- این فصل پوشش میدهد:
- درک شبکههای عصبی کانولوشنی (convnets).
- استفاده از افزایش داده برای کاهش بیشبرازش.
- استفاده از یک convnet از پیش آموزشدیده برای استخراج ویژگی.
- تنظیم دقیق یک convnet از پیش آموزشدیده.
مقدمه
بینایی کامپیوتر اولین و بزرگترین داستان موفقیت یادگیری عمیق است. هر روز، شما با مدلهای بینایی عمیق در تعامل هستید—از طریق Google Photos، جستجوی تصویر گوگل، YouTube، فیلترهای ویدیویی در برنامههای دوربین، نرمافزارهای OCR و بسیاری موارد دیگر. این مدلها همچنین در قلب تحقیقات پیشرفته در رانندگی خودران، رباتیک، تشخیص پزشکی با کمک هوش مصنوعی، سیستمهای پرداخت خودکار خردهفروشی و حتی کشاورزی خودران قرار دارند.
بینایی کامپیوتر حوزه مسئلهای است که منجر به رشد اولیه یادگیری عمیق بین سالهای 2011 تا 2015 شد. نوعی از مدل یادگیری عمیق به نام شبکههای عصبی کانولوشنی، در آن زمان شروع به کسب نتایج قابل توجهی در مسابقات طبقهبندی تصویر کرد، ابتدا با پیروزی دن سیرسان در دو رقابت خاص (رقابت تشخیص کاراکتر چینی ICDAR 2011 و رقابت تشخیص علائم راهنمایی و رانندگی آلمان IJCNN 2011) و سپس به طور قابل توجهی در پاییز 2012 با پیروزی گروه هینتون در چالش تشخیص بصری در مقیاس بزرگ ImageNet. بسیاری از نتایج امیدوارکننده دیگر به سرعت در سایر وظایف بینایی کامپیوتر شروع به ظهور کردند.
جالب اینجاست که این موفقیتهای اولیه در آن زمان برای فراگیر شدن یادگیری عمیق کافی نبودند—چند سال طول کشید. جامعه تحقیقاتی بینایی کامپیوتر سالها را صرف سرمایهگذاری در روشهایی غیر از شبکههای عصبی کرده بود و آمادگی رها کردن آنها را تنها به این دلیل که تازهواردی در صحنه بود، نداشت. در سالهای 2013 و 2014، یادگیری عمیق همچنان با شک و تردید شدید بسیاری از محققان ارشد بینایی کامپیوتر روبرو بود. تنها در سال 2016 بود که سرانجام غالب شد. به یاد میآورم که در فوریه 2014، استاد سابقم را تشویق میکردم که به یادگیری عمیق روی بیاورد. میگفتم: “این موج بزرگ بعدی است!” او پاسخ داد: “خب، شاید فقط یک مد گذرا باشد.” تا سال 2016، کل آزمایشگاه او در حال انجام یادگیری عمیق بود. ایدهای که زمانش فرا رسیده باشد را نمیتوان متوقف کرد.
این فصل شبکههای عصبی کانولوشنی، که به عنوان convnets نیز شناخته میشوند، نوعی از مدل یادگیری عمیق را معرفی میکند که اکنون تقریباً به طور جهانی در کاربردهای بینایی کامپیوتر استفاده میشود. شما یاد خواهید گرفت که convnetها را در مسائل طبقهبندی تصویر به کار ببرید—به ویژه آنهایی که شامل مجموعههای داده آموزشی کوچک هستند، که رایجترین مورد استفاده است اگر شما یک شرکت فناوری بزرگ نباشید.
مقدمهای بر convnet ها
ما در شرف غواصی در نظریه convnetها و چرایی موفقیت آنها در وظایف بینایی کامپیوتر هستیم. اما ابتدا، بیایید نگاهی عملی به یک مثال ساده convnet بیندازیم که ارقام MNIST را طبقهبندی میکند، وظیفهای که در فصل ۲ با استفاده از یک شبکه کاملاً متصل انجام دادیم (دقت آزمایش ما در آن زمان ۹۷.۸٪ بود). حتی اگر convnet ابتدایی باشد، دقت آن مدل کاملاً متصل فصل ۲ ما را به کلی شکست خواهد داد. قطعه کد زیر نشان میدهد که یک convnet ابتدایی چگونه به نظر میرسد. این پشتهای از لایههای Conv2D و MaxPooling2D است. در یک دقیقه دقیقاً خواهید دید که آنها چه کاری انجام میدهند. ما مدل را با استفاده از Functional API، که در فصل قبل معرفی کردیم، خواهیم ساخت.
قطعه کد 8.1: نمونهسازی یک convnet کوچک
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(filters=32, kernel_size=3, activation=”relu”)(inputs)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation=”relu”)(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation=”relu”)(x)
x = layers.Flatten()(x)
outputs = layers.Dense(10, activation=”softmax”)(x)
model = keras.Model(inputs=inputs, outputs=outputs)
مهم این است که یک convnet تنسورهایی با شکل (ارتفاع_تصویر، عرض_تصویر، کانالهای_تصویر) را به عنوان ورودی میگیرد، که شامل بعد دسته نمیشود. در این مورد، convnet را برای پردازش ورودیهایی با اندازه (1, 28, 28) پیکربندی خواهیم کرد که فرمت تصاویر MNIST است.
بیایید معماری convnet خود را نمایش دهیم.
قطعه کد 8.2: نمایش خلاصه مدل
>>> model.summary()
Model: “model”
Layer (type) Output Shape Param #
=================================================================
| input_1 (InputLayer) | [(None, 28, 28, 1)] | 0 |
| conv2d (Conv2D) | (None, 26, 26, 32) | 320 |
| max_pooling2d (MaxPooling2D) | (None, 13, 13, 32) | 0 |
| conv2d_1 (Conv2D) | (None, 11, 11, 64) | 18496 |
| max_pooling2d_1 (MaxPooling2 | (None, 5, 5, 64) | 0 |
| conv2d_2 (Conv2D) | (None, 3, 3, 128) | 73856 |
| flatten (Flatten) | (None, 1152) | 0 |
| dense (Dense) | (None, 10) | 11530 |
=================================================================
Total params: 104,202
Trainable params: 104,202
Non-trainable params: 0
قطعه کد 8.3: آموزش convnet بر روی تصاویر MNIST
from tensorflow.keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype(“float32”) / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype(“float32″) / 255 model.compile(optimizer=”rmsprop”,
loss=”sparse_categorical_crossentropy”,
metrics=[“accuracy”])
model.fit(train_images, train_labels, epochs=5, batch_size=64)
بیایید مدل را روی دادههای آزمایش ارزیابی کنیم.
قطعه کد 8.4: ارزیابی convnet
>>> test_loss, test_acc = model.evaluate(test_images, test_labels)
>>> print(f”Test accuracy: {test_acc:.3f}”)
Test accuracy: 0.991
در حالی که مدل کاملاً متصل از فصل 2 دقت آزمایش 97.8% داشت، convnet پایه دقت آزمایش 99.1% دارد: نرخ خطا را حدود 60% (نسبی) کاهش دادیم. بد نیست!
اما چرا این convnet ساده، در مقایسه با یک مدل کاملاً متصل، اینقدر خوب کار میکند؟ برای پاسخ به این سوال، بیایید به کاری که لایههای Conv2D و MaxPooling2D انجام میدهند، بپردازیم.
عملیات(عملکرد) کانولوشن
تفاوت اساسی بین یک لایه کاملاً متصل و یک لایه کانولوشن این است: لایههای Dense الگوهای کلی را در فضای ویژگی ورودی خود یاد میگیرند (برای مثال، برای یک رقم MNIST، الگوهایی که تمام پیکسلها را درگیر میکنند)، در حالی که لایههای کانولوشن الگوهای محلی را یاد میگیرند—در مورد تصاویر، الگوهایی که در پنجرههای 2 بعدی کوچک ورودیها یافت میشوند (به شکل 8.1 مراجعه کنید). در مثال قبلی، این پنجرهها همگی 3 × 3 بودند.

شکل 8.1: تصاویر را میتوان به الگوهای محلی مانند لبهها، بافتها و غیره تقسیم کرد.
این ویژگی کلیدی به شبکههای کانولوشنی دو خاصیت جالب میدهد:
- الگوهایی که یاد میگیرند ناوردا به انتقال هستند. پس از یادگیری یک الگوی مشخص در گوشه پایین سمت راست یک تصویر، یک convnet میتواند آن را در هر جای دیگر تشخیص دهد: برای مثال، در گوشه بالا سمت چپ. یک مدل کاملاً متصل باید اگر الگو در مکان جدیدی ظاهر میشد، دوباره آن را یاد میگرفت. این امر باعث میشود convnetها در پردازش تصاویر (زیرا دنیای بصری اساساً ناوردا به انتقال است) از نظر داده کارآمد باشند: آنها برای یادگیری نمایشهایی که قدرت تعمیمپذیری دارند، به نمونههای آموزشی کمتری نیاز دارند.
- آنها میتوانند سلسلهمراتب فضایی الگوها را یاد بگیرند. یک لایه کانولوشن اول، الگوهای محلی کوچکی مانند لبهها را یاد میگیرد، یک لایه کانولوشن دوم الگوهای بزرگتری را که از ویژگیهای لایههای اول ساخته شدهاند، یاد میگیرد و همینطور ادامه مییابد (به شکل 8.2 مراجعه کنید). این امر به convnetها اجازه میدهد تا مفاهیم بصری به طور فزاینده پیچیده و انتزاعی را به طور کارآمد یاد بگیرند، زیرا دنیای بصری
اساساً به صورت سلسلهمراتبی فضایی است.
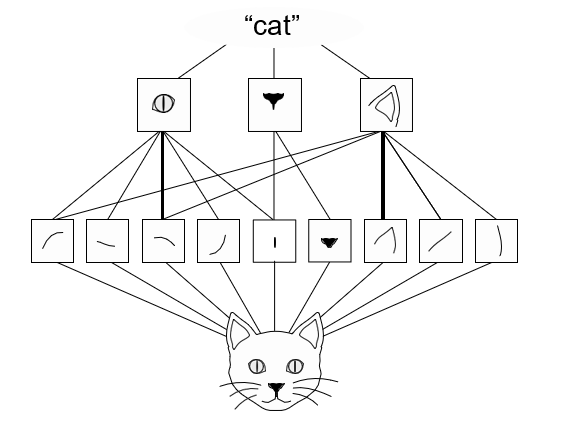
شکل 8.2 دنیای بصری سلسلهمراتبی فضایی از ماژولهای بصری را تشکیل میدهد: خطوط یا بافتهای ابتدایی در اشیاء سادهای مانند چشمها یا گوشها ترکیب میشوند که اینها نیز در مفاهیم سطح بالا مانند “گربه” ترکیب میشوند.
کانولوشنها بر روی تنسورهای رتبه 3 به نام نقشههای ویژگی عمل میکنند، با دو محور مکانی (ارتفاع و عرض) و همچنین یک محور عمق (که محور کانالها نیز نامیده میشود). برای یک تصویر RGB، بعد محور عمق 3 است، زیرا تصویر سه کانال رنگی دارد: قرمز، سبز و آبی. برای یک تصویر سیاه و سفید، مانند ارقام MNIST، عمق 1 است (سطوح خاکستری). عملیات کانولوشن تکهها (patches) را از نقشه ویژگی ورودی خود استخراج کرده و همان تبدیل را بر روی تمام این تکهها اعمال میکند و یک نقشه ویژگی خروجی تولید میکند. این نقشه ویژگی خروجی همچنان یک تنسور رتبه 3 است: دارای عرض و ارتفاع است. عمق آن میتواند دلخواه باشد، زیرا عمق خروجی یک پارامتر لایه است، و کانالهای مختلف در آن محور عمق دیگر نشاندهنده رنگهای خاصی مانند ورودی RGB نیستند؛ بلکه نشاندهنده فیلترها هستند. فیلترها جنبههای خاصی از دادههای ورودی را کدگذاری میکنند: در سطح بالا، یک فیلتر واحد میتواند مفهوم “حضور یک چهره در ورودی” را کدگذاری کند، برای مثال.
در مثال MNIST، اولین لایه کانولوشن یک نقشه ویژگی با اندازه (1, 28, 28) را میگیرد و یک نقشه ویژگی با اندازه (32, 26, 26) را خروجی میدهد: این لایه 32 فیلتر را بر روی ورودی خود محاسبه میکند. هر یک از این 32 کانال خروجی شامل یک شبکه 26 × 26 از مقادیر است، که یک نقشه پاسخ فیلتر بر روی ورودی است و پاسخ آن الگوی فیلتر را در مکانهای مختلف ورودی نشان میدهد (به شکل 8.3 مراجعه کنید).
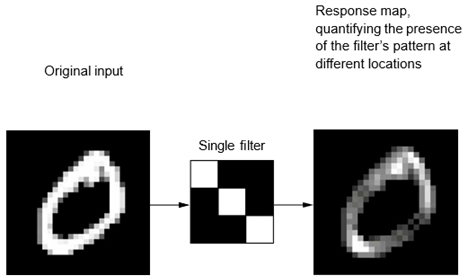
شکل 8.3: مفهوم نقشه پاسخ: یک نقشه 2 بعدی از حضور یک الگو در مکانهای مختلف در یک ورودی
این همان معنای اصطلاح نقشه ویژگی (feature map) است: هر بعد در محور عمق، یک ویژگی (یا فیلتر) است و تنسور رتبه 2 خروجی [:, :, n]، نقشه فضایی 2 بعدی پاسخ این فیلتر بر روی ورودی است.
کانولوشنها توسط دو پارامتر کلیدی تعریف میشوند:
- اندازه تکههای استخراج شده از ورودیها— اینها معمولاً 3 × 3 یا 5 × 5 هستند. در مثال، آنها 3 × 3 بودند که یک انتخاب رایج است.
- عمق نقشه ویژگی خروجی— این تعداد فیلترهای محاسبه شده توسط کانولوشن است. مثال با عمق 32 شروع شد و با عمق 64 به پایان رسید.
در لایههای Conv2D کراس، این پارامترها اولین آرگومانهای ارسال شده به لایه هستند: Conv2D(output_depth, (window_height, window_width)).
یک کانولوشن با اسلاید کردن این پنجرههای 3 × 3 یا 5 × 5 بر روی نقشه ویژگی ورودی 3 بعدی، در هر مکان ممکن توقف میکند و تکه 3 بعدی از ویژگیهای اطراف (شکل (window_height, window_width, input_depth)) را استخراج میکند. سپس هر چنین تکه 3 بعدی به یک بردار 1 بعدی با شکل (output_depth,) تبدیل میشود، که این کار از طریق یک ضرب تنسور با یک ماتریس وزن یادگرفته شده، به نام کرنل کانولوشن، انجام میشود—همین کرنل در هر تکه دوباره استفاده میشود. سپس تمام این بردارها (یکی برای هر تکه) به صورت فضایی در یک نقشه خروجی 3 بعدی با شکل (ارتفاع، عرض، عمق_خروجی) دوباره مونتاژ میشوند. هر مکان فضایی در نقشه ویژگی خروجی متناظر با همان مکان در نقشه ویژگی ورودی است (برای مثال، گوشه پایین سمت راست خروجی حاوی اطلاعاتی درباره گوشه پایین سمت راست ورودی است). برای مثال، با پنجرههای 3 × 3، خروجی بردار [i, j, :] از تکه 3 بعدی input[i-1:i+1, j-1:j+1, :] میآید. فرآیند کامل در شکل 8.4 توضیح داده شده است.
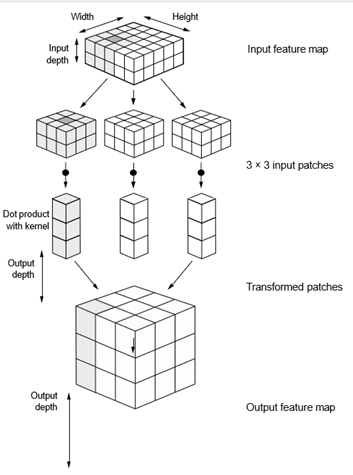
شکل 8.4: نحوه کار کانولوشن
توجه داشته باشید که عرض و ارتفاع خروجی ممکن است به دو دلیل با عرض و ارتفاع ورودی تفاوت داشته باشد:
- اثرات مرزی، که میتوان با پدینگ نقشه ویژگی ورودی آن را خنثی کرد.
- استفاده از گامها (strides)، که در ادامه تعریف خواهم کرد.
بیایید نگاه عمیقتری به این مفاهیم بیندازیم.
درک اثرات مرزی و پدینگ
یک نقشه ویژگی 5 × 5 (مجموعاً 25 کاشی) را در نظر بگیرید. تنها 9 کاشی وجود دارد که میتوانید یک پنجره 3 × 3 را حول آنها متمرکز کنید و یک شبکه 3 × 3 تشکیل دهید (به شکل 8.5 مراجعه کنید). از این رو، نقشه ویژگی خروجی 3 × 3 خواهد بود. این نقشه کمی کوچک میشود: در این حالت دقیقاً دو کاشی در کنار هر بعد. شما میتوانید این اثر مرزی را در مثال قبلی مشاهده کنید: با ورودیهای 28 × 28 شروع میکنید که پس از اولین لایه کانولوشن به 26 × 26 تبدیل میشوند.
اگر میخواهید یک نقشه ویژگی خروجی با همان ابعاد فضایی ورودی به دست آورید، میتوانید از پدینگ (padding) استفاده کنید. پدینگ شامل افزودن تعداد مناسبی از سطرها و ستونها در هر طرف نقشه ویژگی ورودی است تا امکان برازش پنجرههای کانولوشن مرکزی در اطراف هر کاشی ورودی فراهم شود. برای یک پنجره 3 × 3، یک ستون در سمت راست، یک ستون در سمت چپ، یک سطر در بالا و یک سطر در پایین اضافه میکنید. برای یک پنجره 5 × 5، دو سطر اضافه میکنید (به شکل 8.6 مراجعه کنید).
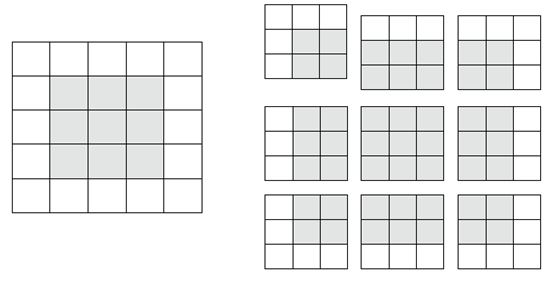
شکل 8.5: مکانهای معتبر پچهای 3 × 3 در یک نقشه ویژگی ورودی 5 × 5.
شکل 8.6: پدینگ یک ورودی 5 × 5 برای استخراج 25 پچ 3 × 3
در لایههای Conv2D، پدینگ از طریق آرگومان padding قابل تنظیم است که دو مقدار میپذیرد: “valid”، به معنای عدم پدینگ (فقط مکانهای معتبر پنجره استفاده خواهند شد)، و “same”، به معنای “پدگذاری به گونهای که خروجی دارای همان عرض و ارتفاع ورودی باشد.” آرگومان padding به طور پیشفرض روی “valid” تنظیم شده است.
درک گامهای کانولوشن (Convolution Strides)
عامل دیگری که میتواند بر اندازه خروجی تأثیر بگذارد، مفهوم گامها (strides) است. توضیحات ما در مورد کانولوشن تاکنون فرض کرده است که کاشیهای مرکزی پنجرههای کانولوشن همگی پیوسته هستند. اما فاصله بین دو پنجره متوالی، پارامتری از کانولوشن است که گام (stride) نامیده میشود و به طور پیشفرض 1 است. امکان انجام کانولوشنهای گامدار (strided convolutions) وجود دارد: کانولوشنهایی با گام بالاتر از 1. در شکل 8.7، میتوانید پچهای استخراج شده توسط یک کانولوشن 3 × 3 با گام 2 بر روی یک ورودی 5 × 5 (بدون پدینگ) را مشاهده کنید.
شکل 8.7: پچهای کانولوشن 3 × 3 با گامهای 2 × 2
استفاده از گام 2 به این معنی است که عرض و ارتفاع نقشه ویژگی با ضریب 2 کاهش نمونهبرداری میشوند (علاوه بر هرگونه تغییر ناشی از اثرات مرزی). کانولوشنهای گامدار (Strided convolutions) به ندرت در مدلهای طبقهبندی استفاده میشوند، اما برای برخی از انواع مدلها مفید هستند، همانطور که در فصل بعدی خواهید دید.
در مدلهای طبقهبندی، به جای گامها، تمایل داریم از عملیات Max-Pooling برای کاهش نمونهبرداری نقشههای ویژگی استفاده کنیم، که در اولین مثال convnet خود آن را در عمل دیدید. بیایید با جزئیات بیشتری به آن نگاه کنیم.
عملیات Max-Pooling
در مثال convnet، شاید متوجه شده باشید که اندازه نقشههای ویژگی پس از هر لایه MaxPooling2D نصف میشود. برای مثال، قبل از اولین لایه MaxPooling2D، نقشه ویژگی 26 × 26 است، اما عملیات Max-Pooling آن را به 13 × 13 نصف میکند. این نقش Max Pooling است: کاهش نمونهبرداری شدید نقشههای ویژگی، بسیار شبیه به کانولوشنهای گامدار.
Max Pooling شامل استخراج پنجرهها از نقشههای ویژگی ورودی و خروجی دادن حداکثر مقدار هر کانال است. از نظر مفهومی شبیه به کانولوشن است، با این تفاوت که به جای تبدیل تکههای محلی از طریق یک تبدیل خطی یادگرفتهشده (کرنل کانولوشن)، آنها از طریق یک عملیات تنسور حداکثر (max tensor operation) کدگذاری شده سخت تبدیل میشوند. یک تفاوت بزرگ با کانولوشن این است که Max Pooling معمولاً با پنجرههای 2 × 2 و گام 2 انجام میشود تا نقشههای ویژگی با ضریب 2 کاهش نمونهبرداری شوند. از سوی دیگر، کانولوشن معمولاً با پنجرههای 3 × 3 و بدون گام (گام 1) انجام میشود.
چرا نقشههای ویژگی را به این شیوه کاهش نمونهبرداری میکنیم؟ چرا لایههای max-pooling را حذف نکنیم و نقشههای ویژگی نسبتاً بزرگی را در تمام مسیر حفظ نکنیم؟ بیایید این گزینه را بررسی کنیم. مدل ما در این صورت شبیه قطعه کد زیر خواهد بود.
قطعه کد 8.5: یک convnet با ساختار نادرست که لایههای max-pooling خود را ندارد.
inputs = keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(filters=32, kernel_size=3, activation=”relu”)(inputs)
x = layers.Conv2D(filters=64, kernel_size=3, activation=”relu”)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation=”relu”)(x)
x = layers.Flatten()(x)
outputs = layers.Dense(10, activation=”softmax”)(x)
model_no_max_pool = keras.Model(inputs=inputs, outputs=outputs)
خلاصه مدل در اینجا آمده است:
>>> model_no_max_pool.summary()
Model: “model_1”
Layer (type) Output Shape Param #
=================================================================
| input_2 (InputLayer) | [(None, 28, 28, 1)] | 0 |
| conv2d_3 (Conv2D) | (None, 26, 26, 32) | 320 |
| conv2d_4 (Conv2D) | (None, 24, 24, 64) | 18496 |
| conv2d_5 (Conv2D) | (None, 22, 22, 128) | 73856 |
| flatten_1 (Flatten) | (None, 61952) | 0 |
| dense_1 (Dense) | (None, 10) | 619530 |
=================================================================
Total params: 712,202
Trainable params: 712,202
Non-trainable params: 0
چه اشکالی در این ساختار وجود دارد؟ دو چیز:
- این ساختار برای یادگیری سلسلهمراتب فضایی ویژگیها مناسب نیست. پنجرههای 3 × 3 در لایه سوم فقط اطلاعاتی را شامل میشوند که از پنجرههای 7 × 7 در ورودی اولیه میآیند. الگوهای سطح بالای آموخته شده توسط convnet همچنان نسبت به ورودی اولیه بسیار کوچک خواهند بود، که ممکن است برای یادگیری طبقهبندی ارقام کافی نباشد (سعی کنید یک رقم را فقط با نگاه کردن به آن از طریق پنجرههای 7 × 7 پیکسلی تشخیص دهید!). ما نیاز داریم که ویژگیهای آخرین لایه کانولوشن حاوی اطلاعاتی درباره کلیت ورودی باشند.
- نقشه ویژگی نهایی دارای 22 × 22 × 128 = 61,952 ضریب کلی در هر نمونه است. این بسیار زیاد است. وقتی آن را مسطح میکنید تا یک لایه Dense با اندازه 10 روی آن قرار دهید، آن لایه بیش از نیم میلیون پارامتر خواهد داشت. این برای چنین مدل کوچکی بسیار بزرگ است و منجر به بیشبرازش شدید میشود.
به طور خلاصه، دلیل استفاده از کاهش نمونهبرداری (downsampling) کاهش تعداد ضرایب نقشه ویژگی برای پردازش، و همچنین القای سلسلهمراتب فیلتر فضایی با وادار کردن لایههای کانولوشن متوالی به نگاه کردن به پنجرههای به طور فزاینده بزرگتر (از نظر کسری از ورودی اصلی که پوشش میدهند) است.
توجه داشته باشید که max pooling تنها راهی نیست که میتوانید به چنین کاهش نمونهبرداری دست یابید. همانطور که قبلاً میدانید، میتوانید از گامها در لایه کانولوشن قبلی نیز استفاده کنید. و میتوانید از average pooling به جای max pooling استفاده کنید، که در آن هر تکه ورودی محلی با گرفتن مقدار میانگین هر کانال بر روی تکه، به جای حداکثر، تبدیل میشود. اما max pooling تمایل دارد بهتر از این راهحلهای جایگزین عمل کند. دلیل آن این است که ویژگیها تمایل دارند حضور فضایی یک الگو یا مفهوم را بر روی کاشیهای مختلف نقشه ویژگی کدگذاری کنند (از این رو اصطلاح نقشه ویژگی)، و نگاه کردن به حداکثر حضور ویژگیهای مختلف آموزندهتر از میانگین حضور آنها است. معقولترین استراتژی نمونهبرداری فرعی (subsampling) این است که ابتدا نقشههای متراکم ویژگیها (از طریق کانولوشنهای بدون گام) را تولید کرده و سپس به فعالسازی حداکثری ویژگیها بر روی تکههای کوچک نگاه کنیم، به جای نگاه کردن به پنجرههای پراکندهتر ورودیها (از طریق کانولوشنهای گامدار) یا میانگینگیری تکههای ورودی، که میتواند باعث شود اطلاعات حضور ویژگی را از دست بدهید یا رقیق کنید.
در این مرحله، شما باید اصول اولیه convnetها—نقشههای ویژگی، کانولوشن و max pooling—را درک کرده باشید و باید بدانید چگونه یک convnet کوچک برای حل یک مسئله ساده مانند طبقهبندی ارقام MNIST بسازید. اکنون بیایید به کاربردهای عملیتر و مفیدتر بپردازیم.
آموزش یکconvnet (شبکه کانولوشنال)از ابتدا بر روی یک مجموعه داده کوچک
نیاز به آموزش یک مدل طبقهبندی تصویر با استفاده از دادههای بسیار کم یک وضعیت رایج است که احتمالاً در عمل با آن روبرو خواهید شد، اگر تا به حال در یک زمینه حرفهای بینایی کامپیوتر انجام دادهاید. “چند” نمونه میتواند از چند صد تا چند ده هزار تصویر باشد. به عنوان یک مثال عملی، بر روی طبقهبندی تصاویر به عنوان سگ یا گربه در یک مجموعه داده حاوی 5,000 عکس گربه و سگ (2,500 گربه، 2,500 سگ) تمرکز خواهیم کرد. ما از 2,000 عکس برای آموزش، 1,000 برای اعتبارسنجی و 2,000 برای آزمایش استفاده خواهیم کرد.
در این بخش، یک استراتژی اساسی برای مقابله با این مشکل را مرور خواهیم کرد: آموزش یک مدل جدید از ابتدا با استفاده از دادههای کمی که دارید. ابتدا به طور سادهلوحانه یک convnet کوچک را بر روی 2,000 نمونه آموزشی، بدون هیچ منظمسازی، آموزش خواهیم داد تا یک خط پایه برای آنچه میتوان به دست آورد، تعیین کنیم. این به ما دقت طبقهبندی حدود 70% را خواهد داد. در آن مرحله، مشکل اصلی بیشبرازش خواهد بود. سپس افزایش داده را معرفی خواهیم کرد، یک تکنیک قدرتمند برای کاهش بیشبرازش در بینایی کامپیوتر. با استفاده از افزایش داده، مدل را بهبود خواهیم داد تا به دقت 80-85% برسد.
در بخش بعدی، دو تکنیک ضروری دیگر برای اعمال یادگیری عمیق در مجموعههای داده کوچک را مرور خواهیم کرد: استخراج ویژگی با یک مدل از پیش آموزشدیده (که دقت را به 97.5% میرساند) و تنظیم دقیق یک مدل از پیش آموزشدیده (که دقت نهایی را به 98.5% میرساند). در مجموع، این سه استراتژی—آموزش یک مدل کوچک از ابتدا، انجام استخراج ویژگی با استفاده از یک مدل از پیش آموزشدیده، و تنظیم دقیق یک مدل از پیش آموزشدیده—ابزار آینده شما برای مقابله با مشکل طبقهبندی تصویر با مجموعههای داده کوچک را تشکیل خواهند داد.
ارتباط (اهمیت) یادگیری عمیق برای مسائل دادههای کوچک
اینکه چه چیزی به عنوان “نمونههای کافی” برای آموزش یک مدل واجد شرایط است، نسبی است—ابتدا نسبت به اندازه و عمق مدلی که سعی در آموزش آن دارید. آموزش یک convnet برای حل یک مسئله پیچیده با تنها چند ده نمونه امکانپذیر نیست، اما چند صد نمونه میتواند به طور بالقوه کافی باشد اگر مدل کوچک و به خوبی منظم شده باشد و وظیفه ساده باشد. از آنجایی که convnetها ویژگیهای محلی و ناوردا به انتقال را یاد میگیرند، آنها در مسائل ادراکی بسیار کارآمد از نظر داده هستند. آموزش یک convnet از ابتدا بر روی یک مجموعه داده تصویری بسیار کوچک نتایج معقولی را با وجود کمبود نسبی داده، بدون نیاز به هیچ مهندسی ویژگی سفارشی، به ارمغان میآورد. این را در این بخش در عمل خواهید دید.
علاوه بر این، مدلهای یادگیری عمیق ذاتاً بسیار قابل استفاده مجدد هستند: میتوانید، برای مثال، یک مدل طبقهبندی تصویر یا گفتار به متن را که بر روی یک مجموعه داده در مقیاس بزرگ آموزش دیده است، بگیرید و آن را با تغییرات جزئی در یک مسئله به طور قابل توجهی متفاوت دوباره استفاده کنید. به طور خاص، در مورد بینایی کامپیوتر، بسیاری از مدلهای از پیش آموزشدیده (معمولاً آموزشدیده بر روی مجموعه داده ImageNet) اکنون به صورت عمومی برای دانلود در دسترس هستند و میتوانند برای راهاندازی مدلهای بینایی قدرتمند با دادههای بسیار کم استفاده شوند. این یکی از بزرگترین نقاط قوت یادگیری عمیق است: استفاده مجدد از ویژگیها. این را در بخش بعدی بررسی خواهید کرد.
بیایید با به دست آوردن دادهها شروع کنیم.
دانلود دادهها
مجموعه داده سگها در برابر گربهها که از آن استفاده خواهیم کرد، با کراس بستهبندی نشده است. این مجموعه داده توسط Kaggle به عنوان بخشی از یک رقابت بینایی کامپیوتر در اواخر سال 2013، زمانی که convnetها هنوز فراگیر نبودند، در دسترس قرار گرفت. میتوانید مجموعه داده اصلی را از www.kaggle.com/c/dogs-vs-cats/data دانلود کنید (اگر قبلاً حساب کاربری Kaggle ندارید، باید یک حساب ایجاد کنید—نگران نباشید، فرآیند بدون دردسر است). همچنین میتوانید از Kaggle API برای دانلود مجموعه داده در Colab استفاده کنید (به نوار کناری “دانلود یک مجموعه داده Kaggle در Google Colaboratory” مراجعه کنید).
دانلود مجموعه دادهKaggle درGoogle Colaboratory
Kaggle یک API با کاربری آسان را برای دانلود برنامهنویسی مجموعهدادههای میزبانی شده در Kaggle فراهم میکند. برای مثال، میتوانید از آن برای دانلود مجموعه داده “Dogs vs. Cats” در یک نوتبوک Colab استفاده کنید. این API به عنوان پکیج Kaggle در دسترس است که از پیش در Colab نصب شده است.
دانلود این مجموعه داده به سادگی اجرای دستور زیر در یک سلول Colab است:
!kaggle competitions download -c dogs-vs-cats
اما، دسترسی به API محدود به کاربران Kaggle است، بنابراین برای اجرای دستور بالا، ابتدا باید خود را احراز هویت کنید. پکیج Kaggle به دنبال اطلاعات ورود شما در یک فایل JSON واقع در ~/.kaggle/kaggle.json خواهد گشت.
مراحل احراز هویت و دانلود
- ایجاد کلید API Kaggle: ابتدا باید یک کلید API Kaggle ایجاد کرده و آن را در دستگاه محلی خود دانلود کنید. فقط کافی است در یک مرورگر وب به وبسایت Kaggle بروید، وارد حساب کاربری خود شوید و به صفحه “My Account” بروید. در تنظیمات حساب خود، یک بخش API پیدا خواهید کرد. با کلیک بر روی دکمه “Create New API Token”، یک فایل کلید kaggle.json تولید میشود و در دستگاه شما دانلود خواهد شد.
- آپلود فایل کلید در Colab: سپس، به نوتبوک Colab خود بروید و فایل JSON کلید API را با اجرای کد زیر در یک سلول نوتبوک، در جلسه Colab خود آپلود کنید:
Python
from google.colab import files
files.upload()
هنگامی که این سلول را اجرا میکنید، دکمه “Choose Files” ظاهر میشود. روی آن کلیک کرده و فایل kaggle.json را که تازه دانلود کردهاید، انتخاب کنید. این فایل را در زمان اجرای محلی Colab آپلود میکند.
3. تنظیم دسترسی امن: در نهایت، یک پوشه ~/.kaggle ایجاد کنید (mkdir ~/.kaggle) و فایل کلید را در آن کپی کنید (cp kaggle.json ~/.kaggle/). به عنوان یک بهترین روش امنیتی، باید اطمینان حاصل کنید که فایل فقط توسط کاربر فعلی، یعنی خودتان، قابل خواندن باشد (chmod 600):
Bash
!mkdir ~/.kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
دانلود و آمادهسازی دادهها :اکنون میتوانید دادههایی را که قصد استفاده از آنها را داریم، دانلود کنید:
!kaggle competitions download -c dogs-vs-cats
اولین باری که سعی میکنید دادهها را دانلود کنید، ممکن است خطای “403 Forbidden” دریافت کنید. این به این دلیل است که باید شرایط و ضوابط مرتبط با مجموعه داده را قبل از دانلود آن بپذیرید — باید به www.kaggle.com/c/dogs-vs-cats/rules (در حالی که وارد حساب Kaggle خود شدهاید) بروید و روی دکمه “I Understand and Accept” کلیک کنید. این کار را فقط یک بار لازم است انجام دهید.
در نهایت، دادههای آموزشی یک فایل فشرده به نام train.zip هستند. اطمینان حاصل کنید که آن را به صورت بیصدا (-qq) از حالت فشرده خارج میکنید (unzip):
!unzip -qq train.zip
تصاویر موجود در مجموعه داده ما، عکسهای رنگی JPEG با وضوح متوسط هستند. شکل 8.8 چند نمونه را نشان میدهد.
جای تعجب نیست که مسابقه اصلی Kaggle سگها در برابر گربهها، که به سال 2013 بازمیگردد، توسط شرکتکنندگانی برنده شد که از convnetها استفاده کرده بودند. بهترین ورودیها تا 95% دقت کسب کردند. در این مثال، ما به این دقت (در بخش بعدی) کاملاً نزدیک خواهیم شد، حتی با وجود اینکه مدلهای خود را با کمتر از 10% دادههای موجود برای رقبا آموزش خواهیم داد.
این مجموعه داده شامل 25,000 تصویر سگ و گربه (12,500 از هر کلاس) است و 543 مگابایت حجم دارد (فشرده). پس از دانلود و از حالت فشرده خارج کردن دادهها، ما یک مجموعه داده جدید حاوی سه زیرمجموعه ایجاد خواهیم کرد: یک مجموعه آموزشی با 1,000 نمونه از هر کلاس، یک مجموعه اعتبارسنجی با 500 نمونه از هر کلاس، و یک مجموعه آزمایش با 1,000 نمونه از هر کلاس. چرا این کار را انجام میدهیم؟ زیرا بسیاری از مجموعههای داده تصویری که در طول فعالیت حرفهای خود با آنها روبرو خواهید شد، تنها چند هزار نمونه دارند، نه دهها هزار. در دسترس بودن دادههای بیشتر، مشکل را آسانتر میکند، بنابراین یادگیری با یک مجموعه داده کوچک تمرین خوبی است.

شکل 8.8: نمونههایی از مجموعه داده سگها در برابر گربهها. اندازهها تغییر نکردهاند: نمونهها در اندازهها، رنگها، پسزمینهها و غیره متفاوت هستند.
مجموعه دادهای که با آن کار خواهیم کرد، ساختار دایرکتوری زیر را خواهد داشت:
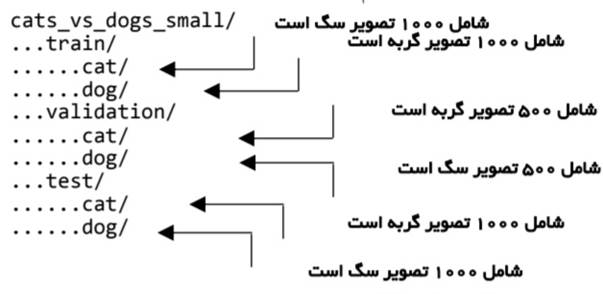
بیایید این کار را در چند فراخوانی به shutil انجام دهیم.
قطعه کد 8.6: کپی کردن تصاویر به دایرکتوریهای آموزش، اعتبارسنجی و آزمایش.
import os, shutil, pathlib
original_dir = pathlib.Path(“train”)
مسیر دایرکتوری که مجموعه داده اصلی در آن از حالت فشرده خارج شده است.
new_base_dir = pathlib.Path(“cats_vs_dogs_small”)
دایرکتوری که مجموعه داده کوچکتر خود را در آن ذخیره خواهیم کرد.
def make_subset(subset_name, start_index, end_index):
تابع کمکی برای کپی کردن تصاویر گربه (و سگ) از شاخص start_index تا شاخص end_index به زیردایرکتوری new_base_dir/{subset_name}/cat (و /dog). “subset_name” یا “train” خواهد بود، یا “validation” یا “test”.
for category in (“cat”, “dog”):
dir = new_base_dir / subset_name / category os.makedirs(dir)
fnames = [f”{category}.{i}.jpg”
for i in range(start_index, end_index)]
for fname in fnames:
shutil.copyfile(src=original_dir / fname,
dst=dir / fname)
make_subset(“train”, start_index=0, end_index=1000)
زیرمجموعه آموزشی را با 1,000 تصویر اول از هر دسته ایجاد کنید.
make_subset(“validation”, start_index=1000, end_index=1500)
زیرمجموعه اعتبارسنجی را با 500 تصویر بعدی از هر دسته ایجاد کنید.
make_subset(“test”, start_index=1500, end_index=2500)
زیرمجموعه آزمایش را با 1,000 تصویر بعدی از هر دسته ایجاد کنید.
ما اکنون 2,000 تصویر آموزشی، 1,000 تصویر اعتبارسنجی، و 2,000 تصویر آزمایش داریم. هر تقسیمبندی شامل تعداد یکسانی از نمونهها از هر کلاس است: این یک مسئله طبقهبندی دودویی متوازن است، به این معنی که دقت طبقهبندی یک معیار مناسب برای موفقیت خواهد بود.
ساخت مدل
ما از همان ساختار مدل عمومی که در مثال اول دیدید، استفاده خواهیم کرد: convnet پشتهای از لایههای متناوب Conv2D )با فعالسازی( relu و MaxPooling2D خواهد بود. اما از آنجایی که با تصاویر بزرگتر و مسئله پیچیدهتری سروکار داریم، مدل خود را متناسب با آن بزرگتر خواهیم کرد: این مدل دو مرحله Conv2D و MaxPooling2D دیگر خواهد داشت. این کار هم ظرفیت مدل را افزایش میدهد و هم اندازه نقشههای ویژگی را بیشتر کاهش میدهد تا هنگام رسیدن به لایه Flatten بیش از حد بزرگ نباشند.
در اینجا، از آنجایی که ما با ورودیهایی با اندازه 180 پیکسل × 180 پیکسل (یک انتخاب تا حدودی دلخواه) شروع میکنیم، درست قبل از لایه Flatten به نقشههای ویژگی با اندازه 7 × 7 میرسیم. نکته: عمق نقشههای ویژگی به تدریج در مدل افزایش مییابد (از 32 به 256)، در حالی که اندازه نقشههای ویژگی کاهش مییابد (از 180 × 180 به 7 × 7). این الگویی است که تقریباً در تمام convnetها خواهید دید.
از آنجایی که ما به یک مسئله طبقهبندی دودویی نگاه میکنیم، مدل را با یک واحد تنها )یک لایه Dense با اندازه 1(و یک فعالسازی سیگموئید به پایان خواهیم رساند. این واحد احتمال اینکه مدل به یک کلاس یا دیگری نگاه میکند را کدگذاری خواهد کرد.
یک تفاوت کوچک نهایی: ما مدل را با یک لایه Rescaling شروع خواهیم کرد، که ورودیهای تصویر (که مقادیر آنها در ابتدا در محدوده [0, 255] هستند) را به محدوده [0, 1] مقیاسبندی میکند.
قطعه کد 8.7: نمونهسازی یک convnet کوچک برای طبقهبندی سگها در برابر گربهها.
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(180, 180, 3))
مدل تصاویر RGB با اندازه 180 × 180 را انتظار دارد.
x = layers.Rescaling(1./255)(inputs)
ورودیها را با تقسیم بر 255 به محدوده [0, 1] مقیاسبندی کنید
x = layers.Conv2D(filters=32, kernel_size=3, activation=”relu”)(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation=”relu”)(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation=”relu”)(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation=”relu”)(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation=”relu”)(x)
x = layers.Flatten()(x)
outputs = layers.Dense(1, activation=”sigmoid”)(x)
model = keras.Model(inputs=inputs, outputs=outputs)
بیایید ببینیم ابعاد نقشههای ویژگی با هر لایه متوالی چگونه تغییر میکنند:
>>> model.summary()
Model: “model_2”
Layer (type) Output Shape Param #
=================================================================
| input_3 (InputLayer) | [(None, 180, 180, 3)] | 0 |
| rescaling (Rescaling) | (None, 180, 180, 3) | 0 |
| conv2d_6 (Conv2D) | (None, 178, 178, 32) | 896 |
| max_pooling2d_2 (MaxPooling2 | (None, 89, 89, 32) | 0 |
| conv2d_7 (Conv2D) | (None, 87, 87, 64) | 18496 |
| max_pooling2d_3 (MaxPooling2 | (None, 43, 43, 64) | 0 |
| conv2d_8 (Conv2D) | (None, 41, 41, 128) | 73856 |
| max_pooling2d_4 (MaxPooling2 | (None, 20, 20, 128) | 0 |
| conv2d_9 (Conv2D) | (None, 18, 18, 256) | 295168 |
| max_pooling2d_5 (MaxPooling2 | (None, 9, 9, 256) | 0 |
| conv2d_10 (Conv2D) | (None, 7, 7, 256) | 590080 |
| flatten_2 (Flatten) | (None, 12544) | 0 |
| dense_2 (Dense) | (None, 1) | 12545 |
=================================================================
Total params: 991,041
Trainable params: 991,041
Non-trainable params: 0
برای مرحله کامپایل، طبق معمول از بهینهساز RMSprop استفاده خواهیم کرد. از آنجا که مدل را با یک واحد سیگموئید به پایان رساندیم، از binary crossentropy به عنوان تابع زیان استفاده خواهیم کرد (به عنوان یادآوری، برای یک برگ تقلب در مورد اینکه از کدام تابع زیان در موقعیتهای مختلف استفاده شود، جدول 6.1 در فصل 6 را بررسی کنید).
قطعه کد 8.8: پیکربندی مدل برای آموزش
model.compile(loss=”binary_crossentropy”,
optimizer=”rmsprop”, metrics=[“accuracy”])
پیشپردازش داده
همانطور که تا کنون میدانید، دادهها باید قبل از تغذیه به مدل، به تنسورهای ممیز شناور که به درستی پیشپردازش شدهاند، فرمت شوند. در حال حاضر، دادهها به صورت فایلهای JPEG روی دیسک قرار دارند، بنابراین مراحل وارد کردن آنها به مدل تقریباً به شرح زیر است:
- فایلهای تصویری را بخوانید.
- محتوای JPEG را به شبکههای پیکسلی RGB رمزگشایی کنید.
- آنها را به تنسورهای ممیز شناور تبدیل کنید.
- آنها را به یک اندازه مشترک تغییر اندازه دهید (ما از 180 × 180 استفاده خواهیم کرد).
- آنها را در دستهها بستهبندی کنید (ما از دستههای 32 تایی تصویر استفاده خواهیم کرد).
این ممکن است کمی دلهرهآور به نظر برسد، اما خوشبختانه کراس ابزارهایی برای انجام خودکار این مراحل دارد. به طور خاص، کراس تابع کاربردی image_dataset_from_directory() را دارد که به شما امکان میدهد به سرعت یک خط لوله داده را راهاندازی کنید که میتواند به طور خودکار فایلهای تصویری روی دیسک را به دستههایی از تنسورهای پیشپردازش شده تبدیل کند. این همان چیزی است که ما در اینجا استفاده خواهیم کرد.
فراخوانی image_dataset_from_directory(directory) ابتدا زیردایرکتوریهای directory را لیست میکند و فرض میکند هر یک حاوی تصاویری از یکی از کلاسهای ما هستند. سپس فایلهای تصویری را در هر زیردایرکتوری فهرست میکند. در نهایت، یک شیء tf.data.Dataset را ایجاد و برمیگرداند که برای خواندن این فایلها، درهمسازی آنها، رمزگشایی آنها به تنسورها، تغییر اندازه آنها به یک اندازه مشترک، و بستهبندی آنها در دستهها پیکربندی شده است.
قطعه کد 8.9: استفاده از image_dataset_from_directory برای خواندن تصاویر.
from tensorflow.keras.utils import image_dataset_from_directory
train_dataset = image_dataset_from_directory(
new_base_dir / “train”,
image_size=(180, 180),
batch_size=32)
validation_dataset = image_dataset_from_directory(
new_base_dir / “validation”,
image_size=(180, 180),
batch_size=32)
test_dataset = image_dataset_from_directory(
new_base_dir / “test”,
image_size=(180, 180),
batch_size=32)
درک اشیاء Dataset TensorFlow
TensorFlow API tf.data را برای ایجاد خطوط لوله ورودی کارآمد برای مدلهای یادگیری ماشین فراهم میکند. کلاس اصلی آن tf.data.Dataset است.
یک شیء Dataset یک iterator است: میتوانید از آن در حلقه for استفاده کنید. این شیء معمولاً دستههایی از دادههای ورودی و برچسبها را برمیگرداند. میتوانید یک شیء Dataset را مستقیماً به متد fit() یک مدل Keras پاس دهید.
کلاس Dataset بسیاری از ویژگیهای کلیدی را مدیریت میکند که در غیر این صورت پیادهسازی دستی آنها دست و پا گیر خواهد بود — به طور خاص، پیشبازیابی ناهمزمان دادهها (asynchronous data prefetching) (پیشپردازش دسته بعدی دادهها در حالی که دسته قبلی توسط مدل پردازش میشود، که اجرای برنامه را بدون وقفه ادامه میدهد).
کلاس Dataset همچنین یک API به سبک تابعی را برای تغییر مجموعهدادهها ارائه میدهد. در اینجا یک مثال سریع آورده شده است: بیایید یک نمونه Dataset را از یک آرایه NumPy از اعداد تصادفی ایجاد کنیم. ما 1,000 نمونه را در نظر میگیریم، که هر نمونه یک بردار با اندازه 16 است:
متد کلاس from_tensor_slices() را میتوان برای ایجاد یک Dataset از یک آرایه NumPy، یا یک tuple یا dict از آرایههای NumPy استفاده کرد.
import numpy as np
import tensorflow as tf
random_numbers = np.random.normal(size=(1000, 16))
dataset = tf.data.Dataset.from_tensor_slices(random_numbers)
در ابتدا، مجموعهداده ما فقط نمونههای تکی را تولید میکند:
>>> for i, element in enumerate(dataset):
>>> print(element.shape)
>>> if i >= 2:
>>> break
(16,)
(16,)
(16,)
میتوانیم از متد .batch() برای دستهبندی دادهها استفاده کنیم:
>>> batched_dataset = dataset.batch(32)
>>> for i, element in enumerate(batched_dataset):
>>> print(element.shape)
>>> if i >= 2:
به طور گستردهتر، ما به مجموعهای از متدهای مفید مجموعه داده دسترسی داریم، مانند:
- .shuffle(buffer_size) — عناصر را در یک بافر به هم میریزد.
- .prefetch(buffer_size) — یک بافر از عناصر را در حافظه GPU پیشبازیابی میکند تا بهرهوری بهتری از دستگاه حاصل شود.
- .map(callable) — یک تبدیل دلخواه را بر روی هر عنصر مجموعه داده اعمال میکند (تابع callable که انتظار میرود یک عنصر واحد تولید شده توسط مجموعه داده را به عنوان ورودی بگیرد).
متد map()، به ویژه، یکی از متدهایی است که اغلب از آن استفاده خواهید کرد. در اینجا مثالی آورده شده است. از آن برای تغییر شکل عناصر در مجموعهداده ساده خود از شکل (16,) به شکل (4, 4) استفاده خواهیم کرد:
>>> reshaped_dataset = dataset.map(lambda x: tf.reshape(x, (4, 4)))
>>> for i, element in enumerate(reshaped_dataset):
>>> print(element.shape)
>>> if i >= 2:
>>> break
(4, 4)
(4, 4)
(4, 4)
در این فصل، اقدامات بیشتری از map() را خواهید دید.
بیایید به خروجی یکی از این اشیاء Dataset نگاه کنیم: این شیء دستههایی از تصاویر RGB با ابعاد 180 × 180 (شکل (32, 180, 180, 3)) و برچسبهای عددی صحیح (شکل (32,)) را تولید میکند. 32 نمونه در هر دسته (اندازه دسته) وجود دارد.
قطعه کد 8.10: نمایش شکلهای داده و برچسبهای تولید شده توسط Dataset.
>>> for data_batch, labels_batch in train_dataset:
>>> print(“data batch shape:”, data_batch.shape)
>>> print(“labels batch shape:”, labels_batch.shape)
>>> break
data batch shape: (32, 180, 180, 3)
labels batch shape: (32,)
بیایید مدل را روی مجموعه داده خود برازش دهیم. ما از آرگومان validation_data در fit() برای پایش معیارهای اعتبارسنجی روی یک شیء Dataset جداگانه استفاده خواهیم کرد.
توجه داشته باشید که ما همچنین از یک Callback ModelCheckpoint برای ذخیره مدل پس از هر دوره استفاده خواهیم کرد. ما آن را با مسیر مشخصکننده محل ذخیره فایل و همچنین آرگومانهای save_best_only=True و monitor=”val_loss” پیکربندی خواهیم کرد: آنها به Callback میگویند که تنها زمانی یک فایل جدید را ذخیره کند (و هر فایل قبلی را بازنویسی کند) که مقدار فعلی معیار val_loss کمتر از هر زمان قبلی در طول آموزش باشد. این تضمین میکند که فایل ذخیره شده شما همیشه حاوی وضعیت مدلی باشد که مربوط به بهترین دوره آموزشی آن است، از نظر عملکرد آن بر روی دادههای اعتبارسنجی. در نتیجه، اگر شروع به بیشبرازش کنیم، مجبور نخواهیم بود یک مدل جدید را برای تعداد کمتری از دورهها دوباره آموزش دهیم: میتوانیم فقط فایل ذخیره شده خود را بارگذاری مجدد کنیم.
قطعه کد 8.11: برازش مدل با استفاده از یک Dataset
callbacks = [
keras.callbacks.ModelCheckpoint( filepath=”convnet_from_scratch.keras”, save_best_only=True,
monitor=”val_loss”)
]
history = model.fit(
train_dataset,
epochs=30,
validation_data=validation_dataset,
callbacks=callbacks)
بیایید زیان و دقت مدل را بر روی دادههای آموزشی و اعتبارسنجی در طول آموزش رسم کنیم (به شکل 8.9 مراجعه کنید)
قطعه کد 8.12: نمایش منحنیهای زیان و دقت در طول آموزش
import matplotlib.pyplot as plt
accuracy = history.history[“accuracy”]
val_accuracy = history.history[“val_accuracy”]
loss = history.history[“loss”]
val_loss = history.history[“val_loss”]
epochs = range(1, len(accuracy) + 1)
plt.plot(epochs, accuracy, “bo”, label=”Training accuracy”)
plt.plot(epochs, val_accuracy, “b”, label=”Validation accuracy”) plt.title(“Training and validation accuracy”)
plt.legend()
plt.figure()
plt.plot(epochs, loss, “bo”, label=”Training loss”)
plt.plot(epochs, val_loss, “b”, label=”Validation loss”) plt.title(“Training and validation loss”)
plt.legend()
plt.show()
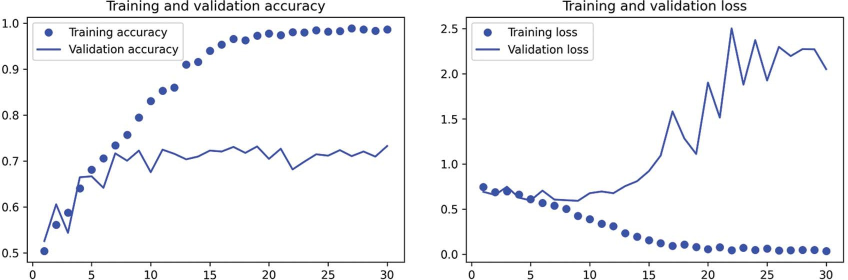
شکل 8.9: معیارهای آموزش و اعتبارسنجی برای یک convnet ساده
این نمودارها مشخصه بیشبرازش (overfitting) هستند. دقت آموزش در طول زمان به صورت خطی افزایش مییابد تا نزدیک به 100% برسد، در حالی که دقت اعتبارسنجی در 75% به اوج میرسد. زیان اعتبارسنجی پس از تنها ده دوره به حداقل خود میرسد و سپس ثابت میماند، در حالی که زیان آموزش با پیشرفت آموزش به صورت خطی کاهش مییابد.
بیایید دقت آزمایش را بررسی کنیم. مدل را از فایل ذخیرهشدهاش بارگذاری مجدد میکنیم تا آن را در حالتی که قبل از شروع بیشبرازش بود، ارزیابی کنیم.
قطعه کد 8.13: ارزیابی مدل بر روی مجموعه آزمایش
test_model = keras.models.load_model(“convnet_from_scratch.keras”)
test_loss, test_acc = test_model.evaluate(test_dataset)
print(f”Test accuracy: {test_acc:.3f}”)
ما دقت آزمایشی 69.5% را به دست میآوریم. (به دلیل تصادفی بودن مقداردهی اولیههای شبکه عصبی، ممکن است اعدادی با اختلاف یک درصد در این محدوده به دست آورید.)
از آنجایی که ما نمونههای آموزشی نسبتاً کمی (2,000) داریم، بیشبرازش (overfitting) نگرانی شماره یک ما خواهد بود. شما از قبل تعدادی تکنیک را میشناسید که میتوانند به کاهش بیشبرازش کمک کنند، مانند دراپاوت (dropout) و کاهش وزن (weight decay) (منظمسازی L2). ما اکنون با یک تکنیک جدید کار خواهیم کرد که مخصوص بینایی کامپیوتر است و تقریباً به طور جهانی هنگام پردازش تصاویر با مدلهای یادگیری عمیق استفاده میشود: افزایش داده (data augmentation) .
استفاده از افزایش(تقویت) داده
بیشبرازش ناشی از داشتن نمونههای بسیار کم برای یادگیری است که شما را قادر به آموزش مدلی که بتواند به دادههای جدید تعمیم یابد، نمیسازد. با دادههای نامحدود، مدل شما در معرض هر جنبه ممکن از توزیع داده موجود قرار میگرفت: شما هرگز بیشبرازش نمیکردید. افزایش داده رویکرد تولید داده آموزشی بیشتر از نمونههای آموزشی موجود را با افزایش نمونهها از طریق تعدادی تبدیل تصادفی که تصاویر باورپذیری را تولید میکنند، در پیش میگیرد. هدف این است که، در زمان آموزش، مدل شما هرگز دقیقاً یک تصویر را دو بار نبیند. این به قرار گرفتن مدل در معرض جنبههای بیشتری از داده کمک میکند تا بتواند بهتر تعمیم یابد.
در Keras، این کار را میتوان با افزودن تعدادی لایه افزایش داده در ابتدای مدل انجام داد. بیایید با یک مثال شروع کنیم: مدل Sequential زیر چندین تبدیل تصادفی تصویر را زنجیرهای میکند. در مدل ما، آن را درست قبل از لایه Rescaling قرار میدهیم.
قطعه کد 8.14: تعریف یک مرحله افزایش داده برای افزودن به یک مدل تصویر
data_augmentation = keras.Sequential(
[
layers.RandomFlip(“horizontal”), layers.RandomRotation(0.1), layers.RandomZoom(0.2),
]
)
اینها تنها چند لایه موجود هستند (برای اطلاعات بیشتر، به مستندات Keras مراجعه کنید). بیایید به سرعت این کد را بررسی کنیم:
- RandomFlip(“horizontal”) — اعمال وارونگی افقی به 50% تصادفی از تصاویری که از آن عبور میکنند.
- RandomRotation(0.1) — تصاویر ورودی را با یک مقدار تصادفی در محدوده [10%–, 10%+] میچرخاند (اینها کسری از یک دایره کامل هستند— بر حسب درجه، محدوده [36 –درجه، 36 +درجه] خواهد بود).
- RandomZoom(0.2) — تصویر را با یک عامل تصادفی در محدوده [20%-, 20%+] بزرگنمایی یا کوچکنمایی میکند. بیایید تصاویر افزایش یافته را ببینیم (به شکل 8.10 مراجعه کنید).
قطعه کد 8.15: نمایش برخی تصاویر آموزشی به صورت تصادفی افزایشیافته.
plt.figure(figsize=(10, 10))
for images, _ in train_dataset.take(1):
میتوانیم از take(N) برای نمونهبرداری فقط N دسته از مجموعه داده استفاده کنیم. این معادل قرار دادن یک break در حلقه پس از N-امین دسته است.
for i in range(9):
augmented_images = data_augmentation(images)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype(“uint8”))
plt.axis(“off”)
اولین تصویر را در دسته خروجی نمایش دهید. برای هر یک از نه تکرار، این یک افزایش متفاوت از همان تصویر است.
مرحله افزایش (augmentation) را بر روی دسته تصاویر اعمال کنید.

شکل 8.10: تولید نسخههای متنوع از یک پسر بسیار خوب با استفاده از افزایش تصادفی داده
اگر یک مدل جدید را با استفاده از این پیکربندی افزایش داده آموزش دهیم، مدل هرگز ورودی یکسانی را دو بار نخواهد دید. اما ورودیهایی که میبیند همچنان به شدت همبسته هستند زیرا از تعداد کمی تصاویر اصلی به دست آمدهاند — ما نمیتوانیم اطلاعات جدیدی تولید کنیم؛ ما فقط میتوانیم اطلاعات موجود را دوباره ترکیب کنیم. به همین دلیل، این ممکن است برای از بین بردن کامل بیشبرازش کافی نباشد. برای مبارزه بیشتر با بیشبرازش، ما همچنین یک لایه دراپاوت (Dropout) را درست قبل از طبقهبند کاملاً متصل به مدل خود اضافه خواهیم کرد.
یک نکته نهایی که باید در مورد لایههای افزایش تصادفی تصویر بدانید: درست مانند دراپاوت، آنها در طول استنباط (هنگام فراخوانی predict() یا evaluate()) غیرفعال هستند. در طول ارزیابی، مدل ما دقیقاً مانند زمانی که شامل افزایش داده و دراپاوت نبود، رفتار خواهد کرد.
قطعه کد 8.16: تعریف یک convnet جدید که شامل افزایش تصویر و دراپاوت است.
inputs = keras.Input(shape=(180, 180, 3))
x = data_augmentation(inputs)
x = layers.Rescaling(1./255)(x)
x = layers.Conv2D(filters=32, kernel_size=3, activation=”relu”)(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=64, kernel_size=3, activation=”relu”)(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=128, kernel_size=3, activation=”relu”)(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation=”relu”)(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=256, kernel_size=3, activation=”relu”)(x)
x = layers.Flatten()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation=”sigmoid”)(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(loss=”binary_crossentropy”,
optimizer=”rmsprop”, metrics=[“accuracy”])
بیایید مدل را با استفاده از افزایش داده و دراپاوت آموزش دهیم. از آنجایی که انتظار داریم بیشبرازش بسیار دیرتر در طول آموزش رخ دهد، برای سه برابر تعداد دورههای قبلی — صد دوره — آموزش خواهیم داد.
قطعه کد 8.17: آموزش convnet منظم شده.
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath=”convnet_from_scratch_with_augmentation.keras”,
save_best_only=True,
monitor=”val_loss”)
]
history = model.fit(
train_dataset,
epochs=100,
validation_data=validation_dataset,
callbacks=callbacks)
بیایید دوباره نتایج را رسم کنیم: شکل 8.11 را ببینید. به لطف افزایش داده و دراپاوت، ما بسیار دیرتر، حدود دورههای 60-70 (در مقایسه با دوره 10 برای مدل اصلی) شروع به بیشبرازش میکنیم. دقت اعتبارسنجی به طور مداوم در محدوده 80-85% قرار میگیرد—یک بهبود بزرگ نسبت به تلاش اول ما. بیایید دقت آزمایش را بررسی کنیم.
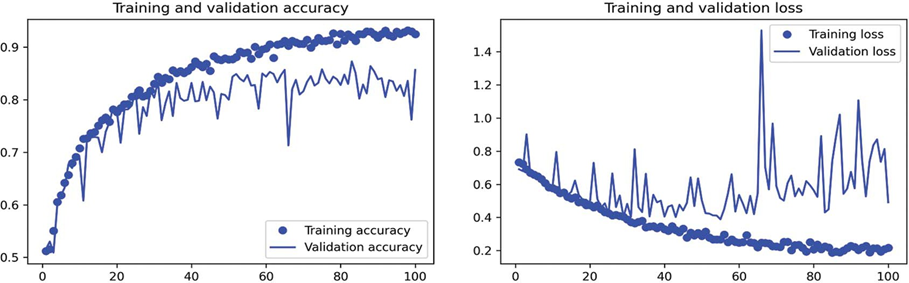
شکل 8.11: معیارهای آموزش و اعتبارسنجی با افزایش داده.
قطعه کد 8.18: ارزیابی مدل بر روی مجموعه آزمایش.
test_model = keras.models.load_model( “convnet_from_scratch_with_augmentation.keras”)
test_loss, test_acc = test_model.evaluate(test_dataset)
print(f”Test accuracy: {test_acc:.3f}”)
ما به دقت آزمایشی 83.5% دست مییابیم. شروع به خوب به نظر رسیدن میکند! اگر از Colab استفاده میکنید، مطمئن شوید که فایل ذخیره شده (convnet_from_scratch_with_augmentation.keras) را دانلود میکنید، زیرا در برخی آزمایشها در فصل بعدی از آن استفاده خواهیم کرد.
با تنظیم دقیقتر پیکربندی مدل (مانند تعداد فیلترها در هر لایه کانولوشن، یا تعداد لایهها در مدل)، ممکن است بتوانیم به دقت حتی بهتری دست یابیم، احتمالاً تا 90%. اما صرفاً با آموزش convnet خودمان از ابتدا، دستیابی به بالاتر از آن دشوار خواهد بود، زیرا دادههای بسیار کمی برای کار داریم. به عنوان گام بعدی برای بهبود دقتمان در این مسئله، باید از یک مدل از پیش آموزشدیده (pretrained model) استفاده کنیم، که تمرکز دو بخش بعدی است.
استفاده از یک مدل از پیش آموزشدیده
یک رویکرد رایج و بسیار مؤثر برای یادگیری عمیق بر روی مجموعههای داده تصویری کوچک، استفاده از یک مدل از پیش آموزشدیده است. یک مدل از پیش آموزشدیده، مدلی است که قبلاً بر روی یک مجموعه داده بزرگ، معمولاً در یک وظیفه طبقهبندی تصویر در مقیاس بزرگ، آموزش دیده است. اگر این مجموعه داده اصلی به اندازه کافی بزرگ و عمومی باشد، سلسلهمراتب فضایی ویژگیهای یادگرفته شده توسط مدل از پیش آموزشدیده میتواند به طور مؤثری به عنوان یک مدل عمومی از دنیای بصری عمل کند، و از این رو، ویژگیهای آن میتوانند برای بسیاری از مسائل مختلف بینایی کامپیوتر مفید باشند، حتی اگر این مسائل جدید ممکن است شامل کلاسهای کاملاً متفاوتی نسبت به کلاسهای وظیفه اصلی باشند. برای مثال، ممکن است یک مدل را بر روی ImageNet (که کلاسها عمدتاً حیوانات و اشیاء روزمره هستند) آموزش دهید و سپس این مدل آموزشدیده را برای چیزی به دوردست مانند شناسایی اقلام مبلمان در تصاویر، دوباره استفاده کنید. چنین قابلیت حمل ویژگیهای یادگرفته شده در مسائل مختلف، یک مزیت کلیدی یادگیری عمیق در مقایسه با بسیاری از رویکردهای یادگیری کمعمق قدیمیتر است و یادگیری عمیق را برای مسائل دادههای کوچک بسیار مؤثر میکند.
در این حالت، بیایید یک convnet بزرگ را که بر روی مجموعه داده ImageNet (1.4 میلیون تصویر برچسبگذاری شده و 1,000 کلاس مختلف) آموزش دیده است، در نظر بگیریم. ImageNet شامل بسیاری از کلاسهای حیوانات، از جمله گونههای مختلف گربه و سگ است، و بنابراین میتوانید انتظار داشته باشید که در مسئله طبقهبندی سگها در برابر گربهها خوب عمل کند.
ما از معماری VGG16، که توسط کارن سیمونیان و اندرو زیسرمن در سال 2014 توسعه یافت، استفاده خواهیم کرد.1 اگرچه این یک مدل قدیمیتر است، بسیار دور از وضعیت فعلی هنر و تا حدودی سنگینتر از بسیاری از مدلهای جدیدتر، من آن را انتخاب کردم زیرا معماری آن مشابه چیزی است که شما قبلاً با آن آشنا هستید، و درک آن بدون معرفی مفاهیم جدید آسان است. این ممکن است اولین برخورد شما با یکی از این نامهای مدلهای زیبا باشد—VGG، ResNet، Inception، Xception، و غیره؛ به آنها عادت خواهید کرد زیرا اگر به کار یادگیری عمیق برای بینایی کامپیوتر ادامه دهید، مکرراً ظاهر خواهند شد.
دو راه برای استفاده از یک مدل از پیش آموزشدیده وجود دارد: استخراج ویژگی و تنظیم دقیق. ما هر دو را پوشش خواهیم داد. بیایید با استخراج ویژگی شروع کنیم.
استخراج ویژگی با یک مدل از پیش آموزشدیده
استخراج ویژگی شامل استفاده از بازنماییهای یادگرفته شده توسط یک مدل از پیش آموزشدیده برای استخراج ویژگیهای جالب از نمونههای جدید است. سپس این ویژگیها از طریق یک طبقهبند جدید اجرا میشوند که از ابتدا آموزش میبیند.
همانطور که قبلاً دیدید، convnetهای مورد استفاده برای طبقهبندی تصویر از دو بخش تشکیل شدهاند: آنها با یک سری از لایههای پولینگ و کانولوشن شروع میشوند و با یک طبقهبند کاملاً متصل به پایان میرسند. بخش اول پایه کانولوشنی (convolutional base) مدل نامیده میشود. در مورد convnetها، استخراج ویژگی شامل گرفتن پایه کانولوشنی یک شبکه از پیش آموزشدیده، اجرای دادههای جدید از طریق آن، و آموزش یک طبقهبند جدید در بالای خروجی است (به شکل 8.12 مراجعه کنید).
چرا فقط پایه کانولوشنی را دوباره استفاده کنیم؟ آیا میتوانیم طبقهبند کاملاً متصل را نیز دوباره استفاده کنیم؟ به طور کلی، انجام این کار باید اجتناب شود. دلیل آن این است که بازنماییهای یادگرفته شده توسط پایه کانولوشنی احتمالاً عمومیتر و بنابراین قابل استفادهتر هستند: نقشههای ویژگی یک convnet، نقشههای حضور مفاهیم عمومی در یک تصویر هستند که احتمالاً صرف نظر از مشکل بینایی کامپیوتر مورد نظر مفید خواهند بود. اما بازنماییهای یادگرفته شده توسط طبقهبند لزوماً مختص مجموعه کلاسهایی خواهند بود که مدل بر روی آنها آموزش دیده است — آنها فقط شامل اطلاعاتی در مورد احتمال حضور این یا آن کلاس در کل تصویر خواهند بود. علاوه بر این، بازنماییهای یافت شده در لایههای کاملاً متصل دیگر حاوی هیچ اطلاعاتی در مورد مکان اشیاء در تصویر ورودی نیستند؛ این لایهها مفهوم فضا را از بین میبرند، در حالی که مکان شیء همچنان توسط نقشههای ویژگی کانولوشنی توصیف میشود. برای مسائلی که مکان شیء مهم است، ویژگیهای کاملاً متصل عمدتاً بیفایده هستند.
توجه داشته باشید که سطح کلیت (و بنابراین قابلیت استفاده مجدد) بازنماییهای استخراج شده توسط لایههای کانولوشن خاص به عمق لایه در مدل بستگی دارد. لایههایی که در ابتدای مدل قرار دارند، نقشههای ویژگی محلی و بسیار عمومی (مانند لبههای بصری، رنگها و بافتها) را استخراج میکنند، در حالی که لایههای بالاتر مفاهیم انتزاعیتری (مانند “گوش گربه” یا “چشم سگ”) را استخراج میکنند. بنابراین اگر مجموعه داده جدید شما تفاوت زیادی با مجموعه دادهای که مدل اصلی بر روی آن آموزش دیده است، داشته باشد، ممکن است بهتر باشد که فقط از چند لایه اول مدل برای استخراج ویژگی استفاده کنید، به جای استفاده از کل پایه کانولوشنی.
در این مورد، از آنجایی که مجموعه کلاس ImageNet شامل چندین کلاس سگ و گربه است، احتمالاً استفاده مجدد از اطلاعات موجود در لایههای کاملاً متصل مدل اصلی مفید خواهد بود. اما ما این کار را نخواهیم کرد تا مورد کلیتری را پوشش دهیم که مجموعه کلاس مسئله جدید با مجموعه کلاس مدل اصلی همپوشانی ندارد. بیایید این را با استفاده از پایه کانولوشنی شبکه VGG16، که بر روی ImageNet آموزش دیده است، برای استخراج ویژگیهای جالب از تصاویر گربه و سگ، و سپس آموزش یک طبقهبند سگ در برابر گربهها در بالای این ویژگیها، عملی کنیم.
مدل VGG16، از جمله موارد دیگر، از پیش بستهبندی شده با Keras عرضه میشود. میتوانید آن را از ماژول keras.applications وارد کنید. بسیاری از مدلهای طبقهبندی تصویر دیگر (همه از پیش آموزشدیده بر روی مجموعه داده ImageNet) به عنوان بخشی از keras.applications در دسترس هستند:
- Xception
- ResNet
- MobileNet
- EfficientNet
- DenseNet
- و غیره.
بیایید مدل VGG16 را نمونهسازی کنیم.
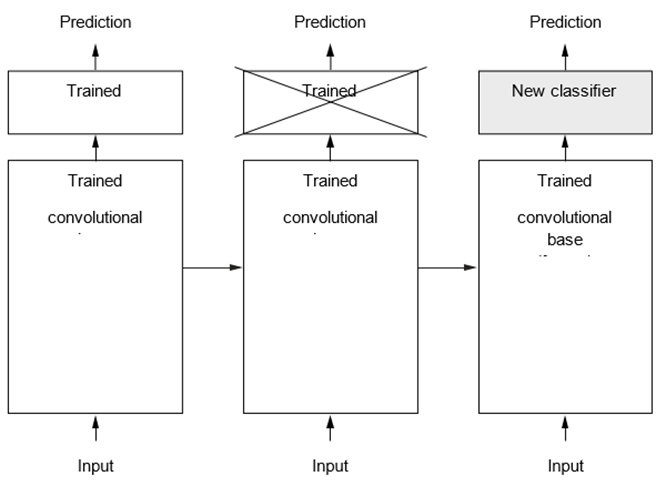
شکل 8.12: جایگزینی طبقهبندی ها با حفظ همان پایه کانولوشنی.
conv_base = keras.applications.vgg16.VGG16(
weights=”imagenet”,
include_top=False,
input_shape=(180, 180, 3))
ما سه آرگومان را به سازنده پاس میدهیم:
- Weights نقطه بازبینی وزن را مشخص میکند که مدل از آن مقداردهی اولیه شود.
- include_top به شامل کردن (یا نکردن) طبقهبند کاملاً متصل در بالای شبکه اشاره دارد. به طور پیشفرض، این طبقهبند کاملاً متصل مربوط به 1,000 کلاس از ImageNet است. از آنجایی که قصد داریم از طبقهبند کاملاً متصل خودمان (فقط با دو کلاس: گربه و سگ) استفاده کنیم، نیازی به گنجاندن آن نداریم.
- input_shape شکل تنسورهای تصویری است که به شبکه تغذیه خواهیم کرد. این آرگومان صرفاً اختیاری است: اگر آن را پاس ندهیم، شبکه قادر به پردازش ورودیها در هر اندازهای خواهد بود. در اینجا آن را پاس میدهیم تا بتوانیم (در خلاصه زیر) ببینیم که چگونه اندازه نقشههای ویژگی با هر لایه کانولوشن و پولینگ جدید کوچک میشود.
این جزئیات معماری پایه کانولوشنی VGG16 است. این معماری شبیه convnetهای سادهای است که از قبل با آنها آشنا هستید:
>>> conv_base.summary()
Model: “vgg16”
Layer (type) Output Shape Param #
=================================================================
| input_19 (InputLayer) | [(None, 180, 180, 3)] | 0 | |||||||
| block1_conv1 (Conv2D) | (None, 180, 180, 64) | 1792 | |||||||
| block1_conv2 (Conv2D) | (None, 180, 180, 64) | 36928 | |||||||
| block1_pool (MaxPooling2D) | (None, 90, 90, 64) | 0 | |||||||
| block2_conv1 (Conv2D) | (None, 90, 90, 128) | 73856 | |||||||
| block2_conv2 (Conv2D) | (None, | 90, | 90, | 128) | 147584 | ||||
| block2_pool (MaxPooling2D) | (None, | 45, | 45, | 128) | 0 | ||||
| block3_conv1 (Conv2D) | (None, | 45, | 45, | 256) | 295168 | ||||
| block3_conv2 (Conv2D) | (None, | 45, | 45, | 256) | 590080 | ||||
| block3_conv3 (Conv2D) | (None, | 45, | 45, | 256) | 590080 | ||||
| block3_pool (MaxPooling2D) | (None, | 22, | 22, | 256) | 0 | ||||
| block4_conv1 (Conv2D) | (None, | 22, | 22, | 512) | 1180160 | ||||
| block4_conv2 (Conv2D) | (None, | 22, | 22, | 512) | 2359808 | ||||
| block4_conv3 (Conv2D) | (None, | 22, | 22, | 512) | 2359808 | ||||
| block4_pool (MaxPooling2D) | (None, | 11, | 11, | 512) | 0 | ||||
| block5_conv1 (Conv2D) | (None, | 11, | 11, | 512) | 2359808 | ||||
| block5_conv2 (Conv2D) | (None, | 11, | 11, | 512) | 2359808 | ||||
| block5_conv3 (Conv2D) | (None, | 11, | 11, | 512) | 2359808 | ||||
| block5_pool (MaxPooling2D) | (None, | 5, 5, 512) | 0 | ||||||
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
نقشه ویژگی نهایی دارای شکل (5, 5, 512) است. این همان نقشه ویژگی است که روی آن یک طبقهبند کاملاً متصل قرار خواهیم داد. در این مرحله، دو راه برای ادامه وجود دارد:
- پایه کانولوشنی را بر روی مجموعه داده خود اجرا کنیم، خروجی آن را در یک آرایه NumPy روی دیسک ثبت کنیم، و سپس از این دادهها به عنوان ورودی برای یک طبقهبند کاملاً متصل مستقل استفاده کنیم، شبیه به آنهایی که در فصل 4 این کتاب دیدید. این راهحل سریع و ارزان است، زیرا تنها نیاز به اجرای پایه کانولوشنی یک بار برای هر تصویر ورودی دارد، و پایه کانولوشنی تا حد زیادی پرهزینهترین بخش خط لوله است. اما به همین دلیل، این تکنیک به ما اجازه استفاده از افزایش داده را نمیدهد.
- مدل موجود خود (conv_base) را با افزودن لایههای Dense در بالای آن گسترش دهیم، و کل سیستم را از ابتدا تا انتها بر روی دادههای ورودی اجرا کنیم. این به ما امکان استفاده از افزایش داده را میدهد، زیرا هر تصویر ورودی هر بار که توسط مدل دیده میشود، از پایه کانولوشنی عبور میکند. اما به همین دلیل، این تکنیک بسیار گرانتر از اولین مورد است.
ما هر دو تکنیک را پوشش خواهیم داد. بیایید کد لازم برای راهاندازی مورد اول را بررسی کنیم: ثبت خروجی conv_base بر روی دادههای ما و استفاده از این خروجیها به عنوان ورودی برای یک مدل جدید.
استخراج سریع ویژگی بدون افزایش داده
با استخراج ویژگیها به عنوان آرایههای NumPy با فراخوانی متد predict() مدل conv_base بر روی مجموعههای داده آموزش، اعتبارسنجی و آزمایش خود شروع میکنیم. بیایید بر روی مجموعههای داده خود تکرار کنیم تا ویژگیهای VGG16 را استخراج کنیم.
قطعه کد 8.20: استخراج ویژگیهای VGG16 و برچسبهای مربوطه.
import numpy as np
def get_features_and_labels(dataset):
all_features = []
all_labels = []
for images, labels in dataset:
preprocessed_images =
keras.applications.vgg16.preprocess_input(images)
features = conv_base.predict(preprocessed_images)
all_features.append(features)
all_labels.append(labels)
return np.concatenate(all_features), np.concatenate(all_labels)
train_features, train_labels = get_features_and_labels(train_dataset)
val_features, val_labels = get_features_and_labels(validation_dataset) test_features, test_labels = get_features_and_labels(test_dataset)
مهم اینکه، predict() فقط تصاویر را انتظار دارد، نه برچسبها را، اما مجموعه داده فعلی ما دستههایی را تولید میکند که هم تصاویر و هم برچسبهای آنها را شامل میشوند. علاوه بر این، مدل VGG16 ورودیهایی را انتظار دارد که با تابع keras.applications.vgg16.preprocess_input پیشپردازش شدهاند، که مقادیر پیکسل را به یک محدوده مناسب مقیاسبندی میکند.
ویژگیهای استخراجشده در حال حاضر شکل (نمونهها، 5, 5, 512) دارند:
>>> train_features.shape
(2000, 5, 5, 512)
در این مرحله، میتوانیم طبقهبند کاملاً متصل خود را تعریف کرده (توجه داشته باشید که از دراپاوت برای منظمسازی استفاده شده است) و آن را روی دادهها و برچسبهایی که تازه ثبت کردیم، آموزش دهیم.
قطعه کد 8.21: تعریف و آموزش طبقهبندی کاملاً متصل.
inputs = keras.Input(shape=(5, 5, 512))
x = layers.Flatten()(inputs)
x = layers.Dense(256)(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation=”sigmoid”)(x)
model = keras.Model(inputs, outputs)
model.compile(loss=”binary_crossentropy”,
optimizer=”rmsprop”, metrics=[“accuracy”
callbacks = [
keras.callbacks.ModelCheckpoint( filepath=”feature_extraction.keras”, save_best_only=True,
monitor=”val_loss”)
]
history = model.fit(
train_features, train_labels,
epochs=20,
validation_data=(val_features, val_labels),
callbacks=callbacks)
توجه داشته باشید که از لایه Flatten قبل از پاس دادن ویژگیها به یک لایه Dense استفاده شده است.
آموزش بسیار سریع است زیرا ما فقط با دو لایه Dense سروکار داریم — یک دوره حتی در CPU کمتر از یک ثانیه طول میکشد.
بیایید به منحنیهای زیان و دقت در طول آموزش نگاه کنیم (به شکل 8.13 مراجعه کنید).
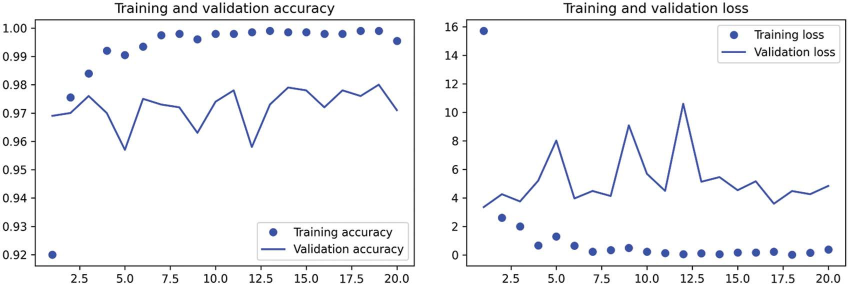
شکل 8.13: معیارهای آموزش و اعتبارسنجی برای استخراج ویژگی ساده.
قطعه کد 8.22: رسم نتایج.
import matplotlib.pyplot as plt
acc = history.history[“accuracy”]
val_acc = history.history[“val_accuracy”]
loss = history.history[“loss”]
val_loss = history.history[“val_loss”]
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, “bo”, label=”Training accuracy”)
plt.plot(epochs, val_acc, “b”, label=”Validation accuracy”) plt.title(“Training and validation accuracy”)
plt.legend()
plt.figure()
plt.plot(epochs, loss, “bo”, label=”Training loss”)
plt.plot(epochs, val_loss, “b”, label=”Validation loss”)
plt.title(“Training and validation loss”)
plt.legend()
plt.show()
ما به دقت اعتبارسنجی حدود 97% میرسیم — بسیار بهتر از آنچه در بخش قبل با مدل کوچک آموزشدیده از ابتدا به دست آوردیم. با این حال، این مقایسه تا حدودی ناعادلانه است، زیرا ImageNet حاوی نمونههای زیادی از سگ و گربه است، به این معنی که مدل از پیش آموزشدیده ما از قبل دقیقاً دانش مورد نیاز برای وظیفه موجود را دارد. این همیشه در هنگام استفاده از ویژگیهای از پیش آموزشدیده صادق نخواهد بود.
با این حال، نمودارها همچنین نشان میدهند که ما تقریباً از همان ابتدا دچار بیشبرازش هستیم — با وجود استفاده از دراپاوت با نرخ نسبتاً بالا. این به این دلیل است که این تکنیک از افزایش داده استفاده نمیکند، که برای جلوگیری از بیشبرازش با مجموعههای داده تصویری کوچک ضروری است.
استخراج ویژگی همراه با افزایش داده
حالا بیایید تکنیک دومی را که برای انجام استخراج ویژگی ذکر کردم، مرور کنیم، که بسیار کندتر و پرهزینهتر است، اما به ما امکان میدهد از افزایش داده در طول آموزش استفاده کنیم: ایجاد مدلی که conv_base را با یک طبقهبند Dense جدید زنجیرهای کند و آن را به صورت سرتاسری بر روی ورودیها آموزش دهد.
برای انجام این کار، ابتدا پایه کانولوشنی را “یخبندان” (freeze) خواهیم کرد. یخبندان کردن یک لایه یا مجموعهای از لایهها به معنای جلوگیری از بهروزرسانی وزنهای آنها در طول آموزش است. اگر این کار را انجام ندهیم، بازنماییهایی که قبلاً توسط پایه کانولوشنی یاد گرفته شدهاند، در طول آموزش تغییر خواهند کرد. از آنجایی که لایههای Dense بالا به صورت تصادفی مقداردهی اولیه شدهاند، بهروزرسانیهای وزن بسیار بزرگی در سراسر شبکه منتشر خواهند شد که به طور مؤثر بازنماییهای قبلاً یادگرفته شده را از بین میبرند.
در Keras، یک لایه یا مدل را با تنظیم ویژگی trainable آن به False یخبندان میکنیم.
قطعه کد 8.23: نمونهسازی و ثابت کردن (freezing) پایه کانولوشنی VGG16.
conv_base = keras.applications.vgg16.VGG16(
weights=”imagenet”, include_top=False) conv_base.trainable = False
تنظیم trainable به False، لیست وزنهای قابل آموزش لایه یا مدل را خالی میکند.
قطعه کد 8.24: چاپ لیست وزنهای قابل آموزش قبل و بعد از ثابت کردن.
>>> conv_base.trainable = True
>>> print(“This is the number of trainable weights “
“before freezing the conv base:”, len(conv_base.trainable_weights))
This is the number of trainable weights before freezing the conv base: 26
>>> conv_base.trainable = False
>>> print(“This is the number of trainable weights “
“after freezing the conv base:”, len(conv_base.trainable_weights))
This is the number of trainable weights after freezing the conv base: 0
حالا میتوانیم یک مدل جدید ایجاد کنیم که این سه را به هم زنجیر میکند:
- یک مرحله افزایش داده
- پایه کانولوشنی ثابت شده ما
- یک طبقهبندی د Dense
قطعه کد 8.25: افزودن یک مرحله افزایش داده و یک طبقهبندی به پایه کانولوشنی.
data_augmentation = keras.Sequential(
[
layers.RandomFlip(“horizontal”), layers.RandomRotation(0.1), layers.RandomZoom(0.2),
]
)
inputs = keras.Input(shape=(180, 180, 3))
x = data_augmentation(inputs)
x = keras.applications.vgg16.preprocess_input(x)
مقیاسبندی مقدار ورودی را اعمال کنید.
x = conv_base(x)
x = layers.Flatten()(x)
x = layers.Dense(256)(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation=”sigmoid”)(x)
model = keras.Model(inputs, outputs)
model.compile(loss=”binary_crossentropy”,
optimizer=”rmsprop”,
metrics=[“accuracy”])
با این تنظیمات، فقط وزنهای دو لایه Dense که ما اضافه کردیم، آموزش خواهند دید. این در مجموع چهار تنسور وزن است: دو تا برای هر لایه (ماتریس وزن اصلی و بردار بایاس). توجه داشته باشید که برای اعمال این تغییرات، ابتدا باید مدل را کامپایل کنید. اگر پس از کامپایل، قابلیت آموزش وزنها را تغییر دهید، باید مدل را دوباره کامپایل کنید، در غیر این صورت این تغییرات نادیده گرفته خواهند شد.
بیایید مدل خود را آموزش دهیم. به لطف افزایش داده، زمان بسیار بیشتری طول میکشد تا مدل شروع به بیشبرازش کند، بنابراین میتوانیم برای دورههای بیشتری آموزش دهیم — بیایید 50 دوره انجام دهیم.
نکته: این تکنیک به اندازهای پرهزینه است که تنها در صورتی باید آن را امتحان کنید که به GPU دسترسی دارید (مانند GPU رایگان موجود در Colab) — روی CPU غیرقابل انجام است. اگر نمیتوانید کد خود را روی GPU اجرا کنید، تکنیک قبلی بهترین راه است.
callbacks = [
keras.callbacks.ModelCheckpoint(
filepath=”feature_extraction_with_data_augmentation.keras”,
save_best_only=True,
monitor=”val_loss”)
]
history = model.fit(
train_dataset,
epochs=50,
validation_data=validation_dataset,
callbacks=callbacks)
بیایید نتایج را دوباره رسم کنیم (به شکل 8.14 مراجعه کنید). همانطور که میبینید، ما به دقت اعتبارسنجی بیش از 98% میرسیم. این یک بهبود قوی نسبت به مدل قبلی است.
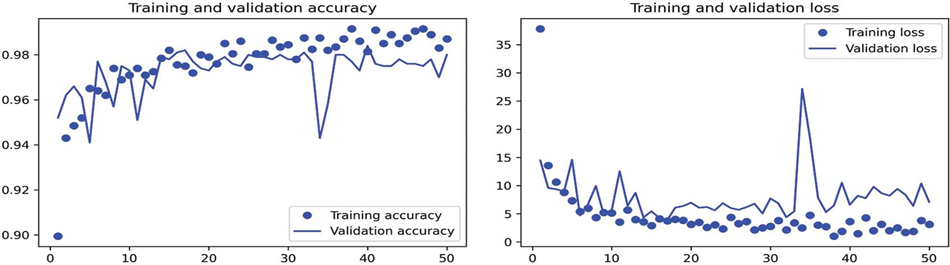
شکل 8.14: معیارهای آموزش و اعتبارسنجی برای استخراج ویژگی با افزایش داده.
بیایید دقت آزمایش را بررسی کنیم.
قطعه کد 8.26: ارزیابی مدل بر روی مجموعه آزمایش
test_model = keras.models.load_model(
“feature_extraction_with_data_augmentation.keras”)
test_loss, test_acc = test_model.evaluate(test_dataset)
print(f”Test accuracy: {test_acc:.3f}”)
ما دقت آزمایش 97.5% را به دست میآوریم. این تنها یک بهبود متوسط در مقایسه با دقت آزمایش قبلی است، که با توجه به نتایج قوی بر روی دادههای اعتبارسنجی کمی ناامیدکننده است. دقت یک مدل همیشه به مجموعه نمونههایی که آن را روی آنها ارزیابی میکنید بستگی دارد! برخی مجموعههای نمونه ممکن است دشوارتر از بقیه باشند، و نتایج قوی بر روی یک مجموعه لزوماً به طور کامل به تمام مجموعههای دیگر منتقل نخواهد شد
تنظیم دقیق یک مدل از پیش آموزشدیده
یکی دیگر از تکنیکهای پرکاربرد برای استفاده مجدد از مدل، که مکمل استخراج ویژگی است، تنظیم دقیق (fine-tuning) است (به شکل 8.15 مراجعه کنید). تنظیم دقیق شامل یخزدایی (unfreezing) چند لایه بالایی از یک پایه مدل یخزده که برای استخراج ویژگی استفاده میشود، و آموزش مشترک هم بخش جدید اضافه شده به مدل (در این مورد، طبقهبند کاملاً متصل) و هم این لایههای بالایی است. این کار تنظیم دقیق نامیده میشود زیرا بازنماییهای انتزاعیتر مدل در حال استفاده مجدد را کمی تنظیم میکند تا برای مسئله موجود مرتبطتر شوند.
پیشتر بیان کردم که یخزدایی پایه کانولوشنی VGG16 برای آموزش یک طبقهبند با مقداردهی اولیه تصادفی بر روی آن ضروری است. به همین دلیل، تنها پس از آموزش طبقهبند بالایی، امکان تنظیم دقیق لایههای بالایی پایه کانولوشنی وجود دارد. اگر طبقهبند قبلاً آموزش ندیده باشد، سیگنال خطای انتشار یافته در شبکه در طول آموزش بسیار بزرگ خواهد بود و بازنماییهای قبلاً یادگرفته شده توسط لایههای در حال تنظیم دقیق از بین خواهند رفت. بنابراین مراحل تنظیم دقیق یک شبکه به شرح زیر است:
- شبکه سفارشی خود را در بالای یک شبکه پایه از پیش آموزشدیده اضافه کنید.
- شبکه پایه را یخزده کنید.
- بخشی را که اضافه کردیم، آموزش دهید.
- برخی از لایهها را در شبکه پایه یخزدایی کنید. (توجه داشته باشید که نباید لایههای “نرمالسازی دسته” را یخزدایی کنید، که در اینجا مرتبط نیستند زیرا چنین لایههایی در VGG16 وجود ندارند. نرمالسازی دسته و تأثیر آن بر تنظیم دقیق در فصل بعدی توضیح داده شده است).
- همزمان این لایهها و بخشی را که اضافه کردیم، آموزش دهید.
شما قبلاً سه گام اول را هنگام انجام استخراج ویژگی انجام دادهاید. بیایید با گام 4 ادامه دهیم: conv_base خود را یخزدایی خواهیم کرد و سپس لایههای منفرد را در داخل آن یخزده خواهیم کرد.
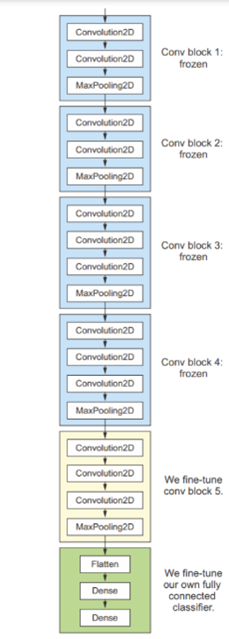
شکل 8.15: تنظیم دقیق آخرین بلوک کانولوشنی شبکه VGG16.
به عنوان یادآوری، پایه کانولوشنی ما اینگونه به نظر میرسد:
>>> conv_base.summary()
Model: “vgg16”
Layer (type) Output Shape Param #
=================================================================
| input_19 (InputLayer) | [(None, 180, 180, 3)] | 0 | |||
| block1_conv1 (Conv2D) | (None, 180, 180, 64) | 1792 | |||
| block1_conv2 (Conv2D) | (None, 180, 180, 64) | 36928 | |||
| block1_pool (MaxPooling2D) | (None, | 90, | 90, | 64) | 0 |
| block2_conv1 (Conv2D) | (None, | 90, | 90, | 128) | 73856 |
| block2_conv2 (Conv2D) | (None, | 90, | 90, | 128) | 147584 |
| block2_pool (MaxPooling2D) | (None, | 45, | 45, | 128) | 0 |
| block3_conv1 (Conv2D) | (None, | 45, | 45, | 256) | 295168 |
| block3_conv2 (Conv2D) | (None, | 45, | 45, | 256) | 590080 |
| block3_conv3 (Conv2D) | (None, | 45, | 45, | 256) | 590080 |
| block3_pool (MaxPooling2D) | (None, | 22, | 22, | 256) | 0 |
| block4_conv1 (Conv2D) | (None, | 22, | 22, | 512) | 1180160 |
| block4_conv2 (Conv2D) | (None, | 22, | 22, | 512) | 2359808 |
| block4_conv3 (Conv2D) | (None, | 22, | 22, | 512) | 2359808 |
| block4_pool (MaxPooling2D) | (None, | 11, | 11, | 512) | 0 |
| block5_conv1 (Conv2D) | (None, | 11, | 11, | 512) | 2359808 |
| block5_conv2 (Conv2D) | (None, | 11, | 11, | 512) | 2359808 |
| block5_conv3 (Conv2D) | (None, | 11, | 11, | 512) | 2359808 |
| block5_pool (MaxPooling2D) | (None, | 5, 5, 512) | 0 | ||
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
ما سه لایه کانولوشنی آخر را تنظیم دقیق خواهیم کرد، به این معنی که تمام لایههای تا block4_pool باید ثابت (frozen) بمانند، و لایههای block5_conv1، block5_conv2 و block5_conv3 باید قابل آموزش باشند.
چرا لایههای بیشتری را تنظیم دقیق (fine-tune) نکنیم؟ چرا کل پایه کانولوشنی را تنظیم دقیق نکنیم؟
شما میتوانید. اما باید موارد زیر را در نظر بگیرید:
- لایههای اولیه در پایه کانولوشنی، ویژگیهای عمومیتر و قابل استفاده مجدد را کدگذاری میکنند، در حالی که لایههای بالاتر ویژگیهای تخصصیتر را کدگذاری میکنند. تنظیم دقیق ویژگیهای تخصصیتر مفیدتر است، زیرا اینها هستند که باید برای مسئله جدید شما دوباره به کار گرفته شوند. بازدهی تنظیم دقیق لایههای پایینتر به سرعت کاهش مییابد.
- هر چه پارامترهای بیشتری را آموزش دهید، خطر بیشبرازش (overfitting) بیشتر است. پایه کانولوشنی 15 میلیون پارامتر دارد، بنابراین تلاش برای آموزش آن بر روی مجموعه داده کوچک شما خطرناک خواهد بود.
بنابراین، در این وضعیت، استراتژی خوبی است که تنها دو یا سه لایه بالایی را در پایه کانولوشنی تنظیم دقیق کنید. بیایید این را تنظیم کنیم، از جایی که در مثال قبلی متوقف شدیم، شروع میکنیم.
قطعه کد 8.27: ثابت کردن تمام لایهها تا لایه چهارم از انتها.
conv_base.trainable = True
for layer in conv_base.layers[:-4]:
layer.trainable = False
حالا میتوانیم تنظیم دقیق مدل (fine-tuning) را آغاز کنیم. این کار را با بهینهساز RMSprop و با استفاده از نرخ یادگیری بسیار پایین انجام خواهیم داد. دلیل استفاده از نرخ یادگیری پایین این است که میخواهیم مقدار تغییراتی را که در بازنماییهای سه لایه در حال تنظیم دقیق ایجاد میکنیم، محدود کنیم. بهروزرسانیهای خیلی بزرگ ممکن است به این بازنماییها آسیب برساند.
قطعه کد 8.28: تنظیم دقیق مدل.
model.compile(loss=”binary_crossentropy”,
optimizer=keras.optimizers.RMSprop(learning_rate=1e-5),
metrics=[“accuracy”])
callbacks = [
keras.callbacks.ModelCheckpoint( filepath=”fine_tuning.keras”, save_best_only=True, monitor=”val_loss”)
]
history = model.fit( train_dataset,
epochs=30,
validation_data=validation_dataset, callbacks=callbacks)
در نهایت میتوانیم این مدل را بر روی دادههای آزمایش ارزیابی کنیم:
model = keras.models.load_model(“fine_tuning.keras”)
test_loss, test_acc = model.evaluate(test_dataset)
print(f”Test accuracy: {test_acc:.3f}”)
در اینجا، ما دقت آزمایشی 98.5% را به دست میآوریم (دوباره، نتایج شما ممکن است تا یک درصد متفاوت باشد). در رقابت اصلی Kaggle پیرامون این مجموعه داده، این یکی از نتایج برتر بود. با این حال، این مقایسه کاملاً منصفانه نیست، زیرا ما از ویژگیهای از پیش آموزشدیده استفاده کردیم که از قبل شامل دانش قبلی در مورد گربهها و سگها بودند، که رقبا در آن زمان نمیتوانستند از آنها استفاده کنند.
از سوی دیگر، با بهرهبرداری از تکنیکهای مدرن یادگیری عمیق، ما توانستیم با استفاده از تنها بخش کوچکی از دادههای آموزشی موجود برای رقابت (حدود 10%) به این نتیجه برسیم. تفاوت زیادی بین توانایی آموزش بر روی 20,000 نمونه در مقایسه با 2,000 نمونه وجود دارد!
اکنون شما مجموعه ابزارهای محکمی برای مقابله با مسائل طبقهبندی تصویر دارید—به ویژه، با مجموعههای داده کوچک.
خلاصه
- Convnetها بهترین نوع مدلهای یادگیری ماشین برای وظایف بینایی کامپیوتر هستند. آموزش یکی از آنها از ابتدا حتی بر روی یک مجموعه داده بسیار کوچک، با نتایج مناسب، امکانپذیر است.
- Convnetها با یادگیری سلسلهمراتبی از الگوها و مفاهیم ماژولار برای نمایش دنیای بصری کار میکنند.
- در یک مجموعه داده کوچک، بیشبرازش مشکل اصلی خواهد بود. افزایش داده یک راه قدرتمند برای مبارزه با بیشبرازش هنگام کار با دادههای تصویری است.
- استفاده مجدد از یک convnet موجود بر روی یک مجموعه داده جدید از طریق استخراج ویژگی آسان است. این یک تکنیک ارزشمند برای کار با مجموعههای داده تصویری کوچک است.
- به عنوان مکملی برای استخراج ویژگی، میتوانید از تنظیم دقیق استفاده کنید، که برخی از بازنماییهای قبلاً یادگرفته شده توسط یک مدل موجود را با یک مسئله جدید تطبیق میدهد. این عملکرد را کمی بیشتر بهبود میبخشد.



