
مقدمه
پرسپترون چندلایه یا Multilayer Perceptron (MLP) یکی از پایهایترین و در عین حال مهمترین مدلها در یادگیری ماشین و یادگیری عمیق است. بسیاری از مفاهیم کلیدی شبکههای عصبی—از لایهها و وزنها گرفته تا توابع فعالسازی و الگوریتم پسانتشار—برای نخستین بار در قالب MLP معنا پیدا میکنند. به همین دلیل، درک درست این مدل نقش مهمی در فهم عمیقتر معماریهای پیشرفتهتر مانند شبکههای کانولوشنی و بازگشتی دارد.
MLP معمولاً بهعنوان نقطه شروع یادگیری شبکههای عصبی شناخته میشود، اما این به معنی ساده یا کماهمیت بودن آن نیست. این مدل توانایی یادگیری روابط غیرخطی را دارد و در بسیاری از مسائل طبقهبندی و پیشبینی همچنان کاربردی است. درک این موضوع که MLP چگونه کار میکند، چه زمانی انتخاب مناسبی است و چه محدودیتهایی دارد، برای هر فردی که وارد دنیای یادگیری عمیق میشود ضروری است.
در این مقاله، بهصورت گامبهگام با پرسپترون چندلایه آشنا میشویم؛ از آمادهسازی دادهها و ساخت مدل گرفته تا آموزش، ارزیابی و بررسی چالشهایی مانند بیشبرازش. هدف این است که MLP را نه صرفاً بهعنوان یک مفهوم تئوریک، بلکه بهعنوان مدلی قابل استفاده در پروژههای واقعی بشناسیم.
تعریف
پرسپترون چندلایه (Multilayer Perceptron یا MLP) نوعی شبکه عصبی پیشخور است که از یک لایه ورودی، یک یا چند لایه پنهان و یک لایه خروجی تشکیل میشود. در این مدل، هر نورون به نورونهای لایه بعدی متصل است و با استفاده از توابع فعالسازی غیرخطی، امکان یادگیری روابط پیچیده میان دادهها فراهم میشود.
MLP با بهرهگیری از الگوریتم پسانتشار (Backpropagation) وزنها و بایاسها را بهصورت تدریجی بهروزرسانی میکند تا اختلاف بین خروجی پیشبینیشده و مقدار واقعی کاهش یابد. به دلیل ساختار ساده اما قدرتمند، پرسپترون چندلایه یکی از پایهایترین مدلها در یادگیری ماشین و نقطه شروع درک بسیاری از معماریهای پیشرفته شبکههای عصبی به شمار میرود.
چرا MLP برای همه چیز مناسب نیست؟
مدلهای MLP تلاش میکنند الگوهای موجود در دادهها را به خاطر بسپارند. به همین دلیل، برای پردازش دادههای چندبعدی (مثل تصاویر با وضوح بالا)، این شبکه به تعداد بسیار زیادی پارامتر نیاز دارد که میتواند منجر به سنگینی بیش از حد مدل شود.
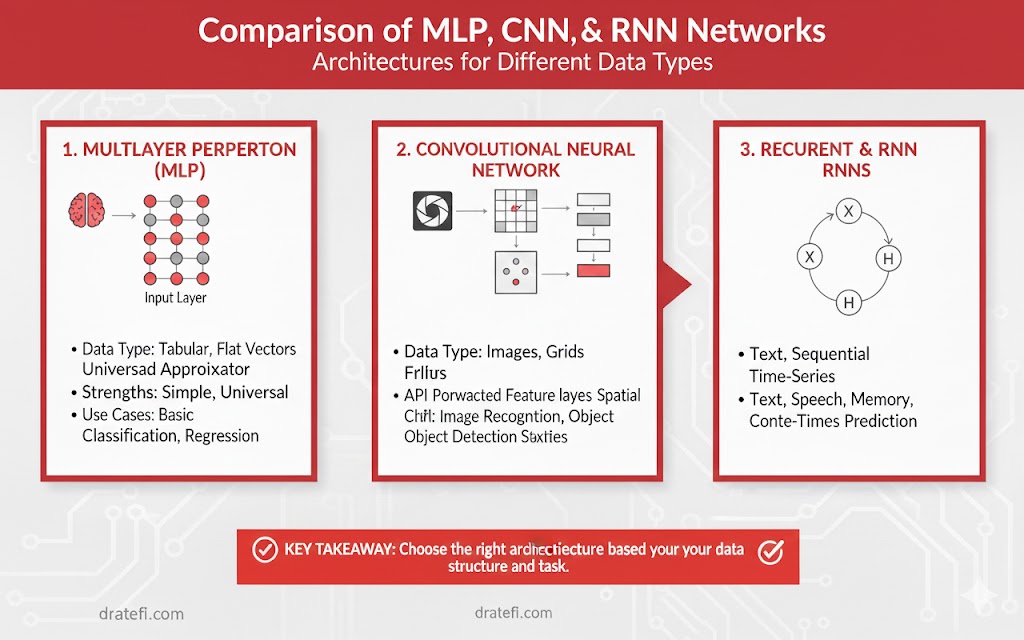
بیایید ببینیم برای دادههای خاص، چه جایگزینهایی وجود دارد:
- دادههای توالیمحور: برای دادههایی که ترتیب در آنها مهم است (مثل متن یا قیمت سهام)، شبکههای عصبی بازگشتی (RNNs) محبوبترین گزینه هستند. این شبکهها به دلیل ساختار خاص خود، وابستگی به دادههای تاریخی را کشف میکنند که برای پیشبینی بسیار حیاتی است.
- دادههای تصویری و ویدئویی: در این حوزه، شبکههای عصبی پیچشی (CNNs) پادشاهی میکنند. آنها در استخراج نقشههای ویژگی (Feature Maps) برای وظایفی مثل دستهبندی و قطعهبندی (Segmentation) تصاویر بینظیرند.
ترکیب برنده در یادگیری عمیق
در اکثر مدلهای مدرن یادگیری عمیق، متخصصان به جای استفاده از تنها یک نوع شبکه، ترکیبی از MLP، CNN و RNN را به کار میگیرند تا از نقاط قوت هر کدام بیشترین بهره را ببرند. برای مثال، ممکن است از یک CNN برای استخراج ویژگیهای تصویر استفاده شود و در لایههای نهایی، یک MLP برای تصمیمگیری و دستهبندی قرار گیرد.
فراتر از ساختار شبکه: پارامترهای حیاتی ⚙️
موفقیت یک مدل هوش مصنوعی فقط به نوع شبکه آن بستگی ندارد. انتخاب درست این سه پارامتر نقش تعیینکنندهای دارد:
- تابع زیان (Loss function): برای اندازهگیری میزان خطای پیشبینی.
- بهینهساز (Optimizer): برای تنظیم وزنها و کاهش خطا (مثل روش پسانتشار که قبلاً بررسی کردیم).
- تنظیمکننده (Regularizer): این بخش بسیار مهم است! وظیفه Regularizer این است که اطمینان حاصل کند مدل به جای حفظ کردن دادههای آموزشی، الگوها را یاد میگیرد تا بتواند روی دادههای جدید (خارج از محیط آموزش) نیز عملکرد خوبی داشته باشد.
دیتاست MNIST: سلام دنیا! در یادگیری عمیق 🔢✍️
تصور کنید هدف ما ساختن یک شبکه عصبی است که بتواند اعداد را از روی دستخط انسان شناسایی کند. برای مثال، وقتی تصویری از عدد 8 را به ورودی شبکه میدهیم، پیشبینی نهایی مدل نیز باید عدد 8 باشد.
این کار، در دنیای هوش مصنوعی یک پروژه کلاسیک در زمینه دستهبندی (Classification) محسوب میشود. برای شروع این مسیر، هیچ منبعی بهتر و معتبرتر از دیتاست MNIST نیست.

چرا MNIST اینقدر محبوب است؟
دیتاست MNIST که توسط مؤسسه ملی استاندارد و فناوری (NIST) تهیه شده، به عنوان Hello World! در دنیای یادگیری عمیق شناخته میشود. یعنی همانطور که برنامهنویسان اولین کد خود را با چاپ عبارت “Hello World” شروع میکنند، متخصصان هوش مصنوعی نیز اولین مدلهای خود را روی این دیتاست آزمایش میکنند.
دلایل اهمیت این دیتاست عبارتند از:
- حجم مناسب: این مجموعه شامل ۷۰,۰۰۰ تصویر از اعداد دستنویس است.
- سادگی و غنای اطلاعات: تصاویر بسیار کوچک هستند (معمولاً ۲۸ در ۲۸ پیکسل) اما اطلاعات کافی برای اثبات و اعتبارسنجی بسیاری از تئوریهای یادگیری عمیق را در خود دارند.
- استاندارد جهانی: به دلیل ساختار منظم، بهترین گزینه برای آموزش مدلهای پرسپترون چندلایه (MLP) است.

مجموعه داده MNIST شامل تصاویری از اعداد ۰ تا ۹ است که به دو بخش اصلی تقسیم میشود: یک مجموعه آموزشی شامل ۶۰,۰۰۰ تصویر برای یادگیری مدل و یک مجموعه آزمایشی (Test Set) شامل ۱۰,۰۰۰ تصویر برای سنجش میزان دقت و هوش مدل پس از آموزش.
استفاده از این دیتاست در کتابخانه TensorFlowبسیار ساده و لذتبخش است، زیرا به صورت پیشفرض در مخازن آن تعبیه شده است.
ساختار تصاویر در MNIST
هر تصویر در این مجموعه، یک عکس سیاه و سفید کوچک با ابعاد ۲۸ در ۲۸ پیکسل است. در دنیای کامپیوتر، این عکس چیزی جز یک ماتریس عددی نیست که هر عدد در آن نشاندهنده شدت روشنایی یک پیکسل (از ۰ برای سیاه تا ۲۵۵ برای سفید) است.
آمادهسازی دادهها برای شبکه عصبی (Pre-processing)
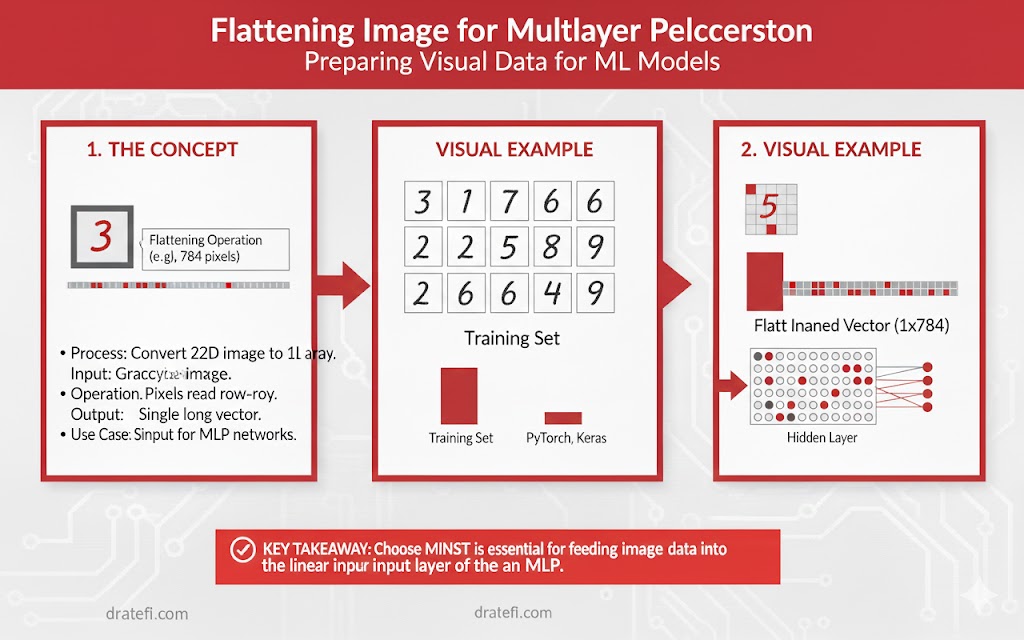
قبل از اینکه دادهها را به خورد شبکه عصبی بدهیم، انجام دو مرحله زیر برای بهبود کارایی مدل ضروری است:
- نرمالسازی: مقادیر پیکسلها را از بازه [۰, ۲۵۵] به بازه [۰, ۱] تغییر میدهیم. این کار باعث میشود فرآیند پسانتشار با سرعت و پایداری بیشتری انجام شود.
- تختسازی: برای یک شبکه پرسپترون چندلایه (MLP)، ماتریس ۲۸×۲۸ باید به یک بردار تکبعدی با ۷۸۴ ورودی (۲۸ × ۲۸ = ۷۸۴) تبدیل شود.
پیادهسازی در پایتون (با استفاده از TensorFlow)
import numpy as np
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
همانطور که اشاره کردید، متد mnist.load_data() یکی از کاربردیترین ابزارها در تنسورفلو است؛ زیرا شما را از چالشهای بارگذاری دستی ۷۰,۰۰۰ فایل تصویر و برچسبهای آنها خلاص میکند.
با این حال، یک نکته بسیار حیاتی قبل از شروع کار با پرسپترون چندلایه (MLP) وجود دارد: دادههای MNIST به صورت تانسورهای دوبعدی (ماتریسهای ۲۸×۲۸) هستند، اما لایه ورودی یک MLP نمیتواند ماتریس را به همان شکل دریافت کند. ما باید دادهها را بسته به نوع شبکه، تغییر شکل یا Reshape کنیم.
تغییر شکل دادهها (Reshaping) برای مدلهای مختلف
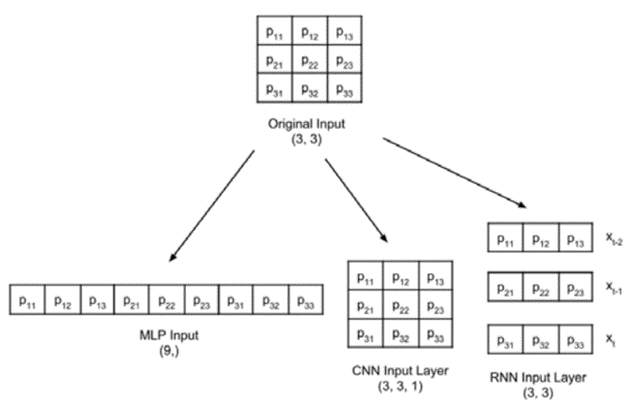
بیایید فرض کنیم یک تصویر کوچک خاکستری (Grayscale) با ابعاد ۳×۳ داریم. نحوه آمادهسازی این تصویر برای ۳ نوع شبکه اصلی متفاوت است:
۱. برای پرسپترون چندلایه (MLP)
در MLP، ورودی باید به صورت یک بردار تکبعدی باشد. به این فرآیند Flattening یا تختسازی میگویند.
- روش کار: پیکسلهای ردیف اول، دوم و سوم پشت سر هم قرار میگیرند.
- مثال: یک تصویر ۳×۳ تبدیل به یک بردار با ۹ ورودی میشود. در مورد MNIST، تصویر ۲۸×۲۸ به یک بردار ۷۸۴ تایی تبدیل میشود.
۲. برای شبکههای عصبی پیچشی (CNN)
شبکههای CNN برخلاف MLP، ساختار فضایی و دوبعدی تصویر را حفظ میکنند، اما نیاز دارند که تعداد کانالهای رنگی نیز مشخص باشد.
- روش کار: دادهها باید به صورت (Height, Width, Channels) تغییر شکل یابند.
- مثال: برای تصاویر MNIST که تکرنگ (خاکستری) هستند، ابعاد به (1, 28, 28) تبدیل میشود. اگر تصویر رنگی بود، عدد آخر ۳ میشد.
۳. برای شبکههای عصبی بازگشتی (RNN)
در RNN، دادهها به صورت متوالی (Sequential) پردازش میشوند.
- روش کار: تصویر به صورت ردیف به ردیف (یا ستون به ستون) در طول زمان به شبکه داده میشود.
- مثال: تصویر ۲۸×۲۸ به صورت ۲۸ گام زمانی (Timesteps) که هر کدام دارای ۲۸ ویژگی (Features) هستند، به مدل تزریق میشود.
همانطور که اشاره کردید، برچسبها (Labels) در دیتاست MNIST به صورت اعداد صحیح از ۰ تا ۹ هستند. با این حال، در دنیای یادگیری عمیق، استفاده مستقیم از این اعداد برای لایه خروجی یک شبکه عصبی (بهویژه در مدلهای دستهبندی) بهترین استراتژی نیست.
num_labels = len(np.unique(y_train))
print("total de labels:t{}".format(num_labels))
print("labels:ttt{0}".format(np.unique(y_train)))
نمایش مستقیم اعداد (مثلاً عدد ۴) برای لایه پیشبینی که وظیفه تولید احتمال برای هر کلاس را دارد، اصلاً مناسب نیست. لایههای نهایی شبکههای عصبی معمولاً با بردارها بهتر صحبت میکنند.
در ادامه، این مفاهیم را از منظر فنی و با نگاهی به ساختارهای دادهای در پایتون بازنویسی میکنیم:
۱. کُدگذاری تک-فعال (One-Hot Encoding): زبان احتمالات
در شبکههای عصبی عمیق، خروجی مدل معمولاً از تابعی به نام Softmax عبور میکند که خروجی آن مجموعهای از احتمالات است. برای اینکه بتوانیم این احتمالات را با واقعیت مقایسه کنیم، باید برچسبهای خود را به فرمت کُدگذاری تک-فعال تبدیل کنیم.
- ساختار: یک بردار ۱۰ بعدی (برای اعداد ۰ تا ۹) که تمام مقادیر آن ۰ است، بهجز جایگاهی که مربوط به کلاس مورد نظر است که مقدار ۱ میگیرد.
- مثال: اگر تصویر ورودی عدد ۴ باشد، برچسب آن به این صورت در میآید:
[0, 0, 0, 0, 1, 0, 0, 0, 0, 0] (خانه پنجم از چپ که اندیس آن ۴ است، فعال میشود).
۲. تانسور (Tensor): واحد بنیادین ذخیرهسازی داده 📦🧠
در یادگیری عمیق، تمام دادهها (از ورودیها گرفته تا وزنها و برچسبها) در ساختارهایی به نام تانسور ذخیره میشوند. تانسور در واقع تعمیمی از مفاهیم ریاضی برای فضاهای چندبعدی است:
| نوع تانسور | اصطلاح فنی | توصیف ساده |
| تانسور 0D | اسکالر (Scalar) | یک عدد تک و تنها (مثلاً ۱۷) |
| تانسور 1D | بردار (Vector) | یک لیست از اعداد (مثل بردار کُدگذاری تک-فعال) |
| تانسور 2D | ماتریس (Matrix) | یک جدول از اعداد (مثل یک تصویر سیاه و سفید) |
| تانسور 3D | تانسور سهبعدی | مجموعهای از ماتریسها (مثل یک تصویر رنگی RGB) |
| تانسور ND | تانسور چندبعدی | ساختارهای پیچیدهتر برای دادههای حجیم یا ویدئویی |
#converter em one-hot
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
از آنجایی که مدل ما یک پرسپترون چندلایه(MLP) است، ورودیهای شما حتماً باید به صورت یک تانسور تکبعدی (1D) باشند. به همین دلیل، دادههای x_train و x_test باید به ابعاد زیرتغییر شکل (Transform) یابند.
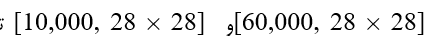
در کتابخانه NumPy، قرار دادن مقدار 1- برای اندازه (Size)، به این معناست که به کتابخانه اجازه میدهید بعد صحیح را خودش به صورت خودکار محاسبه کند. در مورد دادههای x_train این مقدار برابر با ۶۰,۰۰۰ خواهد بود.
image_size = x_train.shape[1]
input_size = image_size * image_size
print("x_train:t{}".format(x_train.shape))
print("x_test:tt{}n".format(x_test.shape))
x_train = np.reshape(x_train, [-1, input_size])
x_train = x_train.astype('float32') / 255
x_test = np.reshape(x_test, [-1, input_size])
x_test = x_test.astype('float32') / 255
print("x_train:t{}".format(x_train.shape))
print("x_test:tt{}".format(x_test.shape))
خروجی:

ساخت مدل
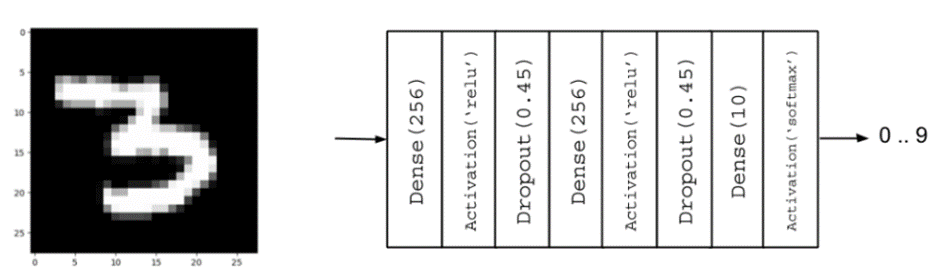
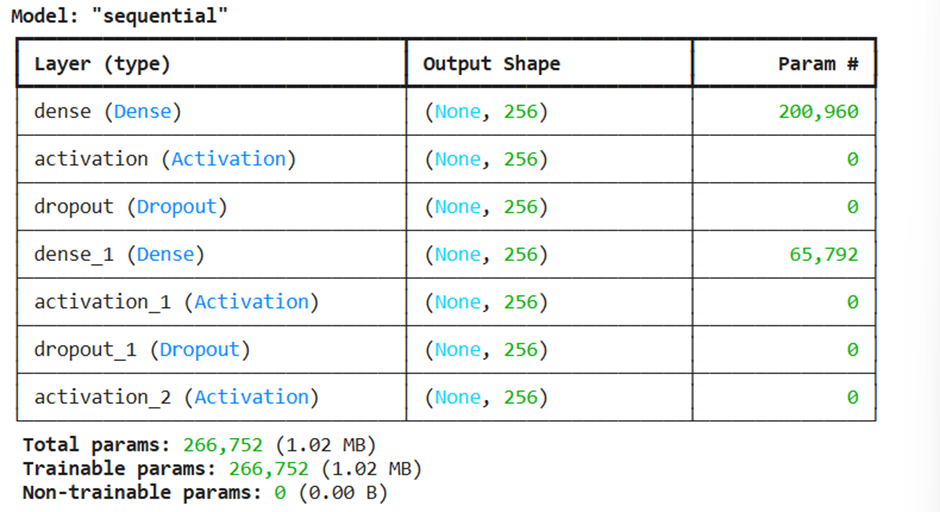
مدل ما از سه لایه پرسپترون چندلایه (MLP) در قالب لایههای Dense (متراکم) تشکیل شده است. لایههای اول و دوم کاملاً مشابه یکدیگر هستند و پس از هر کدام، از تابع فعالسازی ReLU (واحد خطی اصلاحشده) و لایهی Dropout (برای جلوگیری از بیشبرازش) استفاده شده است.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation, Dropout
# Parameters
batch_size = 128 # It is the sample size of inputs to be processed at each training stage.
hidden_units = 256
dropout = 0.45
# Nossa MLP com ReLU e Dropout
model = Sequential()
model.add(Dense(hidden_units, input_dim=input_size))
model.add(Activation('relu'))
model.add(Dropout(dropout))
model.add(Dense(hidden_units))
model.add(Activation('relu'))
model.add(Dropout(dropout))
model.add(Dense(num_labels))
تنظیمکننده (Regularization): جلوگیری از حافظهمحوری مدل
یک شبکه عصبی تمایل زیادی دارد که دادههای آموزشی را به جای یادگیری الگوها، صرفاً حفظ کند؛ بهویژه اگر ظرفیت شبکه (تعداد نورونها و لایهها) بیش از حد نیاز باشد. در این حالت، شبکه روی دادههای تمرینی عالی عمل میکند، اما هنگام مواجهه با دادههای آزمایشی (دادههای جدید) با شکستی فاجعهبار روبرو میشود.
این همان وضعیت کلاسیکی است که مدل در تعمیمدهی (Generalization) شکست میخورد که به آن بیشبرازش (Overfitting) یا در برخی موارد کمبرازش (Underfitting) میگوییم. برای جلوگیری از این روند، مدل از یک لایهی تنظیمکننده به نام Dropout استفاده میکند.
لایه Dropout: قدرت در غیاب نورونها
ایده Dropout بسیار ساده اما هوشمندانه است. با تعیین یک نرخ حذف (که در مدل ما برابر با ۰.۴۵ تنظیم شده است)، این لایه به صورت تصادفی این بخش از واحدها (نورونها) را در هر تکرار حذف میکند.
- مثال عددی: اگر لایه اول دارای ۲۵۶ واحد باشد، پس از اعمال Dropout با نرخ ۰.۴۵، تنها (1 – 0.45) ✕ 256 = 140 واحد در مرحله بعد مشارکت میکنند.
- چرا این کار مفید است؟ Dropout باعث میشود شبکه عصبی در برابر دادههای ورودی پیشبینینشده مقاومتر (Robust) شود؛ زیرا شبکه آموزش میبیند که حتی در صورت غیاب برخی واحدها، پیشبینی درستی انجام دهد. این کار مانع از وابستگی شدید شبکه به نورونهای خاص میشود.
- نکته: لایه Dropout فقط در طول فرآیند آموزش (Training) فعال است و هنگام تست یا استفاده نهایی از مدل، تمام نورونها وارد بازی میشوند.
تابع فعالسازی لایه خروجی: Softmax
لایه خروجی مدل ما دارای ۱۰ واحد است که پس از آن تابع فعالسازی Softmax قرار میگیرد. این ۱۰ واحد دقیقاً متناظر با ۱۰ برچسب یا کلاس ممکن (اعداد ۰ تا ۹ در دیتاست MNIST) هستند.
تابع Softmax خروجیهای خام شبکه را به احتمالات تبدیل میکند، بهطوری که مجموع احتمال تمام کلاسها برابر با ۱ شود. فرمول ریاضی این تابع به شرح زیر است:
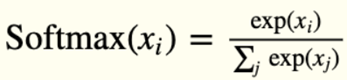
model.add(Activation('softmax'))
model.summary()
خروجی:
بهینهسازی و تجسم مدل (Model Visualization Optimization)
هدف نهایی از (Optimization) در یک شبکه عصبی، به حداقل رساندن تابع زیان (Loss Function) است. ایده اصلی ساده است: اگر بتوانیم میزان خطا یا همان زیان را به سطح قابلقبولی کاهش دهیم، مدل به صورت غیرمستقیم یاد گرفته است که چگونه ورودیها را به خروجیهای درست نگاشت (Map) کند.
برای اینکه متوجه شویم آیا مدل ما واقعاً در حال یادگیری است یا صرفاً در حال تکرار اشتباهات، از معیارهای عملکرد استفاده میکنیم.
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])پس از اینکه تمام قطعات پازل یعنی معماری شبکه، نوع دادهها و تنظیمکنندهها را انتخاب کردیم، حالا نوبت به موتور محرک شبکه عصبی میرسد. برای شروع فرآیند آموزش، باید سه ستون اصلی یادگیری را تعریف کنیم:
۱. تابع زیان (Loss Function): انتروپی متقاطع دستهای 📉
از آنجایی که ما برچسبهای خود را به صورت کُدگذاری تک-فعال (One-Hot Encoding) آماده کردهایم، بهترین انتخاب برای تابع زیان، Categorical Crossentropy است.
- کارکرد: این تابع میزان تفاوت بین دو توزیع احتمال را اندازه میگیرد؛ یعنی توزیع احتمالی که مدل پیشبینی کرده و توزیع واقعی که در بردار کُدگذاری تک-فعال (با یک ۱ و نُه ۰) وجود دارد. هرچه این تفاوت کمتر باشد، مدل ما دقیقتر است.
۲. معیار عملکرد (Metric): دقت (Accuracy)
برای اینکه بفهمیم مدل ما چقدر در دنیای واقعی خوب عمل میکند، از معیار Accuracy استفاده میکنیم.
- چرا این معیار؟ در مسائل دستهبندی (Classification)، این سادهترین و گویاترین راه برای فهمیدن این است که چند درصد از تصاویر )مثلاً اعداد دستنویس MNIST) به درستی تشخیص داده شدهاند.
۳. بهینهساز (Optimizer): الگوریتم آدام (Adam)
الگوریتم Adam یکی از محبوبترین و قدرتمندترین بهینهسازها در یادگیری عمیق مدرن است.
- تفاوت با SGD: برخلاف روش کلاسیک گرادیان کاهشی تصادفی (SGD) که نرخ یادگیری ثابتی دارد، Adam نرخ یادگیری را برای هر وزن به صورت هوشمند و مجزا تنظیم میکند (Adaptive Learning Rate). این کار باعث میشود مدل خیلی سریعتر و پایدارتر به کمترین میزان خطا برسد.
شروع فرآیند آموزش (Training Time)
حالا با داشتن این انتخابها، همهچیز آماده است. ما با فراخوانی دستور آموزش، دادههای تمرینی را به شبکه میدهیم. مدل با استفاده از پسانتشار (Backpropagation) و بهینهساز Adam، وزنها را لایه به لایه اصلاح میکند تا مقدار Categorical Crossentropy به حداقل برسد.
model.fit(x_train, y_train, epochs=20, batch_size=batch_size)خروجی:

ارزیابی نهایی:سنجش عیار مدل
در این مرحله، ساخت مدل تشخیص اعداد MNIST ما به پایان رسیده است. اما اتمام فرآیند آموزش، به معنای اتمام پروژه نیست. گام حیاتی بعدی، ارزیابی عملکرد (Performance Evaluation) است. این مرحله مشخص میکند که آیا مدل آموزشدیده ما یک راهکار بهینه است یا با یک راهکار زیرِ بهینه (Sub-optimal) روبرو هستیم که در دنیای واقعی کاربردی ندارد.
_, acc = model.evaluate(x_test,
y_test,
batch_size=batch_size,
verbose=0)
print("nAccuracy: %.1f%%n" % (100.0 * acc))
خروجی:
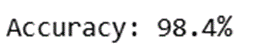
جمع بندی
پرسپترون چندلایه یکی از بنیادیترین مدلهای شبکه عصبی است که نقش مهمی در یادگیری مفاهیم اصلی یادگیری عمیق ایفا میکند. این مدل با استفاده از لایههای متصل به هم و توابع فعالسازی غیرخطی، قادر است الگوهای پیچیده را از دادهها یاد بگیرد و در مسائل مختلف عملکرد قابل قبولی ارائه دهد.
با وجود توانمندیهای MLP، این مدل محدودیتهایی نیز دارد؛ از جمله حساسیت به ساختار دادهها و عملکرد ضعیفتر روی دادههای تصویری و ترتیبی در مقایسه با معماریهای تخصصیتر مانند CNN و RNN. به همین دلیل، شناخت زمان مناسب استفاده از MLP بهاندازه یادگیری نحوه پیادهسازی آن اهمیت دارد.
در نهایت، تسلط بر پرسپترون چندلایه پایهای محکم برای ورود به دنیای شبکههای عصبی پیشرفتهتر ایجاد میکند. اگر بتوانید MLP را بهدرستی درک و پیادهسازی کنید، یادگیری معماریهای پیچیدهتر نهتنها سادهتر، بلکه منطقیتر و هدفمندتر خواهد شد—و این دقیقاً همان نقطهای است که یادگیری عمیق معنا پیدا میکند.



