
فصل چهارم
شبکه های عصبی عمیق
فصل آخر شبکه های عصبی کم عمق را که دارای یک لایه پنهان هستند، تشریح کرد. این فصل شبکه های عصبی عمیق را معرفی می کند که بیش از یک لایه پنهان دارند. با توابع فعالسازی ReLU، شبکههای کم عمق و عمیق، نگاشتهای خطی تکهای را از ورودی تا خروجی توصیف میکنند.
با افزایش تعداد واحدهای پنهان، شبکه های عصبی کم عمق قدرت توصیفی خود را بهبود می بخشند. در واقع، با واحدهای پنهان کافی، شبکه های کم عمق می توانند توابع پیچیده دلخواه را در ابعاد بالا توصیف کنند. با این حال، معلوم می شود که برای برخی از توابع، تعداد مورد نیاز واحدهای پنهان به طور غیرعملی زیاد است. شبکه های عمیق می توانند مناطق خطی بسیار بیشتری نسبت به شبکه های کم عمق برای تعداد معینی از پارامترها تولید کنند. از این رو، از منظر عملی، می توان از آنها برای توصیف یک خانواده گسترده تر از توابع استفاده کرد.
4.1 ساخت شبکه های عصبی
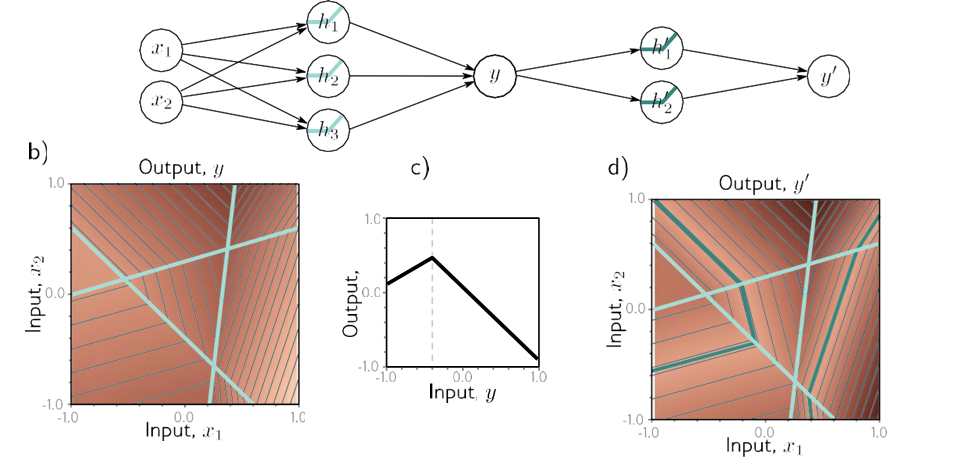
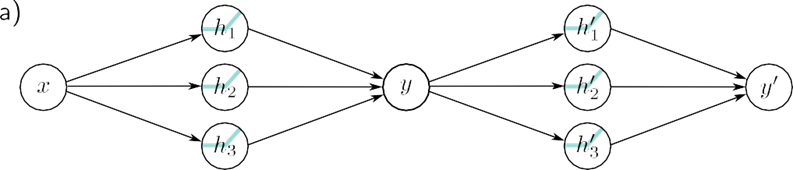
برای به دست آوردن بینشی در مورد رفتار شبکه های عصبی عمیق، ابتدا ترکیب دو شبکه کم عمق را در نظر می گیریم تا خروجی اولی به ورودی شبکه دوم تبدیل شود. دو شبکه کم عمق را با سه واحد پنهان در نظر بگیرید (شکل 4.1a). اولین شبکه یک ورودی x می گیرد و خروجی y را برمی گرداند و به صورت زیر تعریف می شود:
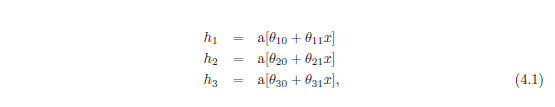
و
![]()
شبکه دوم y را به عنوان ورودی می گیرد و y را برمی گرداند و به صورت زیر تعریف می شود:
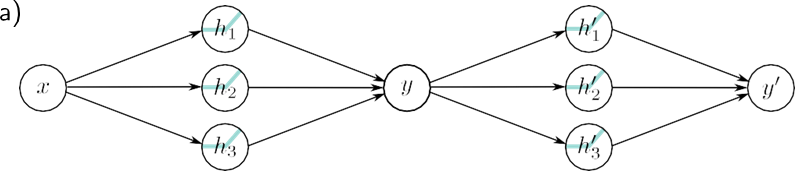
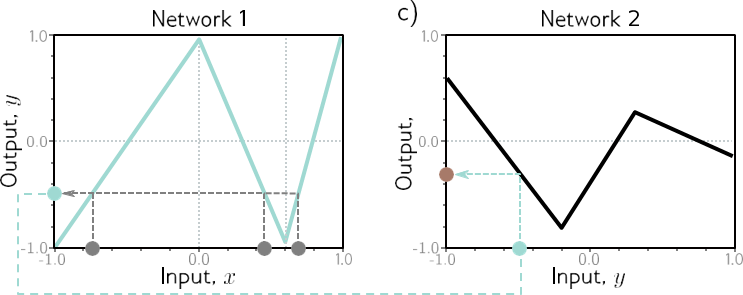
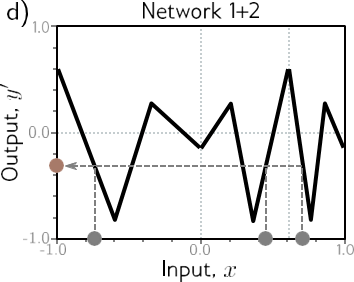
شکل 4.1 ترکیب دو شبکه تک لایه با سه واحد مخفی هر کدام. الف) خروجی y شبکه اول ورودی شبکه دوم را تشکیل می دهد. ب) اولین شبکه ورودی های x [1، 1] را به خروجی های y [1، 1] با استفاده از تابعی شامل سه ناحیه خطی که به گونه ای انتخاب شده اند که علامت شیب خود را جایگزین می کنند، به خروجی های y ترسیم می کند (منطقه خطی چهارم خارج از محدوده نمودار است) . چندین ورودی x (دایره های خاکستری) اکنون به همان خروجی y (دایره فیروزه ای) نگاشت می شوند. ج) شبکه دوم تابعی را شامل سه ناحیه خطی تعریف می کند که y را می گیرد و y’ را برمی گرداند (یعنی دایره فیروزه ای به دایره قهوه ای نگاشت می شود). د) اثر ترکیبی این دو تابع هنگام ترکیب این است که (i) سه ورودی مختلف x به هر مقدار داده شده y توسط شبکه اول نگاشت می شوند و (ii) به همان روش توسط شبکه دوم پردازش می شوند. نتیجه این است که تابعی که توسط شبکه دوم در پانل (c) تعریف شده است، سه بار تکرار میشود، با توجه به شیب نواحی پانل (b) بهصورت مختلف تغییر شکل داده و تغییر مقیاس داده میشود.
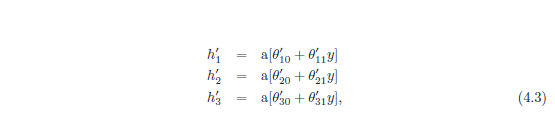
و
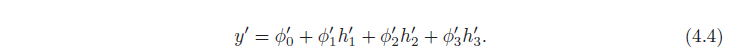
با فعال سازی ReLU، این مدل همچنین خانواده ای از توابع خطی تکه ای را توصیف می کند. با این حال، تعداد مناطق خطی به طور بالقوه بیشتر از یک شبکه کم عمق با شش واحد پنهان است. برای مشاهده این موضوع، اولین شبکه برای تولید سه ناحیه متناوب با شیب مثبت و منفی را در نظر بگیرید (شکل 4.1b). این بدان معنی است که سه محدوده مختلف از x به همان محدوده خروجی y ∈ [-1, 1] و پس از آن نگاشت می شوند.
نقشه برداری از این محدوده y به y سه بار اعمال می شود. اثر کلی این است که Notebook 4.1
تابع تعریف شده توسط شبکه دوم سه بار تکرار می شود تا 9 ناحیه خطی ایجاد شود. همین اصل در ابعاد بالاتر نیز صدق می کند (شکل 4.2).
راه متفاوتی برای اندیشیدن در مورد ایجاد شبکه ها این است که شبکه اول فضای ورودی x را روی خودش “تا” می کند تا چندین ورودی خروجی یکسانی تولید کنند. سپس شبکه دوم تابعی را اعمال می کند که در تمام نقاطی که روی یکدیگر تا شده اند تکرار می شود (شکل 4.3).
4.2 از ایجاد شبکه ها تا شبکه های عمیق
بخش قبل نشان داد که ما میتوانیم توابع پیچیده را با ارسال خروجی یک شبکه عصبی کم عمق به شبکه دوم ایجاد کنیم. اکنون نشان می دهیم که این یک مورد خاص از یک شبکه عمیق با دو لایه پنهان است.
خروجی شبکه اول (y = ϕ0 + ϕ1h1 + ϕ2h2 + ϕ3h3) یک ترکیب خطی از فعالسازیها در واحدهای پنهان است. اولین عملیات شبکه دوم (معادله 4.3 که در آن θ1′ 0 + θ1′ 1y، θ2′ 0 + θ2′ 1y و θ3′ 0 + θ3′ 1y را محاسبه می کنیم) در خروجی شبکه اول خطی هستند. با اعمال یک تابع خطی به تابع دیگر، تابع خطی دیگری به دست می آید. با جایگزینی عبارت y در معادله 4.3 به دست می آید:
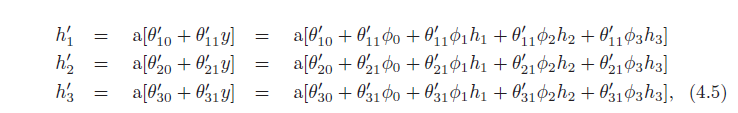
که می توانیم به صورت زیر بازنویسی کنیم:
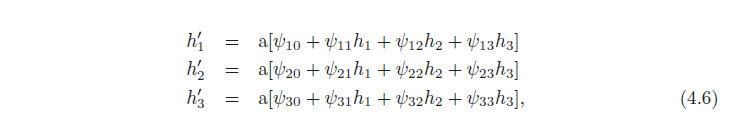
شکل 4.2 ساخت شبکه های عصبی با ورودی 2 بعدی. الف) شبکه اول (از شکل 3.8) دارای سه واحد پنهان است و دو ورودی x1 و x2 را می گیرد و یک خروجی اسکالر y برمی گرداند. این به شبکه دوم با دو واحد مخفی برای تولید y منتقل می شود. ب) شبکه اول تابعی متشکل از هفت ناحیه خطی تولید می کند که یکی از آنها مسطح است. ج) شبکه دوم تابعی را شامل دو ناحیه خطی در y [1,1] تعریف می کند. د) هنگامی که این شبکه ها تشکیل می شوند، هر یک از شش منطقه غیر مسطح از شبکه اول توسط شبکه دوم به دو منطقه جدید تقسیم می شود تا در مجموع 13 منطقه خطی ایجاد شود.
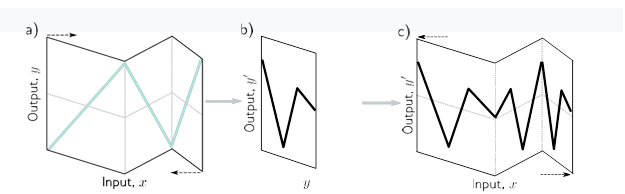
شکل 4.3 شبکه های عمیق به عنوان فضای ورودی تاشو. الف) یکی از راههای فکر کردن به اولین شبکه از شکل 4.1 این است که فضای ورودی را در بالای خود “تا” میکند. ب) شبکه دوم عملکرد خود را در فضای تا شده اعمال می کند. ج) خروجی نهایی با “باز کردن” دوباره آشکار می شود.
شکل 4.4 شبکه عصبی با یک ورودی، یک خروجی و دو لایه پنهان که هر کدام شامل سه واحد پنهان است.
که در آن ψ10 = θ1′ 0 + θ1′ 1ϕ0، ψ11 = θ1′ 1ϕ1، ψ12 = θ1′ 1ϕ2 و غیره. نتیجه یک شبکه با دو لایه پنهان است (شکل 4.4).
نتیجه این است که یک شبکه با دو لایه می تواند خانواده توابع ایجاد شده با ارسال خروجی یک شبکه تک لایه به شبکه دیگر را نشان دهد. در واقع، خانواده وسیع تری را نشان می دهد زیرا در معادله 4.6، 9 پارامتر شیب ψ11، ψ21، . . . ، ψ33 می تواند مقادیر دلخواه بگیرد، در حالی که، در معادله 4.5، این پارامترها محدود شده اند تا محصول بیرونی [θ1′ 1، θ2′ 1، θ3′ 1] T [φ1, φ2, φ3] باشند.
4.3 شبکه های عصبی عمیق و دولایه پنهان
در بخش قبل، نشان دادیم که از ترکیب دو شبکه کم عمق، حالت خاصی از یک شبکه عمیق با دو لایه پنهان به دست میآید. اکنون حالت کلی یک شبکه عمیق با دو لایه پنهان را در نظر می گیریم که هر یک شامل سه واحد پنهان است (شکل 4.4). لایه اول به صورت زیر تعریف می شود:
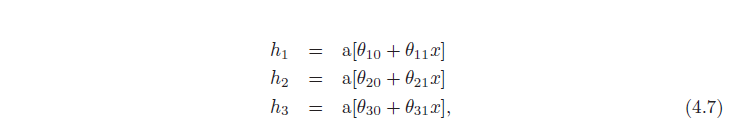
لایه دوم توسط:
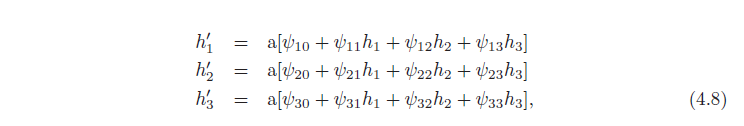
و خروجی توسط:
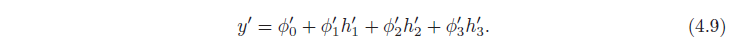
در نظر گرفتن این معادلات منجر به راه دیگری برای تفکر در مورد چگونگی ساخت یک تابع پیچیده تر توسط شبکه می شود (شکل 4.5):
- سه واحد پنهان h1، h2 و h3 در لایه اول طبق معمول توسط تشکیل توابع خطی ورودی و عبور آنها از توابع فعالسازی ReLU (معادله 4.7).
- پیش فعال سازی ها در لایه دوم با گرفتن سه تابع خطی جدید از این واحدهای پنهان محاسبه می شوند (آگومان های توابع فعال سازی در معادله 4.8). در این مرحله، ما به طور موثر یک شبکه کم عمق با سه خروجی داریم. ما سه تابع خطی تکه تکه را با “مفاصل” بین مناطق خطی در همان مکان ها محاسبه کرده ایم (شکل 3.6 را ببینید).
- در لایه پنهان دوم، تابع ReLU دیگری a[ ] برای هر تابع اعمال می شود (معادله 4.8)، که آنها را گیره می کند و “مفاصل” جدیدی به هر کدام اضافه می کند.
- خروجی نهایی ترکیبی خطی از این واحدهای پنهان است (معادله 4.9).
در پایان، میتوانیم هر لایه را بهعنوان «تا کردن» فضای ورودی یا ایجاد توابع جدید در نظر بگیریم که بریده میشوند (ایجاد مناطق جدید) و سپس دوباره ترکیب میشوند. دیدگاه اول بر وابستگیها در تابع خروجی تأکید میکند، اما نه اینکه برش دادن اتصالات جدید را ایجاد میکند، و دومی تأکید مخالف دارد. در نهایت، هر دو توصیف تنها بینشی جزئی از نحوه عملکرد شبکههای عصبی عمیق ارائه میدهند. صرف نظر از این، مهم است که این واقعیت را فراموش نکنید که این فقط یک معادله است که ورودی x را به خروجی y مرتبط می کند. در واقع، ما می توانیم معادلات 4.7-4.9 را برای به دست آوردن یک عبارت ترکیب کنیم:
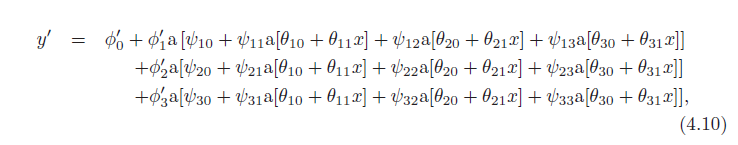
اگرچه درک این امر مسلماً دشوار است.
4.3.1 فراپارامترها و ظرفیت شبکه
ما می توانیم ساخت شبکه عمیق را به بیش از دو لایه پنهان گسترش دهیم. شبکه های مدرن ممکن است بیش از صد لایه با هزاران واحد پنهان در هر لایه داشته باشند. تعداد واحدهای پنهان در هر لایه به عنوان عرض شبکه و تعداد لایه های پنهان به عنوان عمق نامیده می شود. تعداد کل واحدهای پنهان معیاری از ظرفیت شبکه است.
تعداد لایه ها را K و تعداد واحدهای پنهان در هر لایه را D1، D2، . . . ، DK. اینها نمونه هایی از هایپرپارامترها هستند. آنها مقادیری هستند که قبل از یادگیری پارامترهای مدل (به عنوان مثال، شیب و شرایط قطع) انتخاب می شوند. برای فراپارامترهای ثابت (به عنوان مثال، K = 2 لایه با Dk = 3 واحد پنهان در هر یک)، مدل یک خانواده از توابع را توصیف می کند، و پارامترها تابع خاص را تعیین می کنند. از این رو، هنگامی که ما فراپارامترها را نیز در نظر می گیریم، می توانیم شبکه های عصبی را به عنوان نماینده خانواده ای از توابع مرتبط با ورودی به خروجی در نظر بگیریم.
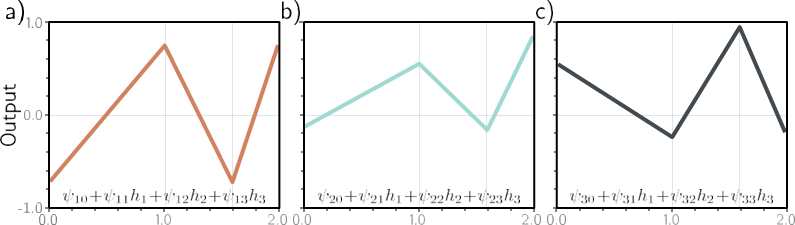
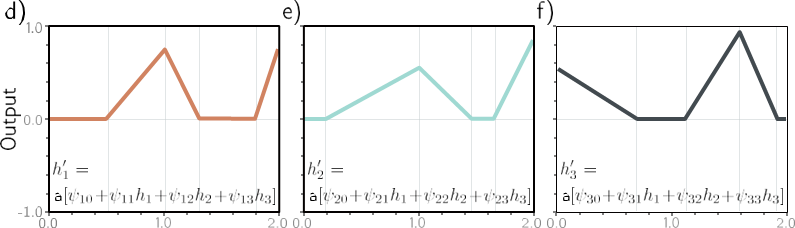
شکل 4.5 محاسبه برای شبکه عمیق در شکل 4.4. الف-ج) ورودیهای لایه پنهان دوم (یعنی پیش فعالسازیها) سه تابع خطی تکه تکه هستند که در آن «مفاصل» بین نواحی خطی در یک مکان هستند (شکل 3.6 را ببینید). d–f) هر تابع خطی تکهای توسط تابع فعالسازی ReLU به صفر میرسد. g–i) این توابع بریده شده سپس با وزن دهی می شوند
پارامترهای ϕ′، ϕ′ و ϕ′ به ترتیب. ی) در نهایت، بریده و وزن توابع جمع می شوند و یک افست ϕ′ که ارتفاع کلی را کنترل می کند اضافه می شود.
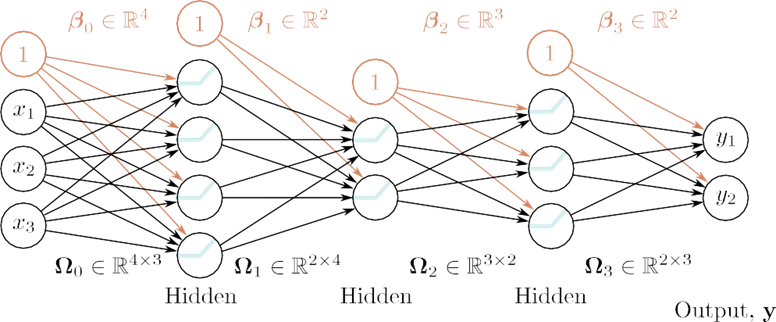
شکل 4.6 نماد ماتریسی برای شبکه با ورودی 3 بعدی X، Do = خروجی 2 بعدی y و K = 3 لایه پنهان h1، h2 و h3 به ترتیب با ابعاد D1 = 4، D2 = 2، و D3 = 3. . وزنها در ماتریسهای Ωk ذخیره میشوند که فعالسازیهای لایه قبلی را از قبل ضرب میکنند تا فعالسازیهای اولیه در لایه بعدی ایجاد شود. به عنوان مثال، ماتریس وزن Ω1 که پیش فعال سازی ها را در h2 از فعال سازی ها در h1 محاسبه می کند دارای ابعاد است.
2 4. بر روی چهار واحد پنهان در لایه یک اعمال می شود و ورودی های دو واحد پنهان در لایه دو را ایجاد می کند. بایاس ها در بردارهای βk ذخیره می شوند و ابعاد لایه ای را دارند که در آن تغذیه می کنند. به عنوان مثال، بردار بایاس β2 طول سه است زیرا لایه h3 شامل سه واحد پنهان است.
4.4 نماد ماتریسی
دیدهایم که یک شبکه عصبی عمیق متشکل از تبدیلهای خطی متناوب است با توابع فعال سازی ما می توانیم معادلات 4.7-4.9 را در نماد ماتریسی به صورت معادل توصیف کنیم:
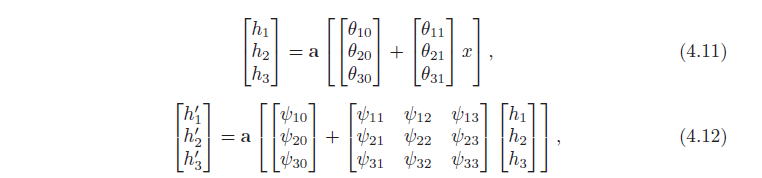
و
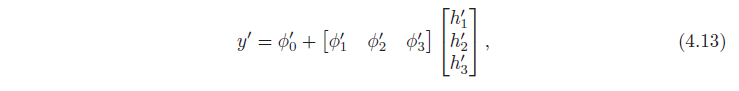
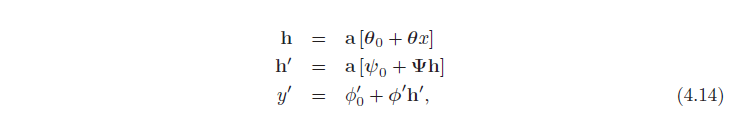
جایی که در هر مورد، تابع a[ ] تابع فعال سازی را به طور جداگانه برای هر عنصر ورودی برداری خود اعمال می کند.
4.4.1 فرمول کلی
این نماد برای شبکه هایی با لایه های زیاد دست و پا گیر می شود. از این رو، از این به بعد، بردار واحدهای پنهان در لایه k را به عنوان hk، بردار بایاس ها (برق ها) که به لایه پنهان k + 1 به عنوان βk کمک می کنند، و وزن ها (شیب ها) که به kth اعمال می شوند، توصیف می کنیم. لایه و به لایه (k+1) ام به عنوان Ωk کمک کنید. یک شبکه عمیق عمومی y = f[x, ϕ] با لایه های K اکنون می تواند به صورت زیر نوشته شود:
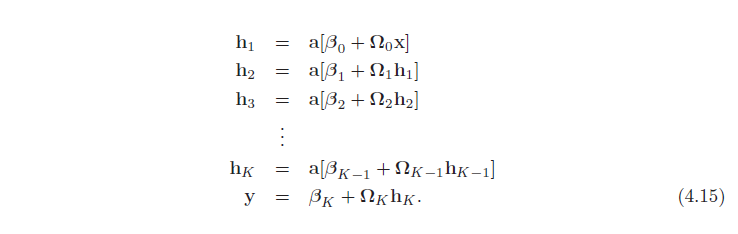
پارامترهای ϕ این مدل شامل همه این ماتریسهای وزنی و بردارهای سوگیری است
ϕ = {βk، Ωk}K.
اگر لایه k دارای واحدهای پنهان Dk باشد، بردار بایاس βk-1 به اندازه Dk خواهد بود. آخرین بردار بایاس βK دارای اندازه Do خروجی است. اولین ماتریس وزن Ω0 دارای اندازه D1 × Di که در آن Di اندازه ورودی است. آخرین ماتریس وزنی ΩK Do × DK است و ماتریس های باقیمانده Ωk Dk+1 × Dk هستند (شکل 4.6).
شبکه های عمیق به طور معادل می توانیم شبکه را به صورت یک تابع بنویسیم:
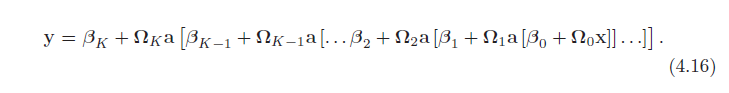
4.5 شبکه های عصبی کم عمق در مقابل عمیق
فصل 3 شبکه های کم عمق (با یک لایه پنهان) را مورد بحث قرار داد و در اینجا شبکه های عمیق (با چندین لایه پنهان) را توضیح دادیم. اکنون این مدل ها را با هم مقایسه می کنیم.
4.5.1 توانایی تقریبی توابع مختلف
در بخش 3.2، ما استدلال کردیم که شبکه های عصبی کم عمق با ظرفیت کافی (واحدهای پنهان) می توانند هر تابع پیوسته را به طور دلخواه از نزدیک مدل کنند. در این فصل دیدیم که یک شبکه عمیق با دو لایه پنهان می تواند ترکیب دو شبکه کم عمق را نشان دهد. اگر دومی از این شبکه ها تابع هویت را محاسبه کند، آنگاه این شبکه عمیق یک شبکه کم عمق را تکثیر می کند. از این رو، همچنین می تواند هر تابع پیوسته را به طور دلخواه با توجه به ظرفیت کافی، تقریب بزند.
4.5.2 تعداد مناطق خطی در هر پارامتر
یک شبکه کم عمق با یک ورودی، یک خروجی و D > 2 واحد پنهان می تواند ایجاد شود به مناطق خطی D + 1 و با پارامترهای 3D + 1 تعریف می شود. یک شبکه عمیق با یک ورودی، یک خروجی، و K لایههای D > 2 واحد پنهان میتواند با استفاده از پارامترهای 3D + 1 + (K 1)D(D + 1) تابعی با حداکثر (D + 1)K ناحیه خطی ایجاد کند. .
شکل 4.7a نشان می دهد که چگونه حداکثر تعداد مناطق خطی به عنوان تابعی از تعداد پارامترها برای شبکه های نگاشت ورودی اسکالر x به خروجی اسکالر y افزایش می یابد. شبکه های عصبی عمیق توابع بسیار پیچیده تری را برای یک بودجه پارامتر ثابت ایجاد می کنند. این اثر با افزایش تعداد ابعاد ورودی Di بزرگتر میشود (شکل 4.7b)، اگرچه محاسبه حداکثر تعداد مناطق سادهتر نیست.
این جذاب به نظر می رسد، اما انعطاف پذیری توابع هنوز با تعداد پارامترها محدود است. شبکه های عمیق می توانند تعداد بسیار زیادی از مناطق خطی ایجاد کنند، اما این ها دارای وابستگی ها و تقارن های پیچیده هستند. هنگامی که شبکه های عمیق را به عنوان “تا کردن” فضای ورودی در نظر گرفتیم، برخی از این موارد را دیدیم (شکل 4.3). بنابراین، مشخص نیست که تعداد بیشتر مناطق یک مزیت است، مگر اینکه (i) تقارن های مشابهی در توابع دنیای واقعی وجود داشته باشد که بخواهیم تقریبی کنیم یا (ii) دلیلی برای این باور داشته باشیم که نگاشت از ورودی به خروجی واقعاً شامل ترکیبی از توابع ساده تر است.
4.5.3 بهره وری در عمق
هر دو شبکه عمیق و کم عمق میتوانند توابع دلخواه را مدلسازی کنند، اما برخی از توابع را میتوان با استفاده از شبکههای عمیق، بسیار کارآمدتر تقریب زد. توابع شناسایی شدهاند که به یک شبکه کم عمق با واحدهای پنهان بهطور تصاعدی بیشتر برای دستیابی به تقریب معادل با شبکه عمیق نیاز دارند. از این پدیده به عنوان کارایی عمق شبکه های عصبی یاد می شود. این ویژگی نیز جذاب است، اما مشخص نیست که توابع دنیای واقعی که میخواهیم تقریبی کنیم در این دسته قرار میگیرند.
4.5.4 ورودی های بزرگ و ساختار یافته
ما شبکههای کاملاً متصل را مورد بحث قرار دادهایم که در آن هر عنصر از هر لایه به هر عنصر لایه بعدی کمک میکند. با این حال، اینها برای بزرگها کاربردی نیستند.
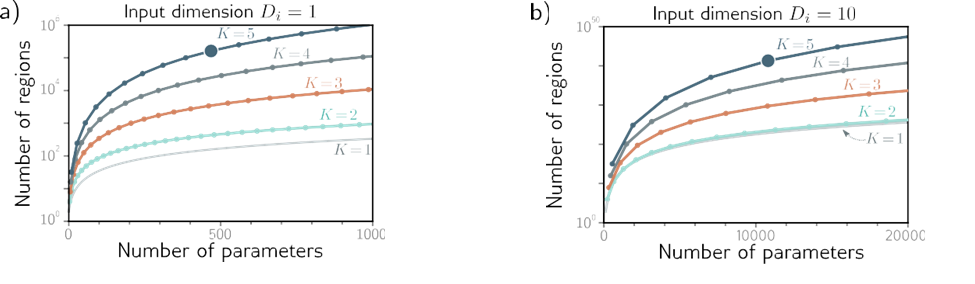
شکل 4.7 حداکثر تعداد مناطق خطی برای شبکه های عصبی به سرعت با عمق شبکه افزایش می یابد. الف) شبکه با ورودی Di = 1. هر منحنی تعداد ثابتی از لایههای پنهان K را نشان میدهد، زیرا ما تعداد واحدهای پنهان D را در هر لایه تغییر میدهیم. برای یک بودجه پارامتر ثابت (موقعیت افقی)، شبکههای عمیقتر مناطق خطی بیشتری نسبت به مناطق کمعمقتر تولید میکنند. شبکه ای با K = 5 لایه و D = 10 واحد پنهان در هر لایه دارای 471 پارامتر (نقطه برجسته) است و می تواند 161051 منطقه ایجاد کند. ب) شبکه با 10 ورودی Di =. هر نقطه بعدی در امتداد یک منحنی نشان دهنده ده واحد پنهان است. در اینجا، مدلی با K = 5 لایه و D = 50 واحد پنهان در هر لایه دارای 10801 پارامتر (نقطه برجسته) است و می تواند بیش از 1040 منطقه خطی ایجاد کند.
ورودی های ساخت یافته مانند تصاویر، که در آن ورودی ممکن است 106 پیکسل باشد. تعداد پارامترها بازدارنده خواهد بود، و علاوه بر این، ما می خواهیم قسمت های مختلف تصویر به طور مشابه پردازش شوند. هیچ فایده ای در یادگیری مستقل تشخیص یک شیء مشابه در هر موقعیت ممکن در تصویر وجود ندارد.
راه حل این است که مناطق تصویر محلی را به صورت موازی پردازش کنید و سپس به تدریج اطلاعات را از مناطق بزرگتر یکپارچه کنید. مشخص کردن این نوع پردازش محلی به جهانی بدون استفاده از چندین لایه دشوار است (به فصل 10 مراجعه کنید).
4.5.5 آموزش و تعمیم
یکی دیگر از مزیت های احتمالی شبکه های عمیق نسبت به شبکه های کم عمق، سهولت اتصال آنها است. معمولاً آموزش شبکه های با عمق متوسط آسان تر از آموزش شبکه های کم عمق است (شکل 20.2 را ببینید). ممکن است مدلهای عمیق بیش از حد پارامتر، خانواده بزرگی از راهحلهای تقریباً معادل داشته باشند که یافتن آنها آسان است. با این حال، با اضافه کردن لایههای پنهان بیشتر، آموزش دوباره دشوارتر میشود، اگرچه روشهای زیادی برای کاهش این مشکل توسعه داده شده است (به فصل 11 مراجعه کنید).
به نظر می رسد شبکه های عصبی عمیق نیز بهتر از شبکه های کم عمق به داده های جدید تعمیم می دهند. در عمل، بهترین نتایج برای اکثر وظایف با استفاده از شبکه هایی با ده ها یا صدها لایه به دست آمده است. هیچ یک از این پدیده ها به خوبی درک نشده اند و ما در فصل 20 به آنها باز می گردیم.
4.6 خلاصه
در این فصل ابتدا در نظر گرفتیم که وقتی دو شبکه کم عمق را می سازیم چه اتفاقی می افتد. ما استدلال کردیم که شبکه اول فضای ورودی را “تا” می کند، و شبکه دوم سپس یک تابع خطی تکه ای اعمال می کند. اثرات شبکه دوم در جایی که فضای ورودی روی خودش جمع می شود تکرار می شود.
سپس نشان دادیم که این ترکیب شبکه های کم عمق، یک مورد خاص از یک شبکه عمیق با دو لایه است. ما توابع ReLU را در هر لایه به صورت بریدن توابع ورودی در مکانهای مختلف و ایجاد «مفاصل» بیشتر در تابع خروجی تفسیر کردیم. ما ایده هایپرپارامترها را معرفی کردیم، که برای شبکه هایی که تاکنون دیده ایم، تعداد لایه های پنهان و تعداد واحدهای پنهان در هر یک را شامل می شود.
در نهایت، شبکه های کم عمق و عمیق را با هم مقایسه کردیم. ما دیدیم که (i) هر دو شبکه می توانند هر تابعی را با توجه به ظرفیت کافی تقریب بزنند، (ب) شبکه های عمیق مناطق خطی بیشتری را در هر پارامتر تولید می کنند، (iii) برخی از توابع را می توان بسیار کارآمدتر توسط شبکه های عمیق تقریب زد، (IV) بزرگ و ساختار یافته ورودی هایی مانند تصاویر به بهترین وجه در چند مرحله پردازش می شوند و (v) در عمل، بهترین نتایج برای اکثر وظایف با استفاده از شبکه های عمیق با لایه های زیاد به دست می آید.
اکنون که مدل های شبکه عمیق و کم عمق را درک می کنیم، توجه خود را به آموزش آنها معطوف می کنیم. در فصل بعد، توابع ضرر را مورد بحث قرار می دهیم. برای هر مقدار پارامتر معین ϕ، تابع ضرر یک عدد منفرد را برمیگرداند که نشاندهنده عدم تطابق بین خروجیهای مدل و پیشبینیهای حقیقت پایه برای یک مجموعه داده آموزشی است. در فصول 6 و 7 به خود فرآیند آموزش می پردازیم که در آن به دنبال مقادیر پارامترهایی هستیم که این تلفات را به حداقل می رساند.
یادداشت ها
یادگیری عمیق:
مدتهاست که درک شده است که می توان با ایجاد شبکه های عصبی کم عمق یا توسعه شبکه هایی با بیش از یک لایه پنهان، توابع پیچیده تری ساخت. در واقع، اصطلاح “یادگیری عمیق” برای اولین بار توسط دچتر (1986) استفاده شد. با این حال، علاقه به دلیل نگرانی های عملی محدود بود. آموزش چنین شبکه هایی به خوبی امکان پذیر نبود. دوران مدرن یادگیری عمیق با پیشرفت های خیره کننده در طبقه بندی تصاویر گزارش شده توسط کریژفسکی و همکاران آغاز شد. (2012). این پیشرفت ناگهانی احتمالاً به دلیل تلاقی چهار عامل بود: مجموعه داده های آموزشی بزرگتر، قدرت پردازش بهبود یافته برای آموزش، استفاده از تابع فعال سازی ReLU، و استفاده از شیب نزول تصادفی (به فصل 6 مراجعه کنید). LeCun و همکاران (2015) مروری بر پیشرفت های اولیه در عصر مدرن یادگیری عمیق ارائه می دهد.
تعداد مناطق خطی:
برای شبکههای عمیق که از مجموع واحدهای پنهان D با فعالسازیهای ReLU استفاده میکنند، کران بالای تعداد مناطق 2 بعدی است (Montufar et al., 2014). همان نویسندگان نشان میدهند که یک شبکه ReLU عمیق با ورودی بعدی و لایههای K، هر کدام
حاوی واحدهای پنهان D ≥ Di، دارای مناطق خطی O (D/Di) (K-1) Di DDi است. Montúfar (2017)
آرورا و همکاران (2016) و سرا و همکاران. (2018) همگی مرزهای بالایی محکم تری ارائه می دهند که این امکان را در نظر می گیرند که هر لایه دارای تعداد واحدهای پنهان متفاوتی باشد. سرا و همکاران (2018) الگوریتمی را ارائه می دهد که تعداد مناطق خطی را در یک شبکه عصبی شمارش می کند، اگرچه فقط برای شبکه های بسیار کوچک عملی است.
اگر تعداد واحدهای پنهان D در هر یک از لایههای K یکسان باشد و D مضرب صحیحی از بعد ورودی Di باشد، حداکثر تعداد مناطق خطی Nr میتواند باشد.
دقیقا محاسبه می شود و این است:
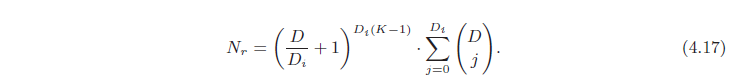
اولین عبارت در این عبارت مربوط به اولین لایههای K 1 شبکه است که میتوان آن را به صورت تا کردن مکرر فضای ورودی در نظر گرفت. با این حال، اکنون باید واحدهای پنهان D/Di را به هر بعد ورودی اختصاص دهیم تا این تاها را ایجاد کنیم. آخرین جمله در این معادله (الف مجموع ضرایب دو جمله ای) تعداد مناطقی است که یک شبکه کم عمق می تواند ایجاد کند و پیوست B.2 است. قابل انتساب به لایه آخر برای اطلاعات بیشتر، با Montufar و همکاران مشورت کنید. (2014)، پاسکانو و همکاران. (2013) و Montúfar (2017).
قضیه تقریب جهانی:
ما در بخش 4.5.1 استدلال کردیم که اگر لایههای یک شبکه عمیق دارای واحدهای پنهان کافی باشد، نسخه عرض قضیه تقریب جهانی اعمال میشود: شبکهای وجود دارد که میتواند هر تابع پیوسته معینی را در یک شبکه تقریبی کند. زیر مجموعه فشرده RDI به دقت دلخواه. لو و همکاران (2017) ثابت کرد که شبکهای با توابع فعالسازی ReLU وجود دارد و حداقل Di + 4 واحد پنهان در هر لایه میتواند هر تابع ادغامپذیر Di-dimensional Lebesgue مشخص شده را با دقت دلخواه با توجه به لایههای کافی تقریب کند. این به عنوان نسخه عمق قضیه تقریب جهانی شناخته می شود.
کارایی عمق:
نتایج متعددی نشان میدهد که عملکردهایی وجود دارند که میتوانند توسط شبکههای عمیق محقق شوند، اما نه توسط هیچ شبکه کم عمقی که ظرفیت آن به صورت نمایی محدود شده است. به عبارت دیگر، برای توصیف دقیق این توابع، تعداد واحدها به طور نمایی بیشتر در یک شبکه کم عمق نیاز است. این به عنوان کارایی عمق شبکه های عصبی شناخته می شود.
Telgarsky (2016) نشان می دهد که برای هر عدد صحیح k، می توان شبکه هایی با یک ورودی، یک خروجی و [k3] لایه هایی با عرض ثابت ساخت که با [k] لایه ها و عرض کمتر از 2k قابل تحقق نیستند. شاید به طرز شگفت انگیزی، الدان و شامیر (2016) نشان دادند که وقتی ورودی های چند متغیره وجود دارد، یک شبکه سه لایه وجود دارد که اگر ظرفیت در بعد ورودی زیر نمایی باشد، توسط هیچ شبکه دو لایه ای قابل تحقق نیست. کوهن و همکاران (2016)، Safran & Shamir (2017)، و Poggio و همکاران. (2017) همچنین توابعی را نشان میدهد که شبکههای عمیق میتوانند به طور موثر تقریبی کنند، اما شبکههای سطحی نمیتوانند. لیانگ و سریکانت (2016) نشان میدهند که برای یک کلاس وسیع از توابع، از جمله توابع تک متغیره، شبکههای کمعمق به طور تصاعدی به واحدهای پنهان بیشتری نسبت به شبکههای عمیق برای یک کران بالای معین در خطای تقریب نیاز دارند.
کارایی عرض:
لو و همکاران. (2017) بررسی می کند که آیا شبکه های کم عمق گسترده ای (یعنی شبکه های کم عمق با تعداد زیادی واحد پنهان) وجود دارد که توسط شبکه های باریکی که عمق آنها به طور قابل ملاحظه ای بزرگتر نیست قابل تحقق نیستند. آنها نشان میدهند که دستههایی از شبکههای گسترده و کمعمق وجود دارند که فقط میتوانند با شبکههای باریک با عمق چند جملهای بیان شوند. این به عنوان کارایی عرض شبکه های عصبی شناخته می شود. این کران پایین چند جملهای در عرض نسبت به کران پایین نمایی در عمق محدودتر است و نشان میدهد که عمق اهمیت بیشتری دارد. واردی و همکاران (2022) متعاقباً نشان داد که قیمت کوچک کردن عرض تنها یک افزایش خطی در عمق شبکه برای شبکههای با فعالسازی ReLU است.
مسائل
مسئله 4.1 ترکیب دو شبکه عصبی در شکل 4.8 را در نظر بگیرید. نموداری از رابطه بین ورودی x و خروجی y′ برای x ∈ [-1, 1] رسم کنید.
مسئله 4.2 چهار فراپارامتر را در شکل 4.6 مشخص کنید.
مسئله 4.3 با استفاده از خاصیت همگنی غیرمنفی تابع ReLU (به مسئله 3.5 مراجعه کنید)، نشان دهید که:
شکل 4.8 ترکیب دو شبکه برای مسئله 4.1. الف) خروجی y شبکه اول به ورودی شبکه دوم تبدیل می شود. ب) شبکه اول این تابع را با مقادیر خروجی y ∈ [-1, 1] محاسبه می کند. ج) شبکه دوم این تابع را در محدوده ورودی y ∈ [-1, 1] محاسبه می کند.
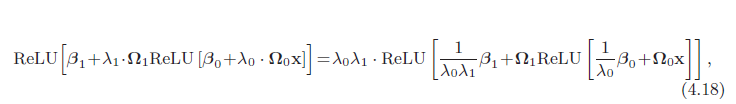
که در آن λ0 و λ1 اسکالرهای غیر منفی هستند. از این رو، می بینیم که ماتریس های وزن را می توان با هر بزرگی مجدداً تغییر داد تا زمانی که بایاس ها نیز تنظیم شوند و فاکتورهای مقیاس را می توان مجدداً در انتهای شبکه اعمال کرد.
مسئله 4.4 معادلات یک شبکه عصبی عمیق را بنویسید که Di = 5 ورودی، Do = 4 خروجی و دارای سه لایه پنهان به اندازه های D1 = 20، D2 = 10، و D3 = 7 به ترتیب در هر دو شکل معادله است. 4.15 و 4.16. اندازه هر ماتریس وزنی Ω• و بردار بایاس β• چیست؟
مسئله 4.5 یک شبکه عصبی عمیق با Di = 5 ورودی، Do = 1 خروجی، و K = 20 لایه پنهان که هر لایه حاوی 30 واحد پنهان D است، در نظر بگیرید. عمق این شبکه چقدر است؟ عرض چقدر است؟
مسئله 4.6 شبکه ای با 1 ورودی Di = 1 خروجی Do = 1 و K = 10 لایه با D = 10 واحد پنهان در هر لایه در نظر بگیرید. اگر عمق را یک یا عرض را یک بار افزایش دهیم، تعداد وزنه ها بیشتر می شود؟ استدلال خود را ارائه دهید
مسئله 4.7 مقادیری را برای پارامترهای ϕ = ϕ0، ϕ1، ϕ2، ϕ3، θ10، θ11، θ20، θ21، θ30، θ31 برای شبکه عصبی کم عمق در معادله 3.1 انتخاب کنید که یک تابع هویت را در محدوده محدود x ∈ [a تعریف می کند. ، ب].
مسئله4.8 شکل 4.9 فعال سازی در سه واحد پنهان یک شبکه کم عمق را نشان می دهد (مانند شکل 3.3). شیب ها در واحدهای پنهان به ترتیب 1.0، 1.0 و -1.0 هستند و “مفاصل” در واحدهای پنهان در موقعیت های 1/6، 2/6 و 4/6 هستند. مقادیر ϕ0، ϕ1، ϕ2 و ϕ3 را بیابید که فعال سازی های واحد پنهان را به صورت ϕ0 + ϕ1h1 + ϕ2h2 + ϕ3h3 ترکیب می کند تا تابعی با چهار ناحیه خطی ایجاد کند که بین مقادیر خروجی صفر و یک در نوسان است. شیب سمت چپ ترین ناحیه باید مثبت، بعدی منفی و غیره باشد. اگر این شبکه را با خودش بسازیم چند ناحیه خطی ایجاد خواهیم کرد؟ اگر آن را با خود K بار بسازیم، چند عدد ایجاد خواهیم کرد؟
مسئله 4.9 به دنبال مسئله 4.8، آیا می توان با استفاده از یک شبکه کم عمق با دو واحد پنهان، تابعی با سه ناحیه خطی ایجاد کرد که بین مقادیر خروجی صفر و یک نوسان کند؟ آیا می توان تابعی با پنج ناحیه خطی ایجاد کرد که با استفاده از یک شبکه کم عمق با چهار واحد پنهان به همان شکل نوسان کند؟
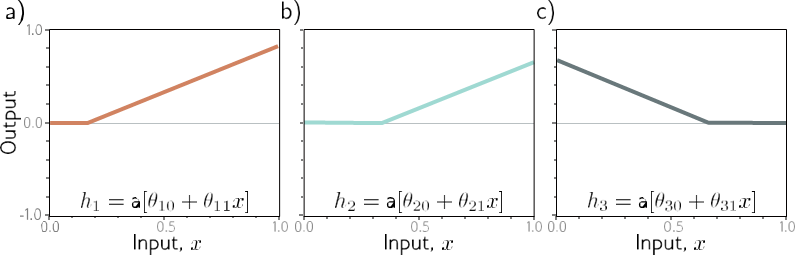
شکل 4.9 فعال سازی واحد پنهان برای مشکل 4.8. الف) واحد پنهان اول دارای یک اتصال در موقعیت x = 1/6 و شیب یک در ناحیه فعال است. ب) واحد پنهان دوم دارای یک اتصال در موقعیت x = 2/6 و شیب یک در ناحیه فعال است. ج) واحد پنهان سوم دارای یک اتصال در موقعیت x = 4/6 و شیب منهای یک در ناحیه فعال است.
مسئله4.10 یک شبکه عصبی عمیق با یک ورودی، یک خروجی و K لایه پنهان را در نظر بگیرید که هر یک شامل D واحدهای پنهان است. نشان دهید که این شبکه در مجموع پارامترهای 3D + 1 + (K − 1)D(D + 1) خواهد داشت.
مسئله 4.11 دو شبکه عصبی را در نظر بگیرید که یک ورودی اسکالر x را به یک خروجی اسکالر y ترسیم می کنند. شبکه اول کم عمق است و دارای D = 95 واحد پنهان است. لایه دوم عمیق است و دارای K = 10 لایه است که هر لایه حاوی D = 5 واحد پنهان است. هر شبکه چند پارامتر دارد؟ هر شبکه چند ناحیه خطی می تواند بسازد؟ کدام یک سریعتر اجرا می شود؟



