
مقدمه
در دنیای هوش مصنوعی، دو اصطلاح یادگیری ماشین (Machine Learning) و یادگیری عمیق (Deep Learning) بیش از هر زمان دیگری شنیده میشوند. بسیاری از افراد این دو مفهوم را بهجای یکدیگر استفاده میکنند، در حالی که تفاوتهای مهمی میان آنها وجود دارد؛ تفاوتهایی که دانستن آنها برای انتخاب روش درست در هر پروژه دادهمحور ضروری است.
یادگیری ماشین سالهاست بهعنوان ابزاری قدرتمند برای تحلیل دادهها و پیشبینی به کار میرود، اما با افزایش حجم و پیچیدگی دادهها، محدودیتهای آن آشکارتر شده است. در همین نقطه، یادگیری عمیق با تکیه بر شبکههای عصبی چندلایه وارد میدان شده و توانسته است در مسائلی مانند تشخیص تصویر، پردازش زبان طبیعی و گفتار، نتایج چشمگیری ارائه دهد.
در این مقاله، یادگیری ماشین و یادگیری عمیق را بهصورت ساده، کاربردی و مقایسهای بررسی میکنیم. هدف این است که بهطور شفاف مشخص شود تفاوت این دو رویکرد چیست، هرکدام چه مزایا و محدودیتهایی دارند و در چه شرایطی باید از کدام استفاده کرد.
یادگیری ماشین و یادگیری عمیق دقیقاً چیست؟
بیایید از مفاهیم پایه شروع کنیم. اگر قبلاً با این تعاریف آشنا شدهاید، میتوانید مستقیماً به بخش دوم بروید. اما اگر میخواهید یکبار برای همیشه این مفاهیم را در ذهنتان طبقهبندی کنید، همراه ما باشید.
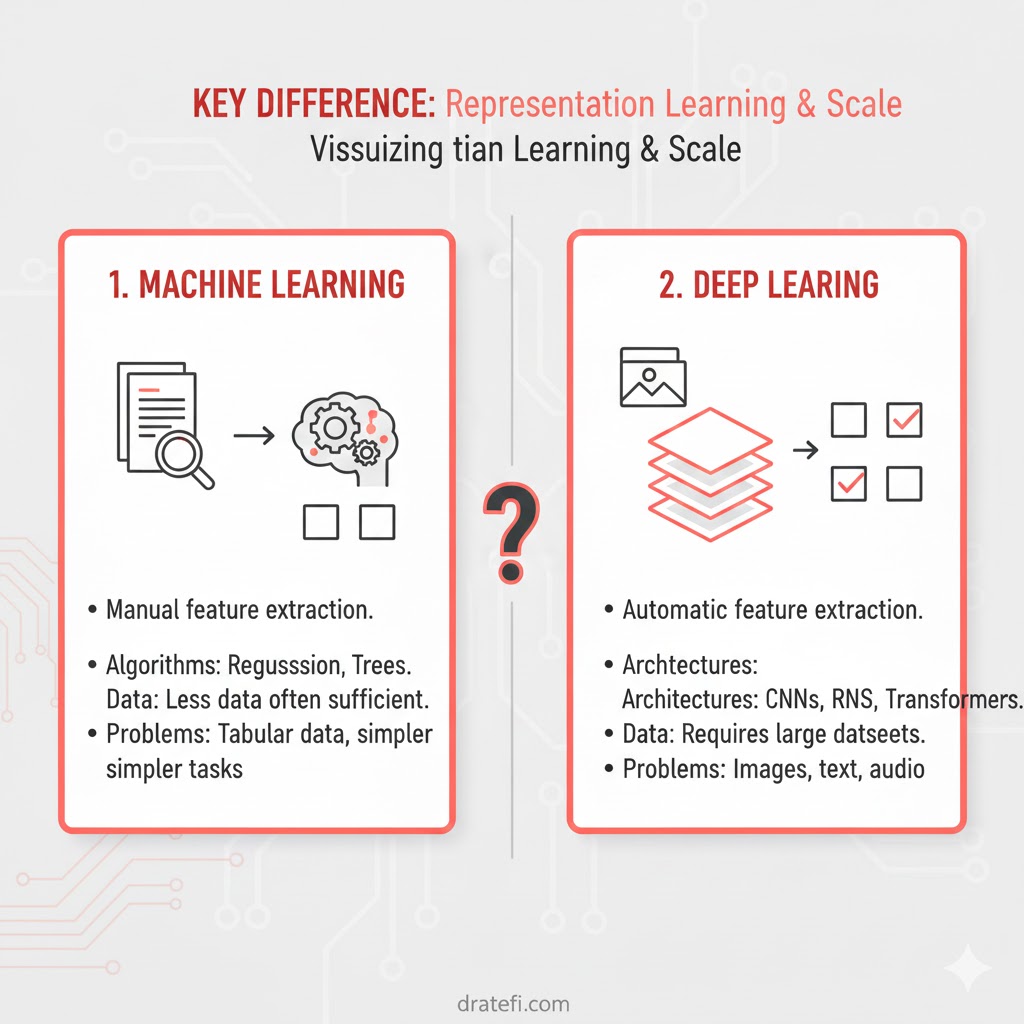
یادگیری ماشین (Machine Learning) چیست؟
شاید بهترین و معروفترین تعریف از یادگیری ماشین، تعریفی باشد که تام میشل ارائه داده است. او میگوید:
یک برنامه کامپیوتری زمانی در حال “یادگیری” است که نسبت به یک سری وظایف (T) و بر اساس یک معیار عملکرد (P)، با کسب تجربه (E)، عملکردش در انجام آن وظایف بهبود پیدا کند.
کمی گیجکننده به نظر میرسد؟ حق دارید! بیایید این تعریف علمی را با یک مثال ملموس و ساده کالبدشکافی کنیم.
مثال ۱: پیشبینی وزن بر اساس قد 📏
فرض کنید میخواهید سیستمی بسازید که قدِ یک فرد را بگیرد و وزنِ تقریبی او را حدس بزند. چنین سیستمی میتواند کاربردهای زیادی داشته باشد؛ مثلاً برای شناسایی دادههای غلط در پرسشنامههای پزشکی یا مچگیری از آمارهای تقلبی.
اولین قدم در این راه، جمعآوری داده است. بیایید تصور کنیم دادههای شما چیزی شبیه به این هستند:
حالا بیایید تعریف تام میشل را روی این مثال پیاده کنیم:
- وظیفه (Task – T): پیشبینی وزن بر اساس قد.
- تجربه (Experience – E): دادههایی که به مدل میدهیم (همین لیست قدها و وزنها).
- معیار عملکرد (Performance – P): اینکه مدل چقدر دقیق وزن را حدس میزند (فاصله بین وزن واقعی و وزنی که مدل حدس زده).
هر چه سیستم ما دادههای بیشتری ببیند (تجربه بیشتر)، خطای پیشبینیاش کمتر میشود و عملکردش بهبود پیدا میکند. این یعنی یادگیری ماشین!
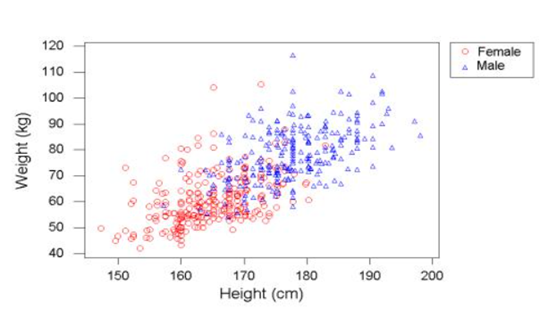
تحلیل دادهها روی نمودار: جادوی یک خط ساده 📈
در قدم اول، ما تمام دادههایی که جمعآوری کردیم را روی یک نمودار میبریم. هر نقطهای که روی این نمودار میبینید، نشاندهنده اطلاعات یک نفر است (ترکیب قد و وزن او).
برای اینکه بتوانیم وزن را بر اساس قد پیشبینی کنیم، سادهترین کار این است که یک خط مستقیم از میان این نقاط عبور دهیم. به عنوان مثال، یک خط ساده مثل این را در نظر بگیرید:
این خط در واقع همان فرمول یا مدل ماست. وقتی قدِ یک فرد جدید را به این خط میدهیم، مدل با نگاه کردن به جایگاه آن روی خط، وزنِ متناظر را به ما اعلام میکند. البته این اولین حدس ماست و شاید خیلی دقیق نباشد، اما شروع مسیر یادگیری ماشین دقیقاً از همینجاست؛ یعنی پیدا کردن بهترین خطی که بتواند با کمترین خطا، از بین تمام این نقاط عبور کند.
Weight (in kg) = Height (in cm) – 100
چطور مدلمان را هوشمندتر کنیم؟
یک خط ساده میتواند به ما در پیشبینی کمک کند، اما نکته مهم این است که بفهمیم این خط چقدر خوب عمل میکند. در واقع، هدف ما این است که فاصله بین پیشبینیها و مقادیر واقعی را تا حد ممکن کم کنیم. این دقیقاً همان معیار عملکرد ماست.
علاوه بر این، دو راه اصلی برای حرفهایتر کردن مدل وجود دارد:
- کسب تجربه بیشتر: هرچه دادههای بیشتری جمعآوری کنیم، مدل ما الگوها را بهتر میشناسد.
- افزودن متغیرهای جدید: میتوانیم فاکتورهای دیگری مثل جنسیت را هم اضافه کنیم و برای هر دسته، خطوط پیشبینی جداگانهای بسازیم تا دقت کار بالاتر برود.
مثال ۲: سیستم پیشبینی طوفان
بیایید سراغ یک مثال کمی چالشبرانگیزتر برویم. تصور کنید میخواهید سیستمی بسازید که وقوع طوفان را پیشبینی کند. شما دادههای تمام طوفانهای گذشته را در اختیار دارید، به اضافهی اطلاعات مربوط به شرایط آب و هواییِ سه ماه قبل از وقوع هر کدام از آنها.
حالا به این فکر کنید: اگر قرار بود به صورت دستی (بدون کمک هوش مصنوعی) یک سیستم پیشبینی طوفان بسازیم، باید چه کارهایی انجام میدادیم؟
ما مجبور بودیم هزاران کاغذ و نمودار را بررسی کنیم، به دنبال الگوهای تکراری در فشار هوا یا دما بگردیم و به صورت دستی قوانینی مثل اگر دما X بود و فشار Y، پس احتمال طوفان Z است را بنویسیم. اما در یادگیری ماشین، ما این کوه داده را به مدل میدهیم و او خودش این قوانین را کشف میکند.

سناریوی اول: تحلیل دستی در مقابل هوش مصنوعی
برای ساختن سیستم پیشبینی طوفان، ابتدا باید تمام دادههای گذشته را زیر و رو کنیم تا الگوهای خاصی پیدا کنیم؛ یعنی بفهمیم دقیقاً چه شرایطی باعث وقوع طوفان میشود. برای این کار دو راه پیش رو داریم:
۱. روش دستی: خودمان قوانینی تعریف کنیم؛ مثلاً بگوییم اگر دما بالای ۴۰ درجه بود و رطوبت بین ۸۰ تا ۱۰۰ درصد، طوفان در راه است. این ویژگیها (Features) را باید خودمان به خوردِ سیستم بدهیم. ۲. روش یادگیری ماشین: اجازه دهیم سیستم خودش از میان دادهها بفهمد که چه مقادیری برای دما و رطوبت، نشاندهنده طوفان هستند.
در روش دوم، سیستم دادههای قدیمی را بررسی میکند و حدس میزند طوفان میشود یا نه. سپس ما عملکرد آن را میسنجیم (مثلاً چند بار درست پیشبینی کرده است؟) و این نتیجه را به عنوان بازخورد به سیستم برمیگردانیم تا در تکرارهای بعدی، خودش را اصلاح کند.
حالا بیایید دوباره از عینک تعریفِ رسمی به این مثال نگاه کنیم:
- وظیفه (T): پیدا کردن شرایط جوی که باعث شروع طوفان میشود.
- عملکرد (P): درصدِ پیشبینیهای درستِ سیستم از میان تمام دادههای ورودی.
- تجربه (E): تکرارها و چرخههای یادگیری که سیستم طی میکند تا باهوشتر شود.
یادگیری عمیق (Deep Learning) چیست؟
مفهوم یادگیری عمیق اصلاً جدید نیست و سالهاست که وجود دارد، اما این روزها به لطف قدرت سختافزارها، حسابی سر و صدا به پا کرده است. بیایید ابتدا تعریف رسمی آن را ببینیم و بعد با یک مثال، آن را کالبدشکافی کنیم:
یادگیری عمیق نوع خاصی از یادگیری ماشین است که قدرت و انعطافپذیری بالایی دارد. این تکنولوژی دنیا را به صورت سلسلهمراتبِ تو در تو از مفاهیم میبیند. در این ساختار، هر مفهومِ پیچیده بر اساس مفاهیم سادهتر تعریف میشود و نمایشهای انتزاعیتر، از ترکیب نمایشهای سادهتر ساخته میشوند.
میدانم، این تعریف هم کمی گیجکننده است! بیایید با یک مثال ساده آن را باز کنیم.
مثال ۱: تشخیص شکلها (مربع) 📐
بیایید ببینیم ذهن ما چطور یک مربع را از بین بقیه شکلها تشخیص میدهد. در یادگیری عمیق، این کار پلهپله انجام میشود:
- لایه اول (ساده): سیستم ابتدا به دنبال خطوط صاف میگردد.
- لایه دوم (ترکیبی): خطوط صاف را ترکیب میکند تا گوشهها یا زاویهها را پیدا کند.
- لایه سوم (انتزاعی): از ترکیب چهار خط و چهار زاویه قائمه، به مفهوم مربع میرسد.
در واقع یادگیری عمیق مثل چیدن بلوکهای لگو است؛ از قطعات ریز شروع میکند تا در نهایت یک ساختار پیچیده را شناسایی کند.

اولین کاری که چشمان ما برای تشخیص یک مربع انجام میدهد، بررسی وجود ۴ خط است (یک مفهوم ساده). اگر ۴ خط پیدا کردیم، سراغ مرحله بعد میرویم: آیا این خطوط به هم متصل هستند؟ آیا یک محیط بسته ایجاد کردهاند؟ آیا بر هم عمود و با هم برابرند؟ (سلسلهمراتبی از مفاهیم تو در تو).
در واقع، ما یک وظیفه پیچیده (تشخیص مربع) را به وظایف سادهتر و عینیتر تقسیم کردیم. یادگیری عمیق دقیقاً همین کار را در مقیاسی بسیار بزرگتر و پیچیدهتر انجام میدهد.
مثال ۲: نبرد سگ و گربه! 🐱🐶
فرض کنید میخواهیم سیستمی بسازیم که تشخیص دهد تصویر متعلق به سگ است یا گربه.
- اگر از یادگیری ماشین (ML) استفاده کنیم: ما باید ویژگیها را دستی تعریف کنیم. مثلاً به مدل میگوییم: بگرد ببین حیوان سبیل دارد؟ گوشهایش نوکتیز است یا افتاده؟. در واقع ما ویژگیهای چهره را لیست میکنیم و سیستم فقط یاد میگیرد که کدامیک از این ویژگیها برای تفکیک سگ از گربه مهمتر هستند.
- اگر از یادگیری عمیق (DL) استفاده کنیم: یک گام فراتر میرویم. اینجا دیگر نیازی نیست ما ویژگیها را دستی به مدل بدهیم؛ مدل خودش آنها را پیدا میکند!
فرآیند یادگیری عمیق به این صورت است: ۱. ابتدا مرتبطترین لبهها (خطوط افقی، عمودی یا مورب) را در تصویر شناسایی میکند. ۲. سپس به صورت سلسلهمراتبی، این لبهها را ترکیب میکند تا به اشکال برسد (مثلاً شکل سبیل یا فرم گوش). ۳. در نهایت با ترکیب این مفاهیم پیچیده، تصمیم میگیرد که کدام ویژگیها نشاندهنده سگ یا گربه هستند.
مقایسه یادگیری ماشین و یادگیری عمیق
حالا که با کلیات هر دو آشنا شدید، بیایید آنها را از چند زاویه مهم با هم مقایسه کنیم.
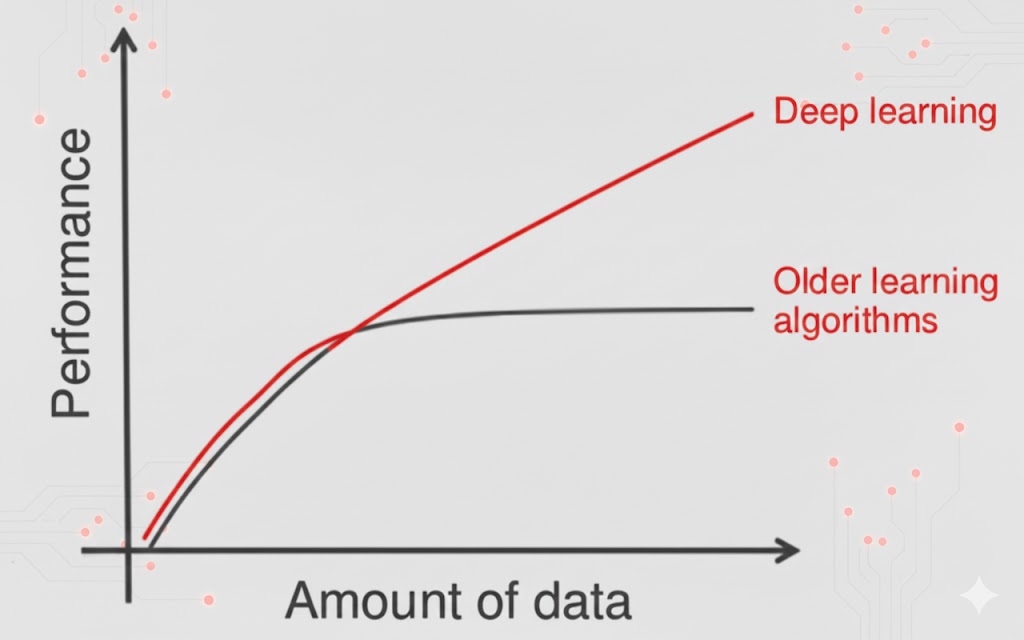
وابستگی به داده (Data Dependencies)
مهمترین تفاوت این دو در نحوه عملکردشان هنگام افزایش حجم دادهها است. وقتی حجم دادهها کم باشد، یادگیری عمیق خیلی خوب عمل نمیکند؛ چون این الگوریتمها برای درک الگوهای پیچیده به خوراک یا همان دادههای بسیار زیادی نیاز دارند. در مقابل، الگوریتمهای یادگیری ماشین سنتی (با همان قوانین دستنویس انسانی) در دادههای کم، عملکرد بهتری دارند و پیروز میدان هستند. نمودار زیر این واقعیت را به خوبی نشان میدهد:
وابستگی به سختافزار (Hardware Dependencies)
الگوریتمهای یادگیری عمیق به شدت به ماشینهای قدرتمند و ردهبالا وابسته هستند؛ برعکسِ الگوریتمهای سنتی یادگیری ماشین که به راحتی روی یک لپتاپ یا سیستم معمولی هم اجرا میشوند.
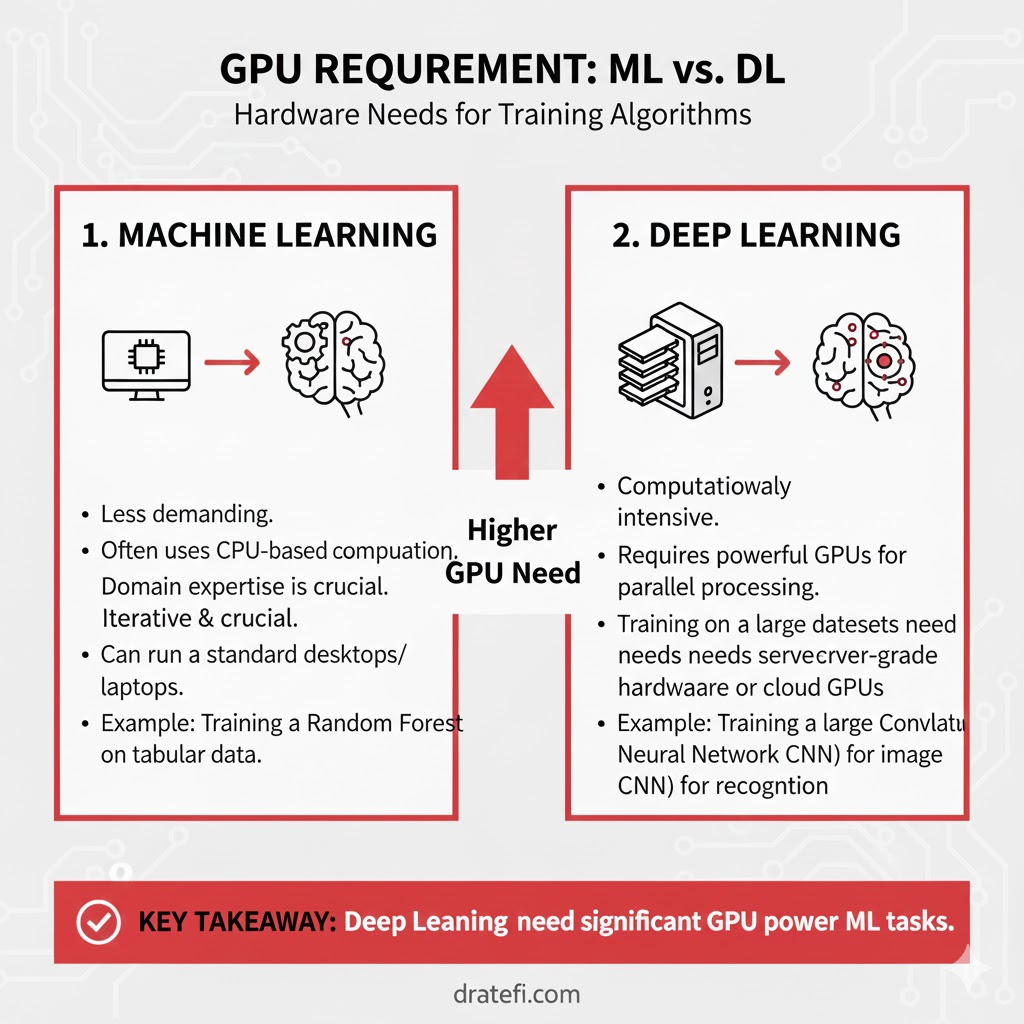
دلیل این موضوع، نیاز حیاتی یادگیری عمیق به GPU (کارت گرافیک) است. ماهیت محاسبات در یادگیری عمیق، شامل حجم عظیمی از ضرب ماتریسها است. از آنجایی که ساختار GPU دقیقاً برای انجام موازی و بهینهی این نوع محاسبات طراحی شده، استفاده از آن برای اجرای شبکههای عصبی ضروری است. بدون GPU، آموزش یک مدل عمیق ممکن است به جای چند ساعت، چندین هفته طول بکشد!
مهندسی ویژگی (Feature Engineering)
مهندسی ویژگی فرآیندی است که در آن متخصصان از دانش خود استفاده میکنند تا ویژگیهای مهم را از دادههای خام استخراج کنند. هدف این است که دادهها سادهتر شوند تا الگوها برای الگوریتم، واضحتر و قابلشناسایی باشند. این کار بسیار دشوار، زمانبر و نیازمند تخصص بالاست.
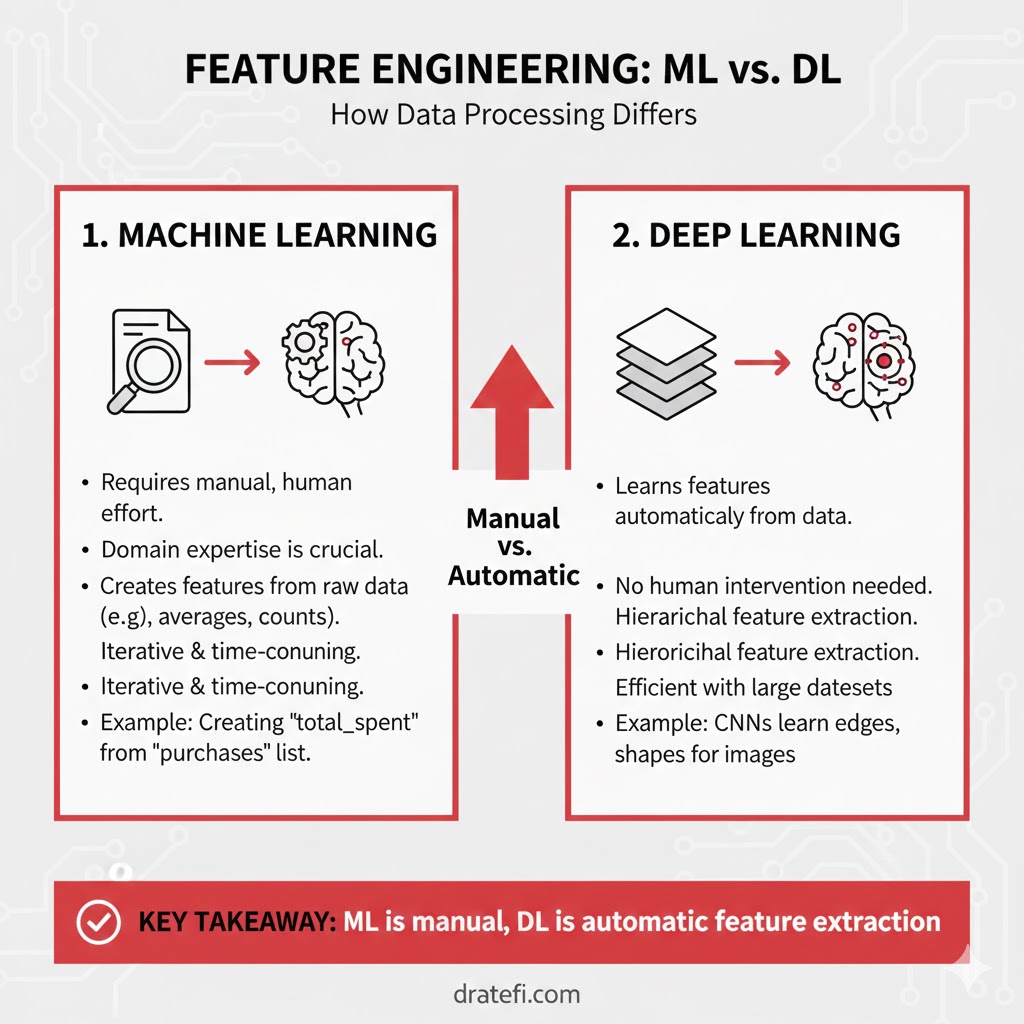
- در یادگیری ماشین: بخش زیادی از این ویژگیها باید توسط یک متخصص شناسایی و سپس به صورت دستی کدنویسی شوند (مثلاً تعریف بافت، لبهها یا موقعیت اشیاء در تصویر). در واقع، دقت مدل یادگیری ماشین مستقیماً به این بستگی دارد که متخصص چقدر در استخراج این ویژگیها دقیق عمل کرده است.
- در یادگیری عمیق: اینجاست که یادگیری عمیق برتری خود را نشان میدهد! این الگوریتمها تلاش میکنند تا ویژگیهای سطح بالا را خودشان از دل دادهها یاد بگیرند. این یک گام بزرگ رو به جلو است، چون دیگر نیاز نیست برای هر مسئله جدید، یک استخراجکننده ویژگیِ مجزا طراحی کنیم.
به عنوان مثال، در یک شبکه عصبی کانولوشن (CNN): ۱. لایههای اولیه، ویژگیهای ساده مثل خطوط و لبهها را یاد میگیرند. ۲. لایههای میانی، اجزای پیچیدهتر مثل بخشهایی از صورت را تشخیص میدهند. ۳. لایههای نهایی، به یک نمایش کامل و انتزاعی از یک چهره میرسند.
رویکرد حل مسئله
در یادگیری ماشین سنتی، پیشنهاد میشود که یک مسئله پیچیده را به بخشهای کوچکتر تقسیم کنید، هر بخش را جداگانه حل کنید و در نهایت نتایج را با هم ترکیب کنید. اما یادگیری عمیق طرفدار حل مسئله به صورت سرتاسری (End-to-End) است.
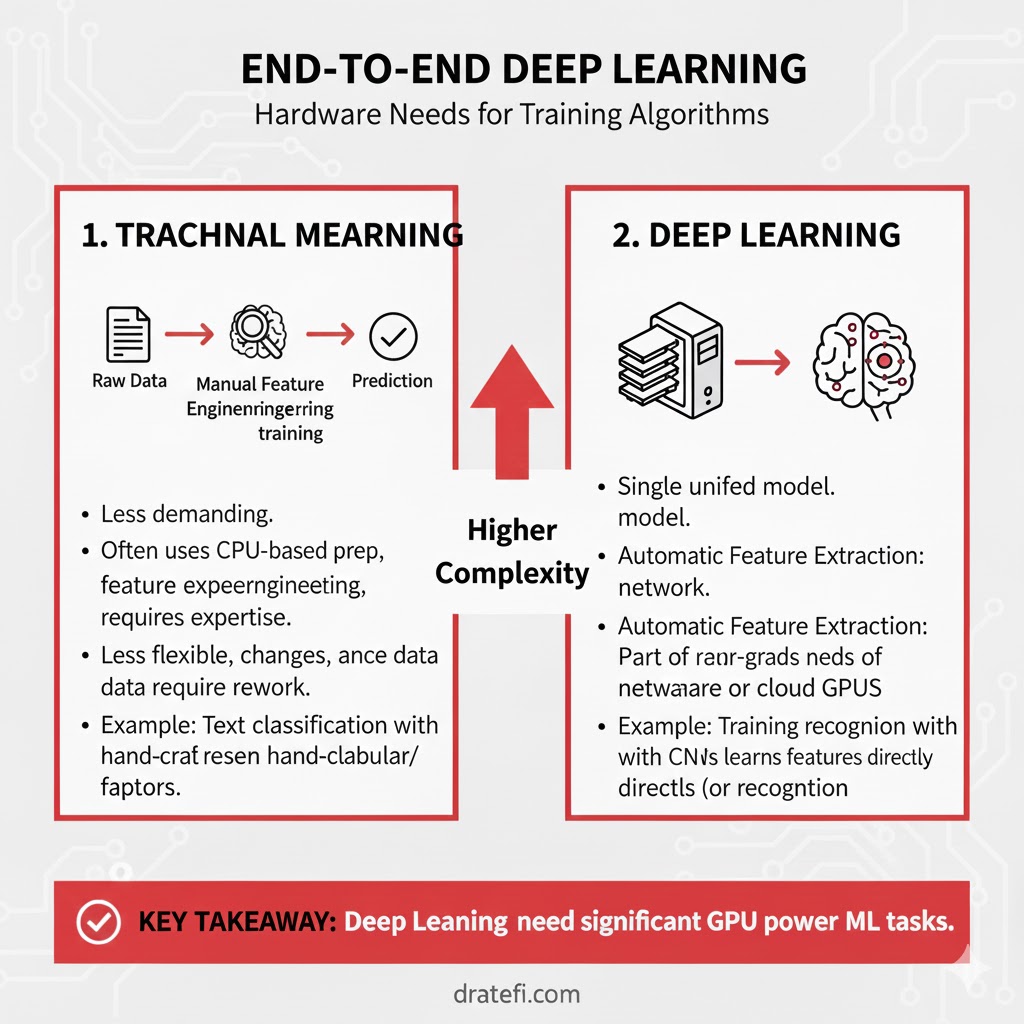
مثال: تشخیص چندین اشیاء در تصویر فرض کنید میخواهید بفهمید در یک تصویر چه اشیایی وجود دارند و دقیقاً کجا هستند.
- روش یادگیری ماشین: ابتدا از یک الگوریتم برای پیدا کردن کادرهای احتمالی دور اشیاء (مثل Grabcut) استفاده میکنید. سپس محتویات هر کادر را به یک الگوریتم دیگر (مثل SVM) میدهید تا شناسایی کند آن شیء چیست. (یک فرآیند دو مرحلهای).
- روش یادگیری عمیق: شما تصویر را به یک شبکه عمیق (مثل الگوریتم معروف YOLO) میدهید و خروجی مستقیماً هم مکان اشیاء و هم نام آنها را به شما میدهد.
زمان اجرا
در دنیای یادگیری عمیق، زمانبندی کمی متفاوت است:
- زمان آموزش: آموزش یک مدل عمیق میتواند بسیار طولانی باشد، چون تعداد پارامترها (وزنها) فوقالعاده زیاد است. مثلاً مدل قدرتمند ResNet ممکن است حدود دو هفته زمان ببرد تا از صفر آموزش ببیند. در مقابل، یادگیری ماشین سریعتر است و آموزش آن از چند ثانیه تا چند ساعت طول میکشد.
- زمان تست: جالب اینجاست که در زمان استفاده (تست)، ورق برمیگردد! مدلهای عمیق پس از آموزش، بسیار سریع پاسخ میدهند. اما برخی مدلهای یادگیری ماشین (مثل KNN) با افزایش حجم دادهها، در زمان پاسخدهی کندتر میشوند.
کاربرد های یادگیری ماشین و عمیق
امروزه این تکنولوژیها در تمام ابعاد زندگی ما نفوذ کردهاند:
- بینایی ماشین: تشخیص پلاک خودروها و باز کردن قفل گوشی با چهره.
- بازیابی اطلاعات: موتورهای جستجوی هوشمند گوگل (متنی و تصویری).
- بازاریابی: ایمیلهای تبلیغاتی شخصیسازی شده و شناسایی مشتریان هدف.
- تشخیص پزشکی: شناسایی زودهنگام سلولهای سرطانی و ناهنجاریهای تصویربرداری.
- پردازش زبان طبیعی (NLP): تحلیل حس و حال متنها (مثبت یا منفی بودن نظرات) و ترجمه خودکار.
آزمون هوش (Pop Quiz): کدام روش مناسب تر است؟
برای اینکه مطمئن شویم تفاوتهای بین یادگیری ماشین (ML) و یادگیری عمیق (DL) را به خوبی درک کردهاید، بیایید این سه سناریو را بررسی کنیم. برای هر مورد، فکر کنید که:
- چطور با رویکرد یادگیری ماشین آن را حل میکنید؟
- چطور با رویکرد یادگیری عمیق به سراغش میروید؟
- در نهایت، کدام روش برای این مسئله منطقیتر است؟
سناریوی اول: خودروهای خودران (هدایت فرمان) 🚗💨
صورت مسئله: سیستمی بسازید که پیکسلهای خام دوربین را بگیرد و زاویه دقیق چرخش فرمان را پیشبینی کند.
- تحلیل پیشنهادی: در یادگیری ماشین، شما باید دستی ویژگیهایی مثل لبههای جاده یا خطکشیها را تعریف کنید. اما در یادگیری عمیق، مدل مستقیماً تصویر را میگیرد و خودش میفهمد فرمان چقدر باید بچرخد.
- نتیجه: یادگیری عمیق (DL) به دلیل پیچیدگی بصری، برنده مطلق است.
سناریوی دوم: تأیید وام بانکی 💰🏦
صورت مسئله: با داشتن سوابق مالی و اطلاعات شخصی، تشخیص دهید که آیا فرد واجد شرایط دریافت وام هست یا خیر.
- تحلیل پیشنهادی: اینجا دادهها عددی و متنی (جدولی) هستند. در این موارد، تفسیرپذیری (اینکه چرا وام رد شد) بسیار مهم است.
- نتیجه: یادگیری ماشین (ML) به دلیل دقت بالا در دادههای جدولی و شفافیت در پاسخگویی، گزینه بهتری است.
سناریوی سوم: ترجمه زبان (روسی به هندی)
صورت مسئله: ساخت سیستمی برای ترجمه فوری سخنرانی یک نماینده روسی برای مردم محلی هند.
- تحلیل پیشنهادی: ترجمه دستی با قوانین گرامری (ML) بسیار سخت و خشک است. اما شبکههای عصبی (مثل ترنسفورمرها) میتوانند لحن و معنای جملات را به زیبایی منتقل کنند.
- نتیجه: یادگیری عمیق (DL) در حوزه زبان (NLP) بیرقیب است.
آینده یادگیری ماشین و یادگیری عمیق
۱. هوش مصنوعی؛ شرط بقا: با توجه به سرعت خیرهکننده نفوذ علم داده در صنعت، شرکتهایی که از یادگیری ماشین در بیزنس خود استفاده نکنند، محکوم به فنا هستند. یادگیری اصول اولیه این حوزه، دیگر یک آپشن نیست، بلکه مثل دانستن زبان انگلیسی، یک ضرورت است.
۲. شگفتیهای روزانه: یادگیری عمیق هر روز با نتایج خیرهکنندهاش (مثل ChatGPT یا تولید تصاویر از متن) ما را غافلگیر میکند. این حوزه به دلیل ارائه بهترین عملکرد ممکن (State-of-the-art)، همچنان پیشتاز خواهد بود.
۳. از دانشگاه تا قلب صنعت: برعکس سالهای گذشته که تحقیقات فقط در آزمایشگاههای دانشگاهی حبس بود، امروزه شرکتهای بزرگ و آکادمی با بودجههای کلان در حال همکاری هستند. این انفجار بودجه و دانش، هوش مصنوعی را به محور اصلی توسعه بشریت تبدیل خواهد کرد.
جمع بندی
یادگیری ماشین و یادگیری عمیق هر دو ابزارهای ارزشمند هوش مصنوعی هستند، اما برای مسائل متفاوتی طراحی شدهاند. یادگیری ماشین معمولاً برای دادههای ساختیافته، حجم متوسط داده و مسائلی که تفسیرپذیری اهمیت دارد، گزینهای مناسب و کمهزینهتر است. در مقابل، یادگیری عمیق زمانی میدرخشد که با دادههای حجیم، پیچیده و بدون ساختار مانند تصویر، صدا و متن سروکار داریم و دقت بالا اولویت اصلی است.
تفاوت اصلی این دو رویکرد در نحوه استخراج ویژگیها، میزان وابستگی به داده، نیاز به منابع محاسباتی و پیچیدگی مدلهاست. یادگیری ماشین بیشتر به مهندسی ویژگی متکی است، در حالی که یادگیری عمیق تلاش میکند ویژگیها را بهصورت خودکار از دادهها یاد بگیرد.
در نهایت، پاسخ این سؤال که «یادگیری ماشین بهتر است یا یادگیری عمیق؟» به خود مسئله بستگی دارد، نه به محبوبیت فناوری. انتخاب آگاهانه میان این دو رویکرد، میتواند مسیر توسعه یک سیستم هوشمند را سادهتر، سریعتر و موفقتر کند—و دقیقاً همین شناخت است که یک تحلیلگر یا توسعهدهنده حرفهای را از دیگران متمایز میکند.



