- این فصل شامل موارد زیر است:
- نگاهی دقیقتر به TensorFlow، Keras و رابطه آنها
- راهاندازی یک فضای کاری یادگیری عمیق
- بررسی اجمالی اینکه چگونه مفاهیم اصلی یادگیری عمیق به Keras و TensorFlow تبدیل میشوند
مقدمه
این فصل قصد دارد هر آنچه برای شروع یادگیری عمیق در عمل نیاز دارید را به شما بدهد. من یک ارائه سریع از Keras (https://keras.io) و TensorFlow (https://tensorflow.org)، ابزارهای یادگیری عمیق مبتنی بر پایتون که در سراسر کتاب از آنها استفاده خواهیم کرد، خواهم داشت. خواهید فهمید که چگونه یک فضای کاری یادگیری عمیق را با TensorFlow، Keras و پشتیبانی GPU راهاندازی کنید. در نهایت، با تکیه بر اولین آشنایی شما با Keras و TensorFlow در فصل 2، اجزای اصلی شبکههای عصبی و نحوه ترجمه آنها به APIهای Keras و TensorFlow را مرور خواهیم کرد.
در پایان این فصل، آماده خواهید بود تا به کاربردهای عملی و واقعی بپردازید، که با فصل 4 آغاز خواهد شد.
تنسورفلو (tensor flow)چیست؟
تنسورفلو یک پلتفرم یادگیری ماشین رایگان، متنباز و مبتنی بر پایتون است که عمدتاً توسط گوگل توسعه یافته است. تنسورفلو، تا حد زیادی مانند نامپای، هدف اصلیاش توانمندسازی مهندسان و محققان برای دستکاری عبارات ریاضی بر روی تنسورهای عددی است. اما تنسورفلو از جنبههای زیر بسیار فراتر از دامنه نامپای میرود:
- میتواند گرادیان هر عبارت مشتقپذیری را به صورت خودکار محاسبه کند (همانطور که در فصل ۲ دیدید)، که آن را برای یادگیری ماشین بسیار مناسب میسازد.
- میتواند نه تنها بر روی CPUها، بلکه بر روی GPUها و TPUها که شتابدهندههای سختافزاری بسیار موازی هستند نیز اجرا شود.
- محاسبات تعریف شده در تنسورفلو را میتوان به راحتی در بین چندین ماشین توزیع کرد.
- برنامههای تنسورفلو را میتوان به سایر محیطهای اجرایی مانند C++، جاوااسکریپت (برای برنامههای مبتنی بر مرورگر)، یا تنسورفلو لایت (برای برنامههایی که بر روی دستگاههای موبایل یا دستگاههای جاسازیشده اجرا میشوند) و غیره صادر کرد. این امر استقرار برنامههای تنسورفلو را در محیطهای عملی آسان میکند.
مهم است که در نظر داشته باشید که تنسورفلو بسیار بیشتر از یک کتابخانه واحد است. این در واقع یک پلتفرم است که میزبان یک اکوسیستم وسیع از مؤلفهها میباشد، که برخی توسط گوگل و برخی توسط اشخاص ثالث توسعه یافتهاند. به عنوان مثال، TF-Agents برای تحقیقات یادگیری تقویتی، TFX برای مدیریت جریان کاری یادگیری ماشین در سطح صنعتی، TensorFlow Serving برای استقرار در تولید، و مخزن مدلهای از پیش آموزشدیده TensorFlow Hub وجود دارد. این مؤلفهها با هم، طیف بسیار گستردهای از موارد استفاده، از تحقیقات پیشرفته گرفته تا برنامههای تولیدی در مقیاس بزرگ را پوشش میدهند.
تنسورفلو به خوبی مقیاسپذیر است: به عنوان مثال، دانشمندان آزمایشگاه ملی اوک ریج از آن برای آموزش یک مدل پیشبینی آب و هوای شدید با ۱.۱ اگزا فلاپس بر روی ۲۷,۰۰۰ GPU ابررایانه IBM Summit استفاده کردهاند. به همین ترتیب، گوگل از تنسورفلو برای توسعه برنامههای یادگیری عمیق بسیار نیازمند به محاسبات، مانند عامل شطرنجباز و گوباز AlphaZero استفاده کرده است. برای مدلهای خودتان، اگر بودجه داشته باشید، میتوانید واقعبینانه امیدوار باشید که مقیاس را تا حدود ۱۰ پتافلاپس بر روی یک پاد کوچک TPU یا یک کلاستر بزرگ از GPUهای اجارهای در Google Cloud یا AWS افزایش دهید. این هنوز حدود ۱% از حداکثر توان محاسباتی برترین ابررایانه در سال ۲۰۱۹ خواهد بود!
کراس (keras)چیست؟
کراس یک API یادگیری عمیق برای پایتون است که بر بستر تنسورفلو ساخته شده و راهی مناسب برای تعریف و آموزش هر نوع مدل یادگیری عمیق فراهم میکند. کراس در ابتدا برای تحقیقات توسعه یافت، با هدف فعال کردن آزمایشهای سریع یادگیری عمیق.
از طریق تنسورفلو، کراس میتواند بر روی انواع مختلف سختافزار (به شکل ۳.۱ مراجعه کنید) — GPU، TPU، یا CPU معمولی — اجرا شود و میتواند به طور یکپارچه تا هزاران ماشین مقیاسبندی شود.
کراس به دلیل اولویت دادن به تجربه توسعهدهنده شناخته شده است. این یک API برای انسانها است، نه ماشینها. این بهترین شیوهها را برای کاهش بار شناختی دنبال میکند: گردش کار سازگار و سادهای ارائه میدهد، تعداد اقدامات مورد نیاز برای موارد استفاده رایج را به حداقل میرساند، و بازخورد واضح و قابل اجرا در هنگام خطای کاربر ارائه میدهد. این امر کراس را برای یک مبتدی آسان برای یادگیری و برای یک متخصص بسیار پربار برای استفاده میکند.

توسعه یادگیری عمیق: لایهها، مدلها، بهینهسازها، خطاها (loss)، معیارها (metrics)…

زیرساخت دستکاری تنسور: تنسورها، متغیرها، تفکیک خودکار، توزیع

سختافزار: اجرا
شکل ۳.۱: کراس و تنسورفلو: تنسورفلو یک پلتفرم محاسباتی تنسور سطح پایین است و کراس یک API یادگیری عمیق سطح بالا است.
کراس تا اواخر سال ۲۰۲۱ بیش از یک میلیون کاربر دارد، که شامل محققان دانشگاهی، مهندسان و دانشمندان داده در استارتاپها و شرکتهای بزرگ، تا دانشجویان تحصیلات تکمیلی و علاقهمندان میشود. کراس در گوگل، نتفلیکس، اوبر، CERN، ناسا، Yelp، Instacart، Square و صدها استارتاپ که در طیف وسیعی از مشکلات در هر صنعتی کار میکنند، استفاده میشود. توصیههای یوتیوب شما از مدلهای کراس نشأت میگیرد. خودروهای خودران Waymo با مدلهای کراس توسعه یافتهاند. کراس همچنین یک فریمورک محبوب در Kaggle، وبسایت مسابقات یادگیری ماشین است، جایی که اکثر مسابقات یادگیری عمیق با استفاده از کراس برنده شدهاند.
از آنجایی که کراس پایگاه کاربری بزرگ و متنوعی دارد، شما را مجبور نمیکند که از یک روش “واقعی” واحد برای ساخت و آموزش مدلها پیروی کنید. بلکه، طیف گستردهای از گردشهای کاری مختلف، از سطح بسیار بالا تا سطح بسیار پایین را، متناسب با پروفایلهای کاربری مختلف، امکانپذیر میسازد. برای مثال، شما مجموعهای از روشها برای ساخت مدلها و مجموعهای از روشها برای آموزش آنها دارید، که هر یک نشاندهنده یک موازنه خاص بین قابلیت استفاده و انعطافپذیری است. در فصل ۵، ما بخش خوبی از این طیف از گردشهای کاری را با جزئیات بررسی خواهیم کرد. شما میتوانید از کراس مانند Scikit-learn استفاده کنید—فقط() fit را فراخوانی کنید و اجازه دهید فریمورک کار خود را انجام دهد—یا میتوانید از آن مانند NumPy استفاده کنید—کنترل کامل هر جزئیات کوچکی را در دست بگیرید.
این بدان معناست که هر آنچه اکنون در حال یادگیری آن هستید و تازه شروع کردهاید، پس از اینکه متخصص شدید نیز همچنان مرتبط خواهد بود. میتوانید به راحتی شروع کنید و سپس به تدریج به گردشهای کاری عمیقتر شیرجه بزنید که در آنها منطق بیشتری را از پایه مینویسید. شما مجبور نخواهید بود که هنگام تغییر از دانشجو به محقق، یا از دانشمند داده به مهندس یادگیری عمیق، به یک فریمورک کاملاً متفاوت روی بیاورید.
این فلسفه بیشباهت به خود پایتون نیست! برخی از زبانها تنها یک راه برای نوشتن برنامه ارائه میدهند—برای مثال، برنامهنویسی شیءگرا یا برنامهنویسی تابعی. در همین حال، پایتون یک زبان چندپارادایم است: مجموعهای از الگوهای استفاده ممکن را ارائه میدهد که همگی به خوبی با هم کار میکنند. این باعث میشود پایتون برای طیف وسیعی از موارد استفاده بسیار متفاوت مناسب باشد: مدیریت سیستم، علم داده، مهندسی یادگیری ماشین، توسعه وب… یا فقط یادگیری نحوه برنامهنویسی. به همین ترتیب، میتوانید کراس را به عنوان پایتونِ یادگیری عمیق در نظر بگیرید: یک زبان یادگیری عمیق کاربرپسند که انواع گردش کار را برای پروفایلهای کاربری مختلف ارائه میدهد.
کراس و تنسورفلو: تاریخچهای مختصر
کراس هشت ماه پیش از تنسورفلو به بازار عرضه شد. این ابزار در مارس ۲۰۱۵ منتشر شد، در حالی که تنسورفلو در نوامبر ۲۰۱۵ عرضه گشت. ممکن است بپرسید، اگر کراس بر بستر تنسورفلو ساخته شده، چگونه میتواند پیش از انتشار تنسورفلو وجود داشته باشد؟ کراس در اصل بر پایه Theano ساخته شده بود، که یک کتابخانه دیگر دستکاری تنسور بود و از تفکیک خودکار و پشتیبانی GPU برخوردار بود — اولین مورد از نوع خود. Theano که در مؤسسه هوش مصنوعی مونترال (MILA) در دانشگاه مونترال توسعه یافته بود، از بسیاری جهات پیشرو تنسورفلو بود. این ابزار پیشگام ایده استفاده از گرافهای محاسباتی ایستا برای تفکیک خودکار و کامپایل کد برای هر دو CPU و GPU بود.
در اواخر سال ۲۰۱۵، پس از انتشار تنسورفلو، کراس به یک معماری چند بکاند (multi-backend) بازسازی شد: امکان استفاده از کراس با Theano یا تنسورفلو فراهم شد و جابجایی بین این دو به آسانی تغییر یک متغیر محیطی بود. تا سپتامبر ۲۰۱۶، تنسورفلو به سطح بلوغ فنی رسید که امکان تبدیل آن به گزینه بکاند پیشفرض برای کراس فراهم شد. در سال ۲۰۱۷، دو گزینه بکاند اضافی جدید به کراس اضافه شد: CNTK (توسعهیافته توسط مایکروسافت) و MXNet (توسعهیافته توسط آمازون). امروزه، هم Theano و هم CNTK دیگر در حال توسعه نیستند، و MXNet نیز در خارج از آمازون به طور گستردهای استفاده نمیشود. کراس دوباره به یک API تک بکاند — بر بستر تنسورفلو — بازگشته است.
کراس و تنسورفلو برای سالها رابطه همزیستی داشتهاند. در طول سالهای ۲۰۱۶ و ۲۰۱۷، کراس به عنوان روشی کاربرپسند برای توسعه برنامههای تنسورفلو شناخته شد و کاربران جدید را به اکوسیستم تنسورفلو سوق داد. تا اواخر سال ۲۰۱۷، اکثریت کاربران تنسورفلو از طریق کراس یا در ترکیب با کراس از آن استفاده میکردند. در سال ۲۰۱۸، رهبری تنسورفلو، کراس را به عنوان API رسمی سطح بالای تنسورفلو انتخاب کرد. در نتیجه، API کراس در تنسورفلو ۲.۰ که در سپتامبر ۲۰۱۹ منتشر شد — یک بازطراحی گسترده تنسورفلو و کراس که بازخورد چهار سال کاربر و پیشرفتهای فنی را در نظر میگیرد — در کانون توجه قرار گرفت.
در این مرحله، شما باید مشتاق شروع به اجرای کد کراس و تنسورفلو در عمل باشید. بیایید شما را آغاز کنیم.
راهاندازی یک محیط کاری یادگیری عمیق
قبل از اینکه بتوانید توسعه برنامههای یادگیری عمیق را شروع کنید، باید محیط توسعه خود را راهاندازی کنید. بسیار توصیه میشود، هرچند کاملاً ضروری نیست، که کد یادگیری عمیق را روی یک GPU مدرن NVIDIA به جای CPU کامپیوتر خود اجرا کنید. برخی از برنامهها—به ویژه پردازش تصویر با شبکههای کانولوشنال—حتی بر روی یک CPU سریع چند هستهای نیز به طرز دردناکی کند خواهند بود. و حتی برای برنامههایی که واقعبینانه میتوانند بر روی CPU اجرا شوند، با استفاده از یک GPU جدید، به طور کلی افزایش سرعت ۵ یا ۱۰ برابری را مشاهده خواهید کرد.
برای انجام یادگیری عمیق روی GPU، سه گزینه دارید:
- خرید و نصب یک GPU فیزیکی NVIDIA روی ایستگاه کاری خود.
- استفاده از نمونههای GPU در Google Cloud یا AWS EC2.
- استفاده از محیط اجرایی رایگان GPU از Colaboratory، یک سرویس نوتبوک میزبانیشده توسط گوگل (برای جزئیات بیشتر در مورد اینکه “نوتبوک” چیست، به بخش بعدی مراجعه کنید).
Colaboratory سادهترین راه برای شروع است، زیرا نیازی به خرید سختافزار و نصب نرمافزار ندارد—فقط کافیست یک تب در مرورگر خود باز کنید و شروع به کدنویسی کنید. این گزینهای است که ما برای اجرای مثالهای کد در این کتاب توصیه میکنیم. با این حال، نسخه رایگان Colaboratory فقط برای حجمهای کاری کوچک مناسب است. اگر میخواهید مقیاس را افزایش دهید، باید از گزینه اول یا دوم استفاده کنید.
اگر از قبل یک GPU قابل استفاده برای یادگیری عمیق (یک GPU NVIDIA جدید و رده بالا) ندارید، اجرای آزمایشهای یادگیری عمیق در فضای ابری راهی ساده و کمهزینه برای شماست تا به حجمهای کاری بزرگتر بپردازید بدون نیاز به خرید سختافزار اضافی. اگر با استفاده از نوتبوکهای Jupyter توسعه میدهید، تجربه اجرا در فضای ابری تفاوتی با اجرای محلی ندارد.
اما اگر شما یک کاربر سنگین یادگیری عمیق هستید، این تنظیمات در بلندمدت—یا حتی برای بیش از چند ماه—پایدار نیست. نمونههای ابری ارزان نیستند: در اواسط سال ۲۰۲۱، برای یک GPU V100 در Google Cloud، ۲.۴۸ دلار در ساعت پرداخت میکردید. در همین حال، یک GPU مصرفکننده قوی حدود ۱,۵۰۰ تا ۲,۵۰۰ دلار هزینه خواهد داشت—قیمتی که در طول زمان نسبتاً پایدار بوده است، حتی با وجود اینکه مشخصات این GPUها بهبود مییابند. اگر یک کاربر سنگین یادگیری عمیق هستید، راهاندازی یک ایستگاه کاری محلی با یک یا چند GPU را در نظر بگیرید.
علاوه بر این، چه به صورت محلی و چه در فضای ابری اجرا کنید، بهتر است از یک ایستگاه کاری یونیکس استفاده کنید. اگرچه از نظر فنی امکان اجرای مستقیم Keras روی ویندوز وجود دارد، اما ما آن را توصیه نمیکنیم. اگر کاربر ویندوز هستید و میخواهید یادگیری عمیق را روی ایستگاه کاری خود انجام دهید، سادهترین راهحل برای راهاندازی همه چیز، تنظیم یک راهاندازی دوگانه اوبونتو روی دستگاهتان، یا استفاده از Windows Subsystem for Linux (WSL) است، که یک لایه سازگاری است و به شما امکان میدهد برنامههای لینوکس را از ویندوز اجرا کنید. این ممکن است دردسرساز به نظر برسد، اما در بلندمدت زمان و دردسر زیادی را برای شما صرفهجویی خواهد کرد.
نوتبوکهای ژوپیتر: روش ترجیحی برای اجرای آزمایشهای یادگیری عمیق
نوتبوکهای ژوپیتر روشی عالی برای اجرای آزمایشهای یادگیری عمیق هستند—به ویژه، مثالهای کد متعدد در این کتاب. آنها به طور گستردهای در جوامع علم داده و یادگیری ماشین استفاده میشوند. یک نوتبوک فایلی است که توسط اپلیکیشن Jupyter Notebook (https://jupyter.org) تولید میشود و میتوانید آن را در مرورگر خود ویرایش کنید. این نوتبوک توانایی اجرای کد پایتون را با قابلیتهای غنی ویرایش متن برای حاشیهنویسی کاری که انجام میدهید، ترکیب میکند. یک نوتبوک همچنین به شما امکان میدهد آزمایشهای طولانی را به قطعات کوچکتر تقسیم کنید که میتوانند به طور مستقل اجرا شوند، که توسعه را تعاملی میکند و به این معنی است که اگر چیزی در اواخر یک آزمایش اشتباه پیش رفت، مجبور نیستید تمام کدهای قبلی خود را دوباره اجرا کنید.
من توصیه میکنم برای شروع کار با کراس از نوتبوکهای ژوپیتر استفاده کنید، البته این یک الزام نیست: شما میتوانید اسکریپتهای پایتون مستقل را نیز اجرا کنید یا کد را از درون یک IDE مانند PyCharm اجرا کنید. تمام مثالهای کد در این کتاب به صورت نوتبوکهای متنباز در دسترس هستند؛ میتوانید آنها را از گیتهاب در آدرس github.com/fchollet/deep-learning-with-python-notebooks دانلود کنید.
استفاده از Colaboratory
Colaboratory (یا به اختصار Colab) یک سرویس رایگان نوتبوک ژوپیتر است که نیازی به نصب ندارد و به طور کامل در فضای ابری اجرا میشود. در واقع، این یک صفحه وب است که به شما امکان میدهد بلافاصله اسکریپتهای Keras را بنویسید و اجرا کنید. این سرویس به شما دسترسی به یک محیط اجرایی رایگان (اما محدود) GPU و حتی یک محیط اجرایی TPU را میدهد، بنابراین مجبور نیستید GPU خود را بخرید. Colaboratory همان چیزی است که ما برای اجرای مثالهای کد در این کتاب توصیه میکنیم.
اولین گامها با Colaboratory
برای شروع کار با Colab، به آدرس https://colab.research.google.com بروید و روی دکمه “New Notebook” کلیک کنید. رابط کاربری استاندارد نوتبوک را که در شکل ۳.۲ نشان داده شده است، خواهید دید.
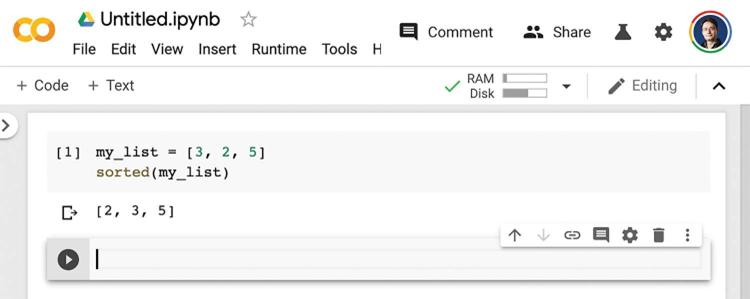
شما دو دکمه را در نوار ابزار مشاهده خواهید کرد: “کد +” و “متن +”. این دکمهها به ترتیب برای ایجاد خانههای کد پایتون قابل اجرا و خانههای متن برای حاشیهنویسی هستند. پس از وارد کردن کد در یک خانه کد، با فشار دادن Shift-Enter آن را اجرا خواهید کرد (به شکل ۳.۳ مراجعه کنید).
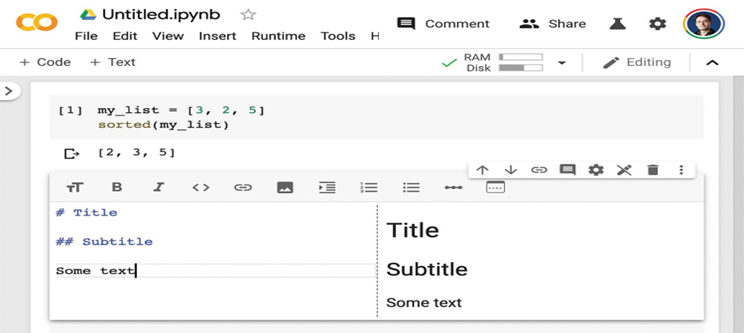
در یک خانه متن، میتوانید از سینتکس Markdown استفاده کنید (به شکل ۳.۴ مراجعه کنید). با فشار دادن Shift-Enter بر روی یک خانه متن، آن رندر میشود.
خانههای متن برای دادن یک ساختار قابل خواندن به نوتبوکهای شما مفید هستند: از آنها برای حاشیهنویسی کد خود با عناوین بخشها و پاراگرافهای توضیحی طولانی یا برای جاسازی اشکال استفاده کنید. نوتبوکها به منظور ارائه یک تجربه چندرسانهای طراحی شدهاند!
نصب پکیجها با Pip
محیط پیشفرض Colab از قبل با TensorFlow و Keras نصب شده است، بنابراین میتوانید بلافاصله بدون نیاز به هیچ مرحله نصبی شروع به استفاده از آن کنید. اما اگر زمانی نیاز به نصب چیزی با Pip داشتید، میتوانید این کار را با استفاده از سینتکس زیر در یک خانه کد انجام دهید (توجه داشته باشید که خط با ! شروع میشود تا نشان دهد که این یک دستور shell است و نه کد پایتون):
!pip install package_name
استفاده از زمان اجرای GRU
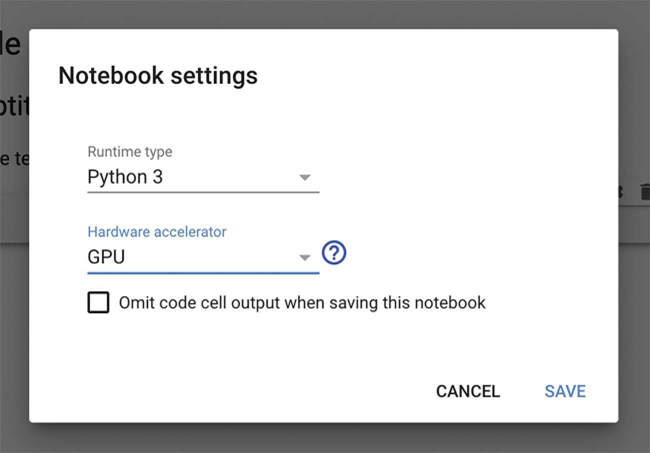
برای استفاده از محیط اجرایی GPU با Colab، در منو گزینهی Runtime > Change Runtime Type را انتخاب کنید و GPU را برای Hardware Accelerator (شتابدهنده سختافزاری) برگزینید (به شکل ۳.۵ مراجعه کنید).
تنسورفلو و کراس در صورت وجود GPU، به طور خودکار روی GPU اجرا خواهند شد، بنابراین پس از انتخاب محیط اجرایی GPU نیازی به انجام کار دیگری ندارید.
شما متوجه خواهید شد که گزینه محیط اجرایی TPU نیز در منوی کشویی “شتابدهنده سختافزاری” (Hardware Accelerator) وجود دارد. برخلاف محیط اجرایی GPU، استفاده از محیط اجرایی TPU با تنسورفلو و کراس نیاز به کمی تنظیمات دستی در کد شما دارد. ما این مورد را در فصل ۱۳ پوشش خواهیم داد. فعلاً، توصیه میکنیم برای دنبال کردن مثالهای کد در کتاب، به محیط اجرایی GPU پایبند باشید.
اکنون شما راهی برای شروع اجرای کد کراس در عمل دارید. در ادامه، بیایید ببینیم که ایدههای کلیدی که در فصل ۲ آموختید چگونه به کد کراس و تنسورفلو ترجمه میشوند.
اولین گامها با تنسورفلو
همانطور که در فصلهای پیشین دیدید، آموزش یک شبکه عصبی حول مفاهیم زیر میچرخد:
- اولاً، دستکاری تنسور در سطح پایین—زیرساختی که زیربنای تمام یادگیری ماشین مدرن است. این به APIهای تنسورفلو ترجمه میشود:
- تنسورها، شامل تنسورهای خاصی که حالت شبکه را ذخیره میکنند (متغیرها)
- عملیاتهای تنسور مانند جمع، ReLU، ضرب ماتریسی
- پسانتشار (Backpropagation)، راهی برای محاسبه گرادیان عبارات ریاضی (که در تنسورفلو از طریق شیء GradientTape مدیریت میشود)
- ثانیاً، مفاهیم یادگیری عمیق در سطح بالا. این به APIهای کراس ترجمه میشود:
- لایهها، که در یک مدل ترکیب میشوند
- یک تابع خطا (loss function)، که سیگنال بازخورد مورد استفاده برای یادگیری را تعریف میکند
- یک بهینهساز (optimizer)، که نحوه پیشرفت یادگیری را تعیین میکند
- معیارها (metrics) برای ارزیابی عملکرد مدل، مانند دقت
- یک حلقه آموزش (training loop) که گرادیان کاهشی تصادفی مینی-بچ را انجام میدهد
در فصل قبلی، شما قبلاً یک آشنایی اولیه با برخی از APIهای متناظر تنسورفلو و کراس داشتید: شما به طور خلاصه از کلاس Variable تنسورفلو، عملیات matmul و GradientTape استفاده کردهاید. شما لایههای Dense کراس را نمونهسازی کردهاید، آنها را در یک مدل Sequential بستهبندی کردهاید و آن مدل را با متد () fit آموزش دادهاید.
اکنون بیایید عمیقتر بررسی کنیم که چگونه تمام این مفاهیم مختلف را میتوان در عمل با استفاده از تنسورفلو و کراس پیادهسازی کرد.
تنسورهای ثابت و متغیرها
برای انجام هر کاری در TensorFlow، به تعدادی تنسور نیاز داریم. تنسورها باید با مقداری اولیه ایجاد شوند. برای مثال، میتوانید تنسورهایی تماماً یک یا تماماً صفر ایجاد کنید (به فهرست ۳.۱ مراجعه کنید)، یا تنسورهایی از مقادیری که از یک توزیع تصادفی نمونهبرداری شدهاند (به فهرست ۳.۲ مراجعه کنید).
قطعه کد ۳.۱: تنسورهای تماماً یک یا تماماً صفر
>>> import tensorflow as tf
>>> x = tf.ones(shape=(2, 1))
معادل np.ones(shape=(2, 1))
>>> print(x)
tf.Tensor( [[1.]
[1.]], shape=(2, 1), dtype=float32)
>>> x = tf.zeros(shape=(2, 1))
معادل np.zeros(shape=(2, 1))
>>> print(x)
tf.Tensor( [[0.]
[0.]], shape=(2, 1), dtype=float32)
قطعه کد ۳.۲: تنسورهای تصادفی
>>> x = tf.random.normal(shape=(3, 1), mean=0., stddev=1.)
تنسوری از مقادیر تصادفی که از یک توزیع نرمال با میانگین ۰ و انحراف معیار ۱ استخراج شدهاند. معادل np.random.normal(size=(3, 1), loc=0., scale=1.).
>>> print(x)
tf.Tensor(
[[-0.14208166]
[-0.95319825]
[ 1.1096532 ]], shape=(3, 1), dtype=float32)
>>> x = tf.random.uniform(shape=(3, 1), minval=0., maxval=1.)
تنسوری از مقادیر تصادفی که از یک توزیع یکنواخت بین ۰ و ۱ استخراج شدهاند. معادل np.random.uniform(size=(3, 1), low=0., high=1.).
>>> print(x)
tf.Tensor(
[[0.33779848]
[0.06692922]
[0.7749394 ]], shape=(3, 1), dtype=float32)
یک تفاوت قابل توجه بین آرایههای NumPy و تنسورهای TensorFlow این است که تنسورهای تنسورفلو قابل انتساب نیستند: آنها ثابتاند. برای مثال، در NumPy میتوانید کارهای زیر را انجام دهید:
قطعه کد ۳.۳: آرایههای NumPy قابل انتساب هستند
import numpy as np
x = np.ones(shape=(2, 2))
x[0, 0] = 0.
در TensorFlow، اگر بخواهید همین کار را انجام دهید، خطایی با عنوان “EagerTensor object does not support item assignment” دریافت خواهید کرد.
قطعه کد ۳.۴: تنسورهای TensorFlow قابل انتساب نیستند.
x = tf.ones(shape=(2, 2))
x[0, 0] = 0.
این عملیات با شکست مواجه خواهد شد، زیرا یک تنسور قابل انتساب نیست.
برای آموزش یک مدل، باید حالت آن را که مجموعهای از تنسورهاست، بهروزرسانی کنیم. اگر تنسورها قابل انتساب نیستند، چگونه این کار را انجام دهیم؟ اینجا است که متغیرها وارد میشوند. tf.Variable کلاسی است که برای مدیریت حالت قابل تغییر در TensorFlow در نظر گرفته شده است. شما قبلاً به طور خلاصه آن را در پیادهسازی حلقه آموزش در پایان فصل ۲ در عمل دیدهاید.
برای ایجاد یک متغیر، باید مقداری اولیه به آن بدهید، مانند یک تنسور تصادفی.
قطعه کد ۳.۵: ایجاد یک متغیر TensorFlow
>>> v = tf.Variable(initial_value=tf.random.normal(shape=(3, 1)))
>>> print(v)
array([[-0.75133973],
[-0.4872893 ],
[ 1.6626885 ]], dtype=float32)>
حالت یک متغیر را میتوان از طریق متد assign آن، به صورت زیر تغییر داد.
قطعه کد ۳.۶: انتساب یک مقدار به یک متغیر TensorFlow.
>>> v.assign(tf.ones((3, 1))) array([[1.],
[1.],
[1.]], dtype=float32)>
این (متد assign متغیرها) برای زیرمجموعهای از ضرایب نیز کار میکند.
قطعه کد ۳.۷: انتساب یک مقدار به زیرمجموعهای از یک متغیر TensorFlow.
>>> v[0, 0].assign(3.)
array([[3.],
[1.],
[1.]], dtype=float32)>
به طور مشابه، () assign_add و () assign_sub معادلهای کارآمد =+ و = -هستند، همانطور که در ادامه نشان داده شده است.
قطعه کد ۳.۸: استفاده از ()assign_add
>>> v.assign_add(tf.ones((3, 1)))
array([[2.],
[2.],
[2.]], dtype=float32)>
عملیاتهای تنسور: انجام محاسبات ریاضی در TensorFlow
درست مانند NumPy، تنسورفلو مجموعهی بزرگی از عملیاتهای تنسور را برای بیان فرمولهای ریاضی ارائه میدهد. در اینجا چند مثال آورده شده است.
قطعه کد ۳.۹: چند عملیات ریاضی پایه
a = tf.ones((2, 2))
b = tf.square(a)
مجذور را بگیر
c = tf.sqrt(a)
جذر را بگیر.
d = b + c
دو تنسور را (عنصر به عنصر) جمع کن.
e = tf.matmul(a, b)
حاصلضرب دو تنسور را (همانطور که در فصل ۲ بحث شد) بگیرید.
e *= d
دو تنسور را (عنصر به عنصر) ضرب کن.
مهم این است که هر یک از عملیاتهای قبلی به صورت “برخط” اجرا میشوند: در هر نقطه، میتوانید نتیجه فعلی را چاپ کنید، درست مانند NumPy. ما این را اجرای بیدرنگ (eager execution) مینامیم.
نگاهی دوباره به API گرادیان تیپ (GradientTape)
تا اینجا، TensorFlow شباهت زیادی به NumPy دارد. اما اینجا چیزی است که NumPy نمیتواند انجام دهد: بازیابی گرادیان هر عبارت مشتقپذیر نسبت به هر یک از ورودیهای آن. کافی است یک اسکوپ GradientTape باز کنید، محاسباتی را روی یک یا چند تنسور ورودی اعمال کنید، و گرادیان نتیجه را نسبت به ورودیها بازیابی کنید.
قطعه کد ۳.۱۰: استفاده از GradientTape.
input_var = tf.Variable(initial_value=3.)
with tf.GradientTape() as tape:
result = tf.square(input_var)
gradient = tape.gradient(result, input_var)
این روش معمولاً برای بازیابی گرادیانهای خطای یک مدل نسبت به وزنهایش استفاده میشود: gradients = tape.gradient(loss, weights). شما این را در فصل ۲ در عمل دیدید.
تا اینجا، شما فقط حالتی را دیدهاید که تنسورهای ورودی در () tape.gradient ، متغیرهای TensorFlow بودند. در واقع، امکانپذیر است که این ورودیها هر تنسور دلخواهی باشند. با این حال، فقط متغیرهای قابل آموزش به طور پیشفرض ردیابی میشوند. با یک تنسور ثابت، باید به صورت دستی آن را با فراخوانی () tape.watch روی آن، برای ردیابی علامتگذاری کنید.
قطعه کد ۳.۱۱: استفاده از GradientTape با ورودیهای تنسور ثابت
input_const = tf.constant(3.)
with tf.GradientTape() as tape:
tape.watch(input_const)
result = tf.square(input_const)
gradient = tape.gradient(result, input_const)
چرا این (ردیابی دستی تنسورهای ثابت) لازم است؟ زیرا ذخیره پیشگیرانه اطلاعات مورد نیاز برای محاسبه گرادیان هر چیزی نسبت به هر چیزی، بسیار پرهزینه خواهد بود. برای جلوگیری از هدر رفتن منابع، tape باید بداند که چه چیزی را ردیابی کند. متغیرهای قابل آموزش به طور پیشفرض ردیابی میشوند زیرا محاسبه گرادیان یک خطا با توجه به لیستی از متغیرهای قابل آموزش، رایجترین کاربرد گرادیان تیپ است.
گرادیان تیپ یک ابزار قدرتمند است، حتی قادر به محاسبه گرادیانهای مرتبه دوم، یعنی گرادیان یک گرادیان، میباشد. برای مثال، گرادیان موقعیت یک شیء نسبت به زمان، سرعت آن شیء است، و گرادیان مرتبه دوم آن، شتاب آن است.
اگر موقعیت یک سیب در حال سقوط را در امتداد یک محور عمودی در طول زمان اندازهگیری کنید و متوجه شوید که معادله
position(time) = 4.9 * time ** 2 را تأیید میکند، شتاب آن چقدر است؟ بیایید از دو گرادیان تیپ تودرتو برای پیدا کردن آن استفاده کنیم.
قطعه کد ۳.۱۲: استفاده از گرادیان تیپهای تودرتو برای محاسبه گرادیانهای مرتبه دوم.
time = tf.Variable(0.)
with tf.GradientTape() as outer_tape:
with tf.GradientTape() as inner_tape:
position = 4.9 * time ** 2
speed = inner_tape.gradient(position, time)
acceleration = outer_tape.gradient(speed, time)
ما از “تیپ” بیرونی برای محاسبه گرادیانِ گرادیانِ “تیپ” درونی استفاده میکنیم. به طور طبیعی، پاسخ ۴.۹ * ۲ = ۹.۸ است.
یک مثال سرتاسری: یک طبقهبندیکننده خطی در TensorFlow خالص
شما درباره تنسورها، متغیرها و عملیاتهای تنسور میدانید، و میدانید چگونه گرادیانها را محاسبه کنید. این برای ساخت هر مدل یادگیری ماشینی مبتنی بر گرادیان کاهشی کافی است. و شما فقط در فصل ۳ هستید!
در یک مصاحبه شغلی یادگیری ماشین، ممکن است از شما خواسته شود یک طبقهبندیکننده خطی را از پایه در TensorFlow پیادهسازی کنید: یک وظیفه بسیار ساده که به عنوان یک فیلتر بین نامزدهایی که حداقل پیشزمینه یادگیری ماشین دارند و آنهایی که ندارند، عمل میکند.
بیایید شما را از این فیلتر عبور دهیم و از دانش جدیدتان در تنسورفلو برای پیادهسازی چنین طبقهبندیکننده خطی استفاده کنیم.
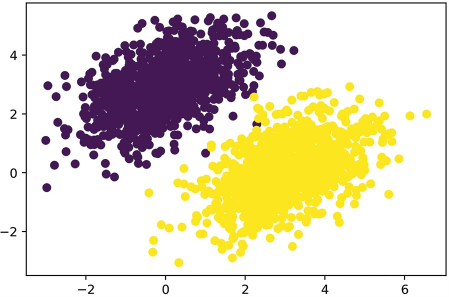
ابتدا، بیایید مقداری داده مصنوعی که به صورت خطی قابل تفکیک و خوب هستند را برای کار با آن ایجاد کنیم: دو کلاس از نقاط در یک صفحه ۲ بعدی. ما هر کلاس از نقاط را با استخراج مختصات آنها از یک توزیع تصادفی با یک ماتریس کوواریانس مشخص و یک میانگین مشخص تولید خواهیم کرد. به طور شهودی، ماتریس کوواریانس شکل ابر نقطه را توصیف میکند، و میانگین موقعیت آن را در صفحه توصیف میکند (به شکل ۳.۶ مراجعه کنید). ما از یک ماتریس کوواریانس یکسان برای هر دو ابر نقطه استفاده خواهیم کرد، اما از دو مقدار میانگین متفاوت استفاده خواهیم کرد—ابرهای نقطه شکل یکسانی خواهند داشت، اما موقعیتهای متفاوتی دارند.
قطعه کد ۳.۱۳: تولید دو کلاس از نقاط تصادفی در یک صفحه ۲ بعدی.
num_samples_per_class = 1000
negative_samples = np.random.multivariate_normal(
mean=[0, 3],
cov=[[1, 0.5],[0.5, 1]],
size=num_samples_per_class)
positive_samples = np.random.multivariate_normal(
mean=[3, 0],
cov=[[1, 0.5],[0.5, 1]],
size=num_samples_per_class)
برای تولید اولین کلاس از نقاط، ۱۰۰۰ نقطه ۲ بعدی تصادفی با ماتریس کوواریانس [[1, 0.5], [0.5, 1]] (که مطابق با یک ابر نقطهای بیضیشکل با جهتگیری از پایین چپ به بالا راست است) را ایجاد میکنیم.
کلاس دیگری از نقاط را با میانگین متفاوت و ماتریس کوواریانس یکسان ایجاد کنید.
در کد قبلی، negative_samples و positive_samples هر دو آرایههایی با شکل (2, 1000) هستند. بیایید آنها را در یک آرایه واحد با شکل (۲, ۲000) روی هم قرار دهیم.
قطعه کد ۳.۱۴: روی هم قرار دادن دو کلاس در یک آرایه با شکل (۲, 2000).
inputs = np.vstack((negative_samples, positive_samples)).astype(np.float32)
بیایید برچسبهای هدف مربوطه را ایجاد کنیم، آرایهای از صفرها و یکها به شکل (1, 2000)، که در آن targets[i,0] اگر inputs[i] متعلق به کلاس ۰ باشد، برابر با ۰ است (و برعکس).
قطعه کد ۳.۱۵: تولید برچسبهای هدف متناظر (۰ و ۱).
targets = np.vstack((np.zeros((num_samples_per_class, 1), dtype=”float32″), np.ones((num_samples_per_class, 1), dtype=”float32″)))
در ادامه، بیایید دادههایمان را با Matplotlib رسم کنیم.
قطعه کد ۳.۱۶: رسم دو کلاس نقطه (به شکل ۳.۶ مراجعه کنید).
import matplotlib.pyplot as plt
plt.scatter(inputs[:, 0], inputs[:, 1], c=targets[:, 0])
plt.show()
بیایید یک طبقهبندیکننده خطی ایجاد کنیم که بتواند این دو توده (blobs) داده را از هم جدا کند. یک طبقهبندیکننده خطی، یک تبدیل آفین (پیشبینی = W • ورودی + b) است که آموزش داده میشود تا مربع تفاوت بین پیشبینیها و هدفها را به حداقل برساند.
همانطور که خواهید دید، این در واقع مثالی بسیار سادهتر از مثال کامل یک شبکه عصبی دو لایهای آزمایشی است که در پایان فصل ۲ دیدید. با این حال، این بار باید بتوانید هر خط کد را، خط به خط، درک کنید.
بیایید متغیرهای W و b خود را ایجاد کنیم، که به ترتیب با مقادیر تصادفی و صفرها مقداردهی اولیه میشوند.
قطعه کد ۳.۱۷: ایجاد متغیرهای طبقهبندیکننده خطی.
input_dim = 2
ورودیها نقاط ۲ بعدی خواهند بود.
output_dim = 1
پیشبینیهای خروجی، یک امتیاز واحد به ازای هر نمونه خواهد بود (نزدیک به ۰ اگر پیشبینی شود که نمونه در کلاس ۰ است، و نزدیک به ۱ اگر پیشبینی شود که نمونه در کلاس ۱ است).
W = tf.Variable(initial_value=tf.random.uniform(shape=(input_dim, output_dim)))
b = tf.Variable(initial_value=tf.zeros(shape=(output_dim,)))
این تابع گذر رو به جلو (forward pass) ما است.
قطعه کد ۳.۱۸: تابع گذر رو به جلو (forward pass).
def model(inputs):
return tf.matmul(inputs, W) + b
از آنجا که طبقهبندیکننده خطی ما بر روی ورودیهای ۲ بعدی عمل میکند، W در واقع فقط دو ضریب اسکالر، w1 و w2 است: W=[[w1],[w2]]. در همین حال، b یک ضریب اسکالر واحد است. به این ترتیب، برای یک نقطه ورودی داده شده [x,y]، مقدار پیشبینی آن برابر است با prediction = [[w1], [w2]] • [x, y] + b = w1 * x + w2 * y + b.
فهرست زیر تابع خطای ما را نشان میدهد.
قطعه کد ۳.۱۹: تابع خطای میانگین مربعات خطا (Mean Squared Error).
def square_loss(targets, predictions):
per_sample_losses = tf.square(targets – predictions)
per_sample_losses یک تنسور با همان شکل targets و predictions خواهد بود که شامل امتیازات خطای به ازای هر نمونه است.
return tf.reduce_mean(per_sample_losses)
ما باید این امتیازات خطای به ازای هر نمونه را به یک مقدار خطای اسکالر واحد میانگینگیری کنیم: این کاری است که reduce_mean انجام میدهد.
در ادامه، گام آموزش است که دادههای آموزشی را دریافت میکند و وزنهای W و b را بهروزرسانی میکند تا خطا را در دادهها به حداقل برساند.
قطعه کد ۳.۲۰: تابع گام آموزش (The training step function).
learning_rate = 0.1
def training_step(inputs, targets):
with tf.GradientTape() as tape:
predictions = model(inputs)
loss = square_loss(predictions, targets)
برای اجرای “گذر رو به جلو” (forward pass) در داخل یک اسکوپ GradientTape در تنسورفلو، باید عملیاتهایی که خروجی مدل را محاسبه میکنند، درون بلاک with tf.GradientTape() as tape: قرار دهید. این کار به tape اجازه میدهد تا تمام عملیاتهای انجام شده روی tf.Variableها را ضبط کند تا بعداً بتوان گرادیانها را محاسبه کرد.
grad_loss_wrt_W, grad_loss_wrt_b = tape.gradient(loss, [W, b])
برای بازیابی گرادیان خطا با توجه به وزنها در تابع گام آموزش، از tf.GradientTape() برای ضبط عملیاتهای گذر رو به جلو و محاسبه خطا استفاده میکنیم، سپس متد tape.gradient() را فراخوانی میکنیم.
W.assign_sub(grad_loss_wrt_W * learning_rate)
b.assign_sub(grad_loss_wrt_b * learning_rate)
return loss
بهروزرسانی وزنها
برای سادگی، به جای آموزش مینی-بچ، آموزش بچ (batch training) را انجام میدهیم: هر گام آموزش (محاسبه گرادیان و بهروزرسانی وزن) را برای تمام دادهها اجرا میکنیم، به جای اینکه بر روی دادهها در بچهای کوچک تکرار کنیم. از یک طرف، این بدان معناست که هر گام آموزش زمان بسیار بیشتری برای اجرا نیاز دارد، زیرا گذر رو به جلو و گرادیانها را برای ۲۰۰۰ نمونه به یکباره محاسبه خواهیم کرد. از طرف دیگر، هر بهروزرسانی گرادیان در کاهش خطای روی دادههای آموزشی بسیار مؤثرتر خواهد بود، زیرا اطلاعات تمام نمونههای آموزشی را در بر میگیرد، به جای مثلاً تنها ۱۲۸ نمونه تصادفی. در نتیجه، به گامهای آموزشی بسیار کمتری نیاز خواهیم داشت، و باید از نرخ یادگیری بزرگتری نسبت به آنچه که معمولاً برای آموزش مینی-بچ استفاده میکنیم، استفاده کنیم (ما از learning_rate = 0.1 استفاده خواهیم کرد که در فهرست ۳.۲۰ تعریف شده است).
قطعه کد ۳.۲۱: حلقه آموزش بچ (Batch Training Loop).
for step in range(40):
loss = training_step(inputs, targets)
print(f”Loss at step {step}: {loss:.4f}”)
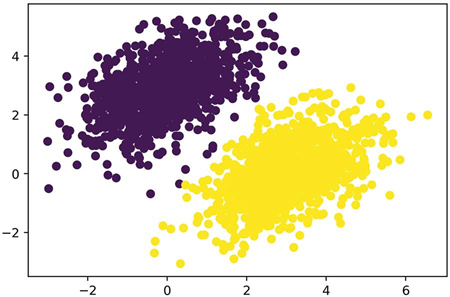
پس از ۴۰ گام، به نظر میرسد خطای آموزش حول ۰.۰۲۵ پایدار شده است. بیایید نحوه طبقهبندی نقاط داده آموزشی توسط مدل خطی خود را رسم کنیم. از آنجا که هدفهای ما صفر و یک هستند، یک نقطه ورودی مشخص به عنوان “۰” طبقهبندی میشود اگر مقدار پیشبینی آن کمتر از ۰.۵ باشد، و به عنوان “۱” طبقهبندی میشود اگر بالاتر از ۰.۵ باشد (به شکل ۳.۷ مراجعه کنید).
predictions = model(inputs)
plt.scatter(inputs[:, 0], inputs[:, 1], c=predictions[:, 0] > 0.5)
به یاد بیاورید که مقدار پیشبینی برای یک نقطه داده شده [x,y] به سادگی برابر است با prediction == [[w1], [w2]] • [x, y] + b == w1 * x + w2 * y + b. بنابراین، کلاس ۰ به صورت w1 * x + w2 * y + b < 0.5 تعریف میشود، و کلاس ۱ به صورت w1 * x + w2 * y + b > 0.5 تعریف میشود. شما متوجه خواهید شد که چیزی که به آن نگاه میکنید در واقع معادله یک خط در صفحه ۲ بعدی است: w1 * x + w2 * y + b = 0.5. بالای خط کلاس ۱ است و زیر خط کلاس ۰ است. ممکن است شما به دیدن معادلات خط به فرم y = a * x + b عادت داشته باشید؛ در همین فرمت، خط ما به y = – w1 / w2 * x + (0.5 – b) / w2 تبدیل میشود.
بیایید این خط را رسم کنیم (در شکل ۳.۸ نشان داده شده است):
x = np.linspace(-1, 4, 100)
برای رسم خطمان، ۱۰۰ عدد با فاصله منظم بین ۱- و ۴ تولید میکنیم.
y = – W[0] / W[1] * x + (0.5 – b) / W[1]
این معادله خط ماست.
plt.plot(x, y, “-r”)
برای رسم خطمان (با رنگ قرمز)، کد زیر را استفاده میکنیم:
plt.scatter(inputs[:, 0], inputs[:, 1], c=predictions[:, 0] > 0.5)
پیشبینیهای مدل خود را روی همان نمودار رسم کنید.
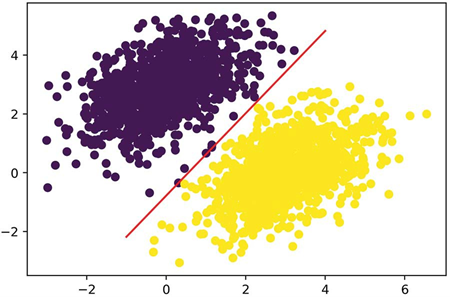
این واقعاً همان چیزی است که یک طبقهبندیکننده خطی به آن میپردازد: یافتن پارامترهای یک خط (یا در فضاهای با ابعاد بالاتر، یک ابرصفحه) که دو کلاس از دادهها را به طور تمیز از هم جدا میکند.
آناتومی (ساختار)یک شبکه عصبی: درک APIهای اصلی Keras
در این مرحله، شما اصول اولیه TensorFlow را میدانید و میتوانید از آن برای پیادهسازی یک مدل آزمایشی از پایه استفاده کنید، مانند طبقهبندیکننده خطی بچ در بخش قبلی، یا شبکه عصبی آزمایشی در پایان فصل ۲. این یک پایه محکم برای ساختن است. اکنون زمان آن است که به مسیری پربارتر و قویتر برای یادگیری عمیق برویم: API Keras.
لایهها: بلوکهای سازنده یادگیری عمیق
ساختار داده بنیادی در شبکههای عصبی، لایه است، که در فصل ۲ با آن آشنا شدید. لایه یک ماژول پردازش داده است که یک یا چند تنسور را به عنوان ورودی میگیرد و یک یا چند تنسور را خروجی میدهد. برخی لایهها بیحالت هستند، اما به طور مکرر لایهها دارای حالت هستند: وزنهای لایه، یک یا چند تنسور که با گرادیان کاهشی تصادفی یاد گرفته شدهاند، که با هم دانش شبکه را شامل میشوند.
انواع مختلف لایهها برای فرمتهای مختلف تنسور و انواع مختلف پردازش داده مناسب هستند. برای مثال، دادههای برداری ساده، که در تنسورهای رنک-۲ با شکل (نمونهها، ویژگیها) ذخیره میشوند، اغلب توسط لایههای با اتصال چگال، که لایههای کاملاً متصل یا لایههای Dense نیز نامیده میشوند (کلاس Dense در Keras) پردازش میشوند. دادههای دنبالهای، که در تنسورهای رنک-۳ با شکل (نمونهها، گامهای زمانی، ویژگیها) ذخیره میشوند، معمولاً توسط لایههای بازگشتی، مانند لایه LSTM، یا لایههای کانولوشن ۱ بعدی (Conv1D) پردازش میشوند. دادههای تصویر، که در تنسورهای رنک-۴ ذخیره میشوند، معمولاً توسط لایههای کانولوشن ۲ بعدی (Conv2D) پردازش میشوند.
شما میتوانید لایهها را به عنوان آجرهای لگو در یادگیری عمیق تصور کنید، استعارهای که توسط Keras به صراحت بیان شده است. ساخت مدلهای یادگیری عمیق در Keras با اتصال لایههای سازگار به یکدیگر برای تشکیل خطوط لوله تبدیل دادههای مفید انجام میشود.
کلاس پایه Layerدر Keras
یک API ساده باید یک انتزاع واحد داشته باشد که همه چیز حول آن متمرکز شود. در Keras، این کلاس Layer است. هر چیزی در Keras یا یک Layer است یا چیزی که ارتباط نزدیکی با یک Layer دارد.
یک Layer یک شیء است که مقداری حالت (وزنها) و مقداری محاسبه (یک گذر رو به جلو) را کپسوله میکند. وزنها معمولاً در متد() build (اگرچه میتوانند در سازنده،() init نیز ایجاد شوند) تعریف میشوند، و محاسبه در متد () call تعریف میشود. در فصل قبل، ما یک کلاس NaiveDense را پیادهسازی کردیم که شامل دو وزن W و b بود و محاسبه output = activation(dot(input, W) + b) را اعمال میکرد. این همان لایهای است که در Keras به نظر میرسد.
قطعه کد ۳.۲۲: یک لایه Dense پیادهسازی شده به عنوان زیرکلاس Layer.
from tensorflow import keras
class SimpleDense(keras.layers.Layer):
تمام لایههای Keras از کلاس پایه Layer ارث میبرند.
def init (self, units, activation=None):
super(). init ()
self.units = units
self.activation = activation
def build(self, input_shape):
input_dim = input_shape[-1]
ایجاد وزن در متد () build انجام میشود.
self.W = self.add_weight(shape=(input_dim, self.units),
initializer=”random_normal”)
() add_weight یک متد میانبر برای ایجاد وزنها است. همچنین میتوان متغیرهای مستقل ایجاد کرد و آنها را به عنوان ویژگیهای لایه، مانند self.W = tf.Variable(tf.random.uniform(w_shape))، اختصاص داد.
self.b = self.add_weight(shape=(self.units,),
initializer=” zeros “)
def call(self, inputs):
ما محاسبات گذر رو به جلو را در متد () call تعریف میکنیم.
y = tf.matmul(inputs, self.W) + self.b
if self.activation is not None:
y = self.activation(y)
return y
در بخش بعدی، هدف از متدهای () build و () call را با جزئیات پوشش خواهیم داد. نگران نباشید اگر هنوز همه چیز را درک نمیکنید!
پس از نمونهسازی، لایهای مانند این میتواند درست مانند یک تابع استفاده شود و یک تنسور TensorFlow را به عنوان ورودی بگیرد:
>>> my_dense = SimpleDense(units=32, activation=tf.nn.relu)
نمونهسازی لایهی ما که قبلاً تعریف شده است،
>>> input_tensor = tf.ones(shape=(2, 784))
ایجاد تعدادی ورودی آزمایشی
>>> output_tensor = my_dense(input_tensor)
فراخوانی لایه بر روی ورودیها، درست مانند یک تابع
>>> print(output_tensor.shape)
(2, 32))
شاید تعجب کنید که چرا مجبور شدیم () call و () build را پیادهسازی کنیم، در حالی که در نهایت با فراخوانی ساده لایه، یعنی با استفاده از متد __ () call __ آن، از لایه خود استفاده کردیم؟ دلیلش این است که ما میخواهیم بتوانیم حالت (state) را “درست به موقع” ایجاد کنیم. بیایید ببینیم که این چگونه کار میکند.
استنتاج خودکار شکل (Automatic shape inference): ساخت لایهها به صورت آنی (on the fly)
درست مانند آجرهای لگو، شما فقط میتوانید لایههایی را به هم “متصل” کنید که با یکدیگر سازگار باشند. مفهوم سازگاری لایه در اینجا به طور خاص به این واقعیت اشاره دارد که هر لایه تنها تنسورهای ورودی با شکل خاصی را میپذیرد و تنسورهای خروجی با شکل خاصی را برمیگرداند. مثال زیر را در نظر بگیرید:
from tensorflow.keras import layers
layer = layers.Dense(32, activation=”relu”)
یک لایه Dense با ۳۲ واحد خروجی.
این لایه یک تنسور را برمیگرداند که بعد اول آن به ۳۲ تبدیل شده است. این لایه فقط میتواند به یک لایه بعدی متصل شود که بردارهای ۳۲ بعدی را به عنوان ورودی خود انتظار دارد.
هنگام استفاده از Keras، بیشتر اوقات لازم نیست نگران سازگاری اندازه باشید، زیرا لایههایی که به مدلهای خود اضافه میکنید، به صورت پویا ساخته میشوند تا با شکل لایه ورودی مطابقت داشته باشند. به عنوان مثال، فرض کنید شما کد زیر را مینویسید:
from tensorflow.keras import models
from tensorflow.keras import layers
model = models.Sequential([
layers.Dense(32, activation=”relu”), layers.Dense(32)
])
لایهها هیچ اطلاعاتی در مورد شکل ورودیهای خود دریافت نکردهاند—در عوض، آنها به طور خودکار شکل ورودی خود را همان شکل اولین ورودیهایی که میبینند، استنتاج کردند.
در نسخه آزمایشی لایه Dense که در فصل ۲ پیادهسازی کردیم (که آن را NaiveDense نامیدیم)، مجبور بودیم اندازه ورودی لایه را به صراحت به سازنده پاس دهیم تا بتوانیم وزنهای آن را ایجاد کنیم. این ایدهآل نیست، زیرا منجر به مدلهایی میشود که شبیه این هستند، که در آنها هر لایه جدید باید از شکل لایه قبلی خود آگاه باشد:
model = NaiveSequential([
NaiveDense(input_size=784, output_size=32, activation=”relu”),
NaiveDense(input_size=32, output_size=64, activation=”relu”),
NaiveDense(input_size=64, output_size=32, activation=”relu”),
NaiveDense(input_size=32, output_size=10, activation=”softmax”)
])
اگر قوانینی که یک لایه برای تولید شکل خروجی خود استفاده میکند پیچیده باشند، وضعیت حتی بدتر خواهد شد. برای مثال، اگر لایه ما خروجیهایی با شکل (batch, input_size * 2 if input_size % 2 == 0 else input_size * 3) برمیگرداند، چه؟
اگر بخواهیم لایه NaiveDense خود را به عنوان یک لایه Keras با قابلیت استنتاج خودکار شکل، دوباره پیادهسازی کنیم، شبیه لایه SimpleDense قبلی خواهد بود (به فهرست ۳.۲۲ مراجعه کنید)، با متدهای () build و () call خود.
در SimpleDense، ما دیگر وزنها را در سازنده مانند مثال NaiveDense ایجاد نمیکنیم؛ در عوض، آنها را در یک متد اختصاصی برای ایجاد حالت، یعنی () build ، ایجاد میکنیم که شکل اولین ورودی دیده شده توسط لایه را به عنوان آرگومان دریافت میکند. متد () build به طور خودکار اولین بار که لایه فراخوانی میشود (از طریق متد __ () call __ آن) فراخوانی میشود. در واقع، به همین دلیل است که ما محاسبات را در یک متد () call جداگانه تعریف کردیم، نه مستقیماً در متد __call__().
متد __call() __ کلاس پایه لایه به صورت شماتیک به این شکل است:
def call (self, inputs):
if not self.built: self.build(inputs.shape)
self.built = True
return self.call(inputs)
با استنتاج خودکار شکل، مثال قبلی ما ساده و مرتب میشود:
model = keras.Sequential([
SimpleDense(32, activation=”relu”), SimpleDense(64, activation=”relu”),
SimpleDense(32, activation=”relu”),
SimpleDense(10, activation=”softmax”)
])
توجه داشته باشید که استنتاج خودکار شکل تنها چیزی نیست که متد __call__ کلاس Layer مدیریت میکند. این متد مسئولیتهای بسیار بیشتری دارد، به ویژه مسیریابی بین اجرای بیدرنگ (eager execution) و اجرای گراف (graph execution) (مفهومی که در فصل ۷ با آن آشنا خواهید شد) و پوششدهی ورودی (input masking) (که در فصل ۱۱ به آن خواهیم پرداخت). فعلاً، فقط به خاطر داشته باشید: هنگام پیادهسازی لایههای خود، گذر رو به جلو (forward pass) را در متد call() قرار دهید.
از لایهها به مدلها
یک مدل یادگیری عمیق، گرافی از لایهها است. در Keras، این همان کلاس Model است. تاکنون، شما فقط مدلهای Sequential (یک زیرکلاس از Model) را دیدهاید، که پشتههای سادهای از لایهها هستند و یک ورودی را به یک خروجی نگاشت میکنند. اما با پیشرفت، با طیف بسیار گستردهتری از توپولوژیهای شبکه آشنا خواهید شد. اینها برخی از توپولوژیهای رایج هستند:
- شبکههای دو شاخه (Two-branch networks)
- شبکههای چند سر (Multihead networks)
- اتصالات باقیمانده (Residual connections)
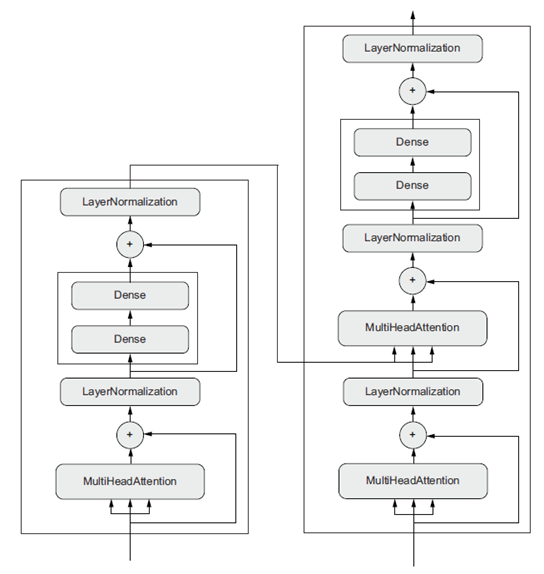
توپولوژی شبکه میتواند بسیار پیچیده شود. به عنوان مثال، شکل ۳.۹ توپولوژی گراف لایههای یک ترنسفورمر (Transformer) را نشان میدهد، که یک معماری رایج طراحی شده برای پردازش دادههای متنی است.
به طور کلی، دو راه برای ساخت چنین مدلهایی در Keras وجود دارد: میتوانید مستقیماً از کلاس Model ارث ببرید، یا میتوانید از Functional API استفاده کنید، که به شما امکان میدهد با کد کمتر، کارهای بیشتری انجام دهید. ما هر دو رویکرد را در فصل ۷ پوشش خواهیم داد.
توپولوژی یک مدل، یک فضای فرضیه را تعریف میکند. ممکن است به خاطر داشته باشید که در فصل ۱، یادگیری ماشین را به عنوان جستجو برای نمایشهای مفید از دادههای ورودی خاص، در یک فضای از پیش تعریفشده از امکانات، با استفاده از راهنمایی یک سیگنال بازخورد، توصیف کردیم. با انتخاب یک توپولوژی شبکه، فضای امکانات (فضای فرضیه) خود را به یک سری خاص از عملیاتهای تنسور محدود میکنید که دادههای ورودی را به دادههای خروجی نگاشت میکنند. آنچه سپس به دنبال آن خواهید بود، مجموعه خوبی از مقادیر برای تنسورهای وزن درگیر در این عملیاتهای تنسور است.
برای یادگیری از دادهها، باید در مورد آنها فرضیاتی داشته باشید. این فرضیات، آنچه را که میتوان آموخت، تعریف میکنند. به این ترتیب، ساختار فضای فرضیه شما—معماری مدل شما—بسیار مهم است. این ساختار، فرضیات شما در مورد مسئلهتان و دانش قبلیای که مدل با آن شروع میکند را کدگذاری میکند. برای مثال، اگر روی یک مسئله طبقهبندی دو کلاسه با مدلی متشکل از یک لایه Dense واحد بدون فعالسازی (یک تبدیل آفین خالص) کار میکنید، فرض میکنید که دو کلاس شما به صورت خطی قابل تفکیک هستند.
انتخاب معماری صحیح شبکه، بیشتر یک هنر است تا یک علم، و اگرچه برخی بهترین شیوهها و اصول وجود دارد که میتوانید به آنها تکیه کنید، تنها تمرین میتواند به شما کمک کند تا یک معمار شبکه عصبی مناسب شوید. چند فصل بعدی هم اصول صریح ساخت شبکههای عصبی را به شما آموزش خواهند داد و هم به شما کمک میکنند تا شهود خود را در مورد اینکه چه چیزی برای مسائل خاص کار میکند یا نمیکند، توسعه دهید. شما شهود محکمی در مورد اینکه چه نوع معماریهای مدل برای انواع مختلف مسائل کار میکنند، چگونه این شبکهها را در عمل بسازید، چگونه پیکربندی یادگیری مناسب را انتخاب کنید و چگونه یک مدل را تنظیم کنید تا نتایج دلخواه را به دست آورد، خواهید ساخت.
گام “کامپایل”: پیکربندی فرآیند یادگیری
پس از تعریف معماری مدل، هنوز باید سه چیز دیگر را انتخاب کنید:
- تابع خطا (Loss function) (تابع هدف)—کمیتی که در طول آموزش به حداقل رسانده میشود. این کمیت، معیار موفقیت برای وظیفه مورد نظر را نشان میدهد.
- بهینهساز (Optimizer) — تعیین میکند که شبکه چگونه بر اساس تابع خطا بهروزرسانی شود. این بهینهساز یک نوع خاص از گرادیان کاهشی تصادفی (SGD) را پیادهسازی میکند.
- معیارها (Metrics) — معیارهای موفقیتی هستند که میخواهید در طول آموزش و اعتبارسنجی پایش کنید، مانند دقت طبقهبندی. برخلاف تابع خطا، آموزش مستقیماً برای این معیارها بهینهسازی نمیکند. به همین دلیل، معیارها نیازی به مشتقپذیر بودن ندارند.
هنگامی که تابع خطا، بهینهساز و معیارهای خود را انتخاب کردید، میتوانید از متدهای داخلی () compile و () fit برای شروع آموزش مدل خود استفاده کنید. متناوباً، میتوانید حلقههای آموزشی سفارشی خود را نیز بنویسید—ما نحوه انجام این کار را در فصل ۷ پوشش خواهیم داد. این کار بسیار بیشتر است! فعلاً، بیایید نگاهی به () compile و () fit بیندازیم.
متد () compile فرآیند آموزش را پیکربندی میکند—شما قبلاً در اولین مثال شبکه عصبی خود در فصل ۲ با آن آشنا شدهاید. این متد آرگومانهای optimizer، loss و metrics (یک لیست) را میگیرد.
model = keras.Sequential([keras.layers.Dense(1)])
تعریف یک طبقه بندی کننده خطی
model.compile(optimizer=”rmsprop”,
برای تعیین بهینهساز با نام “RMSprop” (که به حروف کوچک و بزرگ حساس نیست)، میتوانید آن را به صورت یک رشته در مرحله compile() مدل مشخص کنید.
loss=”mean_squared_error”,
برای تعیین تابع خطا با نام “میانگین مربعات خطا” (Mean Squared Error)، میتوانید آن را به صورت یک رشته در مرحله compile() مدل مشخص کنید.
metrics=[“accuracy”])
برای تعیین لیستی از معیارها، در این حالت تنها دقت (accuracy)، شما میتوانید آن را به عنوان یک لیست در کد مشخص کنید.
در فراخوانی قبلی متد () compile ، ما optimizer، loss و metrics را به صورت رشته (مانند “rmsprop”) ارسال کردیم. این رشتهها در واقع میانبرهایی هستند که به اشیاء پایتون تبدیل میشوند. برای مثال، “rmsprop” به keras.optimizers.RMSprop() تبدیل میگردد. مهم این است که میتوان این آرگومانها را به صورت نمونههای شیء نیز مشخص کرد، مانند این:
model.compile(optimizer=keras.optimizers.RMSprop(),
loss=keras.losses.MeanSquaredError(),
metrics=[keras.metrics.BinaryAccuracy()])
این [اشاره به امکان تعیین آرگومانها به صورت نمونههای شیء به جای رشتهها] مفید است اگر میخواهید توابع خطا (loss) یا معیارهای (metrics) سفارشی خود را ارسال کنید، یا اگر میخواهید اشیائی را که استفاده میکنید بیشتر پیکربندی کنید—برای مثال، با ارسال آرگومان learning_rate به بهینهساز:
model.compile(optimizer=keras.optimizers.RMSprop(learning_rate=1e-4),
loss=my_custom_loss,
metrics=[my_custom_metric_1, my_custom_metric_2])
در فصل ۷، نحوه ایجاد توابع خطا (loss) و معیارهای (metrics) سفارشی را پوشش خواهیم داد. به طور کلی، نیازی به ایجاد توابع خطا، معیارها یا بهینهسازهای خود از پایه نخواهید داشت، زیرا Keras طیف گستردهای از گزینههای داخلی را ارائه میدهد که به احتمال زیاد شامل آنچه نیاز دارید، میشود:
بهینهسازها:
- SGD (با یا بدون مومنتوم)
- RMSprop
- Adam
- Adagrad
- و غیره
توابع خطا (Losses):
- CategoricalCrossentropy
- SparseCategoricalCrossentropy
- BinaryCrossentropy
- MeanSquaredError
- KLDivergence
- CosineSimilarity
- و غیره
معیارها (Metrics):
- CategoricalAccuracy
- SparseCategoricalAccuracy
- BinaryAccuracy
- AUC
- Precision
- Recall
- و غیره
در طول این کتاب، کاربردهای ملموس بسیاری از این گزینهها را خواهید دید.
انتخاب یک تابع خطا(زیان)
انتخاب تابع خطای مناسب برای مسئله مناسب بسیار مهم است: شبکه شما هر راه میانبری را برای به حداقل رساندن خطا در پیش میگیرد، بنابراین اگر هدف به طور کامل با موفقیت در وظیفه مورد نظر همبستگی نداشته باشد، شبکه شما کارهایی را انجام خواهد داد که ممکن است نخواسته باشید.
یک هوش مصنوعی احمق و همهچیزدان را تصور کنید که با SGD و با این تابع هدف بد انتخاب شده آموزش داده شده است: “به حداکثر رساندن میانگین رفاه تمام انسانهای زنده”. برای آسانتر کردن کار خود، این هوش مصنوعی ممکن است تصمیم بگیرد تمام انسانها را به جز تعداد کمی بکشد و بر رفاه باقیماندهها تمرکز کند—زیرا میانگین رفاه تحت تأثیر تعداد انسانهای باقیمانده قرار نمیگیرد. این ممکن است چیزی نباشد که شما در نظر داشتید! فقط به یاد داشته باشید که تمام شبکههای عصبی که میسازید به همان اندازه در کاهش تابع خطای خود بیرحم خواهند بود—پس هدف را عاقلانه انتخاب کنید، در غیر این صورت با عوارض جانبی ناخواسته روبرو خواهید شد.
خوشبختانه، وقتی صحبت از مسائل رایج مانند طبقهبندی، رگرسیون و پیشبینی دنباله میشود، دستورالعملهای سادهای وجود دارد که میتوانید برای انتخاب خطای صحیح دنبال کنید. برای مثال، برای مسئله طبقهبندی دو کلاسه از “binary crossentropy” استفاده خواهید کرد، برای مسئله طبقهبندی چند کلاسه از “categorical crossentropy” و غیره. تنها زمانی که روی مسائل تحقیقاتی واقعاً جدید کار میکنید، مجبور خواهید بود توابع خطای خود را توسعه دهید. در چند فصل بعدی، به طور صریح توضیح خواهیم داد که کدام توابع خطا را برای طیف گستردهای از وظایف رایج انتخاب کنید.
درک متد ()fit
پس از () compile ، نوبت به() fit میرسد. متد () fit خود حلقه آموزش را پیادهسازی میکند. آرگومانهای کلیدی آن عبارتند از:
- دادهها (ورودیها و هدفها) برای آموزش. این دادهها معمولاً به شکل آرایههای NumPy یا یک شیء TensorFlow Dataset ارسال میشوند. در فصلهای بعدی، درباره API Dataset بیشتر خواهید آموخت.
- تعداد اِپوکها برای آموزش: تعداد دفعاتی که حلقه آموزش باید بر روی دادههای ارسال شده تکرار کند.
- اندازه بچ (batch size) برای استفاده در هر اِپوک از گرادیان کاهشی مینی-بچ: تعداد نمونههای آموزشی که برای محاسبه گرادیانها برای یک گام بهروزرسانی وزن در نظر گرفته میشوند.
قطعه کد ۳.۲۳: فراخوانی () fit با دادههای NumPy.
history = model.fit(
inputs,
نمونههای ورودی، به عنوان یک آرایه NumPy.
targets,
هدفهای آموزشی مربوطه، به عنوان یک آرایه NumPy.
epochs=5,
حلقه آموزش ۵ بار بر روی دادهها تکرار خواهد شد.
batch_size=128
(
حلقه آموزش، دادهها را در دستههای ۱۲۸ نمونهای تکرار خواهد کرد.
فراخوانی() fit یک شیء History را برمیگرداند. این شیء شامل یک فیلد history است که یک دیکشنری است و کلیدهایی مانند “loss” یا نامهای خاص معیارها را به لیست مقادیر آنها در هر اِپوک نگاشت میکند.
>>> history.history
{“binary_accuracy”: [0.855, 0.9565, 0.9555, 0.95, 0.951],
“loss”: [0.6573270302042366,
0.07434618508815766,
0.07687718723714351,
0.07412414988875389,
0.07617757616937161]}
پایش خطا (loss) و معیارها (metrics) بر روی دادههای اعتبارسنجی (validation data)
هدف یادگیری ماشین، به دست آوردن مدلهایی نیست که بر روی دادههای آموزشی عملکرد خوبی داشته باشند، که این کار آسان است—تنها کاری که باید انجام دهید این است که گرادیان را دنبال کنید. هدف، به دست آوردن مدلهایی است که به طور کلی، و به ویژه بر روی نقاط دادهای که مدل قبلاً هرگز با آنها مواجه نشده است، عملکرد خوبی داشته باشند. صرف اینکه یک مدل بر روی دادههای آموزشی خود عملکرد خوبی دارد، به این معنی نیست که بر روی دادههایی که قبلاً ندیده است نیز عملکرد خوبی خواهد داشت! برای مثال، ممکن است مدل شما تنها به حفظ یک نگاشت بین نمونههای آموزشی و هدفهای آنها ختم شود، که برای وظیفه پیشبینی هدفها برای دادههایی که مدل قبلاً هرگز ندیده است، بیفایده خواهد بود. ما این نکته را با جزئیات بسیار بیشتری در فصل ۵ بررسی خواهیم کرد.
برای نظارت بر عملکرد مدل بر روی دادههای جدید، یک روش استاندارد این است که زیرمجموعهای از دادههای آموزشی را به عنوان دادههای اعتبارسنجی (validation data) کنار بگذاریم: شما مدل را بر روی این دادهها آموزش نخواهید داد، اما از آنها برای محاسبه مقدار خطا (loss) و معیارها (metrics) استفاده خواهید کرد. این کار را با استفاده از آرگومان validation_data در () fit انجام میدهید. مانند دادههای آموزشی، دادههای اعتبارسنجی را میتوان به صورت آرایههای NumPy یا یک شیء TensorFlow Dataset ارسال کرد.
قطعه کد ۳.۲۴: استفاده از آرگومان validation_data.
model = keras.Sequential([keras.layers.Dense(1)]) model.compile(optimizer=keras.optimizers.RMSprop(learning_rate=0.1),
loss=keras.losses.MeanSquaredError(), metrics=[keras.metrics.BinaryAccuracy()])
indices_permutation = np.random.permutation(len(inputs))
shuffled_inputs = inputs[indices_permutation]
shuffled_targets = targets[indices_permutation]
برای جلوگیری از داشتن نمونههایی تنها از یک کلاس در دادههای اعتبارسنجی، ورودیها و هدفها را با استفاده از یک جایگشت تصادفی از ایندکسها، به هم بریزید.
num_validation_samples = int(0.3 * len(inputs)) val_inputs = shuffled_inputs[:num_validation_samples] val_targets = shuffled_targets[:num_validation_samples]
training_inputs = shuffled_inputs[num_validation_samples:]
training_targets = shuffled_targets[num_validation_samples:]
model.fit(
برای تخصیص ۳۰ درصد از ورودیها و هدفهای آموزشی به منظور اعتبارسنجی (به این معنی که این نمونهها را از آموزش حذف کرده و آنها را برای محاسبه خطای اعتبارسنجی و معیارها کنار میگذاریم)، باید دادهها را تقسیمبندی کنیم.
training_inputs,
training_targets,
دادههای آموزشی، که برای بهروزرسانی وزنهای مدل استفاده میشوند.
epochs=5,
batch_size=16,
validation_data=(val_inputs, val_targets)
)
دادههای اعتبارسنجی، که فقط برای پایش خطای اعتبارسنجی و معیارها استفاده میشوند.
مقدار خطا در دادههای اعتبارسنجی را “خطای اعتبارسنجی” (validation loss) مینامند تا آن را از “خطای آموزش” (training loss) متمایز کنند. توجه داشته باشید که جدا نگه داشتن دقیق دادههای آموزشی و اعتبارسنجی ضروری است: هدف اعتبارسنجی، پایش این است که آیا آنچه مدل در حال یادگیری آن است، واقعاً بر روی دادههای جدید مفید است یا خیر. اگر هر یک از دادههای اعتبارسنجی در طول آموزش توسط مدل دیده شده باشد، خطای اعتبارسنجی و معیارهای شما ناقص خواهند بود.
توجه داشته باشید که اگر میخواهید خطای اعتبارسنجی و معیارها را پس از اتمام آموزش محاسبه کنید، میتوانید متد () evaluate را فراخوانی کنید:
loss_and_metrics = model.evaluate(val_inputs, val_targets, batch_size=128)
() evaluate به صورت دستهای (با اندازهی batch_size) بر روی دادههای ارسالی تکرار میکند و لیستی از مقادیر اسکالر را برمیگرداند، که در آن اولین ورودی، خطای اعتبارسنجی (validation loss) و ورودیهای بعدی، معیارهای اعتبارسنجی (validation metrics) هستند. اگر مدل هیچ معیاری نداشته باشد، تنها خطای اعتبارسنجی برگردانده میشود (به جای یک لیست).
استنباط (Inference): استفاده از مدل پس از آموزش
هنگامی که مدل خود را آموزش دادید، میخواهید از آن برای پیشبینی بر روی دادههای جدید استفاده کنید. به این فرآیند استنتاج (Inference) گفته میشود. برای انجام این کار، یک رویکرد سادهلوحانه صرفاً فراخوانی متد __() call__ مدل خواهد بود:
predictions = model(new_inputs)
یک آرایه NumPy یا تنسور TensorFlow را دریافت میکند و یک تنسور TensorFlow برمیگرداند.
با این حال، این کار تمام ورودیهای موجود در new_inputs را به یکباره پردازش میکند، که ممکن است در صورت حجم بالای دادهها (به ویژه، ممکن است به حافظه بیشتری نسبت به GPU شما نیاز داشته باشد) امکانپذیر نباشد.
روش بهتر برای انجام استنتاج، استفاده از متد () predict است. این متد دادهها را در دستههای کوچک تکرار میکند و یک آرایه NumPy از پیشبینیها را برمیگرداند. و برخلاف __()call __، میتواند اشیاء TensorFlow Dataset را نیز پردازش کند.
predictions = model.predict(new_inputs, batch_size=128)
یک آرایه NumPy یا یک Dataset را دریافت میکند و یک آرایه NumPy برمیگرداند.
برای مثال، اگر () predict را بر روی بخشی از دادههای اعتبارسنجی خود با مدل خطی که قبلاً آموزش دادیم، استفاده کنیم، امتیازات اسکالری به دست میآوریم که با پیشبینی مدل برای هر نمونه ورودی مطابقت دارد:
>>> predictions = model.predict(val_inputs, batch_size=128)
>>> print(predictions[:10])
[[0.3590725 ]
[0.82706255]
[0.74428225]
[0.682058 ]
[0.7312616 ]
[0.6059811 ]
[0.78046083]
[0.025846 ]
[0.16594526]
[0.72068727]]
برای مثال، اگر () predict را بر روی بخشی از دادههای اعتبارسنجی خود با مدل خطی که قبلاً آموزش دادیم، استفاده کنیم، امتیازات اسکالری به دست میآوریم که با پیشبینی مدل برای هر نمونه ورودی مطابقت دارد:
فعلاً، این تمام چیزی است که باید در مورد مدلهای Keras بدانید. شما آمادهاید تا در فصل بعدی به حل مسائل یادگیری ماشین دنیای واقعی با Keras بپردازید.
خلاصه
- TensorFlow یک فریمورک محاسبات عددی با قدرت صنعتی است که میتواند روی CPU، GPU یا TPU اجرا شود. این فریمورک میتواند به طور خودکار گرادیان هر عبارت مشتقپذیری را محاسبه کند، میتواند روی دستگاههای زیادی توزیع شود، و میتواند برنامهها را به محیطهای اجرایی خارجی مختلف—حتی جاوااسکریپت—صادر کند.
- Keras API استاندارد برای انجام یادگیری عمیق با TensorFlow است. این چیزی است که ما در سراسر این کتاب از آن استفاده خواهیم کرد.
- اشیاء کلیدی TensorFlow شامل تنسورها، متغیرها، عملیاتهای تنسور و گرادیان تیپ هستند.
- کلاس اصلی Keras، Layer است. یک لایه شامل تعدادی وزن و مقداری عملیات محاسباتی است. لایهها در کنار هم قرار گرفته و مدلها را تشکیل میدهند.
- قبل از شروع آموزش یک مدل، باید یک بهینهساز (optimizer)، یک تابع خطا (loss) و تعدادی معیار (metrics) را انتخاب کنید که این موارد را از طریق متد () model.compile مشخص میکنید.
- برای آموزش یک مدل، میتوانید از متد () fit استفاده کنید که گرادیان کاهشی مینی-بچ را برای شما اجرا میکند. همچنین میتوانید از آن برای پایش خطا و معیارهای خود بر روی دادههای اعتبارسنجی (validation data) استفاده کنید، که مجموعهای از ورودیها هستند که مدل در طول آموزش آنها را نمیبیند.
- هنگامی که مدل شما آموزش دید، از متد () model.predict برای تولید پیشبینیها بر روی ورودیهای جدید استفاده میکنید.



