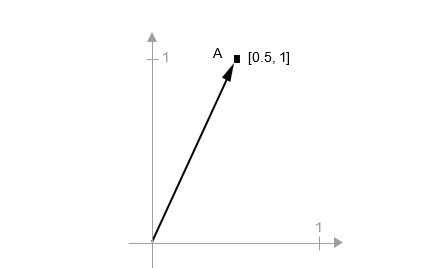
این یک نقطه در یک فضای ۲ بعدی است (به شکل ۲.۶ مراجعه کنید). معمولاً بردار را به صورت فلشی که مبدأ را به نقطه وصل میکند، تصور میکنند، همانطور که در شکل ۲.۷ نشان داده شده است.
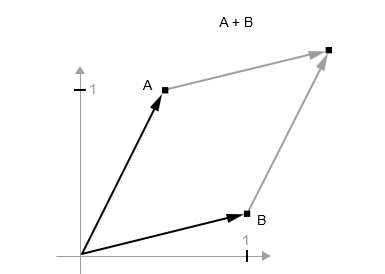
بیایید یک نقطه جدید، [0.25, 1] = B را در نظر بگیریم که آن را به نقطه قبلی اضافه خواهیم کرد. این کار به صورت هندسی با زنجیرهکردن فلشهای بردارها به یکدیگر انجام میشود، به طوری که مکان حاصل، برداری است که مجموع دو بردار قبلی را نشان میدهد (به شکل ۲.۸ مراجعه کنید). همانطور که میبینید، اضافه کردن بردار B به بردار A نشاندهنده عمل کپی کردن نقطه A در مکانی جدید است، که فاصله و جهت آن از نقطه اصلی A توسط بردار B تعیین میشود. اگر همین جمع برداری را به گروهی از نقاط در صفحه (یک “شیء”) اعمال کنید، یک کپی از کل شکل را در مکانی جدید ایجاد خواهید کرد (به شکل ۲.۹ مراجعه کنید). بنابراین، جمع تنسور نشاندهنده عمل انتقال (جابجایی شیء بدون تغییر شکل آن) یک شیء به مقدار معین و در جهتی مشخص است.
به طور کلی، عملیاتهای هندسی ابتدایی مانند انتقال (translation)، دوران (rotation)، مقیاسبندی (scaling)، کجسازی (skewing) و غیره را میتوان به صورت عملیاتهای تنسور بیان کرد. در اینجا چند مثال آورده شده است:
- انتقال (Translation): همانطور که قبلاً دیدید، اضافه کردن یک بردار به یک نقطه، آن نقطه را به میزان ثابت و در جهت ثابت جابجا میکند. این عمل، وقتی به مجموعهای از نقاط (مانند یک شیء دو بعدی) اعمال میشود، “انتقال” نامیده میشود.
- دوران (Rotation): یک دوران پادساعتگرد یک بردار دو بعدی با زاویه تتا (به شکل ۲.۱۰ مراجعه کنید) را میتوان از طریق ضرب داخلی با یک ماتریس ۲ × ۲ به نام R به دست آورد.
R = [[cos(theta),-sin(theta)], [sin(theta), cos(theta)]].
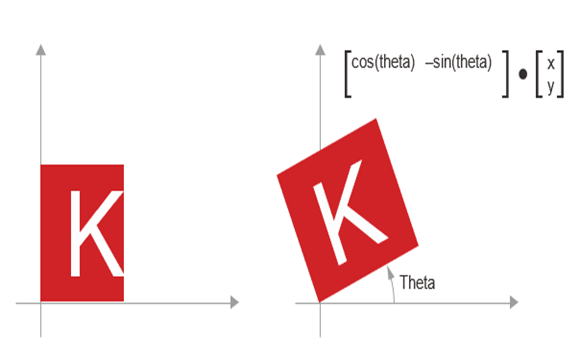
شکل ۲.۱۰: دوران ۲ بعدی (پادساعتگرد) به عنوان یک ضرب داخلی.
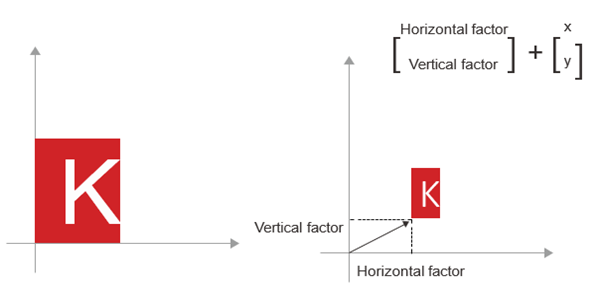
- مقیاسبندی (Scaling): مقیاسبندی عمودی و افقی تصویر (به شکل ۲.۱۱ مراجعه کنید) را میتوان از طریق ضرب داخلی با یک ماتریس ۲ × ۲ به نام S به دست آورد که S = [[horizontal_factor, 0], [0, vertical_factor]] است (توجه داشته باشید که چنین ماتریسی “ماتریس قطری” نامیده میشود، زیرا فقط در “قطر” اصلی خود، از بالا سمت چپ تا پایین سمت راست، ضرایب غیرصفر دارد).
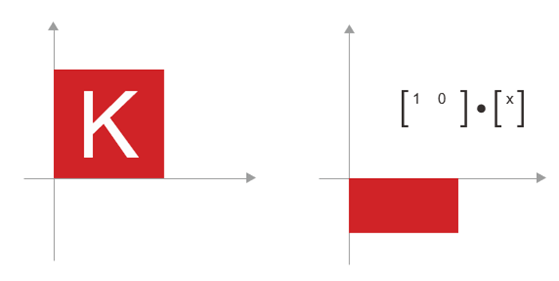
شکل 2.11 مقیاسبندی دو بعدی به عنوان یک ضرب داخلی.
- تبدیل خطی (Linear Transform): یک ضرب داخلی با یک ماتریس دلخواه، یک تبدیل خطی را پیادهسازی میکند. توجه داشته باشید که مقیاسبندی و دوران، که قبلاً ذکر شد، طبق تعریف تبدیلهای خطی هستند.
- تبدیل آفین (Affine Transform): یک تبدیل آفین (به شکل ۲.۱۲ مراجعه کنید) ترکیبی از یک تبدیل خطی (که از طریق ضرب داخلی با یک ماتریس خاص به دست میآید) و یک انتقال (که از طریق جمع برداری به دست میآید) است. همانطور که احتمالاً تشخیص دادهاید، این دقیقاً همان محاسبه y=W⋅x+b است که توسط لایه Dense پیادهسازی میشود! یک لایه Dense بدون تابع فعالسازی، یک لایه آفین است.
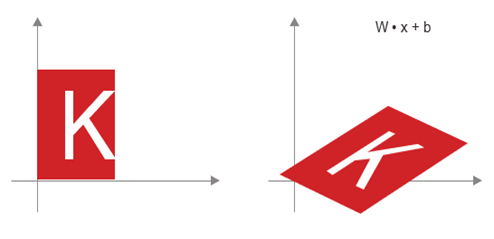
شکل ۲.۱۲: تبدیل آفین در صفحه.
- لایه Dense با فعالسازی ReLU: یک مشاهده مهم در مورد تبدیلهای آفین این است که اگر تعداد زیادی از آنها را به طور مکرر اعمال کنید، باز هم به یک تبدیل آفین ختم میشوید (بنابراین میتوانستید از ابتدا همان یک تبدیل آفین را اعمال کنید). بیایید آن را با دو تبدیل امتحان کنیم: affine2(affine1(x)) = W2 • (W1 • x + b1) + b2 = (W2 • W1) • x + (W2 • b1 + b2). این یک تبدیل آفین است که بخش خطی آن ماتریس W2 • W1 و بخش انتقال آن بردار W2 • b1 + b2 است. در نتیجه، یک شبکه عصبی چند لایه که تماماً از لایههای Dense بدون فعالسازی ساخته شده باشد، معادل یک لایه Dense واحد خواهد بود. این “شبکه عصبی عمیق” فقط یک مدل خطی پنهان خواهد بود! به همین دلیل است که ما به توابع فعالسازی، مانند ReLU نیاز داریم (که در شکل ۲.۱۳ در عمل دیده میشود). به لطف توابع فعالسازی، زنجیرهای از لایههای Dense را میتوان به گونهای ساخت که تبدیلهای هندسی بسیار پیچیده و غیرخطی را پیادهسازی کند، که منجر به فضاهای فرضیه بسیار غنی برای شبکههای عصبی عمیق شما میشود. ما این ایده را در فصل بعدی با جزئیات بیشتری پوشش خواهیم داد.
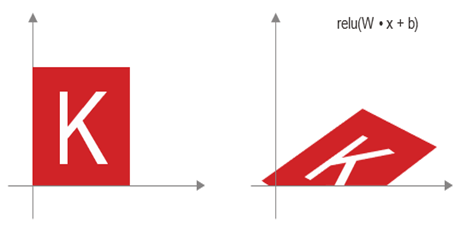
شکل ۲.۱۳: تبدیل آفین که با فعالسازی ReLU دنبال میشود.
تفسیر هندسی یادگیری عمیق
شما به تازگی یاد گرفتید که شبکههای عصبی تماماً از زنجیرهای از عملیاتهای تنسور تشکیل شدهاند و این عملیاتهای تنسور فقط تبدیلهای هندسی سادهای از دادههای ورودی هستند. بنابراین میتوان یک شبکه عصبی را به عنوان یک تبدیل هندسی بسیار پیچیده در یک فضای با ابعاد بالا تفسیر کرد که از طریق مجموعهای از مراحل ساده پیادهسازی شده است.
در فضای سه بعدی، تصویر ذهنی زیر ممکن است مفید باشد. دو ورق کاغذ رنگی را تصور کنید: یکی قرمز و یکی آبی. یکی را روی دیگری قرار دهید. حالا آنها را با هم مچاله کنید تا به یک توپ کوچک تبدیل شوند. این توپ کاغذ مچاله شده، داده ورودی شماست و هر ورق کاغذ، یک کلاس از دادهها در یک مسئله طبقهبندی است. آنچه یک شبکه عصبی قصد انجام آن را دارد، کشف تبدیلی از توپ کاغذی است که آن را باز کند، به طوری که دو کلاس دوباره به طور واضحی از هم جدا شوند (به شکل ۲.۱۴ مراجعه کنید). با یادگیری عمیق، این کار به عنوان مجموعهای از تبدیلهای ساده فضای سه بعدی پیادهسازی میشود، مانند آنهایی که میتوانید با انگشتان خود روی توپ کاغذی اعمال کنید، یک حرکت در یک زمان.
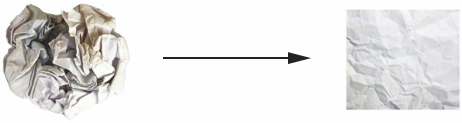
شکل ۲.۱۴: باز کردن یک چندپارگی (manifold) پیچیده از دادهها.
باز کردن توپهای کاغذی همان چیزی است که یادگیری ماشین به آن میپردازد: یافتن نمایشهای دقیق برای منیفولدهای داده پیچیده و بسیار تاخورده در فضاهای با ابعاد بالا (منیفولد یک سطح پیوسته است، مانند ورق کاغذ مچاله شده ما). در این مرحله، باید شهود نسبتاً خوبی داشته باشید که چرا یادگیری عمیق در این کار برتری دارد: این رویکرد را در پیش میگیرد که یک تبدیل هندسی پیچیده را به صورت افزایشی به زنجیرهای طولانی از تبدیلهای ابتدایی تجزیه کند. این دقیقاً همان استراتژی است که یک انسان برای باز کردن یک توپ کاغذی دنبال میکند. هر لایه در یک شبکه عمیق، تبدیلی را اعمال میکند که دادهها را کمی از هم جدا میکند ، و یک پشته عمیق از لایهها، فرآیند گرهگشایی بسیار پیچیده را قابل انجام میکند.
موتور شبکههای عصبی: بهینهسازی مبتنی بر گرادیان (Gradient-based optimization)
همانطور که در بخش قبلی دیدید، هر لایه عصبی از اولین مثال مدل ما، دادههای ورودی خود را به صورت زیر تبدیل میکند:
output = relu(dot(input, W) + b)
در این عبارت، W و b تنسورهایی هستند که ویژگیهای (attributes) لایه محسوب میشوند. آنها وزنها یا پارامترهای قابل آموزش لایه (به ترتیب، ویژگیهای کرنل و بایاس) نامیده میشوند. این وزنها حاوی اطلاعاتی هستند که مدل از طریق مواجهه با دادههای آموزشی یاد گرفته است.
در ابتدا، این ماتریسهای وزن با مقادیر تصادفی کوچک پر میشوند (مرحلهای که مقداردهی اولیه تصادفی نامیده میشود). البته، دلیلی وجود ندارد که انتظار داشته باشیم relu(dot(input, W) + b)، وقتی W و b تصادفی هستند، نمایشهای مفیدی تولید کند. نمایشهای حاصل بیمعنی هستند—اما آنها یک نقطه شروع هستند. آنچه در مرحله بعد میآید، تنظیم تدریجی این وزنها، بر اساس یک سیگنال بازخورد است. این تنظیم تدریجی، که آموزش نیز نامیده میشود، همان یادگیری است که یادگیری ماشین تماماً به آن میپردازد.
این فرآیند در چیزی به نام حلقه آموزش (training loop) اتفاق میافتد که به صورت زیر کار میکند. این مراحل را در یک حلقه تکرار کنید، تا زمانی که به نظر میرسد مقدار زیان (loss) به اندازه کافی پایین آمده است:
۱. یک دستهبندی (batch) از نمونههای آموزشی، x، و اهداف متناظر، y_true را انتخاب کنید.
۲. مدل را روی x اجرا کنید (مرحلهای به نام گذر رو به جلو یا forward pass) تا پیشبینیها، y_pred، را به دست آورید.
۳. مقدار زیان مدل را روی این دستهبندی محاسبه کنید، که معیاری برای اندازهگیری عدم تطابق بین y_pred و y_true است.
۴. تمام وزنهای مدل را به گونهای بهروزرسانی کنید که زیان را در این دستهبندی کمی کاهش دهد.
در نهایت به مدلی دست خواهید یافت که خطای بسیار کمی بر روی دادههای آموزشی خود دارد: عدم تطابق کمی بین پیشبینیها (y_pred) و هدفهای مورد انتظار (y_true). مدل “یاد گرفته است” که ورودیهای خود را به هدفهای صحیح نگاشت کند. از دور ممکن است جادویی به نظر برسد ، اما وقتی آن را به مراحل ابتدایی کاهش دهید، ساده از آب درمیآید.
مرحله ۱ به اندازه کافی آسان به نظر میرسد—فقط کد I/O. مراحل ۲ و ۳ صرفاً کاربرد چند عملیات تنسور هستند ، بنابراین شما میتوانید این مراحل را صرفاً بر اساس آنچه در بخش قبلی آموختید، پیادهسازی کنید. قسمت دشوار مرحله ۴ است: بهروزرسانی وزنهای مدل. با توجه به یک ضریب وزن منفرد در مدل، چگونه میتوانید محاسبه کنید که آیا ضریب باید افزایش یا کاهش یابد و به چه میزان؟
یک راهحل ساده این است که تمام وزنها را در مدل، به جز ضریب اسکالر مورد نظر، ثابت نگه داریم و مقادیر مختلفی را برای این ضریب امتحان کنیم. فرض کنید مقدار اولیه ضریب ۰.۳ است. پس از گذر رو به جلو بر روی دستهای از دادهها، خطای مدل بر روی این دسته ۰.۵ است. اگر مقدار ضریب را به ۰.۳۵ تغییر دهید و گذر رو به جلو را دوباره اجرا کنید، خطا به ۰.۶ افزایش مییابد. اما اگر ضریب را به ۰.۲۵ کاهش دهید، خطا به ۰.۴ کاهش مییابد. در این حالت، به نظر میرسد که بهروزرسانی ضریب با ۰.۰۵- به حداقل رساندن خطا کمک میکند. این کار باید برای تمام ضرایب مدل تکرار شود.
اما چنین رویکردی به طرز وحشتناکی ناکارآمد خواهد بود، زیرا باید برای هر ضریب جداگانه (که تعداد آنها زیاد است، معمولاً هزاران و گاهی تا میلیونها میرسد) دو گذر رو به جلو (که پرهزینه هستند) را محاسبه کنید. خوشبختانه، رویکرد بسیار بهتری وجود دارد: گرادیان کاهشی (gradient descent).
گرادیان کاهشی (Gradient descent) تکنیک بهینهسازی است که شبکههای عصبی مدرن را قدرت میبخشد. اصل مطلب این است: تمام توابعی که در مدلهای ما استفاده میشوند (مانند ضرب داخلی یا جمع) ورودی خود را به شیوهای هموار و پیوسته تبدیل میکنند. برای مثال، اگر به z=x+y نگاه کنید، یک تغییر کوچک در y فقط منجر به یک تغییر کوچک در z میشود. و اگر جهت تغییر در y را بدانید، میتوانید جهت تغییر در z را استنباط کنید. از نظر ریاضی، شما میگویید این توابع مشتقپذیر (differentiable) هستند. اگر چنین توابعی را به صورت زنجیرهای به هم وصل کنید، تابع بزرگتری که به دست میآورید همچنان مشتقپذیر خواهد بود. به طور خاص، این در مورد تابعی که ضرایب مدل را به خطای مدل بر روی دستهای از دادهها نگاشت میکند، صدق میکند: یک تغییر کوچک در ضرایب مدل منجر به یک تغییر کوچک و قابل پیشبینی در مقدار خطا میشود.
این به شما امکان میدهد از یک عملگر ریاضی به نام گرادیان (gradient) برای توصیف اینکه چگونه خطا با حرکت دادن ضرایب مدل در جهات مختلف تغییر میکند، استفاده کنید. اگر این گرادیان را محاسبه کنید، میتوانید از آن برای حرکت دادن ضرایب (همه به یکباره در یک بهروزرسانی واحد، به جای یکییکی) در جهتی که خطا را کاهش میدهد، استفاده کنید.
اگر از قبل میدانید که مشتقپذیر به چه معناست و گرادیان چیست، میتوانید به بخش ۲.۴.۳ بروید. در غیر این صورت، دو بخش بعدی به شما در درک این مفاهیم کمک خواهند کرد.
مشتق چیست؟
تابعی پیوسته و هموار f(x)=y را در نظر بگیرید که یک عدد، x را به عددی جدید، y نگاشت میکند. میتوانیم از تابع در شکل ۲.۱۵ به عنوان مثال استفاده کنیم.
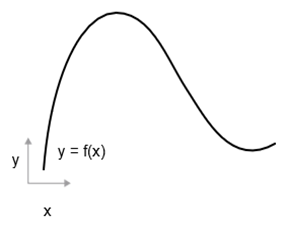
از آنجایی که تابع پیوسته است، یک تغییر کوچک در x تنها میتواند منجر به یک تغییر کوچک در y شود—این شهود مفهوم پیوستگی است. فرض کنید x را با یک عامل کوچک، epsilon_x، افزایش میدهید: این منجر به یک تغییر کوچک epsilon_y در y میشود، همانطور که در شکل ۲.۱۶ نشان داده شده است.
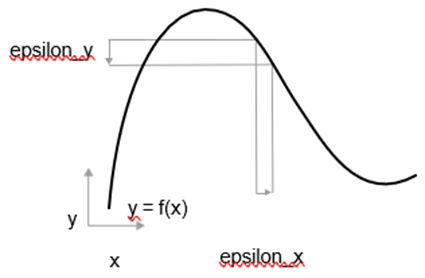
شکل ۲.۱۶: در یک تابع پیوسته، تغییر کوچک در x منجر به تغییر کوچکی در y میشود.
علاوه بر این، چون تابع هموار است (منحنی آن هیچ زاویه ناگهانی ندارد)، وقتی epsilon_x به اندازه کافی کوچک باشد، در اطراف یک نقطه معین p، میتوان f را به عنوان یک تابع خطی با شیب a تقریب زد، به طوری که epsilon_y برابر با epsilon_x * a شود:
f(x + epsilon_x) = y + a * epsilon_x
بدیهی است که این تقریب خطی تنها زمانی معتبر است که x به اندازه کافی به p نزدیک باشد.
شیب a، مشتق f در نقطه p نامیده میشود. اگر a منفی باشد، به این معنی است که افزایش کوچکی در x حول p منجر به کاهش (x) f خواهد شد (همانطور که در شکل ۲.۱۷ نشان داده شده است)، و اگر a مثبت باشد، افزایش کوچکی در x منجر به افزایش (x) f خواهد شد. علاوه بر این، مقدار مطلق a (بزرگی مشتق) به شما میگوید که این افزایش یا کاهش با چه سرعتی رخ خواهد داد.
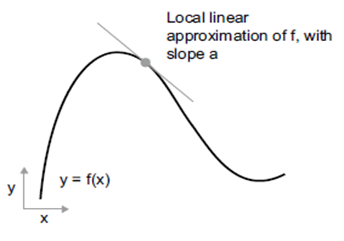
شکل ۲.۱۷: مشتق تابع f در نقطه p.
برای هر تابع مشتقپذیر (x) f (مشتقپذیر به معنای “قابل اشتقاق” است: برای مثال، توابع هموار و پیوسته قابل اشتقاق هستند)، یک تابع مشتق (x)′ f وجود دارد که مقادیر x را به شیب تقریب خطی محلی f در آن نقاط نگاشت میکند. برای مثال، مشتق cos(x) برابر با −sin(x) است، مشتق (x) f =a⋅x برابر با (x)′ f =a است، و غیره.
توانایی اشتقاق توابع، ابزاری بسیار قدرتمند در بهینهسازی است، یعنی وظیفه یافتن مقادیر x که مقدار (x) f را حداقل میکنند. اگر در تلاش برای بهروزرسانی x با یک عامل epsilon_x برای حداقل کردن (x) f هستید، و مشتق f را میدانید، پس کار شما تمام شده است: مشتق به طور کامل چگونگی تغییر (x) f را با تغییر x توصیف میکند. اگر میخواهید مقدار (x) f را کاهش دهید، فقط کافی است x را کمی در جهت مخالف مشتق حرکت دهید.
مشتق یک عملیات تنسور: گرادیان
تابعی که پیشتر به آن میپرداختیم، یک مقدار اسکالر x را به یک مقدار اسکالر دیگر y تبدیل میکرد: میتوانستید آن را به صورت یک منحنی در یک صفحه ۲ بعدی رسم کنید. حالا تابعی را تصور کنید که یک تاپل از اسکالرها (x, y) را به یک مقدار اسکالر z تبدیل میکند: این یک عملیات برداری خواهد بود. میتوانستید آن را به صورت یک سطح ۲ بعدی در یک فضای ۳ بعدی رسم کنید (که توسط مختصات x, y, z ایندکس میشود). به همین ترتیب، میتوانید توابعی را تصور کنید که ماتریسها را به عنوان ورودی میگیرند، توابعی که تنسورهای رنک-۳ را به عنوان ورودی میگیرند و غیره.
مفهوم مشتق را میتوان برای هر یک از این توابع به کار برد، تا زمانی که سطوحی که توصیف میکنند پیوسته و هموار باشند. مشتق یک عملیات تنسور (یا تابع تنسور) گرادیان نامیده میشود. گرادیانها فقط تعمیم مفهوم مشتق به توابعی هستند که تنسورها را به عنوان ورودی میگیرند. به یاد بیاورید که چگونه برای یک تابع اسکالر، مشتق نشاندهنده شیب محلی منحنی تابع بود؟ به همین ترتیب، گرادیان یک تابع تنسور، نشاندهنده انحنای سطح چند بعدی است که توسط تابع توصیف میشود. این گرادیان نحوه تغییر خروجی تابع را هنگامی که پارامترهای ورودی آن تغییر میکنند، مشخص میکند.
بیایید به مثالی در زمینه یادگیری ماشین نگاه کنیم. موارد زیر را در نظر بگیرید:
- یک بردار ورودی، x (یک نمونه در یک مجموعه داده)
- یک ماتریس، W (وزنهای یک مدل)
- یک هدف، y_true (آنچه مدل باید یاد بگیرد که با x مرتبط کند)
- یک تابع خطا، loss (که برای اندازهگیری شکاف بین پیشبینیهای فعلی مدل و y_true طراحی شده است)
شما میتوانید از W برای محاسبه یک کاندید هدف y_pred استفاده کنید، و سپس خطا یا عدم تطابق بین کاندید هدف y_pred و هدف y_true را محاسبه کنید:
y_pred = dot(W, x)
ما از وزنهای مدل، W، برای پیشبینی x استفاده میکنیم.
loss_value = loss(y_pred, y_true)
ما تخمین میزنیم که پیشبینی چقدر انحراف داشته است.
اکنون میخواهیم از گرادیانها استفاده کنیم تا بفهمیم چگونه W را بهروزرسانی کنیم تا loss_value (مقدار خطا) کوچکتر شود. چگونه این کار را انجام دهیم؟
با داشتن ورودیهای ثابت x و y_true، عملیاتهای قبلی را میتوان به عنوان تابعی تفسیر کرد که مقادیر W (وزنهای مدل) را به مقادیر خطا نگاشت میکند:
loss_value = f(W)
f منحنی (یا سطح با ابعاد بالا) را که توسط مقادیر خطا هنگام تغییر W شکل میگیرد، توصیف میکند.
فرض کنید مقدار فعلی W، برابر با W0 است. در این صورت، مشتق تابع f در نقطه W0 یک تنسور به نام grad(loss_value, W0) است. این تنسور شکلی همانند W دارد، که در آن هر ضریب grad(loss_value, W0)[i, j]، نشاندهنده جهت و اندازه تغییری است که در loss_value هنگام تغییر W0[i, j] مشاهده میکنید. این تنسور grad(loss_value, W0)، گرادیان تابع f(W) = loss_value در W0 نامیده میشود که به آن “گرادیان loss_value نسبت به W حول W0” نیز میگویند.
مشتقات جزئی
عملیات تنسور grad(f(W), W) (که یک ماتریس W را به عنوان ورودی میگیرد) را میتوان به صورت ترکیبی از توابع اسکالر grad_ij(f(W), w_ij) بیان کرد. هر یک از این توابع مشتق loss_value = f(W) را نسبت به ضریب W[i, j] از W برمیگرداند، با فرض اینکه تمام ضرایب دیگر ثابت باشند. grad_ij مشتق جزئی f نسبت به W[i, j] نامیده میشود.
به طور ملموس، grad(loss_value, W0) چه چیزی را نشان میدهد؟ پیشتر دیدید که مشتق یک تابع f(x) از یک ضریب واحد را میتوان به عنوان شیب منحنی f تفسیر کرد. به همین ترتیب، grad(loss_value, W0) را میتوان به عنوان تانسوری تفسیر کرد که جهت بیشترین شیب صعود loss_value = f(W) حول W0، و همچنین شیب این صعود را توصیف میکند. هر مشتق جزئی، شیب f را در یک جهت خاص توصیف میکند.
به همین دلیل، درست همانطور که برای یک تابع f(x) میتوانید با حرکت دادن x کمی در جهت مخالف مشتق، مقدار f(x) را کاهش دهید، در مورد یک تابع f(W) از یک تنسور نیز میتوانید loss_value = f(W) را با حرکت دادن W در جهت مخالف گرادیان کاهش دهید: برای مثال، W1 = W0 – step * grad(f(W0), W0) (که step یک عامل مقیاسبندی کوچک است). این به معنای حرکت در خلاف جهت بیشترین شیب صعود f است، که به طور شهودی باید شما را در منحنی پایینتر قرار دهد. توجه داشته باشید که عامل مقیاسبندی step مورد نیاز است زیرا grad(loss_value, W0) تنها منحنی را زمانی که به W0 نزدیک هستید، تخمین میزند، بنابراین نمیخواهید از W0 خیلی دور شوید.
گرادیان کاهشی تصادفی(Stochastic Gradient Descent)
با داشتن یک تابع مشتقپذیر، از لحاظ نظری میتوان حداقل (مینیمم) آن را به صورت تحلیلی پیدا کرد: مشخص است که حداقل یک تابع، نقطهای است که مشتق در آن ۰ است، بنابراین تنها کاری که باید انجام دهید این است که تمام نقاطی را که در آنها مشتق به ۰ میرسد پیدا کرده و بررسی کنید که تابع در کدام یک از این نقاط کمترین مقدار را دارد.
در مورد یک شبکه عصبی، این به معنای یافتن تحلیلی ترکیبی از مقادیر وزن است که کوچکترین مقدار ممکن تابع خطا را به دست میدهد. این کار با حل معادله grad(f(W), W) = 0 برای W قابل انجام است. این یک معادله چندجملهای با N متغیر است که N تعداد ضرایب در مدل است. اگرچه حل چنین معادلهای برای N = 2 یا N = 3 امکانپذیر است، اما برای شبکههای عصبی واقعی که تعداد پارامترها هرگز کمتر از چند هزار نیست و اغلب میتواند چندین ده میلیون باشد، این کار غیرقابل حل است.
در عوض، میتوانید از الگوریتم چهار مرحلهای که در ابتدای این بخش توضیح داده شد استفاده کنید: پارامترها را کمکم بر اساس مقدار خطای فعلی برای یک دسته تصادفی از دادهها تغییر دهید. از آنجایی که شما با یک تابع مشتقپذیر سروکار دارید، میتوانید گرادیان آن را محاسبه کنید، که راهی کارآمد برای پیادهسازی مرحله ۴ به شما میدهد. اگر وزنها را در جهت مخالف گرادیان بهروزرسانی کنید، مقدار خطا هر بار کمی کمتر خواهد شد:
- دستهای از نمونههای آموزشی، x، و هدفهای متناظر، y_true، را استخراج کنید.
- مدل را روی x اجرا کنید تا پیشبینیها، y_pred، را به دست آورید (این “گذر رو به جلو” نامیده میشود).
- خطای مدل را روی دسته محاسبه کنید، که معیاری برای اندازهگیری عدم تطابق بین y_pred و y_true است.
- گرادیان خطا را با توجه به پارامترهای مدل محاسبه کنید (این “گذر رو به عقب” نامیده میشود).
- پارامترها را کمی در جهت مخالف گرادیان حرکت دهید—برای مثال، W -= learning_rate * gradient—بدین ترتیب خطای روی دسته را کمی کاهش دهید. نرخ یادگیری (learning_rate در اینجا) یک عامل اسکالر خواهد بود که “سرعت” فرآیند گرادیان کاهشی را تعدیل میکند.
به همین سادگی! آنچه که ما توصیف کردیم، گرادیان کاهشی تصادفی مینی-بچ (mini-batch stochastic gradient descent) نامیده میشود. اصطلاح “تصادفی” (stochastic) به این واقعیت اشاره دارد که هر دسته از دادهها به صورت تصادفی استخراج میشوند تصادفی یک مترادف علمی برای random است. شکل ۲.۱۸ آنچه را که در ۱ بُعد اتفاق میافتد، زمانی که مدل تنها یک پارامتر و شما تنها یک نمونه آموزشی دارید، نشان میدهد.
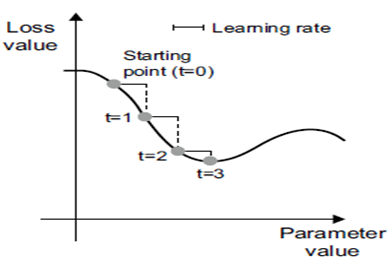
شکل ۲.۱۸: نزول SGD در یک منحنی خطای ۱ بعدی (یک پارامتر قابل یادگیری).
همانطور که میبینید، به صورت شهودی مهم است که یک مقدار منطقی برای عامل learning_rate انتخاب کنید. اگر خیلی کوچک باشد، نزول در امتداد منحنی تکرارهای زیادی طول میکشد و ممکن است در یک حداقل محلی گیر کند. اگر learning_rate خیلی بزرگ باشد، بهروزرسانیهای شما ممکن است شما را به مکانهای کاملاً تصادفی روی منحنی ببرند.
توجه داشته باشید که یک نوع از الگوریتم گرادیان کاهشی تصادفی مینی-بچ (mini-batch SGD) این است که به جای کشیدن یک بچ از دادهها، در هر تکرار یک نمونه و هدف منفرد را استخراج کند. این به عنوان SGD واقعی (در مقابل mini-batch SGD) شناخته میشود. متناوباً، با رفتن به نقطه مقابل افراط، میتوانید هر مرحله را بر روی تمام دادههای موجود اجرا کنید، که به آن گرادیان کاهشی بچ (batch gradient descent) گفته میشود. در این صورت، هر بهروزرسانی دقیقتر خواهد بود، اما بسیار پرهزینهتر. سازش کارآمد بین این دو افراط، استفاده از مینی-بچها با اندازه منطقی است.
اگرچه شکل ۲.۱۸ گرادیان کاهشی را در یک فضای پارامتر ۱ بعدی نشان میدهد، در عمل شما از گرادیان کاهشی در فضاهای بسیار با ابعاد بالا استفاده خواهید کرد: هر ضریب وزن در یک شبکه عصبی یک بُعد آزاد در فضا است، و ممکن است دهها هزار یا حتی میلیونها از آنها وجود داشته باشد. برای کمک به شما در ایجاد شهود در مورد سطوح خطا، میتوانید گرادیان کاهشی را در امتداد یک سطح خطای ۲ بعدی نیز بصریسازی کنید، همانطور که در شکل ۲.۱۹ نشان داده شده است. اما شما نمیتوانید به طور قطعی فرآیند واقعی آموزش یک شبکه عصبی را بصریسازی کنید—نمیتوانید یک فضای ۱,۰۰۰,۰۰۰ بعدی را به شکلی که برای انسانها قابل درک باشد، نمایش دهید. به همین ترتیب، خوب است به خاطر داشته باشید که شهوداتی که از طریق این نمایشهای کمبعدی به دست میآورید، ممکن است همیشه در عمل دقیق نباشند. این به لحاظ تاریخی منبع مشکلاتی در دنیای تحقیقات یادگیری عمیق بوده است.
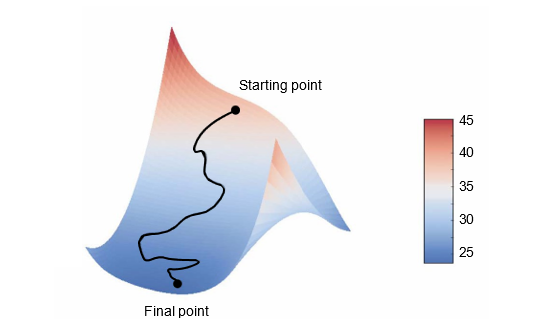
شکل ۲.۱۹: نزول گرادیان کاهشی در یک سطح خطای ۲ بعدی (دو پارامتر قابل یادگیری).
علاوه بر این، چندین نوع مختلف از SGD وجود دارد که با در نظر گرفتن بهروزرسانیهای وزن قبلی هنگام محاسبه بهروزرسانی وزن بعدی، به جای فقط نگاه کردن به مقدار فعلی گرادیانها، با یکدیگر تفاوت دارند. به عنوان مثال، SGD با مومنتوم، و همچنین Adagrad، RMSprop و چندین روش دیگر وجود دارد. این گونه روشها به عنوان روشهای بهینهسازی یا بهینهسازها (optimizers) شناخته میشوند. به طور خاص، مفهوم مومنتوم که در بسیاری از این روشها استفاده میشود، شایسته توجه شماست. مومنتوم دو مشکل SGD را برطرف میکند: سرعت همگرایی و مینیممهای محلی. شکل ۲.۲۰ را در نظر بگیرید، که منحنی یک خطا را به عنوان تابعی از یک پارامتر مدل نشان میدهد.
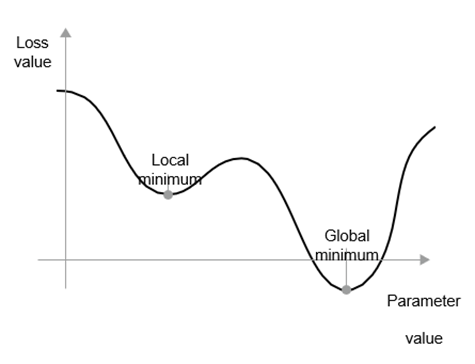
شکل ۲.۲۰: یک حداقل محلی و یک حداقل سراسری.
همانطور که میبینید، در اطراف یک مقدار پارامتر مشخص، یک حداقل محلی (local minimum) وجود دارد: در اطراف آن نقطه، حرکت به سمت چپ منجر به افزایش خطا میشود، و حرکت به سمت راست نیز همینطور. اگر پارامتر مورد نظر با SGD و نرخ یادگیری کوچک بهینهسازی میشد، فرآیند بهینهسازی میتوانست به جای رسیدن به حداقل سراسری (global minimum)، در حداقل محلی گیر کند.
شما میتوانید با استفاده از مومنتوم (momentum) از چنین مشکلاتی جلوگیری کنید، که از فیزیک الهام گرفته شده است. یک تصویر ذهنی مفید در اینجا این است که فرآیند بهینهسازی را به عنوان یک توپ کوچک تصور کنید که در حال غلتیدن در منحنی خطا است. اگر مومنتوم کافی داشته باشد، توپ در یک دره گیر نمیکند و در نهایت به حداقل سراسری خواهد رسید. مومنتوم با حرکت دادن توپ در هر مرحله، نه تنها بر اساس مقدار شیب فعلی (شتاب فعلی) بلکه بر اساس سرعت فعلی (ناشی از شتاب گذشته) پیادهسازی میشود. در عمل، این به معنای بهروزرسانی پارامتر w است، نه تنها بر اساس مقدار گرادیان فعلی، بلکه بر اساس بهروزرسانی پارامتر قبلی، همانند این پیادهسازی ساده:
past_velocity = 0.
momentum = 0.1
ضریب مومنتوم ثابت
while loss > 0.01:
حلقه بهینهسازی
w, loss, gradient = get_current_parameters()
velocity = past_velocity * momentum – learning_rate * gradient w = w + momentum * velocity – learning_rate * gradient past_velocity = velocity
update_parameter(w)
زنجیره مشتقات: الگوریتم پسانتشار (Backpropagation)
در الگوریتم قبلی، ما به طور غیررسمی فرض کردیم که چون یک تابع مشتقپذیر است، میتوانیم به راحتی گرادیان آن را محاسبه کنیم. اما آیا این درست است؟ چگونه میتوانیم گرادیان عبارات پیچیده را در عمل محاسبه کنیم؟ در مدل دو لایهای که فصل را با آن شروع کردیم، چگونه میتوانیم گرادیان خطا را نسبت به وزنها به دست آوریم؟ اینجاست که الگوریتم پسانتشار وارد میشود.
قاعده زنجیرهای
پسانتشار راهی است برای استفاده از مشتقات عملیاتهای ساده (مانند جمع، ReLU، یا ضرب تنسوری) تا گرادیان ترکیبات دلخواه پیچیده از این عملیاتهای اتمی به راحتی محاسبه شود. نکته حیاتی این است که یک شبکه عصبی از بسیاری عملیاتهای تنسور تشکیل شده است که به صورت زنجیرهای به هم متصل شدهاند، و هر یک از آنها مشتق ساده و شناخته شدهای دارد. برای مثال، مدل تعریف شده در فهرست ۲.۲ را میتوان به عنوان تابعی پارامتری شده با متغیرهای W1، b1، W2 و b2 (که به ترتیب به لایههای Dense اول و دوم تعلق دارند) بیان کرد که شامل عملیاتهای اتمی ضرب داخلی (dot)، ReLU، Softmax و جمع (+) و همچنین تابع خطای loss ما میشود، که همگی به راحتی مشتقپذیر هستند:
loss_value = loss(y_true, softmax(dot(relu(dot(inputs, W1) + b1), W2) + b2))
حسابان به ما میگوید که چنین زنجیرهای از توابع را میتوان با استفاده از هویت زیر، که قاعده زنجیرهای نامیده میشود، مشتق گرفت.
دو تابع f و g، و همچنین تابع ترکیبی fg را در نظر بگیرید به طوری که (x) fg == ((x) g) f:
def fg(x):
x1 = g(x)
y = f(x1)
return y
سپس، قاعده زنجیرهای بیان میکند که grad(y, x) == grad(y, x1) * grad(x1, x). این به شما امکان میدهد مشتق fg را تا زمانی که مشتقات f و g را میدانید، محاسبه کنید. قاعده زنجیرهای به این دلیل نامگذاری شده است که وقتی توابع میانی بیشتری اضافه میکنید، شروع به شبیه شدن به یک زنجیره میکند:
def fghj(x):
x1 = j(x)
x2 = h(x1)
x3 = g(x2)
y = f(x3)
return y
grad(y, x) == (grad(y, x3) * grad(x3, x2) *
grad(x2, x1) * grad(x1, x))
اعمال قاعده زنجیرهای به محاسبه مقادیر گرادیان یک شبکه عصبی منجر به الگوریتمی به نام پسانتشار (backpropagation) میشود. بیایید به طور ملموس ببینیم که چگونه این کار میکند.
تفکیک خودکار با گرافهای محاسباتی
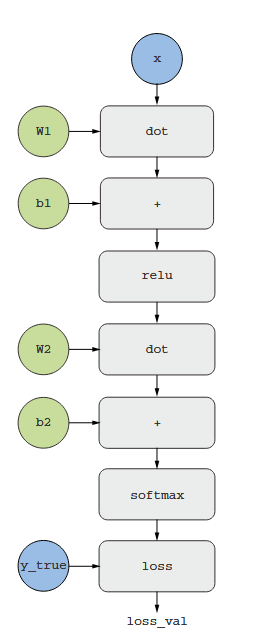
یک روش مفید برای تفکر در مورد پسانتشار (backpropagation) از منظر گرافهای محاسباتی (computation graphs) است. گراف محاسباتی ساختار دادهای است که در قلب تنسورفلو (TensorFlow) و انقلاب یادگیری عمیق به طور کلی قرار دارد. این یک گراف جهتدار بدون دور (directed acyclic graph) از عملیاتها است—در مورد ما، عملیاتهای تنسور. برای مثال، شکل ۲.۲۱ نمایش گرافیکی مدل اول ما را نشان میدهد.
گرافهای محاسباتی در علوم کامپیوتر به دلیل اینکه ما را قادر میسازند تا محاسبات را به عنوان داده در نظر بگیریم، یک انتزاع فوقالعاده موفق بودهاند: یک عبارت قابل محاسبه به عنوان یک ساختار داده قابل خواندن توسط ماشین کدگذاری میشود که میتواند به عنوان ورودی یا خروجی یک برنامه دیگر استفاده شود. برای مثال، میتوانید برنامهای را تصور کنید که یک گراف محاسباتی را دریافت میکند و یک گراف محاسباتی جدید را برمیگرداند که یک نسخه توزیعشده در مقیاس بزرگ از همان محاسبه را پیادهسازی میکند—این بدان معناست که شما میتوانید هر محاسباتی را بدون نیاز به نوشتن منطق توزیع توسط خودتان، توزیع کنید. یا برنامهای را تصور کنید که یک گراف محاسباتی را دریافت میکند و میتواند به طور خودکار مشتق عبارتی را که نشان میدهد، تولید کند. انجام این کارها بسیار آسانتر است اگر محاسبات شما به عنوان یک ساختار داده گراف صریح بیان شود تا مثلاً خطوط کاراکتر ASCII در یک فایل .py.
برای توضیح واضح پسانتشار (backpropagation)، بیایید به یک مثال واقعاً ساده از یک گراف محاسباتی نگاه کنیم (به شکل ۲.۲۲ مراجعه کنید). ما یک نسخه سادهشده از شکل ۲.۲۱ را در نظر میگیریم، که در آن فقط یک لایه خطی داریم و تمام متغیرها اسکالر هستند. ما دو متغیر اسکالر w و b، یک ورودی اسکالر x را میگیریم و عملیاتی را روی آنها اعمال میکنیم تا آنها را در یک خروجی y ترکیب کنیم. در نهایت، یک تابع خطای قدر مطلق را اعمال میکنیم: loss_val = abs(y_true – y). از آنجایی که میخواهیم w و b را به گونهای بهروزرسانی کنیم که loss_val را حداقل کند، علاقهمند به محاسبه grad(loss_val, b) و grad(loss_val, w) هستیم.
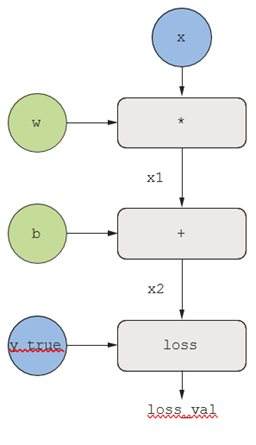
شکل ۲.۲۲: یک مثال پایه از یک گراف محاسباتی.
بیایید مقادیر مشخصی را برای “گرههای ورودی” در گراف تعیین کنیم، یعنی ورودی x، هدف y_true، w و b. این مقادیر را از بالا به پایین، به تمام گرهها در گراف انتشار میدهیم، تا زمانی که به loss_val برسیم. این همان گذر رو به جلو (forward pass) است (به شکل ۲.۲۳ مراجعه کنید).
حالا بیایید گراف را “معکوس” کنیم: برای هر یال در گراف که از A به B میرود، یک یال مخالف از B به A ایجاد میکنیم و میپرسیم، B چقدر تغییر میکند وقتی A تغییر میکند؟ به عبارت دیگر، grad(B, A) چیست؟ هر یال معکوس را با این مقدار مشخص میکنیم. این گراف معکوس، گذر رو به عقب (backward pass) را نشان میدهد (به شکل ۲.۲۴ مراجعه کنید).
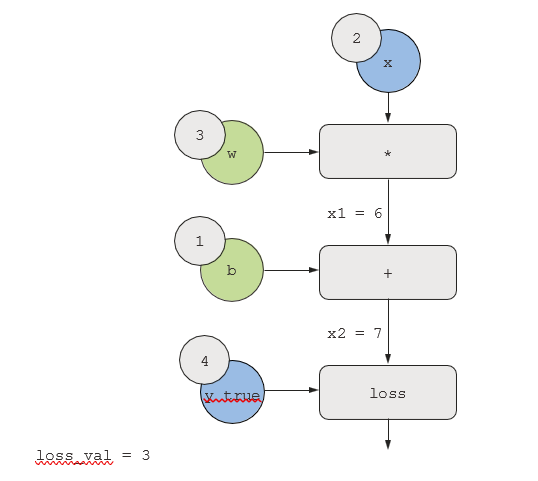
شکل ۲.۲۳: اجرای یک گذر رو به جلو.
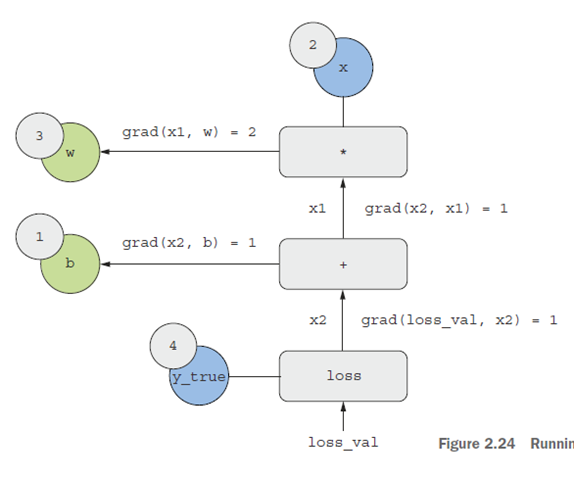
شکل ۲.۲۴: اجرای یک گذر رو به عقب.
ما موارد زیر را داریم:
- grad(loss_val, x2) = 1، زیرا همانطور که x2 به میزان اپسیلون تغییر میکند، loss_val = abs(4 – x2) نیز به همان میزان تغییر میکند.
- grad(x2, x1) = 1، زیرا همانطور که x1 به میزان اپسیلون تغییر میکند، x2 = x1 + b = x1 + 1 نیز به همان میزان تغییر میکند.
- grad(x2, b) = 1، زیرا همانطور که b به میزان اپسیلون تغییر میکند، x2 = x1 + b = 6 + b نیز به همان میزان تغییر میکند.
- grad(x1, w) = 2، زیرا همانطور که w به میزان اپسیلون تغییر میکند، x1 = x * w = 2 * w به اندازه 2 * epsilon تغییر میکند.
آنچه قاعده زنجیرهای در مورد این گراف معکوس میگوید این است که میتوانید مشتق یک گره را نسبت به گره دیگر با ضرب مشتقات برای هر یال در طول مسیری که دو گره را به هم وصل میکند، به دست آورید. برای مثال، grad(loss_val, w) = grad(loss_val, x2) * grad(x2, x1) * grad(x1, w) (به شکل ۲.۲۵ مراجعه کنید).
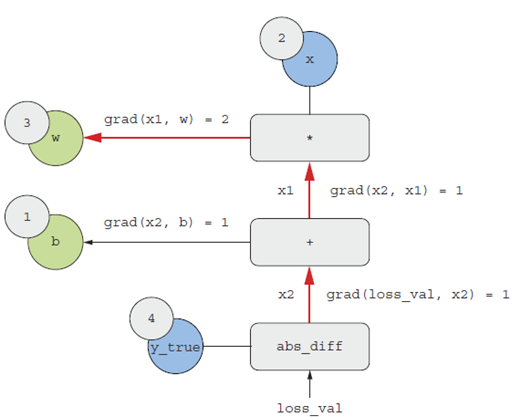
شکل ۲.۲۵: مسیر از loss_val به w در گراف معکوس.
با اعمال قاعده زنجیرهای به گرافمان، به آنچه که به دنبالش بودیم دست مییابیم:
- grad(loss_val, w) = 1 * 1 * 2 = 2
- grad(loss_val, b) = 1 * 1 = 1
توجه: اگر چندین مسیر دو گره مورد نظر، a و b را در گراف معکوس به هم وصل کنند، grad(b, a) را با جمع کردن سهم تمام مسیرها به دست میآوریم.
و با این توضیحات، شما اکنون پسانتشار را در عمل دیدید! پسانتشار صرفاً کاربرد قاعده زنجیرهای در یک گراف محاسباتی است. چیز بیشتری در آن وجود ندارد. پسانتشار با مقدار نهایی خطا شروع میشود و از لایههای بالایی به لایههای پایینی به صورت معکوس عمل میکند و سهم هر پارامتر را در مقدار خطا محاسبه مینماید. نام “پسانتشار” از همینجا میآید: ما سهمهای خطا را از گرههای مختلف در یک گراف محاسباتی “به عقب انتشار میدهیم”.
امروزه مردم شبکههای عصبی را در فریمورکهای مدرن که قادر به تفکیک خودکار هستند، مانند TensorFlow، پیادهسازی میکنند. تفکیک خودکار با همان نوع گراف محاسباتی که تازه دیدید، پیادهسازی میشود. تفکیک خودکار این امکان را فراهم میکند که گرادیانهای ترکیبات دلخواه از عملیاتهای تنسور مشتقپذیر را بدون انجام کار اضافی به جز نوشتن گذر رو به جلو، بازیابی کنید. زمانی که من اولین شبکههای عصبی خود را در دهه ۲۰۰۰ به زبان C مینوشتم، مجبور بودم گرادیانهایم را به صورت دستی بنویسم. اکنون، به لطف ابزارهای مدرن تفکیک خودکار، شما هرگز مجبور نخواهید بود پسانتشار را خودتان پیادهسازی کنید. خودتان را خوششانس بدانید!
گرادیان تیپ در تنسورفلو (The gradient tape in TensorFlow)
API که از طریق آن میتوانید از قابلیتهای قدرتمند تفکیک خودکار تنسورفلو بهره ببرید، GradientTape است. این یک “اسکوپ” پایتون است که عملیاتهای تنسور را که در داخل آن اجرا میشوند، به شکل یک گراف محاسباتی (که گاهی “تیپ” نامیده میشود) “ضبط” میکند. سپس از این گراف میتوان برای بازیابی گرادیان هر خروجی نسبت به هر متغیر یا مجموعهای از متغیرها (نمونههایی از کلاس tf.Variable) استفاده کرد. tf.Variable نوع خاصی از تنسور است که برای نگهداری حالت قابل تغییر طراحی شده است—به عنوان مثال، وزنهای یک شبکه عصبی همیشه نمونههایی از tf.Variable هستند.
import tensorflow as tf
x = tf.Variable(0.)
یک متغیر اسکالر (Scalar Variable) را با مقدار اولیه صفر به شکل زیر تعریف کنیم:
with tf.GradientTape() as tape:
برای باز کردن یک دامنه (scope) از GradientTape
y = 2 * x + 3
در داخل اسکوپ، برخی عملیات تنسور را روی متغیرمان اعمال میکنیم.
grad_of_y_wrt_x = tape.gradient(y, x)
برای استفاده از tape جهت بازیابی گرادیان خروجی z (که همان خروجی نهایی عملیاتها بود) نسبت به متغیر scalar_variable (که شما آن را x نامیدید) در TensorFlow، باید متغیر مورد نظر را در tape.gradient() مشخص کنید.
The GradientTape works with tensor operations:
x = tf.Variable(tf.random.uniform((2, 2)))
برای نمونهسازی یک Variable با شکل (۲, ۲) و مقدار اولیه تماماً صفر در TensorFlow، میتوانید از tf.Variable() استفاده کنید و به آن tf.zeros() را با شکل مورد نظر بدهید.
with tf.GradientTape() as tape:
y = 2 * x + 3
grad_of_y_wrt_x = tape.gradient(y, x)
grad_of_y_wrt_x تنسوری با شکل (۲, ۲) (مانند x) است که انحنای y=2×a+3 حول x=[[0,0],[0,0]] را توصیف میکند.
این روش با لیست متغیرها نیز کار میکند:
W = tf.Variable(tf.random.uniform((2, 2)))
b = tf.Variable(tf.zeros((2,)))
x = tf.random.uniform((2, 2))
with tf.GradientTape() as tape:
y = tf.matmul(x, W) + b
matmul (یا tf.matmul) در تنسورفلو، معادل عملیات “ضرب داخلی” برای ماتریسها یا “ضرب ماتریسی” است.
grad_of_y_wrt_W_and_b = tape.gradient(y, [W, b])
grad_of_y_wrt_W_and_b لیستی از دو تنسور است که به ترتیب دارای شکلهای مشابه W و b هستند.
شما در فصل بعدی درباره “گرادیان تیپ” (gradient tape) خواهید آموخت.
نگاهی دوباره به اولین مثال ما
شما در حال نزدیک شدن به پایان این فصل هستید، و اکنون باید درک کلی از آنچه در پشت صحنه یک شبکه عصبی میگذرد، داشته باشید. آنچه در ابتدای فصل یک جعبه سیاه جادویی بود، به تصویری واضحتر تبدیل شده است، همانطور که در شکل ۲.۲۶ نشان داده شده است: مدل، متشکل از لایههایی که به هم زنجیر شدهاند، دادههای ورودی را به پیشبینیها نگاشت میکند. سپس تابع خطا، این پیشبینیها را با هدفها مقایسه کرده و یک مقدار خطا تولید میکند: معیاری برای اینکه پیشبینیهای مدل چقدر با آنچه انتظار میرفت مطابقت دارند. بهینهساز از این مقدار خطا برای بهروزرسانی وزنهای مدل استفاده میکند.
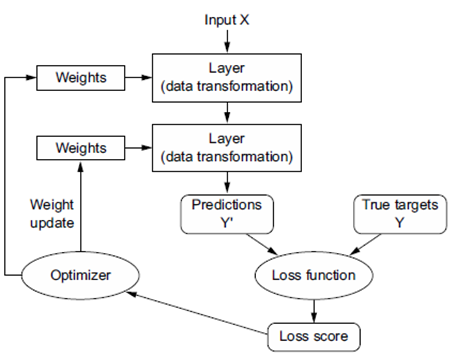
شکل ۲.۲۶: رابطه بین شبکه، لایهها، تابع خطا و بهینهساز.
بیایید به مثال اول این فصل برگردیم و هر بخش از آن را در پرتو آنچه از آن زمان آموختهاید، بازبینی کنیم.
این داده ورودی بود:
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype(“float32”) / 255
test_images= test_images.reshape((10000, 28 * 28))
test_images = test_images.astype(“float32”) / 255
اکنون شما میدانید که تصاویر ورودی در تنسورهای NumPy ذخیره میشوند، که در اینجا به ترتیب به صورت تنسورهای float32 با شکل (۷۸۴, 60000) (دادههای آموزشی) و (۷۸۴, 10000) (دادههای آزمایشی) فرمت شدهاند.
این مدل ما بود:
model = keras.Sequential([
layers.Dense(512, activation=”relu”), layers.Dense(10, activation=”softmax”)
])
اکنون شما میدانید که این مدل از یک زنجیره متشکل از دو لایه Dense تشکیل شده است، که هر لایه چند عملیات ساده تنسور را بر روی دادههای ورودی اعمال میکند، و این عملیاتها شامل تنسورهای وزن هستند. تنسورهای وزن، که ویژگیهای لایهها هستند، جایی است که دانش مدل در آن ماندگار میشود.
این مرحله کامپایل مدل بود:
model.compile(optimizer=”rmsprop”,
loss=”sparse_categorical_crossentropy”,
metrics=[“accuracy”])
اکنون میدانید که sparse_categorical_crossentropy تابع خطایی است که به عنوان سیگنال بازخورد برای یادگیری تنسورهای وزن استفاده میشود، و فاز آموزش تلاش خواهد کرد آن را به حداقل برساند. همچنین میدانید که این کاهش خطا از طریق گرادیان کاهشی تصادفی مینی-بچ (mini-batch stochastic gradient descent) اتفاق میافتد. قوانین دقیقی که بر یک استفاده خاص از گرادیان کاهشی حاکم است، توسط بهینهساز rmsprop که به عنوان اولین آرگومان ارسال شده، تعریف میشوند.
در نهایت، این حلقه آموزشی بود:
model.fit(train_images, train_labels, epochs=5, batch_size=128)
اکنون شما متوجه میشوید که با فراخوانی fit چه اتفاقی میافتد: مدل شروع به تکرار بر روی دادههای آموزشی در مینی-بچهایی با ۱۲۸ نمونه میکند، ۵ بار متوالی (هر تکرار بر روی تمام دادههای آموزشی یک “اِپوک” نامیده میشود). برای هر بچ، مدل گرادیان خطا را با توجه به وزنها محاسبه خواهد کرد (با استفاده از الگوریتم پسانتشار که از قاعده زنجیرهای در حسابان مشتق شده است) و وزنها را در جهتی حرکت میدهد که مقدار خطا را برای این بچ کاهش دهد.
پس از این ۵ اِپوک، مدل ۲,۳۴۵ بهروزرسانی گرادیان (۴۶۹ بهروزرسانی در هر اِپوک) را انجام داده خواهد بود، و خطای مدل به اندازه کافی پایین خواهد آمد که مدل قادر به طبقهبندی ارقام دستنویس با دقت بالا باشد.
در این مرحله، شما بیشتر آنچه را که لازم است در مورد شبکههای عصبی بدانید، میدانید. بیایید با پیادهسازی گام به گام یک نسخه سادهشده از مثال اول “از پایه” در TensorFlow، این را ثابت کنیم.
پیادهسازی مجدد مثال اولمان از پایه در TensorFlow
چه چیزی بهتر از پیادهسازی همهچیز از پایه، درک کامل و بدون ابهام را نشان میدهد؟ البته، منظور از “از پایه” در اینجا نسبی است: ما عملیاتهای پایه تنسور را دوباره پیادهسازی نخواهیم کرد، و پسانتشار را نیز پیادهسازی نمیکنیم. اما به سطحی پایین خواهیم رفت که تقریباً هیچ یک از قابلیتهای Keras را اصلاً استفاده نخواهیم کرد.
نگران نباشید اگر هنوز تمام جزئیات کوچک این مثال را درک نمیکنید. فصل بعدی با جزئیات بیشتری به API تنسورفلو خواهد پرداخت. در حال حاضر، فقط سعی کنید اصل مطلب را دنبال کنید—هدف این مثال کمک به شفافسازی درک شما از ریاضیات یادگیری عمیق با استفاده از یک پیادهسازی ملموس است. بزن بریم!
یک کلاس Dense ساده
پیشتر یاد گرفتید که لایه Dense تبدیل ورودی زیر را پیادهسازی میکند، که در آن W و b پارامترهای مدل هستند، و activation یک تابع عنصر به عنصر است (معمولاً ReLU، اما برای لایه آخر softmax خواهد بود):
output = activation(dot(W, input) + b)
بیایید یک کلاس ساده پایتون به نام NaiveDense را پیادهسازی کنیم که دو متغیر TensorFlow به نامهای W و b را ایجاد میکند و یک متد () call را ارائه میدهد که تبدیل قبلی را اعمال میکند.
import tensorflow as tf
class NaiveDense:
def init (self, input_size, output_size, activation):
self.activation = activation
w_shape = (input_size, output_size)
برای ایجاد یک ماتریس، W، با شکل (input_size, output_size) که با مقادیر تصادفی مقداردهی اولیه شده باشد، میتوانید از tf.Variable به همراه tf.random.uniform در TensorFlow استفاده کنید.
w_initial_value = tf.random.uniform(w_shape, minval=0, maxval=1e-1)
self.W = tf.Variable(w_initial_value)
b_shape = (output_size, b_initial_value = tf.zeros(b_shape)
self.b = tf.Variable(b_initial_value)
برای ایجاد یک بردار، b، با شکل (output_size,) که با صفرهای مقداردهی اولیه شده باشد، میتوانید از tf.Variable به همراه tf.zeros() در TensorFlow استفاده کنید.
def call (self, inputs)::
اعمال گذر رو به جلو (forward pass)
return self.activation(tf.matmul(inputs, self.W) + self.b)
@property
def weights(self):
return [self.W, self.b]
متد راحتی برای بازیابی وزنهای لایه.
یک کلاس Sequential ساده
اکنون، بیایید یک کلاس NaiveSequential برای زنجیرهای کردن این لایهها ایجاد کنیم. این کلاس لیستی از لایهها را در بر میگیرد و یک متد () call را ارائه میدهد که به سادگی لایههای زیرین را به ترتیب بر روی ورودیها فراخوانی میکند. همچنین دارای یک ویژگی weights است تا به راحتی پارامترهای لایهها را پیگیری کند.
class NaiveSequential:
def init (self, layers): self.layers = layers
def call (self, inputs): x = inputs
for layer in self.layers: x = layer(x)
return x
@property
def weights(self): weights = []
for layer in self.layers: weights += layer.weights
return weights
با استفاده از کلاس NaiveDense و کلاس NaiveSequential، میتوانیم یک مدل Keras فرضی ایجاد کنیم:
model = NaiveSequential([
NaiveDense(input_size=28 * 28, output_size=512, activation=tf.nn.relu), NaiveDense(input_size=512, output_size=10, activation=tf.nn.softmax)
])
assert len(model.weights) == 4
مولد دستهای (A BATCH GENERATOR)
در ادامه، به روشی برای تکرار بر روی دادههای MNIST در مینی-بچها (mini-batches) نیاز داریم. این کار آسان است:
import math
class BatchGenerator:
def init (self, images, labels, batch_size=128):
assert len(images) == len(labels) self.index = 0
self.images = images self.labels = labels self.batch_size = batch_size
self.num_batches = math.ceil(len(images) / batch_size)
def next(self):
images = self.images[self.index : self.index + self.batch_size] labels = self.labels[self.index : self.index + self.batch_size] self.index += self.batch_size
return images, labels
اجرای یک گام آموزشی
دشوارترین بخش این فرآیند “گام آموزش” است: بهروزرسانی وزنهای مدل پس از اجرای آن بر روی یک دسته از دادهها. ما نیاز داریم که:
۱. پیشبینیهای مدل را برای تصاویر موجود در دسته محاسبه کنیم.
۲. مقدار خطا را برای این پیشبینیها، با توجه به برچسبهای واقعی، محاسبه کنیم.
۳. گرادیان خطا را با توجه به وزنهای مدل محاسبه میکنیم.
۴. وزنها را به مقدار کمی در جهت مخالف گرادیان حرکت میدهیم.
برای محاسبه گرادیان، از شیء TensorFlow GradientTape که در بخش ۲.۴.۴ معرفی کردیم، استفاده خواهیم کرد.
برای اجرای “گذر رو به جلو” و محاسبه پیشبینیهای مدل در یک اسکوپ GradientTape، باید عملیاتهای مدل را درون بلاک with tf.GradientTape() as tape: قرار دهید. این کار به tape اجازه میدهد تا تمام عملیاتهای انجام شده را برای محاسبه گرادیانهای بعدی ضبط کند.
def one_training_step(model, images_batch, labels_batch):
with tf.GradientTape() as tape: predictions = model(images_batch)
per_sample_losses = tf.keras.losses.sparse_categorical_crossentropy( labels_batch, predictions)
average_loss = tf.reduce_mean(per_sample_losses) gradients = tape.gradient(average_loss, model.weights)
برای محاسبه گرادیان خطا با توجه به وزنها، از متد tape.gradient() استفاده میکنیم. خروجی tape.gradient() لیستی از تنسورهای گرادیان خواهد بود که هر کدام به یک وزن در لیست model.weights مربوط میشوند.
update_weights(gradients, model.weights)
وزنها را با استفاده از گرادیانها بهروزرسانی میکنیم (این تابع را به زودی تعریف خواهیم کرد).
return average_loss
همانطور که قبلاً میدانید، هدف از مرحله “بهروزرسانی وزن” (که با تابع update_weights قبلی نمایش داده میشود) این است که وزنها را “کمی” در جهتی حرکت دهد که خطا را در این دسته کاهش دهد. اندازه این حرکت توسط “نرخ یادگیری” تعیین میشود، که معمولاً یک کمیت کوچک است. سادهترین راه برای پیادهسازی این تابع update_weights این است که gradient * learning_rate را از هر وزن کم کنید : learning_rate = 1e-3
def update_weights(gradients, weights):
for g, w in zip(gradients, weights): w.assign_sub(g * learning_rate)
assign_sub معادل عملگر -= برای متغیرهای TensorFlow است.
در عمل، تقریباً هرگز مرحله بهروزرسانی وزن را به این شکل دستی پیادهسازی نمیکنید. در عوض، از یک نمونه Optimizer از Keras استفاده خواهید کرد، مانند این:
from tensorflow.keras import optimizers
optimizer = optimizers.SGD(learning_rate=1e-3)
def update_weights(gradients, weights):
optimizer.apply_gradients(zip(gradients, weights))
اکنون که گام آموزش در هر بچ (batch) آماده است، میتوانیم به پیادهسازی یک اِپوک کامل آموزش برویم.
حلقه کامل آموزش
یک اِپوک آموزش به سادگی شامل تکرار گام آموزش برای هر دسته در دادههای آموزشی است، و حلقه کامل آموزش صرفاً تکرار یک اِپوک است:
def fit(model, images, labels, epochs, batch_size=128):
for epoch_counter in range(epochs):
print(f”Epoch {epoch_counter}”)
batch_generator = BatchGenerator(images, labels)
for batch_counter in range(batch_generator.num_batches): images_batch, labels_batch = batch_generator.next()
loss = one_training_step(model, images_batch, labels_batch)
if batch_counter % 100 == 0:
print(f”loss at batch {batch_counter}: {loss:.2f}”)
بیایید آن را آزمایش کنیم:
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype(“float32”) / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype(“float32”) / 255
fit(model, train_images, train_labels, epochs=10, batch_size=128)
ارزیابی مدل
ما میتوانیم مدل را با گرفتن آرگماکس پیشبینیهای آن بر روی تصاویر آزمایشی، و مقایسه آن با برچسبهای مورد انتظار، ارزیابی کنیم:
predictions = model(test_images)
predictions = predictions.numpy()
predicted_labels = np.argmax(predictions, axis=1)
matches = predicted_labels == test_labels
print(f”accuracy: {matches.mean():.2f}”)
فراخوانی . () numpy بر روی یک تنسور TensorFlow، آن را به یک تنسور NumPy تبدیل میکند.
همهچیز تمام شد! همانطور که میبینید، انجام دستی کاری که میتوانید با چند خط کد Keras انجام دهید، کار نسبتاً زیادی است. اما به دلیل اینکه این مراحل را طی کردهاید، اکنون باید درک کاملاً واضحی از آنچه هنگام فراخوانی () fit در درون یک شبکه عصبی اتفاق میافتد، داشته باشید. داشتن این مدل ذهنی سطح پایین از آنچه کد شما در پشت صحنه انجام میدهد، شما را قادر میسازد تا بهتر از ویژگیهای سطح بالای Keras API بهره ببرید.
خلاصه
- تنسورها اساس سیستمهای یادگیری ماشین مدرن را تشکیل میدهند. آنها در انواع مختلفی از dtype، رنک و شکل عرضه میشوند.
- میتوانید تنسورهای عددی را از طریق عملیاتهای تنسور (مانند جمع، ضرب تنسوری یا ضرب عنصر به عنصر) دستکاری کنید، که میتوانند به عنوان کدگذاری تبدیلهای هندسی تفسیر شوند. به طور کلی، هر چیزی در یادگیری عمیق مستعد تفسیر هندسی است.
- مدلهای یادگیری عمیق شامل زنجیرهای از عملیاتهای ساده تنسور هستند که توسط وزنها پارامتری شدهاند، و خود وزنها نیز تنسور هستند. وزنهای یک مدل جایی است که “دانش” آن ذخیره میشود.
- یادگیری به معنای یافتن مجموعهای از مقادیر برای وزنهای مدل است که تابع خطا را برای مجموعهای مشخص از نمونههای داده آموزشی و هدفهای متناظر آنها به حداقل میرساند.
- یادگیری با استخراج دستههای تصادفی از نمونههای داده و هدفهایشان و محاسبه گرادیان پارامترهای مدل نسبت به خطای روی دسته اتفاق میافتد. سپس پارامترهای مدل کمی حرکت داده میشوند (میزان حرکت توسط نرخ یادگیری تعریف میشود) در جهت مخالف گرادیان. این فرآیند گرادیان کاهشی تصادفی مینی-بچ (mini-batch stochastic gradient descent) نامیده میشود.
- کل فرآیند یادگیری به دلیل این واقعیت که تمام عملیاتهای تنسور در شبکههای عصبی مشتقپذیر هستند، امکانپذیر است و بنابراین میتوان از قاعده زنجیرهای مشتق برای یافتن تابع گرادیان که پارامترهای فعلی و دسته فعلی داده را به یک مقدار گرادیان نگاشت میکند، استفاده کرد. این فرآیند پسانتشار (backpropagation) نامیده میشود.
- دو مفهوم کلیدی که مکرراً در فصلهای آینده خواهید دید، خطا (loss) و بهینهسازها (optimizers) هستند. اینها دو چیزی هستند که قبل از شروع تغذیه داده به مدل باید تعریف کنید.
- خطا کمیتی است که شما در طول آموزش تلاش خواهید کرد آن را حداقل کنید، بنابراین باید معیاری برای موفقیت در وظیفهای که در تلاش برای حل آن هستید، باشد.
- بهینهساز شیوه دقیق استفاده از گرادیان خطا برای بهروزرسانی پارامترها را مشخص میکند: برای مثال، میتواند بهینهساز RMSProp، SGD با مومنتوم و غیره باشد.



