
1. مقدمه
در دنیای امروز که دادهها با سرعتی بيسابقه توليد ميشوند، علم داده (Data Science) به يكي از ستونهاي اصلي تصميمگيري هوشمند و مديريت كسبوكار تبديل شده است. سازمانها هر روز حجم عظيمي از دادههاي خام از پايگاههاي اطلاعاتي، سنسورها، شبكههاي اجتماعي و تعاملات مشتريان دريافت ميكنند. اما تنها زماني اين دادهها ارزشمند ميشوند كه بتوان آنها را تحليل، تميز و تفسير كرد تا به بينش عملياتي و راهبردي تبديل شوند. اين همان جايي است كه علم داده وارد ميدان ميشود.
علم داده تركيبي از رياضيات، علوم كامپيوتر و دانش تخصصي حوزه كسبوكار است كه با كنار هم قرار گرفتن اين سه ركن، ميتوان الگوهاي پنهان، روندهاي رفتاري مشتريان، نواقص فرايندها و فرصتهاي رشد را كشف كرد. از پيشبيني تقاضاي بازار تا تحليل رفتار كاربران و بهينهسازي مسيرهاي حملونقل نتيجه استفاده صحيح از علم داده است.
اين مقاله، با تكيه بر يك محتواي پايه قوي، تلاش ميكند فرايندها، ابزارها، كاربردها و اهميت علم داده را به شكلي ساده، قابلفهم و همزمان حرفهاي توضيح دهد تا خواننده نهتنها با مفاهيم آشنا شود، بلكه بتواند از آنها در پروژههاي واقعي نيز بهره ببرد.ش پیدا میکنند که آنها را پاکسازی، تحلیل و تفسیر کنیم تا به بینش عملیاتی و استراتژیک دست یابیم. علم داده، با ترکیب ریاضیات، علوم کامپیوتر و دانش حوزهای، الگوهای پنهان را کشف میکند: از پیشبینی تقاضای بازار و تحلیل رفتار مشتری تا بهینهسازی فرآیندها. این مقاله فرآیندها، ابزارها و کاربردهای علم داده را بهصورت ساده، دقیق و کاربردی توضیح میدهد تا خوانندگان بتوانند مفاهیم را نهتنها درک، بلکه در پروژههای واقعی پیادهسازی کنند.
2.علم داده چیست؟
علم داده(Data Science)، دانشِ مطالعه و کاوش در دادههاست که با هدف استخراج بینشهای معنادار برای تصمیمگیریهای تجاری به کار میرود.
این حوزه، تلفیقی قدرتمند از سه رکن اصلی است: ۱. ریاضیات ۲. علوم کامپیوتر و محاسبات ۳. دانش تخصصی حوزه کسبوکار
ترکیب این علوم به ما اجازه میدهد تا مسائل دنیای واقعی را حل کنیم و الگوهایی را که در نگاه اول پنهان هستند، کشف نماییم.
کاربرد عملی: با پردازش دادههای خام، به چالشهای کسبوکار پاسخ میدهد و آینده را پیشبینی میکند. به عنوان مثال، با تحلیل دادههای عظیم یک شرکت، میتوان به سوالات حیاتی زیر پاسخ داد:
- نیاز مشتری: مشتریان دقیقاً چه چیزی میخواهند؟
- بهبود کیفیت: چگونه میتوانیم خدماتمان را بهتر کنیم؟
- پیشبینی بازار: روند فروش در آینده نزدیک چگونه خواهد بود؟
- مدیریت موجودی: برای جشنواره یا فصل فروش پیشرو، دقیقاً به چه میزان کالا در انبار نیاز داریم؟
3. فرآیند علم داده (Data Science Process)
فرآیند علم داده یک مسیر خطی و مشخص دارد که دادههای خام را به ارزش تجاری تبدیل میکند. این مراحل عبارتند از:
3.1. جمعآوری داده (Data Collection)
3.2. پاکسازی و آمادهسازی داده (Data Cleaning)
3.3. تحلیل داده (Data Analysis)
3.4. مصورسازی داده (Data Visualization)
3.5. تصمیمگیری مبتنی بر داده (Decision-Making)
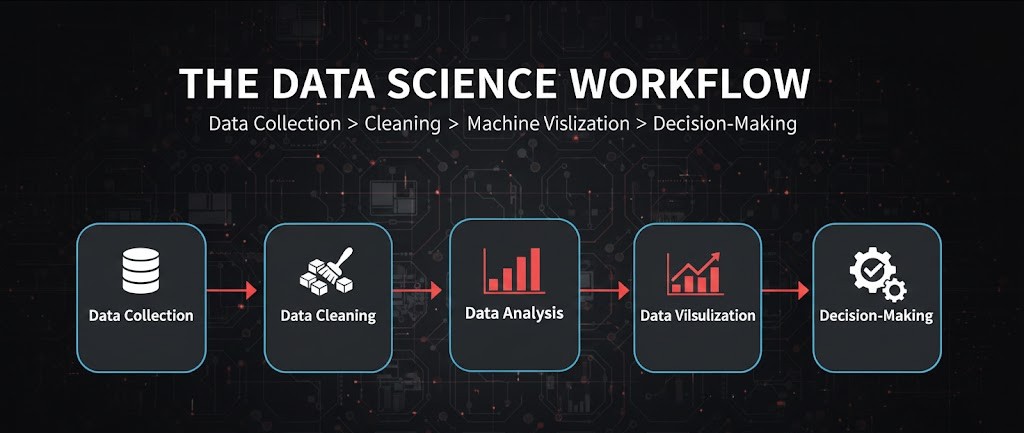
3.1 جمعآوری داده:
گردآوری دادههای خام از منابع متنوع؛ این منابع میتوانند پایگاههای داده (Databases)، سنسورهای اینترنت اشیاء (IoT) یا لاگهای تعاملات کاربران باشند.
3.2 پاکسازی داده:
تضمین اینکه دادهها دقیق، کامل و بدون خطا هستند. در این مرحله دادههای پرت و ناقص برای آمادهسازی جهت تحلیل حذف یا اصلاح میشوند.
3.3 تحلیل داده:
به کارگیری روشهای آماری و محاسباتی برای کشف الگوها، روندها و روابط پنهان در دادهها.
3.4 مصورسازی داده:
خلق نمودارها، گرافها و داشبوردهای مدیریتی برای اینکه یافتههای پیچیده به شکلی شفاف و قابلفهم ارائه شوند.
3.5 تصمیمگیری:
مرحله نهایی که در آن از بینشهای بهدستآمده برای تدوین استراتژی، ارائه راهحل یا پیشبینی نتایج استفاده میشود.
مطالعه موردی
فرض کنید یک روز بارانی در ساعت ۵ عصر (اوج ترافیک) در میدان ونک تهران هستید و درخواست خودرو میدهید. بیایید ببینیم در پشت صحنه چه اتفاقی میافتد:
سیستم درخواست خودرو (اسنپ/تپسی)
۱. جمعآوری داده
سیستم به صورت لحظهای و مداوم در حال مکیدن دادهها از منابع مختلف است:
- دادههای مکانی: موقعیت دقیق GPS هزاران راننده و مسافر.
- دادههای محیطی: وضعیت آبوهوا (از طریق APIهای هواشناسی که نشان میدهد الان باران میبارد).
- دادههای ترافیکی: وضعیت قرمزی یا روانی خیابانها (مثلاً از دادههای گوگلمپ یا دادههای تاریخی خود شرکت).
- لاگهای کاربران: تعداد افرادی که اپلیکیشن را باز کردهاند اما هنوز درخواست ندادهاند.
۲. پاکسازی داده
دادههای خام همیشه تمیز نیستند و نیاز به اصلاح دارند:
- حذف نویزGPS: گاهی GPS راننده به اشتباه موقعیت او را وسط ساختمان یا چند خیابان آنطرفتر نشان میدهد؛ سیستم این پرشهای ناگهانی را اصلاح میکند.
- فیلتر کردن درخواستهای فیک: اگر کاربری ۱۰ بار پشت سر هم درخواست دهد و لغو کند، سیستم این دادهها را به عنوان “تقاضای واقعی” در نظر نمیگیرد تا محاسبات اشتباه نشود.
- مدیریت دادههای ناقص: اگر اطلاعات ترافیکی یک خیابان خاص قطع شود، سیستم از میانگین سرعت خودروهای آن منطقه استفاده میکند.
۳. تحلیل داده
اینجا مغز متفکر سیستم فعال میشود. الگوریتمها شروع به محاسبه میکنند:
- تحلیل عرضه و تقاضا: الگوریتم متوجه میشود که در میدان ونک، الان ۵۰۰ نفر درخواست خودرو دارند (تقاضا)، اما فقط ۵۰ ماشین در دسترس است (عرضه).
- شناسایی الگو: سیستم با مقایسه با دادههای تاریخی، میفهمد که “روزهای بارانی” + “ساعت ۵ عصر” + “میدان ونک” = ترافیک سنگین و زمان سفر ۳ برابر معمول.
- محاسبه ریسک: احتمال اینکه رانندگان به دلیل ترافیک سنگین درخواستها را قبول نکنند، محاسبه میشود.
۴. مصورسازی داده
نتایج تحلیل باید برای مدیران و حتی رانندگان نمایش داده شود:
- برای رانندگان: نقشه تهران برای رانندگان در مناطق پرتقاضا (مثل ونک) به رنگ قرمز در میآید. این یک نمودار بصری است که به راننده میگوید: “اینجا پول بیشتری هست”.
- برای مدیران شرکت: داشبوردهای مدیریتی نشان میدهند که در ساعت گذشته چند درصد درخواستها موفق بوده و نمودار درآمد لحظهای چقدر است.
۵. تصمیمگیری
بر اساس تحلیلها، سیستم (و گاهی مدیران) تصمیم نهایی را میگیرند:
- افزایش قیمت خودکار: قیمت سفر از ۵۰ هزار تومان به ۸۵ هزار تومان افزایش مییابد تا برای راننده جذاب شود (Surge Pricing).
- توزیع منابع: با قرمز کردن منطقه در نقشه، رانندگان از مناطق خلوتتر به سمت ونک هدایت میشوند تا تعادل بین عرضه و تقاضا برقرار شود.
- استراتژی بلندمدت: مدیران با دیدن گزارشها تصمیم میگیرند کمپین تبلیغاتی “تخفیف در روزهای بارانی” را متوقف کنند چون تقاضا به اندازه کافی بالاست.
4. دلایل افزایش تقاضا برای علم داده
اهمیت روزافزون این حوزه به دلایل کلیدی زیر است:
- تصمیمگیری هوشمندانه: کسبوکارها با تحلیل دادهها، روندها را درک کرده و انتخابهایی میکنند که ریسک را کاهش و سود را به حداکثر میرساند.
- افزایش بهرهوری: سازمانها نقاطی را شناسایی میکنند که میتوان در آنها زمان و منابع را صرفهجویی کرد.
- تجربه شخصیسازیشده: علم داده امکان ارائه پیشنهادات و توصیههای سفارشی (مانند نتفلیکس یا آمازون) را فراهم میکند که رضایت مشتری را به شدت بالا میبرد.
- پیشبینی آینده: کسبوکارها میتوانند تقاضای بازار و سایر فاکتورهای حیاتی را قبل از وقوع پیشبینی کنند.
- محرک نوآوری: بسیاری از ایدهها و محصولات جدید، مستقیماً از دلِ بینشهای کشفشده توسط علم داده بیرون میآیند.
- منافع اجتماعی: بهبود خدمات عمومی مانند بهداشت و درمان، آموزش و حملونقل از طریق تخصیص بهینهتر منابع.
5. ابزارهای علم داده
برای کسب تخصص و خبره شدن در حوزه علم داده، صرفاً دانستن تئوری کافی نیست؛ شما باید زیربنای فنی قدرتمندی داشته باشید. اولین و مهمترین قدم، تسلط بر زبانهای برنامهنویسی کلیدی است:
5.1 پایتون و کتابخانههای کلیدی
برای اینکه در علم داده به یک متخصص تمامعیار تبدیل شوید، تنها دانستن زبان پایتون کافی نیست؛ قدرت اصلی پایتون در اکوسیستم کتابخانههای آن نهفته است. برای موفقیت در این حوزه، باید زیربنای فنی قدرتمندی در کتابخانههای زیر داشته باشید:
- پانداس(Pandas): برای دستکاری و تحلیل دادهها پانداس را میتوان «آچار فرانسه» علم داده دانست. این کتابخانه ابزارهای قدرتمندی برای کار با دادههای ساختاریافته (مثل فایلهای Excel و CSV) در قالب دیتافریم فراهم میکند. هر جا نیاز به تمیزکاری، فیلتر کردن و تغییر شکل دادهها باشد، پانداس حضور دارد.
- نامپای(NumPy): برای محاسبات عددی سنگین نامپای (Numerical Python) قلب تپنده محاسبات علمی در پایتون است. این کتابخانه امکان کار با آرایههای چندبعدی و ماتریسهای بزرگ را فراهم میکند و پایهای است که سایر کتابخانهها (مثل پانداس) روی آن بنا شدهاند.
- (Matplotlib): برای مصورسازی پایه این کتابخانه، پدرِ ابزارهای رسم نمودار در پایتون است. با اینکه کمی پیچیده به نظر میرسد، اما بیشترین کنترل را برای خلق هر نوع نمودار استاتیک، متحرک و تعاملی به شما میدهد.
- (Seaborn): برای مصورسازی آماری و زیبا سیبورن بر پایه Matplotlib ساخته شده اما کار با آن سادهتر است. این کتابخانه به صورت پیشفرض نمودارهایی بسیار زیباتر و مدرنتر تولید میکند و برای نمایش الگوهای آماری پیچیده عالی است.
- (Scikit-learn): برای یادگیری ماشین محبوبترین کتابخانه برای پیادهسازی الگوریتمهای کلاسیک یادگیری ماشین. از رگرسیون و طبقهبندی گرفته تا خوشهبندی، همه ابزارهای لازم برای مدلسازی را به شکلی ساده و استاندارد در اختیار شما قرار میدهد.
5.2 ابزارهای مصورسازی
مصورسازی دادهها، هنر استفاده از نمایشهای گرافیکی مانند نمودارها و گرافهاست تا دادههای پیچیده را قابلفهم و قابل تفسیر کنیم. در پایتون، ما ابزارهای متنوعی برای این کار داریم:
5.2.1 مصورسازی با Matplotlib
این کتابخانه، مادر تمام ابزارهای مصورسازی در پایتون است و کنترل کاملی روی اجزای نمودار به شما میدهد.
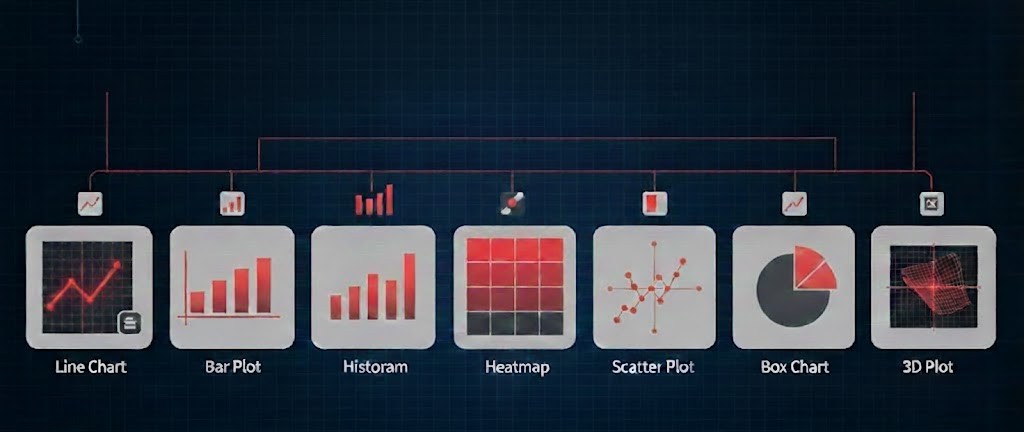
- نمودار خطی(Line Chart): برای نمایش روند تغییرات در طول زمان.
- نمودار میلهای(Bar Plot): برای مقایسه مقادیر در دستههای مختلف.
- هیستوگرام(Histogram): برای مشاهده توزیع فراوانی دادهها (مثلاً توزیع نمرات).
- نقشه حرارتی(Heatmap): نمایش شدت دادهها با طیف رنگی (عالی برای ماتریس همبستگی).
- نمودار جعبهای(Box Plot): بهترین ابزار برای شناسایی دادههای پرت (Outliers) و دامنه تغییرات.
- نمودار پراکندگی(Scatter Plot): برای بررسی رابطه بین دو متغیر عددی.
- نمودار دایرهای(Pie Chart): نمایش سهم هر بخش از کل (استفاده محتاطانه توصیه میشود).
- نمودار سهبعدی(3D Plot): برای نمایش دادههایی با سه بعد متغیر.
5.2.2 مصورسازی با Seaborn
کتابخانهای که روی Matplotlib سوار شده تا رسم نمودارهای آماری پیچیده را ساده و زیبا کند.

- نمودار جفتی(Pair Plot): رسم همزمان رابطه تمام متغیرهای عددی با یکدیگر (دید کلیِ عالی).
- نمودار شمارشی(Count Plot): شبیه نمودار میلهای، اما برای شمارش تعداد تکرار دستهها.
- نمودار ویولن(Violin Plot): ترکیبی از Box Plot و نمودار توزیع؛ هم چارکها را نشان میدهد و هم چگالی دادهها را.
- نمودار نواری (Strip Plot):نمایش نقاط داده به صورت پراکنده روی یک محور دستهبندی شده.
- نمودار تخمین چگالی هسته(KDE Plot): نمایش منحنی نرم توزیع احتمال دادهها.
- نمودار مشترک(Joint Plot): ترکیب نمودار پراکندگی (وسط) و هیستوگرام (کنارهها) برای دو متغیر.
- نمودار رگرسیون(Reg Plot): رسم نمودار پراکندگی همراه با خط رگرسیون (خط برازش) برای دیدن روند خطی.
5.2.3 مصورسازی تعاملی (Interactive Visualization)
گاهی نمودارهای ثابت کافی نیستند و کاربر نیاز دارد روی نمودار زوم کند یا با نگهداشتن موس، جزئیات را ببیند.
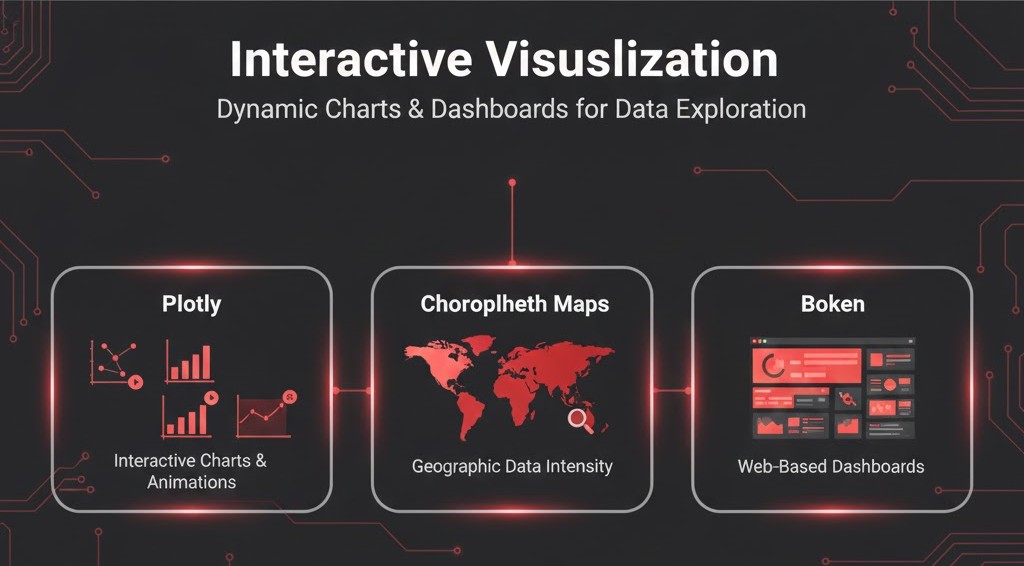
- Plotly: قدرتمندترین ابزار برای ساخت نمودارهای تعاملی (Scatter, Bar, Line) و حتی انیمیشنهای دادهمحور (Animated Data Visualization).
- نقشههای کوروپلث(Choropleth Maps): رنگآمیزی نواحی جغرافیایی بر اساس شدت یک متغیر (مثلاً میزان جمعیت استانها).
- Bokeh: یک جایگزین عالی دیگر برای ساخت داشبوردهای تعاملی تحت وب.
6. ریاضیات لازم برای علم داده
درک عمیق مفاهیم ریاضی برای ساخت مدلهای علم داده حیاتی است. ریاضیات نه تنها ابزار کار، بلکه زبانی است که با آن الگوریتمها را درک میکنیم:
- آمار(Statistics): برای تفسیر دادهها و استنتاج.
- جبر خطی(Linear Algebra): موتور محرک الگوریتمها و کار با ماتریسها.
- حساب دیفرانسیل و انتگرال(Calculus): برای بهینهسازی مدلها.
7. پیشپردازش دادهها (Data Preprocessing)
7.1 پاکسازی دادهها
7.2 مدیریت دادههای گمشده (Missing Data)
7.3 مدیریت دادههای پرت (Outliers)
7.4 انتخاب ویژگی (Feature Selection)
7.5 مهندسی ویژگی (Feature Engineering)
7.6 تقسیم دادهها به Train و Test
پیشپردازش یعنی تبدیل «دادههای خام و کثیف» به «سوخت تمیز و قابل استفاده» برای مدلها. بدون این مرحله، دقیقترین الگوریتمها هم شکست میخورند.
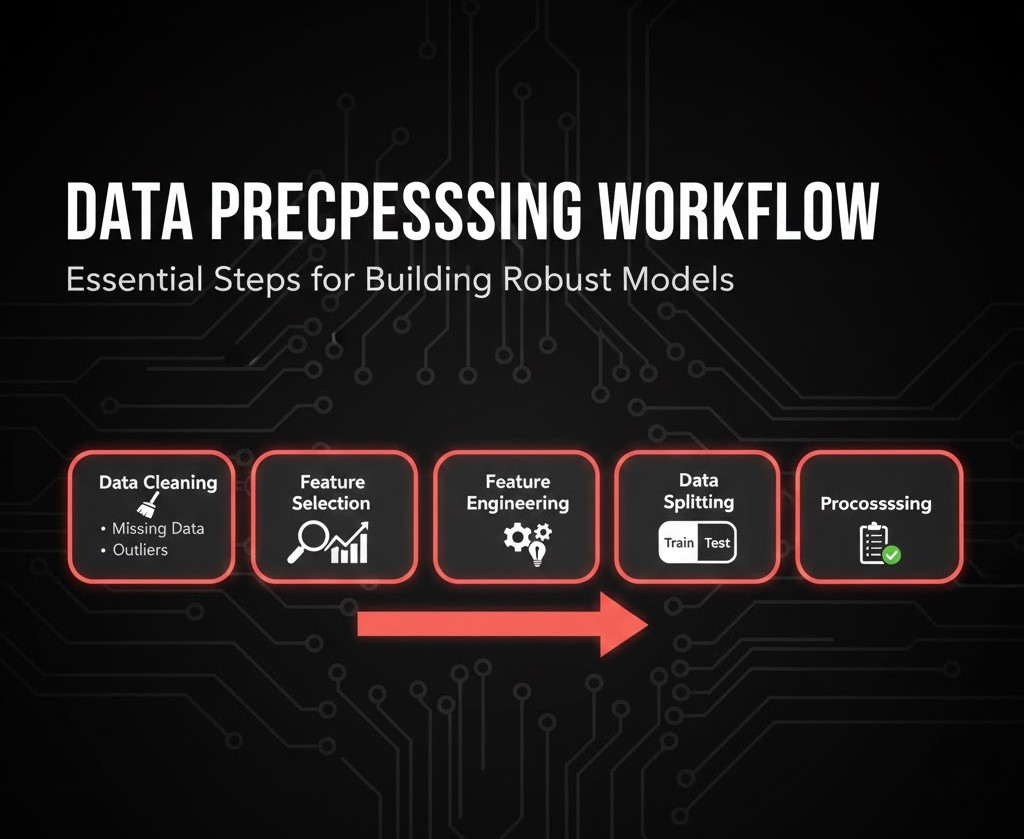
- پاکسازی داده(Data Cleaning): اصلاح خطاها.
- مدیریت دادههای گمشده(Missing Data): پر کردن جاهای خالی با استراتژیهای آماری.
- مدیریت دادههای پرت(Outliers): شناسایی و اصلاح دادههای غیرعادی که نتایج را خراب میکنند.
- انتخاب ویژگی(Feature Selection): انتخاب مهمترین ستونها.
- مهندسی ویژگی(Feature Engineering): خلق ویژگیهای جدید و ارزشمند از دادههای موجود.
- تقسیم دادهها(Splitting Data): جدا کردن دادههای آموزش (Train) و تست . (Test)
مطالعه موردی
هدف پروژه: «پیشبینی قیمت آپارتمان در تهران»
فرض کنید ما ۱۰,۰۰۰ ردیف داده خام از آگهیهای فروش آپارتمان جمعآوری کردهایم. حالا باید این مراحل پیشپردازش را طی کنیم تا دادهها قابل استفاده شوند:
۱. پاکسازی دادهها
مشکل: دادههای واقعی پر از غلط املایی و فرمتهای ناهماهنگ هستند.
- مثال: در ستون «محله»، یک نفر نوشته «تهرانپارس»، نفر دیگر نوشته «تهرانپارس» (با نیمفاصله) و نفر سوم اشتباهاً تایپ کرده «تهران پارس غربی».
- اقدام: تمام اینها باید به یک استاندارد واحد (مثلاً «تهرانپارس») تبدیل شوند. همچنین تبدیل اعداد فارسی (۱۲۰ متر) به اعداد انگلیسی (120) برای اینکه ماشین بتواند محاسبه کند.
۲. مدیریت دادههای گمشده
مشکل: همه آگهیها کامل نیستند. مثلاً در ۵۰۰ آگهی، فیلد «سال ساخت» خالی است.
- راهکار حذف: اگر تعداد کم باشد، آن سطرها را پاک میکنیم.
- راهکار جایگزینی: (روش بهتر) به جای حذف، میانگین سال ساخت آپارتمانهای همان محله را محاسبه کرده و در جاهای خالی قرار میدهیم. مثلاً اگر میانگین سن بنا در سعادتآباد ۱۰ سال است، برای خانههایی که سنشان نامشخص است، عدد ۱۰ را درج میکنیم.
۳. مدیریت دادههای پرت
مشکل: دادههایی که از نظر منطقی یا آماری عجیب هستند و مدل را گمراه میکنند.
- مثال ۱: یک آپارتمان ۵۰ متری که قیمتش اشتباهاً ۱۰۰۰ میلیارد تومان وارد شده (احتمالاً صفر اضافی).
- مثال ۲: خانههایی که قیمتشان «توافقی» یا «۰» وارد شده است.
- اقدام: حذف دادههایی که خارج از محدوده نرمال (مثلاً ۳ انحراف معیار بالاتر از میانگین) هستند تا مدل روی قیمتهای اشتباه آموزش نبیند.
۴. انتخاب ویژگی
مشکل: همه اطلاعات موجود در آگهی روی قیمت تاثیر ندارند و فقط بار محاسباتی را زیاد میکنند.
- مثال: ستونهایی مثل «نام مشاور املاک»، «شماره تماس آگهیدهنده» یا «کد آگهی» تاثیری روی ارزش ملک ندارند.
- اقدام: این ستونهای اضافی را حذف میکنیم و فقط ستونهای موثر مثل «متراژ»، «محله»، «تعداد اتاق» و «طبقه» را نگه میداریم.
۵. مهندسی ویژگی
نکته: این خلاقانهترین بخش کار است؛ ساختن اطلاعات جدید از دادههای موجود.
- مثال ۱: ما ستون «آدرس دقیق» یا «کد پستی» را داریم، اما مدل نمیفهمد خیابان ولیعصر یعنی چه. ما یک ویژگی جدید به نام فاصله تا نزدیکترین ایستگاه مترو میسازیم که عدد است (مثلاً ۵۰۰ متر) و مستقیماً روی قیمت اثر دارد.
- مثال ۲: ویژگیهای «پارکینگ»، «آسانسور» و «انباری» را ترکیب میکنیم و یک ویژگی جدید به نام امکانات کامل میسازیم (اگر هر سه را داشت = ۱، اگر نداشت = ۰).
۶. تقسیم دادهها
هدف: سنجش اینکه آیا مدل واقعاً یاد گرفته یا فقط حفظ کرده است.
- اقدام: از ۱۰,۰۰۰ آگهی که داریم:
- ۸,۰۰۰ آگهی(۸۰٪-Train): را به خورد مدل میدهیم تا الگوی قیمتها را یاد بگیرد (آموزش).
- ۲,۰۰۰ آگهی ( ۲۰٪-Test): را پنهان میکنیم. بعد از آموزش، مشخصات این خانهها را به مدل میدهیم و میگوییم «قیمت را حدس بزن». سپس حدس مدل را با قیمت واقعی مقایسه میکنیم تا دقت مدل سنجیده شود.
8. تحلیل دادهها (Data Analysis)
فرآیند بازرسی دقیق دادهها برای کشف بینشهای معنادار و روندهایی که منجر به تصمیمگیری آگاهانه میشوند.
- تحلیل اکتشافی داده(EDA): اولین نگاه عمیق به دادهها برای شناخت ساختار آنها.
- یافتن همبستگیها(Correlations): کشف رابطه بین ویژگیهای مختلف (مثلاً رابطه دما با میزان فروش).
- تحلیل آماری: اثبات فرضیات با اعداد.
9. یادگیری ماشین
قلب تپنده هوش مصنوعی؛ جایی که الگوریتمهایی میسازیم که به کامپیوتر یاد میدهند بدون برنامهنویسی صریح، از دادهها یاد بگیرد و آینده را پیشبینی کند.
- یادگیری ماشین(ML): این حوزه شامل الگوریتمهای آماری است که به سیستم اجازه میدهد بدون برنامهنویسی صریح و خطبهخط، صرفاً با دیدن دادهها الگوها را یاد بگیرد و تصمیمگیری کند.
- یادگیری عمیق(Deep Learning): زیرشاخهای پیشرفته از یادگیری ماشین است . با الهام از ساختار مغز انسان (شبکههای عصبی چندلایه)، قادر است دادههای بسیار پیچیده و غیرساختاریافته مانند تصاویر، صدا و متن را به طور خودکار درک و تحلیل کند.
جمع بندی
علم داده امروز فراتر از يك مجموعه ابزار تحليلي است؛ بلکه به يك توانمندي راهبردي براي بقا و رشد سازمانها تبديل شده است. هر كسبوكاري — از استارتاپهاي كوچك تا غولهاي فناوري — براي درك رفتار مشتريان، پيشبيني آينده، كاهش ريسك و تصميمگيري دقيق، به تحليل عميق دادهها نياز دارد.
فرآيند علم داده از جمعآوري و پاكسازي دادهها آغاز، با تحليل و مصورسازي ادامه يافته و در نهايت به تصميمگيري مبتني بر بينش ختم ميشود؛ فرايندي پيوسته كه نقش موتور محرک نوآوري را بازي ميكند.
ابزارهای قدرتمند پایتون و کتابخانههایی مانند Pandas، NumPy، Matplotlib، Seaborn و Scikit-learn، همراه با مفاهیم بنیادی ریاضی و مهارت در پیشپردازش دادهها، مسیر را برای ساخت مدلهای دقیق و قابلاعتماد هموار میکنند.
در نهایت، علم داده فقط تحلیل گذشته نیست؛ بلکه ابزاری برای دیدن آینده، پیشبینی رفتارها و ایجاد ارزش پایدار است. هر سازمانی که بتواند دادههای خود را بهتر درک کند، یک گام بزرگتر از رقبا به سمت موفقیت برداشته است.



