
مقدمه
در قلب هر مدل یادگیری ماشین، یک پرسش اساسی وجود دارد:
چگونه میتوان پارامترهای مدل را طوری تنظیم کرد که کمترین میزان خطا را داشته باشد؟
پاسخ این سؤال ما را به یکی از بنیادیترین و پراستفادهترین الگوریتمهای دنیای هوش مصنوعی میرساند: الگوریتم گرادیان کاهشی (Gradient Descent) .
گرادیان کاهشی مکانیزمی است که با اصلاح تدریجی پارامترها، مدل را گامبهگام به سمتی هدایت میکند که اختلاف میان پیشبینیها و مقادیر واقعی کاهش یابد. این الگوریتم نهتنها پایهی بسیاری از مدلهای کلاسیک یادگیری ماشین است، بلکه ستون فقرات آموزش شبکههای عصبی و یادگیری عمیق نیز به شمار میرود.
در این مقاله، گرادیان کاهشی را از سطح شهودی تا ریاضی و سپس در کاربردهای واقعی بررسی میکنیم. با استفاده از مثالهای ملموس، تحلیل هندسی تابع هزینه و بررسی نقش مشتقها، تلاش شده است این الگوریتم نه بهعنوان یک فرمول انتزاعی، بلکه بهعنوان یک فرآیند یادگیری قابلدرک و تصمیمساز معرفی شود.
تعریف
اگر بخواهیم این مفهوم را به صورت علمی بیان کنیم:
- الگوریتم بهینهسازی: بهینهسازی هسته مرکزی هر الگوریتم یادگیری ماشین است. گرادیان کاهشی یک الگوریتم بهینهسازی تکرارشونده (Iterative) از مرتبه اول است.
- یافتن کمینه محلی(Local Minimum): هدف اصلی این الگوریتم، پیدا کردن پایینترین نقطه یا همان “کمینه محلی” در یک تابع مشتقپذیر است. در یادگیری ماشین، این پایینترین نقطه جایی است که خطای مدل ما به حداقل رسیده است.
- کاهش گامبهگام هزینه: در هر مرحله یا تکرار (Iteration)، الگوریتم تلاش میکند پارامترها را طوری تغییر دهد که مقدار تابع هزینه نسبت به مرحله قبل کاهش یابد.
چرا به آن “مرتبه اول” میگوییم؟
این بخش را به متن خود اضافه کنید تا عمق علمی مقاله افزایش یابد: در ریاضیات، الگوریتمهای “مرتبه اول” فقط از مشتق اول تابع (شیب) برای پیدا کردن مسیر استفاده میکنند. گرادیان کاهشی با محاسبه شیب در نقطه فعلی، میفهمد که باید به کدام سمت حرکت کند تا سریعتر به پایین دره (خطای کمتر) برسد.
مثال: بازی پرتاب توپ در سبد
تصور کنید میخواهید توپی را در سبد بیندازید:
- در تلاش اول، با نیروی کمی پرتاب میکنید و توپ قبل از سبد میافتد (خطای مثبت).
- در تلاش دوم، نیرو را زیاد میکنید و توپ از سبد عبور میکند (خطای منفی).
- گرادیان کاهشی دقیقاً مثل مغز شما عمل میکند؛ تفاوت پرتابها را میسنجد و در تکرار بعدی، نیرو را طوری تنظیم میکند که توپ دقیقاً در سبد بنشیند.
کالبدشکافی مدل خطی و هندسه یادگیری
برای اینکه بفهمیم گرادیان کاهشی چه چیزی را تغییر میدهد، باید ابتدا ساختار مدلی که قرار است بهینه شود را بشناسیم. در اینجا از رگرسیون خطی که سنگبنای یادگیری ماشین است، استفاده میکنیم.
۱. آناتومی معادله رگرسیون
معادلهای که مدل ما بر اساس آن پیشبینی میکند، به شرح زیر است:
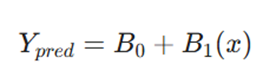
در این معادله کلیدی:
- Y_pred: خروجی پیشبینی شده توسط مدل است.
- B0: عرض از مبدأ (Intercept) است.
- B1: شیب خط (Slope) است.
- x: مقدار ورودی یا متغیر مستقل است.
- B0 و B1: به عنوان ضرایب یا پارامترهای مدل شناخته میشوند که باید توسط الگوریتم بهینه شوند.
۲. تابع هزینه:
در مدلهای خطی، ما با یک مفهوم ریاضی به نام تابع هزینه محدب (Convex Cost Function) روبرو هستیم.
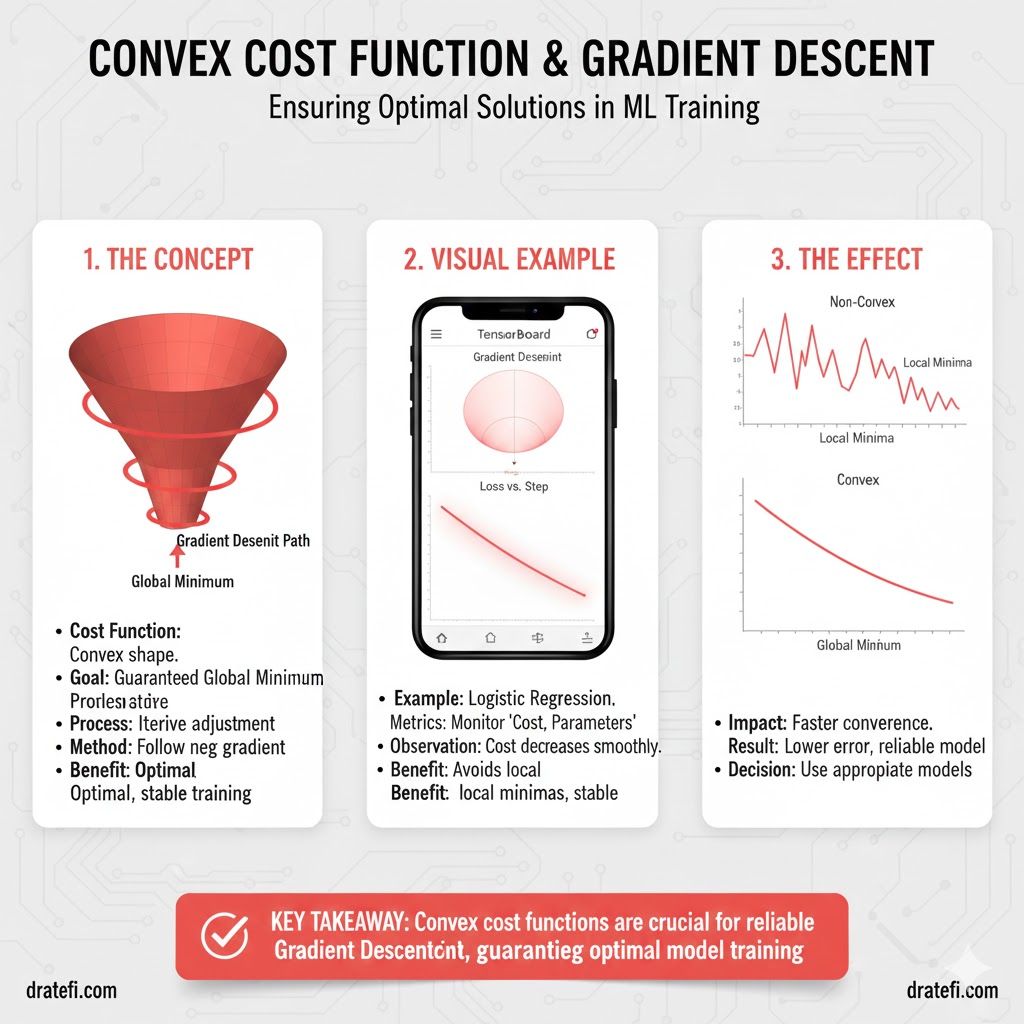
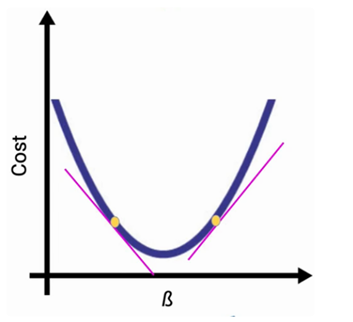
- تصویر بصری: این تابع در فضای هندسی دقیقاً شبیه به یک کاسه است.
- مفهوم ارتفاع: در این کاسه، “ارتفاع” نشاندهنده میزان خطا است. هرچه بالاتر باشید، خطای مدل بیشتر است و هرچه به تهِ کاسه نزدیکتر شوید، مدل شما دقیقتر عمل میکند.
۳. نقشه راه یادگیری مدل
الگوریتم برای رسیدن به کفِ این کاسه، مراحل زیر را طی میکند:
- شروع تصادفی: مدل در ابتدا هیچ ایدهای ندارد؛ بنابراین مقادیری کاملاً تصادفی به B0 و B1 اختصاص میدهد. این کار مثل این است که شما را با چشمبسته در نقطهای نامعلوم از لبهی آن کاسه رها کنند.
- پیشبینی اولیه: با همان مقادیر تصادفی، مدل اولین حدس خود را میزند.
- محاسبه خطا (سنجش فاصله تا واقعیت) : در این مرحله، تفاوت بین حدس مدل و واقعیت محاسبه میشود. این تفاوت به ما میگوید که در کجای دیوارهی کاسه ایستادهایم.
- حرکت استراتژیک روی منحنی: حالا هدف این است که از دیوارهها پایین بیاییم. گرادیان کاهشی با اصلاح هوشمندانه B0 و B1، ما را به سمت پایینترین نقطه (حداقل خطا یا Global Minimum) هدایت میکند.
مکانیسم یادگیری؛ از خطا تا اصلاح پارامترها
اکنون زمان آن است که پردهها را کنار بزنیم و ببینیم گرادیان کاهشی در پشت صحنه چگونه پارامترهای مدل را تنظیم میکند. ما از مدل رگرسیون خطی به عنوان “مدل پایه” (Baseline) استفاده میکنیم تا فرآیند بهینهسازی را به وضوح مشاهده کنیم.
۱. گام اول: مقداردهی اولیه و تولید پیشبینی
در یادگیری ماشین، داشتن یک مدل پایه برای سنجش میزان پیشرفت ضروری است. ما کار را با مقادیر زیر شروع میکنیم:
در یادگیری ماشین، داشتن یک مدل پایه (Baseline) برای سنجش میزان پیشرفت ضروری است. در این مرحله، ما پارامترهای خط را به صورت زیر مقداردهی میکنیم:
- پارامتر β (شیب خط): مقدار آن را برابر با ۰ قرار میدهیم.
- پارامتر b (عرض از مبدأ): مقدار آن را برابر با میانگین تمام متغیرهای مستقل در نظر میگیریم.
با این تنظیمات، اولین پیشبینی مدل (^Y) یک خط افقی ساده خواهد بود:
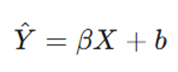
در این معادله، ^Y همان مقدار پیشبینی شده برای هدف (مثلاً حقوق یا Salary) بر اساس تجربه (Experience) است.
مثال: پیشبینی حقوق بر اساس تجربه
در نمودار تجربه و حقوق، چون شیب اولیه صفر است، مدل فرض میکند تجربه هیچ تأثیری روی حقوق ندارد و به همه حقوقی معادل میانگین کل میدهد. فاصله نقاط آبی (واقعیت) تا این خط نارنجی، همان خطایی است که باید کاهش یابد.
۲. گام دوم: محاسبه خطا با معیار MSE
برای اینکه بفهمیم مدل چقدر با واقعیت فاصله دارد، از میانگین مربعات خطا (MSE) استفاده میکنیم. این شاخص میانگینِ مجذورِ تفاوت بین پیشبینی و واقعیت است
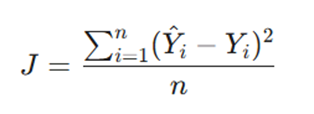
- Y^_i: مقداری که مدل پیشبینی کرده است.
- Y_i: مقدار واقعی موجود در دادهها.
- n: تعداد کل دادهها.
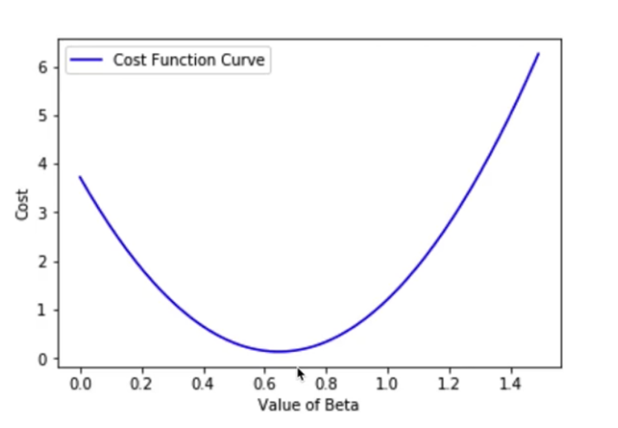
- چرا توان ۲؟ چون میخواهیم خطاها همیشه مثبت باشند و خطاهای بزرگتر، جریمه سنگینتری دریافت کنند.
- موقعیت روی منحنی: اگر مقدار J زیاد باشد، ما در لبههای بالایی منحنی هزینه هستیم. هدف ما لغزیدن به سمت کمینه مطلق (Global Minimum) یا همان کف دره است.
مثال: پیشبینی قیمت مسکن
فرض کنید مدلی دارید که قیمت خانهها را بر اساس متراژ تخمین میزند.
- پیشبینی مدل: ۵ میلیارد تومان.
- قیمت واقعی: ۴.۸ میلیارد تومان.
- خطا: ۲۰۰ میلیون تومان.
گرادیان کاهشی با استفاده از فرمول MSE، مجموع این خطاها را برای تمام خانهها حساب میکند. اگر ببینیم میانگین خطا زیاد است، متوجه میشویم که باید وزنهای مدل (مثلاً تأثیر هر متر مربع بر قیمت) را اصلاح کنیم.
۳. گام سوم: بهروزرسانی پارامترها با مشتقات جزئی
چگونه بفهمیم وزنها را زیاد کنیم یا کم؟ پاسخ در مشتقات جزئی است.
- نقش مشتق: مشتق جزئی، شیب خط مماس بر منحنی هزینه را به ما میدهد که همان گرادیان است.
- تعیین جهت*: اگر شیب منفی باشد، پارامتر را افزایش میدهیم.
- اگر شیب مثبت باشد، پارامتر را کاهش میدهیم تا به سمت پایین حرکت کنیم
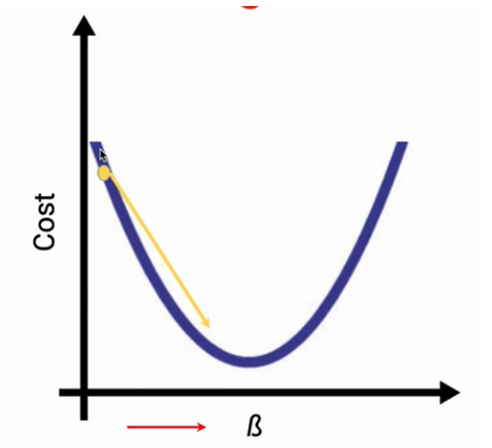
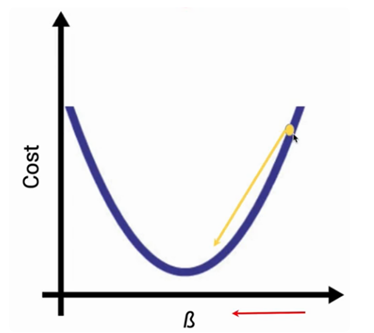
۴. گام چهارم: انتشار بازگشتی و نرخ یادگیری
کل فرآیند اصلاح وزنها، انتشار بازگشتی (Backpropagation) نام دارد. فرمول نهایی بهروزرسانی برای شیب (β) و عرض از مبدأ (b) به این صورت است.
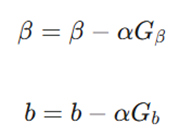
که در آن گرادیان به صورت زیر محاسبه میشود:
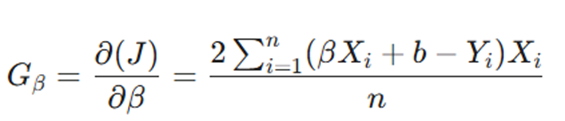
- نرخ یادگیری(α): این یک هایپرپارامتر حیاتی است که سرعت یادگیری یا همان اندازه قدمها را تعیین میکند.
- اهمیت نرخ یادگیری بهینه: اگر α خیلی بزرگ باشد، ممکن است از روی کمینه (Minima) بپریم و مدل هرگز همگرا نشود.
در اینجا نرخ یادگیری (α) یا همان “اندازه قدمها” بسیار حیاتی است:
- اگر α خیلی بزرگ باشد: ممکن است از روی نقطه بهینه بپریم و مدل هرگز همگرا نشود.
- اگر α خیلی کوچک باشد: رسیدن به کمترین خطا بسیار زمانبر و کند خواهد بود.
مزایای کلیدی: چرا انتخاب اول متخصصان است؟
- انعطافپذیری در توابع پیچیده: این الگوریتم محدود به مدلهای ساده نیست و میتواند تقریباً روی هر تابع هزینهای که مشتقپذیر باشد (Differentiable) اعمال شود.
- مقیاسپذیری بینظیر: برخلاف روشهای حل مستقیم ریاضی که با افزایش دادهها به صورت انفجاری کند میشوند، گرادیان کاهشی با استفاده از روش Mini-batch میتواند میلیاردها داده را بدون فشار بیش از حد به حافظه سیستم پردازش کند.
- پایداری در یادگیری عمیق: این الگوریتم ستون فقرات شبکه های عصبی است که اجازه میدهد میلیونها پارامتر به صورت همزمان و هماهنگ بهروزرسانی شوند.
- سادگی و شفافیت منطقی: حرکت در جهت مخالف شیب برای رسیدن به دره، منطقی است که به راحتی توسط توسعهدهندگان درک و عیبیابی (Debug) میشود.
- سازگاری با سختافزار: محاسبات گرادیان به گونهای است که به راحتی روی پردازندههای گرافیکی (GPU) موازیسازی میشود و سرعت آموزش را صدها برابر میکند.
معایب و چالشهای فنی: نقاط کور الگوریتم
- حساسیت شدید به نرخ یادگیری(α): انتخاب نادرست این عدد فاجعهبار است؛ اگر خیلی کوچک باشد، مدل هفتهها در حال آموزش باقی میماند و اگر خیلی بزرگ باشد، مدل دچار «انفجار گرادیان» شده و هرگز به جواب نمیرسد.
- کمینههای محلی و نقاط زینی: در توابع غیرمحدب، الگوریتم ممکن است در یک گودال اشتباه (Local Minimum) گیر بیفتد و تصور کند به بهترین جواب رسیده است، در حالی که نقطه بهینه مطلق (Global Minimum) در جای دیگری است.
- وابستگی شدید به پیشپردازش: اگر ویژگیهای ورودی هممقیاس نباشند (مثلاً یکی سن فرد و دیگری درآمد میلیونی باشد)، منحنی هزینه کشیده میشود و الگوریتم به جای حرکت مستقیم به سمت پایین، به صورت زیگزاگی و بسیار کند حرکت میکند.
- عدم تضمین در توابع غیرمشتقپذیر: اگر تابع هزینه در نقطهای شکستگی داشته باشد، محاسبات ریاضی گرادیان با شکست مواجه میشود.
- توقف در فلاتهای تخت: در مناطقی از تابع که شیب تقریباً صفر است، سرعت حرکت الگوریتم به قدری کم میشود که به نظر میرسد متوقف شده است.
مطالعه موردی: سیستم پیشنهاددهنده نتفلیکس (Netflix)
بیایید ببینیم گرادیان کاهشی چطور ذائقه شما را حدس میزند. فرض کنید نتفلیکس میخواهد امتیاز شما به فیلم “Interstellar” را پیشبینی کند:
- مسئله: میلیونها کاربر و هزاران فیلم وجود دارد. ورودیها با کُدگذاری تک-فعال (One-Hot Encoding) مشخص میشوند تا مشخص شود دقیقاً کدام کاربر با کدام فیلم در حال تعامل است.
- فرآیند یادگیری:
- مدل ابتدا یک امتیاز تصادفی (مثلاً ۲ از ۵) حدس میزند.
- خطا محاسبه میشود (مثلاً شما ۵ دادهاید، پس خطا ۳ است).
- گرادیان کاهشی وارد عمل شده و وزنهای مربوط به علایق شما (مثل ژانر علمی-تخیلی) را در جهت کاهش این خطا آپدیت میکند.
- پس از میلیونها تکرار، مدل یاد میگیرد که ترکیب شما و این ژانر، همیشه منجر به امتیاز بالا میشود.
کاربردها در صنعت مدرن
این الگوریتم در لایه زیرین بسیاری از فناوریهایی است که روزانه استفاده میکنید:
- پزشکی و تشخیص بیماری: در رادیولوژی، برای آموزش مدلهایی که تومورها را در تصاویر MRI تشخیص میدهند، از گرادیان کاهشی برای به حداقل رساندن خطای تشخیص بین بافت سالم و سرطانی استفاده میشود.
- خودروهای خودران: این خودروها باید در میلیثانیه تصمیم بگیرند. گرادیان کاهشی به بهینهسازی توابع کنترلی کمک میکند تا خودرو کمترین انحراف از مسیر و بیشترین فاصله ایمن با موانع را داشته باشد.
- پردازش زبان طبیعی: برای اینکه یک هوش مصنوعی بتواند جمله بعدی را به درستی حدس بزند، میلیاردها پارامتر توسط نسخههای پیشرفته گرادیان کاهشی تنظیم میشوند تا احتمال تولید کلمات نادرست به حداقل برسد.
- هواشناسی و پیشبینی اقلیم: مدلهای جوی پیچیده از این الگوریتم برای تطبیق دادههای سنسورها با مدلهای فیزیکی استفاده میکنند تا دقیقترین پیشبینی بارندگی را ارائه دهند.
- تجارت الکترونیک و قیمتگذاری پویا: وبسایتهای بزرگ از گرادیان کاهشی برای پیدا کردن “نقطه شیرین” قیمتگذاری استفاده میکنند؛ جایی که بیشترین فروش با بیشترین سود ممکن ترکیب شود.
- امنیت سایبری: برای شناسایی الگوهای نفوذ و حملات هکری، مدلهای تشخیص ناهنجاری با این الگوریتم آموزش میبینند تا تفاوت رفتارهای عادی و مشکوک کاربران را با دقت بالا درک کنند.
جمع بندی
الگوریتم گرادیان کاهشی یکی از مهمترین ابزارهای بهینهسازی در یادگیری ماشین است که امکان یادگیری تدریجی از خطاها را فراهم میکند. این الگوریتم با حرکت در جهت مخالف شیب تابع هزینه، پارامترهای مدل را بهگونهای تنظیم میکند که خطای پیشبینی به حداقل برسد و مدل به پاسخهای دقیقتری دست یابد.
در این مقاله دیدیم که گرادیان کاهشی تنها یک مفهوم ریاضی نیست، بلکه یک فرآیند تکرارشوندهی تصمیمگیری است که به عواملی مانند نرخ یادگیری، شکل تابع هزینه و پیشپردازش دادهها وابسته است. مثالهای عددی، هندسی و صنعتی نشان دادند که انتخاب نادرست این پارامترها میتواند منجر به واگرایی، کندی یادگیری یا گیر افتادن در نقاط نامطلوب شود.
در نهایت، گرادیان کاهشی پلی میان ریاضیات و یادگیری واقعی مدلهاست. این الگوریتم پایهی روشهایی مانند پسانتشار (Backpropagation) و بهینهسازهای پیشرفتهتر محسوب میشود و بدون درک آن، فهم عمیق آموزش شبکههای عصبی ممکن نیست. تسلط بر گرادیان کاهشی، گامی اساسی برای حرکت از استفادهی سطحی مدلها به طراحی و تحلیل مهندسی سیستمهای هوشمند است.



