- این فصل پوشش میدهد:
- شاخههای مختلف بینایی کامپیوتر: طبقهبندی تصویر، تقسیمبندی تصویر، تشخیص شیء.
- الگوهای معماری مدرن convnet: اتصالات باقیمانده، نرمالسازی دسته، کانولوشنهای قابل تفکیک عمقی.
- تکنیکهایی برای بصریسازی و تفسیر آنچه convnetها یاد میگیرند.
مقدمه
فصل قبل اولین آشنایی شما را با یادگیری عمیق برای بینایی کامپیوتر از طریق مدلهای ساده (پشتههایی از لایههای Conv2D و MaxPooling2D) و یک مورد استفاده ساده (طبقهبندی تصویر دودویی) فراهم کرد. اما بینایی کامپیوتر چیزی فراتر از طبقهبندی تصویر است! این فصل عمیقتر به کاربردهای متنوعتر و بهترین روشهای پیشرفته میپردازد.
سه وظیفه ضروری بینایی کامپیوتر
تاکنون، ما بر روی مدلهای طبقهبندی تصویر تمرکز کردهایم: یک تصویر وارد میشود، یک برچسب خارج میشود. “این تصویر احتمالاً حاوی یک گربه است؛ آن دیگری احتمالاً حاوی یک سگ است.” اما طبقهبندی تصویر تنها یکی از چندین کاربرد ممکن یادگیری عمیق در بینایی کامپیوتر است. به طور کلی، سه وظیفه ضروری بینایی کامپیوتر وجود دارد که باید با آنها آشنا شوید:
- طبقهبندی تصویر — که هدف آن اختصاص یک یا چند برچسب به یک تصویر است. این میتواند یا طبقهبندی تکبرچسبی (یک تصویر فقط میتواند در یک دسته باشد و سایرین را حذف کند)، یا طبقهبندی چندبرچسبی (برچسبگذاری تمام دستههایی که یک تصویر به آنها تعلق دارد، همانطور که در شکل 9.1 دیده میشود) باشد. برای مثال، هنگامی که یک کلمه کلیدی را در برنامه Google Photos جستجو میکنید، پشت صحنه در حال پرسوجو از یک مدل طبقهبندی چندبرچسبی بسیار بزرگ هستید—مدلی با بیش از 20,000 کلاس مختلف، که بر روی میلیونها تصویر آموزش دیده است.
- تقسیمبندی تصویر — که هدف آن “تقسیمبندی” یا “پارتیشنبندی” یک تصویر به مناطق مختلف است، که هر منطقه معمولاً یک دسته را نشان میدهد (همانطور که در شکل 9.1 دیده میشود). برای مثال، هنگامی که Zoom یا Google Meet در یک تماس ویدیویی یک پسزمینه سفارشی را پشت سر شما نمایش میدهند، از یک مدل تقسیمبندی تصویر برای تشخیص چهره شما از آنچه در پشت آن قرار دارد، با دقت پیکسل استفاده میکند.
- تشخیص شیء — که هدف آن رسم مستطیلهایی (به نام کادرهای محدودکننده) در اطراف اشیاء مورد علاقه در یک تصویر، و مرتبط کردن هر مستطیل با یک کلاس است. یک خودروی خودران میتواند از یک مدل تشخیص شیء برای پایش خودروها، عابران پیاده و علائم در دید دوربینهای خود، برای مثال، استفاده کند.
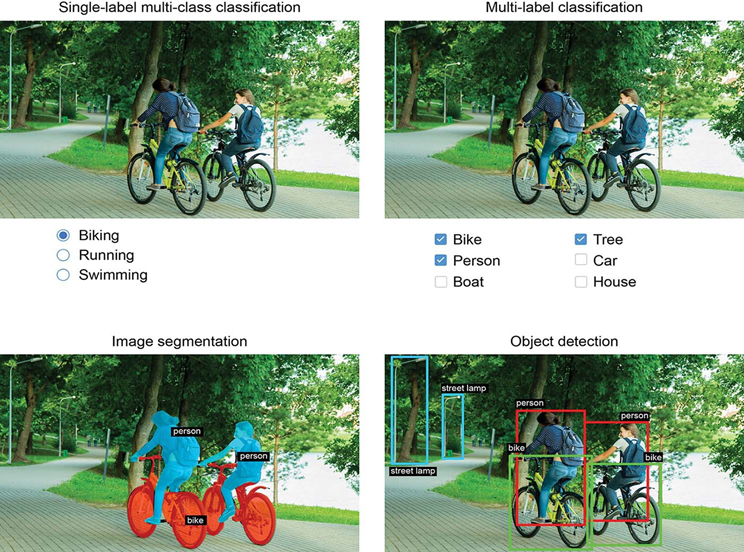
شکل 9.1: سه وظیفه اصلی بینایی کامپیوتر: طبقهبندی، تقسیمبندی، تشخیص.
یادگیری عمیق برای بینایی کامپیوتر همچنین شامل تعدادی وظایف کمی تخصصیتر علاوه بر این سه مورد است، مانند امتیازدهی شباهت تصویر (تخمین میزان شباهت بصری دو تصویر)، تشخیص نقاط کلیدی (مشخص کردن ویژگیهای مورد علاقه در یک تصویر، مانند ویژگیهای صورت)، تخمین وضعیت (pose estimation)، تخمین مش سهبعدی (3D mesh estimation) و غیره. اما در ابتدا، طبقهبندی تصویر، تقسیمبندی تصویر و تشخیص شیء، بنیادی را تشکیل میدهند که هر مهندس یادگیری ماشین باید با آنها آشنا باشد. بیشتر کاربردهای بینایی کامپیوتر به یکی از این سه مورد خلاصه میشوند.
شما طبقهبندی تصویر را در فصل قبلی در عمل دیدید. در ادامه، بیایید به تقسیمبندی تصویر (image segmentation) بپردازیم. این یک تکنیک بسیار مفید و چندمنظوره است، و میتوانید مستقیماً با آنچه تا کنون آموختهاید به آن بپردازید.
توجه داشته باشید که ما تشخیص شیء را پوشش نخواهیم داد، زیرا برای یک کتاب مقدماتی بیش از حد تخصصی و پیچیده خواهد بود. با این حال، میتوانید مثال RetinaNet را در keras.io بررسی کنید، که نشان میدهد چگونه یک مدل تشخیص شیء را از ابتدا در Keras در حدود 450 خط کد بسازید و آموزش دهید (https://keras.io/examples/vision/retinanet/).
یک مثال تقسیمبندی تصویر
تقسیمبندی تصویر با یادگیری عمیق به معنای استفاده از یک مدل برای اختصاص یک کلاس به هر پیکسل در یک تصویر است، بنابراین تصویر را به مناطق مختلف (مانند “پسزمینه” و “پیشزمینه”، یا “جاده”، “ماشین” و “پیادهرو”) تقسیم میکند. این دسته عمومی از تکنیکها را میتوان برای قدرت بخشیدن به انواع قابل توجهی از کاربردهای ارزشمند در ویرایش تصویر و ویدئو، رانندگی خودران، رباتیک، تصویربرداری پزشکی و غیره استفاده کرد.
دو نوع مختلف از تقسیمبندی تصویر وجود دارد که باید با آنها آشنا شوید:
- تقسیمبندی معنایی (Semantic segmentation)، که در آن هر پیکسل به طور مستقل به یک دسته معنایی، مانند “گربه”، طبقهبندی میشود. اگر دو گربه در تصویر وجود داشته باشد، پیکسلهای مربوطه همگی به یک دسته عمومی “گربه” نگاشت میشوند (به شکل 9.2 مراجعه کنید).
- تقسیمبندی نمونه (Instance segmentation)، که نه تنها به دنبال طبقهبندی پیکسلهای تصویر بر اساس دسته است، بلکه به دنبال تجزیه نمونههای شیء منفرد نیز هست. در تصویری با دو گربه، تقسیمبندی نمونه “گربه 1” و “گربه 2” را به عنوان دو کلاس جداگانه از پیکسلها در نظر میگیرد (به شکل 9.2 مراجعه کنید).
در این مثال، ما بر روی تقسیمبندی معنایی تمرکز خواهیم کرد: ما دوباره به تصاویر سگها و گربهها نگاه خواهیم کرد، و این بار یاد خواهیم گرفت که چگونه موضوع اصلی را از پسزمینه آن تشخیص دهیم.
ما با مجموعه داده Oxford-IIIT Pets (www.robots.ox.ac.uk/~vgg/data/pets/) کار خواهیم کرد، که حاوی 7,390 عکس از نژادهای مختلف گربه و سگ، به همراه ماسکهای تقسیمبندی پیشزمینه-پسزمینه برای هر عکس است. یک ماسک تقسیمبندی معادل برچسب در تقسیمبندی تصویر است: این تصویری به همان اندازه تصویر ورودی است، با یک کانال رنگی واحد که در آن هر مقدار صحیح مربوط به کلاس پیکسل متناظر در تصویر ورودی است. در مورد ما، پیکسلهای ماسکهای تقسیمبندی ما میتوانند یکی از سه مقدار صحیح را بگیرند:
- 1 (پیشزمینه)
- 2 (پسزمینه)
- 3 (کنتور)
بیایید با دانلود و از حالت فشرده خارج کردن مجموعه داده خود، با استفاده از ابزارهای shell wget و tar شروع کنیم:
!wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
!wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz
!tar -xf images.tar.gz
!tar -xf annotations.tar.gz
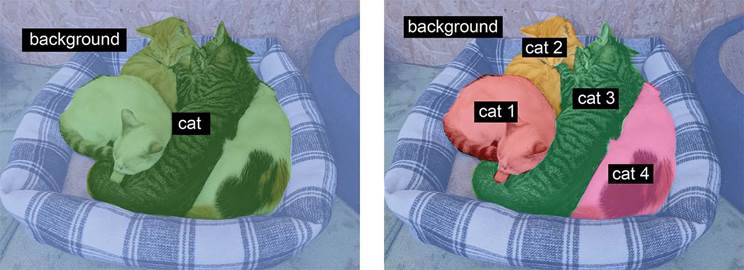
شکل 9.2: تقسیمبندی معنایی در مقابل تقسیمبندی نمونه.
تصاویر ورودی به صورت فایلهای JPG در پوشه images/ (مانند images/Abyssinian_1.jpg) ذخیره شدهاند، و ماسک تقسیمبندی متناظر با همان نام به صورت فایل PNG در پوشه annotations/trimaps/ (مانند annotations/trimaps/Abyssinian_1.png) ذخیره شده است.
بیایید لیست مسیرهای فایل ورودی و همچنین لیست مسیرهای فایل ماسک متناظر را آماده کنیم:
import os
input_dir = “images/”
target_dir = “annotations/trimaps/”
input_img_paths = sorted(
[os.path.join(input_dir, fname)
for fname in os.listdir(input_dir)
if fname.endswith(“.jpg”)])
target_paths = sorted(
[os.path.join(target_dir, fname)
for fname in os.listdir(target_dir)
if fname.endswith(“.png”) and not fname.startswith(“.”)])
حالا، یکی از این ورودیها و ماسک آن چگونه به نظر میرسد؟ بیایید نگاهی سریع بیندازیم. در اینجا یک تصویر نمونه آمده است (به شکل 9.3 مراجعه کنید):
import matplotlib.pyplot as plt
from tensorflow.keras.utils import load_img, img_to_array
plt.axis(“off”) plt.imshow(load_img(input_img_paths[9]))
تصویر ورودی شماره 9 را نمایش دهید

شکل 9.3: یک تصویر نمونه و در اینجا هدف متناظر با آن آمده است (به شکل 9.4 مراجعه کنید):
def display_target(target_array):
normalized_array = (target_array.astype(“uint8”) – 1) * 127
برچسبهای اصلی 1، 2 و 3 هستند. ما 1 را کم میکنیم تا برچسبها از 0 تا 2 باشند، و سپس در 127 ضرب میکنیم تا برچسبها 0 (سیاه)، 127 (خاکستری)، 254 (تقریباً سفید) شوند.
plt.axis(“off”)
plt.imshow(normalized_array[:, :, 0])
img = img_to_array(load_img(target_paths[9], color_mode=”grayscale”))
ما از color_mode=”grayscale” استفاده میکنیم تا تصویری که بارگذاری میکنیم، تک کاناله در نظر گرفته شود.
display_target(img)

شکل 9.4: ماسک هدف متناظر.
بعد از آن، بیایید ورودیها و هدفهای خود را در دو آرایه NumPy بارگذاری کنیم و آرایهها را به یک مجموعه آموزشی و یک مجموعه اعتبارسنجی تقسیم کنیم. از آنجایی که مجموعه داده بسیار کوچک است، میتوانیم همه چیز را مستقیماً در حافظه بارگذاری کنیم:
import numpy as np
import random
img_size = (200, 200)
همه چیز را به 200 × 200 تغییر اندازه میدهیم.
num_imgs = len(input_img_paths)
تعداد کل نمونهها در داده.
random.Random(1337).shuffle(input_img_paths)
random.Random(1337).shuffle(target_paths)
مسیرهای فایلها را به هم بریزید (آنها در ابتدا بر اساس نژاد مرتب شده بودند). ما از همان دانه تصادفی (1337) در هر دو عبارت استفاده میکنیم تا اطمینان حاصل کنیم که مسیرهای ورودی و مسیرهای هدف در یک ترتیب باقی میمانند.
def path_to_input_image(path):
return img_to_array(load_img(path, target_size=img_size))
def path_to_target(path):
img = img_to_array(
load_img(path, target_size=img_size, color_mode=”grayscale”))
img = img.astype(“uint8”) – 1
1 را کم کنید تا برچسبهای ما 0، 1 و 2 شوند.
return img
input_imgs = np.zeros((num_imgs,) + img_size + (3,), dtype=”float32″)
تمام تصاویر را در آرایه input_imgs با نوع float32 و ماسکهای آنها را در آرایه targets با نوع uint8 (با همان ترتیب) بارگذاری کنید. ورودیها دارای سه کانال (مقادیر RGB) و هدفها دارای یک کانال (که شامل برچسبهای صحیح است) هستند.
targets = np.zeros((num_imgs,) + img_size + (1,), dtype=”uint8″)
for i in range(num_imgs):
input_imgs[i] = path_to_input_image(input_img_paths[i])
targets[i] = path_to_target(target_paths[i])
num_val_samples = 1000
1,000 نمونه را برای اعتبارسنجی کنار بگذارید.
train_input_imgs = input_imgs[:-num_val_samples]
train_targets = targets[:-num_val_samples]
val_input_imgs = input_imgs[-num_val_samples:]
val_targets = targets[-num_val_samples:]
دادهها را به یک مجموعه آموزشی و یک مجموعه اعتبارسنجی تقسیم کنید.
حالا وقت آن است که مدل خود را تعریف کنیم:
from tensorflow import keras
from tensorflow.keras import layers
def get_model(img_size, num_classes):
inputs = keras.Input(shape=img_size + (3,))
x = layers.Rescaling(1./255)(inputs)
x = layers.Conv2D(64, 3, strides=2, activation=”relu”, padding=”same”)(x)
فراموش نکنید که تصاویر ورودی را به محدوده [1-0] مقیاسبندی کنید.
x = layers.Conv2D(64, 3, activation=”relu”, padding=”same”)(x)
توجه داشته باشید که چگونه ما در همه جا از padding=”same” استفاده میکنیم تا از تأثیر پدینگ مرزی بر اندازه نقشه ویژگی جلوگیری کنیم.
x = layers.Conv2D(128, 3, strides=2, activation=”relu”, padding=”same”)(x)
x = layers.Conv2D(128, 3, activation=”relu”, padding=”same”)(x)
x = layers.Conv2D(256, 3, strides=2, padding=”same”, activation=”relu”)(x)
x = layers.Conv2D(256, 3, activation=”relu”, padding=”same”)(x)
x = layers.Conv2DTranspose(256, 3, activation=”relu”, padding=”same”)(x)
x = layers.Conv2DTranspose(
256, 3, activation=”relu”, padding=”same”, strides=2)(x)
x = layers.Conv2DTranspose(128, 3, activation=”relu”, padding=”same”)(x)
x = layers.Conv2DTranspose(
128, 3, activation=”relu”, padding=”same”, strides=2)(x)
x = layers.Conv2DTranspose(64, 3, activation=”relu”, padding=”same”)(x)
x = layers.Conv2DTranspose(
64, 3, activation=”relu”, padding=”same”, strides=2)(x)
outputs = layers.Conv2D(num_classes, 3, activation=”softmax”, padding=”same”)(x)
مدل را با یک سافتمکس (softmax) سهحالته برای هر پیکسل به پایان میرسانیم تا هر پیکسل خروجی را در یکی از سه دسته ما طبقهبندی کنیم.
model = keras.Model(inputs, outputs)
return model
model = get_model(img_size=img_size, num_classes=3)
model.summary()
این خروجی فراخوانی model.summary() است:
Model: “model”
Layer (type) Output Shape Param #
=================================================================
| input_1 (InputLayer) | [(None, 200, 200, 3)] | 0 |
| rescaling (Rescaling) | (None, 200, 200, 3) | 0 |
| conv2d (Conv2D) | (None, 100, 100, 64) | 1792 |
| conv2d_1 (Conv2D) | (None, 100, 100, 64) | 36928 |
| conv2d_2 (Conv2D) | (None, 50, 50, 128) | 73856 |
| conv2d_3 (Conv2D) | (None, 50, 50, 128) | 147584 |
| conv2d_4 (Conv2D) | (None, 25, 25, 256) | 295168 |
| conv2d_5 (Conv2D) | (None, 25, 25, 256) | 590080 |
| conv2d_transpose (Conv2DTran | (None, 25, 25, 256) | 590080 |
| conv2d_transpose_1 (Conv2DTr | (None, 50, 50, 256) | 590080 |
| conv2d_transpose_2 (Conv2DTr | (None, 50, 50, 128) | 295040 |
| conv2d_transpose_3 (Conv2DTr | (None, 100, 100, 128) | 147584 |
| conv2d_transpose_4 (Conv2DTr | (None, 100, 100, 64) | 73792 |
| conv2d_transpose_5 (Conv2DTr | (None, 200, 200, 64) | 36928 |
| conv2d_6 (Conv2D) | (None, 200, 200, 3) | 1731 |
=================================================================
Total params: 2,880,643
Trainable params: 2,880,643
Non-trainable params: 0
نیمه اول مدل بسیار شبیه به نوع convnetی است که برای طبقهبندی تصویر استفاده میکنید: پشتهای از لایههای Conv2D، با اندازههای فیلتر به تدریج در حال افزایش. ما تصاویر خود را سه بار با ضریب دو کاهش نمونهبرداری میکنیم و به فعالسازیهایی با اندازه (256, 25, 25) میرسیم. هدف این نیمه اول، کدگذاری تصاویر به نقشههای ویژگی کوچکتر است، جایی که هر مکان فضایی (یا پیکسل) حاوی اطلاعاتی درباره یک بخش فضایی بزرگ از تصویر اصلی است. میتوانید آن را به عنوان نوعی فشردهسازی درک کنید.
یک تفاوت مهم بین نیمه اول این مدل و مدلهای طبقهبندی که قبلاً دیدهاید، نحوه کاهش نمونهبرداری است: در convnetهای طبقهبندی از فصل گذشته، ما از لایههای MaxPooling2D برای کاهش نمونهبرداری نقشههای ویژگی استفاده میکردیم. در اینجا، ما با افزودن گامها (strides) به هر لایه کانولوشن دیگر، کاهش نمونهبرداری میکنیم (اگر جزئیات نحوه کار گامهای کانولوشن را به خاطر ندارید، به “درک گامهای کانولوشن” در بخش 8.1.1 مراجعه کنید). ما این کار را انجام میدهیم زیرا، در مورد تقسیمبندی تصویر، ما به مکان فضایی اطلاعات در تصویر بسیار اهمیت میدهیم، زیرا باید ماسکهای هدف به ازای هر پیکسل را به عنوان خروجی مدل تولید کنیم. وقتی Max Pooling 2 × 2 انجام میدهید، اطلاعات مکان را به طور کامل در هر پنجره پولینگ از بین میبرید: شما یک مقدار اسکالر به ازای هر پنجره برمیگردانید، با دانش صفر در مورد اینکه مقدار از کدام یک از چهار مکان در پنجرهها آمده است. بنابراین در حالی که لایههای Max Pooling برای وظایف طبقهبندی خوب عمل میکنند، برای یک وظیفه تقسیمبندی به ما آسیب زیادی میرسانند. در همین حال، کانولوشنهای گامدار در کاهش نمونهبرداری نقشههای ویژگی، در حالی که اطلاعات مکان را حفظ میکنند، بهتر عمل میکنند. در طول این کتاب، متوجه خواهید شد که ما تمایل داریم به جای Max Pooling در هر مدلی که به مکان ویژگی اهمیت میدهد، مانند مدلهای مولد در فصل 12، از گامها استفاده کنیم.
نیمه دوم مدل پشتهای از لایههای Conv2DTranspose است. آنها چه هستند؟ خب، خروجی نیمه اول مدل یک نقشه ویژگی با شکل (256, 25, 25) است، اما ما میخواهیم خروجی نهایی ما شکلی مشابه ماسکهای هدف، (3, 200, 200) داشته باشد. بنابراین، ما باید نوعی معکوس تبدیلهایی را که تاکنون اعمال کردهایم، اعمال کنیم—چیزی که نقشههای ویژگی را به جای کاهش نمونهبرداری، افزایش نمونهبرداری کند. این هدف لایه Conv2DTranspose است: میتوانید آن را نوعی لایه کانولوشن در نظر بگیرید که یاد میگیرد افزایش نمونهبرداری کند. اگر ورودی با شکل (64, 100, 100) دارید، و آن را از طریق لایه Conv2D(128, 3, strides=2, padding=”same”) عبور دهید، خروجی با شکل (128, 50, 50) به دست میآورید. اگر این خروجی را از طریق لایه Conv2DTranspose(64, 3, strides=2, padding=”same”) عبور دهید، خروجی با شکل (64, 100, 100) را برمیگردانید که همانند اصلی است. بنابراین پس از فشردهسازی ورودیهای خود به نقشههای ویژگی با شکل (256, 25, 25) از طریق پشتهای از لایههای Conv2D، میتوانیم به سادگی دنباله متناظر از لایههای Conv2DTranspose را اعمال کنیم تا به تصاویر با شکل (3, 200, 200) بازگردیم.
اکنون میتوانیم مدل خود را کامپایل و برازش دهیم:
model.compile(optimizer=”rmsprop”, loss=”sparse_categorical_crossentropy”)
callbacks = [
keras.callbacks.ModelCheckpoint(“oxford_segmentation.keras”,
save_best_only=True)
]
history = model.fit(train_input_imgs, train_targets,
epochs=50,
callbacks=callbacks, batch_size=64,
validation_data=(val_input_imgs, val_targets))
بیایید زیان آموزش و اعتبارسنجی خود را نمایش دهیم (به شکل 9.5 مراجعه کنید):
epochs = range(1, len(history.history[“loss”]) + 1)
loss = history.history[“loss”]
val_loss = history.history[“val_loss”]
plt.figure()
plt.plot(epochs, loss, “bo”, label=”Training loss”)
plt.plot(epochs, val_loss, “b”, label=”Validation loss”) plt.title(“Training and validation loss”)
plt.legend()
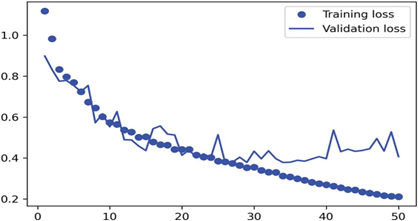
شکل 9.5: نمایش منحنیهای زیان آموزش و اعتبارسنجی.
میتوانید ببینید که ما در میانه راه، حدود دوره 25، شروع به بیشبرازش میکنیم. بیایید بهترین مدل عملکردی خود را بر اساس زیان اعتبارسنجی بارگذاری مجدد کنیم و نحوه استفاده از آن برای پیشبینی یک ماسک تقسیمبندی را نشان دهیم (به شکل 9.6 مراجعه کنید):
from tensorflow.keras.utils import array_to_img
model = keras.models.load_model(“oxford_segmentation.keras”)
i = 4
test_image = val_input_imgs[i]
plt.axis(“off”)
plt.imshow(array_to_img(test_image))
mask = model.predict(np.expand_dims(test_image, 0))[0]
def display_mask(pred):
تابع کمکی برای نمایش پیشبینی مدل.
mask = np.argmax(pred, axis=-1)
mask *= 127
plt.axis(“off”)
plt.imshow(mask)
display_mask(mask)

شکل 9.6: یک تصویر آزمایش و ماسک تقسیمبندی پیشبینیشده آن.
چندین ناهمگونی کوچک در ماسک پیشبینی شده ما وجود دارد که ناشی از اشکال هندسی در پیشزمینه و پسزمینه هستند. با این وجود، به نظر میرسد مدل ما به خوبی کار میکند.
در این مرحله، در طول فصل 8 و ابتدای فصل 9، شما اصول اولیه نحوه انجام طبقهبندی تصویر و تقسیمبندی تصویر را آموختهاید: شما از قبل میتوانید کارهای زیادی را با آنچه میدانید انجام دهید. با این حال، convnetهایی که مهندسان باتجربه برای حل مسائل دنیای واقعی توسعه میدهند، به سادگی آنهایی که ما در نمایشهایمان تاکنون استفاده کردهایم، نیستند. شما همچنان فاقد مدلهای ذهنی ضروری و فرآیندهای فکری هستید که متخصصان را قادر میسازد تا در مورد نحوه کنار هم قرار دادن مدلهای پیشرفته، تصمیمات سریع و دقیقی بگیرند. برای پر کردن این شکاف، باید در مورد الگوهای معماری یاد بگیرید. بیایید وارد جزئیات شویم.
الگوهای معماری convnet مدرن(شبکه کانولوشنال)
“معماری” یک مدل، مجموع انتخابهایی است که در ایجاد آن به کار رفتهاند: کدام لایهها را استفاده کنیم، چگونه آنها را پیکربندی کنیم، و به چه ترتیبی آنها را به هم وصل کنیم. این انتخابها فضای فرضیه مدل شما را تعریف میکنند: فضای توابع ممکن که گرادیان کاهشی میتواند در آن جستجو کند، که توسط وزنهای مدل پارامترسازی شده است. مانند مهندسی ویژگی، یک فضای فرضیه خوب، دانش قبلی شما در مورد مسئله موجود و راهحل آن را کدگذاری میکند. برای مثال، استفاده از لایههای کانولوشن به این معنی است که شما از قبل میدانید الگوهای مرتبط موجود در تصاویر ورودی شما ناوردا به انتقال هستند. برای یادگیری مؤثر از دادهها، باید در مورد آنچه به دنبال آن هستید، فرضیاتی داشته باشید.
معماری مدل اغلب تفاوت بین موفقیت و شکست است. اگر انتخابهای معماری نامناسبی داشته باشید، مدل شما ممکن است با معیارهای نامطلوب مواجه شود و هیچ مقدار داده آموزشی آن را نجات نخواهد داد. برعکس، یک معماری مدل خوب، یادگیری را تسریع میکند و به مدل شما امکان میدهد تا از دادههای آموزشی موجود به طور کارآمد استفاده کند و نیاز به مجموعههای داده بزرگ را کاهش دهد. یک معماری مدل خوب، معماریای است که اندازه فضای جستجو را کاهش میدهد یا همگرایی به یک نقطه خوب در فضای جستجو را آسانتر میکند. درست مانند مهندسی ویژگی و سازماندهی دادهها، معماری مدل نیز همه چیز در مورد سادهتر کردن مسئله برای گرادیان کاهشی است تا آن را حل کند. و به یاد داشته باشید که گرادیان کاهشی یک فرآیند جستجوی نسبتاً احمقانه است، بنابراین به هر کمکی که میتواند دریافت کند، نیاز دارد.
معماری مدل بیشتر یک هنر است تا یک علم. مهندسان یادگیری ماشین باتجربه قادرند به طور شهودی در اولین تلاش خود مدلهای با عملکرد بالا را کنار هم بچینند، در حالی که مبتدیان اغلب برای ایجاد مدلی که اصلاً آموزش ببیند، مشکل دارند. کلمه کلیدی در اینجا “شهودی” است: هیچ کس نمیتواند توضیح واضحی از آنچه کار میکند و آنچه کار نمیکند، به شما بدهد. متخصصان بر تطابق الگوها تکیه میکنند، تواناییای که از طریق تجربه عملی گسترده کسب میکنند. شما شهود خود را در طول این کتاب توسعه خواهید داد. با این حال، همه چیز هم به شهود نیست—در مورد علم واقعی چیز زیادی وجود ندارد، اما همانند هر رشته مهندسی دیگری، بهترین شیوهها وجود دارند.
در بخشهای زیر، چند بهترین روش ضروری معماری convnet را بررسی خواهیم کرد: به طور خاص، اتصالات باقیمانده، نرمالسازی دسته، و کانولوشنهای قابل تفکیک. هنگامی که در استفاده از آنها تسلط پیدا کنید، قادر خواهید بود مدلهای تصویری بسیار مؤثری بسازید. ما آنها را بر روی مشکل طبقهبندی گربه در برابر سگ اعمال خواهیم کرد.
بیایید از نمای پرنده شروع کنیم: فرمول ماژولار بودن-سلسلهمراتب-قابلیت استفاده مجدد (MHR) برای معماری سیستم.
ماژولار بودن، سلسلهمراتب، و قابلیت استفاده مجدد
اگر میخواهید یک سیستم پیچیده را سادهتر کنید، یک دستورالعمل جهانی وجود دارد که میتوانید اعمال کنید: فقط پیچیدگی بیشکل خود را به ماژولها ساختار دهید، ماژولها را در یک سلسلهمراتب سازماندهی کنید، و شروع به استفاده مجدد از همان ماژولها در چندین مکان، در صورت لزوم، کنید (“قابلیت استفاده مجدد” در این متن کلمهای دیگر برای انتزاع است). این همان فرمول MHR (ماژولار بودن-سلسلهمراتب-قابلیت استفاده مجدد) است، و زیربنای معماری سیستم در تقریباً هر حوزهای است که اصطلاح “معماری” در آن استفاده میشود. این در قلب سازماندهی هر سیستمی با پیچیدگی معنیدار قرار دارد، خواه یک کلیسای جامع باشد، بدن خود شما، نیروی دریایی ایالات متحده، یا پایگاه کد Keras (به شکل 9.7 مراجعه کنید).
شکل 9.7: سیستمهای پیچیده از ساختار سلسلهمراتبی پیروی میکنند و به ماژولهای مجزا سازماندهی شدهاند که چندین بار مورد استفاده مجدد قرار میگیرند(مانند چهار اندام شما که همگی نسخههایی از یک طرح اولیه هستند، یا 20 “انگشت” شما).
اگر شما یک مهندس نرمافزار هستید، از قبل به شدت با این اصول آشنا هستید: یک پایگاه کد مؤثر، پایگاهی است که ماژولار، سلسلهمراتبی باشد، و در آن یک چیز را دو بار پیادهسازی نمیکنید، بلکه به کلاسها و توابع قابل استفاده مجدد متکی هستید. اگر کد خود را با پیروی از این اصول فاکتور بگیرید، میتوان گفت در حال انجام “معماری نرمافزار” هستید.
یادگیری عمیق خود به سادگی کاربرد این دستورالعمل در بهینهسازی پیوسته از طریق گرادیان کاهشی است: شما یک تکنیک بهینهسازی کلاسیک (گرادیان کاهشی بر روی یک فضای تابع پیوسته) را انتخاب میکنید، و فضای جستجو را به ماژولها (لایهها) ساختار میدهید، که در یک سلسلهمراتب عمیق (اغلب فقط یک پشته، سادهترین نوع سلسلهمراتب) سازماندهی شدهاند، جایی که هر آنچه را میتوانید (برای مثال، کانولوشنها همگی در مورد استفاده مجدد از اطلاعات یکسان در مکانهای فضایی مختلف هستند) دوباره استفاده میکنید.
به همین ترتیب، معماری مدل یادگیری عمیق عمدتاً در مورد استفاده هوشمندانه از ماژولار بودن، سلسلهمراتب و قابلیت استفاده مجدد است. متوجه خواهید شد که تمام معماریهای convnet محبوب نه تنها به لایهها ساختار یافتهاند، بلکه به گروههای تکراری از لایهها (که “بلوک” یا “ماژول” نامیده میشوند) ساختار یافتهاند. برای مثال، معماری محبوب VGG16 که در فصل قبل استفاده کردیم، به بلوکهای تکراری “conv, conv, max pooling” ساختار یافته است (به شکل 9.8 مراجعه کنید).
علاوه بر این، بیشتر convnetها اغلب دارای ساختارهای هرمیشکل (سلسلهمراتب ویژگی) هستند. برای مثال، پیشرفت در تعداد فیلترهای کانولوشن را که در اولین convnetی که در فصل قبل ساختیم استفاده کردیم، به یاد بیاورید: 32، 64، 128. تعداد فیلترها با عمق لایه افزایش مییابد، در حالی که اندازه نقشههای ویژگی متناسب با آن کاهش مییابد. همین الگو را در بلوکهای مدل VGG16 مشاهده خواهید کرد (به شکل 9.8 مراجعه کنید).
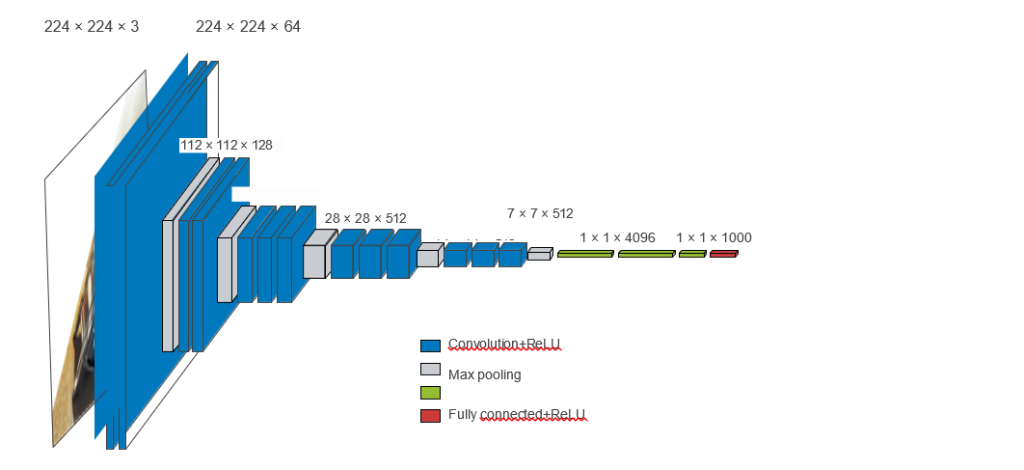
شکل 9.8: معماری VGG16: به بلوکهای لایهای تکراری و ساختار هرمیشکل نقشههای ویژگی توجه کنید. pyramidal.
سلسلهمراتبهای عمیقتر ذاتاً خوب هستند زیرا استفاده مجدد از ویژگیها و در نتیجه انتزاع را تشویق میکنند. به طور کلی، یک پشته عمیق از لایههای باریک بهتر از یک پشته کمعمق از لایههای بزرگ عمل میکند. با این حال، به دلیل مشکل گرادیانهای ناپدید شونده (vanishing gradients)، محدودیتی برای عمق پشتهسازی لایهها وجود دارد. این ما را به اولین الگوی معماری مدل ضروری خود هدایت میکند: اتصالات باقیمانده (residual connections).
در مورد اهمیت مطالعات ابلیشن در تحقیقات یادگیری عمیق
معماریهای یادگیری عمیق اغلب بیشتر تکاملیافته هستند تا طراحیشده — آنها با تلاشهای مکرر و انتخاب آنچه به نظر میرسید کار میکند، توسعه یافتهاند. درست مانند سیستمهای بیولوژیکی، اگر هر تنظیمات پیچیده یادگیری عمیق تجربی را در نظر بگیرید، احتمالاً میتوانید چند ماژول را حذف کنید (یا برخی ویژگیهای آموزشدیده را با ویژگیهای تصادفی جایگزین کنید) بدون از دست دادن عملکرد.
این وضعیت با انگیزههایی که محققان یادگیری عمیق با آن مواجه هستند بدتر میشود: با پیچیدهتر کردن یک سیستم بیش از حد لازم، میتوانند آن را جالبتر یا جدیدتر جلوه دهند و در نتیجه شانس خود را برای پذیرفته شدن مقاله در فرآیند داوری همتا افزایش دهند. اگر مقالات زیادی در زمینه یادگیری عمیق بخوانید، متوجه خواهید شد که آنها اغلب از نظر سبک و محتوا به گونهای برای داوری همتا بهینهسازی شدهاند که به طور فعال به وضوح توضیح و قابلیت اطمینان نتایج آسیب میرساند. برای مثال، ریاضیات در مقالات یادگیری عمیق به ندرت برای فرموله کردن واضح مفاهیم یا استخراج نتایج غیربدیهی استفاده میشود—بلکه به عنوان نشانهای از جدیت، مانند یک کت و شلوار گرانقیمت بر تن یک فروشنده، مورد استفاده قرار میگیرد.
هدف تحقیق نباید صرفاً انتشار باشد، بلکه تولید دانش قابل اعتماد است.
به طور حیاتی، درک علیت در سیستم شما مستقیمترین راه برای تولید دانش قابل اعتماد است. و یک راه با تلاش بسیار کم برای بررسی علیت وجود دارد: مطالعات ابلیشن (ablation studies). مطالعات ابلیشن شامل تلاش سیستماتیک برای حذف بخشهایی از یک سیستم — سادهتر کردن آن — برای شناسایی اینکه عملکرد آن در واقع از کجا نشأت میگیرد، است. اگر متوجه شدید که X + Y + Z نتایج خوبی به شما میدهد، X، Y، Z، X + Y، X + Z، و Y + Z را نیز امتحان کنید و ببینید چه اتفاقی میافتد.
اتصالات باقیمانده (Residual connections)
احتمالاً بازی “تلفن خراب” را میشناسید، که در انگلستان به آن Chinese whispers و در فرانسه به آن téléphonearabe میگویند. در این بازی، یک پیام اولیه در گوش یک بازیکن زمزمه میشود، که سپس آن را در گوش بازیکن بعدی زمزمه میکند و همینطور ادامه مییابد. پیام نهایی شباهت کمی به نسخه اصلی خود پیدا میکند. این یک استعاره سرگرمکننده برای خطاهای تجمعی است که در انتقال متوالی بر روی یک کانال نویزدار رخ میدهد.
همانطور که اتفاق میافتد، پسانتشار (backpropagation) در یک مدل یادگیری عمیق دنبالهای بسیار شبیه به بازی “تلفن خراب” است. شما یک زنجیره از توابع دارید، مانند این:
y = f4(f3(f2(f1(x))))
نام این بازی تنظیم پارامترهای هر تابع در زنجیره بر اساس خطای ثبت شده در خروجی f4 (زیان مدل) است. برای تنظیم f1, باید اطلاعات خطا را از طریق f2,f3, و f4 منتقل کنید. با این حال، هر تابع متوالی در زنجیره مقدار مشخصی نویز را معرفی میکند. اگر زنجیره تابع شما بیش از حد عمیق باشد، این نویز شروع به غلبه بر اطلاعات گرادیان میکند و پسانتشار از کار میافتد. مدل شما اصلاً آموزش نمیبیند. این همان مشکل گرادیانهای ناپدید شونده (vanishing gradients) است.
راه حل ساده است: فقط هر تابع در زنجیره را مجبور کنید که غیرمخرب باشد—تا یک نسخه بدون نویز از اطلاعات موجود در ورودی قبلی را حفظ کند. سادهترین راه برای پیادهسازی این کار، استفاده از یک اتصال باقیمانده (residual connection) است. این کار بسیار آسان است: کافی است ورودی یک لایه یا بلوک از لایهها را دوباره به خروجی آن اضافه کنید (به شکل 9.9 مراجعه کنید). اتصال باقیمانده به عنوان یک میانبر اطلاعاتی در اطراف بلوکهای مخرب یا نویزدار (مانند بلوکهایی که حاوی فعالسازیهای relu یا لایههای دراپاوت هستند) عمل میکند، و امکان انتشار بینویز اطلاعات گرادیان خطا از لایههای اولیه را از طریق یک شبکه عمیق فراهم میکند. این تکنیک در سال 2015 با خانواده مدلهای ResNet (توسعه یافته توسط He و همکاران در مایکروسافت) معرفی شد.
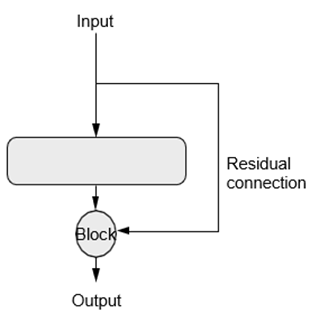
شکل 9.9: یک اتصال باقیمانده در اطراف یک بلوک پردازشی
در عمل، یک اتصال باقیمانده را به صورت زیر پیادهسازی میکنید:
قطعه کد 9.1: یک اتصال باقیمانده در شبهکد
x = …
یک تنسور ورودی
residual = x
یک نشانگر (pointer) به ورودی اصلی ذخیره کنید. این به آن باقیمانده (residual) گفته میشود.
x = block(x)
این بلوک محاسباتی به طور بالقوه میتواند مخرب یا نویزدار باشد، و این خوب است.
x = add([x, residual])
ورودی اصلی را به خروجی لایه اضافه کنید: بنابراین خروجی نهایی همیشه اطلاعات کامل را درباره ورودی اصلی حفظ خواهد کرد.
توجه داشته باشید که افزودن ورودی به خروجی یک بلوک به این معنی است که خروجی باید شکلی مشابه ورودی داشته باشد. با این حال، اگر بلوک شما شامل لایههای کانولوشنی با تعداد فیلترهای افزایشیافته، یا یک لایه Max Pooling باشد، اینطور نیست. در چنین مواردی، از یک لایه Conv2D با ابعاد 1 × 1 و بدون فعالسازی استفاده کنید تا باقیمانده را به صورت خطی به شکل خروجی دلخواه نگاشت کنید (به قطعه کد 9.2 مراجعه کنید).
شما معمولاً از padding=”same” در لایههای کانولوشن در بلوک هدف خود استفاده میکنید تا از کاهش نمونهبرداری فضایی ناشی از پدینگ جلوگیری کنید، و از گامها (strides) در پروجکشن باقیمانده استفاده میکنید تا هرگونه کاهش نمونهبرداری ناشی از یک لایه Max Pooling را تطبیق دهید (به قطعه کد 9.3 مراجعه کنید).
قطعه کد 9.2: بلوک باقیماندهای که در آن تعداد فیلترها تغییر میکند
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(32, 32, 3))
x = layers.Conv2D(32, 3, activation=”relu”)(inputs)
residual = x
باقیمانده را کنار بگذارید.
x = layers.Conv2D(64, 3, activation=”relu”, padding=”same”)(x)
این لایهای است که در اطراف آن یک اتصال باقیمانده ایجاد میکنیم: این لایه تعداد فیلترهای خروجی را از 32 به 64 افزایش میدهد. توجه داشته باشید که ما از padding=”same” استفاده میکنیم
residual = layers.Conv2D(64, 1)(residual)
باقیمانده فقط 32 فیلتر داشت، بنابراین ما از یک Conv2D با ابعاد 1 × 1 برای نگاشت آن به شکل صحیح استفاده میکنیم.
x = layers.add([x, residual])
حالا خروجی بلوک و باقیمانده شکل یکسانی دارند و میتوان آنها را اضافه کرد.
قطعه کد 9.3: حالتی که بلوک هدف شامل یک لایه Max Pooling است.
inputs = keras.Input(shape=(32, 32, 3))
x = layers.Conv2D(32, 3, activation=”relu”)(inputs)
residual = x
باقیمانده را کنار بگذارید.
x = layers.Conv2D(64, 3, activation=”relu”, padding=”same”)(x)
این بلوکی از دو لایه است که در اطراف آن یک اتصال باقیمانده ایجاد میکنیم: شامل یک لایه Max Pooling 2 × 2 است. توجه داشته باشید که ما از padding=”same” هم در لایه کانولوشن و هم در لایه Max Pooling استفاده میکنیم تا از کاهش نمونهبرداری ناشی از پدینگ جلوگیری کنیم.
x = layers.MaxPooling2D(2, padding=”same”)(x)
residual = layers.Conv2D(64, 1, strides=2)(residual)
ما از strides=2 در پروجکشن باقیمانده استفاده میکنیم تا با کاهش نمونهبرداری ایجاد شده توسط لایه Max Pooling مطابقت داشته باشد.
x = layers.add([x, residual])
حالا خروجی بلوک و باقیمانده شکل یکسانی دارند و میتوان آنها را اضافه کرد.
برای ملموستر کردن این ایدهها، در اینجا مثالی از یک convnet ساده آورده شده است که به صورت سری بلوکها ساختار یافته است، که هر بلوک از دو لایه کانولوشن و یک لایه Max Pooling اختیاری تشکیل شده است، با یک اتصال باقیمانده در اطراف هر بلوک:
inputs = keras.Input(shape=(32, 32, 3))
x = layers.Rescaling(1./255)(inputs)
def residual_block(x, filters, pooling=False):
تابع کمکی برای اعمال یک بلوک کانولوشنی با اتصال باقیمانده، با گزینهای برای افزودن max pooling.
residual = x
x = layers.Conv2D(filters, 3, activation=”relu”, padding=”same”)(x)
x = layers.Conv2D(filters, 3, activation=”relu”, padding=”same”)(x)
if pooling:
x = layers.MaxPooling2D(2, padding=”same”)(x)
residual = layers.Conv2D(filters, 1, strides=2)(residual)
اگر از max pooling استفاده کنیم، یک کانولوشن گامدار اضافه میکنیم تا باقیمانده را به شکل مورد انتظار نگاشت کند.
elif filters != residual.shape[-1]:
residual = layers.Conv2D(filters, 1)(residual)
اگر از Max Pooling استفاده نکنیم، تنها در صورتی باقیمانده را نگاشت میکنیم که تعداد کانالها تغییر کرده باشد
x = layers.add([x, residual])
return x
x = residual_block(x, filters=32, pooling=True)
بلوک اول
x = residual_block(x, filters=64, pooling=True)
بلوک دوم؛ به افزایش تعداد فیلترها در هر بلوک توجه کنید.
x = residual_block(x, filters=128, pooling=False)
آخرین بلوک نیازی به لایه Max Pooling ندارد، زیرا ما بلافاصله پس از آن Global Average Pooling را اعمال خواهیم کرد.
x = layers.GlobalAveragePooling2D()(x)
outputs = layers.Dense(1, activation=”sigmoid”)(x)
model = keras.Model(inputs=inputs, outputs=outputs)
model.summary()
| Model: “model” | |||
| Layer (type) | Output Shape | Param # | Connected to |
| ================================================================================================== | |||
| input_1 (InputLayer) | [(None, 32, 32, 3)] | 0 | |
| rescaling (Rescaling) | (None, 32, 32, 3) | 0 | input_1[0][0] |
| conv2d (Conv2D) | (None, 32, 32, 32) | 896 | rescaling[0][0] |
| conv2d_1 (Conv2D) | (None, 32, 32, 32) | 9248 | conv2d[0][0] |
| max_pooling2d (MaxPooling2D) | (None, 16, 16, 32) | 0 | conv2d_1[0][0] |
| conv2d_2 (Conv2D) | (None, 16, 16, 32) | 128 | rescaling[0][0] |
| add (Add) | (None, 16, 16, 32) | 0 | max_pooling2d[0][0] conv2d_2[0][0] |
| conv2d_3 (Conv2D) | (None, 16, 16, 64) | 18496 | add[0][0] |
| conv2d_4 (Conv2D) | (None, 16, 16, 64) | 36928 | conv2d_3[0][0] |
| max_pooling2d_1 (MaxPooling2D) | (None, 8, 8, 64) | 0 | conv2d_4[0][0] |
| conv2d_5 (Conv2D) | (None, 8, 8, 64) | 2112 | add[0][0] |
| add_1 (Add) | (None, 8, 8, 64) | 0 | max_pooling2d_1[0][0] conv2d_5[0][0] |
| conv2d_6 (Conv2D) | (None, 8, 8, 128) | 73856 | add_1[0][0] |
| conv2d_7 (Conv2D) | (None, 8, 8, 128) | 147584 | conv2d_6[0][0] |
| conv2d_8 (Conv2D) | (None, 8, 8, 128) | 8320 | add_1[0][0] |
| add_2 (Add) | (None, 8, 8, 128) | 0 | conv2d_7[0][0] conv2d_8[0][0] |
| global_average_pooling2d (Globa | (None, 128) | 0 | add_2[0][0] |
| dense (Dense) | (None, 1) | 129 | global_average_pooling2d[0][0] |
این خلاصه مدلی است که به دست میآوریم:
==================================================================================================
Total params: 297,697
Trainable params: 297,697
Non-trainable params: 0
با اتصالات باقیمانده، میتوانید شبکههایی با عمق دلخواه بسازید، بدون اینکه نگران گرادیانهای ناپدید شونده باشید.
حالا بیایید به الگوی معماری convnet ضروری بعدی بپردازیم: نرمالسازی دستهای (batch normalization)
نرمالسازی دستهای (Batch normalization)
نرمالسازی دسته، دسته گستردهای از روشها است که به دنبال یکسانتر کردن نمونههای مختلف دیدهشده توسط یک مدل یادگیری ماشین هستند، که به مدل کمک میکند به خوبی یاد بگیرد و به دادههای جدید تعمیم یابد. رایجترین شکل نرمالسازی داده، موردی است که قبلاً چندین بار در این کتاب دیدهاید: مرکز کردن دادهها بر روی صفر با کم کردن میانگین از دادهها، و دادن انحراف معیار واحد به دادهها با تقسیم دادهها بر انحراف معیار آنها. در واقع، این کار فرض میکند که دادهها از یک توزیع نرمال (یا گوسی) پیروی میکنند و مطمئن میشود که این توزیع متمرکز و به واریانس واحد مقیاسبندی شده است:
normalized_data = (data – np.mean(data, axis=…)) / np.std(data, axis=…)
مثالهای قبلی در این کتاب، دادهها را قبل از تغذیه به مدلها نرمالسازی میکردند. اما نرمالسازی داده ممکن است پس از هر تبدیلی که توسط شبکه انجام میشود نیز مورد علاقه باشد: حتی اگر دادههای ورودی به یک شبکه Dense یا Conv2D میانگین 0 و واریانس واحد داشته باشند، هیچ دلیلی وجود ندارد که انتظار داشته باشیم از پیش، این مورد برای دادههای خروجی نیز صادق باشد. آیا نرمالسازی فعالسازیهای میانی میتواند کمک کند؟
نرمالسازی دستهای (Batch normalization) دقیقاً همین کار را انجام میدهد. این نوعی لایه است (BatchNormalization در Keras) که در سال 2015 توسط Ioffe و Szegedy معرفی شد؛2 این لایه میتواند دادهها را حتی در حالی که میانگین و واریانس در طول آموزش تغییر میکنند، به صورت تطبیقی نرمالسازی کند. در طول آموزش، از میانگین و واریانس دسته فعلی داده برای نرمالسازی نمونهها استفاده میکند، و در طول استنباط (هنگامی که یک دسته به اندازه کافی بزرگ از دادههای نماینده ممکن است در دسترس نباشد)، از میانگین متحرک نمایی میانگین و واریانس دستهای دادههای دیدهشده در طول آموزش استفاده میکند.
اگرچه مقاله اصلی بیان کرد که نرمالسازی دستهای با “کاهش تغییر کوواریانس داخلی” عمل میکند، هیچ کس واقعاً مطمئن نیست که چرا نرمالسازی دستهای کمک میکند. فرضیههای مختلفی وجود دارد، اما هیچ قطعیت (قطعیتهایی) وجود ندارد. خواهید دید که این در مورد بسیاری از چیزها در یادگیری عمیق صادق است—یادگیری عمیق یک علم دقیق نیست، بلکه مجموعهای از بهترین شیوههای مهندسی است که دائماً در حال تغییر و به صورت تجربی به دست آمدهاند و توسط روایتهای غیرقابل اعتماد به هم بافته شدهاند. گاهی اوقات احساس خواهید کرد که کتابی که در دست دارید به شما میگوید چگونه کاری را انجام دهید اما به طور کاملاً رضایتبخشی نمیگوید چرا کار میکند: این به این دلیل است که ما “چگونه” را میدانیم اما “چرا” را نمیدانیم. هرگاه یک توضیح قابل اعتماد در دسترس باشد، حتماً آن را ذکر میکنم. نرمالسازی دستهای از آن موارد نیست.
در عمل، به نظر میرسد اثر اصلی نرمالسازی دستهای این است که به انتشار گرادیان کمک میکند—بسیار شبیه به اتصالات باقیمانده—و بنابراین امکان ایجاد شبکههای عمیقتر را فراهم میکند. برخی شبکههای بسیار عمیق تنها در صورتی میتوانند آموزش ببینند که شامل چندین لایه BatchNormalization باشند. برای مثال، نرمالسازی دستهای به طور آزادانه در بسیاری از معماریهای پیشرفته convnet که همراه با Keras ارائه میشوند، مانند ResNet50، EfficientNet و Xception، استفاده میشود.
لایه BatchNormalization را میتوان پس از هر لایه — Dense، Conv2D و غیره — استفاده کرد:
x = …
x = layers.Conv2D(32, 3, use_bias=False)(x)
x = layers.BatchNormalization()(x)
از آنجا که خروجی لایه Conv2D نرمالسازی میشود، لایه نیازی به بردار بایاس خود ندارد.
نکته: هر دو لایه Dense و Conv2D شامل یک بردار بایاس هستند، یک متغیر یادگرفته شده که هدف آن تبدیل لایه از صرفاً خطی به آفین (affine) است. برای مثال، Conv2D به طور شماتیک y=conv(x,kernel)+bias را برمیگرداند، و Dense نیز y=dot(x,kernel)+bias را. از آنجایی که مرحله نرمالسازی مراقب مرکز کردن خروجی لایه بر روی صفر خواهد بود، بردار بایاس دیگر هنگام استفاده از BatchNormalization مورد نیاز نیست، و لایه را میتوان بدون آن از طریق گزینه use_bias=False ایجاد کرد. این باعث میشود لایه کمی سبکتر باشد.
مهم اینکه، من عموماً توصیه میکنم فعالسازی لایه قبلی را بعد از لایه نرمالسازی دسته قرار دهید (اگرچه این هنوز موضوع بحث است). بنابراین به جای انجام آنچه در قطعه کد 9.4 نشان داده شده است، کاری را انجام میدهید که در قطعه کد 9.5 نشان داده شده است.
قطعه کد 9.4: نحوه نادرست استفاده از نرمالسازی دسته.
x = layers.Conv2D(32, 3, activation=”relu”)(x)
x = layers.BatchNormalization()(x)
قطعه کد 9.5: نحوه استفاده از نرمالسازی دسته: فعالسازی در انتها قرار میگیرد.
x = layers.Conv2D(32, 3, use_bias=False)(x)
به عدم وجود فعالسازی در اینجا توجه کنید.
x = layers.BatchNormalization()(x)
x = layers.Activation(“relu”)(x)
فعالسازی را پس از لایه BatchNormalization قرار میدهیم.
دلیل شهودی این رویکرد این است که نرمالسازی دسته ورودیهای شما را بر روی صفر متمرکز میکند، در حالی که فعالسازی relu شما از صفر به عنوان یک نقطه محوری برای حفظ یا حذف کانالهای فعال شده استفاده میکند: انجام نرمالسازی قبل از فعالسازی، استفاده از relu را به حداکثر میرساند. با این حال، این ترتیب بهترین عمل لزوماً حیاتی نیست، بنابراین اگر ابتدا کانولوشن، سپس فعالسازی، و سپس نرمالسازی دسته را انجام دهید، مدل شما همچنان آموزش خواهد دید و لزوماً نتایج بدتری نخواهید دید.
در مورد نرمالسازی دسته و تنظیم دقیق
نرمالسازی دسته دارای ویژگیهای خاص بسیاری است. یکی از اصلیترین آنها به تنظیم دقیق (fine-tuning) مربوط میشود: هنگام تنظیم دقیق مدلی که شامل لایههای BatchNormalization است، توصیه میکنم این لایهها را یخزده (frozen) نگه دارید (ویژگی trainable آنها را بر روی False تنظیم کنید).
در غیر این صورت، آنها به بهروزرسانی میانگین و واریانس داخلی خود ادامه خواهند داد، که میتواند با بهروزرسانیهای بسیار کوچک اعمال شده بر روی لایههای Conv2D اطراف تداخل ایجاد کند.
حالا بیایید به آخرین الگوی معماری در مجموعه ما نگاهی بیندازیم: کانولوشنهای قابل تفکیک عمقی (depthwise separable convolutions).
کانولوشنهای قابل تفکیک(جدا شدنی) عمقی
چه میشد اگر به شما میگفتم لایهای وجود دارد که میتوانید آن را به عنوان جایگزینی مستقیم برای Conv2D استفاده کنید که مدل شما را کوچکتر (پارامترهای وزن قابل آموزش کمتر) و سبکتر (عملیات ممیز شناور کمتر) میکند و باعث میشود چند درصد بهتر عمل کند؟ این دقیقاً همان کاری است که لایه کانولوشن قابل تفکیک عمقی (SeparableConv2D در Keras) انجام میدهد. این لایه یک کانولوشن فضایی را به طور مستقل بر روی هر کانال ورودی خود انجام میدهد، قبل از ترکیب کانالهای خروجی از طریق یک کانولوشن نقطهای (کانولوشن 1 × 1)، همانطور که در شکل 9.10 نشان داده شده است.
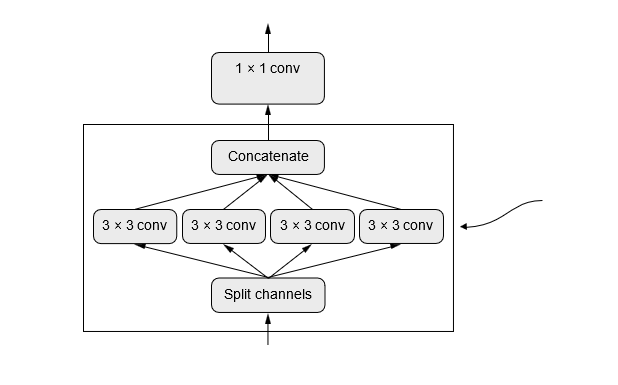
کانولوشن عمقی: کانولوشنهای فضایی مستقل به ازای هر کانال.
شکل 9.10: کانولوشن قابل تفکیک عمقی: یک کانولوشن عمقی و سپس یک کانولوشن نقطهای.
این معادل تفکیک یادگیری ویژگیهای فضایی و یادگیری ویژگیهای کانالمحور است. به همان شیوه که کانولوشن بر این فرض تکیه دارد که الگوهای موجود در تصاویر به مکانهای خاصی گره خورده نیستند، کانولوشن قابل تفکیک عمقی بر این فرض تکیه دارد که مکانهای فضایی در فعالسازیهای میانی به شدت همبسته هستند، اما کانالهای مختلف به شدت مستقل هستند. از آنجایی که این فرض به طور کلی برای بازنماییهای تصویری که توسط شبکههای عصبی عمیق یاد گرفته میشوند، صحیح است، به عنوان یک دانش قبلی مفید عمل میکند که به مدل کمک میکند تا از دادههای آموزشی خود به طور کارآمدتری استفاده کند. مدلی با دانش قبلی قویتر در مورد ساختار اطلاعاتی که باید پردازش کند، مدل بهتری است—به شرطی که دانش قبلی دقیق باشد.
کانولوشن قابل تفکیک عمقی به طور قابل توجهی پارامترهای کمتری نیاز دارد و محاسبات کمتری را در مقایسه با کانولوشن معمولی شامل میشود، در حالی که قدرت بازنمایی قابل مقایسهای دارد. این منجر به مدلهای کوچکتر میشود که سریعتر همگرا میشوند و کمتر مستعد بیشبرازش هستند. این مزایا به ویژه هنگامی که مدلهای کوچک را از ابتدا با دادههای محدود آموزش میدهید، مهم میشوند.
در مورد مدلهای در مقیاس بزرگتر، کانولوشنهای قابل تفکیک عمقی اساس معماری Xception هستند، یک convnet با عملکرد بالا که با Keras بستهبندی شده است. میتوانید در مورد مبانی نظری کانولوشنهای قابل تفکیک عمقی و Xception در مقاله “Xception: Deep Learning with Depthwise Separable Convolutions”3 بیشتر بخوانید.
همتکاملی سختافزار، نرمافزار و الگوریتمها
یک عملیات کانولوشن معمولی را با یک پنجره 3 × 3، 64 کانال ورودی و 64 کانال خروجی در نظر بگیرید. این عملیات از 3×3×64×64=36,864پارامتر قابل آموزش استفاده میکند، و هنگامی که آن را بر روی یک تصویر اعمال میکنید، تعدادی عملیات ممیز شناور(floating-point operations)را اجرا میکند که متناسب با این تعداد پارامتر است. در همین حال، یک کانولوشن قابل تفکیک عمقی معادل را در نظر بگیرید: این فقط شامل 3×3×64+64×64=4,672 پارامتر قابل آموزش و به تناسب عملیات ممیز شناور کمتری است. این بهبود کارایی تنها با افزایش تعداد فیلترها یا اندازه پنجرههای کانولوشن بیشتر میشود.
در نتیجه، انتظار دارید که کانولوشنهای قابل تفکیک عمقی به طرز چشمگیری سریعتر باشند، درست است؟ صبر کنید. این موضوع درست بود اگر شما پیادهسازیهای ساده CUDA یا C از این الگوریتمها را مینوشتید—در واقع، هنگامی که بر روی CPU اجرا میشود، یک افزایش سرعت معنیدار مشاهده میکنید، جایی که پیادهسازی زیربنایی C موازیسازی شده است. اما در عمل، شما احتمالاً از GPU استفاده میکنید، و آنچه بر روی آن اجرا میکنید بسیار دور از یک پیادهسازی “ساده” CUDA است: این یک کرنل cuDNN است، قطعه کدی که به طور فوقالعادهای بهینه شده است، تا هر دستورالعمل ماشینی. قطعاً منطقی است که تلاش زیادی برای بهینهسازی این کد صرف شود، زیرا کانولوشنهای cuDNN بر روی سختافزار NVIDIA هر روز مسئول بسیاری از اگزافلاپس (exaFLOPS) محاسبات هستند. اما یک عارضه جانبی این میکرو-بهینهسازی افراطی این است که رویکردهای جایگزین شانس کمی برای رقابت در عملکرد دارند—حتی رویکردهایی که مزایای ذاتی قابل توجهی دارند، مانند کانولوشنهای قابل تفکیک عمقی. با وجود درخواستهای مکرر از NVIDIA، کانولوشنهای قابل تفکیک عمقی تقریباً از همان سطح بهینهسازی نرمافزاری و سختافزاری کانولوشنهای معمولی بهرهمند نشدهاند، و در نتیجه حتی با وجود اینکه به صورت درجه دوم از پارامترها و عملیات ممیز شناور کمتری استفاده میکنند، تنها به همان سرعت کانولوشنهای معمولی باقی ماندهاند. با این حال، توجه داشته باشید که استفاده از کانولوشنهای قابل تفکیک عمقی همچنان یک ایده خوب است حتی اگر منجر به افزایش سرعت نشود: تعداد پارامتر کمتر آنها به این معنی است که خطر بیشبرازش کمتر است، و فرض آنها مبنی بر اینکه کانالها باید غیرمرتبط باشند، منجر به همگرایی سریعتر مدل و بازنماییهای قویتر میشود.
آنچه در این مورد یک ناراحتی جزئی است، میتواند در موقعیتهای دیگر به یک دیوار غیرقابل عبور تبدیل شود: زیرا کل اکوسیستم سختافزاری و نرمافزاری یادگیری عمیق برای مجموعه بسیار خاصی از الگوریتمها (به ویژه، convnetهای آموزشدیده از طریق پسانتشار) میکرو-بهینه شده است، انحراف از مسیر شناخته شده هزینه بسیار بالایی دارد. اگر بخواهید با الگوریتمهای جایگزین، مانند بهینهسازی بدون گرادیان یا شبکههای عصبی اسپایکینگ، آزمایش کنید، اولین پیادهسازیهای موازی C++ یا CUDA که به ذهنتان میرسد، چندین مرتبه کندتر از یک convnet قدیمی خوب خواهند بود، مهم نیست که ایدههای شما چقدر هوشمندانه و کارآمد باشند. متقاعد کردن سایر محققان برای پذیرش روش شما دشوار خواهد بود، حتی اگر به سادگی بهتر باشد.
میتوان گفت که یادگیری عمیق مدرن محصول یک فرآیند همتکاملی بین سختافزار، نرمافزار و الگوریتمها است: در دسترس بودن GPUهای NVIDIA و CUDA منجر به موفقیت اولیه convnetهای آموزشدیده با پسانتشار شد، که NVIDIA را به بهینهسازی سختافزار و نرمافزار خود برای این الگوریتمها سوق داد، که به نوبه خود منجر به تحکیم جامعه تحقیقاتی پشت این روشها شد. در این مرحله، یافتن مسیری متفاوت نیازمند یک مهندسی مجدد چند ساله از کل اکوسیستم خواهد بود.
ترکیب همه چیز: یک مدل کوچک شبیه Xception
به عنوان یادآوری، در اینجا اصول معماری convnet که تا کنون آموختهاید آمده است:
- مدل شما باید در بلوکهای لایهای تکراری سازماندهی شود، که معمولاً از چندین لایه کانولوشن و یک لایه Max Pooling تشکیل شدهاند.
- تعداد فیلترها در لایههای شما باید با کاهش اندازه نقشههای ویژگی فضایی افزایش یابد.
- عمیق و باریک بهتر از پهن و کمعمق است.
- معرفی اتصالات باقیمانده در اطراف بلوکهای لایه به شما در آموزش شبکههای عمیقتر کمک میکند.
- میتواند مفید باشد که لایههای نرمالسازی دسته را بعد از لایههای کانولوشن خود اضافه کنید.
- میتواند مفید باشد که لایههای Conv2D را با لایههای SeparableConv2D جایگزین کنید، که از نظر پارامتر کارآمدتر هستند.
بیایید این ایدهها را در یک مدل واحد گرد هم آوریم. معماری آن شبیه نسخه کوچکتری از Xception خواهد بود، و ما آن را برای وظیفه سگها در برابر گربهها از فصل گذشته اعمال خواهیم کرد. برای بارگذاری داده و آموزش مدل، به سادگی از تنظیماتی که در بخش 8.2.5 استفاده کردیم، استفاده مجدد خواهیم کرد، اما تعریف مدل را با convnet زیر جایگزین خواهیم کرد:
inputs = keras.Input(shape=(180, 180, 3))
x = data_augmentation(inputs)
ما از همان پیکربندی افزایش داده قبلی استفاده میکنیم.
x = layers.Rescaling(1./255)(x)
فراموش نکنید: مقیاسبندی ورودی!
x = layers.Conv2D(filters=32, kernel_size=5, use_bias=False)(x)
توجه داشته باشید که فرض زیربنایی کانولوشن قابل تفکیک، “کانالهای ویژگی عمدتاً مستقل هستند”، برای تصاویر RGB صادق نیست! کانالهای رنگ قرمز، سبز و آبی در تصاویر طبیعی در واقع به شدت همبسته هستند. به همین دلیل، اولین لایه در مدل ما یک لایه Conv2D معمولی است. پس از آن شروع به استفاده از SeparableConv2D خواهیم کرد.
for size in [32, 64, 128, 256, 512]:
ما مجموعهای از بلوکهای کانولوشنی با عمق ویژگی فزاینده را اعمال میکنیم. هر بلوک شامل دو لایه کانولوشن قابل تفکیک عمقی نرمالسازیشده دستهای و یک لایه max pooling است، با یک اتصال باقیمانده در اطراف کل بلوک
residual = x
x = layers.BatchNormalization()(x)
x = layers.Activation(“relu”)(x)
x = layers.SeparableConv2D(size, 3, padding=”same”, use_bias=False)(x)
x = layers.BatchNormalization()(x)
x = layers.Activation(“relu”)(x)
x = layers.SeparableConv2D(size, 3, padding=”same”, use_bias=False)(x)
x = layers.MaxPooling2D(3, strides=2, padding=”same”)(x)
residual = layers.Conv2D(
size, 1, strides=2, padding=”same”, use_bias=False)(residual)
x = layers.add([x, residual])
x = layers.GlobalAveragePooling2D()(x)
در مدل اصلی، ما از یک لایه Flatten قبل از لایه Dense استفاده میکردیم. در اینجا، از یک لایه GlobalAveragePooling2D استفاده میکنیم.
x = layers.Dropout(0.5)(x)
مانند مدل اصلی، ما یک لایه دراپاوت برای نظمدهی اضافه میکنیم.
outputs = layers.Dense(1, activation=”sigmoid”)(x)
model = keras.Model(inputs=inputs, outputs=outputs)
این convnet دارای 721,857 پارامتر قابل آموزش است که کمی کمتر از 991,041 پارامتر قابل آموزش مدل اصلی است، اما همچنان در همان محدوده قرار دارد. شکل 9.11 منحنیهای آموزش و اعتبارسنجی آن را نشان میدهد.
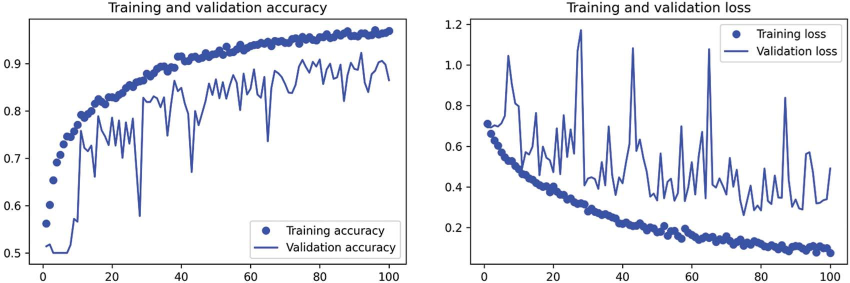
شکل 9.11: معیارهای آموزش و اعتبارسنجی با معماری شبیه Xception.
خواهید دید که مدل جدید ما به دقت آزمایشی 90.8% دست مییابد، در مقایسه با 83.5% برای مدل ساده در فصل گذشته. همانطور که میبینید، پیروی از بهترین شیوههای معماری، تأثیر فوری و قابل توجهی بر عملکرد مدل دارد!
در این مرحله، اگر میخواهید عملکرد را بیشتر بهبود بخشید، باید شروع به تنظیم سیستماتیک هایپرپارامترهای معماری خود کنید—موضوعی که در فصل 13 به تفصیل به آن خواهیم پرداخت. ما در اینجا این مرحله را طی نکردهایم، بنابراین پیکربندی مدل قبلی صرفاً بر اساس بهترین شیوههایی است که بحث کردیم، به علاوه، در مورد سنجش اندازه مدل، مقدار کمی شهود.
توجه داشته باشید که این بهترین شیوههای معماری به طور کلی برای بینایی کامپیوتر مرتبط هستند، نه فقط طبقهبندی تصویر. برای مثال، Xception به عنوان پایه کانولوشنی استاندارد در DeepLabV3، یک راهحل محبوب و پیشرفته تقسیمبندی تصویر، استفاده میشود.
این به پایان معرفی ما به بهترین شیوههای معماری ضروری convnet میرسد. با در دست داشتن این اصول، قادر خواهید بود مدلهای با عملکرد بالاتر را در طیف وسیعی از وظایف بینایی کامپیوتر توسعه دهید. اکنون شما در مسیر تبدیل شدن به یک متخصص ماهر بینایی کامپیوتر هستید. برای عمیقتر کردن تخصص خود، یک موضوع مهم نهایی وجود دارد که باید پوشش دهیم: تفسیر اینکه چگونه یک مدل به پیشبینیهای خود میرسد.
تفسیر آنچه convnetها(شبکه های کانولوشنال ) یاد میگیرند
یک مشکل اساسی در ساخت یک برنامه بینایی کامپیوتر، مشکل قابلیت تفسیر است: چرا طبقهبند شما فکر کرد که یک تصویر خاص حاوی یک یخچال است، در حالی که شما فقط یک کامیون میبینید؟ این به ویژه برای موارد استفادهای که یادگیری عمیق برای تکمیل تخصص انسانی استفاده میشود، مانند موارد استفاده در تصویربرداری پزشکی، مرتبط است. این فصل را با آشنا کردن شما با طیف وسیعی از تکنیکهای مختلف برای بصریسازی آنچه convnetها یاد میگیرند و درک تصمیماتی که میگیرند، به پایان خواهیم رساند.
اغلب گفته میشود که مدلهای یادگیری عمیق “جعبه سیاه” هستند: آنها بازنماییهایی را یاد میگیرند که استخراج و ارائه آنها به شکل قابل درک برای انسان دشوار است. اگرچه این تا حدی برای انواع خاصی از مدلهای یادگیری عمیق صادق است، اما قطعاً برای convnetها صادق نیست. بازنماییهای یادگرفته شده توسط convnetها بسیار مستعد بصریسازی هستند، عمدتاً به این دلیل که آنها بازنماییهای مفاهیم بصری هستند. از سال 2013، طیف گستردهای از تکنیکها برای بصریسازی و تفسیر این بازنماییها توسعه یافته است. ما همه آنها را بررسی نخواهیم کرد، اما سه مورد از قابل دسترسترین و مفیدترین آنها را پوشش خواهیم داد:
- بصریسازی خروجیهای میانی convnet (فعالسازیهای میانی) — برای درک چگونگی تبدیل ورودی توسط لایههای متوالی convnet، و برای به دست آوردن ایده اولیهای از معنای فیلترهای convnet منفرد مفید است.
- بصریسازی فیلترهای convnet — برای درک دقیق اینکه هر فیلتر در یک convnet نسبت به چه الگوی بصری یا مفهومی حساس است، مفید است.
- بصریسازی نقشههای حرارتی فعالسازی کلاس در یک تصویر — برای درک اینکه کدام بخشهای یک تصویر به عنوان متعلق به یک کلاس معین شناسایی شدهاند، و بنابراین به شما امکان میدهد اشیاء را در تصاویر مکانیابی کنید، مفید است.
برای روش اول — بصریسازی فعالسازی — از convnet کوچکی که در بخش 8.2 از ابتدا برای مشکل طبقهبندی سگها در برابر گربهها آموزش دادیم، استفاده خواهیم کرد. برای دو روش بعدی، از یک مدل Xception از پیش آموزشدیده استفاده خواهیم کرد.
بصریسازی(تجسم سازی) فعالسازیهای میانی
بصریسازی فعالسازیهای میانی شامل نمایش مقادیر بازگردانده شده توسط لایههای مختلف کانولوشن و پولینگ در یک مدل، با توجه به یک ورودی خاص (خروجی یک لایه اغلب فعالسازی نامیده میشود، خروجی تابع فعالسازی) است. این دیدگاهی را در مورد نحوه تجزیه یک ورودی به فیلترهای مختلف یادگرفته شده توسط شبکه فراهم میکند. ما میخواهیم نقشههای ویژگی را با سه بعد: عرض، ارتفاع و عمق (کانالها) بصریسازی کنیم. هر کانال ویژگیهای نسبتاً مستقلی را کدگذاری میکند، بنابراین روش صحیح برای بصریسازی این نقشههای ویژگی، رسم مستقل محتویات هر کانال به عنوان یک تصویر 2 بعدی است. بیایید با بارگذاری مدلی که در بخش 8.2 ذخیره کردید، شروع کنیم:
>>> from tensorflow import keras
>>> model = keras.models.load_model(
“convnet_from_scratch_with_augmentation.keras”)
>>> model.summary()
Model: “model_1”
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 180, 180, 0
_________________________________________________________________
sequential (Sequential) (None, 180, 180, 3) 0
_________________________________________________________________
rescaling_1 (Rescaling) (None, 180, 180, 3) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 178, 178, 32) 896
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 89, 89, 32) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 87, 87, 64) 18496
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 43, 43, 64) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 41, 41, 128) 73856
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 20, 20, 128) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 18, 18, 256) 295168
_________________________________________________________________
max_pooling2d_7 (MaxPooling2 (None, 9, 9, 256) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 7, 7, 256) 590080
_________________________________________________________________
flatten_1 (Flatten) (None, 12544) 0
_________________________________________________________________
dropout (Dropout) (None, 12544) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 12545
=================================================================
Total params: 991,041
Trainable params: 991,041
Non-trainable params: 0
در مرحله بعد، یک تصویر ورودی — عکسی از یک گربه، که بخشی از تصاویر آموزشی شبکه نبوده است — را به دست خواهیم آورد.
قطعه کد 9.6: پیشپردازش یک تصویر واحد.
from tensorflow import keras
import numpy as np
img_path = keras.utils.get_file(
fname=”cat.jpg”,
origin=”https://img-datasets.s3.amazonaws.com/cat.jpg”)
یک تصویر آزمایشی را دانلود کنید.
def get_img_array(img_path, target_size):
img = keras.utils.load_img(
img_path, target_size=target_size)
فایل تصویر را باز کنید و اندازه آن را تغییر دهید.
array = keras.utils.img_to_array(img)
تصویر را به یک آرایه NumPy از نوع float32 با شکل (3, 180, 180) تبدیل کنید.
array = np.expand_dims(array, axis=0)
یک بعد اضافه کنید تا آرایه به یک “دسته” از یک نمونه تبدیل شود. شکل آن اکنون (3, 180, 180, 1) است.
return array
img_tensor = get_img_array(img_path, target_size=(180, 180))
بیایید تصویر را نمایش دهیم (به شکل 9.12 مراجعه کنید).
قطعه کد 9.7: نمایش تصویر آزمایش.
import matplotlib.pyplot as plt
plt.axis(“off”)
plt.imshow(img_tensor[0].astype(“uint8”))
plt.show()
برای استخراج نقشههای ویژگی که میخواهیم بررسی کنیم، یک مدل Keras ایجاد خواهیم کرد که دستههایی از تصاویر را به عنوان ورودی میگیرد و فعالسازیهای تمام لایههای کانولوشن و پولینگ را خروجی میدهد.

شکل 9.12: تصویر گربه آزمایش.
قطعه کد 9.8: نمونهسازی مدلی که فعالسازیهای لایه را برمیگرداند.
from tensorflow.keras import layers
layer_outputs = []
layer_names = []
for layer in model.layers:
if isinstance(layer, (layers.Conv2D, layers.MaxPooling2D)):
خروجیهای تمام لایههای Conv2D و MaxPooling2D را استخراج کرده و آنها را در یک لیست قرار دهید.
layer_outputs.append(layer.output)
layer_names.append(layer.name)
نام لایهها را برای بعداً ذخیره کنید.
activation_model = keras.Model(inputs=model.input, outputs=layer_outputs)
مدلی ایجاد کنید که با توجه به ورودی مدل، این خروجیها را برگرداند.
هنگامی که یک تصویر به عنوان ورودی به این مدل داده میشود، مقادیر فعالسازی لایه را در مدل اصلی، به صورت یک لیست برمیگرداند. این اولین باری است که شما در عمل با یک مدل چند-خروجی در این کتاب برخورد میکنید، از زمانی که در فصل 7 در مورد آنها آموختید؛ تا کنون، مدلهایی که دیدهاید دقیقاً یک ورودی و یک خروجی داشتهاند. این مدل یک ورودی و نه خروجی دارد: یک خروجی به ازای هر فعالسازی لایه.
قطعه کد 9.9: استفاده از مدل برای محاسبه فعالسازی لایه.
activations = activation_model.predict(img_tensor)
لیستی از نه آرایه NumPy را برگردانید: یک آرایه به ازای هر فعالسازی لایه.
برای مثال، این فعالسازی اولین لایه کانولوشن برای ورودی تصویر گربه است:
>>> first_layer_activation = activations[0]
>>> print(first_layer_activation.shape) (1, 178, 178, 32)
این یک نقشه ویژگی 178 × 178 با 32 کانال است. بیایید سعی کنیم کانال پنجم فعالسازی لایه اول مدل اصلی را رسم کنیم (به شکل 9.13 مراجعه کنید)
قطعه کد 9.10: بصریسازی کانال پنجم.
import matplotlib.pyplot as plt
plt.matshow(first_layer_activation[0, :, :, 5], cmap=”viridis”)

شکل 9.13: کانال پنجم فعالسازی لایه اول بر روی تصویر آزمایش گربه.
به نظر میرسد این کانال یک آشکارساز لبه مورب را کدگذاری میکند—اما توجه داشته باشید که کانالهای شما ممکن است متفاوت باشند، زیرا فیلترهای خاصی که توسط لایههای کانولوشن یاد گرفته میشوند، قطعی نیستند.
اکنون، بیایید یک بصریسازی کامل از تمام فعالسازیها در شبکه را رسم کنیم (به شکل 9.14 مراجعه کنید). ما هر کانال را در هر یک از فعالسازیهای لایه استخراج و رسم خواهیم کرد، و نتایج را در یک شبکه بزرگ، با کانالهای کنار هم قرار داده شده، روی هم انباشته خواهیم کرد.
قطعه کد 9.11: بصریسازی هر کانال در هر فعالسازی میانی.
images_per_row = 16
for layer_name, layer_activation in zip(layer_names, activations):
روی فعالسازیها (و نام لایههای مربوطه) تکرار کنید.
n_features = layer_activation.shape[-1]
size = layer_activation.shape[1]
فعالسازی لایه دارای شکل (1, اندازه, اندازه, n_features) است.
n_cols = n_features // images_per_row
display_grid = np.zeros(((size + 1) * n_cols – 1,
images_per_row * (size + 1) – 1))
for col in range(n_cols):
for row in range(images_per_row):
channel_index = col * images_per_row + row
channel_image = layer_activation[0, :, :, channel_index].copy()
این یک کانال (یا ویژگی) منفرد است.
if channel_image.sum() != 0:
مقادیر کانال را در محدوده [0, 255] نرمالسازی کنید. تمام کانالهای صفر، صفر میمانند
channel_image -= channel_image.mean()
channel_image /= channel_image.std()
channel_image *= 64
channel_image += 128
channel_image = np.clip(channel_image, 0, 255).astype(“uint8”)
display_grid[
ماتریس کانال را در شبکه خالی که آماده کردهایم، قرار دهید.
col * (size + 1): (col + 1) * size + col,
row * (size + 1) : (row + 1) * size + row] = channel_image
scale = 1. / size
plt.figure(figsize=(scale * display_grid.shape[1],
scale * display_grid.shape[0]))
plt.title(layer_name)
plt.grid(False)
plt.axis(“off”)
plt.imshow(display_grid, aspect=”auto”, cmap=”viridis”)
شبکه (grid) را برای لایه نمایش دهید.
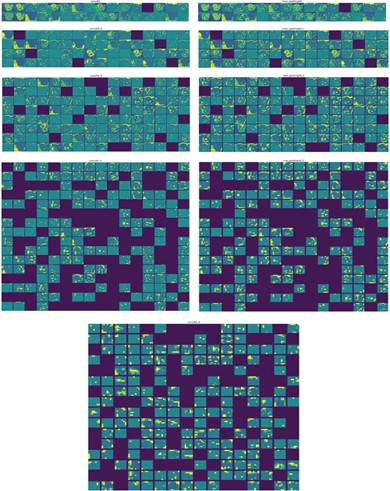
شکل 9.14: هر کانال از هر فعالسازی لایه بر روی تصویر گربه آزمایش.
چند نکته در اینجا وجود دارد:
- لایه اول به عنوان مجموعهای از آشکارسازهای لبههای مختلف عمل میکند. در آن مرحله، فعالسازیها تقریباً تمام اطلاعات موجود در تصویر اولیه را حفظ میکنند.
- همانطور که عمیقتر میشوید، فعالسازیها به طور فزایندهای انتزاعیتر و کمتر قابل تفسیر بصری میشوند. آنها شروع به کدگذاری مفاهیم سطح بالاتر مانند “گوش گربه” و “چشم گربه” میکنند. نمایشهای عمیقتر به طور فزایندهای اطلاعات کمتری در مورد محتوای بصری تصویر، و اطلاعات بیشتری در رابطه با کلاس تصویر حمل میکنند.
- پراکندگی فعالسازیها با عمق لایه افزایش مییابد: در لایه اول، تقریباً تمام فیلترها توسط تصویر ورودی فعال میشوند، اما در لایههای بعدی، فیلترهای بیشتری خالی میمانند. این بدان معنی است که الگوی کدگذاری شده توسط فیلتر در تصویر ورودی یافت نمیشود.
ما به تازگی یک ویژگی جهانی مهم از بازنماییهای یادگرفته شده توسط شبکههای عصبی عمیق را به اثبات رساندیم: ویژگیهای استخراج شده توسط یک لایه با عمق لایه به طور فزایندهای انتزاعیتر میشوند. فعالسازیهای لایههای بالاتر اطلاعات کمتری در مورد ورودی خاص مشاهده شده، و اطلاعات بیشتری در مورد هدف (در این مورد، کلاس تصویر: گربه یا سگ) حمل میکنند. یک شبکه عصبی عمیق به طور مؤثری به عنوان یک خط لوله تقطیر اطلاعات عمل میکند، که در آن دادههای خام وارد میشوند (در این مورد، تصاویر RGB) و به طور مکرر تبدیل میشوند تا اطلاعات نامربوط فیلتر شوند (برای مثال، ظاهر بصری خاص تصویر)، و اطلاعات مفید بزرگنمایی و پالایش شوند (برای مثال، کلاس تصویر). این شبیه به نحوه درک انسان و حیوانات از جهان است: پس از مشاهده یک صحنه برای چند ثانیه، یک انسان میتواند به خاطر بیاورد که چه اشیاء انتزاعی در آن وجود داشته است (دوچرخه، درخت) اما نمیتواند ظاهر خاص این اشیاء را به خاطر بیاورد. در واقع، اگر سعی کنید یک دوچرخه عمومی را از حافظه خود ترسیم کنید، احتمالاً حتی به طور تقریبی نیز نمیتوانید آن را به درستی ترسیم کنید، حتی با وجود اینکه هزاران دوچرخه را در طول زندگی خود دیدهاید (برای مثال، به شکل 9.15 مراجعه کنید). همین الان امتحان کنید: این اثر کاملاً واقعی است. مغز شما یاد گرفته است که ورودی بصری خود را به طور کامل انتزاع کند—آن را به مفاهیم بصری سطح بالا تبدیل کند در حالی که جزئیات بصری نامربوط را فیلتر میکند—که به خاطر سپردن ظاهر اشیاء اطراف شما را به شدت دشوار میسازد.
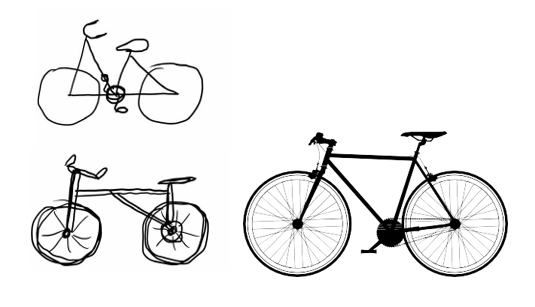
شکل 9.15: چپ: تلاش برای ترسیم دوچرخه از حافظه. راست: دوچرخه شماتیک چگونه باید به نظر برسد.
بصریسازی فیلترهای convnet(شبکه کانولوشنال)
راه آسان دیگر برای بازرسی فیلترهای یادگرفته شده توسط convnetها، نمایش الگوی بصری است که هر فیلتر برای پاسخ به آن طراحی شده است. این کار را میتوان با صعود گرادیان (gradient ascent) در فضای ورودی انجام داد: اعمال گرادیان کاهشی بر روی مقدار تصویر ورودی یک convnet به منظور حداکثر کردن پاسخ یک فیلتر خاص، با شروع از یک تصویر ورودی خالی. تصویر ورودی حاصل، تصویری خواهد بود که فیلتر انتخابی به آن حداکثر پاسخگو است.
بیایید این را با فیلترهای مدل Xception، که از پیش بر روی ImageNet آموزش دیده است، امتحان کنیم. این فرآیند ساده است: ما یک تابع زیان خواهیم ساخت که مقدار یک فیلتر مشخص را در یک لایه کانولوشن مشخص حداکثر میکند، و سپس از گرادیان کاهشی تصادفی برای تنظیم مقادیر تصویر ورودی استفاده خواهیم کرد تا این مقدار فعالسازی را حداکثر کنیم. این دومین مثال ما از یک حلقه گرادیان کاهشی سطح پایین خواهد بود که از شیء GradientTape استفاده میکند (اولین مورد در فصل 2 بود).
ابتدا، بیایید مدل Xception را، که با وزنهای از پیش آموزشدیده بر روی مجموعه داده ImageNet بارگذاری شده است، نمونهسازی کنیم.
قطعه کد 9.12: نمونهسازی پایه کانولوشنی Xception.
model = keras.applications.xception.Xception(
weights=”imagenet”,
include_top=False)
ایههای طبقهبندی برای این مورد استفاده بیربط هستند، بنابراین ما مرحله بالایی مدل را شامل نمیشویم.
ما به لایههای کانولوشنی مدل — لایههای Conv2D و SeparableConv2D — علاقهمندیم. برای بازیابی خروجیهای آنها باید نامهایشان را بدانیم. بیایید نامهای آنها را به ترتیب عمق چاپ کنیم.
قطعه کد 9.13: چاپ نام تمام لایههای کانولوشنی در Xception.
for layer in model.layers:
if isinstance(layer, (keras.layers.Conv2D, keras.layers.SeparableConv2D)):
print(layer.name)
متوجه خواهید شد که لایههای SeparableConv2D در اینجا همگی نامهایی شبیه block6_sepconv1، block7_sepconv2 و غیره دارند. Xception به بلوکهایی ساختار یافته است که هر یک شامل چندین لایه کانولوشنی هستند.
حالا، بیایید یک مدل دوم ایجاد کنیم که خروجی یک لایه خاص را برمیگرداند — یک مدل استخراجکننده ویژگی. از آنجایی که مدل ما یک مدل Functional API است، قابل بازرسی است: میتوانیم خروجی یکی از لایههای آن را پرسوجو کرده و در یک مدل جدید دوباره استفاده کنیم. نیازی به کپی کردن کل کد Xception نیست.
قطعه کد 9.14: ایجاد یک مدل استخراجکننده ویژگی.
layer_name = “block3_sepconv1”
شما میتوانید این را با نام هر لایه در پایه کانولوشنی Xception جایگزین کنید.
layer = model.get_layer(name=layer_name)
این همان شیء لایه است که ما به آن علاقهمندیم.
feature_extractor = keras.Model(inputs=model.input, outputs=layer.output)
ما از model.input و layer.output برای ایجاد مدلی استفاده میکنیم که، با دریافت یک تصویر ورودی، خروجی لایه هدف ما را برمیگرداند.
برای استفاده از این مدل، کافی است آن را روی دادههای ورودی فراخوانی کنید (توجه داشته باشید که Xception نیاز دارد ورودیها از طریق تابع keras.applications.xception.preprocess_input پیشپردازش شوند).
قطعه کد 9.15: استفاده از استخراجکننده ویژگی.
activation = feature_extractor(
keras.applications.xception.preprocess_input(img_tensor)
)
بیایید از مدل استخراجکننده ویژگی خود برای تعریف تابعی استفاده کنیم که یک مقدار اسکالر را برمیگرداند و میزان “فعالسازی” یک فیلتر مشخص در لایه را توسط یک تصویر ورودی مشخص، کمیسازی میکند. این “تابع زیان”ی است که ما در طول فرآیند صعود گرادیان آن را حداکثر خواهیم کرد:
import tensorflow as tf
def compute_loss(image, filter_index):
تابع زیان یک تنسور تصویر و شاخص فیلتری که در حال بررسی آن هستیم (یک عدد صحیح) را میگیرد.
activation = feature_extractor(image)
filter_activation = activation[:, 2:-2, 2:-2, filter_index]
توجه داشته باشید که ما با درگیر کردن تنها پیکسلهای غیرمرزی در زیان، از مصنوعات مرزی (border artifacts) اجتناب میکنیم؛ ما دو پیکسل اول در امتداد کنارههای فعالسازی را کنار میگذاریم.
return tf.reduce_mean(filter_activation)
میانگین مقادیر فعالسازی برای فیلتر را برگردانید.
تفاوت بین model.predict(x) و model(x)
در فصل قبل، ما از predict(x) برای استخراج ویژگی استفاده کردیم. در اینجا، ما از model(x) استفاده میکنیم. چه تفاوتی وجود دارد؟
هر دو y = model.predict(x) و y = model(x) (که x یک آرایه از دادههای ورودی است) به معنای “مدل را روی x اجرا کن و خروجی y را بازیابی کن” هستند. با این حال، آنها دقیقاً یک چیز نیستند.
predict() بر روی دادهها به صورت دستهای (در واقع، میتوانید اندازه دسته را از طریق predict(x, batch_size=64) مشخص کنید) حلقه میزند، و مقدار NumPy خروجیها را استخراج میکند. این به طور شماتیک معادل این است:
def predict(x):
y_batches = []
for x_batch in get_batches(x):
y_batch = model(x).numpy()
y_batches.append(y_batch)
return np.concatenate(y_batches)
این بدان معناست که فراخوانیهای predict() میتوانند به آرایههای بسیار بزرگ مقیاسپذیری داشته باشند.
در همین حال، model(x) به صورت درون-حافظهای (in-memory) اتفاق میافتد و مقیاسپذیر نیست. از سوی دیگر، predict() قابل مشتقگیری نیست: اگر آن را در محدوده GradientTape فراخوانی کنید، نمیتوانید گرادیان آن را بازیابی کنید.
شما باید از model(x) زمانی استفاده کنید که نیاز به بازیابی گرادیانهای فراخوانی مدل دارید، و اگر فقط به مقدار خروجی نیاز دارید، باید از predict() استفاده کنید. به عبارت دیگر، همیشه از predict() استفاده کنید مگر اینکه در حال نوشتن یک حلقه گرادیان کاهشی سطح پایین باشید (همانطور که اکنون هستیم).
بیایید تابع گام صعود گرادیان را با استفاده از GradientTape تنظیم کنیم. توجه داشته باشید که برای افزایش سرعت آن، از دکوراتور tf.function@ استفاده خواهیم کرد.
یک ترفند غیربدیهی برای کمک به فرآیند گرادیان کاهشی که به آرامی پیش برود، نرمالسازی تنسور گرادیان با تقسیم آن بر نرم L2 آن (ریشه مربع میانگین مربع مقادیر در تنسور) است. این تضمین میکند که اندازه بهروزرسانیهای انجام شده بر روی تصویر ورودی همیشه در یک محدوده یکسان باشد.
قطعه کد 9.16: حداکثرسازی زیان از طریق صعود گرادیان تصادفی.
@tf.function
def gradient_ascent_step(image, filter_index, learning_rate):
with tf.GradientTape() as tape:
tape.watch(image)
تنسور تصویر را به صراحت تماشا کنید، زیرا یک متغیر TensorFlow نیست (فقط متغیرها به طور خودکار در یک نوار گرادیان تماشا میشوند).
loss = compute_loss(image, filter_index)
اسکالر زیان را محاسبه کنید، که نشان میدهد تصویر فعلی چقدر فیلتر را فعال میکند.
grads = tape.gradient(loss, image)
گرادیانهای زیان را نسبت به تصویر محاسبه کنید.
grads = tf.math.l2_normalize(grads)
ترفند “نرمالسازی گرادیان” را اعمال کنید.
image += learning_rate * grads
تصویر را کمی در جهتی حرکت دهید که فیلتر هدف ما را قویتر فعال کند.
return image
تصویر بهروزرسانی شده را برگردانید تا بتوانیم تابع گام را در یک حلقه اجرا کنیم.
حالا همه قطعات را داریم. بیایید آنها را در یک تابع پایتون کنار هم قرار دهیم که نام یک لایه و شاخص فیلتر را به عنوان ورودی میگیرد و یک تنسور را برمیگرداند که الگویی را نشان میدهد که فعالسازی فیلتر مشخص شده را حداکثر میکند.
قطعه کد 9.17: تابعی برای تولید بصریسازیهای فیلتر.
img_width = 200
img_height = 200
def generate_filter_pattern(filter_index):
iterations = 30
تعداد گامهای صعود گرادیان برای اعمال.
learning_rate = 10.
دامنه (Amplitude) یک گام واحد.
image = tf.random.uniform(
minval=0.4,
maxval=0.6,
shape=(1, img_width, img_height, 3))
یک تنسور تصویر را با مقادیر تصادفی مقداردهی اولیه کنید (مدل Xception مقادیر ورودی را در محدوده [0, 1] انتظار دارد، بنابراین در اینجا ما محدودهای را در مرکز 0.5 انتخاب میکنیم).
for i in range(iterations):
image = gradient_ascent_step(image, filter_index, learning_rate)
به طور مکرر مقادیر تنسور تصویر را بهروزرسانی کنید تا تابع زیان ما حداکثر شود.
return image[0].numpy()
تنسور تصویر حاصل یک آرایه ممیز شناور با شکل (3, 200, 200) است، با مقادیری که ممکن است اعداد صحیح در [255, 0] نباشند. از این رو، باید این تنسور را پسپردازش کنیم تا به یک تصویر قابل نمایش تبدیل شود. این کار را با تابع کاربردی ساده زیر انجام میدهیم.
قطعه کد 9.18: تابع کمکی برای تبدیل یک تنسور به یک تصویر معتبر.
def deprocess_image(image):
image -= image.mean()
image /= image.std()
image *= 64
image += 128
image = np.clip(image, 0, 255).astype(“uint8”)
image = image[25:-25, 25:-25, :]
برش مرکزی برای جلوگیری از مصنوعات مرزی.
return image
بیایید آن را امتحان کنیم (به شکل 9.16 مراجعه کنید):
>>> plt.axis(“off”)
>>> plt.imshow(deprocess_image(generate_filter_pattern(filter_index=2)))

شکل 9.16: الگویی که کانال دوم در لایه block3_sepconv1 حداکثر پاسخ را به آن میدهد
به نظر میرسد که فیلتر 0 در لایه block3_sepconv1 به الگوی خطوط افقی، تا حدودی شبیه آب یا خز، پاسخگو است.
حالا بخش سرگرمکننده: میتوانید شروع به بصریسازی هر فیلتر در لایه، و حتی هر فیلتر در هر لایه از مدل کنید.
قطعه کد 9.19: تولید یک شبکه (grid) از تمام الگوهای پاسخ فیلترها در یک لایه.
all_images = []
تصویر بصریسازیها را برای 64 فیلتر اول در لایه تولید و ذخیره کنید.
for filter_index in range(64):
print(f”Processing filter {filter_index}”)
image = deprocess_image(
generate_filter_pattern(filter_index)
)
all_images.append(image)
margin = 5
یک بوم خالی برای چسباندن بصریسازیهای فیلتر آماده کنید.
n = 8
cropped_width = img_width – 25 * 2
cropped_height = img_height – 25 * 2
width = n * cropped_width + (n – 1) * margin
height = n * cropped_height + (n – 1) * margin
stitched_filters = np.zeros((width, height, 3))
for i in range(n):
تصویر را با فیلترهای ذخیره شده پر کنید.
for j in range(n):
image = all_images[i * n + j]
stitched_filters[
row_start = (cropped_width + margin) * i
row_end = (cropped_width + margin) * i + cropped_width
column_start = (cropped_height + margin) * j
column_end = (cropped_height + margin) * j + cropped_height
stitched_filters[
row_start: row_end,
column_start: column_end, :] = image
keras.utils.save_img(
f”filters_for_layer_{layer_name}.png”, stitched_filters)
این بصریسازیهای فیلتر (به شکل 9.17 مراجعه کنید) چیزهای زیادی در مورد اینکه لایههای convnet چگونه دنیا را میبینند به شما میگوید: هر لایه در یک convnet مجموعهای از فیلترها را یاد میگیرد به طوری که ورودیهای آنها میتوانند به عنوان ترکیبی از فیلترها بیان شوند. این شبیه به نحوه تجزیه سیگنالها توسط تبدیل فوریه بر روی مجموعهای از توابع کسینوسی است. فیلترها در این بانکهای فیلتر convnet با عمیقتر شدن در مدل، به طور فزایندهای پیچیدهتر و پالودهتر میشوند:
- فیلترهای لایههای اولیه در مدل، لبههای جهتدار ساده و رنگها (یا در برخی موارد، لبههای رنگی) را کدگذاری میکنند.
- فیلترهای لایههای کمی بالاتر در پشته، مانند block4_sepconv1، بافتهای سادهای را که از ترکیب لبهها و رنگها ساخته شدهاند، کدگذاری میکنند.
- فیلترهای لایههای بالاتر شروع به شباهت به بافتهای موجود در تصاویر طبیعی میکنند: پرها، چشمها، برگها و غیره.

شکل 9.17: برخی الگوهای فیلتر برای لایههای block2_sepconv1، block4_sepconv1، و block8_sepconv1.
بصریسازی نقشههای حرارتی فعالسازی کلاس
یک تکنیک بصریسازی نهایی را معرفی خواهیم کرد — تکنیکی که برای درک اینکه کدام بخشهای یک تصویر مشخص منجر به تصمیم طبقهبندی نهایی convnet شدهاند، مفید است. این برای “اشکالزدایی” فرآیند تصمیمگیری یک convnet مفید است، به ویژه در مورد یک اشتباه طبقهبندی (یک حوزه مسئلهای که قابلیت تفسیر مدل نامیده میشود). همچنین میتواند به شما امکان دهد اشیاء خاصی را در یک تصویر مکانیابی کنید.
این دسته عمومی از تکنیکها بصریسازی نقشه فعالسازی کلاس (CAM) نامیده میشود، و شامل تولید نقشههای حرارتی فعالسازی کلاس بر روی تصاویر ورودی است. نقشه حرارتی فعالسازی کلاس، یک شبکه 2 بعدی از امتیازات مرتبط با یک کلاس خروجی خاص است، که برای هر مکان در هر تصویر ورودی محاسبه میشود و نشان میدهد که هر مکان چقدر نسبت به کلاس مورد نظر مهم است. برای مثال، با توجه به تصویری که به یک convnet سگ در برابر گربهها تغذیه میشود، بصریسازی CAM به شما امکان میدهد یک نقشه حرارتی برای کلاس “گربه” تولید کنید، که نشان میدهد بخشهای مختلف تصویر چقدر شبیه گربه هستند، و همچنین یک نقشه حرارتی برای کلاس “سگ” که نشان میدهد بخشهای تصویر چقدر شبیه سگ هستند.
پیادهسازی خاصی که ما استفاده خواهیم کرد، همان است که در مقالهای با عنوان “GradCAM: Visual Explanations from Deep Networks via Gradient-based Localization” توصیف شده است.5
Grad-CAM شامل گرفتن نقشه ویژگی خروجی یک لایه کانولوشن، با توجه به یک تصویر ورودی، و وزندهی هر کانال در آن نقشه ویژگی با گرادیان کلاس نسبت به کانال است. به طور شهودی، یک راه برای درک این ترفند این است که تصور کنید شما یک نقشه فضایی از “میزان فعال کردن شدید کانالهای مختلف توسط تصویر ورودی” را با “میزان اهمیت هر کانال نسبت به کلاس” وزندهی میکنید، که منجر به یک نقشه فضایی از “میزان فعال کردن شدید کلاس توسط تصویر ورودی” میشود.
بیایید این تکنیک را با استفاده از مدل Xception از پیش آموزشدیده نشان دهیم.
قطعه کد 9.20: بارگذاری شبکه Xception با وزنهای از پیش آموزشدیده.
model = keras.applications.xception.Xception(weights=”imagenet”)
توجه داشته باشید که ما طبقهبند کاملاً متصل بالا را شامل میکنیم؛ در تمام موارد قبلی، آن را کنار گذاشتیم.
تصویر دو فیل آفریقایی نشان داده شده در شکل 9.18 را در نظر بگیرید، احتمالاً یک مادر و بچه او، در حال قدم زدن در ساوانا. بیایید این تصویر را به چیزی تبدیل کنیم که مدل Xception میتواند بخواند: مدل بر روی تصاویر با اندازه 299 × 299 آموزش دیده است، که طبق چند قانون که در تابع کاربردی keras.applications.xception.preprocess_input بستهبندی شدهاند، پیشپردازش شدهاند. بنابراین باید تصویر را بارگذاری کنیم، اندازه آن را به 299 × 299 تغییر دهیم، آن را به یک تنسور NumPy از نوع float32 تبدیل کنیم، و این قوانین پیشپردازش را اعمال کنیم.
قطعه کد 9.21: پیشپردازش یک تصویر ورودی برای Xception.
img_path = keras.utils.get_file(
fname=”elephant.jpg”,
origin=”https://img-datasets.s3.amazonaws.com/elephant.jpg”)
تصویر را دانلود کرده و به صورت محلی در مسیر img_path ذخیره کنید.
def get_img_array(img_path, target_size):
img = keras.utils.load_img(img_path, target_size=target_size)
یک تصویر PIL (Python Imaging Library) با اندازه 299 × 299 را برگردانید.
array = keras.utils.img_to_array(img)
یک آرایه NumPy از نوع float32 با شکل (3, 299, 299) را برگردانید.
array = np.expand_dims(array, axis=0)
یک بعد اضافه کنید تا آرایه به یک دسته با اندازه (3, 299, 299, 1) تبدیل شود.
array = keras.applications.xception.preprocess_input(array)
دسته (batch) را پیشپردازش کنید (این کار نرمالسازی رنگ به ازای هر کانال را انجام میدهد).
return array
img_array = get_img_array(img_path, target_size=(299, 299))

شکل 9.18: تصویر آزمایش فیلهای آفریقایی.
اکنون میتوانید شبکه از پیش آموزشدیده را روی تصویر اجرا کنید و بردار پیشبینی آن را به یک فرمت قابل درک برای انسان رمزگشایی کنید:
>>> preds = model.predict(img_array)
>>> print(keras.applications.xception.decode_predictions(preds, top=3)[0])
[(“n02504458”, “African_elephant”, 0.8699266),
(“n01871265”, “tusker”, 0.076968715),
(“n02504013”, “Indian_elephant”, 0.02353728)]
سه کلاس برتر پیشبینی شده برای این تصویر به شرح زیر است:
- فیل آفریقایی (با احتمال 87%)
- فیل نر با عاج (با احتمال 7%)
- فیل هندی (با احتمال 2%)
شبکه تصویر را حاوی تعداد نامشخصی فیل آفریقایی تشخیص داده است. درایه موجود در بردار پیشبینی که حداکثر فعال شده، متناظر با کلاس “فیل آفریقایی” در شاخص 386 است:
>>> np.argmax(preds[0])
386
برای بصریسازی اینکه کدام بخشهای تصویر بیشترین شباهت را به فیل آفریقایی دارند، بیایید فرآیند Grad-CAM را راهاندازی کنیم.
ابتدا، یک مدل ایجاد میکنیم که تصویر ورودی را به فعالسازیهای آخرین لایه کانولوشن نگاشت میکند.
قطعه کد 9.22: راهاندازی مدلی که آخرین خروجی کانولوشنی را برمیگرداند.
last_conv_layer_name = “block14_sepconv2_act”
classifier_layer_names = [
“avg_pool”,
“predictions”,
]
last_conv_layer = model.get_layer(last_conv_layer_name)
last_conv_layer_model = keras.Model(model.inputs, last_conv_layer.output)
دوم، ما مدلی ایجاد میکنیم که فعالسازیهای آخرین لایه کانولوشنی را به پیشبینیهای نهایی کلاس نگاشت میکند.
قطعه کد 9.23: اعمال مجدد طبقهبندی در بالای آخرین خروجی کانولوشنی
classifier_input = keras.Input(shape=last_conv_layer.output.shape[1:])
x = classifier_input
for layer_name in classifier_layer_names:
x = model.get_layer(layer_name)(x)
classifier_model = keras.Model(classifier_input, x)
سپس گرادیان کلاس پیشبینی شده برتر برای تصویر ورودی ما را نسبت به فعالسازیهای آخرین لایه کانولوشن محاسبه میکنیم.
قطعه کد 9.24: بازیابی گرادیانهای کلاس پیشبینی شده برتر.
import tensorflow as tf
with tf.GradientTape() as tape:
last_conv_layer_output = last_conv_layer_model(img_array)
فعالسازیهای آخرین لایه conv را محاسبه کنید و نوار را وادار کنید آن را تماشا کند.
tape.watch(last_conv_layer_output)
preds = classifier_model(last_conv_layer_output)
top_pred_index = tf.argmax(preds[0])
top_class_channel = preds[:, top_pred_index]
کانال فعالسازی مربوط به کلاس پیشبینی شده برتر را بازیابی کنید
grads = tape.gradient(top_class_channel, last_conv_layer_output)
این گرادیان کلاس پیشبینی شده برتر نسبت به نقشه ویژگی خروجی آخرین لایه کانولوشن است.
حالا ما پولینگ و وزندهی اهمیت را بر روی تنسور گرادیان اعمال میکنیم تا نقشه حرارتی فعالسازی کلاس خود را به دست آوریم.
قطعه کد 9.25: پولینگ گرادیان و وزندهی اهمیت کانال.
pooled_grads = tf.reduce_mean(grads, axis=(0, 1, 2)).numpy()
این برداری است که در آن هر درایه، میانگین شدت گرادیان برای یک کانال مشخص است. این بردار اهمیت هر کانال را نسبت به کلاس پیشبینی شده برتر کمیسازی میکند.
last_conv_layer_output = last_conv_layer_output.numpy()[0]
for i in range(pooled_grads.shape[-1]):
هر کانال را در خروجی آخرین لایه کانولوشنی در “میزان اهمیت این کانال” ضرب کنید.
last_conv_layer_output[:, :, i] *= pooled_grads[i]
heatmap = np.mean(last_conv_layer_output, axis=-1)
میانگین کانالمحور نقشه ویژگی حاصل، نقشه حرارتی فعالسازی کلاس ما است.
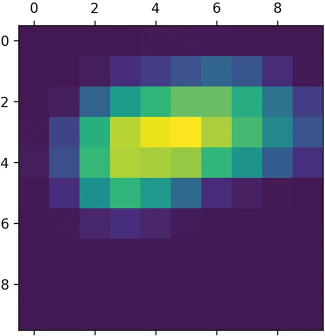
برای اهداف بصریسازی، نقشه حرارتی را بین 0 و 1 نرمالسازی میکنیم. نتیجه در شکل 9.19 نشان داده شده است.
قطعه کد 9.26: پسپردازش نقشه حرارتی.
heatmap = np.maximum(heatmap, 0)
heatmap /= np.max(heatmap)
plt.matshow(heatmap)
در نهایت، بیایید تصویری تولید کنیم که تصویر اصلی را بر روی نقشه حرارتی که تازه به دست آوردیم، قرار دهد (به شکل 9.20 مراجعه کنید)
قطعه کد 9.27: قرار دادن نقشه حرارتی بر روی تصویر اصلی.
import matplotlib.cm as cm
img = keras.utils.load_img(img_path)
img = keras.utils.img_to_array(img)
تصویر اصلی را بارگذاری کنید.
heatmap = np.uint8(255 * heatmap)
نقشه حرارتی را به محدوده 0–255 مقیاسبندی کنید.
jet = cm.get_cmap(“jet”)
jet_colors = jet(np.arange(256))[:, :3]
jet_heatmap = jet_colors[heatmap]
از نقشه رنگی “jet” برای تغییر رنگ نقشه حرارتی استفاده کنید.
jet_heatmap = keras.utils.array_to_img(jet_heatmap)
jet_heatmap = jet_heatmap.resize((img.shape[1], img.shape[0]))
jet_heatmap = keras.utils.img_to_array(jet_heatmap)
تصویری ایجاد کنید که حاوی نقشه حرارتی رنگآمیزی شده باشد.
superimposed_img = jet_heatmap * 0.4 + img
superimposed_img = keras.utils.array_to_img(superimposed_img)
نقشه حرارتی و تصویر اصلی را روی هم قرار دهید، با شفافیت 40% برای نقشه حرارتی.
save_path = “elephant_cam.jpg”
superimposed_img.save(save_path)
تصویر روی هم قرار داده شده را ذخیره کنید.

شکل 9.20: نقشه حرارتی فعالسازی کلاس فیل آفریقایی بر روی تصویر آزمایش.
این تکنیک بصریسازی به دو سوال مهم پاسخ میدهد:
- چرا شبکه فکر کرد این تصویر حاوی یک فیل آفریقایی است؟
- فیل آفریقایی در کجای تصویر قرار دارد؟
به ویژه، جالب است که گوشهای بچه فیل به شدت فعال شدهاند: این احتمالاً همان چیزی است که شبکه میتواند تفاوت بین فیلهای آفریقایی و هندی را تشخیص دهد.
خلاصه
- سه وظیفه ضروری بینایی کامپیوتر وجود دارد که میتوانید با یادگیری عمیق انجام دهید: طبقهبندی تصویر، تقسیمبندی تصویر، و تشخیص شیء.
- پیروی از بهترین شیوههای معماری convnet مدرن به شما کمک میکند تا بیشترین بهره را از مدلهای خود ببرید. برخی از این بهترین شیوهها شامل استفاده از اتصالات باقیمانده، نرمالسازی دسته، و کانولوشنهای قابل تفکیک عمقی است.
- بازنماییهایی که convnetها یاد میگیرند به راحتی قابل بازرسی هستند—convnetها نقطه مقابل جعبههای سیاه هستند!
- میتوانید بصریسازیهایی از فیلترهای یادگرفته شده توسط convnetهای خود، و همچنین نقشههای حرارتی فعالیت کلاس، تولید کنید.



