
مقدمه
در دنیای یادگیری عمیق، شبکههای عصبی نقش ستون فقرات را ایفا میکنند. هر پیشرفتی که امروز در حوزههایی مانند تشخیص تصویر، پردازش زبان طبیعی، خودروهای خودران و سیستمهای هوشمند میبینیم، حاصل استفاده از معماریهای مختلف شبکههای عصبی است. تنوع زیاد این معماریها باعث شده انتخاب مدل مناسب برای بسیاری از افراد چالشبرانگیز باشد.
شبکههای عصبی فقط یک مدل واحد نیستند، بلکه خانوادهای گسترده از معماریها هستند که هرکدام کاربردها، مزایا و محدودیتهای متفاوتی دارند. از شبکههای سادهٔ پیشخور تا معماریهای پیشرفته — مانند کانولوشنی (CNN)، بازگشتی (RNN) و ترنسفورمر — هرکدام برای حل نوع خاصی از مسئله طراحی شدهاند.
در این مقاله، بهصورت گامبهگام با انواع شبکههای عصبی در یادگیری عمیق آشنا میشویم، تفاوتها و کاربردهای آنها را بررسی میکنیم و یاد میگیریم در هر سناریوی واقعی، کدام معماری انتخاب هوشمندانهتری است. هدف این است که بعد از خواندن این مطلب، بتوانید با دیدی روشنتر و تصمیمساز، مسیر مدلسازی خود را انتخاب کنید.
شبکه عصبی چیست و چگونه کار میکند؟
یک شبکهٔ عصبی مدلی محاسباتی است که با الهام از ساختار و عملکرد مغز انسان طراحی شده و از نورونهای مصنوعی تشکیل شدهاند؛ این نورونها بهصورت گرههایی بههمپیوسته، در لایههای مختلف سازمانیافتهاند.
اطلاعات در این لایهها جریان مییابند؛ به این صورت که هر نورون ورودیها را دریافت کرده، یک عملیات ریاضی روی آنها انجام میدهد و خروجی را به لایه بعدی میفرستد. از طریق فرآیندی به نام آموزش (Training)، این شبکهها یاد میگیرند الگوها و روابط پیچیده بین دادهها را شناسایی کنند. این ویژگی، آنها را به ابزاری قدرتمند برای تشخیص چهره، گفتار و پردازش زبان طبیعی تبدیل کرده است.
کالبدشکافی عملکرد شبکههای عصبی
برای درک بهتر، بیایید اجزای اصلی این سیستم را بررسی کنیم:
۱. لایههای معماری
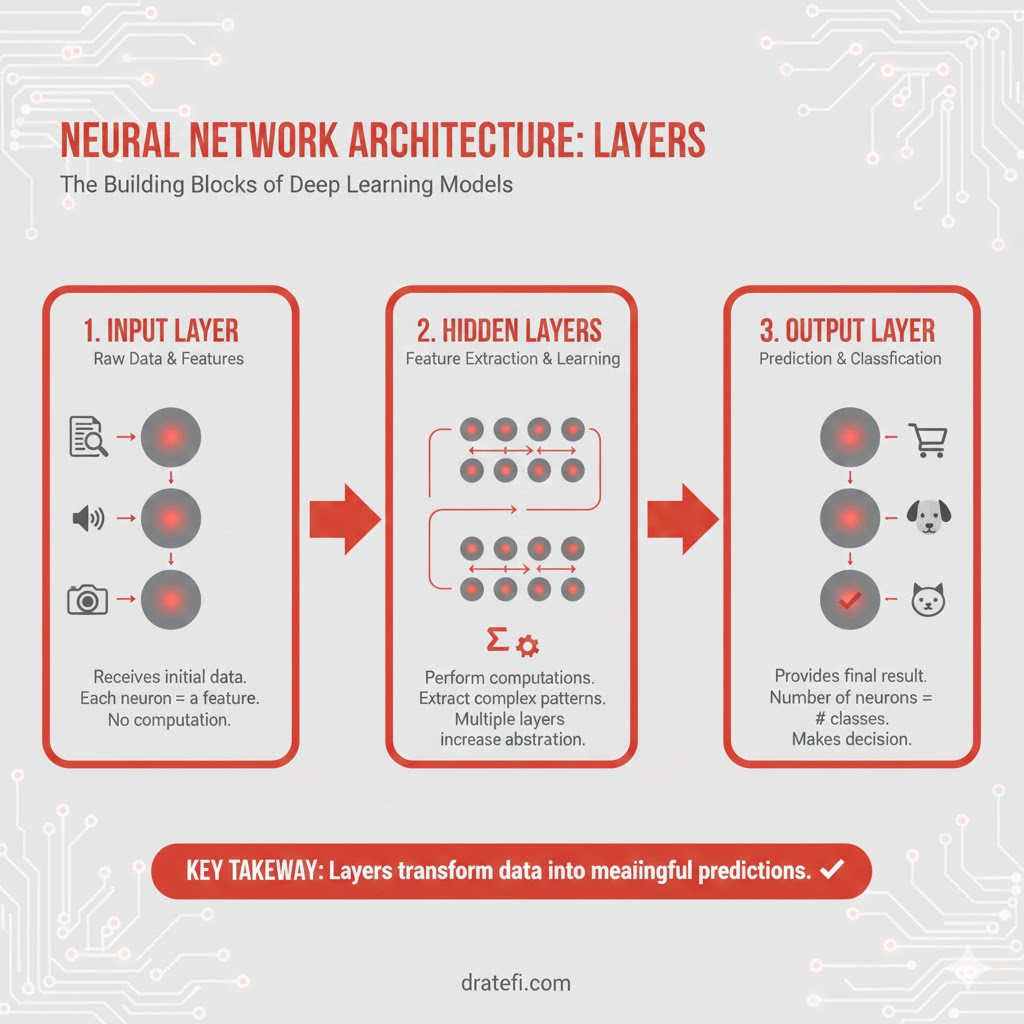
- لایه ورودی: دادههای اولیه را دریافت میکند؛ هر نورون در اینجا نماینده یک ویژگی از دادههای ورودی است.
- لایههای پنهان: جادوی اصلی اینجا اتفاق میافتد! این لایهها محاسبات را انجام میدهند. هر نورون ورودی را از لایه قبل میگیرد، یک تابع ریاضی (تابع فعالسازی) روی آن اعمال میکند و نتیجه را به جلو میفرستد.
- لایه خروجی: پاسخ نهایی مدل را تولید میکند؛ تعداد نورونهای این لایه بستگی به نوع مسئله (مثلاً بله/خیر) دارد.
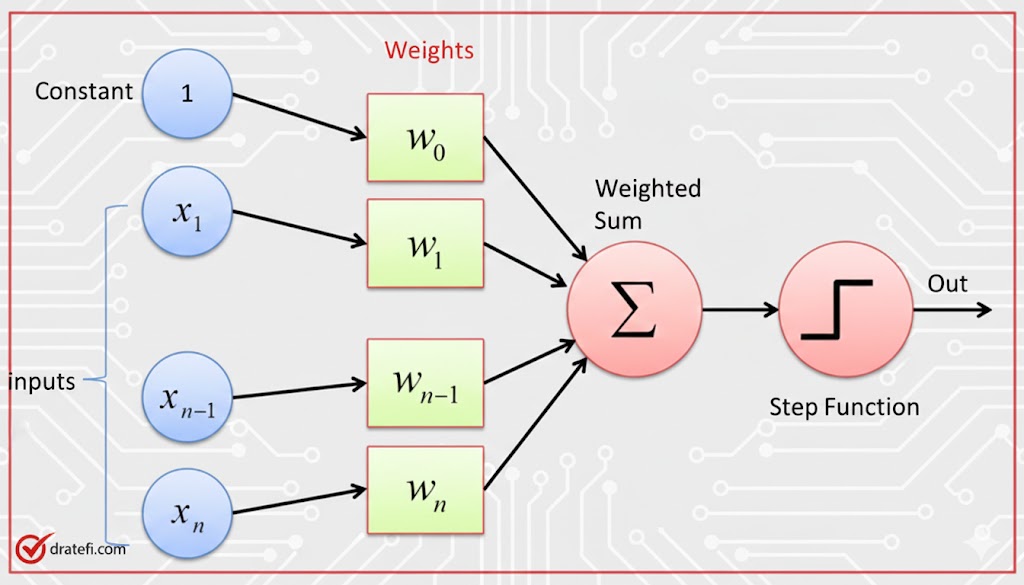
۲. اتصالات و وزنها (Weights)
در یک شبکهٔ تماممتصل معمولی، هر نورون به تمام نورونهای لایهٔ بعدی متصل است. هر اتصال دارای یک وزن است که اهمیت ورودی مربوطه را نشان میدهد. مدل در طول آموزش، این وزنها را تنظیم میکند تا به دقیقترین نتیجه دست یابد.
۳. تابع فعالسازی (Activation Function)
این تابع به شبکه اجازه میدهد روابط غیرخطی و پیچیده را درک کند. بدون آن، شبکهٔ عصبی تنها یک ماشین جمعوتفریق ساده میماند و نمیتوانست مفاهیم پیچیدهای مانند چهرهٔ انسان را تشخیص دهد.
۴. آموزش و پیشبینی (Training & Prediction)
- آموزش: مدل با دیدن هزاران مثال و استفاده از الگوریتمهایی مثل گرادیان نزولی، فاصله بین حدس خود و واقعیت را به حداقل میرساند.
- پیشبینی: پس از پایان آموزش، مدل میتواند درباره دادههای کاملاً جدید با دقت بالایی اظهار نظر کند.
در حقیقت، شبکه عصبی با اصلاح پارامترهای داخلی خود (وزنها)، یاد میگیرد که از مثالهای گذشته درس بگیرد و آینده را پیشبینی کند.
انواع مختلف شبکههای عصبی در یادگیری عمیق
این مقاله بر روی انواع کلیدی شبکههای عصبی تمرکز دارد که سنگبنای اکثر مدلهای پیشرفته و آموزشدیده در دنیای یادگیری عمیق محسوب میشوند. در ادامه، ۱۲ ساختار حیاتی را بررسی میکنیم:
- پروسپترون تکلایه (Single Layer Perceptron)
- پرسپترون چندلایه (MLPs)
- شبکههای عصبی پیشخور (FNNs)
- شبکههای عصبی مصنوعی (ANN)
- شبکههای عصبی بازگشتی (RNN)
- شبکههای حافظه طولانی کوتاهمدت (LSTM)
- شبکههای ترنسفورمر (Transformer)
- شبکههای عصبی کانولوشنال (CNN)
- شبکههای عصبی وا-کانولوشنال (Deconvolutional)
- خودرمزگذارها (Autoencoders)
- شبکههای مولد رقابتی (GANs)
- شبکه عصبی تابع شعاعی (RBF)
بیایید با نگاهی دقیقتر، هر یک از این معماریها و کاربرد آنها را بررسی کنیم.
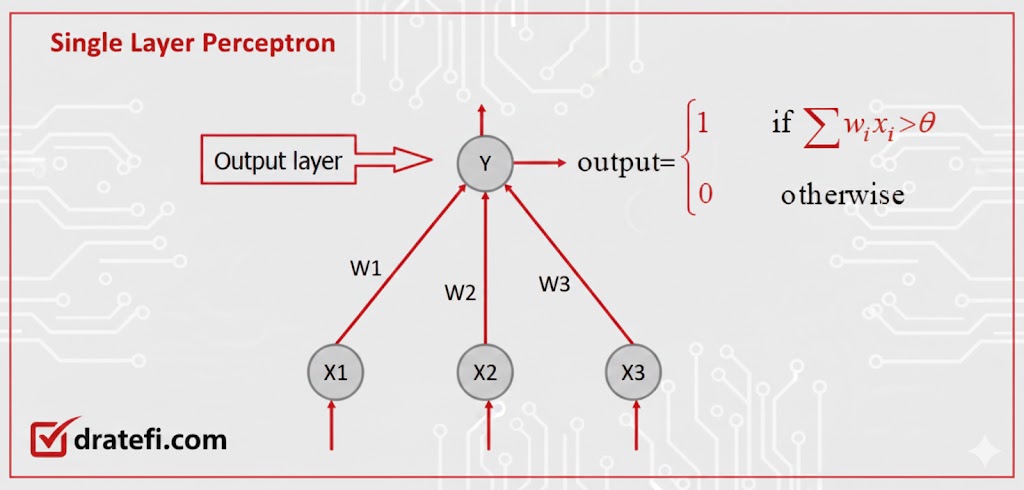
۱. پروسپترون تکلایه (Single Layer Perceptron)
پروسپترون بنیادیترین نوع شبکه عصبی و سنگبنای یادگیری عمیق است که عمدتاً برای وظایف طبقهبندی دودویی (Binary Classification) استفاده میشود. این مدل از یک لایه واحد از نورونهای مصنوعی تشکیل شده که مقادیر ورودی را دریافت کرده، وزنهای مشخصی را روی آنها اعمال میکنند و در نهایت یک خروجی تولید میکنند. جالب است بدانید که یک پروسپترون واحد را میتوان دقیقاً مانند یک مدل رگرسیون لجستیک تصور کرد؛ چرا که مجموع وزندار ورودیها را محاسبه کرده، یک مقدار بایاس به آن اضافه میکند و نتیجه را از یک تابع فعالسازی (مثل سیگموئید برای تولید احتمال بین ۰ و ۱) عبور میدهد.
پروسپترون معمولاً برای دادههایی استفاده میشود که بهصورت خطی تفکیکپذیر هستند، به این معنی که میتوان با یک خط راست آنها را به دو دسته مجزا تقسیم کرد. این مدل در حوزههایی مانند تشخیص الگو، طبقهبندی تصاویر و رگرسیون خطی کاربرد دارد. با این حال، بزرگترین محدودیت آن ناتوانی در مدیریت دادههای پیچیدهای است که مرز جداسازی آنها خطی نیست؛ در واقع این مدل مثل یک شاگرد مبتدی است که فقط مسائل سیاه یا سفید را درک میکند و برای فهم الگوهای پیچیدهتر، به لایههای بیشتری نیاز دارد.
.
کاربردهای اصلی پروسپترون
- طبقهبندی تصاویر: پروسپترونها توانایی دستهبندی تصاویری را دارند که حاوی اشیاء خاصی هستند. این مدلها این کار را از طریق انجام وظایف طبقهبندی دودویی (مانند تشخیص وجود یا عدم وجود یک شیء) به سرانجام میرسانند.
- رگرسیون خطی: پیشبینی خروجیهای پیوسته بر اساس ویژگیهای ورودی.
چالشهای پروسپترون
با وجود سادگی، پروسپترون با دو مانع بزرگ روبروست:
- محدودیت در جداسازی خطی: پروسپترونها در مدیریت دادههایی که بهصورت خطی تفکیکپذیر نیستند دچار مشکل میشوند، زیرا فقط قادر به یادگیری مرزهای تصمیمگیری مستقیم و خطی هستند.
- عدم عمق: به دلیل تکلایهای بودن، این مدل نمیتواند نمایشهای سلسلهمراتبی و پیچیده از دادهها (مثل درک عمق یا بافتهای پیچیده در تصویر) را یاد بگیرد.
.
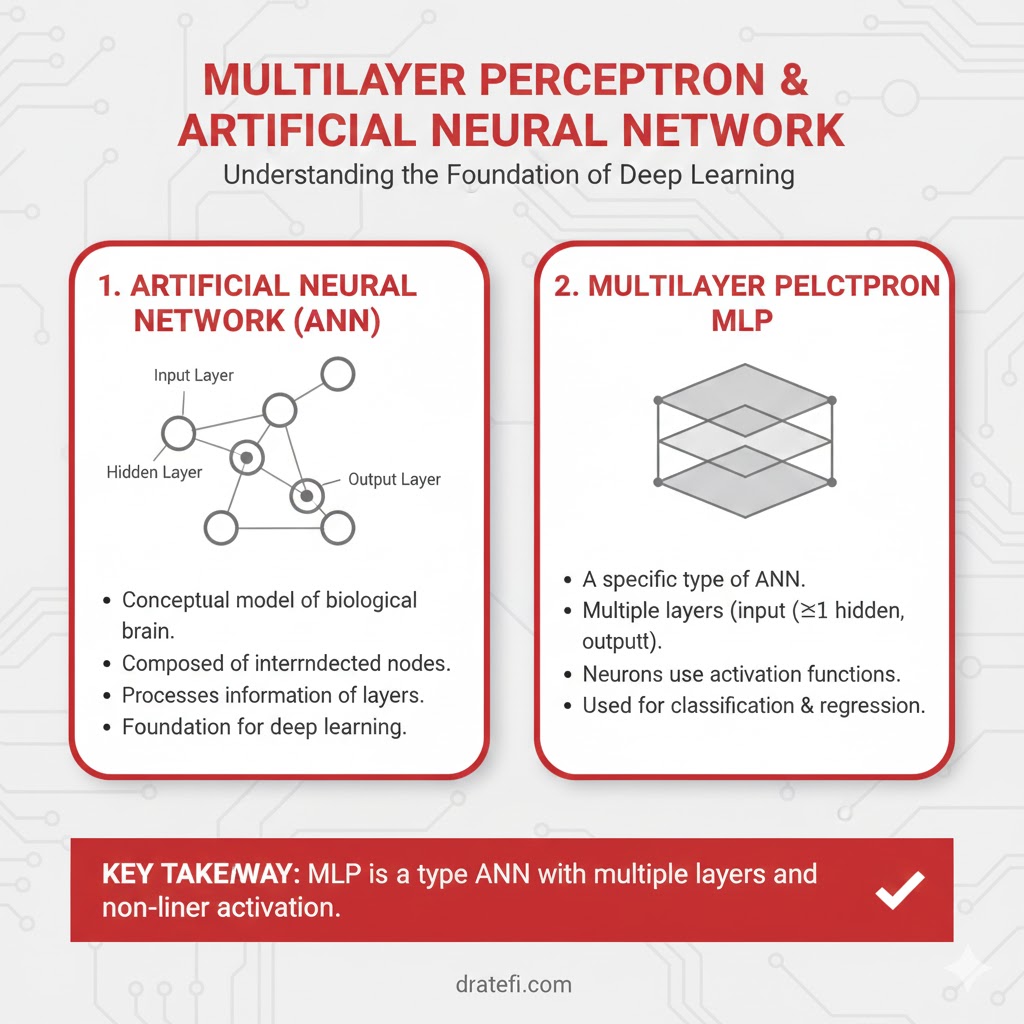
۲. پرسپترون چندلایه (Multilayer Perceptrons – MLP)
اگر پروسپترون تکلایه را واحد پایه در نظر بگیریم، MLP در واقع نسخه تکاملیافته و قدرتمند آن است. این مدل، دستهای از شبکههای عصبی مصنوعی پیشخور (Feedforward) محسوب میشود که برخلاف نسل قبلی خود، حداقل از سه لایه تشکیل شده است: ۱. لایه ورودی: دریافت دادههای خام. ۲. یک یا چند لایه پنهان: جایی که پردازشهای پیچیده انجام میشود. ۳. لایه خروجی: تولید نتیجه نهایی.
کاربردهای MLP
به دلیل توانایی بالا در یادگیری روابط پیچیده، MLP در این حوزهها بسیار محبوب است:
- وظایف طبقهبندی: استفاده گسترده در حل مسائلی مانند تشخیص دستخط (مثلاً اعداد چک بانکی) و تشخیص گفتار.
- تحلیل رگرسیون: پیشبینی مقادیر دقیق در شرایطی که رابطه بین ورودی و خروجی بسیار درهمتنیده و پیچیده است.
چالشهای MLP
- پیچیدگی محاسباتی: آموزش این شبکهها، بهویژه با مجموعهدادههای عظیم، میتواند بسیار سنگین و زمانبر باشد.
- بیشبرازش: این شبکهها مستعد غرق شدن در جزئیات دادههای تمرینی هستند، بهطوری که دادهها را حفظ میکنند و نمیتوانند روی دادههای جدید پیشبینی درستی انجام دهند.
.
۳. شبکههای عصبی پیشخور (Feedforward Neural Networks – FNNs)
شبکه عصبی پیشخور (FNN)، سادهترین نوع معماری در میان شبکههای عصبی مصنوعی محسوب میشود. در این ساختار، اطلاعات فقط در یک جهت یعنی به سمت جلو حرکت میکنند. دادهها از گرههای ورودی وارد شده، از لایههای پنهان (در صورت وجود) عبور میکنند و به لایه خروجی میرسند. نکته اساسی اینجاست که در این شبکه هیچگونه حلقه یا چرخه تکراری وجود ندارد و اطلاعات هرگز به عقب بازنمیگردند.
کاربردها و محدودیتهای FNNs
- تشخیص الگو: این شبکهها در تشخیص نوری کاراکترها (OCR) و سیستمهای اولیه تشخیص چهره کاربرد دارند.
- تخمین تابع: FNNها میتوانند توابع ریاضی پیچیده را تقریب بزنند و در مدلسازیهای پیشبینیکننده استفاده شوند.
- ناتوانی در پردازش دادههای زمانی: این مدلها به دلیل نداشتن حافظه، برای دادههای متوالی (مثل صوت و ویدیو) مناسب نیستند.
- ورودی ثابت: این شبکهها به اندازه ورودی مشخصی نیاز دارند که انعطافپذیری آنها را در برابر دادههایی با طول متفاوت کم میکند.
.
۴. شبکه عصبی مصنوعی (Artificial Neural Network – ANN)
شبکه عصبی مصنوعی یا ANN، مجموعهای از چندین پرسپترون یا نورون در هر لایه است. این ساختار به طور کلی از سه لایه اصلی تشکیل شده است: لایه ورودی که دادهها را دریافت میکند، لایه پنهان که وظیفه پردازش را بر عهده دارد و لایه خروجی که نتیجه نهایی را تولید میکند. در واقع، هر لایه در تلاش است تا با یادگیری وزنهای مشخص، بهترین مسیر را برای تبدیل ورودی به خروجی صحیح پیدا کند. از این شبکهها برای تحلیل دادههای جدولی، تصاویر و متون استفاده میشود.
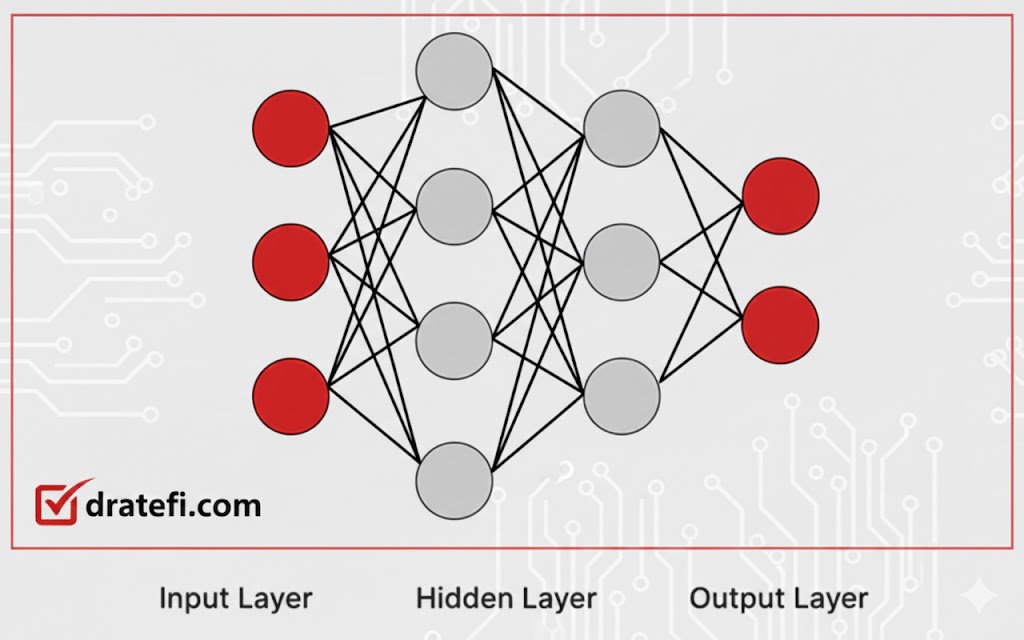
توابع فعالسازی
این شبکهها به عنوان تخمینزنندههای جهانی تابع شناخته میشوند؛ چرا که قادرند هر نوع تابع غیرخطی را یاد بگیرند و ورودیها را به درستی به خروجیها نگاشت کنند. راز این قدرت در توابع فعالسازی (Activation Functions) نهفته است.
در هر نورون، خروجی حاصلِ اِعمال یک تابع فعالسازی بر مجموع وزندار ورودیهاست. بدون این تابع، شبکه فقط روابط خطی را یاد میگیرد و در درک الگوهای پیچیده ناتوان میماند؛ به همین دلیل تابع فعالسازی را نیروگاه یک ANN مینامند.
مزایای شبکههای عصبی مصنوعی (ANN)
- مدلسازی غیرخطی و سازگاری: ANNها روابط پیچیده را یاد میگیرند و خود را با تغییرات دادههای ورودی در سناریوهای واقعی تطبیق میدهند.
- استخراج خودکار ویژگیها: این شبکهها الگوهای مهم را مستقیماً از دادههای خام شناسایی کرده و نیاز به مهندسی دستی ویژگیها را کاهش میدهند.
چالشهای شبکههای عصبی مصنوعی (ANN)
یکی از بزرگترین چالشها هنگام کار با تصاویر رخ میدهد؛ جایی که باید یک تصویر ۲ بعدی را به یک بردار ۱ بعدی تبدیل کرد. این کار دو پیامد منفی دارد:
- افزایش شدید پارامترها: با بزرگ شدن ابعاد تصویر، تعداد پارامترهای آموزشی به شدت بالا میرود.
- از دست رفتن ویژگیهای مکانی: ANN چیدمان پیکسلها و روابط فضایی آنها را که برای درک صحیح تصویر ضروری است، فراموش میکند.
.
۵. شبکه عصبی بازگشتی (Recurrent Neural Network – RNN)
برای درک بهتر، بیایید ابتدا تفاوت بین یک RNN و یک ANN را از منظر معماری بررسی کنیم. به زبان ساده، اگر روی لایههای پنهان یک شبکه عصبی مصنوعی (ANN) یک محدودیت حلقهای اعمال کنیم، آن را به یک شبکه عصبی بازگشتی تبدیل کردهایم.
همانطور که در تصویر بالا مشخص است، RNN دارای یک اتصال بازگشتی در حالت پنهان خود است. وجود این ساختار حلقهای تضمین میکند که اطلاعات مربوط به ترتیب و توالی دادههای ورودی به خوبی حفظ و استخراج شود.
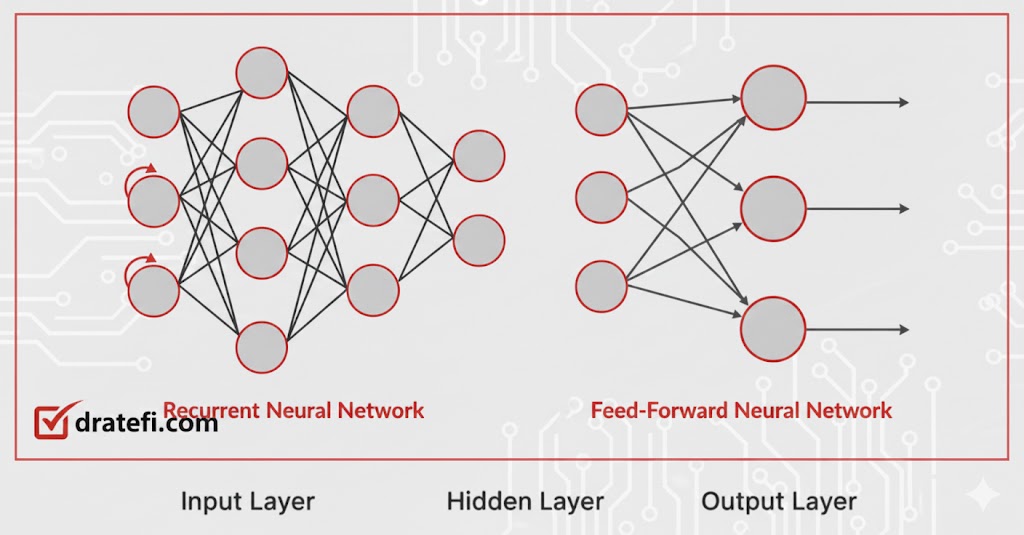
همانطور که مشاهده کردید، شبکه عصبی بازگشتی (RNN) یک اتصال بازگشتی روی حالت پنهان خود دارد. این محدودیت حلقهای تضمین میکند که اطلاعات مربوط به ترتیب و توالی دادهها در ورودیها به خوبی استخراج و حفظ شود.
ما میتوانیم از شبکههای عصبی بازگشتی برای حل مسائلی در حوزههای زیر استفاده کنیم:
- دادههای سری زمانی: مانند پیشبینی تغییرات بورس.
- محتوای متنی: مانند پردازش جملات و کلمات.
- دادههای صوتی: مانند تشخیص گفتار و موسیقی.
اشتراکگذاری پارامترها در RNN
در این شبکهها، خروجی در هر گام زمانی (o1, o2, o3, o4) تنها به کلمه فعلی بستگی ندارد، بلکه تحت تأثیر کلمات قبلی نیز قرار میگیرد. شبکههای RNN پارامترهای خود را در گامهای زمانی مختلف به اشتراک میگذارند؛ فرآیندی که به آن اشتراکگذاری پارامترها (Parameter Sharing) میگویند.
این هوشمندی در طراحی باعث میشود تعداد پارامترهای مورد نیاز برای آموزش کاهش یابد که در نتیجه هزینههای محاسباتی نیز به شدت کم میشود.
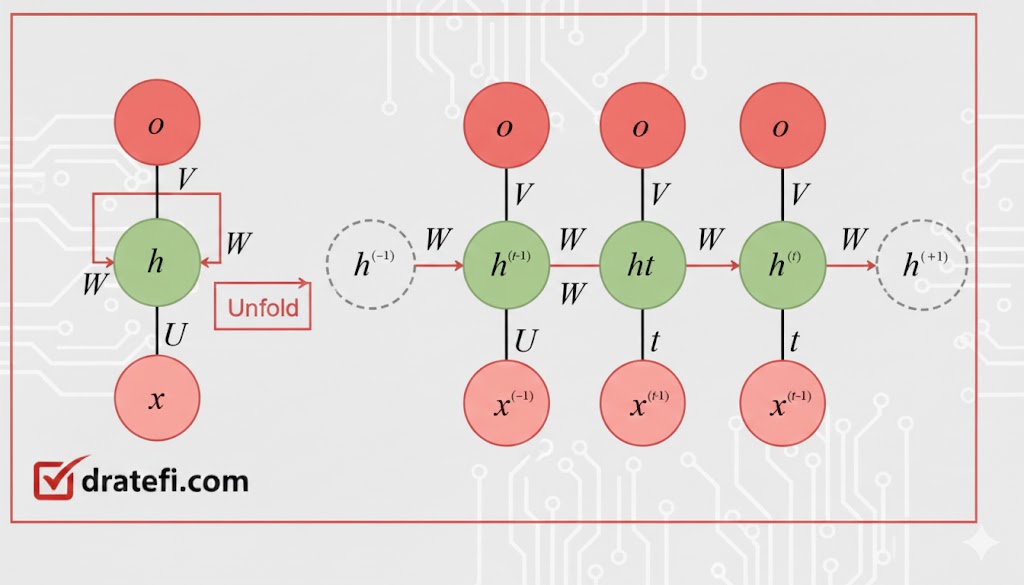
همانطور که در معماری این شبکه مشاهده میشود، سه ماتریس وزن اصلی یعنی U، Wو V پارامترهایی هستند که در تمامی گامهای زمانی به صورت مشترک استفاده میشوند. این ویژگی باعث میشود مدل بتواند الگوهای تکرارشونده را با کارایی بالا یاد بگیرد.
مزایای شبکههای عصبی بازگشتی (RNN)
- مدیریت دادههای متوالی: این شبکهها اختصاصاً برای پردازش و یادگیری از دادههای زنجیرهای طراحی شدهاند که آنها را برای پیشبینی سریهای زمانی، مدلسازی زبان و تشخیص گفتار ایدهآل میکند.
- حفظ بافتار با استفاده از حافظه RNN:ها با حفظ حالتهای داخلی، اطلاعات ورودیهای قبلی را به یاد میسپارند و پیشبینیهای بافتمحور در توالیها ارائه میدهند.
- اشتراکگذاری پارامترها در طول زمان: استفاده مجدد از وزنهای یکسان در تمام گامهای زمانی، پیچیدگی کلی مدل را کاهش داده و کارایی یادگیری در کارهای مبتنی بر توالی را بهبود میبخشد.
چالشهای شبکههای عصبی بازگشتی (RNN)
- با وجود قدرت بالا، RNNها با محدودیتهای فنی سختی روبرو هستند:
- ناپدید شدن یا انفجار گرادیان: در توالیهای طولانی، وقتی مدل سعی میکند به عقب برگردد تا اشتباهاتش را اصلاح کند، مقدار خطا (گرادیان) ممکن است آنقدر کوچک شود که عملاً یادگیری متوقف شود (Vanishing Gradient).
- زمانبر بودن آموزش: به دلیل ماهیت متوالی (که هر مرحله به مرحله قبل وابسته است)، این شبکهها را نمیتوان به راحتی به صورت موازی پردازش کرد، که منجر به کندی در آموزش میشود.
- ضعف در حافظه بلندمدت RNN:های استاندارد در یادآوری اطلاعاتی که خیلی قبلتر دیدهاند (مثلاً ابتدای یک پاراگراف طولانی) ضعیف هستند.
.
۶. شبکههای حافظه طولانی کوتاهمدت (Long Short-Term Memory – LSTM)
شبکههای LSTM نوع خاصی از شبکههای عصبی بازگشتی (RNN) هستند که برای ثبت وابستگیهای بلندمدت در دادههای متوالی طراحی شدهاند. برخلاف شبکههای پیشخور سنتی، شبکههای LSTM دارای سلولهای حافظه و دروازههایی هستند که به آنها اجازه میدهد در طول زمان، اطلاعات را به صورت آگاهانه حفظ کرده یا فراموش کنند.
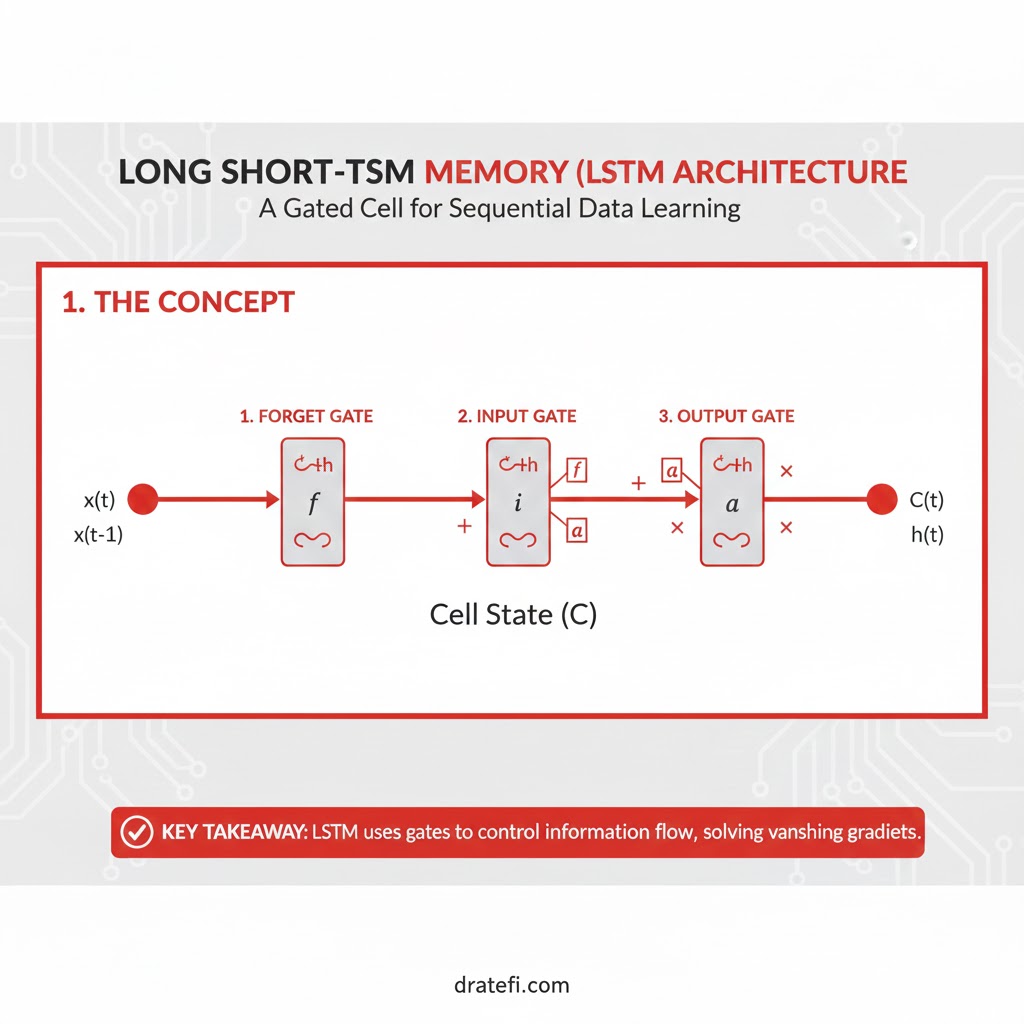
کاربردها و چالشهای LSTM
- کاربردها: این ویژگی باعث شده تا LSTM در تشخیص گفتار، پردازش زبان طبیعی، تحلیل سریهای زمانی و ترجمه بسیار موثر باشد.
- چالشها: چالش اصلی در کار با شبکههای LSTM، انتخاب معماری و پارامترهای مناسب است. همچنین، مقابله با مشکل ناپدید شدن یا انفجار گرادیان در طول فرآیند آموزش همچنان یکی از دغدغههای فنی این مدل است.
کاربردهای شبکه عصبی LSTM
شبکههای LSTM به دلیل توانایی منحصربهفرد در مدیریت حافظه، در حوزههایی که با توالی دادهها سر و کار دارند، بسیار درخشان عمل میکنند:
- پردازش زبان طبیعی: این شبکهها در مدلسازی دادههای متوالی استاد هستند و در وظایفی مانند ترجمه ماشینی، تحلیل لحن و تولید متن بسیار موثر عمل میکنند.
- تشخیص گفتار: از LSTMها برای پردازش دادههای صوتی استفاده میشود که امکان ساخت سیستمهای تشخیص گفتار بسیار دقیق را فراهم میکند.
- تحلیل سریهای زمانی: این مدلها میتوانند وابستگیهای طولانیمدت را در دادههای زمانی شناسایی کنند؛ همین ویژگی آنها را برای پیشبینی بازار بورس و وضعیت آبوهوا به گزینهای ایدهآل تبدیل کرده است.
چالشهای شبکههای LSTM
با وجود قدرت بالا در مدیریت حافظه، شبکههای LSTM با چالشهای فنی خاصی روبرو هستند:
- ناپدید شدن یا انفجار گرادیان: این شبکهها همچنان ممکن است با مشکل ناپدید شدن یا انفجار گرادیان مواجه شوند که آموزش موثر آنها را در توالیهای بسیار طولانی دشوار میکند.
- طراحی معماری مناسب: انتخاب یک معماری دقیق، از جمله تعیین تعداد لایهها و واحدهای پنهان، برای دستیابی به بهترین عملکرد حیاتی و چالشبرانگیز است.
.
۷. شبکههای ترنسفورمر (Transformer Networks)
شبکههای ترنسفورمر به یکی از مهمترین معماریها در دنیای یادگیری عمیق تبدیل شدهاند. این مدلها بهویژه در حوزه پردازش زبان طبیعی (NLP) و ترجمه ماشینی بسیار کاربردی هستند. معماری ترنسفورمر که در سال ۲۰۱۷ با مقاله معروف دقت تنها چیزی است که نیاز دارید (Attention is All You Need) معرفی شد، روش پردازش توالیهای داده توسط ماشینها را به کلی دگرگون کرد.
مولفههای کلیدی شبکههای ترنسفورمر:
- مکانیزم توجه به خود: نوآوری اصلی این مدل، مکانیزم توجه به خود است که به شبکه اجازه میدهد اهمیت کلمات مختلف را در یک توالی، فارغ از جایگاه آنها، بسنجد. برخلاف RNNها و LSTMها که ورودیها را به ترتیب پردازش میکنند، ترنسفورمرها تمام کلمات یک جمله را به صورت همزمان پردازش میکنند که این امر باعث میشود وابستگیهای دوربرد را با کارایی بیشتری درک کنند.
- کدگذاری موقعیتی: از آنجایی که ترنسفورمرها دادهها را به ترتیب پردازش نمیکنند، از کدگذاری موقعیتی برای تزریق اطلاعات مربوط به نظم توالی به مدل استفاده میکنند. این کدگذاری به مدل اجازه میدهد ترتیب کلمات و روابط بین آنها را تشخیص دهد.
- معماری انکودر-دیکودر: ترنسفورمر از یک ساختار انکودر-دیکودر تشکیل شده است. انکودر دادههای ورودی (مانند یک جمله) را پردازش میکند، در حالی که دیکودر خروجی را تولید میکند. هر دو بخش از چندین لایه توجه به خود و شبکههای عصبی پیشخور تشکیل شدهاند.
- توجه چندسره: این تکنیک برای ثبت اطلاعات از موقعیتهای مختلف توالی با استفاده از چندین مکانیزم توجه به صورت موازی به کار میرود. نتایج این بخشها با هم ترکیب و متحول میشوند تا مدل بتواند همزمان بر جنبههای مختلف دادههای ورودی تمرکز کند.
کاربردهای شبکههای ترنسفورمر:
- مدلهای زبانی بزرگ: زیربنای مدلهایی مثل GPT، BERT وT5.
- بینایی ماشین: استفاده در Vision Transformers (ViT) برای طبقهبندی تصاویر.
- خلاصهسازی متن: درک عمیق محتوا برای ایجاد خلاصههای دقیق.
چالشها:
- پیچیدگی محاسباتی: ترنسفورمرها از نظر محاسباتی بسیار سنگین هستند، بهویژه هنگام کار با توالیهای طولانی؛ زیرا محاسبات مکانیزم توجه به خود با افزایش طول ورودی به صورت توان دو (Quadratic) رشد میکند.
- عطش داده و منابع: این مدلها برای رسیدن به بلوغ، به حجم عظیمی از داده و سختافزارهای بسیار قدرتمند (GPU/TPU) نیاز دارند.
.
۸. شبکه عصبی کانولوشنال (Convolutional Neural Network – CNN)
در حال حاضر، شبکههای عصبی کانولوشنال (CNN) در دنیای یادگیری عمیق بسیار محبوب و پرطرفدار هستند. این مدلها در کاربردها و حوزههای بسیار متنوعی استفاده میشوند و بهویژه در پروژههای مربوط به پردازش تصویر و ویدیو حضور چشمگیری دارند.
اجزای سازنده شبکههای CNN، فیلترها (Filters) هستند که با نام کرنل (Kernels) نیز شناخته میشوند. در این شبکهها، از کرنلها برای استخراج ویژگیهای کلیدی از دادههای ورودی با استفاده از عملیات ریاضی خاصی به نام کانولوشن استفاده میشود.
برای درک بهتر اهمیت فیلترها، کافی است تصاویر را به عنوان داده ورودی تصور کنید؛ زمانی که یک تصویر با فیلترهای مختلف ترکیب (Convolve) میشود، خروجی حاصل به عنوان یک نقشه ویژگی (Feature Map) شناخته میشود که جزئیات مهم تصویر (مثل لبهها یا بافتها) را در خود جای داده است.
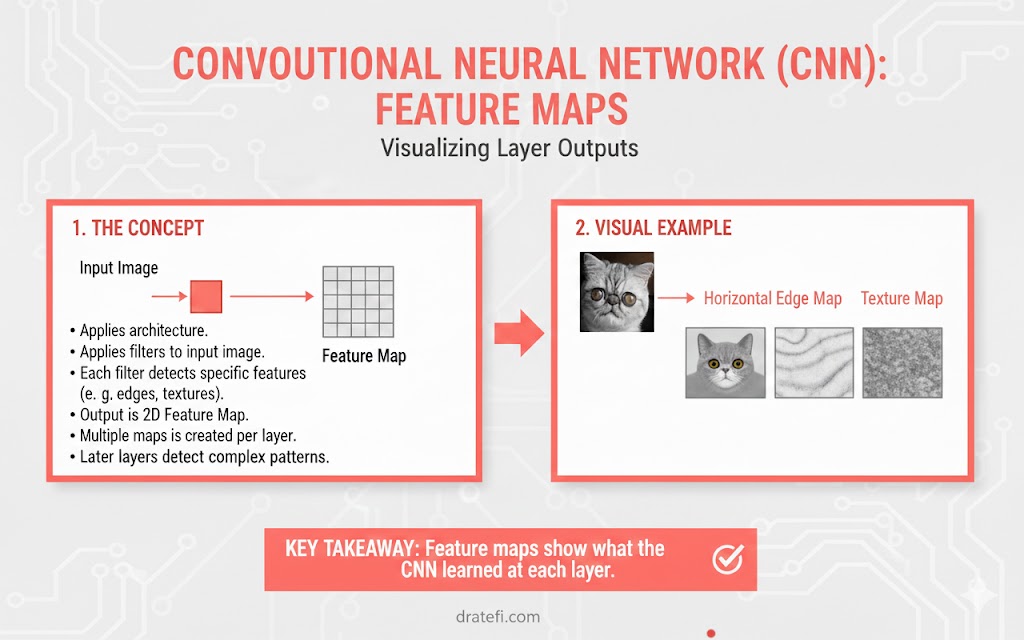
مزایا و ویژگیهای برتر CNN
- یادگیری خودکار: این شبکه خودش یاد میگیرد که چه ویژگیهایی در عکس (مثل گوشها یا سبیل در تشخیص گربه) اهمیت بیشتری دارند.
- درک فضایی: روابط بین پیکسلها را درک میکند و متوجه چیدمان اجزا نسبت به هم میشود.
- اشتراکگذاری پارامتر: استفاده از فیلترهای یکسان روی کل تصویر باعث سبکتر شدن مدل و افزایش هوشمندی آن میشود.
چالشها
- ماهیت جعبه سیاه: درک دقیق منطق تصمیمگیری مدل (اینکه چرا یک تصویر را سگ تشخیص داده) دشوار است.
- ضعف در دادههای متوالی: این شبکهها در درک ترتیب زمانی (مثلاً در ویدیوهای طولانی) ضعیف هستند، مگر اینکه با مدلهای بازگشتی مثل RNN ترکیب شوند.
اگرچه شبکههای عصبی کانولوشنال (CNN) در ابتدا برای غلبه بر چالشهای مربوط به دادههای تصویری طراحی شدند، اما امروزه مشخص شده است که این شبکهها عملکرد بسیار خیرهکنندهای بر روی ورودیهای متوالی (Sequential Inputs) نیز دارند.
چرا CNN در پردازش دادههای متوالی موفق است؟🚀
- استخراج الگوهای محلی: همانطور که CNN لبهها را در تصویر تشخیص میدهد، میتواند الگوهای کلیدی محلی را در متن یا سیگنالهای صوتی نیز شناسایی کند.
- اشتراکگذاری پارامترها: این ویژگی باعث میشود مدل بسیار بهینه باشد و بتواند الگوهای مشابه را در بخشهای مختلف یک توالی (مثل یک کلمه خاص در ابتدا یا انتهای جمله) به خوبی تشخیص دهد.
- پردازش موازی: برخلاف RNNها که دادهها را یکییکی پردازش میکنند، CNN میتواند بخشهای مختلف یک توالی را به صورت همزمان تحلیل کند که سرعت آموزش را بهشدت بالا میبرد.
کاربردها در دادههای متوالی 📈
- تحلیل متن: برای وظایفی مثل طبقهبندی متون یا تحلیل احساسات، جایی که شناسایی کلمات کلیدی در کنار هم اهمیت دارد.
- پیشبینی سریهای زمانی: تحلیل نوسانات قیمت یا سیگنالهای حسگرهای صنعتی که در آنها الگوهای تکرارشونده زمانی وجود دارد.
مزایای شبکه عصبی کانولوشنال (CNN)
- یادگیری خودکار: شبکه CNN فیلترها را به صورت خودکار و بدون نیاز به تعریف صریح یاد میگیرد که این فیلترها به استخراج ویژگیهای درست و مرتبط از دادههای ورودی کمک میکنند.
- تشخیص پیشرفته اشیاء: این شبکه ویژگیهای مکانی (Spatial Features) را از تصویر استخراج میکند که به معنای درک چیدمان پیکسلها و رابطه بین آنهاست؛ این ویژگی به شناسایی دقیق شیء، مکان آن و رابطهاش با سایر اشیاء در تصویر کمک میکند.
- اشتراکگذاری پارامترها: یک فیلتر واحد بر روی بخشهای مختلف ورودی اعمال میشود تا یک نقشه ویژگی (Feature Map) تولید شود که این امر باعث بهینگی مدل میگردد.
چالشهای شبکه عصبی کانولوشنال (CNN)
- نیاز به محاسبات و حافظه بالا: این شبکهها به قدرت پردازشی و حافظه زیادی نیاز دارند، بهویژه در معماریهای عمیق با مجموعهدادههای بزرگ.
- فقدان تفسیرپذیری: این مدلها اغلب مانند یک جعبه سیاه عمل میکنند و درک اینکه چرا و چگونه یک پیشبینی خاص را انجام دادهاند، دشوار است.
- درک زمانی محدود: شبکه CNN در استخراج ویژگیهای مکانی عالی است اما در کار با دادههای متوالی یا زمانی ضعیف عمل میکند، مگر اینکه با RNNها یا سایر مدلهای زمانی ترکیب شود.
.
۹. شبکههای عصبی وا-کانولوشنال (Deconvolutional Neural Networks)
این شبکهها که با نامهای کانولوشن ترانهاده یا Upconvolutional نیز شناخته میشوند، برای عملیات Upsampling (افزایش ابعاد) به کار میروند. در واقع، آنها فرآیند کانولوشن را معکوس کرده و نقشههای ویژگی با وضوح پایین را به نمایشهایی با وضوح بالا تبدیل میکنند. این ویژگی در تولید دادههای باکیفیت از نسخههای فشرده، مانند مدلهای مولد، بسیار حیاتی است.
- کاربردها: بازسازی تصویر از نقشههای ویژگی انتزاعی و بخشبندی معنایی (Semantic Segmentation) برای اختصاص برچسب کلاس به هر پیکسل تصویر، مثلاً در سیستمهای رانندگی خودکار.
- چالشها: احتمال ایجاد اثر شطرنجی (Checkerboard Artifacts) که الگوهای ناخواستهای در تصویر خروجی هستند، و همچنین پیچیدگی در طراحی معماری برای تضمین کیفیت مناسب خروجی.
.
۱۰. خودرمزگذارها (Autoencoders)
خودرمزگذار نوعی شبکه عصبی است که برای یادگیری کدهای فشرده از دادههای بدون برچسب طراحی شده است. این شبکه از دو بخش اصلی تشکیل شده است:
رمزگشا (Decoder): تلاش میکند ورودی اولیه را از روی همان نسخه فشرده بازسازی کند.
رمزگذار (Encoder): ورودی را میگیرد و آن را به یک نمایش فشرده در فضای پنهان تبدیل میکند.
- کاربردها: کاهش ابعاد دادهها (Dimensionality Reduction) و شناسایی الگوهای غیرعادی یا ناهنجاریها (Anomaly Detection).
- چالشها: خطر بیشبرازش (Overfitting) و احتمال یادگیری توابع کپیبرداری ساده، و همچنین احتمال از دست رفتن جزئیات مهم در فرآیند فشردهسازی.
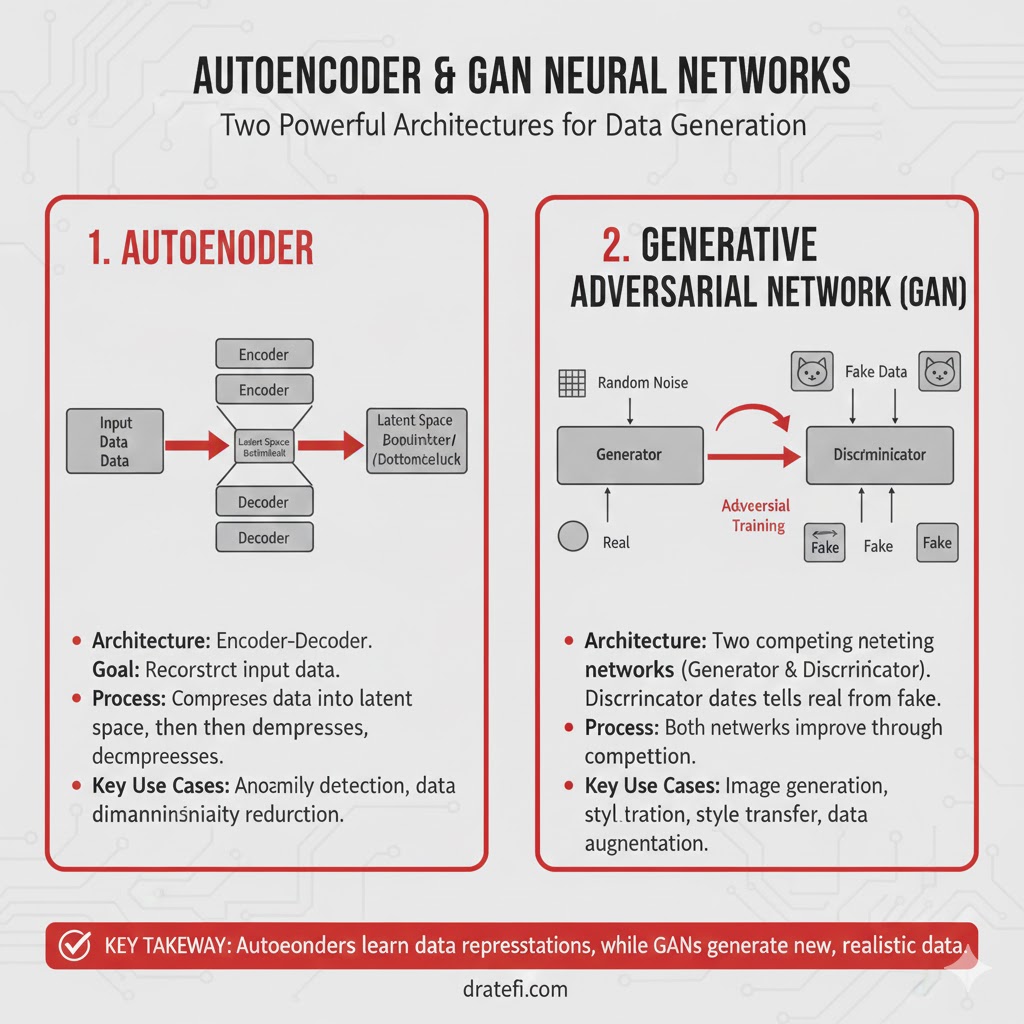
۱۱. شبکههای مولد رقابتی (GANs)
یک شبکه GAN شامل دو شبکه عصبی است: مولد (Generator) و تبعیضگر (Discriminator) که در یک بازی با هم رقابت میکنند. مولد دادههای جعلی میسازد و تبعیضگر اصالت آنها را ارزیابی میکند. این فرآیند تا زمانی ادامه مییابد که مولد دادههایی تولید کند که از دادههای واقعی غیرقابل تشخیص باشند.
- کاربردها: تولید تصاویر واقعی (چهره، اشیاء، مناظر) و افزایش دادهها (Data Augmentation) با تولید نمونههای جدید.
- چالشها: ناپایداری در آموزش که نیاز به تنظیم دقیق هایپرپارامترها دارد، و مشکل فروپاشی مود (Mode Collapse) که در آن مولد تنوع خروجیهای خود را از دست میدهد.
.
۱۲. شبکه عصبی تابع شعاعی (RBF Neural Network)
شبکه RBF یک شبکه پیشخور (Feedforward) است که از توابع شعاعی به عنوان تابع فعالسازی استفاده میکند. این شبکهها شامل یک لایه ورودی، یک یا چند لایه پنهان با توابع شعاعی و یک لایه خروجی هستند و در تشخیص الگو، تقریب توابع ریاضی پیچیده و پیشبینی سریهای زمانی عملکردی عالی دارند.
کاربردهای شبکه عصبی RBF
شبکههای عصبی تابع شعاعی به دلیل ساختار خاص خود در تقریب زدن و شناسایی الگوها بسیار توانمند هستند:
- تقریب تابع: این شبکهها در تخمین و تقریب توابع ریاضی پیچیده و غیرخطی عملکرد بسیار موثری دارند.
- تشخیص الگو: از شبکههای RBF به طور گسترده برای شناسایی چهره، اثر انگشت و تشخیص کاراکترها و حروف استفاده میشود.
- پیشبینی سریهای زمانی: این مدلها قادرند وابستگیهای زمانی را در دادهها درک کرده و پیشبینیهای دقیقی در سریهای زمانی انجام دهند.
چالشهای شبکه عصبی RBF
با وجود دقت بالا، کار با این شبکهها چالشهای خاص خود را دارد:
- انتخاب تابع پایه: برگزیدن تابع شعاعی مناسب برای حل یک مسئله خاص میتواند دشوار باشد.
- تعیین تعداد توابع: مشخص کردن تعداد بهینه توابع پایه در لایه پنهان نیاز به بررسی و تنظیمات دقیق معماری دارد.
- بیشبرازش: این شبکهها مستعد بیشبرازش هستند؛ به این معنا که ممکن است دادههای آموزشی را بیش از حد خوب یاد بگیرند اما در مواجهه با دادههای جدید و ندیده، عملکرد ضعیفی داشته باشند.
.
مقایسه نهایی انواع شبکههای عصبی
در جدول زیر، تفاوتهای کلیدی بین معماریهای مختلف را برای درک سریع و مقایسهای خلاصه کردهایم:
| نوع شبکه عصبی | نوع داده اصلی | اتصالات بازگشتی | اشتراکگذاری پارامتر | روابط مکانی | مشکل گرادیان |
| پروسپترون (Single Layer) | جدولی | ندارد | ندارد | ندارد | دارد |
| MLP / ANN / FNN | جدولی | ندارد | ندارد | ندارد | دارد |
| RNN (بازگشتی) | توالی (متن/صوت) | دارد | دارد | ندارد | دارد |
| LSTM (حافظهدار) | توالی (زمانی) | دارد | دارد | ندارد | کاهشیافته |
| ترنسفورمر | متن/تصویر/توالی | ندارد | دارد | دارد | خنثیشده |
| CNN (کانولوشنال) | تصویر | ندارد | دارد | دارد | دارد |
| Autoencoders | تصویر/متن/جدول | ندارد | دارد | دارد | دارد |
| GANs (مولد) | تصویر/صوت | ندارد | دارد | دارد | دارد |
| RBF (تابع شعاعی) | جدولی | ندارد | ندارد | ندارد | دارد |
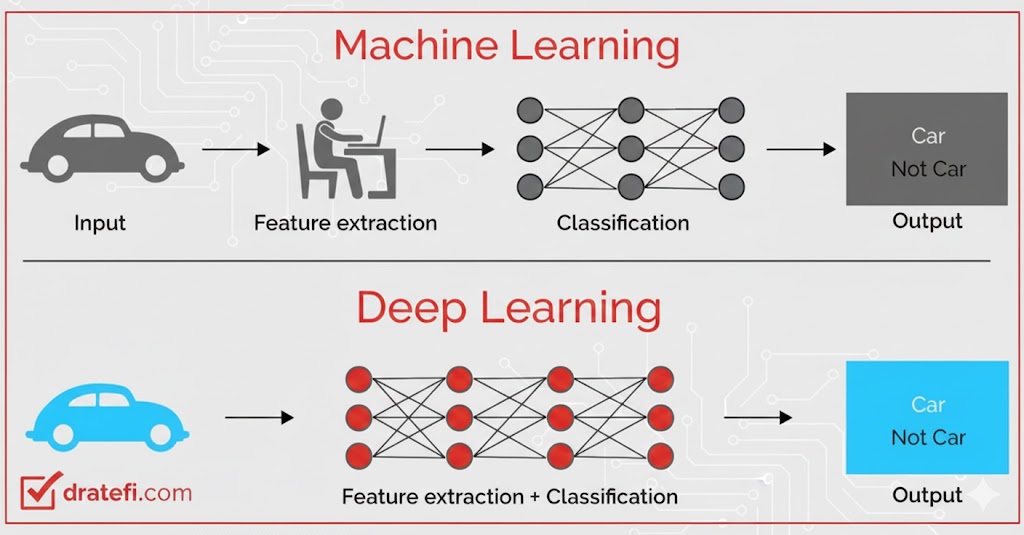
چرا به یادگیری عمیق (Deep Learning) نیاز داریم؟
سؤالی که اغلب مطرح میشود این است: با وجود الگوریتمهای متنوع یادگیری ماشین (Machine Learning)، چرا باید به سمت یادگیری عمیق برویم؟ آیا هزینه سنگین پردازشی آنها واقعاً ارزشش را دارد؟ پاسخ کوتاه این است: بله!
شبکههای عصبی مثل CNN و RNN روش تعامل ما با دنیا را تغییر دادهاند. آنها قلب تپنده فناوریهای انقلابی مثل ماشینهای خودران، پهپادهای هوشمند و سیستمهای تشخیص گفتار هستند.
یادگیری ماشین در مقابل یادگیری عمیق: تفاوت در چیست؟
دو دلیل اصلی وجود دارد که چرا متخصصان یادگیری عمیق را به روشهای سنتی ترجیح میدهند:
۱. مرز تصمیمگیری: الگوریتمهای یادگیری ماشین معمولاً مرزهای ساده و خطی ایجاد میکنند. اما یادگیری عمیق میتواند مرزهای بسیار پیچیده و غیرخطی را برای تفکیک دادهها یاد بگیرد
۲. مهندسی ویژگی: در یادگیری ماشین، انسان باید ویژگیهای مهم را به مدل بگوید (مثلاً لبههای تصویر). اما در یادگیری عمیق، مدل خودش ویژگیها را مستقیماً از دادههای خام استخراج میکند.
یادگیری ماشین در مقابل یادگیری عمیق: مرز تصمیمگیری
هر الگوریتم یادگیری ماشین در تلاش است تا نگاشتی صحیح از ورودی به خروجی پیدا کند. در مدلهای پارامتریک، الگوریتم تابعی را با مجموعهای از وزنها یاد میگیرد:
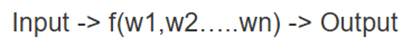
در مسائل طبقهبندی (Classification)، الگوریتم تابعی را یاد میگیرد که دو کلاس را از هم جدا میکند. به این مرز جداکننده، مرز تصمیمگیری(Decision Boundary) گفته میشود. این مرز به ما کمک میکند تشخیص دهیم یک داده خاص به کلاس مثبت تعلق دارد یا کلاس منفی.
به عنوان مثال، در الگوریتم رگرسیون لجستیک، تابع یادگیری یک تابع سیگموئید (Sigmoid) است که تلاش میکند با ترسیم یک مرز، دو کلاس را از هم جدا کند.
تفاوت اصلی اینجاست که الگوریتمهای سنتی یادگیری ماشین اغلب در ترسیم مرزهای پیچیده و غیرخطی ناتوان هستند، در حالی که شبکههای عصبی عمیق با استفاده از لایههای پنهان و توابع فعالسازی، میتوانند مرزهای بسیار منعطف و دقیقی را برای دادههای درهمتنیده خلق کنند.
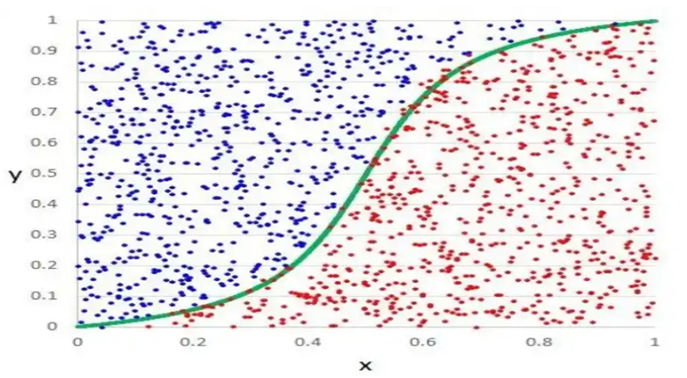
همانطور که در تصویر مشاهده میکنید، الگوریتم رگرسیون لجستیک تنها یک مرز تصمیمگیری خطی را یاد میگیرد. این یعنی اگر دادههای شما ساختار پیچیدهای داشته باشند و به سادگی با یک خط مستقیم از هم جدا نشوند، این مدل در دستهبندی آنها ناتوان خواهد بود.
در دنیای واقعی، دادهها اغلب رفتاری غیرخطی دارند. در چنین شرایطی، رگرسیون لجستیک نمیتواند مرزهای دایرهای یا منحنی شکلی را که برای تفکیک صحیح کلاسها نیاز است، ترسیم کند. این دقیقاً همان نقطهای است که شبکههای عصبی عمیق وارد میدان میشوند؛ آنها با تکیه بر توابع فعالسازی غیرخطی، میتوانند هر نوع مرز تصمیمگیری پیچیدهای را یاد بگیرند و با دقت بسیار بالاتری دادهها را دستهبندی کنند.
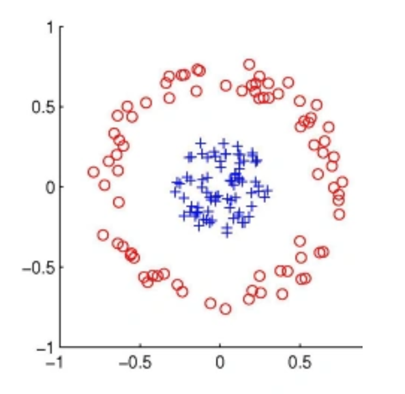
دادههای غیرخطی و برتری یادگیری عمیق
به همین ترتیب، تمام الگوریتمهای یادگیری ماشین قادر به یادگیری تمامی توابع نیستند. این موضوع باعث میشود توانایی این الگوریتمها در حل مسائلی که روابط پیچیدهای دارند، محدود شود. در مقابل، مدلهای یادگیری عمیق در شناسایی الگوها بسیار متبحرتر و نسبت به مدلهای سنتی، بسیار پیچیدهتر هستند. یادگیری عمیق به عنوان یک الگوریتم تخمینگر جهانی عمل میکند و میتواند هر نوع مرز تصمیمگیری مورد نیاز را برای دادههای پیچیده خلق کند.
یادگیری ماشین در مقابل یادگیری عمیق: مهندسی ویژگی (Feature Engineering)
مهندسی ویژگی یکی از مراحل کلیدی در فرآیند ساخت مدل است که از دو بخش تشکیل میشود:
- استخراج ویژگی(Feature Extraction): بیرون کشیدن تمام ویژگیهای مورد نیاز از دادههای خام.
- انتخاب ویژگی (Feature Selection): برگزیدن مهمترین ویژگیهایی که باعث بهبود عملکرد مدل میشوند.
یک مسئله طبقهبندی تصویر را در نظر بگیرید. استخراج دستی ویژگیها از یک تصویر، نیازمند دانش تخصصی بسیار بالا در آن حوزه و تجربه فراوان است؛ فرآیندی که بهشدت زمانبر و طاقتفرساست. اما به لطف یادگیری عمیق، ما میتوانیم کل فرآیند مهندسی ویژگی را به صورت خودکار انجام دهیم! مدلهای عمیق خودشان یاد میگیرند که کدام بخش از تصویر اهمیت بیشتری دارد.
جمعبندی
شبکههای عصبی در یادگیری عمیق متنوع هستند و هرکدام برای نوع خاصی از داده و مسئله طراحی شدهاند:
- شبکههای پیشخور برای مسائل سادهتر،
- شبکههای کانولوشنی برای دادههای تصویری،
- شبکههای بازگشتی برای دادههای ترتیبی،
- ترنسفورمرها برای مدلسازی وابستگیهای پیچیده در مقیاس بزرگ.
شناخت تفاوت این معماریها، کلید موفقیت در طراحی مدلهای کارآمد است.
هیچ شبکهای برای همهٔ مسائل بهترین گزینه نیست. انتخاب معماری مناسب وابسته به نوع داده، حجم داده، هدف مسئله، منابع محاسباتی و نیاز به تفسیرپذیری است. گاهی یک مدل ساده از یک معماری پیچیده هم عملکرد بهتری دارد — بهویژه اگر با دقت انتخاب شده باشد.
در نهایت، آشنایی عمیق با انواع شبکههای عصبی به شما کمک میکند بهجای آزمون و خطای پرهزینه، مسیر مدلسازی را آگاهانه و هدفمند طی کنید. این شناخت، تفاوت میان «استفاده از یادگیری عمیق» و «استفاده درست از یادگیری عمیق» را مشخص میکند—و دقیقاً همین تفاوت است که یک متخصص حرفهای را میسازد.



