
مقدمه
در سالهای اخیر، پیشرفت هوش مصنوعی باعث شده است سیستمهایی ساخته شوند که بتوانند تصویر را تشخیص دهند، متن تولید کنند، صدا را درک کنند و حتی تصمیمهای پیچیده بگیرند. پشت بسیاری از این قابلیتها، مفهومی به نام یادگیری عمیق(Deep Learning) قرار دارد. رویکردی پیشرفته که تحولی جدی در دنیای یادگیری ماشین ایجاد کرده است.
یادگیری عمیق بهویژه زمانی اهمیت پیدا میکند که با دادههای حجیم، پیچیده و بدون ساختار مانند تصویر، متن و صدا سروکار داریم. برخلاف روشهای سنتی که به استخراج دستی ویژگیها وابستهاند. یادگیری عمیق تلاش میکند الگوها را مستقیماً از دادههای خام بیاموزد و بهصورت خودکار به درک عمیقتری از مسئله برسد.
در این آموزش جامع، یادگیری عمیق را از پایه بررسی میکنیم. از تعریف و منطق عملکرد گرفته تا نقش آن در شبکههای عصبی و مسیر یادگیری آن برای ساخت مدلهای هوشمند. این مقاله برای افرادی طراحی شده است که میخواهند یادگیری عمیق را مفهومی، اصولی و قابلدرک یاد بگیرند، نه صرفاً حفظ فرمولها و کدها.
تعریف
یادگیری عمیق شاخهای پیشرفته از یادگیری ماشین است که از شبکههای عصبی مصنوعی چندلایه برای یادگیری الگوهای پیچیده از دادهها استفاده میکند. در این روش با تحلیل دادههای خام و یادگیری تدریجی، روابط پنهان میان ورودیها و خروجیها را کشف میکند.
ویژگی اصلی یادگیری عمیق، توانایی آن در یادگیری سلسلهمراتبی است. به این معنا که هر لایه از شبکه عصبی، ویژگیهای پیچیدهتری نسبت به لایه قبل استخراج میکند. این قابلیت باعث شده است یادگیری عمیق در حوزههایی مانند تشخیص تصویر، پردازش زبان طبیعی، تشخیص گفتار و سیستمهای توصیهگر عملکردی بسیار موفق داشته باشد.
بهطور خلاصه، هر زمان که داده زیاد باشد و الگوها پیچیده و غیرخطی باشند، یادگیری عمیق یکی از قدرتمندترین ابزارهای هوش مصنوعی محسوب میشود.
چرا یادگیری عمیق؟
زمانی که حجم دادهها افزایش مییابد، تکنیکهای سنتی یادگیری ماشین (هرچقدر هم که بهینهسازی شده باشند) از نظر عملکرد و دقت دچار افت کارایی میشوند. در حالی که یادگیری عمیق در چنین شرایطی (حجم بالای داده) عملکرد بسیار بهتری از خود نشان میدهد.
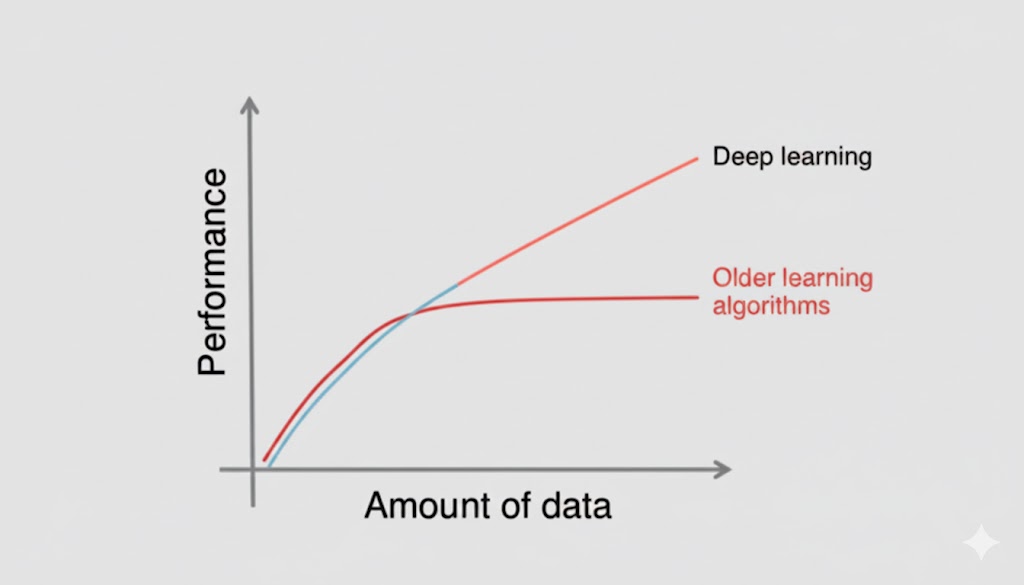
چه مقدار داده بزرگ محسوب میشود؟
نمیتوان آستانه و مرز دقیقی تعیین کرد تا بگوییم دادهها بزرگ هستند. اما به صورت شهودی، شاید داشتن یک میلیون نمونه کافی باشد تا بگوییم این بزرگ است. (اینجا همان جایی است که مایکل اسکات جمله معروفش “That’s what she said” را به زبان میآورد!).
حوزههای کاربرد یادگیری عمیق (DL)
- طبقهبندی تصاویر (Image Classification)
- تشخیص گفتار (Speech recognition)
- پردازش زبان طبیعی (NLP)
- سیستمهای توصیهگر (Recommendation systems)
- و موارد دیگر.
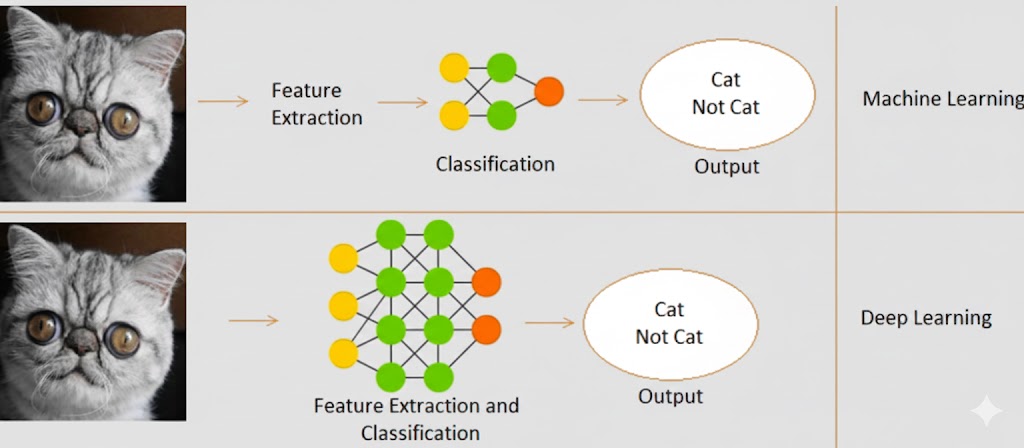
تفاوت بین یادگیری عمیق و یادگیری ماشین
- یادگیری عمیق زیرمجموعهای از یادگیری ماشین است.
- در یادگیری ماشین، ویژگیها (Features) باید به صورت دستی ارائه شوند.
- در حالی که یادگیری عمیق، ویژگیها را مستقیماً از خودِ دادهها یاد میگیرد.
معرفی دیتاست زبان اشاره
ما از مجموعه داده ارقام زبان اشاره (Sign Language Digits Dataset) استفاده خواهیم کرد که در کگل (Kaggle) در دسترس است. حالا بیایید شروع کنیم.
وارد کردن کتابخانههای ضروری
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
# Input data files are available in the "../input/" directory.
# import warnings
import warnings
# filter warnings
warnings.filterwarnings('ignore')
from subprocess import check_output
print(check_output(["ls", "../input"]).decode("utf8"))
نمای کلی دادهها
در این مجموعه داده، ۲۰۶۲ تصویر از ارقام زبان اشاره وجود دارد. از آنجایی که ۱۰ رقم (از ۰ تا ۹) داریم، ۱۰ نوع تصویرِ علامت منحصربهفرد وجود دارد.
در ابتدا، برای اینکه کار را برای یادگیرندگان ساده نگه داریم، فقط از اعداد ۰ و ۱ استفاده میکنیم:
- در این دادهها، علامت دست برای عدد ۰ بین ایندکسهای ۲۰۴ تا ۴۰۸ قرار دارد (۲۰۵ نمونه).
- همچنین، علامت دست برای عدد ۱ بین ایندکسهای ۸۲۲ تا ۱۰۲۷ قرار دارد (۲۰۶ نمونه).
بنابراین، ما از هر کلاس ۲۰۵ نمونه استفاده خواهیم کرد. (نکته: در واقعیت، ۲۰۵ نمونه برای یک مدل یادگیری عمیقِ استاندارد بسیار کم است، اما چون این یک آموزش است، میتوانیم از آن چشمپوشی کنیم).
حالا آرایههای X و Y را آماده میکنیم:
- X: آرایه تصاویر ما (ویژگیها یا Features)
- Y: آرایه برچسبهای ما (0 و 1)
# load data set
x_l = np.load('../input/Sign-language-digits-dataset/X.npy')
Y_l = np.load('../input/Sign-language-digits-dataset/Y.npy')
img_size = 64
plt.subplot(1, 2, 1)
plt.imshow(x_l[260].reshape(img_size, img_size))
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(x_l[900].reshape(img_size, img_size))
plt.axis('off')

آمادهسازی آرایههای داده
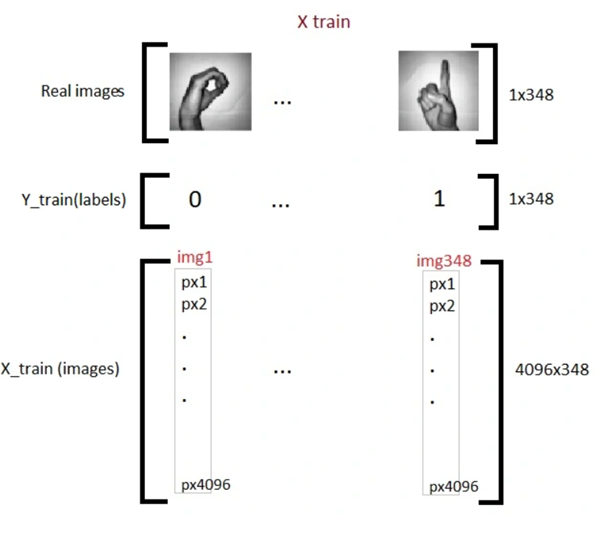
حالا وقت آن است که دادههایمان را برای ورود به دنیای پردازش آماده کنیم. ما تکههای مربوط به تصاویر اعداد ۰ و ۱ در زبان اشاره را برمیداریم . آنها را با هم ادغام میکنیم تا یک آرایه واحد به نام X ساخته شود. همزمان، برای هر کدام از این تصاویر یک برچسب در آرایه Y ایجاد میکنیم تا مدل بداند هر تصویر مربوط به کدام عدد است.
در واقع ما در این مرحله دو کار اصلی انجام میدهیم:
- ساخت آرایهX: تمام تصاویرِ دست که نشاندهنده عدد ۰ و ۱ هستند را پشت سر هم ردیف میکنیم.
- ساخت آرایه Y: یک لیست از صفره و یکها میسازیم که نقش پاسخنامه را برای مدل ایفا میکنند. یعنی به ازای هر تصویر در X، یک برچسب متناظر در Y داریم.
# Join a sequence of arrays along an row axis.
# from 0 to 204 is zero sign and from 205 to 410 is one sign
X = np.concatenate((x_l[204:409], x_l[822:1027] ), axis=0)
z = np.zeros(205)
o = np.ones(205)
Y = np.concatenate((z, o), axis=0).reshape(X.shape[0],1)
print("X shape: " , X.shape)
print("Y shape: " , Y.shape)

سازماندهی آرایهها و تقسیمبندی دادهها
برای ساختن آرایه X، ابتدا بخشهای مربوط به تصاویر نمادهای ۰ و ۱ را از کل مجموعه داده جدا کرده و آنها را به هم میچسبانیم. همین کار را برای آرایه Y هم انجام میدهیم، با این تفاوت که اینجا به جای خودِ تصاویر، از برچسبهای (Labels) آنها استفاده میکنیم.

حالا بیایید نگاهی به خروجی کار بیندازیم:
۱. ابعاد آرایهX: خروجی ما به صورت (64, 64, 410) است.
- عدد 410 یعنی در مجموع ۴۱۰ تصویر داریم (۲۰۵ تصویر برای عدد ۰ و ۲۰۵ تصویر برای عدد ۱).
- عدد 64 هم نشاندهنده این است که ابعاد هر تصویر ما ۶۴ در ۶۴ پیکسل است.
۲. ابعاد آرایهY: خروجی این آرایه (1, 410) است. یعنی شامل ۴۱۰ عدد (ترکیبی از ۰ و ۱) میباشد که مشخص میکند هر تصویر متعلق به کدام دسته است.
۳. تقسیم به مجموعههای آموزش و تست: حالا وقت آن است که دادههایمان را به دو بخش آموزش و تست تقسیم کنیم.
- معمولاً بخشی را برای آموزش مدل و بخش کوچکتری (مثلاً ۱۵ درصد) را برای امتحان گرفتن از مدل (تست) کنار میگذاریم.
- نکته فنی(random_state): ما از یک عدد تصادفی ثابت استفاده میکنیم تا مطمئن شویم هر بار که کد را اجرا میکنیم. دادهها به همان شکل قبلی تقسیم میشوند و نتایج ما قابل ردیابی و ثابت باقی میمانند.
# Then lets create x_train, y_train, x_test, y_test arrays
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.15, random_state=42)
number_of_train = X_train.shape[0]
number_of_test = X_test.shape[0]
تختسازی دادهها: آمادهسازی برای ورود به مدل Flattening
از آنجایی که آرایه ورودی ما (تصاویر) ۳ بعدی است، باید آن را به حالت ۲ بعدی تغییر شکل دهیم (اصطلاحاً آن را Flatten کنیم) تا برای اولین مدل یادگیری عمیق ما قابل درک و استفاده باشد. به زبان ساده، ماتریس مربعشکل تصویر را به یک ستون طولانی از اعداد تبدیل میکنیم. اما در مورد خروجیها (متغیر y)، چون از قبل ۲ بعدی هستند، آنها را به همان شکلی که هستند رها میکنیم و تغییری در آنها نمیدهیم.
X_train_flatten = X_train.reshape(number_of_train,X_train.shape[1]*X_train.shape[2])
X_test_flatten = X_test .reshape(number_of_test,X_test.shape[1]*X_test.shape[2])
print("X train flatten",X_train_flatten.shape)
print("X test flatten",X_test_flatten.shape)

سازماندهی نهایی و جابهجایی آرایهها (Transposing)
حالا ما در مجموع ۳۴۸ تصویر در مجموعه آموزشی (Training) داریم که هر کدام از آنها شامل ۴۰۹۶ پیکسل هستند. همچنین در مجموعه تست، ۶۲ تصویر با همین تراکم پیکسلی (۴۰۹۶) در اختیار داریم.
در این مرحله، ما آرایهها را ترانهاده(Transpose) میکنیم. یعنی جای سطرها و ستونها را با هم عوض میکنیم. شاید بپرسید چرا؟ نویسنده اشاره میکند که این یک انتخاب شخصی برای راحتی در کدنویسی است و در مراحل بعدیِ پیادهسازی ریاضیِ مدل، متوجه خواهید شد که این جابهجایی چقدر کار را سادهتر میکند.
x_train = X_train_flatten.T
x_test = X_test_flatten.T
y_train = Y_train.T
y_test = Y_test.T
print("x train: ",x_train.shape)
print("x test: ",x_test.shape)
print("y train: ",y_train.shape)
print("y test: ",y_test.shape)

پایان مرحله آمادهسازی دادهها
خب، حالا دیگر کارِ آمادهسازی تمام دادههای مورد نیازمان به پایان رسیده است. در حال حاضر، دادههای ما برای ورود به مرحله مدلسازی دقیقاً به این شکل سازماندهی شدهاند:
در واقع ما تصاویر را از حالت ماتریسی خارج کردیم، آنها را ترانهاده کردیم و حالا برچسبهای متناظر (صفر و یک) را هم در کنارشان داریم. حالا همه چیز مهیاست تا سراغ بخش اصلی، یعنی درک نحوه یادگیری این دادهها برویم.
آشنایی با رگرسیون لجستیک: اولین قدم در یادگیری عمیق
حالا وقت آن است که با یکی از مدلهای پایه در یادگیری عمیق (DL) به نام رگرسیون لجستیک (Logistic Regression) آشنا شویم. وقتی صحبت از دستهبندی دودویی (Binary Classification) به میان میآید، اولین مدلی که به ذهن خطور میکند همین رگرسیون لجستیک است.
اما شاید بپرسید: رگرسیون لجستیک چه ربطی به یادگیری عمیق دارد؟ پاسخ ساده است: رگرسیون لجستیک در واقع یک شبکه عصبی بسیار ساده است. از آنجایی که مفاهیم شبکه عصبی و یادگیری عمیق همیشه در کنار هم هستند، درک این مدل پایه، کلید ورود به مباحث پیچیدهتر است. برای درک عمیق رگرسیون لجستیک، ابتدا باید با مفهومی به نام گرافهای محاسباتی آشنا شویم.
گراف محاسباتی (Computation Graph)
گرافهای محاسباتی را میتوان روشی تصویری برای نمایش معادلات و عبارات ریاضی دانست. برای درک بهتر، بیایید یک مثال ساده را بررسی کنیم. فرض کنید یک عبارت ریاضی به شکل زیر داریم:
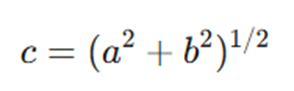
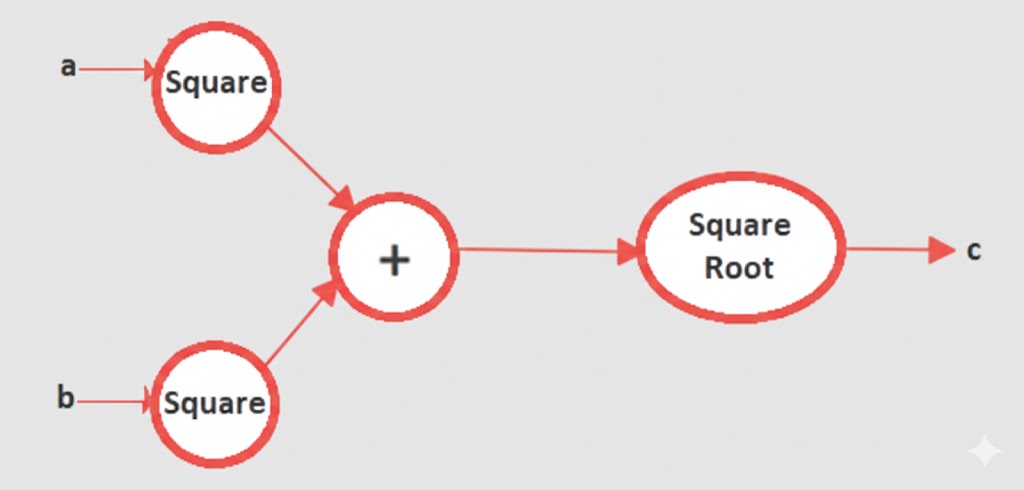
گراف محاسباتی در رگرسیون لجستیک
حالا بیایید نگاهی به گراف محاسباتیِ مخصوص رگرسیون لجستیک بیندازیم:
در این نمودار، ما شاهد جریان دادهها هستیم. همانطور که در تصویر مشاهده میکنید، پارامترهای اصلی مدل یعنی وزنها (Weights) و بایاس (Bias) وارد عمل میشوند:
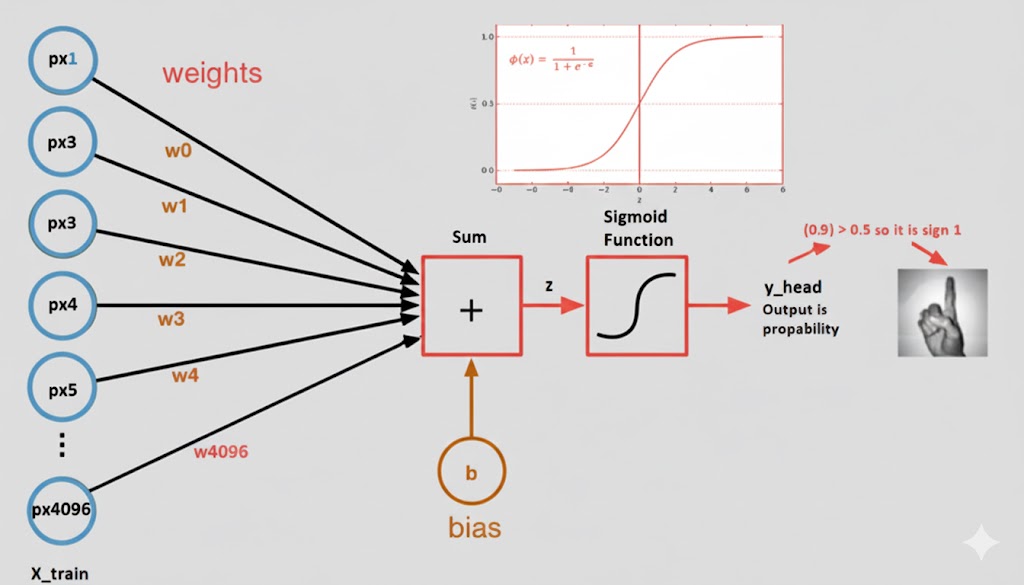
- وزنها (w): در واقع ضریب اهمیت هر پیکسل هستند.
- بایاس (b): عددی است که به مجموع خروجی اضافه میشود تا مدل انعطافپذیری بیشتری داشته باشد.
- فرمول خروجی (Z): حاصلضرب هر پیکسل در وزن مخصوص به خودش، به علاوه بایاس:
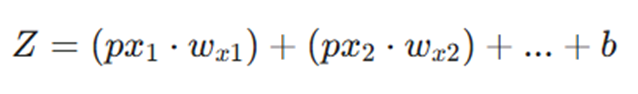
- پیشبینی نهایی (y_head): در نهایت، مقدار Z وارد یک فیلتر به نام تابع سیگموید (Sigmoid Function) میشود.
چرا از تابع سیگموید (Sigmoid) استفاده میکنیم؟
وظیفه اصلی این تابع، مقیاسبندی مقدار Z بین ۰ و ۱ است تا خروجی به صورت یک احتمال بیان شود. دو دلیل اصلی برای انتخاب این تابع وجود دارد:
۱. نتیجه احتمالی: به ما یک خروجی در بازه صفر تا یک میدهد که تفسیر آن به عنوان احتمال بسیار ساده است.
۲. مشتقپذیری: چون این تابع مشتقپذیر است، میتوانیم از آن در الگوریتم گرادیان نزولی (Gradient Descent) برای آپدیت کردن وزنها استفاده کنیم.
حالا بیایید هر یک از اجزای این گراف محاسباتی را با جزئیات بیشتری بررسی کنیم.
مقداردهی اولیه وزنها و بایاس (Initializing Parameters)
در یک شبکه عصبی، هر پیکسل وزن مخصوص به خود را دارد. اما سوال اصلی اینجاست: وزنهای اولیه باید چه مقداری داشته باشند؟ تکنیکهای مختلفی برای این کار وجود دارد که در بخش دوم این مقاله به آنها خواهیم پرداخت، اما فعلاً میتوانیم آنها را با یک مقدار تصادفی کوچک، مثلاً ۰.۰۱، مقداردهی کنیم.
از آنجایی که هر تصویر ما در مجموع شامل ۴۰۹۶پیکسل است، ابعاد (Shape) آرایه وزنهای ما (1, 4096) خواهد بود. همچنین، مقدار اولیه بایاس(Bias) را برابر با ۰ در نظر میگیریم.
# lets initialize parameters
# So what we need is dimension 4096 that is number of pixels as a parameter for our initialize method(def)
def initialize_weights_and_bias(dimension):
w = np.full((dimension,1),0.01)
b = 0.0
return w, b
w,b = initialize_weights_and_bias(4096)انتشار رو به جلو (Forward Propagation)
تمام مراحلی که طی آن دادهها از پیکسلهای ورودی حرکت کرده و در نهایت به تابع هزینه میرسند، انتشار رو به جلو نامیده میشود. در این فرآیند، مدل سعی میکند با استفاده از داشتههای فعلیاش، یک پیشبینی انجام دهد.
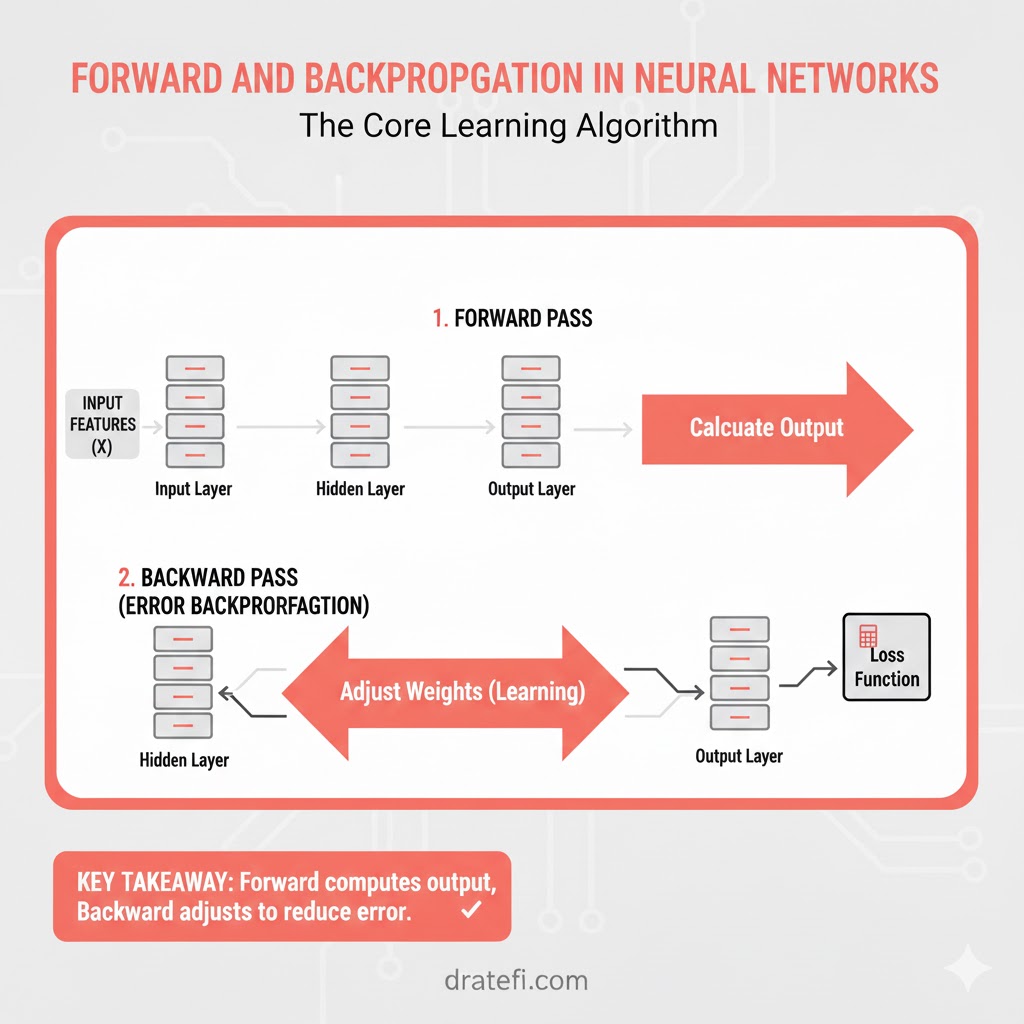
مراحل این فرآیند به شرح زیر است:
- محاسبه Z: برای به دست آوردن مقدار Z، از فرمول Z = (w^T)x + b استفاده میکنیم. در اینجا x آرایه پیکسلها، w وزنها و b مقدار بایاس است.
- تولید پیشبینی(y_head): پس از محاسبه Z، آن را به تابع سیگموید میدهیم که خروجی آن همان y_head یا احتمال پیشبینی شده است.
- محاسبه تابع زیان(Loss Function): بلافاصله پس از پیشبینی، میزان خطای آن تکنمونه را محاسبه میکنیم.
- تابع هزینه(Cost Function): این تابع در واقع مجموع تمام زیانها (خطاها) در کل دادههای آموزشی است. تابع هزینه مدل را به خاطر پیشبینیهای اشتباه مجازات میکند و این دقیقاً همان روشی است که مدل یاد میگیرد پارامترهایش را اصلاح کند.
# calculation of z
#z = np.dot(w.T,x_train)+b
def sigmoid(z):
y_head = 1/(1+np.exp(-z))
return y_head
y_head = sigmoid(0)
y_head
> 0.5
عبارت ریاضی تابع زیان (Log Loss)
همانطور که پیشتر اشاره کردیم، برای محاسبه میزان خطای پیشبینیهای مدل، از یک تابع ریاضی استفاده میکنیم. در رگرسیون لجستیک، این تابع به نام Log Loss یا همان تابع زیان لگاریتمی شناخته میشود. فرمول ریاضی آن به شکل زیر است:
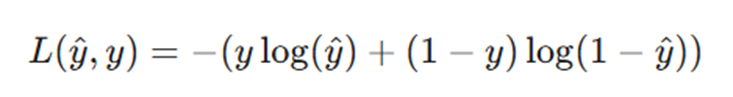
نقش تابع زیان در جریمه کردن اشتباهات
همانطور که قبلاً اشاره کردیم، وظیفه اصلی تابع زیان (Loss Function) این است که مدل را به خاطر پیشبینیهای اشتباهش مجازات یا جریمه کند. هرچه پیشبینی مدل از واقعیت دورتر باشد، این جریمه سنگینتر است و به مدل میفهماند که باید وزنهایش را بیشتر تغییر دهد.
در ادامه، قطعه کد مربوط به انتشار رو به جلو(Forward Propagation) آورده شده است؛ فرآیندی که در آن دادهها وارد میشوند، محاسبات ریاضی روی آنها انجام میگیرد و در نهایت میزان خطا (هزینه) محاسبه میشود.
# Forward propagation steps:
# find z = w.T*x+b
# y_head = sigmoid(z)
# loss(error) = loss(y,y_head)
# cost = sum(loss)
def forward_propagation(w,b,x_train,y_train):
z = np.dot(w.T,x_train) + b
y_head = sigmoid(z) # probabilistic 0-1
loss = -y_train*np.log(y_head)-(1-y_train)*np.log(1-y_head)
cost = (np.sum(loss))/x_train.shape[1] # x_train.shape[1] is for scaling
return cost
بهینهسازی با الگوریتم گرادیان نزولی
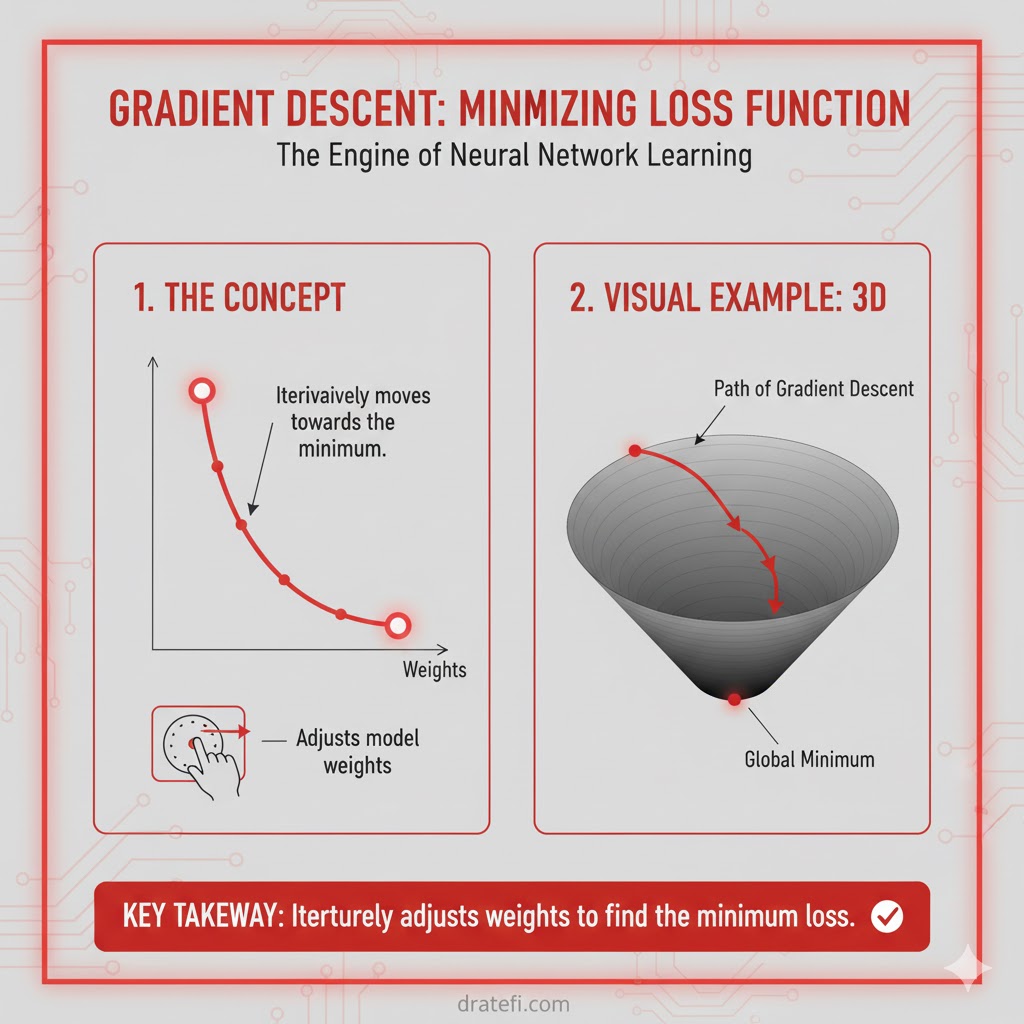
هدف اصلی: یافتن کمترین میزان خطا
هدف ما این است که مقادیری برای پارامترهای مدل (وزنها و بایاس) پیدا کنیم که به ازای آنها، مقدار تابع زیان (Loss Function) به حداقل ممکن برسد. در واقع ما به دنبال نقطهای هستیم که پیشبینیهای مدل کمترین فاصله را با واقعیت داشته باشند. برای رسیدن به این هدف، از معادله گرادیان نزولی (Gradient Descent) استفاده میکنیم:
این معادله به ما میگوید که چطور در هر مرحله، وزنها را کمی تغییر دهیم تا به سمت پایینترین نقطه نمودار خطا حرکت کنیم.
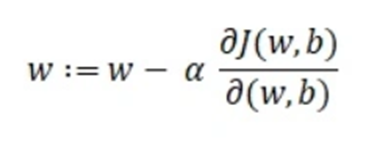
کالبدشکافی معادله گرادیان نزولی
در این معادله، هر نماد وظیفه خاصی بر عهده دارد:
- w: نشاندهنده وزن یا همان پارامتر مدل است که قصد اصلاحش را داریم.
- α (حرف یونانی آلفا): به آن اندازه گام (Stepsize) یا نرخ یادگیری میگویند. این عدد مشخص میکند که در مسیر پایین رفتن از شیب خطا برای رسیدن به کمینه محلی (Local Minima)، هر بار چه گامهایی برداریم.
- باقیمانده عبارت: همان مشتق تابع زیان است که به آن گرادیان (Gradient) نیز گفته میشود.
الگوریتم گرادیان نزولی به زبان ساده
الگوریتم گرادیان نزولی فرآیند بسیار سادهای دارد که به صورت چرخهای تکرار میشود:
۱. انتخاب نقطه شروع: ابتدا یک نقطه تصادفی روی نمودار دادهها انتخاب کرده و شیب (Slope) آن را پیدا میکنیم.
۲. تعیین جهت: مسیری را پیدا میکنیم که در آن مقدار تابع زیان (خطا) کاهش مییابد.
۳. بهروزرسانی وزنها: با استفاده از فرمول بالا، وزنها را اصلاح میکنیم (این روش در شبکههای عصبی اصطلاحاً پسانتشار یا Backpropagation نیز نامیده میشود).
۴. برداشتن گام بعدی: با در نظر گرفتن اندازه گام (α)، نقطه بعدی را روی نمودار انتخاب میکنیم.
۵. تکرار: این مراحل را آنقدر تکرار میکنیم تا به کمترین خطای ممکن برسیم.
# In backward propagation we will use y_head that found in forward progation
# Therefore instead of writing backward propagation method, lets combine forward propagation and backward propagation
def forward_backward_propagation(w,b,x_train,y_train):
# forward propagation
z = np.dot(w.T,x_train) + b
y_head = sigmoid(z)
loss = -y_train*np.log(y_head)-(1-y_train)*np.log(1-y_head)
cost = (np.sum(loss))/x_train.shape[1] # x_train.shape[1] is for scaling
# backward propagation
derivative_weight = (np.dot(x_train,((y_head-y_train).T)))/x_train.shape[1] # x_train.shape[1] is for scaling
derivative_bias = np.sum(y_head-y_train)/x_train.shape[1] # x_train.shape[1] is for scaling
gradients = {"derivative_weight": derivative_weight,"derivative_bias": derivative_bias}
return cost,gradients
بهروزرسانی پارامترهای یادگیری
# Updating(learning) parameters
def update(w, b, x_train, y_train, learning_rate,number_of_iterarion):
cost_list = []
cost_list2 = []
index = []
# updating(learning) parameters is number_of_iterarion times
for i in range(number_of_iterarion):
# make forward and backward propagation and find cost and gradients
cost,gradients = forward_backward_propagation(w,b,x_train,y_train)
cost_list.append(cost)
# lets update
w = w - learning_rate * gradients["derivative_weight"]
b = b - learning_rate * gradients["derivative_bias"]
if i % 10 == 0:
cost_list2.append(cost)
index.append(i)
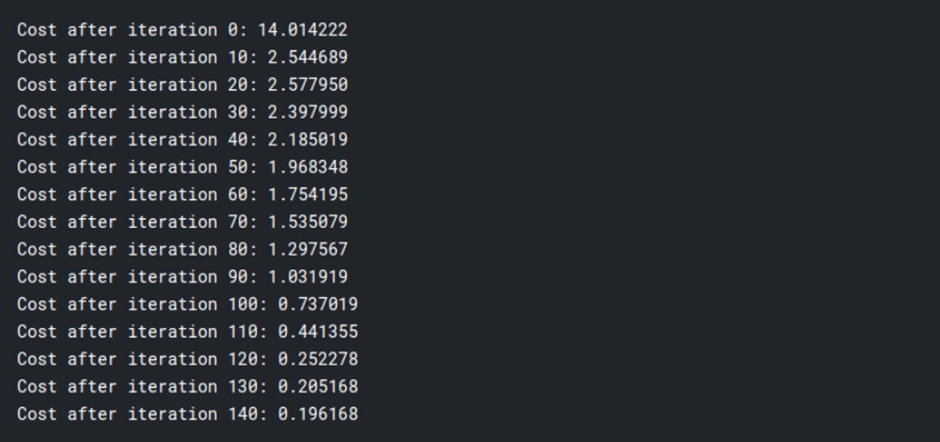
print ("Cost after iteration %i: %f" %(i, cost))
# we update(learn) parameters weights and bias
parameters = {"weight": w,"bias": b}
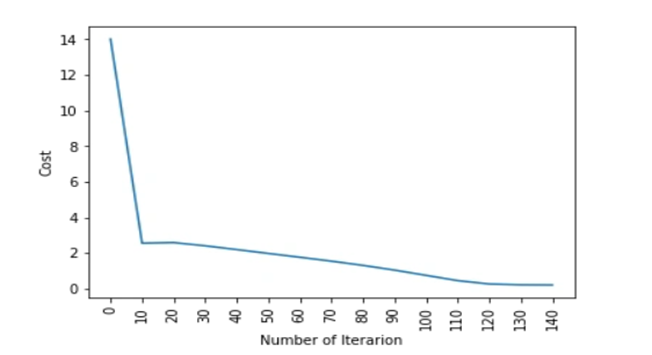
plt.plot(index,cost_list2)
plt.xticks(index,rotation='vertical')
plt.xlabel("Number of Iterarion")
plt.ylabel("Cost")
plt.show()
return parameters, gradients, cost_list
parameters, gradients, cost_list = update(w, b, x_train, y_train, learning_rate = 0.009,number_of_iterarion = 200)
مرحله پیشبینی: لحظه استفاده از دانش (Prediction Step)
تا اینجای کار، ما پارامترهای مدل (وزنها و بایاس) را یاد گرفتهایم ؛ این یعنی مدل ما روی دادههای آموزشی برازش (Fitting) شده و الگوها را درک کرده است. حالا نوبت به مرحله پیشبینی میرسد. در این مرحله، ما دادههای جدیدی به نام x_test را به عنوان ورودی به مدل میدهیم. مدل با استفاده از همان دانشی که به دست آورده (پارامترهای بهینه شده)، یک انتشار رو به جلو (Forward Prediction) انجام میدهد تا سرنوشت دادههای جدید را حدس بزند.
در واقع در این مرحله، دیگر خبری از یادگیری یا تغییر وزنها نیست؛ بلکه مدل فقط از فرمولی که یاد گرفته استفاده میکند تا به ما بگوید هر تصویر جدید مربوط به کدام عدد (۰ یا ۱) است.
# prediction
def predict(w,b,x_test):
# x_test is a input for forward propagation
z = sigmoid(np.dot(w.T,x_test)+b)
Y_prediction = np.zeros((1,x_test.shape[1]))
# if z is bigger than 0.5, our prediction is sign one (y_head=1),
# if z is smaller than 0.5, our prediction is sign zero (y_head=0),
for i in range(z.shape[1]):
if z[0,i]<= 0.5:
Y_prediction[0,i] = 0
else:
Y_prediction[0,i] = 1
return Y_prediction
predict(parameters["weight"],parameters["bias"],x_test)
اجرای پیشبینی: زمانِ کنار هم گذاشتنِ قطعات پازل
حالا نوبت به مرحله نهایی رسیده است؛ یعنی انجام پیشبینیها. بیایید تمام آموختههایمان را در کنار هم قرار دهیم تا ببینیم این مغز مصنوعی چطور کار میکند. مدل ما از دادههای تستی که قبلاً هیچوقت ندیده است استفاده میکند و با عبور دادن آنها از فیلتر وزنها و بایاسهایی که طی آموزش به دست آورده، حدس نهایی خود را اعلام میکند.
در این مرحله، تمام قطعات ریاضی که یاد گرفتیم (از ضرب ماتریسها تا تابع سیگموید) در یک جریان هماهنگ با هم ترکیب میشوند تا از دلِ پیکسلهای خام، یک نتیجه معنادار (مثلاً این تصویر عدد ۱ است) استخراج شود. این لحظه، در واقع میوه تمام تلاشهای مدل در طول یادگیری است که به بار مینشیند.
def logistic_regression(x_train, y_train, x_test, y_test, learning_rate , num_iterations):
# initialize
dimension = x_train.shape[0] # that is 4096
w,b = initialize_weights_and_bias(dimension)
# do not change learning rate
parameters, gradients, cost_list = update(w, b, x_train, y_train, learning_rate,num_iterations)
y_prediction_test = predict(parameters["weight"],parameters["bias"],x_test)
y_prediction_train = predict(parameters["weight"],parameters["bias"],x_train)
# Print train/test Errors
print("train accuracy: {} %".format(100 - np.mean(np.abs(y_prediction_train - y_train)) * 100))
print("test accuracy: {} %".format(100 - np.mean(np.abs(y_prediction_test - y_test)) * 100))
logistic_regression(x_train, y_train, x_test, y_test,learning_rate = 0.01, num_iterations = 150)

همانطور که مشاهده کردید، حتی ابتداییترین مدل یادگیری عمیق هم چالشهای خاص خودش را دارد. یادگیری این مفاهیم در ابتدا اصلاً ساده نیست و کاملاً طبیعی است که افراد مبتدی با مطالعه یکباره تمام این مطالب، کمی احساس سردرگمی کنند. اما واقعیت این است که ما هنوز حتی وارد دنیای واقعیِ یادگیری عمیق نشدهایم؛ اینها فقط لایههای رویی و سطحی این اقیانوس بیکران هستند. مطالب بسیار بیشتری وجود دارد که در بخش دوم این مقاله به آنها خواهم پرداخت.
حالا که منطق و ریاضیات پشت پرده رگرسیون لجستیک را به خوبی یاد گرفتید، خبر خوب این است که میتوانید از کتابخانهای به نام SKlearn استفاده کنید. این کتابخانه بسیاری از مدلها و الگوریتمها را به صورت پیشفرض در خود دارد؛ بنابراین در پروژههای واقعی، دیگر نیازی نیست همه چیز را از صفر مطلق بنویسید
پیاده سازی رگرسیون لجستیک با استفاده از Sklearn

شما حالا دیگر تقریباً تمام منطق و شهود ریاضی پشت رگرسیون لجستیک را میدانید. اگر مشتاق هستید درباره جزئیات کتابخانه Sklearn بیشتر بدانید، میتوانید مستندات رسمی آن را مطالعه کنید. اما حالا به کد زیر نگاه کنید؛ مطمئنیم از اینکه میبینید انجام تمام آن مراحل با چقدر تلاشِ ناچیز و کدِ کوتاهی امکانپذیر است، شگفتزده خواهید شد:
همانطور که میبینید، تمام آن انتشار رو به جلو، محاسبه خطا و بهروزرسانی وزنها که ساعتها دربارهشان صحبت کردیم، اکنون در یک کپسولِ قدرتمند جمع شدهاند تا شما بتوانید تمرکز خود را به جای محاسبات دستی، روی حل مسائل بزرگتر بگذارید.
from sklearn import linear_model
logreg = linear_model.LogisticRegression(random_state = 42,max_iter= 150)
print("test accuracy: {} ".format(logreg.fit(x_train.T, y_train.T).score(x_test.T, y_test.T)))
print("train accuracy: {} ".format(logreg.fit(x_train.T, y_train.T).score(x_train.T, y_train.T)))

وقتی علم به عمل تبدیل میشود: جادوی یکخطی
تمام آن مسیری که طی کردیم، فقط برای همین بود. شاید بپرسید اگر قرار بود با یک خط کد به نتیجه برسیم، پس چرا آن همه ریاضیات پیچیده را یاد گرفتیم؟
پاسخ این است: کتابخانه Sklearn مثل یک ماشین پیشرفته است که شما را به مقصد میرساند، اما یادگیری آن مفاهیم دستی، به شما گواهینامه رانندگی و توانایی تعمیر موتور را داد. حالا شما نه تنها میدانید چطور کد بزنید، بلکه میفهمید وقتی مدل در حال آموزش است، در اعماق آن چه اتفاقی میافتد.
جمعبندی
یادگیری عمیق یکی از مهمترین و تأثیرگذارترین رویکردهای یادگیری ماشین است که امکان تحلیل دادههای پیچیده و حجیم را فراهم میکند. با استفاده از شبکههای عصبی چندلایه، این روش قادر است الگوهایی را شناسایی کند که با روشهای سنتی بهسختی قابل کشف هستند.
با وجود مزایای چشمگیر، یادگیری عمیق نیازمند داده زیاد، توان محاسباتی بالا و طراحی دقیق مدل است. بنابراین استفاده از آن باید آگاهانه و متناسب با مسئله انجام شود. در بسیاری از پروژهها، انتخاب درست بین روشهای سادهتر و یادگیری عمیق میتواند تفاوت میان موفقیت و شکست باشد.
در نهایت، اگر هدف ساخت سیستمهایی است که بتوانند از دادههای واقعی یاد بگیرند، تطبیق پیدا کنند و تصمیمهای هوشمندانه بگیرند، یادگیری عمیق یکی از بهترین گزینههاست. این رویکرد نهتنها پایه بسیاری از فناوریهای امروزی است، بلکه نقش کلیدی در آینده هوش مصنوعی ایفا خواهد کرد.



